 Shotaro Okajima1,2*
Shotaro Okajima1,2* Maxime Tournier2
Maxime Tournier2 Fady S. Alnajjar2,3
Fady S. Alnajjar2,3 Mitsuhiro Hayashibe2,4Yasuhisa Hasegawa1
Mitsuhiro Hayashibe2,4Yasuhisa Hasegawa1 Shingo Shimoda2
Shingo Shimoda2- 1Department of Mechanical Science and Engineering, Graduate School of Engineering, Nagoya University, Nagoya, Japan
- 2Intelligent Behavior Control Unit (BTCC), Brain Science Institute (BSI), RIKEN, Nagoya, Japan
- 3College of IT, United Arab Emirates University, Al-Ain, United Arab Emirates
- 4Department of Robotics, Tohoku University, Sendai, Japan
An important function missing from current robotic systems is a human-like method for creating behavior from symbolized information. This function could be used to assess the extent to which robotic behavior is human-like because it distinguishes human motion from that of human-made machines created using currently available techniques. The purpose of this research is to clarify the mechanisms that generate automatic motor commands to achieve symbolized behavior. We design a controller with a learning method called tacit learning, which considers system–environment interactions, and a transfer method called mechanical resonance mode, which transfers the control signals into a mechanical resonance mode space (MRM-space). We conduct simulations and experiments that involve standing balance control against disturbances with a two-degree-of-freedom inverted pendulum and bipedal walking control with humanoid robots. In the simulations and experiments on standing balance control, the pendulum can become upright after a disturbance by adjusting a few signals in MRM-space with tacit learning. In the simulations and experiments on bipedal walking control, the robots realize a wide variety of walking by manually adjusting a few signals in MRM-space. The results show that transferring the signals to an appropriate control space is the key process for reducing the complexity of the signals from the environment and achieving diverse behavior.
1. Introduction
Can robots be good neighbors? Despite much effort by many researchers to make robots be good partners, robotic systems remain limited to being merely useful tools in factories and houses1. This is the case even though mobility control for rough terrain2and artificial intelligence for understanding human speech3,4 and behavior have improved drastically in recent years. What is the critical difference that distinguishes people from human-made machines?
We think that an important function that is currently missing from robotic systems is a way to create behavior from symbolized information. For instance, when walking, we deliberately attend to symbolized behavioral purposes such as “walk faster” and “turn right” or more symbolic forms such as “go to the station.” The detailed control signals that create such motion, such as joint trajectories and muscle activations, are then generated automatically.
It is said that these automatic control signals are created by the activities of local neural systems including the cerebellum and spinal cord. In our daily lives, we attend only to symbolized behavioral purposes that are highly specialized. The appropriate behavior and detailed control signals that achieve those purposes are then chosen according to the prevailing situation and the surrounding environment. If we could share such symbolized behavioral purposes with robots, and if the robots and we could create the appropriate behavior independently according to not only the surroundings but also the features of our respective functions, then we would feel that the robots are really our partners. Therefore, generating behavior from symbolized purpose could be an important way to assess the extent to which robots could be our partners with human-like behavior.
In this paper, we discuss the process of creating behavior from symbolized behavioral purpose, focusing on creating motor commands from simple behavioral targets through body–environment interactions. There have been various attempts to clarify the mechanisms that generate automatic motor commands from symbolized purposes, an important approach being a physiological one. Recently, Takei et al. (2017) reported the existence of neurons in the spinal cords of monkeys that commonly activate in association with various hand actions, suggesting that a small control signal, with dimensionality lower than the number of muscles, can encode complicated hand motion.
Model-based approaches provide the conceptual basis for the aforementioned physiological approach. A bow-tie structure (Csete and Doyle, 2004; Zhao et al., 2006) has been proposed to represent a biological control system whereby information acquired from the environment is gradually symbolized to reduce its dimensions, while control signals are created from this symbolized information to increase their dimension. The notions of muscle synergy (Bernstein, 1967; Tresch et al., 1999; d'Avella et al., 2003; Chvatal et al., 2011; Alnajjar et al., 2013; Barroso et al., 2014; Gonzalez-Vargas et al., 2015; Garcia et al., 2018; Kogami et al., 2018) and joint synergy (Schenkman et al., 1990; Latash, 2000; Yamasaki and Shimoda, 2016) that represent the output side of this bow-tie structure are prominent examples of estimating lower-dimensional signals from observable signals such as electromyographic signals. The sensor synergy representing the input side of the bow-tie structure has been discussed regarding estimating sensor signals from the environment (Ting, 2007; Latash, 2008; Alnajjar et al., 2015).
Another important approach to clarifying the mechanisms that generate automatic motor commands is the development of artificial controllers that have the same features as those of biological controllers. The autoencoders discussed in artificial intelligence (Hinton and Salakhutdinov, 2006; Hosseini-Asl et al., 2016) share the same idea as the bow-tie structure. Recently, there have been various discussions about using autoencoders to control robots (Noda et al., 2014; Finn et al., 2016; van Hoof et al., 2016; Kondo and Takahashi, 2017). KullbackLeibler control (Todorov, 2009) is an interesting task-dependent approach to control robot (Uchibe and Doya, 2014; Matsubara et al., 2015) with combination of control policies.
These computational approaches clarified that small control signals, with dimensionality lower than the number of motors, can represent behavioral features, suggesting that lower-dimensional control signals play the role of symbolized behavioral purposes. Shimoda et al. proposed a bio-mimetic behavior-adaptation architecture known as tacit learning (Shimoda and Kimura, 2010; Shimoda et al., 2013; Hayashibe and Shimoda, 2014) and have used it to generate bipedal walking from a roughly defined walking gait (Shimoda et al., 2013), to control the wrist joint of a forearm prosthesis in response to the wearer's shoulder movements (Oyama et al., 2016), and to control a lower-limb exoskeleton robot in response to the wearer's movements (Shimoda et al., 2015). Through experiments on this tacit learning adaptation, they established that two types of adaptation process could work simultaneously to adapt the behavior to an unorganized environment. One of these processes is selecting appropriate behavior and the other is adapting reactive behavior to unpredictable disturbances and small changes in body parameters and environment without changing the behavioral purpose.
Even though it has been established that it is important for these two processes to operate in parallel, the conditions of the controllers needed to realize such adaptation remain under discussion. Herein, we advance this discussion by using an artificial controller that can adapt the motor commands to real-time changes in the symbolized purpose, and we clarify the conditions for adapting in real time to both the environment and the symbolized purpose. We begin in section 2 by designing a controller with tacit learning and that transfers the control signals into a different control space know as mechanical resonance mode space (MRM-space). In MRM-space, the signals are used to control the mechanical resonance modes of the robot. This makes it easy to understand how the robot behavior changes when the control signal is changed in MRM-space. In sections 3 and 4, we propose an adaptation method in MRM-space using a two-degree-of-freedom (2DoF) inverted pendulum, 27DoF humanoid robot, and the NAO humanoid robot5, respectively. We show through simulation and experiment that this controller can adapt the motion to the environment. In section 5, we discuss the importance of body mechanisms in the process of simultaneous adaptation and how that process can be used to evaluate the human-like motion of a robot.
