 Anna I. Bellido Rivas
Anna I. Bellido Rivas Xavi Navarro
Xavi Navarro Domna Banakou
Domna Banakou Ramon Oliva
Ramon Oliva Veronica Orvalho3
Veronica Orvalho3 Mel Slater
Mel Slater- 1Event Lab, Faculty of Psychology, University of Barcelona, Barcelona, Spain
- 2Institute of Neurosciences of the University of Barcelona, Barcelona, Spain
- 3Universidade do Porto, Instituto de Telecominicações, Porto, Portugal
Virtual Reality can be used to embody people in different types of body—so that when they look towards themselves or in a mirror they will see a life-sized virtual body instead of their own, and that moves with their own movements. This will typically give rise to the illusion of body ownership over the virtual body. Previous research has focused on embodiment in humanoid bodies, albeit with various distortions such as an extra limb or asymmetry, or with a body of a different race or gender. Here we show that body ownership also occurs over a virtual body that looks like a cartoon rabbit, at the same level as embodiment as a human. Furthermore, we explore the impact of embodiment on performance as a public speaker in front of a small audience. Forty five participants were recruited who had public speaking anxiety. They were randomly partitioned into three groups of 15, embodied as a Human, as the Cartoon rabbit, or from third person perspective (3PP) with respect to the rabbit. In each condition they gave two talks to a small audience of the same type as their virtual body. Several days later, as a test condition, they returned to give a talk to an audience of human characters embodied as a human. Overall, anxiety reduced the most in the Human condition, the least in the Cartoon condition, and there was no change in the 3PP condition, taking into account existing levels of trait anxiety. We show that embodiment in a cartoon character leads to high levels of body ownership from the first person perspective and synchronous real and virtual body movements. We also show that the embodiment influences outcomes on the public speaking task.
Introduction
When you put on a head-tracked stereo head-mounted display and you look down towards yourself, if it has been so programmed you will see a life-sized virtual body substituting your real unseen body. Your body movements can be tracked in real-time and mapped to the movements of the virtual body so that as you move and look down towards yourself you will see the virtual body move correspondingly and in synchrony with your movements. A mirror can be programmed so that looking into it you will see a reflection of your virtual body that would move synchronously and in correspondence with your real body movements. In our whole lives whenever we have looked down towards ourselves we have seen our own body, similarly in mirror reflections and similarly when we move our limbs it is our own limbs that we see moving correspondingly and synchronously. It is no surprise therefore that in such a setup in virtual reality (VR) people typically have the strong perceptual illusion that the virtual body that they see is their own body, even though they know for sure that this is not the case. This is referred to as a body ownership illusion, a concept inspired originally by the rubber hand illusion (RHI), where participants can feel a rubber hand as their own when it is seen to be touched, with touch that is felt synchronously on the corresponding real out-of-sight hand (Botvinick and Cohen, 1998). It is an example of an illusion resulting from multisensory stimulation (first person perspective over the hand, synchronous vision and touch) that provides evidence to the brain that the rubber hand is part of the body. In our opening example we refer to synchrony between proprioception and vision as well as first person perspective over the body. Full body ownership in VR is discussed extensively in (Kilteni et al., 2012a) and body consciousness more generally in (Ehrsson and Stein, 2012; Blanke et al., 2015).
Certain conditions must be satisfied for the RHI to occur. For example, the rubber hand should be in an anatomically plausible position in relation to the real body (Ehrsson et al., 2004) and using a VR version of the illusion it has been shown that there should be continuity between the virtual hand and the rest of the virtual body (Perez-Marcos et al., 2011; Tieri et al., 2015). However, with respect to the virtual hand illusion there is inconsistent evidence regarding ownership of non-hand objects—for example (Yuan and Steed, 2010) found stronger ownership over a hand than over an arrow, six different hand representations were compared in (Lin and Jörg, 2016) with wide variation in ownership though with strongest overall level corresponding to the most realistic hand. It was shown in (Guterstam et al., 2013) that with appropriate multisensory stimulation that there could even be an illusion of ownership over empty space. Moreover major distortions can occur with ownership preserved: having a third arm (Guterstam et al., 2011), an extra finger (Hoyet et al., 2016), one very long arm (Kilteni et al., 2012b), a body with a tail (Steptoe et al., 2013), and non-human bodies that can be moved by the self in unusual ways—e.g., moving a leg by arm movements (Won et al., 2015a; Won et al., 2015b). With respect to the full body ownership illusion in VR again there is remarkable plasticity—adult men embodied successfully as a young girl (Slater et al., 2010), adults in small or very large bodies (van der Hoort et al., 2011), or as children (Banakou et al., 2013; Tajadura-Jiménez et al., 2017), in bodies of a different race (Peck et al., 2013; Banakou et al., 2016), or age (Banakou et al., 2018; Slater et al., 2019), or alien bodies (Barberia et al., 2018).
The question that we address is whether body ownership is afforded through appropriate multisensory integration providing evidence to the brain that the virtual body is the person’s own body, thus leading to the illusion of body ownership, or whether appearance of the body has a fundamental role. Therefore, here our first goal was to test whether embodiment in a virtual body that is deliberately designed to look like a cartoon character can also result in the body ownership illusion. Our second goal was to exploit this representation to examine whether it would have an impact over public speaking anxiety. It is known that embodiment in different types of bodies has an impact on attitudes and behaviour, for example people in a body taller than their own will be more confident in negotiations (Yee and Bailenson, 2007), or being embodied as Einstein leads to better cognitive test performance compared to being embodied in another body (Banakou et al., 2018), and there are several studies that show that embodiment of Caucasian people in a dark skinned virtual body decreases their implicit racial bias—summarized in (Maister et al., 2015), with a mechanism presented in (Bedder et al., 2019). These are all examples of what was termed by Yee and Bailenson (Yee and Bailenson, 2007) as the ‘Proteus Effect’.
It has long been known that people with public speaking anxiety exhibit this also talking with entirely virtual audiences (Pertaub et al., 2002; Aymerich-Franch et al., 2014), and VR has been used for psychological therapy to overcome this aspect of social phobia, for example (Vanni et al., 2013). Our idea here, however, was that if the speaker with public speaking anxiety is embodied as a cartoon character, and the audience itself is a deliberate cartoon audience, then possibly the humour of the situation or the likelihood that the cartoon audience would not be seen as having expertise in any particular topic, would lead to a reduction of anxiety that would carry over to a later exposure of speaking to a virtual audience representing people rather than cartoons. Factors such as the size of the audience and their expertise level have been shown to influence anxiety in a public speaking task (Jackson and Latané, 1981; Ayres, 1990). The authors in these real-life studies found that the larger the audience and the more expert they were, the higher the anxiety level. Hence, we can infer that a positive audience consisting of a reduced number of non-experts would be an easier context for people with public speaking anxiety to deliver a speech. Immersion in such an environment may allow them to establish new positive associations with the feared speaking task, which may give rise to a progressive systematic desensitization, session after session.
Methods
Overview
In order to examine these ideas we carried out a between-groups experiment with 45 participants with three conditions. Each participant visited the virtual reality lab on two occasions separated by mean 5.3 ± 2.3 (S.D.) days. On the first visit they gave a speech embodied either as a cartoon character from first person perspective (1PP) speaking to a cartoon audience, or as a human from 1PP speaking to a human audience, or as a cartoon character speaking to a cartoon audience from a third person perspective (3PP). Then in the same session they gave another talk under the same condition. On the second visit, some days later, they gave a third speech, but this time embodied from 1PP as a human speaking to a human audience. This last exposure was considered as a test of the outcome of the first exposures. Our two questions were 1) whether the level of body ownership would differ between the three conditions and 2) whether embodiment as the cartoon character would lead to less anxiety for the public speaking in front of humans at the second visit.
