 Frontiers Production Office
Frontiers Production OfficeA Correction on
Optimizing architectural-feature tradeoffs in Arabic automatic short answer grading: comparative analysis of fine-tuned AraBERTv2 models
by Mahmood, S. A. (2025). Front. Comput. Sci. 7:1683272. doi: 10.3389/fcomp.2025.1683272
There was a mistake in the article as published. Tables 1–7 and Figures 1–8 were published as supplementary material when they should have been added to the main article. The corrected figures and tables appear below.

Table 1. Distribution of answers by question type.

Table 2. Detailed distribution of randomly sampled responses across selected questions.

Table 3. Performance evaluation of AraBERTv2 with MLP model using different feature sets: training vs. testing results.
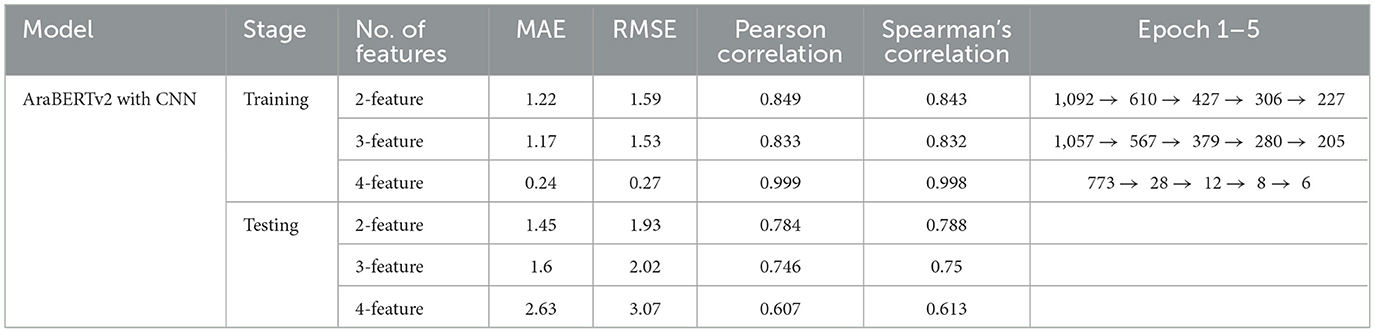
Table 4. Performance evaluation of AraBERTv2 with CNN model using different feature sets: training vs. testing results.
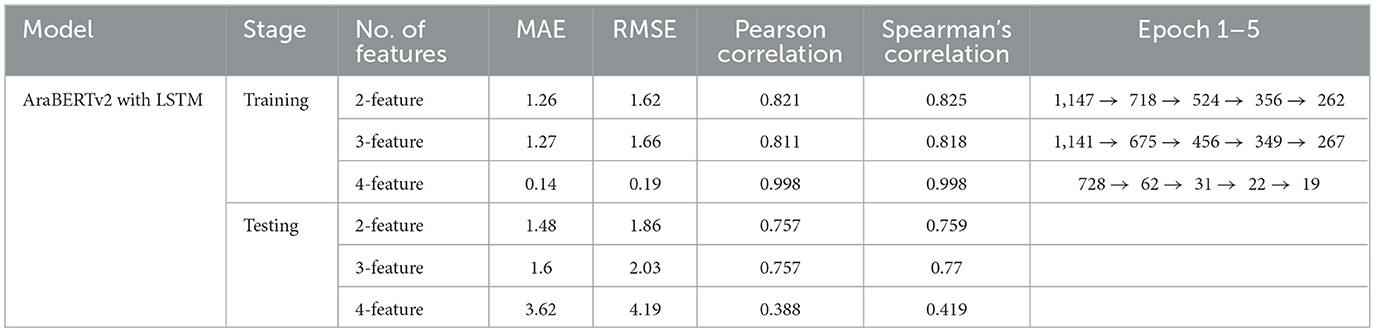
Table 5. Performance evaluation of AraBERTv2 with LSTM model using different feature sets: training vs. testing results.
