 Franziska Knolle
Franziska Knolle Michael Schwartze
Michael Schwartze Erich Schröger
Erich Schröger Sonja A. Kotz
Sonja A. Kotz- 1Department of Psychiatry, University of Cambridge, Cambridge, United Kingdom
- 2Department of Neuroradiology, Technical University of Munich, Munich, Germany
- 3Department of Neuropsychology and Psychopharmacology, Maastricht University, Maastricht, Netherlands
- 4Institute of Psychology, Leipzig University, Leipzig, Germany
- 5Department of Neuropsychology, Max Planck Institute of Cognitive and Brain Sciences, Leipzig, Germany
It has been suggested that speech production is accomplished by an internal forward model, reducing processing activity directed to self-produced speech in the auditory cortex. The current study uses an established N1-suppression paradigm comparing self- and externally initiated natural speech sounds to answer two questions: (1) Are forward predictions generated to process complex speech sounds, such as vowels, initiated via a button press? (2) Are prediction errors regarding self-initiated deviant vowels reflected in the corresponding ERP components? Results confirm an N1-suppression in response to self-initiated speech sounds. Furthermore, our results suggest that predictions leading to the N1-suppression effect are specific, as self-initiated deviant vowels do not elicit an N1-suppression effect. Rather, self-initiated deviant vowels elicit an enhanced N2b and P3a compared to externally generated deviants, externally generated standard, or self-initiated standards, again confirming prediction specificity. Results show that prediction errors are salient in self-initiated auditory speech sounds, which may lead to more efficient error correction in speech production.
Introduction
Speaking is a highly complex human capacity: It does not only involve a motor act, but also leads to the perception and the monitoring of one’s own voice. The distinction between self-produced speech from speech of others is proposed to be accomplished by a “motor-to-sensory discharge” (Paus et al., 1996) or an internal forward model (Ventura et al., 2009; Tian and Poeppel, 2010; Hickok, 2012). The idea of an internal forward model suggests that an efference copy (von Holst and Mittelstädt, 1950) of a motor act is generated that predicts its sensory consequences (Wolpert et al., 1995). The prediction prepares a respective cortical area to perceive the predicted sensory input. Consequently, brain activity directed to incoming sensation is suppressed (Chen et al., 2011).
Interestingly, the suppression effect has been reported in many vocalization studies. It was shown that speech production elicits smaller event-related potentials (ERPs) or fields (ERFs) than passively perceived speech (Numminen and Curio, 1999; Numminen et al., 1999; Curio et al., 2000; Gunji et al., 2001; Ford et al., 2007; Ventura et al., 2009; Ott and Jäncke, 2013). Based on a non-human primate study (Müller-Preuss and Ploog, 1981; replication and extension of non-human primate investigations by Eliades and Wang, 2003), Creutzfeldt et al. (1989) recorded intracranial neuronal activity from the right and left superior, middle and inferior temporal gyri in patients undergoing surgery for epilepsy. Results revealed suppressed activity in response to vocalization. Relatedly, Chen et al. (2011) conducted an electrocorticography (ECoG) study during human vocalization. They reported neural phase synchrony in the gamma band between Broca’s area and the auditory cortex. This phase synchrony that preceded a speaker’s speech onset was greater during vocalizing than when listening to their own speech passively (i.e., pre-recorded), indicating that phase synchrony in the gamma band between the two brain regions may describe the transmission of a motor efference copy.
In a PET-study, Hirano et al. (1996, 1997) found strong cerebellar activation for distorted self-produced speech (i.e., delayed or changed in pitch), possibly indicating the role of the cerebellum in generating internal forward predictions based on an efference copy. Along similar lines, we have shown that the cerebellum is involved in generating motor-to-auditory predictions when processing self-initiated sounds (Knolle et al., 2012, 2013a). We utilized a N1-suppression paradigm (Schäfer and Marcus, 1973) to compare self-initiated (via finger tap) with externally generated sinusoidal tones. We found that patients with focal cerebellar lesions did not show a significant N1-suppression effect in response to self-initiated sounds. This indicates that the cerebellum is involved in generating auditory forward predictions – or their (sensory) attenuation.
In a further study (Knolle et al., 2013b), we compared self- and externally generated sounds including 30% unexpected deviant, or “oddball,” sounds (i.e., sounds altered in frequency). We investigated the violation of a prediction when processing a self-generated deviant sound; furthermore we investigated the reflection of such prediction errors in the ERP. The results revealed that precise predictions concerning the acoustic features of a self-generated sound were formed (i.e., modulated N1 suppression). The result was supported by an enhancement of “auditory responsiveness” toward a self-generated deviant shown in an increase in amplitude of the N2b and P3a components. The increased saliency of self-generated deviant sounds may lead to more efficient processing compared to externally generated deviants. In other words, the increased salience of certain stimuli may reverse the sensory attenuation induced by agency. Thus, the study provides a more complete picture concerning auditory forward prediction and prediction errors with respect to self-generated sinusoidal sounds. Note that the detection of prediction errors is not in the service of detecting the content or cause of a stimulus – but in evaluating how predictable that stimulus was. This is a subtle but important point, which speaks to the predictive processing of the precision or predictability of different stimuli in different settings.
Based on this study the question arose, if precise predictions are also generated in response to complex auditory stimuli, such as speech sounds. Former studies (Heinks-Maldonado et al., 2005, 2006; Fu et al., 2006; Behroozmand et al., 2011, 2016; Christoffels et al., 2011) which compared natural and altered self-produced vocalizations suggest that this is indeed the case. They reported a reduced N1-suppression effect in response to altered compared to unchanged vocal feedback, indicating the generation of a precise prediction. Although altered auditory feedback creates prediction errors, these studies did not aim to investigate the detection of deviance (i.e., altered auditory feedback), nor have they discussed feedback alterations in terms of prediction errors. Although these studies used a carefully conducted design which aimed at reducing as many confounding factors as possible (i.e., participants were asked to hold head, jaw, and tongue in a stationary position to reduce muscle contraction to a minimum), an inherent limitation of these studies is that it is impossible to control for motor activity induced by self-produced vocalization. Hence, a motor command is conducted in order to produce the sound. Based on the motor command, a sensory input is predicted. Consequently, the motor command may influence the ERP in response to the auditory output. Thus, we believe that an appropriate motor control condition (e.g., internal sound production) is necessary in order to control for such effects in the auditory ERPs. Furthermore, Heinks-Maldonado et al. (2005) point out that the differences in sound quality between a speaking and a listening condition could substantially influence the results, and possibly create the suppression effect. Nonetheless, these findings provide support the notion that predictions are generated based on precise patterns, also capturing complex auditory stimuli. However, as the motor-to-auditory links are much tighter with self-vocalization than the motor-to-auditory links involved when generating a sound via a finger tap, it is of interest whether the results obtained with self-vocalization can be generalized to other forms of self-generation of speech sounds.
In contrast to previous studies, the current study investigated whether predictions are formed on a precise pattern also in response to manually initiated complex, natural sounds (i.e., speech sounds), and whether the generation of a precise prediction leads to differential processing of self- compared to externally produced complex deviant stimuli, seen in prediction errors specific to stimuli type. In a first experiment, a standard N1-suppression paradigm was used which has been studied extensively using click sounds, sinusoidal sounds or complex instrumental sounds (Martikainen et al., 2005; Baess et al., 2008, 2011; Lange, 2011; Knolle et al., 2012 (MEG); Schäfer and Marcus, 1973; McCarthy and Donchin, 1976). Here, we compared complex, natural vowels that were self-initiated via a finger tap to the same vowels, externally produced (i.e., pre-recorded vowels/a:/), similarly to a recent study by Pinheiro et al. (2018). This first experiment examined whether the N1-suppression paradigm was applicable to complex stimuli, such as speech sounds in a highly controlled setup. Based on our preceding studies (Knolle et al., 2012, 2013a) investigating sinusoidal tones in a N1-suppression paradigm, we expected to find a N1-suppression followed by a P2-reduction in response to self-initiated vowels. Whereas the N1-suppression may reflect the unconscious, automatic formation of a prediction, preparing the auditory cortex to receive sensory input, the P2-reduction may reveal a later, more conscious processing stage of the generation of a prediction (i.e., the conscious detection of a self-initiated vowel).
In a second experiment, we investigated the violation of a precise prediction regarding self-generated complex speech sounds by introducing surprising, unpredictable events, and furthermore we explored the reflection of such prediction errors in the corresponding ERP components. Thus, we modified the N1-suppression paradigm of experiment one corresponding to a former study on self- and externally generated deviant sounds (Knolle et al., 2013b). We compared self-initiated and externally produced natural vowels, of which 30% were altered in quality (either/a:/which is an open front unrounded vowel, or/o:/which is a mid-close back rounded vowel), creating self-initiated and externally produced deviants (Knolle et al., 2013b). If precise predictions were generated to process self-initiated vowels, the N1-suppression effect should be modified when a self-initiated deviant vowel is elicited. Furthermore, if self-initiated deviant vowels which created a prediction error were more salient than externally produced deviant vowels they should reveal an enhanced N2b and P3a (Knolle et al., 2013b). These results would provide additional support for the generation of a precise prediction, which impacts the neural suppression and the detection of prediction errors in self-generated complex speech sounds.
