 Philippe Desjardins-Proulx
Philippe Desjardins-Proulx Timothée Poisot
Timothée Poisot Dominique Gravel1
Dominique Gravel1- 1Université de Sherbrooke, Sherbrooke, QC, Canada
- 2Université de Montréal, Montreal, QC, Canada
The grand ambition of theorists studying ecology and evolution is to discover the logical and mathematical rules driving the world's biodiversity at every level from genetic diversity within species to differences between populations, communities, and ecosystems. This ambition has been difficult to realize in great part because of the complexity of biodiversity. Theoretical work has led to a complex web of theories, each having non-obvious consequences for other theories. Case in point, the recent realization that genetic diversity involves a great deal of temporal and spatial stochasticity forces theoretical population genetics to consider abiotic and biotic factors generally reserved to ecosystem ecology. This interconnectedness may require theoretical scientists to adopt new techniques adapted to reason about large sets of theories. Mathematicians have solved this problem by using formal languages based on logic to manage theorems. However, theories in ecology and evolution are not mathematical theorems, they involve uncertainty. Recent work in Artificial Intelligence in bridging logic and probability theory offers the opportunity to build rich knowledge bases that combine logic's ability to represent complex mathematical ideas with probability theory's ability to model uncertainty. We describe these hybrid languages and explore how they could be used to build a unified knowledge base of theories for ecology and evolution.
1. Introduction
Almost four decades ago, Ralph W. Lewis argued for the formalization of evolutionary theory and the recognition of evolution as a system of theories. In his words, “when theories are partially formalized […] the intra- and interworkings of theories become more clearly visible, and the total structure of the discipline becomes more evident” (Lewis, 1980). Supporting Lewis' point, Queller recently showed how Fisher's fundamental theorem of natural selection, Price's theorem, the Breeder equation of quantitative genetics, and other key formulas in ecology and evolution were related (Queller, 2017). In the same vein, Rice formulated an axiomatic theory of evolution based on a stochastic version of Price's theorem (Rice and Papadopoulos, 2009). These projects fall under the scope of automated theorem proving, one of the oldest and most mature branches of Artificial Intelligence (Harrison, 2009a). Theories can be written in some formal language, such as first-order logic or type theory, and then algorithms are used to ensure the theories can be derived from a knowledge base of axioms and existing results. In the last few decades, mathematicians have built knowledge bases with millions of helper theorems to assist the discovery of new ideas (Kaliszyk and Urban, 2015). For example, the Mizar Mathematical Library is a growing library of theorems, which are added after new candidate theorems are approved by the proof checker and peer-reviewed for style. Such libraries help mathematicians juggle with a growing body of knowledge and offers a concrete answer to the issue of knowledge synthesis. Mizar uses a language powerful enough for the formalization of evolutionary theories envisioned by Lewis and the result of Queller on Price's theorem and its relationship to other theories. It is also expressive enough to build a knowledge base out of Rice's axiomatic theory of evolution. Doing so would force us to think more clearly about the theoretical structure of evolution, with theoretical ecology facing a similar state of disorganization (Lewis, 1980). Case in point: theoretical community ecologists have been criticized for focusing on a single prediction for theories capable of making several (McGill et al., 2007). An example of this is Hubbell's neutral theory of biodiversity (Hubbell, 2001), which uses an unrealistic point-mutation model that does not fit with our knowledge of speciation, leading to odd predictions (Etienne and Haegeman, 2011; Desjardins-Proulx and Gravel, 2012a,b). In logic-based (also called symbolic) systems like Mizar, all formulas involving speciation would be implicitly linked together. Storing ecological theories in such knowledge base would automatically prevent inconsistencies and highlight the consequences of theories.
Despite the importance of formalization, it remains somewhat divorced from an essential aspect of theories in ecology and evolution: their probabilistic and fuzzy nature. As a few examples: a surprisingly common idea found in ecological theories is that predators are generally larger than their prey, a key assumption of the food web model of Williams and Martinez (2000); deviations from the Hardy-Weinberg principle are not only common but tend to give important information on selective pressures; and nobody expects the Rosenzweig-MacArthur predator-prey model to be exactly right. In short, important ideas in ecology and evolution do not fit the true/false epistemological framework of systems like Mizar, and ideas do not need to be derived from axiomatic principles to be useful. We are often less concerned by whether a formula can be derived from axioms than in how it fits a particular dataset. In the 1980s, Artificial Intelligence experts developed probabilistic graphical models to handle large probabilistic systems (Pearl, 1988). While probabilistic graphical models are capable of answering probabilistic queries for large systems of variables, they cannot represent or reason with sophisticated mathematical formulas. Alone, neither logic nor probability theory is enough to elucidate the structure of theories in ecology and evolution.
For decades, researchers have tried to unify probability theory with rich logics to build knowledge bases both capable of the sophisticated mathematical reasoning found in automated theorem provers and the probabilistic reasoning of graphical models. Recent advances moved us closer to that goal (Richardson and Domingos, 2006; Getoor et al., 2007; Wang and Domingos, 2008; Nath and Domingos, 2015; Hu et al., 2016; Staton et al., 2016; Bach et al., 2017). Using these systems, it is possible to check if a mathematical formula can be derived from existing results and also possible to ask probabilistic queries about theories and data. The probabilistic nature of these representations is a good fit to learn complex logical and mathematical formulas from data (Kok and Domingos, 2009). Within this framework, there is no longer a sharp distinction between theory and data, since the knowledge base defines a probability distribution over all objects, including logical relationships and mathematical formulas.
For this article, we introduce key ideas on methods at the frontier of logic and probability, beginning with a short survey of knowledge representations based on logic and probability. First-order logic is described, along with how it can be used in a probabilistic setting with Markov logic networks (Richardson and Domingos, 2006). We detail how theories in ecology and evolution can be represented with Markov logic networks, as well as highlighting some limitations. We present a case study involving a tritrophic system to demonstrate the strengths and weaknesses of Markov logic networks. Synthesis in ecology and evolution has been made difficult by the sheer number of theories involved and their complex relationships (Poisot et al., 2018). Practical representations to unify logic and probability are relatively new, but we argue they could be used to achieve greater synthesis by allowing the construction of large, flexible knowledge bases with a mix of mathematical and scientific knowledge.
2. Knowledge Representations
Traditional scientific theories and models are mathematical, or logic-based. Einstein's e = mc2 established a relationship between energy e, mass m, and the speed of light c. This mathematical knowledge can be reused: in any equation with energy, we could replace e with mc2. This ability of mathematical theories to establish precise relationships between concepts, which can then be used as foundations for other theories, is fundamental to how science grows and forms an interconnected corpus of knowledge. The formula is implicitly connected to other formulas involving the same symbol, such that if we were to establish a different but equivalent way to represent the speed of light c, it could automatically substitute c in e = mc2.
