 Courtney Hutton Pospick
Courtney Hutton Pospick Evan Suma Rosenberg
Evan Suma Rosenberg- The Illusioneering Lab, Department of Computer Science and Engineering, University of Minnesota, Minneapolis, MN, United States
Mixed reality offers unique opportunities to situate complex tasks within spatial environments. One such task is the creation and manipulation of intricate, three-dimensional paths, which remains a crucial challenge in many fields, including animation, architecture, and robotics. This paper presents an investigation into the possibilities of spatially situated path creation using new virtual and augmented reality technologies and examines how these technologies can be leveraged to afford more intuitive and natural path creation. We present a formative study (n = 20) evaluating an initial path planning interface situated in the context of augmented reality and human-robot interaction. Based on the findings of this study, we detail the development of two novel techniques for spatially situated path planning and manipulation that afford intuitive, expressive path creation at varying scales. We describe a comprehensive user study (n = 36) investigating the effectiveness, learnability, and efficiency of both techniques when paired with a range of canonical placement strategies. The results of this study confirm the usability of these interaction metaphors and provide further insight into how spatial interaction can be discreetly leveraged to enable interaction at scale. Overall, this work contributes to the development of 3DUIs that expand the possibilities for situating path-driven tasks in spatial environments.
1 Introduction
Mixed reality has unlocked new possibilities for interaction in immersive 3D experiences, providing a unique opportunity to situate complex tasks within spatial environments. With spatially situated interactions, 3D user interfaces (3DUIs) can allow users to directly interact in ways that were previously impossible. This has led to a renewed interest in providing expressive, intuitive ways to engage with the environment, particularly for complex workflows.
Path creation is one such task. Deceptively simple in two dimensions, the creation and manipulation of complex, three-dimensional paths remains an unsolved problem in both physical and virtual spaces. While algorithmic approaches can generate approximately optimal paths for a given space, there are a broad range of use cases where this approach is neither required nor desirable. Supporting human-assisted path creation and manipulation expands the application space for path creation; it remains a critical task for many domains including animation, architecture, and robotics.
One driver of the renewed interest in 3D path creation has been the application of mixed reality to interdisciplinary domains, and the intersection of mixed reality and human-robot interaction (HRI) in particular. Mixed reality offers the possibility for new advances in human-robot interaction and cooperative tasks with autonomous agents. By embedding 3D imagery within the operating environment, mixed reality can enable completely new forms of communication between humans and autonomous agents. Moreover, the use of spatial input devices and interaction techniques provides a rich canvas for users to issue increasingly complex commands to robotic teammates. Realizing these capabilities will require alternative interfaces and tools that allow human operators to engage directly with the environment while programming robotic agents.
Unfortunately, there is limited research available to inform these designs. Early work investigating 3DUIs and spatial interaction often focused on indirect interaction techniques or ground-constrained paths. The devices that were used to design and evaluate these methods lacked the advanced capabilities that are now available with current headsets and tracking systems, particularly for spatial mapping and 3D interaction. As low-cost devices have become increasingly commonplace, 3D path creation and manipulation interfaces have tentatively begun to appear in consumer applications. For 3DUIs focused on HRI, the emphasis is often on marker or waypoint placement, without the capability for human modification or manipulation. Currently, 3DUIs often make trade-offs between precision and efficiency, or between intuitive interactions and expressive flexibility. Technology-assisted 3D interaction continues to grow in accessibility for a wide range of users and applications, demanding the development and evaluation of 3DUIs that meet the needs of this space.
In this paper, we explore the possibilities for spatially situated path creation that are offered by new virtual reality and augmented reality technologies, and we examine how these technologies can be leveraged to afford more intuitive and natural path creation. We present an initial interface for path creation in augmented reality alongside a formative user study to evaluate this initial design and the problem space. Based on the findings of this evaluation, we detail the development of more sophisticated interfaces for 3D path creation, including two novel path manipulation techniques. These two techniques enable the creation and manipulation of complex three-dimensional paths at a distance in a simple, intuitive manner. To facilitate the development and thorough assessment of these techniques, we made a deliberate shift to a virtual reality paradigm. This allows for more intricate interactions and a more reliable, reproducible experimental design than what is achievable with current generation AR devices. We subsequently describe a comprehensive user study testing the effectiveness, learnability, and efficiency of these new techniques in combination with common placement techniques: raycasting, iSith, and a world-in-miniature. To the best of our knowledge, this represents the first formal evaluation and empirical comparison of iSith with other placement techniques. The results of this study confirm the usability of these interaction metaphors for path planning tasks, and provide further insight for how spatial interaction can be discretely leveraged to enable interaction at scale. In addition, the results demonstrate significant support for the efficacy of iSith, and a strong participant preference for the technique.
Collectively, this work contributes the following:
• A formative study, n = 20, investigating an initial path planning interface situated in the context of AR and HRI that examines how users interact with these interfaces.
• An evaluation of these findings and their implications for 3DUIs and the more general problem of path creation in immersive environments.
• Two novel techniques for spatially situated path planning and manipulation, both designed to afford intuitive, expressive path creation at varying scales.
• A comprehensive user study, n = 36, assessing the effectiveness, learnability, and efficiency of both techniques when paired with a range of common placement strategies.
2 Related work
Path creation and manipulation in mixed reality have been the subject of extensive research, with numerous techniques and applications explored across a broad spectrum of domains. Initially, path generation and manipulation in mixed reality was primarily used for simple, ground-constrained locomotion tasks or for authoring animation curves in 3D modeling software. More recently, the advent of consumer headsets has expanded the spatial capabilities for mixed reality path creation and it has been applied to more sophisticated and complex tasks.
2.1 3DUIs for path creation
Creating paths, particularly complex, three-dimensional paths, generally requires applying techniques used for 3D manipulation. These techniques can be broadly classified as “direct” or “indirect” based on the type of interaction they afford. With indirect metaphors, the user interacts with and modifies parameters to create and manipulate a path, while direct metaphors require the user to physically interact with the path.
Many techniques for indirect path creation and manipulation in 3D environments arguably grew out of 2D camera-control metaphors for early computer-based 3D modeling and animation programs (LaViola et al., 2001; Burigat and Chittaro, 2007; Cohen et al., 1999). Subsequent research has largely focused on developing more natural and efficient indirect techniques for path manipulation and creation. Keefe et al. (2007) presented “Drawing on Air”, a desktop-based virtual reality (VR) technique for drawing controlled 3D curves through space. This work described two strategies for creating 3D curves: a unimanual drag-drawing method, and a bimanual tape-drawing method. In both, the user provides the tangent of the curve to draw the shape. Later, Keefe et al. (2008) expanded on this work with the development of a dynamic pen-dragging technique that enabled novice users to create 3D paths with high curvature, while automatically smoothing out input from the user. Ha et al. (2012) proposed an augmented reality (AR) virtual hand technique that employs a tangible prop to generate and manipulate the control points of animation splines. While these techniques were effective for 3D modelling, users required training and prior understanding of 3D curves to manipulate their paths.
Direct interaction is of particular interest to 3DUI researchers, as it offers the potential to harness a user’s spatial understanding of the environment and deliver a more intuitive and natural experience. In an early example of direct mixed reality path creation, Igarashi et al. (1998) proposed path drawing as a technique for route-planning in virtual walkthroughs. With this technique, a user drew a ground-constrained path onto the environment using a tablet integrated with the virtual display. Other early examinations into path creation highlighted its potential for navigation and locomotion Bowman and Wingrave (2001).
Zhai et al. (1999) proposed a dual joystick navigation design for 3D navigation in a screen-based 3D environments. This interface was based on a bimanual “magic carpet” or “bulldozer” metaphor where each joystick “pushes” the path forward to carve through space. This interface outperformed the traditional mouse-mapping interface in a free-flying navigation evaluation.
Do and Lee (2010) explored a drawing-based approach for authoring animation paths in an AR environment. This method relied on a marker-based freehand technique in which users draw curves around a specified axis using a physical marker. The user then adjusts the object’s rotation at each time step using two virtual buttons.
2.2 Mixed reality path creation for HRI
Recently, rapid advances in self-contained augmented reality (AR) headsets, like the Microsoft HoloLens and Magic Leap, have made headset-based 3D path planning accessible for a wider range of AR-based applications. Navigation and object path-planning have remained an area of interest in research, with a particular focus on controlling robotic agents. These interfaces often focus on natural, intuitive interaction, and leverage the spatial interaction and immersion capabilities of mixed reality to do so.
Gesture-based path creation and manipulation has been studied as one method for combining spatial interaction with a more intuitive interface. Sanna et al. (2013) tested path creation through gesture-based control using the Microsoft Kinect, but this implementation required users to memorize a set of full body poses in order to use it. A gesture elicitation study by Cauchard et al. (2015) showed strong agreement for some gesture-based path controls, such as stopping and beckoning. However, this agreement occurred for less than half of the common interactions and controls that were tested. It is also noteworthy that purely gesture-based interfaces are often tiring for users (Guiard, 1987).
Suárez Fernández et al. (2016) explored natural user interfaces for creating paths for aerial robotic agents. This approach involved using physical markers to define a path that the robotic agent could follow, as well as having it follow the user’s path from a set height. Unfortunately, this approach to path creation is limited by the reach and physical capabilities of the user. As features such as propeller guards have become commonplace for aerial robotic agents, direct touch has also been proposed as an interaction method (Abtahi et al., 2017). As with “follow me” method, this type of path creation interface is not suitable for interacting at a distance.
Paterson et al. (2019) examined VR as a medium for 3D aerial path planning and found the VR interface to be safer and more efficient for path planning than both standard 2D touchscreen interfaces and manual controller based path creation. The VR interface reduced the time required for path creation by 48%. However, the paths created with this interface were simplistic: they consisted of straight-line navigation at a fixed altitude, with no way for the user to modify the curvature or shape of the path. This problem is common among interfaces that target ground-based and aerial robotic agents. While some of these limitations can be explained by the movement capabilities of robotic agents, many are due to restrictions imposed by existing interfaces (Marvel et al., 2020).
Some recent research has attempted to target this problem. Quintero et al. (2018) proposed an trajectory specification system for the HoloLens with an interface to create surface-constrained and free-space paths for robotic arms. Users could specify these waypoints using a number of specific voice commands that were executed in a particular sequence. For free-space paths, two control points were set, and the system used B-splines to interpolate between them. Path modifications involved adjusting one of the control points. In a small pilot study comparing the proposed AR interface with a kinesthetic gamepad interface, researchers found that while the AR interface took less time to learn, it introduced a mental workload nearly five times higher than the gamepad method during path creation.
Krings et al. (2022) presented an AR-assisted path creation system for ground-constrained robot paths that tested both waypoint-based planning and path drawing against Mindstorms1 programming. In an initial evaluation with 18 participants, AR path creation outperformed the computer-based Mindstorms approach in usability and efficiency, likely because it eliminated the need for trial and error when programming positions. However, as with the system developed by Suárez Fernández et al., the paths created by this interface were primitive straight-line paths, and while they were generated in three dimensions, the paths did not have the same range.
Unfortunately, few of these interfaces offer intuitive ways to modify existing paths. Interaction in 3D space has been repeatedly cited as an area that is critically lacking for generalized cases of 3D path planning Vaquero-Melchor and Bernardos (2019); Burri et al. (2012) and for human-robot collaboration in general (Marvel et al., 2020). It is also notable that the interfaces described here do not generally afford users the ability to interact with 3D paths at a distance, though the basic problem of interacting at scale has been studied in 3D interaction literature.
