 Masatoshi Nagano1*
Masatoshi Nagano1* Tomoaki Nakamura1
Tomoaki Nakamura1 Takayuki Nagai2,3
Takayuki Nagai2,3 Daichi Mochihashi4
Daichi Mochihashi4 Ichiro Kobayashi5
Ichiro Kobayashi5 Wataru Takano6
Wataru Takano6- 1Department of Mechanical Engineering and Intelligent Systems, The University of Electro-Communications, Tokyo, Japan
- 2Graduate School of Engineering Science, Osaka University, Osaka, Japan
- 3Artificial Intelligence Exploration Research Center, The University of Electro-Communications, Tokyo, Japan
- 4Department of Statistical Inference and Mathematics, The Institute of Statistical Mathematics, Tokyo, Japan
- 5Advanced Sciences, Graduate School of Humanities and Sciences, Ochanomizu University, Tokyo, Japan
- 6Center for Mathematical Modeling and Data Science, Osaka University, Osaka, Japan
Humans perceive continuous high-dimensional information by dividing it into meaningful segments, such as words and units of motion. We believe that such unsupervised segmentation is also important for robots to learn topics such as language and motion. To this end, we previously proposed a hierarchical Dirichlet process–Gaussian process–hidden semi-Markov model (HDP-GP-HSMM). However, an important drawback of this model is that it cannot divide high-dimensional time-series data. Furthermore, low-dimensional features must be extracted in advance. Segmentation largely depends on the design of features, and it is difficult to design effective features, especially in the case of high-dimensional data. To overcome this problem, this study proposes a hierarchical Dirichlet process–variational autoencoder–Gaussian process–hidden semi-Markov model (HVGH). The parameters of the proposed HVGH are estimated through a mutual learning loop of the variational autoencoder and our previously proposed HDP-GP-HSMM. Hence, HVGH can extract features from high-dimensional time-series data while simultaneously dividing it into segments in an unsupervised manner. In an experiment, we used various motion-capture data to demonstrate that our proposed model estimates the correct number of classes and more accurate segments than baseline methods. Moreover, we show that the proposed method can learn latent space suitable for segmentation.
1. Introduction
Humans perceive continuous high-dimensional information by dividing it into meaningful segments, such as words and units of motion. For example, we recognize words by segmenting speech waves, and we perceive particular motions by segmenting continuous motion. Humans learn words and motions by appropriately segmenting continuous information without explicit segmentation points. We believe that such unsupervised segmentation is also important for robots, in order for them to learn language and motion.
In this paper, we define the segments as arbitrary temporal patterns that appear multiple times in the time-series data. Additionally, we have proposed a method to extract the segments by capturing such a nature stochastically. One of our previous methods is the hierarchical Dirichlet process–Gaussian process–hidden semi-Markov model (HDP-GP-HSMM) (Nagano et al., 2018). HDP-GP-HSMM is a non-parametric Bayesian model that is a hidden semi-Markov model, the emission distributions of which are Gaussian processes (MacKay, 1998), and it facilitates the segmentation of time-series data in an unsupervised manner. In this model, segments are continuously represented using a Gaussian process. Moreover, the number of segmented classes can be estimated using hierarchical Dirichlet processes (Teh et al., 2006). The Dirichlet processes assume an infinite number of classes. However, only a finite number of classes are actually used. This is accomplished by stochastically truncating the number of classes using a slice sampler (Van Gael et al., 2008).
However, our HDP-GP-HSMM cannot handle high-dimensional data, and feature extraction is required to reduce the dimensionality in advance. Indeed, segmentation largely depends on this feature extraction, and it is difficult to extract effective features, especially in the case of high-dimensional data. To overcome this problem, this study introduces a variational autoencoder (VAE) (Kingma et al., 2013) to HDP-GP-HSMM. Thus, the model we propose in this paper is a hierarchical Dirichlet process–variational autoencoder–Gaussian process–hidden semi-Markov model (HVGH1). Figure 1 shows an overview of HVGH. The observation sequence is compressed and converted into a latent variable sequence by the VAE, and the latent variable sequence is divided into segments by HDP-GP-HSMM. Furthermore, parameters learned by HDP-GP-HSMM are used as the hyperparameters for the VAE. In this way, the parameters are optimized in a mutual learning loop, and appropriate latent space for segmentation can be learned by the VAE. In experiments, we evaluated the efficiency of the proposed HVGH using real motion-capture datasets. The experimental results show that HVGH achieves a higher accuracy compared to baseline methods.
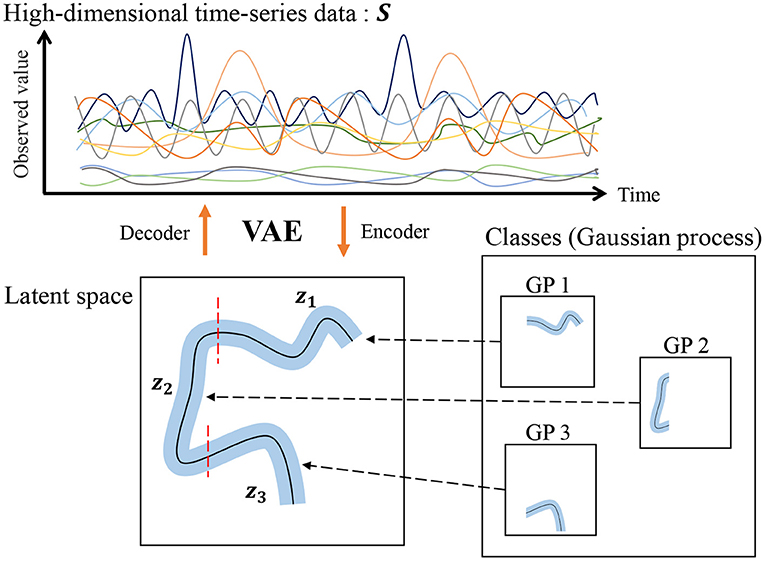
Figure 1. Overview of the generative process of the HVGH.
Many studies on unsupervised motion segmentation have been conducted. However, heuristic assumptions are used in many of them (Lioutikov et al., 2015; Wächter et al., 2015; Takano et al., 2016). Wächter et al. proposed a method for segmenting object-manipulation motion in robots and used contact between the end-effector and the object as a segmentation clue (Wächter et al., 2015). Lioutikov et al. proposed a method that requires candidates for the segmentation points in advance (Lioutikov et al., 2015). In addition, the method proposed by Takano et al. used errors between the predicted and actual values as criteria for segmentation (Takano et al., 2016). Moreover, some methods use motion features such as the zero velocity of joint angles (Fod et al., 2002; Shiratori et al., 2004; Lin et al., 2012). However, this assumption typically induces over-segmentation (Lioutikov et al., 2015).
Furthermore, studies have proposed methods of detecting change points in time-series data in an unsupervised manner (Yamanishi et al., 2002; Lund et al., 2007; Liu et al., 2013; Haber et al., 2014). These are the methods of finding points with different fluctuations based on previous observations. Therefore, these methods assume that similar temporal patterns are repeated between the change points. On the other hand, in this study, we consider that the segments comprise not only repeated patterns but also an arbitrary pattern. Thus, the change points do not necessarily indicate the segment boundaries.