Materials and Methods
Participants
Sixteen volunteers (eight females) participated in the current study. All participants were right-handed according to the Edinburgh Handedness Inventory (Oldfield, 1971). The mean age was 24.9 years (SD: 1.8 years) and ranged from 23 to 27 years. Participants were students of the University of Leipzig and were recruited via the participants’ database of the Max-Planck Institute for Human Cognitive and Brain Sciences, Leipzig, Germany. None of the participants reported any neurological dysfunction, but normal or corrected-to-normal visual acuity, and normal hearing. All participants gave their written informed consent and were paid for their participation. The study was conducted in accordance with the Declaration of Helsinki and approved by the Ethics Committee of the Leipzig University.
Speech Stimuli
In order to obtain individual vowels, we recorded vowel samples from all participants using the program AlgoRecTM TerraTec Edition. Thus, throughout the experiment each participant listened to the vowels that they had previously produced. We asked the participants to produce “ah” and “oh” as in the German words/a:ba/(aber; engl. but) and/o:ba/(Ober; engl. waiter). We recorded 10 trials for each vowel per participant. For each participant we picked the vowel that best matched the average characteristics within the 10 trials. Using Praat 5.2.03 (1992–2010 by Paul Boersma and David Weenink; University of Amsterdam, Amsterdam, Netherlands) we applied minimal normalization procedures to duration, intensity and pitch to maintain natural sound quality. The vowel duration of/a:/was approximately 360.69 ms (SD: 65.66 ms) and pitch around 77.44 Hz (SD: 3.80 Hz). The vowel/o:/had an average duration of 366.31 ms (SD: 77.75 ms) and an average pitch of 80.76 Hz (SD: 3.84 Hz). For both vowels, the sound intensity was calibrated at about 80 dB SPL and an average loudness of 70 dB was maintained by all subjects.
Experimental Conditions – Experiment 1
The first experiment contained two experimental conditions and one control condition (Figure 1, white background). In the vowel-motor condition (VMC-1) participants induced finger taps about every 2.4 s (see Knolle et al., 2012 for a detailed description of the paradigm). Each tap elicited an immediate presentation of the vowel/a:/(delay of 2–4 ms due to the loading of the stimuli) via headphones. The acoustic stimulation, including self-initiated vowels, was recorded online and used as an ‘external vowel sequence’ in the vowel-only condition (VOC-1). During VOC-1 participants did not produce finger taps, but were simply asked to listen and attend to the vowels. Lastly, participants carried out a motor-only condition (MOC-1), in which they also performed self-paced finger taps every 2.4 s. However, in contrast to VMC-1, no sound was induced via the finger tap. This condition controlled for motor activity in VMC-1.
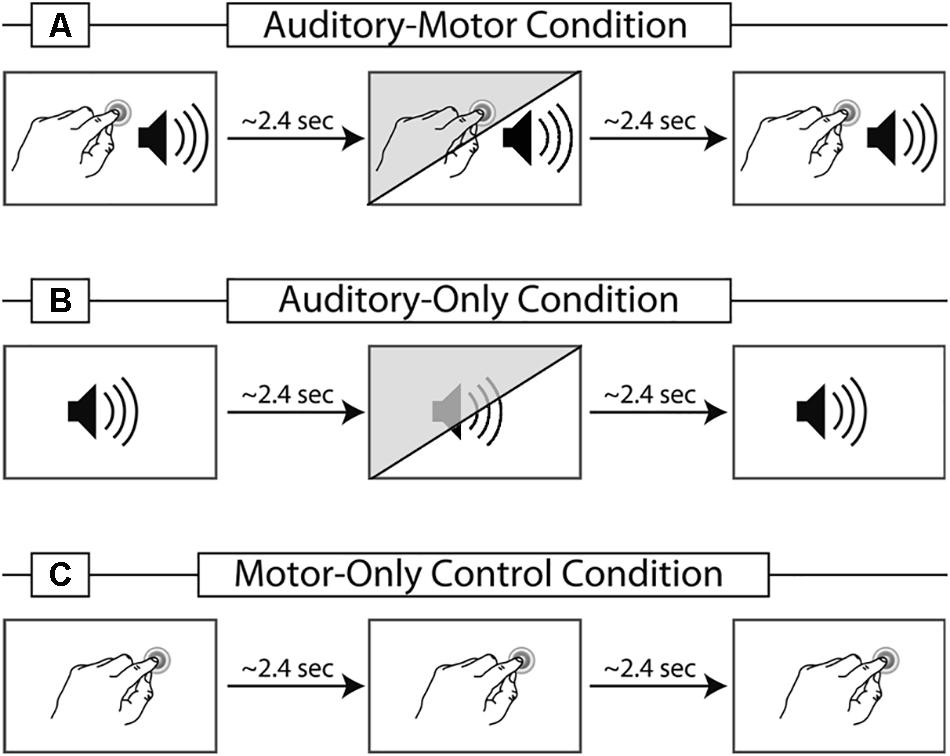
Figure 1. Schematic illustration of the three different conditions used in the studies. Panel (A) represents the vowel-motor condition (VMC-1/2): A vowel is self-initiated via a finger tap. In experiment 2, 30% of the finger taps elicit a vowel deviant, indicated in the illustration via the diagonal shading. Panel (B) represents the vowel-only condition (VOC-1/2): The vowel sequence is presented externally, containing all vowels from the VMC-1/2 accordingly. The diagonal shading presents the inclusion of deviant vowels used in experiment 2. Panel (C) illustrates the motor-only control condition (MOC-1/2): taps are required, but no sound is elicited. The motor-only condition is identical in experiment 1 and 2.
Experimental Conditions – Experiment 2
In experiment 2, two experimental and one control condition were presented (Figure 1B). In the vowel-motor condition (VMC-2) participants induced finger taps about every 2.4 s. Each tap elicited an immediate presentation of either the vowel/a:/or/o:/via headphones. In 30% of the taps a deviant was presented. If the standard stimulus was the vowel/a:/, the deviant was the vowel/o:/and vice versa. The timing of the acoustic stimulation was recorded online. This information was used to produce an identical but externally generated vowel sequence in the vowel-only condition (VOC-2). Thus, participants received exactly the same set of stimuli in both experimental conditions. During VOC-2 participants did not produce finger taps, but were simply asked to listen attentively to the auditory stimuli. As in experiment 1 MOC-2 served as a control condition for motor activity in VMC-2.
Both experimental runs were preceded by two training blocks each. In the first block, participants practiced to tap every 2.4 s. The second training block included visual feedback to indicate whether a trial was too slow (tapping interval longer than 3 s) or too fast (tapping interval shorter than 1.8 s). The feedback ensured that participants had learned to estimate the time between two successive finger taps without counting. Trials outside the range of 1.8–2.4 s were treated as errors. During the experimental run, no feedback was given.
Experimental Procedure
Participants were comfortably seated in an electrically shielded and sound-attenuated experimental chamber. A fixation cross was displayed in the middle of a computer screen. To ensure that the motor activity was comparable across participants in the auditory-motor and the motor-only condition, they were instructed to change hands (index finger) whenever indicated on the screen. Hence all participants tapped in equal parts with left and right hand. The order of tapping hands was randomized across participants. Each tap triggered the instantaneous presentation of a vowel via headphones (Sennheiser HD 202) to both ears in VMC-1/2 and VOC-1/2. An in-house built, highly sensitive tapping device was used to record the finger taps. Participants wore headphones in order to cover them up from all sounds possibly emitted by the taps. In the second experiment, the participants performed a combination of VMC-2 and VOC-2: during one run the standard vowel that was triggered via a tap was the vowel/a:/and the deviant was the vowel/o:/. In the other run, the allocation of standard and deviant vowel was a reversed. The first experiment consisted of 100 trials in each condition. Additionally, we collected 100 trials in MOC-1/2. In the second experiment, we recorded 200 trials in each the VMC-2 and VOC-2 with 70%/a:/as standard and 30%/o:/as deviant and vice versa. In total, 700 trials were recorded in both experiments. Experimental conditions were presented in blocks of 100 trials each. Block order was restricted: The VMC-1/2 always preceded VOC-1/2, but the MOC-1/2 was randomized across participants.
Electrophysiological Recordings
The electroencephalogram (EEG) was recorded continuously from 59 Ag–AgCl electrodes according to the International 10–20 system. In addition, activity from the left and right mastoids and the sternum (ground electrode) was recorded. The EEG was sampled at a rate of 500 Hz (Refa amplifiers system, TMS international, Enschede, Netherlands) and an anti-aliasing filter of 135 Hz was applied. To control for eye movements, vertical and horizontal electrooculograms (EOG) were recorded bipolarly. The impedance of all electrodes was kept below 5 kΩ. The recordings were online referenced to the left mastoid. EEP 3.2.1 Max-Planck-Institute of Cognitive Neuroscience, Leipzig, Germany was used to process the data.
Data Analysis – Behavioral Data
Tapping intervals shorter than 1.8 s or longer than 3.0 s were treated as errors, and were excluded from further EEG analysis. We acquired tapping intervals for VMC-1/2 and MOC-1/2 using the Presentation software (Neurobehavioral Systems, Inc., Albany, CA, United States). For each participant we generated the mean length of the tapped interval per condition and the overall performance accuracy (percent correct; ACCURACY) separately for VMC-1/2 and MOC-1/2.