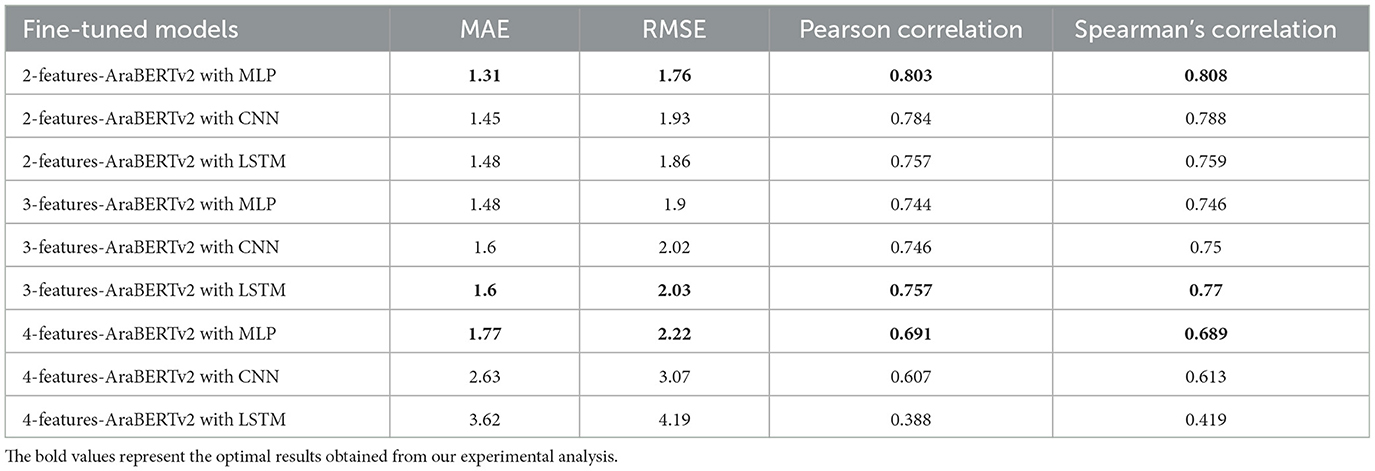
Table 6. Performance comparison of AraBERTv2 fine-tuned models with MLP, CNN, and LSTM architectures using different feature sets.
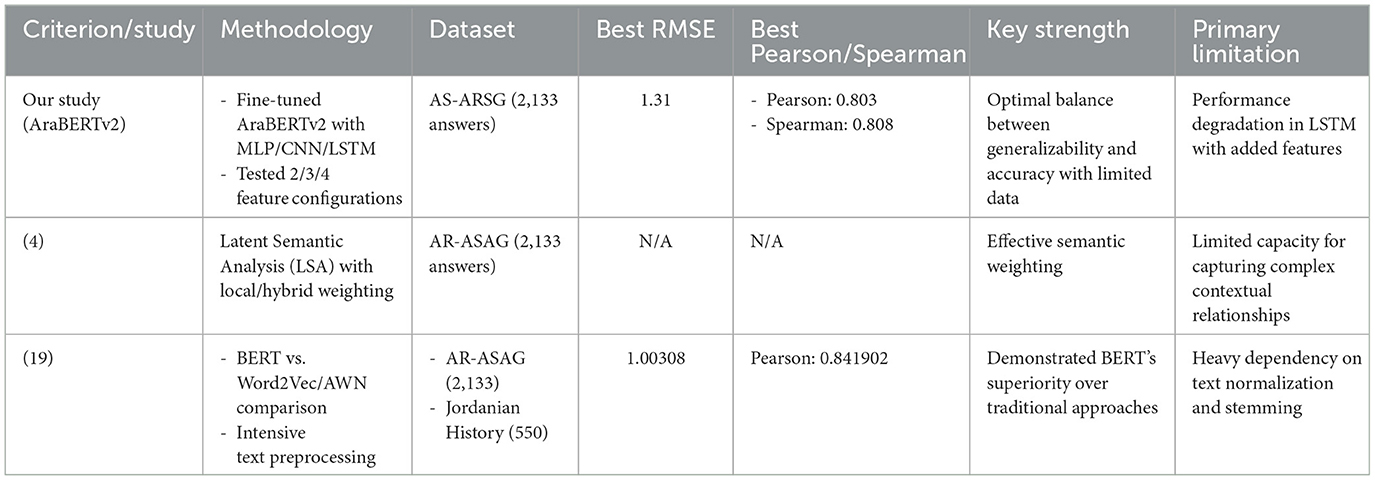
Table 7. Comparative performance evaluation of Arabic Automated Short Answer Grading (ASAG) systems.

