 Ke Lian1
Ke Lian1 Wenyao Zhu
Wenyao Zhu Hui Wang
Hui Wang- 1Department Shanxi Bethune Hospital, Shanxi Academy of Medical Sciences, Tongji Shanxi Hospital, Third Hospital of Shanxi Medical University, Taiyuan, China
- 2Department of Radiotherapy, The Affiliated Yantai Yuhuangding Hospital of Qingdao University, Yantai, China
- 3Department of Cancer Prevention and Control, Shanxi Province Cancer Hospital Shanxi Hospital Affiliated to Cancer Hospital, Chinese Academy of Medical Sciences Cancer Hospital Affiliated to Shanxi Medical University, Taiyuan, China
- 4Department of Oncology, Houma People’s Hospital, Houma, Shanxi, China
- 5School of Data Sciences, Zhejiang University of Finance and Economics, Hangzhou, China
Objective: The objective of this study is to evaluate the incidence, prognostic value, and risk factors of progression of disease within 12 months (POD12) in patients with diffuse large B-cell lymphoma (DLBCL).
Methods: A retrospective analysis of the clinical, pathological, and follow-up data was carried out on 69 DLBCL cases in Shanxi Bethune Hospital from January 2016 to June 2020. One-way ANOVA and multivariate Cox regression analysis were used to explore the correlation between POD12 and prognosis, and logistic regression analysis was used to explore the risk factors of POD12, accompanied by prediction models based on convolutional neural networks and long short-term memory (CNN-LSTM), as well as particle swarm optimization and general regression neural network (PSO-GRNN) models.
Results: (1) POD12 is significantly correlated with PFS (p< 0.001) and OS (p = 0.008). (2) From the univariate logistic regression analysis corrected by the first-line chemotherapy regimen, LDH, β2-MG, stage, ECOG, NLR, and SII are identified as risk factors for POD12 (p< 0.1), while β2-MG and ECOG are identified as independent risk factors from the multivariate logistic regression analysis (p< 0.05). (3) A prediction model for POD12 is established based on LDH, β2-MG, stage, ECOG, NLR, and SII. The AUC is 0.846 (95% CI: 0.749~0.944, p< 0.001), suggesting that the model is reasonable. A prediction method for the characteristic variables of POD12 risk is proposed using the CNN-LSTM deep learning model based on chaotic time series. Comparatively, the CNN-LSTM and PSO-GRNN models are the most suitable to predict the risk level of the POD12 in the future.
1 Introduction
Diffuse large B-cell lymphoma (DLBCL) is a type of hematological malignancy with high heterogeneity in biological characteristics, clinical manifestations, and prognosis, which is influenced by many factors. Although more than 60% of patients can achieve a complete cure or long-term survival by the first-line standard immunochemotherapy, a large number of patients still eventually die due to disease recurrence or treatment resistance (1, 2).
Many recent investigations (3, 4) have found that, among DLBCL patients receiving first-line antitumor therapy, disease progression within 12 months after diagnosis (POD12) is a significant adverse prognostic factor, and these patients may not even benefit from rescue treatment combined with autologous hematopoietic stem cell transplantation (AHSCT). Therefore, it is necessary to provide personalized therapy beyond standard immunochemotherapy based on the first-line treatment to improve patient survival, and it is crucial to identify such patients effectively at an early stage.
In addition, since POD12 can only be evaluated after treatment, it cannot be used to guide decision-making in previously untreated patients, which limits its clinical value. Therefore, how to predict POD12 is an urgent problem to be solved. However, at present, there are few investigations on the predictive factors of POD12 (4), and thus, no effective prediction tools or methods for POD12 are available in the clinic.
The objective of this study is to evaluate the prognostic values and risk factors of POD12 through cohort analysis, and to further establish a clinical prediction model of POD12 to provide a theoretical basis for accurate prognostic stratification and personalized therapy for DLBCL.
2 Materials and methods
2.1 Case data
A retrospective analysis was carried out on 69 DLBCL cases, of which 6 were lost and 63 were complete, in Shanxi Bethune Hospital from January 2016 to June 2020. Inclusion criteria: DLBCL diagnosed and graded by the latest diagnostic standards of the World Health Organization (WHO) in 2008, and first-line chemotherapy, and complete medical records and follow-up data. Exclusion criteria: (1) Double-hit or triple-hit patients confirmed by the fluorescence in situ hybridization (FISH) detection in the pathological tissues; (2) Patients with other malignant tumors; (3) Those who lost follow-up or died without POD12 after diagnosis. The intact DLBCL paraffin tissue preserved in the pathology department was collected and consecutively sectioned into 4μm thickness for immunohistochemical detection. The clinical data of patients were collected, including the sexual distinction, age, clinical stage, ECOG score, absolute value of neutrophils and lymphocytes, platelet and hemoglobin levels, etc. The values of the neutrophil to lymphocyte ratio (NLR), platelet-to-lymphocyte ratio (PLR), lymphocyte to monocyte ratio (LMR), and systemic immune-inflammatory index (SII) were calculated, and the corresponding optimal cutoff values were obtained according to the ROC curve.
2.2 Methods
2.2.1 Immunohistochemistry
The antibodies, such as Myc, Bcl-2, Bcl-6, CD10, MUM-1, Ki-67, and P53, were all purchased from Beijing Zhongshan Jinqiao Biotechnology Co. Ltd. (Beijing, China) and the secondary antibody reagents were obtained from Ventana Medical Systems (Rotkreuz, Switzerland). The EnVision two-step method was employed using the Roche BenchMark XT automatic immunohistochemical instrument. Myc protein was localized in the nucleus and, based on the percentage of positive cells, was graded as follows: grade 0 (0), grade 1 (1%~25%), grade 2 (26%~50%), grade 3 (51%~75%), and grade 4 (76%~100%), respectively (8). Bcl-2 positivity is defined as the presence of tumor cells (≥ 50%) with brownish-yellow particles in the cytoplasm and membrane, while Bcl-6 positivity is defined as the presence of brownish-yellow particles (≥ 50%) in the nuclei (5, 6). When the percentage of tumor cells with the brownish-yellow granules in the cytoplasm or nuclei is more than 30%, the positive expression of CD10 or MUM-1 is confirmed. Based on the number of P53-positive cells in the nuclei, expression is graded as follows: 0 (no positive cells), grade 1 (≤ 5%), grade 2 (6%~10%), grade 3 (11%~40%), grade 4 (≥ 41%), respectively, and grades 2~4 are considered the overexpression (7). In addition, the immunohistochemical results of Myc, Bcl-2, CD10, Bcl-6, and MUM-1 proteins were analyzed using the Hans method (9), and the germinal center B (GCB) and non-GCB subtypes were determined according to the COO types.
2.2.2 FISH method
The tumor area was selected based on HE staining, using C-Myc, Bcl-2, and Bcl-6 gene break-apart probes purchased from Guangzhou Anbiping Pharmaceutical Technology Co. Ltd. (Guangzhou, China). More than 100 nuclear signals of tumors were recorded under high-power magnification (× 100) with a Zeiss Axioimager fluorescence microscope. Each probe consists of a red fluorescent and a green fluorescent component. In normal cells, two yellow fusion signals or adjacent red and green signals are observed. In cases of gene translocation, a separation between the yellow with red signals is observed. When the ratio of the separated signal exceeds 10%, the result is considered positive. If more than three yellow fusion signals are present in the same nucleus, it is regarded as a gene duplication.
2.2.3 Follow-up
Telephone and outpatient inquiries were the main follow-up method, and follow-up continued until 31 December 2021. The follow-up period was from the time of diagnosis to the end of follow-up or the date of death. POD12 refers to recurrence or progression within 12 months after diagnosis (3, 4). To accurately observe and compare the effect of POD12 on the subsequent survival of DLBCL patients, the prognostic value of POD12 was verified. The definition of overall survival (OS) in this study is consistent with other relevant studies (3, 4), referring to the interval from 1 year after diagnosis (non-POD12 group) or the date of POD determination (POD group) to the patient’s death or the last follow-up.
2.3 Statistical analysis
SPSS 24.0 software was used for the statistical analysis. One-way analysis of variance (ANOVA) and multivariate Cox regression analysis were used to explore the correlation between POD12 and the prognosis of DLBCL. Univariate and multivariate logistic regression analyses were used to explore the risk factors of POD12. The calculation method of model prediction accuracy was defined as the ratio of the total number of true-negative and true-positive patients to the total number of patients. The calculation method of model prediction accuracy is confirmed.
3 Deep learning prediction model of CNN-LSTM and PSO-GRNN
3.1 Prediction of the POD12 state parameters based on the phase space reconstruction
Aiming at the chaos of the characteristic variables of POD12, the time series data were first reconstructed, and two parameters of the reconstructed phase space were obtained, namely the embedding dimension (m), calculated by the false nearest-neighbor (FNN) method, and the latency [delay time (τ)], by the mutual information method, to restore the original space. The values of m and τ were then taken as the input items for the CNN model to extract the sequence of spatial features, and the state of the POD12 characteristic variable at time t could be predicted using the LSTM model (see Figure 1).
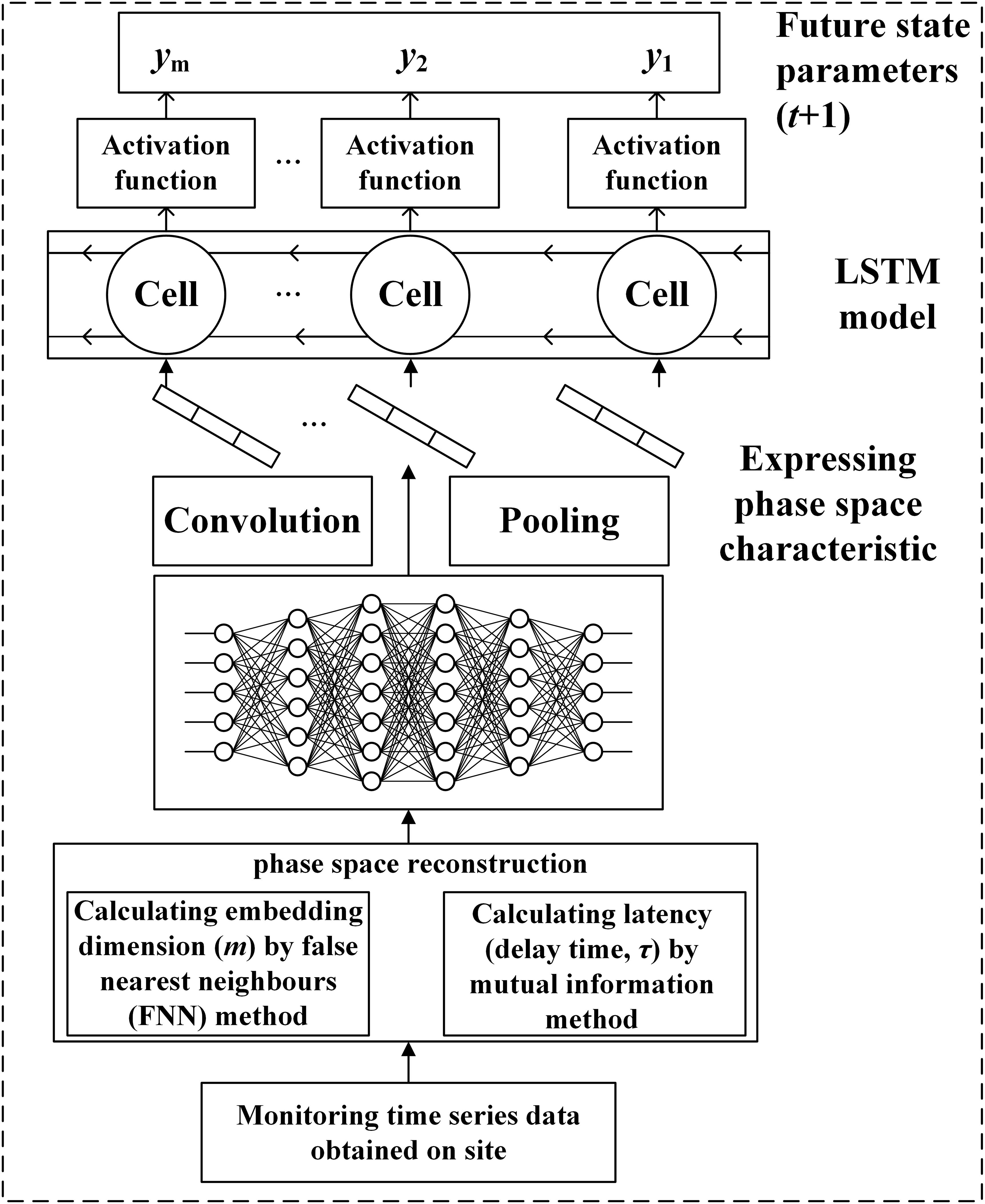
Figure 1. Prediction flowchart of the future state using the CNN-LSTM model.