2.3 3D interaction at scale
A variety of metaphors have been explored to present information and enable interaction at scale in virtual environments. These generalized techniques accomplish this by leveraging both egocentric and allocentric spatial reference frames. Egocentric frames are a body-centered frame defined relative to the individual, while allocentric frames are to a world-centered frame defined relative to other objects. Common egocentric techniques for interaction at a distance include arm-extension metaphors (Poupyrev et al., 1996) and raycasting metaphors (Bowman and Hodges, 1997). iSith Wyss et al. (2006) is a bimanual, egocentric technique for placing points in mid air. This metaphor places an object at a projected intersection point found by the shortest distance between two skew rays, removing the burden of creating a genuine intersection point. To the best of our knowledge, this technique has not been formally evaluated. Stoakley et al. (1995) contributed a classic allocentric metaphor for interaction at scale: the “Worlds in Miniature” (WiM) interface. This used a scalable virtual model to interact in the environment, though it broke down for fine-gained, small-scale manipulations. Recent comparative evaluations of WiM interfaces and raycasting techniques have frequently focused on their application to navigation (Chheang et al., 2022; Yu et al., 2022) and for locomotion techniques (Englmeier et al., 2021; Berger and Wolf, 2018). These evaluations support the viability of WiM interfaces for these applications in complex environments. However, placing and manipulating paths in 3D space is a vastly different task, and there is limited prior research comparing these interfaces within this context. Their performance and usability in this space remains an open question.
Current interaction techniques for 3D path creation often force a trade-off between ease of use and expressiveness or effectiveness at scale. This research aims to address this gap by designing and evaluating novel path creation techniques that are easy to use and leverage the spatial capabilities of mixed reality, without requiring the user to memorize sets of commands or specific action sequences.
3 Methods and materials
Given the relative novelty of consumer AR headsets, we began by developing an initial path creation and manipulation interface and gathering feedback through a formative user study. This formative study provided design insights that guided subsequent development. Based on these findings, we developed a more sophisticated set of 3D user interfaces for 3D path planning, including two novel path manipulation techniques that leverage egocentric and allocentric reference frames for gesture-free manipulation. We then conducted a within-subjects user study to evaluate these techniques in combination with three classical interaction metaphors adapted for waypoint placement. This evaluation includes a quantitative assessment of the effectiveness, learnability, and efficiency of the techniques, along with an evaluation of user feedback.
3.1 Formative evaluation
Given the number of use cases for HRI and mixed reality, and in particular AR, we situated our formative study in the context of path planning for an aerial robotic agent. This study examined the design space for 3D path creation; specifically, we wanted to understand how users interacted with the AR interfaces, and what factors contributed to perceived efficacy and usability.
3.1.1 System design
We developed an initial path creation interface using Unity 2018.1 and the Magic Leap Creator One AR headset. The spatial mapping capability of the Magic Leap creates a 3D mesh of the physical environment that the user can interact with. Our initial interface design sought to leverage these qualities to allow users to create customised paths. In addition, it also took advantage of the Magic Leap’s controller to extend users’ interaction capabilities. To do this, it divided path creation into two steps: waypoint placement and path manipulation. This task separation is common in current interfaces (Quintero et al., 2018; Krings et al., 2022) and is often justified as lowering the cognitive load of path creation. We developed our interface in a similar fashion to evaluate the effects of this paradigm.
3.1.1.1 Waypoint placement
Initially, the user positions a series of waypoints to create the outline of their path. Placement occurs with a visualization plane, seen in Figure 1A; this allows the user to view the height that waypoints will appear at. This plane is always parallel to the ground and is placed by pointing with the controller; it can be relocated at any time. It can be moved up or down with the controller, and can be moved closer or further away with the touchpad.
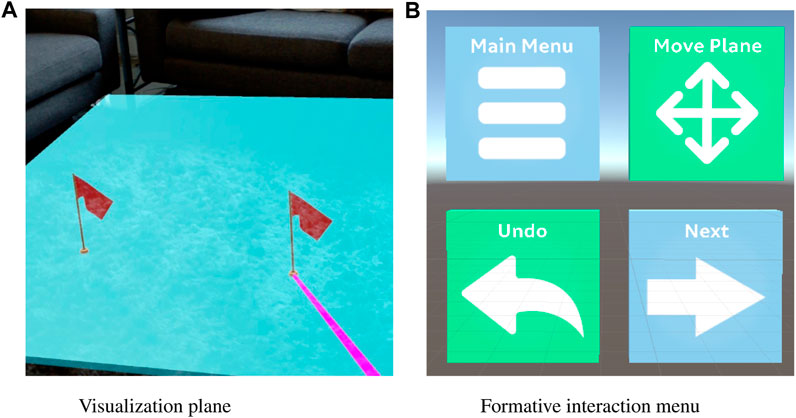
FIGURE 1. The initial interface for creating paths in the formative evaluation. (A) The visualization plane and pointing ray used to place waypoints in the formative design. (B) The 3D-menu visible to users, shown in the Unity development environment. Created with Unity Editor®. Unity is a trademark or registered trademark of Unity Technologies.
Waypoints are placed by raycasting to the visualization plane through a pointing ray emanating from the controller, shown in Figure 1A. They can be repositioned or deleted as necessary. Once a user has a pair of waypoints, a 3D dotted-line path segment appears between the two points. The dotted-line path was chosen to avoid obstructing information in the physical environment and to prevent visual clutter, given the limited field of view.
3.1.1.2 Path manipulation
When a user is done creating waypoints, they can manipulate the path. They can select a path segment by raycasting to a distant segment, or by reaching out and physically grabbing a virtual representation of a segment. The user can then edit the altitude and arc of a path in either the XZ- or XY-plane. This design choice was intended to simplify the cognitive load for the user.
3.1.1.3 User interface
A 3D menu in the physical space allows the user to switch between each mode of interaction, and is shown in Figure 1B. The menu position updates when the user moves more than a set distance away from it; in pilot testing this was found to be 1.25 m. It positions itself roughly 1 m in front of the user, and it is offset by about 30° in the direction opposite the users’ dominant hand.
There were several motivations for choosing a 3D menu over a 2D heads-up-display (HUD). Hiding and showing an HUD menu requires an additional, “invisible” interaction step; persistent HUD menus can distract the user or obstruct the task (Vortmann and Putze, 2020). Most significantly, current AR headsets have severe field-of-view limitations: the Magic Leap Creator One has a FOV of 40° horizontally and 30° vertically. Until display hardware improves, every pixel for visualization is at a premium. A 3D environmental menu maximizes the visual space available for the path planning task.
3.1.2 Formative user study
The formative user study investigated the viability of AR as a medium for 3D path planning and gathered feedback to inform the design of future interfaces. Formative studies are a behavioral and observational evaluation of a preliminary system, and are a well-documented part of the iterative design process (Egan et al., 1989; Rex Hartson et al., 2003). They do not judge a completed design against benchmarked systems or specific hypotheses. Formative testing aims to identify user strategies, potential system issues, and areas where a design can be improved. While informal tests or pilot studies often recruit users internally, formative studies can deliberately recruit individuals that are unfamiliar with a project and are representative of end users. This increases the reliability of the results, particularly when one of the main goals is to identify potential user strategies.
For this study, we sought to elicit user feedback, observe the physical and virtual interactions performed by novice users, and to identify future design considerations for efficient and intuitive 3D path planning interfaces. All study procedures and recruitment methods were approved by the University of Minnesota Institutional Review Board.
3.1.2.1 Study environment
We deployed the initial AR interface at the Minnesota State Fair in a pre-assigned research space, cordoned off from the rest of the building. We constructed a physical obstacle course in this area; it consisted of four circular targets 36” in diameter, shown in Figure 2. The targets were numbered to indicate the order the user should traverse them in. Other obstacles were also present in the space, including tables and chairs. Participants had freedom to move around, and could move out of the curtained area into the larger building space. The area was spatially mapped prior to the start of the study, and this procedure was performed periodically to standardize the experience.

FIGURE 2. The obstacle course setup for the formative user study. Numbered hoops representing ordered targets were placed at various locations and heights. (A) The study area and two of the targets. (B) The final target, approximately 3 m off the ground. (C) A path created by a study participant. Created with Unity Editor®. Unity is a trademark or registered trademark of Unity Technologies.
3.1.2.2 Participants
Over 2 million individuals attended the Fair (State Fair, 2022), providing a rich opportunity to gather data from a diverse sample. Participants were recruited from the general public; most self-selected to participate while walking by the research area. All individuals were required to have normal vision or vision that was corrected by contact lenses–this was necessary as the Magic Leap does not accommodate eyeglasses. Participants were over the age of 18 and were asked to self-report the number of alcoholic drinks they had consumed in the past 2 h. Anyone who reported having more than two drinks in that time frame or who was visibly intoxicated was excluded from participation. Individuals received a branded bag for participating.
A total of 21 participants took part in the study; 20 completed the full protocol. One participant was called away and could not finish the task. Of the 20 participants who completed the study, 10 identified as male and 10 identified as female. The median age was 33.5, with a range from 24 to 68 years old. Three participants had prior experience flying aerial robotic agents, and 12 had some type of prior experience with a VR headset.
3.1.2.3 Procedure
Participants were asked to use the interface to plot a path for an aerial robotic agent through all four targets, in sequential order. The experimenter helped fit the headset to the individual to ensure it was worn properly. They received a verbal tutorial in how to use the device and the controller. This tutorial covered the task and the controls, including how to use the visualization plane, placing waypoints, and manipulating paths. Participants were encouraged to ask questions at any time, and to verbalize any comments or confusion while using the system. Experimenters made note of comments that were made.
The Kennedy-Lane Simulator Sickness Questionnaire (SSQ) (Kennedy et al., 1993) was taken before and after the protocol. After the study, demographics information and qualitative usability feedback were collected. Qualitative feedback questions were based on interaction, movement, and ease of use, with some drawn from the system usability score (SUS) questionnaire. They were presented to participants as a seven-point Likert questionnaire, with response anchors ranging from strongly disagree to strongly agree. The study took no longer than 25 min to complete, inclusive of the consent process, tutorial, and questionnaires.
3.1.3 Findings
The majority of participants completed the AR portion of the study in less than 13 min.
For this study, there was no limit on the number of path segments or waypoints a participant could place. The number of waypoints placed by participants ranged from 6 to 18, with a median of 9 waypoints. Only 4 participants edited each path segment. Of the remaining 16 participants, 3 did not edit any path segments, and 13 edited less than half of their path segments.
All participants were able to create a path that traversed the first three targets. The fourth target, seen in Figure 2, had the lowest success rate; this target was placed approximately 3 m off the ground, above head height. Five participants (25%) successfully cleared the target, while four (20%) did not attempt to traverse the target. Two of the four participants who did not attempt to traverse the fourth target indicated that they had not even noticed the target. The participants who missed the target (55%) were all too low to clear the hoop, and some paths were off center. Multiple participants placed waypoints or created paths through obstacles. Most commonly, these obstacles were the curtains hanging around the research area, which can be seen in Figure 2.
A visual breakdown of the results from the post-experiment questionnaire can be seen in Figure 3. Overall, 19 participants agreed that they felt comfortable moving around the environment; 4 agreed that they stayed in one place while creating their path. 14 participants agreed that the tutorial prepared them to use the interface, while 6 disagreed with this statement. Additionally, 8 participants agreed with the statement “I did not understand how to use the interface” while 9 disagreed. Regarding waypoint placement, 17 participants agreed that they could place waypoints where they wanted them to be, while 3 disagreed. For path manipulation, 14 participants agreed with the statement “It was difficult to edit the path I created”, while 5 disagreed.
