 Ayse Yarali1,2*
Ayse Yarali1,2* Bertram Gerber1,3
Bertram Gerber1,3
- 1 Neurobiologie und Genetik, Biozentrum, Universität Würzburg, Würzburg, Germany
- 2 Behavioural Genetics, Max Planck Institut für Neurobiologie, Martinsried, Germany
- 3 Genetik, Institut für Biologie, Universität Leipzig, Leipzig, Germany
What is particularly worth remembering about a traumatic experience is what brought it about, and what made it cease. For example, fruit flies avoid an odor which during training had preceded electric shock punishment; on the other hand, if the odor had followed shock during training, it is later on approached as a signal for the relieving end of shock. We provide a neurogenetic analysis of such relief learning. Blocking, using UAS-shibirets1, the output from a particular set of dopaminergic neurons defined by the TH-Gal4 driver partially impaired punishment learning, but left relief learning intact. Thus, with respect to these particular neurons, relief learning differs from punishment learning. Targeting another set of dopaminergic/serotonergic neurons defined by the DDC-Gal4 driver on the other hand affected neither punishment nor relief learning. As for the octopaminergic system, the tbhM18 mutation, compromising octopamine biosynthesis, partially impaired sugar-reward learning, but not relief learning. Thus, with respect to this particular mutation, relief learning, and reward learning are dissociated. Finally, blocking output from the set of octopaminergic/tyraminergic neurons defined by the TDC2-Gal4 driver affected neither reward, nor relief learning. We conclude that regarding the used genetic tools, relief learning is neurogenetically dissociated from both punishment and reward learning. This may be a message relevant also for analyses of relief learning in other experimental systems including man.
Introduction
Having no idea as to what will happen next is not only bewildering, but can also be dangerous. This is why animals learn about the predictors for upcoming events. For example, a stimulus that had preceded a traumatic event can be learned as a predictor for this event and is later on avoided. Such predictive learning qualitatively depends on the relative timing of events: a stimulus that occurred once a traumatic event had subsided later on supports opposite behavioral tendencies, such as approach, as it signals what may be called relief (Solomon and Corbit, 1974; Wagner, 1981) or safety (Sutton and Barto, 1990; Chang et al., 2003). Such opposing memories about the beginning and end of traumatic experiences are common to distant phyla (e.g., dog: Moskovitch and LoLordo, 1968, rabbit: Plotkin and Oakley, 1975, rat: Maier et al., 1976, snail: Britton and Farley, 1999, adult fruit fly: Tanimoto et al., 2004; Yarali et al., 2008, 2009; Murakami et al., 2010, larval fruit fly: Khurana et al., 2009), including man (Andreatta et al., 2010). This timing-dependency may reflect a universal adaptation to what one may call the “causal texture” of the world, such that whatever precedes X is likely to be the cause of X, and whatever follows X may be responsible for X’s disappearance (Dickinson, 2001). Correspondingly, pleasant experiences, too, support opposing kinds of memory for stimuli that respectively precede and follow them (e.g., pigeon: Hearst, 1988; honeybee: Hellstern et al., 1998). Thus, to fully appreciate the behavioral consequences of affective experiences, it is necessary to study the mnemonic effects of their beginning and their end.
To do so, the fruit fly offers a fortunate possibility for fine grained behavioral analyses, combined with a small, experimentally accessible brain. Once trained with odor-electric shock pairings, fruit flies avoid this odor as a signal for punishment (Tully and Quinn, 1985); training with a reversed timing of events, that is first shock and then the odor, on the other hand, results in approach toward this odor as a predictor for relief (in adults: Tanimoto et al., 2004; Yarali et al., 2008, 2009; Murakami et al., 2010; in larvae: Khurana et al., 2009). Presenting an odor together with a sugar reward establishes conditioned approach, too (Tempel et al., 1983).
Punishment and reward learning are well-studied, including how the respective kinds of reinforcement are signaled. Shock activates a set of fruit fly dopaminergic neurons (Riemensperger et al., 2005), defined by the TH-Gal4 driver; blocking the output from these neurons impairs punishment learning, but not reward learning (in adults: Schwaerzel et al., 2003; Aso et al., 2010; in larvae: Honjo and Furukubo-Tokunaga, 2009; Selcho et al., 2009; regarding the former larval study, Gerber and Stocker (2007) filed caveats which may challenge the associative nature of the used paradigm). Also, loss of function of the dopamine receptor DAMB selectively impairs punishment rather than reward learning in fruit fly larvae (Selcho et al., 2009). Accordingly, in the cricket and the honey bee as well, punishment rather than reward learning is impaired by dopamine receptor antagonists (Unoki et al., 2005, 2006; Vergoz et al., 2007). Finally, activating a set of dopaminergic neurons, defined by the TH-Gal4 driver in adult (Claridge-Chang et al., 2009; Aso et al., 2010) and reportedly also in larval (Schroll et al., 2006) fruit flies substitutes for punishment during training. Altogether, these results point to dopamine as covered by the applied genetic tools, to be necessary and sufficient to signal punishment.
As for reward signaling, this reinforcing role seems to be fulfilled by octopamine. In the honeybee, activity of a sugar responsive octopaminergic neuron “VUMmx1,” innervating the olfactory pathway, is sufficient to substitute for the rewarding, but not the reflex-releasing, effects of sugar during training (Hammer, 1993), as does injecting octopamine at various sites along the olfactory pathway (Hammer and Menzel, 1998). In turn, interfering with the honey bee or cricket octopamine receptors impairs reward learning, but leaves punishment learning intact (Farooqui et al., 2003; Unoki et al., 2005, 2006; Vergoz et al., 2007). Accordingly, in the fruit fly, compromising octopamine biosynthesis via the tbhM18 mutation impairs reward learning, but not punishment learning (Schwaerzel et al., 2003; Sitaraman et al., 2010). Finally, in larval fruit flies, the output from a particular set of octopaminergic/tyraminergic neurons, defined by the TDC2-Gal4 driver seems to be required selectively for reward learning (see Honjo and Furukubo-Tokunaga, 2009, but see above); in turn, activating these neurons reportedly substitutes for the reward during training (Schroll et al., 2006).
These findings together suggest a double dissociation between the roles of dopamine and octopamine in signaling punishment and reward, respectively. This double dissociation however may need qualification, as the function of the fruit fly dopamine receptor dDA1 turns out to be required for both kinds of learning (in adults: Kim et al., 2007; in larvae: Selcho et al., 2009). The picture becomes more complicated with the additional role of dopaminergic neurons in signaling the state of hunger, which is a determinant for the behavioral expression of the sugar-reward memory in adult fruit flies (Krashes et al., 2009; in other insects, too, octopamine and dopamine affect the behavioral expression of memory, Farooqui et al., 2003; Mizunami et al., 2009; also in crabs: Kaczer and Maldonado, 2009). Finally, in a fruit fly operant place learning paradigm, where high temperature acts as punishment and preferred temperature as potential reward, neither dopamine nor octopamine signaling seems to be critical (Sitaraman et al., 2008, 2010). Thus, the scope of what octopamine and dopamine do for punishment and reward learning, memory, and retrieval remains open, including (except for the seminal case of the VUMmx1 neuron in the bee, Hammer, 1993,and a recent study on dopaminergic signaling in the fly,Aso et al., 2010) the assignment of these putative roles to specific amine-releasing and receiving neurons and the receptors involved, as well as the utility of the genetic tools available. Here, we ask for the neurogenetic bases of relief learning, comparing the underpinnings of relief learning to punishment and reward learning.
Materials and Methods
Flies
Drosophila melanogaster were reared as mass culture at 25°C, 60–70% relative humidity, under a 14:10 h light:dark cycle.
We used shibirets1 for temperature-controlled, reversible blockage of synaptic output (Kitamoto, 2001). shibirets1 expression was directed to different sets of neuron by crossing the males of the respective Gal4 strains (Table 1) to females of a UAS-shibirets1 strain (Kitamoto, 2001; first and third chromosomes); thus the offspring were heterozygous for both the Gal4-driver and UAS-shibirets1. We refer to these flies with the name of the Gal4-driver together with “shits1” (e.g., “TH/shits1”). To obtain proper genetic controls, we crossed each of the UAS-shibirets1 or the Gal4-driver strains to white1118 flies, thus obtaining flies heterozygous either for the Gal4-driver or for UAS-shibirets1. We refer to these as, e.g., “TH/+” and “shits1/+,” respectively.
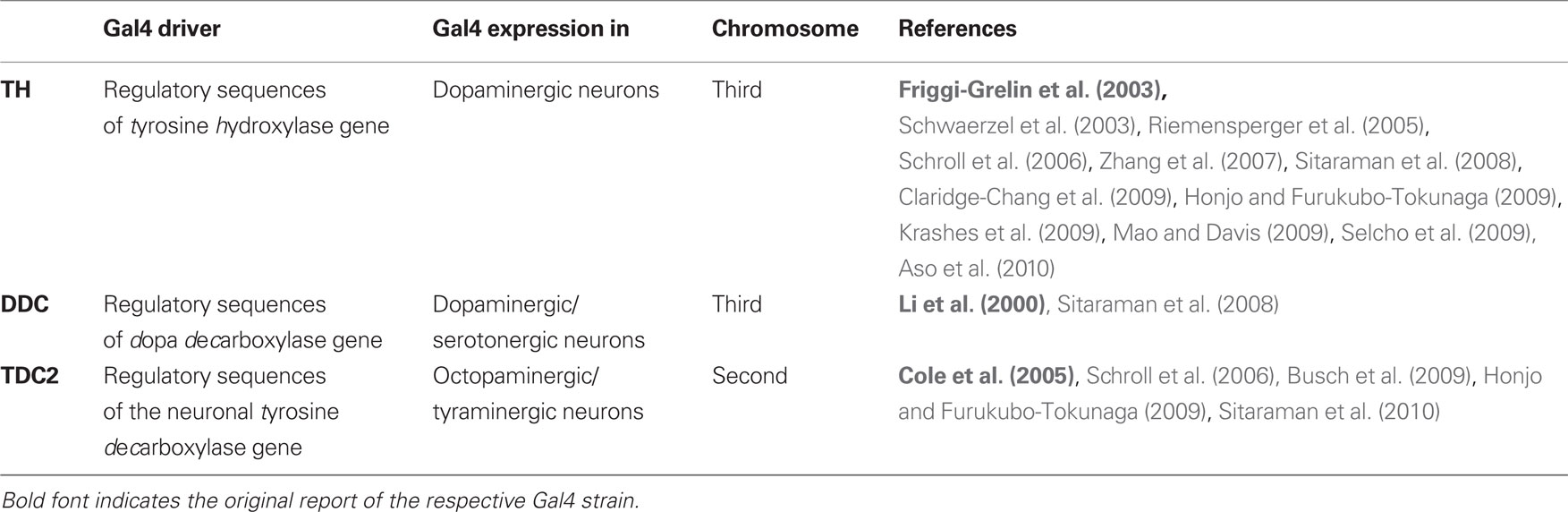
Table 1. The Gal4 driver strains that were used.