2. Methods Used to Design a Control Structure
Transfer to MRM-space and behavior adaptation by tacit learning are the key analytical methods of the present study. Because both methods are discussed in detail elsewhere (mechanical resonance mode Kry et al., 2009; tacit learning Shimoda and Kimura, 2010; Shimoda et al., 2013; Hayashibe and Shimoda, 2014), we explain their essential points only briefly herein.
2.1. Mechanical Resonance Mode
A mechanical resonance mode is defined by the position and the condition of the robot joints. For instance, a 2DoF inverted pendulum has two mechanical resonance modes as shown in Figures 1A,B. A mechanical resonance mode is characterized mathematically by mode vectors and eigenvalues. Writing the equation of motion of a 2DoF inverted pendulum as
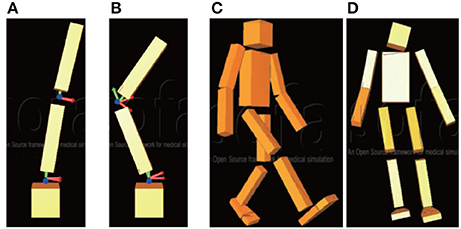
Figure 1. Modes of two-degree-of-freedom (2DoF) inverted pendulum and 27DoF humanoid robot: (A) first mode of pendulum (same-phase posture); (B) second mode of pendulum (anti-phase posture); (C) first mode of robot (bipedal leg swinging); (D) eighth mode (leg swinging on frontal plane).
where θ ∈ R2 implies the angles of the joints, the mode vectors and eigenvalues are calculated by a singular-value decomposition (SVD) of M−1 K:
where M ∈ R2 × 2 is the inertia matrix of the pendulum linearized around θ = 0 and K ∈ R2 × 2 is a stiffness matrix that has the spring coefficients of the joints on its main diagonal. The first mode (v1) corresponds to the smallest eigenvalue (λ1) and the second mode (v2) corresponds to the next-largest eigenvalue (λ2). The mode vector represents the shape of the pendulum oscillation.
The state variable θ of the pendulum can be represented as a superposition of the mode vectors as follows:
where w1, w2 represent the weights of each mode vector and T can be defined as a transfer matrix. We can define the weights of the mode vectors as symbolized state variables in MRM-space.
The adjustment of the symbolized state variables is reflected in the movement of individual joints by the transfer matrix. This is much like the top-down process in people, namely changing one's behavior by means of symbolized information without having to attend to the actions of individual joints.
2.2. Tacit Learning
Tacit learning is an adaptive learning method inspired by two features of living beings. First, living beings can perform adaptive behavior globally even though control is realized by only a summation of local nerve-cell firings. Second, adaptive learning and behavioral control are calculated in parallel; this is unlike machine learning, whose calculation is divided into a learning phase and an action phase.
To apply these features to artificial controller, action targets and the concept of “reflex” are used in tacit learning. The reflex plays a role in directing the movement of the controlled system toward a state in situations in which the system does not receive many environmental stimuli from a global perspective. By enhancing the reflex by accumulating reflex commands, the system can acquire a state autonomously through system–environment interactions, where there are fewer environmental stimuli without having to distinguish between the learning phase and the action phase.
Other learning methods use behavioral functions or teaching signals to adjust the controlled system behavior and achieve adaptive behavior in a top-down manner. In that sense, tacit learning can be defined as a bottom-up learning process, adjusting the behavior through system–environment interactions. However, it can control the system to achieve adaptive behavior from a global perspective. Herein, we use tacit learning to develop a bio-mimetic adaptation process.
3. Standing Balance Control With 2DoF Inverted Pendulum
In this section, we introduce the controller with tacit learning in MRM-space and apply it to standing balance control of a 2DoF inverted pendulum. We show that the tacit learning controller can maintain balance against larger disturbances than the case without learning.
3.1. Model of 2DoF Inverted Pendulum
Figure 2 shows the 2DoF inverted pendulum model used in this simulation. Its equation of motion is
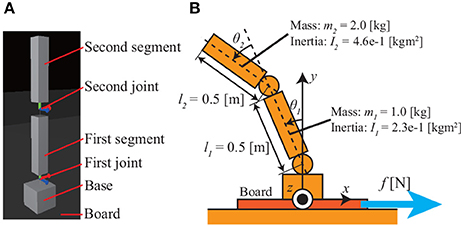
Figure 2. Model of 2DoF inverted pendulum: (A) pendulum model in simulator; (B) definitions of joint angles and system parameters. The pendulum sits on a board that is moved horizontally by a force f [N], thereby imparting disturbances to the pendulum.
where θ is a 2 × 1 vector consisting of the joint angles, τ is a 2 × 1 torque vector that affects each joint, and M(θ) is a 2 × 2 inertia matrix given by
where a1 = l1/2, a2 = l2/2, , ξ = l1m2a2, and is
where g1 = (m1a1 + m2l1)g, g2 = m2a2g, and g = 9.81 m/s2.
3.2. Standing Balance Control Structure
Figure 3 shows a standing balance controller designed by using the transfer matrix T described in 4 and tacit learning. Terms θi and τi are the angle and torque, respectively, of joint i. The torque vector τ for each joint is
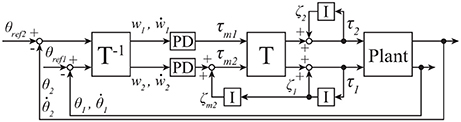
Figure 3. Block diagram for standing balance control of 2DoF inverted pendulum; see section 3.2 for details.
Δθ and are
where θ and are state variables:
θref is a reference for each joint:
Terms A and B are diagonal matrices:
where kp1 and kp2 are proportional (P) gains of the proportional-derivative (PD) controller in MRM-space, kd1 and kd2 are derivative gains of the PD controller in MRM-space, and T−1 is the transfer matrix from joint space to MRM-space.
Term ζ is a vector that consists of the integration of τ as follows:
where k1 and k2 are the coefficients of the integrators that accumulate the joint torques and output the integrated values. These accumulations correspond to tacit learning, and these integrators adjust the individual joint torques and work to keep the pendulum upright after disturbance through pendulum–environment interaction, as in Shimoda et al. (2013).
Term ζm a vector that consists of the integration of ζ as follows:
where km2 is the coefficient of the integrator in MRM-space that accumulates ζ1 and outputs the integrated values. km2 can change the level of learning in standing balance control. km2 = 0 is defined as “without learning,” and km2 > 0 is defined as “with learning.” ζm adjusts the movement of the second mode, which we selected based on visual inspection of the movement of all modes. Because any disturbance has a pronounced effect on joint 1, the torque of the second mode is adjusted based on the torque of joint 1.