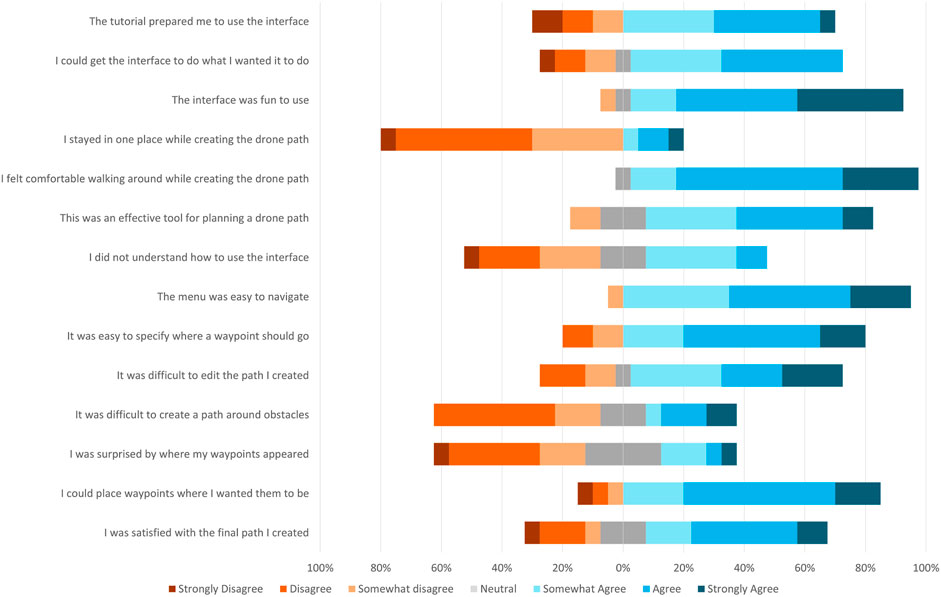
FIGURE 3. The results from a post-experiment Likert survey of participant impressions of the targeting plane interface. Values to the right of the center line indicate agreement with the statement; values to the left indicate disagreement; neutral responses are split across the center.
There were several notable comments made by participants and observations made by the experimenters. Several participants made large arm motions when trying to place the visualization plane, such as drawing their arm above their shoulder or behind their ear. Participants were also observed turning away from their path creation to interact with the menu: either to manipulate the visualization plane or to edit a waypoint. This was likely due to the field of view afforded by the Magic Leap, and due to the offset of the menu.
A Shapiro-Wilk test revealed a violation of normality for SSQ scores. Consequently, the data were analyzed with non-parametric tests and descriptive statistics are reported as median (Mdn) and interquartile range (IQR); these data can be seen in Table 1, along with minimum and maximum values for each test. A Wilcoxon signed-rank test revealed no significant difference in pre-SSQ scores (Mdn = 3.74, IQR = 7.48) compared to post-SSQ scores (Mdn = 0.00, IQR = 7.48), W = 10.0, p = 0.10.
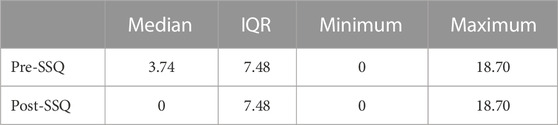
TABLE 1. Pre- and Post-Test SSQ scores for study participants, n = 20.
3.1.4 Discussion
There are several takeaways from this formative experiment.
3.1.4.1 User feedback
The majority of participants indicated a positive assessment of the interface in the post-study survey, though these responses are likely inflated due to a novelty bias. We believe that observations and data highlight significant room for improvement.
Critically, nearly half of the participants indicated difficulty in understanding how to use the interface. While additional training time was not possible due to the time constraints of the event, it could potentially mitigate this confusion. However, this result may also suggest that the separate steps in this interface may not be the most intuitive interaction metaphor for novice users. The latter theory is supported by the number of participants who found it difficult to edit the path they created, and the participants who did not edit any path segments.
3.1.4.2 Spatial interaction and path creation strategies
Survey results indicate that participants were comfortable moving around the physical space and physically interacting with the interface, including using large, broad gestures. Observations supported this. In some cases, these motions seemed to be an intuitive reaction to change the scale of the ray or another virtual object. This behavior is somewhat surprising, given that few participants had prior experience with immersive interaction. Most participants would be more familiar with the 2D interaction paradigms that are common to desktop and screen interfaces. This suggests that this type of physical, spatial behavior is an instinctive response for immersive environments.
Experimenters also observed a wide variety of approaches to planning paths: some individuals placed a large number of waypoints to created very precise sequences, while others placed fewer waypoints and attempted to traverse multiple targets by manipulating their path. Unsurprisingly, some participants attempted to complete the course as quickly as possible, while others focused on curating an “ideal” path. This range of approaches can be seen in the range of the data, and is likely due to the unconstrained nature of the task. This choice was intentional: we intended to elicit a variety of responses to identify trouble spots and previously unseen issues.
The inability to traverse the fourth target suggests that this interface is ineffective for path planning at a distance. This may be due to the use of the visualization plane, which could block the user’s view if placed too high, or to the complete decoupling of placement and manipulation. We suspect that some of the errors in placement occurred due to errors in depth perception, a known problem in virtual and augmented environments. Most participants expressed a preference for manipulating the path segments while creating waypoints. Participants likely felt that the task was simple enough to combine the two actions.
3.1.4.3 Design considerations
Clearly, these results indicates the need for a flexible system that can accommodate a wide variety of planning strategies, but also highlights the need for a well-defined test environment to limit confounding interactions caused by different strategies. The physicality displayed by participants also suggests that path creation is well-suited to spatially situated interaction metaphors, and that these may be more intuitive for inexperienced users. Given the difficulty with traversing objects at a distance, future designs will need to incorporate tools and interactions to specifically address this task. These techniques can improve the usability of a system and expand its flexibility beyond co-located HRI tasks.
3.2 System design
Based on the evaluation and results for the interface in our formative study, we developed a set of more sophisticated 3D user interfaces for 3D path planning, including two novel path manipulation techniques. These interfaces were created with three goals in mind. First and foremost, each interface must be effective: users must be able to complete a path-planning task correctly, minimizing the number of errors, and completely, accurately reaching the intended goal. Additionally, each interface must be intuitive; given the nebulous definition of this term, we focused on the learnability of an interface as a proxy for its intuitiveness. Finally, each interface must be efficient. Once they are familiar with a design, a user must be able to perform a task quickly.
3.2.1 Path manipulation techniques
Two novel path creation and manipulation strategies were developed and implemented to achieve these goals. All of the paths described in this system, paths were interpolated as Catmull-Rom splines using the Dreamteck Splines plugin for Unity (Dreamteck, 2021). By definition, a Catmull-Rom spline guarantees that each user-specified point would be included in the final curve, a significant advantage for intuitive use. After placing two waypoints, a straight-line trajectory between the points would appear to allow user’s to visualize the connection. The user then replaces this trajectory with their path, creating a shape that avoids the geometry of the environment and conforms to their objectives.
3.2.1.1 Pathbend
The first interface is based on a metaphor of pathbending. Pathbending is a bimanual technique where the user manipulates the shape of a path using two hands. The path curves and bends in response to the motion and position of the hands; there are no proscribed gesture mappings for manipulating the path.
Computationally, each of the user’s hands acts as one point of a 3D triangle, with a third point fixed and grounded behind the user’s head. This triangle forms an inherent egocentric reference frame, while the head offers an easily tracked point in 3D space. The angular displacement of the centroid of this triangle is calculated each frame, and applied to the control point of the spline representing the path. This allows the user to push, pull, twist, and shift the path. It also allows the user to control the rate of transformation. By moving only one hand, the rate of change remains smaller and more controlled; by moving both hands in tandem, the rate of change is proportionally larger. This relationship provides the user with an innate and intuitive sense of scale.
The user is not informed about these relationships, but is told to grab and move the path as they see fit. They can visualize the approximate position of the center of the path, which is also the location of the control point. This control point can be seen in Figure 4A, where a study participant is in the process of warping a path to travel around a corner and through a circular target.

FIGURE 4. Participants using the path manipulation techniques to modify their 3D paths. (A) Modifying a path to traverse around a corner using the pathbending interface; the yellow sphere is a reference to the center of the path (B) Creating a path using the bulldozer replica model. The red pool table in the replica environment can be seen in the background of the image. Created with Unity Editor®. Unity is a trademark or registered trademark of Unity Technologies.
3.2.1.2 Bulldozer
The second interface was loosely inspired by the bulldozer metaphor for screen-based first-person navigation, described in the related work (Zhai et al., 1999). In this screen-based metaphor the user “carves” a path through space using two keyboard-embedded joysticks, affording bimanual control of translation and yaw.
Our technique was originally implemented as an asymmetric bimanual metaphor: the non-dominant hand was held stationary and represented the end waypoint. From the start waypoint, the dominant hand “carves” a path through the air in front of the user to link the start and end waypoints. The path simultaneously appears in the environment. Ultimately, extensive pilot testing revealed that users failed to use the non-dominant hand as a marker, and when it was employed, it offered no discernable benefit. Thus, this method evolved into a unimanual technique. After selecting a path to manipulate, a small replica of the environment appears, centered on the user. This world-in-miniature displays the nearby environment, along with the start and end waypoints for the path under manipulation. The user creates their path in this space using a path drawing technique, and the corresponding path simultaneously appears in the environment. This technique can be seen in Figure 4B: here, a participant is drawing a path from a waypoint within the replica environment. The interface allows a user to create a precise path between points in a single continuous movement. The user can also erase their path by moving their controller backwards. Misalignment between the user’s controller and the path is prevented by deactivating drawing and erasing when the user travels too far away from the head of the path.
3.2.2 Waypoint placement techniques
Three interaction metaphors were chosen as placement techniques: raycasting, world-in-miniature (Stoakley et al., 1995), and iSith (Wyss et al., 2006). These metaphors were modified to accommodate waypoint placement, and relabeled for ease of understanding and recall by participants during experimental evaluation. These metaphors were chosen to provide a more comprehensive picture of the capabilities and limitations of the path manipulation techniques.
3.2.2.1 Point-click
The point-click metaphor is a classic raycasting technique that allowed users to place objects directly in the space. Users raycast to the ground plane and view a cursor indicating the target placement, then click to place the waypoint. These waypoints appear as a “pedestal,” shown in Figure 5A. Once a second waypoint is placed, a straight-line path appears and connects the two points via the shortest distance.

FIGURE 5. Participants using the waypoint placement techniques to plan their 3D paths. (A) The two types of waypoints created by the placement interfaces, pictured in the tutorial environment. On the left, a pedestal-style waypoint, and on the right, a floating-style waypoint. (B) The mini-model shown to users for the WiM waypoint placement technique, seen with paths modified through pathbending. (C) The two-rays waypoint placement technique, shown with the creation of a “floating” style waypoint. Created with Unity Editor®. Unity is a trademark or registered trademark of Unity Technologies.