To approximate the patterns of Gal4 expression, we used the respective drivers (Table 1) to express the UAS-controlled transgene mCD8GFP, which encodes for a green fluorescent protein (GFP) to insert into cellular membranes. To do this, we crossed males from each driver strain to females of a UAS-mCD8GFP strain (Lee and Luo, 1999; second chromosome) and stained the brains of the progeny against the Synapsin protein to visualize the neuropils and against GFP to approximate the pattern of Gal4 expression. Note however that the pattern of GFP-immunoreactivity does not necessarily reflect which neurons would be targeted had another effector, e.g., shibirets1 been expressed using the same Gal4 driver (Ito et al., 2003): first, UAS-mCD8GFP and UAS-shibirets1 may support different levels and patterns of background expression without any Gal4; this background expression then adds up with the driven expression when the Gal4 is present. Second, the level of mCD8GFP expression sufficient for immunohistochemical detection may well be different from the level of shibirets1 expression sufficient to block neuronal output; thus potentially, not all neurons that are visualized by immunohistochemistry may be affected by shibirets1 or vice versa.
To test for an effect of an octopamine biosynthesis deficiency, we used the mutant strain tbhM18 (Monastirioti et al., 1996; also see Schwaerzel et al., 2003; Saraswati et al., 2004; Scholz, 2005; Brembs et al., 2007; Certel et al., 2007; Hardie et al., 2007; Sitaraman et al., 2010). These flies have reduced or no octopamine (Monastirioti et al., 1996), due to the deficiency of the tyramine β-hydroxylase enzyme, which catalyzes the last step of octopamine biosynthesis (Figure 2). Since the original tbhM18 strain (Monastirioti et al., 1996) contains an additional mutation in the white gene, we instead used a recombinant strain with a wild-type white+ allele, which was generated by Schwaerzel et al. (2003). As genetic control, we used a non-recombinant strain with wild-type tbh+ and white+ alleles, which was generated in parallel; we refer to this strain simply as “Control.”
Immunohistochemistry
Brains were dissected in saline and fixed for 2 h in 4% formaldehyde with PBST as solvent (phosphate-buffered saline containing 0.3% Triton X-100). After a 1.5 h incubation in blocking solution (3% normal goat serum [Jackson Immuno Research Laboratories Inc., West Grove, PA, USA] in PBST), brains were incubated overnight with the monoclonal anti-Synapsin mouse antibody SYNORF1, diluted 1:20 in PBST (Klagges et al., 1996) and polyclonal anti-GFP rabbit antibody, diluted 1:2000 in PBST (Invitrogen Molecular Probes, Eugene, OR, USA). These primary antibodies were detected after an overnight incubation with Cy3 goat anti-mouse Ig, diluted 1:250 in PBST (Jackson Immuno Research Laboratories Inc., West Grove, PA, USA) and Alexa488 goat anti-rabbit Ig, diluted 1:1000 in PBST (Invitrogen Molecular Probes, Eugene, OR, USA). All incubation steps were followed by multiple PBST washes. Incubations with antibodies were done at 4°C; all other steps were performed at room temperature. Finally, brains were mounted in Vectashield mounting medium (Vector Laboratories Inc., Burlingame, CA, USA) and examined under a confocal microscope (Leica SP1, Leica, Wetzlar, Germany).
Behavioral Assays
Flies were collected from fresh food vials and kept for 1–4 days at 18°C and 60–70% relative humidity before experiments. For reward learning as well as for the punishment learning experiments shown in Figures 6B,B′, flies were instead starved overnight for 18–20 h at 25°C and 60–70% relative humidity in vials equipped with a moist tissue paper and a moist filter paper. Those experiments that did not use shibirets1 were performed at 22–25°C and 75–85% relative humidity. For inducing the effect of shibirets1, flies were first exposed to 34–36°C and 60–70% relative humidity for 30 min; then the experiment took place under these same conditions, which are referred to as “@ high temperature.” The condition referred to as “@ low temperature” in turn involved exposing the flies to 20–23°C and 75–85% relative humidity for 30 min; then the experiment followed also under these conditions.
The experimental setup was in principle as described by Tully and Quinn (1985) and Schwaerzel et al. (2003). Flies were trained and tested as groups of 100–150. Trainings took place under dim red light which does not allow flies to see, tests were in complete darkness.
As odorants, 90 μl benzaldehyde (BA), 340 μl 3-octanol (OCT), 340 μl 4-methylcyclohexanol (MCH), 340 μl n-amyl acetate (AM) and 340 μl isoamyl acetate (IAA) (CAS 100-52-7, 589-98-0, 589-91-3, 628-63-7, 123-92-2; all from Fluka, Steinheim, Germany) were applied in 1 cm-deep Teflon containers of 5, 14, 14, 14, and 14 mm diameters, respectively. For the experiments in Figures 6A,B,C MCH and OCT were diluted 100-fold in paraffin oil (Merck, Darmstadt, Germany, CAS 8012-95-1), whereas for Figures 6A′,B′, AM and IAA were diluted 36-fold. All other experiments used undiluted BA and OCT.
For punishment learning (Figure 1A), flies received six training trials. Each trial started by loading the flies into the experimental setup (0:00 min). From 4:00 min on, the control odor was presented for 15 s. Then, from 7:15 min on, the to-be-learned odor was presented also for 15 s. From 7:30 min on, electric shock was applied as four pulses of 100 V; each pulse was 1.2 s-long and was followed by the next with an onset-to-onset interval of 5 s. Thus the to-be-learned odor preceded shock with an onset-to-onset interval of 15 s. The control odor on the other hand preceded the shock by an onset-to-onset interval of 210 s, which does not result in a measurable association between the two (Tanimoto et al., 2004; Yarali et al., 2008, loc. cit. Figures 1D and 2F, Yarali et al., 2009, loc. cit. Figure 1B). For relief learning (Figure 1B), keeping all other parameters unchanged, we reversed the relative timing of events: that is, the to-be-learned odor was presented from 8:10 min on, thus following shock with an onset-to-onset interval of 40 s. At 12:00 min, flies were transferred out of the setup into food vials, where they stayed for 16 min until the next trial. At the end of the sixth training trial, after the usual 16 min break, flies were loaded back into the setup. After a 5 min accommodation period, they were transferred to the choice point of a T-maze, where they could escape toward either the control odor or the learned odor. After 2 min, the arms of the maze were closed and flies on each side were counted. A preference index (PREF) was calculated as:
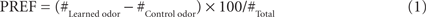
# indicates the number of flies found in the respective maze-arm. Two groups of flies were trained and tested in parallel (Figure 1D). For one of these, e.g., 3-octanol (OCT) was the control odor and BA was to be learned; the second group was trained reciprocally. PREFs from the two reciprocal measurements were then averaged to obtain a final learning index (LI):

Subscripts of PREF indicate the learned odor in the respective training. Positive LIs indicate conditioned approach to the learned odor; negative values reflect conditioned avoidance.
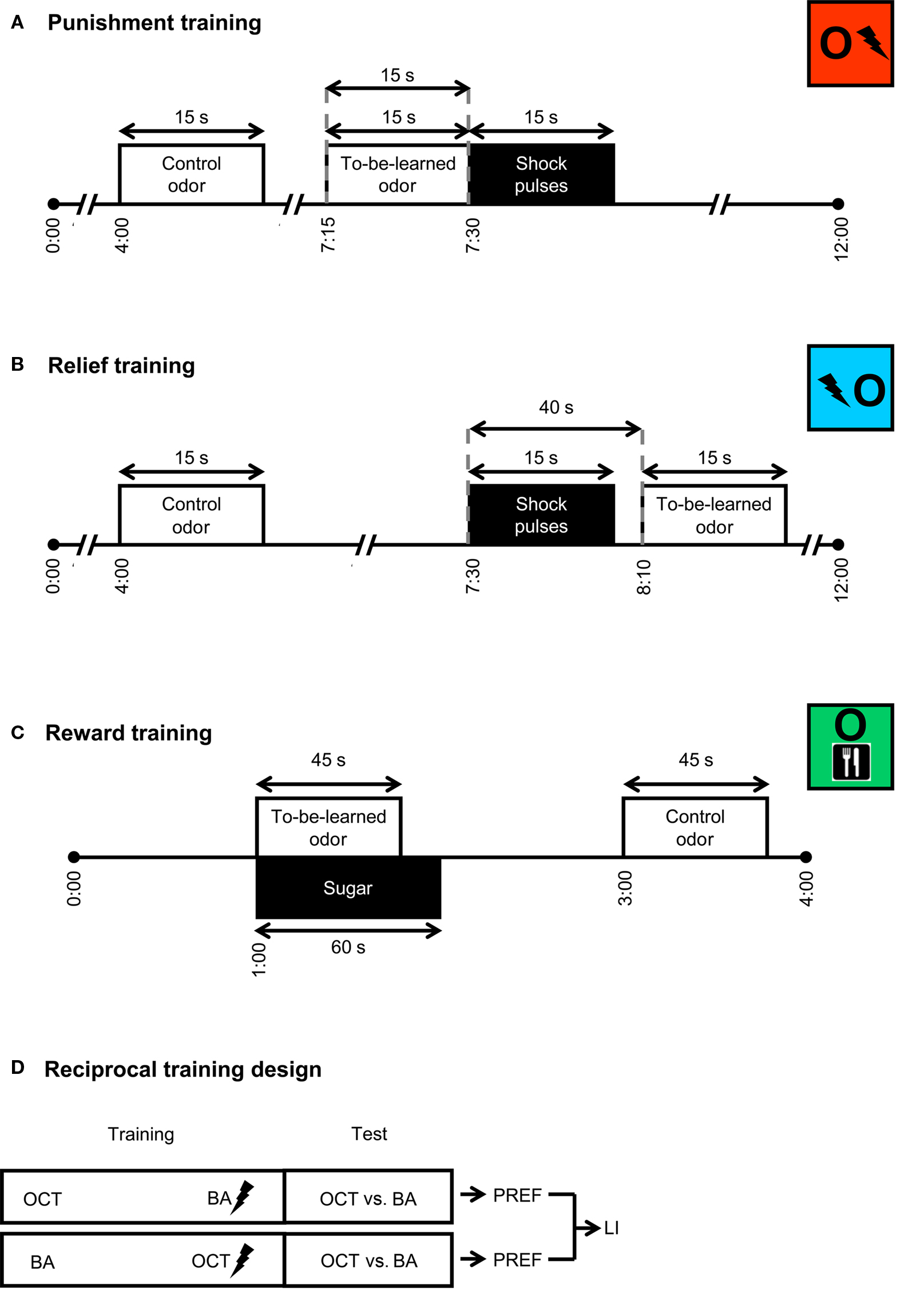
Figure 1. Training. For punishment training (A), flies received two odors and pulses of electric shock. A control odor was presented long before shock; a to-be-learned odor preceded shock with an onset-to-onset interval of 15 s. For relief training (B), while all other parameters were unchanged, the to-be-learned odor followed shock with an onset-to-onset interval of 40 s. For reward training (C), flies were successively exposed to a to-be-learned odor in the presence of sugar and then to a control odor without any sugar. Although not shown here, in half of the cases, reward training started with the control odor instead of the to-be-learned odor and sugar. For each kind of training, we used a reciprocal design (D): two groups were trained in parallel; for one of these, e.g., 3-octanol (OCT) was the control odor and benzaldehyde (BA) was to be learned; the other group was trained reciprocally. Each group was then given the choice between the two odors. Based on the flies’ distribution, preference indices (PREF) were calculated. Based on the two reciprocal PREF values, we calculated a learning index (LI). The situation is sketched for punishment learning, but also applies to relief and reward learning.
