 Cosima Rughiniș
Cosima Rughiniș Simona-Nicoleta Vulpe
Simona-Nicoleta Vulpe Dinu Țurcanu
Dinu Țurcanu Răzvan Rughiniș
Răzvan Rughiniș- 1Faculty of Sociology and Social Work, University of Bucharest, Bucharest, Romania
- 2Faculty of Electronics and Telecommunications, National Institute of Innovations in Cybersecurity “CYBERCOR”, Technical University of Moldova, Chișinău, Moldova
- 3Faculty of Automatic Control and Computers, National University of Science and Technology Politehnica Bucharest, Bucharest, Romania
Introduction: This study examines how academic institutions conceptualize and regulate artificial intelligence in knowledge production, focusing on institutional strategies for managing technological disruption while preserving academic values.
Methods: Using boundary work theory and actor-network approaches, we conducted qualitative content analysis of AI policies from 16 prestigious universities and 12 major publishers. We introduced analytical concepts of dual black-boxing and legitimacy-dependent hybrid actors to explore institutional responses to AI integration.
Results: Institutions primarily address AI’s opacity through transparency requirements, focusing on usage pattern visibility. Boundary-making strategies include categorical distinctions, authority allocation, and process-oriented boundaries that allow AI contributions while restricting final product generation. Universities demonstrated a more flexible recognition of hybrid actors compared to publishers’ stricter authorship boundaries.
Discussion: The study discusses how established knowledge institutions navigate technological change by adapting existing academic practices. Institutions maintain human authority through delegated accountability, showing a diversified approach to integrating AI while preserving core academic integrity principles.
1 Introduction
Recent studies indicate a swiftly evolving field of artificial intelligence adoption within academic environments, with both students and researchers integrating AI tools into their educational and scholarly activities. The Digital Education Council’s 2024 Global AI Student Survey found that 86% of students already use AI in their studies, with 54% doing so at least weekly and 24% reporting daily usage (DEC Global Survey, 2024). Similarly, the Wiley study, ExplanAItions, found that 45% of researchers had incorporated AI into their research processes, though its usage mostly focuses on specialized activities such as translation, proofreading, and ideation (Wiley, 2024).
Despite this growing adoption, both studies identified barriers to broader implementation. The Wiley survey found that 63% of researchers cite a lack of clear guidelines and consensus on acceptable AI use as a primary obstacle (Wiley, 2024). The student survey indicated uncertainty about expectations, as 86% of students reported being unaware of their universities’ AI guidelines (DEC Global Survey, 2024). This uncertainty exists despite the perception of the growing importance of AI, as 69% of researchers believe acquiring AI skills will be at least somewhat important within the next 2 years, and over 50% believe these skills will become very important within 5 years (Wiley, 2024). Both categories exhibit a strong interest in using AI in various academic activities. The student survey indicated that information searching (69%), grammar checking (42%), and document summarizing (33%) are the most common AI applications among students (DEC Global Survey, 2024). For researchers, Wiley identified 39 use cases (out of 43 surveyed) where a majority expressed interest in personally using AI in the near future, with 23 of these cases indicating a prevailing notion that AI outperforms humans (DEC Global Survey, 2024).
Both reports indicate that AI adoption in academic contexts is no longer a question of “if” but rather “how” and “when.” This situation aligns with previous work by Zarifis and Efthymiou (2022), who proposed a typology of four business models for AI adoption in higher education. Their analysis, based on interviews with university leaders, distinguished between institutions that aim to (1) focus and disaggregate by doing less but better, (2) enhance their existing educational models with AI, (3) expand beyond their current models by integrating new AI-driven processes, or (4) act as disruptors entering the education space from outside traditional academia. These models offer a roadmap for institutional transformation and emphasize the need for alignment between technological capabilities, organizational processes, and human expertise. This framework shows that AI adoption is not monolithic: institutional strategies reflect different visions of educational authority, risk tolerance, and the role of human–machine collaboration.
As stakeholders anticipate widespread acceptance of various AI applications within the next 2 years, there is an urgent need for enhanced usability standards and training. With 70% of researchers desiring publishers to provide clear guidelines on acceptable AI use in scholarly publishing (DEC Global Survey, 2024) and 93% of students feeling there is room for improvement in their universities’ AI policies (Wiley, 2024), the academic community faces the challenge of developing suitable frameworks for AI integration. In a comparative study, Rughiniș et al. (2025) analyzed how prestigious universities and publishers mobilize competing orders of worth, such as civic, industrial, and domestic, to justify AI governance. In the study, the authors showed that institutional policies are shaped by value-based compromises and not by technical concerns alone.
Alqahtani and Wafula (2025) examined AI-related strategies and policies across 25 globally ranked universities. They identified three dominant orientations: structured early adoption with pedagogical guidance, cautious experimentation shaped by ethical concerns, and delayed engagement pending clearer regulatory consensus. These patterns show that institutional responses to AI are embedded in broader visions of educational responsibility, academic integrity, and technological risk. The study stresses the importance of institutional discourse in shaping the perceived legitimacy of AI use and reinforces the view that governance practices define the boundaries of acceptable human–machine collaboration.
In addition to institutional policies, recent sociological and ethnographic research has drawn attention to how everyday actors interpret and classify AI in relation to competence, authorship, and legitimacy. Public discourse increasingly frames generative AI (GenAI) not only as a tool but as a marker of social status and technological literacy. This framing shapes the perceived legitimacy of hybrid human–AI configurations and contributes to the social boundaries subsequently formalized by institutions. The vocabularies emerging in these discourses show how users attribute skill and intelligence to AI-mediated performances, contributing to new distinctions between competent AI users and their less adept counterparts (Bran et al., 2023). These classifications carry implications for educational inclusion, professional identity, and epistemic authority.
AI-related challenges, such as semantic ambiguity, moral contestation, and temporal framing, require new interpretive and methodological tools. Flaherty et al. (2025) explored how five large language models (LLMs) differently interpret temporally charged metaphors in personal accounts, revealing inconsistencies that complicate normative alignment. Furthermore, Rughiniș et al. (2025a) focused on the detection of discursive violence and uncovered epistemic and ethical tensions in delegating sensitive interpretive tasks to LLMs. In a complementary analysis, Rughiniș et al. (2025b) proposed a typology of vocabularies of AI competence and assessed the reliability of multiple LLMs in extracting policy-relevant meanings from institutional texts. Obreja and Rughiniş (2023) investigated how AI models raise ethical concerns and reproduce affective intensities in hostile discourses, particularly hate and incitement.
As digital technologies mediate collective memory and meaning-making, they raise new governance challenges that extend beyond factual accuracy. This is illustrated in studies of historical video games, which function as cultural artifacts shaping public understandings of the past. Matei (2023) analyzed how these games negotiate tensions between representational fidelity and mnemonic resonance, while Obreja (2023) argued that video games should be understood as social institutions that formalize symbolic orders, norms, and interpretive frames. Extending this perspective to generative AI, Matei (2024) showed how LLMs reconfigure practices of remembering, prioritizing responsivity and emotional engagement over verifiable historical accounts. Other studies revealed the heterogeneity of AI imaginaries and the persistent tensions between innovation and accountability across disciplinary boundaries (Obreja et al., 2024; Obreja et al., 2025).
A complementary perspective comes from the case study conducted by Gupta (2024) on AI adoption in the University of Toronto library system. The results showed the value of small-scale, reversible experimentation as a strategic response to the uncertainty and hype surrounding AI technologies. Rather than relying on top-down regulation alone, Gupta (2024) documented a hybrid model that combines centralized guidance with bottom-up experimentation by individual librarians, supported by peer knowledge-sharing and co-creation with students. This strategy supports dynamic capabilities within the institution and enables librarians to differentiate between market-driven hype and contextually relevant tools. This analysis illustrates how AI adoption can evolve both through policy frameworks and also through locally embedded practices that remain partly invisible in formal documentation.
At the same time, the politics of AI legitimacy extend beyond academia. Recent contributions on AI-generated content in online environments have demonstrated that generative systems can reinforce discriminatory narratives, functioning as what might be called “social engines of hate” (Rughiniș et al., 2024). These concerns complicate the institutional move toward formalizing the role of AI in knowledge production, as the same tools carry risks of amplifying harmful or biased outputs in less regulated settings. Complementing these debates, ethnographic studies of repair practices highlight how human-technology relations remain contingent and embodied, even in highly digitized societies. Repair work foregrounds tacit knowledge, improvisation, and material engagement, presenting a divergent approach to the frequently abstracted role of AI in policy discourse (Jderu, 2022, 2023).
Challenges of AI reliability resonate with broader shifts in how digital information is framed, received, and contested. Cristea and Firtala (2023) argued that fake news often stems from selective framing and contextual ambiguity. Their analysis suggested that informational trust today depends less on factual accuracy and more on interpretive alignment, a dynamic that becomes even more salient with generative AI, where plausibility and affect often outweigh verifiability.
To contribute to this ongoing discussion of how AI is incorporated in academic practice, we use a conceptual framework utilizing boundary work theory and actor-network approaches. We propose two novel concepts, dual black-boxing and legitimacy-dependent hybrid actors, to better understand the tensions that arise when AI systems enter knowledge production processes and to guide our empirical investigation.
Social groups establish cultural boundaries to distinguish legitimate from non-legitimate knowledge claims, as Gieryn (1983) argued in the analysis of scientific boundary work. These boundaries take various forms in academic settings: epistemic boundaries separating reliable from unreliable knowledge, procedural boundaries delineating legitimate academic processes, and attribution boundaries governing proper credit allocation. Lamont and Molnár (2002) described boundary maintenance as the ongoing social processes necessary for institutional stability and professional identity. As AI tools gain prominence in academic work, these boundaries require renegotiation and new maintenance mechanisms. As a result, boundary reconfiguration raises questions about how different academic institutions conceptualize and enforce the legitimacy of AI contributions.
