 Lukas Hecker
Lukas Hecker Rebekka Rupprecht
Rebekka Rupprecht Ludger Tebartz Van Elst
Ludger Tebartz Van Elst Jürgen Kornmeier
Jürgen Kornmeier- 1Department of Psychiatry and Psychotherapy, University of Freiburg Medical Center, Freiburg, Germany
- 2Faculty of Medicine, University of Freiburg, Freiburg, Germany
- 3Institute for Frontier Areas of Psychology and Mental Health (IGPP), Freiburg, Germany
- 4Faculty of Biology, University of Freiburg, Freiburg, Germany
- 5Machine Learning Lab, University of Freiburg, Freiburg, Germany
The electroencephalography (EEG) is a well-established non-invasive method in neuroscientific research and clinical diagnostics. It provides a high temporal but low spatial resolution of brain activity. To gain insight about the spatial dynamics of the EEG, one has to solve the inverse problem, i.e., finding the neural sources that give rise to the recorded EEG activity. The inverse problem is ill-posed, which means that more than one configuration of neural sources can evoke one and the same distribution of EEG activity on the scalp. Artificial neural networks have been previously used successfully to find either one or two dipole sources. These approaches, however, have never solved the inverse problem in a distributed dipole model with more than two dipole sources. We present ConvDip, a novel convolutional neural network (CNN) architecture, that solves the EEG inverse problem in a distributed dipole model based on simulated EEG data. We show that (1) ConvDip learned to produce inverse solutions from a single time point of EEG data and (2) outperforms state-of-the-art methods on all focused performance measures. (3) It is more flexible when dealing with varying number of sources, produces less ghost sources and misses less real sources than the comparison methods. It produces plausible inverse solutions for real EEG recordings from human participants. (4) The trained network needs <40 ms for a single prediction. Our results qualify ConvDip as an efficient and easy-to-apply novel method for source localization in EEG data, with high relevance for clinical applications, e.g., in epileptology and real-time applications.
1. Introduction
1.1. The EEG and the Inverse Problem
Electroencephalography (EEG) is among the most used imaging techniques for noninvasive measurements of electromagnetic brain activity. Its main advantage over other methods (e.g., functional magnetic resonance imaging [fMRI]) is the high temporal resolution, which comes at the cost of a considerably low spatial resolution (Luck, 2014). As a consequence, EEG was mainly used to study temporal brain dynamics at fine time scales. In the past decades, however, there has been a steady growth of interest in the neural sources underlying the EEG signal (Koles, 1998; Pascual-Marqui, 1999; Grech et al., 2008; He et al., 2018; Michel and Brunet, 2019). The non-invasive estimations of neural generators, based on their projections to the scalp electrodes/sensors, constitutes an inverse problem. Without further constraints, it is ill posed because it lacks an unique solution, since multiple configurations of neural sources can produce identical topographies of electrical activity at the scalp (see e.g., Nunez and Srinivasan, 2006).
Invasive multimodal methods (e.g., using combined EEG and electrocorticography) help to bridge the gap between scalp recordings and neural generators, and thus in handling the inverse problem in this constellation. However, access to these methods is limited and the conclusions that can be drawn are constrained by various factors such as placement of the cortical electrodes or coverage of brain areas that project to the scalp electrodes. Combined EEG-fMRI has also been shown as a useful tool in providing insight into the spatiotemporal dynamics of the EEG (Ritter and Villringer, 2006). However, the costs of this technique are considerably high and the relation between electromagnetic and metabolic dynamics is yet not fully understood.
1.2. Classical Approaches to the EEG Inverse Problem
Introducing some constraints on the solution, one can solve the inverse problem or at least reduce the number of possible solutions. One approach is the equivalent current dipole model, which is based on the assumption that the source of a signal, measured with the EEG, can be modeled by a single (or sometimes few) dipole(s) (Kavanagk et al., 1978; Scherg, 1990; Delorme et al., 2012). Although single-dipole sized sources are too small to generate detectable scalp potentials (Nunez and Srinivasan, 2006), they can produce reasonable results (Ebersole, 1994; Lantz et al., 1996; Willemse et al., 2016; Sharma et al., 2018).
A more physiologically realistic approach is the distributed dipole model in which activity is expected to extend over larger areas of the brain (as opposed to tiny dipoles). Distributed dipole models aim to find the 3D distribution of neural activity underlying the EEG measurement (Hämäläinen and Ilmoniemi, 1994; Pascual-Marqui et al., 1994). A distributed dipole model proposes that sources of the EEG are better modeled using hundreds to many thousand dipoles and therefore aim to find a distributed activity that can explain the EEG data. This model can be viewed opposed to single- to few-dipole models, which assume that EEG data can be sufficiently modeled using point sources.
A popular family of distributed dipole solutions is the Minimum Norm Estimates (MNE; Ioannides et al., 1990; Hämäläinen and Ilmoniemi, 1994), which aim to find the source configuration that minimizes the required power to generate a given potential at the scalp electrodes. Low Resolution Electromagnetic Tomography (LORETA) is a famous proponent of the MNE-family that assumes sources to be smoothly distributed (Pascual-Marqui et al., 1994). In the most sophisticated version, exact LORETA (eLORETA, Pascual-Marqui, 2007) showed zero localization error when localizing single sources in simulated data (Pascual-Marqui, 2007).
Another popular family of inverse solutions is the beamforming approach. The linear constrained minimum variance (LCMV) beamforming approach is a spatial filter that assumes that neural sources are uncorrelated and in which portions of the data that do not belong to the signal are suppressed (Van Veen et al., 1997). Drawbacks of the LCMV approach are the susceptibility to imprecisions in the forward model and that correlated sources are often not found.
Growing interest toward a Bayesian notation of the inverse problem could be observed in the past two decades (Friston et al., 2008; Wipf and Nagarajan, 2009; Chowdhury et al., 2013). One prominent Bayesian approach is the maximum entropy on the mean (MEM) method, which aims to make the least assumptions on the current distribution by maximizing entropy (Amblard et al., 2004; Grova et al., 2006; Chowdhury et al., 2013).
1.3. Artificial Neural Networks and Inverse Solutions
Artificial neural networks (ANN)-based inverse solutions follow a data-driven approach and were of increasing interest in the past years (Awan et al., 2019). A large number of simulated EEG data samples is used to train an ANN to correctly map electrode-space signals to source-space locations (Jin et al., 2017). Long training periods are usually required for an ANN to generalize beyond the training set. After successful training, it is capable of predicting the coordinates and orientations of a dipole correctly, given only the measurements at the scalp electrodes without further priors (Zhang et al., 1998; Abeyratne et al., 2001).
Robert et al. (2002) reviewed the literature on ANN-based methods to solve the inverse problem of single dipoles and found that all reports achieved localization errors of <5%. The low computational time (once trained) and robustness to measurement noise was highlighted when compared to classical approaches. However, the classical approaches were capable of achieving zero localization error in single-dipole simulations under zero-noise conditions (Hoey et al., 2000).
In an effort to predict source locations of two dipoles, Yuasa et al. (1998) presented a feed-forward network with two hidden layers and achieved localization errors in a range between 3 and 9%. They found that if multiple simulated dipoles have a sufficient distance among each other the localization success of ANNs even for multiple simulated sources is equal to classical approaches, making a strong case for the feasibility of ANNs for the EEG inverse problem, already in 1998. Although ANNs as such gained popularity in the past decade on other areas (e.g., image classification or natural language processing), the idea of ANN-based solutions to the EEG inverse problem received little further attention.
Only very recently several studies about ANN-based solutions to the inverse problem have been published. Cui et al. (2019) showed that a neural network can be trained to reconstruct the position and time course of a single source using a long-short term memory (LSTM) recurrent neural network architecture (Hochreiter and Schmidhuber, 1997). LSTMs allow to not only use single time instances of (e.g., EEG) data but instead learn from temporally lagged information.
In a recent work, Razorenova et al. (2020) showed that the inverse problem for cortical potential imaging could be solved using a deep U-Net architecture, once more providing a strong case for the feasibility of ANNs to solve the EEG inverse problem (Fedorov et al., 2020).
Tankelevich (2019) showed that a deep feed-forward network can find the correct set of source clusters that produced a given scalp signal. To our knowledge, this was the first ANN approach to calculate distributed dipole solutions.
In the very recent years, convolutional neural networks (CNNs) have proven to be a useful tool in a steadily increasing number of domains, like image classification (Krizhevsky et al., 2012), natural language processing (Kim, 2014), and decoding of single trial EEG (Schirrmeister et al., 2017). CNNs are capable of learning patterns in data with a preserved temporal (e.g., time sequences) or spatial (e.g., images) structure by optimizing filter kernels that are convolved with a given input. Two famous CNNs are AlexNet (Krizhevsky et al., 2012) and VGG16 (Simonyan and Zisserman, 2014) that won the ImageNet classification competition in 2012 and 2014, respectively.
In the current study, we explored the feasibility of CNNs to solve the EEG inverse problem. Specifically, we constructed a CNN, named ConvDip, that is capable of detecting multiple sources using training data with biologically plausible constraints. ConvDip solves the EEG inverse problem using a distributed dipole solution in a data-driven approach. ConvDip was trained to work on single time instances of EEG data and predicts the position of sources from potentials measured with scalp electrodes.
2. Methods
A Python package to create a forward model, simulate data, train an ANN, and perform predictions is available at https://github.com/LukeTheHecker/ESINet.
2.1. Forward Model
To simulate EEG data realistically, one has to solve the forward problem and construct a generative model (GM). An anatomical template was used as provided by the Freesurfer image analysis suite (http://surfer.nmr.mgh.harvard.edu/) called fsaverage (Fischl et al., 1999).
We calculated the three shell boundary element method (BEM, Fuchs et al., 2002) head model with 5120 vertices per shell using the python package MNE (v 19, Gramfort et al., 2013) and the functions make_bem_model and make_bem_solution therein. The conductivity, measured by Siemens per square meter, was set to 0.3 S/m2 for brain and scalp tissue and 0.06 S/m2 for the skull.