The whole system can be expressed by combining (5) and (8) as follows:
3.3. Standing Balance Control Simulation and Results
The two mode vectors v1, v2 of the pendulum defined in Figure 2 are given as
As shown in Figures 3A,B, the first mode v1 represents same-phase posture and the second mode v2 represents anti-phase posture. The transfer matrix T is
Standing balance control simulations are conducted as follows.
1. The pendulum is placed upright on a board that can move horizontally.
2. The board is moved for 0.2 s with the disturbance f [N].
3. A simulation is ended once the height of the center of mass(CoM) of the pendulum falls below 0.2 m or the pendulum become upright.
We conduct simulations with each of f = 170,…, 210 N. The gains are , and . The references are θref1 = θref2 = 0.0.
Table 1 gives the results of whether the pendulum falls down in the process of trying to maintain standing balance. The pendulum is clearly more stable with tacit learning in MRM-space than without tacit learning in MRM-space.

Table 1. Stability changes due to different coefficients.
Figure 4 shows an overview of standing balance control simulations without and with learning in MRM-space. The pendulum CoM falls lower in the process of regaining balance when tacit learning is applied in MRM-space. Figure 5 shows the trajectories of joints 1 and 2 in the process of regaining balance. In the case without learning in MRM-space shown in Figure 5A, the pendulum becomes upright after the disturbance by moving joints 1 and 2 in phase. By contrast, in the case with learning in MRM-space shown in Figure 5B, joints 1 and 2 move in anti-phase.
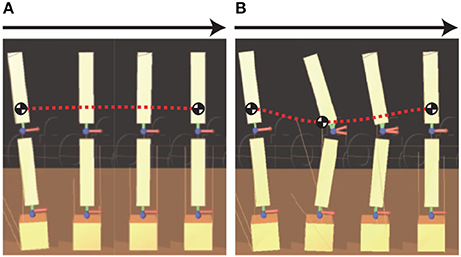
Figure 4. Overview of standing balance control simulation: (A) without learning; (B) with learning. “Without learning” means that tacit learning is applied to only joint space, and “With learning” means that tacit learning is applied to joint space and MRM-space. The red dotted line is the general trajectory of the center of mass (CoM) of the pendulum in the process of regaining balance after a disturbance. The CoM falls lower while regaining balance with tacit learning in MRM-space.
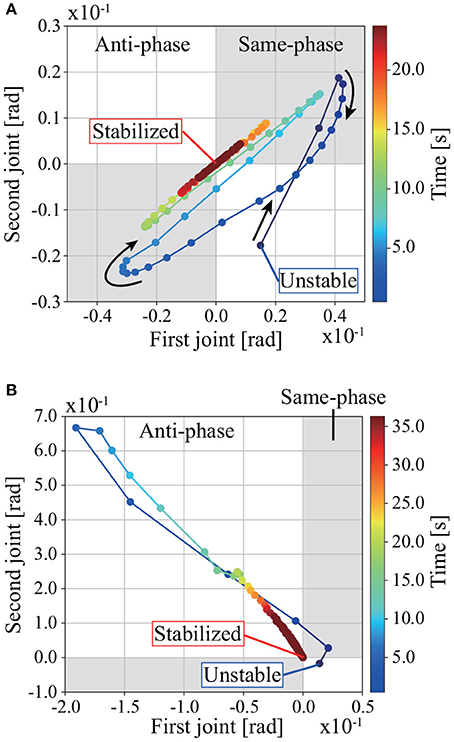
Figure 5. Trajectories of joints 1 and 2 while regaining balance in the simulation: (A) without learning; (B) with learning. The gray areas are where the joints move in phase, the white areas are where they move in anti-phase. Joints 1 and 2 move in phase while regaining balance without tacit learning in MRM-space. Joints 1 and 2 move in anti-phase while regaining balance with tacit learning in MRM-space. The disturbance is f = 184 N. The gain of tacit learning in MRM-space is km2 = 5.0 × 10−4.
Figure 6 shows the relationship between the disturbance and the energy consumption E per unit time, which is calculated from
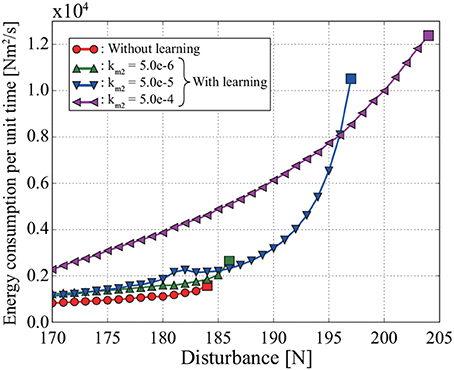
Figure 6. Relationship between energy consumption per unit time and disturbance in the simulation. Each square represents the maximum disturbance for which the pendulum can become upright. For example, the pendulum cannot become upright against a disturbance of 185 N or more without learning in MRM-space. Both the energy consumption per unit time and the stability against disturbance increase with the coefficient of tacit learning in MRM-space.
where T is the time until the pendulum becomes upright. We also calculate E when the simulation is conducted with tacit learning in MRM-space by using different integral coefficients, namely and 5.0 × 10−5.
The pendulum can become upright against a larger disturbance with learning in MRM-space than without learning in MRM-space. The size of disturbance that the pendulum can withstand without falling over increases with the integral coefficient km2 for tacit learning. However, E also increases with km2.
3.4. Standing Balance Control Experiment and Results
We conducted an experiment on a real 2DoF inverted pendulum with the same block diagram as in the simulation. The transfer matrix was calculated based on the physical parameters of the pendulum, whereas the gains in the block diagram were determined by trial and error. The experimental conditions can be seen in the Supplementary Video. Figure 7A shows the actual 2DoF inverted pendulum. Figure 7B shows the trajectories of joints 1 and 2 in the process of regaining balance. The pendulum becomes upright by moving joints 1 and 2 in anti-phase, as in the simulation with tacit learning in MRM-space.
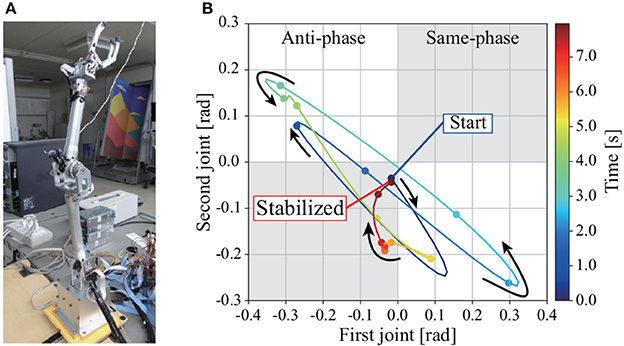
Figure 7. (A) 2DoF inverted pendulum. (B) Trajectories of joints 1 and 2 in the process of regaining balance in the experiment. Each point is supplemented with a spline curve. The gray areas are where the joints move in phase, the white areas are where they move in anti-phase. Joints 1 and 2 move in anti-phase in the process of regaining balance, as in the simulation with tacit learning.