We propose the concept of “dual black-boxing” to extend Latour’s (1987) original notion of how technological processes become invisible through successful implementation. In the context of academic AI use, we identify two distinct but interrelated forms of opacity. The first is the internal black-boxing of AI systems, produced by their hidden algorithmic processes, invisible training data that may include copyrighted materials, and embedded biases that shape generated content. The second is the usage of black-boxing, the opacity surrounding how academics employ AI in their work, including undisclosed reliance on AI for various processes and obscured boundaries between human and AI contributions. Star and Strauss (1999) noted that making invisible work visible is essential for recognizing distributed labor, and academic contexts must address opacity at both technical and practical levels. Ananny and Crawford (2018) highlighted similar limitations in transparency mechanisms for algorithmic systems, noting that seeing inside systems does not necessarily provide accountability or understanding.
While these two forms of opacity, internal and usage, are analytically distinct, they frequently interact in institutional governance. Internal black-boxing limits the extent to which even well-intentioned users can understand or explain the origins, biases, or reliability of AI outputs, constraining their ability to verify content or ensure compliance with academic standards. Usage black-boxing, in turn, obscures when and how AI tools are used, especially in early stages of academic work such as ideation, structuring, or preliminary drafting. This dual opacity complicates the design of institutional policies. Such policies tend to emphasize usage transparency through disclosure and attribution but they largely acknowledge internal opacity as a constraint beyond institutional control. For example, many university guidelines require students to cite AI tools but also warn that such tools may hallucinate or plagiarize, without providing a mechanism to assess those risks. The concept of dual black-boxing thus foregrounds the asymmetry in current governance strategies and the structural difficulty of rendering AI contributions fully visible, accountable, and auditable within academic settings.
Our second novel concept, “legitimacy-dependent hybrid actors,” builds on Pickering (1995) notion of “mangles of practice,” where human and technological agencies intertwine in knowledge production. We define legitimacy-dependent hybrid actors as configurations of human–AI collaboration whose institutional legitimacy is not intrinsic but conditional. The same hybrid practice, such as AI-assisted text generation, may be considered legitimate in one context and illegitimate in another, depending on factors such as disclosure, attribution, role expectations, or institutional norms. This concept shows that legitimacy is not determined solely by what the hybrid actor does, but by how it is positioned and made visible within institutional frameworks. We observe that the same human–AI configuration can shift from illegitimate to legitimate through disclosure and attribution practices, rather than through any change in the actual work performed. This shows how academic legitimacy is being reconstructed around transparency rather than the nature of the work itself, an interesting shift from traditional academic values that focused on the origin of ideas.
Abbott (1988) described legitimacy as established through professional jurisdiction and control, and we see similar processes occurring with AI integration. As shown below, academic contexts generally accept hybrids that enhance rather than replace human academic skills, contribute to process rather than final products, and maintain clear attribution of AI contributions. The temporal dimension of these relationships remains undertheorized, with most attention focused on discrete instances of AI use rather than ongoing partnerships. This variation in hybrid actor legitimacy raises questions about which configurations are privileged in different academic contexts and why.
Our concepts of dual black-boxing and legitimacy-dependent hybrid actors provide a framework for understanding AI in academic settings. As Callon (1986) argues, technological actors are actively enrolled in networks and assigned specific roles and responsibilities. Our framework underlines the tensions inherent in this enrollment process, particularly how academic practices attempt to maintain the visibility of human authority while incorporating increasingly powerful AI tools whose inner workings and actual usage remain opaque.
Recent scholarship has examined how universities and academic publishers respond to GenAI integration through boundary work, visibility mechanisms, and the legitimation of specific human–AI hybrid configurations. Research shows that institutions are engaged in boundary work to establish parameters for legitimate AI use in academia. For example, Jin et al. (2025) examined policies from 40 universities across six global regions, finding that all emphasized “academic integrity and ethical use of AI,” representing explicit demarcation strategies to distinguish legitimate from illegitimate academic practices. Similarly, McDonald et al. (2025) found that 63% of U. S. research universities encourage GenAI use while simultaneously implementing boundary maintenance protocols through citation requirements (38%), syllabus statements (56%), and assignment design guidelines (54%).
These boundary-making efforts typically extend existing frameworks rather than create entirely new boundaries. As Nagpal (2024) observed, universities are not imposing “a blanket ban on GenAI tools. Instead, they advocate for their appropriate and ethical use in educational contexts” (p. 63). Western University, for example, emphasized that “creating policies for rapidly evolving technologies is challenging” and chose to rely on existing academic integrity policies rather than formulate new ones specifically for GenAI (Nagpal, 2024).
Publishers use similar boundary work, with Perkins and Roe (2023) finding that all analyzed publishers established authorship as an exclusively human domain. MIT Press explicitly stated that they “do not allow artificial intelligence (AI) tools such as ChatGPT or large language models (LLMs) to be listed as authors of our publications” because AI tools “cannot assume ethical and legal responsibility for their work” (Perkins and Roe, 2023).
Institutions are implementing various transparency mechanisms to address both forms of black-boxing: the internal opacity of AI functioning and the hidden ways humans use AI in academic work. McDonald et al. (2025) identified that 60% of universities implemented privacy disclosures, and 53% established discussion protocols requiring faculty to engage students in conversations about AI’s limitations and ethical dimensions. For making AI contributions visible, citation and documentation requirements are common. Moorhouse et al. (2023) found that 57% of the university guidelines analyzed defined proper acknowledgment protocols for AI contributions. However, Hofmann et al. (2024) noted considerable variation in documentation requirements, as some universities require detailed citation including “exact application, query date, and prompt in the appendix,” while others consider traditional citation unnecessary due to “lack of copyright.”
Publishers take a similar approach to transparency. The Committee on Publication Ethics (COPE) guidelines, as analyzed by Perkins and Roe (2023), require authors who use AI tools to “be transparent in disclosing in the Materials and Methods (or similar section) of the paper how the AI tool was used and which tool was used.” Nonetheless, most university guidelines discourage reliance on AI detection tools. Moorhouse et al. (2023) found that 61% of guidelines expressed concerns about their accuracy, and Nagpal (2024) quoted Concordia University stating: “Online detectors, like GPTZero are known to be unreliable—commonly producing both false positive and false negative results” (p. 57).
Previous research indicates that institutions conceptualize and selectively legitimize specific human–AI hybrid configurations while delegitimizing others. McDonald et al. (2025) identified several forms that universities recognize: “AI as collaborative partner” in brainstorming and critical thinking, “AI as editor/reviewer” for refinement of human work, and “AI as tutor/study buddy” for personalized learning. Nagpal (2024) study indicated similar hybrid configurations being legitimized, including “Human-as-experimenter with AI,” “Human-AI writing collaborations,” and “Human-as-critical evaluator of AI.” Publishers establish different levels of legitimacy for hybrid collaborations based on domain. While some publishers, like Thieme, acknowledge that “AI tools such as ChatGPT can make scholarly contributions to papers,” others are more restrictive, with Edward Elgar specifically prohibiting “the use of AI tools such as ChatGPT (or related platforms) to generate substantive content, such as the analysis of data or the development of written arguments” (Perkins and Roe, 2023).
Several tendencies are visible across these studies. First, most institutions permit rather than prohibit AI use, with Hofmann et al. (2024) finding that 85% of policies allow AI tools while establishing parameters. Second, there is a shift toward process-focused assessment as a boundary maintenance strategy. Moorhouse et al. (2023) found that 74% of guidelines suggested redesigning assessment tasks to emphasize aspects of work that remain distinctly human. Third, institutions converge on transparency as the primary mechanism for addressing dual black-boxing, with citation, documentation, and disclosure requirements becoming standard. However, the efficacy of these measures remains uncertain, with McDonald et al. (2025) describing much of this as “incomplete visibility work” that creates a paradoxical situation where institutions simultaneously encourage AI use while failing to fully address its opacity. The fluid nature of these policies indicates ongoing boundary reconfiguration. Perkins and Roe (2023) documented publishers like Elsevier stating they “will monitor developments around generative AI and AI-assisted technologies and will adjust or refine this policy should it be appropriate,” and Springer noting, “as we expect things to develop rapidly in this field in the near future, we will review this policy regularly and adapt it if necessary.”
Based on our conceptual framework and the review of previous literature, we formulate three research questions to guide our empirical investigation:
a) How do academic institutions establish and maintain boundaries around legitimate AI use in knowledge production?
b) What visibility mechanisms do institutions develop to address the dual black-boxing of AI systems?
c) Which legitimacy-dependent hybrid actors receive institutional legitimacy?
2 Materials and methods
We used a qualitative content analysis methodology to examine how academic institutions conceptualize and regulate the use of AI, especially generative AI, in knowledge production. We also analyzed official AI policy documents from two key stakeholder groups: universities and academic publishers, enabling us to compare institutional approaches across different contexts within academia.
2.1 Data collection
We collected AI policy documents from two primary sources. First, we identified and analyzed official AI usage guidelines from 16 major research universities across the United States and the United Kingdom. These institutions were selected based on their academic prominence (the eight Ivy League universities and the top eight UK universities according to the Times Higher Education ranking). Second, we examined official AI usage guidelines from 12 major academic publishers, selected based on their prominence in scholarly publishing, diverse disciplinary coverage, and the availability of comprehensive AI policies. The universities analyzed in this study are Brown University, Columbia University, Cornell University, Dartmouth College, Harvard University, University of Pennsylvania, Princeton University, Yale, University of Oxford, University of Cambridge, Imperial College London, University College London (UCL), University of Edinburgh, King’s College London, London School of Economics and Political Science, and University of Manchester. The publishers analyzed are the following: Cambridge University Press, Elsevier, Frontiers, IEEE, MDPI, MIT Press, Oxford University Press, PLoS, SAGE, Springer Nature, Taylor & Francis, and Wiley.
2.2 Analytical approach
We used an iterative qualitative content analysis approach, combining deductive coding based on our conceptual framework with inductive coding that facilitated the emergence of sub-themes. Our analysis proceeded through three stages. In the initial coding phase, we coded each policy document using a preliminary coding scheme derived from our conceptual framework. This initial coding focused on identifying boundary-making strategies and maintenance mechanisms, transparency requirements addressing AI opacity, sanctioned and unsanctioned human–AI configurations, and legitimacy factors for different hybrid actors.
After initial coding and code refinement, we conducted a thematic analysis to identify patterns across institutions and stakeholder groups. This analysis focused on comparing boundary work approaches between universities and publishers, identifying common and divergent visibility mechanisms, mapping legitimacy hierarchies across different academic contexts, and tracing institutional responses to dual black-boxing.