Ethics
This experiment was approved by the Comisión de Bioética de la Universitat de Barcelona (IRB00003099). Participants gave written and informed consent.
Recruitment
Participants were recruited from the Mundet campus of the University of Barcelona and were independent from our own research group. A previous virtual reality study found a greater level of fear of public speaking for women compared to men (Pertaub et al., 2002) and a large sample study amongst college students found the same (Ferreira Marinho et al., 2017). Since our goal was to recruit participants with relatively high levels of public speaking anxiety the most convenient was to recruit women. The inclusion criteria was participants who scored at least 18 on the Personal Report of Confidence as a Speaker (PRCS) (Paul, 1966; Gallego et al., 2009). This is a set of 30 questions with yes/no answers and a maximum score of 30 indicating a high degree of anxiety. The mean ± SD score was 22.4 ± 2.86 with scores ranging from 18 to 28. Participants had to be at least 18 years, and the mean ± SD age of participants was 24.5 ± 9.31. A further exclusion criteria was obtained using the LSB-50 questionnaire that was used to screen out participants with potentially serious psychological disorders (Abuín and Rivera, 2014). Further details of the sample are given in Supplementary Table S1.
Experimental Design
This was a between groups experiment with three groups: Cartoon, Human and 3PP. In the Cartoon condition participants were embodied as a cartoon character and spoke to an audience of cartoon characters. Embodiment was from 1PP and visuomotor synchrony so that the virtual body moved in synchrony with real body movements. In the Human condition the participant was embodied in a female virtual body with visuomotor synchrony. In the 3PP condition the participant saw the cartoon virtual body from 3PP and it did not move with their body movements. However, they still had full control of the head and visual updates to the images in the head-mounted display were based on their own head movements. However, the displayed cartoon body did not show the participant’s head movements. The virtual audience also consisted of cartoon characters (Figure 1). We maintained the audience as the same type as the embodied character in order to avoid effects solely caused by difference between these two. Each condition was assigned 15 participants selected by a pseudo random number generator. The experiment is illustrated in Supplementary Video S1.

FIGURE 1. The scenario (A) The Cartoon condition. (B) The Human condition. The 3PP condition looked the same as the Cartoon except that the participant was not embodied in the bunny rabbit.
Implementation
Participants used a stereo NVIS nVisor SX111 head-mounted display. This has dual SXGA displays with 76H × 64V (degrees) field of view (FOV) per eye, with a wide field-of-view 111° horizontal with 50 (66%) overlap and 64 vertical, with a resolution of 1280 × 1024 pixels per eye displayed at 60 Hz. Head tracking was performed by a 6-DOF Intersense IS-900 device. Participants wore an OptiTrack full body motion capture suit that uses 37 markers and the corresponding software (https://optitrack.com/software/motive/) to track their movements. This used a 12-camera truss setup by OptiTrack. Participants were assisted to don and calibrate the head-mounted display (HMD) following the method described in (Jones et al., 2008).
The virtual room in which the speech took place was the same for all conditions. It was designed to be neutral, and it included a wooden platform on which participants virtually stood while delivering a speech. A virtual mirror was located on the left of the participant, which helped her inspect the body assigned. The mirror was carefully located so that it was in full view of the participant throughout the speech while she was looking at the audience. A virtual clock was added to the opposite wall of the room in order to help the participant keep track of the time.
The avatars generated for the Cartoon and 3PP conditions were cartoon-like, not culturally offensive, anthropomorphic figures of animals to make them look friendly and humorous, and were rigged so that they could be animated. The human avatars used in the Human condition were formed of male and female avatars from a RocketBox collection (Gonzalez-Franco et al., 2020). Both human and cartoon audiences were located in the same places in the virtual room. All the animations generated were for one audience and retargeted to the other so that the audience behaviors were identical.
Assessing Anxiety
Public speaking anxiety was measured using the State-Trait Anxiety Inventory (STAI) (Spielberger, 1983; Spielberger, 2010), a commonly used measure to diagnose anxiety and to distinguish it from depressive syndromes. The STAI measures two types of anxiety, state anxiety, or anxiety about an event, and trait anxiety, or anxiety level as a personal characteristic. Form Y is its most popular version and includes 20 items for assessing trait anxiety and 20 items for state anxiety, rated on a 4-point scale from “Almost Never” to “Almost Always”. Scores range from 20 to 80, where 20 indicates absence of anxiety and 80 its maximum value. The STAI is translated into Spanish and validated (Seisdedos, 1988). It has good test-retest reliability (Cronbach alpha of 0.90 for the state scale and 0.84 for the trait scale). Examples of State questions include: “I am tense; I am worried” and “I feel calm; I feel secure.” Trait questions include: “I worry too much over something that really doesn’t matter” and “I am content; I am a steady person.” The STAI Trait was used as a background variable for the participant’s general self-assessed anxiety, since how people might respond to a particular incident would be influenced by their general predisposition to anxiety, so that this is a critical covariate. The STAI State was used to assess the participant’s state before and after each talk.
Procedures
The experiment was carried out in three phases: a pre-experimental phase and two experimental sessions. The first phase was used to recruit only those participants who had sufficient level of fear of speaking in public using the PRCS as described above. A day was then arranged to hold the first session, and the participants were asked to choose two topics they could talk about for 5 minutes. They had two exposures in their assigned condition.
At the first session participants were given an information sheet to read, a consent form to sign, and if they agreed to participate in the study, they were asked to complete the LSB-50 and the STAI-Trait questionnaires. They were then assigned to one of the three conditions (Cartoon, Human or 3PP) following a pseudo-random method that guaranteed the same number of participants per condition. Prior to and after each VR exposure the participant was asked to complete the STAI-State.
The sequence of events started with 1 min 40 s of audio instructions the participants had to follow while looking at a virtual mirror in order to get them to move their head, arms and legs. This also allowed them to become acquainted with the virtual environment and their virtual body (or their relationship to it in the 3PP condition) in order to provide time for the body ownership illusion to be induced (or not). After the audio instructions, the participant was asked to move freely (although within the tracking area) for 1 min and 20 s and wait for a brief 3 s clap of the audience, which was the sign of the beginning of the talk. After 5 min, the audience applauded resoundingly indicating the end of the speech. The virtual environment slowly faded out and the experimenter helped the participant take off the HMD. Finally, she filled in the post-experiment questionnaires and a brief informal interview on their experience followed. Participants went through the virtual reality experiment twice (first and second session) with a 15 min break in between. After the end of the second session, a day for the third session was arranged. It had to be not sooner than 2 days nor later than a week, and they were asked to think of another topic to talk about. The participant was paid 5€ and left. In the third session, participants had to perform only one talk (third talk) always in the Human condition, so they went through the experimental procedure only once, which was identical to that of the first two sessions. After completion of the third talk, the participant was paid 15€ and debriefed.
Response Variables
Body Ownership
Body ownership was assessed using the questionnaire shown in Table 1 administered immediately after each VR exposure. The first three questions assess body ownership itself. The twobodies question is a control question—since if there is strong body ownership we would expect participants to report the feeling of having one body (the virtual) rather than two. The last question is a test of the extent to which the tracking system and mapping real movements to the movements of the virtual bodies was successful. If the variable

TABLE 1. Subjective evaluation of the body ownership illusion. The questionnaire was answered after completing each talk. Answers were rated on a 7-point Likert scale, where 1 was “Not at all” and 7 was “Completely”.
