1
Wellcome Trust Centre for Neuroimaging, University College London, London, UK
2
ESRC Centre for Economic Learning and Social Evolution, University College London, London, UK
The origin of altruism remains one of the most enduring puzzles of human behaviour. Indeed, true altruism is often thought either not to exist, or to arise merely as a miscalculation of otherwise selfish behaviour. In this paper, we argue that altruism emerges directly from the way in which distinct human decision-making systems learn about rewards. Using insights provided by neurobiological accounts of human decision-making, we suggest that reinforcement learning in game-theoretic social interactions (habitisation over either individuals or games) and observational learning (either imitative of inference based) lead to altruistic behaviour. This arises not only as a result of computational efficiency in the face of processing complexity, but as a direct consequence of optimal inference in the face of uncertainty. Critically, we argue that the fact that evolutionary pressure acts not over the object of learning (‘what’ is learned), but over the learning systems themselves (‘how’ things are learned), enables the evolution of altruism despite the direct threat posed by free-riders.
Many social interactions are self-beneficial if we behave positively and pro-cooperatively towards others. Opportunities to benefit from cooperation are widespread, and reflect the extrinsic fact that the natural environment is often best harvested, insofar as rewards can be accrued and threats avoided, by working together. But the decision to cooperate is not always straightforward, as in some situations it leaves us vulnerable to exploitation by others.
Game theory specifies a set of potential social interactions in which outcomes of cooperation and defection systematically differ, allowing both experimentalists and theoreticians to probe an individual’s propensity for cooperation in different situations (Camerer, 2003
). These outcomes typically vary in the extent to which competitive actions may seem preferable and where a short-sighted temptation to exploit the cooperativeness of others has a capacity to subvert cooperation later. Fortunately, the ability to look beyond the immediate returns of defection towards longer-term cooperation allows humans to escape from otherwise competitive equilibria, and this can be viewed as a hallmark of rational, sophisticated behaviour.
However, humans appear to behave positively towards each other in situations in which there is no capacity to benefit from long-term cooperation: for instance, when they play single games in which they never meet the same opponent again, and when their identities are kept anonymous (Fehr et al., 1993
; Berg et al., 1995
; Fehr and Fischbacher, 2003
). This removes the capacity for both direct reciprocity (tit-for-tat) (Trivers, 1971
; Axelrod, 1984
), and the ability to earn a cooperative and trustworthy reputation that can be communicated by a third-party (Harbaugh, 1998
; Bateson et al., 2006
; Ariely and Norton, 2007
). Furthermore, they will do this even if it is costly to themselves (Xiao and Houser, 2005
; Henrich et al., 2006
). From an economic perspective this appears to be genuinely altruistic, being strictly irrational since it incurs a direct personal cost with no conceivable long-term benefit.
Arguments against altruistic interpretations of experimentally observed behaviour include suggestions that individuals do not understand the rules of the game, are prone to misbelieve they (or their kin) will interact with opponents again in the future, or falsely infer they are being secretly observed and accordingly act to preserve their reputation in the eyes of experimenters (Smith, 1976
). However, the widespread observation of altruism (both rewarding and punishing) across cultures (Henrich et al., 2001
), and within meticulously designed experiments conducted by behavioural economists provide compelling support for its presence as a clear behavioural disposition. Furthermore, in fMRI experiments, altruistic actions correlate with brain activity, suggesting that they derive from some sort of intended or motivated behaviour and are not an expression of mere ‘effector noise’ (i.e. decision error) (de Quervain et al., 2004
).
The very existence of altruism raises the difficult question as to why evolution has allowed otherwise highly sophisticated brains to behave so selflessly. This directs attention towards the decision-making systems that subserve economic and social behaviour (Lee, 2006
, 2008
; Behrens et al., 2009
), and questions whether they are structured in such a way that yields altruism either inadvertently, or necessarily. The broader consequence is that if they do, then this reframes the question regarding the ultimate (evolutionary) causes of altruism towards the evolution of these very decision systems, and away from the phenomenological reality of altruism per se.