3 AI at the universities’ gates
3.1 Boundary work in academic AI usage policies
3.1.1 Establishing legitimacy boundaries
Universities use various strategies to establish boundaries around legitimate AI use in academic knowledge production. A primary boundary-making strategy involves explicitly defining conditions under which AI use is permitted or prohibited. Columbia University establishes a prohibitive boundary: “Absent a clear statement from a course instructor granting permission, the use of Generative AI tools to complete an assignment or exam is prohibited.” Similarly, Dartmouth College adopts an exclusionary default position: “Students may not use GenAI tools for coursework unless expressly permitted.” This approach reflects a boundary configuration that defaults to restriction rather than permission.
Some institutions employ categorical boundary-making to structure legitimate AI use. These categorical boundaries create structured frameworks that define the parameters of acceptable AI engagement. University College London (UCL) establishes three distinct categories that demarcate appropriate AI usage: “Category 1: GenAI tools cannot be used,” “Category 2: GenAI tools can be used in an assistive role,” and “Category 3: GenAI has an integral role.” The London School of Economics adopts a similar approach, with “Position 1: No authorized use of generative AI in assessment,” “Position 2: Limited authorized use of generative AI in assessment,” and “Position 3: Full authorized use of generative AI in assessment.”
Authority allocation represents another important boundary-making strategy. Universities establish who has the authority to determine legitimate AI use, typically assigning this responsibility to instructors. This allocation of authority creates a distributed boundary-making system where legitimacy is determined at the course level rather than through centralized policy. For example, Cornell University states: “Cornell encourages a flexible framework in which faculty and instructors can choose to prohibit, to allow with attribution, or to encourage generative AI use.” Similarly, Harvard University notes: “Faculty should be clear with students they are teaching and advising about their policies on permitted uses, if any, of generative AI in classes and on academic work.”
Some institutions establish boundaries through functional distinctions that specify permissible uses while prohibiting others. King’s College London, for example, identifies appropriate functions for AI: “Help generate ideas and frameworks for study and assessments,” “Upscale and organize rough typed notes,” and “Provide explanations of concepts you are struggling to understand through dialogic exchanges.” Similarly, the University of Edinburgh delineates acceptable functions: “Brainstorming ideas through prompts,” “Getting explanations of difficult ideas, questions and concepts,” and “Self-tutoring through conversation with the GenAI tool.” Interestingly, these functional boundaries focus on process-oriented rather than product-oriented collaboration between humans and AI.
3.1.2 Maintenance mechanisms
Beyond establishing boundaries, universities implement various mechanisms to maintain them over time. Citation and attribution requirements represent a primary boundary maintenance strategy. Brown University states: “Do cite or acknowledge the outputs of generative AI tools when you use them in your work. This includes direct quotations and paraphrasing, as well as using the tool for tasks like editing, translating, idea generation, and data processing.”
Universities also maintain boundaries through verification protocols that preserve credibility across the human–AI boundary. For example, Columbia University instructs users to “Confirm the accuracy of the output provided by Generative AI tools prior to relying on such information.” University of Pennsylvania also recommends: “The user of AI should endeavor to validate the accuracy of created content with trusted first party sources and monitor the reliability of that content.”
Accountability allocation serves as another boundary maintenance mechanism that maintains the human–AI boundary by assigning final responsibility to human actors while acknowledging the role of AI in the knowledge production process. Yale University emphasizes personal responsibility: “We are each responsible for the content of our work product. Always review and verify outputs generated by AI tools, especially before publication.” Cornell University notes: “You are accountable for your work, regardless of the tools you use to produce it.”
Several institutions maintain boundaries through explicit categorization of misconduct. Again, Columbia University states: “The unauthorized use of AI shall be treated similarly to unauthorized assistance and/or plagiarism.” Imperial College London also notes: “Unless explicitly authorized to use as part of an assessment, the use of generative AI tools to create assessed work can be considered a form of contract cheating.” These misconduct definitions serve as boundary enforcement mechanisms that reinforce distinctions between legitimate and illegitimate practices.
3.1.3 Boundary objects and hybridization
The university guidelines show how AI tools function as boundary objects that exist at the intersection of computational and academic worlds. Some institutions explicitly acknowledge the hybrid nature of human–AI knowledge production. King’s College London states that when AI is used properly, student work “can still be considered as my own words,” suggesting a form of distributed authorship where AI contributions are incorporated into human work without replacing human agency.
The University of Manchester addresses this hybridity in visual content: “AI tools should help support the creative process and its final output—not replace it.” This statement positions AI as a boundary object that can contribute to knowledge production while maintaining human centrality in the process. Brown University also navigates the human–AI boundary by advising: “Be flexible in your approach to citing AI-generated content, because emerging guidelines will always lag behind the current state of technology.”
3.2 Demarcation strategies and visibility mechanisms
3.2.1 Protection of human autonomy
A key demarcation strategy involves protecting human autonomy in knowledge production by restricting AI to supportive rather than primary roles. For example, the University of Cambridge maintains a boundary against full AI authorship: “We do not publish any content that has been written 100% by text generators.” King’s College London establishes a comparable boundary: “Learn with your chats and interactions with AI, but never copy-paste text generated from a prompt directly into summative assignments.”
3.2.2 Visibility and transparency requirements
Universities use transparency requirements as demarcation strategies to maintain the visibility of human–AI collaboration. The University of Edinburgh requires: “Credit use of tools: Before handing in your assessed work, make sure you acknowledge the use of GenAI, where used.” Imperial College London requires: “You should include a statement to acknowledge your use of generative AI tools for all assessed work, in accordance with guidelines from your department or course team.” These visibility requirements counteract what could be described as usage black-boxing by making the role of AI in academic work explicit.
Universities integrate these visibility mechanisms into existing academic processes to ensure their implementation. One integration approach involves incorporating AI attribution into standard citation practices. For instance, Brown University notes: “When in doubt, remember that we cite sources for two primary purposes: first, to give credit to the author or creator; and second, to help others locate the sources you used in your research.” Several institutions also integrate visibility mechanisms with academic integrity processes. Dartmouth College warns: “Failure to cite or acknowledge GenAI use may result in disciplinary action.” These integrations enhance visibility by connecting AI transparency to existing academic integrity frameworks with established consequences.
Disclosure requirements also reveal what would otherwise be hidden AI contributions to academic work. The most common approach involves mandatory disclosure and attribution requirements. Columbia University requires users to “Disclose the use of Generative AI tools” when leveraging them to produce written materials.
Furthermore, some universities implement formalized declaration frameworks that render AI usage visible through standardized statements. These binary declaration options create formal visibility around the presence or absence of AI contributions in academic work. King’s College London requires students to include a declaration statement, choosing between: “I declare that no part of this submission has been generated by AI software. These are my own words.” or “I declare that parts of this submission has contributions from AI software and that it aligns with acceptable use as specified as part of the assignment brief/guidance and is consistent with good academic practice.”
Several institutions go beyond general attribution to require detailed documentation of AI use. Imperial College London requires a statement that includes: “name and version of the tool used, publisher, URL, brief description of how the tool was used, and confirmation the work is your own.” The University of Edinburgh similarly requires acknowledging “Name and version (if included) of the GenAI system used,” “Publisher (the company that made the GenAI system),” “URL of the GenAI system,” and a “Brief description (single sentence) of context in which the tool was used.”
Some institutions also explicitly acknowledge the hybrid nature of AI-assisted academic work. Imperial College London provides an attribution example: “I acknowledge the use of ChatGPT 3.5 (OpenAI)1 to generate an outline for background study. I confirm that no content generated by AI has been presented as my own work.” This example creates visibility around the specific contribution of AI while maintaining human ownership of the final product. It introduces what could be described as visible seams in the hybrid human–AI knowledge production process.
3.2.3 Data protection boundaries
Many universities establish firm and cautious boundaries regarding what information can be shared with AI tools. Princeton University states: “Data protection: Do not use non-public Princeton data in public Gen AI tools.” Harvard University similarly advises: “You should not enter data classified as confidential (Level 2 and above, including non-public research data, finance, HR, student records, medical information, etc.) into publicly-available generative AI tools.” These data protection boundaries reflect concerns about the dual black-boxing of AI in the context of widespread privacy issues about digital technologies in general and AI in particular, referring to both the opacity of AI’s internal functioning and the invisible flow of sensitive information into AI systems.
3.2.4 Verification and responsibility allocation
Universities maintain boundaries by assigning verification responsibilities to human users, thereby maintaining the boundary between human and AI authority by positioning humans as critical evaluators of AI outputs. As an illustration, Yale University states: “Be alert for bias and inaccuracy. AI-generated responses can be biased, inaccurate, inappropriate, or may contain unauthorized copyrighted information.” Columbia University advises: “Check the output of Generative AI tools for bias.”
Universities implement various mechanisms to address what Latour (1987) would characterize as the black-boxing of AI systems, concerning both their internal functioning and actual usage patterns. One such mechanism involves acknowledging the inherent limitations of AI systems. For example, Imperial College London directly addresses the internal opacity of AI: “Generative AI tools’ outputs are, fundamentally, not reliable nor trustworthy as pure statements of fact.” The University of Cambridge also highlights the limitations of AI: “Generative AI tools do not produce neutral answers because the information sources they are drawing from have all been created by humans and contain our biases and stereotypes” and “These tools also often create content that contains errors and ‘hallucinations’.”
Several institutions go further than acknowledging general limitations and specify particular aspects of AI’s internal opacity, creating focused visibility around certain aspects of AI’s black-boxed internal processes. Yale University details specific concerns: “AI-generated responses can be biased, inaccurate, inappropriate, or may contain unauthorized copyrighted information.” The University of Cambridge mentions copyright issues related to AI-generated content: “The risk of plagiarism is high with lifting something completely from an AI content generator, and these tools are often opaque about their original sources and who owns the output.”
Some universities address the opacity of AI through mandatory verification routines that require users to scrutinize AI outputs. For example, Cornell University instructs: “When using generative AI tools, always verify the information for errors and biases and exercise caution to avoid copyright infringement.” The University of Edinburgh similarly requires: “Verify facts: Always check GenAI output for factual accuracy, including references and citations.”
