 Bakir Hadžic´
Bakir Hadžic´ Lou Therese Brandner
Lou Therese Brandner Thomas Weber1
Thomas Weber1- 1Reutlingen University, Reutlingen, Germany
- 2International Center for Ethics in the Sciences and Humanities (IZEW), University of Tübingen, Tübingen, Germany
AI-based recruiting is emerging as a critical tool for companies to attract and engage candidates. In this interdisciplinary study, we present a framework for AI-based active sourcing in recruitment to explore opportunities for incorporating considerations of contestability, i.e., the openness of an AI system to human intervention by those affected. The proposed framework is structured around four key modules: Active searching, skills extraction, skills matching, and automated and personalized approach. After introducing the design and functionality of each module, we critically examine the associated opportunities and challenges regarding contestability, including their connection to other ethical aspects like transparency. We conclude with a discussion of pertinent challenges and points of concern, as well as potential practical solutions to enhance contestability and mitigate ethical risks. Our work aims to explore contestability in the context of responsible, ethically acceptable development and application of AI-driven active sourcing systems in human resource management. Future research should empirically assess the integration of contestability aspects in active sourcing approaches in practice.
1 Introduction
Solutions based on artificial intelligence (AI) are increasingly arriving in the field of hiring and recruitment. AI-based technology promises to support human resources (HR) experts in the identification of suitable applicants through more efficient and effective hiring processes not only by saving resources but also by making the application processes fairer and less prone to subjective decisions (Raghavan et al., 2020). Particularly the first stages of the recruitment process—like candidate outreach and pre-selection—have significant potential for AI utilization (Danner et al., 2023b). Given that these technical systems depend on human input and on data originating from often prejudiced and discriminatory social contexts, AI applications can, however, reproduce existing biases and automate them accordingly (Barocas et al., 2023; Eubanks, 2018; Houser, 2019). This bears a risk to perpetuate existing job market discrimination toward groups like disabled people, racial minorities, women, and other marginalized communities (Johnson et al., 2016; Schumann et al., 2020). The question of how human actors can comprehend, assess, and scrutinize AI processes and outputs, especially in complex and potentially discriminatory contexts like hiring and recruiting, is thus becoming more and more important. Contestability, which refers to the openness and responsiveness of an AI system to human intervention by those people directly or indirectly impacted by the system (Alfrink et al., 2023b), has been proposed as a safeguarding instrument to ensure human control over automated systems (Lyons et al., 2021a). In the context of AI recruitment, contestability strategies should allow both candidates and recruiters to understand, question, and intervene in the models' decisions and/or predictions.
This interdisciplinary contribution explores strategies of contestability in the context of active sourcing through a normative lens. Active sourcing is a proactive recruitment strategy in which recruiters use a variety of digital platforms and networks to actively find, interact with, and attract potential candidates, often people who may not be actively looking for work (Rechsteiner, 2019). We first define the notions of active sourcing, AI-based recruiting, and contestability, and provide an overview of relevant literature. Focusing on the German labor market, we propose a novel approach to automated active sourcing, which is structured in four modules: active searching, skills extraction, skills matching, and automated and personalized approach. This modular approach can increase accuracy and efficiency in the recruiting process, but it also raises issues regarding contestability at every step. The description of every module is thus followed by an analysis of pertinent ethical aspects, particularly in regard to contestability. We then discuss the main findings of this analysis and attempt to find potential solutions to increase contestability. The contribution concludes with some final remarks.
The structure of this contribution is intended as a dialogue between the technical descriptions from a data science and machine learning perspective and a normative critique that incorporates ethics and social science considerations. The overall objective is to explore opportunities for—and potential shortcomings of—contestability in the context of interdisciplinary technology development with the concrete case of an active sourcing system. Along the description of the proposed active sourcing model, we can demonstrate how ethical considerations can be integrated already during the design phases of automated systems, but also the difficulties that come with it.
2 Background and literature review
In this section, we will define essential terms and give a brief overview of relevant literature in this regard. We first explain the meaning of active sourcing as a hiring approach, before moving on to the notion of AI-based recruiting, both in general terms and in connection with active sourcing procedures. We then introduce the concept of AI contestability and why it might be of particular interest for AI-based active sourcing.
2.1 Active sourcing
Active sourcing in general has been employed in hiring procedures for executive, high-ranked positions for quite a while. The term “active sourcing” describes the proactive process of finding possible applicants through focused searches on social or professional media networks and approaching them with an open job position for which they would be a suitable candidate (Rechsteiner, 2019; Pangarso et al., 2024; Rubio-Leal et al., 2024). A recent change is that recruiters started to utilize active sourcing for a wide range of positions where traditional recruiting strategies do not manage to attract enough suitable candidates (Kroll et al., 2021). Despite growing trends of active sourcing utilization (Weitzel et al., 2020), external job postings remain the primary recruitment method for most German companies (Freuding and Garnitz, 2022), as around one-third of the surveyed recruiting companies do not use active sourcing at all. Only 13% of the 1,000 best-performing German companies invest more than €10,000 annually in their active sourcing expenditures, including costs for database access and social media licenses (Weitzel et al., 2020). This suggests that active sourcing holds a lot of potential, especially for small and medium-sized businesses (SMEs) with limited financial resources (Danner et al., 2023b).
The trend of active sourcing use is especially noted in the IT industry (Weitzel et al., 2020), for niche experts and high-ranked positions (Dannhäuser and Braehmer, 2017), and in industries where an international workforce is needed (Walter and Matar, 2023). This indicates that active sourcing can be an effective tool for positions requiring highly specialized skills, for smaller companies with less established recruiting brands, or where the local job market is insufficient. Furthermore, the majority of jobseekers generally are in favor of being directly approached by potential employers, which indicates that active sourcing might be a promising strategy to reach candidates (Weitzel et al., 2020).
Yet, active sourcing holds certain limitations and potential risks. Trost and Trost (2014) labels active sourcing as a direct and aggressive approach in the “global war for talents,” where maintaining a very sensitive balance between ethical considerations and legal boundaries is of crucial importance. An extensive data analysis of active sourcing patterns by German recruiting companies indicates that in the active sourcing process, companies approach female, older, and foreign candidates significantly less frequently, which hints at potential discriminatory dynamics at play (Kroll et al., 2021). Additionally, the process of manual candidate search and outreach is very time-consuming (Dannhäuser and Braehmer, 2017), making active sourcing a less suited approach for high-volume hiring (Trost and Trost, 2014). Due to over-messaging and communication fatigue, such strategies may also drive away top talent (Weitzel et al., 2020). Approximately 50% of contacted candidates never reply back; only around 25% of the candidates reached out to respond positively and participate in the recruiting process (Weitzel et al., 2020).
Searching for candidates online on job-related social media platforms (e.g., LinkedIn, Xing, ResearchGate, GitHub) has proven to be an efficient approach, particularly for professions where candidates maintain an active presence on such networks (Freuding and Garnitz, 2022). These professions tend to be white-collar jobs; in contrast, blue-collar workers typically leave less digital footprints, which means that in their case active sourcing methods are less successful than initially expected (Danner et al., 2023b). In these professions, for instance nursing, alternative sourcing techniques with a greater emphasis on personal recommendations and referrals are necessary, and communication with potential candidates often requires a more personalized approach (Ernst, 2021).
This overview demonstrates the potential of active sourcing techniques in current recruiting practices, but it also identifies a number of drawbacks, such as the long duration of the procedure, existing biases and discrimination, as well as challenges to making a scalable approach. However, these limitations could potentially be addressed by automating active sourcing through the integration of different machine learning techniques. The following section will outline the concept of AI-based recruiting, which can include AI-based active sourcing.
2.2 AI-based recruiting
According to recent studies, AI is transforming the recruiting process by expediting the sourcing, screening, and selection of candidates while cutting expenses and increasing productivity of the process (Albassam, 2023; Tay et al., 2024). Besides increasing the pace of the process by rendering it scalable to larger amounts of data, such systems can hold potential to overcome biases that are very frequent in traditional recruiting procedures due to human prejudice (Tsiskaridze et al., 2023; Danner et al., 2023b).
Currently, such AI-based tools are used across numerous stages of the hiring process (Hunkenschroer and Luetge, 2022). One of the most frequent applications of AI is in the task of resume screening and parsing, where AI-based systems evaluate larger datasets of resumes to extract relevant skills and candidate qualifications. These approaches mostly use natural language processing (NLP) technologies. Frequently, several NLP techniques are combined for skill extraction, including Named Entity Recognition (NER), Part of Speech (PoS) Tagging or Word Embeddings (e.g., Word2Vec). Together, they achieve very respectable precision results (Gugnani and Misra, 2020; Zhang et al., 2022). The AI-supported task of skills matching in the recruitment process involves aligning the skills extracted from candidates' resumes with the requirements specified in the given job descriptions using advanced techniques beyond simple keyword matching, such as ontology-based methods and semantic vector-based approaches. These methodologies enhance the precision of candidate selection by capturing the nuances and contextual relationships between skills, ultimately facilitating more effective recruitment decisions (Danner et al., 2023a). This trend has become especially pronounced in recent years with the increasing adoption of transformer models (e.g., BERT, GPT, Llama) in recruitment technologies (Kavas et al., 2024; Bocharova et al., 2023).