3.5. Discussion of Standing Balance Control
The pendulum can remain upright against larger disturbances as the coefficient of tacit learning in MRM-space is increased (see Figure 6). However, a problem is that the energy consumption per unit time in same disturbance also increases as the coefficient is increased. Another problem is that, although we did not analyze the stability of this system, too large an integral tacit learning coefficient makes the system unstable (see Shimoda et al., 2012). To regain balance efficiently after a disturbance, it is necessary to change the tacit learning coefficient according to the disturbance.
It is well-known that people change their standing balance strategies between ankle and hip strategies (Horak and Nashner, 1986; Runge et al., 1999; Robinovitch et al., 2002) according to the prevailing disturbances. Each strategy is shown in Figure 8. The ankle strategy is a standing balance control method in which the person mainly moves the ankle joints in response to a relatively small disturbance, whereas the hip strategy is a standing balance control method in which the person moves the hip and ankle joints in anti-phase in response to a larger disturbance. The movements involved in the hip strategy are similar to those of the 2DoF pendulum when tacit learning is applied in MRM-space. It is interesting that our method of adjusting signals in MRM-space with tacit learning has something in common with a human strategy.
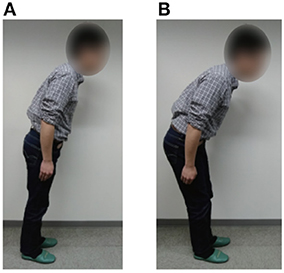
Figure 8. Standing balance control strategies of a person (Horak and Nashner, 1986; Runge et al., 1999; Robinovitch et al., 2002). (A) Ankle strategy: the person mainly moves the ankle joints and can balance against small disturbances only. (B) Hip strategy: the person moves the hip and ankle joints in anti-phase and can balance against larger disturbances. The participant of this figure gave informed consent to appear on the current work.
4. Bipedal Walking Control on Flat Plane With 27DoF Humanoid Robot
In section 3, we discussed the use of standing balance control of allow a 2DoF pendulum to react to disturbances. In this section, we add a “top-down” signal to include intentional behavioral changes. We apply the same control strategies to a 27DoF humanoid robot walking control with the added top-down signal. The weight and the length of segments of the robot is decided based on the NASA biometric research (NASA). We show through simulation and experiment that the signal added to the controller in MRM-space plays the role of behavioral intentions to change walking direction while maintaining walking balance.
4.1. Bipedal Walking Control Structure
Figure 9 shows a bipedal walking controller designed by using the transfer matrix T and tacit learning. Terms θ, are vectors of state variables. Terms is a vector of angle references. The torque vector τ ∈ R27 for each joint is represented as
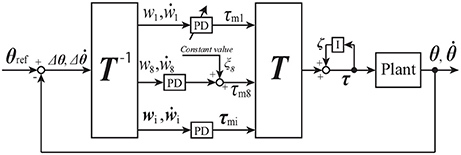
Figure 9. Block diagram for bipedal walking control of 27DoF robot; see section 4.1 for details.
where ζ is a vector that consists of the integral values of tacit learning, and tacit learning is applied to only the left and right ankle joints. The balance in the sagittal plane is maintained by tacit leaning, as in Shimoda et al. (2013). Terms klankle and krankle are the integral coefficients for the left and right ankle joints, respectively. Terms Δθ and are
Terms A and B are diagonal matrices:
where kp1, …, kp27 are values obtained by multiplying the eigenvalues of each mode by 10, and kd1, …, kd27 are values obtained by multiplying the eigenvalues of each mode by 0.1. The eigenvalues are given by the mechanical resonance mode of the robot.
Term c is a vector that consists of the constant value of the torque of the eighth mode and is given by
where ξ8 is a constant that can be adjusted manually.
The transfer matrix T ∈ R27 × 27 of the 27DoF robot can be calculated using the method given in section 2.1. The movement of all modes can be seen in the Supplementary Video. In controlling the robot behavior, we focus on two specific modes from all the modes, namely the first and eighth modes (see Figures 1 C,D). We expect to realize two specific types of walking. Adjusting only the signal of the first mode while changing the P gain kp1 can make the robot change its walking velocity on a flat plane. Adjusting the signal of the eighth mode with the constant value c can make the robot turn left and right on a flat plane with fixing kp1 for the robot to walk forward.
4.2. Bipedal Walking Simulation and Results
Bipedal walking is performed as shown in Figure 10A, with one cycle of walking consisting of eight steps. The integral coefficients for the left and right ankle joints are klankle = krankle = 1.0e − 4. The references for each joint at each step in the simulation are described in Table 2. After finishing one cycle, the reference returns to the beginning of the cycle.
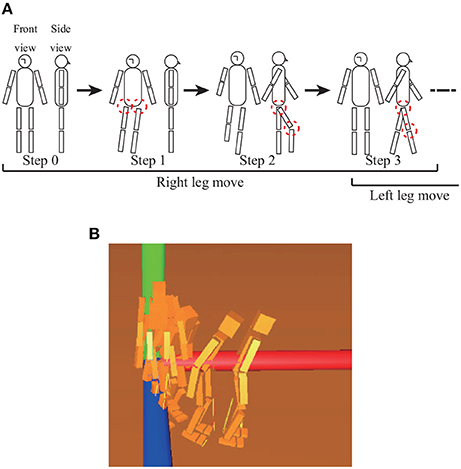
Figure 10. (A) Posture of each target set, for which the joints enclosed by dashed circles are controlled. Steps 5–7 (not shown) are the bifrontally symmetric postures of steps 1–3. Steps 4 and 8 (not shown) involve waiting for a time while holding the posture of the corresponding previous target set. References for joints are given in Table 2. (B) Overview of walking simulation for adjusting the eighth mode. By adding positive constant values to the eighth mode, the robot can turn left.
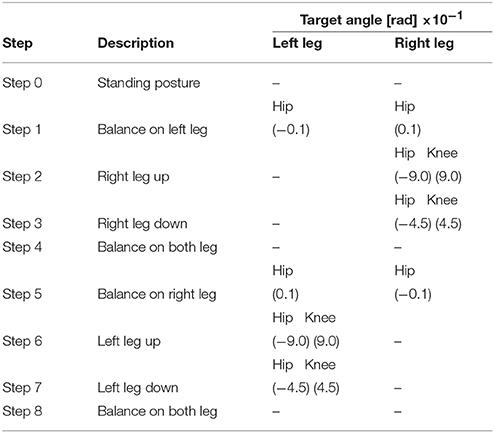
Table 2. Target set for bipedal walking control simulation.
Each step shifts to the next step under specific conditions. When the robot raises a foot, that step shifts to the next step when a knee joint angle of the robot equals the reference of the knee joint angle. When the robot puts a foot down, that step shifts to the next step when the sole of the foot touches the ground. If the robot falls down while walking, the robot is moved to the initial position while holding the integral values of tacit learning.