In this paper, we first review the structure of distinct human decision-making systems by considering a goal-directed (cognitive) system, a habitual system, and an innate (Pavlovian) action system and their interactions. We consider how these systems might operate in social contexts where the key problem is how to make optimal decisions when outcomes depend on the uncertainty associated with other agents and their motives. In the face of such computational complexity, we then consider how optimal actions can be approximated by habit-based decision-making when outcomes are reliably predicted. In this context – through habits – altruism emerges as a consequence of a net economy of computational cost. We also consider the problem of evaluating the best policy when the payoff matrix is unknown but where individuals have an opportunity to learn from others. Observational learning rests upon inferences that might utilise such conspicuous attributes as their personal wealth. We frame observation as an inverse reinforcement learning problem, and consider value functions (including goals and subgoals) that are inferred from others actions, as well as by simpler strategies such as imitation. Notably, with incomplete information – a consequence of not being around to observe the long-term benefits of pro-cooperative behaviours, altruistic outcomes may be inferred as surrogate goals. In this context, altruism arises through optimal inference with incomplete information.
Studies of decision-making in behavioural neuroscience and psychology have tended to concentrate on elemental decision-making problems, such as reward accrual in simple, stochastic, non-social environments. This enterprise has been very successful and has combined ingenious experimental designs with more classical focal brain lesion paradigms to yield insights into the underlying structure of decision-making systems. One key emerging insight is the likelihood that there is no singly monolithic decision-making system in the brain. Indeed, the best evidence suggest there are at least three distinct decision-making systems comprising a goal-directed, habitual, and innate (Pavlovian) system – with behavioural control being an admixture of cooperation or independence (Dickinson and Balleine, 2002
; Dayan, 2008
).
Goal-directed decision-making systems function by building an internal model of the environment. In the simplest case this may simply involve representing the identity of the expected outcome. In more complicated instances, it involves detailed knowledge of the structure of the environment and one’s position within it. Although a goal-directed system may subsume several distinct sub-mechanisms, a wide variety of evidence suggest it localises to prefrontal cortex (Daw et al., 2006
; Kim et al., 2006
; Valentin et al., 2007
), hippocampus (Corbit and Balleine, 2000
; Kumaran and Maguire, 2006
; Lengyel and Dayan, 2007
) and dorsomedial striatum (Balleine and Dickinson, 1998
; Corbit et al., 2003
; Yin et al., 2005
).
Habits, on the other hand, lack specific knowledge of the outcome of their decisions. In the parlance of computer science their values are ‘cached’, and represent only a scalar quantity which describes how good or bad an action is (Daw et al., 2005
). In animal learning, such values are characterised by their insensitivity to devaluation: changes in state (e.g. moving from hunger to satiety) do not alter the value of the action, since there is no access to the new value of the goal (Dickinson and Balleine, 1994
; Daw et al., 2005
). Habits are acquired through experience, and ‘rationalised’ on account of their reliability in predicting rewarding outcomes. This efficiency derives entirely from the way in which they learn: rewards reinforce actions that are statistically predictive of their occurrence, with reinforced actions acquiring value through simple associative learning rules (Rescorla and Wagner, 1972
; Holman, 1975
; Adams and Dickinson, 1981
). These are well described by Reinforcement Learning algorithms (such as Q learning and SARSA; Sutton and Barto, 1998
), and localise to dorsolateral striatum (O’Doherty et al., 2003
; Tricomi et al., 2009
) and dopaminergic projections from substantia nigra.
Control over decisions is often dynamic and frequently transfers from goal-directed mechanisms (early in a task) to a habit-based system (late in a task). Indeed, this transfer can be manipulated by selective lesions to the neural substrates that underlie each of these systems (Balleine et al., 2009
). In formalising accounts of how these systems interact current views centre on the idea of control being mediated by the respective uncertainties with which each system predicts outcomes, a view that provides a reasonable normative account of experimental findings (Daw et al., 2005
). At a broader level, the evolutionary rationale for such a dual system is based on computational cost, since habits are vastly less resource demanding than goal-directed mechanisms.
Lastly, animals including humans have an innate, ‘hard-wired’, decision system. This is often referred to as a Pavlovian system, characterised by the expression of values and responses acquired through simple state-based associative learning. Unconditioned and conditioned Pavlovian responses represent an evolutionarily acquired behavioural repertoire that reflect basic, reliable knowledge gleaned from an organisms evolutionary history: embodying such knowledge structures that approaching sweet tasting fruit and withdrawing from bitter tasting fruit are inherently useful responses to enact. But whereas, on average, this inbuilt knowledge structure is enormously valuable to a naïve individual, it may also be a curse in the (usually) uncommon situations in which it is incorrect. The competitive (inhibitory) interaction between decisions based on experience (instrumental habit and goal-directed mechanisms) and those based on Pavlovian impulse localises to brain regions such as the amygdala and ventral striatum (Cardinal et al., 2002
; Seymour and Dolan, 2008
). This interaction reflects the classic tension between apparently emotional irrational and rational cognitive systems whereby the emotional expresses an apparent irrationality by way of some peculiarity of the environment.
