Gatsby Computational Neuroscience Unit, UCL, London, UK.
Complex cognitive tasks present a range of computational and algorithmic challenges for neural accounts of both learning and inference. In particular, it is extremely hard to solve them using the sort of simple policies that have been extensively studied as solutions to elementary Markov decision problems. There has thus been recent interest in architectures for the instantiation and even learning of policies that are formally more complicated than these, involving operations such as gated working memory. However, the focus of these ideas and methods has largely been on what might best be considered as automatized, routine or, in the sense of animal conditioning, habitual, performance. Thus, they have yet to provide a route towards understanding the workings of rule-based control, which is critical for cognitively sophisticated competence. Here, we review a recent suggestion for a uniform architecture for habitual and rule-based execution, discuss some of the habitual mechanisms that underpin the use of rules, and consider a statistical relationship between rules and habits.
Figure 1
A shows a cognitively complex task (called the 12AX task) which one might attempt to teach to a macaque or explain to a human subject (Frank et al., 2001
). The task is called a conditional one-back task, since at its heart are two different one-back tasks. One requires a particular response to X when preceded by A; the other to Y preceded by B. Which of the two tasks is active depends on whether the most recent digit seen was a 1 or a 2. Thus the task has a hierarchical structure with the outer loop involving the storage of the most recent digit (the 1 or 2), and inner loops involving the two one-back tasks. The subjects are required to press one (L) of the two buttons as the particular response for the one-back task that is in operation, and otherwise to press the other button (R). The complexity of the task derives from the hierarchy, and also the long outer loops.
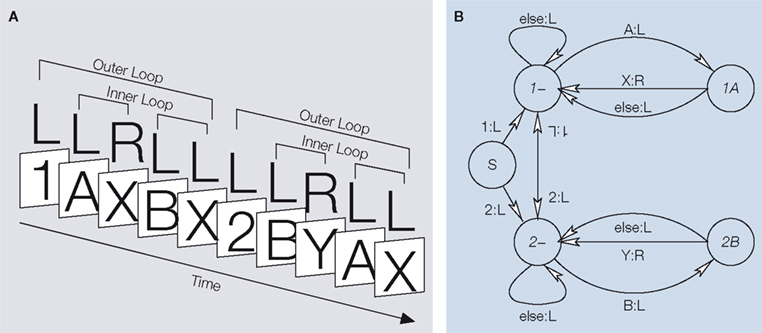
Figure 1. The 12AX task (from O’Reilly and Frank, 2006
, rendered by Krueger and Dayan, 2007
). (A) Subjects see a sequence of numbers and letters (in boxes), and have to respond by pressing one of two keys (L or R; correct responses are shown). They should choose L every time, except to respond R if the most recent digit is a 1 and X directly follows A, or the most recent digit is a 2 and Y directly follo-ws B. There can be many AX or BY subsequences following each 1 or 2, and inner loops always involve pairs of symbols. Different variants of the task impose slightly different constraints on the symbols in the non-one-back inner loops. (B) A finite state representation of one procedural solution to the task
. S is the start state; the links are labelled with the observation and the action. The main states are annotated with a representation of the contents of working memory (in italics). ‘1:L’ is upside down indicating it labels the link from 2- to 1-; ‘2:L’ on the same arrow labels the link from 1- to 2-.
Sophisticated tasks of this sort (Badre et al., 2005
; Frank et al., 2001
; Fusi et al., 2007
; Koechlin and Summerfield, 2007
; Koechlin et al., 1999
, 2003
) pose a variety of challenges for neurally inspired computational theories in terms of both acquisition and execution. However, despite their neuropsychological and neuroimaging importance, until rather recently, they fell between large cracks in computational cognitive science and neuroscience. They were too simple for the wing of the field interested in realizing artificial intelligence (AI) architectures in connectionist form (e.g. Derthick, 1990
; Hinton, 1990
; Plate, 2003
; Shastri and Ajjanagadde, 1993
; Smolensky, 1990
; Touretzky and Hinton, 1988
; Wermter and Sun, 2000
), which largely seeks to represent and manipulate arbitrary symbolic structures. Conversely, they were too complicated to be readily accommodated by the more straightforward feedforward (Fukushima, 1980
; Riesenhuber and Poggio, 2000
) or recurrent (Hopfield, 1982
) processing architectures popular in supervised, unsupervised, and reinforcement learning (Rumelhart and McClelland, 1986
; Sutton and Barto, 1998
).