(i) Walking forward and backward
Figure 11A shows time series of the CoM position in the direction in which the robot walks and the P gain kp1 used to adjust the movement of the first mode. In the early stage of walking, the P gain is set as kp1 = 270.0. It can be seen that the robot walks forward and backward according to the adjustment of the P gain. An overview of the simulation can be seen in the Supplementary Video.
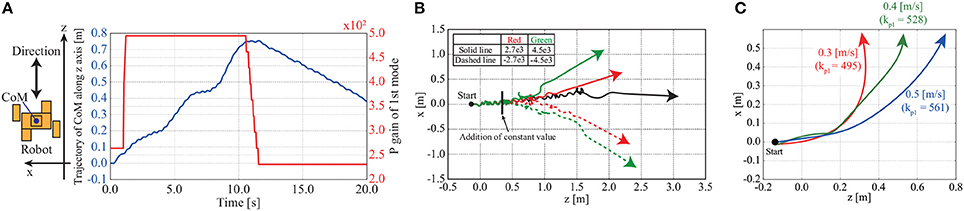
Figure 11. Trajectory and time series of CoM position in turning and walking forward and backward in simulation: (A) Time series of CoM position in the direction in which the robot walks and the P gain of the first mode in the simulation. In the early stage of walking, the P gain is set as kp1 = 270.0. The robot walks forward and backward according to changes in the P gain of the first mode. (B) Trajectories of robot CoM in walking simulation with adjusting the movement of the eighth mode. The robot walks from the left to the right of the figure. The black line is a trajectory of the robot walking forward without adjusting the movement of the eighth mode. The walking direction is changed depending on the constant value. The robot turns more as the constant value is increased. (C) Directions of robot CoM in turning with different walking velocities. Solid lines represent walking directions. The constant value is set as ξ8 = 4.5e3. Walking velocity can be changed in turning behavior with different P gain kp1, and the walking direction is affected by walking velocity.
(ii) Turning left and right
Figure 10B shows an overview of the walking simulation adjust the movement of the eighth mode by adding positive constant values to the signal of the eighth mode with an appropriate P gain kp1 to walk forward. The robot can be seen turning left.
Figure 11B shows the trajectories of the CoM of the robot from the top view; the robot walks from the left of the figure to the right with teh appropriate P gain kp1. From Figure 11B, it can be seen that the walking direction is changed depending on the constant value used to adjust the movement of the eighth mode. The robot turns more as the constant value is increased. An overview of the simulation can be seen in the Supplementary Video.
Figure 11C shows the trajectories of the CoM of the robot from the top view; the robot walks from the left of the figure to the right with a fixed constant value ξ8 = 4.5e3. From Figure 11C, it can be seen that P gain kp1 is a key factor that affects the velocity in turning behaviors, and the walking direction is changed.
4.3. Bipedal Walking Experiment and Results
We conducted not only simulations but also walking experiments by using an actual robot, namely the humanoid robot NAO made by Aldebaran. This has 25DoF, and we can control the angle of each of its joints. NAO is controlled by angle inputs rather than torque inputs. We designed a control structure that generates reference joint angles by using the transfer matrix T.
The reference joint angle for a wide variety of walking can be described as
where ϕ ∈ R25 is a vector that consists of joint-angle references for walking, and ϕ′ ∈ R25 is an adjusted vector. Term T† is a transfer matrix modified from the transfer matrix T to fit the DoF of NAO. Term kp1 works like the P gain in the simulation of walking forward and backward. Term α8 works like the constant value in the simulation of turning. Walking balance is acquired by applying tacit learning to joint space in the same way as 2DoF inverted pendulum postural control.
Experiments are conducted using the same scheme as that shown in Figure 10A. The target joint angles at each step in the simulation are described in Table 3. Each step shifts to the next step under specific conditions. When NAO raises a foot, that step shifts to the next step when the knee joint angle of the robot equals the reference knee joint angle. When NAO puts a foot down, that step shifts to the next step when the sole of the foot touches the ground.
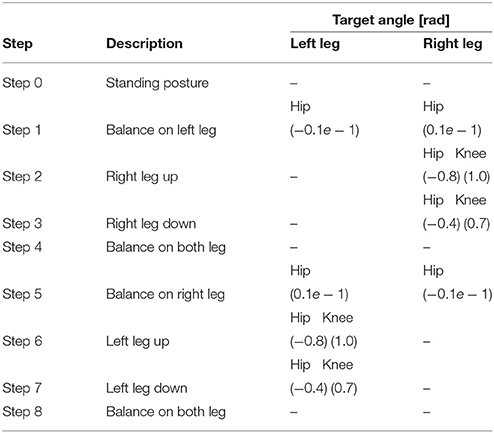
Table 3. Target set for bipedal walking control experiment.
(i) Walking forward and backward
NAO can walk forward and backward when we adjust only the movement of the first mode by adjusting its gain. An overview of the experiment can be seen in the Supplementary Video. Figure 12 shows time series of the left hip joint and left knee joint angles while walking forward and backward. When walking is switched from forward to backward by adjusting the movement of the first mode, the hip joint angle decreases and the knee joint angle increases (see around 150 s in Figure 12).
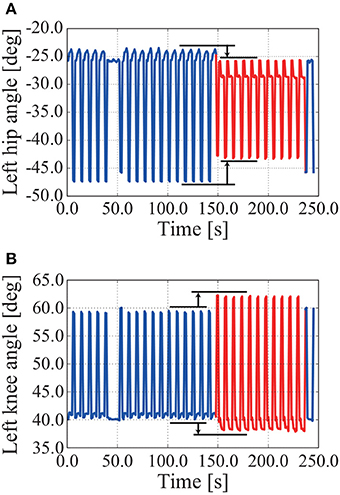
Figure 12. Time series of left hip and left knee joint angles in an experiment involving walking forward and backward. The P gain kp1 for adjusting the movement of the first mode changes as follows: kp1 = 1.0 for 0–150 s, kp1 = 1.1 for 150–240 s, and kp1 = 1.0 for 240–250 s. NAO walks forward for 0–150 s and backward for 150–240 s. When walking is switched from forward to backward by adjusting the movement of the first mode, the hip joint angle decreases and the knee joint angle increases. (A) Left hip angle. (B) Left knee angle.
(ii) Turning right and left
Figure 13A shows NAO turning left adjust the movement of the eighth mode by adding a positive constant value to the signal of the eighth mode with an appropriate P gain kp1 to walk forward. Figures 13B,C shows the trajectories of the CoM and feet when the movement of the eighth mode is adjusted with positive and negative constant values. Figure 14 shows time series of the knee angles when NAO turns left and right.
