 Alex Ho Shing Chik
Alex Ho Shing Chik Philip J. Schmidt1
Philip J. Schmidt1 Monica B. Emelko
Monica B. Emelko- 1Department of Civil and Environmental Engineering, Faculty of Engineering, University of Waterloo, Waterloo, ON, Canada
- 2Institute of Hydraulic Engineering and Water Resources Management, Vienna University of Technology, Vienna, Austria
- 3Department of Earth Sciences, Faculty of Geosciences, Utrecht University, Utrecht, Netherlands
Accurate estimation of microbial concentrations is necessary to inform many important environmental science and public health decisions and regulations. Critically, widespread misconceptions about laboratory-reported microbial non-detects have led to their erroneous description and handling as “censored” values. This ultimately compromises their interpretation and undermines efforts to describe and model microbial concentrations accurately. Herein, these misconceptions are dispelled by (1) discussing the critical differences between discrete microbial observations and continuous data acquired using analytical chemistry methodologies and (2) demonstrating the bias introduced by statistical approaches tailored for chemistry data and misapplied to discrete microbial data. Notably, these approaches especially preclude the accurate representation of low concentrations and those estimated using microbial methods with low or variable analytical recovery, which can be expected to result in non-detects. Techniques that account for the probabilistic relationship between observed data and underlying microbial concentrations have been widely demonstrated, and their necessity for handling non-detects (in a way which is consistent with the handling of positive observations) is underscored herein. Habitual reporting of raw microbial observations and sample sizes is proposed to facilitate accurate estimation and analysis of microbial concentrations.
1. Introduction
Whether describing pathogens in water or the density of red blood cells, the concentration of discrete objects cannot be measured directly. In these cases, concentration is estimated by enumerating or detecting the objects in finite sample portions (e.g., volumes); such approaches are used extensively in health, food, and water applications. These estimates are required for decision making, during which they are typically evaluated against concentration-based criteria or targets (Dickey et al., 1999; Lund et al., 2000; Havelaar et al., 2001; Gerba and Rose, 2003; Gracias and McKillip, 2004; Koepke et al., 2007; Schijven and de Roda Husman, 2011; Davis, 2014; World Health Organization, 2017). This underscores the importance of accurate representation and analysis of detection- and enumeration-based data, especially where the protection of public health is at stake.
Regardless of application area, concentration estimates derived from non-detects (NDs) or low counts are widely perceived to be more uncertain and less reliable than those based on higher counts. This has often led to a desire to quantify enough of these objects by modifying the enumerated sample portion so that the count falls in a range that is deemed acceptable (Emelko et al., 2008; American Public Health Agency et al., 2017; United States Food and Drug Administration, 2017). When this is not possible, resulting NDs are widely reported as being less than a detection limit (e.g., <1 per analytical sample size) and used as a statement about true source concentration. This convention has been widely implemented and deemed precautionary because it usually leads to higher (i.e., conservative) mean concentration estimates. Approaches for handling this type of ND data are often developed out of computational convenience, though more elaborate approaches also continue to be developed. One important reason for the development of more complex approaches arises from the recognition that true microbe concentrations are imperfectly estimated by the analytical methodologies used to obtain counts from samples (Nieminski et al., 1995; Allen et al., 2000). For example, the impact of measurement error (e.g., random sampling error and imperfect and/or variable analytical recovery) on microbial concentration estimates has been widely demonstrated and thoroughly discussed (Nahrstedt and Gimbel, 1996; Gronewold et al., 2008; Gonzales-Barron and Butler, 2011; Schmidt and Emelko, 2011; Commeau et al., 2012; Pouillot et al., 2013; Duarte et al., 2015). Measurement error applies universally to all microbial detection and enumeration methods and refers to the random discrepancy between the actual concentration in the presumably homogeneous source and the concentration estimate obtained from a sample (Emelko et al., 2010). Failure to account for measurement error properly has been shown to bias concentration estimates and associated risk estimates, sometimes by orders of magnitude (Pouillot et al., 2013; Schmidt et al., 2013). In contrast, the implications of interpreting and handling NDs using approaches that mishandle measurement error have not been thoroughly discussed. Current reporting conventions for NDs frequently obfuscate their interpretation, so data analysis approaches have been tailored to how these data are reported rather than what the NDs truly represent.
Here, methods used to characterize microbial concentrations from detection- and enumeration-based data are reviewed, and common misconceptions associated with the reporting and handling of NDs are discussed. Examples that draw upon conventions and standards in the drinking water industry are provided to demonstrate why common approaches that treat NDs as censored data are incorrect and lead to bias in interpretation. Finally, recommendations to facilitate standardized reporting and analysis of such data are provided.
2. State of Scientific Practice
Microbial concentrations in food and water are often estimated using detection- and enumeration-based methods. A detection test produces either an ND or positive (≥1 microorganism) result. With a series of repeated presence/absence tests (e.g., Colilert Quanti-Tray®) and assumed Poisson-distributed numbers of microorganisms in each test (as a function of aliquot size and shared source concentration), the most probable number (MPN) approach yields a maximum likelihood estimate (MLE) of concentration (Pouillot et al., 2013). In these detection methods, reporting of raw aliquot sizes and presence/absence results is necessary for concentration estimation. Enumeration-based methods are distinguished from detection-based methods because they yield a whole number count of target microorganisms within an analytical sample size. These include cultivation plate counts of colonies or virus plaques and cell counts obtained using microscopy or flow-/solid-phase cytometry. We suggest that the concepts addressed in this paper also apply to increasingly common biochemical molecular methods (e.g., qPCR, 16s rRNA gene sequencing); however, such methods are excluded from the scope of this work due to additional assumptions and complexities in the inference of concentrations using these methods, which remain hotly debated (Keer and Birch, 2003).