Moreover, AI has been integrated into interview processes through tools that conduct structured video interviews, going as far as analyzing facial expressions, vocal cues, and behavioral patterns to assess soft skills and overall fit (Hewage, 2023), or through recruitment chatbots and automated communication interfaces to enhance candidate engagement and streamline the dissemination of information throughout the recruitment cycle (Albassam, 2023), as well as for crafting personalized messages to attract the attention of potential employees for open positions (Vishwanath and Vaddepalli, 2023; Danner et al., 2023b).
Despite these advantages, numerous studies underscore ethical and operational challenges inherent in AI-driven recruitment. Researchers have critically examined the potential for AI algorithms to perpetuate existing biases in recruiting, inherited from real world data (Köchling and Wehner, 2020; Kroll et al., 2021), leading to systematic discrimination based on factors like ethnicity, age, or gender (Mujtaba and Mahapatra, 2019; Hunkenschroer and Luetge, 2022; Danner et al., 2023a; Wilson and Caliskan, 2024). Other studies have explored aspects like the privacy (Harper and Millard, 2023; Kim and Bodie, 2020; Yam and Skorburg, 2021), transparency (Balasubramaniam et al., 2023; Chen et al., 2025; Yanamala, 2023), and explainability (Magham, 2024; Jamal et al., 2024) of AI hiring systems. Specific algorithms and tools have demonstrated notable success in identifying biases within datasets and proposing effective mitigation strategies to ethical concerns in a hiring context (Balayn et al., 2021; Bellamy et al., 2019; Houser, 2019; Peña et al., 2023). However, the contestability of AI hiring systems, which will be examined in the next section, is an aspect that so far has not been research extensively, despite being of importance for the ethical and human-centered development and use of such technologies.
2.3 Contestability
Contestability refers to an AI system's openness and responsiveness to human intervention by those people directly or indirectly impacted by the system (Alfrink et al., 2023b; Almada, 2019; Hirsch et al., 2017). It can serve as an instrument to ensure human self-determination and control over automated systems (Lyons et al., 2021a). A right to contestation has been advanced as a more effective safeguard against the risks of automatic decision making over a right to explanation (Sarra, 2020). In the context of AI-based recruiting systems, contestability refers to the ability of candidates (whose data are analyzed), HR professionals (who base further decisions on the AI-based analysis), and other stakeholders to challenge and seek redress for decisions made by these systems. AI contestability has received increasing academic attention over the last years, for instance focusing on the legal right to contestation (Kaminski and Urban, 2021), government AI systems (Landau et al., 2024), education (Hong et al., 2024), computational argumentation (Leofante et al., 2024), or public AI (Alfrink et al., 2023a). A recent publication explores AI system operator contestability with recruitment systems as a use case (Veluwenkamp and Buijsman, 2025). Sheard (2022) states that from a legal perspective, discriminatory decisions automated hiring systems are currently often not contestable. Beyond this, the concept of contestability has, to the knowledge of the authors, not yet been addressed in-depth in connection with AI recruitment and specifically with active sourcing. The application of contestability strategies in practice is still limited (Raees et al., 2024).
The issue of human intervention is particularly interesting in the context of active sourcing because this recruitment approach inherently reduces the participation of humans in the outreach to suitable candidates. While active sourcing can be convenient both for recruiters and for job searchers by reducing the amount of labor during the application stage, it renders both groups more passive and can further reduce the transparency of the recruitment process. This poses the question of how contestability, which involves critically evaluating and, if necessary, contesting AI mechanisms, assumptions and predictions (Alfrink et al., 2023b), can be facilitated in active sourcing systems. Particularly in systems that are designed to be somewhat opaque, designing for contestability is a challenge (Vaccaro et al., 2019).
Furthermore, AI recruiting overall and active sourcing in particular are suitable contexts for testing contestability strategies, given that as high-risk contexts (Lyons et al., 2021b) they can have significant impact on individuals and groups, but are neither extremely high stakes (in contrast to, e.g., autonomous weapons), nor is the need for human intervention extremely time-sensitive (in contrast to, e.g., autonomous driving) (Alfrink et al., 2023b); they can be classified as slow systems (Veluwenkamp and Buijsman, 2025). Lastly, contestability should not only be considered after a system's implementation, but throughout the entire AI lifecycle (Almada, 2019); systems should be conceptualized and designed to be contestable from the beginning (Alfrink et al., 2023b), rendering contestability a deep system property to facilitate joint, interative decisions between humans and algorithms (Vaccaro et al., 2019).
Considering the existing body of research, our study aims to analyse opportunities and obstacles for contestability based on a proposed holistic automated active sourcing system. Hence, in the following section, we will present our modular framework on how to effectively integrate various machine learning tools and techniques into an efficient automated active sourcing model. For each module, contestability aspects and challenges will be specifically explored at each step of the pipeline, including the intersection of contestability concerns and other ethical issues connected to, for instance, transparency and fairness. The focus lies both on contestability for candidates, given that as the data subjects of active sourcing technology they are the most impacted by such systems, and, where pertinent, on contestability for recruiters as the primary users of active sourcing systems.
3 Methodology and design of the active sourcing model
Active sourcing is a complex process that depends on the smooth coordination of multiple interrelated procedures. Our framework, shown visually in Figure 1, identifies four separate modules that need to be carried out in sequence to successfully perform the task of active sourcing: (1) Active Searching, (2) Skills Extraction, (3) Skills Matching, and (4) Automated and Personalized Approach. In the following subsections, all steps of the introduced module are elaborated in-depth, explaining the techniques and tools necessary for their utilization. Secondly, for each module, the most pertinent ethical aspects, particularly in regard to contestability, are analyzed.
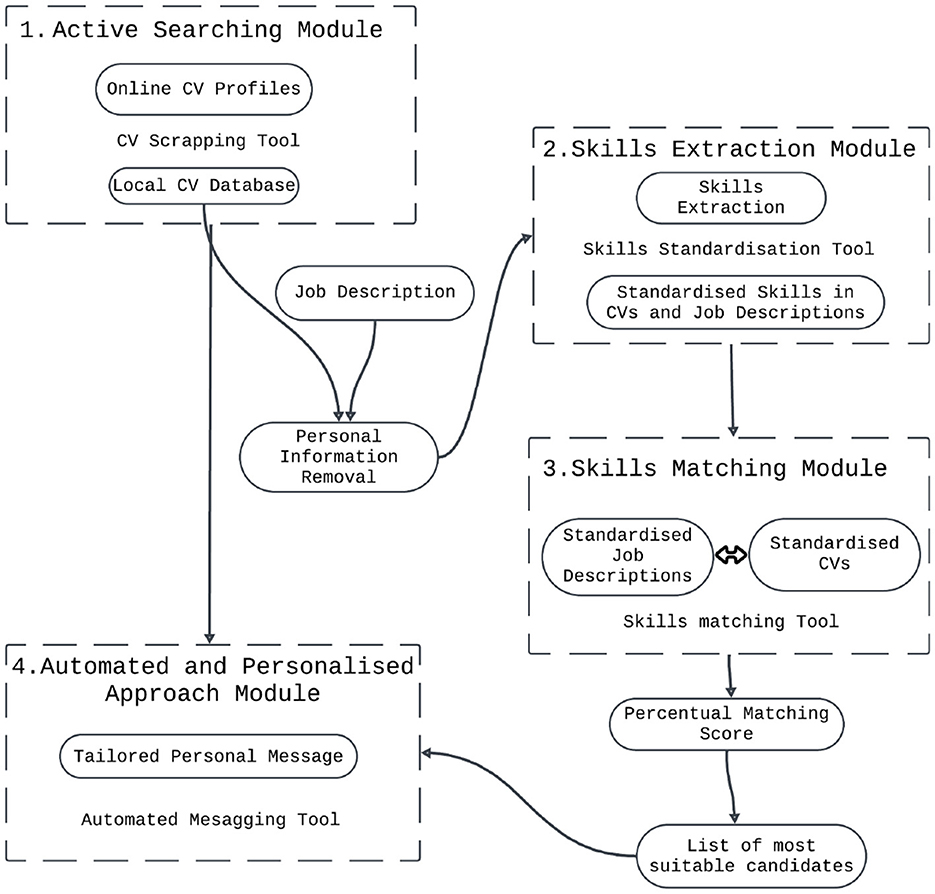
Figure 1. Active sourcing framework.
3.1 Active searching module
The Active Searching module is the initial stage in this framework and includes tasks of automatically expanding the size of the local database or updating it at regular time intervals. This initial phase leverages API access or advanced web scraping tools to gather CVs from various relevant online sources, including professional social media platforms. All collected data is stored in the local CV database. Before the data is used in the following phase, all potentially personal identifying information (PII) is removed from the CVs, as well as from job descriptions of vacant positions.
3.1.1 Detailed description
The Active Searching module is a crucial component of modern recruitment strategies, as an outcome of these tasks is generating an initial database of profiles that are stepping stones of the automated recruiting process. If the local dataset or talent pool is not already available, this module leverages APIs from professional networking sites like LinkedIn, Xing, GitHub, ResearchGate and other relevant platforms to extract candidate information efficiently and in a structured manner. These APIs allow easy access to public profiles, enabling the automated extraction of relevant information on a large scale and without or with minimal manual effort.
Many professional networking websites have implemented strict limitations on data extraction through their official APIs, which often prevent developers from accessing comprehensive profile information, even with API credentials. Platforms usually deploy such measures to maintain control over the platform's data. As a result, specialized web scraping tools have been developed to address this challenge. These tools are designed to navigate the complexities of extracting profile data while respecting the platform's terms of service and legal boundaries. For instance, tools like Bright Data and Proxycurl and similar offer dedicated scraping solutions that can retrieve public profile information without relying solely on the official API.