In some studies, segmentation is formulated stochastically using hidden Markov models (HMMs) (Beal et al., 2002; Fox et al., 2011; Taniguchi et al., 2011; Matsubara et al., 2014). However, it is difficult for HMMs to represent complicated motion patterns. Instead, we use Gaussian processes in our model, which is a type of non-parametric model that can better represent complicated time-series data compared to HMMs. Figure 2B shows how an HMM represents the trajectory of data points shown in Figure 2A. The HMM represents the trajectory using five Gaussian distributions. However, one can see that the details of the trajectory are lost. On the other hand, in HDP-GP-HSMM (Figure 2C), the trajectory can be represented continuously using two Gaussian processes (GPs). We confirmed that our GP-based model can estimate segments more accurately than HMM-based methods (Nagano et al., 2018).
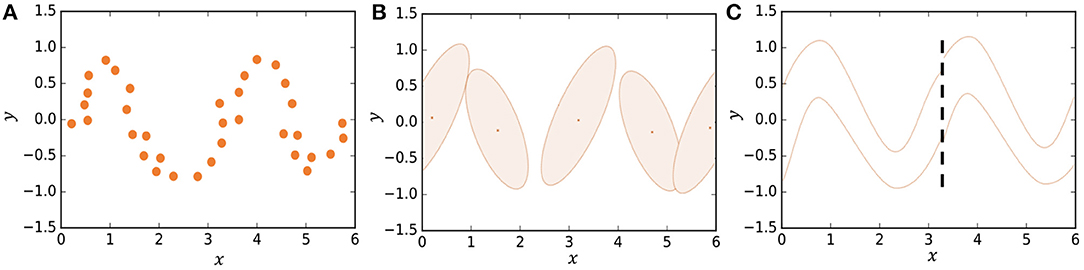
Figure 2. Representing a trajectory: (A) Observed data points, (B) representation by HMM, and (C) representation by HDP-GP-HSMM.
In some studies, the number of classes is estimated by introducing a hierarchical Dirichlet process (HDP) into an HMM (Beal et al., 2002; Fox et al., 2007). An HDP is a method of estimating the number of classes by assuming an infinite number of classes. Fox et al. extended an HDP–HMM to develop a so-called sticky HDP-HMM, which prevents over-segmentation by increasing the self-transition probability (Fox et al., 2007).
Among methods of combining statistical models with neural networks, a method of classifying complicated data using a GMM and VAE was proposed (Johnson et al., 2016). In contrast, our proposed HVGH is a model that combines a statistical model with a VAE for segmenting high-dimensional time-series data.
2. Hierarchical Dirichlet Process–Variational Autoencoder–Gaussian Process–Hidden Semi-Markov Model (HVGH)
Figure 3 shows a graphical model of our proposed HVGH, which is a generative model of time-series data. In this model, cj(j = 1, 2, ··· , ∞) denotes the classes of the segments, where the number of classes is assumed to be countably infinite. β denotes an infinite-dimensional multinomial distribution, which is generated from the GEM distribution (Pitman, 2002), parameterized by γ. GEM denotes the co-authors Griffiths, Engen, and McCloskey—with the so-called stick-breaking process (SBP) (Sethuraman, 1994). The probability πc denotes the transition probability, which is generated by the Dirichlet process (Teh et al., 2006), parameterized by β:
γ and η are the concentration parameters of the Dirichlet processes; the smaller the value of the concentration parameter, the sparser the generated distribution is. The process by which the probability distribution is constructed through a two-phase Dirichlet process is called a hierarchical Dirichlet process (HDP) (Teh et al., 2006). HDP is described in detail in Nagano et al. (2018).
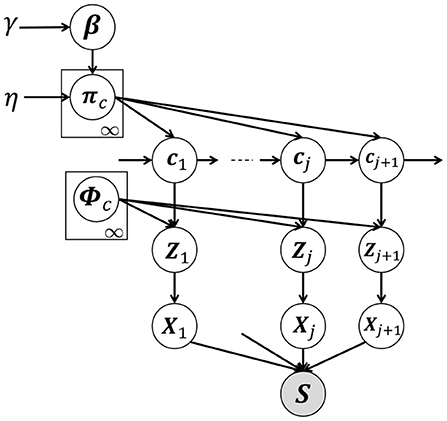
Figure 3. Graphical model of HVGH. The white nodes represent unobserved variables, and the gray node represents the high-dimensional observed sequence that is obtained by concatenating segments.
The class cj of the j-th segment is determined by the class of the (j − 1)-th segment and transition probability πc. The segment of latent variables Zj is generated by a Gaussian process (MacKay, 1998) with the parameter ϕc as follows:
where ϕc represents the parameter of the Gaussian process corresponding to the class c and is a set of segments classified into the class c in the learning phase. The segment Xj is generated from the segment of the latent variables Zj by using the decoder pdec of the VAE:
The observed sequence s = X1, X2, ··· , XJ is assumed to be generated by connecting segments Xj sampled by the above generative process. Similarly, the sequence of the latent variables is obtained by connecting the segments of the latent variables Zj. In this paper, the i-th data point included in Xj is described as xji, and the i-th data point included in Zj is described as zji. If the characters represent what they obviously are, we omit their subscripts.
The generative process of the observed sequence s described above is summarized in Algorithm 1. This pseudo code represents the generative process, and it is difficult to directly implement this code because the number of classes is infinite. The details on how to address this problem are described in section 3.

Algorithm 1: Generative process of s by HVGH
2.1. Gaussian Process (GP)
In this paper, each class represents a continuous trajectory by learning the emission zi of time step i using a Gaussian process (MacKay, 1998). In the Gaussian process, given tc and ic, which are the vectors of the latent variable zi that is classified into class c and its time step i, respectively (details are explained later), the predictive distribution of ẑ of time step î is a Gaussian distribution with the parameters μ and σ2:
Here, C is a matrix having the following elements:
where k(·, ·) denotes the kernel function and ω denotes a hyperparameter that represents noise in the observations. k is a vector with the elements k(ip, î), and ρ is k(î, î). ϕc represents a set of the segments of latent variables that are classified into the class c, and tc and ic are the vectors where a respective latent variable zi and time step i in ϕc are arranged. For example, assuming that the latent variables have one dimension, and segments Z1, Z2, ··· are classified into class c, we can compute tc and ic as follows:
Once tc and ic are computed, they are shared to compute the probability of (ẑ, î) being classified into class c. A Gaussian process can represent complicated time-series data owing to the kernel function. In this paper, we used the following kernel function:
where θ* denotes the parameters of the kernel, which are fixed for all classes in our experiments. The reason why we select this kernel is that the motions are generally smooth and, hence, we consider the latent variable to also be temporally smooth. Figure 4 illustrates the samples from various kernels: linear, exponential, periodic, and radial basic function (RBF) kernels (Bishop, 2006). As can be observed in this figure, it is difficult for the linear and periodic kernels to represent a non-linear and non-periodic pattern, and the sample of the exponential kernel is not smooth. On the other hand, the RBF kernel can represent a smooth temporal pattern. Therefore, we use the kernel based on the RBF kernel, which is generally used for Gaussian processes (Bishop, 2006). However, it is not evident as to which kernel is the most appropriate. Moreover, the appropriate kernel depends on the task. This issue will be considered in future work because it exceeds the scope of this paper.