Although many of the aforementioned microbial enumeration methods have been standardized, protocols for the representation, reporting, and analysis of resulting data remain largely inconsistent. Standard microbiological methods, such as those stipulated within Standard Methods for the Examination of Water and Wastewater, Part 9000 (American Public Health Agency et al., 2017), ASTM D5465-16 (American Society for Testing and Materials, 2016), ISO 8199:2005, and ISO 7218:2007/2013 (International Standards Organization, 2005, 2013), advise that observations should be reported as a count per analytical sample size (e.g., volume). These data (count and sample size) are raw in the sense that the original information pertaining to the precision of the count has not been lost, whereas neither the count nor sample size can be deduced when only a concentration estimate is reported (e.g., 1 microorganism in 64.4 L is more informative than just a reported concentration estimate of 0.0155 microorganisms/L).
In many cases, counts beyond certain thresholds are considered unreliable and avoided if possible. For example, when counting colonies in plating protocols (American Society for Testing and Materials, 2016; American Public Health Agency et al., 2017), an upper bound is often reasonably suggested because of overcrowding and difficulty in distinguishing between individual colonies. In these cases, an upper threshold is often applied beyond which a result of “too numerous to count” (TNTC) is reported. Notably, many conventions related to lower thresholds and NDs also exist. For example, some methods (e.g., in which counts are obtained from a dilution series) suggest that NDs should be omitted in concentration estimation (United States Pharmacopeial Convention, 2014). It has been a common convention to report NDs as <1 microorganism per analytical sample size (International Standards Organization, 2013; Forum on Environmental Measurements (FEM) Microbiology Action Team, 2016; United States Food and Drug Administration, 2017), which is the purported method detection limit (MDL). This is frequently interpreted at face value as the de facto concentration for statistical analyses and regulatory compliance—despite the recently stipulated caveat that MDLs are inapplicable to “methods that do not produce results with a continuous distribution such as […] presence/absence methods, and microbiological methods that involve counting colonies” (United States Environmental Protection Agency, 2016).
2.1. NDs in Analytical Chemistry
To understand the widespread convention of reporting NDs as values below MDLs in microbiology, it is important to understand the origin and motivation behind the concept of an MDL. The MDL (also known as the “limit of detection”) was developed as a performance criterion for chemical analyses (Glaser et al., 1981). This concept has remained largely unchanged since its original conception (Currie, 1999). Although slight variations of this concept exist, the MDL can be operationally defined as the minimum measurement of concentration of a substance that can be reported with a high degree of confidence (commonly 95 or 99%) that the concentration is actually greater than zero (Armbruster and Pry, 2008) (i.e., that the measurement is unlikely to be just random noise despite actual absence of the substance). In stark contrast to the field of microbiology where NDs reflect the inability to collect and/or observe a single microorganism in a particular analysis, analytical chemistry results are much less susceptible to influence by small numbers of analyte particles—signals obtained for quantification arise from the collective effect of very large numbers of atoms/molecules/ions per mole (e.g., 6.022 × 1023). In fact, merely 50 ng of lead in a liter of water (a detection limit attainable by current lead analysis methods) is comprised of more than 1.45 × 1014 lead atoms due to the magnitude of Avogadro's number. In chemistry, random sampling errors associated with specific numbers of analyte particles in a well-mixed sample is largely insignificant compared to errors introduced through the application of the analytical method itself—the accuracy of the measurement is limited by the precision of the measurement instrument. The construct of the MDL is intended to reflect these method-specific errors to facilitate comparisons of data generated using different analytical methods for the same analyte at the lower end of concentration ranges.
Although the MDL construct can be useful, concentration observations falling below these thresholds are not devoid of meaning and it has been recommended that these data should be reported as measured chemical detections. They are still valid observations from which true concentrations can be estimated (albeit with greater uncertainty) by applying appropriate statistical approaches (e.g., that make relevant assumptions concerning randomly distributed error, unbiased analytical methodology, and interference effects) (Analytical Methods Committee, 1987). However, some policies require substances to be described as “absent, present in only a limited number of samples, or present in less than a specified number or amount of a given quantity” (National Research Council (US NRC) Subcommittee on Microbiological Criteria, 1985) in regulatory and contractual frameworks, leading to the adoption of reporting limits (i.e., a value below which data are not reported) by many laboratories.
While these reporting conventions are not themselves problematic, they become problematic if these data are incorrectly interpreted or statistically analyzed. The implications of NDs in environmental chemistry have long been recognized (Analytical Methods Committee, 1987; Lambert et al., 1991). Unaltered zero concentrations preclude the calculation of geometric means and cannot be fit by many continuous distributions (without their explicit accommodation through a zero-inflated model). Values reported as below detection or reporting limits have commonly been either omitted or substituted with a function of the limit (Helsel, 2006) to facilitate computationally convenient analysis. These approaches are deemed conservative, but sacrifice information about data reliability and uncertainty that may be critical in decision making. Chemical concentration data reported as less than a detection limit are an example of censored continuous measurements (where the exact measured value within the specified interval is unknown), for which appropriate statistical approaches do exist (Helsel, 2005).