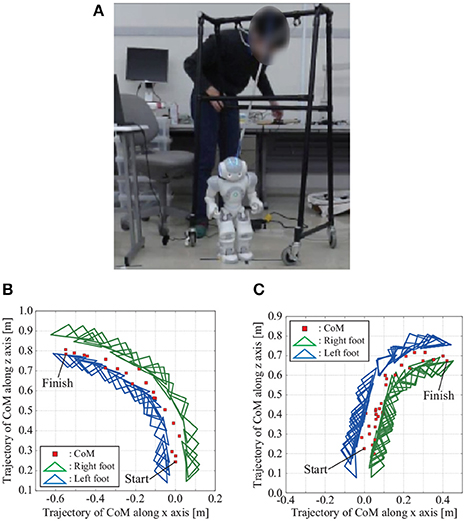
Figure 13. Overview of walking experiment with NAO, and CoM and foot trajectories when NAO turns left and right in the experiment. (A) Overview of walking experiment with NAO. (B) Turning left: NAO can turn left when the constant value α8 for adjusting the movement of the eighth mode is positive. (C) Turning right: NAO can turn right when the constant value α8 for adjusting the movement of the eighth mode is negative. The participant of this figure gave informed consent to appear on the current work.
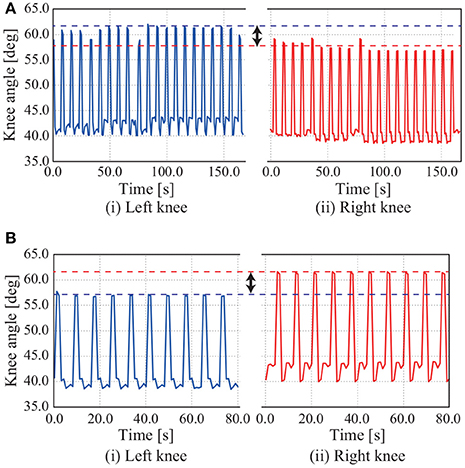
Figure 14. Time series of knee joint angle in turning experiment: (A) turning right; (B) turning left. When NAO turns right, the amplitude of the left knee joint angle is bigger than that of the right knee joint angle in adjusting the movement of the eighth mode by the constant value α8 = −25.0. When the constant value is negative, NAO turns left.
NAO can turn left and right by adjusting the movement of the eighth mode, as in the simulation. As shown in Figure 14A, the amplitude of the left knee joint angle is bigger than that of the right knee joint angle in adjusting the movement of the eighth mode by the constant value α8 = −25.0, whereupon NAO turns left. The converse holds in Figure 14B.
4.4. Discussion of Bipedal Walking Control
The robot NAO could turn left and right by adjusting the movement of the eighth mode, that is, adjusting the bending of the robot and NAO at the waist on the frontal plane by adjusting the constant value. Adjusting the movement of the eighth mode deflected the CoM to the left-hand or right-hand side of the body, whereupon one foot took a larger step than did the other foot. This phenomenon can be confirmed from the fact that the amplitude of the left knee joint angle was bigger than that of the right knee joint angle (see Figure 14A).
The robot and NAO could walk forward and backward by adjusting the movement of the first mode. The robot and NAO differed in how the gain was adjusted, but we consider this to be because the gains of the other modes differed between the robot and NAO. When the movement of the first mode is adjusted, the degree to which the legs are opened is adjusted, whereupon the position at which the foot touches the ground can be adjusted. This can be confirmed from the fact that the hip joint angle decreases and the knee joint angle increases when walking switches from forward to backward (see Figure 12).
It is normally difficult to make a robot walk in a wide variety of ways because that necessitates designing a plurality of controllers and preparing references concerning each combination of individual joints. Instead, our method realizes turning and walking forward and backward smoothly by adjusting a few symbolized parameters in MRM-space without having to care about each combination of 27 joints and switching controllers. This is because there is a pattern of movements according to the mode, and the pattern to adjust is easy to understand visually.
A person can change behavior while caring intentionally only about “turn left and right” or “forward and backward.” Likewise, our method can adjust signals and realize behavior without caring about each joint, which is important in considering human-like movement in the robot under consideration.
5. Discussion
As discussed in section 1, the aim of this paper is to clarify the mechanisms of generating automatic motor commands to achieve a symbolized behavioral purpose. Our approach is to develop an artificial controller that embodies those mechanisms and derive the important features of that function to assess the extent to which the robot behavior is human-like.
We reasoned that the key problem in developing a controller with those mechanisms would be realizing bio-mimetic adaptation with two-way behavioral adaptation. The first way is selecting the appropriate behavior that progresses in a top-down manner, and the second is adjusting the behavior according to the environment, which is a bottom-up process that progresses through body–environment interactions.
In the preliminary study, we discussed the standing balance control of a 2DoF inverted pendulum to introduce our control strategies, focusing only on the bottom-up adaptation process. In our control strategy, the control signals to each joint are transferred to another space computed by using the mechanical resonance modes, whereby we can easily understand the behavioral pattern that each control signal creates. We applied tacit learning in MRM-space and developed the controller to maintain standing against various levels of disturbance. The simulation and experimental results showed that the standing balance control capability was increased when the 2DoF inverted pendulum was controlled using MRM-space, suggesting that the simple adaptation mechanism is enough to improve the behavioral performance of standing balance when behavior control is conducted in a space where we can set the direction of behavior by adjusting to the change of the disturbance. The similarities between the mechanical resonance modes used in this system and the hip and ankle motion strategies of people must be another indication of the importance of reacting to a wide range of disturbances in a space in which the body parameters are well represented.
In the bipedal walking study using NAO, we discussed two-way adaptation. To represent the top-down process in which the behavioral purpose is selected, we chose the appropriate resonance mode with which to adjust the behavior to the desired one. As described in Figure 13, when we adjust the parameter of the eighth mode, the robot begins to turn left and right while maintaining walking balance. Walking balance was maintained by tacit learning applying the method in Shimoda et al. (2013) to joint space in the same way as 2DoF inverted pendulum control as a bottom-up process. In the simulation and the experiments, we succeeded in changing the behavior to turn left/right and go forward/backward by stimulating different mechanical resonance modes.
We consider that the signals added to the specified mode control can be treated as symbolized behavioral purpose in our study. The detailed commands to the joint control were created in two processes, namely, transferring the control signal from MRM-space to joint space, and tacit learning for maintaining walking balance while reacting to environmental inputs. Therefore, these results suggest that one-dimensional signal change can create the complicated combinations of the 25DoF of NAO required to change the behavior when the appropriate mode is stimulated.
Joint control is much more complicated in people than it is in robots because complicated combinations of muscles are required in the former. The notion of muscle synergy introduced in section 1 shares the same features as those of the mechanical resonance mode used in our method for robot control because the muscle-synergy space represents the behavioral features of body mechanisms and contributes to adjusting behavior in our case by using lower-dimensional signals.
These results and discussion suggest that transferring the signals to the appropriate control space is the key process for reducing the complexity of the signals from the environment. Discussing muscle synergy in a human controller and the mechanical resonance mode is only one step to the final output. If such steps were to be accumulated to form a larger network as described in Figure 15, we could form various behaviors from the more-symbolized behavioral target such as “go to the station.”
