 Peter D. Karp1*
Peter D. Karp1* Natalia Ivanova2
Natalia Ivanova2 Markus Krummenacker1
Markus Krummenacker1 Nikos Kyrpides2Mario Latendresse1
Nikos Kyrpides2Mario Latendresse1 Peter Midford1
Peter Midford1 Wai Kit Ong1
Wai Kit Ong1 Suzanne Paley1
Suzanne Paley1 Rekha Seshadri2
Rekha Seshadri2- 1Bioinformatics Research Group, SRI International, Menlo Park, CA, United States
- 2DOE Joint Genome Institute, Walnut Creek, CA, United States
Microbial genome web portals have a broad range of capabilities that address a number of information-finding and analysis needs for scientists. This article compares the capabilities of the major microbial genome web portals to aid researchers in determining which portal(s) are best suited to their needs. We assessed both the bioinformatics tools and the data content of BioCyc, KEGG, Ensembl Bacteria, KBase, IMG, and PATRIC. For each portal, our assessment compared and tallied the available capabilities. The strengths of BioCyc include its genomic and metabolic tools, multi-search capabilities, table-based analysis tools, regulatory network tools and data, omics data analysis tools, breadth of data content, and large amount of curated data. The strengths of KEGG include its genomic and metabolic tools. The strengths of Ensembl Bacteria include its genomic tools and large number of genomes. The strengths of KBase include its genomic tools and metabolic models. The strengths of IMG include its genomic tools, multi-search capabilities, large number of genomes, table-based analysis tools, and breadth of data content. The strengths of PATRIC include its large number of genomes, table-based analysis tools, metabolic models, and breadth of data content.
1. Introduction
A number of web portals provide the scientific community with access to the thousands of microbial genomes that have been sequenced to date. This article compares the capabilities of the major microbial genome web portals to aid researchers in determining which portal(s) best serve their information-finding and analytical needs.
The power that a genome web portal provides to its users is a function of what data the portal contains, and of the types of software tools the portal provides to users for querying, visualizing, and analyzing the data. Query tools enable researchers to find what they are looking for. Visualization tools speed the understanding of the information that is found. Analysis tools enable extraction of new relationships from the data.
We assess the data content of each portal both according to the types of data it provides (e.g., does it provide regulatory network information, protein localization data, or Gene Ontology annotations?), and according to the number of genomes it provides. We assess the software tools provided by each portal in several major areas: genomics tools, metabolic tools, advanced search and analysis tools, web services, table-based analysis, and user accounts. Omics data analysis capabilities are also assessed, but are distributed among the preceding areas. In each area, we enumerate multiple software capabilities, such as the ability to paint omics data onto pathway diagrams. We must emphasize that many of the portals include a significant number of other capabilities that we consider to be outside the scope of a microbial-genome web portal, and that are therefore not within the purview of this study. The Results section examines the comparison criteria in detail; for a higher level summary of the results, see the Discussion section.
Search tools are a particularly important part of a portal because they determine the user's ability to find information of interest; therefore, we provide detailed comparisons of the search tools that each portal provides for finding genes, proteins, DNA and RNA sites, metabolites, and pathways. We call these multi-search tools because they enable the user to search multiple database (DB) fields in combination.
Although user friendliness is a critical aspect of any website, it is extremely difficult to assess objectively. We have assessed a small number of relatively objective user friendliness criteria, such as the types of user documentation available, the presence of explanatory tooltips (small information windows that appear when the user hovers over regions of the screen), and the speed of the site's gene page.
Our criteria for inclusion in the comparison were portals with a perceived high level of usage, large number of genomes, a relatively rich collection of tools, and sites that are actively maintained and developed. The portals we compare are BioCyc Caspi et al. (2018) (version 22.0, April 2018), KEGG Kanehisa et al. (2017) (version 87.1, August 2018), Ensembl Bacteria Kersey et al. (2018) (Release 40, July 2018), KBase Arkin et al. (2018) (versions during August 2018 to October 2018), IMG Chen et al. (2017) (version 5.0 August 2018), and PATRIC Wattam et al. (2014) (version 3.5.21, July 2018).
Related portals that are not included in this comparison are Entrez Genomes (whose capabilities are similar to Ensembl Bacteria), MicroScope Vallenet et al. (2017) (which uses Pathway Tools for its metabolic component and therefore has the same metabolic functionality as BioCyc), ModelSEED Henry et al. (2010) (which is a metabolic model portal, not a genome portal), the SEED Overbeek et al. (2014) (which has been inactive for a number of years and was subsumed by the PATRIC project), MicrobesOnline Dehal et al. (2010), iMicrobe (https://www.imicrobe.us/—a portal for metagenomes and transcriptomes, not for single genomes), and Microme (http://www.microme.eu/—the Microme website largely shut down as of January 2018).
1.1. Summary of the Portals
Here we introduce each portal. Note that some portals have some capabilities that are not covered in this comparison. For each portal we provide a hyperlink to a sample gene page.
BioCyc
BioCyc Caspi et al. (2016) and Karp et al. (2017) is a microbial genome web portal that integrates sequenced genomes with curated information from the biological literature, with information imported from other biological DBs, and with computational inferences. BioCyc data include metabolic pathways, regulatory networks, and gene essentiality data. BioCyc provides extensive query and visualization tools, as well as tools for omics data analysis, metabolic path searching, and for running metabolic models. We omit discussion of many BioCyc comparative genomics and metabolic operations under its Analysis → Comparative Analysis menu. Scientists can use the Pathway Tools software associated with BioCyc to perform metabolic reconstructions and create BioCyc-like DBs for in-house genome data.
BioCyc contains information curated from 89,500 publications. The curated information includes experimentally determined gene functions and Gene Ontology terms, experimentally studied metabolic pathways, and experimentally determined parameters such as enzyme kinetics data and enzyme activators and inhibitors. Curated information also includes textual mini-reviews that summarize information about genes, pathways, and regulation, with citations to the primary literature. The large amount of curated information within BioCyc is unique with respect to other genome portals.
Home page: https://biocyc.org/
Sample gene page (full): https://biocyc.org/gene?orgid=ECOLI&id=EG10823
Sample gene page (short): https://tinyurl.com/yd9pcwcq
Bulk download site: Available after licensing via https://biocyc.org/download.shtml.
KEGG
The Kyoto Encyclopedia of Genes and Genomes is a resource for understanding high-level functions of a biological system from molecular-level information. It includes a focus on data relevant for biomedical research (e.g., KEGG DISEASE and KEGG DRUG databases) and includes tools for analysis of large-scale molecular datasets generated by high-throughput experimental technologies.
Home page: https://www.kegg.jp/
Sample gene page (full): https://www.kegg.jp/dbget-bin/www_bget?eco:b2699
Sample gene page (short): https://tinyurl.com/yd8d9th8
Bulk download site: https://www.kegg.jp/kegg/download/
Ensembl Bacteria
Ensembl Bacteria is a portal for bacterial and archaeal genomes. It does not have any data or tools for metabolism, pathways or compounds, focusing on genes and proteins. Its strengths seem to be in its large collection of gene and protein family data. Its capabilities are somewhat different from other Ensembl sites. In addition to BLAST, it includes a hidden Markov model (HMM) search tool for protein motifs. Pan-taxonomic comparative tools are available for key species. It also includes Ensembl's variant effect predictor, which can predict functional consequences of sequence variants.
