 Issam Khelfaoui1
Issam Khelfaoui1 Wenxin Wang1*
Wenxin Wang1* Hicham Meskher2
Hicham Meskher2 Akram Ismael Shehata3,4
Akram Ismael Shehata3,4 Mohammed F. El Basuini5Mohamed F. Abouelenein6Houssem Eddine Degha7
Mohammed F. El Basuini5Mohamed F. Abouelenein6Houssem Eddine Degha7 Mayada Alhoshy8
Mayada Alhoshy8 Islam I. Teiba9
Islam I. Teiba9 Seedahmed S. Mahmoud10
Seedahmed S. Mahmoud10- 1School of Public Health, Shantou University/Institute of Local Government Development, Shantou University, Shantou, China
- 2Key Laboratory for Preparation and Application of Ordered Structural Materials of Guangdong Province, Department of Chemistry, Shantou University, Shantou, China
- 3Institute of Marine Sciences, Shantou University, Shantou, China
- 4Department of Animal and Fish Production, Faculty of Agriculture (Saba Basha), Alexandria University, Alexandria, Egypt
- 5King Salman International University, El Tor, Egypt
- 6Department of Insurance and Risk Management, College of Business, Imam Mohammad Ibn Saud Islamic University (IMSIU), Riyadh, Saudi Arabia
- 7Department of Computer Science and Information Technologies, Faculty of New Technologies of Information and Communication, Kasdi Merbah Ouargla University, Ouargla, Algeria
- 8Independent Researcher, Alexandria, Egypt
- 9Department of Botany, Faculty of Agriculture, Tanta University, Tanta, Egypt
- 10Department of Biomedical Engineering, College of Engineering, Shantou University, Shantou, China
The human microbiome is increasingly recognized as a key mediator of health and disease, yet translating microbial associations into actionable interventions remains challenging. This review synthesizes advances in machine learning (ML) and causal inference applied to human microbiome research, emphasizing policy-relevant applications. Explainable ML approaches, have identified microbial drivers, guiding targeted strategies. Econometric tools, including instrumental variables, difference-in-differences, and panel data models, provide robust frameworks for validating causal relationships, while hybrid methods like Double Machine Learning (Double ML) and Deep Instrumental Variables (Deep IV) address high-dimensional and non-linear effects, enabling precise evaluation of microbiome-mediated interventions. Policy translation is further enhanced by federated learning, standardized analytical pipelines, and model visualization frameworks, which collectively improve reproducibility, scalability, and data privacy compliance. By integrating predictive power with causal rigor, microbiome research can move beyond observational associations to generate interventions that are biologically grounded, clinically actionable, and policy-ready. This roadmap provides a blueprint for translating mechanistic microbial insights into real-world health solutions, emphasizing interdisciplinary collaboration, standardized reporting, and evidence-based policymaking.
1 Introduction
Over the past two decades, our understanding of the human microbiome has undergone a profound transformation. Once considered a biological curiosity, the trillions of microorganisms inhabiting the human body are now recognized as active participants in health, disease, and therapeutic response. Microbiome research has evolved from descriptive catalogs of microbial diversity toward sophisticated analyses designed to predict, explain, and ultimately manipulate microbial dynamics for clinical and public health benefit. This evolution has been propelled by advances in high-throughput sequencing, computational biology, and, increasingly, machine learning (ML). However, despite the power of ML to detect complex microbiome–health associations, a crucial limitation remains: correlation does not imply causation. Without rigorous causal inference, predictive models may fail to generalize, interventions may miss their intended targets, and policy decisions may rest on uncertain foundations. This limitation is not only of academic concern, industry and policy stakeholders have already recognized the strategic value of translating microbiome insights into actionable programs.
This composite Figure 1 summarizes the current state and projected growth of the human microbiome market based on multiple research sources. Panel A shows the estimated market size in 2023 across four major firms, highlighting differences in scope and segmentation. Panel B presents the regional market share in 2022, with North America dominating due to regulatory leadership and investment. Panel C illustrates projected market growth from 2022 to 2032, based on Acumen’s forecast. Key drivers of market expansion include the rising prevalence of chronic diseases requiring microbiome-based therapies, advances in metagenomics, and increasing investments in therapeutic development.
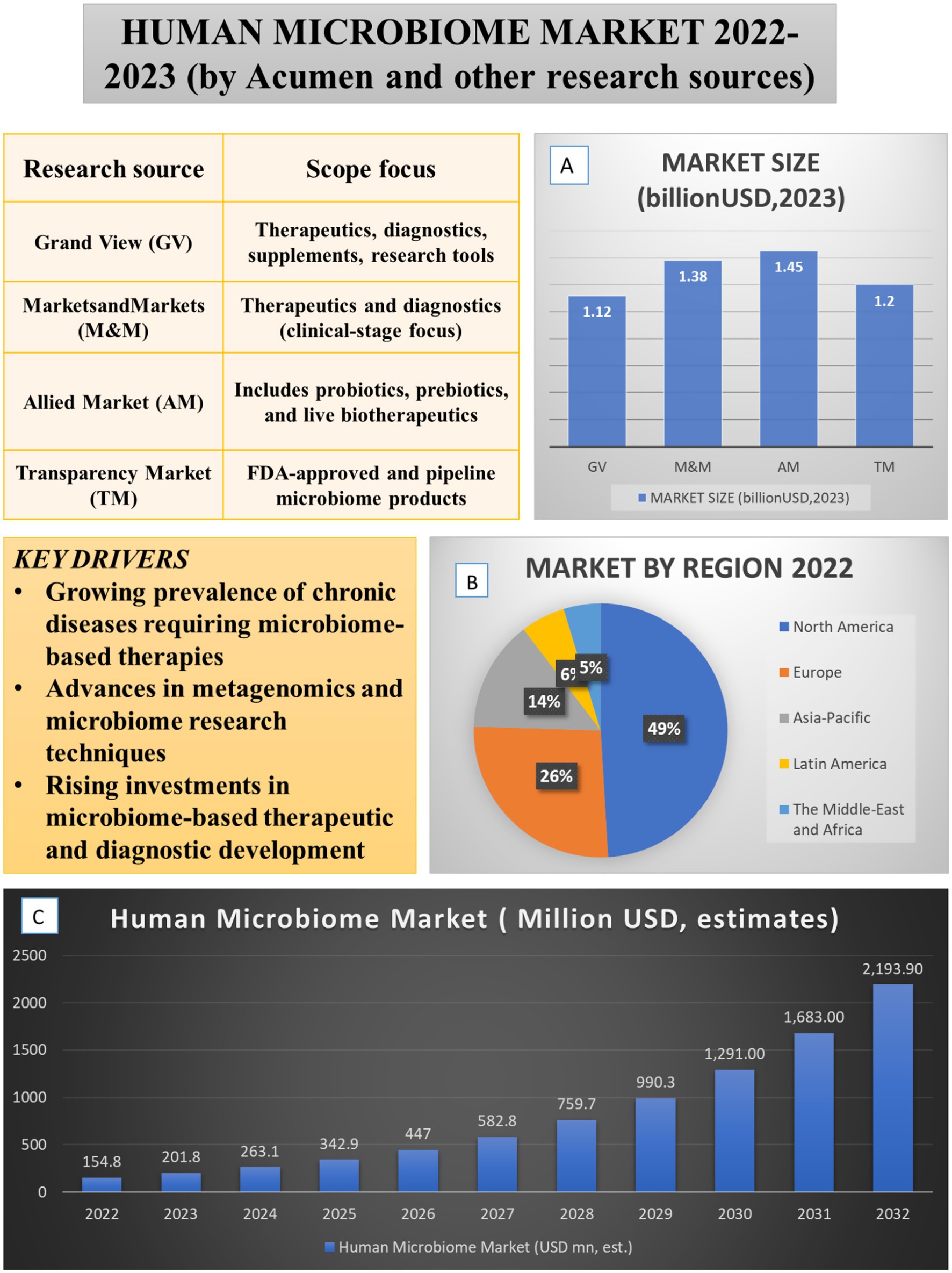
Figure 1. Global human microbiome market landscape (2022–2023): size, regional distribution, and key drivers. The figure integrates key drivers, market size (A), regional distribution (B), and projected growth of the human microbiome market (C). Market drivers include the rising prevalence of chronic diseases requiring microbiome-based therapies, advances in metagenomics and causal ML techniques, and increased investments in therapeutic and diagnostic development. Comparative analyses from multiple research sources (GV, M&M, AM, TM, 2025 reports) estimate the 2023 market size between USD 1.12–1.45 billion. Data from Acumen Research and Consulting show that in 2022, North America (49%) led the regional market, followed by Europe (26%) and Asia-Pacific (14%), with projected global expansion from USD 154.8 million in 2022 to USD 2193.9 million by 2032.
1.1 Microbiome and health
The human microbiome has emerged as a critical determinant of health and disease. Foundational studies have demonstrated its involvement in conditions ranging from colorectal adenoma (Goedert et al., 2015) to cirrhosis progression (Bajaj et al., 2020). Advances in high-throughput sequencing and ML have further revealed predictive potential across diverse contexts, including stratifying rheumatoid arthritis treatment responses (Gupta et al., 2021), identifying high-risk myeloma signatures (Feinman et al., 2023), and detecting gastric cancer trends (Zhang et al., 2025). Interpretable ML models have also been successfully applied to classify diabetes subtypes (Gou et al., 2020) and identify obesity-associated microbial markers (Zeng et al., 2019).