2.2. NDs in Enumeration-Based Microbial Methods
The direct application of analytical chemistry MDL concepts and associated censoring conventions to microbial enumeration data has inflicted similar challenges for statistical analysis in microbiology. Taking NDs as zeros and weighing them with other non-zero counts based on their respective analytical sample sizes is sufficient for the simple calculation of mean concentrations provided the microorganisms are randomly dispersed and a representative sample was obtained (i.e., from a source where the spatial distribution of the analyte is not heterogeneous); however, this approach is insufficient for fitting concentration distributions and quantifying data reliability or uncertainty in the calculated mean (Parkhurst and Stern, 1998). Commonly used omission and substitution methods borrowed from analytical chemistry for summarizing and reporting mean microbial concentrations in water introduce bias; substitution methods have been demonstrated to be increasingly biased with greater proportions of NDs in both chemical and microbial data (Parkhurst and Stern, 1998; Helsel, 2005; Roser and Ashbolt, 2005). While the bias introduced using substitution methods can offer a substantial safety factor when harmful microorganisms are rare (by considering them to be present when they are not or they have not been detected), it is critical to note that this bias offers no factor of safety when it is most needed (e.g., when pathogens are routinely observed) (Parkhurst and Stern, 1998).
The acknowledgement that “…[data reported as censored] cannot be treated statistically without modification” (American Public Health Agency et al., 2017) and the growing need to quantify uncertainty in the concentration estimate have led to the development of various statistical tools for analyzing these data. Critically, NDs in microbial data are in fact observed counts of zero commonly misrepresented as censored data. Their misrepresentation has led to the adoption of censored data approaches for handling microbial NDs (Lorimer and Kiermeier, 2007; Busschaert et al., 2010; Williams and Ebel, 2012). While many statistical analyses have assumed that microbial concentrations are measured directly and precisely, markedly different statistical methods have been developed that acknowledge the probabilistic relationship between actual observed data (including NDs) and the underlying microbial concentrations by accounting for measurement error (Nahrstedt and Gimbel, 1996; Gronewold et al., 2008; Gonzales-Barron and Butler, 2011; Schmidt and Emelko, 2011; Commeau et al., 2012; Pouillot et al., 2013; Duarte et al., 2015). As would be expected, different approaches for handling microbial NDs can result in substantially different outcomes. Specifically, the statistical analysis of inappropriately censored NDs may lead to erroneous microbial concentration estimates and subsequent interpretations—this is demonstrated by the examples below. It is critical to recognize that data for which both raw counts and sample sizes are known are not censored—these include NDs that are based on counts of zero in known sample sizes. These data are not censored and must not be statistically treated as such.
3. Results: Evidence That Microbial Non-Detects Are Not Censored Data
3.1. Occurrences of Microbial NDs Are Not Solely a Function of Analyte Concentrations
All microbial concentration estimates are imprecise, not only NDs. An ND can arise when either the concentration is truly zero or when target microorganisms are present in the source but not successfully detected. Because of the latter case, it is commonly understood that an ND does not necessarily imply that the concentration is truly zero. Indeed, consistent with the aphorism “absence of evidence is not evidence of absence,” a concentration of zero cannot actually be proven by an ND for this reason.
Figure 1 examines factors leading to ND results at non-zero concentrations (derivation in Supplementary Material S1). Figure 1A depicts the probability of observing an ND as a function of the true concentration and the sample volume assuming Poisson-distributed organism counts and a method with 100% analytical recovery. Probability of ND profiles are presented for volumes of 0.010, 1.0, and 100 L to illustrate the impact of 100-fold increases in the analytical sample size. Common sample volumes for total coliform/Escherichia coli and protozoan (oo)cyst analyses are 0.100 and 100 L, respectively. Intuitively, the probability of an ND observation from a single sample increases with decreasing concentration and analytical sample size. In practice, the occurrence of random NDs can be reduced by increasing sample size.
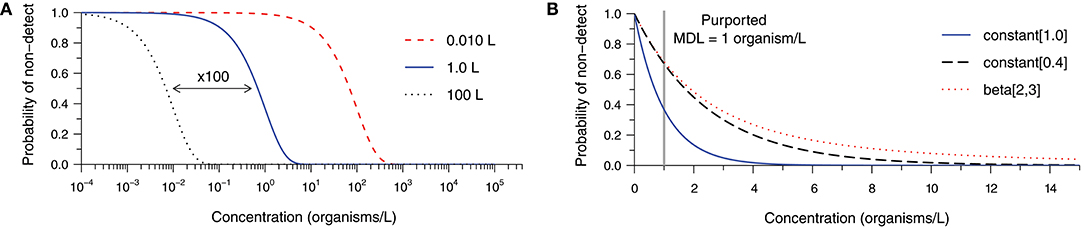
Figure 1. Probability of a non-detect observation as a function of organism concentration and (A) various analytical sample volumes given 100% analytical recovery, and (B) various analytical recovery profiles given a 1.0-L sample, each assuming Poisson random sampling error. The constant [0.4] and beta-distributed [beta(2,3)] recovery profiles share a mean of 40% analytical recovery, but the latter is more variable.