However, developments in larger-scale architectures in behavioural neuroscience (Frank et al., 2001
; O’Reilly and Frank, 2006
; O’Reilly and Munakata, 2000
), ideas about more sophisticated multiply-articulated models of decision-making (Daw et al., 2005
), and indeed the new attention being paid to the neural basis of general-purpose cognitive architectures such as ACT-R (Anderson et al., 2008
) have breathed new life into the solution of such tasks (Frank et al., 2001
; Hazy et al., 2007
; Rigotti and Fusi, 2006
; Rigotti et al., 2007
). Here, we review Dayan’s (2007)
nascent attempt to meld aspects of these traditions so that a plausible route towards solving the more complex, AI-inspired, tasks can be mapped.
The premise of that paper is that there are procedural approaches to the challenges at two different levels, which we describe as rules and habits
. The actual rules of a task such as 12AX can be described in a few sentences of a natural language (as indeed in the first paragraph of this introduction). More formally, they could easily be rendered as the productions of production-system cognitive architectures such as SOAR (Newell, 1990
) or ACT-R (Anderson and Lebiere, 1998
), employing a blackboard-like working memory
(e.g. Newell, 1990
) to remember facts such as which digit was most recently presented. However, using productions of this sort poses particular computational difficulties, including retrieving a rule most appropriate to the current state, checking that its preconditions actually match the state of the input and the working memory, and then executing the rule in the sense of producing an appropriate output action and/or storing aspects of the input in working memory. This process is somewhat analogous to running an interpreted language on a computer, involving substantial mediation between the rules themselves and their underlying execution.
The whole architecture of the policy for solving this task that underlies the hand-crafted solution in Frank et al. (2001) and the learned solution in Hazy et al. (2006)
is completely different from this. It is a single, relatively complex, procedural entity, putatively realized by interactions between basal ganglia and the prefrontal cortex (PFC), and requiring neither retrieval nor checking. Rigotti and Fusi (2006) and Rigotti et al. (2007)
considered a similarly complex procedural solution to a slightly different task, but in their case considering hidden units within PFC rather than interactions with the basal ganglia.
Borrowing a term in broad use, but that has been most clearly defined in the animal conditioning community (Dickinson and Balleine, 2002
), we call such solutions habits, in the sense that they are forms of complex stimulus-response, or conditional input–output mapping, where the stimulus includes both the externally presented letter or digit and the contents of working memory, and the response can be both external, such as pressing a button, and internal, storing a stimulus in working memory. Like conventional habits, these are cognitively impenetrable and inflexible, in that parts of them cannot be edited separately. The main differences from the notion of a conventional habit is that they include the coordinated responses to many stimuli, rather than the more conventional view which generally (though not exclusively; Balleine et al., 1995
) concentrates more on single stimuli and single responses, and that they involve complex actions such as storing a stimulus in working memory. If the use of rules can be likened to running a interpreted, high-level computer language, then the use of a habit is more like the execution of assembly language. Indeed, we briefly discuss two notions of compilation below, also providing a link with popular notions of automatization
(Anderson, 1982
; Anderson and Lebiere, 1998
; Anderson et al., 2004
; Crossman, 1959
; Fitts, 1964
; Logan, 1988
; Newell, 1990
; Newell and Rosenbloom, 1981
; Taatgen et al., 2008
).
In conditioning, the normal opposites of habits are goal-directed actions
(Dickinson and Balleine, 2002
). However, rules are procedural, whereas goal-directed actions are declarative, a term with resonance in both neuroscience (Eichenbaum and Cohen, 2004
) and computer science (as in programming languages such as PROLOG). Goal-directed methods are declarative since they specify a set of facts about a domain (understood by Daw et al., 2005
in terms of reinforcement learning as a form of forward model; Wolpert and Kawato, 1998
; Wolpert and Miall, 1996
) leaving out the hard deductive task of figuring out from these facts (e.g. searching the forward model) to determine what it is best to do. We consider issues surrounding declarative control towards the end of the paper. Nevertheless, like goal-directed control, the system of rules can be highly labile to new information about a task (by virtue of changing the contents of the store of rules). This is one of their most critical differences from habits.