Data Analysis – EEG Data
The EEG data were filtered with a 0.3–15 Hz bandpass filter (1601 Hamming windowed filter). The EEG data were re-referenced to linked mastoids. ERPs were time-locked to the stimulus onset of all critical trials. Each analyzed epoch lasted 600 ms including a 100 ms pre-stimulus baseline. The critical epochs were automatically scanned to reject horizontal and vertical eye-movements, muscle artifacts, and electrode drifts. Trials exceeding 30 μV at the eye channels and 40 μV at CZ were rejected. This automatic rejection was corrected manually by applying an eye-movement correction.
We controlled for motor activity by computing a difference-wave between VMC-1/2 and MOC-1/2 to compare the sensory activity elicited in the two experimental conditions. This corrected condition was labeled vowel-corrected condition (VCC-1, VCC-2). In the first experiment, we only compared fully predictable self-initiated and externally produced vowels (i.e.,/a:/). In the second experiment, we investigated two types of self-initiated vowels – standard (VCS-2) and deviant (VCD-2) vowels, as well as two types of externally produced vowels – self-initiated standard and deviant vowels (VOS-2; VOD-2). As the statistical analysis of the ERP-results in response to standard vowel/a:/and standard vowel/o:/as well as to deviant vowel/a:/and deviant vowel/o:/did not differ significantly, we combined the standard vowels/a:/and/o:/as well as deviant vowel/a:/and/o:/for all further statistical analyses.
Group-average ERPs were generated for standards and deviants. In the first experiment, the difference waves (i.e., responses to externally generated minus self-initiated vowels) revealed two ERP responses, a negative one in the time window of the N1 peaking at approximately 90 ms, and a positive response in the P2 time window peaking at approx. 190 ms. Statistical analyses were calculated based on individual amplitudes, in the time windows of 70–110 ms for the N1 and 170–210 ms for the P2. In experiment 2, difference waves revealed two ERP responses for standard vowels: a negative one in the N1 time window, peaking at approx. 90 ms followed by a positive one in the P2 time window peaking at approx. 190 ms; and four ERP responses to deviant vowels: a N1 and P2, as well as an N2b peaking at approx. 170 ms and a later positive response in the time window of the P3a peaking at approx. 310 ms. Statistical analyses were calculated based on individual amplitudes in the following time windows: 70–110 ms for the N1, 150–190 ms for the N2b, 170–210 ms for the P2, and 260–360 ms for the P3a. Furthermore, we applied a regions of interest (ROI) analysis using five ROIs [central (ZZ): FZ, CZ, PZ, FCZ, CPZ; left lateral (LL): F7, T7, P7, FT7, TP7; left medial (LM): F3, C3, P3, FC3, CP3; right lateral (RL): F8, T8, P8, FT8, TP8; right medial (RM): F4, C4, P4, FC4, CP4].
Statistical Analyses
For the statistical analysis, the SAS 8.20.20 (Statistical Analysis System, SAS Institute Inc., Cary, NC, United States) software package was used. Only significant results are presented and where required, the Greenhouse–Geisser correction was applied. Furthermore, we conducted Bonferroni corrected post hoc tests.
In the first experiment, comparing self-initiated/a:/-vowels to externally produced/a:/-vowels, we ran two analyses of variance (ANOVA), one for each ERP component, including the within-subject factors CONDITION (self-initiated: VCC-1; externally produced: VOC-1) and ROI (RL,RM, ZZ, LM, LL). For the statistical analyses of each individual ERP component in the second experiment, we ran a 2 × 2 × 5 ANOVA using the within-subject factors CONDITION (self-initiated: VCC-2; externally produced: VOC-2), TYPE (standard vs. deviant), and ROI (LL, LM, RM, RL, ZZ).
Results
Behavioral Data
In the first experiment, the average tapping interval duration was 2469.79 ms (SD: 360.77 ms) in VMC-1. Furthermore, participants tapped with an overall accuracy of 85.80% (SD: 18.73%). The Kolmogorov–Smirnov-Test revealed no deviance from the normal distribution (p = 0.18). In the second experiment, the results were similar. The average tapping interval was 2233.15 ms (SD: 257.43 ms) in VMC-2. Furthermore, participants tapped with an overall correctness of 92.92% (SD: 6.06%). The Kolmogorov–Smirnov-Test revealed a normal distribution (p = 0.82). In MOC-1/2 we found similar results, the average length of the tapping interval was 2388.94 ms (SD: 267.44 ms). Participants performed with an overall accuracy of 93.25% (SD: 8.14%; normal distribution: p = 0.52).
ERP Data – Experiment 1
The statistical results are presented in Table 1, and summarized below. The CONDITION (self-initiated, externally initiated) × ROI (LL, LM, ZZ, RM, RR) ANOVA revealed a significant effects in the time window of N1 and P2. In the N1 time window, results confirmed significant differences between the two conditions of self-initiated and externally initiated vowels; as well as significant interaction between conditions and region. Self-initiated vowels elicited a N1-suppression compared to externally produced vowels (N1: mean amplitude VCC-1: −2.20 μV, mean amplitude VOC-1: −3.09 μV)(Figure 2).
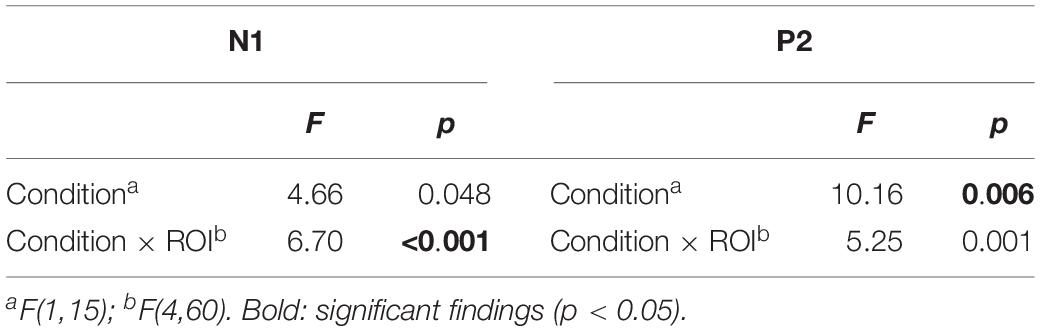
Table 1. Results of omnibus ANOVA in Experiment 1.
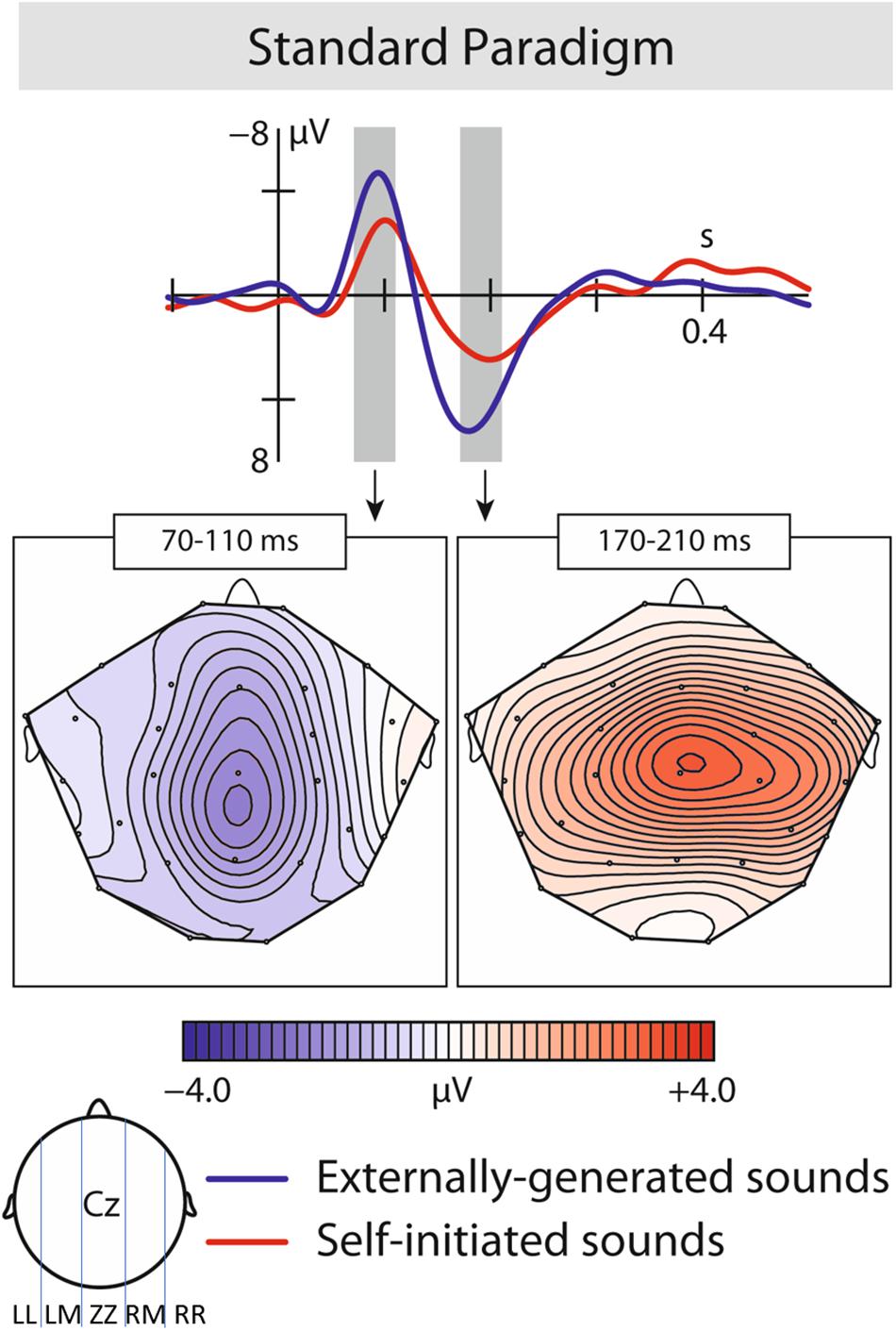
Figure 2. Results of the first experiment: ERP responses: Brain responses elicited by self-initiated and externally produced vowels in the central region. The blue solid line represents externally produced vowels (VOC-1), whereas the red solid line shows responses elicited by self-initiated vowels (VCC-1). Brain maps: Grand average scalp maps showing the spatial distribution of the difference waves (VOC-1–VCC-1) in the analyzed N1 and P2 time window.