Artificial Intelligence researchers have long been interested in expert systems capable of scientific discoveries, or simply capable of storing scientific and medical knowledge in a single coherent system. Dendral, arguably the first expert system, could form hypotheses to help identify new molecules using its knowledge of chemistry (Lindsay et al., 1993). In the 1980s, Mycin was used to diagnose blood infections (and did so more accurately than professionals) (Buchanan and Shortliffe, 1984). Both systems were based on logic, with Mycin adding a “confidence factor” to its rules to model uncertainty. These expert systems generally relied on a simple logic system not powerful enough to handle uncertainty. With few exceptions, the rules were hand-crafted by human experts. After the experts established the logic formulas, the systems acted as static knowledge bases and unable to discover new rules. Algorithms have been developed to learn new logic rules from data (Muggleton and Feng, 1990; Muggleton and de Raedt, 1994), but the non-probabilistic nature of the resulting knowledge base makes it difficult to handle real-world uncertainty. In addition to expert systems, logic systems are used to store mathematical knowledge and perform automatic theorem proving (Harrison, 2009a). Pure logic has rarely been used in ecology and evolution, but recent studies have shown its ability to reconstruct food webs from data (Bohan et al., 2011; Tamaddoni-Nezhad et al., 2013).
There are many different logics for expert systems and automatic theorem proving (Harrison, 2009a; Program, 2013; Nederpelt and Geuvers, 2014). We will focus on first-order logic, the most commonly used logic in efforts to unify logic with probability. A major reason for adopting rich logics, whether first-order or higher-order, is to allow for the complex relationships found in ecology and evolution to be expressed in concise formulas. Stuart Russell noted that “the rules of chess occupy 100 pages in first-order logic, 105 pages in propositional logic, and 1038 pages in the language of finite automata” (Russell, 2015). Similarly, first-order logic allows us to directly express complex ecological ideas in a simple but formal language.
In mathematics, a function f maps terms X (its domain) to other terms Y (its codomain) f : X → Y. The number of arguments of a function, |X|, is called its arity. The atomic element of first-order logic is the predicate: a function that maps 0 or more terms to a truth value: false or true. In first-order logic, terms are either variables, constants, or functions. A variable ranges over a domain, for example x could range over integers, p over a set of species, and city over a set of cities. Constants represent values such as 42, Manila, π. Lastly, functions map terms to other terms such as multiplication, integration, sin, CapitalOf (mapping a country to its capital). Variables have to be quantified either universally with ∀ (forall), existentially with ∃ (exists), or uniquely with ∃!. ∀x : p(x) means p(x) must hold true for all possible values of x. ∃x : p(x) means it must hold for at least one value of x while ∃!x : p(x) means it must hold for exactly one value of x. Using this formal notation, we can write the relationship between the basal metabolic rate (BMR) and body mass (Mass) for mammals (Ahlborn, 2004):
This formula has one variable m which is universally quantified: ∀m ∈ Mammal reads “for all m in the set Mammal.” It has two constants: the numbers 4.1 and 0.75, along with four functions (BMR, Mass, multiplication, exponentiation). The equal sign = is the sole predicate.
A first-order logic formula is either a lone predicate or a complex formula formed by linking formulas using the unary connective ¬ (negation) or binary connectives (and ∧, or ∨, implication ⇒, see Table 1). For example, PreyOn(sx, sy) is a predicate that maps two species to a truth value, in this case whether the first species preys on the second species, and IsParasite(s) is a predicate that is true if species s is a parasite. We could also have a function Mass(sx) mapping a species to its body mass. We can build more complex formulas from there, for example:
The first formula says that species don't prey on themselves. The second formula says that predators are larger than their prey (> is a shorthand for the greater than predicate). The third formula refines the second one by adding that predators are larger than their prey unless the predator is a parasite. None of these rules are expected to be true all the time, which is where mixing probability with logic will come in handy. The Rosenzweig-MacArthur equation can also easily be expressed with first-order logic:
This formula has four functions: the time differential ẋ ≡ dx/dt, multiplication, addition, and subtraction. Prey x and predator y are universally quantified variables while r0, K, C, D, X, δ0 are constants. The formula has only one predicate, = , and both sides of the formula are connected by ∧, the symbol for conjunction (“and”).
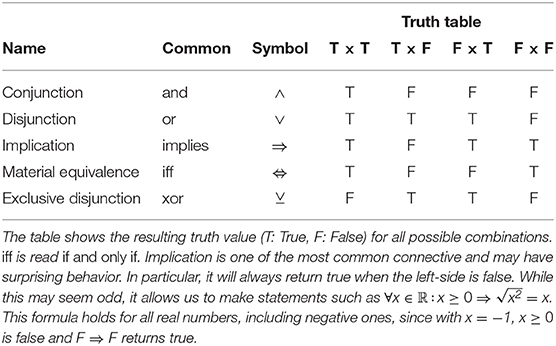
Table 1. Common binary connectives.
A knowledge base in first-order logic is a set of formulas . First-order logic is expressive enough to represent and manipulate complex logic and mathematical ideas. It can be used for simple ideas such that predators are generally larger than their prey (Equation 2b), mathematical formulas for predator-prey systems equation (Equation 3), and also to establish the logical relationship between various predicates. We may want a PreyOn predicate to tell us whether sx preys on sy, but also a narrower PreyOnAt(sx, sy, l) predicate to model whether sx preys on sy at a specific location l. In this case, it would be a good idea to have the formula ∀sx, sy, l : PreyOnAt(sx, sy, l) ⇒ PreyOn(sx, sy). Given this formula and the data point PreyOnAt(Wolverine, Rabbit, Quebec), we do not need PreyOn(Wolverine, Rabbit) to be explicitly stated, ensuring the larger metaweb (Poisot et al., 2016) is always consistent with information from local food webs.
An interpretation defines which object, predicate, or function is represented by which symbol, e.g., it says PreyOnAt is a predicate with three arguments, two species and one location. The process of replacing variables with constants is called grounding, and we talk of ground terms / predicates / formulas when no variables are present. Together with an interpretation, a possible world assigns truth values to each possible ground predicate, which can then be used to assign truth values to a knowledge base's formulas. PreyOn(sx, sy) can be neither true nor false until we assign constants to the variables sx and sy. Constants are typed, so a set of constants may include two species {Gulo gulo, Orcinus orca} and three locations {Quebec, Fukuoka, Arrakis}. The constants yield 22 × 3 possible ground predicates for PreyOnAt(sx, sy, l):
and only two possible ground predicates for IsParasite:
We say a possible world satisfies a knowledge base (or a single formula) if all the formulas are true given the ground predicates. A basic question in first-order logic is to determine whether a knowledge base entails a formula f, or . Formally, the entailment means that for all possible worlds in which all formulas in are true, f is also true. More intuitively, it can be read as the formula following from the knowledge base (Russell and Norvig, 2009). A proof in first-order logic can be derived using inference rules such as Modus Ponens:
This notation reads: infer β if α ⇒ β is true and α is true. See Harrison (2009a) for a detailed look at inference rules in first-order logic.
Probabilistic graphical models, which combine graph theory with probability theory to represent complex probability distributions, can provide an alternative to logic-based representations (Koller and Friedman, 2009; Barber, 2012). There are primarily two motivations behind probabilistic graphical models. First, even for binary random variables, we need to learn 2n − 1 parameters for a distribution of n variables. This is unmanageable on many levels: it is computationally difficult to do inference with so many parameters, requires a large amount of memory, and makes it difficult to learn parameters without an unreasonable volume of data (Koller and Friedman, 2009). Second, probabilistic graphical models provide important information about independences and the overall structure of the distribution. Probabilistic graphical models were also used as expert systems: Munin had a network of more than 1,000 nodes to analyze electromyographic data (Andreassen et al., 1996), while PathFinder assisted medical professionals for the diagnostic of lymph-node pathologies (Heckerman and Nathwani, 1992) (Figure 1).