Dayan’s (2007)
intent was to build a model that provides two explicit links between rules and habits. One concerns the relationship between the execution component of each. For tasks such as 12AX, rule execution involves exactly the same class of internal and external effects as a habit. It is just that the complexities of the stimulus-response mapping have largely been removed by the processes of rule matching and checking, leaving a simple stimulus-response map. In fact, depending on the exact form of the rule, the process of checking might obviate the need for any conditionality even on the stimulus. The commonality between rules and habits is important because it suggests that a rather simple architecture might implement parts of both, and also provides a route towards seeing how a set of verbal commands could ultimately translate into a set of activities in populations of neurons that actually execute them
1
.
We consider a uniform architecture, in which rule execution indeed involves just the same operations as a habit. This then leads to a set of issues about the structural and statistical relationships between the execution components of rules and habits, and how one might emerge from the other. Again arguing by analogy, unsupervised learning methods applied to the natural statistics of sensory inputs build models that use basis representations to split up complex perceptual scenes into their separate pieces (Rao et al., 2002
). Top-down effects in perception depend on the ability to use these models to synthesize the internal activities associated with new, imagined, scenes. We consider the possibility that there could be habitual basis functions in the space of policies that can be acquired in a similar manner, and that the equivalent of synthesizing a new scene is synthesizing the execution aspect of a rule.
The other link between rules and habits stems from the observation that the tasks involved in interpreting rules themselves involve the execution of some particular internally directed actions, including memory retrieval for the rule (which we consider to be associative) and condition checking. In our computer analogy, interpretation of a high-level language (the rules) requires execution of assembly language (the habits) associated with the interpreter. We thus consider some of the habits associated with rule use.
We first consider the habitual elements, crudely, the form of processor that underlies performance in such tasks. We then consider rules, and finally generalizations beyond the work in Dayan (2007)
.
The 12AX task (and indeed the other conditional input–output mapping task modelled in detail in Dayan, 2007
) poses two particular computational problems associated with: (1) working memory (for stimuli 1, 2, A and B), and (2) the mappings from the current input to the required output conditional on the contents of the working memory. Both of these can be solved using particular forms of non-linear interactions based on simple neural representations of the input stimuli and working memory. Figure 1
B shows a habitual solution to this task in a finite state representation. Working memory (annotated inside the nodes) is used to realize the states; at least two ‘slots’ are needed, one for 1 or 2, and one for A or B. The conditional input–output mappings realize the actions and the transitions. Frank et al. (2001)
, O’Reilly and Frank (2006)
, Rigotti and Fusi, (2006) and Rigotti et al. (2007)
suggest rather different approaches to implementing such a solution, which were partially integrated in Dayan (2007)
.
Based on the analysis of Hochreiter and Schmidhuber (1997)
, Frank et al. (2001) and O’Reilly and Frank (2006)
build a model of gated working memory called PBWM (prefrontal, basal ganglia working memory). The idea is that regions (stripes; Pucak et al., 1996
) in the PFC are disposed to provide the sort of activity-based storage frequently observed in electrophysiological studies of neurons in this area (Fuster, 1997
), for specific information available in inputs from higher order sensory areas. In our case, this on-line storage is the substrate for the representation of the slots, i.e., the persistent states associated with the inner and outer loops in the task. In this framework, control over working memory amounts to control over reading information into (and out of; Gers et al., 2000
) the memory. O’Reilly and Frank (2006)
suggest that this is implemented by plastic connections between the PFC and the basal ganglia that learn to implement appropriate gating operations at suitable points in the performance of the task. Other connections through the basal ganglia realize the mapping necessary to generate motor outputs. Frank et al. (2001)
show that it is possible to wire up such a gated working memory system in a way that executes the 12AX task; O’Reilly and Frank (2006)
provide a rather complex reinforcement learning mechanism that can acquire this ability from (substantial) experience. However, the sloth of learning may be at least partially ameliorated through structured shaping of competence, itself an underinvestigated topic (Krueger and Dayan, 2007
).