3.2 Phase space reconstruction of characteristic variables of POD12
The monitoring time series data exhibit obvious chaotic characteristics. To restore the original space, it is necessary to calculate the embedding dimension (m) and latency (τ) variables of the phase space for the reconstructed POD12 state. Based on chaos theory, the delay time was calculated using the mutual information method, and the embedding dimension was determined using the false nearest-neighbor method. The phase spaces of the original monitoring data were then reconstructed using these parameters to restore their real spaces. According to the embedding theorem, for the monitoring time-series data (i = 1, 2,ċ, I; where I is the number of characteristic variables and N is the length of the time series), the reconstruction space state of the ith characteristic variable could be expressed as Equation 1
Where Xi,n denotes the phase space of the ith characteristic variable, and Xi is a point in the phase space of the ith characteristic variable. mi and τi are the embedding dimension and delay time of the ith characteristic variable, with n∈[1, 2, …, N]. The dimension number (m) of the state space formed by Xn could be expressed as Equation 2:
After the phase space reconstruction, there is a mapping function G: Rm → Rm, subject to Equation 3
Or there is a mapping function Gi: Rm → R, subject to Equation 4
Where l denotes the number of the prediction steps. In other words, the state of the time series Xn + l (i.e., the next l steps) can be predicted based on the reconstructed state variable.
3.3 Prediction of POD12 characteristics based on the CNN-LSTM model
CNN is used to extract the spatial characteristics of the reconstructed phase space. CNN is a model that performs convolution operations within a deep network and has strong expressive ability for spatial data. It is well known that the occurrence of POD12 is not only a gradual process of incubation and evolution but also a nonlinear dynamic process. To further describe this nonlinear process, LSTM is used to predict the characteristic quantity of POD12. LSTM can dynamically memorize historical information and has been widely used. By using LSTM to learn new information from the original POD12 monitoring data while maintaining the status of the historical information of the monitoring data, the new information from the original POD12 monitoring data could be fully learned, and the status of the historical information of the monitoring data could be completely remembered by using LSTM.
The LSTM repeated module is composed of three activation function gates (i.e., forget gate (σ1), input gate (σ2), and output gate (σ3)) and two tanh activation functions regarding the output, as shown in Figure 2. The bullet symbol (·) represents the concatenation operation, and the π and Σ symbols represent element-wise multiplication and addition, respectively. The fundamental component of LSTM is the cell state, where a line comes from the previous block memory (St − 1) and connects to the current block memory (St). Afterward, the flow of information straight down the line is allowed. In other words, the forgetting part of the memory in the cell state is determined by the input of the cell state at the previous time point in the forget gate, the memory, and the intermediate output of the cell state. The data to be added to the cell state are adjusted by the sigmoid function, and the intermediate output is determined by the updated memory cell state and the output. In this work, the characteristic sequence of the phase space extracted and reconstructed by CNN was modeled using an LSTM model. By learning the characteristic time series, the nonlinear process of POD12 evolution is represented, the future state of POD12 (i.e., at time t + 1) is predicted more accurately, and the risk level of POD12 is evaluated according to the future state of the POD12 characteristic variables.
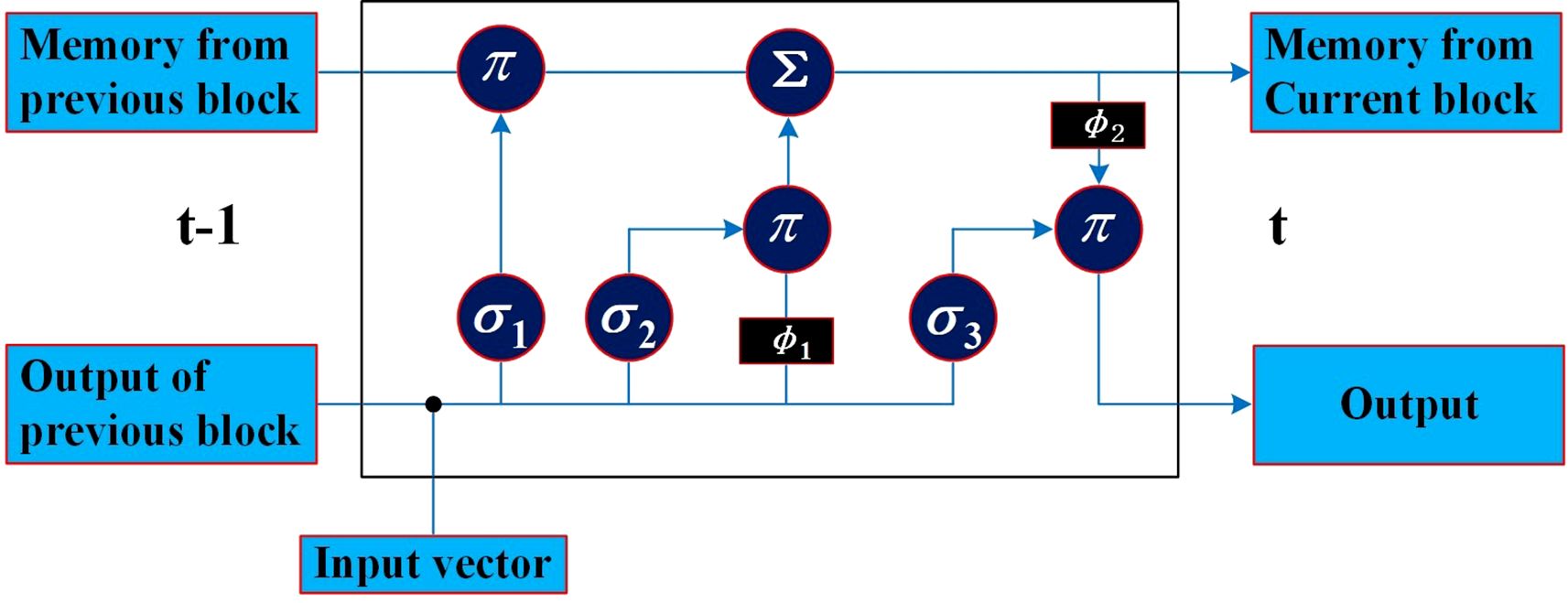
Figure 2. LSTM repeating module.
The CNN-LSTM model consists of the CNN and LSTM parts. The former is used to express and extract the spatial feature information of the reconstructed phase space as the input of LSTM, while the latter is used to receive the output of the CNN-extracted information and use its memory characteristics in the time series to accurately extract time-series features. Thus, the future POD12 state could be predicted. The main process of predicting the future state variables of the POD12 characteristics with the CNN-LSTM model is as follows.
(1) In the CNN part, the reconstructed phase space state represented by a two-dimensional matrix is taken as the input. In this matrix, the “row” represents the reconstructed phase space point with a length of m, and the “column” represents the length of the time series. This two-dimensional matrix is input to the CNN, and the high-dimensional characteristic information is then extracted using the convolution function H(x), as shown in Equation 5. After the important characteristics are selected through the pooling layer, the input is transformed into a one-dimensional vector by the flatten layer, and thus, the time series with high-dimensional characteristic information is output.
Where f and g are integrable functions, and x and u are the variables within them.
(2) In the LSTM part, the output time series from the CNN is used as the input. A traditional recurrent neural network (RNN) is prone to gradient disappearance or explosion when handling long sequences. To overcome these problems caused by long-term memory, a gating mechanism is introduced into LSTM, which greatly improves the ability of the data expression for RNN. In general, the characteristic time series are predicted using a single-layer structure in LSTM. During model training, unreasonable training data often lead to overfitting. The L2 parametric regularization method (weight loss) can be used to mitigate this to some extent. In this method, a regularization item is added to the objective function to bring it closer to the origin by attenuating the weight. The weight loss function of the optimization objective can be expressed as Equation 6:
Where λ is the hyperparameter and W is the hyperlink weight of the neural network.
(3) CNN-LSTM model training. Firstly, the dataset is divided into training and test sets. Next, the hyperparameters (i.e., epoch data and loss functions) and the optimizer are set, including parameters such as weight and learning rate. Finally, the LSTM model is trained by using the training data to extract the temporal features of the reconstructed phase space data.
(4) After the CNN-LSTM model is successfully trained, the test set is input to obtain the prediction results.
(5) The accuracy of the prediction results in step (4) is evaluated. If the accuracy meets the predefined threshold, step (6) is proceeded; otherwise, step (3) is returned to, and training is continued until the model converges.
(6) The evolution state value of the POD12 at time t + 1 is predicted by using the above model trained perfectly.
The prediction process of the risk level for POD12 includes two steps. (1) Quantitative discrimination of the risk level of POD12—that is, the discrimination of the risk level of POD12 at the time of t + 1. Firstly, the future state values of the characteristic variables obtained by the CNN-LSTM model (i.e., the state values of the POD12 characteristic variables at the time of t + 1) are taken as the input. Based on the PSO-GRNN model, the risk level of POD12 at the time of t + 1 is then obtained by the regression method. (2) Prediction of the risk level of POD12 in the future. To predict the POD12 risk level of the test set based on the monitoring variables, the test set data are used as input variables to obtain the future state value of the POD12 risk level of the test set. At the same time, this serves as a comparative experiment to verify the effectiveness of the method in predicting the future risk level of POD12.
GRNN is an artificial neural network that uses the radial basis function as its activation function. Compared with the backpropagation (BP) neural network, it has stronger approximation and learning capabilities. Even with a small sample size, it can effectively identify the risk index of POD12. The purpose of introducing the PSO algorithm is to obtain a more stable regression prediction model. If the smoothing factor of the GRNN model is selected manually, issues such as low efficiency and reduced accuracy may arise. The determination of the smoothing factor is essentially an optimization problem—that is, by finding an optimal smoothing factor, the mean square deviation between the output values and the actual values of the training sample is minimized. By this method, the best smoothing factor can be obtained.
PSO is an intelligent algorithm inspired by the cooperative behavior of birds searching for food. Compared with the classical genetic algorithm, it can converge to the optimal solution faster. Assuming that the solution to the objective optimization problem is a d-dimensional vector and each particle in the swarm represents a possible solution, each possible solution can be evaluated by calculating the fitness of each particle in the swarm. This allows the identification of a particle Lbest that contains the optimal solution in the d-dimensional space. Thus, the problem of determining the smoothing factor can be transformed into finding Lbest using the PSO algorithm.