Pedestal waypoints can be manipulated after placement. Hovering over a waypoint displays a UI that allows the waypoint to be deleted, repositioned, or scaled. Deletion merges any connected paths into a straight line. Repositioning allows the user to raycast the waypoint to a new location; any connected paths stretch to reach the new point. Scaling changes the vertical height of the waypoint. This occurs through a bimanual motion: bringing both hands closer together shrinks the waypoint along the y-axis, while moving both hands apart grows the waypoint along the y-axis.
3.2.2.2 Mini model
The mini-model placement method draws on the WiM (Stoakley et al., 1995) and the Voodoo Dolls (Pierce et al., 1999) techniques. The model is displayed in front of the user and illustrates the space around them. The user can translate, rotate, and scale the depiction through direct interaction with the model. The user can scale the model using the same process as described for scaling a waypoint. Touching the floor of the model with the controller allows the user to translate the depiction and change the view. The model can be rotated using a twisting motion with the controller pointed downward, similar to a screwdriver. These metaphors were chosen for their simplicity and affordance of direct interaction.
To place waypoints, the user raycasts into the mini-model to specify a location. The map and environment update in real-time in response to the user’s actions and follow the user around the environment as they move. Initially, this was developed as a bimanual technique: the non-dominant hand could hold the model, while the dominant hand could interact and place waypoints. However, extensive pilot testing revealed that users found this fatiguing, a well-known limitation of bimanual techniques. Subsequently, the mini-model was changed to appear in front of the user at approximately half the individual’s height. This allowed users to use either hand to interact with the mini-model. An example of the mini-model can be seen in Figure 5B.
3.2.2.3 Two-rays
The two-rays technique is an implementation of the iSith technique (Wyss et al., 2006), relabeled for clarity. A ray is cast from each controller, and if the lines are skewed, a ghost waypoint appears at the point of nearest intersection. Unlike the waypoints created by the point-click technique, this waypoint is a floating platform, seen in Figure 5. This bimanual placement method allows the user to immediately place the point at the desired height. These waypoints can be deleted, however, they cannot be repositioned or scaled. Scaling and repositioning were redundant for these waypoints, given the precision with which they are initially specified.
3.3 User study
We conducted a comprehensive user study to investigate the efficacy, learnability, and efficiency of the refined interfaces. Early versions of the interfaces described in Sections 3.2.1 and 3.2.2 were implemented in Unity 2019.3 for the Magic Leap Creator One. These designs were extended from the implementations described in Section 3.1.1. However, after the start of the COVID-19 pandemic, we were not able to continue this research in our lab. Due to practical limitations, it was necessary to convert this project for deployment on more readily available consumer VR equipment. The VR application was designed to provide an experience that simulates augmented reality. Currently, the hardware limitations of the Magic Leap and similar devices constrain the amount of visual information that can be presented; as a first-gen device, the tracking capabilities of the device were also restricted. Previous research (Ren et al., 2016) comparing task performance in AR across different fields of view revealed that limited FoV significantly increases task time, and may increase mental workload (Quintero et al., 2018). Simulating AR using virtual reality has been validated as a viable method for overcoming this limitation (Ragan et al., 2009; Lee et al., 2010), and for testing AR interface designs (Pfeiffer-Leßmann and Pfeiffer, 2018; Jetter et al., 2020).
Moving to a simulated-AR environment provides several notable advantages. This paradigm allows for flexible, rapid prototyping and evaluation within a tightly controlled virtual environment. This standardizes the participant experience and improves the reliability of the benchmarks obtained in the study. It also increases the repeatability of the results, particularly given the sensitivity of AR devices to lighting and other environmental disturbances Ragan et al. (2009). As an additional benefit, using a simulated-AR environment gave us the freedom to explore more sophisticated user interfaces that we believe will be applicable for next generation immersive devices, unconstrained by hardware limitations that can be reasonably expected to disappear in the future.
3.3.1 Test environment
As in the formative study, we evaluated the techniques using an obstacle course: participants had to create a path through five numbered targets and clear as many as possible. The path had to pass through each target in order. Participants could use a maximum of 7 waypoints, and they had 3.25 min to complete the course. These values were chosen during pilot testing to make it difficult, but not impossible, to complete the task. Participants could navigate using a point-to-steer locomotion technique; this was intended to preserve spatial mapping, and to leave the participant free to look around as they moved. Locomotion speeds were set through pilot testing to a maximum of 2.5 m/s, with an acceleration factor of 0.1 m/s2. Users started the trial near the first target, and the timer began after they placed their first waypoint. To reduce cognitive load, the time remaining was displayed on the wall in each room of the environment, along with the number of waypoints actively in use out of the total allotment. To prevent users from learning the location of the targets and gaining an advantage, they could not move beyond the area surrounding the first target until they placed their first waypoint. At the end of the trial, the user watched a quadcopter fly the path they created, and sound effected were played when it successfully passed through a target. We included this element to add some gamification to the task and keep users engaged.
A textured 3D mesh from the Matterport3D data set (Chang et al., 2017) was chosen as a test environment due to the large amount of data accompanying the mesh, including room and wall segmentations. The mesh was chosen for its varied architecture: narrow corridors, high ceilings, low arches, and multiple interspersed obstacles. A second photorealistic environment was chosen as a tutorial space; this environment was a large, rectangular brick room with a single door. This distinction was intended to prevent any learning effects regarding the layout of the trial environment. The study was conducted with a Vive Pro headset and two Vive Wand controllers in a 2.2 m × 2.2 m tracking space. Participants could view the tracked controller models in the VR environment. Prior research indicates that this representation does not impact task performance (Lougiakis et al., 2020; Venkatakrishnan et al., 2023).
3.3.2 Study design
The study was constructed as a 2 × 3 within-subjects experiment, where each path manipulation technique (pathbend and bulldozer) was paired with each waypoint placement technique (point-click, mini-model, and two-rays) exactly once during a session. To control for sequence and order effects, conditions were ordered according to balanced Latin square counterbalancing (Bradley, 1958).
To control for learning effects, we created six separate obstacle courses with five numbered targets. The total distance from the first to the last target was approximately equal between all courses. Each course was designed so that 4 of the 5 targets were not visible from the preceding target; exactly two of the targets are visible from the preceding target. The height between these two targets varied significantly, by roughly 3.5 m, to prevent users from traversing the targets with a straight line path. All study procedures and recruitment methods were approved by the local Institutional Review Board.
3.3.3 Participants
Individuals were recruited from the local population via social media and word of mouth. All participants were required to have normal vision or vision that was corrected to normal by glasses or contact lenses. Participants were given a $15 gift card after completing the protocol. The protocol took no more than 85 min to complete.
A total of 40 individuals completed the study, and 36 were included in the final analysis. Two were excluded due to data corruption, one failed to follow instructions, and one had a total completion time more than two standard deviations below the median. After completing the experiment, participants were surveyed for their biological sex; 12 were female and 24 were male. All participants were between the ages of 18 and 34.92% of participants had video game experience, and nearly 75% had some sort of prior VR experience. 15 participants had at least one prior experience flying a recreational drone or quadcoptor.
3.3.4 Procedure
At the beginning of the study, each participant received a verbal overview of the task and an outline of the experiment, and then were introduced to the equipment and controls. The SSQ pre-test was administered, then the experimenter fit the headset on the user and helped the user adjust the inter-pupillary distance. Once the study began, participants were guided through each section of the experience by a pre-recorded electronic voice-over. They could ask questions at any time.
Participants began in a tutorial environment with an initial overview of basic interactions: how to select objects and how to move around. This initial overview also introduced participants to the different waypoint types they would see, and showed them how to reposition, delete, and scale the pedestal waypoints. Participants had to demonstrate each interaction before the tutorial moved on to the next element. In the case of bimanual interactions like scaling, a pair of virtual controllers visually demonstrated the motion. After this general tutorial, participants received instruction on the path manipulation techniques. The presentation of these techniques was counterbalanced based on the user’s group assignment. As before, the motions were demonstrated by an animated controller, and the user was required to follow along and correctly manipulate the path at each step before the tutorial would advance.
After covering the path manipulation techniques, the following sequence was repeated six times, with a 5 min break after the second repetition. The participant was introduced to a placement technique through a brief guided tutorial, in the same environment and manner as the previous tutorials. The tutorial took 1–2 min to complete. Subsequently, the participant had the option to practice the placement technique and the paired manipulation technique for up to 2.5 min. After the tutorial and practice session, the participant entered the trial environment and were verbally reminded of the constraints and objectives of the trial. The trial began after they placed their first waypoint. After the trial, participants watched an animated quadcopter fly along their path. Participants were then presented with the Single Ease Question (SEQ) (Sauro and Dumas, 2009), detailed in Section 3.3.5 and shown in Figure 6. Afterwards, this sequence would repeat, starting with the next placement technique in the condition.
FIGURE 6. The SEQ as presented virtually to participants immediately after completing a trial. Created with Unity Editor®. Unity is a trademark or registered trademark of Unity Technologies.
Due to the study design, a participant would always experience each placement tutorial twice (once with each pairing of a path manipulation technique); based on feedback during pilot testing, participants were given the option to skip the second instance of a tutorial. The sequence would then advance to the optional practice segment.
Each instance of this sequence took 5–9 min to complete. Together with the initial overview, participants spent approximately 40–55 min in virtual reality. Afterwards, participants exited the headset and completed a survey that included the SSQ post-test, qualitative feedback, and demographics information.
3.3.5 Measures
The experimental measures we chose were organized according to the three major design criteria (effectiveness, learnability, and efficiency). To increase the comparability of our results, many of the measures we chose are evaluated as ratios instead of absolute counts. Measures for perceived ease of use and user preference are also described.
3.3.5.1 Effectiveness
To examine how effective a technique was, we looked at indicators of how completely and how correctly a user performed the task. One measure of both completeness and correctness is the number of targets a user successfully traverses. A target is considered successfully traversed if it is visited in the correct order and a path enters and exits the target without hitting a wall. A target is considered attempted, rather than successful, if the path hits a wall before entering or after exiting, if the target is traversed out of order, or if the path passes within 0.2 m of the target without entering and exiting. The number of targets successfully traversed can be used as a metric for efficacy.
Correctness can also be assessed for waypoint placement techniques based on the ratio of deleted waypoints versus the total number of waypoints placed. While some waypoints can be repositioned or scaled, all waypoints can be deleted; additionally, deleting a waypoint indicates that the user perceives that some type of error was made. In some cases, the waypoint may be unnecessary, or it may cause the user to exceed the maximum number of allowed waypoints. To measure the efficacy of a waypoint placement technique, we looked at the ratio of deleted to placed waypoints, calculated by Equation 1
Here, wpp is the total number of waypoints placed, and wpp is the number of waypoints deleted. For this measure, values closer to one indicate a more effective technique, since users were always constrained to the same maximum number of waypoints.
3.3.5.2 Learnability
In 2D user experience (UX) evaluations, a technique’s learnability can be evaluated by the degree of lostness a user faces while completing a task. Here, lostness is presumed to be a state that has a measurable, detrimental effect on performance (Elm and Woods, 1985). The lostness metric, L, shown in Equation 2 (Smith, 1996; Sharon, 2016) is used to evaluate the degree of difficulty a user encounters the first time they face an interface. This equation has a history of use in across multiple human-computer interaction (HCI) domains (Wilson, 1997) and has been repeatedly validated (Albert and Tullis, 2013; Sauro and Lewis, 2016).
Here, N is the number of unique actions a user performs: the first time a waypoint is placed, scaled, or repositioned, and the first time a path is manipulated. S is the total number of actions a user performs: the sum of all placements, scales, repositionings, deletions, and manipulations that occur. R is the optimum, or minimum, number of actions it takes to complete the task.