Home page: https://bacteria.ensembl.org/
Sample gene page (full): https://bacteria.ensembl.org/Escherichia_coli_str_k_12_substr_mg1655/Gene/Summary?g=b2699;r=Chromosome:2822708-2823769;t=AAC75741;db=core
Sample gene page (short): https://tinyurl.com/ya8onsem
Bulk download site: https://bacteria.ensembl.org/info/website/ftp/index.html
KBase
KBase is an environment for systems biology research that provides more than 160 applications to support user-driven analysis of a variety of data ranging from raw reads to fully assembled and annotated genomes, and metabolic models. In addition to its genome-portal capabilities, KBase Arkin et al. (2016) enables users to assemble and annotate genomes, to analyze transcriptomics data, and to create metabolic models for organisms with sequenced genomes. Once a model is created, it can be analyzed using phylogenetic, expression analysis, and comparative tools. KBase also allows users to integrate custom code into their analysis pipeline and enables addition of external applications by their developers using a software development kit (SDK). Its other major aim is to support reproducible computational experiments, on models, that can be published and shared with other users.
Home page: https://kbase.us/
Sample gene page (full): https://narrative.kbase.us/#dataview/35926/2/1?sub=Feature&subid=b2699
Sample gene page (short): https://tinyurl.com/y8twmntz
Bulk download site: The KBase website says that a bulk download site is coming soon.
IMG
The Integrated Microbial Genomes (IMG) system is a resource for annotation and analysis of sequence data, integrated with environmental and other metadata to support genome and microbiome comparisons. In addition to being the vehicle for release of the data generated by the DOE Joint Genome Institute, it provides a suite of analytical and visualization tools available to explore and mine the data for biological inference. Custom data marts dedicated to specific research topics like synthesis of secondary metabolite (IMG-ABC) or viral eco-genomics (IMG/VR), are also included. Users can submit their own data and metadata for integration in the system.
Home page: https://img.jgi.doe.gov/
Sample gene page (full): https://img.jgi.doe.gov/cgi-bin/m/main.cgi?section=GeneDetail&page=geneDetail&gene_oid=646314661
Sample gene page (short): https://tinyurl.com/y988yzc9
Bulk download site: https://genome.jgi.doe.gov/portal/
PATRIC
PATRIC is designed to support the biomedical research community's work on bacterial infectious diseases via integration of vital pathogen information with data and analysis tools. Data is integrated across sources, data types, molecular entities, and organisms. Data types include genomics, transcriptomics, protein-protein interactions, 3D protein structures, sequence typing data, and metadata. It supports both genome assembly and annotation (RAST), and RNA-seq data analysis via a job submission system.
Home page: https://www.patricbrc.org/
Sample gene page (full):https://www.patricbrc.org/view/Feature/PATRIC.511145.12.NC_000913.CDS.2820730.2821791.rev
https://www.patricbrc.org/view/Feature/PATRIC.511145.12.NC_000913.CDS.2820730.2821791.rev
Sample gene page (short): https://tinyurl.com/ybkynwy9
Bulk download site: ftp://ftp.patricbrc.org/
2. Results
We assessed the software and data content capabilities of each portal according to a number of topic areas, such as genomics-related tools and metabolism-related tools. We chose topic areas that we considered to be core elements of a microbial genome information portal—that is, a web site that counts among its primary missions providing users with data and knowledge regarding sequenced microbial genomes. A number of the portals contain functionality outside of that mission, for example, some portals contain software tools for annotating microbial genomes (e.g., performing assembly and gene-function prediction). We did not include such functionality because we considered it outside the scope of a microbial genome information portal. In many cases, we added new criteria within a topic area (meaning rows within our comparison tables) as we learned about each portal, such as adding the ability of Ensembl Bacteria to predict the effects of sequence variants. Our choice of criteria is validated by the fact that many of the criteria are shared among some or many of the portals.
For several of the topic areas, we provide multiple tables to assess software capabilities, with one or two tables focusing on DB search capabilities and another table focusing on other capabilities in that area. For example, Tables 2, 3 describe genomics multi-search tools, and Table 1 describe other genomics software tools.
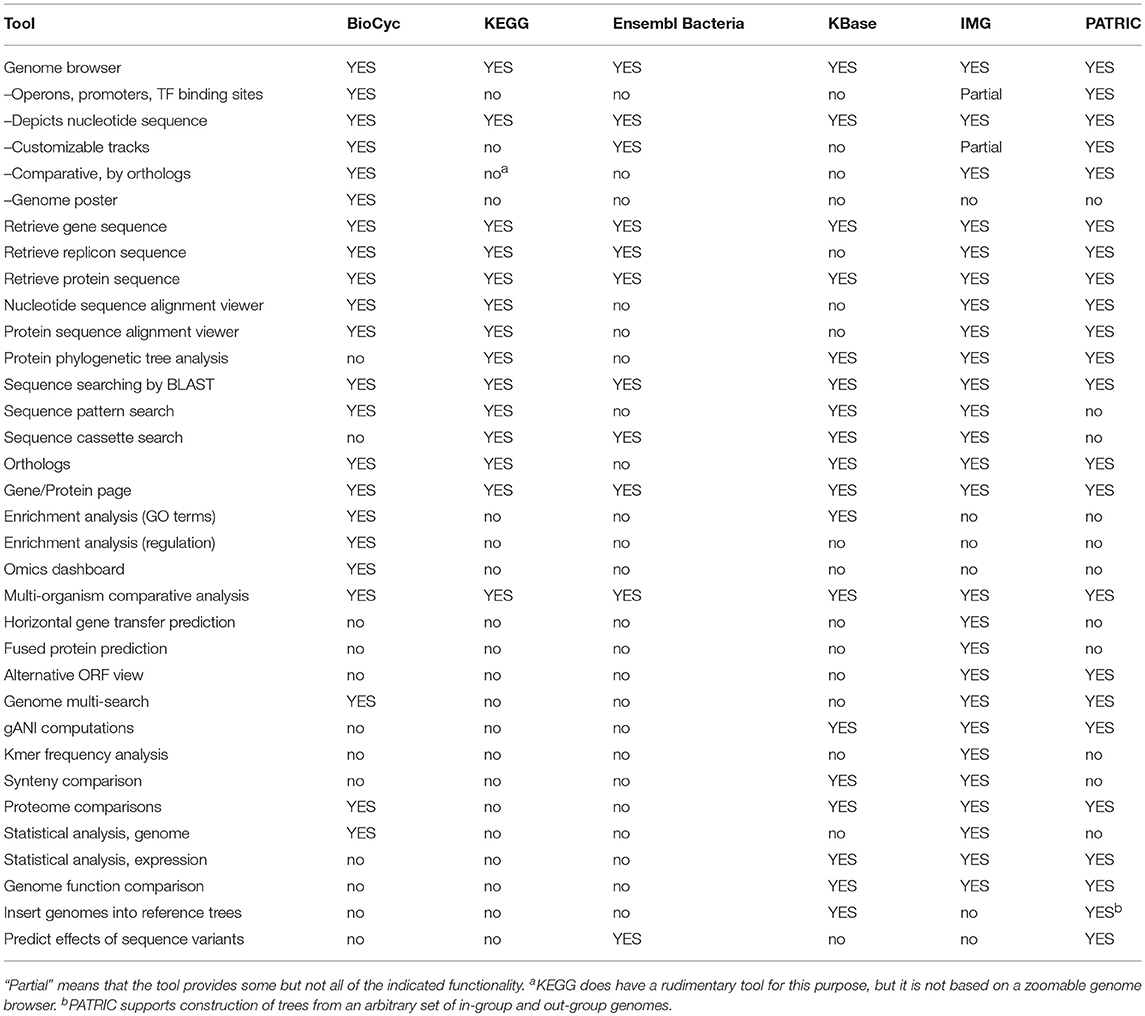
Table 1. Genomics tools comparison.
2.1. Genomics Tools
Genomics tools enable researchers to query, analyze, and compare genome-related information within an organism DB. Table 1 assesses most genomics tools; Tables 2, 3 describe genomics multi-search tools.