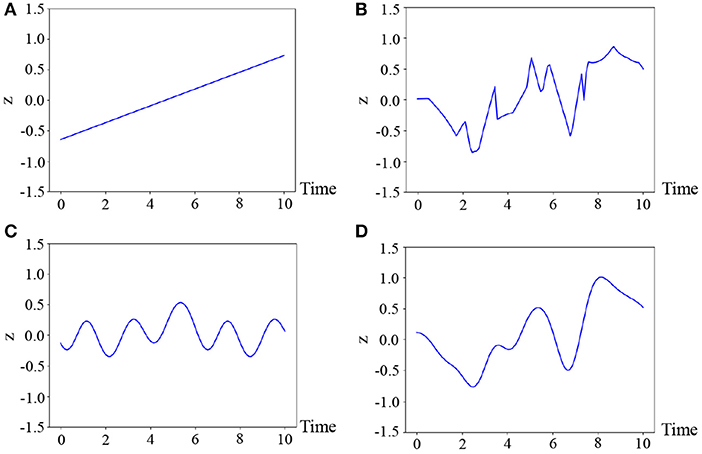
Figure 4. Four temporal patterns sampled from the Gaussian processes, where (A) linear : ipiq, (B) exponential : exp(−|ip − iq|), (C) periodic : exp(cos|ip − iq|), and (D) RBF : are used.
Additionally, if the observations are composed of multidimensional vectors, we assume that each dimension is independently generated. Therefore, the predictive distribution by which the emission z = (z(1), z(2), ··· ) of time step i is generated using a Gaussian process of class c is computed as follows:
By using this probability, the latent variables can be classified into the classes. Moreover, because each dimension is independently generated, the mean vector μc(i) and the variance–covariance matrix Σc(i) of are represented as follows:
where (μ1, μ2, μ3, ··· ) and , respectively, represent the mean and variance of each dimension. HVGH is a model in which the VAE and GP influence each other mutually with the use of μc(i) and Σc(i) as the prior distribution of the VAE.
2.2. Overview of the Variational Autoencoder
In this paper, we compress a high-dimensional time-series observation into low-dimensional latent variables using the VAE (Kingma et al., 2013). The VAE is a neural network that can learn the correspondence between a high-dimensional observation x and the latent variable z. Generally, in a probabilistic model, the posterior distribution of z can be expressed as follows:
However, if a neural network that has expressive power is used for the generative model pdec(x|z), Equation (18) cannot be analytically derived. To solve this problem, in the VAE, p(z|x) is approximated by qenc(z). Figure 5 shows an overview of the VAE. A Gaussian distribution with a mean μenc(x) and variance Σenc(x) that are estimated by using encoder networks from input x is used as qenc(z):
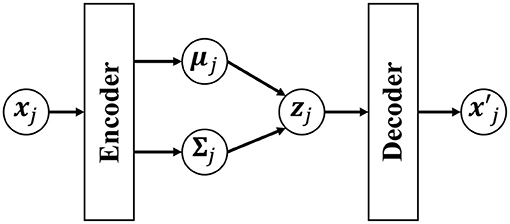
Figure 5. Overview of the variational autoencoder (VAE). The low-dimensional latent variable zj is obtained by compressing the observed data point xj through the encoder network. is an observation reconstructed by the decoder from the latent variable zj.
The latent variable z is stochastically determined by this distribution, and x′ is generated through decoder networks pdec:
The parameters of the encoder and decoder are determined to maximize the likelihood by using the variational Bayesian method. Generally, the prior distribution of the VAE is a Gaussian distribution, the mean of which is the zero vector 0, and the variance–covariance matrix is the identity matrix e. On the other hand, HVGH uses a Gaussian distribution whose parameters are μc(i) and Σc(i) of class c into which zji is classified. As a result, latent space suitable for segmentation can be constructed. By using this VAE, a sequence of the observation s = X1, X2, ··· , XJ is converted into a sequence of the latent variables through the encoder.
3. Parameter Inference
The log likelihood of HVGH is expressed as follows:
In Equation (24), the first and second factors are computed in HDP-GP-HSMM, and the third factor is computed in VAE. It is difficult to directly maximize Equation (22); therefore, HDP-GP-HSMM and the VAE are alternately optimized, and the parameters that approximately maximize Equation (22) are computed. Figure 6 depicts an outline of the parameter estimation for HVGH. A sequence of observations s = X1, X2, ··· , XJ is converted into a sequence of latent variables by the VAE. Then, through HDP-GP-HSMM, the sequence of latent variables is divided into segments of latent variables Z1, Z2, ··· , ZJ, and the parameters μc(i) and Σc(i) of the predictive distribution of z are computed. This predictive distribution is used as a prior distribution of the VAE. Thus, the parameters of the VAE and HDP-GP-HSMM are mutually optimized.
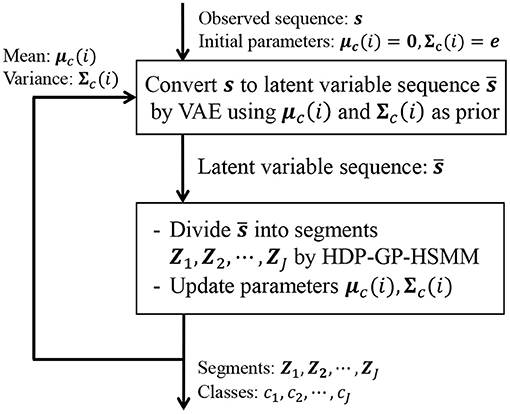
Figure 6. Overview of parameter estimation for HVGH. The parameters are learned by a mutual learning loop of the VAE and HDP-GP-HSMM.
3.1. Parameter Inference of HDP-GP-HSMM
3.1.1. Blocked Gibbs Sampler
In HDP-GP-HSMM, segments and classes of latent variables are determined by sampling. For efficient estimation, we utilize a blocked Gibbs sampler (Jensen et al., 1995), in which all segments and their classes in one observed sequence are sampled. First, all sequences of the latent variables are randomly divided into segments and randomly classified into classes. Next, the segments of latent variables Znj(j = 1, 2, ··· , Jn) obtained by segmenting the n-th sequence are excluded from the training data, and the parameters of the Gaussian process ϕc and transition probabilities P(c|c′) are updated. The segments of latent variables and their classes are sampled as follows:
The parameters of the Gaussian process of each class ϕc and transition probability P(c|c′) are updated by using the sampled segments and their classes. The parameters are optimized by iterating this procedure. Algorithm 2 is the pseudo code of the blocked Gibbs sampler. Ncnj and Ncnj, cn,j+1 are parameters to compute the transition probability in Equation (29). However, it is difficult to compute Equation (25) because an infinite number of classes is assumed. To overcome this problem, we use a slice sampler to compute these probabilities by stochastically truncating the number of classes.
Moreover, the probabilities of all possible patterns of segments and classifications are required in Equation (25), and these cannot be computed naively owing to the large computational cost. To compute Equation (25) efficiently, we utilize forward filtering–backward sampling (Uchiumi et al., 2015).

Algorithm 2: Blocked Gibbs Sampler
3.1.2. Slice Sampler
In the HDP, we assumed that the number of classes is countably infinite. However, it is difficult to compute Equation (25) because c can have infinite possibilities. To overcome this problem, we use a slice sampler (Van Gael et al., 2008) to stochastically truncate the number of classes. In the slice sampler, an auxiliary variable uj that follows the distribution for each time step j is introduced:
where ξ(A) = 1 if condition A is true; otherwise, it is 0. By truncating the classes with a transition probability πcj−1, cj that is less than uj, the number of classes becomes finite, as shown in Figure 7.
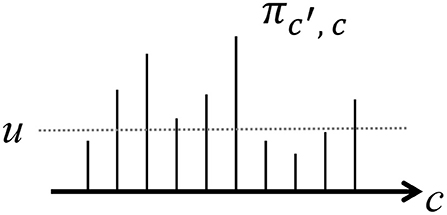
Figure 7. Slice sampling truncates the number of classes by thresholding .