State Anxiety
We refer to the STAI State questionnaire prior to an exposure as
This is the difference between STAI state after the final exposure to the Human condition, and the mean of the STAI states prior to the first two exposures. We consider the mean of the first two exposures since the first alone may induce anxiety simply due to a new and unknown forthcoming event. By the second time participants would know what to expect, and therefore be less anxious. So the first may overestimate anxiety and the second underestimate it, so taking the mean of the two is a balance. However, we have also carried out the analysis using instead
The STAI Trait, assessed in the pre-experimental meeting was used as a covariate since participants may respond differently depending on their underlying normal level of anxiety.
The anxiety variables are summarized in Table 2.

TABLE 2. The anxiety scores. In general “trait anxiety” refers to a stable attribute of personality, whereas “state anxiety” refers to anxiety with respect to a particular situation or event. The STAI refers to the State-Trait Anxiety Inventory questionnaire (Spielberger, 1983).
Results
In this section we will first present descriptive results for body ownership and anxiety, and then a statistical analysis for all the results together.
Body Ownership
Figures 2A,B shows the box plots for the scores on the questions of Table 1 for the three exposures. For exposures 1 and 2 where participants were embodied as Cartoon, Human or the 3PP, it is clear that the scores on the three embodiment questions are very high, and much higher than the scores on the control question twobodies for the Cartoon and Human conditions, and the scores are always low for the 3PP condition. In the third exposure (Figure 2C) all were embodied as Human (the conditions refer to how they had been embodied in the first two exposures) and all body ownership scores are high, and again much greater than the control question. In all conditions and exposures except for 3PP the mymovements scores are very high, indicating that the tracking system and mapping of real movements to movements of the virtual body worked well.
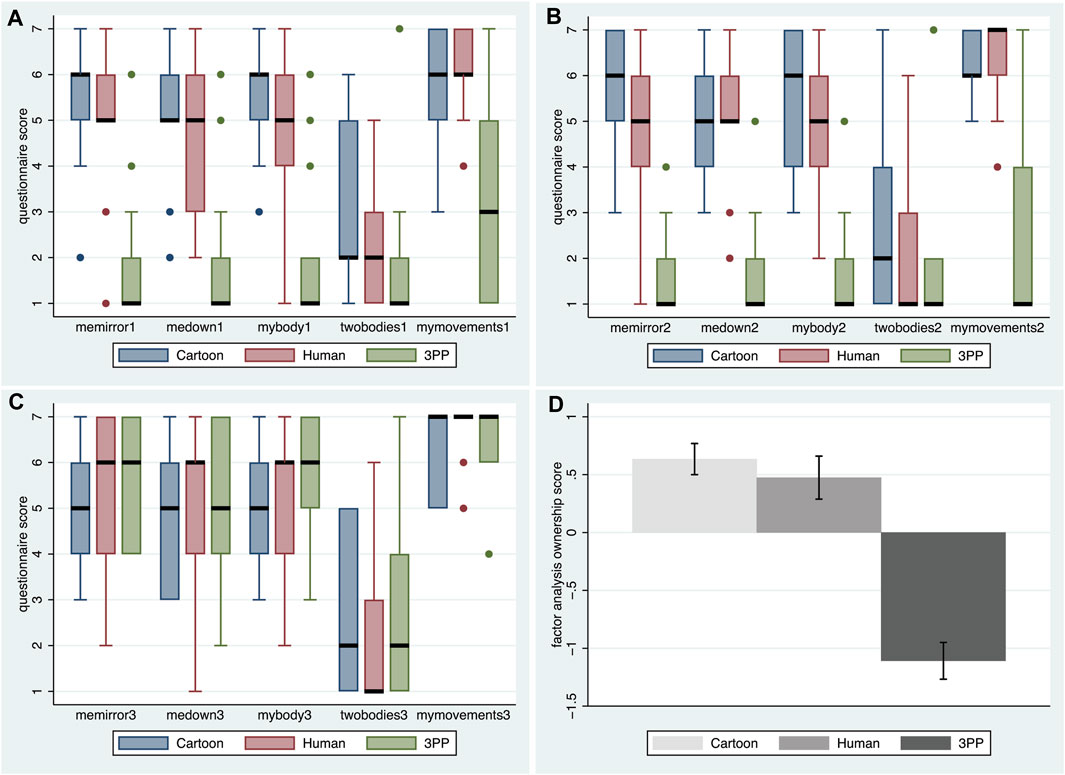
FIGURE 2. Scores on the ownership questions from Table 1. (A) Box plot for exposure 1, session 1. (B) Box plot for exposure 2, session 1. (C) Box plot for the exposure embodied as Human for session 2, but where the conditions refer to those of session 1. (D) Bar charts showing means and standard errors of the factor scores from the principal component factor analysis of the ownership scores of the first two exposures only.
The critical embodiments were those of exposures 1 and 2, since the goal was to understand how experiencing the public speaking in the Human or Cartoon conditions would influence anxiety in the final test in the Human condition (exposure 3). We carried out a principal components factor analysis with varimax rotation on the scores mybody, medown, memirror and twobodies for exposures 1 and 2 (i.e., eight variables). This was with the Stata program 16.1 (https://www.stata.com/) using the “factor” command. Two factors were retained, the first accounting for 68% of the variance and the second for 23% of the variance, thus cumulatively 91%. Then regression scores were obtained for each of the two factors resulting in two uncorrelated variables with the scoring coefficients shown in Table 3. The first factor is proportional to the mean of all the scores apart from twobodies, and the second factor is proportional to the mean of the twobodies scores. Hence the factor structure is consistent with the meaning of the questionnaire. The interest is only on the first factor, which measures the overall level of ownership in the first two exposures, and we refer to this factor as own, which we will use in subsequent analysis. The means and standard errors are shown in Figure 2D, demonstrating no difference between the Cartoon and Human conditions, which are both much greater than the 3PP condition.
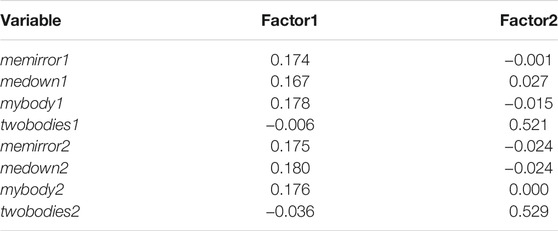
TABLE 3. Scoring coefficients for the principal components factor analysis of the questionnaire scores of exposures 1 and 2. (Method = regression based on varimax rotated factors).
Anxiety
Figures 3A–C shows the scatter diagrams of dstai (Eq. 1) by the covariate staitrait, the trait anxiety measured some days prior to the first exposure. The results suggest that dstai is positively associated with staitrait in the Cartoon condition, negatively in the Human condition, and there seems to be no association in the 3PP condition. Figure 3D shows the means and standard errors of dstai by the conditions without taking into account background anxiety, suggesting the decrease in anxiety is greater for the Cartoon and 3PP conditions. The means and standard errors are also shown in Supplementary Table S2. However, these do not take into account the predisposition towards anxiety as measured by staitrait.