While there is a large degree of variation between the physical paths created by individual users, there is far less variation in the actions required to construct a path. The obstacle course was constructed with this metric in mind so that an optimum could be constructed for each combination of courses and techniques. As mentioned in Section 3.3.1, each course was designed so that 4 of the 5 targets required moving a path around a corner or wall to reach the next target. In each set, exactly two targets are simultaneously visible to the other target, but are at vastly different heights. The targets in these positions, while different in each layout, always corresponded to the 2nd and 3rd target, or to the 3rd and 4th target.
Because of these features and the target layout, each course can be completed without manipulating any waypoints. Therefore, the problem of finding an optimum number of actions reduces to the sum of the number waypoint placements and path manipulations. The number of paths is always one less than the number of waypoints, x, thus the optimum can be represented as 2x − 1. When the pathbending technique is used, x = 5 (as the two targets that are simultaneously visible can be traversed by a single path), and R = 9. When the bulldozer technique is used, x = 3 and R = 5. The size of the bulldozer replica model requires an intermediate waypoint to traverse all the targets. Because each participant did not attempt to traverse every target, the R value is adjusted based on the number of targets actually attempted.
3.3.5.3 Efficiency
Completion time is a traditional metric for measuring how efficiently a user can perform a task (Gabbard et al., 1997), however, the trials in this study were deliberately time-constrained to allow participants with barely enough time to complete the task. Therefore, completion time is not an accurate measure for estimating the efficiency of a technique. Presumably, an action is most efficient when it does not need to be modified or repeated. To measure the efficiency of a technique, we examined the ratio of unique actions to the total number of actions. As with the lostness metric, a unique action occurs the first time a waypoint is placed, scaled, or repositioned, and the first time a path is manipulated. The total number of actions is the sum of all placements, scales, repositionings, deletions, and manipulations. For this measure, values closer to one indicate a more effective technique: ideally, a participant will only need to perform one unique action per waypoint (placement) and one manipulation per path, thus unique actions equal the total number of actions.
3.3.5.4 Ease of use
In addition to objective metrics, we also collected subjective and qualitative feedback. During the study, individuals were asked the SEQ (Sauro and Dumas, 2009) after each trial. This question appeared in its standard format: “Overall, completing this task was?” followed by a seven-point scale ranging from “very easy” to “very difficult” (Finstad, 2010b). A visual of this scale as presented in the virtual environment can be seen in Figure 6.
Deploying this scale in this manner gathered immediate, in-situ feedback on each interaction technique, avoiding the recency biases of post-study surveys (Müller et al., 2014). Deploying the questionnaires in-situ was meant to expedite the study and avoid any potential discontinuity to the participant’s experience. Current research (Alexandrovsky et al., 2020; Halbig and Latoschik, 2021; Wagener et al., 2020) suggests that for questionnaires unrelated to cybersickness, there is no significant difference in scores when deploying a survey in the virtual environment or outside of the environment.
While the SEQ can measure the ease of a technique, it can also serve as an analogous measure participant preference (Sauro and Lewis, 2016). We expect the latter will hold true for users in this study, however, we do not expect participants to have much context for judging 3D path creation interfaces, which will limit the power of their feedback on this question. To compensate for this limitation, participant preference was also assessed via a post-study survey.
3.3.5.5 User preference
After the study, users were presented with questions regarding their preferences for each path manipulation technique and waypoint placement technique. Following best practices, each technique was addressed and surveyed separately; users were not asked to rank their choices (Albert and Tullis, 2013). A pair of 7-point Likert-scale questions asked how easy or difficult it was to learn the technique and to use the technique (Finstad, 2010a). They were also asked which placement technique they preferred to use with a specific path manipulation technique, and vice versa.
Participants were presented with two hypothetical path shapes that could be created using any combination of the placement and manipulation techniques. Participants were asked which manipulation technique they would prefer to use to mimic the path shape, and subsequently, they were asked why they had chosen that specific technique. These questions and surveys were intended to elicit feedback that was not teased out by the quantitative metrics during the experiment.
3.3.6 Hypotheses
Scientific hypotheses are grouped according to the design criteria described in Section 3.2 and the measures specified in Section 3.3.5.
For efficacy, we made the following hypotheses, measured by the number of targets traversed and by the ratio of deleted waypoints to number of waypoints placed:
E-H1: We bulldozer will be more effective than pathbend due to the precision afforded by the replica, as measured by the number of targets successfully traversed.
E-H2: When using pathbend, we expect the allocentric viewpoint of mini-model to reduce the number of deleted waypoints, making it more effective than any other technique, as measured by Equation 1.
E-H3: When using bulldozer, we expect the allocentric viewpoint of mini-model to reduce the number of deleted waypoints, making it more effective than any other technique, as measured by Equation 1.
For learnability, we evaluated how easy it was for the user to accomplish their task the first time they encountered the interface. We expected the learnability of a technique to be roughly inversely proportional to the number of affordances it offered, and we made the following hypotheses, measuring each by the degree of lostness shown in Equation 2:
L-H1: Pathbend will be easier to learn than bulldozer, given the spatial interactivity of the interface.
L-H2: When using pathbend, we expect the relative familiarity of point-click will make it easier to learn than any other technique.
L-H3: When using bulldozer, we expect the relative familiarity of point-click will make it easier to learn than any other technique.
For efficiency, we expected more efficient techniques to require a lower number of unnecessary manipulations and actions. We made the following hypotheses and evaluated each based on the ratio of total actions to unique actions:
F-H1: We expect bulldozer will be more efficient than pathbend due to the spatial context provided by the replica.
F-H2: When using pathbend, we expect mini-model to reduce the number of unnecessary actions, making it more efficient than any other technique.
F-H3: When using bulldozer, we expect the relative simplicity of point-click to lead to fewer errors, making it more efficient than any other technique.
Observations made during the initial formative study informed our expectations regarding participant preferences. We made the following hypotheses and evaluated them using the user feedback metrics:
Q-H1: Users will prefer bulldozer over pathbend, due to its efficacy.
Q-H2: When using pathbend, users will prefer point-click over any other technique due to its relative familiarity.
Q-H3: When using bulldozer, users will prefer mini-model over any other technique, as it complements the replica in the bulldozer method.
4 Results
Shapiro-Wilk tests revealed violations of normality for all variables. Consequently, we analyzed the data using non-parametric tests and report descriptive statistics as median (Mdn) and interquartile range (IQR). To evaluate the main effects of path manipulation technique, the overall average of all three trials for each technique was compared using a Wilcoxon signed-rank test. For the waypoint placement techniques, separate analyses were conducted for the bulldozer and pathbending techniques using Friedman tests. Statistical tests assumed a significance value of α = .05, and post-hoc comparisons were adjusted using a Holm-Bonferroni correction.
4.1 Efficacy
Efficacy results are shown in Figure 7. A Wilcoxon signed-rank test revealed that bulldozer (Mdn = 4.33, IQR = 1.08) significantly increased the number of targets successfully traversed compared to pathbend (Mdn = 4.00, IQR = 2.00), W = 319.50, p = .03. These results support E-H1.
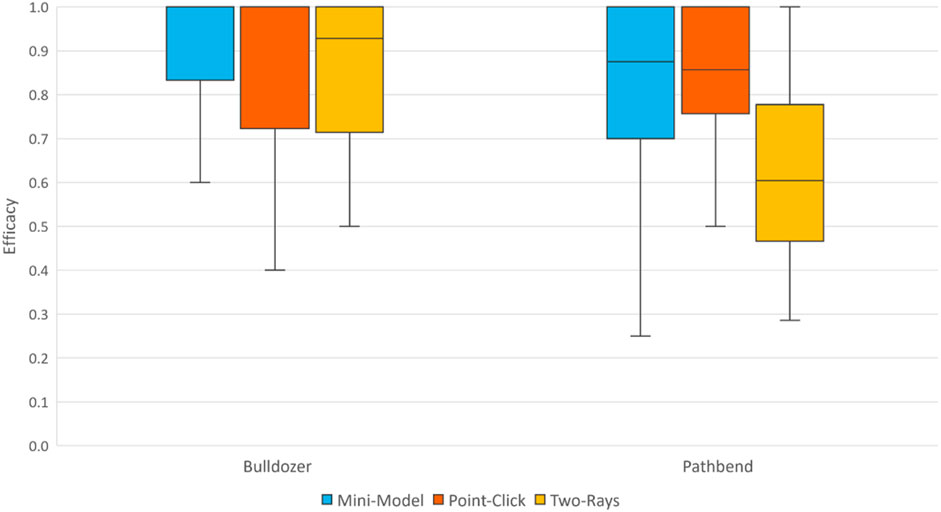
FIGURE 7. Box plot showing efficacy, as measured by the ratio of waypoints deleted to waypoints placed.
When using pathbend, a Friedman test revealed a significant effect of placement technique for the ratio of waypoints deleted to waypoints placed, χ2(2) = 16.60, p < .001. Pairwise comparisons were conducted using a Conover post-hoc test. Two-rays (Mdn = 0.60, IQR = 0.29) performed worse compared to both mini-model (Mdn = 0.88, IQR = 0.26), p < .01, and point-click (Mdn = 0.86, IQR = 0.23), p < .01. The difference between mini-model and point-click was not significant, p = .85. These results partially support E-H2.
When using bulldozer, a Friedman test did not find a significant effect of placement technique for the ratio of waypoints deleted to waypoints placed, p = 0.20. These results do not support E-H3.
4.2 Learnability
A Wilcoxon signed-rank test revealed that lostness was significantly lower for bulldozer (Mdn = 0.48, IQR = 0.11) compared to pathbend, (Mdn = 0.52, IQR = 0.17), W = 165, p < .01. These results do not support L-H1 and are shown in Figure 8.
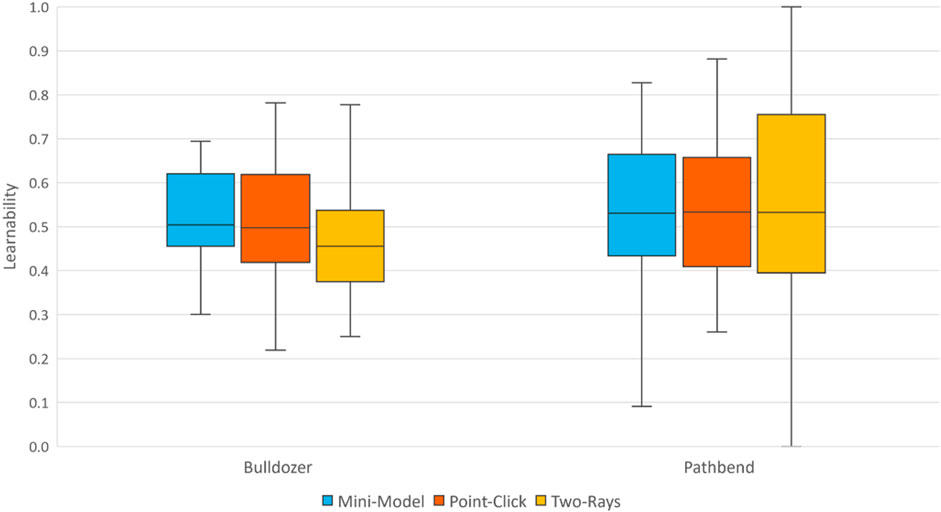
FIGURE 8. Box plot showing learnability, as measured by lostness. A lower lostness value is better.