Building upon the previous example, Figure 1B addresses the occurrence of NDs given a 1.0 L sample volume and various analytical recovery profiles. The bold curve in Figure 1B is identical to the one in Figure 1A, but plotted on a linear concentration scale. It represents 100% analytical recovery, whereas the second curve addresses the scenario of a constant analytical recovery of 40% (i.e., the probability of observation for each microorganism initially gathered is 40% in any sample). Logically, the probability of NDs increases as microorganisms are more likely to be lost during sample processing. The remaining curve retains a mean recovery of 40%; however, substantial variation in recovery among samples is described by a beta distribution. This further inflates the probability of an ND observation because some samples would have relatively low recovery. Clearly, the occurrence of NDs is sensitive not only to the source concentration and the analytical sample size, but also the analytical recovery profile of the method for the particular sample matrix.
It may be useful to consider the concentration beyond which NDs become improbable (e.g., probability <1%) when comparing alternative methods, choosing a target sample volume, or determining the appropriateness of a method for a particular application. We propose that this threshold may be called a method sensitivity limit (MSL) because sensitivity is the probability of detection when the target microorganisms are actually present in the source. Considering the examples in Figure 1B and allowing for 1% probability of observing a non-detect, the scenario with 100% analytical recovery has an MSL of 4.6 organisms per liter. With 40% analytical recovery, the MSL increases to 11.5 organisms per liter. The MSL is 32.5 organisms per liter in the final scenario, illustrating the pronounced effect of variability in analytical recovery upon sensitivity of microbial analytical methods. While this calculated value could be useful, it is important to note that it is sensitive to uncertainty in the parameters and shape of the analytical recovery distribution (where low recovery values are common), and would not be practical to evaluate for every method and sample matrix.
3.2. Uncertainty in Concentration Estimates Precludes MDL-Based Interpretation of Results
The statistical analysis of inappropriately censored microbial data ultimately leads to erroneous concentration estimates and subsequent interpretations. Bayesian techniques (Gelman et al., 2014) provide a means of demonstrating the uncertainty surrounding the concentration estimate obtained from microbial enumeration data (Gronewold et al., 2008; Gonzales-Barron and Butler, 2011; Schmidt and Emelko, 2011; Duarte et al., 2015). Accounting for measurement error, these methods describe the relative probability of alternative values of the true microbial concentration given the count observation obtained from the analytical sample and a prior representing beliefs about the plausible values of concentration before data analysis. Figure 2 illustrates what a single ND observation (Figure 2A) and an observation of two microorganisms (Figure 2B) within a 1.0 L sample volume imply about concentration assuming perfect analytical recovery and using a relatively uninformative semi-infinite uniform prior (derivation in Supplementary Material S2).
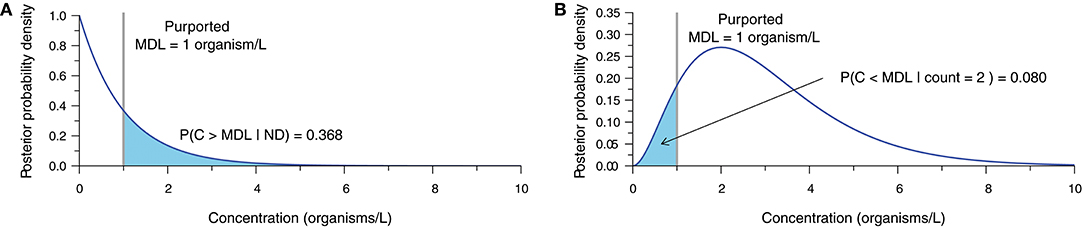
Figure 2. Posterior probability density function (PDF) characterizing uncertainty in the true concentration given (A) an ND observation, and (B) an observation of two organisms, each based on a 1.0-L sample, 100% analytical recovery, and a semi-infinite uniform prior. The purported MDL of 1 organism/L is shown with the probability of the true concentration exceeding or falling short of the purported MDL, respectively.
When an ND is observed (Figure 2A), there is still a large probability (≈ 37% in this example) that the actual concentration exceeds the purported MDL, therefore invalidating the assertion that an ND means that the actual concentration is <MDL. Conversely, a count of two organisms (Figure 2B) leads to a considerable probability (≈ 8% in this example) that the actual concentration could still be less than the purported MDL. This simple demonstration shows that the interpretation of NDs as censored data below the purported MDL is inappropriate, and further underscores that point estimates of concentration ought not be treated as exact measurements.
3.3. Censoring in Detection- and Enumeration-Based Microbial Methods
Although NDs in microbial detection and enumeration methods are not censored data, there are scenarios in which certain microbial methods yield truly censored data. Censored data occur when there is incomplete knowledge about an observed measurement above, below, or between specified values (Millard et al., 2012). Such censoring can be inherent to the method or imposed deliberately by the analyst as exemplified below. In either case, censoring applies to raw measurements (e.g., count test results) rather than calculated values that are not measured directly (e.g., concentration estimates).
An ND in presence-absence tests (e.g., Colilert®, Rapid HiColiform™, AquaCHROM™) implies a count of zero within the associated analytical sample volume. A positive test result can be construed as an inherently censored count of at least one microorganism because the method cannot reveal the exact number of microorganisms leading to detection. For a series of presence-absence tests, MPN approaches implicitly reflect censored data analysis by using the cumulative probability of all non-zero counts (i.e., the complement of the probability of a ND) to represent a positive test result in the likelihood function.