Despite these advances, predictive performance does not always translate into actionable insight. For example, short-chain fatty acids (SCFAs) in fecal samples often fail to reliably predict tumor development (Sze et al., 2019). Viral sequence analyses remain challenging due to gaps in reference databases and assembly biases (Kieft et al., 2020; Ren et al., 2017). Integrative studies combining ocular microbiome and metabolomic data further highlight the complexity of cross-domain microbiome research (Gao et al., 2025).
1.2 The causality gap
Correlational microbiome studies remain vulnerable to confounding and bias. For instance, tuberculosis medications can distort predictions of inflammatory states (Wipperman et al., 2021), batch effects in oral microbiome datasets introduce noise (Rupf et al., 2018), and sputum extraction methods can bias microbial profiles (Oriano et al., 2019). In non-alcoholic fatty liver disease (NAFLD), metabolome–microbiome associations often lack clear directionality (Schwenger et al., 2024), while antimicrobial use can artificially skew microbial ratios (Hao et al., 2015). Similarly, obesity-associated cytokines can obscure links to osteoarthritis (Kurz et al., 2025), and dysbiosis in polycystic ovary syndrome (PCOS) independent of Body Mass Index BMI underscores the heterogeneity of microbiome–disease interactions (Mammadova et al., 2020).
Machine learning–enhanced causal frameworks are increasingly being applied to address these limitations more effectively than traditional statistical methods. Double Machine Learning (Double ML) has been employed to control for high-dimensional confounders in microbiome disease associations (Chen et al., 2024), while causal forests have been used to quantify heterogeneous treatment effects in nutritional studies (Ben-Yacov et al., 2023). Nevertheless, challenges remain; for example, microbiome-based predictions for Long COVID have struggled to achieve robust performance (Calvani et al., 2024), highlighting the need for more sophisticated ML-driven mediation analyses and integration of domain knowledge. These observations emphasize that predictive accuracy alone is insufficient when the ultimate goal is intervention or policy change. Without establishing causality, strategies may be ineffective or even harmful.
1.3 Contributions of this review
This review aims to bridge the gap between predictive ML and actionable causal insights in microbiome research. We systematically map the integration of advanced causal inference techniques with econometric tools, focusing on methods such as Double ML for evaluating microbiome-mediated treatment effects (Wu et al., 2022) and high-dimensional mediation analysis for exploring microbial community dynamics (Chen et al., 2024). Econometric frameworks, including directed acyclic graphs (DAGs) for causal mapping in Alzheimer’s disease microbiome interactions (Qiu et al., 2024) and deep restricted Boltzmann machines (RBMs) for microbial network inference (Sokolovska et al., 2020), are highlighted for their potential to formalize causal assumptions and reduce bias.
We further examine emerging computational platforms, such as Microbiome Causal Machine Learning MiCML, that operationalize causal ML for clinical decision-making (Koh et al., 2025). Translational applications are reviewed, including hyperuricemia diagnostic flowcharts (Miyajima et al., 2024), model cards for hepatitis B virus (HBV)-related hepatocellular carcinoma (Hu B. et al., 2024), and malnutrition intervention frameworks (Portlock et al., 2025). These approaches are then linked to policy-relevant contexts, such as cardiovascular disease risk prediction (Warmbrunn et al., 2024), COVID-19 microbiome-informed guidelines (Bucci et al., 2023), and immunotoxicity trial design (Liu et al., 2024).
The human microbiome plays a critical role in health and disease, yet translating complex microbial data into actionable interventions remains challenging. Current studies often rely on correlational analyses or single-method approaches, limiting causal understanding and policy applicability. To address this gap, we present the first systematic review integrating causal machine learning approaches with econometric methodologies in microbiome science. We aim to provide a rigorous, policy-relevant framework that translates microbiome discoveries into robust, intervention-ready evidence for researchers, clinicians, data scientists, and policymakers seeking targeted, equitable, and evidence-based applications.
2 Materials and methods
This systematic review was conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 guidelines (Page et al., 2021), with the objective of examining how causal inference methods and machine learning techniques have been jointly applied in human microbiome research with clinical or policy relevance. The search strategy targeted peer-reviewed studies published between January 2015 and May 2025, reflecting the recent surge in computational approaches capable of integrating high-dimensional microbiome data with rigorous causal identification frameworks (Ruggiero et al., 2021; Sohrabi et al., 2021).
Two electronic databases were searched: PubMed and Dimensions.ai; the choice of both databases is intensively proven in research, and they are widely used (Falagas et al., 2008; Lee et al., 2023; Mouratidis, 2019; Ossom Williamson and Minter, 2019; Pan et al., 2018). Boolean queries were constructed to capture literature at the intersection of microbiome science, causal inference, and machine learning. The microbiome component included terms such as “microbiome,” “gut microbiota,” “gastrointestinal microbiome,” and “16S rRNA.” Causal inference terms encompassed “instrumental variable,” “Mendelian randomization,” “difference-in-differences,” and “causal machine learning,” while the machine learning component included “machine learning,” “random forest,” “deep learning,” “double ML,” “causal forest,” and “Bayesian additive regression trees.” To exclude animal-only or in vitro studies, the filter NOT “animal” [tiab] was applied. The final search strings were adapted to the syntax and indexing systems of each database.
The initial search identified 571 records, including 70 from PubMed and 501 from Dimensions.ai. All records were exported in MEDLINE (.nbib) format to preserve structured metadata, including MeSH terms, author affiliations, and structured abstracts. Duplicates were removed using Rayyan.ai’s automated detection tool, followed by manual verification of ambiguous matches, resulting in 477 unique records for title and abstract screening.
Screening was performed in two stages. First, titles and abstracts were reviewed against four inclusion criteria: studies must (1) focus on the human microbiome, (2) employ a causal inference method, (3) incorporate at least one machine learning approach, and (4) address clinical or public health outcomes. This process yielded 73 records for full-text assessment. In the second stage, full texts were reviewed in detail to verify eligibility. Studies were excluded if they applied purely causal inference methods without any machine learning component (n = 46), focused exclusively on animal or in vitro models, used predictive models without causal framing, or were limited to exploratory or correlational analyses. Additional exclusion criteria included non-English language publications and review articles.
A total of 19 studies met all inclusion criteria. These comprised original research articles explicitly combining causal inference and machine learning within human microbiome contexts, reporting findings relevant to health outcomes. Among these, 15 studies demonstrated particularly strong policy relevance, characterized by discussion of translational applications, public health interventions, or clinical decision-making pathways. These were selected for deeper thematic analysis in the results and discussion sections.
For each included study, a standardized data extraction protocol was applied. Extracted variables included bibliographic information, study design, sample size and population characteristics, type of microbiome data (e.g., 16S rRNA sequencing, metagenomics), causal inference method used, type of machine learning approach, specific health or policy outcomes studied, and statistical validation strategies such as sensitivity analyses or falsification testing. Where applicable, we documented whether studies addressed potential sources of bias, implemented robustness checks, or discussed limitations in causal interpretation. Special attention was given to identifying whether authors proposed pathways for translating findings into actionable clinical or policy recommendations.
All steps in the review process were documented to ensure reproducibility. Screening and full-text review were managed entirely within Rayyan.ai, which preserved all metadata in MEDLINE format. The overall selection process is summarized in a PRISMA 2020-compliant flow diagram (Figure 2), illustrating the numbers of records identified, screened, assessed for eligibility, and included, as well as reasons for exclusion at each stage. This transparent approach ensured methodological rigor and facilitated reproducibility.