These scraping tools employ various techniques to mimic human browsing behavior, manage rate limits, and bypass anti-bot measures, often utilizing proxy networks and advanced browser fingerprinting to avoid detection. As a result of such approaches, data is usually stored as an original PDF file or in a raw data format consisting of structured JSON or XML. This allows for efficient storage and easy parsing of the extracted information. The raw data typically includes key details such as first name, last name, current and past work experience, education history, skills (both soft and hard skills), endorsements, certifications, publications or projects and location information, as well as the email address of the candidates.
In the subsequent step of this module, before data is used further in the pipeline, a filtering tool is implemented to reduce the effect of potential bias. This involves applying advanced anonymization techniques to both candidate CVs and job descriptions for vacant positions. The process, in literature, often referred to as “blind recruitment,” involves systematically removing or obscuring personal information that could potentially lead to systematic bias (Vivek, 2022). This includes but is not limited to: names, gender indicators, age or date of birth, photographs, names of any locations, educational institution names, as well as any possible hints to candidates' ethnicity, race, or nationality.
State-of-the-art NLP tools and techniques, including the use of open-source large language models (LLMs), are leveraged to detect and remove such information while keeping only relevant professional information. For job descriptions, the focus is on eliminating language that might inadvertently favor certain demographics. This could involve removing gendered terms, age-related phrases, or cultural references that are not directly relevant to the job requirements. The resulting anonymized documents ensure that in further stages, the search for the most suitable candidates depends solely on skills, experience, and qualifications, thereby promoting a more equitable and merit-based selection process. Furthermore, such personal information has no significance in evaluating professional qualifications or skills of a potential candidate and therefore, is not relevant for the process. The anonymized and preprocessed data is then accessible for the following modules.
3.1.2 Active searching module: ethical aspects and points of contestability
The Active Searching module already reveals a core issue concerning the contestability of active sourcing procedures: Candidates commonly are not informed about an active search taking place, i.e., they do not know that their profiles on professional networking sites or other platforms are being analyzed by AI models for an active sourcing procedure. Given that professional networking sites like LinkedIn try to prevent data extraction, users might assume the external analysis of their profiles is not possible. Candidates do not have the opportunity to actively consent to or opt out of being part of an active sourcing process, which impacts their informational self-determination (Hoffmann, 2022).
Furthermore, the lack of insight into the API query ranking and structure renders the Active Searching process somewhat of a black box (Almada, 2019; Burrell, 2016). The complexity and non-transparent architecture of proprietary algorithms thus makes it difficult for candidates to understand what makes their profiles (un)suitable. Candidates that were not selected for further steps face even more significant challenges: Assuming someone's profile was analyzed and they were not included in the candidate pool, they usually do not learn at all that their profile has been assessed, which renders any contestation or verification of the reasons for this exclusion impossible.
Similarly, recruiters can also face challenges when trying to understand why candidates have been identified as promising candidates; the origin of the data used in these systems is often unclear, raising concerns about whether the information was actually posted by the candidates themselves or, for instance, they shared posts by other individuals on their profiles.
A main reason as to why contestability is crucial is that AI systems can perpetuate societal biases (Eubanks, 2018). In the case of Active Searching, NLP tools used to detect relevant information in the profiles can contain discriminatory biases; problematic semantic relationships such as “man—computer programmer” and “woman—housewife” that perpetuate sexist stereotypes have been identified in NLP word embeddings (Barocas et al., 2023; Bolukbasi et al., 2016). Particularly for job seekers who belong to underrepresented and/or marginalized groups there may thus be a need for efficient means of contesting the fairness of the search process. In the context of active sourcing, sampling biases are also interesting to consider: For instance, gendered differences in online professional self-promotion have been found (Kalhor et al., 2024) and ethnic minorities tend to use professional networking sites less than white individuals altogether (Bauer et al., 2023). What kind of information individuals add to their profiles—and if they have profiles at all—of course determines if and how they are assessed by the Active Searching component. If recruiters rely entirely on an active sourcing procedure for certain roles, that can thus directly impact the composition, diversity, and inclusivity of the resulting candidate pools.
Furthermore, while personal data and therefore also potentially sensitive data on protected characteristics, such as gendered terms, age-related phrases, or cultural references, are removed, proxy indicators are worth considering here (Datta et al., 2017): AI models can sometimes learn indicators during training that allow inferences to be made about protected characteristics even if they were omitted. In CVs, for example, indicators such as place of residence or educational institution may point to characteristics such as economic status or gender (e.g., the attendance of a women's university). Additionally, due to the risk of re-contextualization and de-anonymization, even non-personal data and anonymized data can become personal data (Podda, 2023). In these cases, unfair treatment is exceptionally difficult to prove for data subjects, given that protected characteristics were not explicitly included in the decision processes. This adds another layer to the difficulty in achieving contestability in the case of Active Searching, an already non-transparent process.
3.2 Skills extraction module
In the second phase of the process, the Skills Extraction component extracts all relevant soft and hard skills from CVs and job descriptions. These extracted skills are then stored in a standardized, editable, and easily parsable format. Because resumes and job descriptions can be written in specific, diverse styles, the same skills can be described using different synonyms or terms. Therefore, the task of standardizing the skills to describe the same terms across datasets is the second main task of this module.
3.2.1 Detailed description
Automated CV parsing and skills extraction have become essential components of modern recruitment processes due to their efficiency in processing large quantities of information. Nowadays, almost every recruiting company incorporates some degree of automation, with sophisticated systems using state-of-the-art AI techniques to convert unstructured resumes into structured, actionable data. Advanced resume parsing tools employ sophisticated techniques such as NLP, machine learning algorithms, and pattern recognition to extract relevant information from resumes. These parsers can accurately identify and categorize various elements, including work experience, education, and, most importantly, skills. The extraction process typically involves preprocessing the document, segmenting the text into logical sections, and then parsing each section to extract specific data points.
Our first trials in this direction were based on the work of (Zhang et al. 2022), utilizing Bidirectional Encoder Representations from Transformers (BERT) to extract soft and hard skills and evaluate experience from the resumes. While the model performed well in extracting soft skills, technical skills were overlooked as the model was trained mostly on publicly available fictional data. Therefore, this specific framework requires fine-tuning on datasets for specific professions. In the second phase of our development, we tested the approach introduced by Reimers and Gurevych (2019), called Sentence BERT (SBERT), intended for comparing two sentences or sub-sentences to identify their similarity. In their approach, the similarity of one skill toward several other skills is identified by calculating the cosine similarity between the output embeddings from SBERT of two text parts. However, this does not work for the similarity between skills or knowledge that are semantically different but belong to the same job, e.g. “data science” and “machine learning.” Therefore, this model needs to be adjusted for accurate performance and fine-tuned on the specific dataset of skills in order to perform satisfactorily.
In recent years, state-of-the-art large language models (LLMs) have demonstrated remarkable performance. They consistently outperform their predecessors across a wide range of tasks and industries, even in zero-shot settings, exhibiting strong generalization capabilities on unseen data and tasks for which they were not specifically optimized.
To evaluate which of the available language models would be most suitable for the given task, we conducted a small-scale experiment. The testing dataset consisted of N = 5 manually annotated CVs. The CVs were created by a researcher who was not involved in the annotation process to ensure neutrality and avoid potential bias. All profiles were based on publicly available CV templates and examples, and were fully fictitious. Independent experts manually extracted all relevant skills listed in each CV, which served as the ground truth for subsequent evaluation.
In the next stage, the same CV content was provided to several large language models (LLMs) using the following prompt:
“You are an experienced recruiter. Carefully read the following CV and extract all skills explicitly or implicitly mentioned in the profile. Return the list of skills as concise keywords or short phrases, avoiding duplicates and unrelated information.”
It is important to note that we deliberately chose open-source models, as candidate resumes can be classified as sensitive data. This decision was guided by privacy and data protection considerations, leading us to avoid proprietary state-of-the-art models such as GPT or DeepSeek. Therefore, we opted for the use of the most efficient open-source model that could run locally on our campus servers. Subsequently, we compared the performance of four of the most promising open-source language models: Meta-Llama-3.2-3B, Mistral-Nemo-Instruct-2407-bnb-4bit, Mistral-7B-Instruct-v0.3-bnb-4bit, and Phi-3.5-mini-instruct. The outputs generated by these models were independently reviewed by objective researchers. All models were evaluated in a zero-shot setting, meaning that they were used out of the box without any additional fine-tuning or few-shot learning. This approach was chosen to assess the models' generalization capabilities when applied directly to previously unseen data. The outputs generated by each model were independently reviewed and evaluated by objective researchers. A simple matching percentage was calculated to quantify the overlap between the skills manually annotated by manually extracted skills and those automatically extracted by the models. Results of the analysis are shown in Table 1.
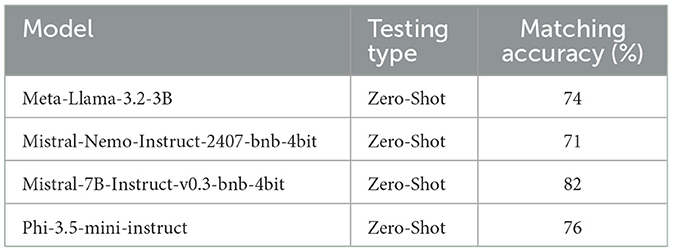
Table 1. Comparison of skill extraction accuracy across open-source LLMs.