A challenge for decision neuroscience is to understand how basic decision-making systems operate within socially interactive environments. Consider the game in Table 1
: the repeated Prisoner’s dilemma. Subjects must choose between one of two actions: cooperate or defect, and their payoff depends on this and the choice of the opponent. Now consider a goal-directed, cognitive decision-making policy in the game, which has the ability to consider multiple future hypothetical scenarios (Figure 1
A). If you neither know, nor care, what the other player does then the best strategy is to defect on the first round, since the outcome is always better regardless of what the other player does. For the same reason, even if you know what he/she will do, it is still better to defect.

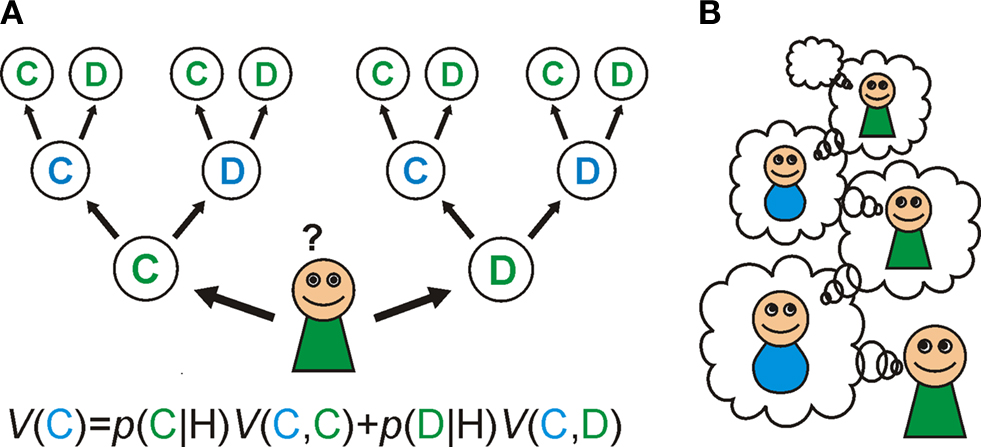
Figure 1. Goal-directed learning of Prisoner’s dilemma. (A) In goal-directed learning, players learn the probability of other player’s action: cooperation (C) or defection (D) based on the history of their actions (H) as p(C|H) and p(D|H). They estimate the value of their own actions: V(C) and V(D) using the prediction from the learned model and the expected reward from the pair of actions. (B) In social games, the model of others leads a recursive process: my model of your action includes a model of your estimate of my actions, and so on. Cooperation in the Prisoner’s dilemma depends on these recursive representations; since when I decide to cooperate this time, I must estimate that you are going to cooperate next time as you believe that I am going to cooperate with you.
However, it is also clear that in the long run, both players are better off if they cooperate: this mutually prescribes the best exploitation of environmental resources. Clearly, you need some way of both knowing that your opponent is committed to cooperation as well as a means of signalling to him/her your intention to cooperate. That is, you need to know that she is sophisticated enough to realise that cooperation is worthwhile, and you yourself need to be sophisticated enough to realise this. There is nothing truly altruistic about this, since you are both just trying to maximise your own payoff in an environment that contains another intelligent agent.
Thus, the existence of another intelligent agent in the environment makes the problem more complex than simpler decision-making problems that exploit inanimate environments. In the latter, the payoff probability usually depends fully on the observable states (they are ‘fully observable Markov decision problems’; Bellman, 1957
). That is, although the payoff may be probabilistic (either involving risk or ambiguity or both), your predictions depend in no way on how you came to arrive at that state in the first place. In social interactions, this assumption does not apply because outcomes depend on what the state thinks about you. If you have recently behaved uncooperatively, then this history negatively influences the payoff you expect to receive. That is, the outcome depends on unobservable states in the environment (making the problem ‘partially observable’). If you find yourself in a seemingly identical state to a previous occasion, for instance playing opponent x in the game y, then the expected payoffs are not independent of how you got there, since opponent x may have a memory of you.