Reward learning (Figure 1C) used two training trials. Each trial started by loading the flies into the setup (0:00 min). One minute later, flies were transferred to a tube lined with a filter paper which was soaked the previous day with 2 ml of 2 M sucrose solution, and then was left to dry over night. This tube was scented with the to-be-learned odor. After 45 s, the to-be-learned odor was removed, and after 15 additional seconds flies were taken out of the tube. At the end of a 1 min waiting period, they were transferred into another tube lined with a filter paper which was soaked with pure water and then dried. This second tube was scented with the control odor. After 45 s, control odor was removed and 15 s later, flies were taken out of this second tube. The next trial started immediately. This transfer between the two kinds of tube during training should prevent the learning of an association between the control odor and the sugar. For half of the cases, training trials started with the to-be-learned odor and sugar; in the other half, control odor was given precedence. Once the training was completed, after a 3 min waiting period, flies were transferred to the choice point of a T-maze between the control odor and the learned odor. After 2 min, the arms of the maze were closed, flies on each side were counted and a preference index (PREF) was calculated according to Eq. 1. As detailed above (also see Figure 1D), two groups were trained reciprocally and the LI was calculated based on their PREF values according to Eq. 2.
Finally, a modified punishment training procedure (not shown in Figure 1) imitated the reward learning as in Figure 1C, but sugar presentation was replaced by 12 pulses of 100 V electric shock, each lasting 1.2 s and separated by an onset-to-onset interval of 5 s.
Statistics
All data were analyzed using non-parametric statistics and are reported as box plots, showing the median as the midline and 10, 90, and 25, 75% as whiskers and box boundaries, respectively. For comparing scores of individual groups to 0, we used one-sample sign tests. Mann–Whitney U-tests and Kruskal–Wallis tests were used for pair-wise and global between-group comparisons, respectively. When multiple tests of one kind were performed within a single experiment, we adjusted the experiment-wide error-rate to 5% by Bonferroni correction: we divided the critical P < 0.05 by the number of tests. One-sample sign tests were done using a web-based tool (http://www.fon.hum.uva.nl/Service/Statistics/Sign_Test.html). All other statistical analyses were performed with the software Statistica (Statsoft, Tulsa, OK, USA). Sample sizes are reported in the figure legends.
Results
Blocking Output from Two Different Sets of Dopaminergic Neurons
First, we compared relief learning to punishment learning in terms of the roles of dopaminergic neurons. We confirmed that blocking the output from a particular set of dopaminergic neurons, using the temperature-sensitive UAS-shibirets1 in combination with the TH-Gal4 driver (Friggi-Grelin et al., 2003, Table 1; Figures 2 and 3A), impairs punishment learning: when trained and tested at high temperature, TH/shits1 flies showed less negative learning scores than the genetic controls (Figure 4A @ high temperature: Kruskal–Wallis test: H = 11.44, d.f. = 2, P < 0.05). This impairment in punishment learning, however, was obviously partial in the TH/shits1 flies (Figure 4A @ high temperature: one-sample sign tests: P < 0.05/3 for each genotype), as was the case in previous studies (Schwaerzel et al., 2003; Aso et al., 2010). This residual learning ability may be due to incomplete coverage of dopaminergic neurons by the TH-Gal4 driver (Friggi-Grelin et al., 2003; Sitaraman et al., 2008; Claridge-Chang et al., 2009; Mao and Davis, 2009; see the Discussion for details) and/or to an incomplete block of neuronal output by shibirets1. At low temperature, as shibirets1 was benign, TH/shits1 flies performed comparably to the genetic controls in punishment learning (Figure 4A @ low temperature: Kruskal–Wallis test: H = 2.06, d.f. = 2, P = 0.36).
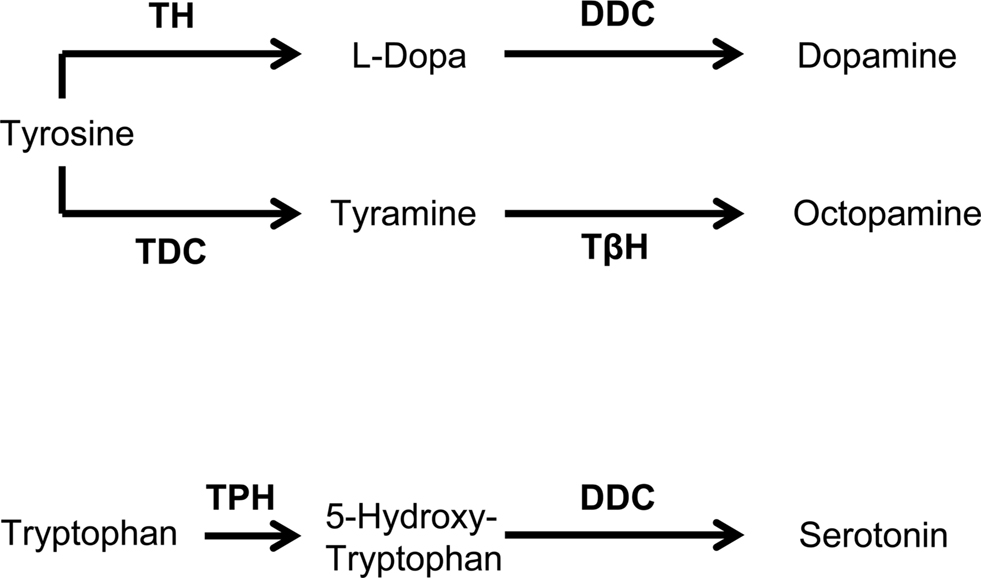
Figure 2. Biosynthesis of dopamine, tyramine, octopamine, and serotonin. DDC, dopa decarboxylase; TβH, tyramine β-hydroxylase; TDC, tyrosine decarboxylase; TH, tyrosine hydroxylase; TPH, tryptophan hydroxylase. Modified from Monastirioti (1999).
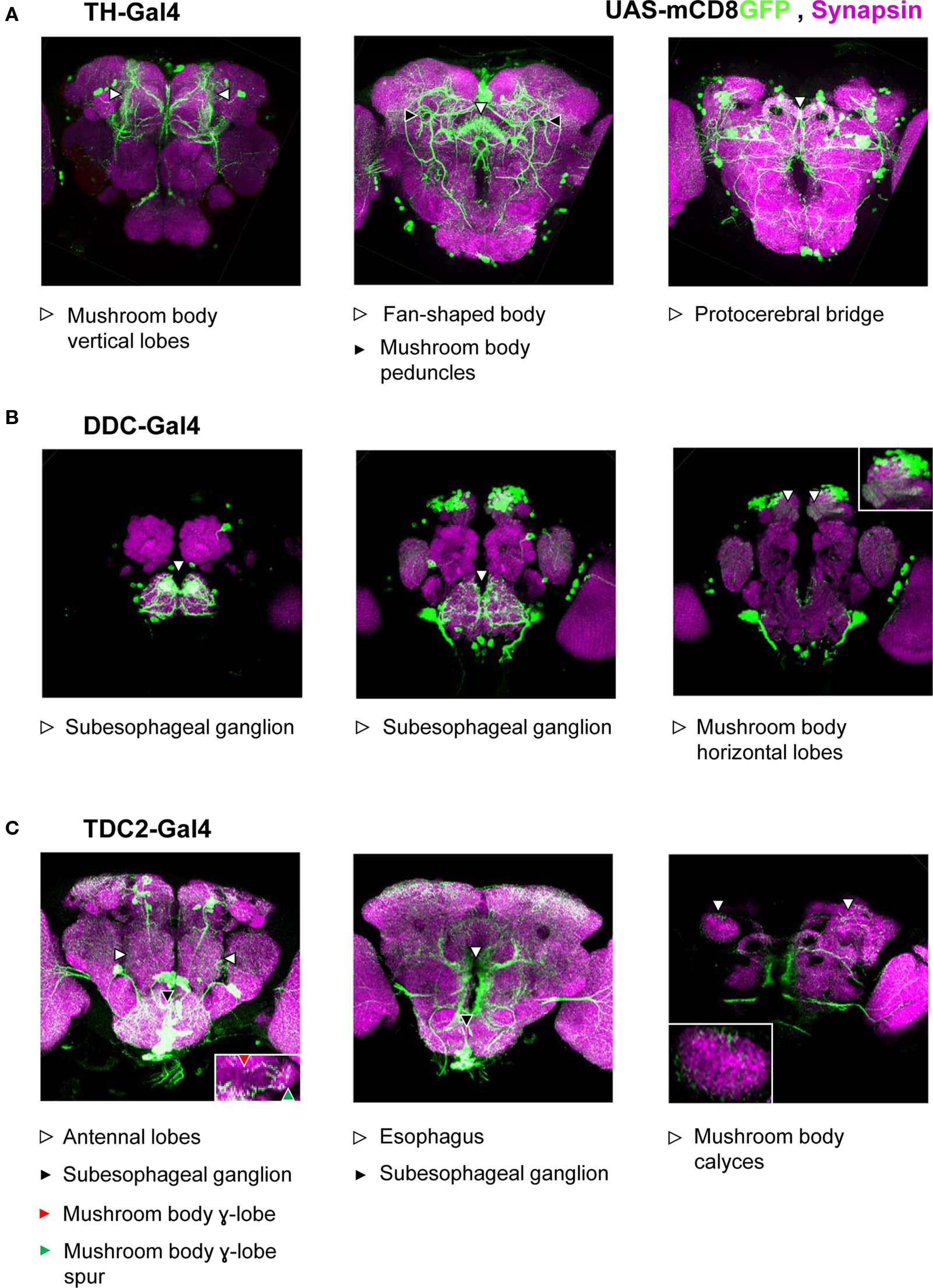
Figure 3. Approximated patterns of Gal4 expression by the used drivers. We drove the expression of a membrane bound green fluorescent protein (mCD8GFP) using three different Gal4 drivers. Patterns of GFP-immunoreactivity (green) should approximate the respective patterns of Gal4-expression; Synapsin-immunoreactivity (magenta) shows the organization of the neuropils. We display projections of frontal optical sections of 0.9 μm, each. In each row, the leftmost panel shows the anterior-most projection; in each panel, dorsal is to the top. When driven by TH-Gal4 (A), GFP was expressed in neurons that innervate the mushroom body vertical lobes and peduncles (left and middle panels) as well as the fan-shaped body (middle panel) and the protocerebral bridge (right panel). We found no innervation of the antennal lobes or the mushroom body calyces (but see Mao and Davis, 2009). Under the control of the DDC-Gal4 driver (B), GFP was expressed in neurons that innervate the subesophageal ganglion (left and middle panels) as well as the horizontal lobes of the mushroom body (right; see also the inset). Neurons that express GFP, driven by TDC2-Gal4 (C) innervated the antennal lobes (left panel), mushroom body γ-lobes and their spurs (left panel, inset), the subesophageal ganglion (left and middle panels), the areas surrounding the esophagus (middle panel), and the mushroom body calyces (right panel; see also the inset).