The demarcation strategies adopted by universities indicate an emerging model of human–AI collaboration that maintains human primacy while also acknowledging the role of AI in academic knowledge production. The boundaries established are neither entirely rigid nor completely permeable, but rather selectively permeable, allowing certain types of AI contributions while restricting others. This approach reflects what could be described as a human-centered collective formation, where AI is integrated in academic networks in limited, visible, and peripheral ways.
3.2.5 Limitations of current visibility mechanisms
Despite these efforts, current visibility mechanisms reveal several limitations in addressing the dual black-boxing of AI systems. Most notably, university policies primarily address usage black-boxing while providing limited mechanisms for penetrating the internal black box of AI. While institutions acknowledge the internal opacity of AI through general warnings about hallucinations and biases, they provide few concrete methods for rendering these internal processes transparent beyond human verification of outputs.
The emphasis on human verification as a visibility mechanism places significant responsibility on individual users who may lack the expertise to effectively evaluate AI outputs. Princeton University advises: “Maintain oversight and always review and validate AI-generated content to ensure accuracy and appropriateness.” These verification requirements assume users can effectively detect AI errors, which may not always be possible given AI’s opacity. Notably, several universities acknowledge the inherent limitations of current visibility mechanisms. Such acknowledgments reflect an awareness that existing transparency mechanisms may be inadequate for addressing rapidly changing AI systems.
3.3 Legitimacy hierarchies in human–AI academic configurations
3.3.1 Typology of legitimized hybrid actors
Universities implicitly or explicitly acknowledge specific configurations of human–AI collaboration while delegitimizing others, thus creating legitimacy hierarchies in academic knowledge production. These approvals show distinct types of hybrid actors that receive institutional approval (see Figure 1).
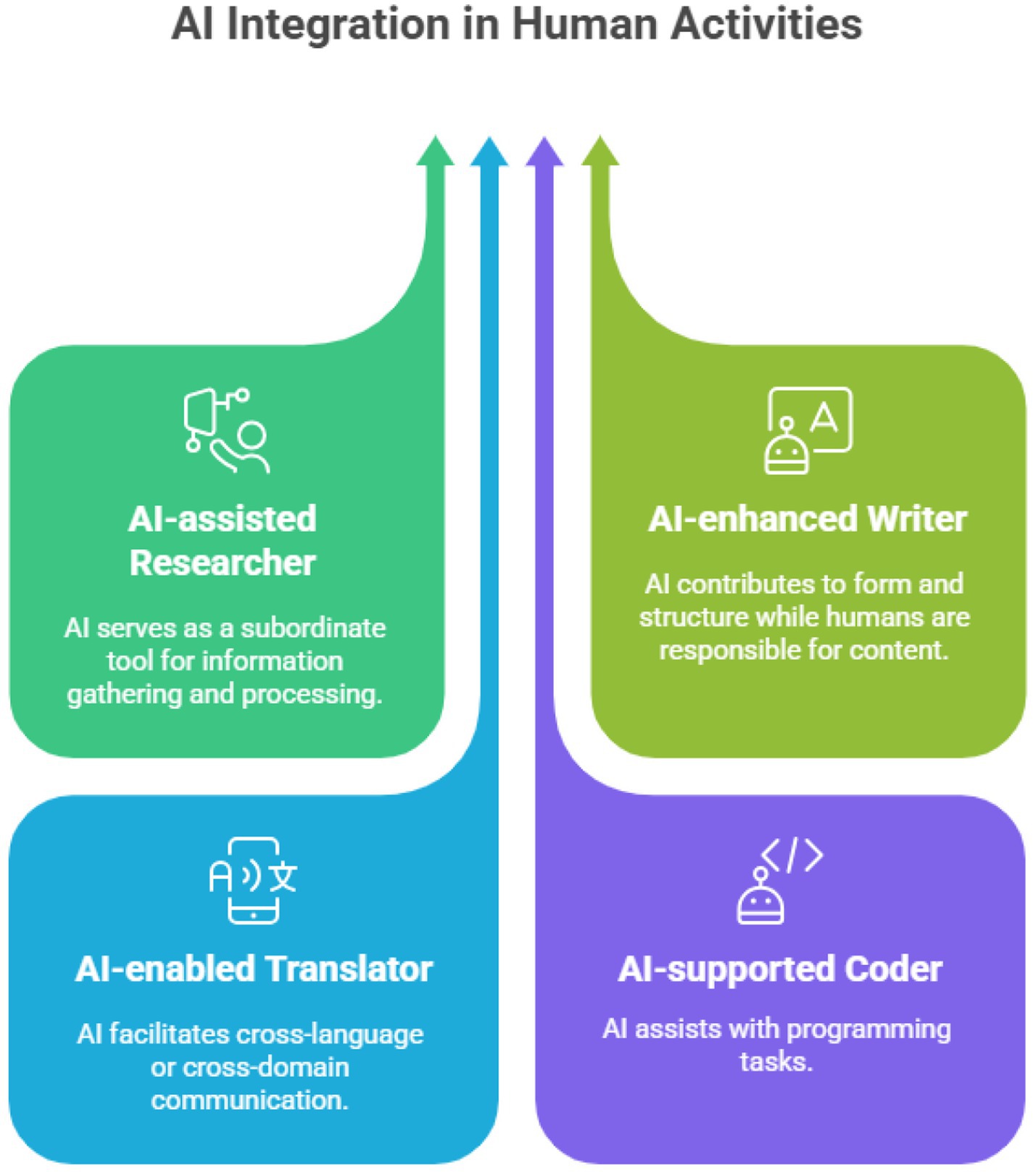
Figure 1. Types of hybrid actors legitimized by universities. Source: Authors’ analysis. Visualization made with Napkin AI.
The most widely recognized hybrid configuration is what could be termed the “AI-assisted researcher,” in which AI serves as a subordinate tool for information gathering and processing. Concerning this configuration, the University of Oxford states: “Generative AI tools may be useful in supporting you to develop your academic reading skills.” They suggest specific assistance modes, such as “asking for tables of key terms” and “generating thought-provoking questions.” King’s College London similarly legitimizes this configuration by approving AI use to “Help generate ideas and frameworks for study and assessments” and “Provide explanations of concepts you are struggling to understand through dialogic exchanges.” This research-assistant configuration positions AI as a subordinate contributor to human-centered academic work.
A second hybrid actor legitimized is the “AI-enhanced writer,” in which AI contributes to the writing process while humans maintain authorial control. This enhanced-writer configuration positions AI as a writing assistant, contributing to form and structure while humans are responsible for content. The University of Oxford approves this configuration, noting that “Generative AI tools can be useful in developing your academic writing skills and providing initial feedback on them.” They suggest specific writing assistance functions, including “getting examples of writing styles,” “receiving feedback,” and “overcoming writer’s block.” The University of Edinburgh further legitimizes this configuration by approving AI use for “Planning and structuring your writing,” “Summarizing a text, article or book,” and “Helping to improve your grammar, spelling, and writing.”
A third legitimized hybrid configuration is the “AI-enabled translator,” in which AI facilitates cross-language or cross-domain communication. The University of Oxford approves AI use for “translating sections” of academic texts. The University of Edinburgh also legitimizes “Translation of texts in other languages” as an acceptable use of AI. This translator configuration situates AI as a boundary-crossing agent that facilitates communication across linguistic or disciplinary domains while humans maintain interpretive authority.
Some institutions also legitimize what could be termed the “AI-supported coder,” where AI assists with programming tasks. This code-assistant configuration positions AI as a technical collaborator that contributes to programming processes while humans maintain design control and accountability for the final code.
3.3.2 Factors determining legitimacy
Several factors shape whether specific human–AI configurations receive institutional legitimacy. The distribution of agency between human and AI elements appears to be a primary legitimacy factor. Configurations maintaining clear human dominance receive stronger institutional legitimacy than those suggesting equal or AI-dominant agency. The University of Manchester emphasizes human primacy: “We will not publish any content that has been written 100% by text generators.” Such statements establish human agency as a prerequisite for legitimacy in academic knowledge production.
The visibility of AI contributions represents a second key legitimacy factor. Configurations that make the role of AI transparent receive institutional approval, while those that obscure the contributions of AI are delegitimized. Requirements establish transparency as a condition for legitimacy in human–AI academic work.
A third legitimacy factor involves the temporal positioning of AI’s contributions within the knowledge production process. Configurations where AI supports early-stage processes receive stronger institutional approval than those where AI is used to generate final products. Temporal distinctions establish process contribution rather than product generation as a legitimacy condition.
3.3.3 Context-dependent legitimacy variations
The data show significant variation in which hybrid configurations are approved across different academic contexts. Classroom settings generally impose stricter legitimacy constraints than research environments. Legitimacy also varies by discipline and task type. University College London acknowledges this variation by noting that “Category 1” assessments, where AI cannot be used, include “In-person unseen examinations, Class tests, Vivas, Some laboratories and practicals, Discussion-based assessments, Presentations with a significant Q&A/viva component.”
3.3.4 Legitimacy through academic values alignment
A final legitimation factor involves alignment with core academic values. Configurations that support established educational goals receive stronger institutional approval than those that risk undermining these goals. King’s College London legitimizes certain AI uses by noting they can “Help challenge some of the issues in study experienced by neurodivergent students.” This statement establishes educational accessibility as a legitimation factor for human–AI hybridity. Some institutions delegitimize configurations that could undermine academic values. University of Edinburgh warns: “Generative AI may, in some cases, undermine development of your academic reading skills (e.g., asking an AI tool to summarize an article rather than undertaking the task yourself).”
4 AI at the publishers’ gates
4.1 Boundary work in academic AI usage—publishers’ perspectives
4.1.1 Establishing legitimacy boundaries
Academic publishers, like universities, engage in boundary work to distinguish legitimate from illegitimate AI use in knowledge production. In publishing contexts, these boundaries take several distinct forms.
A primary boundary-making strategy involves defining legitimate authorship. Publishers universally establish a demarcation that excludes AI from authorship roles. For example, Elsevier states: “Authors should not list AI and AI-assisted technologies as an author or co-author, nor cite AI as an author. Authorship implies responsibilities and tasks that can only be attributed to and performed by humans.” Cambridge University Press also declares: “AI does not meet the Cambridge requirements for authorship, given the need for accountability.”