When using culture-based methods, counts beyond an upper limit are conventionally reported as TNTC [e.g., 150 or 200 colony forming units (cfu) for spread plates, 80 cfu for membrane filtration, and 300 cfu for pour plates, American Society for Testing and Materials 2016; American Public Health Agency et al. 2017]. If a specific observed count is replaced with TNTC, then this is an example of imposed censoring. In contrast, censoring is inherent if counting is terminated upon reaching the limit or is not attempted because the count would clearly exceed it. Such truly censored observations may be incorporated into the Bayesian method described previously (or any likelihood-based method) using cumulative density for the censored range of counts rather than just probability density associated with particular observed counts. Some standards (American Public Health Agency et al., 2017) recommend completing a new analysis with dilution to replace TNTC results. We suggest that TNTC results should be retained in subsequent statistical analyses by using likelihood-based methods that allow inference from both the TNTC result and the count obtained through re-analysis of the sample. This would enable more accurate description of knowledge about the concentration by harnessing all of the available information rather than omitting inconvenient data.
4. Implications for Policy and Practice
Many environmental science and public health decision-making and regulatory frameworks rely upon the accurate evaluation of microbial concentrations and comparison with concentration-based criteria. For example, evaluation of source water pathogen concentrations is used to determine minimum treatment infrastructure requirements in the provision of safe drinking water (United States Environmental Protection Agency, 2006; Alberta Environment and Sustainable Resource Development, 2012). Here, concentration estimates that bias high may lead to misallocation of resources including costly infrastructure investments and operational adjustments.
Giardia has been the most commonly reported intestinal protozoan in North America and worldwide; it is also likely the most common cause of surface water-borne infectious disease outbreaks (Adam et al., 2016; Efstratiou et al., 2017). A set of eight source water Giardia cyst counts (Table 1) from the larger City of Calgary database were used to illustrate the potential impacts of various ND data analysis approaches. The impact of inappropriate ND data analysis approaches will vary in accordance to characteristics of each dataset; greater bias can be expected when NDs constitute a larger proportion of the dataset and perfect analytical recovery is not attainable. However, more detailed analysis regarding the scale of implications associated with such characteristics (e.g., number of samples, proportion of zeros, distribution of positive detections, etc.) was beyond the scope of the present investigation. Consistent with current practice and interpretation of the regulations, the raw data were not adjusted for viability or infectivity, with 100% analytical recovery assumed.

Table 1. Summary of raw water samples analyzed for Giardia cysts from City of Calgary, AB, Canada—October, 2012.
The data were used to obtain MLEs of the mean and standard deviation of Giardia cyst concentrations (United States Environmental Protection Agency, 2006; Alberta Environment and Sustainable Resource Development, 2012) assuming log-normally distributed concentrations and independence among sampling events. NDs were omitted in Approach A and substituted with the MDL and half the MDL in Approaches B and C (approaches critiqued by Helsel, 2005), and were handled as censored data in Approach D (Busschaert et al., 2010; Williams and Ebel, 2012). The purported MDL of one cyst per volume analyzed is critical for substitution and censored data methods. For Approach D, the cumulative density between zero and the purported MDL was used for NDs (Busschaert et al., 2010). Maximum likelihood estimation was applied for Approaches A–D using the fitdistrplus package (v. 1.0–9) (Delignette-Muller et al., 2017) in R. In Approach E, a Poisson distribution was used to account for random sampling error with log-normally distributed concentrations, using the poilog package (v. 0.4) (Grøtan and Engen, 2008) in R (details provided in Supplementary Material S3). It is important to note that Approaches A–D are based only on reported concentration estimates whereas Approach E (like other approaches that account for measurement error) necessitates the reporting of raw data. Statistics from this analysis are summarized in Table 2.

Table 2. Comparison of Giardia cyst concentration statistics obtained using various approaches for handling microbial NDs.
As would be expected, Approaches A–D yielded substantially higher mean Giardia cyst concentrations relative to Approach E because the NDs were omitted or represented as non-zero values. Omission and substitution approaches are known to lead to biased mean concentration estimates relative to methods appropriate for censored data (Helsel, 2005). However, the types of microbial ND data considered herein are fundamentally not censored, as discussed above. There is a critical difference between censored data approaches (Approach D) and those that actually incorporate NDs as legitimate, discrete observations by accounting for measurement error (e.g., Approach E). In this example, the parasite concentrations were overestimated relative to Approach E by a factor of 2.1–3.9 when NDs were inappropriately handled (Approaches A–D).
Given sufficient and suitable information, the MLE approach incorporating random sampling error (Approach E) can be extended to account for analytical recovery. However, model fitting by MLE becomes more difficult with increasing model complexity—numerical integration required for evaluating the resulting likelihood function becomes practically intractable in many cases. Bayesian methods can be used to fit more complex probabilistic models to data, but also suffer from substantial parametric uncertainty where insufficient data and/or data that are relatively uninformative about model parameters are available (Gleit, 1985; Helsel and Cohn, 1988). Indeed, small statistical sample sizes are often inevitable when using time- and/or resource-intensive microbial analytical methods [such as those for protozoan (oo)cyst enumeration (United States Environmental Protection Agency2005, 2012)]. For example, utilities undertaking minimum source water monitoring requirements for the determination of drinking water treatment targets (Alberta Environment and Sustainable ResourceDevelopment, 2012) would be determining running mean Giardia cyst concentrations based on monthly samples collected over the course of 2 years (i.e., n = 24). The impact of small statistical sample sizes on concentration distribution parameter estimates is exacerbated when all of the data available are NDs, in which case statistical analysis is not possible without strongly subjective priors.