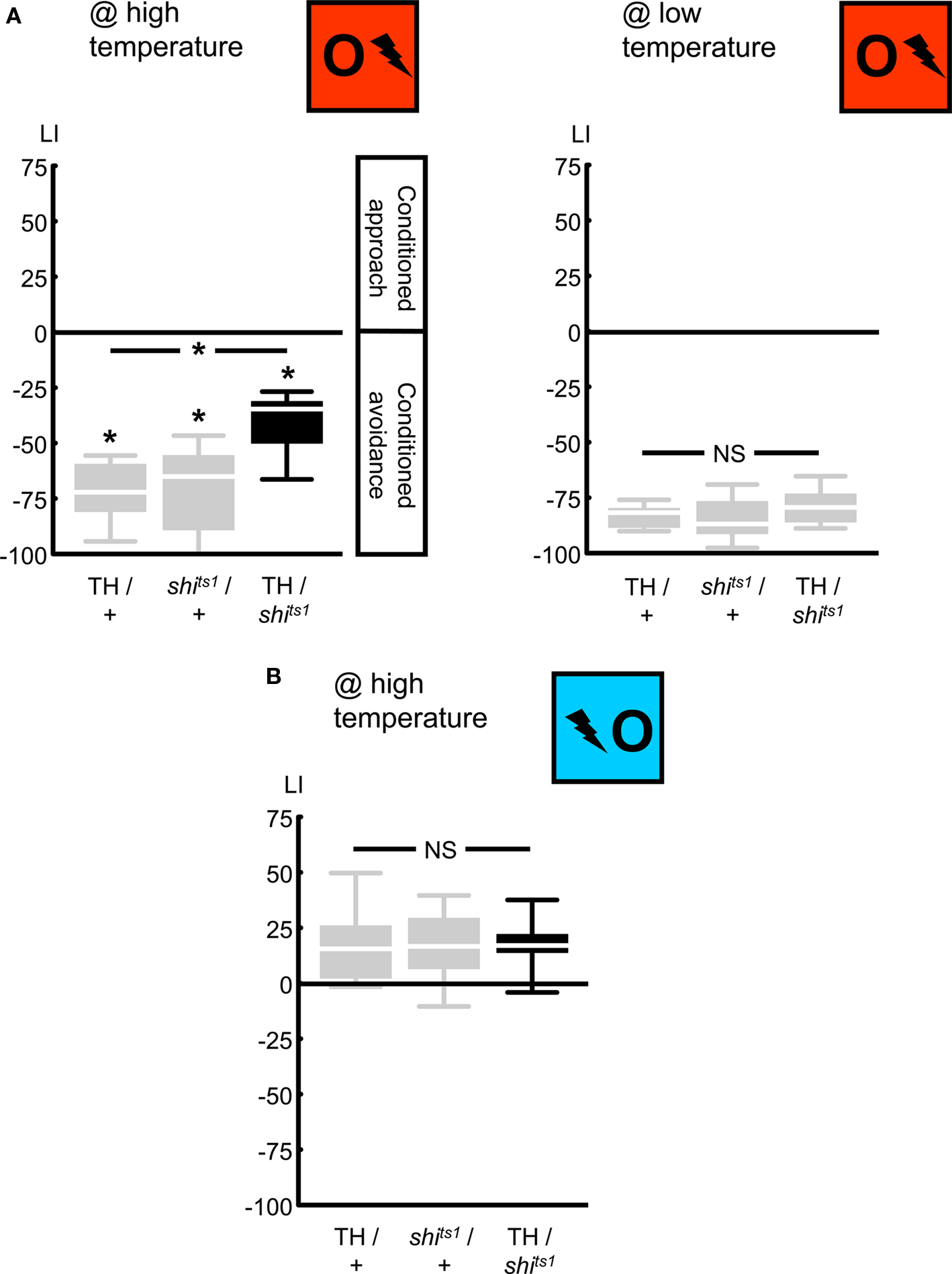
Figure 4. Targeting a set of dopaminergic neurons, using the TH-Gal4 driver. We expressed shibirets1 in the set of dopaminergic neurons defined by the TH-Gal4 driver. Punishment learning was partially impaired at high temperature (A, left), but not at low temperature (A, right). Contrarily, relief learning remained unaffected even at high temperature (B). *P < 0.05 and NS: P > 0.05 while comparing between genotypes. While comparing scores of each genotype to 0 *P < 0.05/3, to keep the experiment-wide error-rate at 5% (i.e., Bonferroni correction). Sample sizes were N = 8, each in (A) and 13, each in (B). Box plots show the median as the midline; 25 and 75% as the box boundaries and 10 and 90% as whiskers.
Importantly, blocking output from TH-Gal4 neurons, a treatment which did impair punishment learning, left relief learning intact: with training and test at high temperature, we found relief learning scores of TH/shits1 flies to be indistinguishable from the genetic controls (Figure 4B @ high temperature: Kruskal–Wallis test: H = 0.10, d.f. = 2, P = 0.96). Accordingly pooling the data, we found conditioned approach (Figure 4B @ high temperature: one-sample sign test for the pooled data set: P < 0.05). One might argue that the generally low relief learning scores may not allow detecting a possible partial impairment due to neurogenetic intervention. This however does not apply to Figure 4B, as relief learning in the TH/shits1 flies does not even tend to be inferior to the genetic controls (similarly, see Figures 5B, 6C, and 7B). We note that punishment and relief learning procedures differ only with respect to the timing of the to-be-learned odor during training; otherwise they entail the same handling and stimulus–exposure. Therefore, intact relief learning in the TH/shits1 flies (Figure 4B) excludes sensory and/or motor problems as potential cause for the impairment in punishment learning (Figure 4A, left).
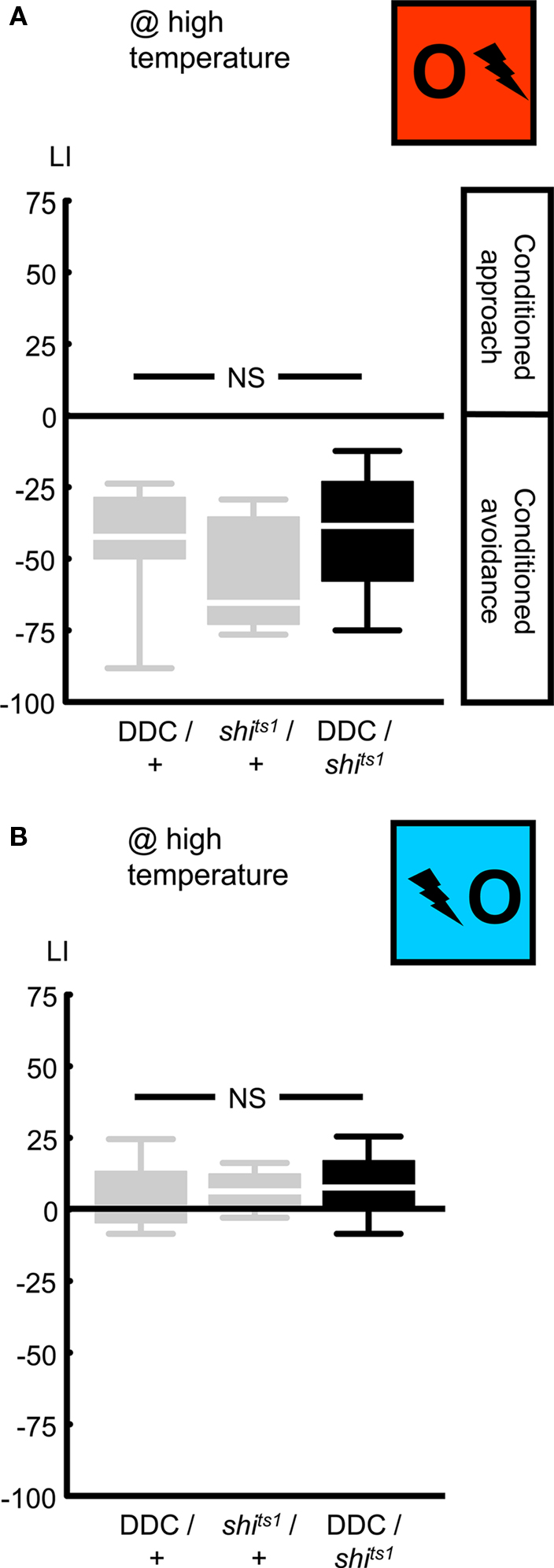
Figure 5. Targeting a set of dopaminergic/serotonergic neurons, using the DDC-Gal4 driver. We expressed shibirets1 in the set of dopaminergic/serotonergic neurons defined by the DDC-Gal4 driver. At high temperature, neither punishment learning (A), nor relief learning (B) was affected. NS: P > 0.05, while comparing between genotypes. Sample sizes were from left to right N = 13, 11, 12 in (A) and 12, 11, 12 in (B). Box plots are as detailed in Figure 4.