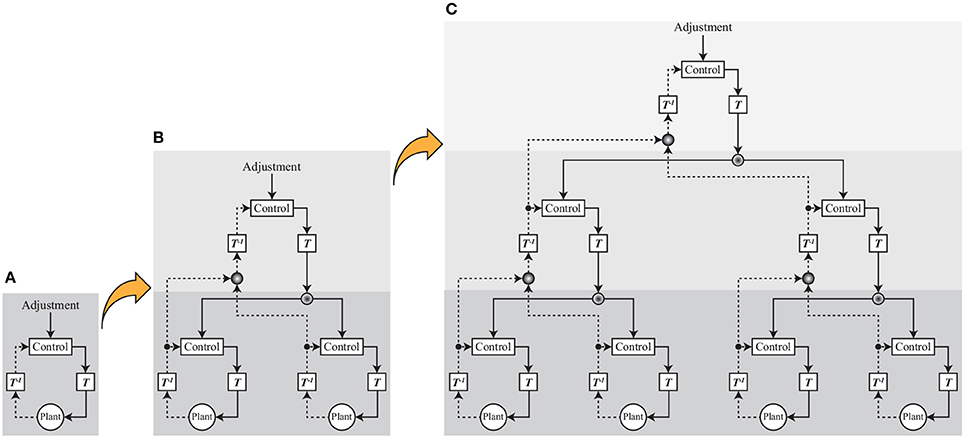
Figure 15. Neuro-synergy system concept. (A) One layer. This is a schematic diagram that is used in the simulations and experiments. T−1 plays the role of integrating complex signals from the environment and generating semantic information, and T plays the role of converting semantic information to specific control signals. In this paper, standing balance and walking control is realized by adjusting part of the signals in a transfer space. (B) Two layers. Part of the integrated signals is integrated, and an upper layer is formed. Control and adjustment are conducted in the upper layer, and the output signals from the upper layer play the role of adjusting in the lower layer. (C) Three layers. The layer step-up is accumulated to form a larger network, and we can produce various behaviors from the more-symbolized behavioral target.
We reason that the extent to which a symbolized target that is represented by the lower-dimensional signals is used to create the robot behavior is the critical assessment for evaluating the extent to which the robot behavior is human-like. The results in this paper are just one step up from pure motor-control signals, implying far from human-like behavior. Further discussion is required to elevate the proposed system to using more-symbolized behavioral targets such as “go to the station.” A key problem is automatic creation of the mechanical resonance mode. Non-linear transfer for more complicated environment is another important problem. Even in the control of human behavior, the process of creating muscle synergy remains mysterious. We are now on the way to clarifying the process to a morehierarchical system in both physiological and artificial ways.
Author Contributions
MT explained the concept of mechanical resonance mode of the robot to SO. MT made a model of robot control structure using the mechanical resonance mode. MH and SS explained the concept of a biological learning method called tacit learning and gave advices on how to use tacit learning to SO. To clarify the mechanisms that generate automatic motor commands to achieve symbolized behavior, SO made the concept of adaptive control method using mechanical resonance mode and a biological learning method called tacit learning, designed a control structure to realize symbolized behavior purpose in discussions with FA, MH, YH, MT, and SS. SO conducted standing balance control simulations and bipedal walking control simulations with a 2DoF inverted pendulum and 27DoF humanoid robot, respectively. In discussions with FA, MH, YH, and SS, SO conducted standing balance control experiments and bipedal walking control experiments with an actual 2DoF inverted pendulum and an actual humanoid robot, respectively. SS helped in using the actual pendulum and humanoid robot in experiments.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This study was funded by a grant from the European Commission within its Seventh Framework Programme (IFP7-ICT-2013-10-611695: BioMot - Smart Wearable Robots with Bioinspired Sensory-Motor Skills).
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnbot.2018.00043/full#supplementary-material
Footnotes
1. ^Roomba. iRobot Corporation. Available online at: https://www.irobot.com/
2. ^Atlas. Boston Dynamics. Available online at: https://www.bostondynamics.com/
3. ^Amazon Echo. Amazon.com, Inc. Available online at: https://www.amazon.com/dp/B00X4WHP5E
4. ^Google Home. Google LLC. Available online at: https://store.google.com/product/google_home
5. ^NAO. SoftBank Robotics. Available online at: https://www.ald.softbankrobotics.com/en/robots/nao
References
Alnajjar, F., Itkonen, M., Berenz, V., Tournier, M., Nagai, C., Shimoda, S., et al. (2015). Sensory synergy as environmental input integration. Front. Neurosci. 8:436. doi: 10.3389/fnins.2014.00436
Alnajjar, F., Wojtara, T., Kimura, H., and Shimoda, S (2013). Muscle synergy space: learning model to create an optimal muscle synergy. Front. Comput. Neurosci. 7:136. doi: 10.3389/fncom.2013.00136
Barroso, F. O., Torricelli, D., Moreno, J. C., Taylor, J., Gomez-Soriano, J., Bravo-Esteban, E., et al. (2014). Shared muscle synergies in human walking and cycling. J. Neurophysiol. 112, 1984–1998. doi: 10.1152/jn.00220.2014
Chvatal, S. A., Torres-Oviedo, G., Safavynia, S. A., and Ting, L. H. (2011). Common muscle synergies for control of center of mass and force in nonstepping and stepping postural behaviors. J. Neurophysiol. 106, 999–1015. doi: 10.1152/jn.00549.2010
Csete, M., and Doyle, J. (2004). Bow ties, metabolism and disease. Trends Biotechnol. 22, 446–450. doi: 10.1016/j.tibtech.2004.07.007
d'Avella, A., Saltiel, P., and Bizzi, E. (2003). Combinations of muscle synergies in the construction of a natural motor behavior. Nat. Neurosci. 6, 300–308. doi: 10.1038/nn1010
Finn, C., Tan, X. Y., Duan, Y., Darrell, T., Levine, S., and Abbeel, P. (2016). Deep spatial autoencoders for visuomotor learning,” IEEE International Conference on Robotics and Automation (ICRA) (Stockholm).