3.1.3. Forward Filtering–Backward Sampling
The number of classes can be truncated by slice sampling. Consequently, forward filtering–backward sampling (Uchiumi et al., 2015) can be applied to compute Equation (25). In forward filtering, the probability that k samples before time step t form a segment of class c is as follows:
where denotes the maximum number of classes estimated by slice sampling and K denotes the maximum length of segments. Plen(k|λ) represents a Poisson distribution with a mean parameter λ:
This corresponds to the distribution of the segment lengths. In addition, P(c|c′, β, η) is the transition probability, which can be computed as follows:
where represents the number of segments of class c and denotes the number of transitions from c′ to c. In addition, k′ and c′ are the length and class of possible segments before , respectively, and these probabilities are marginalized out in Equation (27). Moreover, α[t][k][*] = 0 if t − k < 0, and α[0][0][*] = 1.0. Equation (27) can be recursively computed from α[1][1][*] using dynamic programming, as shown in Figure 8A. This figure depicts an example of computing α[t][2][2], which is the probability that the two samples before t become a segment having the class c. In this case, the length is two and, therefore, all the segments with end points t − 2 can potentially transit to this segment. In α[t][2][2], these possibilities are marginalized out. Finally, the length of segments and their classes can be sampled through backward sampling from t = T:
Figure 8B depicts an example of backward sampling. The length of segment k1 and its class c1 are sampled from the probabilities α[t][*][*]. If k1 = 2, k2 and c2 are sampled from α[t − 2][*][*]. By iterating this procedure until t = 0, the segments and their classes can be determined. Algorithm 3 shows the pseudo-code of forward filtering–backward sampling with slice sampling.
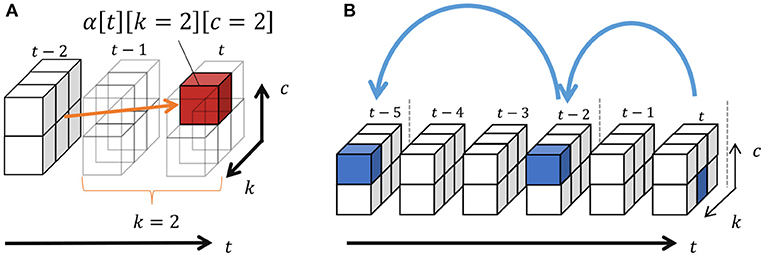
Figure 8. (A,B) Forward filtering–backward sampling.

Algorithm 3: Forward Filtering–Backward Sampling
3.2. Parameter Inference of the VAE
The parameters of the encoder and decoder of VAE are estimated to maximize the likelihood p(x). However, it is difficult to maximize the likelihood directly. Instead, the normal VAE maximizes the following variational lower limit:
where ∫ qenc(zji|xji) log pdec(xji|zji)dzji represents the reconstruction error. Moreover, is a prior distribution of zji, which is a Gaussian distribution whose mean is 0, and the variance–covariance matrix is e. is the Kullback–Leibler divergence, and this functions as a regularization term. On the other hand, in HVGH, the mean μc(i) and the variance–covariance matrix Σc(i) are used as the parameters of the prior distribution. These are the parameters of the predictive distribution of class c into which zji is classified, and they are estimated by HDP-GP-HSMM:
Figure 9 illustrates the difference in prior distributions between Equations (31, 32). In the normal VAE using Equation (31), the prior distribution is against all data points, as shown in Figure 9A. On the other hand, the parameters of the prior distribution of HVGH are computed by the Gaussian process, as shown in Figure 9B. Because the GP restricts data points that have closer time steps to being more similar values, zji becomes a similar value to zj,i−1 and zj,i+1. Therefore, the latent space learned by the VAE can reflect the characteristics of time-series data. Moreover, these parameters have different values depending on the class of the data point. Therefore, the latent space can also reflect the characteristics of each class.
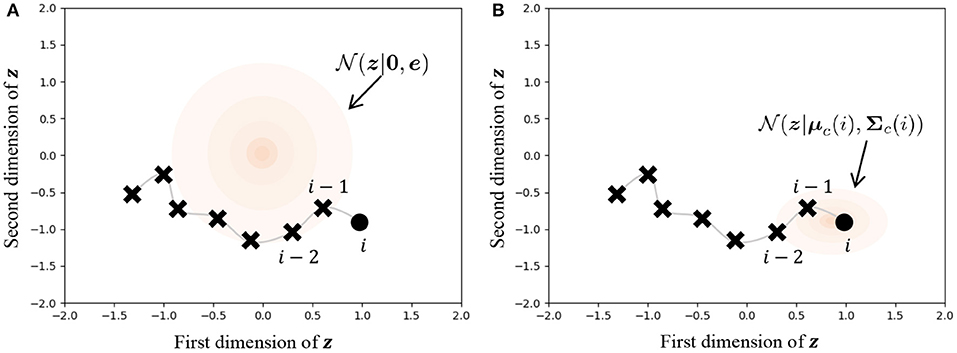
Figure 9. Influence of prior distribution. The orange region represents the standard deviation. (A) The same prior distribution is used for any data points in the normal VAE. (B) The distribution is varied depending on the time step and the class of the data point in the VAE in HVGH.
4. Experiments
To validate the proposed HVGH, we applied it to several types of time-series data. For comparison, we used HDP-GP-HSMM (Nagano et al., 2018), HDP-HMM (Beal et al., 2002), HDP-HMM+NPYLM (Taniguchi et al., 2011), BP-HMM (Fox et al., 2011), and Autoplait (Matsubara et al., 2014) as baseline methods.
4.1. Experimental Setup
To evaluate the validity of the proposed method, we used the following four motion-capture datasets.
• Chicken dance: We used a sequence of motion-capture data of a human performing a chicken dance from the CMU Graphics Lab Motion Capture Database2. The dance includes four motions, as shown in Figure 10.
• “I'm a little teapot” dance (teapot dance): We also used two sequences from the teapot dance motion-capture data from subject 29 in the CMU Graphics Lab Motion Capture Database3. These sequences include seven motions, as shown in Figure 11.
• Exercise motion 1: To determine the validity against more complicated motions, we used three sequences of exercise motion-capture data from subject 13 in the CMU Graphics Lab Motion Capture Database. These sequences include seven motions, as shown in Figure 12.
• Exercise motion 2: Furthermore, we used three sequences of different exercises from the motion-capture data from subject 14 in the CMU Graphics Lab Motion Capture Database. These sequences include 11 motions, as shown in Figure 13.
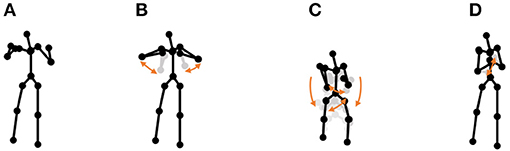
Figure 10. Four unit motions included in the chicken dance: (A) beaks, (B) wings, (C) tail feathers, and (D) claps.
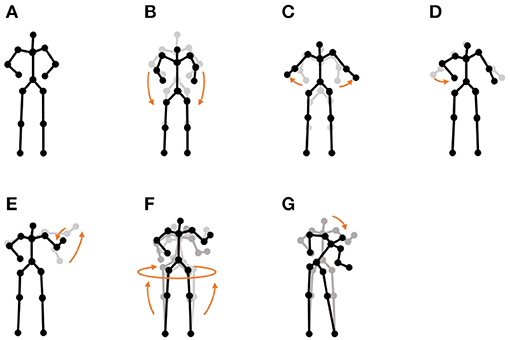
Figure 11. Seven unit motions included in the “I'm a little teapot” dance: (A) short and stout, (B) bending knee, (C) spread arms, (D) handle, (E) spout, (F) steam up, and (G) pour.