Although treatment requirements are not typically determined based on mean Giardia cyst concentrations estimated from a handful of samples, these data may exemplify monitoring results from utilities that draw upon high quality source waters. Such systems, especially those that have limited treatment, operational, and/or monitoring capacity, are particularly vulnerable to the implications associated with overestimated mean concentrations. As demonstrated in this analysis, concentration estimates may be biased high by a factor of two or more just by handling NDs as censored. This could lead to operational and maintenance costs/adjustments (e.g., energy for UV disinfection, alteration of design flow rates) (Cotton et al., 2001) that are inordinate given the levels of pathogens actually present in the source. Thus, such bias can also inappropriately affect assessments of water treatment plant “firm capacity,” which indicates pathogen treatment capacity in absence of one key treatment barrier and therefore informs infrastructure needs. While application of these approaches may result in bias that invokes more conservative levels of treatment (Parkhurst and Stern, 1998), it is better to analyze microbial concentrations accurately and apply consistent safety factors—regardless of the data—than to apply flawed data analysis approaches with unspecified safety factors attributable to preventable bias. This precludes the universal and equitable application of microbial standards, and ultimately undermines the consistent level of public health protection that the industry strives to maintain.
5. Conclusions
• Non-detect microbial detection and enumeration data are fundamentally not censored data and should not be reported or analyzed as such.
• Method detection limits are not intended to be used for, and have therefore been misapplied in, detection- and enumeration-based methods that count discrete microorganisms.
• The convention of reporting non-detects as censored values relative to a method detection limit is misleading when using enumeration-based methods and has resulted in the misuse of censored data statistical approaches for microbial data analysis.
• It is inconsistent to consider the uncertainty in non-detects by representing them as censored data while ignoring the inherent uncertainty in all non-zero counts.
• Censored data approaches should be reserved for data correctly interpreted as being censored, such as too numerous to count plate counts where the actual count is known only to exceed a specified threshold.
• This work re-emphasizes that raw microbial data must be reported to facilitate proper statistical analysis approaches that account for measurement error.
Author Contributions
PS, ME, and AC designed the work. AC, PS, and ME analyzed the data and prepared the manuscript.
Funding
We acknowledge the support of the Natural Sciences and Engineering Research Council of Canada (NSERC), [CRDPJ 484588 - 15] and the City of Calgary.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank the staff of the City of Calgary for providing the microbial water quality dataset for analysis. We are also grateful to Alfred Paul Blaschke (Vienna University of Technology, Vienna, Austria), Jack F. Schijven (RIVM & Utrecht Universiteit, Netherlands), Norma J. Ruecker (City of Calgary, AB, Canada), and two reviewers for their review of this manuscript.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmicb.2018.02304/full#supplementary-material
References
Adam, E. A., Yoder, J. S., Gould, L. H., Hlavsa, M. C., and Gargano, J. W. (2016). Giardiasis outbreaks in the United States, 1971–2011. Epidemiol. Infect. 144, 2790–2801. doi: 10.1017/S0950268815003040
Alberta Environment and Sustainable Resource Development (AESRD) (2012). Standards and Guidelines for Municipal Waterworks, Wastewater and Storm Drainage Systems. Edmonton, AB: Alberta Queen's Printer.
Allen, M. J., Clancy, J. L., and Rice, E. W. (2000). The plain, hard truth about pathogen monitoring. J. AWWA 92, 64–76. doi: 10.1002/j.1551-8833.2000.tb09005.x
Analytical Methods Committee (1987). Recommendations for the definition, estimation and use of the detection limit. Analyst 112, 199–204. doi: 10.1039/an9871200199
American Public Health Agency (APHA) American Water Works Association (AWWA), and Water Environment Federation (WEF). (2017). Standard Methods For the Examination of Water & Wastewater, 23rd Edn. Washington, DC: American Public Health Assn.
Armbruster, D. A., and Pry, T. (2008). Limit of blank, limit of detection and limit of quantitation. Clin. Biochem. Rev. 29(Suppl. 1):S49–S52.
American Society for Testing and Materials (ASTM) (2016). ASTM D5465-16 - Standard Practices for Determining Microbial Colony Counts from Waters Analyzed by Plating Methods. ASTM.
Busschaert, P., Geeraerd, A. H., Uyttendaele, M., and Van Impe, J. F. (2010). Estimating distributions out of qualitative and (semi) quantitative microbiological contamination data for use in risk assessment. Int. J. Food Microbiol. 138, 260–269. doi: 10.1016/j.ijfoodmicro.2010.01.025
Commeau, N., Parent, E., Delignette-Muller, M.-L., and Cornu, M. (2012). Fitting a lognormal distribution to enumeration and absence/presence data. Int. J. Food Microbiol. 155, 146–152. doi: 10.1016/j.ijfoodmicro.2012.01.023
Cotton, C. A., Owen, D. M., Cline, G. C., and Brodeur, T. P. (2001). UV disinfection costs for inactivating Cryptosporidium. J. Am. Water Works Assoc. 93, 82–94. doi: 10.1002/j.1551-8833.2001.tb09228.x
Currie, L. A. (1999). Detection and quantification limits: origins and historical overview. Anal. Chim. Acta 391, 127–134.