The source model was created with p = 5124 dipoles along the cortical surface provided by Freesurfer with icosahedral spacing. We chose q = 31 electrodes based on the 10–20 system (Fp1, F3, F7, FT9, FC5, FC1, C3, T7, TP9, CP5, CP1, Pz, P3, P7, O1, Oz, O2, P4, P8, TP10, CP6, CP2, Cz, C4, T8, FT10, FC6, FC2, F4, F8, and Fp2). The leadfield K ∈ ℝq×p was then calculated using the head model with dipole orientations fixed orthogonal to the cortical surface (see e.g., Michel and Brunet, 2019 for explanation).
Additionally, we created a second forward model that we refer to as the alternative generative model (AGM). The AGM will be used to simulate data for the model evaluation and serves the purpose to avoid the inverse crime. The inverse crime is committed when the same GM is used to both simulate data and calculate inverse solutions, leading to overoptimistic results (Wirgin, 2004). First, electrode positions were changed by adding random normal distributed noise to the X, Y, and Z coordinate of each electrode. This resulted in an average displacement per electrode of ≈ 3.7 mm. Furthermore, we changed the tissue conductivity in the BEM solution to 0.332 S/m2 for brain and scalp tissue and 0.0113 S/m2 for skull tissue (values were adapted from Wolters et al., 2010). This step was done in order to introduce some alterations in the volume conduction of the brain-electric signals, which are never known precisely a priori. Importantly, this changes the skull-to-brain conductivity ratio from 1:50 to 1:25. Last, we changed the spacing of the dipoles along the cortical sheet from icosahedral to octahedral with a higher resolution. This resulted in 8,196 dipoles in the source model of the AGM, all of which were placed at slightly different locations on the cortex compared to the source model of the GM. The idea of increasing the resolution of the source model to avoid the inverse crime was adapted from Kaipio and Somersalo (2006). All simulations in the evaluation section were carried out using this AGM, whereas the calculation of the inverse solutions of cMEM, eLORETA, and LCMV beamformer was based on the GM. Likewise, data used for training ConvDip was simulated using only the GM.
2.2. Simulations
Training data for ConvDip were created using the GM, whereas the data for the evaluation of the model were created using the AGM. Since AGM and GM have different source models, we implemented a function which transforms a source vector jAGM to a source vector jGM. This was achieved by K nearest-neighbor interpolation, i.e., each value in the target space was assigned the average value of the K nearest neighbors in the initial space. K was set to 5 neighbors. Since the source model of AGM contained almost twice as many dipoles as that of the GM, a source vector translated from AGM to GM will effectively loose total source power. We therefore normalized the resulting source vector jGM to have equal energy (sum of all dipole moments) as jAGM.
In summary, different sets of simulated EEG samples were generated to (1) create training data for ConvDip and (2) for evaluation of ConvDip and other inverse solutions.
Each simulation contained at least one dipole cluster, which can be considered as a smooth region of brain activity. A dipole cluster was generated by selecting a random dipole in the cortical source model and then adapting a region growing approach as described in Chowdhury et al. (2013). In brief, we recursively included all surrounding neighbors starting from a single seeding location, thereby creating a larger source extent with each iteration. The number of iterations define the neighborhood order s, where the first order s1 entails only the single selected dipole. Each seed location was assigned a dipole moment between 5 and 10 Nano-Ampere Meter (nAm). The neighboring dipoles were assigned attenuated moments based on the distance to seeding location. The attenuation followed a Gaussian distribution with a mean of the seeding dipole moment and a standard deviation of half the radius of the dipole cluster, yielding smooth source patches.
After generating this spatial pattern, we added a temporal dimension to the data as follows. We considered an epoch length of 1 s at a sampling frequency of 100 Hz (i.e., t = 100 time points). The time course was modeled by a central peak of 100 ms temporal extension using half a period of a 5 Hz sinusoidal, surrounded by zeros. Each dipole moment was then multiplied by this time course. The simulated source J ∈ ℝp×t of p = 5,124 dipoles was then projected to q = 31 EEG electrodes M ∈ ℝq×t by solving the forward problem using the leadfield K ∈ ℝq×p:
To generate realistic training data, we added real noise from pre-existing EEG recordings, conducted with the same set of electrodes as described above. Therefore, from a set of different raw EEG recordings, we extracted 200 random segments. These EEG segments were filtered beforehand using a band-pass between 0.1 and 30 Hz. Each segment contained 1 s of EEG data. The sampling frequency was reduced from 1,000 to 100 Hz. Baseline correction was applied based on the first 100 ms, and the resulting data were re-referenced to common average. For each sample, we then created 20 EEG trials by adding a randomly selected noise segment to the simulated EEG. Prior to this, the noise was scaled to yield a signal-to-noise ratio (SNR) of 1 within single trials. The average of these 20 trials, i.e., the event-related potential, should therefore exhibit a theoretical SNR of 4.5 () at the ERP peak.
The extent of the sources was defined between two (s2) and five (s5) neighborhood orders, which corresponds to diameters between ≈ 21 and ≈ 58 mm (or 19–91 dipoles).
2.2.1. Training Data
For training ConvDip, we simulated in total 100,000 samples using the GM as described above. Each sample contained between 1 and 5 source clusters of extent between 2 and 5 neighborhood orders. Since ConvDip operates on single time instances of EEG or ERP data, we only used the EEG at the signal peak as input.
2.2.2. Evaluation Data
Two separate sets of simulations of 1,000 samples each were created for the evaluation. The first set contained samples of single source clusters with varying extents from two to seven neighborhood orders, which we will refer to as single-source set. The second set contained samples with varying numbers of source clusters from 1 to 10 and with varying extents from 2 to 7 neighborhood orders or diameters from ≈ 21 to ≈ 58 mm (or 16–113 dipoles in the AGM). We will refer to this as the multi-source set. Source extents have different diameters for different source models, especially in our case where the source model of GM has roughly half the number of dipoles compared to AGM. This explains why s7 for the AGM has approximately as many dipoles as s6 in the GM. Note that both sets were created using simulations of brain-electric activity based on an AGM that differs from that used in the inversion/training process. This was done in order to avoid the inverse crime (for details, see Methods section 2.1).
2.3. ConvDip
In this section, the architecture of ConvDip, a CNN which solves the inverse problem, is described and a mathematical description in the classical notation of inverse solutions is given.
2.3.1. I/O of ConvDip
Since ConvDip was designed to operate on single time instances of EEG data, we extracted from each simulated data sample only the time point of the peak source activity. The EEG data at this time frame was then interpolated on a 2D image of size 7 × 11. This is necessary, given that the architecture of ConvDip (Figure 1) requires a 2D matrix input to perform spatial convolutions on. Note that this interpolation procedure does not add information to the EEG data. The output of ConvDip is a vector of size 5,124 corresponding to the dipoles in the source model (see Figure 1).
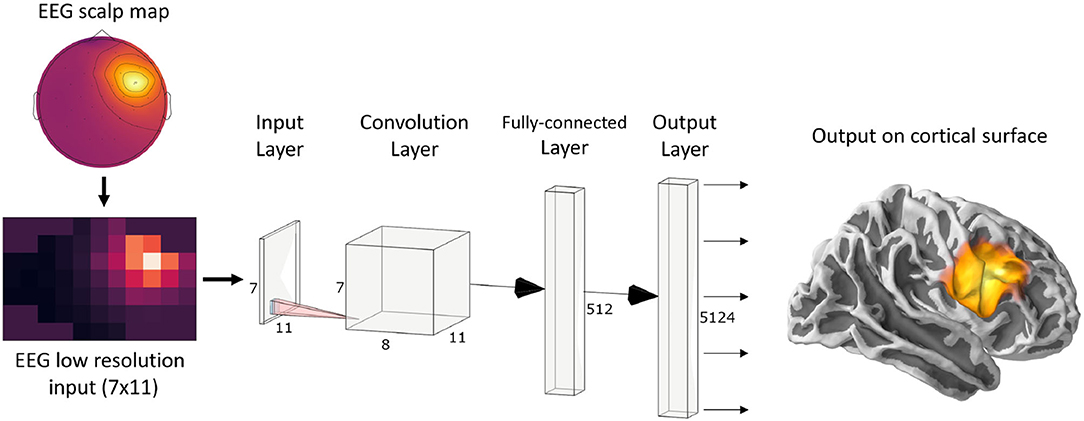
Figure 1. ConvDip architecture. The values from a single time point of EEG data were interpolated to get a 7 × 11 matrix as an input (see illustration on the bottom left). The subsequent convolution layer has only 8 convolution kernels of size 3 × 3 pixels. The convolution layer is followed by a fully connected (FC) layer consisting of 512 neurons. Finally, the output layer contains 5124 neurons that correspond to the voxels in the brain (plotted on a cortical surface on the right) (This diagram was created using a web application at http://alexlenail.me/NN-SVG/).
2.3.2. ConvDip Architecture
The design and training of the neural network was accomplished using the Tensorflow (Abadi et al., 2016) and Keras (Chollet, 2015) libraries, which are based on Python 3. Training was partially accomplished on a Nvidia Titan V graphical processing unit (GPU) and an Nvidia RTX 2070.
The architecture of ConvDip (Figure 1) is inspired by CNNs for image classification, in which the input layer is forwarded to a series of convolutional layers followed by a series of fully connected layers followed by the output layer (e.g., AlexNet; Krizhevsky et al., 2012). In typical CNNs, the convolution layers are followed by pooling layers to reduce dimensionality and to promote invariance to an object's position Deru and Ndiaye (2019). Notice that in ConvDip no pooling layers were used since spatial information would get lost or at least blurred. While invariance to the position of an object is desirable in image classification tasks (what-task), it would be detrimental in the case of source localization problems (where-task). Finally, we decided for a moderately shallow architecture with a single convolution layer followed by a fully connected layer and an output layer.
We decided to use Rectified Linear Units (ReLUs) as activation functions after each layer (Nair and Hinton, 2010; Glorot et al., 2011). ReLUs have shown to exhibit the best performance in our preliminary tests compared to alternatives (e.g., sigmoid function). After each of the inner layers, we added a batch normalization layer (Ioffe and Szegedy, 2015) in order to speed up training and to reduce internal covariance shifts. In the current version of ConvDip, the output layer consists of 5,124 neurons, which equals the number of voxels in the modeled brain. ReLU activation functions were used in the output layer. Typical CNNs for regression use linear activation functions, however, since predictions are by definition non-negative in our application, ReLUs appeared to us as an appropriate alternative.