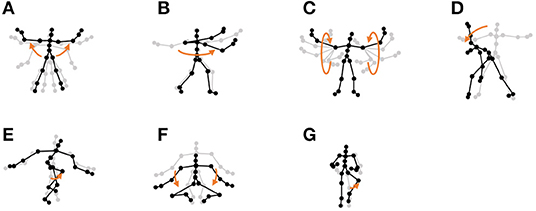
Figure 12. Seven unit motions included in exercise motion 1: (A) jumping jack, (B) twist, (C) arm circle, (D) bend over, (E) knee raise, (F) squatting, and (G) jogging.
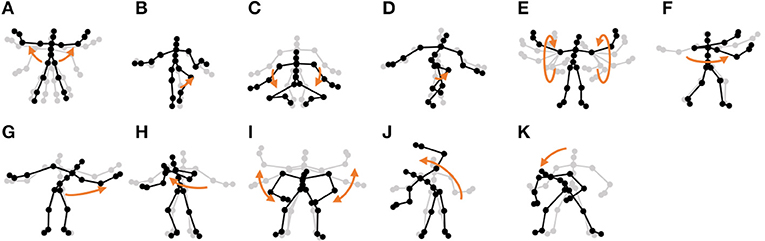
Figure 13. Eleven unit motions included in exercise motion 2: (A) jumping jack, (B) jogging, (C) squatting, (D) knee raise, (E) arm circle, (F) twist, (G) side reach, (H) boxing, (I) arm wave, (J) side bend, and (K) toe touch.
To reduce computational cost, all the sequences were preprocessed by down sampling to 4 fps. These motion-capture datasets included the directions of 31 body parts, each of which was represented by a three-dimensional Euler angle. Therefore, each frame was constructed in 93-dimensional vectors. We used sequences of 93-dimensional vectors as input. Moreover, HVGH requires hyperparameters, and we set them to λ = 14.0, θ0 = 1.0, θ1 = 1.0, θ2 = 0.0, and θ3 = 16.0, which were empirically determined for the segmentation of the 4-fps sequences. For the chicken dance exclusively, we set λ to half that of the others because its motion-capture data was shorter than the others. To train the VAE, we used 1/4 of all the data points as a mini batch, Adam (Kingma et al., 2017) was used for the optimization, and the optimization was iterated 150 times. To train HDP-GP-HSMM, the blocked Gibbs sampler was iterated 10 times to converge the parameters. Furthermore, the mutual learning loop of the VAE and HDP-GP-HSMM was iterated until the variational lower limit converged.
4.2. Evaluation Metrics
To evaluate the segmentation accuracy, we used four measures: the normalized Hamming distance, precision, recall, and F-measure.
The normalized Hamming distance represents the error rate of the classification of the data points, and it is computed as follows:
where c and , respectively, represent sequences of estimated classes and correct classes in the data points in the observed sequence. Moreover, represents the Hamming distance between two sequences, and is the length of the sequence. Therefore, the normalized Hamming distance ranges from zero to one, and smaller values indicate that the estimated classes are more similar to the ground truth.
To compute the precision, recall, and F-measure, we evaluated boundary points (boundaries between segments) as true positives (TPs), true negatives (TNs), false positives (FPs), and false negatives (FNs), as shown in Figure 14. A TP is assigned to the points that are correctly estimated as boundary points. An estimated boundary point is treated as correct if the estimated boundary is within the error range, as shown in Figure 14, Frame (2). The error range is defined as ±ψ% of the sequence length, and ψ represents the percentage of the error range. A TN is assigned to the points that are correctly estimated not to be boundary points, as shown in Figure 14, Frame (3). Conversely, FPs and FNs are assigned to points that are falsely estimated as boundary points, as shown in Figure 14, Frame (10), and falsely estimated not to be boundary points, as shown in Figure 14, Frame (6), respectively. From these boundary evaluations, the precision, recall, and F-measure are computed as follows:
where NTP, NFP, and NFN represent the number of boundary points estimated as TP, FP, and, FN, respectively.
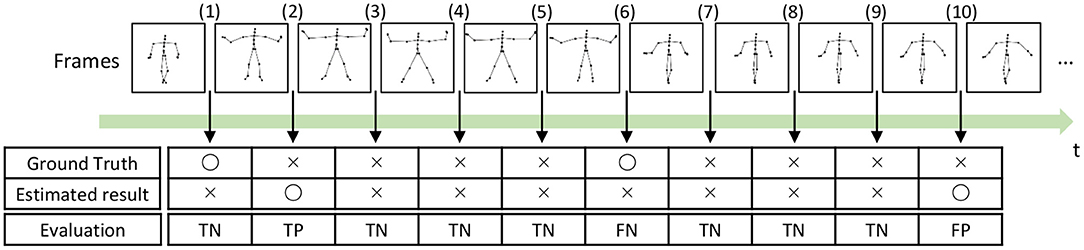
Figure 14. Example of segmentation evaluation: TP is assigned to the boundary (2) because the estimated boundary is within the error range from the true boundary.
Figure 15 depicts the results of a preliminary experiment to determine the error range. The horizontal axis represents the percentages of error range ψ, and the vertical axis represents the average F-measures of the segmentation of four datasets used in the experiments. The details of the datasets are described in section 4.1. Figure 16 shows the result of the average Hamming distance of the four datasets used in the experiments.
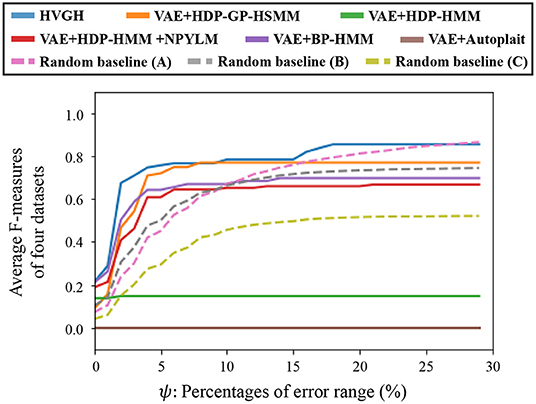
Figure 15. Variation of F-measure with the error range.
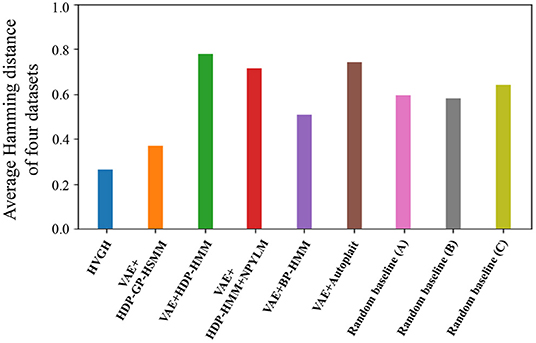
Figure 16. Hamming distance of each method.