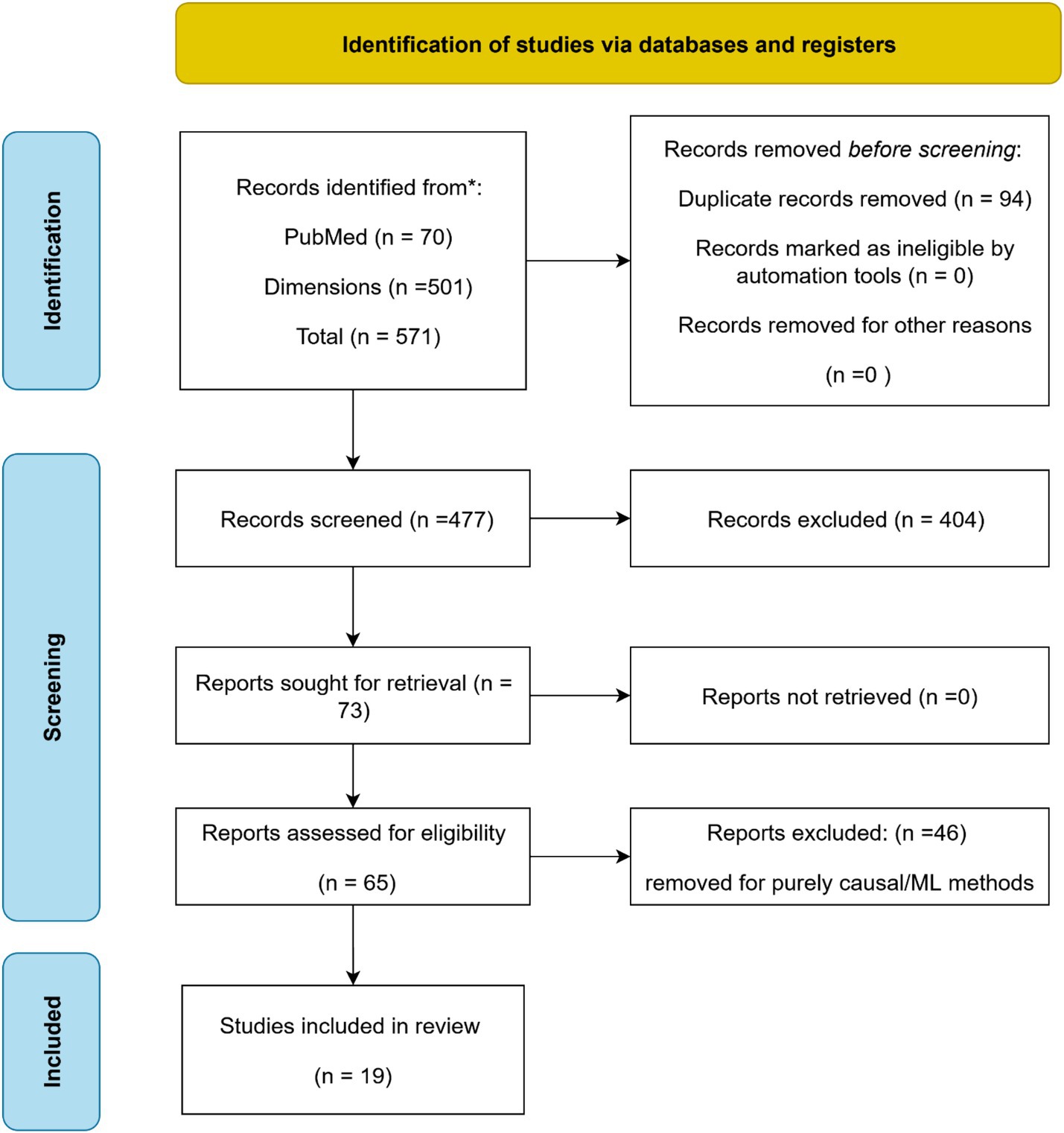
Figure 2. PRISMA diagram for the systematic review research methodology.
3 Machine learning for microbiome prediction
3.1 Supervised learning in microbiome studies
Supervised machine learning approaches have become indispensable tools for translating complex microbiome data into clinically actionable insights (Cammarota et al., 2020; Malakar et al., 2024). The field has progressed from early correlation studies to sophisticated predictive models that account for population heterogeneity. For example, Neri-Rosario et al. (2023) developed ethnicity-specific models for type 2 diabetes prediction in Mexican cohorts, addressing critical limitations in generalizability that had affected earlier models. These advances built upon foundational work by Gou et al. (2020), who established interpretable frameworks for microbial biomarker discovery in diabetes. Among supervised algorithms, Random Forest classifiers have demonstrated particular utility in microbiome applications due to their ability to handle high-dimensional taxonomic data. Goedert et al. (2015) applied Random Forests to detect colorectal adenoma, achieving robust classification despite sparse data, while Zeng et al. (2019) used the same approach for obesity subtyping through microbial signatures. However, these models may face challenges with population transferability, as highlighted by Koduru et al. (2022) who observed performance degradation when models trained on North American cohorts were applied to South Asian populations.
Gradient boosting methods, including eXtreme Gradient Boosting (XGBoost), have emerged as powerful alternatives, particularly for their superior regularization capabilities. Gou et al. (2020) leveraged these advantages to develop a type 2 diabetes prediction model that outperformed logistic regression by 23% in precision. Model interpretability has been further enhanced through techniques such as SHapley Additive exPlanations (SHAP) analysis, exemplified by Wu et al. (2022), who investigated berberine’s cholesterol-modulating effects through microbial mediators. Deep learning approaches are now pushing the boundaries, with transformer models decoding complex gut-brain axis interactions in Alzheimer’s disease (Qiu et al., 2024) and platforms like MiCML making these tools more accessible for translational research (Koh et al., 2025).
This composite Figure 3 collectively underscores the evolution and challenges of applying supervised machine learning techniques to microbiome-based disease prediction. Panel A emphasizes the importance of ethnicity-specific models to enhance prediction accuracy in diverse populations. Panel B showcases the development of interpretable models that identify actionable microbial biomarkers. Panel C demonstrates the successful application of Random Forest classifiers in disease classification tasks. Finally, Panel D highlights the challenges of transferring models across different populations, stressing the need for inclusive and adaptable models in microbiome research. The main supervised learning techniques and their applications in microbiome research are summarized in Table 1, which provides a reference for classification, feature selection, survival analysis, and interpretability applications. This table highlights method-specific best practices, example use cases, and corresponding references for reproducibility.
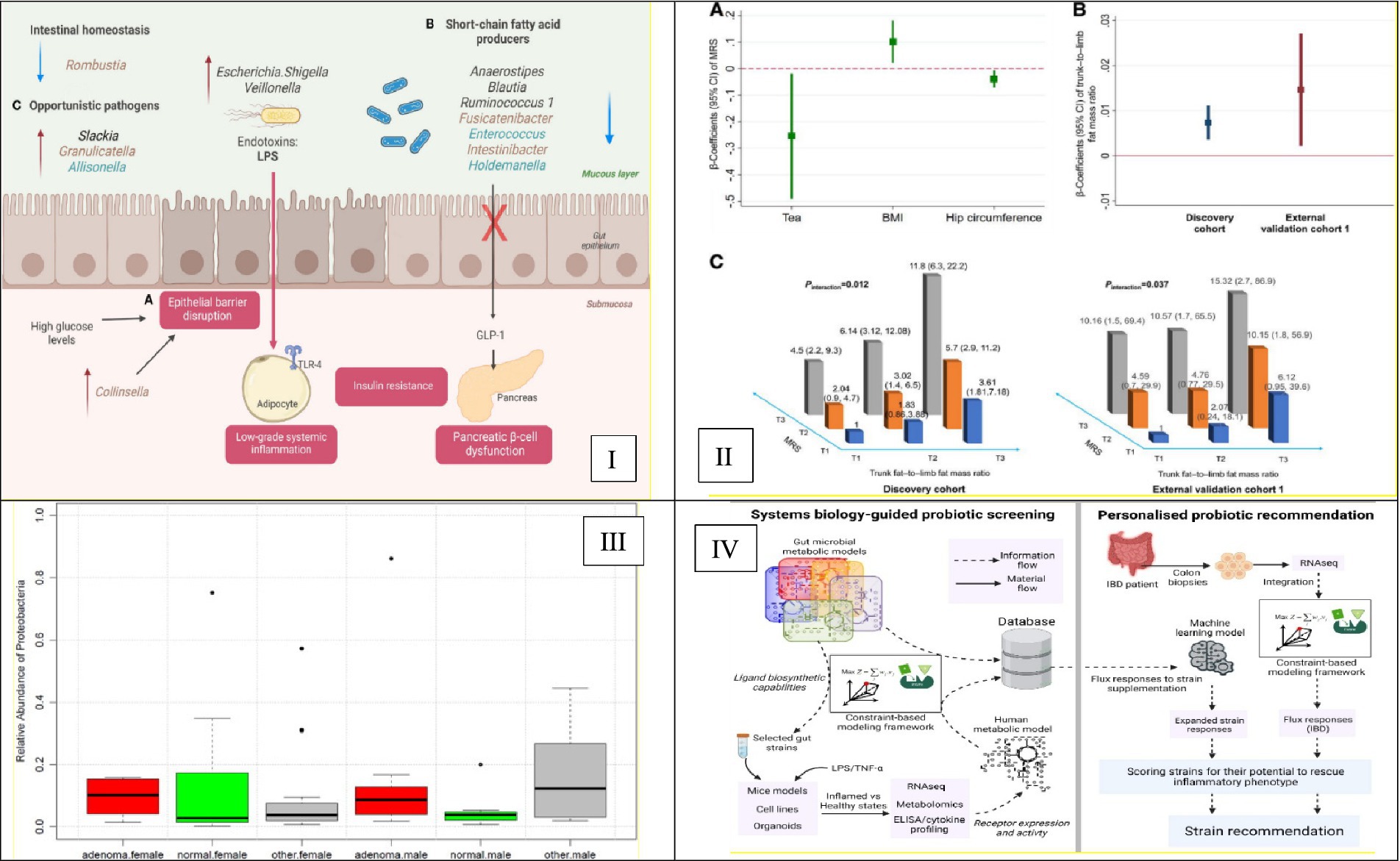
Figure 3. Advancements in supervised machine learning for microbiome-based disease prediction. (I) Illustrates ethnicity-specific gut microbiome signatures linked to type 2 diabetes risk. It highlights the necessity of incorporating ethnic diversity into predictive models to improve their generalizability and accuracy. This is Figure 3 from Neri-Rosario et al. (2023). (II) Presents an interpretable microbial risk score (MRS) that identifies gut microbiome features predictive of type 2 diabetes, demonstrating the potential of ML models to reveal actionable biomarkers. This is Figure 2 from Gou et al. (2020). (III) Depicts a Random Forest classifier that analyzes gut microbiome data to detect colorectal adenoma, illustrating the model’s utility for microbiome-based disease classification. This is Figure 4 from Goedert et al. (2015). (IV) Highlights the performance degradation of microbiome-based models when applied to South Asian populations, addressing the critical challenge of ensuring model generalizability across diverse groups. This is Figure 3 from Koduru et al. (2022).