ConvDip can be described as a function , with p = 5124 that maps a single time instance of 2D-interpolated EEG data M to a source vector :
The architecture of ConvDip starts with a convolution layer with only 8 filters Fi, i = {1, …8} of size 3 × 3. The weights of these filters are determined during the training period. In the forward pass, the padded input EEG data M are convolved with each filter Fi, resulting in one feature map .
The feature maps Gi, i ∈ {1, …, 8} are stacked to a tensor G ∈ ℝ7×11×8 and reshaped to a vector (also called flattening) to enable a connection to the next FC Layer. The flattened vector consists of 616 output nodes. Each node is connected to every neuron of the following FC Layer.
For each of the 512 neurons in the hidden fully connected layer, we transform its input using the weight vector w, bias b, and the activation function h:
The hidden layer is finally connected to the output layer of 5,124 neurons.
2.3.3. Optimization and Loss Function
Convolution filters, weights, and biases were optimized using adaptive momentum estimation (ADAM, Kingma and Ba, 2014) with default settings as suggested by the authors (learning_rate = 0.001, β1 = 0.9, β2 = 0.999, ϵ = 108).
We tried out various loss functions for the training of ConvDip. The mean squared error loss is a classical loss for regression tasks. For EEG inverse solutions, however, it is not appropriate since it operates pixel-wise, i.e., the error does not provide information on how close a wrong prediction is to the true source. This is especially problematic when ConvDip is designed to find focal sources. Various approaches exist to tackle this issue, e.g., by solving an optimal transport problem (e.g., using Wasserstein metric) or by calculating the distance between two sets of coordinates (e.g., Hausdorff distance). We decided for the weighted Hausdorff distance (WHD) as described by Ribera et al. (2019)1.
The WHD has shown to perform well on image segmentation tasks and allowed for a fast convergence of ConvDip compared to MSE. Note that WHD requires a normalization of the prediction and target to ensure all values are between 0 and 1. Therefore, only positional information is regarded in this loss. The rationale for this is to disentangle the problem of estimating absolute dipole moments and that of estimating dipole positions.
As mentioned above, ConvDip predicts source locations without correct global scaling (see also Equation 2). To obtain the true amplitude of the sources, we used Brent's method (Brent, 1971) to find a scalar ŝ that minimizes the mean squared error between the forward solution () of the predicted sources () and the unscaled EEG vector x:
The scalar ŝ can then be used to scale the prediction.
2.4. Implementation of cMEM, eLORETA, and LCMV
To evaluate ConvDip, we calculated inverse solutions on the same set of simulations using eLORETA, LCMV beamformer, and cMEM, and compared the different methods with each other.
eLORETA and LCMV were carried out by the implementations in the Python library MNE. Using the same head model as described in section 2.1, each inverse algorithm was subjected to each sample of the evaluation set as described in section 2.2. The first 400 ms of each trial were used to estimate the noise covariance matrices. Regularization of the noise covariance was established using the standard MNE procedure as described in Gramfort et al. (2014). We choose the regularization parameter for eLORETA inverse solutions at and for LCMV beamforming we set the data covariance regularization to λ = 0.05, which both correspond to MNE's default parameters. Dipole orientations were restricted to be fixed orthogonal to the cortical surface.
cMEM inverse solutions were calculated with Brainstorm (Tadel et al., 2011), which is documented and freely available for download online under the GNU general public license (http://neuroimage.usc.edu/brainstorm). The same template brain (fsaverage) was used to calculate a forward model in Brainstorm. Furthermore, the BEM solution was calculated using the same parameters as in MNE. cMEM inverse solutions were calculated using a neighborhood order of 4 with temporally stable clusters. Precomputed noise covariance matrices were imported from MNE Python to ensure that inverse solutions were calculated under the same conditions in Brainstorm and MNE. After calculating all inverse solutions, the files were exported again for further evaluation in Python.
2.5. Evaluation Metrics
We calculated a number of performance metrics to assess the quality of an inverse solution. Note that for each sample in the evaluation sets, we only analyzed the central peak activity.
1) Area under the ROC curve: We calculated the area under the receiver operator curve (ROC) to assess the ability to estimate the correct spatial extent of sources. We adapted a similar procedure as described in Grova et al. (2006) and Chowdhury et al. (2013) with minor changes to the procedure. The dipole clusters in the target source vector j have a Gaussian distribution of dipole moments in our simulations. Therefore, we had to normalize all members of all dipole clusters (i.e. the target source vector) to unit amplitude (i.e. values between 0 and 1). The estimated source vector was normalized between 0 and 1 by division of the maximum. The AUC metric requires equal as many positives as there are negatives in the data. However, in our simulations only few dipoles were active (positives) compared to those not being active (negatives). Therefore, we adapted the procedure as described by Grova et al. (2006) and Chowdhury et al. (2013) by calculating two types of AUC: Both AUCs included all positives and only differ in the selection of negatives. AUCclose contained negative examples that closely surrounded the positive voxels by sampling randomly from the closest 20% voxels. This metric therefore captures how well the source extent is captured. AUCfar on the other hand sampled the negatives from voxels far away from true sources, therefore capturing possible false positives in the estimated source vector . Far negatives were sampled from the 50% of the farthest negatives to the next active dipole. The overall AUC was then calculated by taking the average of AUCclose and AUCfar.
2) Mean localization error (MLE): The Euclidean distance between the locations of the predicted source maximum and the target source maximum is a common measure of inverse solution accuracy as it captures the ability to localize the source center accurately. MLE was calculated between the positions of the maxima of and j. This metric is only suitable for calculating MLE when a single source patch is present.
For multiple sources, we adapted the following procedure. First, we identified local maxima in both the true source vector j and the estimated source vector . First, local maxima were identified where a voxel value is larger than all of its neighboring voxels. This then yields many local maxima, which had to be filtered in order to achieve reasonable results. First, we removed all maxima whose neighbors were not sufficiently active (<20% of the maximum). This takes care of false positive maxima that do not constitute an active cluster of voxels. Then, we removed those maxima that had a larger maximum voxel in close neighborhood within a radius of 30 mm. These procedures result in a list of coordinates of maxima for both j and . We then calculated the pairwise Euclidean distances and between the two lists of coordinates of maxima. For each true source, we identified the closest estimated source and calculated the MLE by averaging of these minimum distances. We further labeled those estimated sources that were ≥ 30 mm away from the next true maximum as ghost sources. True maxima that did have an estimated source within a radius of 30 mm were labeled as found sources, whereas those true maxima that did not have an estimated maximum within a radius of 30 mm were labeled as missed sources. Finally, we calculated the percentage of found sources, i.e., the ratio of the number of correctly identified sources and the number of all true sources.
3) Mean squared error (MSE): The MSE is calculated voxel-wise between the true source vector j and the predicted source vector :
4) Normalized mean squared error (nMSE): The nMSE is calculated by first normalizing both and j to values between 0 and 1. Then, the voxel-wise MSE is calculated as described above.
2.6. Statistics
Statistical comparison between the outcomes of different inverse solutions was done using an unpaired permutation test with 106 permutations. The rationale behind this choice is that most distributions did not meet the criteria for parametric and rank-based tests. Additionally, Cohens d is given for each statistical test (Cohen, 1992).
2.7. Evaluation With Real Data
To evaluate the performance of ConvDip and the other inverse algorithms in a more realistic set-up, we used data of a real EEG recording. The data were recorded while a single participant (first author of this article) viewed fast presentations of faces and scrambled faces. The participant had to indicate whether a face was presented by button press. The duration of a stimulus presentation was 600 ms, followed by 200 ms of black screen. Note that 300 trials of both faces and scrambled faces were presented, which corresponds to a total of 4 min.
The EEG was recorded with 31 electrodes of the 10–20 system using the ActiCap electrode cap and the Brain Vision amplifier ActiCHamp. Data was sampled at 1, 000Hz and filtered online using a band-pass of 0.01–120 Hz. The EEG data were imported to MNE Python and filtered using a band-pass filter between 0.1 and 30 Hz. Data were re-referenced to common average. The trials in which faces were presented were then selected and baseline corrected by subtracting the average amplitude in the interval –0.06 to 0.04 s relative to stimulus onset.
3. Results
In this section, we evaluate the performance of ConvDip and compare it to state-of-the-art inverse algorithms, namely eLORETA, LCMV beamformer, and cMEM. Note that the evaluation set was not part of the training set of ConvDip, hence it is unknown to the model. Furthermore, all samples in the evaluation set were created using the AGM in order to avoid the inverse crime. Exemplary and representative samples are shown in Appendices A, B.
3.1. Evaluation With Single Source Set
3.1.1. Evaluation of Source Extents
We will now evaluate the ability of ConvDip to estimate the correct size of sources and to correctly localize sources with varying depth. For this purpose, we used the data samples from the single-source set. An exemplary and representative sample is shown in Appendix–A.
One of the advantages of inverse algorithms such as cMEM over minimum norm solutions is their capability to estimate not only the position of a source cluster but also its spatial extent. This can be tested using the AUC metric. Chowdhury et al. (2013) suggested that an AUC of 80% and above can be considered acceptable.
This criterion is met by all inverse algorithms in the present evaluation (Table 1). ConvDip achieves the best scores in this comparison with an overall AUC of 98%, closely followed by LCMV (95%) and cMEM (91%). Furthermore, ConvDip inverse solutions show the highest global similarity with nMSE at 0.0033, which is less than half of the error yielded by cMEM. Moreover, the other two methods are far behind (Table 1). MLE of ConvDip is lowest with 11.05 mm, which is remarkably small considering the variance introduced by the AGM. eLORETA yields significantly larger MLE than ConvDip ().

Table 1. Comparison of inverse algorithm performance for samples containing a single source cluster.