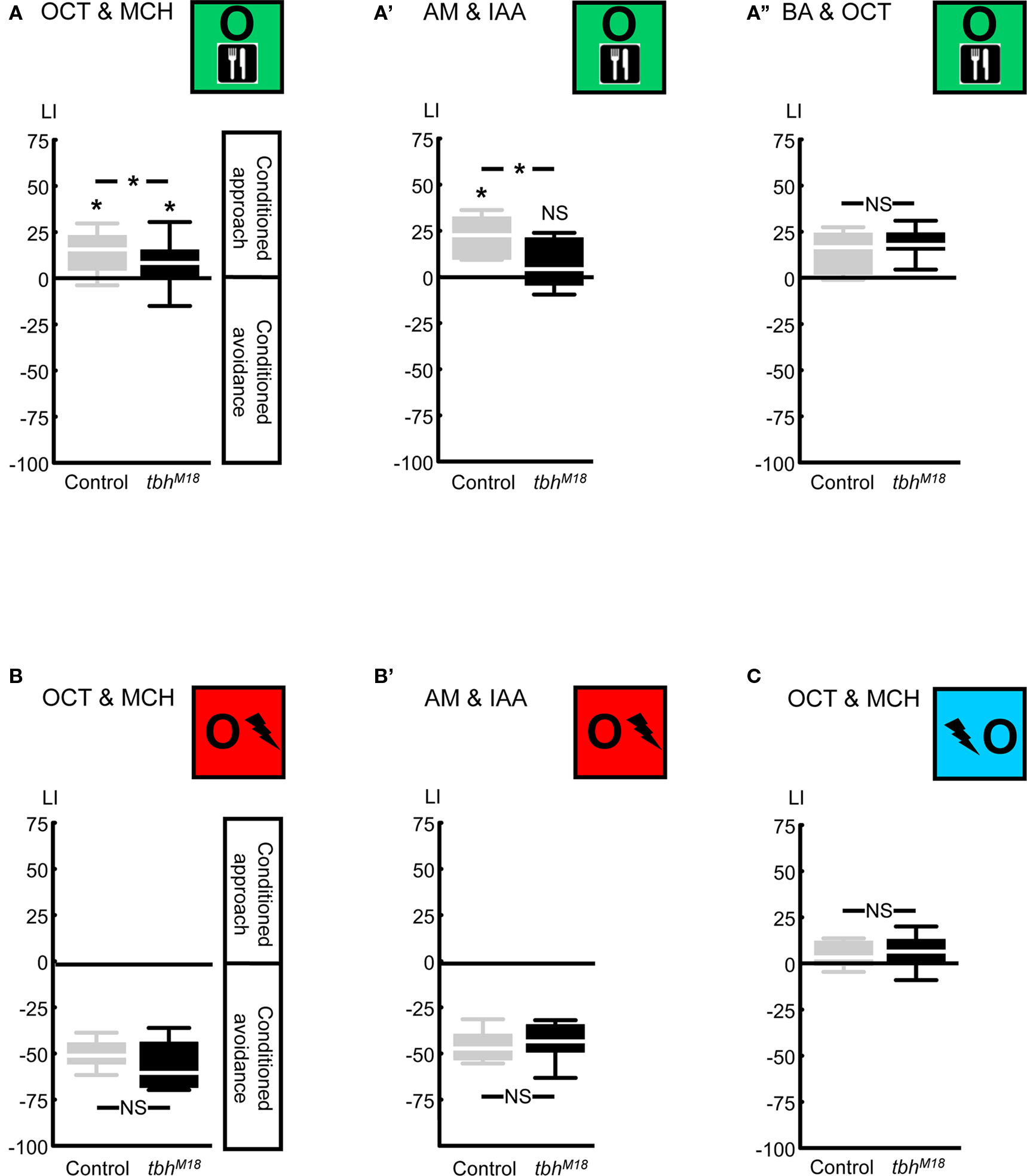
Figure 6. Compromising octopamine biosynthesis using the TβH mutant. We used the tbhM18 mutant, which has reduced or no octopamine. When the odors 3-octanol (OCT) and 4-methylcyclohexanol (MCH) were used, reward learning was partially impaired (A). Using the odors n-amyl acetate (AM) and isoamyl acetate (IAA) revealed complete lack of reward learning in the tbhM18 mutant (A′). When the odors OCT and benzaldehyde (BA) were used, tbhM18 mutant was intact in reward learning (A′′). A modified punishment learning procedure, which was identical to reward learning, except that the shock pulses were replaced by sugar presentation, revealed no impairment in the tbhM18 mutant, when either the odors OCT and MCH (B) or AM and IAA (B′) were used. Finally, under those conditions for which reward learning of the tbhM18 mutant was partially impaired, i.e., using the odors OCT and MCH, relief learning remained unaffected (C). For this experiment, the odors AM and IAA were not used, as these do not support relief learning (Yarali et al., 2008, loc. cit. Figure 5D). *P < 0.05, NS: P > 0.05, while comparing between genotypes. While comparing scores of each genotype to 0 *P < 0.05/2, NS: P > 0.05/2 (i.e., Bonferroni correction). Sample sizes were from left to right N = 40, 39 in (A), 11, 13 in (A′), 23, 22 in (A′′), 12, 12 in (B), 9, 9 in (B′), and 20, 20 in (C). Box plots are as detailed in Figure 4.
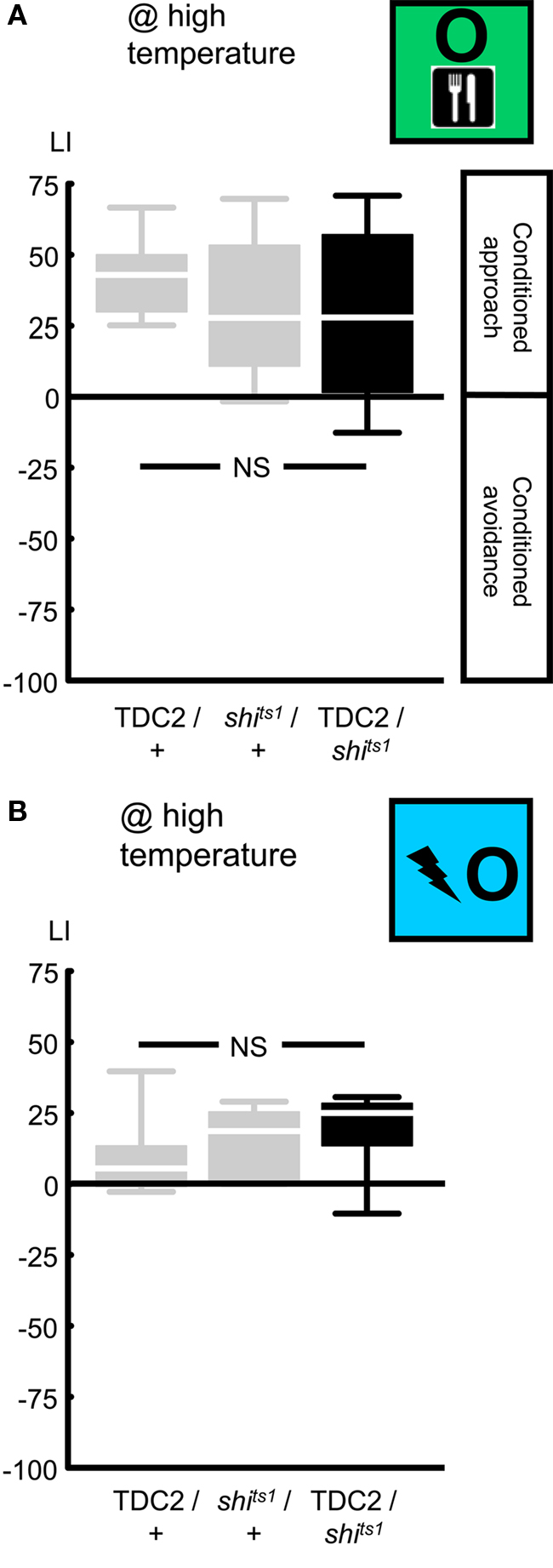
Figure 7. Targeting a set of octopaminergic/tyraminergic neurons, using the TDC2-Gal4 driver. We expressed shibirets1 in the set of octopaminergic/tyraminergic neurons defined by the TDC2-Gal4 driver. At high temperature, neither reward learning (A) nor relief learning (B) was impaired. NS: P > 0.05, while comparing between genotypes. Sample sizes were from left to right N = 24, 27, 27 in (A) and 11, each in (B). Box plots are as detailed in Figure 4.
Next, we used an independent driver, DDC-Gal4 (Li et al., 2000; Table 1; Figures 2 and 3B), to express UAS-shibirets1 in a set of dopaminergic/serotonergic neurons. Blocking the output from these neurons left punishment learning unaffected: when trained and tested at high temperature, DDC/shits1 flies showed learning scores comparable to the genetic controls (Figure 5A @ high temperature: Kruskal–Wallis test: H = 2.14, d.f. = 2, P = 0.34). Thus pooling the scores across genotypes, we observed conditioned avoidance (Figure 5A @ high temperature: one-sample sign test for the pooled data set: P < 0.05). This lack of effect on punishment learning may be caused by (i) the DDC-Gal4 driver not covering all dopaminergic neurons; (ii) incomplete overlap to those dopaminergic neurons targeted by the TH-Gal4 (Sitaraman et al., 2008; Claridge-Chang et al., 2009; Mao and Davis, 2009; see the Discussion for details), (iii) incomplete block of synaptic output by shibirets1; (iv) a dominant-negative effect of DDC-Gal4, which is non-additive with the effect of shibirets1 expression in these neurons (see below).