To support the evaluation, we used three random baseline methods (A-C). The random baselines were computed given the number of segments as follows: a sequence is divided into the specified number of segments by using a uniform distribution, and classes of the segments are randomly sampled from the uniform distribution. The random baselines (A-C) represent the results of baseline segmentation using the correct number of segments, double the number, and half the number, respectively. The sequences are divided by iterating this procedure 100 times, and the values in the figures represent the averages of the 100 segmentation trials. As shown in Figure 15, in a smaller error range, the F-measure of the random baseline (B) is greater than that of the random baseline (A). This is because the number of boundary points of the random baseline (B) is greater than that of the random baseline (A), the more boundary points of (B) are likely to be within the error range, and TP increases. On the other hand, in a larger error range, the F-measure of the random baseline (B) is less than that of the random baseline (A). This is because the more boundary points of the random baseline (A) are also within the error range in the case of a larger error range, and TP increases. Moreover, the precision of the random baseline (B) decreases and recall increases with an increase in FP because the number of boundary points is greater than that for the random baseline (A). In contrast, the F-measure of the random baseline (C) is less than that of the random baseline (A). This is because precision increases and recall decreases with an increase in FN. In the case of the percentages of error range where the F-measure is saturated, the F-measure is lower in both cases in which the number of segments is larger or smaller because of the trade-off relationship between recall and precision. These results indicate that F-measure reflects the accuracy of boundary points as well as the correctness of the number of segments. From Figure 15, we can see that the F-measure begins to saturate at the 5% error range in all methods except for the random baselines; therefore, we use a 5% error range in the subsequent experiments.
4.3. Segmentation of Motion-capture Data
First, we applied baseline methods to the 93-dimensional time-series data. However, the baseline methods were not able to segment the 93-dimensional time-series data appropriately, because of high dimensionality. Therefore, we applied the VAE with the same parameters as HVGH, and sequences of three-dimensional latent variables were used for segmentation of the baseline methods. Tables 1–4 show the results of segmentation on each of the four motion-capture datasets. The random baselines in the tables indicate the results of the random segmentation, which are described in section 4.2.
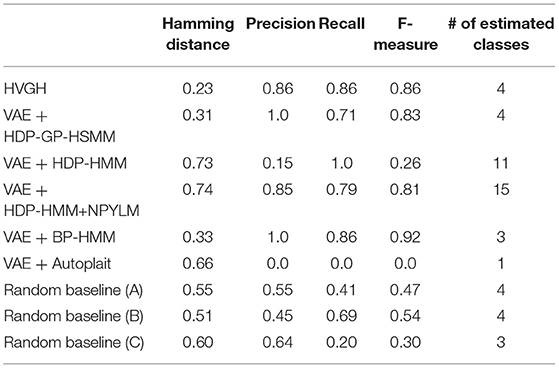
Table 1. Segmentation results for the chicken dance.
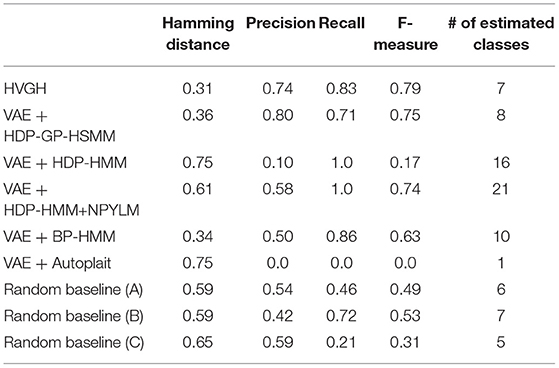
Table 2. Segmentation results for the teapot dance.
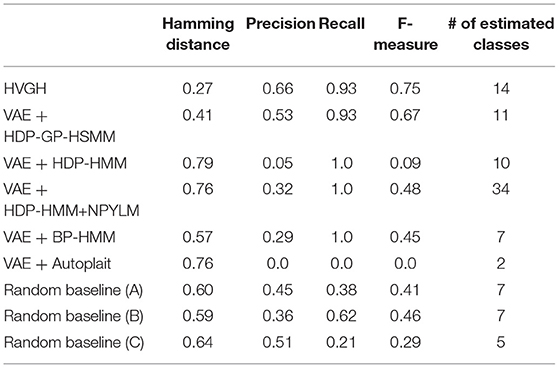
Table 3. Segmentation results for the exercise motion 1: subject 13.
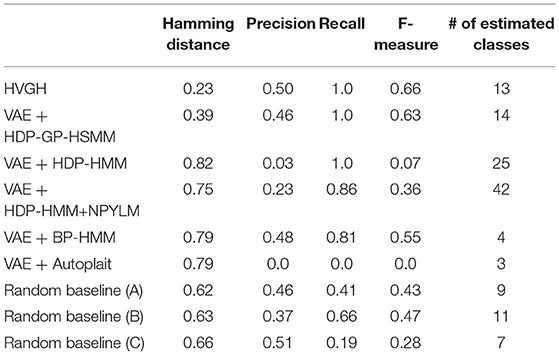
Table 4. Segmentation results for the exercise motion 2: subject 14.
VAE+HDP-GP-HSMM and VAE+BP-HMM were able to segment the motion-capture data from the chicken dance and teapot dance. However, in the results with exercise motion obtained using VAE+BP-HMM, the value of the normalized Hamming distance was larger and the F-measure was smaller than those for the dance motions. This is because simple and discriminative motions were repeated in the chicken dance and teapot dance. Therefore, BP-HMM, which is an HMM-based model, was able to segment them. In contrast, the Gaussian process used in HVGH and HDP-GP-HSMM is non-parametric, making it possible to represent complicated motion patterns in the exercise data. Moreover, HVGH achieved more accurate segmentation than HDP-GP-HSMM. We believe that this is because the appropriate latent space for the segmentation was constructed by using the predictive distribution of the GP as the prior distribution of the VAE in HVGH.
Furthermore, the number of motion classes in the chicken dance and teapot dance was correctly estimated by HVGH. In the exercise motion, larger numbers were estimated because their sequences included complicated motions. In the case of exercise motion 1, 14 classes were estimated by HVGH—more than the correct number seven. This is because the stationary state was estimated as a unit of motion, and symmetrical motion was separately classified as left-sided and right-sided motion in different classes. Moreover, 13 classes—more than the correct number 11—were estimated by HVGH in exercise motion 2. Again, this is because stationary motion was estimated as one motion and because the symmetrical motion shown in Figure 13J was divided into two classes: left- and right-sided motion. However, it is reasonable to estimate the stationary state as a unit of motion. Further, dividing a symmetrical motion into two classes was not erroneous, because the observed values for the left- and right-sided motion were different. Therefore, we conclude that HVGH yielded better results in this case.
Figure 17 illustrates the segmentation results for exercise motion 2. In this graph, the horizontal axis represents time steps, the color reflects motion classes, and the top bar is the ground truth of the segmentation. It is clear that the segments and their classes estimated by HVGH are the most similar to the ground truth.
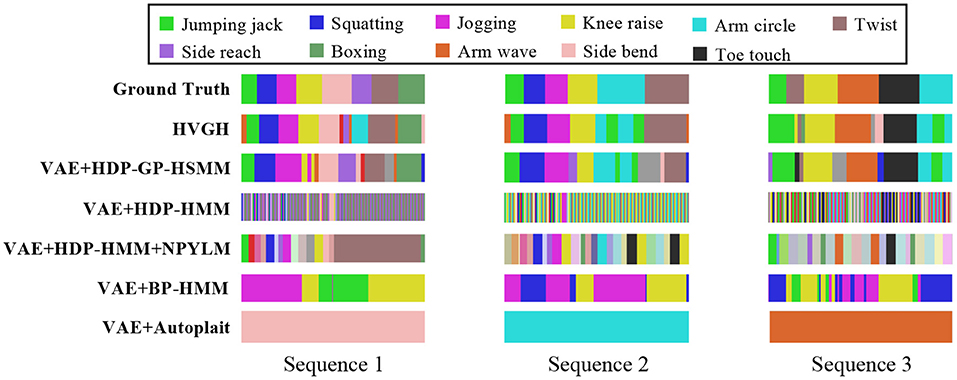
Figure 17. Segmentation results for exercise motion 2.