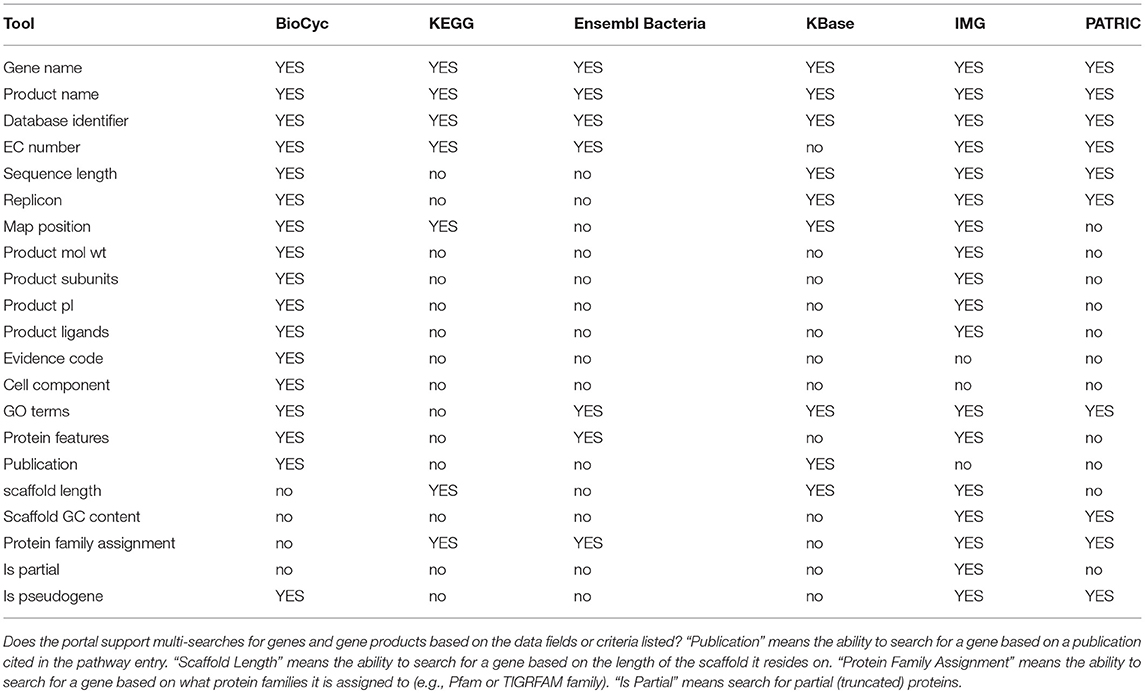
Table 2. Gene/protein multi-search capabilities.
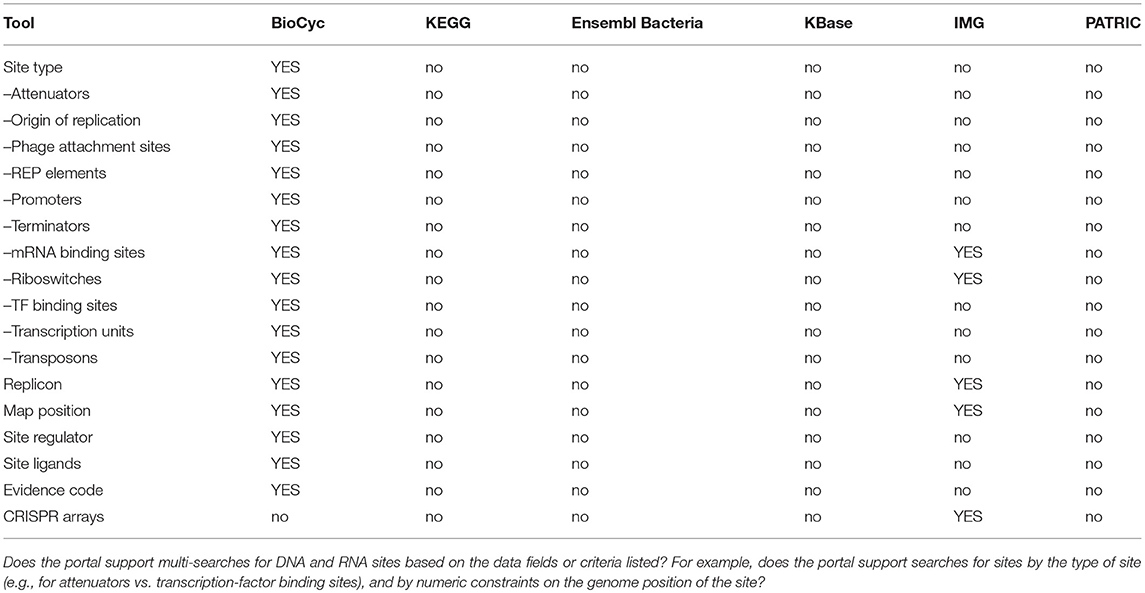
Table 3. DNA/RNA Site Multi-Search Capabilities.
An explanation of the rows within Table 1 is as follows.
• Genome Browser: Can a user browse a chromosome at different zoom levels to see the genomic features present?
- Are operons, promoters, and transcription-factor binding sites depicted in the genome browser?
- Is the nucleotide sequence depicted in the genome browser?
- Customizable Tracks: Can a user add additional tracks to the genome browser, which show user-supplied data?
- Comparative, by Orthologs: Can a user compare chromosome regions from several genomes side-by-side, with orthologous genes indicated?
- Genome Poster: Can the portal generate a printable, detailed, wall-sized poster of the entire genome, e.g., one that depicts every gene in the genome?
• Retrieve Gene Sequence: Can a user retrieve the nucleotide sequence of a gene?
• Retrieve Replicon Sequence: Can a user retrieve the nucleotide sequence of a specified region of a replicon?
• Retrieve Protein Sequence: Can a user retrieve the amino-acid sequence of a protein?
• Nucleotide Sequence Alignment Viewer: Can a user compare the nucleotide sequence of a gene with orthologs from other organisms?
• Protein Sequence Alignment Viewer: Can a user compare the amino-acid sequence of a protein with orthologs from other organisms?
• Protein Phylogenetic Tree Analysis: Can a user construct a phylogenetic tree from a set of protein sequences?
• Sequence Searching by BLAST: Is searching for a sequence in a genome by BLAST supported?
• Sequence Pattern Search: Is sequence searching by short sequence patterns supported?
• Sequence Cassette Search: Is sequence searching by protein family recognition patterns supported?
• Orthologs: Can a user query for the orthologs of a given gene in other organisms?
• Gene/Protein Page: Does the portal provide gene pages, showing relevant information such as the gene products and links to other DBs?
• Enrichment Analysis (GO Terms): Can a user find which GO terms are statistically enriched, given a set of genes?
• Enrichment Analysis (Regulation): Given a set of genes, can a user compute which regulators of those genes are statistically over-represented in the gene set?
• Omics Dashboard: Can a user submit a transcriptomics dataset for analysis using a visual dashboard tool that enables interactive summarization and exploration of the dataset in a manner similar to the BioCyc Omics Dashboard Paley et al. (2017)?
• Multi-Organism Comparative Analysis: Can a user globally compare a variety of different data types between several organisms?
• Horizontal Gene Transfer Prediction: Can the site show which genes may have been acquired by horizontal gene transfer?
• Fused Protein Prediction: Can the portal show which genes result from fusions of genes that can be found separately in other organisms?
• Alternative ORF Search (6-frame translation): Can a user assess alternative ORFs to the ones predicted on a given genomic region?
• Genome Multi-Search: Does the portal support search and retrieval across all genomes using sequencing, environmental, or other metadata attributes?
• gANI (Whole-genome Average Nucleotide Identity) Computations: Whole-genome based average nucleotide identity (gANI) has been proposed as a measure of genetic relatedness of a pair of genomes. gANI for a pair of genomes is calculated by averaging the nucleotide identities of orthologous genes. The fraction of orthologous genes (alignment fraction or AF) is also reported as a complementary measure of similarity of the two genomes.