Gating information into or out of working memory is a particular sort of non-linear computational operation. In PBWM, one can interpret the neurons in the basal ganglia pathway as hidden units with trainable inputs (to accommodate the different operations that are required) and fixed outputs (i.e. gating particular pathways from sensory cortices to PFC) associated with this non-linearity. By contrast, although Rigotti and Fusi (2006) and Rigotti et al. (2007)
also consider working memory attractors as the core substrate of PFC, they employ hidden units that are intended to form part of PFC itself, with random, fixed, inputs, but trainable outputs. They do not consider gating operations as a particular, separate, class, with their own specific (striato-thalamo-cortical) mechanism, instead treating them like any other computational operation. Rigotti and Fusi (2006) and Rigotti et al. (2007)
show first that many simple computational operations associated with conditional input–output mappings are not linearly-separable, and so cannot be performed without such hidden units, and then that, given only a modest number of random, fixed, hidden units, an impressively large fraction of all possible single operations becomes viable.
Both these ideas can be thought of in terms of procedural primitives, out of which more general competence can be fashioned, for instance through learning. Dayan (2007)
adopted the notion of gating from Frank et al. (2001)
, with explicit operations for reading into and out of working memory. However, rather than employing the random hidden units of Rigotti and Fusi (2006) and Rigotti et al. (2007)
, this model used a bilinear form (Koenderink and Van Doorn, 1997
; Tenenbaum and Freeman, 2000
), which is a rather simpler structure that is an abstraction of the sort of multidimensional basis functions that are frequently considered in neural terms (Poggio, 1990
), particularly in the context of coordinate transformations in the parietal cortex (Olshausen et al., 1993
; Poggio, 1990
; Pouget, 1997
). This overall habitual architecture (Figure 1
A,B in Dayan, 2007
, with the solution to the 12AX task being shown in Figure 7) provides a computational substrate that is rich enough to encompass a whole range of tasks. One important question for future work is whether this is formally broad enough, i.e., in some sense Turing equivalent (bar the infinite tape), possibly when coupled to an ability to create new representations of combined sensory input and internal states that are also coupled to their own working memory units.
The target article considered this part of the architecture as being habitual, because it realizes a direct mapping between internal and external stimuli and internal and external responses. In the literature from which this term was borrowed, the distinction is made between goal-directed actions, which are performed because (computationally, as a deductive consequence of the fact that) subjects have good reason to (1) expect that they will give rise to particular outcomes; and (2) value those outcomes, and habits, which form a more amorphous class of control, including stimulus-response mappings, that do not respect one or other of these precepts (Dickinson, 1985
; Dickinson and Balleine, 2002
). For instance, if a subject learns that a formerly valuable outcome is currently worthless (for instance having been poisoned), under goal-directed control, it should refuse to perform an action leading to that outcome. The policies realized by the bilinear architecture are not based in any way on the sort of reasoning processes inherent to goal-directed actions, and cannot be changed in the sort of on-line way implied by the poisoning experiment. This underlies their habitual moniker.
Another way of viewing the habitual solution is that it is automatic, in the terms of Chaiken and Trope (1999)
, Dickinson (1985)
, Epstein (1994)
, Evans (2003)
, Kahneman and Frederick (2002)
, Schneider and Shiffrin (1977)
, Shiffrin and Schneider (1984)
, Sloman, (1996) and Stanovich and West (2002)
. These authors all consider dual process theories, setting up different, but inter-related dichotomies between different systems. One of these, which involves the equivalent of habits, is typically inflexible and slow to learn, but fast to execute and attentionally undemanding. The other, ‘System 2’ in the sense of Kahneman and Frederick (2002) and Stanovich and West (2002)
, is rule-based, and subject to something more akin to attentional or deliberate control
2
. We now turn to this flexible, but demanding and computationally expensive (and hence likely inaccurate, Daw et al., 2005
) system.