In the P2 time window, similarly to the N1, we found a significant difference between the two conditions and a significant interaction of condition and region, with self-initiated vowels being significantly suppressed compared to externally produced vowels (P2: mean amplitude VCC-1: 1.73 μV, mean amplitude VOC-1: 3.44 μV) (Figure 2).
Experiment 1 revealed the expected N1-suppression effect as well as a reduced P2 in response to self-initiated vowels.
ERP Data – Experiment 2
All statistical results are presented in Table 2. For all ERP components we conducted a CONDITION (self-initiated, externally initiated) × ROI (LL, LM, ZZ, RM, RR) × TYPE (standard, deviant).
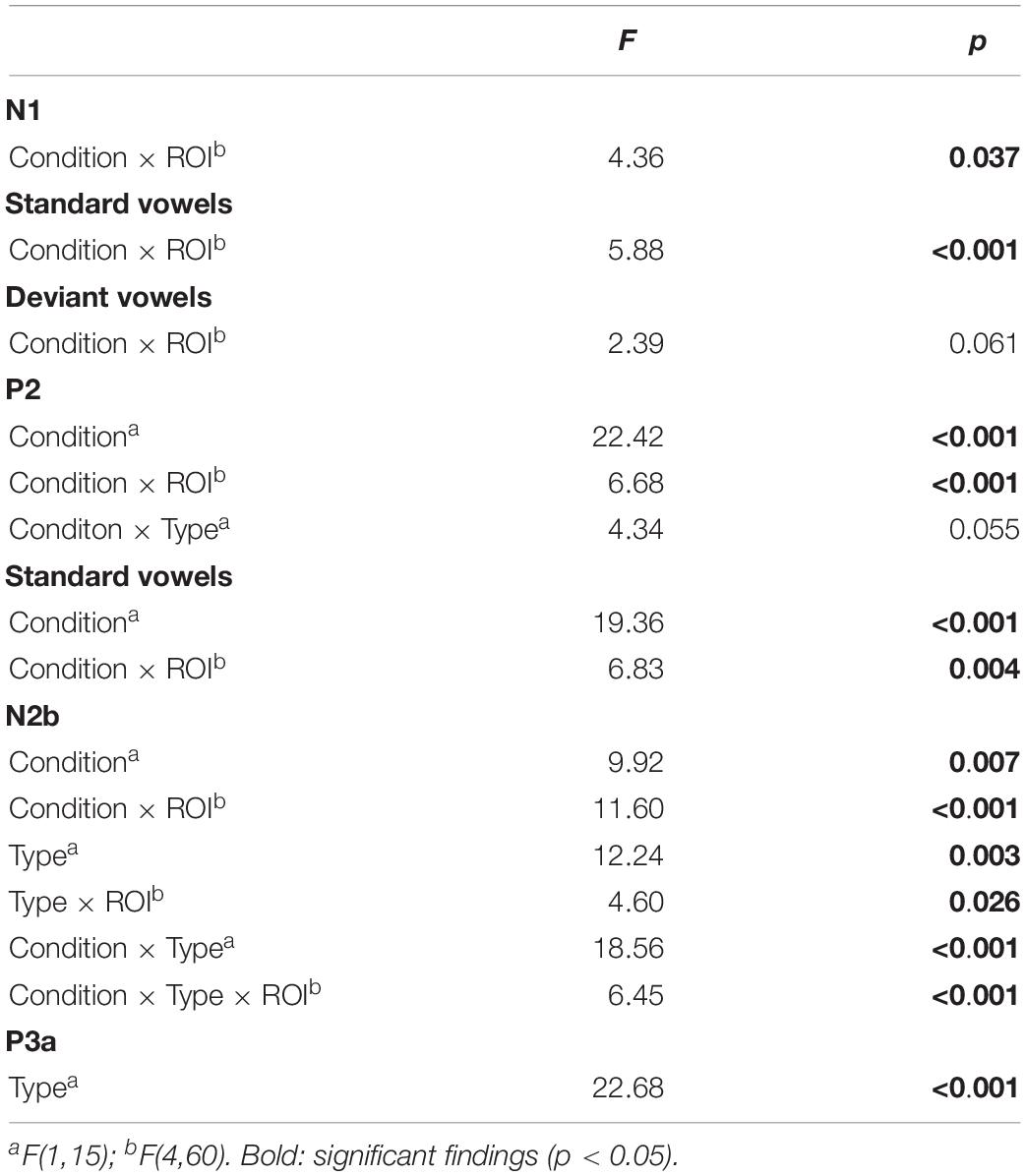
Table 2. Results of omnibus ANOVA in Experiment 2.
In the N1 time window, the ANOVA revealed significant differences between condition and region. According to our hypothesis, we conducted a planned analysis, investigating condition effects within the different vowel types: In the standard vowels (Figure 3A) we found a significant suppression effect in response to self-initiated vowels which was shown by an interaction of condition and region (mean amplitudes standard vowels: VCS-2 mean amplitude: −2.98 μV, VOS-2 mean amplitude: −3.77 μV). In the deviant vowels (Figure 3B), the suppression effect did not reach significance (mean amplitudes deviant vowels: VCD-2 mean amplitude: −3.81 μV, VOD-2 mean amplitude: −4.04 μV).
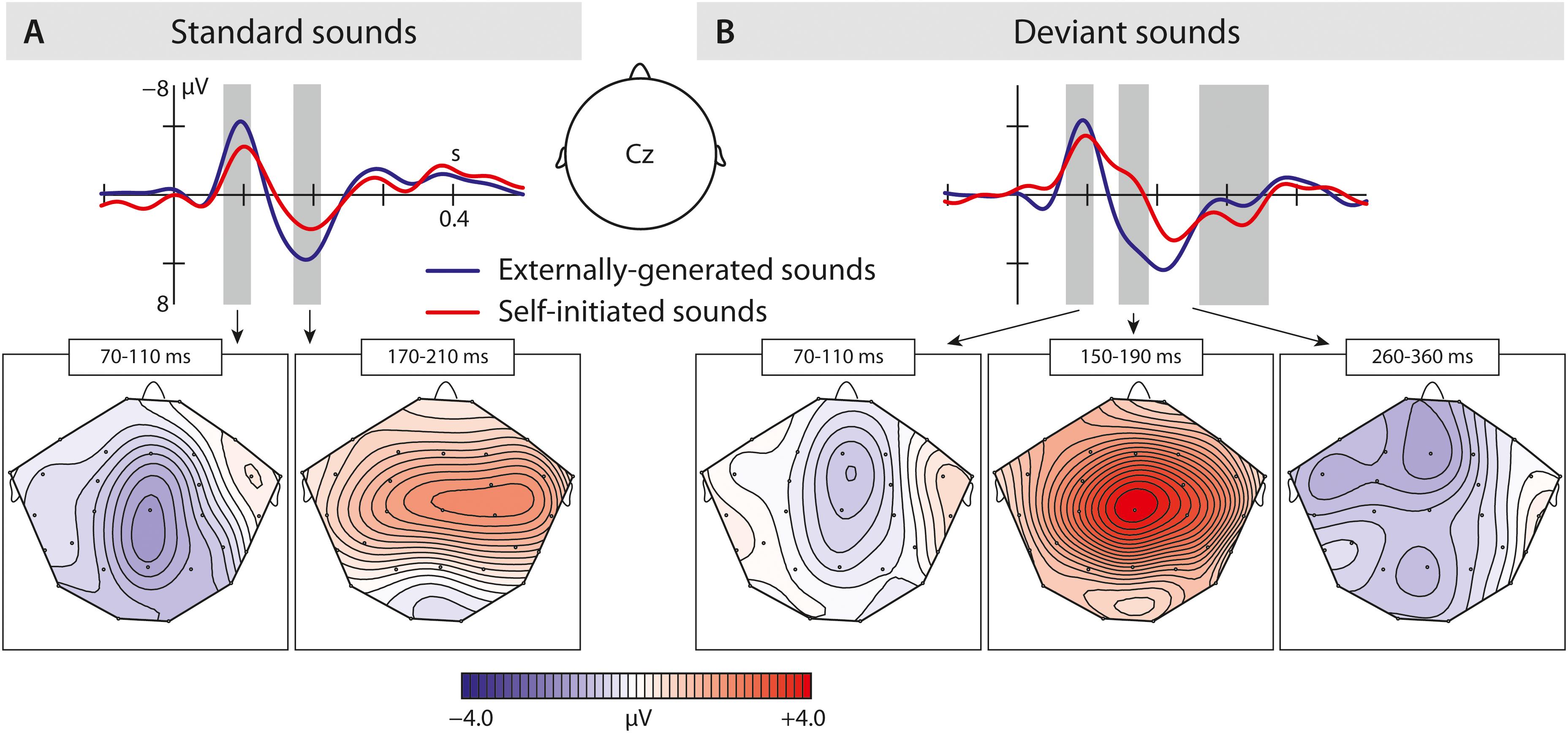
Figure 3. Results of the second experiment: (A) Brain responses elicited by self-initiated and externally produced standard vowels in the central region. The blue solid line represents externally produced standard vowels (VOS-2), whereas the red solid line shows responses elicited by self-initiated standard vowels (VCS-2). (B) Brain responses elicited by self-initiated and externally produced deviant vowels also in the central region. The blue solid line shows externally produced standard vowels (VOD-2), and the red solid line shows responses to self-initiated deviant vowels (VCD-2). The brain maps show the distribution of the effect (for standard vowels: VOS-2 minus VCS-2; for deviant vowels: VOD-2 minus VCD-2). Gray bar reflect analyzed in the time window of the N1, N2b, and P3a.