Publishers also establish boundaries through categorical distinctions between permissible and impermissible AI uses. SAGE creates a fundamental boundary by distinguishing between “Assistive AI tools” that “make suggestions, corrections, and improvements to content you have authored yourself” and “Generative AI tools” that “produce content, whether in the form of text, images, or translations.” This categorical boundary serves to differentiate acceptable from unacceptable AI contributions based on the nature of the technological intervention.
Many publishers establish boundaries around image creation and manipulation, reflecting concerns about authenticity and verification in scientific evidence. Elsevier prohibits specific graphical uses: “We do not permit the use of Generative AI or AI-assisted tools to create or alter images in submitted manuscripts. This may include enhancing, obscuring, moving, removing, or introducing a specific feature within an image or figure.” Also, Taylor & Francis states: “Taylor & Francis currently does not permit the use of Generative AI in the creation and manipulation of images and figures, or original research data for use in our publications.”
Several publishers establish role-specific boundaries that delineate appropriate AI use based on participant role in the publishing process. Elsevier creates distinct boundaries for authors, reviewers, and editors. For reviewers: “Generative AI or AI-assisted technologies should not be used by reviewers to assist in the scientific review of a paper.” For editors: “Generative AI or AI-assisted technologies should not be used by editors to assist in the evaluation or decision-making process of a manuscript.” The role-specific boundaries create differentiated legitimacy frameworks for various publishing participants.
4.1.2 Maintenance mechanisms
Publishers implement various mechanisms to maintain their boundaries around legitimate AI use. Disclosure requirements represent a primary boundary maintenance strategy. IEEE requires: “The use of content generated by artificial intelligence (AI) in a paper (including but not limited to text, figures, images, and code) shall be disclosed in the acknowledgments section of any paper submitted to an IEEE publication.” Oxford University Press also mandates: “The use of any AI in content generation or preparation must be disclosed to your Acquisitions Editor. It must also be appropriately cited in-text and/or in notes.” These disclosure requirements function as visibility work that makes AI’s contributions transparent within the publication process.
Some publishers implement detailed documentation mechanisms to maintain boundaries around AI use. These documentation practices create structured visibility around the specific nature of AI contributions to academic work. For example, SAGE requires a comprehensive disclosure template including: “Full title of the submission,” “Type of submission,” “Name of the Generative AI tool used,” “Brief description of how the tool was used,” “Rationale for AI use,” “Final prompt given,” “Final response generated,” and “Location of AI-generated content in the submission.”
Publishers similarly maintain boundaries through verification requirements that position humans as responsible for validating AI outputs. SAGE instructs authors to “Carefully verify the accuracy, validity, and appropriateness of AI-generated content or AI-produced citations: Large Language Models (LLMs) can sometimes ‘hallucinate’.” Oxford University Press mandates: “Authors must themselves verify the accuracy and appropriate attribution of any content, the creation of which has been supported by using AI.” Through such verification requirements, human authority is maintained in knowledge production by establishing humans as the ultimate arbiters of accuracy.
Several publishers maintain boundaries through explicit consequences for non-compliance, using enforcement mechanisms as boundary maintenance strategies that ensure adherence to established demarcations. SAGE warns: “Where we identify published articles or content with undisclosed use of generative AI tools for content generation, we will take appropriate corrective action.” PLOS also notes: “If concerns arise about noncompliance with this policy, PLOS may notify the authors’ institution(s) and the journal may reject (pre-publication), retract (post-publication), or publish an editorial notice on the article.”
4.1.3 Demarcation strategies
Publishers use several specific demarcation strategies to distinguish legitimate from illegitimate AI use in academic publishing, maintaining the centrality of human agency in scholarly knowledge production. A primary strategy involves protecting human accountability in knowledge production. Springer Nature emphasizes: “In all cases, there must be human accountability for the final version of the text and agreement from the authors that the edits reflect their original work.” MDPI similarly states: “Authors are fully responsible for the content of their manuscript, even those parts produced by an AI tool, and are thus liable for any breach of publication ethics.”
Publishers also employ demarcation strategies that distinguish processes from products in AI use. Taylor and Francis approves AI use for “idea generation and idea exploration,” “language improvement,” and “interactive online search with LLM-enhanced search engines,” but prohibits “text or code generation without rigorous revision.”
Confidentiality requirements represent another demarcation strategy. Elsevier instructs reviewers: “Reviewers should not upload a submitted manuscript or any part of it into a generative AI tool as this may violate the authors’ confidentiality and proprietary rights.” Similarly, PLOS mandates: “submission content may not be uploaded by handling editors or reviewers to generative AI platforms, websites, databases, or other tools; this is essential for protecting the confidentiality of unpublished work.”
The demarcation strategies of publishers reflect what could be described as a principle of selective permeability, allowing certain types of AI contributions while restricting others. This selective approach maintains human primacy in knowledge production while acknowledging AI’s potential contributions to specific aspects of the publishing process. The boundaries established are neither entirely rigid nor completely permeable, creating a workable, pragmatic framework for legitimate human–AI collaboration in academic publishing.
4.2 Visibility mechanisms addressing dual black-boxing in academic publishing
4.2.1 Transparency mechanisms for AI’S internal opacity
Publishers implement various mechanisms to address the black-boxing of AI systems. These efforts aim to render visible aspects of AI’s internal functioning that would otherwise remain opaque in academic knowledge production. Several publishers directly acknowledge the inherent limitations of AI systems, highlighting their potential for error. These acknowledgments serve as educational transparency mechanisms that make visible specific aspects of AI’s internal opacity. Taylor & Francis explicitly identifies “inaccuracy and bias” as a key risk of AI tools, noting they “are of a statistical nature (as opposed to factual) and, as such, can introduce inaccuracies, falsities (so-called hallucinations) or bias, which can be hard to detect, verify, and correct.” Springer Nature warns about “considerable limitations” of AI tools: “they can lack up-to-date knowledge and may produce nonsensical, biased or false information.”
Some publishers address the internal opacity of AI through detailed documentation requirements that expose the “black box” of AI prompts and outputs. SAGE requires authors to document the “Final prompt given” and “Final response generated” when using generative AI tools. Frontiers also “encourage[s] authors to upload all input prompts provided to a generative AI technology and outputs received from a generative AI technology in the supplementary files for the manuscript.”
Publishers also address the opacity of AI through system identification requirements that reveal the specific AI tools used, thereby creating visibility around the specific AI technologies contributing to academic work. IEEE mandates: “The AI system used shall be identified, and specific sections of the paper that use AI-generated content shall be identified and accompanied by a brief explanation regarding the level at which the AI system was used to generate the content.” Similarly, Frontiers requires disclosure of “the name, version, model, and source of the generative AI technology.”
4.2.2 Making AI usage patterns visible
Publishers implement various mechanisms to make AI usage patterns visible in academic publishing. Detailed attribution frameworks represent a primary visibility mechanism. SAGE, for instance, requires a comprehensive disclosure template that documents how AI was used, including “Brief description of how the tool was used,” “Rationale for AI use,” and “Location of AI-generated content in the submission.”
Some publishers implement categorical disclosure frameworks that distinguish between types of AI use requiring different levels of visibility, creating visibility requirements that vary based on the nature of AI’s contribution. SAGE creates different disclosure requirements for “Assistive AI” and “Generative AI,” stating: “You are not required to disclose the use of assistive AI tools in your submission” but “You are required to inform us of any AI-generated content appearing in your work.” Springer Nature exempts certain AI uses from disclosure: “The use of an LLM (or other AI-tool) for ‘AI assisted copy editing’ purposes does not need to be declared.”
Publishers also promote visibility around AI use through location-specific disclosure requirements that direct authors to acknowledge AI contributions in specific sections of academic publications. IEEE requires disclosure “in the acknowledgments section of any paper.” PLOS mandates disclosure “in a dedicated section of the Methods, or in the Acknowledgements section for article types lacking a Methods section.” These location-specific requirements generate standardized visibility for AI contributions within established publication structures.
Several publishers implement permission requirements that make AI use visible to editorial gatekeepers before publication. Oxford University Press requires: “Authors must receive written permission from OUP to deliver AI-generated content (including the collection and analysis of data or the production of graphical elements of the text) as part of their submission.” Pre-publication permission requirements aim to produce early visibility around AI contributions within the publishing process.
4.2.3 Integration of visibility mechanisms in publishing processes
Publishers integrate visibility mechanisms into existing publishing processes to ensure their implementation, embedding AI visibility requirements within established ethical review processes. One integration approach involves connecting AI visibility to publication ethics frameworks. SAGE, for example, notes: “Sage and the Journal Editor will lead a joint investigation into concerns raised about the inappropriate or undisclosed use of Generative AI in a published article. The investigation will be undertaken in accordance with guidance issued by COPE and our internal policies.”
Several publishers also integrate visibility mechanisms with peer review processes. PLOS requires: “Any use of AI tools in peer review (e.g., for data assessment, translation, or language editing) must be clearly disclosed to authors in the review form (reviewers) or decision letter (editors).” This integration creates visibility around the role of AI in evaluating academic work, not just its creation. In addition, some publishers create distinct visibility protocols for specific content types, particularly images. Springer Nature requires that AI-generated images “must be labeled clearly as generated by AI within the image field.”
4.2.4 Limitations of current visibility mechanisms
Current visibility mechanisms reveal ongoing challenges in addressing the dual black-boxing of AI systems. Publisher policies provide limited mechanisms for making the internal training data of AI systems visible. While acknowledging potential plagiarism and copyright concerns, publishers do not implement specific mechanisms to trace how AI systems might incorporate copyrighted academic content in their outputs. Taylor & Francis identifies the risk that “Generative AI providers may reuse the input or output data from user interactions (e.g., for AI training),” but provides limited mechanisms for making this process visible.
The emphasis on human verification as a visibility mechanism puts significant responsibility on individual authors who may lack the expertise to effectively evaluate AI outputs. SAGE instructs authors to “Carefully verify the accuracy, validity, and appropriateness of AI-generated content,” but provides limited guidance on how to perform this verification effectively. This verification gap limits the effectiveness of current visibility mechanisms in addressing AI’s internal opacity. Several publishers also acknowledge the fast-changing nature of AI technology and the potential inadequacy of current visibility mechanisms. Springer Nature notes it “is monitoring ongoing developments in this area closely and will review (and update) these policies as appropriate.” This acknowledgment recognizes that current transparency mechanisms need ongoing adaptation to address fast-paced AI systems.