Despite the small sample size, which was insufficient for in-depth quantitative statistical analysis, the initial results and qualitative evaluations conducted by the research team were highly encouraging. After performing both quantitative and qualitative assessments, Mistral−Small−3.1 − 24b−instruct−2503−q80.gguf emerged as the optimal candidate, striking an ideal balance between computational efficiency and performance on our campus hardware. As the name indicates, the model is a 24-billion parameter instruction-tuned variant of Mistrals small series (version 3.1), quantised to 8-bit precision using GGUF formatting and reducing file size to 25 GB while retaining almost original performance. The model is specifically designed for consumer-grade hardware, balancing speed, resource usage, and optimal performance.
It is capable of parsing both the PDF format of a resume as well as raw data stored in JSON or XML format. The skills and experiences of each candidate are then evaluated based on the entire text given in the resume. Using this approach, the most important skills of a candidate can be identified. In the initial phases of testing, we have noticed that simple skills extraction is not a fair approach, as that way, candidates who mention several years of experience with specific skills, and beginners in those skills, would not be distinguished. Therefore, the task of evaluating the level of specific skills and recency (experience of practicing the skills) is integrated in this module. Otherwise, extracted skills would stand without accurate information about the candidate's competence in that skill. However, as the experience the candidate holds is not always mentioned, precise information extraction depends on a general context understanding of the model. An example of our solution to this problem is shown in Table 2.
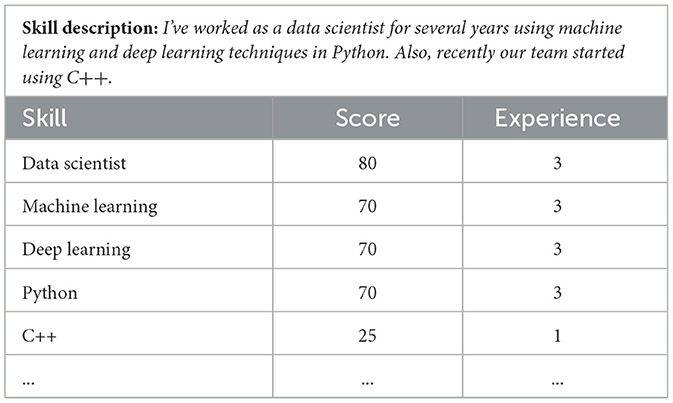
Table 2. Example of extracted skills.
In the presented table, an example of the skill description in a resume is given, followed by the skills extracted, estimated competence (estimation in range 0–100) and experience with the skill (years since skill acquisition). Although this is a relatively simple text, it shows that the model was able to not only successfully extract the relevant skills from the profile but also to extract experience and competence with each skill, based only on the general context of the given sentences. Important to note is that the used model is not fine-tuned for this task explicitly, but performs out of the box.
Furthermore, in the Figure 2, we show an example of one resume in its original form on the left side, and on the right side set of extracted skills. In this case, a resume is not anonymized, as this resume is a synthetic resume created only for testing purposes. As visible from the figure, the model is quite capable of extracting the skills and assigning them competence scores and experience (years since acquiring skills) based on the contextual information given in the text.

Figure 2. Example of resume (left) and set of extracted skills (right).
One of the main challenges in the task of skill extraction trials is the inconsistent recognition of semantically similar skills. For example, the model treats “project management,” “project facilitation,” and “project coordination” as distinct entities, despite their close conceptual overlap. To address this issue, the European Skills, Competences, Qualifications and Occupations (ESCO) classification system developed by the European Comission (2024) can be integrated to enhance the model's ability to identify and group related skills more effectively, as well as for the job descriptions. The European Skills, Competences, Qualifications and Occupations (ESCO) dataset is a multilingual classification system developed by the European Comission (2024) to standardize and categorize skills, competences, and occupations across the EU labor market. It provides a structured taxonomy that supports semantic alignment between job profiles, candidate skills, and training content, facilitating interoperability and transparency in recruitment and education systems.
State-of-the-art large language models (LLMs) have already been trained on such publicly available datasets and demonstrate strong performance in aligning extracted information with standardized skill taxonomies without any fine-tuning necessary. Additionally, the ESCO database API access, can further facilitate modular communication and real-time referencing of standardized skills.
After skills from both resumes and job descriptions are extracted and standardized in the same form, they are processed for the next module of the system.
3.2.2 Skills extraction module: ethical aspects and points of contestability
Similarly to the Active Searching module, the algorithms used for parsing can be complex and opaque, making it difficult for candidates to understand how their CVs were interpreted and why certain information was prioritized or overlooked; they have no means of overseeing or controlling which skills were extracted or how their information was interpreted, if they even know that their CV was analyzed by an algorithm at all (Sheard, 2022).
To an extent, this is also true for recruiters: There is often little transparency regarding how the skills of candidates were extracted, only final scores are provided. The usage of the ESCO classification system (European Comission, 2024) on the one hand can enhance a model's ability to identify and group related skills and job descriptions, as well as increase transparency and traceability. But on the other hand, these predetermined European skills, competences, qualifications, and occupations can become outdated in dynamic, rapidly evolving labor markets and can perpetuate a Eurocentric view on candidates, which potentially can lead to the exclusion of suitable candidates from other cultural backgrounds.
Beyond this, AI systems can be prone to errors while parsing CVs, such as misinterpreting skills, experience, or job titles (Deepa et al., 2025). For instance, rare or domain-specific skills may be overlooked in the standardization process, or the system might interpret a longer CV with more content as a better fit than a shorter CV regardless of their accuracy of fit. When CVs provided by candidates are analyzed, different CV formats and styles can also lead to inconsistencies in parsing (Delalić et al., 2025). There is no mechanism for candidates to learn about—let alone contest—these errors and thus to ensure that their qualifications are accurately represented and evaluated.
The usage of pre-trained language models such as Sentence BERT (SBERT) can also lead to the introduction of different biases. For instance, racial bias has been found in BERT's contextual word models (Tan and Celis, 2019), and measuring and reducing biases can be particularly difficult in multilingual contexts. Suitable methods for detecting gender bias in English-language BERT models may be particularly unsuitable for more gender-specific languages such as German (Bartl et al., 2020). We can consider for example that a German company is looking for a “Projektmanager (m/w/d)”. While the job title is indicated in the male form “Projektmanager” instead of the female form “Projektmanagerin” or a gender-inclusive form such as “Projektmanager*in”, the bracket (“m/w/d”, meaning “male/female/diverse”) specifies that the role is not gender-specific. A model not specifically trained for detecting these specifications might deduct the role is meant to be assumed by a male person and exclude all other individuals from the recruiting process.
3.3 Skills matching module
The third module, Skills Matching, includes the task of comparing and matching among skills identified in profiles and job descriptions. The outcome of this module is a percentage matching score from the comparison between the two files, with a list of candidates that have a higher match with the vacant position.
3.3.1 Detailed description
One of the core challenges in automating candidate-job matching lies in accurately comparing relevant skills from unstructured data such as CVs and job descriptions. To address this challenge, we propose three distinct approaches that leverage Large Language Models (LLMs) for the matching task to align candidate profiles with job requirements.
The first, most time-efficient option is zero-shot prompting, where a pre-trained LLM is directly prompted to infer skills from the CVs with skills from the job description, enabling a straightforward semantic overlap analysis. This method relies entirely on the LLM's general language understanding and its pretraining on publicly available databases. The advantage of this approach is its simplicity and adaptability across domains, though it may be sensitive to prompt formulation and variations in text quality. To ensure data protection, proprietary models should be avoided, and as our preliminary tests indicate, state-of-the-art open source models can be a successful replacement. As a strength of such an approach, we can point out simplicity and how fast such models can be employed. Furthermore, with zero-shot prompting use of the models, there is no need for huge amount of fine-tuning data sources. As models are already pre-trained on a large corpus of data, the generalization capability of the models can be applied to a wide spectrum of jobs and skills. But such models also have significant limitations that have to be considered, such as sensitivity to prompt quality and clarity or memory limitations for huge databases.
As an alternative approach, the matching task can be framed as an information retrieval problem enhanced through Retrieval-Augmented Generation. Following such an approach, candidate CVs are embedded as an external knowledge base, and the LLM is prompted with a job description to retrieve and rank the most relevant CVs based on the required skill set. This method leverages the LLM's ability to combine contextual reasoning with retrieved documents, allowing it to provide nuanced justifications for candidate-job fit. The RAG framework is especially suitable when matching requires reasoning beyond surface-level keyword overlap, and when job requirements are highly specific or dynamic. Additionally, such an approach can easily handle large databases without overloading the context window of the model. But compared to the zero-shot approach, its outputs are produced significantly slower. Likewise, it also requires significantly more setup time, better infrastructure and well well-structured retrieval pipeline for embeddings and vector storage.
Further alternatives can involve fine-tuning an open-source LLM to directly match resumes from the CV and specific ESCO-based jobs. This supervised method enables the model to learn domain-specific associations between natural language descriptions of experience and the structured ESCO skill labels. Once the standardized skill set is predicted, simple statistical or rule-based matching methods can be used to compute similarity between candidate and job profiles. The majority of the state-of-the-art LLMs are already pre-trained on the ESCO database, consisting of standardized skills and job descriptions common in the European labor market. Therefore, such models could be utilized without crafting a specific job description for the new position opening, but rather the ESCO job description can be referred to. This approach holds great promise, as well as it provides interoperability and scalability, but it requires access to labeled training datasets and constant system refinement and adaptations. The fine-tuning approach learns subtle mappings that zero-shot or RAG approaches might miss, but is less flexible than the other two approaches. The model may have more difficulty than a RAG system if new job or skill forms emerge that are not in ESCO database or were not in the training dataset.