Figure 1. General workflow of the proposed automated Arabic short-answer grading model using AraBERTv2.
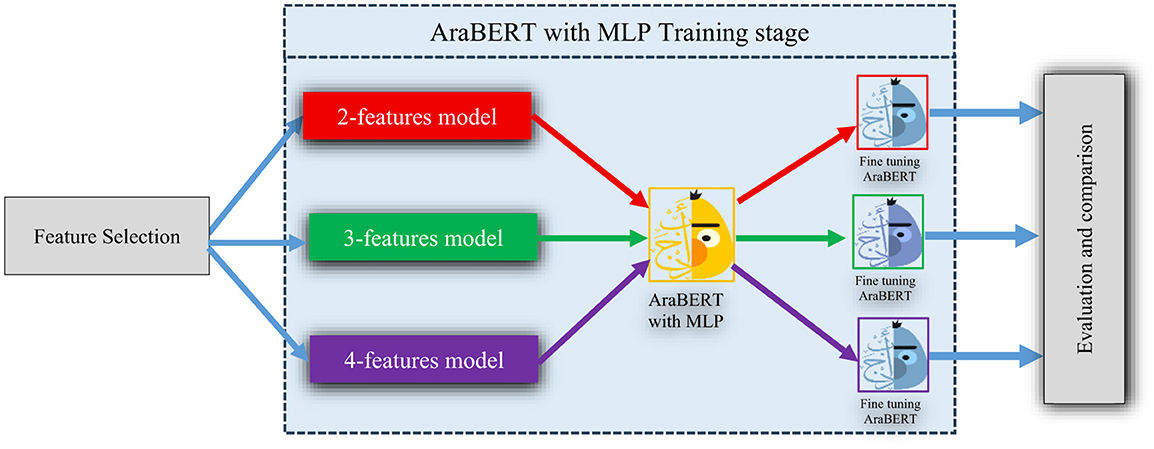
Figure 2. The AraBERT_MLP training methodology.

Figure 3. The AraBERT_CNN training methodology.

Figure 4. The AraBERT_LSTM training methodology.
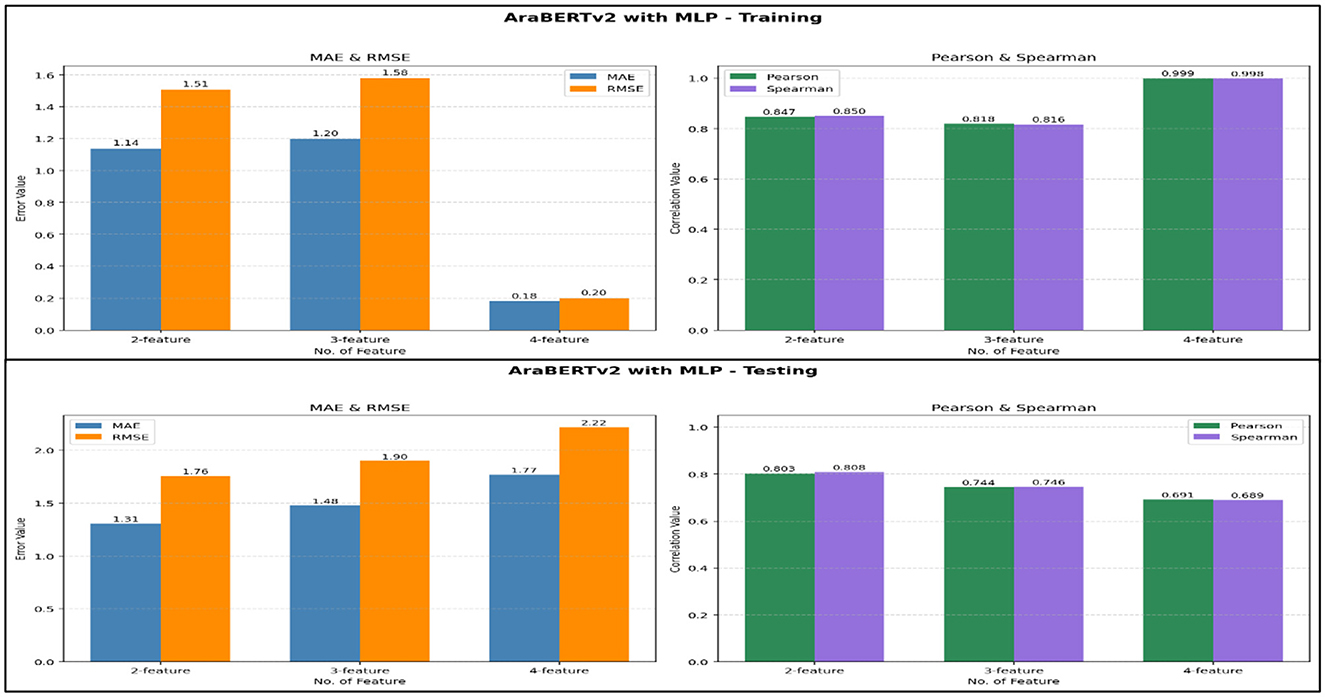
Figure 5. Performance evaluation of AraBERTv2 with MLP model using different feature sets: training vs. testing results.