In any case, we probed for an effect of blocking output from the DDC-Gal4 neurons on relief learning and found none: after training and test at high temperature, learning scores were not different between genotypes (Figure 5B @ high temperature: Kruskal–Wallis test: H = 1.24, d.f. = 2, P = 0.54). We thus pooled the data and found weak yet significant conditioned approach (Figure 5B @ high temperature: one-sample sign test for the pooled data set: P < 0.05). We note that the DDC/+ flies tended to show less pronounced punishment and relief learning when compared to the TH/+ flies (compare Figure 4 versus Figure 5) as well as when compared to the shits1/+ flies (Figure 5). In the case of punishment learning, as we used a Kruskal–Wallis test across all three experimental groups, this effect of the DDC-Gal4 driver construct may have obscured an actual effect of blocking the output from DDC-Gal4-targeted neurons (compare shits1/+ to DDC/shits1 in Figure 5A). For relief learning, however, no corresponding trend is noted (compare shits1/+ to DDC/shits1 in Figure 5B). In any case, with respect to the role of the neurons defined by DDC-Gal4, our results do not offer an argument to dissociate punishment from relief learning.
To summarize, concerning the neurons defined by TH-Gal4, we found a clear dissociation between punishment and relief learning (Figure 4), while for the DDC-Gal4 neurons the situation remains inconclusive (Figure 5). We would like to stress that this does not at all exclude a role for the dopaminergic system in relief learning, given that first, in neither experiment did we cover all dopaminergic neurons at once, and second, as a general concern, blockage of neuronal output by shibirets1 may well be incomplete (see the Discussion for details).
Compromising Octopamine Biosynthesis
Next, we compared relief learning to reward learning in terms of the role of octopamine. We first confirmed that compromising octopamine biosynthesis via the tbhM18 mutation in the key enzyme tyramine β-hydroxylase (Monastirioti et al., 1996; Figure 2) impairs reward learning: after odor-sugar training, using the odors 3-octanol (OCT) and 4-methylcyclohexanol (MCH), the tbhM18M mutant showed significantly less conditioned approach than the genetic Control (Figure 6A: U-test: U = 544.00, P < 0.05). Residual reward learning ability was however detectable in the tbhM18 mutant (Figure 6A: one-sample sign tests: P < 0.05/2 for each genotype). This contrasts to the report of Sitaraman et al. (2010), who had shown a complete loss of reward learning using the same odors; the discrepancy may be due to the different genetic backgrounds used in the two studies (i.e., the present study uses the strains from Schwaerzel et al., 2003, whereas Sitaraman et al., 2010 uses those from Certel et al., 2007). Schwaerzel et al. (2003) found no reward learning ability in the tbhM18 mutant, using the odors ethyl acetate and isoamyl acetate (IAA); indeed, using n-amyl acetate (AM) and IAA as odors, we also found a complete loss of reward learning in the tbhM18 mutant (Figure 6A′: U-test: U = 33.00, P < 0.05; one-sample sign tests: P < 0.05/2 for Control, and P = 0.58 for the tbhM18 mutant). Surprisingly however, when the odors OCT and benzaldehyde (BA) were used, tbhM18 mutant flies showed fully intact reward learning (Figure 6A′′: U-test: U = 204.50, P = 0.27; one-sample sign test for the pooled data set: P < 0.05). This lack of effect in Figure 6A′′ should not be due to the relatively low learning indices of the Control flies, since in Figure 6A, we could detect even a partial effect of the tbhM18 mutation despite such low Control scores. Note that using the present two-odor reciprocal training design (Figure 1D), the contribution of each odor to the LI, and hence the question whether the tbhM18 mutation affects learning about any one given odor but not the other, remains unresolved. We can however conclude that the reward learning impairment of the tbhM18 mutant can be partial, complete, or absent, depending on the combination of odors used and likely also on the genetic background; this suggests residual octopaminergic function and/or an octopamine-independent compensatory mechanism (see the Discussion for details).
To test for an effect of the tbhM18 mutation on punishment learning, we used a modified training, which entailed the same pre-starvation, handling, and stimulus–exposure as reward learning, except the sugar presentation was replaced by shock pulses. In such modified punishment learning, the tbhM18 mutant performed comparably to the genetic Control, using either the odors OCT and MCH (Figure 6B: U-test: U = 47.00, P = 0.15; one-sample sign test for the pooled data set: P < 0.05) or AM and IAA (Figure 6B′: U-test: U = 38.00, P = 0.82; one-sample sign test for the pooled data set: P < 0.05). Thus, confirming Schwaerzel et al. (2003), we can conclude that reward and punishment learning are dissociated in terms of the effect of the tbhM18 mutation. In addition, normal performance of the tbhM18 mutant in this modified punishment learning makes deficiencies in odor perception or motor control unlikely as causes for the reward learning impairment (Figures 6A,A′).
In order to test for an effect of the tbhM18 mutation on relief learning, we used the odors OCT and MCH, because the odors AM and IAA do not support relief learning (Yarali et al., 2008, loc. cit. Figure 5D). Under conditions for which the tbhM18 mutant did show a reward learning impairment, however partial (i.e., using the odors OCT and MCH), relief learning ability remained unaffected: learning scores were statistically indistinguishable between genotypes (Figure 6C: U-test: U = 168.00, P = 0.40), with no apparent trend for lower scores in the tbhM18 mutant. We thus pooled the data and found weak yet significant conditioned approach (Figure 6C: one-sample sign test for the pooled data set: P < 0.05).
Blocking the Output from a Set of Octopaminergic/Tyraminergic Neurons
As an additional, independent assault toward the octopaminergic system, we blocked the output from a set of octopaminergic/tyraminergic neurons, using UAS-shibirets1, in combination with the TDC2-Gal4 driver (Cole et al., 2005; Table 1; Figures 2 and 3C). We first tested for an effect on reward learning: when trained and tested at high temperature, TDC2/shits1 flies performed comparably to the genetic controls (Figure 7A @ high temperature: Kruskal–Wallis test: H = 3.03, d.f. = 2, P = 0.22). Accordingly pooling the learning scores across genotypes, we found conditioned approach (Figure 7A @ high temperature: one-sample sign test for the pooled data set: P < 0.05). This lack of effect on reward learning may be because the TDC2-Gal4 driver does not target all octopaminergic neurons (Busch et al., 2009; see the Discussion for details) and/or the output from the targeted neurons is not completely blocked by the shibirets1.
Nevertheless, we probed for an effect on relief learning and found none: after training and test at high temperature, learning scores were statistically indistinguishable between genotypes (Figure 7B @ high temperature: Kruskal–Wallis test: H = 2.43, d.f. = 2, P = 0.30). Accordingly pooling the data, we found conditioned approach (Figure 7B @ high temperature: one-sample sign test for the pooled data set: P < 0.05). To summarize, while reward and relief learning are apparently dissociated when considering the tbhM18 mutant, we can put no distinction between these two kinds of learning in terms of the role of the neurons covered by the TDC2-Gal4 driver. Again, this does not rule out a role for the octopaminergic system in relief learning, as these conclusions refer only to the specific genetic manipulations used.
Discussion
We compared relief learning to both punishment learning and reward learning, focusing on the involvement of aminergic modulation by dopamine and octopamine.
As previously reported (Schwaerzel et al., 2003; Aso et al., 2010), directing the expression of UAS-shibirets1 to a particular set of dopaminergic neurons defined by the TH-Gal4 driver partially impaired punishment learning (Figure 4A). Relief learning however was left intact (Figure 4B). Expressing UAS-shibirets1 with another driver, DDC-Gal4, on the other hand affected neither punishment nor relief learning (Figure 5).
All dopaminergic neuron clusters in the fly brain are targeted by the TH-Gal4 driver; some clusters however, are covered only partially, e.g., 80–90% of the anterior medial “PAM cluster” neurons are left out (Friggi-Grelin et al., 2003; Sitaraman et al., 2008; Claridge-Chang et al., 2009; Mao and Davis, 2009). Contrarily, the DDC-Gal4 driver, along with serotonergic neurons, likely targets most of the PAM cluster dopaminergic neurons, while possibly leaving out dopaminergic neurons in other clusters (Sitaraman et al., 2008; Figure 3B). In a mixed classical-operant olfactory punishment learning task, Claridge-Chang et al. (2009) found no impairment upon blocking the activity of most PAM cluster neurons with an inwardly rectifying K+ channel (UAS-kir2.1), driven by HL9-Gal4. Although relying on both a different Gal4 driver and a different effector, this result is in agreement with the intact punishment learning we found when expressing UAS-shibirets1 with the DDC-Gal4 driver (Figure 5A). Thus, as far as short-term punishment learning is concerned, there is so far no evidence for a role for the PAM cluster neurons (for middle-term punishment learning, see Aso et al., 2010). Nevertheless, targeting the remaining dopaminergic neuron clusters by the TH-Gal4 driver only partially impairs punishment learning (Schwaerzel et al., 2003; Aso et al., 2010; Figure 4A). Conceivably, the TH-Gal4 driver may leave out few dopaminergic neurons in clusters other than PAM; these may then carry a punishment signal, redundant to that carried by the TH-Gal4-targeted neurons. This scenario would readily accommodate Schroll et al.’s (2006) report that activity of the TH-Gal4-targeted neurons in larval fruit flies substitutes for punishment. The intact relief learning upon expressing UAS-shibirets1 with TH-Gal4 can also be explained by this scenario. Alternatively, the level of shibirets1 expression driven by TH-Gal4 may fall short of effectively blocking the neuronal output required for relief learning, and/or an additional, shibirets1-resistant neurotransmission mechanism may be employed in relief learning. Further, if punishment were to be signaled by a shock-induced increase in the activity of the TH-Gal4 neurons and relief was to be signaled by a decrease in their activity below the baseline at the shock offset, incomplete blockage of output from these neurons could partially impair punishment learning, while leaving relief learning intact. In face of these caveats, we find it too early to exclude any role of dopamine or of the TH-Gal4 neurons. What then is a safe minimal conclusion? Given that while punishment learning is partially impaired (Figure 4A) relief learning does not even tend to be impaired (Figure 4B), these two kinds of learning do differ in terms of whether and which role the TH-Gal4-covered neurons play. This does dissociate punishment and relief learning in terms of their underlying mechanisms.
Turning to the octopaminergic system, we confirmed Schwaerzel et al. (2003) in that the tbhM18 mutant with compromised octopamine biosynthesis is impaired in reward learning (Figures 6A,A′), but not in punishment learning (Figures 6B,B′). The effect on reward learning was however conditional on the kinds of odor used (Figures 6A,A′,A′′). Under the conditions that significantly impaired reward learning, we found relief learning intact (Figure 6C). Although the tbhM18 mutant we used revealed no octopamine content in immunohistochemical and high pressure liquid chromatography (HPLC) analyses (Monastirioti et al., 1996), it may retain an amount of octopamine below the detection thresholds of these methods but sufficient to signal reward and/or relief. Furthermore, HPLC analysis reveals a ∼10-fold increase in the amount of octopamine-precursor tyramine in this mutant (Monastirioti et al., 1996); this excessive tyramine may compensate for the lack of octopamine (Uzzan and Dudai, 1982).