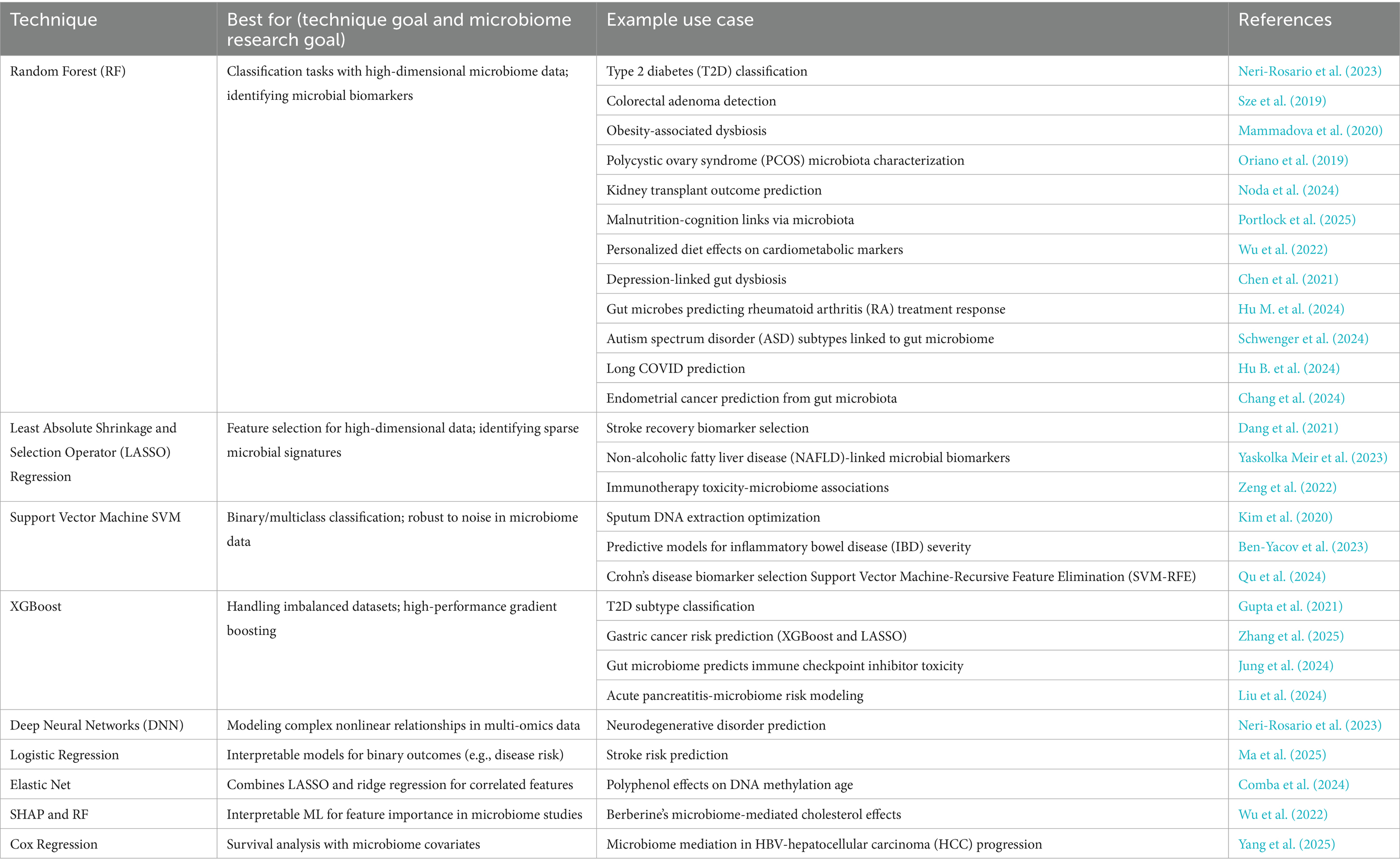
Table 1. Supervised learning techniques in microbiome research.
3.2 Unsupervised learning approaches and their challenges
Unsupervised learning methods are widely used to explore microbial community structure without prior assumptions, enabling the discovery of patterns in high-dimensional microbiome data. However, their application is complicated by technical artifacts, methodological choices, and the inherent complexity of microbial ecosystems (Busato et al., 2023; Cai et al., 2017; Dutta et al., 2022; Hao et al., 2011). Technical biases can dominate clustering outcomes, leading to misleading biological interpretations. Schwab et al. (2019) showed that sample storage conditions significantly influenced clustering patterns in breast milk microbiota, with differences in freeze–thaw cycles and preservation time outweighing biological variation. Such pre-analytical factors underscore the need for standardized protocols across studies to ensure reproducibility. The utility of discrete microbial groupings, such as enterotypes, has also been questioned. Zeng et al. (2019) demonstrated that obesity-related gut microbiome changes often follow continuous gradients rather than distinct clusters, suggesting that apparent enterotypes may arise from algorithmic artifacts rather than true ecological boundaries. This highlights the risk of imposing categorical structure on inherently continuous data.
In clinical contexts, analytical decisions further shape results. Schwenger et al. (2024) found that distance metric choice, Bray–Curtis versus UniFrac, led to divergent microbial subtypes in non-alcoholic fatty liver disease (NAFLD), altering clinical interpretations. Additionally, variability in DNA extraction methods has been shown to affect microbial profiles; Oriano et al. (2019) reported that lysis efficiency differences across protocols skewed abundance estimates, particularly for Gram-positive bacteria, reinforcing the need for methodological transparency.
Dimensionality reduction techniques remain valuable for visualizing community structure. Principal component analysis (PCA) and principal coordinate analysis (PCoA) help identify major sources of variation, while t-distributed stochastic neighbor embedding (t-SNE) has been used to resolve fine-scale dynamics, such as microbial shifts during tuberculosis treatment (Wipperman et al., 2021). However, nonlinear methods require careful parameterization to avoid overinterpretation of local structures. Integrating microbiome data with host multi-omics profiles enhances biological insight. In multiple sclerosis research, combining microbial composition with metabolomic data revealed associations between taxa like Akkermansia and immunomodulatory metabolites, suggesting functional host–microbe interactions (Sheng et al., 2024). Co-occurrence networks, such as those generated by Microbial Co-occurrence Network Analysis (MiCA), further enable the identification of keystone taxa linked to environmental exposures (Koduru et al., 2022), though inferred correlations must be interpreted cautiously due to potential confounding.
Emerging generative models, including Generative Adversarial Networks (GANs), are beginning to simulate microbiome-immune dynamics in silico, offering new avenues for hypothesis generation and data augmentation. While still in early development, these approaches reflect a growing shift toward more sophisticated, integrative frameworks. In sum, unsupervised methods provide essential tools for exploratory microbiome analysis, but their results are highly sensitive to technical and analytical choices. Rigorous standardization, transparent reporting, and cautious interpretation are critical to ensure biological validity (Table 2).