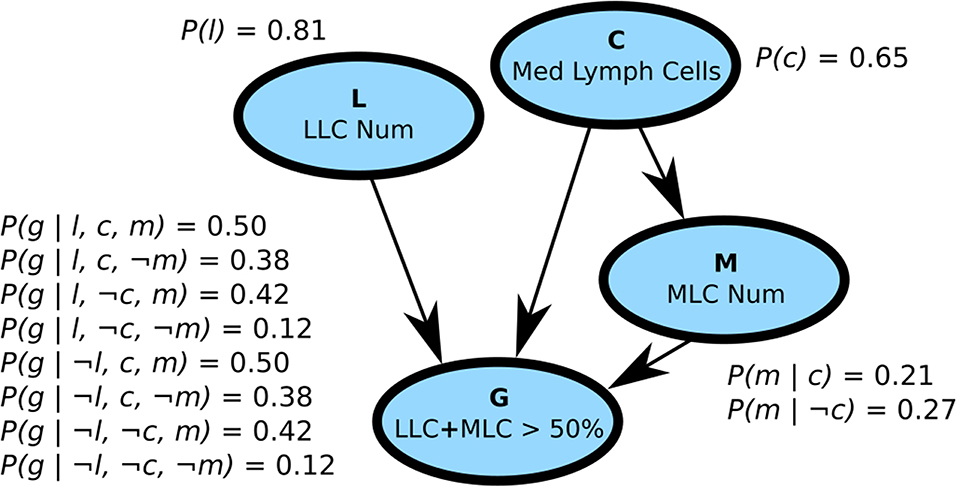
Figure 1. A Bayesian network with four binary variables (the vertices) and possible conditional probability tables. Bayesian networks encode the distribution as directed acyclic graphs such that P(X = x) = ∏iP(xi|Pa(xi)), where Pa(xi) is the set of parents of variable xi. Because no cycles are allowed, the variables form an ordering so the set Pa(xi) can only involve variables already seen on the left of xi. Thus, P(a)P(b|a)P(c) is a valid Bayesian networks but not P(a)P(b|c)P(c|b). The four vertices represented here were extracted from PathFinder, a Bayesian network with more than 1,000 vertices used to help diagnose blood infections (Heckerman and Nathwani, 1992). The vertices represent four variables related to blood cells and are denoted by a single character (in bold in the figure): C, M, L, G. We denote a positive value with a lowercase letter and a negative value with ¬ (e.g.,: C = c, M = ¬m). Since P(¬x|y) = 1−P(x|y), we need only 2|Pa(x)| parameters per vertex, with |Pa(x)| being the number of parents of vertex x. The structure of Bayesian networks highlights the conditional independence assumptions of the distribution and reduces the number of parameters for learning and inference. As a example query: P(l, ¬c, m, ¬g) = P(l)P(¬c)P(m|¬c)P(¬g|l, ¬c, m) = 0.81 × (1 − 0.65) × 0.27 × (1 − 0.42) = 0.044. See Darwiche (2009) for a detailed treatment of Bayesian networks and Koller and Friedman (2009) for a more general reference on probabilistic graphical models.
The two key inference problems in probabilistic machine learning are finding the most probable joint state of the unobserved variables (maximum a posteriori, or MAP) and computing conditional probabilities (conditional inference). In a simple presence/absence model for 10 species (s0, s1, …, s9), given that we know the state of species s0 = Present, s1 = Absent, s2 = Absent, MAP inference would tell us the most likely state for species s3, …, s9, while conditional inference could answer queries such as P(s4 = Absent|s0 = Present).
3. Markov Logic
At this point we have first-order logic, which is capable of manipulating complex logic and mathematical formulas but cannot handle uncertainty, and probabilistic graphical models, which cannot be used to represent mathematical formulas (and thus theories in ecology and evolution) but can handle uncertainty. The limit of first-order logic can be illustrated with our previous example: predators generally have a larger body weight (Mass) than their prey, which we expressed in predicate logic as ∀sx, sy : PreyOn(sx, sy) ⇒ Mass(sx) > Mass(sy), but this is obviously false for some assignments such as sx : grey wolf and sy : moose. However, it is still useful knowledge that underpins many ecological theories (Williams and Martinez, 2000). When our domain involves a great number of variables, we should expect useful rules and formulas that are not always true.
A core idea behind many efforts to unify rich logics with probability theory is that formulas can be weighted, with higher values meaning we have greater certainty in the formula. In pure logic, it is impossible to violate a single formula. With weighted formulas, an assignment of concrete values to variables is only less likely if it violates formulas, and how much less likely will depend on the weight assigned to the violated formula. The higher the weight of the formula violated, the less likely the assignment is. It is conjectured that all perfect numbers are even (∀x : Perfect(x) ⇒ Even(x)), thus, if we were to find a single odd perfect number, that formula would be refuted. It makes sense for mathematics but for many disciplines, such as biology, important principles are only expected to be true most of the time. If we were to find a single predator smaller than its prey, it would definitely not make our rule useless.
The idea of weighted formulas is not new. Markov logic networks (or just Markov logic), invented a decade ago, allows for logic formulas to be weighted (Richardson and Domingos, 2006; Domingos and Lowd, 2009). Similar efforts also use weighted formulas (Hu et al., 2016; Bach et al., 2017). Markov logic supports algorithms to add weights to existing formulas given a dataset, learn new formulas or revise existing ones, and answer probabilistic queries (MAP or conditional). As a case study, Yoshikawa et al. used Markov logic to understand how events in a document were time-related (Yoshikawa et al., 2009). Their research is a good case study of interaction between traditional theory-making and artificial intelligence. The formulas they used as a starting point were well-established logic rules to understand temporal expressions. From there, they used Markov logic to weight the rules, adding enough flexibility to their system to beat the best approach of the time. Brouard et al. (2013) used Markov logic to understand gene regulatory networks, noting how the resulting model provided clear insights, in contrast to more traditional machine learning techniques. Markov logic greatly simplifies the process of growing a base of knowledge: two research labs with different knowledge bases can simply put all their formulas in a single knowledge base. The only steps required to merge two knowledge bases is to put all the formulas in a single knowledge base and reevaluate the weights.