3.1.1.1. AUC
In Figure 2 (left graph), the AUC for each inverse algorithm is depicted per simulated source extent. ConvDip is able to reach best performance for extents of s3 and s4 (AUCconvdip,s3,s4 = 99%) with attenuated AUC especially for larger sizes (AUCconvdip,s7 = 94%). The AUC drops by ≈ 5.2% from s3 to s7. cMEM, an inverse algorithm aiming at estimating both location and size of source clusters, shows similar properties. cMEM shows it is best AUC at s2 (AUCcMEM,s2 = 93%). The AUC decreases by ≈ 5.5% from the smallest to the largest source extent, which is comparable to ConvDip. We conclude that while ConvDip yields significantly higher AUC overall (p ≤ 10−6, d > 0.40), its behavior to varying source sizes is similar to that of cMEM. The other inverse algorithms perform significantly worse (Figure 2).
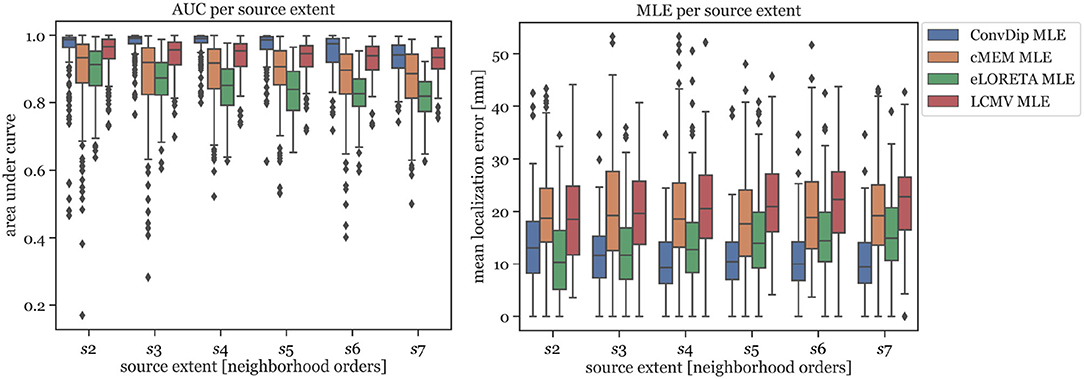
Figure 2. Area under the curve and mean localization error for each inverse solution algorithm grouped by the source extent. AUC reflects capability of finding source at correct location, estimating its size and reducing false positives. MLE reflects the capability to correctly localize the center of the source cluster. Simulations used for this analysis contained only a single source cluster per sample with varying size from two to seven neighborhood orders.
3.1.1.2. MLE
MLE of ConvDip is affected by source extent, as MLEconvdip,s2 is 39% higher compared to MLEconvdip,s7. This observation does not apply to the MLE yielded by inverse solutions of cMEM, which is fairly stable (7% variation). Overall, MLE was smaller for ConvDip inverse solutions compared to the other three inverse algorithms. One particular exception is the case of small source clusters (s2), for which eLORETA yields the most accurate estimates (MLEeLORETA,s2 = 10.34 mm, see Figure 2).
3.1.2. Evaluation of Source Eccentricity
Next, we evaluated the ability of ConvDip to correctly localize source clusters of different eccentricity (i.e., distance from all electrodes). The further away a source is from the electrodes, the harder it is to localize due to volume conduction.
3.1.2.1. AUC
In Figure 3 left, the AUC metric is shown for each inverse algorithm grouped by bins of eccentricity. Bins were defined from 20 mm (deep source clusters) to 80 mm (superficial source clusters). Since deeper sources are harder to localize accurately, AUC is expected to be correlated with eccentricity. However, this could be verified only for ConvDip (r = 0.27, p < 10−16) and cMEM (r = 0.31, p < 10−23). For LCMV beamformer, depth is barely associated with AUC (r = 0.07, p < 0.05) and for eLORETA no such association could be found (r = 0, p > 0.9). Despite these interesting dynamics, ConvDip shows for all eccentricities higher AUC compared to almost all other inverse algorithms. Only the LCMV beamformer shows a non-significant tendency (p < 0.1, d = 0.2) for a higher AUC for low eccentricity of 20 mm (median = 93.39% ± 3.19) than ConvDip (median = 93.44% ± 5.35).
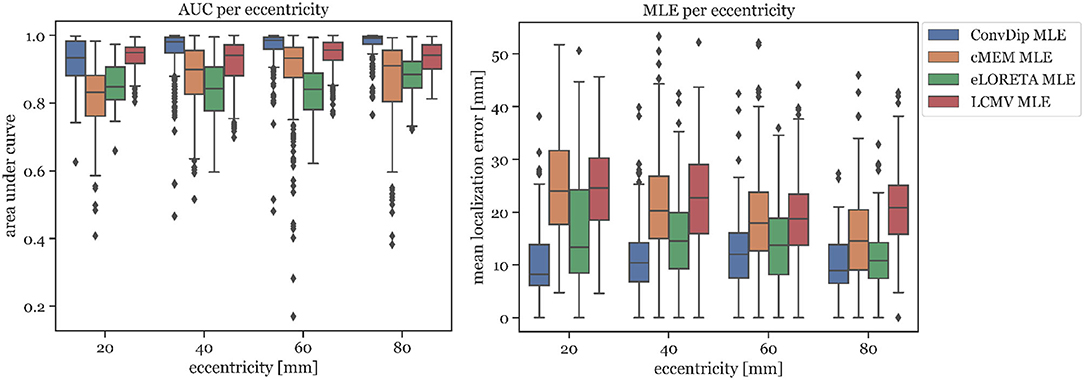
Figure 3. Area under the curve and mean localization error for each inverse algorithm grouped by the source eccentricity. Simulations used for this analysis contained only a single source cluster per sample of varying size from two to seven neighborhood orders.
3.1.2.2. MLE
MLE is also affected by source depth as can be seen in Figure 3 right. We calculated the ratio between the MLE of the deepest source clusters (eccentricity = 20 mm) to the MLE of superficial source clusters (eccentricity = 80 mm) in order to calculate depth sensitivity of each inverse algorithm, henceforth called drop-off. cMEM shows a drop-off of 64%, eLORETA has a drop-off of 23%, and LCMV beamformer has a drop-off of 18%. ConvDip shows the lowest MLEs across eccentricities, compared to the other inverse methods. Moreover, ConvDip shows an inverted U-shaped behavior, with lowest MLE for the deepest and most superficial source clusters. MLE of ConvDip decreases slightly with depth of the source cluster and are not correlated with eccentricity (r = −0.02, p > 0.5), whereas this relation was found for all other inverse algorithms: cMEM (r = −0.30, p < 10−21), eLORETA (r = −0.15, p < 10−5), and LCMV beamformer (r = −0.09, p < 0.01).
Concluding, we find no drop-off in localization accuracy with depth of source clusters when using ConvDip, highlighting a systematically more robust behavior of ConvDip compared to all other inverse algorithms. With depth, however, the ability to estimate the extent of a source cluster is reduced.
3.1.3. Evaluation of Dipole Moments
Finally, we utilized the single-source set to evaluate how well the moments of the dipoles was reconstructed by ConvDip and the other inverse algorithms. We calculated the MSE between each true and predicted source vector (as described in section 2.5). We find that the scaled predictions of ConvDip yielded the lowest MSE (3.93 · 10−19 ± 2.91 · 10−19), followed by cMEM (4.32 · 10−13 ± 3.24 · 10−12) and eLORETA (6.40 · 10−8 ± 1.05 · 10−7). We excluded LCMV beamformer since the approach does not yield dipole moments that can be interpreted in this way. This result is less surprising in the light of the aforementioned results since ConvDip is able to estimate the extent of sources well, which facilitates the estimation of correct dipole moments through the scaling process (refer to section 2.3.3 for an explanation of our scaling approach).
3.2. Evaluation With Multiple Sources
In a realistic situation, the EEG may pick up signals originating from many regions in the brain simultaneously, aggravating the inversion process. Due to the low spatial resolution of the EEG, not all sources can be identified reliably. To evaluate the performance of the inverse algorithms in reconstructing more challenging samples of the multi-source set, we calculated the aforementioned metrics that are summarized in Table 2.
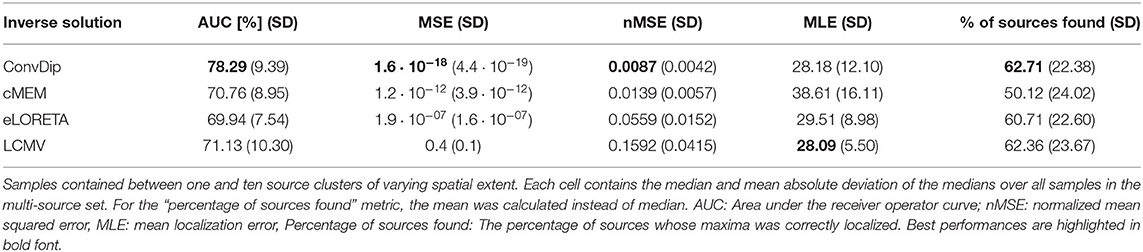
Table 2. Comparison of inverse algorithm performance for samples containing multiple source clusters.
3.2.1. AUC
Overall, the AUC for the multi-source set is low since the desirable 80% AUC is undercut by each inverse algorithm. ConvDip achieved the highest AUC of 78%, thereby surpassing the next best competitor LCMV by ≈ 7.2%.
3.2.2. nMSE
nMSE is substantially smaller for ConvDip inverse solutions compared to all other inverse algorithms with 60% lower nMSE compared to the next best performing algorithm cMEM.
3.2.3. MLE
LCMV beamforming is the only inverse solution (of the tested ones) with lower MLE than ConvDip (Table 2), albeit the absolute difference of the median MLEs is small (diff_MLE ≈ 0.1 mm, p = 10−6, d = 0.22).