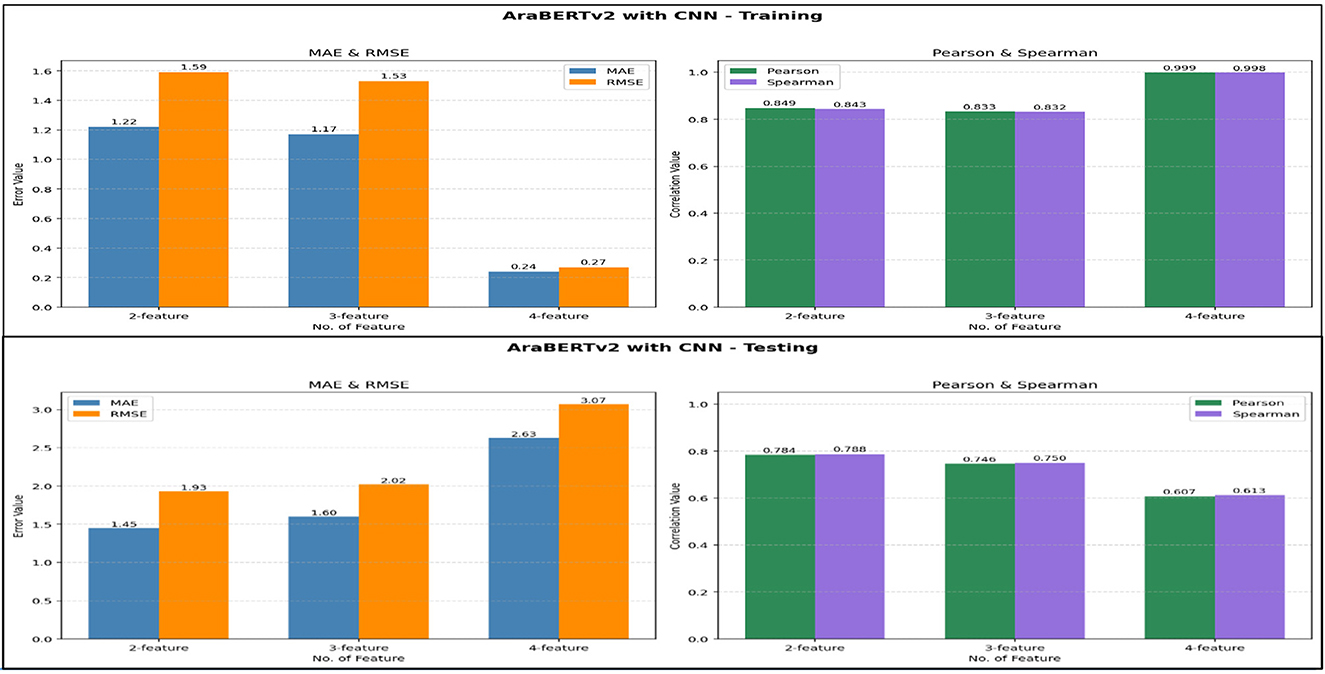
Figure 6. Performance evaluation of AraBERTv2 with CNN model using different feature sets: training vs. testing results.