4.2.5 From opacity to visible hybridization
The visibility mechanisms publishers rely on also reflect an emerging paradigm of visible hybridization in academic knowledge production, mirroring trends seen in universities. Rather than allowing AI to remain invisible in academic work or positioning it as an autonomous agent, publishers establish frameworks for visible human–AI collaboration that acknowledge the hybrid nature of AI-assisted academic publishing while maintaining human authority. Taylor & Francis, for instance, affirms this hybridization: “Taylor & Francis welcomes the new opportunities offered by Generative AI tools, particularly in: enhancing idea generation and exploration, supporting authors to express content in a non-native language, and accelerating the research and dissemination process.”
The visibility mechanisms represent efforts to counteract the previously discussed dual opacity, namely the internal black-boxing of AI systems and the potential invisibility of AI’s role in academic work. Although these mechanisms have limitations in fully addressing the internal opacity of AI, they nonetheless establish frameworks for making the academic contributions of AI increasingly visible.
4.3 Legitimacy-dependent hybrid actors in academic publishing
4.3.1 Typology of legitimized hybrid actors
Publishers implicitly or explicitly legitimize specific configurations of human–AI collaboration while delegitimizing others (see Figure 2). A widely approved hybrid configuration is what could be termed the “AI-assisted language editor,” where AI contributes to linguistic refinement while humans maintain content responsibility. Springer Nature explicitly approves this configuration by exempting “AI assisted copy editing’ purposes” from disclosure requirements, defining this as “AI-assisted improvements to human-generated texts for readability and style, and to ensure that the texts are free of errors in grammar, spelling, punctuation and tone.” IEEE notes: “The use of AI systems for editing and grammar enhancement is common practice and, as such, is generally outside the intent of the above policy.” This language-editor configuration situates AI as a stylistic assistant that improves form while humans maintain responsibility for content.
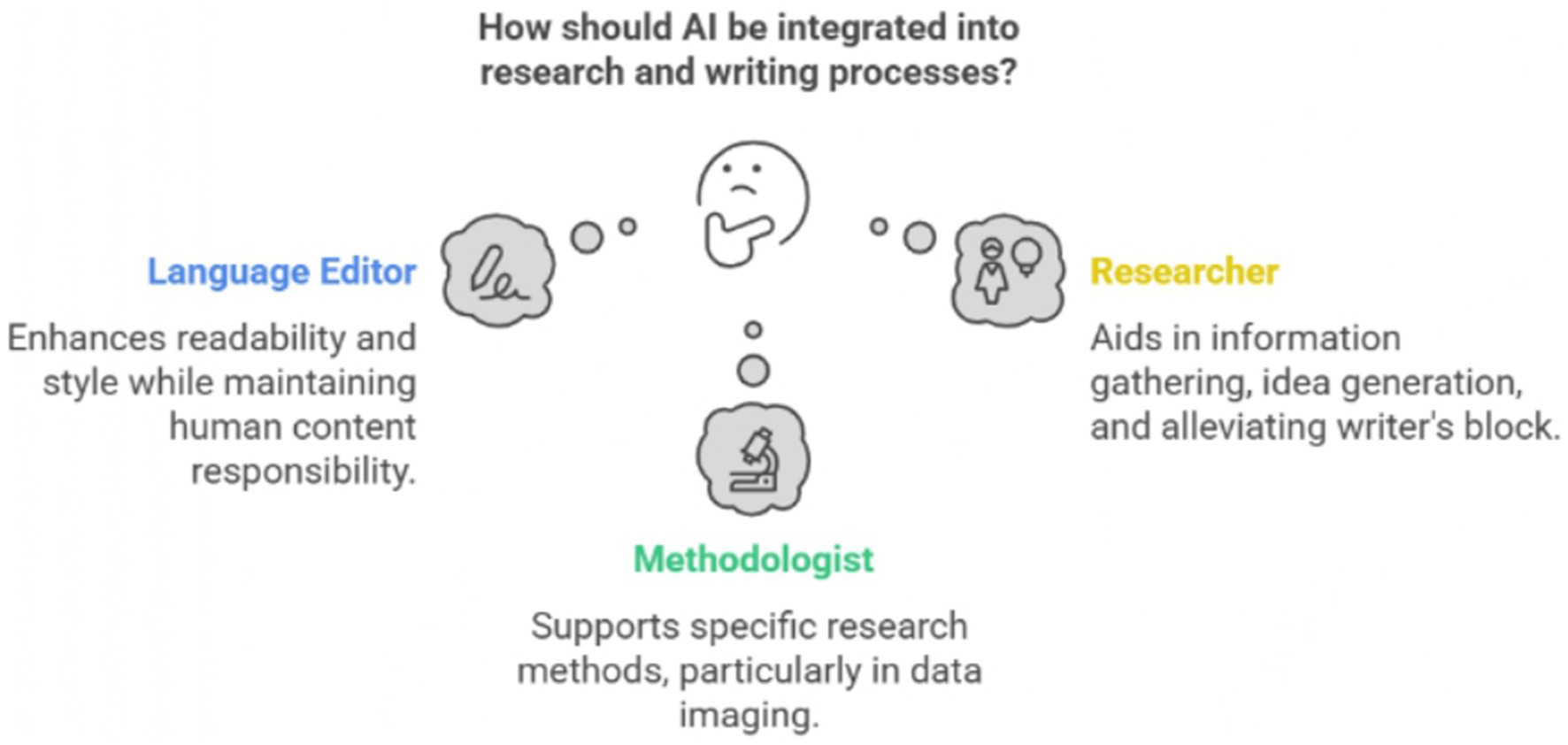
Figure 2. Types of hybrid actors legitimized by publishers. Source: Authors’ analysis. Visualization made with Napkin AI.
A second legitimized hybrid actor is the “AI-assisted researcher” who uses AI for information gathering and processing. SAGE approves AI use for “providing authors with fresh ideas, alleviating writer’s block, and optimizing editing tasks.” Similarly, Taylor & Francis approves AI use for “idea generation and exploration,” “language improvement,” and “interactive online search with LLM-enhanced search engines.” This research-assistant configuration positions AI as a subordinate contributor to human-centered academic work.
Some publishers legitimize what could be termed the “AI-enabled methodologist,” in which AI contributes to specific research methods. This methodologist’s role positions AI as a specialized technical contributor to specific research methods while humans maintain interpretive authority. For example, Elsevier permits AI use in figures only when “the use of AI or AI-assisted tools is part of the research design or research methods (such as in AI-assisted imaging approaches to generate or interpret the underlying research data, for example in the field of biomedical imaging).” Springer Nature also allows “the use of generative AI tools developed with specific sets of underlying scientific data that can be attributed, checked and verified for accuracy.”
4.3.2 Factors determining legitimacy
There are several factors underlying the specific human–AI configurations that receive approval from publishers. The agency distribution between human and AI elements is a legitimacy factor. Configurations maintaining human dominance receive stronger institutional legitimacy than those suggesting equal or AI-dominant agency. Cambridge University Press declares: “It’s obvious that tools like ChatGPT cannot and should not be treated as authors.”
Accountability allocation represents a second legitimacy factor. Configurations that maintain human accountability for content receive stronger legitimacy than those that obscure responsibility. MDPI emphasizes: “Authors are fully responsible for the content of their manuscript, even those parts produced by an AI tool, and are thus liable for any breach of publication ethics.” Similarly, Oxford University Press states: “Authors are responsible for the accuracy, integrity, and originality of their works, as well as any AI generated content these may include.” These accountability requirements establish human responsibility as a condition for legitimacy in human–AI academic work.
The temporal positioning of AI’s contributions in the knowledge production process is a third legitimacy factor. Configurations where AI contributes to early-stage or supporting processes receive stronger approval than those where AI generates final products. These distinctions establish process contribution rather than product generation as a legitimacy condition. For example, SAGE approves AI use for “developing your academic writing skills” but prohibits passing off AI-generated content as one’s own.
4.3.3 Context-dependent legitimacy variations
The data show variation in which hybrid configurations receive legitimacy in different publishing contexts, thereby creating content-dependent legitimacy hierarchies that vary between textual and visual domains. Legitimacy varies by content type, with stronger restrictions typically applied to images than to text. Springer Nature also notes: “While legal issues relating to AI-generated images and videos remain broadly unresolved, Springer Nature journals are unable to permit its use for publication.”
Legitimacy also varies by participant role in the publishing process. Publishers generally permit more AI use by authors than by reviewers or editors. Elsevier instructs reviewers: “Generative AI or AI-assisted technologies should not be used by reviewers to assist in the scientific review of a paper.” PLOS mandates: “AI tools cannot serve as reviewers or as decision-issuing editors.” Thus, we witness the appearance of role-dependent legitimacy determinations that restrict AI’s contributions to evaluation more severely than content creation.
Some publishers also create discipline-specific legitimacy variations, where certain fields receive greater latitude for AI use than others. For example, Elsevier allows AI-generated images only “in the field of biomedical imaging.”
4.3.4 Emergent models of hybrid agency
The publisher guidelines show novel conceptualizations of hybrid agency in academic knowledge production. This positions AI as contributing to human creativity without supplanting human agency, thus creating a hybrid configuration where both elements contribute to knowledge production while maintaining distinct roles. Taylor & Francis similarly conceptualizes hybrid agency by “welcoming the new opportunities offered by Generative AI tools” while emphasizing that “human oversight, intervention and accountability is essential to ensure the accuracy and integrity of the content we publish.”
The legitimation frameworks established by publishers establish a model of what could be described as supervised hybridization, where AI contributions are permitted under specific conditions of human oversight, accountability, and disclosure.
4.3.5 Legitimacy through academic values alignment
A final legitimation factor for publishers involves alignment with core academic values. Configurations that support established scholarly norms receive stronger institutional approval than those undermining these norms. Cambridge University Press, for example, legitimizes certain AI uses by noting they must help “researchers use generative AI tools like ChatGPT, while upholding academic standards around transparency, plagiarism, accuracy and originality.”
Publishers delegitimize configurations that may undermine academic values. This warning establishes equity and fairness as legitimation factors, delegitimizing configurations that risk reproducing harmful biases. SAGE warns about bias in AI systems: “Be aware of bias: Because LLMs have been trained on text that includes biases, and because there is inherent bias in AI tools because of human programming, AI-generated text may reproduce these biases.”