The results show that we only find a N1-suppression effect in response to self-initiated standard.
In the P2 time window, the ANOVA analysis revealed a significant difference between conditions – self-initiated versus externally initiated – and types – standard versus deviants, as well as significant interactions between condition and region aa well as a marginally significant effect between condition and type. In response to standard vowels (Figure 3A), we found a significant suppression effect in response to self-initiated vowels compared to externally initiated vowels (Standard: VCS-2 mean amplitude: 1.05 μV, VOS-2 mean amplitude: 2.62 μV) shown by a condition effect as well as a condition by region interaction. Deviant vowels showed a different pattern (Figure 3B). In response to externally generated deviant vowels we found a P2 (VOD-2 mean amplitude: 2.55 μV) that did not differ significantly from externally produced standards (VOS-2 mean amplitude: 2.62 μV) (Figure 4A). The visual inspection of the ERPs in response to the self-initiated deviants showed a very small shoulder following the N1, which may reflect a P2. However, this component was overlaid by a strong N2b effect, which was elicited in the time window of the P2, and described below.
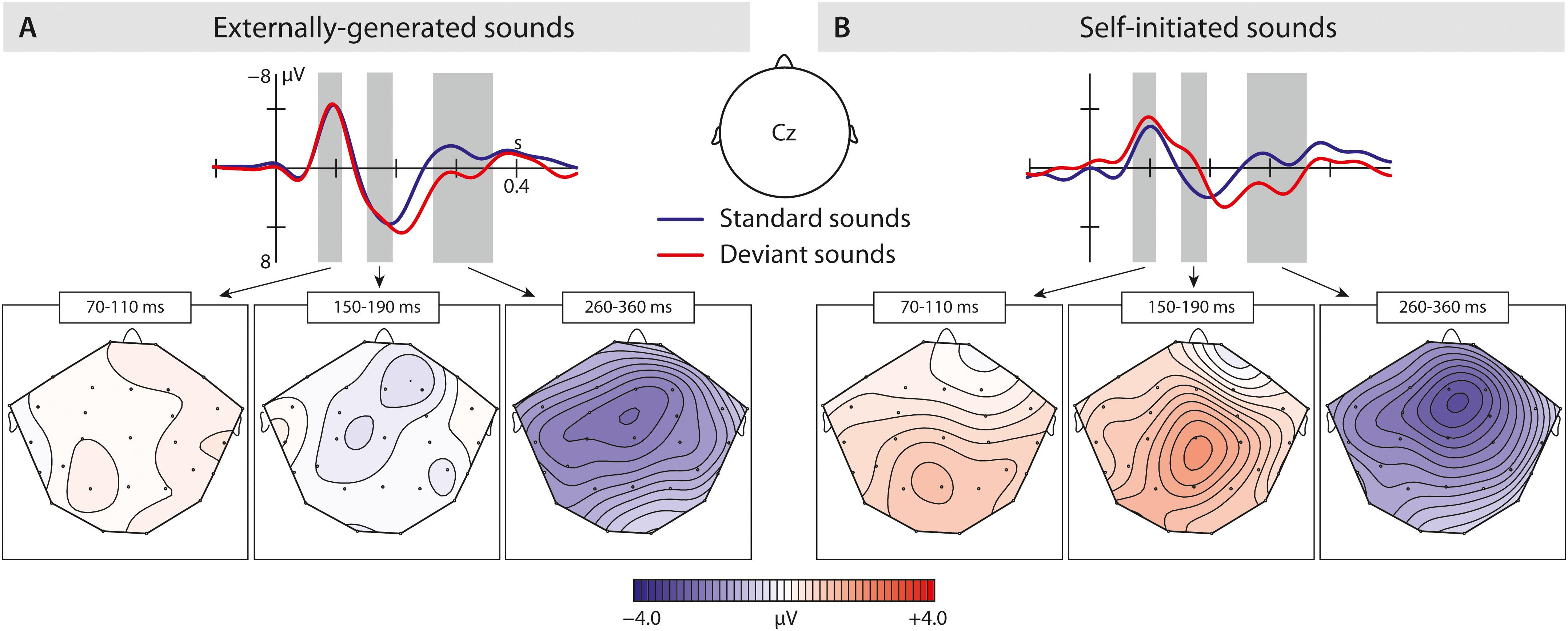
Figure 4. Results of the second experiment: (A) Brain responses elicited by externally produced standard and deviant vowels in the central region. The blue solid line represents externally produced standard vowels (VOS-2), whereas the red solid line shows responses elicited by externally produced deviant vowels (VOD-2). (B) Brain responses elicited by self-initiated standard and deviant vowels also in the central region. The blue solid line shows self-produced standard vowels (VCS-2), and the red solid line shows responses to self-initiated deviant vowels (VCD-2). The brain maps show the distribution of the effect (for externally produced vowels: VOS-2 minus VOD-2; for self-initiated vowels: VCS-2 minus VCD-2). Gray bar reflect analyzed in the time window of the N1, N2b, and P3a.
Taken together, the results show a significant P2-reduction in response to self-initiated standard sounds compared to externally produced standards. Although externally produced deviant and standard vowels elicited a similar P2 effect, a possible P2 in response to self-initiated deviant vowels cannot be statistically evaluated due to potential overlay effects.
In the N2b time window, we found a significant difference between conditions (self-initiated, externally generated) and types (standard, deviant), as well as a significant interaction between condition and region, type and region, condition and type, and condition, type and region. The post hoc analysis of condition, revealed a significant difference between vowel types, as well as a significant interaction between vowel type and region, showing that only self-initiated deviant vowels elicited an N2b effect (standard vowels: VCS-2 mean: −0.29 μV; deviant vowels: VCD-2 mean: −1.48 μV).
In contrast (Figure 4A), we did not find a significant difference when comparing externally produced standard and deviant vowels, indicating similar processing effort, also seen in the mean amplitude values (standard vowel: VOS-2 mean:0.85 μV; deviant vowels: VOD-2 mean:0.69 μV).
In conclusion, the N2b was only elicited in response to self-initiated deviant vowels.
In the P3a time window (Figures 3B, 4A,B), we found a significant difference between the vowel types [TYPE F(1,15) = 22.68; p = 0.0005]. In a post hoc analysis we resolved the type effect, analyzing standard and deviant sounds separately. We found a significant difference between the two conditions in the deviant vowels [CONDITION F(1,15) = 5.24; p = 0.037], revealing a significantly enhanced P3a in response to self-initiated deviant vowels (VCC-2 mean amplitude: 1.60 μV) compared to externally produced deviant vowels (VOC-2 mean amplitude:0.64 μV) (Figure 3B). However, we did not find a significant difference between self-initiated standard vowels and externally produced standard vowels (VCC-2 mean amplitude: −0.44 μV, VOC-2 mean amplitude: −0.48 μV) (Figure 3A). The result suggested that only deviant vowel elicited a significant P3a effect which was significantly enhanced in response to self-initiated compared to externally produced deviant vowels.
Discussion
The current study investigated the questions whether precise predictions are generated to process self-initiated complex speech sounds (i.e., vowels) by applying an internal forward model and whether prediction errors regarding self-generated deviant vowels are reflected in corresponding ERP components. In order to address these questions, two experiments were conducted. In the first experiment, we used a standard N1-suppression paradigm comparing self- and externally produced individually pre-recorded vowels in order to test whether the N1-suppression paradigm suffices to investigate complex auditory stimuli such as speech sounds. The results revealed a strong N1-suppression effect in response to self-initiated vowels. This finding confirms the successful generation of a forward prediction independent of the complexity of an anticipated stimulus.
Moreover, we found a reduced P2 response elicited by self-initiated vowels. Although the literature is very diverse regarding the P2, with some studies showing a suppression effect (Houde et al., 2002; Knolle et al., 2012, 2013a,b; Wang et al., 2014), whereas others do not (Martikainen et al., 2005; Baess et al., 2008; Behroozmand et al., 2011; Chen et al., 2013), the pattern we find in the current data is comparable to our previous results utilizing sounds (Knolle et al., 2012, 2013a,b). Thus, we suggest that the present data may indicate two processing stages of forming a prediction: Whereas the N1 reflects a fast and automatic forward prediction that prepares the auditory cortex to receive predicted sensory input, the P2 effect represents a more cognitive response (De Chicchis et al., 2002; Crowley and Colrain, 2004), as in distinguishing self- from externally produced vowels by consciously detecting a self-initiated sensation. This notion is supported by patient studies (Knolle et al., 2012, 2013a). The results of these studies revealed that patients with cerebellar lesions did not show an N1-suppression effect in response to self-initiated sinusoidal sounds, indicating an inability to generate a fast and automatic forward prediction. However, the patients showed a reduced P2 indicating that they had consciously recognized a respective sound as a self-generated one.