• Kmer Frequency Analysis: Can the portal display principal component analysis plots of oligonucleotide frequencies along genome length; allow comparison of genomes by the similarity of oligonucleotide composition, and identify sequences with abnormal oligonucleotide composition, such as horizontally transferred sequences and contaminating contigs/scaffolds?
• Synteny Comparisons: Does the portal provide a tool for evaluating conservation of gene order by plotting pairwise genome alignment? Potential translocations, inversions, or gaps relative to reference can be visualized. Such a tool gives a quick snapshot of how closely related two strains might be.
• Proteome Comparisons: Find proteins that are shared between two or more genomes or unique to a given genome.
• Statistical Analysis, Genome: Example statistical analyses include counts of genes assigned to a “feature” (such as presence of a COG/Pfam/TIGRFAM/KEGG domains), and counts of genes in different Gene Ontology categories.
• Statistical Analysis, Expression: Does the portal provide tools for calculating statistical significance of gene expression data?
• Genome Function Comparison: Genomes can be clustered based on a function profile (e.g., COG/Pfam/TIGRFAM/KEGG features) and viewed as a hierarchical cluster tree, principal component analysis, principal coordinate analysis plot, or other options, to assess relatedness of selected genomes.
• Insert Genomes into Reference Trees: Enables a user to determine evolutionary relationships between a genome of interest and nearby reference genomes by building a tree of 49 concatenated universal sequences.
• Predict Effects of Sequence Variants: Enables users to predict effects of variation, including SNPs and indels on transcripts in the region of the variant.
2.2. Metabolic Tools
Metabolic tools enable researchers to query, analyze, and compare information about metabolic pathways and reactions within an organism DB, to run metabolic models, and to analyze high-throughput data in the context of metabolic networks. Table 4 assesses most metabolic tools; Table 5 describes metabolite multi-search capabilities and Table 6 describes pathway multi-search capabilities.
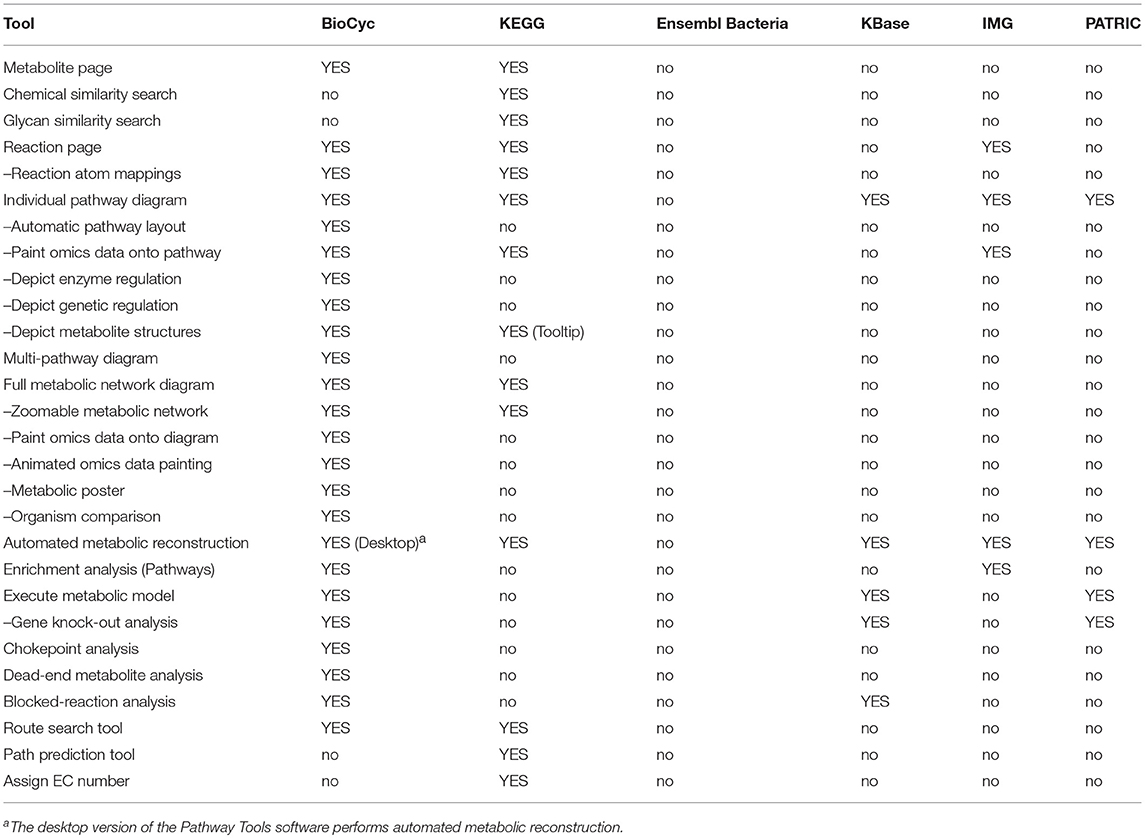
Table 4. Metabolic tools comparison.
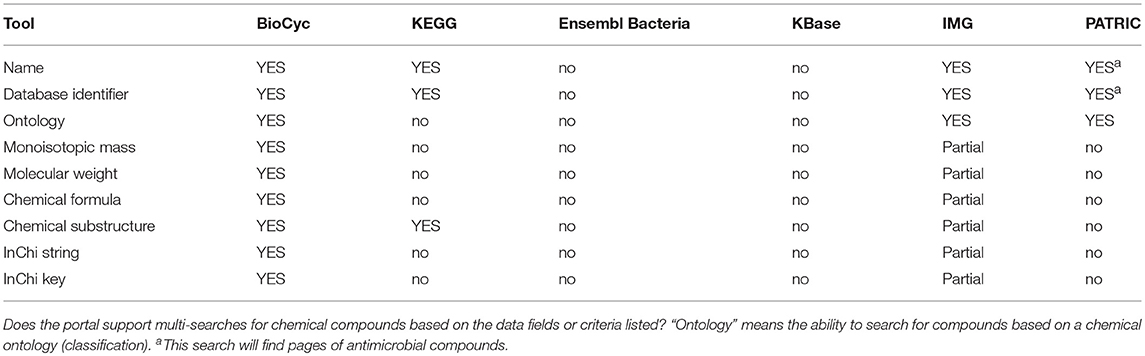
Table 5. Compound multi-search capabilities.
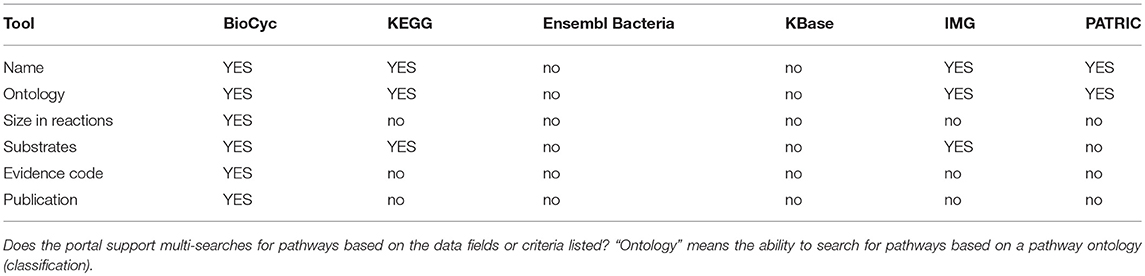
Table 6. Pathway multi-search capabilities.
An explanation of the rows within Table 4 is as follows.
• Metabolite Page: Does the site provide a metabolite page, showing relevant information such as synonyms, chemical structure, and reactions in which the metabolite occurs?
• Chemical Similarity Search: Can the user search for chemicals that have similar structures to a provided chemical?
• Glycan Similarity Search: Can the user search for glycans that have similar structures to a provided glycan?