Assuming that N particles are randomly scattered in d-dimensional space and their positions are Li = (lb1, lb2, ···, lbd) (i =1, 2, ···, n), Li is substituted into the function F(L) to calculate its fitness Fi. Based on the fitness values, the optimal positions of the ith particle and all particles in the swarm are obtained, denoted as Pid = (Pi1, Pi2, ···, Pid) and Gb = (Pg1, Pg2, ···, Pgd) (g = 1, 2, ···, N), respectively. In this way, each particle updates its individual position based on the current position Li, the optimal position Pid found by itself, and the optimal position Pgd found in the whole particle swarm.
In the initial operation, a large flight speed is necessary for the PSO algorithm to avoid being trapped in a local optimal solution. However, when the particle swarm approaches the optimal solution, the particle flying speed should not be too large as the number of iterations increases. Otherwise, it will be difficult for the particles to accurately converge on the optimal solution. To reduce fluctuations near the optimal solution, it is necessary to introduce an adaptive inertia factor w. As the number of iterations increases, the adaptive inertia factor w gradually decreases, which means that the particle flight speed decreases—ensuring the optimal smoothing factor and ultimately yielding more accurate prediction results. These relationships are described by Equations 7–9.
Where is the velocity vector of particle i when the kth particle swarm is searching for the “food”; C1 and C2 are learning factors; r1 and r2 are random numbers in the (0,1) interval; and w is the inertia factor. Wmax and Wmin are the upper and lower bounds of the inertia factor, respectively. I and Imax are the current number and maximum iteration numbers, respectively. Once the model reaches the iteration criterion, the optimal solution is obtained.
4 Results and discussion
4.1 General characteristics
4.1.1 Clinical features
There are 63 patients, including 29 men and 34 women. The median age is approximately 67 years (21~89), with 44 (69.8%) patients over 60 years old. There are 18 cases (28.6%) of Ann Arbor stages I~II and 45 cases (71.4%) at stages III~IV; 16 cases (25.4%) presented with B symptoms; 29 cases (46%) had an ECOG score of ≥ 2; 24 cases (38%) had extranodal involvement at more than two sites; 12 cases (19%) had large masses (> 7.5 cm); 31 cases (49.2%) had β2-MG values exceeding the normal upper limit; 30 cases (47.6%) had elevated lactate dehydrogenase (LDH) values (or levels); 50 cases (79.4%) had serum albumin values< 40 g/L; 0 case had ALT values above the normal upper limit; five cases (7.9%) had elevated AST values; and two cases (3.2%) had elevated ALP values (exceeding the normal upper limit). A total of 53 patients (84.1%) received rituximab combined with chemotherapy, while 10 cases (15.9%) received chemotherapy alone.
In addition, this study employed Youden’s index to determine the optimal cut-off values for NLR, PLR, LMR, and SII. Youden’s index serves as a diagnostic performance metric for evaluating the ability of a screening method to distinguish between true patients and nonpatients. It is computed by subtracting (1 − specificity) from sensitivity, and the test variable value corresponding to its maximum represents the diagnostic threshold for that particular method. Furthermore, ROC curves for NLR, PLR, LMR, and SII were plotted separately using the occurrence of POD12 as the study endpoint (Figure 3). The sensitivity and specificity values corresponding to the maximum Youden’s index for these curves were (0.483, 0.853), (0.897, 0.382), (0.862, 0.412), and (0.345, 0.794), respectively. By integrating the actual clinical values from 63 patients, the optimal cut-off values were further determined to be 1.73, 306.494, 4.867, and 304.2, respectively.
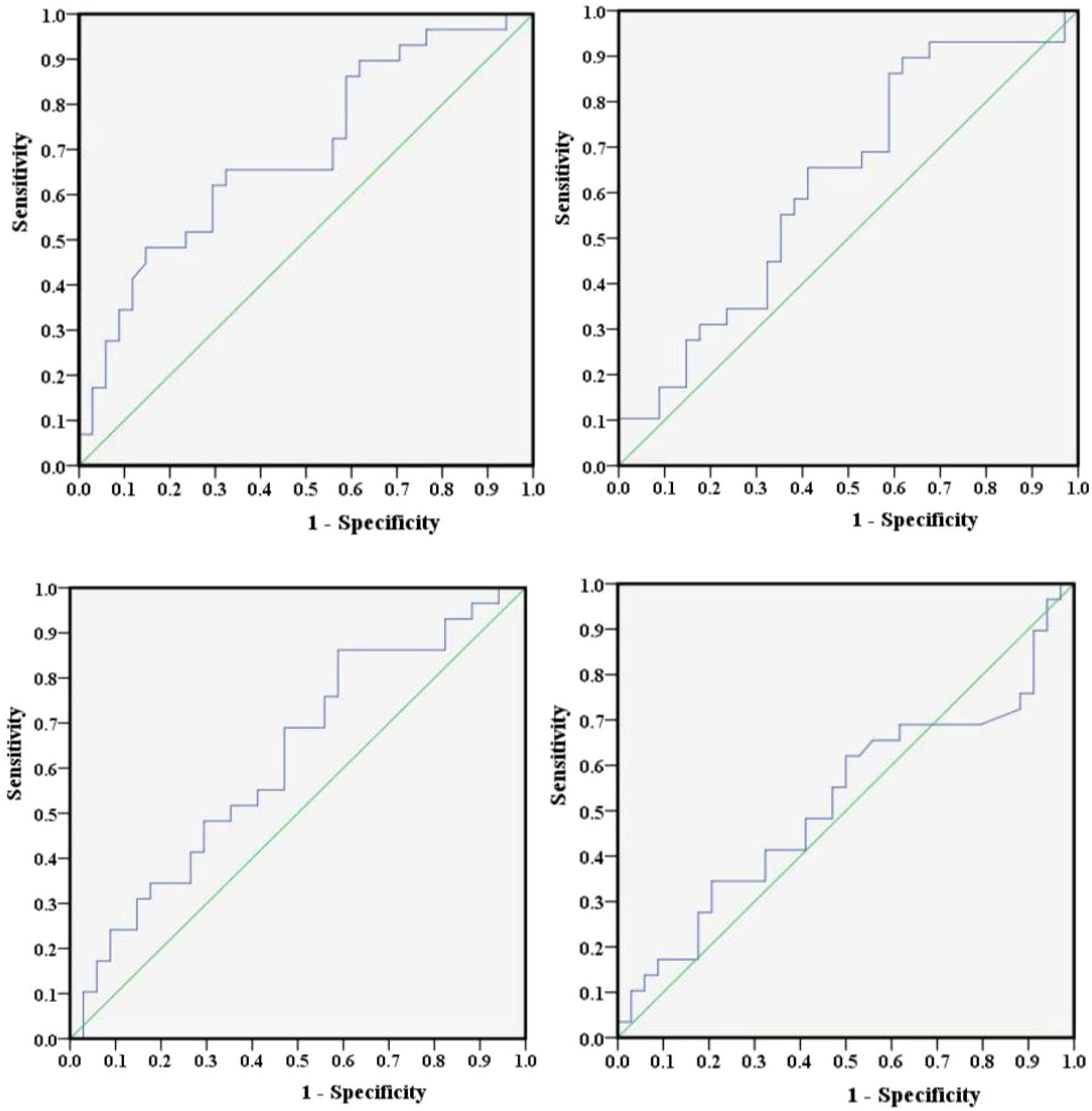
Figure 3. ROC curves of NLR, PLR, LMR, and SII.
4.1.2 Pathological characteristics
Among 63 patients, 21 (33.3%) cases had pathological GCB and 42 (66.7%) cases had non-GCB; 26 cases (41.3%) were Myc positive (grades 3–4); 47 cases (69.3%) were Bcl-2 positive (≥ 50%); and 45 cases (71.4%) were Bcl-6 positive (≥ 50%). There were 12 cases (19%) of P53 expression with grades 1~2 and 51 cases (81%) with grades 3~4. Based on FISH testing, three cases (4.8%) were Myc positive, 0 cases (0%) were Bcl-2 positive, and six cases (9.5%) were Bcl-6 positive.
4.2 POD12 and its relationship with prognosis in patients with DLBCL
Prior to conducting the analysis, this study employed a single-proportion power test to calculate the statistical power for POD12. The sample size was set at 63 (the number of cases used), and the comparison proportion was set at 46% (the proportion of POD12 occurrence). The calculated power value was 0.927878, indicating that the sample size was sufficient for detecting statistical associations.
Among 63 previously untreated DLBCL patients, 29 cases (46%) experienced POD12. The OS values in the POD12 group were significantly lower than those in the non-POD12 group (p< 0.001; Figure 4), with 3-year OS rates of 3.45% and 23.53%, respectively.
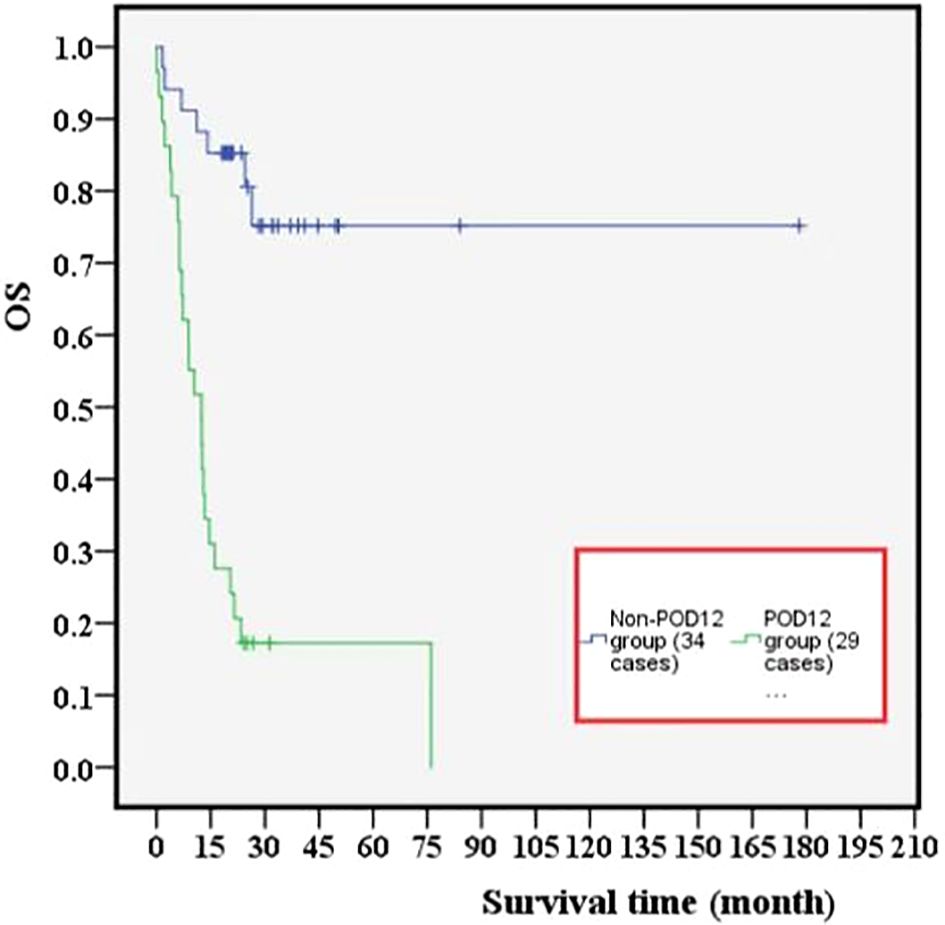
Figure 4. Effect of POD12 on OS in patients with DLBCL.