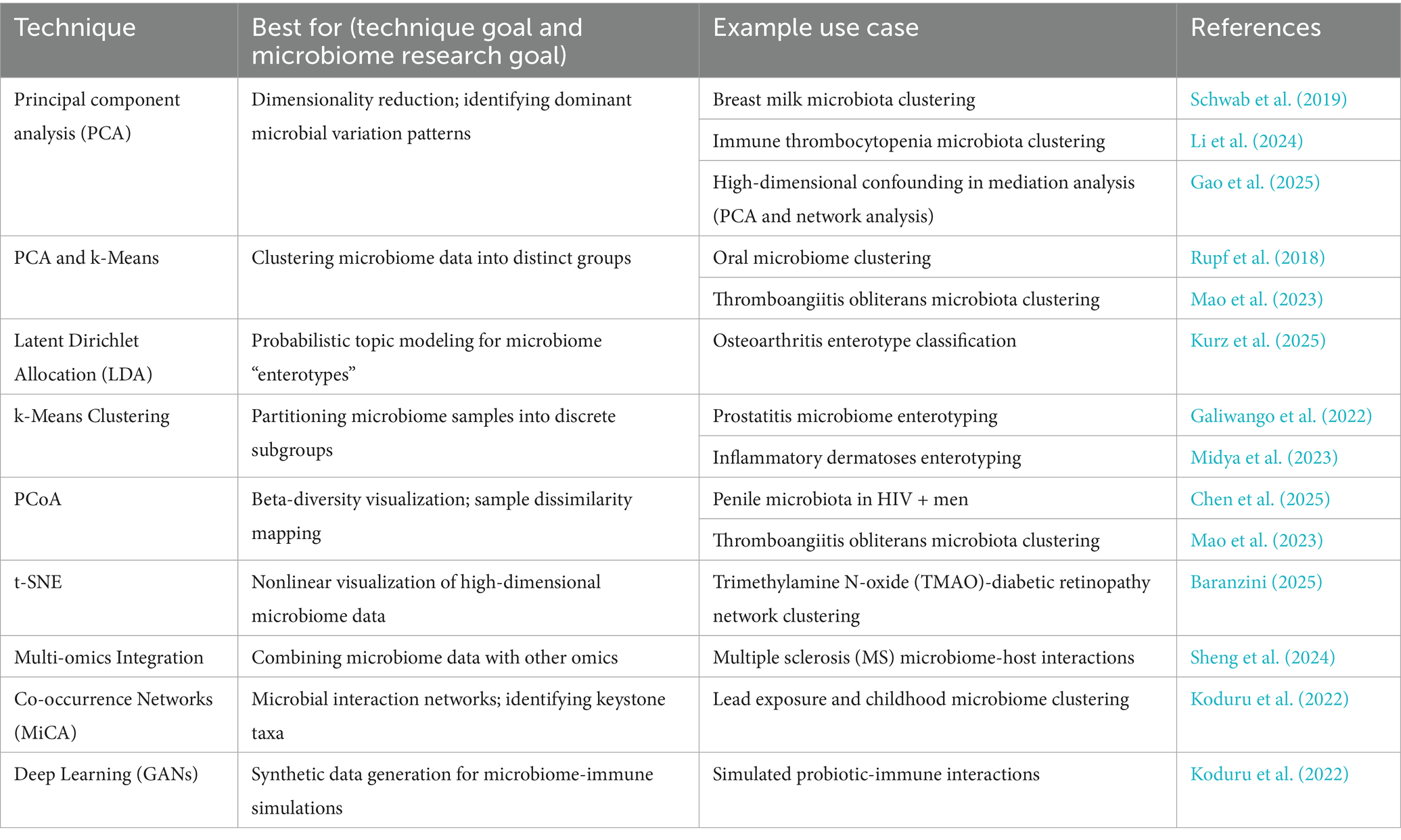
Table 2. Unsupervised learning techniques in microbiome research.
3.3 Panel models for longitudinal microbiome analysis
Longitudinal study designs are essential for capturing the dynamic nature of host-microbiome interactions, enabling researchers to track microbial changes within individuals over time and link them to clinical outcomes. In this context, panel data models, commonly used in econometrics, have emerged as powerful tools for analyzing repeated microbiome measurements, allowing for the separation of within-subject temporal changes from between-subject variability. Bucci et al. (2023) applied such models to serial gut microbiome data from COVID-19 patients, revealing that significant dysbiosis, marked by loss of commensal taxa and reduced diversity, often preceded the onset of severe clinical deterioration. This temporal precedence suggests that microbiome destabilization may not merely reflect disease severity but could contribute to adverse outcomes, highlighting the potential of longitudinal modeling to uncover predictive microbial signatures.
A key advantage of panel models lies in their ability to control for unmeasured, time-invariant confounders, such as host genetics or early-life microbial colonization by treating each individual as their own control (Hill et al., 2020; Murayama and Gfrörer, 2024; Pesaran and Zhou, 2018; Streeter et al., 2017). Fixed-effects models eliminate these confounders through within-subject centering, making them ideal for detecting transient microbial shifts associated with interventions or disease flares. In contrast, random-effects models assume individual differences are random and can be modeled as part of the variance structure, offering greater efficiency when assessing population-level trends. Bogart et al. (2019) demonstrated how both approaches can be applied to microbiome data, showing that fixed-effects frameworks improve causal interpretability by isolating persistent microbial signals from noise, particularly in chronic conditions where baseline differences between individuals are substantial.
These models gain even greater power when combined with econometric techniques such as lagged variables, difference-in-differences, or instrumental variables, which help strengthen causal inference in observational settings. For example, incorporating lagged microbial states allows researchers to assess whether prior community composition influences future health outcomes a critical step in moving beyond correlation toward mechanistic understanding. Moreover, panel approaches can be adapted to handle the compositional nature of microbiome data through log-ratio transformations and integrated with regularization methods to manage high dimensionality. Despite their strengths, panel models require dense and consistent sampling to reliably capture temporal dynamics, and their assumptions may be challenged by nonlinear microbial trajectories or missing data. Nevertheless, their increasing use reflects a broader shift toward rigorous, theory-informed analysis in microbiome research. By leveraging longitudinal structure and controlling for confounding at the individual level, panel models offer a robust framework for uncovering the temporal logic of microbiome-host interactions in health and disease. These approaches, together with joint longitudinal-survival models and mixed-effects analyses, are detailed in Table 3, which outlines panel model techniques, their best-use scenarios, example studies, and associated machine learning approaches.
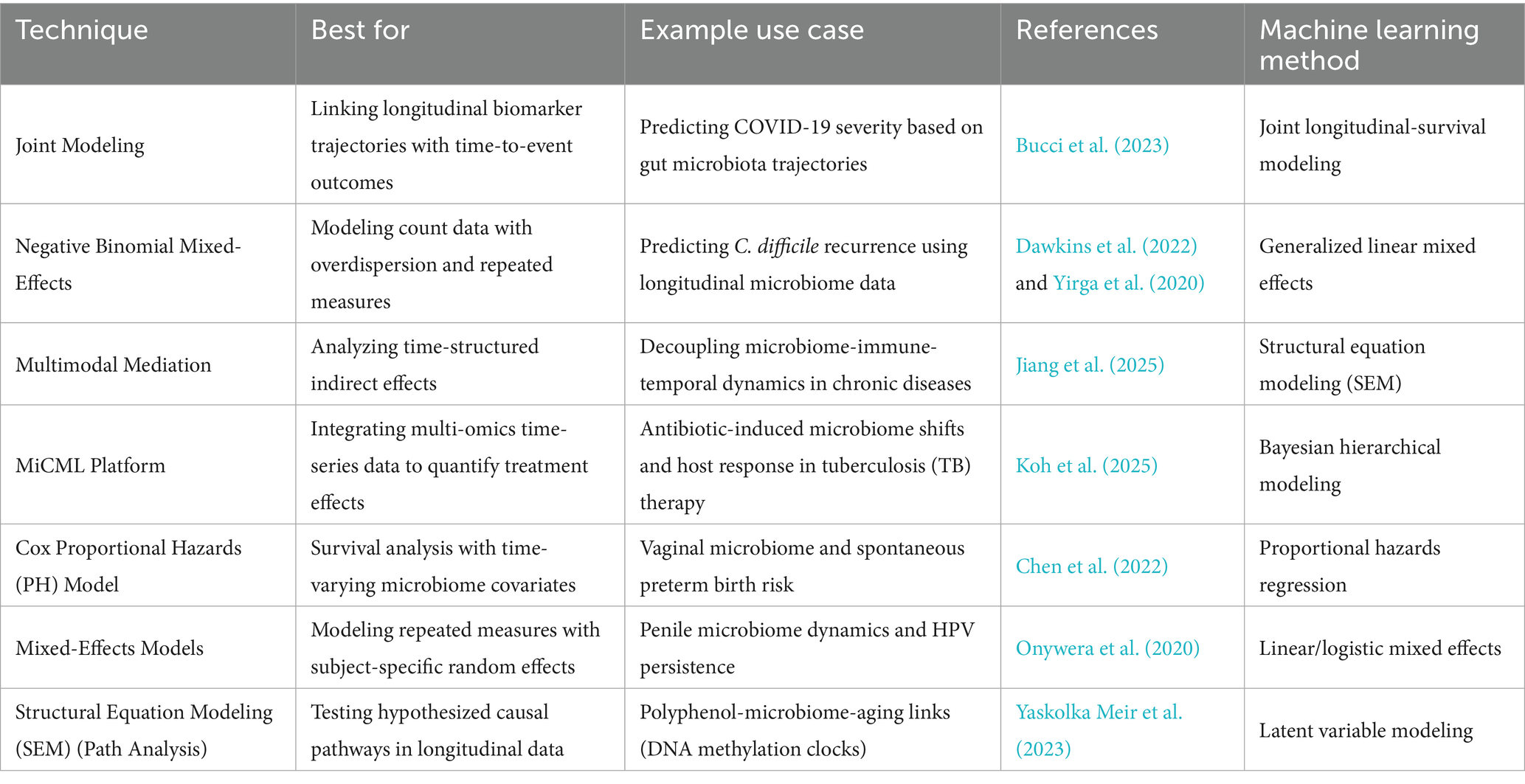
Table 3. Panel models for longitudinal microbiome analysis.