As an additional approach, we blocked the output from a set of octopaminergic/tyraminergic neurons, expressing UAS-shibirets1 with the TDC2-Gal4 driver; this impaired neither reward, nor relief learning (Figure 7). The TDC2-Gal4 driver targets, along with tyraminergic neurons, octopaminergic neurons in three paired and one unpaired neuron clusters (Busch et al., 2009). Among these, the unpaired “VM cluster” harbors octopaminergic neurons innervating on the one hand the subesophageal ganglion (SOG), and on the other hand the antennal lobes, mushroom bodies, and the lateral horn (Busch et al., 2009); such connectivity would enable signaling gustatory reward onto the olfactory pathway. Indeed, in the honey bee, activation of a single octopaminergic neuron, VUMmx1, with such innervation pattern, is sufficient to carry the reward signal for olfactory learning (Hammer, 1993). Surprisingly however, although all octopaminergic neurons in the VM cluster are targeted by the TDC2-Gal4 (Busch et al., 2009), using this driver with UAS-shibirets1, we found reward learning intact (Figure 7A). This may be because the level UAS-shibirets1 expression falls short of completely blocking the neuronal output. Alternatively, given that activation of the TDC2-Gal4-targeted neurons in fruit fly larvae reportedly substitutes for reward (Schroll et al., 2006), the VM cluster neurons may indeed carry a reward signal, but other octopaminergic neurons outside this cluster, left out by the TDC2-Gal4 driver (Busch et al., 2009) may redundantly do so. Either kind of argument could also explain the lack of effect on relief learning (Figure 7B). Thus, although we find no evidence for a role for the octopaminergic system in relief learning, we refrain from excluding such a role. Still, given that the tbhM18 mutation affects reward learning, but not relief learning, these two forms of learning are to some extent dissociated in their genetic requirements.
Obviously, the question whether dopaminergic and octopaminergic systems are involved in relief learning remains open. Follow up studies should extend our neurogenetic approach to further tools. For example, dopamine biosynthesis can be specifically compromised in the fly nervous system using a tyrosine hydroxylase mutant in combination with a hypoderm-specific rescue construct (Hirsh et al., 2010). Also, for two different dopamine receptors, DAMB and dDA-1, loss of function mutations are available (Kim et al., 2007; Selcho et al., 2009). Notably, by means of the dDA-1 receptor loss of function mutant, the role of the dopaminergic system in reward learning was revealed (Kim et al., 2007; Selcho et al., 2009), which had been overlooked with the tools used in the present study. In addition, a pharmacological approach would be useful. Antagonists for the vertebrate D1 and D2 receptors have been successfully used in the fruit fly (Yellman et al., 1997; Seugnet et al., 2008) and other insects (Unoki et al., 2005, 2006; Vergoz et al., 2007) (regarding the octopamine receptors: Unoki et al., 2005, 2006; Vergoz et al., 2007). Such pharmacological approach could be extended to other aminergic, as well as peptidergic systems and could also test for the effects of human psychotherapeuticals. The results of such studies may then guide subsequent analyses at the cellular level.
To summarize, while this study has shed no light on how relief learning works, it did show that relief learning works in a way neurogenetically different from both punishment learning and reward learning, likely at the level of the roles of aminergic neurons. Interestingly, at this level also punishment and reward learning are dissociated. However, all three kinds of learning also share genetic commons, for example with respect to the role of the synapsin gene, likely critical for neuronal plasticity (Godenschwege et al., 2004; Michels et al., 2005; Knapek et al., 2010; T. Niewalda, Universität Würzburg, personal communication). Thus, punishment-, relief-, and reward-learning may conceivably rely on common molecular mechanisms of memory trace formation, which however are triggered by experimentally dissociable reinforcement signals, and/or operate in distinct neuronal circuits. This may be a message relevant also for analyses of relief learning in other experimental systems, including rodent (Rogan et al., 2005), monkey (Tobler et al., 2003; Belova et al., 2007; Matsumoto and Hikosaka, 2009), and man (Seymour et al., 2005; Andreatta et al., 2010).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The continuous support of the members of the Würzburg group, especially of M. Heisenberg, K. Oechsener and H. Kaderschabek, is gratefully acknowledged. Special thanks to T. Niewalda, Y. Aso and M. Appel for comments on the manuscript. The authors are grateful to E. Münch for the generous support to Ayse Yarali during the startup phase of her PhD. This work was supported by the Deutsche Forschungsgemeinschaft (DFG) via CRC-TR 58 Fear, Anxiety, Anxiety Disorders, and a Heisenberg Fellowship (to Bertram Gerber); Ayse Yarali was supported by the Boehringer Ingelheim Fond. Dedicated to our respective daughters.
References
Andreatta, M., Mühlberger, A., Yarali, A., Gerber, B., and Pauli, P. (2010). A rift between implicit and explicit conditioned valence in human pain relief learning. Proc. Biol. Sci. 277, 2411–2416.
Aso, Y., Siwanowicz, I., Bräcker, L., Ito, K., Kitamoto, T., and Tanimoto, H. (2010). Specific dopaminergic neurons for the formation of labile aversive memory. Curr. Biol. 20, 1445–1451.
Belova, M. A., Paton, J. J., Morrison, S. E., and Salzman, C. D. (2007). Expectation modulates neural responses to pleasant and aversive stimuli in primate amygdala. Neuron 55, 970–984.
Brembs, B., Christiansen, F., Pfluger, H. J., and Duch, C. (2007). Flight initiation and maintenance deficits in flies with genetically altered biogenic amine levels. J. Neurosci. 27, 11122–11131.
Britton, G., and Farley, J. (1999). Behavioral and neural bases of noncoincidence learning in Hermissenda. J. Neurosci. 19, 9126–9132.
Busch, S., Selcho, M., Ito, K., and Tanimoto, H. (2009). A map of octopaminergic neurons in the Drosophila brain. J. Comp. Neurol. 513, 643–667.
Certel, S. J., Savella, M. G., Schlegel, D. C., and Kravitz, E. A. (2007). Modulation of Drosophila male behavioral choice. Proc. Natl. Acad. Sci. U.S.A. 104, 4706–4711.
Chang, R. C., Blaisdell, A. P., and Miller, R. R. (2003). Backward conditioning: mediation by the context. J. Exp. Psychol. Anim. Behav. Process. 29, 171–183.
Claridge-Chang, A., Roorda, R. D., Vrontou, E., Sjulson, L., Li, H., Hirsh, J., and Miesenboeck, G. (2009). Writing memories with light-addressable reinforcement circuitry. Cell 139, 405–415.
Cole, S. H., Carney, G. E., McClung, C. A., Willard, S. S., Taylor, B. J., and Hirsh, J. (2005). Two functional but noncomplementing Drosophila tyrosine decarboxylase genes: distinct roles for neural tyramine and octopamine in female fertility. J. Biol. Chem. 280, 14948–14955.
Dickinson, A. (2001). The 28th Bartlett Memorial Lecture. Causal learning: an associative analysis. Q. J. Exp. Psychol. 54, 3–25.
Farooqui, T., Robinson, K., Vaessin, H., and Smith, B. H. (2003). Modulation of early olfactory processing by an octopaminergic reinforcement pathway in the honeybee. J. Neurosci. 23, 5370–5380.
Friggi-Grelin, F., Coulom, H., Meller, M., Gomez, D., Hirsh, J., and Birman, S. (2003). Targeted gene expression in Drosophila dopaminergic cells using regulatory sequences from tyrosine hydroxylase. J. Neurobiol. 54, 618–627.
Gerber, B., and Stocker, R. F. (2007). The Drosophila larva as a model for studying chemosensation and chemosensory learning: a review. Chem. Senses 32, 65–89.
Godenschwege, T. A., Reisch, D., Diegelmann, S., Eberle, K., Funk, N., Heisenberg, M., Hoppe, V., Hoppe, J., Klagges, B. R., Martin, J. R., Nikitina, E. A., Putz, G., Reifegerste, R., Reisch, N., Rister, J., Schaupp, M., Scholz, H., Schwärzel, M., Werner, U., Zars, T. D., Buchner, S., and Buchner, E. (2004). Flies lacking all synapsins are unexpectedly healthy but are impaired in complex behaviour. Eur. J. Neurosci. 20, 611–622.
Hammer, M. (1993). An identified neuron mediates the unconditioned stimulus in associative olfactory learning in honeybees. Nature 366, 59–63.
Hammer, M., and Menzel, R. (1998). Multiple sites of associative odor learning as revealed by local brain microinjections of octopamine in honeybees. Learn. Mem. 5, 146–156.
Hardie, S. L., Zhang, J. X., and Hirsh, J. (2007). Trace amines differentially regulate adult locomotor activity, cocaine sensitivity, and female fertility in Drosophila melanogaster. Dev. Neurobiol. 67, 1396–1405.
Hearst, E. (1988). “Learning and cognition,” in Stevens’ Handbook of Experimental Psychology, 2nd Edn, Vol. 2, eds R. C. Atkinson, R. J. Herrnstein, G. Lindzey, and R. D. Luce (New York: Wiley), 3–109.
Hellstern, F., Malaka, R., and Hammer, M. (1998). Backward inhibitory learning in honeybees: a behavioral analysis of reinforcement processing. Learn. Mem. 4, 429–444.
Hirsh, J., Riemensperger, T., Coulom, H., Iche, M., Coupar, J., and Birman, S. (2010). Roles of dopamine in circadian rhythmicity and extreme light sensitivity of circadian entrainment. Curr. Biol. 20, 209–214.
Honjo, K., and Furukubo-Tokunaga, K. (2009). Distinctive neural networks and biochemical pathways for appetitive and aversive memory in Drosophila larvae. J. Neurosci. 29, 852–862.
Ito, K., Okada, R., Tanaka, N. K., and Awasaki, T. (2003). Cautionary observations on preparing and interpreting brain images using molecular biology-based staining techniques. Microsc. Res. Tech. 62, 170–186.
Kaczer, L., and Maldonado, H. (2009). Contrasting role of octopamine in appetitive and aversive learning in the crab Chasmagnathus. PLoS ONE 4, e6223. doi: 10.1371/journal.pone.0006223.
Khurana, S., AbuBaker, M. B., and Siddiqi, O. (2009). Odour avoidance learning in the larva of Drosophila melanogaster. J. Biosci. 34, 621–631.