When using pathbend, a Friedman test did not find a significant effect of placement technique on lostness, p = 0.58. Similarly, when using bulldozer, a Friedman test was not significant, p = 0.57. These results do not support L-H2 or LH-3.
4.3 Efficiency
A Wilcoxon signed-rank test showed that the ratio of unique to total actions was significantly greater for bulldozer (Mdn = 0.81, IQR = 0.16) compared to pathbend (Mdn = 0.62, IQR = 0.28), W = 652, p < .01. These results support F-H1 and are shown in Figure 9.
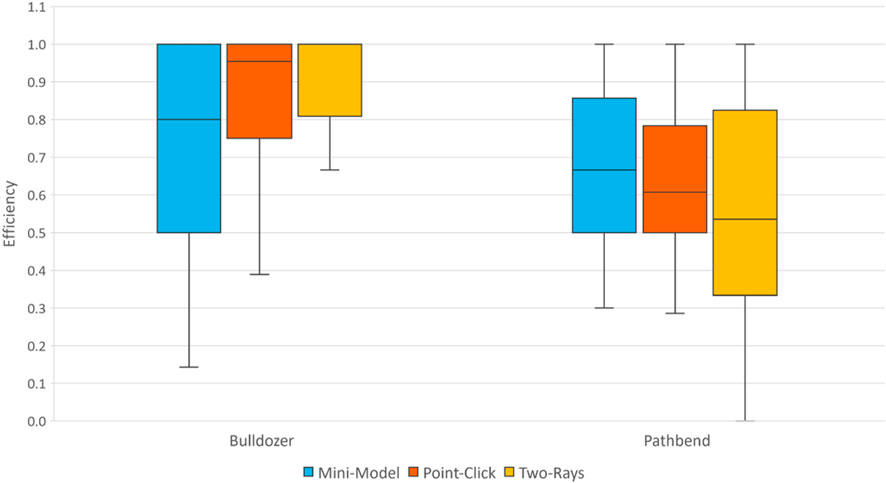
FIGURE 9. Box plot showing efficiency, as measured by the ratio of unique to total actions. Higher values are better.
When using pathbend, a Friedman test revealed no significant effects for the ratio of unique to total actions, p = 0.09. These results do not support F-H2.
When using bulldozer, a Friedman test showed a significant effect for the ratio of unique to total actions, χ2(2) = 7.50, p = .02. Pairwise comparisons were evaluated using a Conover post-hoc test. Two-rays (Mdn = 1.00, IQR = 0.18) performed better compared to mini-model (Mdn = 0.80, IQR = 0.50), p < 0.01. Point-click (Mdn = 0.96, IQR = 0.25) was not significantly different from mini-model, p = 0.07, or two-rays, p = 0.40. These results partially contradict F-H3.
4.4 User preference
Results of the Likert-scale questions from the post-questionnaire are shown in Figure 10. These responses were mapped from 0 to 6, with 0 representing the negative anchor and 6 representing the positive anchor. When asked about learning the bulldozer interface, 78% of participants indicated it was “somewhat easy”, “easy”, or “very easy”, while 11% of participants indicated it was “somewhat difficult” or “difficult”. When asked about learning the pathbending interface, 83% of participants indicated it was “somewhat easy”, “easy”, or “very easy”, while 11% of participants indicated it was “somewhat difficult” or “difficult”. A Wilcoxon signed-rank test did not show a significant difference between bulldozer (Mdn = 4.50, IQR = 2.00) and pathbend (Mdn = 5.00, IQR = 2.00) on perceived learnability, W = 213.00, p = .69. These results do not support Q-H1.
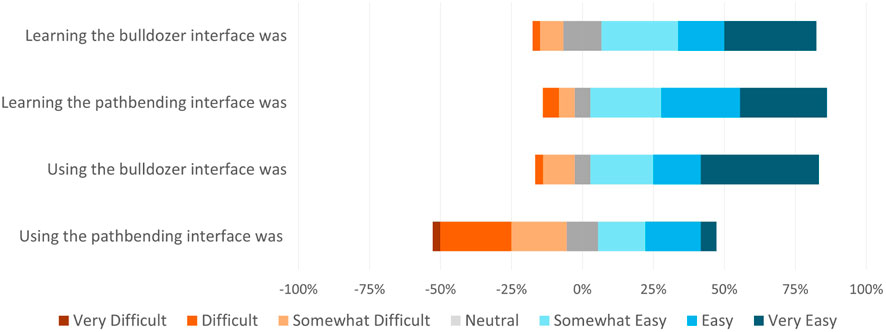
FIGURE 10. The results from a post-study Likert survey of participant impressions of the manipulation techniques. Values to the right of the center line indicate agreement with the statement; values to the left indicate disagreement; neutral values are split in the center.
When asked about using the bulldozer interface, 81% of participants indicated it was “somewhat easy”, “easy”, or “very easy”, while 14% of participants indicated it was “somewhat difficult” or “difficult”. When asked about using the pathbending interface, 41% of participants indicated it was “somewhat easy”, “easy”, or “very easy”, while 47% of participants indicated it was “somewhat difficult”, “difficult”, or “very difficult”. A Wilcoxon signed-rank test indicated that bulldozer (Mdn = 5.00, IQR = 2.00) was perceived as easier to use than pathbend (Mdn = 3.00, IQR = 3.75), W = 436.00, p < .01. These results support Q-H1.
4.5 Ease of use
The results from the SEQ scores are shown in Figure 11. The SEQ scores were mapped from 0 to 6, with 0 indicating that an interface was very easy to use, and 6 indicating that it was very difficult to use. A Wilcoxon signed-rank test revealed that average SEQ scores for bulldozer (Mdn = 1.67, IQR = 1.08) were significantly lower than pathbend (Mdn = 2.33, IQR = 1.08), W = 118.50, p < .01. These results support Q-H1.
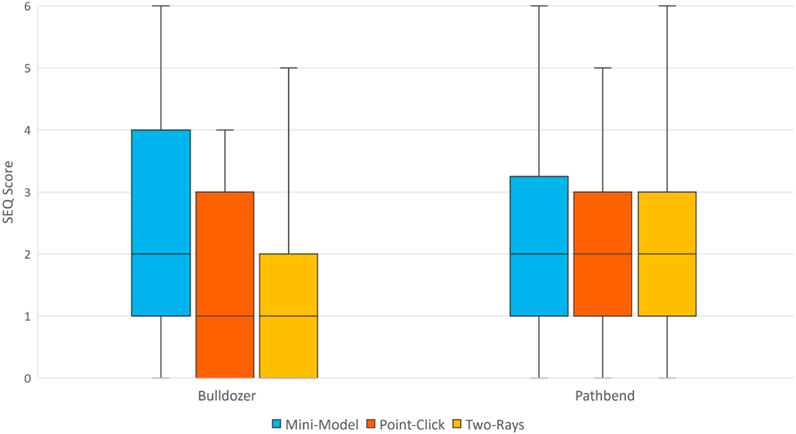
FIGURE 11. Box plot showing SEQ scores from participants, n =36. Lower values are better.
When using pathbend, a Friedman test did not show a significant effect of placement technique on SEQ scores, p = 0.84. These results do not support Q-H2.
When using bulldozer, a Friedman test revealed a significant effect of placement technique on SEQ scores, χ2(2) = 8.52, p = .01. Pairwise comparisons were evaluated using a Conover post-hoc test. Mini-model (Mdn = 2.00, IQR = 3.00) performed worse compared to two-rays (Mdn = 1.00, IQR = 1.25), p = 0.01, but better compared to point-click (Mdn = 1.00, IQR = 2.00), p = 0.02. The difference between point-click and two-rays was not significant, p = 0.80. These results partially contradict Q-H3.
4.6 Cybersickness
A Wilcoxon signed-rank test showed a significant increase in pre-SSQ scores (Mdn = 3.74, IQR = 7.48) compared to post-SSQ scores (Mdn = 18.70, IQR = 31.79), W = 911, p < .001. No hypotheses were made regarding cybersickness.
5 Discussion
This user study evaluated two path creation and manipulation techniques when paired with three canonical waypoint placement techniques on several outcomes. Overall, the data analysis shows support for our hypotheses; in particular, bulldozer outperformed pathbending. Surprisingly, two-rays was a more efficient placement technique than mini-model, and was strongly preferred by participants.
5.1 Path manipulation techniques
5.1.1 Efficacy
Our hypothesis regarding the differences between the efficacy of bulldozer and pathbend were supported: the bulldozer path manipulation technique increased the number of targets that users successfully cleared relative to the number of targets. In general, we expected that the allocentric view provided by the world-in-miniature would enable participants to more easily plan the entire path through the space. Conversely, pathbending often required users to glance between points while manipulating the path. This motion may induce an additional cognitive burden as users attempted to egocentrically manipulate the path relative to points that were outside their immediate field-of-view. Participant commentary supports this idea, with one participant specifically noting that the pathbend method “is hard to adjust when we see it from a different angle.”
5.1.2 Learnability
Interestingly, our hypothesis regarding the learnability of each path manipulation technique was contradicted; our results showed that based on the lostness measure, bulldozer was easier to learn than pathbending. This was surprising because pathbending is an egocentric technique designed to manipulate the path relative to the participant’s physical motion. Given that lostness was calculated based on the number of unique and total actions relative to the optimum, it could be that the precision of the bulldozer technique made it easier to complete the obstacle course with fewer total actions. Interestingly, several participants wrote comments to this effect in the post-study survey, noting that they could use fewer waypoints with the bulldozer method.
5.1.3 Efficiency
Our hypothesis for the efficiency of each path manipulation technique (F-H1) was supported: bulldozer more efficient technique than pathbend when measured by the ratio of unique to total actions. As with learnability, the precision of the bulldozer technique may have made it easier to complete the course with fewer actions. Another possible explanation is that the allocentric view offered by the bulldozer technique was more efficient given the scale of the task. Recent theories in cognitive science suggest that allocentric representations may be incorporated more quickly for navigation tasks which cannot be solved from a single viewpoint (Ekstrom et al., 2014), such as in the complex space participants navigated in this study.
5.2 Waypoint placement techniques
The results for the placement techniques were surprisingly mixed. While E-H2 was partially supported, there was no support for our hypotheses regarding the learnability of each technique. Furthermore, some of our hypotheses regarding the efficiency and preferences were directly contradicted.
We had expected pathbend and mini-model to be the most effective combination; this was partially supported: mini-model was more effective than two-rays in this situation. A possible explanation could be that mini-model offers more affordances for solutions that require more waypoints, which is the case when using pathbend. Even with an optimal solution, this technique requires more waypoints, as described in Section 3.3.5.
We additionally expected bulldozer and mini-model to be a highly efficient combination. Our hypothesis was based on the assumption that the spatial knowledge provided by the mini-model interface would lead to more accurate and optimal waypoint placement and to fewer errors, thereby reducing the total number of actions. We expected this effect to be amplified given the precision afforded by the bulldozer technique. Generally, we expected that the combination of two allocentric viewpoints afforded by each technique would be more consistent, and therefore, more efficient. Surprisingly, our hypothesis was partially contradicted: the two-rays technique outperformed the mini-model technique. This result can potentially be explained by the choice of metric and the precision afforded by each placement technique. Additionally, waypoint placement generally requires information that can be obtained egocentrically. This combination of techniques may have been more efficient because it allowed participants to incorporate information obtained from both egocentric and allocentric perspectives.