Interestingly, a recent study (Pinheiro et al., 2018) testing non-clinical voice hearers using a similar setup as the first experiment in the current study, also using natural vowel sounds, showed that the N1-supression effect is reversed in non-clinical voice hearers with high symptom scores compared to those with low symptom scores whereas the P2-supression effect is maintained in both groups. This is in accordance with findings in schizophrenia patients (Ford et al., 2014) using a similar paradigm, which indicates that alterations in generating motor-to-auditory predictions might be linked to developing auditory hallucinations (Brébion et al., 2016; Pinheiro et al., 2017).
In the second experiment, we adapted the N1-suppression paradigm by comparing self- and externally produced standard and deviant vowels. The deviant vowels (30%) were either an/a:/or an/o:/dependent on which of these two vowels represented the standard vowel. Comparable to the results of the first experiment, standard vowels elicited a suppressed N1 and P2 component in response the self-initiated vowels indicating that motor-to-auditory predictions are generated in order to process self-initiated vowels. Self-initiated deviant vowels, on the other hand, did not elicit a clear N1-suppression effect, indicating the violation of a precise prediction. In contrast, externally produced deviants did not differ from externally produced standard vowels showing that the difference in the N1-suppression effect was not elicited due to deviant detection. Additionally, our results show that the P2 in response to deviant vowels reveals a more complicated pattern: The P2 elicited by externally produced deviants is well pronounced and very similar to the P2 in response to externally produced standard vowels. In contrast, the potential P2 component in response to self-initiated deviant vowels is overlaid by an N2b response (Näätänen et al., 1982; for a review, see Näätänen and Gaillard, 1983), and cannot easily be interpreted.
Furthermore, deviant vowels elicited an N2b effect, which suggests the conscious detection of an unexpected, infrequent stimulus (Näätänen et al., 1982; Horváth et al., 2008). The effect was enhanced in response to self- compared to externally generated deviants. A further study (Kotz et al., 2014) revealed an increased N2b response to deviant sounds. Although Kotz et al. (2014) did not use a self-generation paradigm they investigated predictability by changing timing and context information to create different degrees of predictability. Their results show that irregular deviants elicit the biggest N2b response showing the detection of a prediction error. This is in accordance to our finding which provides further support for the notion that precise predictions in response to complex stimuli are generated, because only if a prediction concerning a specific feature of the auditory input (i.e., vowel quality) or temporal structure exists, its violation can be detected faster compared to unpredictable auditory input. As these deviants create a prediction error, the result suggests that prediction errors with respect to self-initiated stimuli are more salient, as a self-initiated stimulus is still temporally predictable. This suggestion is supported by our findings of a P3a response to infrequent, unexpected stimuli, to which attention is drawn (Squires et al., 1975; Snyder and Hillyard, 1976; Linden, 2005; Polich, 2007). Here, we report an enhanced P3a effect in response to self-initiated deviants, providing further evidence for the saliency of self-initiated prediction errors (Nittono and Ullsperger, 2000; Ford et al., 2010).
The results of the current study replicated the pattern of components found in a previous study on deviancy processing in sinusoidal sounds (Knolle et al., 2013b). This strongly suggests that predictive processing and the detection of prediction errors occurs independently of stimulus complexity. Additionally, the results reveal that the suppression paradigm is applicable to complex, speech-like sounds, suggesting that the internal forward model provides a theoretical explanation for processing self-produced speech. It can be postulated that by applying an internal forward model, the amplitude of the N1 is modulated when a speech sound is self-initiated compared to when this same speech sound is externally triggered (Paus et al., 1996; Ventura et al., 2009). In the same line of thought, many studies, using different methods and paradigms, compared spontaneous, self-produced speech to externally produced speech. They consistently find that spontaneously self-produced speech elicits suppressed cortical responses compared to recorded speech (fMRI: Hashimoto and Sakai, 2003; Christoffels et al., 2007, 2011; MEG: Curio et al., 2000; Houde et al., 2002; Heinks-Maldonado et al., 2006; Aliu et al., 2009; Ventura et al., 2009; Kauramäki et al., 2010; EEG: Ford et al., 2001; Heinks-Maldonado et al., 2005).
However as we hypothesized that the N1-suppression effect reflects the precision of the prediction, we modulated the standard paradigm introducing deviant vowels (second experiment) to reduce the prior knowledge concerning an anticipated stimulus and engenders a prediction error. The results show that precise predictions are generated (Bendixen et al., 2012; Ford and Mathalon, 2012; Knolle et al., 2013b) as the N1-suppression effect is modified in response to self-initiated deviant vowels. We propose that a prediction generated to process a self-initiated vowel holds a concrete representation of the vowel including for example, its frequency, onset, and intensity. This prediction is violated when a deviant is elicited. It is less precise, as it contains incorrect information on a vowel’s acoustic quality. However, as the concept is still correct with regard to vowel intensity and temporal occurrence, the suppression effect is maintained but modulated. The vocalization literature investigating altered auditory feedback consistently reports a similar effect. For example, Behroozmand et al. (2011) reported a reduced N1-suppression effect in response to self-produced but pitch- or onset-altered vocalizations. Thus, participants formed a precise prediction concerning the temporal and acoustic appearance of their voice. When the auditory feedback was altered in frequency or in onset, the prediction was violated. Consequently, the N1-suppression effect was reduced in response to altered auditory feedback, compared to unchanged feedback. Interestingly, two very similar MEG studies show a reduction of the suppression effect of the N1m with regard to altered self-produced speech sounds (Niziolek et al., 2013; Ylinen et al., 2014). In accordance to our interpretation Ylinen et al. (2014) argue that the reduced suppression reflects a precise motor-to-auditory forward prediction used for concrete speech monitoring. Based on very similar results, Niziolek et al. (2013) argue that specific speech monitoring allows error detection as well as concrete error correction mechanisms, which is in accordance to our interpretation.
The assumption that precise predictions are generated also in response to complex self-initiated stimuli receives further support from the enhanced N2b effect in response to self-initiated deviant vowels. Similar to our previous study (Knolle et al., 2013b), we consider that the N2b indicates the conscious detection of a prediction error, which represents an infrequent stimulus (Näätänen et al., 1982; Horváth et al., 2008). As the N2b is very much enhanced in response to self-initiated deviant vowels, it can be suggested that a prediction error increased the saliency of a deviant (Ford et al., 2010). More generally speaking, when a prediction error is generated, the detection of such violation is processed more efficiently in self-produced compared to externally produced deviant vowels. This is supported by our finding that externally produced deviant vowels also show a reduced P3a compared to self-produced deviants, revealing a less salient response (Ford et al., 2010).
The results concerning the detection of deviants nicely complements the results presented in the literature on speech monitoring and processing of speech errors (Postma, 2000; Tourville et al., 2008; Zheng et al., 2010; Christoffels et al., 2011) which most reliably show an increased blood oxygenation level dependent (BOLD) response during altered auditory feedback compared to normal feedback, indicating that increased activity is necessary to accomplish the monitoring effort or error coding. In the current study we show that violated predictions – prediction errors – are reflected in specific ERP components (i.e., enhanced N2b and P3a), which can be compared to error coding in fMRI studies.
In the current study, we have investigated motor-to-auditory predictions, framed within a forward model account, which is specific to motor control and uses the concept of a efference copy to generate a prediction. Other current accounts of surprising (e.g., oddball or deviant) responses in a more general, modality-independent framework are usually cast in terms of predictive coding (e.g., Brown et al., 2013; Shipp, 2016; Friston, 2018). In these models, the brain uses a hierarchical forward or generative model inferring the causes of sensations from its sensory consequences. Violations or mismatches from these predicted sensations result in a prediction error that can be differently weighted based on their precision (Haarsma et al., 2019) and is used for belief updating in cortical hierarchies. How does this concept link to agency? To explain self-produced action, such as speech, current accounts treat motor commands as predictions of proprioceptive and somatosensory consequences of an intended act, while the efference copy or corollary discharge corresponds to the predictions in the exteroceptive (e.g., auditory or visual) domain (Sterzer et al., 2018). Crucially, to act, it is necessary to attenuate the gain or precision of ascending prediction errors. Psychologically, this manifests as sensory attenuation as measured psychophysically. Physiologically, this is usually manifest as an attenuation or suppression of evoked responses that are generated by self, relative to another, as shown in this study.
Conclusion
In conclusion, the present study presents two experiments: The first investigates whether forward predictions are generated to process self-initiated complex speech sounds (i.e., vowel)? And the second addresses the question whether prediction error regarding self-initiated deviant, are these predictions based on precise patterns, as in holding a concrete representation of the anticipated vowel? Addressing the first question, the results revealed N1 and P2 suppression elicited by self-initiated vowels, indicating a successful generation of predictions in response to complex self-initiated speech sounds. This finding supports the notion that processing of self-produced speech mirrors components of a forward model, preparing respective cortical areas for incoming sensory consequences of self-produced speech. Investigating the second question, we found N1-suppression in response to self-initiated vowels compared to externally generated vowels. In addition, we report an enhanced N2b and P3 effect in response to self-initiated compared to externally produced deviant vowels. These findings imply that specific predictions are generated. Furthermore, we show that prediction errors are more salient in self-initiated speech sounds compared to externally produced sounds. More generally, our results speak to a key role of agency in predictive processing formulations; namely, a key role in mediating sensory attention and its reversal when attending to the consequences of self-generated acts.