In a nutshell, a knowledge base in Markov logic is a set of formulas f0, f1, f2, … along with their weights w0, w1, w2, … :
Given constants , defines a Markov network (an undirected probabilistic graphical model) which can be used to answer probabilistic queries. Weights are real numbers in the −∞, ∞ range. The intuition is: the higher the weight associated with a formula, the greater the penalty for violating it (or alternatively: the less likely a possible world is). The cost of an assignment is the sum of the weights of the unsatisfied formulas (those that are false). The higher the cost, the less likely the assignment is. Thus, if a variable assignment violates 12 times a formula with a weight of 0.1 and once a formula with a weight of 1.1, while another variable assignment violates a single formula with a weight of 5, the first assignment has a higher likelihood (cost of 2.3 vs. 5). Formulas with an infinite weight act like formulas in pure logic: they cannot be violated without setting the probabilities to 0. In short, a knowledge base in pure first-order logic is exactly the same as a knowledge base in Markov logic where all the weights are infinite. In practice, it means mathematical ideas and axioms can easily be added to Markov logic as formulas with an infinite weight. Formulas with weights close to 0 have little effect on the probabilities and the cost of violating them is small. A formula with a negative weight is expected to be false. It is often assumed that all weights are positive real numbers without loss of generality since (f, −w) ≡ (¬f, w). See Jain (2011) for a detailed treatment of knowledge engineering with Markov logic. Markov logic can answer queries of complex formulas of the form:
where f0 and f1 are first-order logic formulas while is a weighted knowledge base and a set of constants. It's important to note that neither f0 nor f1 need to be in . Logical entailment is equivalent to finding (Domingos and Lowd, 2009).
We build a small knowledge base for an established ecological theory: the niche model of trophic interactions (Williams and Martinez, 2000). The first iteration of the niche model posits that all species are described by a niche position N (their body size for instance) in the [0, 1] interval, a diet D in the [0, N] interval, and a range R such that a species preys on all species with a niche in the [D − R/2, D + R/2] interval. We can represent these ideas with three formulas:
As pure logic, this knowledge base makes little sense. Formula 9a is obviously not true all the time but often is since most pairs of species do not interact. In Markov logic, it is common to have a formula for each lone predicate, painting a rough picture of its marginal probability (Domingos and Lowd, 2009; Jain, 2011). We could also add that cannibalism is rare ∀x : ¬PreyOn(x, x) and that predator-prey relationships are generally asymmetrical ∀x, y : PreyOn(x, y) ⇒ ¬PreyOn(y, x) (although this formula is redundant with the idea that predators are generally larger than their prey). Formulas that are often wrong are assigned a lower weight but can still provide useful information about the system. The second formula says that the diet is smaller than the niche value. The last formula is the niche model: species x preys on y if and only if species y's niche is within the diet interval of x. Using Markov logic and a dataset, we can learn a weight for each formula in the knowledge base. This step alone is useful and provides insights into which formulas hold best in the data. With the resulting weighted knowledge base, we can make probabilistic queries and even attempt to revise the theory automatically. We could find, for example, that the second rule does not apply to parasites or some group and get a revised rule such as ∀x : ¬IsParasite(x) ⇒ D(x) < N(x).
4. Fuzziness
First-order logic provides a formal language for expressing mathematical and logical ideas while probability theory provides a framework for reasoning about uncertainty. A third dimension often found in discussions on unifying logic with probability is fuzziness. A struggle with applying logic to ecology is that all predicates are either true or false. Even probabilistic logics like Markov logic define a distribution over binary predicates. Going back to Rosenzweig-MacArthur (Equation 3), this formula's weight in Markov logic is almost certainly going to be zero since it's never exactly right. If the Rosenzweig-MacArthur equation predicts a population size of 94 and we observe 93, the formula is false. Weighted formulas help us understand how often a formula is true, but in the end the formula has to give a binary truth value: true or false, there is no place for nuance. Logicians studied more flexible logics where truth is a real number in the [0, 1] range. These logics are said to be “infinitely many-valued” or “fuzzy.” In this setting: 0 is false, 1 is true, and everything in-between is used to denote nuances of truth (Zadeh, 1965; Behounek et al., 2011). Predicates returning truth values in the [0, 1] range are called fuzzy predicates, while standard predicates returning false, true are said to be bivalent. To show fuzziness in action, let's look at a simple formula that says that small populations experience exponential growth:
Variables s, l, t, respectively, denote a species, a location, and time. Function N returns the population size of a species at a specific location and time while function R returns the growth rate of the species. The predicates SmallPopSize and = are both problematic from a bivalent perspective. Equality poses problem for the same reason it did with the Rosenzweig-MacArthur example: we do not expect this formula to be exactly right. The notion of a small population size should also be flexible, yet logic forces us to determine a strict threshold where SmallPopSize will change from true to false. Using truth values in the [0, 1] range makes it possible to have a wide range of nuances for both SmallPopSize and equality. See Table 2 for the definitions of fuzzy logic connectives.
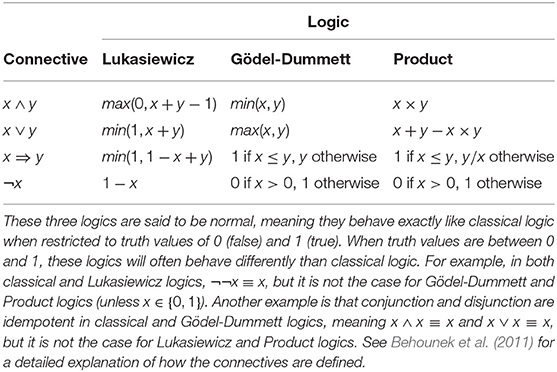
Table 2. Definitions of logic connectives for the three main fuzzy logics.
Fuzzy logic is not a replacement for probability theory. The most interesting aspect of fuzzy logic is how it interacts with probability theory to form truly flexible languages. For examples, fuzzy predicates are used in both probabilistic soft logic (Kimmig et al., 2012; Bach et al., 2017) and deep learning approaches to predicate logic (Hu et al., 2016; Zahavy et al., 2016). Hybrid Markov logic (Wang and Domingos, 2008; Domingos and Lowd, 2009) extends Markov logic by allowing not only weighted formulas but terms like soft equality, which applies a Gaussian penalty to deviations from equality. While not exactly a full integration of fuzzy logic into Markov logic, soft equality behaves in a similar matter and is a good fit for formulas like the Rosenzweig-MacArthur system or our previous example with exponential growth. Hybrid Markov logic is not as well-developed as standard Markov logic, for example there are no algorithms to learn new formulas from data. On the other hand, Hybrid Markov logic solves many of the problems caused by bivalent predicates while retaining the ability to answer conditional queries. In the next section we'll explore hybrid Markov logic and its application to an ecological dataset. Several languages for reasoning have combined fuzziness with probability or logic (Figure 2). It has been argued that, in the context of Bayesian reasoning, fuzziness plays an important role in bridging logic with probability (Jacobs and Zanasi, 2018; Nedbal and Serafini, 2018). However, how to effectively combine rich logics with probability theory remains an open question, as is the role of fuzziness.