Because placement efficacy was evaluated based on the number of deletions relative to the total placements, mini-model has an advantage: the pedestal waypoints can be repositioned and scaled after placement. This affordance was intended to compensate for reduced precision. While two-rays allowed users to place waypoints at exactly the height they desired, they could not reposition the waypoint. This could lead to more deletions, accounting for the lower efficacy, while the mini-model condition would see more repositioning and scaling actions, accounting for the decreased efficiency. Additionally, distance and depth estimation errors are a well-documented phenomenon in both virtual and augmented reality; this could account for the increased deletions in the two-rays technique (Cutting and Vishton, 1995).
One possible explanation for the greater relative efficiency is that users gain additional knowledge from the environment at-large when using the two-rays method that they do not receive from the mini-model. This could relate to sight lines, obstacles, or other spatial information that is not readily apparent at a smaller scale. This is not what we expected, given previous positive findings regarding the use of WiM models for locomotion (Bowman and Hodges, 1997; Englmeier et al., 2021). However, during the trials, some participants made errors when placing waypoints using the mini-model that surprised them. The waypoint was at the physical location within the WiM that they expected; however, the overall configuration of the WiM coordinate space was not what they anticipated. We believe that mentally aligning the egocentric viewpoint of the space with the allocentric viewpoint from the mini-model could lead to more errors and require more actions to compensate for. This further supports the reasoning for why the combination of bulldozer and two-rays was overall more efficient than mini-model.
Contrary to our expectations, participants preferred two-rays over the mini-model when using bulldozer for path manipulation. In addition to the mini-model limitations discussed above, the precision afforded by the two-rays technique in all dimensions may have provided a greater benefit than initially anticipated.
5.3 Cybersickness
In general, the SSQ scores reported after immersion in our study environment are considered mild for VR experiences (Chang et al., 2020). Although participants reported higher levels of symptoms after completing the study, this is not unreasonable given the relative length of immersion. Overall, there were no observations that indicate cybersickness impacted participant’s performance and the validity of other measures.
5.4 Participant preference
Both the SEQ scores and the post-study survey results indicate that users preferred bulldozer to pathbend, though qualitative feedback suggests that participants found both simple to use. The SEQ scores for each interface support this conclusion. A score of 0 corresponds with being “very easy” to use, and bulldozer and pathbend received median scores of 1.67 and 2.33 respectively. The values indicate that bulldozer was easy to use, and that pathbend was somewhat easy to use. The Likert scores for bulldozer support this conclusion, while the Likert scores for pathbend reveal a more mixed attitude. Qualitative feedback and comments signal that participants found the pathbend interface easy to operate and to use in isolation, but that it lacked enough precision to be effective in the complex environment. This sentiment may explain the stronger preference for bulldozer.
Given the nature of the task, we expected that participants would prefer the precision of bulldozer over the simplicity of pathbend. This conclusion is clearly supported in the comments written by several participants, who preferred the bulldozer method for creating “more elaborate” paths and “complex shapes”. Notably, several participants also preferred bulldozer when attempting to finish the task quickly. The time limit introduced a game-like challenge, and one participant even asked if they could return and attempt to “speed run” the course. Generally, participants preferred the ability to use fewer waypoints, which is particularly noteworthy given the prevalence of waypoint-based methods.
The results shown in Figure 10 do not show a clear preference for the learnability of either technique, however, they do show a strong preference for using the bulldozer technique over the pathbending technique. This sentiment was strongly supported by comments from participants; when asked why they would choose the bulldozer method to create a particular path, over half (58%) explicitly stated that they found it easier to work with. While this sentiment was not captured in the survey data, it is supported by the learnability and SEQ results, which indicated less lostness and greater ease of use for bulldozer.
Interestingly, participant feedback also indicated a general disinclination towards the mini-model placement method that is not fully captured by the quantitative results. This is particularly true for the bulldozer/mini-model combination. One participant noted that they found using both together to be “confusing”, while another noted that they “tended to use it as a navigational aid.” Participants also noted that they preferred the two-rays placement method, despite the lack of a height configuration. This method “felt quickest” and was “fast and easy” to use.
5.5 Limitations
In this work, we presented two possibilities for natural, intuitive path creation in spatial environments. We chose a virtual reality paradigm to facilitate more intricate interactions and to allow for a more thorough assessment of these techniques than current hardware is capable of. One of the most notable consequences of this change is that the participants in our study had an unrestricted field of view, relative to current AR headsets. In the presence of this field of view restriction, the amount of head movement required to create a path would increase, and would restrict the amount of information a user can perceive or induce additional fatigue. This could alter the performance of these techniques, however, advances in AR display technology will likely lead to improved FOV ranges. Additionally, further evaluation is needed to make generalizations about egocentric and allocentric path creation in spatial environments. However, current neuroscience and cognitive science research has suggested that navigation and route-planning in large, complex spaces requires integrating both allocentric and egocentric cognitive maps (Wolbers and Wiener, 2014; Ekstrom et al., 2014; Muffato and Meneghetti, 2020).
The results showing that the mini-model was less performant when combined with the bulldozer technique should be taken cautiously. Visually, there were some similarities between the bulldozer replica using for path creation and the mini-model used for placement. The bulldozer replica was larger, slightly less than 1 m in diameter, and centered around the participant’s location, while the mini-model was smaller, roughly half a meter in diameter, and appeared directly in font of the user. The similarities between the two may have led some participants to expect similar affordances in each, and may have negatively influenced the perception of the mini-model.
It should also be noted that this work was tested in an architecturally complex indoor environment. Outdoor spaces or large, open environments may be more favorable towards techniques such as pathbending, where less complexity is required. Several participants stated that they wished there was a way to modify more control points with the pathbending technique, and additional features such as these could improve its efficacy and precision. Additionally, the sampled population is not fully representative of the general population. In particular, female participants and older participants are underrepresented, which may limit the applicability of the results.
5.6 Conclusion
In this research, we present the development of two novel methods for 3D path manipulation in mixed reality. Each method leverages a different spatial reference frame to allow users to create 3D paths without memorizing a prescribed set of gestures or commands. Subsequently, we offer and evaluation of the efficacy, learnability, and efficiency of each technique when combined with common placement methods. Both techniques proved to be a viable for creating and interacting with 3D paths at a distance, an area of research that has previously been lacking. In particular, our research highlights the advantages of the bulldozer technique, an allocentric path-drawing metaphor, which is preferred by users as well as more effective, learnable, and efficient. Surprisingly, we found that the two-rays placement method was both preferred by users and more efficient than the mini-model technique. This research focuses on the 3D interaction necessary for path planning, but further research is necessary to adapt these techniques for the physical constraints of an HRI systems. In future research, we hope to further explore the applications of 3D path creation to navigation in virtual spaces. In addition, we hope to specifically evaluate the cognitive burden introduced by each technique, and to examine merging some of the egocentric manipulation capabilities of the pathbending method with the bulldozer technique.
Data availability statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by the University of Minnesota institutional review board. The studies were conducted in accordance with the local legislation and institutional requirements. The ethics committee/institutional review board waived the requirement of written informed consent for participation from the participants or the participants’ legal guardians/next of kin because study was determined to be exempt by the IRB under federal guidelines.
Author contributions
CHP and ESR conceived of the study ideas and design. CHP implemented the techniques, administered the studies, and collected data. CHP conducted the statistical analysis, which were verified by ESR. CHP wrote the initial draft of the manuscript, with contributions by ESR. All authors contributed to the article and approved the submitted version.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frvir.2023.1192757/full#supplementary-material
Footnotes
1Mindstorms is a visual-coding tool similar to scratch or blockly, where users can drag and drop control blocks to form programs.
References
Abtahi, P., Zhao, D. Y., E, J. L., and Landay, J. A. (2017). Drone near me: exploring touch-based human-drone interaction. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 1, 1–8. doi:10.1145/3130899
Albert, B., and Tullis, T. (2013). Measuring the user experience: collecting, analyzing, and presenting usability metrics (newnes).
Alexandrovsky, D., Putze, S., Bonfert, M., Höffner, S., Michelmann, P., Wenig, D., et al. (2020). “Examining design choices of questionnaires in VR user studies,” in Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (New York, NY, USA: Association for Computing Machinery), CHI ’20, 1–21.
Berger, L., and Wolf, K. (2018). “WIM: fast locomotion in virtual reality with spatial orientation gain and without motion sickness,” in Proceedings of the 17th International Conference on Mobile and Ubiquitous Multimedia (New York, NY, USA: Association for Computing Machinery), MUM ’18, 19–24.
Bowman, D. A., and Hodges, L. F. (1997). “An evaluation of techniques for grabbing and manipulating remote objects in immersive virtual environments,” in Proceedings of the 1997 symposium on Interactive 3D graphics (New York, NY, USA: Association for Computing Machinery), I3D ’97, 35. ff.
Bowman, D. A., and Wingrave, C. A. (2001). Design and evaluation of menu systems for immersive virtual environments. Proc. IEEE Virtual Real., 149–156. doi:10.1109/VR.2001.913781
Bradley, J. V. (1958). Complete counterbalancing of immediate sequential effects in a Latin square design. J. Am. Stat. Assoc. 53, 525–528. doi:10.1080/01621459.1958.10501456
Burigat, S., and Chittaro, L. (2007). Navigation in 3D virtual environments: effects of user experience and location-pointing navigation aids. Int. J. human-computer Stud. 65, 945–958. doi:10.1016/j.ijhcs.2007.07.003
Burri, M., Nikolic, J., Hürzeler, C., Caprari, G., and Siegwart, R. (2012). “Aerial service robots for visual inspection of thermal power plant boiler systems,” in 2012 2nd International Conference on Applied Robotics for the Power Industry (CARPI) (IEEE Computer Society), vol. 2012-January, 70–75.
Cauchard, J. R., E, J. L., Zhai, K. Y., and Landay, J. A. (2015). “Drone and me: an exploration into natural human-drone interaction,” in Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing (New York, NY, USA: Association for Computing Machinery), UbiComp ’15, 361–365.
Chang, A., Dai, A., Funkhouser, T., Halber, M., Nießner, M., Savva, M., et al. (2017). Matterport3D: learning from RGB-D data in indoor environments. Int. Conf. 3D Vis., 667–676. 3DV. doi:10.1109/3DUI.2017.7893337
Chang, E., Kim, H. T., and Yoo, B. (2020). Virtual reality sickness: a review of causes and measurements. Int. J. Human–Computer Interact. 36, 1658–1682. doi:10.1080/10447318.2020.1778351
Chheang, V., Heinrich, F., Joeres, F., Saalfeld, P., Preim, B., and Hansen, C. (2022). “Group WiM: a group navigation technique for collaborative virtual reality environments,” in 2022 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), 556–557.
Cohen, J. M., Markosian, L., Zeleznik, R. C., Hughes, J. F., and Barzel, R. (1999). “An interface for sketching 3D curves,” in Proceedings of the 1999 symposium on Interactive 3D graphics (New York, NY, USA: Association for Computing Machinery), I3D ’99, 17–21.
Cutting, J. E., and Vishton, P. M. (1995). “Chapter 3 - perceiving layout and knowing distances: the integration, relative potency, and contextual use of different information about depth*,” in Perception of space and motion. Editors W. Epstein, and S. Rogers 2 (San Diego: Academic Press), 69–117. chap. 3.