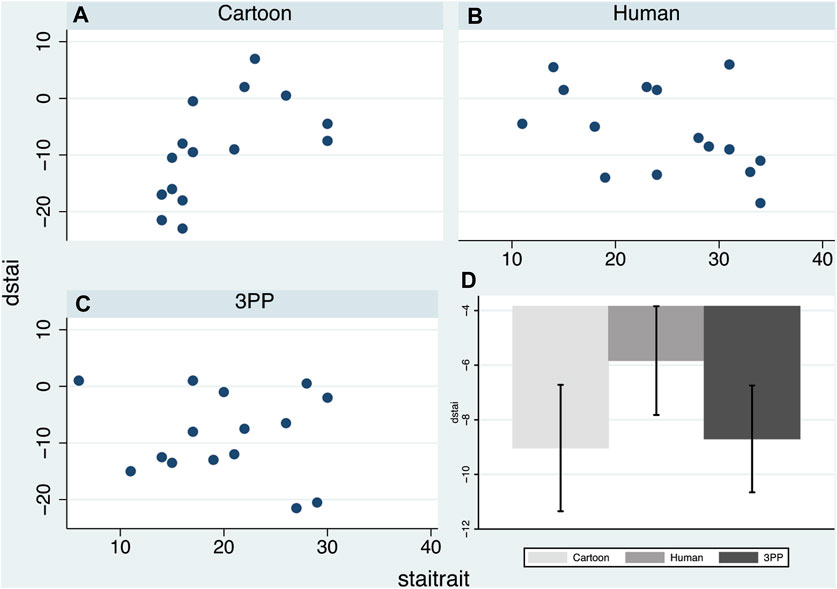
FIGURE 3. Plots of dstai (Eq. 1)—the difference between the anxiety score after exposure 3 compared to the mean anxiety score prior to exposures 1 and 2 by staitrait. (A–C)—scatter diagrams by condition. (D) Bar chart of dstai showing the means and standard errors by condition.
Statistical Analysis
Bayesian statistical methods have been increasingly employed over recent years including in psychology (Kruschke, 2011; Van De Schoot et al., 2017). In classical (frequentist) statistics, in order to consider whether a parameter value is in a certain range (for example, the mean of a population being positive compared with being zero) we compute the probability that the particular observed data would have been generated on the assumption that the parameter value were 0, referred to as the significance level. If this probability is small (typically <0.05) then we reject the hypothesis that the parameter value is 0. In classical statistics the probability of an event is based exclusively on its long run frequency of occurrence in a large number of independent trials. Hence this method essentially compares the observed data with what might have been observed in a large number of independent repetitions of the experiment. In Bayesian statistics in contrast we start with a probability distribution for the parameter based on prior knowledge (or a distribution with large variance in the absence of prior knowledge) and then we can compute a posterior distribution conditional on the observed data, so that the data updates our prior. From this we can compute probabilities of the parameter value being in any range of interest. Moreover, if there are multiple parameters the posterior distribution will be the joint distribution of all the parameters, and we can make as many probability statements as we like over several parameters. In classical statistics when we carry out more than one significance test then the significance levels are no longer valid and we have to resort to ad hoc corrections such as Bonferroni. In classical statistics confidence intervals are mathematically equivalent to significance tests, and a 95% confidence interval cannot be interpreted as a probability of 0.95 of a parameter being between the computed limits. In Bayesian statistics a 95% credible interval is a range of values where the actual probability of a parameter value being within that range is 0.95. What is particularly informative is to compare the credible interval based on the prior distribution of the parameter and the credible interval calculated from the posterior distribution. This is a very useful way to understand how the data has updated the credible interval.
A Bayesian analysis was carried out that includes both response variables (dstai and own) simultaneously. The method is equivalent to an analysis of variance model with a covariate in the case of dstai, and a simpler model without a covariate in the case of own. The mathematical formulation is identical to ANOVA except that the parameters have prior distributions.
Let
The parameter
The prior distributions of the parameters are chosen as weakly informative—e.g. (Lemoine, 2019), i.e., assuming very little prior information. Weakly informative priors are proper probability distributions, but with wide variance. Specifically
For own the model is similar but simpler since there is no covariate:
with the same prior distributions for the parameters.
The model was implemented using the Stan probabilistic programming language (Stan Development Team, 2011-2019; Carpenter et al., 2017) (https://mc-stan.org/) through the RStudio interface (https://www.rstudio.com/). The execution used 2000 iterations on four chains. All Rhat = 1 indicating that the four chains converged and successfully mixed. Use of the ‘leave-one-out’ method (Vehtari et al., 2017), equivalent to repeated fits to the data with one observation left out each time, similarly indicated no problem with convergence or outliers.
Table 4 shows the summaries of the posterior distributions of the parameters. Notice that the posterior 95% credible intervals are narrow compared to the prior intervals. For example, for
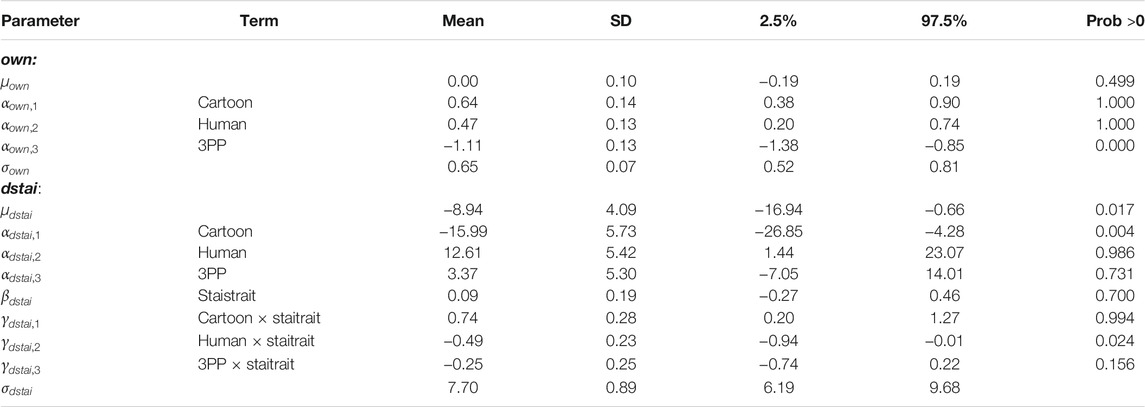
TABLE 4. Summaries of the posterior distributions of the parameters showing the distribution means, standard deviations, 95% credible intervals. Prob >0 is the posterior probability that the parameter is positive.
From the first block of Table 4 the posterior probabilities of the parameters of Cartoon
In the case of dstai the interaction terms are important. Notice how the mean (CI: credible interval) for Cartoon × staitrait is 0.74 (CI: 0.20 to 1.27) whereas for Human it is -0.49 (CI: −0.94 to −0.01). Hence, for those in the Cartoon condition the greater the staitrait the greater the dstai (prob = 0.994) so that the state variable is proportional to the trait. However, for those in the Human condition the relationship is reversed—the greater the trait the lower the value of dstai. The distribution of the coefficient has mean −0.49 with credible interval −0.94 to −0.01, and the probability of it being positive is 0.024 (so it has prob = 1—0.024 = 0.976 of being negative). For those in the 3PP condition there is a moderate probability of there being a small negative association between state and trait (prob = 1—0.156 = 0.844). Hence, overall, and with high posterior probability, for those in the Cartoon condition dstai is positively correlated with trait, for those in the Human condition dstai is negatively correlated with trait. The correlation between dstai and trait is possibly negative for the 3PP condition. These results are in accord with Figures 3A–C.
The equivalent to Table 4 for the alternative response variables dstai1 and dstai2 where the staitrait in the third (human) exposure is compared to staitrait in the first or second exposure, is given in Supplementary Table S3.
The mean staitrait is 21.4 ± 7.0 (S.D.) and the median is 21. In addition to examining the relationship between the change in STAI state (dstai) and this covariate, we can consider what happens at its mean. Figure 4 shows the posterior distributions for the predicted dstai for each of the Cartoon, Human and 3PP conditions. It can be seen that the distributions reflect Figure 3D. From these distributions we can compute the posterior probabilities of, for example, dstai < −10, and dstai < −5, and the two corresponding vertical lines are shown in Figure 4, and the probabilities we require are the areas to the left of those lines under the curves.