As an output of such models, the percentage representing the matching between CV and job requirements should be produced, offering a list of the most suitable candidates. In order to evaluate such approaches, establishing reliable ground truth data remains a key challenge, as this task typically relies on either manually annotated CVs or retrospective hiring decisions. Both of these sources are susceptible to inherent biases. Careful interpretation of the results and bias mitigation strategies are necessary to ensure fairness and generalizability of the matching models. Given that each of the three suggested options has particular advantages and limitations, considerations including data accessibility, scalability, and the state of the technology infrastructure should all be taken into account when choosing a strategy in specific use cases.
3.3.2 Skills matching module: ethical aspects and points of contestability
The ethical aspects and contestability considerations for the Skills Matching module are similar to the Skills Extraction module. Also in this case, the algorithms matching CVs with job descriptions are complex and non-transparent; candidates have no insight into the process and, even if they obtain insight, may not be able to comprehend or interpret correctly the criteria used for matching or how their CV was evaluated. There additionally might be biases in the matching process, such as favoring candidates from certain educational backgrounds—which can implicitly indicate protected attributes like ethnicity—or with specific keywords in their CVs (Bhatnagar et al., 2025; Iso et al., 2025). Contesting these biases can be challenging due to the ever-present lack of transparency (Sheard, 2022).
Both zero-shot prompting and fine-tuning an open-source LLMs for the matching task carry certain risks. Beyond the typical general limitations of prompting LLMs, given that they often produce overly simplistic or flawed outputs (Patil and Gudivada, 2024), pre-trained LLMs like Mistral do not communicate the training logic for their models and the used training datasets. It can therefore not be excluded that those models contains biases; given their opacity, challenging decisions made on the basis of such an LLM would be very difficult. The fine-tuning option involves, as mentioned in the description of the Skills Matching module, access to labeled training datasets and constant system refinement and adaptations. Job descriptions are dynamic and can evolve over time; linked to the point already made on the ESCO classification system, AI systems might not be updated to reflect these changes, which can result in candidates being matched (or not matched) based on outdated criteria. Matching candidates based on predetermined, non-dynamic criteria might also lead to the oversight of highly suitable candidates with novel, unusual backgrounds (Nugent and Scott-Parker, 2022).
Establishing reliable ground truth data for the list of most suitable candidates raises further ethical questions. As mentioned above, both relying on manually annotated CVs and on retrospective hiring decisions can lead to biased outcomes; historical hiring data often encodes existing systemic biases in recruitment practices, while manual annotations may reflect subjective human judgments. Labels and annotations are thus not only a technical but also a social problem. Perceived ground truths can be contingent on sociocultural and individual factors, which can influence how certain attributes—such as skills and characteristics—are defined and labeled (D́ıaz, 2020; Prabhakaran et al., 2022). Discriminatory effects can thus be introduced into the matching by how organizations or individual labellers define target variables and class labels (Barocas and Selbst, 2016).
3.4 Automated and personalized approach module
The final module of the framework, the Automated and Personalized Approach, pulls information from the original database to obtain PII of the most suitable candidates and tailors personal messages containing job details and reasons justifying their suitability for the advertised job. The best fitting candidates are then presented with the vacant position, explained why they are suitable, and offered a chance to apply for the open position.
3.4.1 Detailed description
According to a study done by Trost and Trost (2014), participants are about six times more likely to respond when they are approached with a personal message on social platforms like LinkedIn or Xing when compared to a generic, impersonal approach. By leveraging AI, organizations can move beyond generic outreach strategies and deliver messages that resonate more deeply with individual candidates. This is particularly useful in competitive labor markets, where high-skilled professionals receive multiple job offers and are more likely to engage with recruiters who demonstrate genuine interest and understanding of their profiles.
Building on this insight, the final step following a successful match by the algorithm involves composing a personalized message to the identified candidate. This message typically includes a personalized greeting, key information about the matched position, a direct link to the job advertisement, and several tailored reasons explaining why the individual may be a strong fit for the role.
To enhance the level of personalisation at this stage, certain personal information, excluded during the earlier skill extraction module due to fairness and bias mitigation, can now be reintegrated, as its use is no longer holding discriminatory potential. However, to maintain strict data protection standards, it is essential to design the system such that sensitive personal information remains inaccessible to the matching algorithm. This emphasizes once again why modular architecture is required, where each step operates independently, ensuring data privacy while still allowing for high-quality, personalized communication in the final stages of automated hiring systems.
The message presented in Table 3 ilustrate how output of such model looks like. Based on the candidate's qualifications and relevant experiences presented in the resume introduced already in Figure 2, the system produces a friendly and engaging message that not only conveys job-related details but also establishes a more personal connection. This improves candidate responsiveness and contributes to a more positive overall recruitment experience, bridging the gap between automation and human-centric communication.

Table 3. Prompt and personalized message generated with LLM.
3.4.2 Automated and personalized approach module: ethical aspects and points of contestability
While the Automated and Personalized Approach module as the last step of the active sourcing procedure cannot introduce new biases into the matching process itself, it still raises ethical questions regarding fair treatment, transparency, and contestability. Firstly, there is a risk that personalized messages based on AI-driven insights might stereotype recipients on the basis of, e.g., gender or ethnicity (Lambillotte and Poncin, 2023). Beyond concerns that automated messages might be perceived as spam, they might thus also be offensive toward individuals, if no effective human control of the communication is in place. A further, similar risk is that the personalisation ends up inadvertently profiling the candidates based on personal information contained in the data (Hermann, 2022). It is thus advisable to implement human oversight with automated personalized communication (Will Arachchige et al., 2024).
While the example provided in Table 3 specifies that AI was involved in the recruiting process, it does not provide in-depth information on the active sourcing process. The message states that the usage of AI helps the organization to identify talent “fairly,” but does not elaborate on why, in what sense or how this is the case. Furthermore, no clear channels for feedback or complaints are provided, which would present a simple means of contestation (Lyons et al., 2021a). This overall might for instance lead to candidates under- or overestimating the extent of AI usage, scare or concern them, or impact how much they trust the procedure. The lack of more detailed information about the procedure, e.g. through a “learn more” link, can furthermore result in feelings of frustration or powerlessness. On the other hand, including too much or complex information about technological details could also overwhelm candidates (Bester et al., 2016); simply giving data subjects as much information as possible is therefore not a suitable countermeasure for opacity or an effective contestability strategy. Rather, the goal should be facilitating a basic understanding of how AI functions and how it is used in the recruitment process to avoid information overload (Arrieta et al., 2020).
4 Discussion
Overall, from a technical point of view, the proposed modular framework of the AI-based active sourcing offers several advantages: The system provides operational flexibility and thus enables organizations to adopt individual modules—such as active search, skill extraction, matching, or automated candidate outreach—independently or as an integrated holistic solution. This modularity ensures practical usability depending on organizational needs and resources, while addressing key challenges in the recruiting industry such as scalability, time-efficiency, and the personalisation of the process.
The framework is designed with contestability and transparency in mind. However, as addressed in the “Ethical aspects and points of contestability” subsections, normative concerns remain. Active sourcing approaches come with inherent problems regarding transparency, human oversight, and contestability. In the following paragraphs, we outline particular remaining challenges for the incorporation of contestability aspects into active sourcing systems and propose potential solutions.
4.1 Lack of transparency and consent
The somewhat inherent lack of transparency and informed consent by data subjects is the most pervasive issue in active sourcing procedures, impacting all stages of the process. Only candidates who are aware of their participation can meaningfully contest decisions made by the system; therefore, informed consent and participation are preconditions for contestable systems. But in active sourcing processes, candidates lack fundamental awareness and control over the AI's actions. They are typically not informed that their public profiles or submitted CVs are being collected from online sources and analyzed by AI. From an ethical as well as legal perspective, this can undermine basic principles of data autonomy, violating informational self-determination and the right to opt out.
Furthermore, excluded candidates are usually not notified their profile was assessed, making it impossible to correct inaccurate or outdated information in the collected data, to contest algorithmic errors—such as a misinterpretation of skills or the overlooking of qualifications—or to question the reasons for their exclusion.
To address the most pertinent transparency issues—and to comply with data protection measures imposed by the GDPR—, mandatory notification and opt-out options for candidates must be implemented (Almada, 2019). This means that candidates should be informed upfront that their profiles and/or CVs are being collected and analyzed for an active sourcing process, and they should have clear, easy mechanisms to opt out of the procedure. They must furthermore be informed and asked for permission to retain their profiles in the talent database, with the right to request deletion at any time.
4.2 Explainability beyond transparency
Proprietary and complex algorithms for searching, extraction, and matching are commonly not explainable, easily rendering active sourcing systems black boxes both for candidates and recruiters. Candidates often cannot understand in-depth why they were included or, more commonly, excluded. Excluded candidates are also a particular problem for recruiters, who might overlook promising individuals if they have no insight into those excluded, as well as into why they were excluded.