• Reaction Page: Does the site provide a reaction page, showing relevant information such as EC numbers, reaction equation, and enzymes catalyzing the reaction?
• Reaction Atom Mappings: Can the reaction equation be shown with metabolite structures that depict the trajectories of atoms from reactants to products?
• Pathway Diagrams: Can pathway diagrams be depicted?
• Automatic Pathway Layout: Are pathway diagrams generated automatically by the software, thereby avoiding manual drawing?
• Paint Omics Data onto Pathway: Can a user visualize omics data on pathway diagrams?
• Depict Enzyme Regulation: Can pathway diagrams show regulation of enzymes by metabolites, to depict information such as feedback inhibition?
• Depict Genetic Regulation: Can pathway diagrams show genetic regulation of enzymes, such as by transcription factors and attenuation?
• Depict Metabolite Structures: Can pathway diagrams show the chemical structures of metabolites?
• Multi-Pathway Diagram: Can users interactively create diagrams consisting of multiple interacting metabolic pathways?
• Full Metabolic Network Diagram: Can the entire metabolic reaction network of a genome be depicted and explored by an interactive graphical interface?
• Zoomable Metabolic Network: Does the metabolic network browser enable zooming in and out?
• Paint Omics Data onto Network: Can a user visualize an omics dataset (e.g., gene expression, metabolomics) on the metabolic network diagram?
• Animated Omics Data Painting: Can several omics data points be visualized as an animation on the metabolic network diagram?
• Metabolic Poster: Can the portal generate a printable wall-sized poster of the organism's metabolic network?
• Organism Comparison: Can a user compare the metabolic networks of two organisms via the full metabolic network diagram?
• Automated Metabolic Reconstruction: Starting from a functionally annotated genome, can the metabolic reaction network (and pathways) be inferred in an automated fashion?
• Enrichment Analysis (Pathways): Can the site compute statistical enrichment of pathways within a large-scale dataset?
• Execute Metabolic Model: Can a user execute a steady-state metabolic flux model via the portal?
• Gene Knock-out Analysis: Can a user run flux-balance analysis (FBA) on the metabolic network by systematically disabling (knocking-out) various genes, to investigate how knock-outs perturb the network, and to predict gene essentiality?
• Chokepoint Analysis: Can the site compute chokepoint reactions (possible drug targets) in the full metabolic reaction network? A chokepoint reaction is a reaction that either uniquely consumes a specific reactant or uniquely produces a specific product in the metabolic network.
• Dead-End Metabolite Analysis: Can the portal compute dead-end metabolites in the full metabolic reaction network? Dead-end metabolites are those that are either only consumed, or only produced, by the reactions within a given cellular compartment, including transport reactions.
• Blocked-Reaction Analysis: Can the portal compute blocked reactions in the full metabolic reaction network? Blocked reactions cannot carry flux because of dead-end metabolites upstream or downstream of the reactions.
• Route Search Tool: Given a starting and an ending metabolite, can the site compute an optimal series of known reactions (routes) that converts the starting metabolite to the ending metabolite?
• Path Prediction Tool: Given a starting chemical compound, can the site predict a series of previously unknown enzyme-catalyzed reactions that will act upon the input compound and the products of previous reactions?
• Assign EC Number: Can the portal compute an appropriate Enzyme Commission number for a user-provided reaction?
2.3. Regulation Tools
BioCyc has a number of regulatory informatics tools that are not provided by any of the portals. We list those tools here rather than providing a table.
• BioCyc includes a regulatory-network browser that depicts the full transcriptional regulatory network of the organism. The network diagram can be queried interactively and painted with transcriptomics data.
• The BioCyc transcription-unit page depicts operon structure including promoters, transcription factor binding sites, and terminators, the evidence for each, and describes regulatory interactions between these sites and associated transcription factors and small RNA regulators.
• BioCyc generates diagrams that summarize all regulatory influences on a gene, including regulation of transcription, translation, and of the gene product.
• BioCyc depicts transcription-factor regulons as diagrams of all operons regulated by a transcription factor.
• BioCyc can depict regulatory influences on metabolism by highlighting the regulon of a transcription factor on the BioCyc metabolic map diagram.
• BioCyc SmartTables can list the regulators or regulatees of each gene within a SmartTable.
• BioCyc can generate a report comparing the regulatory networks of two or more organisms.
2.4. Advanced Search and Analysis
These tools (see Table 7) enable researchers to perform complex searches and analyses, to retrieve data via web services and bulk downloads, and to create and manipulate user accounts.
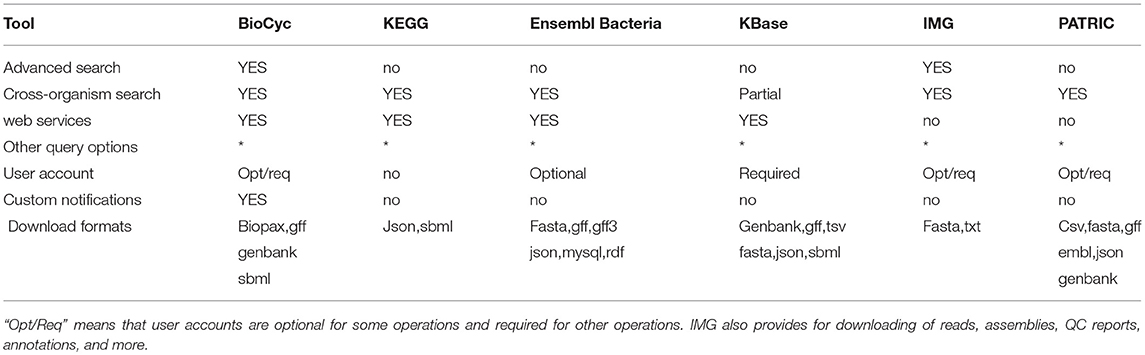
Table 7. Comparison of advanced search and analysis, web Services, and user accounts.
An explanation of the rows within Table 7 is as follows.
• Advanced Search: Does the site enable the user to construct multi-criteria queries that search arbitrary DB fields using combinations of AND, OR, and NOT?
• Cross-Organism Search: Can a user search all organisms, specified organism sets, or taxonomic groups of organisms, for genes, metabolites, or pathways?
• Web Services: Can DBs within the portal be queried programmatically by means of web services, using for example XML protocols?
• Other Query Options: What other query options are provided by the portal?
- BioCyc supports queries via its BioVelo query language1. Users can download BioCyc data files for text searches, and can load those data files into a locally installed version of SRI's BioWarehouse system for SQL query access. Users can download bundled versions of subsets of BioCyc plus Pathway Tools, and query the DBs via APIs for Python, Lisp, Java, Perl, and R.
- Users can download KEGG data files for text searches.
- Ensembl Bacteria provides a Perl API and public MySQL servers.
- KBase includes code cells for adding python code blocks to enable custom analyses, for which applications do not exist, or for programmatically calling Kbase native apps to automate large scale analyses.
- PATRIC provides a downloadable command line interpreter application that allows interactive submission of DB queries using a query language.
• User Account: Are user accounts available for logging in, and for storing data and preferences? “Opt/Req” means accounts are optional for some operations and required for other operations.
• Custom Notifications: Does the portal enable the user to register to be notified of curation updates in biological areas of interest to the user?
• Bulk Download Formats: What formats are supported by the portal for large scale data downloads? The websites for bulk downloads are provided in section 1.1.
2.5. Table-Based Analysis Tools
Table-based analysis tools enable users to define lists of genes, proteins, metabolites, or pathways that are stored within the portal, and can be displayed, analyzed, manipulated, and shared with other users. These tools are called SmartTables by BioCyc and are called Carts by IMG. A typical series of SmartTable operations are to define a SmartTable containing a list of genes (such as from a transcriptomics experiment); to configure which DB properties are displayed for each gene within the SmartTable (such as displaying the gene name, accession number, product name, and genome map position); performing a set operation on the SmartTable such as taking the intersection with another gene SmartTable; and transforming the gene SmartTable to say a SmartTable of the metabolic pathways containing those genes, or the set of transcriptional regulators for those genes.