Consequently, social decision-making benefits greatly from constructing some sort of internal model of the key aspects of the environment. In social games this model needs to capture the intentions of the other player (a component of ‘Theory of Mind’). Indeed, your model should also include your opponent’s estimate of your intentions: with this model, you can strategically plan to signal to your opponent your intention to cooperate, knowing that it will change their model of you (Figure 1
B). Accordingly, they should then be more willing to cooperate with you, and you will both be better off in the long run.
It can be seen that this sort of model of others’ intentions, and their model of your intentions, captures features of reciprocity, trust, and reputation formation. Indeed maintaining cooperation is in everyone’s selfish interest in repeated games when the end of play is not in sight. It does, however, require players to be able to resist the short-term temptation to exploit this mutual reciprocity by the treachery of defection.
Of course, there is no reason why an internal representation of an other-agent’s belief model need stop at a knowing the representation of your intentions in their mind. At the next level, it could include your understanding that they know that you know that they know your intentions, and so on. That there are infinite levels of embedded beliefs that make any perfect decision-policy intractable, has inspired models of strategic behaviour that either bound the upper limit of reciprocal beliefs (an example of ‘bounded rationality’) (Camerer et al., 2004a
; Hampton et al., 2008
), or estimate the level of reciprocal belief in their opponent directly (Yoshida et al., 2008
).
Experimental evidence indicates that in repeated games with the same opponent, people reliably cooperate, as theory predicts. Critically, however, the theory predicts that people shouldn’t cooperate towards the end of repeated exchanges, when they play people that they will never meet again and who can’t communicate with others that can. The observation that people do cooperate in these situations suggests something is either incorrect about the goal-directed model, or as we suggest, other decision-making systems compete to bias behaviour.
In simple environments, habits allow you to navigate towards goals and avoid harm with speed and computational efficiency. Habits operate by allowing recently experienced rewards to reinforce actions that are statistically predictive of them. If an outcome is reliably predicted by an action, then the value of that action becomes high. The action set available to an individual at any one time is elicited by the configuration of cues and contexts in the environment, which represents the current ‘state’. Importantly, habits don’t themselves have access to any specific representation of their outcome, they merely know their value on an ordinal value scale.
Now consider action control in social games. Imagine you are playing a selfish but sophisticated opponent in endless rounds of the Prisoner’s dilemma. Early in the game, your model-based system has the ability to consider multiple future rounds of the game, in which mutual cooperation is evaluated as valuable, since you know your opponent also knows this. Accordingly, mutual cooperation is rewarded as the game dictates. After a few rounds, actions associated with ‘cooperate’ begin to reliably predict rewarding outcomes, and so the habit learning system, operating concurrently with goal-orientated systems, acquires greater predictive certainty. As this accrues, control is transferred to the habit system, and the computational cost of considering multiple future rounds is relieved. In simple terms, cooperation becomes more ‘automatic’.
The critical feature of this type of habit learning is what defines the state by which the habit can be elicited. In animal learning theory, this is termed the ‘discriminative stimulus’, and is typically experimentally determined by the presence of a cue (Mackintosh, 1983
). However, the discriminative stimulus in social games is more complex, and in principle could be determined by the nature of the game being played (Prisoner’s dilemma, stag-hunt and so on) or by the identity of the opponent. Below, we consider both possibilities:
Imagine that you ignore the identity of your opponent, and by good fortune play the prisoners dilemma with multiple cooperative opponents: i.e. you exist within a population of sophisticated cooperators (Figure 2
A). Different types of social interaction will have distinct payoff matrices: some will benefit cooperation, others will not. If you know which game you are playing when you engage in an action, then if your action (e.g. to cooperate) is reliably rewarded it will be accessible to acquisition by a habit learning system that simply encodes that in a given game, cooperation or competition is reliably beneficial.