The legitimation frameworks emerging from publisher guidelines indicate a pragmatic approach to human–AI hybridization in academic knowledge production. Rather than adopting binary positions that either fully embrace or entirely reject AI contributions, publishers establish selective legitimation frameworks that permit specific hybrid configurations while restricting others.
5 Comparing universities and publishers: AI governance in academia
5.1 Boundary work and demarcation strategies
Universities and publishers in our sample establish boundaries around legitimate AI use, though with distinct institutional approaches. Universities primarily construct pedagogical boundaries that sometimes default to restriction unless explicitly permitted by instructors, creating a distributed authority structure where legitimacy determinations occur at the course level. Their boundaries usually emphasize process-oriented collaboration, legitimizing AI use for learning activities while restricting its role in formal assessments. In contrast, publishers implement more centralized, editorially-controlled boundaries focused on maintaining publication integrity. They develop detailed, product-oriented restrictions that protect the final scholarly record, emphasizing visual content integrity that reflects concerns about scientific evidence. While both institutions in our sample exclude AI from authorship roles and maintain human accountability, universities focus more on functional boundaries defining permitted assistance uses. In contrast, publishers emphasize production boundaries restricting the role of AI in outputs.
5.2 Visibility mechanisms addressing dual black-boxing
Both institutions implement mechanisms to address AI’s opacity, though their transparency approaches differ in scope and emphasis. On the one hand, universities focus on usage transparency, requiring disclosure of AI contributions but providing limited mechanisms for piercing the internal black box of AI beyond general acknowledgments of potential errors. Their visibility requirements typically connect to academic integrity frameworks, focusing on making AI visible within established attribution practices. On the other hand, publishers sometimes implement stricter documentation mechanisms that address both usage and internal opacity. Some require detailed documentation of specific prompts and responses, creating partial visibility into the otherwise opaque process of AI-generated content. Publishers also create more role-specific visibility requirements, with different disclosure standards for authors, reviewers, and editors. While both institutions position humans as verifiers responsible for validating AI outputs, publishers show greater concern with confidentiality issues and proprietary rights in their visibility frameworks, reflecting the commercial dimensions of scholarly publishing.
5.3 Legitimacy-dependent hybrid actors
Both universities and publishers in our sample approve specific human–AI configurations while delegitimizing others, though with different legitimation patterns. Universities more readily approve AI for educational purposes, legitimizing hybrid configurations that support learning and skill development. Their legitimation frameworks emphasize student growth and educational accessibility, creating student-specific legitimacy hierarchies that vary across learning contexts. However, publishers focus more on research integrity, legitimizing methodological AI use in specific research contexts while implementing stricter verification requirements. Their legitimation frameworks create detailed role-based hierarchies spanning the publication lifecycle, with different standards for authors, reviewers, and editors. Both institutions share key legitimation factors, including human accountability, transparency, and agency distribution. However, publishers place greater emphasis on verification and oversight, reflecting their gatekeeping function in knowledge dissemination. Both ultimately seek configurations that maintain human primacy while selectively incorporating contributions of AI to specific aspects of academic work.
The governance approaches of universities and publishers reflect their distinct institutional roles within academic knowledge production. As educational institutions, universities create more flexible, context-dependent frameworks that empower instructors to determine legitimate AI use based on pedagogical goals. However, publishers, as guardians of the scholarly record, implement more standardized documentation requirements and centralized editorial controls.
6 Discussion
Our study applies boundary work theory and actor-network approaches to analyze how universities and publishers regulate AI in academic contexts. The concepts of dual black-boxing and legitimacy-dependent hybrid actors helped structure our analysis of AI policies from 16 prestigious universities and 12 major publishers.
We found that institutions recognize both forms of AI opacity, specifically algorithmic processes and usage patterns; however, they address them differently. Most policies focus on making AI usage transparent through disclosure requirements rather than addressing the internal workings of AI systems. This asymmetry reflects practical limitations in what academic policies can realistically address regarding proprietary AI systems.
Our analysis also shows that institutions primarily use transparency requirements rather than technological detection or prohibition to maintain boundaries around legitimate AI use. Thus, academic institutions are adapting existing governance mechanisms rather than creating entirely new frameworks for AI.
Our study contributes to a growing body of research examining institutional responses to AI integration in education and knowledge infrastructures. Building on recent typologies of strategic orientations (Zarifis and Efthymiou, 2022; Alqahtani and Wafula, 2025), we show that beyond formal variation in policy design, universities and publishers engage in distinct forms of boundary work that define, authorize, or exclude AI–human configurations. While Zarifis and Efthymiou (2022) emphasize leadership-driven models of digital transformation, and Alqahtani and Wafula (2025) focus on pedagogical framings and ethical positioning, our study extends this literature by analyzing how institutions operationalize legitimacy through visibility mechanisms, such as disclosure requirements, authorship criteria, or usage prohibitions. Gupta’s work (2024) on experimentation in library contexts highlights how informal, distributed innovation may remain under the radar of formal policy, aligning with our distinction between internal and usage black-boxing. In this sense, our study complements existing frameworks by connecting institutional strategies to organizational models and also to epistemic roles, discursive classifications, and material constraints.
6.1 Boundary work strategies
Our examination of university and publisher policies indicated several specific boundary-making strategies. These strategies include categorical distinctions (e.g., UCL’s three categories of AI use), authority allocation (typically to instructors or editors), and functional demarcations that specify acceptable and unacceptable uses.
A visible pattern in both university and publisher policies is the preference for process-oriented rather than product-oriented AI contributions. Institutions generally permit AI use for tasks such as brainstorming, editing, and translation, while restricting its role in generating final academic outputs. Both types of institutions maintain human accountability through verification requirements. These verification requirements aim to strengthen human oversight while allowing selective AI contributions.
6.2 Documentation and disclosure practices
In our analysis, we identified specific documentation practices that institutions use to address AI opacity. Both universities and publishers acknowledge practical implementation challenges in their visibility mechanisms. This recognition of technical limitations shapes institutional responses, leading to a greater focus on disclosure and verification rather than detection. Therefore, rather than creating entirely new citation systems, institutions adapt existing academic attribution practices, indicating that traditional citation frameworks can be extended to encompass AI contributions.
6.3 Legitimized hybrid actors
We found interesting patterns in how prestigious U. S. and UK universities conceptualize legitimate human–AI configurations compared to the broader academic landscape described in the previous literature. While prior studies examined a wider range of institutions globally, our focused sample of prestigious universities shows both convergence with theoretical frameworks and distinctive institutional approaches to AI integration.
Our analysis of prestigious universities led us to observe a somewhat different set of legitimized hybrid actors: the AI-assisted researcher, the AI-enhanced writer, the AI-enabled translator, and the AI-supported coder. Several hybrid actor configurations indicate alignment between the literature and our empirical findings. The AI-assisted author/researcher concept appears consistently across frameworks, positioning AI as a subordinate tool while maintaining human primacy. Similarly, both frameworks recognize legitimate roles for AI in language improvement and editorial assistance, with humans retaining responsibility for content.
However, significant differences appear between broader theoretical conceptualizations and the specific approaches of top universities. While the literature presents more balanced agency distribution between humans and AI, our sampled universities consistently emphasize stricter human primacy, positioning AI in more narrowly defined supportive roles. This difference manifests particularly in evaluation contexts—the literature describes configurations where AI evaluates human work, while our sampled universities primarily legitimize humans evaluating AI outputs, maintaining more apparent evaluative authority.
Prestigious universities also formulate more context-sensitive legitimation frameworks than theoretical models suggest. They create differentiated standards for classroom versus research contexts and show stronger legitimation of process-oriented configurations (idea generation, planning) than product-oriented ones (drafting, completing assignments). This temporal differentiation, preferring early-stage over late-stage AI contributions, appears more pronounced in our sample of prestigious institutions than in the broader literature.
The university and publisher guidelines show emerging conceptualizations of hybrid agency in academic knowledge production. Rather than positioning AI as entirely separate from or fully integrated with human agency, institutions establish frameworks for shared agency between human and non-human elements. The legitimation frameworks established by universities and publishers indicate an emerging model of what could be described as supervised hybridization, where AI contributions are permitted under specific conditions of human oversight and ownership.
Comparing university and publisher approaches shows additional information about how different academic stakeholders legitimize human–AI configurations. Publishers in our sample permit an even narrower range of hybrid actors than universities, primarily recognizing three key configurations: the AI-assisted language editor for stylistic and grammatical refinement, the AI-assisted researcher for idea generation and information processing, and the AI-enabled methodologist for specific technical applications.
Publishers strongly delegitimize the “AI-author” configuration, explicitly prohibiting AI from being listed as an author or generating primary content. While both universities and publishers maintain human-centric frameworks, publishers enforce more restrictive boundaries around visual content and require more detailed documentation requirements for AI contributions. Publishers also create more role-specific legitimacy hierarchies, with stricter limitations on AI use by reviewers and editors than by authors. This indicates that gatekeeping functions in knowledge dissemination receive greater protection from AI integration than knowledge production processes themselves. The more constrained range of legitimate hybrid configurations in publishing contexts reflects publishers’ particular concern with maintaining the integrity of the scholarly record while allowing selective AI contributions that enhance rather than challenge traditional academic publishing norms.
6.4 Implications
We identified a shift in how academic work gains legitimacy through transparency. The same AI-assisted work may be deemed illegitimate if undisclosed, but legitimate if properly acknowledged. This represents a practical adaptation of academic integrity concepts to accommodate AI tools. We also observed a gap between institutional requirements for verifying AI outputs and the practical ability of users to perform this verification. While policies such as the one developed by Yale University instruct users to “be alert for bias and inaccuracy” in AI outputs, they provide limited guidance on how to effectively perform this verification. This gap reflects a practical challenge for implementation.
The variation in permitted AI uses between universities and publishers may create challenges for researchers and students. Universities generally permit more AI uses in educational contexts than publishers allow in scholarly outputs, which may create tension as students transition to publishing their work.