To increase explainability beyond transparency, candidates must be provided a basic, non-overwhelming understanding (Arrieta et al., 2020) of the AI's role, the criteria used for assessment, and, later on, the specific reasons for their inclusion or exclusion. Candidates should be able to request access to information about which skills were extracted, how these were rated, and how their CVs were ranked when compared to the other candidates. Recruiters should also be able to access detailed insights into the process to facilitate a deeper understanding of the procedure and to ensure that they remain in control. For instance, the weighting of matching criteria should be transparent, including explanations of how experience or education are scored; otherwise, matching modules may favor longer or more detailed CVs simply because they contain more extractable data, regardless of their relevance or overall quality.
4.3 Bias as a contestation issue
As discussed, biases can be introduced throughout the active sourcing process, from the initial search to the final matching, potentially leading to unfair and even discriminatory outcomes. Automated hiring systems often suffer from sampling bias: Not all professions or demographic groups are equally represented online, and marginalized or less visible candidates may be systematically overlooked. This may skew outcomes in favor of standardized profiles, failing to capture the value of diverse experiences or domain-specific expertise. Similarity-based matching, common in AI systems, can further reinforce these biases, privileging candidates with conventional resumes and disadvantaging those with unconventional career paths or interdisciplinary experts.
Bias and fairness should also be perceived as connected to contestability: auditing processes and the ongoing monitoring and mitigating of bias can be seen as contestation at scale (Vaccaro et al., 2019). Even when an active sourcing system is designed as transparent as possible, perceiving discrimination— and then contesting—on an individual level is difficult. Independent oversight in the form of audits can thus strengthen contestability (Lyons et al., 2021a). Therefore, rigorous, regular internal tests and external audits of all AI components should be conducted to identify and actively mitigate discriminatory biases, especially those related to gender, ethnicity, and language.
Utilizing standardized taxonomies like ESCO can further introduce a Eurocentric bias, excluding competencies not fitting conventional classifications and disadvantaging non-European candidates or those with non-traditional career paths. Skill and matching systems should thus be dynamic and regularly updated to reflect evolving job markets instead of relying on fixed classification systems, which can quickly become outdated or can be based on culturally limited predetermined criteria. Beyond the internal fairness of the active sourcing process, solely relying on active sourcing for candidate pools should be avoided. Complementing AI sourcing with traditional or alternative methods can ensure more diverse and inclusive candidate pools.
Additionally, sensitive personal data should only be reintegrated at the final stage of communication, separated from the other modules, providing personalization while minimizing the opportunity for biases to emerge in other stages. Even so, the potential presence of proxy indicators introducing biases during earlier stages should be kept in mind (Datta et al., 2017). Strict data handling must be enforced to minimize the risk of re-contextualization and de-anonymization, ensuring that non-personal data does not become a vehicle for discrimination (Podda, 2023).
4.4 Automation vs. human oversight
While the proposed framework facilitates full automation, we emphasize the need for continuous human oversight and stakeholder involvement, ensuring that both applicants and recruiters have opportunities to contest model outcomes at each stage. Such stage-wise attention to each step of the process strengthens adherence to legal and ethical norms and can enhance user trust and acceptance of automated hiring systems. Recommendations and hints for human supervision can be integrated into the technology itself during development, e.g., in the form of textual hints or the provision of support structures. There must always be the opportunity for human actors to intervene in the process or to retrospectively track it and correct decisions if necessary, e.g., in the classification into groups of suitable and less suitable candidates. The user's decision should always takes precedence over the system's decision.
In the final module, the automated candidate outreach, efficiency gains come with potential risks of dehumanization and impersonal communication. Repetitive or poorly targeted messages can over-fatigue candidates, and there is a danger of unintentionally sending messages with insensitive content regarding, e.g., gender or ethnicity. HR professionals should oversee the personalized messages to prevent stereotyping and profiling.
Both recruiters and candidates should be given opportunities to provide feedback on the AI system's decisions to promote continuous improvement and adaptation to real-world requirements. Simple channels for feedback and complaints should thus be established in all automated communication to allow for questions and direct contestation of perceived errors or unfairness. To provide even more options for human oversight to candidates, they could be given the option to correct errors. For instance, if their CV is being analyzed, they could view and, if necessary, contest and correct the extracted profile and skills list to ensure their qualifications are accurately represented.
On the other hand, it is important to approach the solution of human oversight in a nuanced manner: Human supervision and control of AI systems and algorithms are often presented as cure-all solutions to the problems of (semi-)automated decision-making, but human decisions can also be flawed, biased, and opaque; humans are thus not inherently better decision makers or reviewers than AI systems (Lyons et al., 2021a). At the same time, the concrete form of efficient human oversight is unclear, as the concept often remains vague and incomplete, including in legislation like the European AI Act (Enqvist, 2023). If human supervision is conceptualized as an individual responsibility it can result in the scapegoating single actors, e.g., blaming an individual recruiter for discriminatory outcomes of an AI-assisted hiring process or blaming a candidate for not having corrected their data. From the development to the evaluation and use of AI, many steps and stages of responsibility for different actors are involved; single stakeholders usually do not have the competencies to oversee the entire AI lifecycle (Zweig et al., 2018). Meaningful human oversight can thus not be seen as an individual responsibility but as a structural and organizational task that involves both oversight mechanisms already implemented into the system and specific training for intended human overseers (Lyons et al., 2021a).
5 Conclusion
While AI-based active sourcing systems hold considerable promise to render the search for talent more efficient and effective, they overall raise significant contestability concerns. A lack of contestability mechanisms exposes candidates to risks of biased, unfair treatment and threatens their informational self-determination. Transparency can be viewed as a prerequisite in this regard: Given the inherent lack of transparency in active sourcing, which usually remains invisible to candidates until they are eventually approached, they are largely unaware that there might be anything to contest. This also holds risks for recruiters who might not be able to interpret and retrace system outcomes correctly and as a result might miss out on promising candidates or even end up inadvertently discriminating against already marginalized groups of job seekers. Without feedback channels, rigorous fairness checks, the implementation of meaningful human oversight, external access to information about training data, evaluation criteria et cetera, these systems cannot be truly contestable for the involved actors. They may amplify existing inequalities, undermine fair hiring practices, and damage human autonomy in the process.
There is a need to empirically assess the proposed contestability strategies. Further studies in the field of AI-based active sourcing and hiring should therefore evaluate contestability measures in practice, i.e., if they indeed create meaningful safeguards, if and how candidates utilize them, or how they impact the candidates' perception of an AI system. The focus should lie on advancing both AI development and contestability guidelines in tandem, ensuring that technical innovation is aligned with transparent, accountable, and ethically grounded recruitment practices, resulting from interdisciplinary work of computer scientists, ethicists, legal experts, and HR professionals.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
BH: Conceptualization, Data curation, Methodology, Validation, Writing – original draft, Writing – review & editing. LB: Conceptualization, Investigation, Writing – original draft, Writing – review & editing. TW: Software, Validation, Visualization, Writing – original draft. MR: Conceptualization, Funding acquisition, Supervision, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This article is based on research in the project “FAIR: Fair and Intelligent Automated Recruiting” as part of the funding programme “Invest BW - Innovation II” of the Baden-Württemberg State Ministry of Economic Affairs, Labour and Tourism, Germany with funding number BW1_4056.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that Gen AI was used in the creation of this manuscript. During the preparation of this work, the authors partially utilized AI-powered tools to improve the language editing. All content was subsequently reviewed and edited by the authors, who take full responsibility for the final version of the publication.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Albassam, W. A. (2023). The power of artificial intelligence in recruitment: an analytical review of current AI-based recruitment strategies. Int. J. Prof. Bus. Rev. 8:4. doi: 10.26668/businessreview/2023.v8i6.2089
Alfrink, K., Keller, I., Doorn, N., and Kortuem, G. (2023a). “Contestable camera cars: a speculative design exploration of public AI that is open and responsive to dispute,” in Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (New York, NY: ACM), 1–16. doi: 10.1145/3544548.3580984
Alfrink, K., Keller, I., Kortuem, G., and Doorn, N. (2023b). Contestable AI by design: towards a framework. Minds Mach. 33, 613–639. doi: 10.1007/s11023-022-09611-z
Almada, M. (2019). “Human intervention in automated decision-making: toward the construction of contestable systems,” in Proceedings of the Seventeenth International Conference on artificial intelligence and Law (New York, NY: ACM), 2–11. doi: 10.1145/3322640.3326699
Arrieta, A. B., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., et al. (2020). Explainable artificial intelligence (XAI): concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 58, 82–115. doi: 10.1016/j.inffus.2019.12.012
Balasubramaniam, N., Kauppinen, M., Rannisto, A., Hiekkanen, K., and Kujala, S. (2023). Transparency and explainability of AI systems: from ethical guidelines to requirements. Inf. Softw. Technol. 159:107197. doi: 10.1016/j.infsof.2023.107197
Balayn, A., Lofi, C., and Houben, G.-J. (2021). Managing bias and unfairness in data for decision support: a survey of machine learning and data engineering approaches to identify and mitigate bias and unfairness within data management and analytics systems. VLDB J. 30, 739–768. doi: 10.1007/s00778-021-00671-8
Barocas, S., Hardt, M., and Narayanan, A. (2023). Fairness and Machine Learning: Limitations and Opportunities. Cambridge, MA: MIT press.