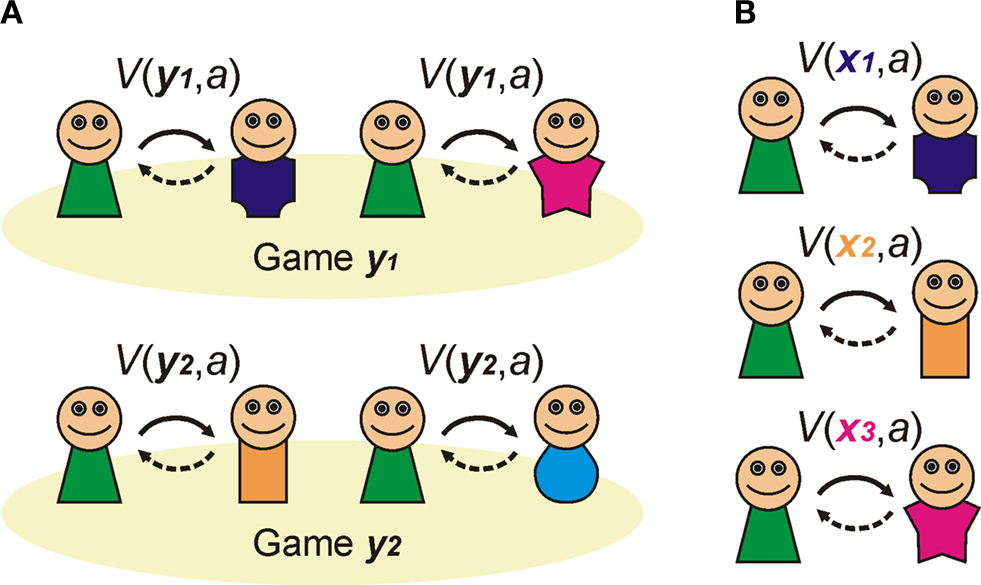
Figure 2. Habitual learning of Prisoner’s dilemma. (A) Habit learning in specific games. An agent plays an action a when in a particular state that is defined by the game type, e.g. game y1. If the outcome is rewarded, then the action is reinforced, and is more likely to be emitted when the same state is encountered again. (B) Habit learning with specific opponents. An agent (in green) plays action a (cooperate) when interacting with a particular agent (who defines the state, or discriminative stimulus SD as x1, for example). If the outcome is rewarding, then the reward reinforces action a, such that it’s value V(x1,a) increases, and is more likely to be chosen again in the same state in future.
Indeed even if the payoff matrix is not known, for instance in a novel game in an uncertain environment, a reasonable strategy may be to play by trial and error. This entails exploring different actions and seeing what the outcome is, in which case actions can be reinforced directly by habit systems. Simulation studies demonstrate how readily cooperative equilibria can be reached by simple associative algorithms (such as Q learning) without any model-based control at all (Littman, 1994
; Claus and Boutilier, 1998
; Hu and Wellman, 2004
).
Alternatively, you may choose to ignore the payoff matrix of the game, but concentrate instead on the identity of your opponent (Figure 2
B). For instance, if you play a specific opponent in a variety of games, and she reliably cooperates with you to your benefit, then you may learn the habitual action to cooperate whenever you play her. In this way, she becomes a positive discriminative stimulus that evokes actions that engage pro-cooperatively with her.
The above mechanisms may acquire control of behaviour if several criteria are satisfied: the state and/or opponent are clearly discernable; the game (i.e. its payoff matrix) is relatively static (or changes slowly) allowing equilibria to be reached; and your internal preferences are stable. However, habit mechanisms are less reliable in the face of perceptual uncertainty, in which case an internal belief model of possible states may be required; if there are sudden changes in the environment that require rapid new learning, or a search for causal antecedents; or if your motivational state changes substantially (cooperation for food becomes less valuable when you are sated). Note that there is no evidence that habit systems ‘switch off’ in situations in which they behave poorly, rather their influence on control diminishes when their predictions become unreliable (Daw et al., 2005
).
Although providing a plausible mechanism for social decision-making it turns out that, to date, evidence for habitised control of social behaviour is largely indirect. First, simple reinforcement learning algorithms do a remarkably good job at predicting behaviour in experiments across a variety of games (Erev and Roth, 1998
, 2007
). Second, neuroimaging studies show opponent-specific value-related responses accruing according to opponents’ cooperativity/competitiveness in games (Singer et al., 2004
). Third, neuroimaging studies have also identified dynamic reinforcement learning-like (prediction error) signals during games (King-Casas et al., 2005
). Fourth, in single neuron recordings from non-human primates, lateral inter-parietal sulcus neurons in monkeys appear to encode value signals predicted by reinforcement learning in mixed-strategy games (Seo et al., 2009
), which adds to previous observations that neurons in dorsolateral prefrontal and anterior cingulate cortex encode quantities related to choice and reinforcement history, respectively (Barraclough et al., 2004
; Seo and Lee, 2008
).