3.2.4. Percentage of Found Sources
The percentage of sources found was fairly similar for ConvDip, eLORETA, and LCMV and 10% lower for cMEM (Table 2). Figure 4 shows the results for the metrics AUC and nMSE grouped by the number of sources present in the samples. It is apparent that the accuracy of all inverse solutions depends strongly on the total number of sources that contribute to the EEG signal on the scalp since for each inverse algorithm, the results worsen with increasing numbers of source clusters present in the sample. Pearson correlation between AUC and the number of present source clusters was strong and statistically significant for each inverse algorithm: ConvDip (r = 0.70, p < 10−147), cMEM (r = 0.60, p < 10−97), eLORETA (r = 0.73, p < 10−163), and LCMV (r = 0.73, p < 10−167).
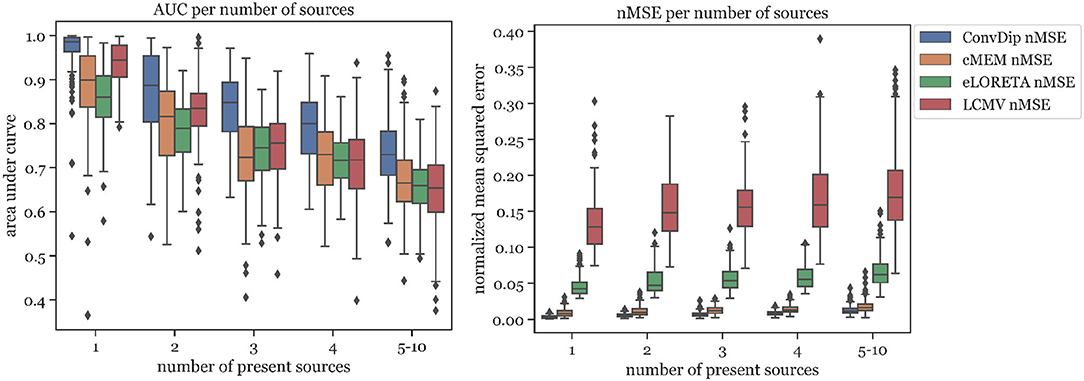
Figure 4. Area under the curve and normalized mean squared error for each inverse algorithm grouped by the number of present source clusters. The right-most columns in each of the graphs display the results for samples containing between 5 and 10 source clusters.
This relationship was also found to exists between MLE and the number of source clusters. For large numbers of source clusters (≥5), LCMV shows the lowest MLE (29.41 mm) or 4.24 mm less than ConvDip (p = 10−6, d = 0.60, Figure 5). This may be a result of the inherent noise-suppressing properties of the LCMV beamformer.
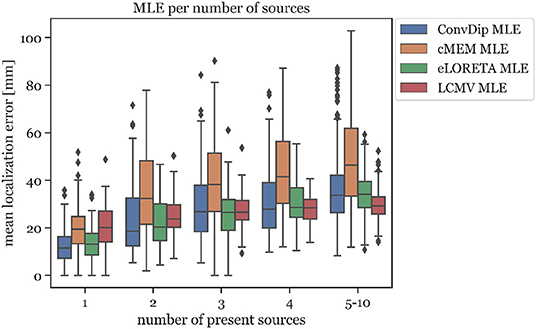
Figure 5. Mean localization error for each inverse algorithm grouped by the number of present source clusters. The rightmost column displays the results for samples containing between 5 and 10 source clusters.
A core result of this analysis is that although ConvDip was trained with samples containing between 1 and 5 source clusters, it is capable of inverting more challenging samples as well (Figure 4).
Furthermore, we showed that discrepancies between the assumed GM and the true bio-physical properties underlying an EEG measurement (e.g., tissue conductivity, precise electrode locations, spacing of the discrete dipole model) can be handled by ConvDip.
ConvDip provides inverse solutions that are valid for samples generated with the AGM and different configurations (namely, different numbers of source clusters). This shows that ConvDip is able to generalize well beyond samples within the training set. This in turn confirms the validity of this purely data-driven approach to solve the EEG inverse problem.
4. Discussion
4.1. Overview
We have presented ConvDip, a CNN that aims to find extended sources of EEG signals. The approach of using a neural network to solve the inverse problem is distinct from classical methods, mainly because it works purely data driven. All constraints on the solution of ConvDip are given implicitly. The performance of ConvDip was evaluated and tested against commonly used inverse algorithms cMEM, eLORETA, and LCMV beamforming. In the following, we discuss the significance of these results.
4.2. Using ANNs to Solve the Inverse Problem
One major result of this work is that the CNN ConvDip was capable to reliably find the locations of neural sources that give rise to the EEG. ConvDip transforms a 7 × 11 image to a large vector of 5,124 voxels. In image classification, CNNs are utilized to do the opposite: To extract hidden information from a large input matrix and output, a single value that indicates some property, e.g., the presence of a cat or a dog. Our work verifies that CNNs are capable to solve an underdetermined problem. This issue was already addressed by Lucas et al. (2018), who demonstrated the advantages of ANNs over analytical approaches to solve the inverse problem.
We trained ConvDip on data generated by GM and subsequently evaluated ConvDip on simulated samples that were generated by the AGM in order to avoid committing the inverse crime. Overall, the performance of ConvDip was sometimes comparable but in most cases better than the classical inverse solutions cMEM, eLORETA, and LCMV beamformer. This provides evidence that ConvDip learned to generalize beyond samples in the training data and remains robust to deviations from the training data. This holds for small deviations in the position of the electrodes (±3.7 mm), tissue conductivities, but also in the configuration of sources (number and size of clusters, deviations from the GM source model grid), and provides another remarkable advantage of these data-driven approach.
We evaluated the performance of ConvDip and the alternative inverse algorithms concerning multiple objectives, the results of which we will discuss in the following.
4.3. Estimating Source Extent
The ability to estimate not only the location of a neural source but also its extent was tested for all inverse algorithms on the single-source set using the AUC and nMSE performance. We find that ConvDip reaches a nearly perfect AUC of ≈ 98%, which is not met by any other inverse algorithm. nMSE, a measure of global similarity between the true and estimated source, was smallest using ConvDip, with less than half the error compared to the next best inverse solutions yielded from cMEM (Table 1). ConvDip furthermore estimated different source sizes appropriately (Figure 2) with higher AUC than all other inverse algorithms. Although these findings are remarkable we have to regard that the shape and size of the sources was rather predictable for ConvDip. All sources in the training and evaluation set had a more or less circular shape due the region growing approach we chose. It may be presumably a large challenge for ConvDip to estimate ellipitical shapes or shapes that are even more deviant to a circle. Despite this caveat, it is remarkable how well ConvDip performs in this comparison considering the variability introduced by the AGM.
4.4. Localizing Deep Sources
A further surprising result for us during the evaluation was that for ConvDip the MLE did not depend on the depth of the source cluster, i.e., ConvDip is capable to correctly localize even deep sources with nearly no drop-off (see Figure 3). This finding was a strong contrast to the findings from other inverse algorithms, which all tend to mislocate deeper sources more than superficial ones. Although source depth did not influence the MLE of ConvDip, we find that the AUC is indeed compromised by depth. This holds also true for cMEM but not for eLORETA and barely for LCMV beamformer. Overall, ConvDip achieved comparable AUCs and MLEs for various depth of source clusters, compared to other inverse solutions, rendering it a viable option for localizing deep sources.
4.5. Performance With Multiple Active Source Clusters
In section 3.2, we evaluated how ConvDip performs when many source clusters are simultaneously active. We observed a drop-off in AUC with increasing numbers of active source clusters from ≈ 99% with single sources to ≈ 73% when 5 or more sources were active simultaneously. Similar behavior was observed for all inverse algorithms tested (see Figure 4). But, ConvDip achieved the highest AUC compared to all alternatives tested, surpassing the best competitor LCMV by ≈ 7.2%. Furthermore, ConvDip also outperformed all other inverse algorithms concerning nMSE (Table 2). Only when five or more source clusters are present, we find slightly lower MLE using LCMV beamformer compared to ConvDip. This increased localization ability of LCMV beamformer could be due to the active suppression of noise signals in the beamforming process. Another reason could be that ConvDip was never trained with samples that contained more than five active source clusters, therefore struggling to accurately localize at least a subset of the source clusters.
4.6. Computation Speed
As already pointed out by Sclabassi et al. (2001), ANNs naturally yield faster inverse solutions than classical methods. On our workstation (CPU: Intel i5 6400, GPU: Nvidia RTX 2070, 16 Gb RAM), one forward pass of ConvDip took on average ≈ 31 ms on the GPU. When all necessary preprocessing steps (such as re-referencing, scaling, and interpolation to 2-D scalp maps) are taken into account, we reached ≈ 32 ms of computation time on average. In comparison, it takes ≈ 129 ms (≈factor 4) to calculate the eLORETA inverse solution using MNE, ≈ 98 ms ms (≈factor 3) for LCMV beamforming and astonishing 11.55 s (≈factor 360) to calculate the iterative cMEM inverse solution using brainstorm. Additionally, one has to provide the noise covariance matrix, which takes on average ≈ 45 ms to compute using the empirical estimation of MNE. In practical terms, ConvDip is capable to compute 31.25 inverse solutions per second (ips) on a GPU, whereas eLORETA reaches 7.75 ips LCMV beamformer 10.20 ips on a CPU. Possibly, implementations of eLORETA and LCMV beamforming that can be run on a GPU achieve lower computation times compared to CPU. The short computation times of ConvDip are at a distinct advantage over other inverse solutions, e.g., in real-time applications as in neurofeedback experiments or in the development of brain–computer interfaces. When comparing our approach to the existing literature on ANN-based inverse solutions, we can now confirm that an ANN not only provides competitively accurate single dipole locations but also a distributed dipole model of the brain-electric activity, taking into account more than one dipole. This can be attributed mostly to the rapid developments in the machine learning domain such as the introduction of convolutional layers (LeCun and Bengio, 1995) and the improvements of GPUs that render the training of large ANNs possible in acceptable time.