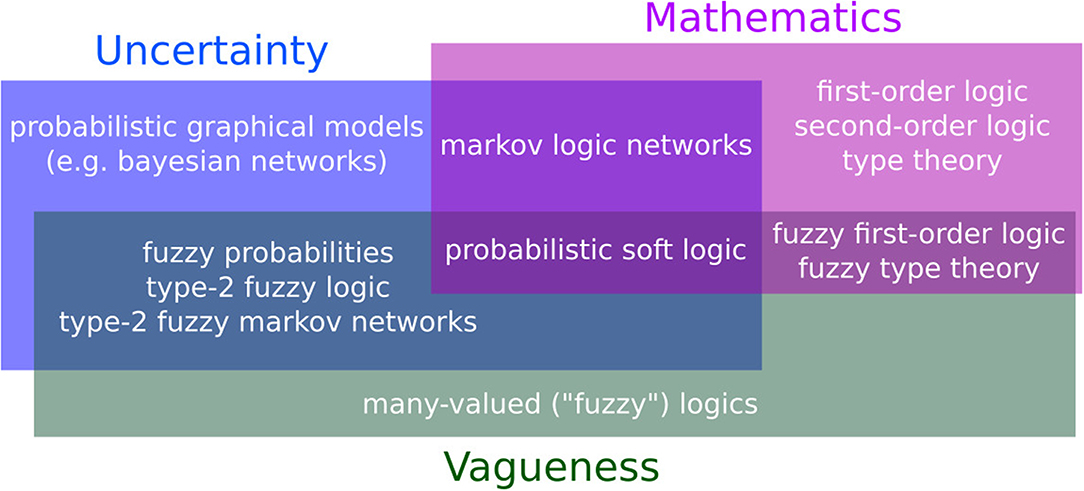
Figure 2. Various languages and their ability to model uncertainty, vagueness, and mathematics (the size of the rectangles has no meaning). In the blue rectangle: languages capable of handling uncertainty. Probabilistic graphical models combine probability theory with graph theory to represent complex distributions (Koller and Friedman, 2009). Alternatives to probability theory for reasoning about uncertainty include possibility theory and Dempster-Shafer belief functions, see Halpern (2003) for an extended discussion. In the green rectangle: Fuzzy logic extends standard logic by allowing truth values to be anywhere in the [0, 1] interval. Fuzziness models vagueness and is particularly popular in linguistics, engineering, and bioinformatics, where complex concepts and measures tend to be vague by nature. See Kosko (1990) for a detailed comparison of probability and fuzziness. In the purple rectangle: languages capable of modeling mathematical formulas. It is important to note that while first-order logic is expressive enough to express a large class of mathematical ideas, many languages rely on a restricted from of first-order logic without functions. Alone, these languages are not powerful enough to express scientific ideas, we must thus focus on what lies at their intersection. Type-2 Fuzzy Logic is a fast-expanding (Sadeghian et al., 2014; Mendel, 2017) extension to fuzzy logic, which, in a nutshell, models uncertainty by considering the truth value itself to be fuzzy (Mendel and Bob John, 2002; Zeng and Liu, 2008). Markov logic networks (Richardson and Domingos, 2006; Domingos and Lowd, 2009) extends predicate logic with weights to unify probability theory with logic. Probabilistic soft logic (Kimmig et al., 2012; Bach et al., 2015) also has formulas with weights, but allows the predicates to be fuzzy, i.e., have truth values in the [0, 1] interval. Some recent deep learning studies also combine all three aspects (Garnelo et al., 2016; Hu et al., 2016).
5. Markov Logic and the Salix Tritrophic System
The primary goal of unifying logic and probability is to be able to grow knowledge bases of formulas in a clear, precise language. For Markov logic, it means a set of formulas in first-order logic. For this example, we used Markov logic to build a knowledge base for ecological interactions around the Salix dataset (Kopelke et al., 2017). The Salix dataset has 126 parasites, 96 species of gallers (insects), and 52 species of salix, forming a tritrophic ecological network (Parasite → Galler → Salix). Furthermore, we have partial phylogenetic information for the species, their presence/absence in 374 locations, interactions, and some environmental information on the locations. To fully illustrate the strengths and limits of Markov logic in this setting, we will not limit ourselves to the data available for this particular dataset (e.g., we do not have body mass for all species).
Data in first-order logic can be organized as a set of tables (one for each predicate). For our example, we have a table named PreyOnAt with three columns (its arguments) and a table named IsParasitoid with only one column. This format implies the closed-world assumption: if an entry is not found, it is false (see Table 3 for an example). For this problem we defined several functions and predicates to describe everything from predator-prey relationships, whether pairs of species often co-occurred, along with information on locations such as humidity, precipitation, and temperature (see Table 4). We ran the basic learning algorithm from Alchemy-2 (Richardson and Domingos, 2006), which is used both to learn new formulas and weight them. The weights are listed at the end of each formula. We use the “?” character at the end of the formula involving data that were unavailable for this dataset (and thus, we could not learn the weight). Here's a sample of a knowledge base where the first three formulas were learned directly from our dataset and the last two serve as example for Hybrid Markov logic:
The first two formulas correctly define the tritrophic relationship between parasites, galler and salix, while the third shows a solid, but not as strong, relationship between predation and co-occurence. Formula (9c) would require hybrid Markov logic and a fuzzy predicate ≈.
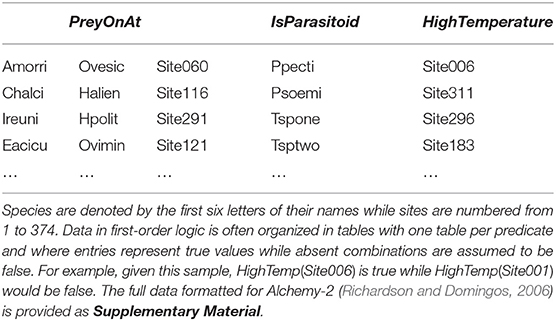
Table 3. A sample of three tables for the Salix dataset (Kopelke et al., 2017).

Table 4. Predicates and functions used for the Salix example.
Integration of macroecology and food web ecology may rely on a better understanding of macroecological rules (Baiser et al.). These rules are easy to express with first-order logic, for example Equation (11e) is a formulation of Bergmann's rule. We also used the learning algorithm to test whether closely related species had similar prey, but the weight attributed to the formula was almost zero, telling us the formula was right as often as it was wrong:
This example shows both the promise and the current issues with hybrid logic-probabilistic techniques. Many of the predicates would benefit from being fuzzy, for example, PreyOn should take different values depending on how often predation occurs. We also had to use arbitrary cut-offs for predicates like CloselyRelated and HighTemperature. Fortunately, many recent approaches integrate logic with both fuzziness and probability theory (Adams and Jacobs, 2015; Hu et al., 2016; Bach et al., 2017). Weights are useful to understand which relationship is strong in the data, and this example shows the beginning of a knowledge base for food web ecology. The next step would be to discover new formulas, whether manually or using machine learning algorithms, and add data to revise the weights. If a formula involves a predicate operating on food webs and we want to apply our knowledge base to a dataset without food webs, this formula will simply be ignored (because it won't have grounded predicates to evaluate it; see section 2). This is a strong advantage of this knowledge representation: our little knowledge base here can be used as a basis for any other ecological datasets even if they quite different. With time, it's possible to grow an increasingly connected knowledge base, linking various ideas from different fields together.
6. Bayesian Higher-Order Probabilistic Programming
Artificial Intelligence has a long history with first-order logic (Russell and Norvig, 2009) but type theory (or higher-order logic), a more expressive logic, is currently more popular both as a tool to formalize mathematics and as foundation for programming languages. We explored hybrid approaches based on first-order logic and, for this section, we'll briefly discuss Bayesian Higher-Order Probabilistic Programming (BHOPP) along with its relationship with type theory. Probabilistic programming languages are programming languages built to describe probabilistic models and simplify the inference process. Stan Carpenter et al. (2017) and BUGS Lunn et al. (2012) are two popular examples of probabilistic programming languages used for Bayesian inference, but even more flexible languages for Bayesian probabilistic programming have recently emerged. These languages, like Church Goodman et al. (2008) and Anglican Wood et al. (2014), accept higher-order constructs (that is: functions accepting other functions as arguments). The ambition is that “ultimately we would like simply to be able to do probabilistic programming using any existing programming language as the modeling language” (van de Meent et al., 2018).