Davis, C. (2014). Enumeration of probiotic strains: review of culture-dependent and alternative techniques to quantify viable bacteria. J. Microbiol. Methods 103, 9–17. doi: 10.1016/j.mimet.2014.04.012
Delignette-Muller, M.-L., Dutang, C., Pouillot, R., Denis, J.-B., and Siberchicot, A. (2017). Fitdistrplus: Help to Fit of a Parametric Distribution to Non-Censored or Censored Data. Available online at: https://cran.r-project.org/web/packages/fitdistrplus/fitdistrplus.pdf
Dickey, R. P., Pyrzak, R., Lu, P. Y., Taylor, S. N., and Rye, P. H. (1999). Comparison of the sperm quality necessary for successful intrauterine insemination with World Health Organization threshold values for normal sperm. Fertil. Steril. 71, 684–689. doi: 10.1016/S0015-0282(98)00519-6
Duarte, A. S. R., Stockmarr, A., and Nauta, M. J. (2015). Fitting a distribution to microbial counts: making sense of zeroes. Int. J. Food Microbiol. 196, 40–50. doi: 10.1016/j.ijfoodmicro.2014.11.023
Efstratiou, A., Ongerth, J. E., and Karanis, P. (2017). Waterborne transmission of protozoan parasites: review of worldwide outbreaks - an update 2011-2016. Water Res. 114, 14–22. doi: 10.1016/j.watres.2017.01.036
Emelko, M. B., Schmidt, P. J., and Reilly, P. M. (2010). Particle and microorganism enumeration data: enabling quantitative rigor and judicious interpretation. Environ. Sci. Technol. 44, 1720–1727. doi: 10.1021/es902382a
Emelko, M. B., Schmidt, P. J., and Roberson, J. A. (2008). Quantification of uncertainty in microbial data—reporting and regulatory implications. J. AWWA 100, 94–104. doi: 10.1002/j.1551-8833.2008.tb09584.x
Forum on Environmental Measurements (FEM) Microbiology Action Team (2016). Method Validation of U.S. EPA Microbiological Methods of Analysis. Technical Report 2009-01.
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., and Rubin, D. B. (2014). Bayesian Data Analysis, Vol. 2. Boca Raton, FL: CRC Press.
Gerba, C. P., and Rose, J. B. (2003). International guidelines for water recycling: microbiological considerations. Water Sci. Technol. 3, 311–316. doi: 10.2166/ws.2003.0077
Glaser, J. A., Foerst, D. L., McKee, G. D., Quave, S. A., and Budde, W. L. (1981). Trace analyses for wastewaters. Environ. Sci. Technol. 15, 1426–1435. doi: 10.1021/es00094a002
Gleit, A. (1985). Estimation for small normal data sets with detection limits. Environ. Sci. Technol. 19, 1201–1206. doi: 10.1021/es00142a011
Gonzales-Barron, U., and Butler, F. (2011). A comparison between the discrete Poisson-gamma and Poisson-lognormal distributions to characterise microbial counts in foods. Food Control 22, 1279–1286. doi: 10.1016/j.foodcont.2011.01.029
Gracias, K. S., and McKillip, J. L. (2004). A review of conventional detection and enumeration methods for pathogenic bacteria in food. Can. J. Microbiol. 50, 883–890. doi: 10.1139/w04-080
Gronewold, A. D., Borsuk, M. E., Wolpert, R. L., and Reckhow, K. H. (2008). An assessment of fecal indicator bacteria-based water quality standards. Environ. Sci. Technol. 42, 4676–4682. doi: 10.1021/es703144k
Grøtan, V., and Engen, S. (2008). Poilog: Poisson Lognormal and Bivariate Poisson Lognormal Distribution. R Package Version 0.4. Available online at: https://cran.r-project.org/web/packages/poilog/poilog.pdf
Havelaar, A., Blumenthal, U. J., Strauss, M., Kay, D., and Bartram, J. (2001). “Guidelines: the current position,” Water Quality: Guidelines, Standards and Health, eds L. Fewtrell and J. Bartram (London: IWA Publishing), 17–42.
Helsel, D. R. (2006). Fabricating data: how substituting values for nondetects can ruin results, and what can be done about it. Chemosphere 65, 2434–2439. doi: 10.1016/j.chemosphere.2006.04.051
Helsel, D. R., and Cohn, T. A. (1988). Estimation of descriptive statistics for multiply censored water quality data. Water Resour. Res. 24, 1997–2004. doi: 10.1029/WR024i012p01997
International Standards Organization (ISO) (2005). ISO 8199:2005 General Guidance on the Enumeration of Micro-organisms by Culture. Technical Report ISO 8199:2005, International Organization for Standardization, Geneva, Switzerland.
International Standards Organization (ISO) (2013). Microbiology of Food and Animal Feeding Stuffs – General Requirements and Guidance for Microbiological Examinations. Technical Report ISO 7218:2007, International Organization for Standardization, Geneva, Switzerland.