In humans, rules for this controlled processor can be provided through verbal instructions, which can obviously only impact behaviour by affecting the underlying mechanisms of choice, putatively, exactly the same elements of working memory and conditional input–output control as above. We think of the mapping from precept to procedure as a problem of compilation or translation, an area that is ripe for further investigation. However, at a minimum, there must be a set of pre-existing execution competences that can be the targets of such mappings. In our uniform architecture, we consider these competences to be simple habits themselves, and suggest that simple habits form a basis set for the rule-governed execution of tasks.
The first step is to consider what rules might look like for a task such as 12AX. One view of a rule is that it captures an appropriate procedure for a restricted piece of the task, as in a (formalized) part of the description given at the start of this paper. Examples of this include requiring that 1 or 2 be stored in working memory when it occurs (rules 1 and 2 of Table 4 in Dayan, 2007
), or that if 1A is stored and is followed by an X then the R button should be pressed, and the A (but not the 1) forgotten. This latter rule (rule 5 in the table) has a limited domain (i.e. only applying at a restricted set of steps of the trial). A whole collection of rules has to be combined to create performance that is appropriate overall. Different sets of rules can be computationally equivalent, just as different algorithms rendered in different programming language can realize the same computation in different ways (Marr, 1982
), posing greater or lesser loads on different aspects of neural competence.
Cast in this manner, the action part of a rule is really an isolated, basic procedure that can be implemented using the same mechanism that realises the complete, complex, habit for 12AX (that we discussed in Section ‘Habits’). This uniform realization is very important, since it provides a natural means of melding rules and habits in the same structure. We can imagine a whole task such as 12AX ultimately becoming the execution component of a rule all on its own, illustrating a compositional route to more sophisticated functionality.
Of course, the rule itself can only be simple if the complexity of extracting it from the store of rules that collectively solve the task, and deciding which of this collection should be active at what point in the task, is addressed by some other mechanism. We argue that rule storage and extraction is the job for a content-addressable episodic memory; and testing the exact conditions for the match of a rule is a specialized, but bilinearly simple, procedure all of its own, based on matching conditions that form a critical part of the representation of the rule.
The rules describing a complex task, like the rules describing a board game, can readily exceed the limited explicit storage capacity of working memory (Halford et al., 2007
). It therefore seems likely that they are stored in long-term memory, extracted by associative match with the sensory input and the contents of working memory. However, there is a critical computational difference between associative matching and rule matching that has to do with exclusion. Rules can have exclusion conditions – for instance firing only if some aspect of the input does not match a particular feature, whereas associative recall is generally more promiscuous, using any available information as a key to recall. It is straightforward to specify a bilinear matching process that tests inclusion and exclusion conditions associated with a rule; this can be seen as another specialized procedure or habit itself.
In sum, we have created all the elements for rule storage, recall, testing and execution. The execution component of rules are, just like habits, stimulus-response mappings, but with the conditionality that plays an important part in the full habitual representation of a whole task such as 12AX being replaced by an explicit test of a set of conditions that the input must meet, or must fail to meet. In Dayan (2007
), these conditions are simple to enforce, since the representations of inputs and the contents of working memory are unary. We assume that the associative matching procedure can recall a number of candidate rules; the testing process winnows this down to the one that is appropriate; its associated habit is then executed in exactly the same (bilinear) manner as the overall habit for 12AX.
Rule-based execution of a task is more computationally involved than habitual execution, because of the sequential process of retrieving, testing and realizing the procedures associated with multiple rules. This computational challenge, and the resulting possibility of error, provides a spur towards automatization and the learning and acquisition of habitual competence.
The target article Dayan (2007)
contains an extensive discussion of the gaps in, and immediate extensions of, this work, notably to cases in which multiple rules may be appropriate at any point in a task, and to more complex matching conditions. However, two issues merit more notice, namely the relationships between habitual, rule-based, and declarative control, and the provenance of the basis sets of rules.