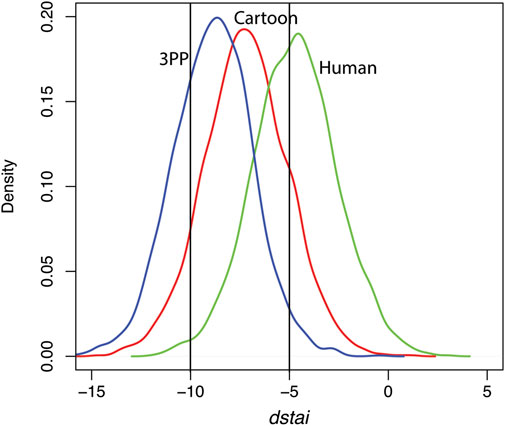
FIGURE 4. Posterior distributions of dstai at the mean level of staitrait for the Cartoon, Human and 3PP conditions.
The probabilities are shown in Table 5. A decrease of five in dstai has probability almost double for the Cartoon condition compared to the Human, and more than double in the case of the 3PP condition. For a decrease of 10 the Cartoon condition has a probability of 10 times the Human condition, and the 3PP condition more than 30 times greater. Hence although considered overall the 3PP condition dstai does not change much with staitrait and the Cartoon condition is proportional to it, the model predicts that for a participant with the average trait anxiety the 3PP condition appears to be the one that reduces anxiety the most.

TABLE 5. Posterior probabilities of the change in dstai being less than −5 or −10 at the mean level of staitrait.
Goodness of Fit of the Model
Using the Stan program 4000 pseudo random observations were generated from the model, leading to posterior predicted distributions of the two response variables for each individual. We take the mean of each of these distributions per individual as a point estimate for the predicted value so that for each individual we obtain predicted values of the two response variables. The correlation between the observed and predicted values of own is r = 0.79, with 95% confidence interval 0.66 to 0.88. For dstai the correlation is r = 0.50, with 95% confidence interval 0.24 to 0.69. We quote confidence intervals here not for formal significance, but only to show the strength of the relationships. Hence, overall we conclude that the model fit to the data is acceptable.
Discussion
There are two findings of this study. The first is that the level of body ownership did not differ between embodiment in a cartoon character or as a human, and that the level of body ownership was high and comparable with previous results. In contrast the level of body ownership was lower for the 3PP condition. The second is that contrary to our original idea embodiment as the cartoon character, in the more humorous situation, did not result in a reduction of anxiety in relation to the background trait anxiety, but the change in state anxiety was proportional to the level of trait anxiety. However, in the case of human embodiment and audience the change in state anxiety was inversely related to trait anxiety. There was little or no effect of the 3PP condition, which means that irrespective of trait the change in state anxiety was essentially constant and small, with some evidence of a small decline. Further, a prediction of the model is that for the average level of trait anxiety the 3PP condition is associated with the greatest reduction in state anxiety.
In the remainder of this section we first discuss the findings in relation to body ownership, paying particular attention to embodiment of non-human characters. We then review studies of public speaking anxiety in VR, and move on to provide a possible explanation of our findings in relation to a well-known theoretical model of social anxiety. We conclude by pointing out some limitations of our study and future work.
Body Ownership
Although given the state of technology, all studies of embodiment in VR inevitably use characters that are not photorealistic, and could be described as ‘cartoony’, our study was different in the sense that the character was deliberately designed as a cartoon character, a bunny rabbit. Our question was whether this deliberately non-human character would lead to levels of body ownership we have seen in previous studies with embodiment as humans (e.g., (Banakou and Slater, 2014)). Our expectation was that this would be the case, since as discussed in the introduction the form of the virtual body does not seem to influence the level of body ownership, which is derived from multisensory integration rather than top down identification with the appearance of the body. However, all our previous studies have been with human characters, even if distorted by having a long arm or a tail, or being of the colour purple, or being a different age or race.
There have been several studies with non-human characters. In (Ahn et al., 2016) participants were embodied with a virtual cow body using 1PP and visuomotor synchrony (the cow body moved with the movements of the participant on all fours) and there was visuotactile synchrony (the cow body was prodded which was felt synchronously by the participant). The results showed that the level of body ownership was significantly higher than a condition where participants watched a video of the same events. However, the mean reported level of ownership was 2.57 on a five point scale, which is proportionally equivalent to 3.6 on a 7 point scale. In absolute terms this is much lower than the typical values we obtain (median at least 5, with the whole interquartile range above the mid-point of 4) as can be seen in Figures 2A–C, although the questionnaire used in the two cases overlapped but were different. In (Krekhov et al., 2019) participants were embodied in several different types of animal body—a bat, spider, tiger as well as human. Their equivalent scores for body ownership (“acceptance”) were on a scale from 0 to 6. Embodiment as the human had the lowest mean score (2.79 equivalent to 3.3 on a 7-point scale), the score for the bat was considerably higher (4.33) and for the spider 3.63. Again, the questionnaires overlapped with ours but were not the same, but the low score for human embodiment is unusual. This may be related to the fact that a measure of the degree of control over the virtual bodies was highest for the bat. This was a within-groups study so that participants were comparing the different experiences, and it is possible that factors such as novelty or excitement played a role in the different evaluations. In (Charbonneau et al., 2017) participants were embodied in a giant Godzilla-like creature. Body ownership was not directly measured, but the point was to use this embodiment to improve gait while using a rehabilitation walking device. Since there was some evidence of gait improvement it is likely that there was an element of body ownership involved. In (Aymerich-Franch et al., 2017; Aymerich-Franch et al., 2019) people were embodied in physical humanoid robots that they saw through a HMD mounted as eyes on the robot, and ownership scores were high and comparable those typical of VR embodiment studies.
We suggest the following summary. It is possible to obtain some level of body ownership in completely non-human characters, and when there is multisensory integration that provides evidence that the virtual body is the person’s body, then there will be greater scores in that synchronous condition than in other control conditions. However, these are based on comparisons. What’s equally important is not just that a synchronous multisensory condition results in higher scores than a control condition but that the absolute scores also are themselves greater than would be expected by chance. In other words if we obtain random results on a questionnaire that is on a 7 point scale, then the median result will be around 4. A high score in absolute terms should be clearly greater than this, and there is little evidence of this at the moment. However, if the virtual body is humanoid, upright, with a face and limbs approximating humans, then the absolute body ownership scores will be high in themselves not just in comparison with a non-synchronous condition. In (Osimo et al., 2015; Slater et al., 2019) participants were able to compare embodiment in a virtual body that closely resembled their own body, and embodiment in a much older body. Even though one of the virtual bodies looked like themselves still the body ownership scores were not different between these two conditions. In the present study we have a direct comparison between embodiment as a bunny rabbit and a human body, in a between groups situation so that participants did not know of the other conditions. Still, we found that the body ownership was high and the same across these conditions, but dropped greatly for the non-synchronous (3PP) condition. This lends weight to the hypothesis suggested above.
Public Speaking Anxiety
Although in our experiment we did not find that the humorous situation (embodiment as a bunny rabbit with a cartoon audience) improved outcomes overall, our finding is in accord with large number of previous studies. In our case two embodiments as a human with a human audience led to a reduction of state anxiety in comparison with trait anxiety at the third session, supporting previous findings with respect to exposure therapy.
The first study of the efficacy of virtual reality for public speaking anxiety was reported in (North et al., 1998). It exposed participants to an audience of about 100 in a large auditorium, and although the characters forming the audience were static they could be heard to speak and could ask questions. There were five sessions in an exposure therapy, and the control group had equivalent VR exposure, but unrelated to public speaking. It was found that the VR exposure therapy was successful in reducing public speaking anxiety compared to the control group. This approach is standard for the use of VR to help people with anxiety disorders, where the VR is used as a substitute for a real life experience. Logistically it is far easier for the clinician to expose people to the anxiety provoking situation in the office, in real-time with the clinician there, than to arrange real situations such as getting an audience together for multiple sessions, or to give the client “homework” which is carried out in the absence of the clinician.