Keer, J. T., and Birch, L. (2003). Molecular methods for the assessment of bacterial viability. J. Microbiol. Methods 53, 175–183. doi: 10.1016/S0167-7012(03)00025-3
Koepke, J. A., Van Assendelft, O. W., Brindza, L. J., Davis, B. H., Fernandes, B. J., Gewirtz, A. S., et al. (2007). Reference Leukocyte (WBC) Differential Count (Proportional) and Evaluation of Instrumental Methods; Approved Standard. Clinical and Laboratory Standards Institute (CLSI) Document H2O-A2.
Lambert, D., Peterson, B., and Terpenning, I. (1991). Nondetects, detection limits, and the probability of detection. J. Am. Stat. Assoc. 86, 266–277. doi: 10.2307/2290558
Lorimer, M. F., and Kiermeier, A. (2007). Analysing microbiological data: Tobit or not Tobit? Int. J. Food Microbiol. 116, 313–318. doi: 10.1016/j.ijfoodmicro.2007.02.001
Lund, B., Baird-Parker, T. C., and Gould, G. W. (2000). Microbiological Safety and Quality of Food, Vol. 1. Gaithersburg, MD: Springer Science & Business Media.
Millard, S. P., Neerchal, N. K., and Dixon, P. (2012). Environmental Statistics with R and S-Plus, 2nd Edn. London: Taylor & Francis Group.
Nahrstedt, W., and Gimbel, R. (1996). A statistical method for determining the reliability of the analytical results in the detection of Cryptosporidium and Giardia. Aqua 45, 101–111.
National Research Council (US NRC) Subcommittee on Microbiological Criteria (1985). Definitions, Purposes, and Needs for Microbiological Criteria. Washington DC: National Academies Press (US).
Nieminski, E. C., Schaefer, F. W., and Ongerth, J. E. (1995). Comparison of two methods for detection of Giardia cysts and Cryptosporidium oocysts in water. Appl. Environ. Microbiol. 61, 1714–1719.
Parkhurst, D. F., and Stern, D. A. (1998). Determining average concentrations of Cryptosporidium and other pathogens in water. Environ. Sci. Technol. 32, 3424–3429. doi: 10.1021/es970748q
Pouillot, R., Hoelzer, K., Chen, Y., and Dennis, S. (2013). Estimating probability distributions of bacterial concentrations in food based on data generated using the most probable number (MPN) method for use in risk assessment. Food Control 29, 350–357. doi: 10.1016/j.foodcont.2012.05.041
Roser, D. J., and Ashbolt, N. J. (2005). Source Water Quality Assessment and the Management of Pathogens in Surface Catchments and Aquifers. Salisbury, SA: CRC for Water Quality and Treatment.
Schijven, J. F., and de Roda Husman, A. M. (2011). “Applications of quantitative microbial source tracking and quantitative microbial risk assessment,” in Microbial Source Tracking: Methods, Applications & Case Studies, eds C. Hagedorn, A. R. Blanch, and V. J. Harwood (New York, NY: Springer), 559–583.
Schmidt, P. J., and Emelko, M. B. (2011). QMRA and decision-making: are we handling measurement errors associated with pathogen concentration data correctly? Water Res. 45, 427–438. doi: 10.1016/j.watres.2010.08.042
Schmidt, P. J., Emelko, M. B., and Thompson, M. E. (2013). Analytical recovery of protozoan enumeration methods: have drinking water QMRA models corrected or created bias? Water Res. 47, 2399–2408. doi: 10.1016/j.watres.2013.02.001
United States Pharmacopeial Convention (2014). < 61> Microbiological Examination of Nonsterile Products: Microbial Enumeration Tests. Technical Report USP 37, United States Pharmacopeial Convention.
United States Environmental Protection Agency (US EPA) (2005). Cryptosporidium and Giardia in Water by Filtration/IMS/FA. Technical Report EPA 815-R-05-002.
United States Environmental Protection Agency (US EPA) (2006). National Primary Drinking Water Regulations: Long Term 2 Enhanced Surface Water Treatment Rule.
United States Environmental Protection Agency (US EPA) (2012). Method 1623.1: Cryptosporidium and Giardia in Water by Filtration/IMS/FA. Technical Report EPA 816-R-12-001.
United States Environmental Protection Agency (US EPA) (2016). Definition and Procedure for the Determination of the Method Detection Limit, Revision 2. Technical Report EPA821-R-16-0 06, US EPA Office of Water, Washington, DC.
United States Food and Drug Administration (US FDA) (1998/2017). Bacteriological Analytical Manual. Technical Report Edition 8 Revision A 1998, US Food and Drug Administration.
World Health Organization (WHO) (2017). Guidelines for Drinking-Water Quality: 4th Edn. Technical Report, World Health Organization.
Keywords: QMRA, microbial risk assessment, zeros, detection limit, censored data, presence-absence, pathogens
Citation: Chik AHS, Schmidt PJ and Emelko MB (2018) Learning Something From Nothing: The Critical Importance of Rethinking Microbial Non-detects. Front. Microbiol. 9:2304. doi: 10.3389/fmicb.2018.02304
Received: 10 March 2018; Accepted: 10 September 2018;
Published: 05 October 2018.
Edited by:
Aldo Corsetti, Università degli Studi di Teramo, ItalyReviewed by:
Antonio Valero, Universidad de Córdoba, SpainMaria Aponte, Università degli Studi di Napoli Federico II, Italy
Copyright © 2018 Chik, Schmidt and Emelko. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Monica B. Emelko, bWJlbWVsa29AdXdhdGVybG9vLmNh