From one-way ANOVA, POD12 is significantly correlated with progression-free survival (PFS; p< 0.001; Table 1) and OS (p = 0.008; Table 2). When factors with p< 0.2 in the one-way ANOVA are included in the multivariate Cox regression analysis, and the effect of first-line treatment on the prognosis of DLBCL is corrected for, POD12 remains the most significant independent prognostic factor in PFS (HR = 0.235, 95% confidence interval (CI): 0.106~0.524, p< 0.001; Table 1) and OS (HR = 0.274, 95% CI: 0.123~0.606, p = 0.001; Table 2).
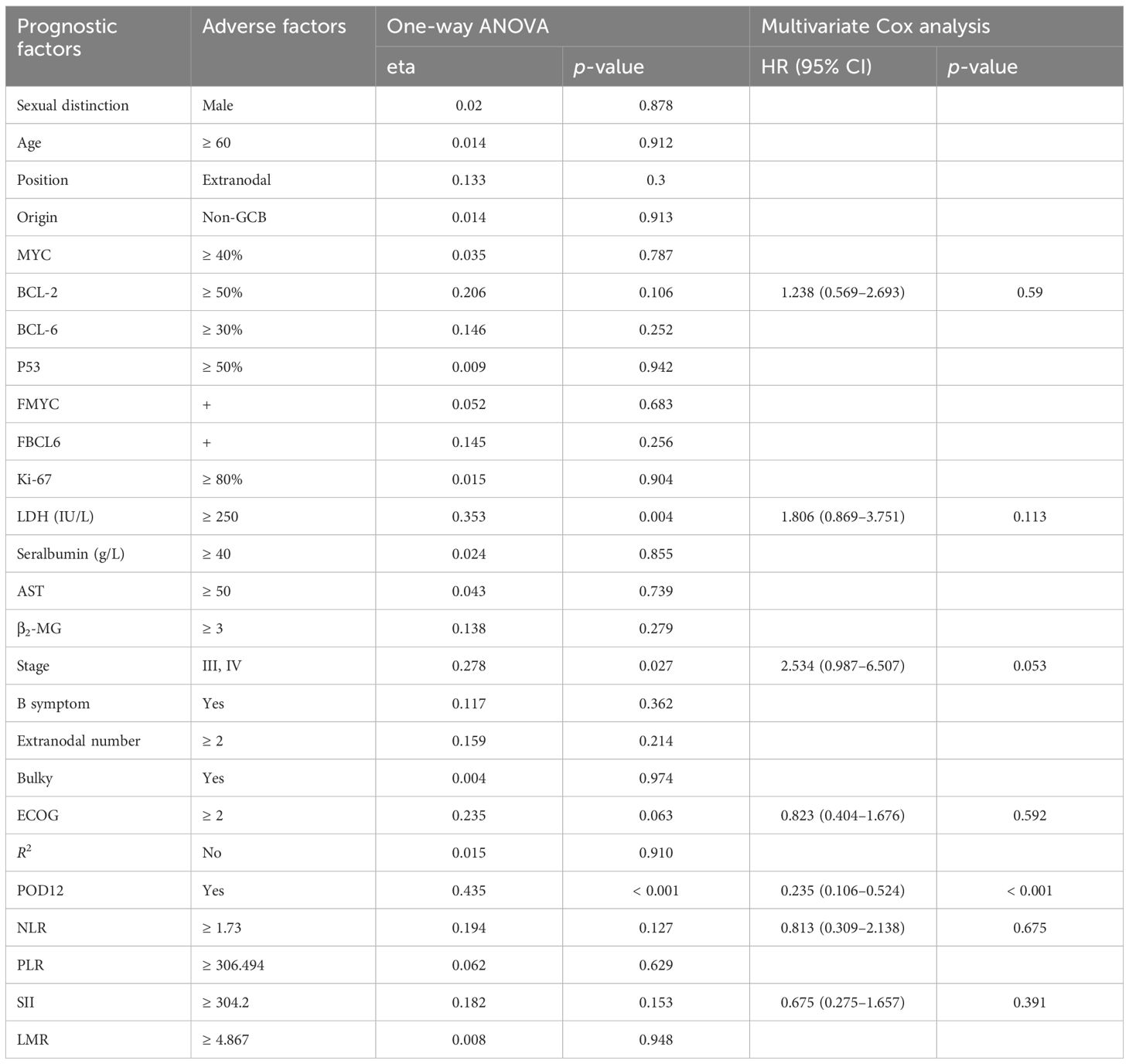
Table 1. Univariate and multivariate Cox analysis of prognostic factors for DLBCL (PFS).
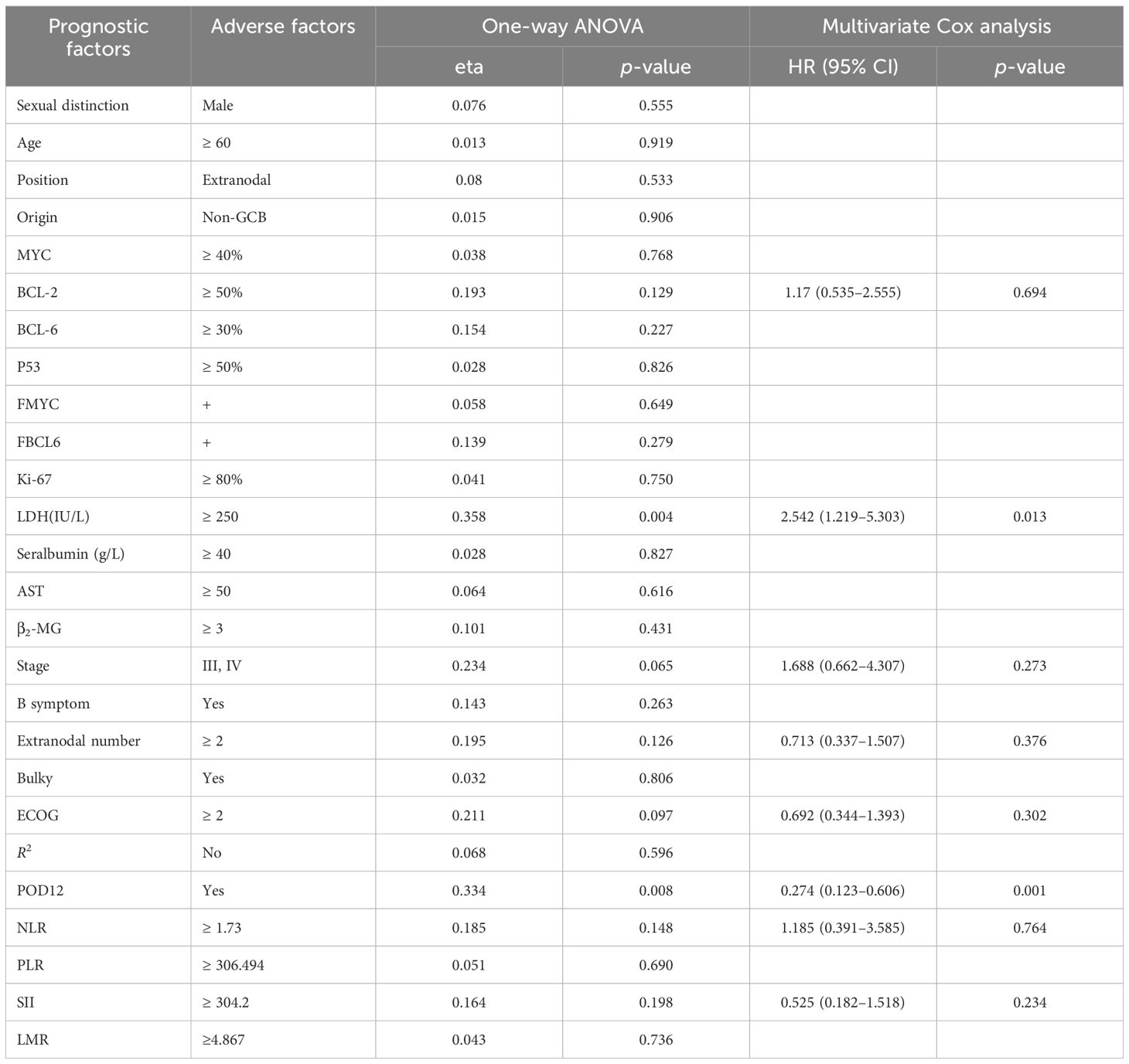
Table 2. Univariate and multivariate Cox analysis of prognostic factors in DLBCL (OS).
4.3 Risk factor analysis of POD12
Among the 63 patients who underwent immunohistochemical detection, univariate logistic regression analysis—adjusted for the first-line chemotherapy regimen—identified LDH ≥ 250 IU/L, β2-MG ≥ 3 µmol/L, stages III–IV, ECOG ≥ 2, NLR ≥ 1.73, SII ≥ 304.2 as potential risk factors for POD12 (Table 3). Furthermore, multivariate logistic regression analysis revealed that β2-MG ≥ 3 µmol/L and ECOG ≥ 2 were independent risk factors for POD12 (p< 0.05; Table 4).
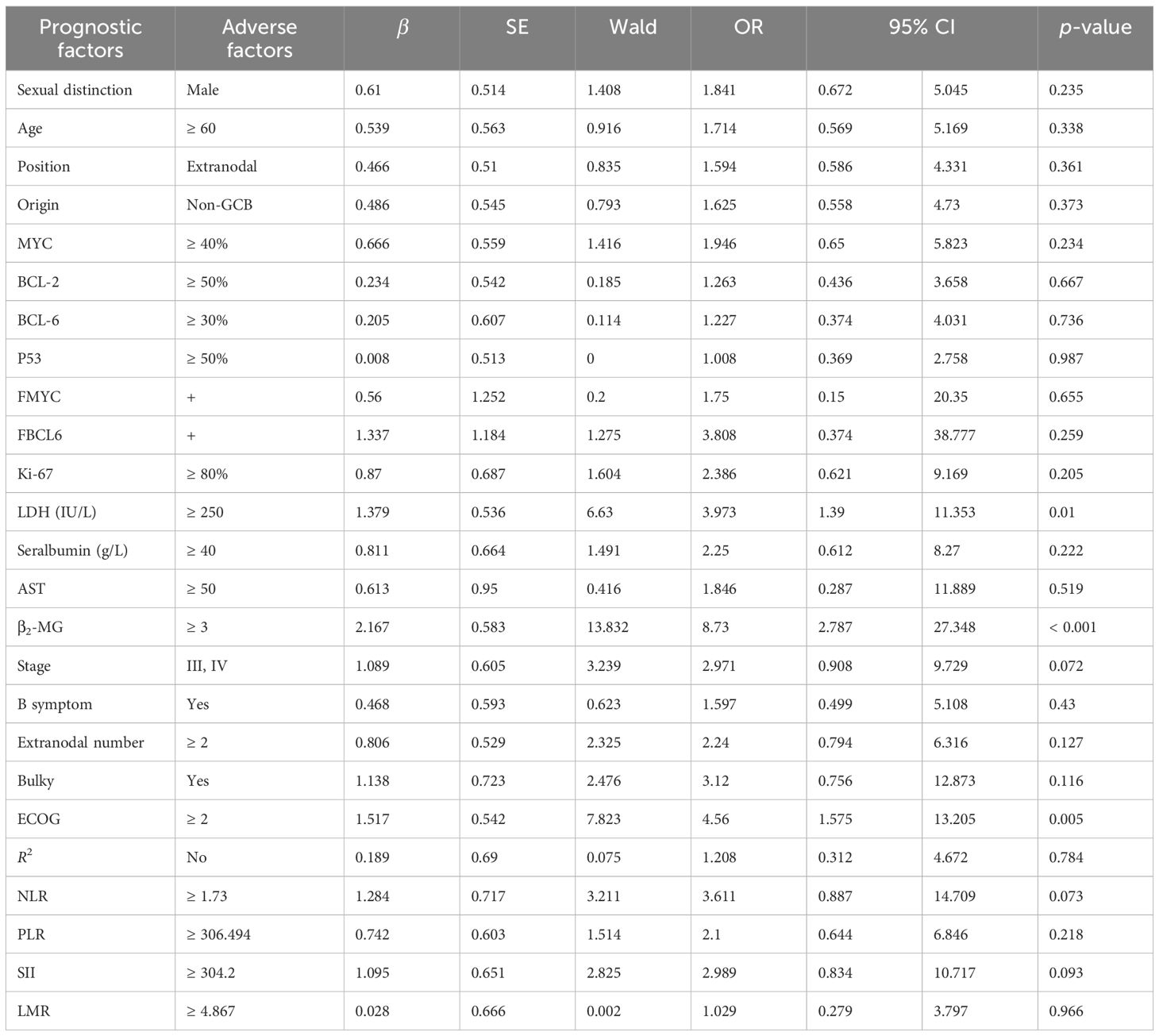
Table 3. Univariate logistic regression analysis adjusted for the first-line chemotherapy regimen for POD12.