In reality, humans might be expected to habitise their actions in the context of state information that incorporates both opponent and game type. Although a diversity of subtly different payoff matrices may be common in experiments, it is likely that social interactions in different scenarios represent a relatively discrete set of payoff matrices. When there are small differences between different games, habit systems may generalise across salient features that have characteristic predictive power for beneficial outcomes.
One especially important social scenario arises when a person interacts with others who are significantly more expert at social interaction. This can occur for a number of reasons: if the payoff matrix that defines the interaction is unknown to us but known to others – either through their experience or private information; because information about other players is known to them but not to us – again through either experience or their own vicariously acquired knowledge; of if they are more sophisticated – for instance they are more mature or intellectually able. In these situations, you have the choice to engage in interactions and acquire the information directly through your own experience or, better, to observe apparently successful social agents and vicariously acquire knowledge.
As long as success is discernable, as a hallmark of social expertise, then observational learning is likely to yield useful information. The computational problem becomes how to interpret the actions of others, and use observed actions to optimise your own. Computationally, inverse reinforcement learning describes this problem of how to reverse engineer observed actions to evaluate their values and goals, and is particularly difficult in situations in which actions do not immediately lead to their benefits. Unfortunately social interactions often display exactly this property: the benefits of cooperation are often long-term, through reputation formation and establishment of trust, and unless an observer has observational access to extended sequences of actions and their ultimate outcomes, the problem becomes even harder.
In general, there are two broad classes of solution. The first is simply to imitate others (Price and Boutilier, 2003
). Imitation is the observational twin of habit learning, insofar as the resulting action has no specific representation of the outcome: it simply learns that a particular action is reliably performed in state s. The actions it bears are habit-like, elicited by a discriminative state that represents the environment in which they were learned. Accordingly, the ease of imitation depends on the discernability of the state of the observer. In Figure 3
A, we illustrate this for a situation in which the state is defined by the game type: as long as it is clear to the subject that they are playing, say Game y = Prisoners Dilemma, then the imitated action will be ‘cooperate when playing game y’. The imitated state-action pair could equally well be defined by the identity of the opponent. In this case, the resulting action will be ‘cooperate when playing opponent x’. Note that the values of the actions can also be inferred by the frequency with which they are elicited by observation, allowing imitation to encode action values, and not just stimulus-responses.
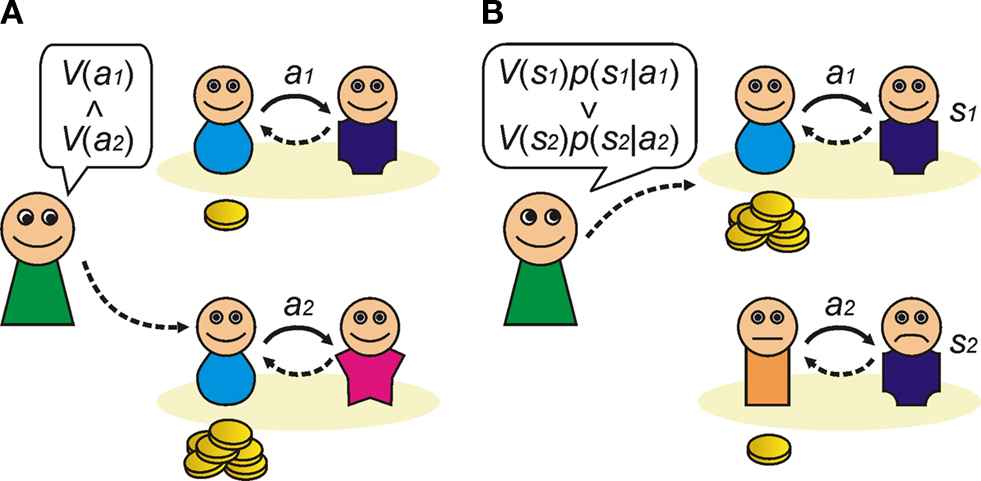
Figure 3. Observation learning of Prisoner’s dilemma. Observers learn the strategy from the observation of other players playing a game. (A) Imitation learning. An observer estimates the value of action a from other players’ actions and simply imitates an action which maximises the payoff in a particular environment, which can be defined by game or opponent (or both). Here we show an example in which the environment is ‘game = y’ and it does not take into account the opponent’s type (x) who they are playing with. (B) Inverse reinforcement learning. An observer estimates the players’ value from their actions, for example using subgoals. This means the observer assumes that the players using a model-based learning; i.e. they have a forward model of their opponents. For example, in a repeated Prisoner’s dilemma, cooperative actions (a1) will predict a state of the other players’ happiness (s1) which leads mutual cooperation in the future. The value of action a is calculated as the value of state (e.g. other player’s emotional state), V(s), multiplied by the probability of occurrence of the state followed by the action, p(s|a).