Do, T. V., and Lee, J.-W. (2010). 3DARModeler: a 3D modeling system in augmented reality environment. World Acad. Sci. Eng. Technol. Int. J. Math. Comput. Phys. Electr. Comput. Eng. 4, 377–386. doi:10.5281/zenodo.1082871
Egan, D. E., Remde, J. R., Gomez, L. M., Landauer, T. K., Eberhardt, J., and Lochbaum, C. C. (1989). Formative design evaluation of superbook. ACM Trans. Inf. Syst. Secur. 7, 30–57. doi:10.1145/64789.64790
Ekstrom, A. D., Arnold, A. E. G. F., and Iaria, G. (2014). A critical review of the allocentric spatial representation and its neural underpinnings: toward a network-based perspective. Front. Hum. Neurosci. 8, 803. doi:10.3389/fnhum.2014.00803
Elm, W. C., and Woods, D. D. (1985). Getting lost: a case study in interface design. Proc. Hum. Factors Soc. Annu. Meet. 29, 927–929. doi:10.1177/154193128502901006
Englmeier, D., Sajko, W., and Butz, A. (2021). “Spherical world in miniature: exploring the tiny planets metaphor for discrete locomotion in virtual reality,” in 2021 IEEE Virtual Reality and 3D User Interfaces (VR), 345–352.
Finstad, K. (2010a). Response interpolation and scale sensitivity: evidence against 5-point scales. J. usability Stud. 5, 104–110. doi:10.5555/2835434.2835437
Finstad, K. (2010b). The usability metric for user experience. Interact. Comput. 22, 323–327. doi:10.1016/j.intcom.2010.04.004
Gabbard, J. L. (1997). A taxonomy of usability characteristics in virtual environments. Virginia Tech. Ph.D. thesis.
Guiard, Y. (1987). Asymmetric division of labor in human skilled bimanual action: the kinematic chain as a model. J. Mot. Behav. 19, 486–517. doi:10.1080/00222895.1987.10735426
Ha, T., Billinghurst, M., and Woo, W. (2012). An interactive 3D movement path manipulation method in an augmented reality environment. Interact. Comput. 24, 10–24. doi:10.1016/j.intcom.2011.06.006
Halbig, A., and Latoschik, M. E. (2021). A systematic review of physiological measurements, factors, methods, and applications in virtual reality. Front. Virtual Real. 2. doi:10.3389/frvir.2021.694567
Igarashi, T., Kadobayashi, R., Mase, K., and Tanaka, H. (1998). “Path drawing for 3D walkthrough,” in Proceedings of the 11th annual ACM symposium on User interface software and technology (New York, NY, USA: Association for Computing Machinery), UIST ’98, 173–174.
Jetter, H.-C., Rädle, R., Feuchtner, T., Anthes, C., Friedl, J., and Klokmose, C. N. (2020). “In VR, everything is possible!”: sketching and simulating spatially-aware interactive spaces in virtual reality,” in Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (New York, NY, USA: Association for Computing Machinery), CHI ’20, 1–16.
Keefe, D., Zeleznik, R., and Laidlaw, D. (2007). Drawing on air: input techniques for controlled 3D line illustration. IEEE Trans. Vis. Comput. Graph. 13, 1067–1081. doi:10.1109/tvcg.2007.1060
Keefe, D. F., Zeleznik, R. C., and Laidlaw, D. H. (2008). “Tech-note: dynamic dragging for input of 3D trajectories,” in 2008 IEEE Symposium on 3D User Interfaces, 51–54.
Kennedy, R. S., Lane, N. E., Berbaum, K. S., and Lilienthal, M. G. (1993). Simulator sickness questionnaire an enhanced method for quantifying simulator sickness. Int. J. Aviat. Psychol. 3, 203–220. doi:10.1207/s15327108ijap0303_3
Krings, S. C., Yigitbas, E., Biermeier, K., and Engels, G. (2022). “Design and evaluation of AR-assisted end-user robot path planning strategies,” in Companion of the 2022 ACM SIGCHI Symposium on Engineering Interactive Computing Systems (New York, NY, USA: Association for Computing Machinery), EICS ’22 Companion, 14–18.
LaViola, J. J., Feliz, D. A., Keefe, D. F., and Zeleznik, R. C. (2001). “Hands-free multi-scale navigation in virtual environments,” in Proceedings of the 2001 symposium on Interactive 3D graphics (New York, NY, USA: Association for Computing Machinery), I3D ’01, 9–15.
Lee, C., Bonebrake, S., Bowman, D. A., and Hollerer, T. (2010). “The role of latency in the validity of AR simulation,” in 2010 IEEE Virtual Reality Conference (VR) (IEEE), 11–18.
Lougiakis, C., Katifori, A., Roussou, M., and Ioannidis, I.-P. (2020). “Effects of virtual hand representation on interaction and embodiment in HMD-based virtual environments using controllers,” in 2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), 510–518.
Marvel, J. A., Bagchi, S., Zimmerman, M., and Antonishek, B. (2020). Towards effective interface designs for collaborative HRI in manufacturing: metrics and measures. J. Hum.-Robot Interact. 9, 1–55. doi:10.1145/3385009
Muffato, V., and Meneghetti, C. (2020). Learning a path from real navigation: the advantage of initial view, cardinal north and visuo-spatial ability. Brain Sci. 10, 204. doi:10.3390/brainsci10040204
Müller, H., Sedley, A., and Ferrall-Nunge, E. (2014). “Survey research in HCI,” in Ways of knowing in HCI. Editors J. S. Olson, and W. A. Kellogg (New York, NY: Springer New York), 229–266.
Paterson, J. R., Han, J., Cheng, T., Laker, P. H., McPherson, D. L., Menke, J., et al. (2019). “Improving usability, efficiency, and safety of UAV path planning through a virtual reality interface,” in Symposium on spatial user interaction (New York, NY, USA: Association for Computing Machinery). no. Article 28 in SUI ’19, 1–2.
Pfeiffer-Leßmann, N., and Pfeiffer, T. (2018). “ExProtoVAR: a lightweight tool for experience-focused prototyping of augmented reality applications using virtual reality,” in HCI international 2018 – posters’ extended abstracts (Cham: Springer International Publishing), 311–318.
Pierce, J. S., Stearns, B. C., and Pausch, R. (1999). “Voodoo dolls: seamless interaction at multiple scales in virtual environments,” in Proceedings of the 1999 symposium on Interactive 3D graphics (New York, NY, USA: Association for Computing Machinery), I3D ’99, 141–145.
Poupyrev, I., Billinghurst, M., Weghorst, S., and Ichikawa, T. (1996). “The go-go interaction technique: non-linear mapping for direct manipulation in VR,” in Proceedings of the 9th annual ACM symposium on User interface software and technology (New York, NY, USA: Association for Computing Machinery), UIST ’96, 79–80.
Quintero, C. P., Li, S., Pan, M. K., Chan, W. P., Machiel Van der Loos, H. F., and Croft, E. (2018). “Robot programming through augmented trajectories in augmented reality,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (ieeexplore.ieee.org), 1838–1844.
Ragan, E., Wilkes, C., Bowman, D. A., and Hollerer, T. (2009). “Simulation of augmented reality systems in purely virtual environments,” in 2009 IEEE Virtual Reality Conference, 287–288.
Ren, D., Goldschwendt, T., Chang, Y., and Höllerer, T. (2016). “Evaluating wide-field-of-view augmented reality with mixed reality simulation,” in 2016 IEEE Virtual Reality (VR), 93–102.
Rex Hartson, H., Andre, T. S., and Williges, R. C. (2003). Criteria for evaluating usability evaluation methods. Int. J. Human–Computer Interact. 15, 145–181. doi:10.1207/s15327590ijhc1501_13
Sanna, A., Lamberti, F., Paravati, G., and Manuri, F. (2013). A Kinect-based natural interface for quadrotor control. Entertain. Comput. 4, 179–186. doi:10.1016/j.entcom.2013.01.001
Sauro, J., and Dumas, J. S. (2009). “Comparison of three one-question, post-task usability questionnaires,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (New York, New York, USA: Association for Computing Machinery), 1599–1608.
Sauro, J., and Lewis, J. R. (2016). Quantifying the user experience: practical Statistics for user research (morgan kaufmann).
Smith, P. A. (1996). Towards a practical measure of hypertext usability. Interact. Comput. 8, 365–381. doi:10.1016/s0953-5438(97)83779-4
Stoakley, R., Conway, M. J., and Pausch, R. (1995). “Virtual reality on a WIM: interactive worlds in miniature,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (USA: ACM Press/Addison-Wesley Publishing Co.), CHI ’95, 265–272.
Suárez Fernández, R. A., Sanchez-Lopez, J. L., Sampedro, C., Bavle, H., Molina, M., and Campoy, P. (2016). “Natural user interfaces for human-drone multi-modal interaction,” in 2016 International Conference on Unmanned Aircraft Systems (ICUAS) (IEEE), 1013–1022.
Vaquero-Melchor, D., and Bernardos, A. M. (2019). “Alternative interaction techniques for drone-based mission definition: from desktop UI to wearable AR,” in Proceedings of the 18th International Conference on Mobile and Ubiquitous Multimedia (New York, NY, USA: Association for Computing Machinery), no. Article 51 in MUM ’19, 1–5.
Venkatakrishnan, R., Venkatakrishnan, R., Raveendranath, B., Pagano, C. C., Robb, A. C., Lin, W.-C., et al. (2023). How virtual hand representations affect the perceptions of dynamic affordances in virtual reality. IEEE Trans. Vis. Comput. Graph. 29, 2258–2268. doi:10.1109/tvcg.2023.3247041
Vortmann, L.-M., and Putze, F. (2020). “Attention-aware brain computer interface to avoid distractions in augmented reality,” in Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems (New York, NY, USA: Association for Computing Machinery), CHI EA ’20, 1–8.
Wagener, N., Stamer, M., Schöning, J., and Tümler, J. (2020). “Investigating effects and user preferences of extra- and intradiegetic virtual reality questionnaires,” in Proceedings of the 26th ACM Symposium on Virtual Reality Software and Technology (New York, NY, USA: Association for Computing Machinery), VRST ’20, 11.
Wilson, J. R. (1997). Virtual environments and ergonomics: needs and opportunities. Ergonomics 40, 1057–1077. doi:10.1080/001401397187603
Wolbers, T., and Wiener, J. M. (2014). Challenges for identifying the neural mechanisms that support spatial navigation: the impact of spatial scale. Front. Hum. Neurosci. 8, 571. doi:10.3389/fnhum.2014.00571
Wyss, H. P., Blach, R., and Bues, M. (2006). “iSith - intersection-based spatial interaction for two hands,” in 3D user interfaces (3DUI’06) (IEEE), 59–61.
Yu, K., Eck, U., and Navab, N. (2022). “Spatial exploration with a WiM for capturing 3D dioramic snapshots,” in 2022 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), 900–901.
Keywords: human-computer interaction (HCI), 3D user interface design, 3D path planning, virtual reality (VR), augmented reality (AR), mixed reality (MR), user studies
Citation: Hutton Pospick C and Suma Rosenberg E (2023) Creating and manipulating 3D paths with mixed reality spatial interfaces. Front. Virtual Real. 4:1192757. doi: 10.3389/frvir.2023.1192757
Received: 23 March 2023; Accepted: 30 October 2023;
Published: 06 December 2023.
Edited by:
Florian Daiber, German Research Center for Artificial Intelligence (DFKI), GermanyCopyright © 2023 Hutton Pospick and Suma Rosenberg. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Courtney Hutton Pospick, aHV0dDA3MEB1bW4uZWR1