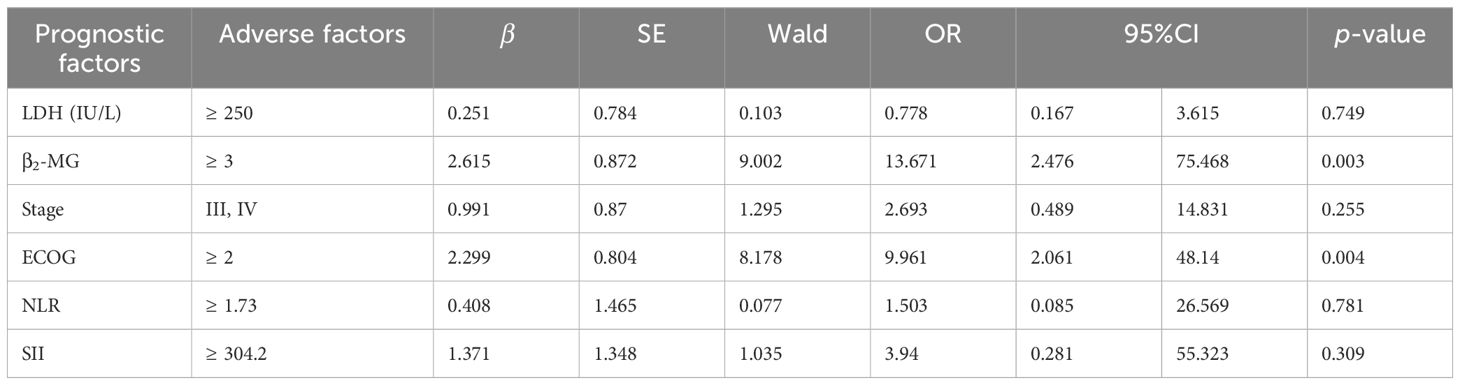
Table 4. Multivariate logistic regression analysis for POD12.
According to the analysis of POD12 in previously untreated DLBCL patients, the risk factors for POD12 are LDH ≥ 250 IU/L, β2-MG ≥ 3 µmol/L, stages III–IV, ECOG ≥ 2 score, NLR ≥ 1.73, and SII ≥ 304.2. From the prediction model A, which includes the above six factors, the logistic regression coefficient β values are 0.251, 2.615, 0.991, 2.299, 0.408, and 1.371, respectively. The larger the regression coefficient, the stronger the correlation between the corresponding risk factors and POD12. The regression coefficient value involving β2-MG ≥ 3 µmol/L is the largest, giving a score of 2, while the risk factors LDH ≥ 250 IU/L, stages III–IV, ECOG ≥ 2, NLR ≥ 1.73, and SII ≥ 304.2 are each assigned 1 point. The ROC curve was obtained based on the patient’s scores and whether POD12 occurred. The area from the curve is 0.846 (95% CI: 0.749–0.944), and the best cut-off value is a score of 4, which divides the patients into a low-risk group (< 4) and a high-risk group (≥ 4). Upon verification in 63 patients with DLBCL with complete clinical data, it was found that 26 patients with previously untreated DLBCL had scores less than 4, among whom 23 (88.46%) did not develop POD12. POD12 occurred (i.e., ≥ 4 score) in 26 of 37 patients (70.27%). The positive predictive rate (PPV) is 70.27%, the negative predictive rate (NPV) is 88.46%, and the overall accuracy is 77.78%. The platelet-to-lymphocyte ratio (PLR) is 2.769, indicating that the risk of POD12 in patients with DLBCL with a score of ≥ 4 was 2.769 times higher than in those with a score of< 4. Model A can also be used to predict the OS of patients. For patients with a score of< 4, the median OS was not reached, whereas the median OS for those with a score of ≥ 4 was 13 months; the difference was statistically significant (p< 0.001). Logistic regression analysis corrected by the first-line treatment regimen showed that the risk of POD12 in patients with scores ≥ 4 was significantly higher than in those with scores< 4 (OR = 18.121, 95% CI: 4.494–73.078, p< 0.001; Table 5). Compared with NCCN-IPI, the accuracy of POD12 prediction increased from 57.14% to 77.0%, and the risk of POD12 in the high-risk patients was significantly higher than in low-risk patients (OR = 12, 95% CI: 2.456–58.631, p = 078%; Figure 5). In addition, prediction model B was established based on the independent risk factors β2-MG and ECOG for POD12. The high-risk group was defined as having ECOG ≥ 2 and β2-MG ≥ 3 µmol/L; the medium-risk group included patients with either ECOG ≥ 2 and β2-MG< 3 µmol/L, or ECOG< 2 and β2-MG ≥ 3 µmol/L; and the low-risk group included those with ECOG< 2 and β2-MG< 3 µmol/L. According to the logistic regression analysis corrected by the first-line treatment regimen, the predictive ability of this model was medium-high at 002 (see Table 5). Its prediction accuracy was higher than that of NCCN-IPI but lower than that of prediction model A (see Figure 5). Therefore, in this study, prediction model A was selected as the final prediction model for POD12.

Table 5. Comparison of single-factor logistic regression analysis between the NCCN-IPI and the prediction model.
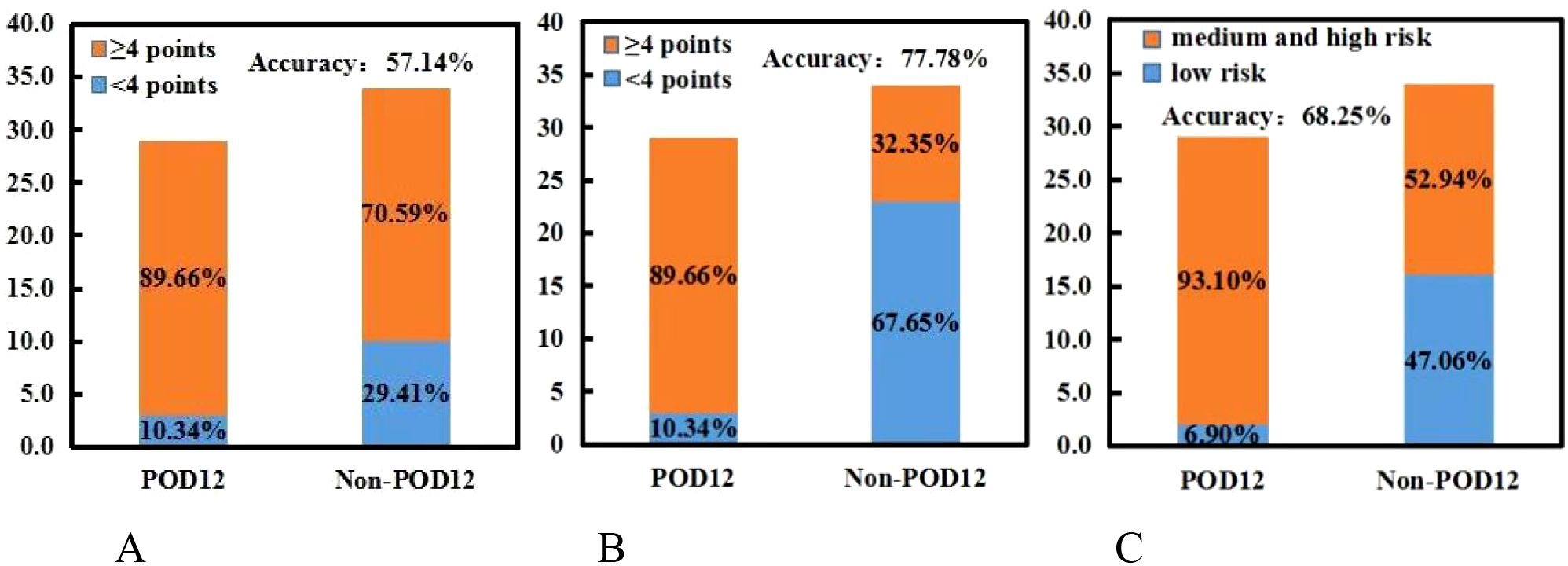
Figure 5. NCCN-IPI and two prediction models, (A, B). (A) NCCN-IPI. (B) Prediction model (A). (C) Prediction model (B).
Different from the PFS or OS, POD12 is not influenced by deaths caused by other factors (such as treatment-related adverse reactions) or by second-line treatment. It may better reflect the invasiveness and/or treatment resistance of the disease itself. At present, some conventional clinical prognostic evaluation systems, such as the international prognostic index (IPI) (10), cell-of-origin classification (11, 12), simultaneous Bcl-2 and C-Myc and/or Bcl-6 rearrangement, dual expression (DE) of C-Myc and Bcl-2, increased expression of mutant p53 protein (13–16), high-grade B-cell lymphoma, double-hit/triple-hit DLBCL (15, 17, 18), can be used to predict the overall survival of patients with DLBCL. However, the relationship between these prognostic factors and POD12 in DLBCL remains uncertain (19). In addition, patients with POD12 may initially achieve CR with first-line treatment but then experience rapid disease progression. Their tumor cells may not respond well to follow-up therapies, resulting in poor overall survival (OS) (20, 21). Similarly, POD12 has been shown to have important prognostic value. Ma et al. (4) found that DLBCL patients treated with first-line rituximab + cyclophosphamide + adriamycin + vincristine + prednisone (R-CHOP) had significantly lower OS rates if they experienced POD12 compared to those who did not (p< 0.001). These patients also responded poorly to subsequent rescue treatment, indicating that POD12 carries strong prognostic significance across various conventional treatment regimens.