4.7. Realistic Simulations
The simulation of EEG data in this study was based on different assumptions on the number, distribution, and shape of electromagnetic fields, which is inspired by Nunez and Srinivasan (2006). The validity of predictions of any inverse solution is only granted if the assumptions on the origin of the EEG signal are correct. This is indeed one of the critical challenges toward realistic inverse solutions in general, both for data-driven inverse solutions (such as ConvDip) as well as classical inverse solutions with physiological constraints (e.g., eLORETA). Therefore, when interpreting the applicability of ConvDip to real data, it is important to specify and justify these assumptions. We show that the knowledge about brain-electric activity underlying EEG signals is emulated by ConvDip after it was trained. However, it is evident from the present work, how critical the particular choice of parameters is with respect to the performance, as ConvDip produces solutions that closely resemble the training samples (see Appendices A, B). A more sophisticated approach to this problem would be to diversify the training data, e.g., by changing the region-growing procedure to produce sources with higher variety of shapes beyond simple spheric source clusters. Nonetheless, ConvDip finds reasonable source clusters when presented with real data (see Appendix–C for an example).
An important observation in real EEG data is the inter-individual variability, which is in part a direct result of individual brain anatomies. For ConvDip application to real EEG data, particularly with group data, it is thus advised to collect anatomical MRI brain scans of each individual subject. Individual neural networks then need to be trained based on each subjects' individual anatomy provided by the MRI data. This may help to achieve accurate group-study source estimations. This, however, raises the problem of computation time, since training individual CNNs is time consuming. A solution to this is an inter-individual transfer learning approach, where ConvDip is trained on one subjects' anatomy and fine-tuned for each additional subject with new training data of the individual anatomies. Fine tuning could be achieved by replacing the output-layer, lowering the learning rate and retraining for only few epochs. Training time per se is another important topic, when considering CNNs to handle the inverse problem.
4.8. Training Time
Although the availability of high-performing hardware resources (e.g., high performing graphic cards) is growing rapidly, the training of the presented neural network architecture requires a considerable amount of processing power and processing time. The version of ConvDip shown in this work required ≈ 10.5 h of training for 500 epochs and 100,000 samples of data using a NVIDIA RTX 2070 GPU. Improving the architecture of ConvDip to shorten training time is an important task for future research, especially when individualized models are required. Limiting the solution space to fewer voxels may be one way to decrease the computation time since most trainable parameters are located at the final fully connected layers. The easiest way would be to reduce the number of parameters of the neural network, e.g., by targeting a CNN with volumetric output of the ANN corresponding to a volumetric source model of the brain. This could spare the computationally expensive fully connected layers and reduce the number of weights in the network. Another possibility is to segment the cortical surface into parcels, i.e., clusters of neighboring dipole positions. This would reduce the size of the output layer by one to two orders of magnitude and thereby reduce the number of trainable parameters dramatically. The feasibility of such a dimension reduction is to be investigated in future developments.
Another computationally expensive processing step is the generation of realistic artificial training data. In this study, we projected neural activity using a three-layer BEM head model. Generating 100,000 simulations of neural activity took 12 min using a PC with CPU @ 4 × 4.3 GHz and 16 GB of RAM. Software that enables EEG researchers to perform physiologically realistic simulations of neural activity for their own ConvDip application is available from different resources, e.g., from the MNE library in Python (Gramfort et al., 2014).
4.9. Further Perspectives for Improvement
The present version of ConvDip is trained on single time instances of EEG data. From a single EEG data point, it is, however, not possible to estimate a noise baseline. As a consequence, such a baseline has not yet been taken into account in ConvDip, which leaves room for improvements toward more regularized and adaptive solutions that are computed flexibly depending on noise conditions. In contrast, LCMV, eLORETA, and cMEM explicitly make use of a noise covariance matrix, which is used to regularize the inverse solution. ConvDip could be improved by extending the data input to an EEG time series, allowing the neural network to learn spatiotemporal patterns.
Possible further advances could be made by preserving the 3D structure of the output space by, instead of a flattened output layer. This can be realized using a deconvolutional neural network for 2D-3D projections (Lin et al., 2018) or by using spatiotemporal information with a LSTM network (Cui et al., 2019). One obvious further way to improve the performance of ConvDip may be to increase the capacity of the neural network, e.g., by adding more layers. In our initial testing phase, we tried different neural architectures without observing significant improvements by adding more layers that justify the increase in training time. Neural architecture search should be used to find a compact, well-performing architecture to solve the EEG inverse problem (Liu et al., 2018).
Finally, the development of a both meaningful and computationally inexpensive loss function, which makes training faster and allows for faster convergence, is key for ANN-based approaches to the inverse problem that can run on ordinary PC within a reasonable amount of time.
4.10. Outlook
We showed that ConvDip, a shallow CNN, is capable of solving the inverse problem using a distributed dipole solution. The association between single time points of EEG measurements and underlying source distributions can be learned and used to predict plausible inverse solutions. These inverse solutions were, furthermore, shown to globally reflect the topology of the brain-electric activity given by the training data.
Predictions yielded from ConvDip are in rare cases comparable to but in the majority of cases better than the here tested existing inverse algorithms in the measures we focused on. Furthermore, the application of ConvDip to real EEG data yields reasonable results. The fully trained ConvDip requires only little computational costs of 32 ms, which makes it a promising tool for real-time applications where only single time points of EEG data are available.
We want to emphasize the importance of realistic simulations of real neural activity that can be measured by EEG. Although a lot of knowledge about the generation of scalp potentials was implemented in our EEG simulations, including more physiological constraints can further reduce the complexity of the inverse problem. One example is the estimation of cortical column orientation (Bonaiuto et al., 2019) or the incorporation of empirical knowledge about region-specific activity from in-vivo (e.g., electrocorticogram) studies. Taking into account these additional aspects may further improve ConvDip's performance.
The current ConvDip version was based on single time points of artificial EEG data. Exploiting temporal aspects of brain dynamics (neighboring time points) may provide additional valuable information and increase the predictive power that may further refine future ConvDip versions.
Data Availability Statement
The simulations and the ConvDip model can be reproduced using the python package located at: https://www.github.com/LukeTheHecker/ESINet.
Ethics Statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
LH conceptualisation, initial idea, implementation, testing, evaluation, and writing the manuscript. RR technical supervision for mathematics, implementation, and artificial neural networks. LT conceptualisation, remarks on results, manuscript, and remarks on future perspectives. JK conceptualization, writing and revising the manuscript, development of evaluation procedure, and discussion. All authors participated in discussing the methodology and evaluating the results and revising the manuscript.
Funding
The project was funded by the European Campus (Eucor) seeding money.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors want to thank NVIDIA Corporation for supplying us with a Titan V GPU as part of the academic seeding program. We thank Roman Tankelevich for his remarks in the early stage of the project.
Footnotes
1. ^Implementation was adapted from https://github.com/N0vel/weighted-hausdorff-distance-tensorflow-keras-loss/.
References
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G. S., et al. (2016). Tensorflow: large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467.
Abeyratne, U. R., Zhang, G., and Saratchandran, P. (2001). EEG source localization: a comparative study of classical and neural network methods. Int. J. Neural Syst. 11, 349–359. doi: 10.1142/S0129065701000813
Amblard, C., Lapalme, E., and Lina, J.-M. (2004). Biomagnetic source detection by maximum entropy and graphical models. IEEE Trans. Biomed. Eng. 51, 427–442. doi: 10.1109/TBME.2003.820999
Awan, F. G., Saleem, O., and Kiran, A. (2019). Recent trends and advances in solving the inverse problem for EEG source localization. Inverse Prob. Sci. Eng. 27, 1521–1536. doi: 10.1080/17415977.2018.1490279
Bonaiuto, J. J., Afdideh, F., Ferez, M., Wagstyl, K., Mattout, J., Bonnefond, M., et al. (2019). Estimates of cortical column orientation improve MEG source inversion. bioRxiv 810267. doi: 10.1101/810267
Brent, R. P. (1971). An algorithm with guaranteed convergence for finding a zero of a function. Comput. J. 14, 422–425. doi: 10.1093/comjnl/14.4.422
Chollet, F. (2015). Keras. Available online at: https://keras.io
Chowdhury, R. A., Lina, J. M., Kobayashi, E., and Grova, C. (2013). MEG source localization of spatially extended generators of epileptic activity: comparing entropic and hierarchical bayesian approaches. PLoS ONE 8:e55969. doi: 10.1371/journal.pone.0055969
Cohen, J. (1992). Statistical power analysis. Curr. Direct. Psychol. Sci. 1, 98–101. doi: 10.1111/1467-8721.ep10768783
Cui, S., Duan, L., Gong, B., Qiao, Y., Xu, F., Chen, J., et al. (2019). EEG source localization using spatio-temporal neural network. China Commun. 16, 131–143. doi: 10.23919/JCC.2019.07.011
Delorme, A., Palmer, J., Onton, J., Oostenveld, R., and Makeig, S. (2012). Independent EEG sources are dipolar. PLoS ONE 7:e30135. doi: 10.1371/journal.pone.0030135
Deru, M., and Ndiaye, A. (2019). Deep learning with tensorFlow, keras and tensorFlow. js. Rheinwerk Comput. 1, 15–55.
Ebersole, J. S. (1994). Non-invasive localization of the epileptogenic focus by EEG dipole modeling. Acta Neurol. Scand. 89, 20–28. doi: 10.1111/j.1600-0404.1994.tb05179.x
Fedorov, M., Koshev, N., and Dylov, D. V. (2020). “Deep learning for Non-invasive cortical potential imaging,” in Machine Learning in Clinical Neuroimaging and Radiogenomics in Neuro-Oncology: Third International Workshop, MLCN 2020, and Second International Workshop, RNO-AI 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, October 4–8, 2020, Proceedings, Vol. 12449, (Springer Nature), 45.
Fischl, B., Sereno, M. I., Tootell, R. B., and Dale, A. M. (1999). High-resolution intersubject averaging and a coordinate system for the cortical surface. Hum. Brain Mapp. 8, 272–284. doi: 10.1002/(SICI)1097-0193(1999)8:4<272::AID-HBM10>3.0.CO;2-4
Friston, K., Harrison, L., Daunizeau, J., Kiebel, S., Phillips, C., Trujillo-Barreto, N., et al. (2008). Multiple sparse priors for the M/EEG inverse problem. NeuroImage 39, 1104–1120. doi: 10.1016/j.neuroimage.2007.09.048
Fuchs, M., Kastner, J., Wagner, M., Hawes, S., and Ebersole, J. S. (2002). A standardized boundary element method volume conductor model. Clin. Neurophysiol. 113, 702–712. doi: 10.1016/S1388-2457(02)00030-5
Glorot, X., Bordes, A., and Bengio, Y. (2011). “Deep sparse rectifier neural networks,” in Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (Fort Lauderdale, FL), 315–323.