Moreover, we compared the VAE with other dimensional compression methods in HDP-GP-HSMM. Table 5 presents the results of the segmentation of exercise motion 2 obtained using the methods in which dimensional compression is performed through principal component analysis (PCA) (Pearson, 1901) and independent component analysis (ICA) (Hyvärinen et al., 2000) instead of VAE. PCA and ICA are generally used for dimensional compression. We used the general FastICA4 as the ICA implementation, and their three-dimensional output was used identical to the latent variables of VAE. In the case of PCA and ICA, the min-max normalization, in which the values are normalized to a range from –1 to 1, was applied for the sequence of latent variables, as with Nagano et al. (2018).
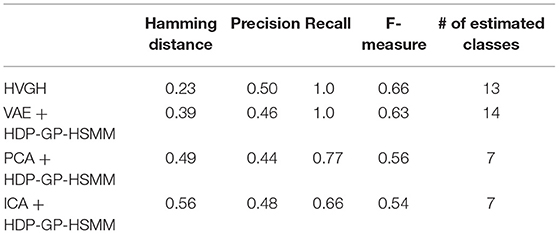
Table 5. Segmentation results of comparison with other compression methods.
Additionally, we described the results of HVGH and VAE+HDP-GP-HSMM for comparison. PCA and ICA compress the high-dimensional data into low-dimensional data by linear transform, and complicated high-dimensional time-series data cannot be converted into low-dimensional data appropriate for segmentation by using these methods. On the other hand, VAE non-linearly compresses high-dimensional data by using a neural network and enables the conversion of the high-dimensional time-series data into low-dimensional data appropriate for segmentation.
With regard to exercise motion 1, Figure 18 shows the latent variables estimated by the VAE, and Figure 19 shows the latent variables learned by mutual learning with HVGH. In these figures (a-c), respectively, represent the first and second, first and third, and second and third dimensions of the latent variables. The color of each point reflects the correct motion class. In Figure 18, latent variables do not necessarily reflect the motion class, because they were estimated with the VAE exclusively. In contrast, in Figure 19, the latent variables in the same class have more similar values. This means that latent space is estimated to represent the features of unit motions. However, it is difficult to fully understand the meaning of latent space because the VAE represents a non-linear relationship between high-dimensional output and low-dimensional latent variables. Thus, we qualitatively analyze them by comparing the latent variables with motions, where each dimension roughly represents the following motions:
• Positive region in the first dimension: right and left motions of the arms
• Negative region in the first dimension: up and down motions of the arms
• Positive region in the second dimension: twisting of the upper body to the left
• Negative region in the second dimension: twisting of the upper body to the right
• Positive region in the third dimension: motions of the legs
• Negative region in the third dimension: bending of the upper body
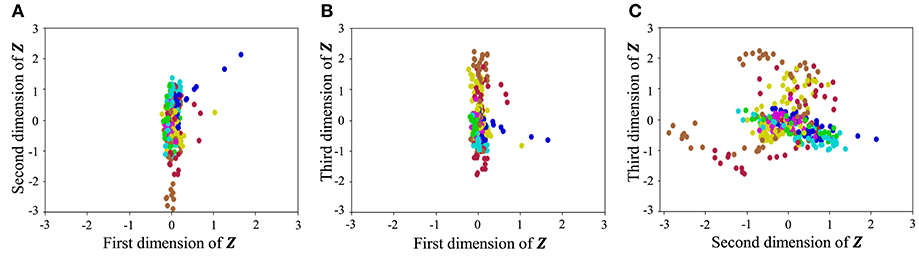
Figure 18. Latent space of the VAE: (A–C) respectively represent the first and second, first and third, and second and third dimension of the latent variables. The color of each point, which is latent variable reflects the correct motion class.
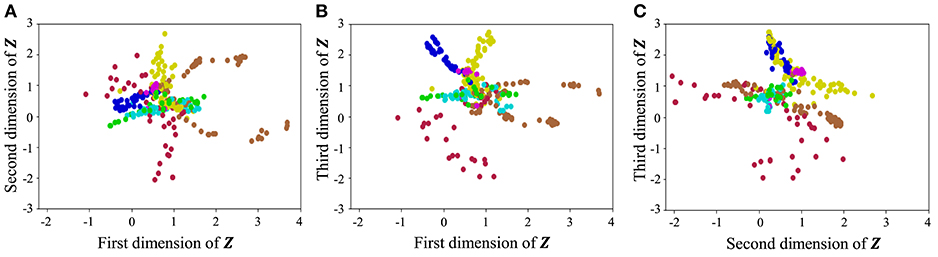
Figure 19. Latent space of the HVGH: (A–C) respectively represent the first and second, first and third, and second and third dimension of the latent variables. The color of each point, which is latent variable reflects the correct motion class.
From these results, we conclude that HVGH can estimate the correct number of classes and accurate segments from high-dimensional data by using the proposed mutual learning loop.
5. Conclusion
In this paper, we proposed HVGH, which segments high-dimensional time-series data by mutual learning of a VAE and HDP-GP-HSMM. In the proposed method, high-dimensional vectors are converted into low-dimensional latent variables representing features of unit motions with the VAE. Using these latent variables, HVGH achieves accurate segmentation. The experimental results showed that the segments, their classes, and the number of classes could be estimated correctly using the proposed method. Moreover, the results showed that HVGH is effective with various types of high-dimensional time-series data compared to a model where the VAE and HDP-GP-HSMM are used independently.
However, the computational cost of HVGH is very high because it takes O(N3) to learn N data points using a Gaussian process, and this is repeated in the mutual learning loop. Because of this problem, HVGH cannot be applied to large-scale time-series data. We plan to reduce the computational cost by introducing the approximation method for the Gaussian process proposed in Nguyen-Tuong et al. (2009) and Okadome et al. (2014).
Moreover, to simplify the computation, we assumed that the dimensions of the observation were independent, and we consider this assumption reasonable because the experimental results demonstrated that the proposed method works well. However, the dimensions of the observation are not actually independent, and the dependency between the dimensions will need to be considered to model more complicated whole-body motion. We believe that multi-output Gaussian processes can be used to represent dependencies between dimensions (Álvarez et al., 2010; Dürichen et al., 2014).
In HVGH, we do not consider the time warp of the time-series data. Although GP can deal with motions whose speeds are slightly different by estimating the variance, motions whose speeds are considerably different are classified into different classes. Therefore, we will investigate the robustness of HVGH against time warp in a future study and extend it to a method considering time warp.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: http://mocap.cs.cmu.edu/.
Author Contributions
MN, TNak, TNag, and DM conceived, designed, and developed the research. MN and TNak performed the experiment and analyzed the data. MN wrote the manuscript with support from TNak, TNag, DM, and IK. DM, IK, and WT supervised the project. All authors discussed the results and contributed to the final manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was supported by JST CREST Grant Number JPMJCR15E3 and JSPS KAKENHI Grant Number JP18H03295. We thank IEEE for permission to reuse figures in (Nagano et al., 2018).
Footnotes
1. ^HVGH stands for hierarchical Dirichlet process, variational autoencoder, Gaussian process, and hidden semi-Markov model.
2. ^http://mocap.cs.cmu.edu/: subject 18, trial 15.
3. ^http://mocap.cs.cmu.edu/: subject 29, trials 3 and 8.