The second strategy is more complex, and involves trying to reverse engineer actions so as to evaluate their value or actual outcome (Ng and Russell, 2000
). This requires constructing some sort of internal model of the action. For sequential actions, a computationally useful strategy is to represent subgoals – intermediate outcome states that appear to be reliable pre-requisites to eventual success (Abbeel and Ng, 2004
). In the case of cooperative games, these subgoals ought to include the welfare of the other cooperators, since this is a powerful determinant of future cooperation. For example, in a repeated Prisoner’s dilemma, sophisticated cooperators will themselves predict reward when their opponents cooperate with them, since they have a forward model of future beneficial interactions. Assuming their reward-predicting state is discernable by observations of their emotional state s (their happiness), then this state becomes a statistically reliable subgoal. That is, it follows that the inference that eliciting the state of happiness in another player is a valid predictor of an agent’s success (Figure 3
B).
Although in the case of the agent being observed this is merely an intermediary state in ultimately selfish reciprocal interactions, this information (and its selfishness) is not available to the observer. Even so, it is still valuable knowledge as long as the observer is fortunate enough to use the information in situations in which it actually is beneficial: i.e. in repeated social exchanges. As long as repeated social exchanges outnumber un-repeated exchanges, then observational inference is likely to be a better strategy than ignoring others.
Observational learning in games, and especially putative inverse reinforcement learning, remains relatively under-explored. It is well known that humans use both model-free (imitative) and model-based (inverse-inference) strategies when learning non-social actions through observation (Heyes and Dawson, 1990
). Recent imaging evidence shows that people learn values through instruction using similar neural mechanisms involved in personal experience based learning (Behrens et al., 2008
), and make inferences about values by pure third-party observation (Klucharev et al., 2009
). Furthermore, pro-social feelings towards others (empathic reward), and it’s neural representation, have been shown to be modulated by perceived similarity with that person (Mobbs et al., 2009
), as one might predict from perspective-taking theories of social observation (Wolpert et al., 2003
).
We have argued that consideration of the neurobiological mechanisms of learning and decision-making in humans can yield an explanatory account of true altruism. At the heart of this account are the learning systems that allow the brain to optimise reward and efficiency in complex environments. Critically, since evolution is likely to operate primarily over learning and decision mechanisms, and not the content of those systems – how they learn, not what they learn, the ensuing altruistic behaviours are perfectly permissible, despite the fact that they may in some instances become strictly irrational. This is strengthened by the fact that habit-based and observational learning systems have uses way beyond social decision-making per se. The latter, for instance, is elegantly utilised in complex behaviours such as food preparation, tool use, and even language. Hence evolutionary selection for such mechanisms may be driven by a much broader range of decision-making problems than purely social interaction. Accordingly, such learning based accounts may offer both proximate and ultimate explanations for altruism.
The value of the inherent flexibility of learning systems is that it allows them to adapt to a wide range of potentially new and unexpected situations, appropriate for the diversity of the natural environment. But this flexibility carries the cost of inadvertently allowing individually economically disadvantageous actions to emerge, albeit rarely. However, we propose that on average these costs are heavily outweighed by benefits. Part of this supposition incorporates the fact that an innate representation of the caveats of flexible learning in social decision-making (for instance: don’t cooperate in one-shot, anonymous exchanges in large groups) is itself cripplingly complex and maladaptive to novelty (it itself becomes a form of impulsivity). In other words, any social decision-making system that attempted to capture the enormous range of possible encounters and interactions, and individually specify optimal policies, would impair rather than augment decision-making under uncertainty. As such, efficient learning based systems are likely to be selected in the course of evolution.