There has been significant additional research over the past 3 decades. In a meta-analysis of 30 randomised control trials that attempted to reduce fear of public speaking using a variety of methods (Ebrahimi et al., 2019) it was found that there were no differences between outcomes that used face-to-face counseling and virtual reality. In the general area of social anxiety disorders a further study found that VR based therapy was effective in reducing anxiety, and in comparison with in vivo or exposure based on imagination again there was no difference in effect size (Chesham et al., 2018). Overall a comprehensive meta-analysis of VR based psychology therapy found that it is effective, although studies are often small in size and not always RCTs (Freeman et al., 2017).
By the time of the third talk, participants in the Human condition would have already given two previous talks, to the same virtual human audience and under the same conditions. Therefore, in accord with exposure therapy it is not surprising that their level of stress declined relative to their trait level of stress. However, those in the Cartoon condition had previously given two talks to the cartoon audience so that the third “test” scenario was the first time that they had experienced this Human audience. Since the humour idea was ineffective then the simpler explanation for the results is based on number of exposures.
The Cognitive Model of Social Phobia
Why did the cartoon idea not work in the sense that the change in state anxiety simply reflected trait anxiety? Our original idea was that the humour of the situation would allow participants to speak without anxiety to an audience, and thereby learn that this is possible, with this learning carrying over to later talks in front of a human audience. In the cognitive model of social phobia by Clark and Wells (Clark et al., 1995) one of the factors is self-focussed attention and the accentuation of negative thoughts about the self especially with respect to the notion of supposed negative evaluation from others. In that case if a person with social phobia had to talk in front of an audience but as someone else we should expect that their anxiety would be reduced, which is what we expected for the Cartoon condition. In the study reported in (Aymerich-Franch et al., 2014) participants gave a speech in front of a human virtual audience embodied in a human virtual body with a face that was their own likeness or the face of another. In a pre-exposure test participants indicated preference for the face that was unlike their own. However, the exposure results showed that there was at best a marginal reduction of anxiety for those with the dissimilar face.
However, we did not take into account the possibility that even in the cartoon situation participants might still interpret the audience as responding negatively. In the Clark and Wells model social phobia sufferers, to the extent that they process external cues rather than be internally focussed, would be likely to interpret such cues as negative: “In particular, they may be more likely to notice and remember responses from others that they interpret as signs of disapproval” and that this would be particularly pointed in public speaking (Clark, 2001). In the Cartoon condition the cartoon audience, since it was so strange, would be particularly salient. However, for people with strong social phobia there would be no reason why they would not interpret the responses of the audience as negative, even seemingly positive events such as clapping being interpreted as negative (e.g., “They are only clapping because they feel sorry for me”).
Our results suggest that at the average level of trait anxiety the 3PP condition proved to be the one that had the greatest probability of reducing anxiety. This fits the Clark and Wells model since the 3PP condition was the one where they saw themselves from the outside, and thus had the maximum psychological distance from themselves as speaker. This accords well with self-distancing theory (Kross and Ayduk, 2017) where people recall an event that caused anxiety from a third person perspective as a “fly on the wall” rather than from an embodied first person perspective. Participants are instructed when recalling an affectively negative past event: “Now take a few steps back. Move away from the situation to a point where you can now watch the event unfold from a distance and see yourself in the event.” Research on self-distancing theory shows that this leads to a reduction of negative affect. Participants answered the questionnaire after the event itself, so it is possible that their disembodied third-person experience resulted in less stress. However, this finding about the average level of trait anxiety is an inference from the posterior statistical model and would need to be verified with a further experimental study.
Limitations
The first limitation of this study is that the sample consisted only of women, and it remains to be seen if these results would generalise to other genders. Second, the sample sizes were relatively small, however, the posterior distributions were clearly dominated by the data, as evidenced by the narrow and focussed posterior credible intervals compared to the prior intervals. Third, it would be possible to extend the experimental design to two factors: type of embodiment (Cartoon, Human, 3PP) and type of audience (Cartoon, Human). This would be interesting further work to elicit how much the results were due to the embodiment and the audience, the design being able to separate these two factors.
Although we did not find any advantage for the Cartoon condition in this application to fear of public speaking, it is possible that it may be beneficial in other psychological conditions. The role of humour in promoting mental and physical health is well-known—e.g., (Gelkopf and Kreitler, 1996)—and has in particular been studied in relation to overcoming depression (Tagalidou et al., 2019). This could be a useful line of further research.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Ethics Statement
The studies involving human participants were reviewed and approved by This experiment was approved by the Comisión de Bioética de la Universitat de Barcelona (IRB00003099). The patients/participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
Author Contributions
AB designed and implemented the virtual reality scenario, carried out the experiment and compiled the data. XN contributed to the implementation of the virtual reality scenario. DB and RO contributed to the design and implementation of the experiment. VO contributed to the design and implementation of the characters. MS formulated the original concept, designed the experiment, carried out the analysis, wrote the first draft of the paper and obtained the funding. All authors contributed to a review of the draft paper.
Funding
This research was originally funded under the European Seventh Framework Program, Future and Emerging Technologies (FET), Project Virtual Embodiment and Robotic Re-Embodiment (VERE) Grant Agreement Number 257695, and completed under the ERC Advanced Grant MoTIVE 742989.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors would like to thank Sofia Seinfeld for helping with the experiments, and Xenxo Álvarez for helping with the cartoon avatars.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frvir.2021.695673/full#supplementary-material