Gramfort, A., Luessi, M., Larson, E., Engemann, D. A., Strohmeier, D., Brodbeck, C., et al. (2013). MEG and EEG data analysis with MNE-Python. Front. Neurosci. 7:267. doi: 10.3389/fnins.2013.00267
Gramfort, A., Luessi, M., Larson, E., Engemann, D. A., Strohmeier, D., Brodbeck, C., et al. (2014). MNE software for processing MEG and EEG data. Neuroimage 86, 446–460. doi: 10.1016/j.neuroimage.2013.10.027
Grech, R., Cassar, T., Muscat, J., Camilleri, K. P., Fabri, S. G., Zervakis, M., et al. (2008). Review on solving the inverse problem in EEG source analysis. J. Neuroeng. Rehabil. 5:25. doi: 10.1186/1743-0003-5-25
Grova, C., Daunizeau, J., Lina, J.-M., Bénar, C. G., Benali, H., and Gotman, J. (2006). Evaluation of EEG localization methods using realistic simulations of interictal spikes. Neuroimage 29, 734–753. doi: 10.1016/j.neuroimage.2005.08.053
Hämäläinen, M. S., and Ilmoniemi, R. J. (1994). Interpreting magnetic fields of the brain: minimum norm estimates. Med. Biol. Eng. Comput. 32, 35–42. doi: 10.1007/BF02512476
He, B., Sohrabpour, A., Brown, E., and Liu, Z. (2018). Electrophysiological source imaging: a noninvasive window to brain dynamics. Ann. Rev. Biomed. Eng. 20, 171–196. doi: 10.1146/annurev-bioeng-062117-120853
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
Hoey, G. V., Clercq, J. D., Vanrumste, B., de Walle, R. V., Lemahieu, I., D'Havé, M., et al. (2000). EEG dipole source localization using artificial neural networks. Phys. Med. Biol. 45, 997–1011. doi: 10.1088/0031-9155/45/4/314
Ioannides, A. A., Bolton, J. P. R., and Clarke, C. J. S. (1990). Continuous probabilistic solutions to the biomagnetic inverse problem. Inverse Probl. 6:523. doi: 10.1088/0266-5611/6/4/005
Ioffe, S., and Szegedy, C. (2015). Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167.
Jin, K. H., McCann, M. T., Froustey, E., and Unser, M. (2017). Deep convolutional neural network for inverse problems in imaging. IEEE Trans. Image Proc. 26, 4509–4522. doi: 10.1109/TIP.2017.2713099
Joos, E., Giersch, A., Hecker, L., Schipp, J., Heinrich, S. P., Tebartz van Elst, L., et al. (2020). Large EEG amplitude effects are highly similar across Necker cube, smiley, and abstract stimuli. PLoS ONE 15:e0232928. doi: 10.1371/journal.pone.0232928
Kaipio, J., and Somersalo, E. (2006). Statistical and Computational Inverse Problems. Luxemburg: Springer Science & Business Media.
Kanwisher, N., and Yovel, G. (2006). The fusiform face area: a cortical region specialized for the perception of faces. Philos. Trans. R. Soc. B Biol. Sci. 361, 2109–2128. doi: 10.1098/rstb.2006.1934
Kavanagk, R. N., Darcey, T. M., Lehmann, D., and Fender, D. H. (1978). Evaluation of methods for three-dimensional localization of electrical sources in the human brain. IEEE Trans. Biomed. Eng. 25, 421–429. doi: 10.1109/TBME.1978.326339
Kim, Y. (2014). Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882. doi: 10.3115/v1/D14-1181
Kingma, D. P., and Ba, J. (2014). Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Koles, Z. J. (1998). Trends in EEG source localization. Electroencephalogr. Clin. Neurophysiol. 106, 127–137. doi: 10.1016/S0013-4694(97)00115-6
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems (Lake Tahoe, NV), 1097–1105.
Lantz, G., Holub, M., Ryding, E., and Rosén, I. (1996). Simultaneous intracranial and extracranial recording of interictal epileptiform activity in patients with drug resistant partial epilepsy: Patterns of conduction and results from dipole reconstructions. Electroencephalogr. Clin. Neurophysiol. 99, 69–78. doi: 10.1016/0921-884X(96)95686-6
LeCun, Y., and Bengio, Y. (1995). Convolutional networks for images, speech, and time series. Handbook Brain Theory Neural Netw. 3361:1995.
Lin, C.-H., Kong, C., and Lucey, S. (2018). “Learning efficient point cloud generation for dense 3d object reconstruction,” in Thirty-Second AAAI Conference on Artificial Intelligence (New Orleans, LA).
Liu, C., Zoph, B., Neumann, M., Shlens, J., Hua, W., Li, L.-J., et al. (2018). “Progressive neural architecture search,” in Proceedings of the European Conference on Computer Vision (ECCV) (Munich), 19–34.
Lucas, A., Iliadis, M., Molina, R., and Katsaggelos, A. K. (2018). Using deep neural networks for inverse problems in imaging: beyond analytical methods. IEEE Signal Proc. Mag. 35, 20–36. doi: 10.1109/MSP.2017.2760358
Michel, C. M., and Brunet, D. (2019). EEG source imaging: a practical review of the analysis steps. Front. Neurol. 10:325. doi: 10.3389/fneur.2019.00325
Nair, V., and Hinton, G. E. (2010). “Rectified linear units improve restricted boltzmann machines,” in Proceedings of the 27th International Conference on Machine Learning (ICML-10) (Madison, WI), 807–814.
Nunez, P. L., and Srinivasan, R. (2006). Electric Fields of the Brain: The Neurophysics of EEG. Oxford: Oxford University Press, USA.
Pascual-Marqui, R., Michel, C. M., and Lehmann, D. (1994). Low-resolution electromagnetic tomography–a new method for localizing electrical activity in the brain. Int. J. Psychophysiol. 18, 49–65. doi: 10.1016/0167-8760(84)90014-X
Pascual-Marqui, R. D. (1999). Review of methods for solving the EEG inverse problem. Int. J. Bioelectromagn. 1, 75–86.
Pascual-Marqui, R. D. (2007). Discrete, 3D distributed, linear imaging methods of electric neuronal activity. Part 1: Exact, zero error localization. arXiv preprint arXiv:0710.3341.
Razorenova, A., Yavich, N., Malovichko, M., Fedorov, M., Koshev, N., and Dylov, D. V. (2020). “Deep Learning for Non-Invasive Cortical Potential Imaging,” in Machine Learning in Clinical Neuroimaging and Radiogenomics in Neuro-Oncology (Lima: Springer), 45–55.
Ribera, J., Guera, D., Chen, Y., and Delp, E. J. (2019). “Locating objects without bounding boxes,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (San Juan), 6479–6489.
Ritter, P., and Villringer, A. (2006). Simultaneous EEG–fMRI. Neurosci. Biobehav. Rev. 30, 823–838. doi: 10.1016/j.neubiorev.2006.06.008
Robert, C., Gaudy, J.-F., and Limoge, A. (2002). Electroencephalogram processing using neural networks. Clin. Neurophysiol. 113, 694–701. doi: 10.1016/S1388-2457(02)00033-0
Scherg, M. (1990). Fundamentals of dipole source potential analysis. Auditory Evoked Magn. Fields Electr. Potent. Adv. Audiol. 6, 40–69.
Schirrmeister, R. T., Springenberg, J. T., Fiederer, L. D. J., Glasstetter, M., Eggensperger, K., Tangermann, M., et al. (2017). Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 38, 5391–5420. doi: 10.1002/hbm.23730
Sclabassi, R. J., Sonmez, M., and Sun, M. (2001). EEG source localization: a neural network approach. Neurol. Res. 23, 457–464. doi: 10.1179/016164101101198848
Sharma, P., Scherg, M., Pinborg, L. H., Fabricius, M., Rubboli, G., Pedersen, B., et al. (2018). Ictal and interictal electric source imaging in pre-surgical evaluation: a prospective study. Eur. J. Neurol. 25, 1154–1160. doi: 10.1111/ene.13676
Simonyan, K., and Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
Tadel, F., Baillet, S., Mosher, J. C., Pantazis, D., and Leahy, R. M. (2011). Brainstorm: a user-friendly application for MEG/EEG analysis. Comput. Intell. Neurosci. 2011:879716. doi: 10.1155/2011/879716
Tankelevich, R. (2019). Inverse problem's solution using deep learning: An EEG-based study of brain activity. Part 1. Available online at: https://www.researchgate.net/publication/331153114_Inverse_Problem's_Solution_Using_Deep_Learning_An_EEG-based_Study_of_Brain_Activity_Part_1_-_rel_10
Van Veen, B. D., van Drongelen, W., Yuchtman, M., and Suzuki, A. (1997). Localization of brain electrical activity via linearly constrained minimum variance spatial filtering. IEEE Trans. Biomed. Eng. 44, 867–880. doi: 10.1109/10.623056
Willemse, R. B., Hillebrand, A., Ronner, H. E., Peter Vandertop, W., and Stam, C. J. (2016). Magnetoencephalographic study of hand and foot sensorimotor organization in 325 consecutive patients evaluated for tumor or epilepsy surgery. Neuroimage Clin. 10, 46–53. doi: 10.1016/j.nicl.2015.11.002
Wipf, D. and Nagarajan, S. (2009). A unified Bayesian framework for MEG/EEG source imaging. Neuroimage 44, 947–966. doi: 10.1016/j.neuroimage.2008.02.059
Wolters, C. H., Lew, S., MacLeod, R. S., and Hämäläinen, M. (2010). Combined EEG/MEG source analysis using calibrated finite element head models. Biomed. Technik Biomed. Eng. Rostock Germany 55(Suppl. 1), 64–68.