First-order logic allowed us to model intricate theories but, in practice, almost all modern systems used to formalize mathematics are based on type theory (higher-order logic) (Nederpelt and Geuvers, 2014). The “first” in first-order logic refers to the limitation that quantification can only be done on individual elements of a set, but not on higher-order structures like sets, predicates, or functions. As a consequence, several important concepts in mathematics cannot be formalized directly with first-order logic. Since type theory supports higher-order quantification, it is used as a foundation to reason about mathematics. Coq, HOL, HOL Light, and Microsoft's LEAN are all popular languages for automated theorem proving based on different forms of type theory (The Coq Development Team, 2004; Harrison, 2009b; de Moura et al., 2015). Programming languages in general, not just those targeted at mathematicians, tend to also rely on type theory as foundation (Pierce, 2002). See Farmer (2008) and Nederpelt and Geuvers (2014) for an introduction to type theory. Here is where it gets confusing: the higher in higher-order logic has a different meaning than in higher-order probabilistic programming and yet, Bayesian higher-order probabilistic programming languages (BHOPPL) may hold the key to sound inference mixed with type theory. In BHOPPL, higher-order means functions can take functions as arguments, a common capability of modern programming languages. This is necessary for higher-order logic but not sufficient. Where it gets exciting is that a lot of progress is being made in framing BHOPPL in the language of type theory (Borgström et al., 2016). In effect, it would bring Bayesian and higher-order logic reasoning together.
Furthermore, software-wise, BHOPPLs are well ahead of the approaches described in previous sections such as hybrid Markov logic networks. Current higher-order probabilistic programming languages operate on variants of well-known languages: Anglican is based on Clojure (Wood et al., 2014), Pyro is based on Python (Bingham et al., 2019), Turing.jl uses Julia (Ge et al., 2018). Many BHOPPLs have been designed to exploit the high-performance architecture developed for deep learning such as distributed systems of GPUs (graphics cards). GPUs have been important in the development of fast learning and inference in deep learning (Goodfellow et al., 2016). Pyro (Bingham et al., 2019) is a BHOPPL built on top of PyTorch, one of the most popular frameworks for deep learning, allowing computation to be distributed on systems of GPUs. In contrast, there are no open-source implementations of Markov logic networks running on GPUs. The main downside of BHOPPLs is that, while in theory they may support the richer logics used to formalize modern mathematics, in practice higher-order probability theory is itself not well understood. This is an active research topic (van de Meent et al., 2018) but formalization faces serious issues. For one, there are incompatibilities with the standard measure-theoretic foundation of probability theory, which may require rethinking how probability theory is formulated (Borgströ et al., 2011; Staton et al., 2016; Heunen et al., 2017; Staton, 2017; Ścibior et al., 2018). First-order logic is among the most studied formal languages, making it easy to use a first-order knowledge base with various software. The current informal nature of BHOPPLs make them hard to recommend for the synthesis of knowledge in ecology and evolution, even though they may very well hold the most potential.
7. Where's Our Unreasonably Effective Paradigm?
Legitimate abstractions can often obfuscate how much various subfields are related. Natural selection is a good example. Many formulas in population genetics rely on fitness. Nobody disputes the usefulness of this abstraction, it allows us to think about changes in populations without worrying whether selection is caused by predation or climate change. On the other hand, fitness has also allowed the development of theoretical population genetics to evolve almost independently of ecology. There is a realization that much of the complexity of evolution is related to how selection varies in time and space, which puts evolution in ecology's backyard (Bell, 2010). Achieving Lewis' goal of formalization would not prevent the use of fitness, but having formulas with fitness cohabiting with formulas explaining the components of fitness would implicitly link ecology and evolution. This goes in both directions: what are the consequences of new discoveries on speciation and adaptive radiations on the formation of metacommunities? How can community dynamics explain the extinction and persistence of new species? If there isn't a single theory of biodiversity, the imperative is to understand biodiversity as a system of theories. Given the scope of ecology and evolution and the vast number of theories involved, it seems difficult to achieve a holistic understanding without some sort of formal system to see how the pieces of the puzzle fit together. Connolly et al. noted how theories for metacommunities were divided between those derived from first principles and those based on statistical methods (Connolly et al., 2017). In systems unifying rich logics with a probabilistic representation, this distinction does not exist, theories are fully realized as symbolic and statistical entities. Efforts to bring theories in ecology and evolution into a formal setting should be primarily seen as an attempt to put them in context, to force us to be explicit about our assumptions and see how our ideas interact (Suppes, 1968).
Despite recent progress at the frontier of logic and probability, there are still practical and theoretical issues to overcome to make a large database of knowledge for ecology and evolution possible. Inference can be difficult in rich knowledge representations, not all methods have robust open-source implementations, and some approaches such as Bayesian higher-order probabilistic programming are themselves not well understood. Plus, while mathematicians benefit from decades of experience making large databases of theorems, there have been no such efforts for ecology and evolution. Lewis' case for the formalization is worth repeating: “when theories are partially formalized […] the intra- and interworkings of theories become more clearly visible, and the total structure of the discipline becomes more evident” (Lewis, 1980). This vision might soon become reality thanks to increased access to data in evolution and evolution and recent advances at the frontier of logic and probability. Given the pressing need to understand a declining biodiversity, ecologists and evolutionary biologists should be at the forefront of the efforts to organize theories in unified knowledge bases.
Data Availability Statement
All datasets generated for this study are included in the article/Supplementary Material.
Author Contributions
PD-P wrote the manuscript, designed, and performed the experiments. PD-P, TP, and DG edited the manuscript.
Funding
PD-P has been funded by an Alexander Graham Bell Graduate Scholarship from the National Sciences and Engineering Research Council of Canada, an Azure for Research award from Microsoft, and benefited from the Hardware Donation Program from NVIDIA. DG was funded by the Canada Research Chair program and NSERC Discovery grant. TP was funded by an NSERC Discovery grant and an FQRNT Nouveau Chercheur grant.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The reviewer, ZC, declared a past co-authorship with one of the authors, DG, to the handling Editor.
Acknowledgments
We thank three reviewers for their helpful comments.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fevo.2019.00402/full#supplementary-material
References
The Coq development team (2004). The Coq Proof Assistant Reference Manual. LogiCal Project. Version 8.0.
Adams, R., and Jacobs, B. (2015). A type theory for probabilistic and bayesian reasoning. CoRR abs/1511.09230.
Ahlborn, B. (2004). Zoological Physics: Quantitative Models of Body Design, Actions, and Physical Limitations of Animals. Berlin; Heidelberg: Springer.