References
Abuín, M. R., and Rivera, L. d. (2014). La medición de síntomas psicológicos y psicosomáticos: el Listado de Síntomas Breve (LSB-50). Clínica y Salud 25 (2), 131–141. doi:10.1016/j.clysa.2014.06.001
Ahn, S. J. G., Bostick, J., Ogle, E., Nowak, K. L., McGillicuddy, K. T., and Bailenson, J. N. (2016). Experiencing Nature: Embodying Animals in Immersive Virtual Environments Increases Inclusion of Nature in Self and Involvement with Nature. J. Comput-mediat Comm. 21 (6), 399–419. doi:10.1111/jcc4.12173
Aymerich-Franch, L., Kishore, S., and Slater, M. (2019). When Your Robot Avatar Misbehaves You Are Likely to Apologize: an Exploration of Guilt during Robot Embodiment. Int. J. Soc. Robotics 12, 217–226. doi:10.1007/s12369-019-00556-5
Aymerich-Franch, L., Kizilcec, R. F., and Bailenson, J. N. (2014). The Relationship between Virtual Self Similarity and Social Anxiety. Front. Hum. Neurosci. 8, 944. doi:10.3389/fnhum.2014.00944
Aymerich-Franch, L., Petit, D., Ganesh, G., and Kheddar, A. (2017). Non-human Looking Robot Arms Induce Illusion of Embodiment. Int. J. Soc. Robotics 9 (4), 479–490. doi:10.1007/s12369-017-0397-8
Ayres, J. (1990). Situational Factors and Audience Anxiety. Commun. Educ. 39 (4), 283–291. doi:10.1080/03634529009378810
Banakou, D., Kishore, S., and Slater, M. (2018). Virtually Being Einstein Results in an Improvement in Cognitive Task Performance and a Decrease in Age Bias. Front. Psychol. 9 (917), 917. doi:10.3389/fpsyg.2018.00917
Banakou, D., Groten, R., and Slater, M. (2013). Illusory Ownership of a Virtual Child Body Causes Overestimation of Object Sizes and Implicit Attitude Changes. Proc. Natl. Acad. Sci. 110, 12846–12851. doi:10.1073/pnas.1306779110
Banakou, D., Hanumanthu, P. D., and Slater, M. (2016). Virtual Embodiment of White People in a Black Virtual Body Leads to a Sustained Reduction in Their Implicit Racial Bias. Front. Hum. Neurosci. 10, 601. doi:10.3389/fnhum.2016.00601
Banakou, D., and Slater, M. (2014). Body Ownership Causes Illusory Self-Attribution of Speaking and Influences Subsequent Real Speaking. Proc. Natl. Acad. Sci. USA 111 (49), 17678–17683. doi:10.1073/pnas.1414936111
Barberia, I., Oliva, R., Bourdin, P., and Slater, M. (2018). Virtual Mortality and Near-Death Experience after a Prolonged Exposure in a Shared Virtual Reality May lead to Positive Life-Attitude Changes. PloS one 13 (11), e0203358. doi:10.1371/journal.pone.0203358
Bedder, R. L., Bush, D., Banakou, D., Peck, T., Slater, M., and Burgess, N. (2019). A Mechanistic Account of Bodily Resonance and Implicit Bias. Cognition 184, 1–10. doi:10.1016/j.cognition.2018.11.010
Blanke, O., Slater, M., and Serino, A. (2015). Behavioral, Neural, and Computational Principles of Bodily Self-Consciousness. Neuron 88 (1), 145–166. doi:10.1016/j.neuron.2015.09.029
Botvinick, M., and Cohen, J. (1998). Rubber Hands 'feel' Touch that Eyes See. Nature 391 (6669), 756. doi:10.1038/35784
Carpenter, B., Gelman, A., Hoffman, M. D., Lee, D., Goodrich, B., Betancourt, M., et al. (2017). Stan: A Probabilistic Programming Language. J. Stat. Softw. 76 (1), 1–32. doi:10.18637/jss.v076.i01
Charbonneau, P., Dallaire-Côté, M., Côté, S. S-P., Labbe, D. R., Mezghani, N., and Shahnewaz, S. (2017). “Gaitzilla: Exploring the Effect of Embodying a Giant Monster on Lower Limb Kinematics and Time Perception,” in 2017 International Conference on Virtual Rehabilitation (ICVR) (IEEE). doi:10.1109/icvr.2017.8007535
Chesham, R. K., Malouff, J. M., and Schutte, N. S. (2018). Meta-analysis of the Efficacy of Virtual Reality Exposure Therapy for Social Anxiety. Behav. Change 35 (3), 152–166. doi:10.1017/bec.2018.15
Clark, D. M. (2001). “A Cognitive Perspective on Social Phobia,” in International Handbook of Social Anxiety: Concepts, Research and Interventions Relating to the Self and Shyness, 405ñ30.
Clark, D. M., and Wells, A. (1995). “A Cognitive Model of Social Phobia,” in Social Pobia: Diagnosis, Assessment, and Treatment. Editors R Heimberg, M Liebowitz, D A. Hope, and R. Schneier (New York: Guilford Press), 69–93.
Ebrahimi, O. V., Pallesen, S., Kenter, R. M. F., and Nordgreen, T. (2019). Psychological Interventions for the Fear of Public Speaking: a Meta-Analysis. Front. Psychol. 10, 488. doi:10.3389/fpsyg.2019.00488
Ehrsson, H. H. (2012). “The Concept of Body Ownership and its Relation to Multisensory Integration,” in The New Handbook of Multisensory Processes. Editor B E Stein (Cambridge, MA, USA: MIT Press), 775–792.
Ehrsson, H. H., Spence, C., and Passingham, R. E. (2004). That's My Hand! Activity in Premotor Cortex Reflects Feeling of Ownership of a Limb. Science 305, 875–877. doi:10.1126/science.1097011
Ferreira Marinho, A. C., Mesquita de Medeiros, A., Côrtes Gama, A. C., and Caldas Teixeira, L. (2017). Fear of Public Speaking: Perception of College Students and Correlates. J. Voice 31 (1), 127–e11. e7-e11. doi:10.1016/j.jvoice.2015.12.012
Freeman, D., Reeve, S., Robinson, A., Ehlers, A., Clark, D., Spanlang, B., et al. (2017). Virtual Reality in the Assessment, Understanding, and Treatment of Mental Health Disorders. Psychol. Med. 47, 2393–2400. doi:10.1017/S003329171700040X
Gallego, M. J., Botella, C., Quero, S., Garcia-Palacios, A., and Baños, R. M. (2009). Validation of the Personal Report Confidence as Speaker in a Spanish Clinical Sample. Behav. Psychol. 17 (3), 413–431. Available at: https://www.behavioralpsycho.com/producto/validacion-del-cuestionario-de-confianza-para-hablar-en-publico-en-una-muestra-clinica-espanola/
Gelkopf, M., and Kreitler, S. (1996). Is Humor Only Fun, an Alternative Cure or Magic? the Cognitive Therapeutic Potential of Humor. J. Cogn. Psychother 10 (4), 235–254. doi:10.1891/0889-8391.10.4.235
Gonzalez-Franco, M., Ofek, E., Pan, Y., Antley, A., Steed, A., Spanlang, B., et al. (2020). The Rocketbox Library and the Utility of Freely Available Rigged Avatars. Front. Virtual Real. 1, 561558. doi:10.3389/frvir.2020.561558
Guterstam, A., Gentile, G., and Ehrsson, H. H. (2013). The Invisible Hand Illusion: Multisensory Integration Leads to the Embodiment of a Discrete Volume of Empty Space. J. Cogn. Neurosci. 25 (7), 1078–1099. doi:10.1162/jocn_a_00393
Guterstam, A., Petkova, V. I., and Ehrsson, H. H. (2011). The Illusion of Owning a Third Arm. PloS one 6 (2), e17208. doi:10.1371/journal.pone.0017208
Hoyet, L., Argelaguet, F., Nicole, C., and Lécuyer, A. (2016). "Wow! I Have Six Fingers!": Would You Accept Structural Changes of Your Hand in VR? Front. Robot. AI 3, 27. doi:10.3389/frobt.2016.00027
Jackson, J. M., and Latané, B. (1981). All Alone in Front of All Those People: Stage Fright as a Function of Number and Type of Co-performers and Audience. J. Personal. Soc. Psychol. 40 (1), 73–85. doi:10.1037/0022-3514.40.1.73
Jones, J. A., Swan, J. E., Singh, G., Kolstad, E., and Ellis, S. R. (2008). “The Effects of Virtual Reality, Augmented Reality, and Motion Parallax on Egocentric Depth Perception,” in Proceedings of the 5th Symposium on Applied Perception in Graphics and Visualization (Los Angeles, CA, USA: ACM).