At present, there are few investigations on the predictive factors of POD12, with high heterogeneity in biological characteristics. It is necessary to establish a POD12 prediction model to help identify high-risk groups, formulate personalized therapy plans, and improve prognosis. In this study, the incidence of POD12 is high (46%), and OS is significantly worse in patients with early progression compared to those without. This may be closely related to factors such as advanced disease stage, high tumor burden, and limited sample size, which need to be further verified in large-sample clinical trials. In addition, this study included patients who received immunochemotherapy and chemotherapy, and the effect of first-line treatment on the prognosis of DLBCL was corrected; POD12 remained the most significant independent prognostic factor for both PFS and OS. This work confirms that POD12 is a reliable adverse prognostic factor for DLBCL. Therefore, it is necessary to identify high-risk patients early and implement individualized treatment in a timely manner to reduce the incidence of POD12. Ma et al. (4) found that, in addition to the progression of the disease, neither the prognostic factors in traditional IPI nor others, such as double expression, TP53, and COO, can serve as independent predictors of POD12. Combining the CD79B mutation, PIM1 mutation, and Ann Arbor staging can further improve prediction efficiency, with POD12 showing the highest accuracy. Therefore, some scholars have attempted to predict POD12 by combining clinical features and gene mutations. However, these prediction tools require expensive and time-consuming gene sequencing and related tests, which are currently difficult to implement in clinical practice. After screening the baseline clinical and pathological factors, we found that certain risk factors, such as LDH ≥ 250 IU/L, β2-MG ≥ 3 µmol/L, stages III–IV, ECOG ≥ 2 score, NLR ≥ 1.73, and SII ≥ 304.2, are strongly associated with POD12. Accordingly, a new prognostic model was established. Sixty-three previously untreated DLBCL patients with complete clinical data were divided into low-risk (score 0–3) and high-risk (score ≥ 4) groups. The risk of the POD12 in previously untreated DLBCL patients with a score ≥ 4 was 2.769 times higher than that in patients with a score of 0–3. In addition, the POD12 prediction model can also predict the OS of previously untreated DLBCL patients.
There is currently no optimal prognostic model for diffuse large B-cell lymphoma that accurately predicts early disease progression. Clinical indicators, immune microenvironment, and pathological indicators may influence the prognosis of DLBCL. The indicators selected in this study provide a comprehensive evaluation by combining clinical, pathological, and microenvironment-related indicators. It is well known that inflammation plays an important role in tumor progression and treatment response, and peripheral blood cell counts, which to some extent reflect the inflammatory state, are closely related to the progression of cancer (22, 23). In this work, prognostic indicators of inflammation are included. NLR (24–28) and SII (29) are considered to have prognostic value for DLBCL. A recent meta-analysis showed that NLR was associated with poor OS and was considered a low-cost prognostic factor in 2,297 patients with DLBCL (30). Based on neutrophils, platelets, and lymphocytes, SII may reflect inflammatory status and tumor activity more accurately than PLR and NLR, and it has been proven to be an independent predictor of various malignancies, such as breast cancer and lung cancer (31, 32). However, the data on non-Hodgkin lymphoma are limited. To our knowledge, the relationship between the above indicators and POD12 outcomes in DLBCL has not been explored. Therefore, we conducted this investigation to evaluate the prognostic value of NLR, PLR, SII, and LMR in POD12 of DLBCL and found that NLR and SII were prognostic risk factors for POD12. In addition, we found that patients with LDH ≥ 250 IU/L and stages III–IV were more likely to develop POD12, but these were not independent risk factors. Myc, p53, Bcl-2, and Bcl-6 did not influence the occurrence of POD12.
Among the clinical factors included in this study, β2-MG and ECOG scores were identified as the independent risk factors for POD12, while LDH ≥ 250 IU/L, stages III–IV, NLR ≥ 1.73, and SII ≥ 304.2 were also associated with increased risk. In diagnosis, attention should be paid to the identification of these high-risk patients, and personalized therapy should be initiated promptly to improve prognosis. In the new model developed in this study, patients were divided into high- and low-risk groups, with the former showing a significantly higher risk of POD12. Compared with NCCN-IPI alone, the new model demonstrated improved sensitivity and accuracy in predicting POD12, accurately identifying 70.27% of POD12 cases, though with slightly reduced specificity. Given the current lack of efficient POD12 prediction models, and considering that this new model is more economical and simpler than molecular clinical models, the findings of this study hold practical significance.
4.4 Risk level prediction for POD12 with CNN-LSTM
For the deep learning prediction model of POD12 using CNN-LSTM and PSO-GRNN, as mentioned above, LDH, β2-MG, III-IV, ECOG, NLR, and SII are selected as the risk factors for POD12. These characteristic variables are divided into two combinations: one consists of LDH, β2-MG, and stages III–IV, and the other consists of ECOG, NLR, and SII.
In the pretreatment process, a small number of missing monitoring results are filled using the “before and after mean” method (i.e., xi = (xi −1 + xi+ 1)/2). A control parameter μ (μ = 0.85) is introduced to correct them with xi = μxi (xi = LDH, β2-MG, III-IV, ECOG, NLR, and SII), to ensure the relative stability of the monitoring time series and the reliability of the prediction results.
The risk rank of POD12 can be evaluated using a comprehensive index, which is calculated from each single index of the risk rank reflected by each POD12 characteristic variable at each time. The calculation of the POD12 comprehensive risk index mainly includes the following steps.
Calculation of the risk factors of a single index (Wi(t)) (Equation 10)
Where is the amplitude of the monitoring index (such as LDH, β2-MG, III-IV, ECOG, NLR, and SII) at time t, and and are the average and maximum values of the amplitude of the monitoring index under the normal conditions.
Determining the weight factor (pi(t)) of the risk factors of the single index to calculate the comprehensive risk factors (Wz(t)) of the multivariable characteristics of POD12, based on the risk factors and their respective weights (Equation 11).
The rank of the risk for POD12 could then be determined by the comprehensive risk index. The risk ranking is divided into four categories: risk, subsidiary risk, subsidiary safe, and safe.
Based on chaos theory, for six characteristic variables of POD12 (i.e., LDH, β2-MG, stages III–IV, ECOG, NLR, and SII), the delay time (τ) was calculated using the mutual information method, and the embedding dimension (m) was determined using the false nearest-neighbor method, where m corresponds to the value with the minimum false proximity rate.
The characteristic time series were predicted using a single-layer structure in LSTM. The number of neurons is set to 100, and the hyperparameter λ is 0.01. The CNN-LSTM model was used for training. In the process of training the model, the training time step was set to the embedded dimension m, the activation function was Relu, and the optimizer was Adam. The number of epochs was set to 100, and the learning rate was 0.01, with an experimental time step of 1 h.To assess the performance of the prediction models, the mean absolute percentage error (MAPE) is a commonly used criterion. Specifically, given a dataset , let the predicted values output by a certain prediction model be denoted as
, then Equation 12
It can be seen from the calculation formula that the smaller the MAPE value, the better the performance of the model. In order to better describe the prediction ability of the model, this study cited the evaluation scale introduced in Xu et al. (33). Its details are as follows: when the MAPE is less than 10%, the prediction ability is considered “highly accurate”; when the MAPE is between 10% and 20%, the prediction ability is “good”; when the MAPE is between 20% and 50%, the prediction ability is “reasonable”; and when the MAPE is greater than 50%, the prediction ability is considered “weak and inaccurate”.
In addition, the mean absolute scaled error (MASE) can also be used to measure the performance of prediction models and is expressed as Equation 13:
Subsequently, to comparatively evaluate the predictive performance of the models, this study divided the case dataset into a training set and a test set at a ratio of 9:1. First, the GRNN, DB-LSTM [introduced by Zhou and Xu (34)], DeepSurv [introduced by Katzman et al. (35)], and CNN-LSTM models were trained on the training set. After training, the models were applied to the test set, with the results presented in Table 6.
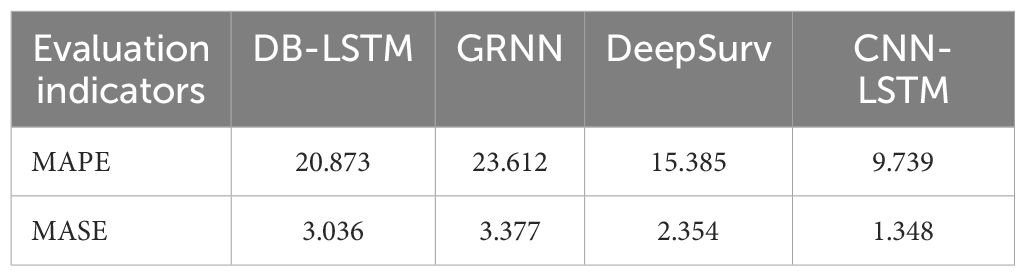
Table 6. MAPE (%) and MASE values of the different prediction models.
For the prediction of the POD12 comprehensive risk index using LDH, β2-MG, III-IV, ECOG, NLR, and SII, as shown in Table 6, CNN-LSTM exhibits the smallest MAPE and MASE values (bold values in Table 6), indicating highly accurate prediction performance. Compared with the maximum value of MAPE among the four models, the MAPE value of CNN-LSTM is reduced by 58.75%. In addition, the MASE values of the other three models are 2.25 times, 2.51 times, and 1.75 times that of CNN-LSTM, respectively.
4.5 Assessment of the impact of different combinations on the risk level of POD12
To verify the effectiveness of the PSO-GRNN method, experiments were conducted on the discrimination of the risk level of POD12 and the prediction of the risk level of POD12 in the future.
According to the characteristic variables of two combinations (“LDH, β2-MG, and III-IV” and “ECOG, NLR, and SII”), the POD12 risk levels were comprehensively evaluated.
In order to obtain the optimal model, the fourfold cross-validation method is adopted. The ratio of the training set to the test set is 9:1. The number of particles is 10, the learning factor is 0.2, and the inertia weight is 0.7. The iteration stop condition is that the number of cycle steps exceeds 100 or the training error is less than 0.0010. Taking the obtained weight threshold as the initial value, the network is trained using the GRNN algorithm.
Figure 6 shows the optimization curves of the fitness function and the smoothing factor. Single-step prediction was adopted, and the mean square error between the predicted and test values is used as the fitness. The smaller the fitness, the better the training effect of the model. Based on the characteristic variables of two combinations (“LDH, β2-MG, and III-IV” and “ECOG, NLR, and SII”), the optimal fitness values are 0.0052 and 0.0089, and the optimal smoothing factors are 0.0753 and 0.0868, respectively. The improved PSO algorithm can effectively avoid missing the optimal solution and can find the global optimal solution. Using the optimized GRNN, the risk level of the current state of POD12 is determined.