4. ^https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.FastICA.html
References
Álvarez, M., Luengo, D., Titsias, M., and Lawrence, N. D. (2010). “Efficient multioutput Gaussian processes through variational inducing kernels,” in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (Sardinia), 25–32.
Beal, M. J., Ghahramani, Z., and Rasmussen, C. E. (2002). “The infinite hidden Markov model,” in Advances in Neural Information Processing Systems (Vancouver, BC), 577–584.
Dürichen, R., Pimentel, M. A., Clifton, L., Schweikard, A., and Clifton, D. A. (2014). Multitask Gaussian processes for multivariate physiological time-series analysis. IEEE Trans. Biomed. Eng. 62, 314–322. doi: 10.1109/TBME.2014.2351376
Fod, A., Matarić, M. J., and Jenkins, O. C. (2002). Automated derivation of primitives for movement classification. Auton. Robots 12, 39–54. doi: 10.1023/A:1013254724861
Fox, E. B., Sudderth, E. B., Jordan, M. I., and Willsky, A. S. (2007). The sticky HDP-HMM: Bayesian nonparametric hidden Markov models with persistent states. in Arxiv preprint.
Fox, E. B., Sudderth, E. B., Jordan, M. I., and Willsky, A. S. (2011). Joint modeling of multiple related time series via the beta process. arXiv preprint arXiv:1111.4226.
Haber, D., Thomik, A. A., and Faisal, A. A. (2014). “Unsupervised Time Series Segmentation for High-Dimensional Body Sensor Network Data Streams,” in IEEE International Conference on Wearable and Implantable Body Sensor Networks (Zurich), 121–126.
Hyvärinen, A., and Oja, E. (2000). Independent component analysis: algorithms and applications. Neural Netw. 13, 411–430. doi: 10.1016/S0893-6080(00)00026-5
Jensen, C. S., Kjærulff, U., and Kong, A. (1995). Blocking Gibbs sampling in very large probabilistic expert systems. Int. J. Hum. Comput. Stud.. 42, 647–666. doi: 10.1006/ijhc.1995.1029
Johnson, M. J., Duvenaud, D. K., Wiltschko, A., Adams, R. P., and Datta, S. R. (2016). “Composing graphical models with neural networks for structured representations and fast inference,” in Advances in Neural Information Processing Systems (Barcelona), 2946–2954.
Kingma, D. P., and Ba, J. (2017). ADAM: a Method for stochastic optimization. arXiv preprint arXiv:1412.6980v9.
Lin, J. F. S., and Kulić, D. (2012). “Segmenting human motion for automated rehabilitation exercise analysis,” in Conference of IEEE Engineering in Medicine and Biology Society (San Diego, CA), 2881–2884.
Lioutikov, R., Neumann, G., Maeda, G., and Peters, J. (2015). “Probabilistic segmentation applied to an assembly task,” in IEEE-RAS International Conference on Humanoid Robots (Seoul), 533–540.
Liu, S., Yamada, M., Collier, N., and Sugiyama, M. (2013). Change-point detection in time-series data by relative density-ratio estimation. arXiv[Preprint].arXiv:1203.0453v2
Lund, R., Wang, X. L., Lu, Q. Q., Reeves, J., Gallagher, C., and Feng, Y. (2007). Changepoint detection in periodic and autocorrelated time series. J. Climate 20, 5178–5190. doi: 10.1175/JCLI4291.1
MacKay, D. J. (1998). “Introduction to Gaussian processes,” in NATO ASI Series F Computer and Systems Sciences, Vol. 168 (Springer-Verlag), 133–166.
Matsubara, Y., Sakurai, Y., and Faloutsos, C. (2014). “Autoplait: automatic mining of co-evolving time sequences,” in ACM SIGMOD International Conference on Management of Data (Snowbird, UT), 193–204.
Nagano, M., Nakamura, T., Nagai, T., Mochihashi, D., Kobayashi, I., and Kaneko, M. (2018). “Sequence pattern extraction by segmenting time series data using GP-HSMM with hierarchical dirichlet process,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (Madrid), 4067–4074.
Nguyen-Tuong, D., Seeger, M., and Peters, J. (2009). “Local Gaussian process regression for real time online model learning and control,” in Advances in Neural Information Processing Systems 21 (Vancouver, BC), 1193–1200.
Okadome, Y., Urai, K., Nakamura, Y., Yomo, T., and Ishiguro, H. (2014). Adaptive LSH based on the particle swarm method with the attractor selection model for fast approximation of Gaussian process regression. Artif. Life Robot. 19, 220–226. doi: 10.1007/s10015-014-0161-1
Pearson, K. (1901). LIII. On lines and planes of closest fit to systems of points in space. Philos. Magaz. J. Sci. 2, 559–572. doi: 10.1080/14786440109462720
Pitman, J. (2002). Poisson-Dirichlet and GEM invariant distributions for split-and-merge transformations of an interval partition. Combin. Probabil. Comput. 11,501–514. doi: 10.1017/S0963548302005163
Shiratori, T., Nakazawa, A., and Ikeuchi, K. (2004). “Detecting dance motion structure through music analysis,” in IEEE International Conference on Automatic Face and Gesture Recognition (Seoul), 857–862.
Takano, W., and Nakamura, Y. (2016). Real-time unsupervised segmentation of human whole-body motion and its application to humanoid robot acquisition of motion symbols. Robot. Auton. Syst 75, 260–272. doi: 10.1016/j.robot.2015.09.021
Taniguchi, T., and Nagasaka, S. (2011). “Double articulation analyzer for unsegmented human motion using Pitman–Yor language model and infinite hidden Markov model,” in IEEE/SICE International Symposium on System Integration (Kyoto), 250–255.
Teh, Y. W., Jordan, M. I., Beal, M. J., and Blei, D. M. (2006). Hierarchical Dirichlet processes. J. Am. Stat. Assoc. 101, 1566–1581. doi: 10.1198/016214506000000302
Uchiumi, K., Tsukahara, H., and Mochihashi, D. (2015). “Inducing Word and Part-of-Speech with Pitman-Yor Hidden Semi-Markov Models,” in Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Beijing), 1774–1782.
Van Gael, J., Saatci, Y., Teh, Y. W., and Ghahramani, Z. (2008). “Beam Sampling for the Infinite Hidden Markov Model,” in International Conference on Machine Learning (Helsinki), 1088–1095.
Wächter, M., and Asfour, T. (2015). “Hierarchical segmentation of manipulation actions based on object relations and motion characteristics,” in International Conference on Advanced Robotics (Istanbul), 549–556.
Keywords: motion segmentation, Gaussian process, variational autoencoder, hidden semi-Markov model, motion capture data, high-dimensional time-series data
Citation: Nagano M, Nakamura T, Nagai T, Mochihashi D, Kobayashi I and Takano W (2019) HVGH: Unsupervised Segmentation for High-Dimensional Time Series Using Deep Neural Compression and Statistical Generative Model. Front. Robot. AI 6:115. doi: 10.3389/frobt.2019.00115
Received: 31 March 2019; Accepted: 22 October 2019;
Published: 20 November 2019.
Edited by:
Georg Martius, Max Planck Institute for Intelligent Systems, GermanyReviewed by:
Arash Mehrjou, Max Planck Institute for Intelligent Systems, GermanyDominik M. Endres, University of Marburg, Germany
Copyright © 2019 Nagano, Nakamura, Nagai, Mochihashi, Kobayashi and Takano. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Masatoshi Nagano, n1832072@edu.cc.uec.ac.jp