Kilteni, K., Groten, R., and Slater, M. (2012). The Sense of Embodiment in Virtual Reality. Presence: Teleoperators and Virtual Environments 21, 373–387. doi:10.1162/pres_a_00124
Kilteni, K., Normand, J.-M., Sanchez-Vives, M. V., and Slater, M. (2012). Extending Body Space in Immersive Virtual Reality: A Very Long Arm Illusion. PLoS ONE 7, e40867. doi:10.1371/journal.pone.0040867
Krekhov, A., Cmentowski, S., and Krüger, J. (2019). “The Illusion of Animal Body Ownership and its Potential for Virtual Reality Games,” in 2019 IEEE Conference on Games (CoG) (IEEE). doi:10.1109/cig.2019.8848005
Kross, E., and Ayduk, O. (2017). “Self-Distancing,” in Advances in Experimental Social Psychology (Elsevier), 81–136. doi:10.1016/bs.aesp.2016.10.002
Kruschke, J. K. (2011). Introduction to Special Section on Bayesian Data Analysis. Perspect. Psychol. Sci. 6 (3), 272–273. doi:10.1177/1745691611406926
Lemoine, N. P. (2019). Moving beyond Noninformative Priors: Why and How to Choose Weakly Informative Priors in Bayesian Analyses. Oikos 128 (7), 912–928. doi:10.1111/oik.05985
Lin, L., and Jörg, S. (2016). “Need a Hand? How Appearance Affects the Virtual Hand Illusion,” in SAP '16: Proceedings of the ACM Symposium on Applied Perception, Anaheim, CA, July 22–23, 2016 (New York City, NY: ACM), 69–76. doi:10.1145/2931002.2931006
Maister, L., Slater, M., Sanchez-Vives, M. V., and Tsakiris, M. (2015). Changing Bodies Changes Minds: Owning Another Body Affects Social Cognition. Trends Cogn. Sci. 19 (1), 6–12. doi:10.1016/j.tics.2014.11.001
North, M. M., North, S. M., and Coble, J. R. (1998). Virtual Reality Therapy: an Effective Treatment for the Fear of Public Speaking. Ijvr 3 (3), 1–6. doi:10.20870/ijvr.1998.3.3.2625
Osimo, S. A., Pizarro, R., Spanlang, B., and Slater, M. (2015). Conversations between Self and Self as Sigmund Freud-A Virtual Body Ownership Paradigm for Self Counselling. Sci. Rep. 5, 13899. doi:10.1038/srep13899
Paul, G. L. (1966). Insight vs. Desensitization in Psychotherapy: An experiment in Anxiety Reduction. Stanford University Press.
Peck, T. C., Seinfeld, S., Aglioti, S. M., and Slater, M. (2013). Putting Yourself in the Skin of a Black Avatar Reduces Implicit Racial Bias. Conscious. Cogn. 22, 779–787. doi:10.1016/j.concog.2013.04.016
Perez-Marcos, D., Sanchez-Vives, M. V., and Slater, M. (2011). Is My Hand Connected to My Body? the Impact of Body Continuity and Arm Alignment on the Virtual Hand Illusion. Cogn. Neurodyn 6 (4), 295–305. doi:10.1007/s11571-011-9178-5
Pertaub, D.-P., Slater, M., and Barker, C. (2002). An experiment on Public Speaking Anxiety in Response to Three Different Types of Virtual Audience. Presence: Teleoperators & Virtual Environments 11 (1), 68–78. doi:10.1162/105474602317343668
Seisdedos, N. (1988). Adaptación Española del STAI, Cuestionario de ansiedad estado-rasgo [Spanish adaptation of the STAI, State-Trait Anxiety Inventory]. Madrid: Tea Ediciones.
Slater, M., Neyret, S., Johnston, T., Iruretagoyena, G., Crespo, M. Á. d. l. C., Alabèrnia-Segura, M., et al. (2019). An Experimental Study of a Virtual Reality Counselling Paradigm Using Embodied Self-Dialogue. Sci. Rep. 9 (1), 10903. doi:10.1038/s41598-019-46877-3
Slater, M., Spanlang, B., Sanchez-Vives, M. V., and Blanke, O. (2010). First Person Experience of Body Transfer in Virtual Reality. PLOS ONE 5 (5), e10564. doi:10.1371/journal.pone.0010564
Spielberger, C. D. (1983). Manual for the State-Trait Anxiety Inventory STAI (Form Y) (“self-Evaluation Questionnaire”).
Spielberger, C. D. (2010). “State‐Trait Anxiety Inventory,” in The Corsini Encyclopedia of Psychology, 1.
Steptoe, W., Steed, A., and Slater, M. (2013). Human Tails: Ownership and Control of Extended Humanoid Avatars. IEEE Trans. Vis. Comput. Graphics 19, 583–590. doi:10.1109/tvcg.2013.32
Tagalidou, N., Distlberger, E., Loderer, V., and Laireiter, A. R. (2019). Efficacy and Feasibility of a Humor Training for People Suffering from Depression, Anxiety, and Adjustment Disorder: a Randomized Controlled Trial. BMC psychiatry 19 (1), 93–13. doi:10.1186/s12888-019-2075-x
Tajadura-Jiménez, A., Banakou, D., Bianchi-Berthouze, N., and Slater, M. (2017). Embodiment in a Child-like Talking Virtual Body Influences Object Size Perception, Self-Identification, and Subsequent Real Speaking. Sci. Rep. 7 (1), 9637. doi:10.1038/s41598-017-09497-3
Tieri, G., Tidoni, E., Pavone, E. F., and Aglioti, S. M. (2015). Mere Observation of Body Discontinuity Affects Perceived Ownership and Vicarious agency over a Virtual Hand. Exp. Brain Res. 233 (4), 1247–1259. doi:10.1007/s00221-015-4202-3
Van De Schoot, R., Winter, S. D., Ryan, O., Zondervan-Zwijnenburg, M., and Depaoli, S. (2017). A Systematic Review of Bayesian Articles in Psychology: The Last 25 Years. Psychol. Methods 22 (2), 217–239. doi:10.1037/met0000100
van der Hoort, B., Guterstam, A., and Ehrsson, H. H. (2011). Being Barbie: the Size of One's Own Body Determines the Perceived Size of the World. PLoS ONE 6, e20195. doi:10.1371/journal.pone.0020195
Vanni, F., Conversano, C., Del Debbio, A., Landi, P., Carlini, M., Fanciullacci, C., et al. (2013). A Survey on Virtual Environment Applications to Fear of Public Speaking. Eur. Rev. Med. Pharmacol. Sci. 17 (12), 1561–1568. Available at: https://europepmc.org/article/med/23832719
Vehtari, A., Gelman, A., and Gabry, J. (2017). Practical Bayesian Model Evaluation Using Leave-One-Out Cross-Validation and WAIC. Stat. Comput. 27 (5), 1413–1432. doi:10.1007/s11222-016-9696-4
Won, A. S., Bailenson, J., Lee, J., and Lanier, J. (2015). Homuncular Flexibility in Virtual Reality. J. Comput-mediat Comm. 20 (3), 241–259. doi:10.1111/jcc4.12107
Won, A. S., Bailenson, J. N., and Lanier, J. (2015). “Homuncular Flexibility: the Human Ability to Inhabit Nonhuman Avatars,” in Emerging Trends in the Social and Behavioral Sciences: An Interdisciplinary, Searchable, and Linkable Resource, 1–16. doi:10.1002/9781118900772.etrds0165
Yee, N., and Bailenson, J. (2007). The Proteus Effect: The Effect of Transformed Self-Representation on Behavior. Hum. Comm Res 33, 271–290. doi:10.1111/j.1468-2958.2007.00299.x
Keywords: embodiment, virtual reality, body ownership, fear of public speaking, cartoon
Citation: Bellido Rivas AI, Navarro X, Banakou D, Oliva R, Orvalho V and Slater M (2021) The Influence of Embodiment as a Cartoon Character on Public Speaking Anxiety. Front. Virtual Real. 2:695673. doi: 10.3389/frvir.2021.695673
Received: 15 April 2021; Accepted: 14 September 2021;
Published: 22 October 2021.
Edited by:
Regis Kopper, University of North Carolina at Greensboro, United StatesReviewed by:
Rabindra Ratan, Michigan State University, United StatesMina C. Johnson-Glenberg, Arizona State University, United States
Copyright © 2021 Bellido Rivas, Navarro, Banakou, Oliva, Orvalho and Slater. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mel Slater, bWVsc2xhdGVyQHViLmVkdQ==
†Present address: Netquest, Barcelona, Spain
‡Present address: VISYON, Barcelona, Spain.