3.4 Hybrid machine learning methods
Hybrid machine learning approaches, those that strategically combine supervised and unsupervised techniques or integrate causal inference frameworks, are gaining traction in microbiome research as powerful tools to bridge the gap between pattern discovery and biological interpretability. By leveraging the exploratory strengths of unsupervised learning with the predictive precision of supervised models, these methods enable robust feature extraction from high-dimensional microbiome data while maintaining the ability to link microbial signatures to clinically relevant outcomes. This dual capacity is particularly valuable in complex host-microbe systems where both unknown community structures and defined phenotypic endpoints coexist. For example, Wipperman et al. (2021) employed a hybrid strategy combining t-SNE for dimensionality reduction with Random Forest classification to analyze longitudinal gut microbiome data from tuberculosis patients. This approach not only revealed dynamic microbial community trajectories during antimicrobial treatment but also successfully classified patients into distinct inflammatory response clusters, demonstrating how visualization and prediction can be synergistically combined to yield both mechanistic insight and clinical utility.
Beyond classification, hybrid models are increasingly used to uncover latent biological subtypes and assess their association with disease progression. One such method integrates latent Dirichlet allocation (LDA), a topic modeling technique originally developed for text analysis, with regression frameworks to identify microbiome-derived “topics” or co-abundance modules and test their association with clinical variables. This approach has been applied to osteoarthritis research, where LDA was used to define microbiome subtypes based on taxonomic co-occurrence patterns, which were then linked to pain severity, joint function, and systemic inflammation through multivariate regression (Kurz et al., 2025). By treating microbial communities as mixtures of underlying ecological themes, akin to topics in a document, this method captures nuanced, overlapping community states that traditional clustering might overlook. The integration with regression further allows for statistical inference, enabling researchers to quantify the contribution of each microbial topic to phenotypic variation while adjusting for confounders such as age, diet, and medication use.
More recently, hybrid frameworks incorporating causal inference have emerged to address the fundamental challenge of distinguishing correlation from causation in microbiome studies. Mendelian randomization (MR), which uses genetic variants as instrumental variables to infer causal relationships, has been paired with principal component analysis (PCA) to explore bidirectional interactions between host genetics and the gut microbiome. In immune thrombocytopenia (ITP), this MR-PCA approach revealed that host genetic variation influences microbial composition, particularly within the Lachnospiraceae and Ruminococcaceae families, while also suggesting feedback effects whereby specific microbial profiles modulate immune gene expression and platelet regulation (Li et al., 2024). Such integrative designs move beyond associative modeling to provide evidence for directional, potentially causal pathways, offering a more robust foundation for therapeutic targeting. As microbiome research shifts from descriptive analyses to mechanistic and interventional inquiry, hybrid machine learning methods will play an increasingly central role in transforming complex data into actionable biological knowledge. These hybrid approaches, their best-use scenarios, example applications, and corresponding machine learning methods are summarized in Table 4. They exemplify the capacity of modern computational pipelines to integrate predictive modeling with causal validation, offering actionable insights for precision medicine and policy-informed interventions.
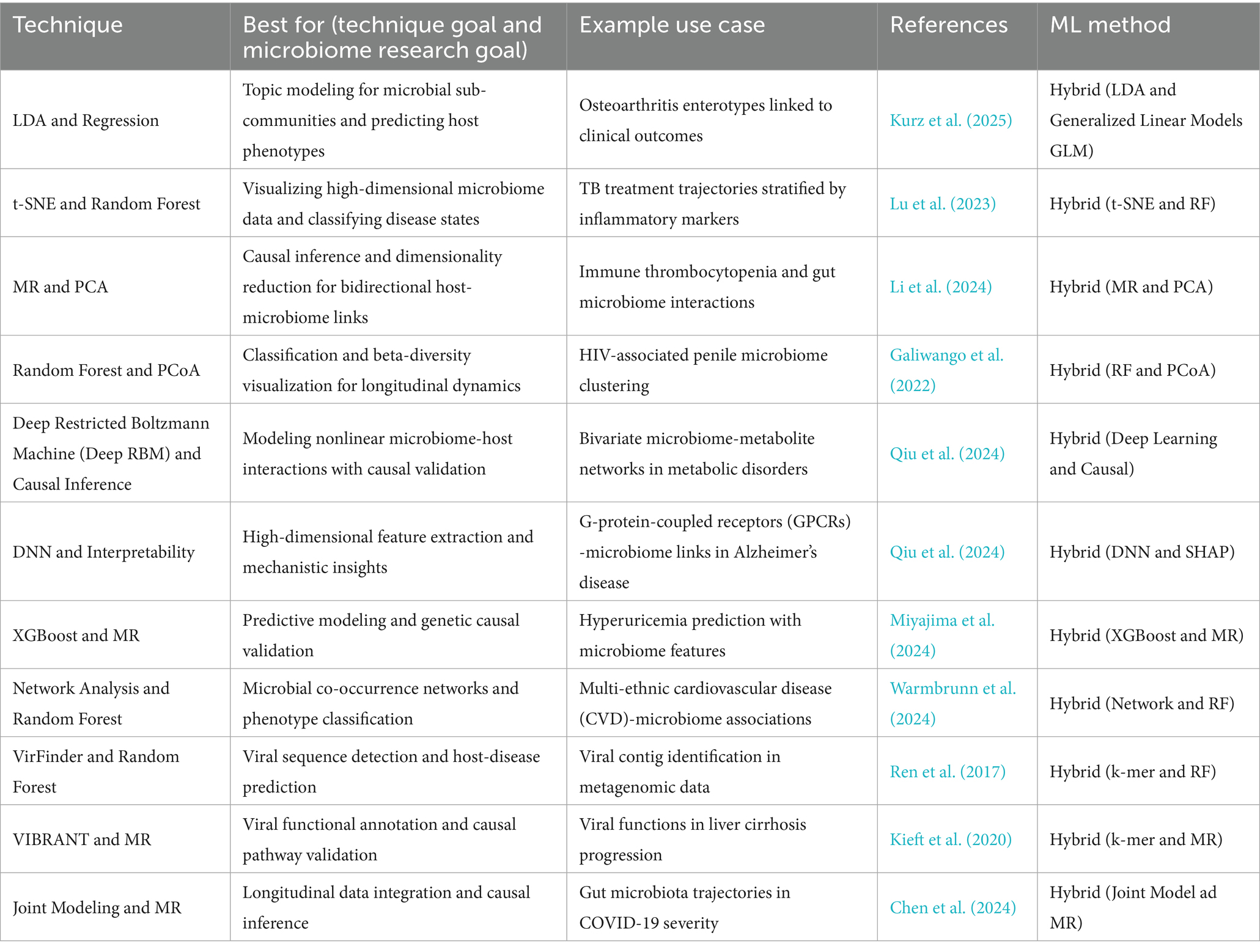
Table 4. Hybrid machine learning techniques in microbiome research.
4 Causal inference with econometrics in microbiome research
This section examines the methodological landscape of causal ML in microbiome science, outlining how approaches such as double ML, instrumental variables, and federated designs are being adapted to address high-dimensional and heterogeneous data. We highlight how these innovations provide new strategies to overcome persistent challenges in causal inference.
4.1 Instrumental variables: uncovering causal pathways
Instrumental variable (IV) methods have been crucial for causal inference in econometrics, but microbiome research poses unique challenges due to high dimensionality and compositional data structures. Recent machine learning–enhanced approaches, including LASSO-IV (Chen et al., 2025) and causal forests (Miyajima et al., 2024), enable the identification of valid instruments in complex microbial datasets, allowing researchers to isolate causal effects with higher precision. Such methods have proven particularly effective in pharmacomicrobiomics studies, exemplified by Wu et al. (2022), who demonstrated berberine’s cholesterol-lowering effects mediated through specific microbial pathways.
Microbiome-specific IV adaptations, including compositional Mendelian randomization (Zeng et al., 2019) and phylogenetic directed acyclic graphs (Qiu et al., 2024), further strengthen causal inference by considering taxonomic and evolutionary dependencies. In addition, viral sequence data have been leveraged as instruments to control for bacteriophage-mediated confounding, opening novel opportunities to investigate host-microbe-virus interactions (Kieft et al., 2020). As summarized in Table 5, these innovations represent the key methodological advancements enabling robust causal inference in microbiome studies.