KBase does not have a tables mechanism, but it does have a data sharing mechanism called narratives, which is not table-based.
Table-based capabilities are summarized within Table 8; an explanation of its rows is as follows.
• Datatypes Tables can Contain: What types of entities may be stored in tables within each portal? The more types of entities can be manipulated within tables, the more versatile the table mechanism is.
• Create Table from Uploaded File: Can tables be defined by uploading a data file that lists the entities within the table?
• Create Table from DB Query Result: Can tables be defined from the result of a query within the portal?
• Include DB Properties as Table Columns: Can a user add columns to the table containing information from the DB about a given entity, such as the accession number of a gene or the nucleotide coordinate of a gene, or a diagram of the chemical structure of a metabolite?
• Create Table Columns as Computational Transformations: Can table columns contained information computed from another column, such as adding a column that computes the pathways in which a gene participates?
• Set Operations Among Tables: Can the portal create a new table by computing set operations between two other tables, such as taking the union of the list of genes in two other tables?
• Filter Table Rows: Can the portal remove rows from a table according to a search, such as removing all entries from a table of metabolites where the metabolite name contains “arginine”?
• Export Table to File: Can the portal export the contents of a table to a data file?
• Share Table with Selected Users: Can a user share a table with a specific set of users?
• Share Table with the Public: Can a user share a table with the general public?
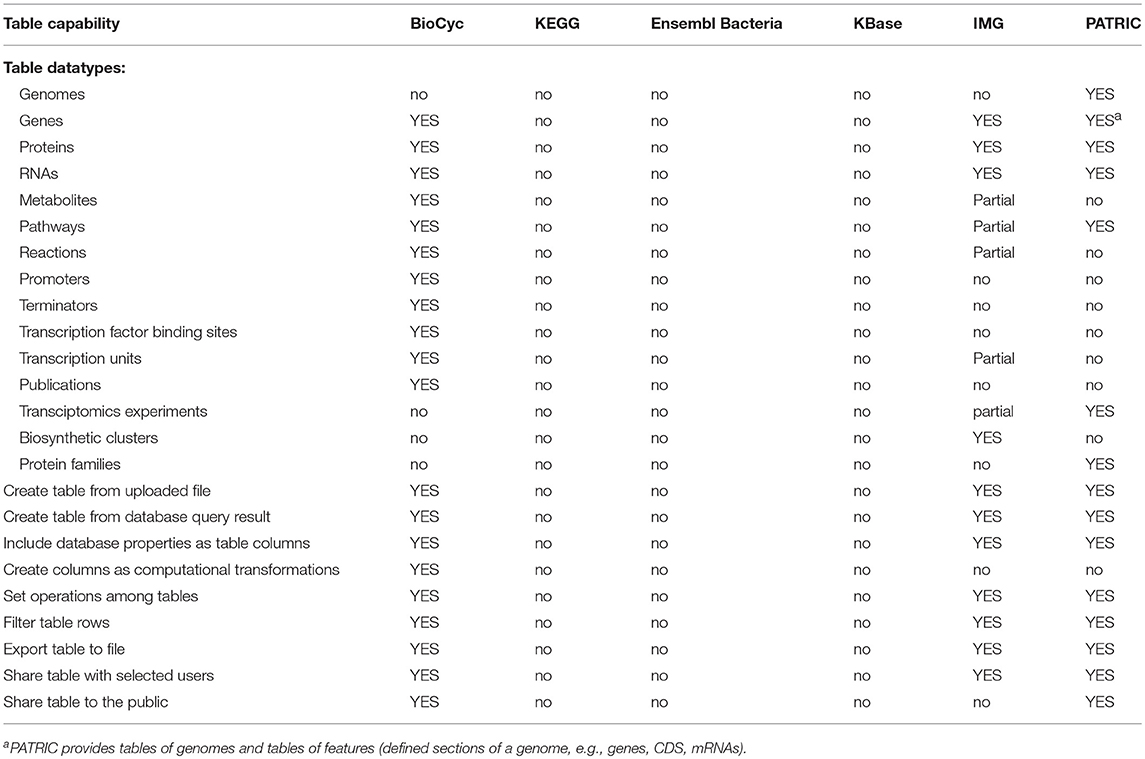
Table 8. Table-based analysis capabilities.
2.6. Data Content Among the Portals
Table 9 describes the types and quantities of data present in each web portal. An explanation of the rows within the Table 9 is as follows.
• Genomes (Bact./Arch.): How many bacterial genomes (organisms) does the portal provide access to? Only bacteria and archaea are counted here, although some resources provide eukaryotic and viral genomes. BioCyc genomes are sourced from RefSeq, GenBank, and from the Human Microbiome Project. KEGG genomes are sourced from GenBank and RefSeq. Ensembl Bacteria genomes are sourced from the European Nucleotide Archive at the EBI, GenBank, and the DNA Database of Japan. KBase genomes are sourced from “various public sources.” IMG genomes are sourced from GenBank, RefSeq, and DOE JGI-generated data arising from their user programs. PATRIC genomes are sourced from GenBank, RefSeq, and collaborators.
• Genome Metadata: Does the portal contain genome metadata, such as the lifestyle of the organism, and the location of where the organism sample was obtained?
• Regulatory Networks: Is (gene) regulatory information provided by the site? Eleven BioCyc DBs provide regulatory networks larger than 100 transcriptional regulatory interactions.
• Protein Localization: Does the portal contain protein cellular locations?
• Protein Features: Are annotations of features of protein sequences provided by the portal? Such features include which residues bind to cofactors or to metal ions, and where signaling peptide sequences reside. IMG provides transmembrane and signal peptide features.
• GO Terms: Are GO term annotations provided by the site? IMG provides evidence codes for GO terms. BioCyc provides evidence terms for gene functions, pathway presence, operon presence.
• Evidence Codes: Are evidence codes for the annotations provided by the resource, so the level of validity of the data can be assessed?
• Operons: Are genes grouped into operons, where applicable?
• Prophages: Are potential prophages indicated on the genomes?
• Growth Media: Are growth media for known growth conditions of the organisms provided by the site? (BioCyc provides growth-media data for two organisms).
• Gene Essentiality: Are gene essentiality data under various growth conditions provided by the site? (BioCyc provides gene-essentiality data for 36 organisms).
• Gene Clusters for Secondary Metabolites: Does the site identify putative operons of genes encoding enzymes for the production of secondary metabolites?
• Gene pairs with correlated expression: Pairs of genes with correlated expression based on experimental evidence.
• Protein-Protein interactions: Pairs of protein with either experimental or computational evidence of interacting.
• AMR phenotypes: Can the site display phenotypes for antimicrobial resistance (e.g., is a strain resistant or susceptible to a particular antimicrobial compound)?