Data Availability Statement
The datasets generated for this study are available on request to the corresponding author.
Ethics Statement
The studies involving human participants were reviewed and approved by the Ethics Committee of the Leipzig University, Leipzig, Germany. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
FK, SK, and ES developed the design and concept. FK collected and analyzed the data. MS contributed to the analysis. FK wrote the first draft. FK, SK, ES, and MS discussed the results and edited draft for final submission. All authors have approved the final version of the manuscript.
Funding
The research was funded by a DFG-Reinhart-Koselleck grant to ES and a DFG KO 2268/6-1 grant to SK.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank K. Ina Koch and Eleni Beyer for their support in the data collection. We also thank Kerstin Flake for graphics support and Helga Smallwood for proofreading. Furthermore, we would like to thank Alexandra Emmendorfer for help with the data analysis.
References
Aliu, S. O., Houde, J. F., and Nagarajan, S. S. (2009). Motor-induced suppression of the auditory cortex. J. Cogn. Neurosci. 21, 791–802. doi: 10.1162/jocn.2009.21055
Baess, P., Horváth, J., Jacobsen, T., and Schröger, E. (2011). Selective suppression of self-initiated sounds in an auditory stream: an ERP study. Psychophysiology 48, 1276–1283. doi: 10.1111/j.1469-8986.2011.01196.x
Baess, P., Jacobsen, T., and Schröger, E. (2008). Suppression of the auditory N100 event-related potential component with unpredictable self-initiated tones: evidence for internal forward models with dynamic stimulation. Int. J. Psychophysiol. 70, 137–143. doi: 10.1016/j.ijpsycho.2008.06.005
Behroozmand, R., Liu, H., and Larson, C. R. (2011). Time-dependent neural processing of auditory feedback during voice pitch error detection. J. Cogn. Neurosci. 23, 1205–1217. doi: 10.1162/jocn.2010.21447
Behroozmand, R., Sangtian, S., Korzyukov, O., and Larson, C. R. (2016). A temporal predictive code for voice motor control: evidence from ERP and behavioral responses to pitch-shifted auditory feedback. Brain Res. 1636, 1–12. doi: 10.1016/j.brainres.2016.01.040
Bendixen, A., SanMiguel, I., and Schröger, E. (2012). Early electrophysiological indicators for predictive processing in audition: a review. Int. J. Psychophysiol. 83, 120–131. doi: 10.1016/j.ijpsycho.2011.08.003
Brébion, G., Stephan-Otto, C., Ochoa, S., Roca, M., Nieto, L., and Usall, J. (2016). Impaired self-monitoring of inner speech in schizophrenia patients with verbal hallucinations and in non-clinical individuals prone to hallucinations. Front. Psychol. 7:1381. doi: 10.3389/fpsyg.2016.01381
Brown, H., Adams, R. A., Parees, I., Edwards, M., and Friston, K. (2013). Active inference, sensory attenuation and illusions. Cogn. Process. 14, 411–427. doi: 10.1007/s10339-013-0571-3
Chen, C. M., Mathalon, D. H., Roach, B. J., Cavus, I., Spencer, D. D., and Ford, J. M. (2011). The corollary discharge in humans is related to synchronous neural oscillations. J. Cogn. Neurosci. 23, 2892–2904. doi: 10.1162/jocn.2010.21589
Chen, Z., Jones, J. A., Liu, P., Li, W., Huang, D., and Liu, H. (2013). Dynamics of vocalization-induced modulation of auditory cortical activity at mid-utterance. PLoS One 8:e60039. doi: 10.1371/journal.pone.0060039
Christoffels, I. K., Formisano, E., and Schiller, N. O. (2007). Neural correlates of verbal feedback processing: an fMRI study employing overt speech. Hum. Brain Mapp. 28, 868–879. doi: 10.1002/hbm.20315
Christoffels, I. K., van de Ven, V., Waldorp, L. J., Formisano, E., and Schiller, N. O. (2011). The sensory consequences of speaking: parametric neural cancellation during speech in auditory cortex. PLoS One 6:e18307. doi: 10.1371/journal.pone.0018307
Creutzfeldt, O., Ojemann, G., and Lettich, E. (1989). Neuronal activity in the human lateral temporal lobe. II. Responses to the subjects own voice. Exp. Brain Res. 77, 476–489. doi: 10.1007/bf00249601
Crowley, K. E., and Colrain, I. M. (2004). A review of the evidence for P200 being an independent component process: age, sleep and modality. Clin. Neurophysiol. 115, 732–744. doi: 10.1016/j.clinph.2003.11.021
Curio, G., Neuloh, G., Numminen, J., Jousmaki, V., and Hari, R. (2000). Speaking modifies voice-evoked activity in the human auditory cortex. Hum. Brain Mapp. 9, 183–191. doi: 10.1002/(sici)1097-0193(200004)9:4<183::aid-hbm1>3.0.co;2-z
De Chicchis, A. R., Carpenter, M., Cranford, J. L., and Hymel, M. R. (2002). Electrophysiologic correlates of attention versus distraction in young and elderly listeners. J. Am. Acad. Audiol. 13, 383–391.
Eliades, S. J., and Wang, X. (2003). Sensory-motor interaction in the primate auditory cortex during self-initiated vocalizations. J. Neurophysiol. 89, 2194–2207. doi: 10.1152/jn.00627.2002
Ford, J. M., Gray, M., Faustman, W. O., Roach, B. J., and Mathalon, D. H. (2007). Dissecting corollary discharge dysfunction in schizophrenia. Psychophysiology 44, 522–529. doi: 10.1111/j.1469-8986.2007.00533.x
Ford, J. M., and Mathalon, D. H. (2012). Anticipating the future: automatic prediction failures in schizophrenia. Int. J. Psychophysiol. 83, 232–239. doi: 10.1016/j.ijpsycho.2011.09.004
Ford, J. M., Mathalon, D. H., Heinks, T., Kalba, S., Faustman, W. O., and Roth, W. T. (2001). Neurophysiological evidence of corollary discharge dysfunction in schizophrenia. Am. J. Psychiatry 158, 2069–2071. doi: 10.1176/appi.ajp.158.12.2069
Ford, J. M., Palzes, V. A., Roach, B. J., and Mathalon, D. H. (2014). Did i do that? Abnormal predictive processes in schizophrenia when button pressing to deliver a tone. Schizophr. Bull. 40, 804–812. doi: 10.1093/schbul/sbt072
Ford, J. M., Roach, B. J., Miller, R. M., Duncan, C. C., Hoffman, R. E., and Mathalon, D. H. (2010). When it’s time for a change: failures to track context in schizophrenia. Int. J. Psychophysiol. 78, 3–13. doi: 10.1016/j.ijpsycho.2010.05.005
Friston, K. (2018). Does predictive coding have a future? Nat. Neurosci. 21:1019. doi: 10.1038/s41593-018-0200-7
Fu, C. H. Y., Vythelingum, G. N., Brammer, M. J., Williams, S. C. R., Amaro, E., Andrew, C. M., et al. (2006). An fMRI study of verbal self-monitoring: neural correlates of auditory verbal feedback. Cereb. Cortex 16, 969–977. doi: 10.1093/cercor/bhj039
Gunji, A., Hoshiyama, M., and Kakigi, R. (2001). Auditory response following vocalization: a magnetoencephalographic study. Clin. Neurophysiol. 112, 514–520. doi: 10.1016/s1388-2457(01)00462-x
Haarsma, J., Fletcher, P., Griffin, J., Taverne, H., Ziauddeen, H., Spencer, T., et al. (2019). Precision-weighting of superior frontal cortex unsigned prediction error signals benefits learning, is mediated by dopamine, and is impaired in psychosis. bioRxiv [Preprint]. doi: 10.1101/558478
Hashimoto, Y., and Sakai, K. L. (2003). Brain activations during conscious self-monitoring of speech production with delayed auditory feedback: an fMRI study. Hum. Brain Mapp. 20, 22–28. doi: 10.1002/hbm.10119
Heinks-Maldonado, T. H., Mathalon, D. H., Gray, M., and Ford, J. M. (2005). Fine-tuning of auditory cortex during speech production. Psychophysiology 42, 180–190. doi: 10.1111/j.1469-8986.2005.00272.x
Heinks-Maldonado, T. H., Nagarajan, S. S., and Houde, J. F. (2006). Magnetoencephalographic evidence for a precise forward model in speech production. Neuroreport 17, 1375–1379. doi: 10.1097/01.wnr.0000233102.43526.e9
Hickok, G. (2012). Computational neuroanatomy of speech production. Nat. Rev. Neurosci. 13, 135–145. doi: 10.1038/nrn3158
Hirano, S., Kojima, H., Naito, Y., Honjo, I., Kamoto, Y., Okazawa, H., et al. (1996). Cortical speech processing mechanisms while vocalizing visually presented languages. Neuroreport 8, 363–367. doi: 10.1097/00001756-199612200-00071
Hirano, S., Kojima, H., Naito, Y., Honjo, I., Kamoto, Y., Okazawa, H., et al. (1997). Cortical processing mechanism for vocalization with auditory verbal feedback. Neuroreport 8, 2379–2382. doi: 10.1097/00001756-199707070-00055