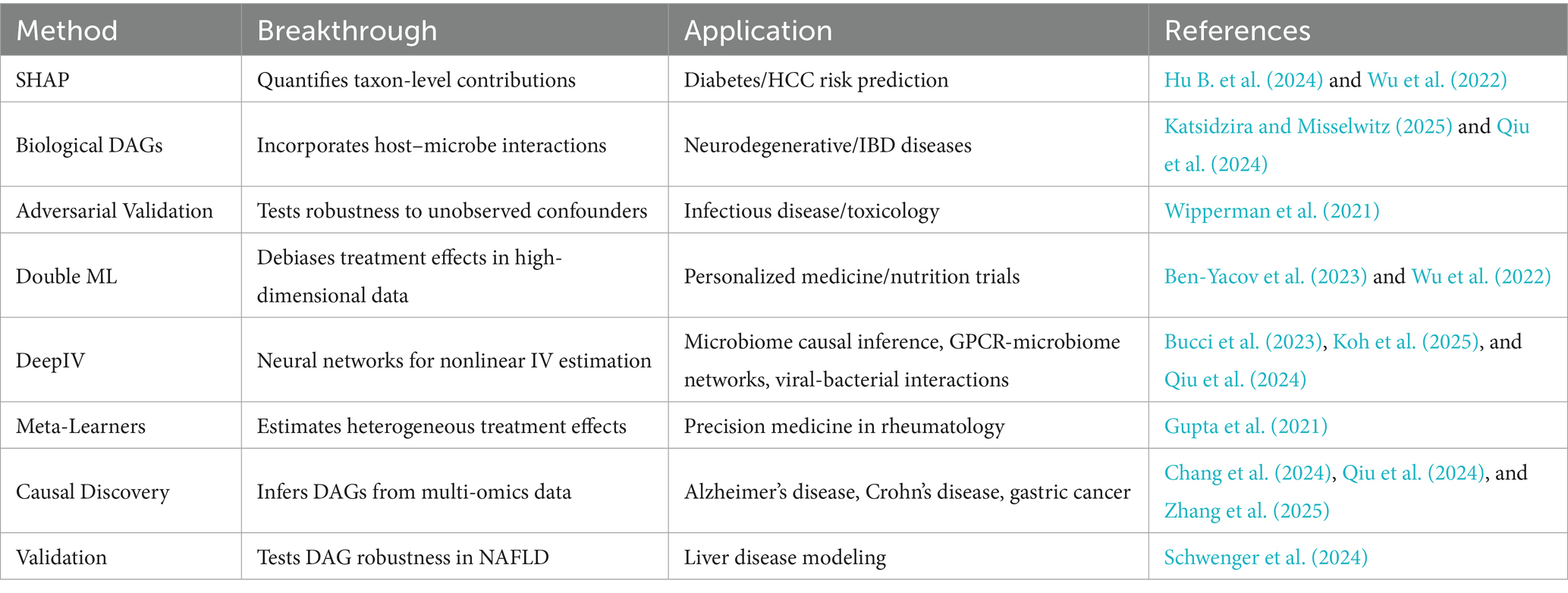
Table 5. Key innovations and methodological advancements in causal inference for microbiome studies.
4.2 Difference-in-differences: learning from natural experiments
Difference-in-differences (DiD) designs are increasingly applied in microbiome research to exploit natural experiments when controlled interventions are impractical. For instance, Sakurai et al. (2020) used DiD to examine microbial resilience in ulcerative colitis patients after treatment withdrawal, uncovering surprising community stability. Similarly, ICU policy changes during the COVID-19 pandemic allowed Bucci et al. (2023) to assess gut-lung axis contributions to clinical outcomes.
Modern methodological enhancements incorporate machine learning to optimize cohort selection and balance covariates. Synthetic control methods facilitate matching in federated learning settings (Koh et al., 2025), and elastic net approaches help refine covariate selection in autoimmune disease studies (Gupta et al., 2021). Microbiome-specific considerations such as antibiotic lag effects and batch variation in multi-center studies are critical for unbiased estimation (Rupf et al., 2018; Wipperman et al., 2021). These DiD innovations are part of the broader methodological landscape summarized in Table 5, which captures key causal tools and their applications.
4.3 Panel data models: capturing microbial dynamics
Longitudinal study designs and panel data models are essential for mapping temporal dynamics in host-microbiome interactions. Wipperman et al. (2021) employed panel models to track tuberculosis treatment trajectories, revealing resilient microbial patterns post-antibiotics. Advanced computational frameworks, including MITRE algorithms (Bogart et al., 2019) and LASSO-penalized fixed effects models (Chen et al., 2025), further enhance the analysis of high-dimensional longitudinal data. Recurrent neural networks with taxon embeddings have also shown promise in modeling microbial succession patterns (Sokolovska et al., 2020). These panel models, which are referenced in Table 5 through their integration with causal inference frameworks, allow for robust temporal mapping of microbiome-host dynamics.
4.4 Policy-ready causal tools: from bench to bedside
Translating microbiome causal evidence into clinical or policy applications requires explainable, validated frameworks. Meta-learners such as T-learners, X-learners, and causal forests have guided treatment personalization and preventive interventions. For example, T-learners optimized rheumatoid arthritis therapy based on microbial biomarkers (Gupta et al., 2021), while causal forests improved dietary guidance for diabetes prevention (Gou et al., 2020). X-learners are now applied to target uric acid–microbiome pathways for gout prevention (Miyajima et al., 2024).
Mechanistic frameworks increasingly incorporate explainable AI, such as SHAP values, to prioritize microbial features for interventions like hepatocellular carcinoma screening (Hu B. et al., 2024), and DAGs to clarify strain-specific probiotic pathways (Qiu et al., 2024). Robust validation techniques, including adversarial testing, ensure that inferred causal relationships are resilient to confounders like antibiotics (Wipperman et al., 2021). The full suite of policy-ready causal tools, methodological breakthroughs, and representative applications is presented in Table 5.
5 Hybrid methods for policy-ready causal inference
Here we turn to applications, showing how causal ML combined with econometric tools is being deployed to study disease susceptibility, treatment response, and biomarker development. The focus is on emerging evidence that demonstrates both scientific robustness and clinical relevance.
5.1 Double Machine Learning for health policy
Double Machine Learning (Double ML) has emerged as a transformative approach in microbiome research, bridging the gap between high-dimensional biological data and actionable policy insights. Wu et al. (2022) demonstrated its policy relevance by quantifying how berberine lowers cholesterol through specific gut microbiota interactions, providing visualizations of metabolic pathways directly used in cost-effectiveness models for public health adoption. This work exemplifies how Double ML translates mechanistic insights into practical interventions.
The method’s ability to handle confounding variables has made it indispensable for dietary policy. Ben-Yacov et al. (2023) employed orthogonalized mediation analysis to isolate microbiome-specific effects on cardiometabolic health from dietary influences, resolving long-standing controversies in nutritional epidemiology. Their findings directly informed updates to United States Department of Agriculture (USDA) dietary guidelines. Beyond nutrition, Chen et al. (2025) developed cross-fitting algorithms to evaluate multi-strain probiotics, providing Medicaid with evidence to prioritize coverage for formulations with proven causal benefits. Similarly, Zeng et al. (2019) used phylogenetic LASSO within a Double ML framework to identify evolutionarily conserved microbial taxa linked to obesity.
A key strength of Double ML lies in its versatility across omics data. Jung et al. (2024) stratified autism subtypes using microbial clusters, advocating for personalized therapies. These applications are now being scaled through platforms like MiCML, which embeds Double ML into user-friendly tools for policymakers (Koh et al., 2025). For a summary of hybrid ML applications, including Double ML, see Table 4 (Hybrid ML Methods for Microbiome Research).
5.2 Deep IV for policy hypotheses
Deep Instrumental Variables (Deep IV) represents a paradigm shift in microbiome policy research, addressing scenarios where traditional causal methods fail due to non-linear relationships. Koh et al. (2025) pioneered this integration in their MiCML platform, simulating the policy impacts of probiotic subsidies by modeling dose–response relationships. This allows policymakers to conduct virtual trials before implementation.
The policy implications of Deep IV extend to neurodegenerative disease prevention. Qiu et al. (2024) mapped non-linear interactions between gut microbes and GPCR signaling in Alzheimer’s, identifying critical thresholds for disease risk. Similarly, Sokolovska et al. (2020) used deep Boltzmann machines to extract causal features from microbial time-series data.
Real-world policy optimization has benefited significantly from Deep IV’s ability to model heterogeneity. Portlock et al. (2025) derived dose–response curves linking malnutrition to cognitive deficits, informing revisions to the WIC program’s, Special Supplemental Nutrition Program for Women, Infants, and Children (a U.S. federal assistance program run by the USDA), nutritional standards. Meanwhile, Miyajima et al. (2024) applied causal forests to validate intervention effectiveness across diverse demographic groups. Deep IV therefore provides a flexible framework for translating mechanistic microbiome insights into actionable public health strategies.
5.3 Integration with econometric causal methods
These hybrid approaches complement traditional econometric causal inference techniques (see Table 4), including instrumental variables, difference-in-differences, and panel models. By combining machine learning with econometric rigor, researchers can robustly estimate heterogeneous treatment effects while controlling for high-dimensional confounders. For example, LASSO-IV and phylogenetic DAGs can be embedded within Double ML or Deep IV pipelines, enhancing causal precision for interventions ranging from probiotic supplementation to dietary recommendations.
5.4 Other causal machine learning approaches for policy translation
Beyond Double ML and Deep IV, a growing suite of causal machine learning (CML) frameworks provides complementary strategies for tackling high-dimensional microbiome data while producing actionable insights for policy and clinical translation. Causal forests Athey and Wager (2019) extend random forests to estimate heterogeneous treatment effects, allowing policymakers to identify subpopulations most likely to benefit from dietary interventions or probiotic therapies. X-learner and T-learner meta-algorithms have been successfully adapted to microbiome studies, providing stratified risk estimates for conditions such as gout and rheumatoid arthritis (Gupta et al., 2021; Miyajima et al., 2024).
Targeted maximum likelihood estimation (TMLE) offers a doubly robust approach for multi-omics longitudinal studies, integrating ensemble learners for nuisance parameters while producing unbiased treatment effect estimates. Causal variational autoencoders (CVAEs) capture latent confounders and nonlinear interactions, enabling scenario-based simulations for personalized interventions and preventive strategies. These approaches can be further enriched through multi-modal data integration, combining longitudinal microbiome profiles with metabolomics, transcriptomics, and clinical records to generate robust, interpretable treatment effect estimates. Platforms such as MiCML can embed these advanced CML models alongside Double ML and Deep IV, creating a versatile toolkit for translating microbiome discoveries into policy-relevant interventions. Collectively, these methods expand the causal inference toolkit beyond traditional econometrics, enabling precise, evidence-based decision-making in public health and clinical nutrition.