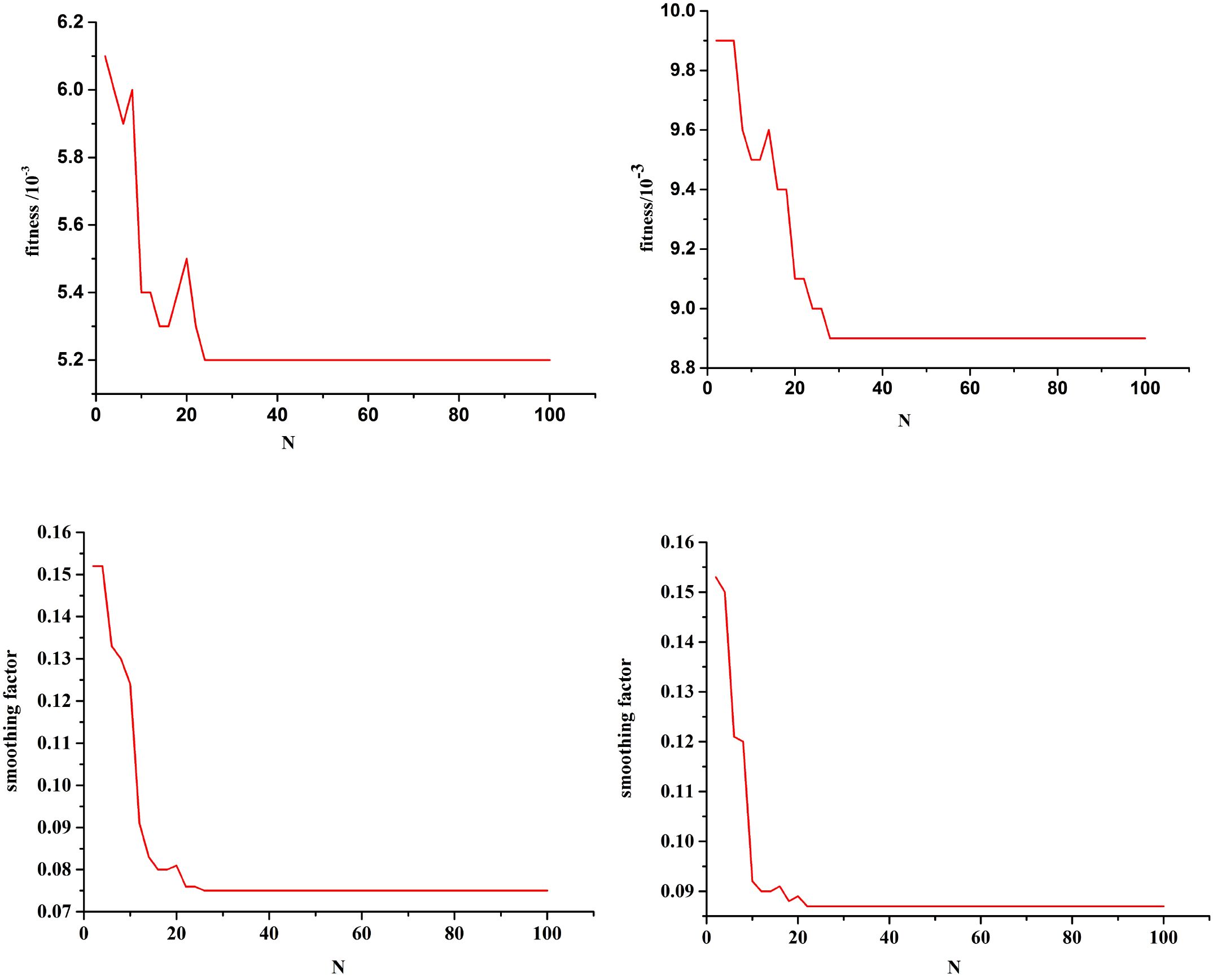
Figure 6. Fitness function optimization curve and smoothing optimization curve. Combination (LDH, β2-MG, and III-IV) Combination (ECOG, NLR, and SII). Combination (LDH, β2-MG, and III-IV) Combination (ECOG, NLR, and SII).
To predict the future risk level of POD12, the CNN-LSTM model was first used to forecast the future state values of the characteristic variables. Subsequently, the PSO-GRNN model was employed to predict the future state value of the characteristic variables (i.e., the risk level of POD12 at the time of t + 1). To maintain methodological consistency, the training and verification sets were kept unchanged. However, the prediction dataset consisted of the forecasted future state values of the characteristic variables associated with POD12. Fourfold cross-verification was adopted, with parameter settings remaining consistent throughout the process.
Single-step prediction was adopted, and the mean square error between the predicted and test values was used as the fitness. Figure 7 shows the optimization curves for the fitness function and the smoothing factor for future POD12 prediction. The algorithm demonstrated robustness; for example, in the combination of LDH, β2-MG, and stages III–IV, the optimal fitness value and smoothing factor were 0.0127 and 0.0859, respectively, which closely align with the previously reported experimental results.
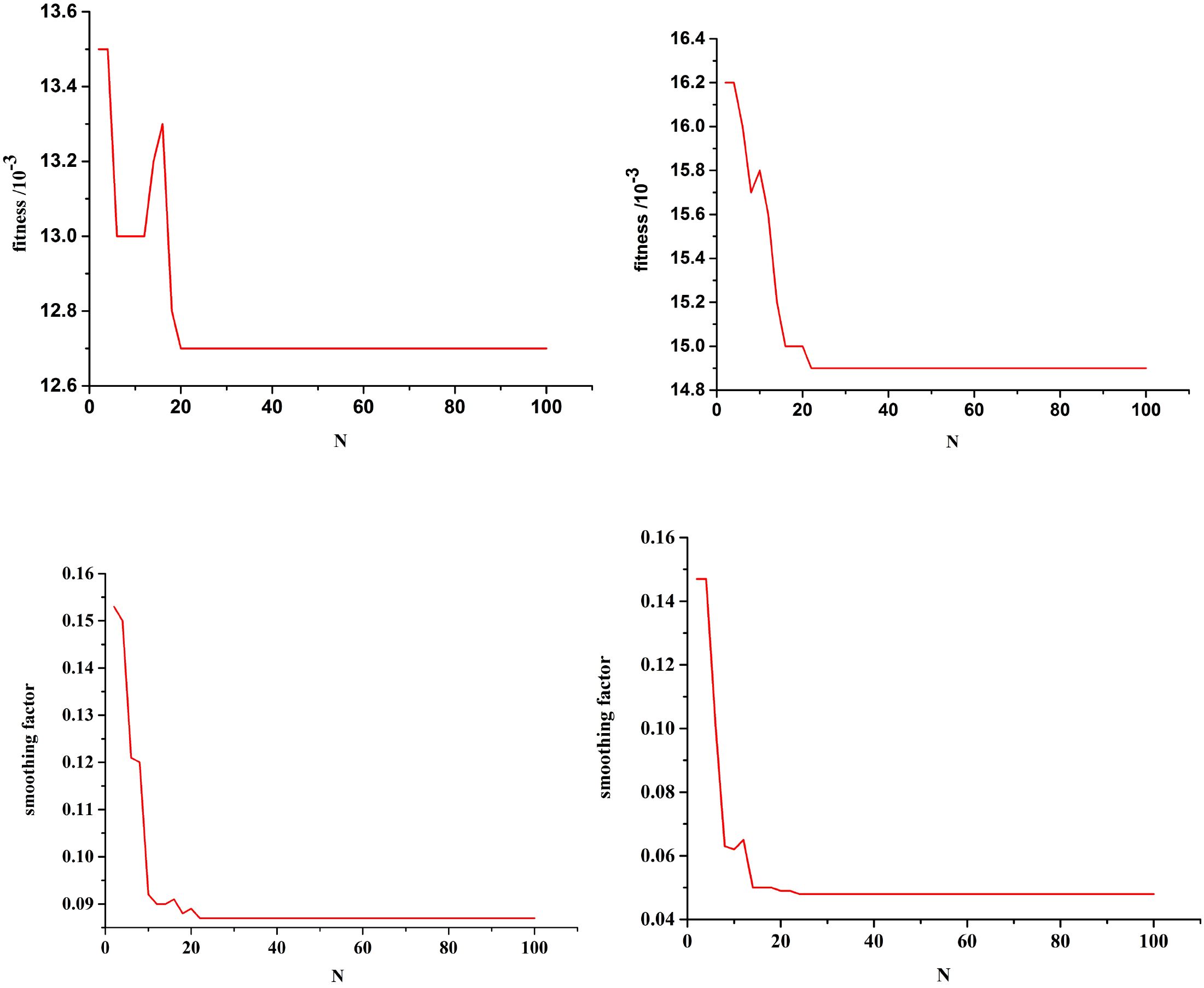
Figure 7. Fitness function optimization curve with future state of POD12, and smoothing optimization curve with future state of POD12. Combination (LDH, β2-MG, and III-IV) Combination(ECOG, NLR, and SII). Combination (LDH, β2-MG, an.
Using the optimized GRNN, the risk level of POD12 in the future was predicted at Shanxi Bethune Hospital from January 2016 to June 2020. It can be seen that, with the help of the method in this work, not only can the POD12 evolution state be accurately fitted, but the risk level of the current state of POD12 can also be judged, and that in the future can be predicted as well. The prediction accuracy of the characteristic variable and risk level of the POD12 in the future is high. This can provide an important basis for timely mastering the future state of POD12 activities, i.e., the risk level of POD12 in the hospital.
To sum up, by analyzing the incidence and risk factors of POD12 in patients with previously untreated DLBCL, a clinical prediction model of POD12 was established, and the prediction efficiency of the model was also verified. It was further found that the model can also predict OS. Therefore, the prediction model is helpful to evaluate, simply and effectively, the risk of POD12 in previously untreated DLBCL patients, and then formulate personalized therapy plans for high-risk patients to reduce the risk of POD and prolong overall survival time. However, this study is a single-center retrospective study with a limited sample size and a lack of external validation, and it is unclear whether the POD12 prediction model based on clinical characteristics and immunohistochemical molecules is applicable to populations in different regions and various treatment cases. It is urgent to further explore large-sample clinical trials under the cooperation of multiple centers. The CNN-LSTM and PSO-GRNN models are the most suitable to predict the risk level of the POD12 in the future. This can provide an important basis for timely mastering the future state of POD12.
5 Conclusion
The POD12 prediction model, based on LDH, β2-MG, stage, ECOG, NLR, and SII, can be used to effectively predict the early recurrence and progression of DLBCL. Among the models evaluated, CNN-LSTM and PSO-GRNN demonstrated the highest suitability for forecasting the risk level of POD12, providing an important basis for the timely assessment of patient prognosis. In addition, the model can be applied clinically through the following steps to support physicians in developing optimized treatment plans:
(1) Indicator input: clinicians input six routine clinical indicators—LDH, β2-MG, stage, ECOG, NLR, and SII;
(2) Automatic scoring: the model calculates the POD12 risk score in real time;
(3) Risk stratification: for low-risk patients, standard R-CHOP therapy can be recommended; for high-risk patients, personalized intensive regimens may be considered in combination with other indicators;
(4) Dynamic monitoring: clinicians update patient indicators every month and use the CNN-LSTM model to predict the probability of disease progression within 12 months in a single-step prediction.
6 Future directions
While this study primarily employs statistical and deep learning methodologies to identify prognostic patterns in clinical data, we acknowledge that incorporating biological principles could enhance model interpretability and generalizability. Our immediate next steps include:
(1) Integrating single-cell transcriptomics to map molecular subtypes to POD12 trajectories;
(2) Modeling tumor-immune ecosystem dynamics using spatially resolved proteomics as biological constraints for CNN-LSTM;
(3) Developing mechanistic hybrid models in which neural networks parameterize differential equations describing lymphoma proliferation and immune interactions. These efforts aim to bridge data-driven predictions with causal biological reasoning.
Data availability statement
The data analyzed in this study is subject to the following licenses/restrictions: The datasets generated during and analysed during the current study are not publicly available due the data in the study involves personal privacy but are available from the corresponding author on reasonable request. Requests to access these datasets should be directed to Hui Wang, d2hfZGF0YTAwN0B6dWZlLmVkdS5jbg==.
Ethics statement
The studies involving humans were approved by Shanxi Bethune Hospital, Shanxi Academy of MedicalSciences, Medical ethics committee. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
LK: Data curation, Formal analysis, Resources, Supervision, Writing – original draft, Writing – review & editing. WZ: Conceptualization, Investigation, Supervision, Writing – review & editing. ZH: Conceptualization, Formal analysis, Software, Writing – original draft. FS: Investigation, Resources, Validation, Writing – original draft. CX: Formal analysis, Supervision, Writing – original draft. HW: Conceptualization, Funding acquisition, Methodology, Software, Validation, Visualization, Writing – review & editing, Writing – original draft.
Funding
The author(s) declare financial support was received for the research and/or publication of this article. This work is supported by First-Class Discipline of Zhejiang-A (Zhejiang University of Finance and Economics-Statistics).