Andreassen, S., Rosenfalck, A., Falck, B., Olesen, K. G., and Andersen, S. K. (1996). Evaluation of the diagnostic performance of the expert EMG assistant MUNIN. Electroencephalogr. Clin. Neurophysiol. 101, 129–144. doi: 10.1016/0924-980X(95)00252-G
Bach, S., Broecheler, M., Huang, B., and Getoor, L. (2015). Hinge-loss markov random fields and probabilistic soft logic. arXiv: 1505.04406.
Bach, S., Broecheler, M., Huang, B., and Getoor, L. (2017). Hinge-loss markov random fields and probabilistic soft logic. J. Mach. Learn. Res. 18, 1–67.
Baiser, B., Gravel, D., Cirtwill, A., Dunne, J., Fahimipour, A., Gilarranz, L., et al. (2009). Ecogeographical rules and the macroecology of food webs. Glob. Ecol. Biogeogr. 28, 1204–1218. doi: 10.1111/geb.12925
Behounek, L., Cintula, P., and Hájek, P. (2011). “Introduction to mathematical fuzzy logic,” in Handbook of Mathematical Fuzzy Logic volume 1, Chap. 1, eds P. Cintula, P. Hájek, and C. Noguera (London: College Publications), 1–101.
Bell, G. (2010). Fluctuating selection: the perpetual renewal of adaptation in variable environments. Phil. Trans. R. Soc. B 365, 87–97. doi: 10.1098/rstb.2009.0150
Bingham, E., Chen, J., Jankowiak, M., Obermeyer, F., Pradhan, N., Karaletsos, T., et al. (2019). Pyro: deep universal probabilistic programming. J. Mach. Learn. Res. 20, 973–978.
Bohan, D. A., Caron-Lormier, G., Muggleton, S., Raybould, A., and Tamaddoni-Nezhad, A. (2011). Automated discovery of food webs from ecological data using logic-based machine learning. PLoS ONE 6:e29028. doi: 10.1371/journal.pone.0029028
Borgströ, J., Gordon, A., Greenberg, M., Margetson, J., and Gael, J. V. (2011). “Measure transformer semantics for bayesian machine learning,” in Programming Languages and Systems, ed G. Barthe (Berlin; Heidelberg: Springer), 77–96.
Borgström, J., Dal Lago, U., Gordon, A., and Szymczak, M. (2016). “A lambda-calculus foundation for universal probabilistic programming,” in Proceedings of the 21st ACM SIGPLAN International Conference on Functional Programming, ICFP 2016 (Nara), 33–46.
Brouard, C., Vrain, C., Dubois, J., Castel, D., D, M., and d'Alche Buc, F. (2013). Learning a markov logic network for supervised gene regulatory network inference. BMC Bioinformatics 14:273. doi: 10.1186/1471-2105-14-273
Buchanan, B., and Shortliffe, E. (1984). Rule-based Expert Systems: The Mycin experiments of the Stanford Heuristic Programming Project. Reading, MA: Addison-Wesley.
Carpenter, B., Gelman, A., Hoffman, M., Lee, D., Goodrich, B., Betancourt, M., et al. (2017). Stan: a probabilistic programming language. J. Stat. Softw. 76, 1–32. doi: 10.18637/jss.v076.i01
Connolly, S. R., Keith, S., Colwell, R., and Rahbek, C. (2017). Process, mechanism, and modeling in macroecology. Trends Ecol. Evol. 32, 835–844. doi: 10.1016/j.tree.2017.08.011
Darwiche, A. (2009). Modeling and Reasoning with Bayesian Networks. Cambridge: Cambridge University Press.
de Moura, L., Kong, S., Avigad, J., van Doorn, F., and von Raumer, J. (2015). “The lean theorem prover,” in 25th International Conference on Automated Deduction (CADE-25) (Berlin).
Desjardins-Proulx, P., and Gravel, D. (2012a). A complex speciation-richness relationship in a simple neutral model. Ecol. Evol. 2, 1781–1790. doi: 10.1002/ece3.292
Desjardins-Proulx, P., and Gravel, D. (2012b). How likely is speciation in neutral ecology? Am. Nat. 179, 137–144. doi: 10.1086/663196
Domingos, P., and Lowd, D. (2009). Markov Logic: An Interface Layer for Artificial Intelligence. San Rafael, CA: Morgan & Claypool Publishers.
Etienne, R., and Haegeman, B. (2011). The neutral theory of biodiversity with random fission speciation. Theor. Ecol. 4, 87–109. doi: 10.1007/s12080-010-0076-y
Farmer, W. (2008). The seven virtues of simple type theory. J. Appl. Logic 6, 267–286. doi: 10.1016/j.jal.2007.11.001
Garnelo, M., Arulkumaran, K., and Shanahan, M. (2016). Towards deep symbolic reinforcement learning. arXiv:1609.05518v2.
Ge, H., Xu, K., and Ghahramani, Z. (2018). “Turing: a language for flexible probabilistic inference,” in Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, Vol. 84, eds A. Storkey and F. Perez-Cruz (Playa Blanca), 1682–1690.
Getoor, L., Friedman, N., Koller, D., Pfeffer, A., and Taskar, B. (2007). “Probabilistic relational models,” in Introduction to Statistical Relational Learning, eds L. Getoor and B. Taskar (Cambridge: MIT Press).
Goodman, N., Mansinghka, V., Roy, D., Bonawitz, K., and Tenenbaum, J. (2008). Church: a language for generative models. Uncertainty Artific. Intell. arXiv:1206.3255
Harrison, J. (2009a). Handbook of Practical Logic and Automated Reasoning. Cambridge: Cambridge University Press.
Harrison, J. (2009b). “Hol light: an overview,” in Theorem Proving in Higher Order Logics, eds S. Berghofer, T. Nipkow, C. Urban, and M. Wenzel (Berlin; Heidelberg: Springer Berlin Heidelberg), 60–66.
Heckerman, D. E., and Nathwani, B. N. (1992). An evaluation of the diagnostic accuracy of Pathfinder. Comput. Biomed. Res. 25, 56–74. doi: 10.1016/0010-4809(92)90035-9
Heunen, C., Kammar, O., Staton, S., and Yang, H. (2017). “A convenient category for higher-order probability theory,” in Proceedings of 32nd Annual ACM/IEEE Symposium on Logic in Computer Science (LICS). doi: 10.1109/LICS.2017.8005137
Hu, Z., Ma, X., Liu, Z., Hovy, E., and Xing, E. (2016). Harnessing deep neural networks with logic rules. arXiv:1603.06318. doi: 10.18653/v1/P16-1228
Hubbell, S. (2001). The Unified Neutral Theory of Biodiversity and Biogeography, Volume 32 of Monographs in Population Biology. Princeton, NJ: Princeton University Press.
Jacobs, B., and Zanasi, F. (2018). The logical essentials of bayesian reasoning. CoRR abs/1804.01193.
Jain, D. (2011). “Knowledge engineering with markov logic networks: a review,” in DKB 2011: Proceedings of the Third Workshop on Dynamics of Knowledge and Belief (Hershey, PA).
Kaliszyk, C., and Urban, J. (2015). Learning-assisted theorem proving with millions of lemmas. J. Symb. Comput. 69, 109–128. doi: 10.1016/j.jsc.2014.09.032
Kimmig, A., Bach, S., Broecheler, M., Huang, B., and Getoor, L. (2012). “A short introduction to probabilistic soft logic,” in Proceedings of the NIPS Workshop on Probabilistic Programming (Barcelona).