Horváth, J., Roeber, U., Bendixen, A., and Schröger, E. (2008). Specific or general? The nature of attention set changes triggered by distracting auditory events. Brain Res. 1229, 193–203. doi: 10.1016/j.brainres.2008.06.096
Houde, J. F., Nagarajan, S. S., Sekihara, K., and Merzenich, M. M. (2002). Modulation of the auditory cortex during speech: an MEG study. J. Cogn. Neurosci. 14, 1125–1138. doi: 10.1162/089892902760807140
Kauramäki, J., Jääskeläinen, I. P., Hari, R., Möttönen, R., Rauschecker, J. P., and Sams, M. (2010). Lipreading and covert speech production similarly modulate human auditory-cortex responses to pure tones. J. Neurosci. 30, 1314–1321. doi: 10.1523/JNEUROSCI.1950-09.2010
Knolle, F., Schröger, E., Baess, P., and Kotz, S. A. (2012). The cerebellum generates motor-to-auditory predictions: ERP lesion evidence. J. Cogn. Neurosci. 24, 698–706. doi: 10.1162/jocn_a_00167
Knolle, F., Schröger, E., and Kotz, S. A. (2013a). Cerebellar contribution to the prediction of self-initiated sounds. Cortex 49, 2449–2461. doi: 10.1016/j.cortex.2012.12.012
Knolle, F., Schröger, E., and Kotz, S. A. (2013b). Prediction errors in self- and externally-generated deviants. Biol. Psychol. 92, 410–416. doi: 10.1016/j.biopsycho.2012.11.017
Kotz, S. A., Stockert, A., and Schwartze, M. (2014). Cerebellum, temporal predictability and the updating of a mental model. Phil. Trans. R. Soc. 369:20130403. doi: 10.1098/rstb.2013.0403
Lange, K. (2011). The reduced N1 to self-generated tones: an effect of temporal predictability? Psychophysiology 48, 1088–1095. doi: 10.1111/j.1469-8986.2010.01174.x
Linden, D. E. J. (2005). The P300: where in the brain is it produced and what does it tell us? Neuroscientist 11, 563–576. doi: 10.1177/1073858405280524
Martikainen, M. H., Kaneko, K., and Hari, R. (2005). Suppressed responses to self-triggered sounds in the human auditory cortex. Cereb. Cortex 15, 299–302. doi: 10.1093/cercor/bhh131
McCarthy, G., and Donchin, E. (1976). The effects of temporal and event uncertainty in determining the waveforms of the auditory Event Related Potential (ERP). Psychophysiology 13, 581–590. doi: 10.1111/j.1469-8986.1976.tb00885.x
Müller-Preuss, P., and Ploog, D. (1981). Inhibition of auditory cortical neurons during phonation. Brain Res. 215, 61–76. doi: 10.1016/0006-8993(81)90491-1
Näätänen, R., and Gaillard, A. W. K. (1983). “The N2 deflection of the ERP and the orienting reflex,” in EEG Correlates of Information Processing: Theoretical Issues, eds A. W. K. Giallard and W. Ritter, (Amsterdam: Elsevier), 119–141. doi: 10.1016/s0166-4115(08)62036-1
Näätänen, R., Simpson, M., and Loveless, N. E. (1982). Stimulus deviance and evoked potentials. Biol. Psychol. 14, 53–98. doi: 10.1016/0301-0511(82)90017-5
Nittono, H., and Ullsperger, P. (2000). Event-related potentials in a self-paced novelty oddball task. Neuroreport 11, 1861–1864. doi: 10.1097/00001756-200006260-00012
Niziolek, C. A., Nagarajan, S. S., and Houde, J. F. (2013). What does motor efference copy represent? Evidence from speech production. J. Neurosci. 33, 16110–16116. doi: 10.1523/JNEUROSCI.2137-13.2013
Numminen, J., and Curio, G. (1999). Differential effects of overt, covert and replayed speech on vowel-evoked responses of the human auditory cortex. Neurosci. Lett. 272, 29–32. doi: 10.1016/s0304-3940(99)00573-x
Numminen, J., Salmelin, R., and Hari, R. (1999). Subject’s own speech reduces reactivity of the human auditory cortex. Neurosci. Lett. 265, 119–122. doi: 10.1016/s0304-3940(99)00218-9
Oldfield, R. (1971). The assessment and analysis of handedness: the Edinburgh inventory. Neuropsychologia 9, 97–113. doi: 10.1016/0028-3932(71)90067-4
Ott, C. G., and Jäncke, L. (2013). Processing of self-initiated speech-sounds is different in musicians. Front. Hum. Neurosci. 7:41. doi: 10.3389/fnhum.2013.00041
Paus, T., Perry, D. W., Zatorre, R. J., Worsley, K. J., and Evans, A. C. (1996). Modulation of cerebral blood flow in the human auditory cortex during speech: role of motor-to-sensory discharges. Eur. J. Neurosci. 8, 2236–2246. doi: 10.1111/j.1460-9568.1996.tb01187.x
Pinheiro, A. P., Rezaii, N., Rauber, A., Nestor, P. G., Spencer, K. M., and Niznikiewicz, M. (2017). Emotional self–other voice processing in schizophrenia and its relationship with hallucinations: ERP evidence. Psychophysiology 54, 1252–1265. doi: 10.1111/psyp.12880
Pinheiro, A. P., Schwartze, M., and Kotz, S. A. (2018). Voice-selective prediction alterations in nonclinical voice hearers. Sci. Rep. 8:14717. doi: 10.1038/s41598-018-32614-9
Polich, J. (2007). Updating P300: an integrative theory of P3a and P3b. Clin. Neurophysiol. 118, 2128–2148. doi: 10.1016/j.clinph.2007.04.019
Postma, A. (2000). Detection of errors during speech production: a review of speech monitoring models. Cognition 77, 97–132. doi: 10.1016/s0010-0277(00)00090-1
Schäfer, E. W., and Marcus, M. M. (1973). Self-stimulation alters human sensory brain responses. Science 181, 175–177. doi: 10.1126/science.181.4095.175
Shipp, S. (2016). Neural elements for predictive coding. Front. Psychol. 7:1792. doi: 10.3389/fpsyg.2016.01792
Snyder, E., and Hillyard, S. (1976). Long-latency evoked potentials to irrelevant, deviant stimuli. Behav. Biol. 16, 319–331. doi: 10.1016/s0091-6773(76)91447-4
Squires, N. K., Squires, K. C., and Hillyard, S. A. (1975). Two varieties of long-latency positive waves evoked by unpredictable auditory stimuli in man. Electroencephalogr. Clin. Neurophysiol. 38, 387–401. doi: 10.1016/0013-4694(75)90263-1
Sterzer, P., Adams, R. A., Fletcher, P., Frith, C., Lawrie, S. M., Muckli, L., et al. (2018). The predictive coding account of psychosis. Biol. Psychiatry 84, 634–643.
Tian, X., and Poeppel, D. (2010). Mental imagery of speech and movement implicates the dynamics of internal forward models. Front. Psychol. 1:166. doi: 10.3389/fpsyg.2010.00166
Tourville, J. A., Reilly, K. J., and Guenther, F. H. (2008). Neural mechanisms underlying auditory feedback control of speech. Neuroimage 39, 1429–1443. doi: 10.1016/j.neuroimage.2007.09.054
Ventura, M. I., Nagarajan, S. S., and Houde, J. F. (2009). Speech target modulates speaking induced suppression in auditory cortex. BMC Neurosci. 10:58. doi: 10.1186/1471-2202-10-58
von Holst, E., and Mittelstädt, H. (1950). Das reafferenzprinzip. Naturwissenschaften 37, 464–476. doi: 10.1007/bf00622503
Wang, J., Mathalon, D. H., Roach, B. J., Reilly, J., Keedy, S. K., Sweeney, J. A., et al. (2014). Action planning and predictive coding when speaking. Neuroimage 1, 91–98. doi: 10.1016/j.neuroimage.2014.01.003
Wolpert, D. M., Ghahramani, Z., and Jordan, M. I. (1995). An internal model for sensorimotor integration. Science 269, 1880–1882. doi: 10.1126/science.7569931
Ylinen, S., Nora, A., Leminen, A., Hakala, T., Huotilainen, M., Shtyrov, Y., et al. (2014). Two distinct auditory-motor circuits for monitoring speech production as revealed by content-specific suppression of auditory cortex. Cereb. Cortex doi: 10.1093/cercor/bht351 [Epub ahead of print].
Keywords: N1 attenuation, self-generated speech, vowels, novelty, forward prediction, prediction error
Citation: Knolle F, Schwartze M, Schröger E and Kotz SA (2019) Auditory Predictions and Prediction Errors in Response to Self-Initiated Vowels. Front. Neurosci. 13:1146. doi: 10.3389/fnins.2019.01146
Received: 14 June 2019; Accepted: 10 October 2019;
Published: 25 October 2019.
Edited by:
Jonathan B. Fritz, University of Maryland, College Park, United StatesReviewed by:
Karl Friston, University College London, United KingdomJochen Kaiser, Goethe University Frankfurt, Germany
Copyright © 2019 Knolle, Schwartze, Schröger and Kotz. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Franziska Knolle, ZmsyOUBjYW0uYWMudWs=; ZnJhbnppc2thLmtub2xsZUB0dW0uZGU=; Sonja A. Kotz, a290ekBjYnMubXBnLmRl