Barocas, S., and Selbst, A. D. (2016). Big data's disparate impact. Calif. Law Rev. 104:671. doi: 10.2139/ssrn.2477899
Bartl, M., Nissim, M., and Gatt, A. (2020). Unmasking contextual stereotypes: measuring and mitigating bert's gender bias. arXiv [preprint]. arXiv:2010.14534. doi: 10.48550/arXiv.2010.14534
Bauer, J. C., Murray, M. A., and Ngondo, P. S. (2023). Who's missing out? The impact of digital networking behavior & social identity on PR job search outcomes. Public Relat. Rev. 49:102367. doi: 10.1016/j.pubrev.2023.102367
Bellamy, R. K., Dey, K., Hind, M., Hoffman, S. C., Houde, S., Kannan, K., et al. (2019). AI fairness 360: an extensible toolkit for detecting and mitigating algorithmic bias. IBM J. Res. Dev. 63, 4–1. doi: 10.1147/JRD.2019.2942287
Bester, J., Cole, C. M., and Kodish, E. (2016). The limits of informed consent for an overwhelmed patient: clinicians' role in protecting patients and preventing overwhelm. AMA J. Ethics 18, 869–886. doi: 10.1001/journalofethics.2016.18.9.peer2-1609
Bhatnagar, S., Shetty, S., Arora, N., Sachdev, V., and Bahrini, A. (2025). “Beyond traditional biases in AI hiring: exposing the hidden systemic challenges in resume screening,” in 2025 Systems and Information Engineering Design Symposium (SIEDS) (Charlottesville, VA: IEEE), 280–285. doi: 10.1109/SIEDS65500.2025.11021210
Bocharova, M., Malakhov, E., and Mezhuyev, V. (2023). Vacancysbert: the approach for representation of titles and skills for semantic similarity search in the recruitment domain. arXiv [preprint]. arXiv:2307.16638. doi: 10.48550/arXiv.2307.16638
Bolukbasi, T., Chang, K.-W., Zou, J. Y., Saligrama, V., and Kalai, A. T. (2016). “Man is to computer programmer as woman is to homemaker? Debiasing word embeddings,” in Advances in Neural Information Processing Syststem, 29 (Barcelona).
Burrell, J. (2016). How the machine ‘thinks': understanding opacity in machine learning algorithms. Big Data Soc. 3:2053951715622512. doi: 10.1177/2053951715622512
Chen, A., Han, F., Zhang, X., and Lu, Y. (2025). Cracking the AI recruitment code: striving for transparency in finding the right person-job fit. Inf. Manag. 62:104156. doi: 10.1016/j.im.2025.104156
Danner, M., Hadžić, B., Radloff, R., Su, X., Peng, L., Weber, T., et al. (2023a). “Overcome ethnic discrimination with unbiased machine learning for facial data sets,” in Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications-Volume 5 VISAPP: VISAPP, Vol. 5 (Lisbon: SciTePress), 464–471. doi: 10.5220/0011624900003417
Danner, M., Hadžić, B., Weber, T., Zhu, X., and Rätsch, M. (2023b). “Towards equitable AI in HR: designing a fair, reliable, and transparent human resource management application,” in International Conference on Deep Learning Theory and Applications (Cham: Springer), 308–325. doi: 10.1007/978-3-031-39059-3_21
Dannhäuser, R., and Braehmer, B. (2017). “Active sourcing in der praxis,” in Praxishandbuch Social Media Recruiting: Experten Know-How/Praxistipps/Rechtshinweise (Cham: Springer), 407–433. doi: 10.1007/978-3-658-16281-8_11
Datta, A., Fredrikson, M., Ko, G., Mardziel, P., and Sen, S. (2017). Proxy non-discrimination in data-driven systems. arXiv [preprint]. arXiv:1707.08120. doi: 10.48550/arXiv.1707.08120
Deepa, Y. G., Sindhu, A., Shruthi, A., and Neha, B. (2025). Automated resume parsing: a review of techniques, challenges and future directions. Int. J. Multidiscip. Res. Growth Eval. 6, 1065–1069.
Delalić, S., Kadrić, Z., Jerkić, J., and Mehmedović, F. (2025). “Efficient CV parsing: lightweight models and heuristic methods for diverse and non-standard formats,” in 2025 MIPRO 48th ICT and Electronics Convention (Opatija: IEEE), 125–130.
Díaz, M. (2020). Biases as Values: Evaluating Algorithms in Context. PhD thesis, Northwestern University, Evanston, IL.
Enqvist, L. (2023). ‘Human oversight' in the EU artificial intelligence act: what, when and by whom? Law Innov. Technol. 15, 508–535. doi: 10.1080/17579961.2023.2245683
Ernst, C. (2021). Von der stellenanzeige zum active sourcing. Heilberufe 73, 63–66. doi: 10.1007/s00058-021-1959-6
Eubanks, V. (2018). Automating Inequality: How High-tech Tools Profile, Police, and Punish the Poor. New York, NY: St. Martin's Press.
European Comission (2024). European Skills, Competences, Qualifications and Occupations (ESCO). Available online at: https://esco.ec.europa.eu/ (Accessed November 11, 2025).
Freuding, J., and Garnitz, J. (2022). Klassisches recruiting vs. active sourcing: externe stellenausschreibung weiterhin dominierend. ifo Schnelldienst 75, 70–73.
Gugnani, A., and Misra, H. (2020). Implicit skills extraction using document embedding and its use in job recommendation. Proc. AAAI Conf. Artif. Intell. 34, 13286–13293. doi: 10.1609/aaai.v34i08.7038
Harper, E., and Millard, J. (2023). Artificial intelligence in employment law: legal issues in AI-driven hiring and employment practices. Legal Stud. Digit. Age 2, 48–60.
Hermann, E. (2022). Artificial intelligence and mass personalization of communication content—an ethical and literacy perspective. New Media Soc. 24, 1258–1277. doi: 10.1177/14614448211022702
Hewage, A. (2023). The applicability of artificial intelligence in candidate interviews in the recruitment process. J. Manag. Stud. Dev. 2, 174–197. doi: 10.56741/jmsd.v2i02.388
Hirsch, T., Merced, K., Narayanan, S., Imel, Z. E., and Atkins, D. C. (2017). “Designing contestability: interaction design, machine learning, and mental health,” in Proceedings of the 2017 Conference on Designing Interactive Systems (New York, NY: ACM), 95–99. doi: 10.1145/3064663.3064703
Hoffmann, M. (2022). Möglichkeit und Zulässigkeit von Künstlicher Intelligenz und Algorithmen im Recruiting–Personalsuche 4.0. Neue Zeitschrift Arbeitsrecht 39, 19–24.
Hong, S., Cai, C., Du, S., Feng, H., Liu, S., Fan, X., et al. (2024). “My grade is wrong!”: a contestable AI framework for interactive feedback in evaluating student essays. arXiv [preprint]. arXiv:2409.07453. doi: 10.48550/arXiv.2409.07453
Houser, K. A. (2019). Can AI solve the diversity problem in the tech industry: mitigating noise and bias in employment decision-making. Stan. Tech. Law Rev. 22:290.
Hunkenschroer, A. L., and Luetge, C. (2022). Ethics of AI-enabled recruiting and selection: a review and research agenda. J. Bus. Ethics 178, 977–1007. doi: 10.1007/s10551-022-05049-6
Iso, H., Pezeshkpour, P., Bhutani, N., and Hruschka, E. (2025). Evaluating bias in LLMS for job-resume matching: gender, race, and education. arXiv [preprint]. arXiv:2503.19182. doi: 10.48550/arXiv.2503.19182
Jamal, A., Aissaoui, K., and Kassal, S. (2024). “Enhancing recruitment transparency and efficiency with explainable AI (XAI),” in 2024 3rd International Conference on Embedded Systems and Artificial Intelligence (ESAI) (Fez: IEEE), 1–6. doi: 10.1109/ESAI62891.2024.10913744
Johnson, S. K., Hekman, D. R., and Chan, E. T. (2016). If there's only one woman in your candidate pool, there's statistically no chance she'll be hired. Harv. Bus. Rev. 26, 1–7.
Kalhor, G., Gardner, H., Weber, I., and Kashyap, R. (2024). Gender gaps in online social connectivity, promotion and relocation reports on linkedin. Proc. Int. AAAI Conf. Web Soc. Media 18, 800–812. doi: 10.1609/icwsm.v18i1.31353
Kaminski, M. E., and Urban, J. M. (2021). The right to contest AI. Columbia Law Rev. 121, 1957–2048.
Kavas, H., Serra-Vidal, M., and Wanner, L. (2024). “Using large language models and recruiter expertise for optimized multilingual job offer-applicant CV matching,” in Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (Jeju), 8696–8699.
Kim, P. T., and Bodie, M. T. (2020). Artificial intelligence and the challenges of workplace discrimination and privacy. ABAJ Lab. Emp. Law 35:289.