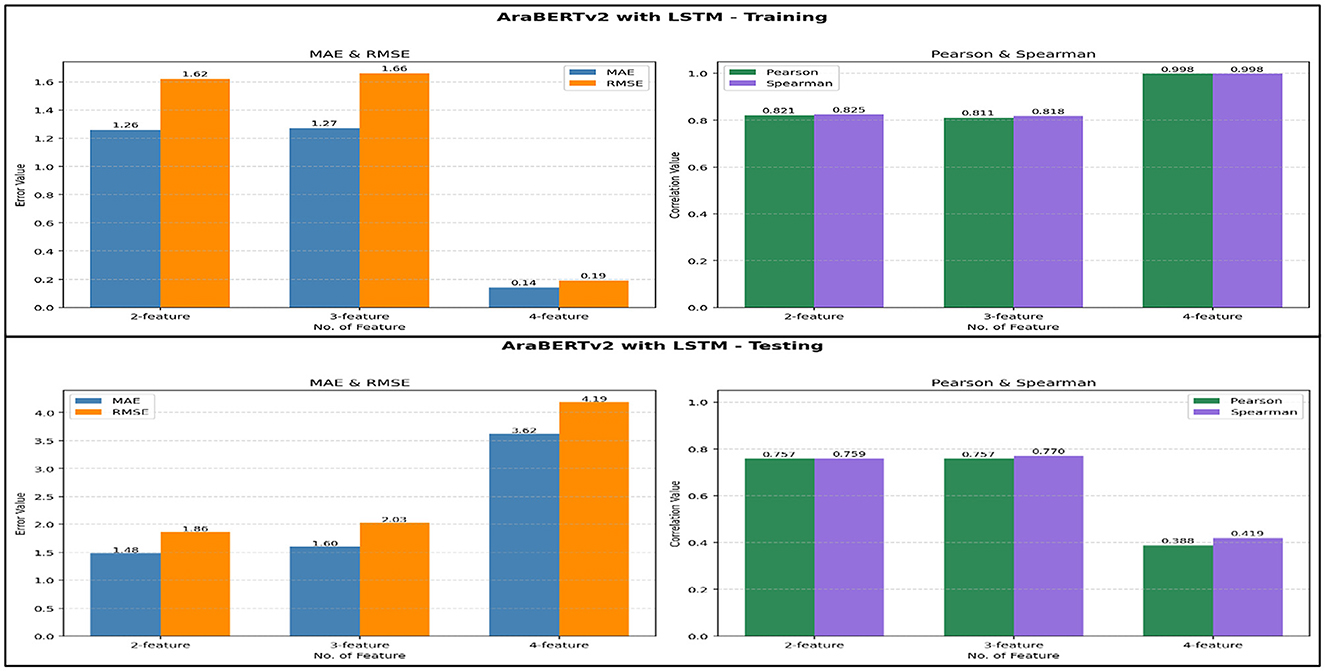
Figure 7. Performance evaluation of AraBERTv2 with LSTM model using different feature sets: training vs. testing results.

Figure 8. Fine-tuned models performance: MAE vs. spearman correlation.
All in-text Supplementary Table and Supplementary Figure in-text citations have been changed to Table and Figure in-text citations.
The original version of this article has been updated.
Generative AI statement
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Keywords: large language model (LLMs), AraBERT, neural network, Arabic natural language processing, educational assessment, Automated Short Answer Grading (ASAG)
Citation: Frontiers Production Office (2025) Correction: Optimizing architectural-feature tradeoffs in Arabic automatic short answer grading: comparative analysis of fine-tuned AraBERTv2 models. Front. Comput. Sci. 7:1734114. doi: 10.3389/fcomp.2025.1734114
Received: 28 October 2025; Accepted: 28 October 2025;
Published: 12 November 2025.
Approved by:
Frontiers Editorial Office, Frontiers Media SA, SwitzerlandCopyright © 2025 Frontiers Production Office. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Frontiers Production Office, cHJvZHVjdGlvbi5vZmZpY2VAZnJvbnRpZXJzaW4ub3Jn