Kim, Y.-C., Lee, H.-G., and Han, K.-A. (2007). D1 dopamine receptor dDA1 is required in the mushroom body neurons for aversive and appetitive learning in Drosophila. J. Neurosci. 27, 7640–7647.
Kitamoto, T. (2001). Conditional modification of behavior in Drosophila by targeted expression of a temperature-sensitive shibire allele in defined neurons. J. Neurobiol. 47, 81–92.
Klagges, B. R., Heimbeck, G., Godenschwege, T. A., Hofbauer, A., Pflugfelder, G. O., Reifegerste, R., Reisch, D., Schaupp, M., Buchner, S., and Buchner, E. (1996). Invertebrate synapsins: a single gene codes for several isoforms in Drosophila. J. Neurosci. 16, 3154–3165.
Knapek, S., Gerber, B., and Tanimoto, H. (2010). Synapsin is selectively required for anesthesia-sensitive memory. Learn. Mem. 17, 76–79.
Krashes, M. J., DasGupta, S., Vreede, A., White, B., Armstrong, J. D., and Waddell, S. (2009). A neural circuit mechanism integrating motivational state with memory expression in Drosophila. Cell 139, 416–427.
Lee, T., and Luo, L. (1999). Mosaic analysis with a repressible cell marker for studies of gene function in neuronal morphogenesis. Neuron 22, 451–461.
Li, H., Chaney, S., Roberts, I. J., Forte, M., and Hirsh, J. (2000). Ectopic G-protein expression in dopamine and serotonin neurons blocks cocaine sensitization in Drosophila melanogaster. Curr. Biol. 10, 211–214.
Maier, S. F., Rapaport, P., and Wheatley, K. L. (1976). Conditioned inhibition and the UCS-CS interval. Anim. Learn. Behav. 4, 217–220.
Mao, Z., and Davis, R. L. (2009). Eight different types of dopaminergic neurons innervate the Drosophila mushroom body neuropil: anatomical and physiological heterogeneity. Front. Neural Circuits 3:5. doi: 10.3389/neuro.04.005.2009
Matsumoto, M., and Hikosaka, O. (2009). Representation of negative motivational value in the primate lateral habenula. Nat. Neurosci. 12, 77–84.
Michels, B., Diegelmann, S., Tanimoto, H., Schwenkert, I., Buchner, E., and Gerber, B. (2005). A role for Synapsin in associative learning: the Drosophila larva as a study case. Learn. Mem. 12, 224–231.
Mizunami, M., Unoki, S., Mori, Y., Hirashima, D., Hatano, A., and Matsumoto, Y. (2009). Roles of octopaminergic and dopaminergic neurons in appetitive and aversive memory recall in an insect. BMC Biol. 7, 46–61. doi: 10.1186/1741-7007-7-46.
Monastirioti, M. (1999). Biogenic amine systems in the fruit fly Drosophila melanogaster. Microsc. Res. Tech. 45, 106–121.
Monastirioti, M., Linn, C. E. Jr., and White, K. (1996). Characterization of Drosophila tyramine beta-hydroxylase gene and isolation of mutant flies lacking octopamine. J. Neurosci. 16, 3900–3911.
Moskovitch, A., and LoLordo, V. M. (1968). Role of safety in the Pavlovian backward fear conditioning procedure. J. Comp. Physiol. Psychol. 66, 673–678.
Murakami, S., Dan, C., Zagaeski, B., Maeyama, Y., Kunes, S., and Tabata, T. (2010). Optimizing Drosophila olfactory learning with a semi-automated training device. J. Neurosci. Methods 188, 195–204.
Plotkin, H. C., and Oakley, D. A. (1975). Backward conditioning in the rabbit (Oryctolagus cuniculus). J. Comp. Physiol. Psychol. 88, 586–590.
Riemensperger, T., Voller, T., Stock, P., Buchner, E., and Fiala, A. (2005). Punishment prediction by dopaminergic neurons in Drosophila. Curr. Biol. 15, 1953–1960.
Rogan, M. T., Leon, K. S., Perez, D. L., and Kandel, E. (2005). Distinct neural signatures for safety and danger in the amygdala and striatum of the mouse. Neuron 46, 309–320.
Saraswati, S., Fox, L. E., Soll, D. R., and Wu, C. F. (2004). Tyramine and octopamine have opposite effects on the locomotion of Drosophila larvae. J. Neurobiol. 58, 425–441.
Scholz, H. (2005). Influence of the biogenic amine tyramine on ethanol-induced behaviors in Drosophila. J. Neurobiol. 63, 199–214.
Schroll, C., Riemensperger, T., Bucher, D., Ehmer, J., Voller, T., Erbguth, K., Gerber, B., Hendel, T., Nagel, G., Buchner, E., and Fiala, A. (2006). Light-induced activation of distinct modulatory neurons triggers appetitive or aversive learning in Drosophila larvae. Curr. Biol. 16, 1741–1747.
Schwaerzel, M., Monastirioti, M., Scholz, H., Friggi-Grelin, F., Birman, S., and Heisenberg, M. (2003). Dopamine and octopamine differentiate between aversive and appetitive olfactory memories in Drosophila. J. Neurosci. 23, 10495–10502.
Selcho, M., Pauls, D., Han, K.-A., Stocker, R., and Thum, A. (2009). The role of dopamine in Drosophila larval classical conditioning. PLoS ONE 6, e5897. doi: 10.1371/journal.pone.0005897
Seugnet, L., Suzuki, Y., Vine, L., Gottschalk, L., and Shaw, P. J. (2008). D1 receptor activation in the mushroom bodies rescues sleep-loss-induced learning impairments in Drosophila. Curr. Biol. 18, 1110–1117.
Seymour, B., O’Doherty, J. P., Koltzenburg, M., Wiech, K., Frackowiak, R., Friston, K., and Dolan, R. (2005). Opponent appetitive-aversive neural processes underlie predictive learning of pain relief. Nat. Neurosci. 8, 1234–1240.
Sitaraman, D., Zars, M., Laferriere, H., Chen, Y. C., Sable-Smith, A., Kitamoto, T., Rottinghaus, G. E., and Zars, T. (2008). Serotonin is necessary for place memory in Drosophila. Proc. Natl. Acad. Sci. U. S. A. 105, 5579–5584.
Sitaraman, D., Zars, M., and Zars, T. (2010). Place memory formation in Drosophila is independent of proper octopamine signaling. J. Comp. Physiol. A. Neuroethol. Sens. Neural. Behav. Physiol. 196, 299–305.
Solomon, R. L., and Corbit, J. D. (1974). An opponent-process theory of acquired motivation. I. Temporal dynamics of affect. Psychol. Rev. 81, 119–145.
Sutton, R. S., and Barto, A. G. (1990). “Time derivative models of Pavlovian reinforcement,” in Learning and Computational Neuroscience: Foundations of Adaptive Networks, eds M. R. Gabriel and J. W. Moore (Cambridge, MA: MIT Press), 497–537.
Tanimoto, H., Heisenberg, M., and Gerber, B. (2004). Experimental psychology: event timing turns punishment to reward. Nature 430, 983.
Tempel, B. L., Bonini, N., Dawson, D. R., and Quinn, W. G. (1983). Reward learning in normal and mutant Drosophila. Proc. Natl. Acad. Sci. U. S. A. 80, 1482–1486.
Tobler, P. N., Dickinson, A., and Schulz, W. (2003). Coding of predicted reward omission by dopamine neurons in a conditioned inhibition paradigm. J. Neurosci. 23, 10402–10410.
Tully, T., and Quinn, W. G. (1985). Classical conditioning and retention in normal and mutant Drosophila melanogaster. J. Comp. Physiol. A. Neuroethol. Sens. Neural. Behav. Physiol. 157, 263–277.
Unoki, S., Matsumoto, Y., and Mizunami, M. (2005). Participation of octopaminergic reward system and dopaminergic punishment system in insect olfactory learning revealed by pharmacological study. Eur. J. Neurosci. 22, 1409–1416.
Unoki, S., Matsumoto, Y., and Mizunami, M. (2006). Roles of octopaminergic and dopaminergic neurons in mediating reward and punishment signals in insect visual learning. Eur. J. Neurosci. 24, 2031–2038.
Uzzan, A., and Dudai, Y. (1982). Aminergic receptors in Drosophila melanogaster: responsiveness of adenylate cyclase to putative neurotransmitters. J. Neurochem. 38, 1542–1550.
Vergoz, V., Roussel, E., Sandoz, J. C., and Giurfa, M. (2007). Aversive learning in honeybees revealed by the olfactory conditioning of the sting extension reflex. PLoS ONE 2, e288. doi: 10.1371/journal.pone.0000288
Wagner, A. R. (1981). “SOP: a model of automatic memory processing in animal behavior,” in Information Processing in Animals: Memory Mechanisms, eds N. E. Spear and R. R. Miller (Hillsdale, NJ: Erlbaum), 5–47.
Yarali, A., Krischke, M., Michels, B., Saumweber, T., Mueller, M. J., and Gerber, B. (2009). Genetic distortion of the balance between punishment and relief learning in Drosophila. J. Neurogenet. 23, 235–247.
Yarali, A., Niewalda, T., Chen, Y., Tanimoto, H., Duerrnagel, S., and Gerber, B. (2008). “Pain-relief” learning in fruit flies. Anim. Behav. 76, 1173–1185.
Yellman, C., Tao, H., He, B., and Hirsh, J. (1997). Conserved and sexually dimorphic behavioral responses to biogenic amines in decapitated Drosophila. Proc. Natl. Acad. Sci. U.S.A. 94, 4131–4136.
Keywords: dopamine, fruit fly, octopamine, olfaction, reinforcement signaling, relief learning
Citation: Yarali A and Gerber B (2010) A neurogenetic dissociation between punishment-, reward-, and relief-learning in Drosophila. Front. Behav. Neurosci. 4:189. doi: 10.3389/fnbeh.2010.00189
Received: 01 June 2010;
Accepted: 02 December 2010;
Published online: 23 December 2010.
Edited by:
Martin Giurfa, Centre National de la Recherche Scientifique-Université Paul Sabatier-Toulouse III, FranceCopyright: © 2010 Yarali and Gerber. This is an open-access article subject to an exclusive license agreement between the authors and the Frontiers Research Foundation, which permits unrestricted use, distribution, and reproduction in any medium, provided the original authors and source are credited.
*Correspondence: Ayse Yarali, Behavioral Genetics, Max Planck Institut für Neurobiologie, Am Klopferspitz 18, 82152 Martinsried, Germany. e-mail:eWFyYWxpQG5ldXJvLm1wZy5kZQ==