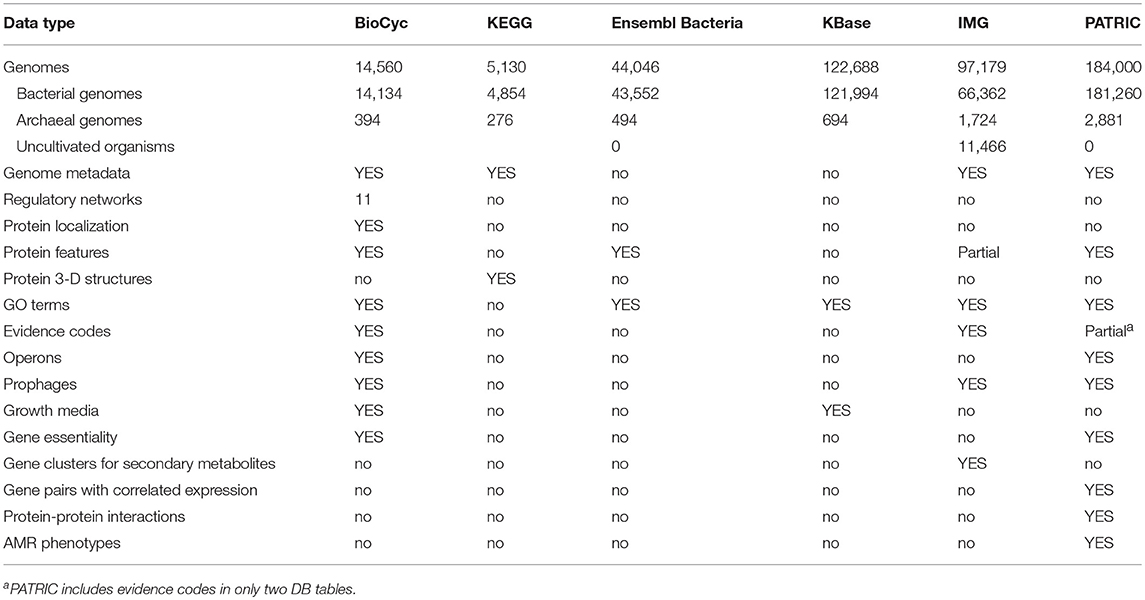
Table 9. Data types comparison.
2.7. User Experience
Table 10 contains several features that reflect the usability of the various portals. These include average loading times for typical gene pages for each portal; and other features and resources that assist the user in learning to use each portal.
• Mean Load Time for Gene Pages: Since gene pages are among the most commonly visited information pages within a genome web portal, the time required for the page to load in a web browser is central to the user experience. The values in this row are the average number of seconds required for each portal to load a gene page. The values are averaged across six sessions, conducted from Menlo Park, California and Richmond, Virginia to average out geographic distances to each portal. Each session tested five genes on each of the six portals. Testing was conducted using the Chrome browser version 68.0, running on MacOS 10.13.6. Testing consisted of clearing the browser cache, and pasting the URL of the gene page into the browser. The load was monitored using the ‘Network’ panel of Chrome's Developer Tools (More Tools → Developer Tools). The page was allowed to completely load (including loading large files and waiting for Ajax calls to complete). The number used is the “Finish” time in the bottom line of the panel. While some portals were disadvantaged by starting from an empty cache, forcing large files to be loaded, others were slowed by long Ajax calls. We have removed the single worst time recorded of the 30 times (5 genes × 6 sessions) for each portal.
• Portal Information: Lists the availability of a userguide, extensive explanatory tooltips throughout the site, recorded webinars (either downloadable files or on YouTube or similar site), and user workshops.
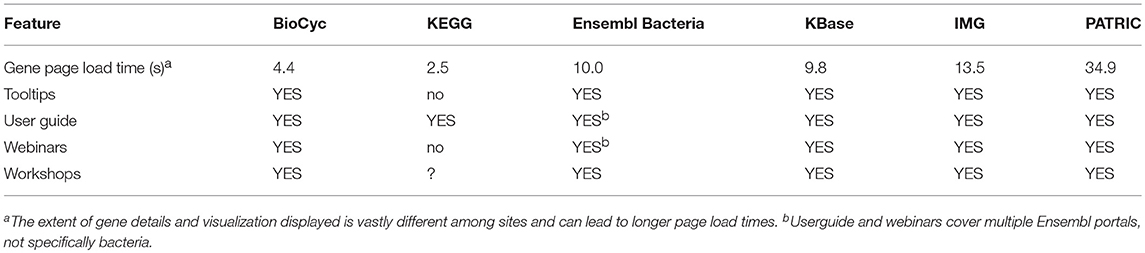
Table 10. User experience features.
3. Discussion
Table 11 summarizes the number of capabilities present in each portal. In each row of Table 11 we have summed the counts in the column for each portal from the specified tables, with each “YES” counted as 1, each “partial” counted as 1/2, and each “no” counted as 0. These data are also presented in Figure 1.
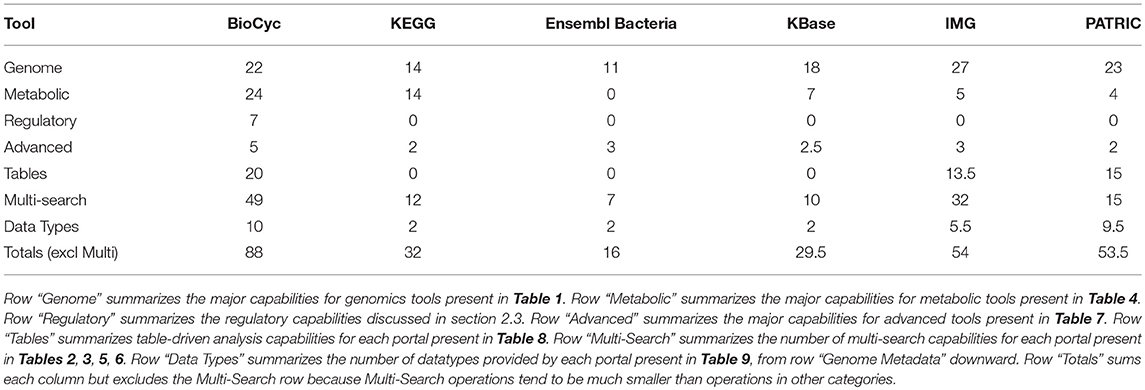
Table 11. Tallies of portal capabilities from previous tables.
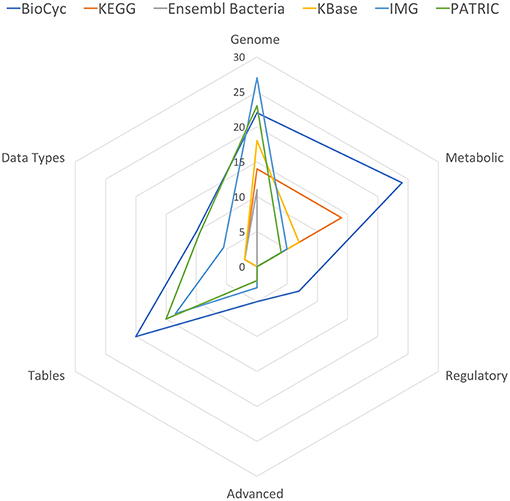
Figure 1. Spider plot of the data in Table 11, excluding the Multi-Search row to enhance resolution.
BioCyc received the highest tally (88). IMG (54) and PATRIC (53.5) were essentially tied for second. KEGG, KBase, and Ensembl Bacteria ranked fourth, fifth, and sixty with tallies of 32, 29.5, and 16, respectively.
BioCyc has the most extensive multi-search capabilities, with IMG in second place; these portals provide users with the most extensive capabilities for finding desired information.
IMG has the most genomics capabilities, with PATRIC and BioCyc second and third. Ensembl Bacteria has the fewest genomics capabilities. BioCyc and IMG have the most powerful gene/protein multi-search capabilities. BioCyc has the most extensive capabilities for DNA/RNA site multi-searches.
BioCyc has the most extensive metabolic capabilities. KEGG ranks second; it lacks metabolic modeling capabilities, and it lacks network analysis tools such as dead-end metabolite analysis and chokepoint analysis. BioCyc has the most extensive metabolic multi-search capabilities, with IMG second.
Table-analysis tools make extensive data analysis capabilities available to users that in many cases would otherwise require assistance from a programmer. BioCyc has the most extensive table-based capabilities, with PATRIC ranking second and IMG ranking third. KEGG, Ensembl Bacteria, and KBase completely lack table-based capabilities.