Our work was partly inspired by the analysis of the difference between goal-directed and habitual control (Dickinson and Balleine, 2002
) in terms of model-based and model-free reinforcement learning (Daw et al., 2005
). Both forms of reinforcement learning attempt to acquire optimal policies. Model-based mechanisms do it by building a model of the world, which is typically straightforward and can readily change with new information. However, using such a model requires its inverse. For instance, for the case of a Markov decision problem, this requires taking a description of the transition structure of a domain and outcome utilities, and performing an operation equivalent to dynamic programming to calculate the optimal actions (Sutton and Barto, 1998
). This amounts to a form of search in the tree that comprises the transitions and outcomes produced by actions. Search is computationally expensive, taxing on working memory, and error-prone. Daw et al., (2005)
suggested that these challenges motivated model-free mechanisms, which learn the inverse by substituting experience and sampling for search. This makes them slower to acquire optimal behaviour, and less adaptable, but also much easier to use in practice.
However, the requirement for tree search points out an important distinction between model-based and rule-based control. The most natural form of model is a forward or generative (Dayan et al., 1995
; Wolpert and Miall, 1996
) account of the domain that specifies the transitions and outcomes that result from actions. However, this is a declarative form of representation of a problem, and hides the (search) complexities of how this knowledge can be used to work out what to do.
There are at least two straightforward analogies for this. One is with logic or theorem proving – the model is like a set of axioms, the task of working out what to do is like deducing a consequence that is true. Deciding which of the declarative facts to use in this deduction and in what order, is well known to be a tough computational problem. A second analogy is to generative (or synthesis) and recognition (or analysis) models in statistical unsupervised learning for sensory input (Dayan et al., 1995
; Hinton and Zemel, 1994
; Hinton et al., 1995
; Kawato et al., 1993
; Neisser, 1967
). Consider the case of vision – the generative model is a form of graphics model that indicates what a scene would look like given that it contains certain objects, lit in particular ways and viewed from some angle. The recognition model takes a view of a scene, and reverse-engineers it to work out what objects and lighting generated it. This is also well known as a computationally challenging inverse problem; and indeed the recognition model is often seen as the (Bayesian statistical) inverse of the generative model.
For us, the rules of the task are actually themselves already an inverse, i.e., they already determine an effective procedure for executing the task successfully. One can also imagine a set of rules that is more declarative
in form – a set of generative rules which describes the workings of a task without directly indicating its solution (that is, a generative model without an inverse). Indeed, by contrast with imperative programming languages such as BASIC, there are declarative languages like PROLOG which require inverting in a somewhat analogous manner, employing a similar form of tree search. Our architecture should generalize to cases in which tree search is required based on a declarative specification of a task; this would then combine goal-directed and rule-based aspects of cognitive competence.
Despite being procedural rather than declarative, the sort of rules that we have considered do share one important characteristic with goal-directed actions, namely that they can readily be changed. Depending on the flexibility of storage and controlled forgetting in the associative memory, it would be straightforward to add new rules, and erase old ones and have them work appropriately, without changing everything about the existing rule-base. This is impossible for habits. Of course, if sets of rules come to conflict as they change, behaviour will be confused – declarative representations face a similar concern in the form of the infamous frame problem (McCarthy and Hayes, 1969
).
In conditioning, behaviour that is initially goal-directed, emanating from the model-based system, often becomes habitual, controlled in a model-free manner, over the course of experience. This is related to the notions of automatization cited above. One difference is that the distinction in conditioning between goal-directed and habit systems has a somewhat sharper operationalization than for the other cases. There is an active debate in the field about the nature of the transfer from the former to the latter, for instance, whether it is for reasons of decreased perceived covariance between action and outcome arising from overly regular choices (Dickinson, 1985
), or the relative uncertainties of the two systems arising from their different statistical and computational profiles (Daw et al., 2005
). The characterizations of transfer in the other treatments of automatization again appear somewhat less formal than these.However, Dayan (2007)
focussed on the representation of policies rather than their evolution over the course of skill learning; the latter is an important direction for the future.
Note that Anderson (1982)
; Taatgen et al. (2008)
, building on the notion of ‘chunking’ in SOAR (Newell and Rosenbloom, 1981
), consider that one aspect of automatization is turning a declarative representation of a task that is solved (inverted) by general-purpose procedures into a rule-based representation in terms of productions. They call this knowledge or procedural compilation, which is slightly different from the compilation step that Dayan (2007)
suggested as being involved in the translation from a verbal to a rule-based specification of the policy for a task.