Kok, S., and Domingos, P. (2009). “Learning markov logic network structure via hypergraph lifting,” in Proceedings of the 26nd international conference on Machine learning (Montreal, QC).
Kopelke, J. P., Nyman, T., Cazelles, K., Gravel, D., Vissault, S., and Roslin, T. (2017). Food-web structure of willow-galling sawflies and their natural enemies across europe. Ecology 98:1730. doi: 10.1002/ecy.1832
Kosko, B. (1990). Fuzziness vs probability. Int. J. Gen. Syst. 17, 211–240. doi: 10.1080/03081079008935108
Lewis, R. (1980). Evolution: a system of theories. Perspect. Biol. Med. 23, 551–572. doi: 10.1353/pbm.1980.0053
Lindsay, R., Buchanan, B., Feigenbaum, E., and Lederberg, J. (1993). Dendral: a case study of the first expert system for scientific hypothesis formation. Artif. Intell. 61, 209–261. doi: 10.1016/0004-3702(93)90068-M
Lunn, D., Jackson, C., Best, N., Thomas, A., and Spiegelhalter, D. (2012). The BUGS Book – A Practical Introduction to Bayesian Analysis. Boca Raton, FL: Chapman and Hall/CRC.
McGill, B. J., Etienne, R., Gray, J., Alonso, D., Anderson, M., Benecha, H., et al. (2007). Species abundance distributions: moving beyond single prediction theories to integration within an ecological framework. Ecol. Lett. 10, 995–1015. doi: 10.1111/j.1461-0248.2007.01094.x
Mendel, J., and Bob John, R. (2002). Type-2 fuzzy sets made simple. IEEE Trans. Fuzzy Syst. 10, 117–127. doi: 10.1109/91.995115
Muggleton, S., and de Raedt, L. (1994). Inductive logic programming: theory and methods. J. Logic Programm. 19–20, 629–679. doi: 10.1016/0743-1066(94)90035-3
Muggleton, S., and Feng, C. (1990). “Efficient induction of logic programs,” in New Generation Computing (Academic Press).
Nath, A., and Domingos, P. (2015). “Learning relational sum-product networks,” in Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence (Austin, TX), 2878–2886.
Nedbal, R., and Serafini, L. (2018). “Bayesian markov logic networks,” in AI*IA 2018 – Advances in Artificial Intelligence (Trento), 348–361.
Nederpelt, R., and Geuvers, H. (2014). Type Theory and Formal Proof: An Introduction. New York, NY: Cambridge University Press.
Poisot, T., Labrie, R., Larson, E., and Rahlin, A. (2018). Data-based, synthesis-driven: setting the agenda for computational ecology. bioRxiv 150128. doi: 10.1101/150128
Poisot, T., Stouffer, D., and Kéfi, S. (2016). Describe, understand and predict: why do we need networks in ecology? Funct. Ecol. 30, 1878–1882. doi: 10.1111/1365-2435.12799
Program, T. U. F. (2013). Homotopy Type Theory: Univalent Foundations of Mathematics. Princeton, NJ: Institute for Advanced Study.
Rice, S. H., and Papadopoulos, A. (2009). Evolution with stochastic fitness and stochastic migration. PLoS ONE 4:e7130. doi: 10.1371/journal.pone.0007130
Richardson, M., and Domingos, P. (2006). Markov logic networks. Mach. Learn. 62, 107–136. doi: 10.1007/s10994-006-5833-1
Russell, S., and Norvig, P. (2009). Artificial Intelligence: A Modern Approach, 3rd Edn. Upper Saddle River, NJ: Prentice Hall.
Sadeghian, A., Mendel, J., and Tahayori, H. (2014). Advances in Type-2 Fuzzy Sets and Systems. Springer.
Ścibior, A., Kammar, O., Vákár, M., Staton, S., Hongseok, Y., Cai, Y., et al. (2018). Denotational validation of higher-order bayesian inference. Proc. ACM Progr. Lang. 2, 60:1–60:29. doi: 10.1145/3158148
Staton, S. (2017). “Commutative semantics for probabilistic programming,” in Programming Languages and Systems, ed H. Yang (Berlin, Heidelberg: Springer), 855–879.
Staton, S., Yang, H., Wood, F., Heunen, C., and Kammar, O. (2016). Semantics for probabilistic programming: higher-order functions, continuous distributions, and soft constraints. Logic Comp. Sci. 525–534. doi: 10.1145/2933575.2935313
Suppes, P. (1968). The desirability of formalization in science. J. Philos. 65, 651–664. doi: 10.2307/2024318
Tamaddoni-Nezhad, A., Milani, G., Raybould, A., Muggleton, S., and Bohan, D. (2013). Construction and validation of food webs using logic-based machine learning and text mining. Adv. Ecol. Res. 49, 225–289. doi: 10.1016/B978-0-12-420002-9.00004-4
van de Meent, J.-W., Paige, B., Yang, H., and Wood, F. (2018). An introduction to probabilistic programming. ArXiv:1809.10756
Wang, J., and Domingos, P. (2008). “Hybrid markov logic networks,” in AAAI'08 Proceedings of the 23rd National Conference on Artificial Intelligenc (Menlo Park, CA), Vol. 2, 1106–1111.
Williams, R., Anandanadesan, A., and Martinez, N. (2010). The probabilistic niche model reveals the niche structure and role of body size in a complex food web. PLoS ONE 5:e12092. doi: 10.1371/journal.pone.0012092
Williams, R. J., and Martinez, N. D. (2000). Simple rules yield complex food webs. Nature 404, 180–183. doi: 10.1038/35004572
Wood, F., van de Meent, J., and Mansinghka, V. (2014). “A new approach to probabilistic programming inference,” in Proceedings of the 17th International Conference on Artificial Intelligence and Statistics (Reykjavik), 1024–1032.
Yoshikawa, K., Riedel, S., Asahara, M., and Matsumoto, Y. (2009). “Jointly identifying temporal relations with Markov Logic,” in ACL 2009, Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP (Singapore). doi: 10.3115/1687878.1687936
Zahavy, T., Ben-Zrihem, N., and Mannor, S. (2016). Graying the black box: understanding DQNS. arXiv: 1602.02658.
Keywords: artificial intelligence, theoretical biology, theoretical ecology, evolution, theoretical population genetics, machine learning, knowledge representation
Citation: Desjardins-Proulx P, Poisot T and Gravel D (2019) Artificial Intelligence for Ecological and Evolutionary Synthesis. Front. Ecol. Evol. 7:402. doi: 10.3389/fevo.2019.00402
Received: 27 May 2019; Accepted: 08 October 2019;
Published: 29 October 2019.
Edited by:
David Andrew Bohan, INRA Centre Dijon Bourgogne Franche-Comté, FranceReviewed by:
Battle Karimi, INRA Centre Dijon Bourgogne Franche-Comté, FranceZacchaeus Greg Compson, University of New Brunswick Fredericton, Canada
Copyright © 2019 Desjardins-Proulx, Poisot and Gravel. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Philippe Desjardins-Proulx, philippe.d.proulx@gmail.com