Acknowledgments
The authors thank the study participants, investigators, and study teams involved in this trial.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Correction note
This article has been corrected with minor changes. These changes do not impact the scientific content of the article.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Coiffier B, Thieblemont C, Van Den Neste E, Lepeu G, Plantier I, Castaigne S, et al. Long-term outcome of patients in the LNH-98.5 trial, the first randomized study comparing rituximab-CHOP to standard CHOP chemotherapy in DLBCL patients: a study by the Groupe d’Etudes des Lymphomes de l’Adulte. Blood. (2010) 116:2040–5. doi: 10.1182/blood-2010-03-276246, PMID: 20548096
2. Ngo L, Hee SW, Lim LC, Tao M, Quek R, Yap SP, et al. Prognostic factors in patients with diffuse large B cell lymphoma: Before and after the introduction of rituximab. Leuk Lymphoma. (2008) 49:462–9. doi: 10.1080/10428190701809156, PMID: 18297522
3. Gisselbrecht C, Glass B, Mounier N, Devinder SG, Linch DC, Marek T, et al. Salvage regimens with autologous transplantation for relapsed large B-cell lymphoma in the rituximab era. J Clin Oncol. (2010) 28:4184–4190. doi: 10.1200/JCO.2010.28.1618, PMID: 20660832
4. Jialin M. Exploration of a novel genetic predictive model and precision treatment for early progression of diffuse large B-cell lymphoma. Zhengzhou, Henan Province, China: Zhengzhou University (2020).
5. Miyaoka M, Kikuti YY, Carreras J, Ikoma H, Hiraiwa S, Ichiki A, et al. Clinicopathological and genomic analysis of double- hit follicular lymphoma: comparison with highgrade B-cell lymphoma with MYC and BCL2 and/or BCL6 rearrangements. Mod Pathol. (2018) 31:313–26. doi: 10.1038/modpathol.2017.134, PMID: 28984304
6. Kridel R, Mottok A, Farinha P, Ben-Neriah S, Ennishi D, Zheng Y, et al. Cell of origin of transformed follicular lymphoma. Blood. (2015) 126:2118–27. doi: 10.1182/blood-2015-06-649905, PMID: 26307535
7. Pennanen H, Kuittinen O, Soini Y, and Turpeenniemi-Hujanen T. Prognostic significance of p53 and matrix metalloproteinase-9 expression in follicular lymphoma. Eur J Haematol. (2008) 81:289–97. doi: 10.1111/j.1600-0609.2008.01113.x, PMID: 18616513
8. Chisholm KM, Bangs CD, Bacchi CE, Kirsch HM, Cherry A, and Natkunam Y. Expression profiles of MYC protein and MYC gene rearrangement in lymphomas. Am J Surg Pathol. (2015) 39:294–303. doi: 10.1097/PAS.0000000000000365, PMID: 25581730
9. Hans CP, Weisenburger DD, Greiner TC, Gascoyne R, Delabie J, Ott G, et al. Confirmation of the molecular classification of diffuse large B-cell lymphoma by immunohistochemistry using a tissue microarray. Blood. (2004) 103:275–82. doi: 10.1182/blood-2003-05-1545, PMID: 14504078
10. International Non-Hodgkin’s Lymphoma Prognostic Factors P. A predictive model for aggressive non-Hodgkin’s lymphoma. N Engl J Med. (1993) 329:987–94. doi: 10.1056/NEJM199309303291402, PMID: 8141877
11. Alizadeh AA, Eisen MB, Davis RE, Ma C, Lossos IS, Rosenwald A, et al. Distinct types of diffuse large B-cell lymphoma identified by gene expression profiling. Nature. (2000) 403:503–11. doi: 10.1038/35000501, PMID: 10676951
12. Lenz G, Wright G, Dave SS, Xiao W, Powell J, Zhao H, et al. Stromal gene signatures in large-B-cell lymphomas. N Engl J Med. (2008) 359:2313–23. doi: 10.1056/NEJMoa0802885, PMID: 19038878
13. Horn H, Ziepert M, Becher C, Barth TFE, and Ott G. MYC status in concert with BCL2 and BCL6 expression predicts outcome in diffuse large B-cell lymphoma. Blood. (2013) 121:2253–63. doi: 10.1182/blood-2012-06-435842, PMID: 23335369
14. Johnson NA, Slack GW, Savage KJ, Connors JM, and Gascoyne RD. Concurrent expression of MYC and BCL2 in diffuse large B-cell lymphoma treated with rituximab plus cyclophosphamide, doxorubicin, vincristine, and prednisone. J Clin Oncol. (2012) 30:3452–9. doi: 10.1200/JCO.2011.41.0985, PMID: 22851565
15. Cheah CY, Oki Y, Westin JR, and Turturro F. A clinician’s guide to double hit lymphomas. Br J Haematol. (2015) 168:784–95. doi: 10.1111/bjh.13276, PMID: 25529575
16. Xu-Monette ZY, Wu L, Visco C, Tai YC, Tzankov A, Liu WM, et al. Mutational profile and prognostic significance of TP53 in diffuse large B-cell lymphoma patients treated with R-CHOP: report from an International DLBCL Rituximab-CHOP Consortium Program Study. Blood. (2012) 120:3986–96. doi: 10.1182/blood-2012-05-433334, PMID: 22955915
17. Aukema SM, Siebert R, Schuuring E, Van Imhoff GW, Kluin-Nelemans HC, Boerma EJ, et al. Double-hit B-cell lymphomas. Blood. (2011) 117:2319–31. doi: 10.1182/blood-2010-09-297879, PMID: 21119107
18. Sarkozy C, Traverse-Glehen A, and Coiffier B. Double-hit and double-protein-expression lymphomas: aggressive and refractory lymphomas. Lancet Oncol. (2015) 16:e555–67. doi: 10.1016/S1470-2045(15)00005-4, PMID: 26545844
19. Ma J, Yan Z, Zhang J, Zhou W, Yao Z, Wang H, et al. A genetic predictive model for precision treatment of diffuse large B-cell lymphoma with early progression. biomark Res. (2020) 26:33. doi: 10.1186/s40364-020-00214-3, PMID: 32864130
20. Martin A, Conde E, Arnan M, Canales MA, Deben G, Sancho JM, et al. R-ESHAP as salvage therapy for patients with relapsed or refractory diffuse large B-cell lymphoma: the influence of prior exposure to rituximab on outcome. A GEL/TAMO study. Haematologica. (2008) 93:1829–36. doi: 10.3324/haematol.13440, PMID: 18945747
21. Hamlin PA, Zelenetz AD, Kewalramani T, Jing Q, Satagopan JM, Verbel D, et al. Age-adjusted International Prognostic Index predicts autologous stem cell transplantation outcome for patients with relapsed or primary refractory diffuse large B-cell lymphoma. Blood. (2003) 102:1989–96. doi: 10.1182/blood-2002-12-3837, PMID: 12676776
22. Diakos CI, Charles KA, McMillan DC, and Clarke SJ. Cancer-related inflammation and treatment effectiveness. Lancet Oncol. (2014) 15:e493–503. doi: 10.1016/S1470-2045(14)70263-3, PMID: 25281468
23. Ocana A, Nieto-Jimenez C, Pandiella A, and Templeton AJ. Neutrophils in cancer: prognostic role and therapeutic strategies. Mol Cancer. (2017) 16:137. doi: 10.1186/s12943-017-0707-7, PMID: 28810877
24. Li ZM, Huang J J, Xia Y, Sun J, Huang Y, Yu W, et al. B lood lymphocyte-to-monocyte ratio identifies high-risk patients in diffuse large B-cell lymphoma treated with R-CHOP. PloS One. (2017) 7:e41658. doi: 10.1371/journal.pone.0041658, PMID: 22911837
25. Lu A, Haifeng L, Yuming Z, Tang M, Li J, Wu H, et al. Prognostic significance of neutrophil to lymphocyte ratio,Lymphocyte to monocyte ratio,and platelet to lymphocyte ratio in patients with nasopharyngeal carcinoma. BioMed Res Int. (2017) 2017:1–6. doi: 10.1155/2017/3047802, PMID: 28321405
26. Siqian, Wang, Yongyong, Ma, Lan, Sun, et al. Prognostic significance of pretreatment neutrophil/lymphocyte ratio and platelet/lymphocyte ratio in patients with diffuse large B-cell lymphoma. BioMed Res Int. (2018) 2018:1–8. doi: 10.1155/2018/9651254, PMID: 30643825
27. Rou J, Xiong Z, Wen Hu, Fan YY, Yan Y, Zhang MX, et al. The elevated pretreatment platelet-to-lymphocyte ratio predicts poor outcome in nasopharyngeal carcinoma patients. Tumor Biol. (2015) 36:7775–87. doi: 10.1007/s13277-015-3505-0, PMID: 25944165
28. Jin Y, Ye X, He C, Zhang B, and Zhang Y. Pretreatment neutrophil-to-lymphocyte ratio as predictor of survival for patients with metastatic naspharyngeal carcinoma. Head Neck. (2015) 37:69–75. doi: 10.1002/hed.23565, PMID: 24327524
29. Lin F, Hu H, Ye B, and Xiang M. Clinical characteristic of nasopharyngeal lymphoma and its association with tumor microenvironment. Chin J Ophthalmol Otorhinolaryngology. (2021) 21:399–401.
30. Wang J, Zhou X, Liu Y, Li Z, and Li X. Prognostic significance of neutrophil-to-lymphocyte ratio in diffuse large B-cell lymphoma: A meta-analysis. PloS One. (2017) 12:e0176008. doi: 10.1371/journal.pone.0176008, PMID: 28441396
31. Chen L, Kong X, Wang Z, Wang X, Fang Y, and Wang J. Pre-treatment systemic immune-inflammation index is a useful prognostic indicator in patients with breast cancer undergoing neoadjuvant chemotherapy. J Cell Mol Med. (2020) 24:2993–3021. doi: 10.1111/jcmm.14934, PMID: 31989747
32. Tong YS, Tan J, Zhou XL, Song YQ, and Song YJ. Systemic immune-inflammation index predicting chemoradiation resistance and poor outcome in patients with stage III non-small cell lung cancer. J Transl Med. (2017) 15:221. doi: 10.1186/s12967-017-1326-1, PMID: 29089030
33. Xu N, Dang Y, and Gong Y. Novel grey prediction model with nonlinear optimized time response method for forecasting of electricity consumption in China. Energy. (2017) 118:473–80. doi: 10.1016/j.energy.2016.10.003
34. Zhou J and Xu W. End-to-end learning of semantic role labeling using recurrent neural networks. In: The 53rd annual meeting of the association for computational linguistics and the 7th international joint conference on natural language processing, vol. 1. Beijing China: ACL (2015). p. 1127–37.
Keywords: diffuse large B cell lymphoma, prognosis, prediction model of POD12, early progression, risk factor
Citation: Lian K, Zhu W, Hu Z, Su F, Xu C and Wang H (2025) Investigation into the prognostic factors of early recurrence and progression in previously untreated diffuse large B-cell lymphoma and a statistical prediction model for POD12. Front. Immunol. 16:1539924. doi: 10.3389/fimmu.2025.1539924
Received: 05 December 2024; Accepted: 07 July 2025;
Published: 06 August 2025; Corrected: 11 August 2025.
Edited by:
Hong Zan, Prellis Biologics, United StatesReviewed by:
Sudarshan Pant, University College Dublin, IrelandYijiang Xu, Biogen Idec, United States
Copyright © 2025 Lian, Zhu, Hu, Su, Xu and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hui Wang, d2hfZGF0YTAwN0B6dWZlLmVkdS5jbg==