PATRIC has the largest number of genomes, with KBase and IMB ranked second and third, respectively; KEGG has the smallest number of genomes. Most of the PATRIC genomes were assembled from whole-genome shotgun data and thus are expected to be of lower quality—only 11,803 PATRIC bacterial genomes are complete genomes.
KEGG provides the fastest loading gene pages; BioCyc pages are the second fastest. Pages for KBase, Ensembl Bacteria, and IMG are significantly slower. PATRIC gene pages are the slowest, loading 13.96 times slower than KEGG gene pages.
BioCyc contains the most extensive analysis capabilities for metabolomics and transcriptomics data, including painting omics data onto individual pathways, multi-pathway diagrams, and zoomable metabolic maps; enrichment analysis for GO terms, regulation, and pathways; and an Omics Dashboard.
BioCyc contains extensive unique content not included in any of the other portals including regulatory network data, data on growth under different nutrient conditions, experimental gene essentiality data, reaction atom mappings (also present in KEGG), and thousands of textbook page equivalents of mini-review summaries. KEGG is particularly lacking a diverse range of datatypes, for example, KEGG lacks protein features, localization information, GO terms, and evidence codes.
4. Conclusions
Microbial genome web portals have a broad range of capabilities, and are quite variable in terms of what capabilities they provide. We assessed the capabilities of BioCyc, KEGG, Ensembl Bacteria, KBase, IMG, and PATRIC. BioCyc provided the most capabilities overall in terms of bioinformatics tools and breadth of data content; it also provides a level of curated data content (curated from 89,000 publications) that far exceeds that within the other sites. IMG ranked second overall, second in bioinformatics tools, and second in number of genomes. KEGG ranked third overall, PATRIC ranked fourth, KBase ranked fifth, and Ensembl Bacteria ranked sixth. IMG provided the most extensive genome-related tools, with BioCyc a close second. BioCyc provided the most extensive metabolic tools, with KEGG ranked second. Ensembl Bacteria provided no metabolic tools. PATRIC provided the largest number of genomes. BioCyc provided extensive regulatory network tools (and data) that are not present in any of the other portals. BioCyc provided the most extensive SmartTable tools and the most extensive omics data analysis tools.
Author Contributions
PK directed the project and wrote much of the manuscript. NI, MK, NK, ML, PM, WO, SP, and RS researched the portals and contributed to the manuscript.
Funding
Research reported in this publication was supported by SRI International and by the National Institute Of General Medical Sciences of the National Institutes of Health under Award Numbers 5R01GM080745 and GM075742. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. For JGI contributors, the work presented in this paper was supported by the Director, Office of Science, Office of Biological and Environmental Research, Life Sciences Division, U.S. Department of Energy under Contract No. DE-AC02-05CH11231.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank Dr. Nishadi De Silva of the European Bioinformatics Institute for comments and corrections regarding Ensembl Bacteria. We thank the KBase team for comments and corrections regarding KBase. We thank Maulik Shukla of Argonne National Laboratory and the University of Chicago and Rebecca Wattam of Virginia Tech for comments and corrections regarding PATRIC.
Footnotes
1. ^The BioVelo Query Language. Available online at: https://biocyc.org/bioveloLanguage.html
References
Arkin, A. P., Stevens, R. L., Cottingham, R. W., Maslov, S., Henry, C. S., Dehal, P., et al. (2016). The DOE Systems Biology Knowledgebase (KBase). Available online at: https://www.biorxiv.org/content/early/2016/12/22/096354
Arkin, A. P., Cottingham, R. W., Henry, C. S., Harris, N. L., Stevens, R. L., Maslov, S., et al. (2018). KBase: The United States Department of Energy Systems Biology Knowledgebase. Nat. Biotechnol. 36, 566–569. doi: 10.1038/nbt.4163
Caspi, R., Billington, R., Ferrer, L., Foerster, H., Fulcher, C. A., Keseler, I. M., et al. (2016). The MetaCyc database of metabolic pathways and enzymes and the BioCyc collection of Pathway/Genome Databases. Nuc Acids Res. 44, D471–D480. doi: 10.1093/nar/gkv1164
Caspi, R., Billington, R., Fulcher, C. A., Keseler, I. M., Kothari, A., Krummenacker, M., et al. (2018). The MetaCyc database of metabolic pathways and enzymes. Nuc Acids Res. 46, D633–D639. doi: 10.1093/nar/gkx935
Chen, I. A., Markowitz, V. M., Chu, K., Palaniappan, K., Szeto, E., Pillay, M., et al. (2017). IMG/M: integrated genome and metagenome comparative data analysis system. Nuc. Acids Res. 45, D507–D516. doi: 10.1093/nar/gkw929
Dehal, P. S., Joachimiak, M. P., Price, M. N., Bates, J. T., Baumohl, J. K., Chivian, D., et al. (2010). MicrobesOnline: an integrated portal for comparative and functional genomics. Nuc. Acids Res. 38, D396–D400. doi: 10.1093/nar/gkp919
Henry, C. S., DeJongh, M., Best, A. A., Frybarger, P. M., Linsay, B., and Stevens, R. L. (2010). High-throughput generation, optimization and analysis of genome-scale metabolic models. Nat. Biotechnol. 28, 977–82. doi: 10.1038/nbt.1672
Kanehisa, M., Furumichi, M., Tanabe, M., Sato, Y., and Morishima, K. (2017). KEGG: new perspectives on genomes, pathways, diseases and drugs. Nuc Acids Res. 45, D353–D361. doi: 10.1093/nar/gkw1092
Karp, P. D., Billington, R., Caspi, R., Fulcher, C. A., Latendresse, M., Kothari, A., et al. (2017). The BioCyc collection of microbial genomes and metabolic pathways. Brief. Bioinformat. bbx085. doi: 10.1093/bib/bbx085
Kersey, P. J., Allen, J. E., Allot, A., Barba, M., Boddu, S., Bolt, B. J., et al. (2018). Ensembl genomes 2018: an integrated omics infrastructure for non-vertebrate species. Nuc. Acids Res. 46, D802–D808. doi: 10.1093/nar/gkx1011
Overbeek, R., Olson, R., Pusch, G. D., Olsen, G. J., Davis, J. J., Disz, T., et al. (2014). The SEED and the Rapid Annotation of microbial genomes using Subsystems Technology (RAST). Nuc. Acids Res. 42, D206–D214. doi: 10.1093/nar/gkt1226
Paley, S. M., Parker, K., Spaulding, A., Tomb, J. F., O'Maille, P., and Karp, P. D. (2017). The Omics Dashboard for interactive exploration of gene-expression data. Nuc. Acids Res. 45, 12113–12124. doi: 10.1093/nar/gkx910
Vallenet, D., Calteau, A., Cruveiller, S., Gachet, M., Lajus, A., Josso, A., et al. (2017). Microscope in 2017: an expanding and evolving integrated resource for community expertise of microbial genomes. Nuc. Acids Res. 45, D517–D528. doi: 10.1093/nar/gkw1101
Keywords: genome portals, microbial genomics, microbial genomes, genome databases, microbial genome databases
Citation: Karp PD, Ivanova N, Krummenacker M, Kyrpides N, Latendresse M, Midford P, Ong WK, Paley S and Seshadri R (2019) A Comparison of Microbial Genome Web Portals. Front. Microbiol. 10:208. doi: 10.3389/fmicb.2019.00208
Received: 12 November 2018; Accepted: 24 January 2019;
Published: 22 February 2019.
Edited by:
Angel Angelov, Technische Universität München, GermanyReviewed by:
Damien Eveillard, University of Nantes, FranceUlas Karaoz, University of California, Berkeley, United States
Copyright © 2019 Karp, Ivanova, Krummenacker, Kyrpides, Latendresse, Midford, Ong, Paley and Seshadri. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Peter D. Karp, cGthcnBAYWkuc3JpLmNvbQ==