Yuasa, M., Zhang, Q., Nagashino, H., and Kinouchi, Y. (1998). “EEG source localization for two dipoles by neural networks,” in Proceedings of the 20th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Vol. 20 Biomedical Engineering Towards the Year 2000 and Beyond (Cat. No. 98CH36286), Vol. 4 (Hong Kong: IEEE), 2190–2192.
Zhang, Q., Yuasa, M., Nagashino, H., and Kinouchi, Y. (1998). “Single dipole source localization from conventional EEG using BP neural networks,” in Proceedings of the 20th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Vol. 20 Biomedical Engineering Towards the Year 2000 and Beyond (Cat. No. 98CH36286), Vol. 4 (IEEE), 2163–2166.
A. Appendix
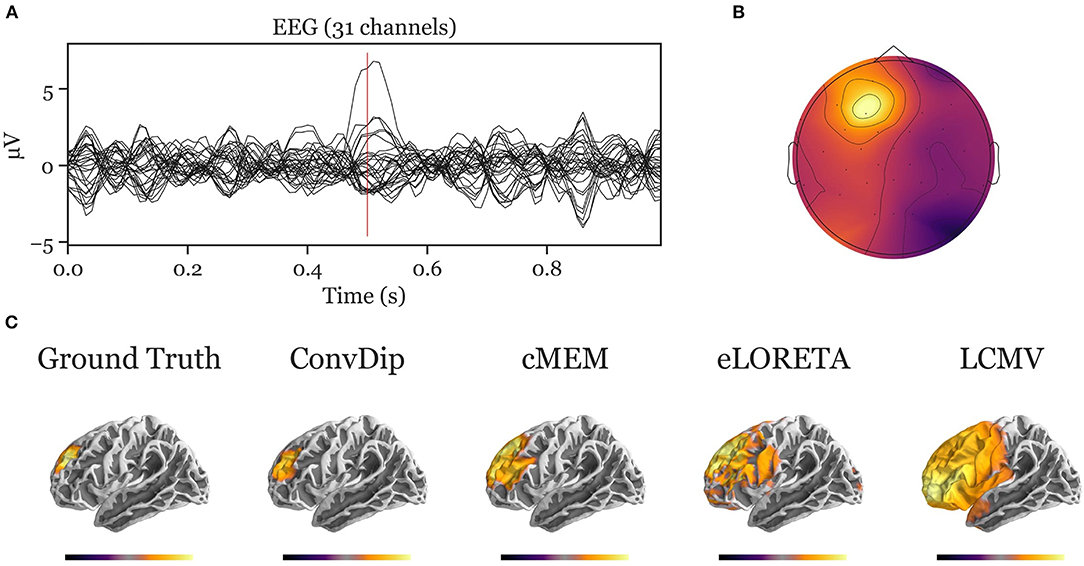
Figure A1. Inverse solution of a simulation containing a single source cluster. An exemplary, representative sample of inverse solutions for a single source cluster. (A) The ERP at each of the 31 channels containing both signal (central peak) and realistic noise from real recordings. (B) The scalp map at the central ERP peak (as indicated by the vertical red line in A). (C) The dipole moments plotted on the white matter surface of the template brain in lateral view of the left hemisphere. On the left, the ground truth source pattern is depicted with a source cluster in the frontal cortex of the left hemisphere. Various inverse solutions that aim to recover this pattern are depicted next to it. Voxels below 25% of the respective maximum are omitted for a clearer representation of the current distribution.
B. Appendix
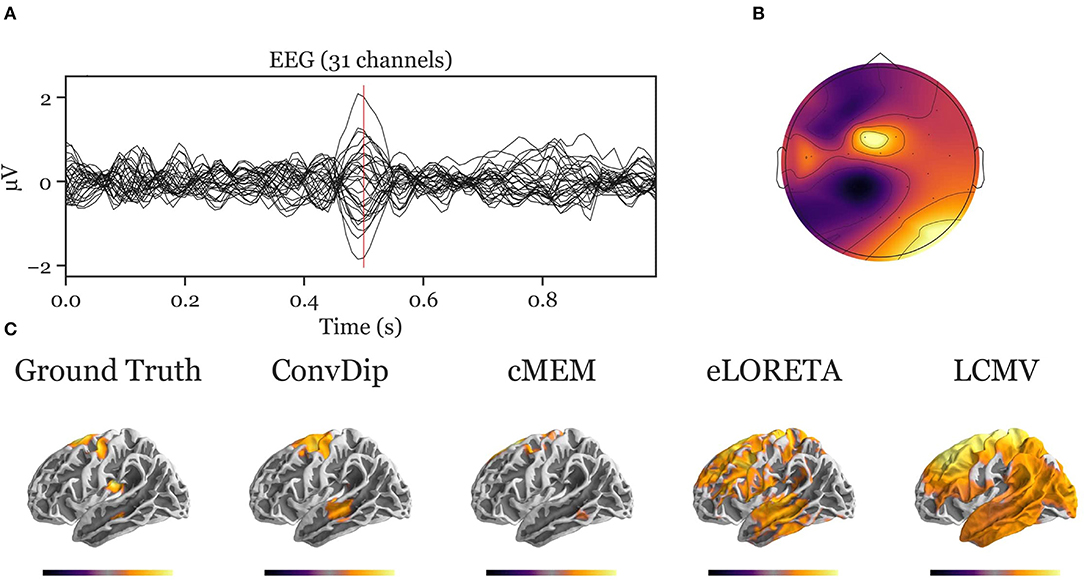
Figure A2. Inverse solution of a simulation containing four source clusters. An exemplary, representative sample of inverse solutions for four source clusters. (A) The ERP at each of the 31 channels containing both signal (central peak) and realistic noise from real recordings. (B) The scalp map at the central ERP peak (vertical red line in A). (C) The dipole moments plotted on the white matter surface of the template brain in lateral view of the left hemisphere. On the left, the ground truth source pattern is depicted with a source cluster in the motor cortex, supplementary motor area, insula and the middle temporal lobe of the left hemisphere. Various inverse solutions that aim to recover this pattern are depicted next to it. Voxels below 25% of the respective maximum are omitted for a clearer representation of the current distribution.
C. Appendix
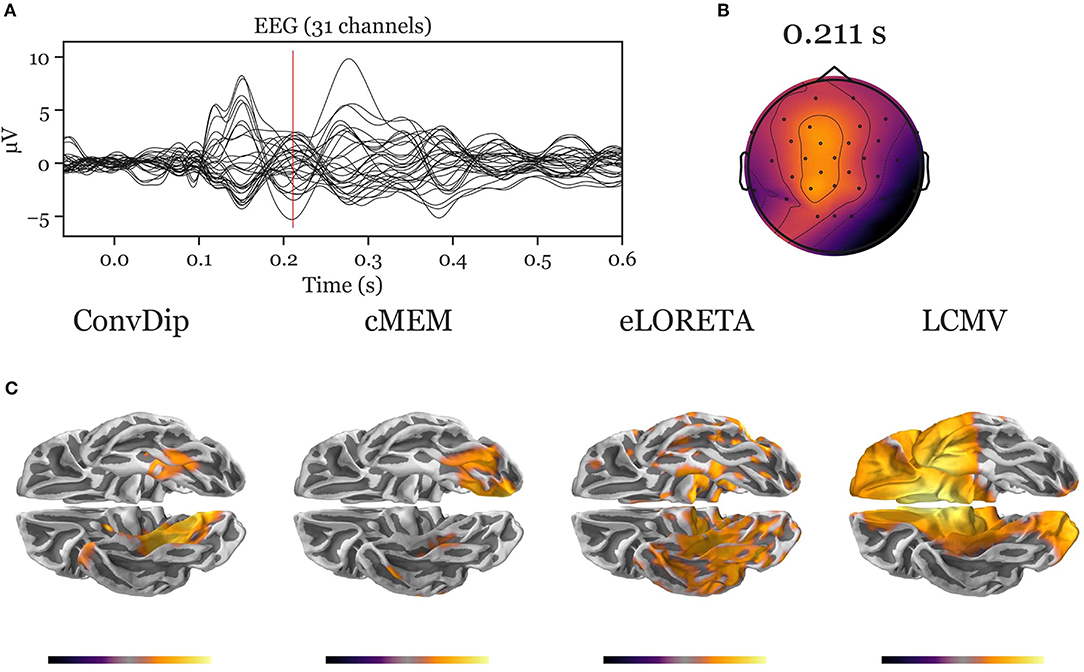
Figure A3. Inverse solution of real face-evoked data. All inverse algorithms were subjected to real EEG data recorded from a single participant containing 150 trials of face-evoked potentials. (A) The ERP at each of the 31 channels. (B) The scalp map at a N170-like component (vertical red line in A, 211 ms after stimulus onset). (C) The dipole moments plotted on the white matter surface of the template brain in ventral view of the right hemisphere to reveal the inferior temporal cortex (ITC). Various inverse solutions show activity in the ITC. Notably, ConvDip and cMEM recover a focal source cluster close or within the fusiform face area, a region known to be involved in face processing (e.g., Kanwisher and Yovel, 2006; Joos et al., 2020). Voxels below 25% of the respective maximum are omitted for a clearer representation of the current distribution.
Keywords: EEG-electroencephalogram, artificial neural networks, convolutional neural networks (CNN), inverse problem, machine learning, electrical source imaging
Citation: Hecker L, Rupprecht R, Tebartz Van Elst L and Kornmeier J (2021) ConvDip: A Convolutional Neural Network for Better EEG Source Imaging. Front. Neurosci. 15:569918. doi: 10.3389/fnins.2021.569918
Received: 05 June 2020; Accepted: 14 April 2021;
Published: 09 June 2021.
Edited by:
Alard Roebroeck, Maastricht University, NetherlandsReviewed by:
Annalisa Pascarella, Istituto per le Applicazioni del Calcolo “Mauro Picone” (IAC), ItalyMiguel Castelo-Branco, Coimbra Institute for Biomedical Imaging and Translational Research (CIBIT), Portugal
Copyright © 2021 Hecker, Rupprecht, Tebartz Van Elst and Kornmeier. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Lukas Hecker, bHVrYXNfaGVja2VyQHdlYi5kZQ==