Learning based accounts differ from the conventional approach of studying cooperation in behavioural economics, which often considers static, heuristic decision-policies, such as ‘tit-for-tat’, ‘cooperate and punish’, and ‘free-ride’. Such models typically succumb to free-riders, including sophisticated (higher-order) free-riders that cooperate but don’t enforce or encourage cooperation in others. However, a valuable insight of these models has been the recognition that resistance to free-riders can be provided by acquisition (and defence) of cultural norms of behaviour (Boyd and Richerson, 1988
; Boyd et al., 2003
; Bowles and Gintis, 2004
). Key underlying components of norm-abidance are likely to be observational learning and inference based mechanisms, since these form simple elements of cultural learning. The current paucity of biologically implemented algorithmic models and mechanisms of observational and cultural learning is therefore likely to be an important area of future research. In particular, the relative privacy of culturally acquired information within specific groups is likely to be an important factor in the development of parochialism, which may further allow group-based selection of altruistic behaviour (Bernhard et al., 2006
; Choi and Bowles, 2007
).
Learning based accounts do not negate innate mechanisms of altruism in the brain. Such mechanisms are thought to underlie many aspects of human impulsivity and irrationality, through their occasionally inflexible competition with instrumental actions (Dayan et al., 2006
). If cooperation was so consistently advantageous through human social evolution, that it is quite possible there might be some innate coding. Indeed, the environment in which the social brain evolved is likely to have had a much higher proportion of repeated interactions with the same individuals than our modern environment in which cooperation can occasionally be economically disadvantageous. Innate actions can be thought of as action priors over and above which more sophisticated goal-directed instrumental actions can assume control as experience accrues. Their Achilles heel, however, is the fact that they appear often difficult to overcome (inhibit) completely: they have a residual and significant weight that consistently biases actions in their favour. If such innate coding of cooperation exists in the human brain, then it follows that altruism would be akin to more basic forms of impulsivity.
We note that control by innate systems is characterised by the intrinsic (typically ‘emotional’) value of a stimulus, as well as by the action it elicits. Accordingly, the states associated with putatively pro-social innate actions could include that following the act of sharing, generosity or generation of equity (Tomasello et al., 2005
). In this way, they become intrinsic internal rewards that, phenomenologically, are elicited because they are personally satisfying (and akin to non-social innate behaviours such as novelty-seeking (Wittmann et al., 2008
)).
The complexity of different putative accounts of human altruism appeals to neuroscience as an arbitrator (Camerer et al., 2004b
). Distinguishing different decision systems purely on anatomical grounds may be difficult, however: brain regions such as the striatum, orbitofrontal cortex, amygdala and hippocampus for instance, appear to be convergence areas for all decision systems. For example the observation of activation of striatum in a study on altruistic punishment (de Quervain et al., 2004
), whilst providing a convincing illustration of the fact that such behaviour has a clear proximate basis, says little about the nature of that behaviour in terms of whether it is innate or learned. This underlines the importance for brain imaging techniques that have the ability to distinguish between competing models based on identifying coding of their underlying central parameters (O’Doherty et al., 2007
), in situations in which behaviour alone is necessarily ambiguous (Yoshida et al., 2008
).
Both habit-based and observation-based accounts of pro-social behaviour make specific experimental predictions. First, if the identities of others can act as discriminative stimuli, then cooperation should carry over between different games with the same individual. Second, if game types can act as discriminative stimuli, then cooperation should carry over between the same game with different individuals. Third, the duration of play should predict the degree of unfolding of cooperation towards the end of repeated games, since extended durations permit stronger habit formation and less susceptibility to anticipatory defection. Fourth, the operation of associative learning mechanisms should be determinable by the use of co-incident cues associated with previous cooperative or uncooperative players, which ought to bias individuals behaviour in future games: in fact evidence already exists for this (Vlaev and Chater, 2006
; Chater et al., 2008
). Fifth, observational learning can be studied directly by allowing individuals to passively watch interactions between others before engaging in similar games, or different games with the observed opponents. Indeed evidence does exist that previous observation has an influence on future social behaviour, in that people do seem to be biased towards the behaviour of others. What is more difficult to establish is exactly how this information is represented: either as a cached imitated value, or as a model-based representation.
Finally, we note that learning based accounts of altruism are by no means immune to exploitation by selfish and intelligent learning agents. Any sophisticated model of other agents’ behaviour can incorporate the fact that they are habit and observational learners. Consequently, highly sophisticated models of other agents could in theory incorporate representations of their different decision systems: thus knowing that people are habit learners gives predictive insight into what is likely to guide their behaviour in various situations. Whereas determining this might not always be simple to an agent from passive observation, it might be in part revealed by probing: intentionally behaving in a certain way (such as maliciously cultivating pro-social cultures) to manipulate how values are acquired by others, so that they can be exploited later.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.