Köchling, A., and Wehner, M. C. (2020). Discriminated by an algorithm: a systematic review of discrimination and fairness by algorithmic decision-making in the context of hr recruitment and hr development. Bus. Res. 13, 795–848. doi: 10.1007/s40685-020-00134-w
Kroll, E., Veit, S., and Ziegler, M. (2021). The discriminatory potential of modern recruitment trends—a mixed-method study from germany. Front. Psychol. 12:634376. doi: 10.3389/fpsyg.2021.634376
Lambillotte, L., and Poncin, I. (2023). Customers facing companies' content personalisation attempts: paradoxical tensions, strategies and managerial insights. J. Mark. Manag. 39, 213–243. doi: 10.1080/0267257X.2022.2105384
Landau, S., Dempsey, J. X., Kamar, E., Bellovin, S. M., and Pool, R. (2024). Challenging the machine: contestability in government AI systems. arXiv [preprint]. arXiv:2406.10430. doi: 10.48550/arXiv.2406.10430
Leofante, F., Ayoobi, H., Dejl, A., Freedman, G., Gorur, D., Jiang, J., et al. (2024). Contestable AI needs computational argumentation. arXiv [preprint]. arXiv:2405.10729. doi: 10.4550/arXiv.2405.10729
Lyons, H., Velloso, E., and Miller, T. (2021a). Conceptualising contestability: perspectives on contesting algorithmic decisions. Proc. ACM Hum.-Comput. Interact. 5, 1–25. doi: 10.1145/3449180
Lyons, H., Velloso, E., and Miller, T. (2021b). Fair and responsible AI: a focus on the ability to contest. arXiv [preprint]. arXiv:2102.10787. doi: 10.48550/arXiv.2102.10787
Magham, R. K. (2024). Mitigating bias in AI-driven recruitment: the role of explainable machine learning (XAI). Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 10, 461–469. doi: 10.32628/CSEIT241051037
Mujtaba, D. F., and Mahapatra, N. R. (2019). “Ethical considerations in AI-based recruitment,” in 2019 IEEE International Symposium on Technology and Society (ISTAS) (Medford, MA: IEEE), 1–7. doi: 10.1109/ISTAS48451.2019.8937920
Nugent, S. E., and Scott-Parker, S. (2022). “Recruitment AI has a disability problem: anticipating and mitigating unfair automated hiring decisions,” in Towards Trustworthy Artificial Intelligent Systems (Cham: Springer), 85–96. doi: 10.1007/978-3-031-09823-9_6
Pangarso, A., Setyorini, R., Umbara, T., and Latan, H. (2024). “Green organizational culture and competitive advantage in indonesian higher education: the mediation roles of green human capital management and absorptive capacity,” in Green Human Resource Management: A View from Global South Countries (Cham: Springer), 139–161. doi: 10.1007/978-981-99-7104-6_8
Patil, R., and Gudivada, V. (2024). A review of current trends, techniques, and challenges in large language models (LLMs). Appl. Sci. 14:2074. doi: 10.3390/app14052074
Peña, A., Serna, I., Morales, A., Fierrez, J., Ortega, A., Herrarte, A., et al. (2023). Human-centric multimodal machine learning: recent advances and testbed on AI-based recruitment. SN Comput. Sci. 4:434. doi: 10.1007/s42979-023-01733-0
Podda, E. (2023). Big Data Analysis Systems in IoE Environments for Managing Privacy and data Protection: Pseudonymity, De-anonymization and the Right to be Forgotten. PhD thesis, University of Bologna, Bologna.
Prabhakaran, V., Qadri, R., and Hutchinson, B. (2022). Cultural incongruencies in artificial intelligence. arXiv [preprint]. arXiv:2211.13069. doi: 10.48550/arXiv.2211.13069
Raees, M., Meijerink, I., Lykourentzou, I., Khan, V.-J., and Papangelis, K. (2024). From explainable to interactive AI: a literature review on current trends in human-AI interaction. Int. J. Hum.-Comput. Stud. 189:103301. doi: 10.1016/j.ijhcs.2024.103301
Raghavan, M., Barocas, S., Kleinberg, J., and Levy, K. (2020). “Mitigating bias in algorithmic hiring: evaluating claims and practices,” in Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (New York, NY: ACM), 469–481. doi: 10.1145/3351095.3372828
Rechsteiner, F. (2019). Active sourcing, content recruiting & cultural fit: smarte wege zu neuen mitarbeitern. Wissensmanagement 1, 34–36. doi: 10.1007/s43443-019-0062-1
Reimers, N., and Gurevych, I. (2019). Sentence-Bert: sentence embeddings using siamese bert-networks. arXiv [preprint]. arXiv:1908.10084. doi: 10.48550/arXiv.1908.10084
Rubio-Leal, Y., Madero-Gómez, S. M., Barboza, G., and Olivas-Luján, M. R. (2024). “Mapping sustainable human resource management in Latin America: future directions,” in Green Human Resource Management: A View from Global South Countries (Cham: Springer), 1–41. doi: 10.1007/978-981-99-7104-6_2
Sarra, C. (2020). Put dialectics into the machine: protection against automatic-decision-making through a deeper understanding of contestability by design. Glob. Jurist 20:20200003. doi: 10.1515/gj-2020-0003
Schumann, C., Foster, J., Mattei, N., and Dickerson, J. (2020). “We need fairness and explainability in algorithmic hiring,” in International Conference on Autonomous Agents and Multi-agent Systems (AAMAS) (Auckland).
Sheard, N. (2022). No notice and no explanation: the incontestability of hiring discrimination by algorithm. Aust. J. Labour Law 35, 119–148.
Tan, Y. C., and Celis, L. E. (2019). “Assessing social and intersectional biases in contextualized word representations,” in Advance in Neural Information Processing System, 32 (Vancouver, BC).
Tay, C. E., Ying, C. Y., Yeo, S. F., and Cheah, C. S. (2024). Revolutionizing recruitment: the rise of artificial intelligence in talent acquisition. PaperASIA 40(6b), 191–199. doi: 10.59953/paperasia.v40i6b.270
Trost, A., and Trost, A. (2014). “Active sourcing strategies,” in Talent Relationship Management: Competitive Recruiting Strategies in Times of Talent Shortage (Berlin: Springer), 57–89. doi: 10.1007/978-3-642-54557-3_6
Tsiskaridze, R., Reinhold, K., and Jarvis, M. (2023). Innovating HRM recruitment: a comprehensive review of AI deployment. Marketing Menedžment Innovacij 14, 239–254. doi: 10.21272/mmi.2023.4-18
Vaccaro, K., Karahalios, K., Mulligan, D. K., Kluttz, D., and Hirsch, T. (2019). “Contestability in algorithmic systems,” in Companion Publication of the 2019 Conference on Computer Supported Cooperative Work and Social Computing (New York, NY: ACM), 523–527. doi: 10.1145/3311957.3359435
Veluwenkamp, H., and Buijsman, S. (2025). Design for operator contestability: control over autonomous systems by introducing defeaters. AI Ethics 5, 3699–3711. doi: 10.1007/s43681-025-00657-0
Vishwanath, B., and Vaddepalli, S. (2023). The future of work: implications of artificial intelligence on hr practices. Tuijin Jishu/J. Propuls. Technol. 44, 1711–1724. doi: 10.52783/tjjpt.v44.i3.562
Vivek, R. (2022). Is blind recruitment an effective recruitment method. Int. J. Appl. Res. Bus. Manag. 3, 56–72. doi: 10.51137/ijarbm.2022.3.3.4
Walter, C., and Matar, Z. (2023). “Employer branding und active sourcing: statt recruiting und bewerbermanagement,” in Internationale Fachkräfte für die DACH-Region: Finden, Binden und Entwickeln in Einer Arbeitswelt der Zukunft (Cham: Springer), 53–65. doi: 10.1007/978-3-658-41417-7_4
Weitzel, T., Maier, C., Oehlhorn, C., Weinert, C., Wirth, J., Laumer, S., et al. (2020). Social Recruiting und Active Sourcing. Ausgewählte Ergebnisse der Recruiting Trends. Bamberg. Available online at: https://cris.fau.de/publications/235457539/ (Accessed November 11, 2025).
Will Arachchige, I. S., Jahankhani, H., Oshadi Karunanayaka, K., and Amin Metwally Hussien, O. A. (2024). “Exploring the balance between personalisation and automation in human-AI interaction,” in Market Grooming: The Dark Side of AI Marketing (Leeds: Emerald Publishing Limited), 199–234. doi: 10.1108/978-1-83549-001-320241010
Wilson, K., and Caliskan, A. (2024). Gender, race, and intersectional bias in resume screening via language model retrieval. Proc. AAAI/ACM Conf. AI Ethics Soc. 7, 1578–1590. doi: 10.1609/aies.v7i1.31748
Yam, J., and Skorburg, J. A. (2021). From human resources to human rights: impact assessments for hiring algorithms. Ethics Inf. Technol. 23, 611–623. doi: 10.1007/s10676-021-09599-7
Yanamala, K. K. R. (2023). Transparency, privacy, and accountability in AI-enhanced hr processes. J. Adv. Comput. Syst. 3, 10–18. doi: 10.69987/JACS.2023.30302
Zhang, M., Jensen, K. N., Sonniks, S. D., and Plank, B. (2022). Skillspan: hard and soft skill extraction from english job postings. arXiv [preprint]. arXiv:2204.12811. doi: 10.48550/arXiv.2204.12811
Keywords: artificial intelligence, recruiting, active sourcing, contestability, transparency, human resource management, machine learning
Citation: Hadžic´ B, Brandner LT, Weber T and Rätsch M (2025) AI-driven active sourcing in recruitment: addressing contestability in automated hiring systems. Front. Comput. Sci. 7:1629522. doi: 10.3389/fcomp.2025.1629522
Received: 16 May 2025; Accepted: 03 November 2025;
Published: 27 November 2025.
Edited by:
Astadi Pangarso, Telkom University, IndonesiaReviewed by:
Vijayakumar Gajenderan, Sir Theagaraya College, IndiaXuming Zhang, Guangdong University of Science and Technology, China
Dana Volosevici, Petroleum & Gas University of Ploieşti, Romania
Copyright © 2025 Hadžic´, Brandner, Weber and Rätsch. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Bakir Hadžic´, YmFraXIuaGFkemljQHJldXRsaW5nZW4tdW5pdmVyc2l0eS5kZQ==