Garcia, A. C., Itkonen, M., Yamasaki, H., Shibata-Alnajjar, F., and Shimoda, S. (2018). A novel approach to the segmentation of sEMG data based on the activation and deactivation of muscle synergies during movement. IEEE Robot. Automat. Lett. 3, 1972–1977. doi: 10.1109/LRA.2018.2811506
Gonzalez-Vargas, J., Sartori, M., Dosen, S., Torricelli, D., Pons, J. L., Farina, D., et al. (2015). A predictive model of muscle excitations based on muscle modularity for a large repertoire of human locomotion conditions. Front. Comput. Neurosci. 9:114. doi: 10.3389/fncom.2015.00114
Hayashibe, M., and Shimoda, S. (2014). Synergetic motor control paradigm for optimizing energy efficiency of multijoint reaching via tacit learning. Front. Comput. Neurosci. 8:21. doi: 10.3389/fncom.2014.00021
Hinton, G. E., and Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science 313, 504–507. doi: 10.1126/science.1127647
Horak, F. B., and Nashner, L. M. (1986). Central programming of postural movements: adaptation to altered support-surface configurations. J. Neurophysiol. 55, 1369–1381. doi: 10.1152/jn.1986.55.6.1369
Hosseini-Asl, E., Zurada, J. M., and Nasraoui, O. (2016). Deep learning of part-based representation of data using sparse autoencoders with nonnegativity constraints. IEEE Trans. Neural Netw. Learn. Syst. 27, 2486–2498. doi: 10.1109/TNNLS.2015.2479223
Kogami, H., An, Q., Yang, N., Yamakawa, H., Tamura, Y., Yamashita, A., et al. (2018). Effect of physical therapy on muscle synergy structure during standing-up motion of hemiplegic patients. IEEE Robot. Automat. Lett. 3, 2229–2236. doi: 10.1109/LRA.2018.2811050
Kondo, Y., and Takahashi, Y. (2017). “Real-time whole body imitation by humanoid robot based on particle filter and dimension reduction by autoencoder,” in Joint 17th World Congress of International Fuzzy Systems Association and 9th International Conference on Soft Computing and Intelligent Systems (IFSA-SCIS 2017) (Otsu).
Kry, P. G., Reveret, L., and Faure, F. (2009). Modal locomotion: animating virtual characters with natural vibrations. Eurographics 28, 289–298. doi: 10.1111/j.1467-8659.2009.01368.x
Latash, M. L. (2000). The organization of quick corrections within a two-joint synergy in conditions of unexpected blocking and release of a fast movement. Clin. Neurophysiol. 111, 975–987. doi: 10.1016/S1388-2457(00)00263-7
Matsubara, T., Asakura, T., and Sugimoto, K. (2015). Dynamic linear bellman combination of optimal policies for solving new tasks. IEICE Trans. Fundament. Electron. Commun. Comput. Sci. E98.A, 2187–2190. doi: 10.1587/transfun.E98.A.2187
NASA. Man-System Integration Standards. Vol.1, Sec. 3. Available online at: http://msis.jsc.nasa.gov/sections/section03.htm.
Noda, K., Arie, H., Suga, Y., and Ogata, T. (2014). Multimodal integration learning of robot behavior using deep neural networks. Robot. Auton. Syst. 62, 721–736. doi: 10.1016/j.robot.2014.03.003
Oyama, S., Shimoda, S., Alnajjar, F., Iwatsuki, K., Hoshiyama, M., Tanaka, H., et al. (2016). Biomechanical reconstruction using the tacit learning system: intuitive control of prosthetic hand rotation. Front. Neurorobot. 10:19. doi: 10.3389/fnbot.2016.00019
Robinovitch, S. N., Heller, B., Lui, A., and Cortez, J (2002). Effect of strength and speed of torque development on balance recovery with the ankle strategy. J. Neurophysiol. 88, 613–620. doi: 10.1152/jn.2002.88.2.613
Runge, C. F., Shupert, C. L., Horak, F. B., and Zajac, F. E. (1999). Ankle and hip postural strategies defined by joint torques. Gate Posture 10, 161–170. doi: 10.1016/S0966-6362(99)00032-6
Schenkman, M., Berger, R. A., Riley, P. O., Mann, R. W., and Hodge, W. A. (1990). Whole-body movements during rising to standing from sitting. Phys. Ther. 70, 638–648. doi: 10.1093/ptj/70.10.638
Shimoda, S., Costa, A., Asin-Prieto, G., Okajima, S., Ináẽz, E., Hasegawa, Y., et al. (2015). “Joint stiffness tuning of exoskeleton robot H2 by tacit learning,” in International Workshop on Symbiotic Interaction (Berlin: Springer International Publishing), 138–144.
Shimoda, S., and Kimura, H. (2010). Biomimetic approach to tacit learning based on compound control. IEEE Trans. Syst. Man Cybern. B Cybern. 40, 70–90. doi: 10.1109/TSMCB.2009.2014470
Shimoda, S., Yoshihara, Y., Fujimoto, K., Yamamoto, T., Maeda, I., and Kimura, H. (2012). “Stability analysis of tacit learning based on environment signal accumulation,” in Intelligent Robots and Systems (IROS), IEEE/RSJ International Conference (Vilamoura), 2613–2620.
Shimoda, S., Yoshihara, Y., and Kimura, H. (2013). Adaptability of tait learning in bipedal locomotion. IEEE Trans. Auton. Ment. Dev. 5, 152–161. doi: 10.1109/TAMD.2013.2248007
Takei, T., Confais, J., Tomatsu, S., Oya, T., and Seki, K. (2017). Neural basis for hand muscle synergies in the primate spinal cord. Proc. Natl. Acad. Sci. U.S.A. 114, 8643–8648. doi: 10.1073/pnas.1704328114
Ting, L. H. (2007). Dimensional reduction in sensorimotor systems: a framework for understanding muscle coordination of posture. Prog. Brain Res. 165, 299–321. doi: 10.1016/S0079-6123(06)65019-X
Todorov, E. (2009). “Compositionality of optimal control laws,” in Advances in Neural Information Processing Systems 22 (Vancouver, BC: Curran Associates, Inc.), 1856–1864.
Tresch, M. C., Saltiel, P., and Bizzi, E. (1999). The construction of movement by the spinal cord. Nat. Neurosci. 2, 162–167. doi: 10.1038/5721
Uchibe, E., and Doya, K. (2014). “Combining learned controllers to achieve new goals based on linearly solvable MDPs,” in Robotics and Automation (ICRA), 2014 IEEE International Conference on (Hong Kong).
van Hoof, H., Chen, N., Karl, M., van der Smagt, P., and Peters, J. (2016). “Stable reinforcement learning with autoencoders for tactile and visual data,” in Intelligent Robots and Systems(IROS), IEEE/RSJ International Conference (Daejeon).
Yamasaki, H. R., and Shimoda, S. (2016). Spatiotemporal modular organization of muscle torques for sit-to-stand movements. J. Biomech. 49, 3268–3274. doi: 10.1016/j.jbiomech.2016.08.010
Keywords: mechanical resonance mode, tacit learning, control structure, symbolized information, human-like movement
Citation: Okajima S, Tournier M, Alnajjar FS, Hayashibe M, Hasegawa Y and Shimoda S (2018) Generation of Human-Like Movement from Symbolized Information. Front. Neurorobot. 12:43. doi: 10.3389/fnbot.2018.00043
Received: 01 February 2018; Accepted: 27 June 2018;
Published: 17 July 2018.
Edited by:
Katja Mombaur, Universität Heidelberg, GermanyReviewed by:
Eiji Uchibe, Advanced Telecommunications Research Institute International (ATR), JapanManuel Giuliani, University of the West of England, United Kingdom
Copyright © 2018 Okajima, Tournier, Alnajjar, Hayashibe, Hasegawa and Shimoda. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Shotaro Okajima, c2hvdGFyby5va2FqaW1hQHJpa2VuLmpw