Our account stresses an additional feature of the interaction between the systems, namely the dependence of rule-based control on habitual mechanisms. First, the action components of rules are seen as being just like simple habits. Second, rule matching can be performed by a bilinear computational substrate just like the one assumed for the execution of other habits. Rules influence other rules directly by changing the contents of working memory (which acts like a form of blackboard; Newell, 1990
), and indirectly by causing actions in the world, which may then change (observable) state. In principle, the cognitive operations associated with rule-based control, such as influencing or manipulating associative matching, could themselves be rule-based or habitual. However, this recursion must in the end be habitually grounded. The operations required to invert a declarative specification of a task would be yet more complicated.
We have argued that rules employ a basis set of habitual primitives. This poses an obvious question as to the origin and choice of these primitives. Much of the work on connectionist structure-sensitive rule and symbol processing (Hinton, 1990
; Plate, 2003
; Smolensky, 1990
) has focussed on universality, i.e. on the implementation of a small set of powerful operations that can be combined and manipulated in a nearly arbitrary manner. By contrast, motivated by notions about structured visual representations (Dayan, 2006
), we suggested considering this basis set in an hierarchical manner as the result of an unsupervised representational learning process (Rao et al., 2002
) applied to the internal descriptions of habitual procedures, just like the internal descriptions in early sensory cortices of visual, auditory or other sensory input that arise in the paired generative and recognition models that we discussed above.
The representational learning process that creates these paired models involves taking an ensemble of patterns and determining and parameterizing their underlying statistical structure. Given this, (old and) new members of the ensemble can be represented according to their parameter values with respect to this structural decomposition. This representation is the product of the recognition or analytical model. Along with this model comes the statistical generative model that can synthesize new instances of the ensemble. Unsupervised learning applied to the internal representations of habits would decompose complex ones into their individual parts, and provide a mechanism by which new habits, and the execution components of new rules, can be synthesized from their elemental pieces. One can imagine basing learning of a sophisticated representational system for habits, which will be automatically appropriate for rules, on the acquisition over the course of a developmental period of a whole range of different tasks.
The main goal of Dayan (2007)
was to provide a uniform architecture into which habits and instructed, rule-based, competence both fit. Although the former provides the ultimate, automatic, means by which we and animals negotiate simple and complex tasks, instructed rule-based performance is very important, at least for humans. Further, the issues for instantiating rules, such as the notion of hierarchically specified basis sets of habits created by a representational learning procedure, are important even in the absence of instruction. The other point stressed in the paper is the rather strong reliance of rule instantiation and execution on habits. Not only is the action component of a rule a habit, but also we have suggested that mechanisms such as matching that are associated with using rules, depend on habits too. At a most fundamental level, it is habits that are in control.
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
I am very grateful to David Badre, Paul Burgess, Nick Chater, Mark D’Esposito, Stefano Fusi, Kai Krueger, Tim Shallice and Wako Yoshida for discussion, models and ideas associated with the original article. Funding was from the Gatsby Charitable Foundation.
Rule: A combination of a (typically simple) inputâÂÂoutput mapping and a set of conditions defining this mappingâÂÂs applicability. Rules require retrieval from memory, having their conditions be checked, and then their actions executed. The paper considers a uniform architecture involving habits and rules.
Working memory: Many complex tasks require information from the recent past to be stored temporarily to influence ongoing choices, and, in reinforcement learning terms, to resolve ambiguities about state. In this paper, we borrow an idea about gated working memory, allowing explicit internally directed actions to control reading information in and out of such memories.
Automatization:
In conditioning, behaviour can transfer from being under goal-directed control to being habitual, and therefore automatic in a particular sense. Related and expanded notions of automatization in skill learning appear in many forms in the literature, including a transfer from declarative to procedural representations, and streamlined procedural forms.
Declarative representation of a task solution: Crudely, this describes the contingencies of the task (e.g. âÂÂpressing the left button in state P leads to state Q; pressing the right button in state Q leads to rewardâÂÂ) leaving a search problem to work out the appropriate action. Programming languages such as PROLOG are declarative; in the text, we relate such representations to model-based control.
- ^ Dayan (2007) labels this process compilation, but does not implement it.
- ^ Although, of course, it is not clear how similar are all these different dichotomies, which span different species and different computational problems.