6.5 Limitations and future research
In this analysis of AI policies from prestigious universities and major publishers, we bring to light practical approaches to integrating AI in academic work while maintaining academic integrity standards. These institutions are adapting existing academic practices rather than creating entirely new frameworks, thereby focusing particularly on transparency and human accountability as key governance mechanisms. The patterns that we identified reflect pragmatic responses to the dual challenges of leveraging the capabilities of AI while preserving core academic values.
Our analysis focused exclusively on officially sanctioned institutional documents, publicly available AI policies from universities and academic publishers. While these documents offer important information about formal governance frameworks and boundary-setting strategies, they do not capture informal practices, tacit norms, or situated negotiations that often shape AI use in daily academic work. Informal guidance from peers, unwritten classroom expectations, disciplinary conventions, and pragmatic workarounds often diverge significantly from formal regulations. As such, our findings reflect normative aspirations and institutional messaging rather than empirical implementation. Future ethnographic or interview-based research is needed to examine how actors interpret, comply with, or circumvent these formal policies in practice.
Our sample is formed of top U. S. and UK universities and major publishers. Research examining a broader range of institutions, including community colleges, teaching-focused universities, and smaller publishers, across the globe, would help determine which patterns we identified are specific to top institutions and which represent broader trends in academic AI governance. Given the acceleration of AI technology, longitudinal studies tracking how these policies change over time are necessary, considering that both universities and publishers acknowledge the provisional nature of their current policies.
Data availability statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author/s.
Author contributions
CR: Conceptualization, Data curation, Methodology, Writing – original draft, Writing – review & editing. S-NV: Conceptualization, Data curation, Methodology, Writing – original draft, Writing – review & editing. DȚ: Conceptualization, Data curation, Methodology, Writing – original draft, Writing – review & editing. RR: Conceptualization, Data curation, Methodology, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The authors declare that Gen AI was used in the creation of this manuscript. The authors declare that Anthropic’s Claude AI was used for final language proofing and style improvements to enhance clarity and grammatical accuracy in this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
References
Abbott, A. (1988). The system of professions: an essay on the division of expert labor. Chicago: University of Chicago Press.
Alqahtani, N., and Wafula, Z. (2025). Artificial intelligence integration: pedagogical strategies and policies at leading universities. Innov. High. Educ. 50, 665–684. doi: 10.1007/s10755-024-09749-x
Ananny, M., and Crawford, K. (2018). Seeing without knowing: limitations of the transparency ideal and its application to algorithmic accountability. New Media Soc. 20, 973–989. doi: 10.1177/146144481667664
Bran, E., Rughinis, C., Nadoleanu, G., and Flaherty, M. G. (2023) ‘The emerging social status of generative AI: vocabularies of AI competence in public discourse’, in 2023 24th International Conference on Control Systems and Computer Science (CSCS). 2023 24th International Conference on Control Systems and Computer Science (CSCS), Bucharest, Romania, pp. 391–398. doi: 10.1109/CSCS59211.2023.00068
Callon, M. (1986). Some elements of a sociology of translation: domestication of the scallops and the fishermen of St Brieuc Bay. London: Routledge.
Cristea, D., and Firtala, V. (2023). Fakenews is much more than fake content. Technium Soc. Sci. J. 46, 290–297. doi: 10.47577/tssj.v46i1.9241
DEC Global Survey (2024) ‘Digital education council global AI student survey 2024 ’. Available online at: https://www.digitaleducationcouncil.com/post/digital-education-council-global-ai-student-survey-2024 (Accessed: 28 March 2025).
Flaherty, M. G., Rughiniș, C., and Stoicescu, M. V. (2025) ‘Generative content analysis: five AI models interpret the time work of love at first sight’, in. Proceedings of CSCS25 – The 25th International Conference on Control Systems and Computer Science, Bucharest, Romania.
Gieryn, T. F. (1983). Boundary-work and the demarcation of science from non-science: strains and interests in professional ideologies of scientists. Am. Sociol. Rev. 48, 781–795. doi: 10.2307/2095325
Gupta, V. (2024). From hype to strategy: navigating the reality of experimental strategic adoption of AI technologies in libraries. Ref. Serv. Rev. 53, 1–14. doi: 10.1108/RSR-08-2024-0042
Hofmann, P., Brand, A., Späthe, E., Lins, S., and Sunyaev, A. (2024). “AI-based tools in higher education: a comparative analysis of university guidelines” in Proceedings of Mensch und Computer 2024 (New York, NY: Association for Computing Machinery (MuC ‘24)), 665–673.
Jderu, G. (2022). Motorcycling in a repair society: a maintenance and repair–centered approach to automobility. East Eur. Politics Soc. 36, 604–625. doi: 10.1177/0888325420950802
Jderu, G. (2023). Fixing motorcycles in post-repair societies: Technology, aesthetics and gender. New York, NY: Berghahn Books.
Jin, Y., Yan, L., Echeverria, V., Gašević, D., and Martinez-Maldonado, R. (2025). Generative AI in higher education: a global perspective of institutional adoption policies and guidelines. Comp. Educ. 8:100348. doi: 10.1016/j.caeai.2024.100348
Lamont, M., and Molnár, V. (2002). The study of boundaries in the social science. Annu. Rev. Sociol. 28, 167–195. doi: 10.1146/annurev.soc.28.110601.141107
Matei, Ș. (2023). The technological mediation of collective memory through historical video games. Games Cult. 20, 477–498. doi: 10.1177/15554120231206862
Matei, Ș. (2024). Generative artificial intelligence and collective remembering. The technological mediation of mnemotechnic values. J. Hum. Technol. Relat. 2, 1–22. doi: 10.59490/jhtr.2024.2.7405
McDonald, N., Johri, A., Ali, A., and Collier, A. H. (2025). Generative artificial intelligence in higher education: evidence from an analysis of institutional policies and guidelines. Comput. Hum. Behav. 3:100121. doi: 10.1016/j.chbah.2025.100121
Moorhouse, B. L., Yeo, M. A., and Wan, Y. (2023). Generative AI tools and assessment: guidelines of the world’s top-ranking universities. Comput. Educ. Open 5:100151. doi: 10.1016/j.caeo.2023.100151
Nagpal, H. (2024). Policies, procedures, and guidelines: are universities effectively ensuring AI (academic integrity) in the era of generative AI? Thunder Bay, Ontario: Lakehead University.
Obreja, D. (2023). Video games as social institutions. Games Cult. 19, 831–850. doi: 10.1177/15554120231177479
Obreja, D. M., and Rughiniş, R. (2023) ‘The moral status of artificial intelligence: exploring users’ anticipatory ethics in the controversy regarding LaMDA’s sentience’, in 2023 24th International Conference on Control Systems and Computer Science (CSCS). 2023 24th International Conference on Control Systems and Computer Science (CSCS), Obreja and Rughiniş, 2023 - Bucharest, Romania, pp. 411–417. doi: 10.1109/CSCS59211.2023.0007
Obreja, D., Rughiniș, R., and Rosner, D. (2024). Mapping the conceptual structure of innovation in artificial intelligence research: a bibliometric analysis and systematic literature review. J. Innov. Knowl. 9:100465. doi: 10.1016/j.jik.2024.100465
Obreja, D., Rughiniş, R., and Rosner, D. (2025). Mapping the multidimensional trend of generative AI: a bibliometric analysis and qualitative thematic review. Comput. Hum. Behav. Rep. 17:100576. doi: 10.1016/j.chbr.2024.100576
Perkins, M., and Roe, J. (2023). Academic publisher guidelines on AI usage: a ChatGPT supported thematic analysis. F1000Res 12:1398. doi: 10.12688/f1000research.142411.2
Pickering, A. (1995). The mangle of practice: time, agency, and science. Chicago: University of Chicago Press.
Rughiniș, C., Dascălu, M., and Rasnayake, S. (2025a) ‘GenAI reliability in content analysis: assessing agreement between LLMs in measuring discursive violence’, in. Proceedings of CSCS25 – The 25th International Conference on Control Systems and Computer Science, Bucharest, Romania.
Rughiniș, C., Matei, Ș., and Corcaci, A. (2025b) ‘Generative content analysis for policy research: comparing LLM reliability in analyzing institutional AI discourse’, in. Proceedings of CSCS25 – The 25th International Conference on Control Systems and Computer Science, Bucharest, Romania.
Rughiniș, R., Rughiniș, C., and Bran, E. (2024). “Generative AI and social Engines of Hate” in Regulating hate speech created by generative AI. (New York: Auerbach Publications).
Rughiniș, R., Vulpe, S.-N., and Țurcanu, D. (2025) ‘Generative AI at the crossroads of values: competing orders of worth in university and Publisher regulations’, in. Proceedings of CSCS25 – The 25th International Conference on Control Systems and Computer Science, Bucharest, Romania.
Star, S. L., and Strauss, A. (1999). Layers of silence, arenas of voice: the ecology of visible and invisible work. Comput. Support. Coop. Work 8, 9–30. doi: 10.1023/A:1008651105359
Wiley (2024) ExplanAItions an AI study by Wiley. Available online at: https://www.wiley.com/en-us/ai-study (Accessed March 28, 2025).
Zarifis, A., and Efthymiou, L. (2022) The four business models for AI adoption in education: giving leaders a destination for the digital transformation journey, in 2022 IEEE Global Engineering Education Conference (EDUCON). 2022 IEEE Global Engineering Education Conference (EDUCON), Tunis, Tunisia, pp. 1868–1872. doi: 10.1109/EDUCON52537.2022.9766687
Keywords: artificial intelligence, generative AI, academic integrity, boundary work, higher education policy, academic publishing, hybrid actors, knowledge production
Citation: Rughiniș C, Vulpe S-N, Țurcanu D and Rughiniș R (2025) AI at the knowledge gates: institutional policies and hybrid configurations in universities and publishers. Front. Comput. Sci. 7:1608276. doi: 10.3389/fcomp.2025.1608276
Edited by:
Andrej Košir, University of Ljubljana, SloveniaReviewed by:
Alex Zarifis, University of Southampton, United KingdomCesare Giulio Ardito, The University of Manchester, United Kingdom
Ilane Ferreira Cavalcante, Instituto Federal do Rio Grande do Norte, Brazil
Copyright © 2025 Rughiniș, Vulpe, Țurcanu and Rughiniș. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Simona-Nicoleta Vulpe, c2ltb25hLW5pY29sZXRhLnZ1bHBlQGZzYXMudW5pYnVjLnJv