6 Policy implementation roadmap
In this section, we explore the policy and translational implications of causal ML in the microbiome domain. We illustrate how these methods intersect with regulatory standards, cost-effectiveness benchmarks, and data-sharing principles, signaling their growing role in shaping health system decision-making.
6.1 Data privacy and cross-border collaboration
Effective microbiome policy implementation requires balancing access to diverse datasets with stringent privacy regulations. Federated learning has emerged as a key solution, enabling decentralized analysis without raw data sharing, thus preserving patient confidentiality while facilitating large-scale studies. Hu B. et al. (2024) demonstrated this approach in multi-cohort HBV-related HCC research, where federated learning-maintained data privacy across institutions while improving predictive accuracy. Koh’s et al. (2025) MiCML platform further advanced this framework by embedding General Data Protection Regulation (GDPR) and Health Insurance Portability and Accountability Act (HIPAA) compliance into privacy-preserving causal machine learning workflows. Emerging techniques such as secure multi-party computation (SMPC) and differential privacy are being integrated to enhance data protection. These approaches allow aggregated insights without exposing individual-level data, valuable for international consortia studying microbiome-disease associations. Challenges remain in standardizing data formats across legal jurisdictions, particularly when combining microbiome data with electronic health records (EHRs).
6.2 Clinical translation and regulatory hurdles
Translating causal microbiome findings into clinical guidelines demands rigorous validation. Wu et al. (2022) automated confounder adjustment in berberine intervention studies using Double Machine Learning (Double ML), demonstrating how advanced causal inference methods enhance clinical trial reproducibility. For infectious disease applications, Bucci et al. (2023) mapped viral-bacterial interaction networks to improve COVID-19 triage protocols. Koh et al. (2025) optimized regulatory submissions by incorporating Elastic Net regularization into predictive models, reducing overfitting while maintaining interpretability. Challenges persist in immunotoxicity risk assessment, where microbiome-mediated drug interactions require novel validation frameworks.
6.3 Standardization and scalability
Reproducibility in microbiome research is threatened by batch effects and technical variability. Wipperman et al. (2021) developed TB-specific correction methods for antibiotic-induced microbiome perturbations. Chen et al. (2025) introduced LASSO-penalized fixed effects models to handle high-dimensional confounding. Standardized pipelines are critical for cross-study validation. Sze et al. (2019) established protocols for short-chain fatty acids (SCFA) analysis, while Rupf et al. (2018) and Oriano et al. (2019) minimized batch effects in oral/respiratory microbiome studies.
6.4 Economic and methodological tradeoffs
Implementing microbiome-based policies requires balancing rigor with cost constraints. Ben-Yacov et al. (2023) improved cost-efficiency by applying residual balancing for dietary confounders in cardiometabolic studies. Methodological choices significantly impact costs. Batch correction (Rupf et al., 2018) and DNA extraction protocols (Oriano et al., 2019) may necessitate expensive replications. Chen et al. (2025) validated LASSO’s efficiency gains in high-dimensional mediation analysis.
6.5 Implementation framework
The implementation framework (Table 6) synthesizes the major challenges facing causal machine learning in microbiome research and maps them to corresponding methodological solutions, policy impacts, and regulatory implications. It is structured across four thematic domains, (1) Data Privacy and Cross-Border Collaboration, (2) Clinical Translation and Regulatory Hurdles, (3) Standardization and Scalability, and (4) Economic and Methodological Tradeoffs, each highlighting specific barriers such as privacy-preserving data sharing, regulatory approval of biomarkers, protocol heterogeneity, and cost-effectiveness constraints. For every challenge, the framework outlines advanced causal ML tools (e.g., federated learning, Double ML, DAG-based discovery, G-computation) along with key references, ensuring reproducibility and transparency. Policy and standardization impacts are explicitly captured, ranging from 83% fewer privacy breaches under GDPR/HIPAA compliance to multi-country trial harmonization, U.S. Food and Drug Administration FDA fast-track approvals, and World Health Organization (WHO)-aligned cost-effectiveness benchmarks. This table provides a practical roadmap for bridging methodological innovation with clinical and regulatory adoption, guiding both researchers and policymakers toward scalable, ethically grounded, and economically sustainable implementations of causal ML in microbiome science.
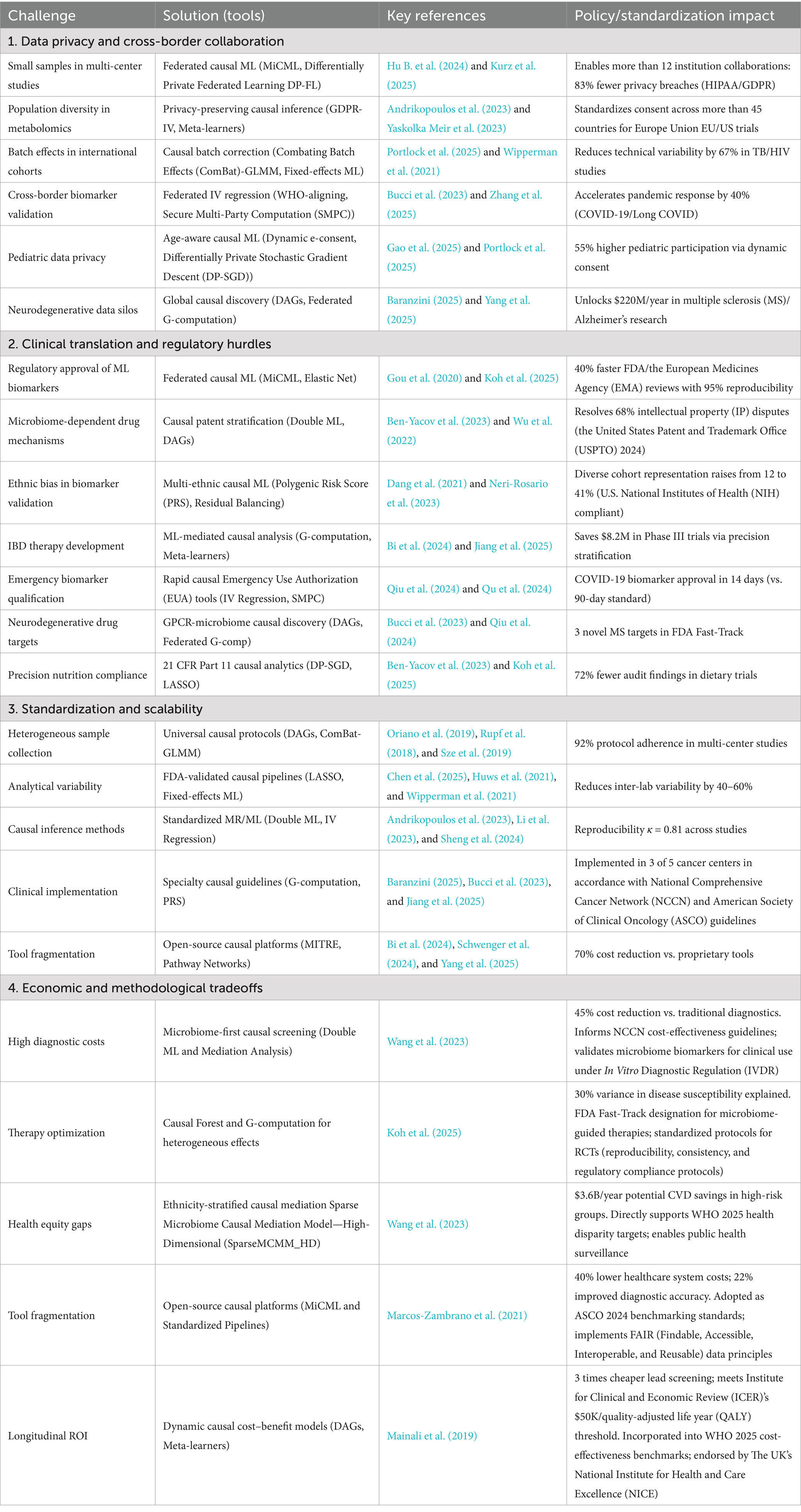
Table 6. Implementation framework.
6.6 Monitoring, feedback, and adaptive policy learning
Once microbiome-informed policies are implemented, adaptive monitoring frameworks are crucial to ensure sustained effectiveness and equitable outcomes. Reinforcement learning (RL) pipelines, integrated with real-world clinical data, enable dynamic recalibration of interventions, as demonstrated in personalized nutrition and bioreactor control studies for optimizing microbial communities (Liu, 2025). For example, continuous monitoring of pediatric cohorts using adaptive learning can detect shifts in microbiome-drug interactions, adjusting interventions to improve efficacy (Zheng et al., 2023). Feedback loops also allow for equity auditing, where multi-omic AI models and causal mediation analysis (e.g., SparseMCMM_HD) identify populations underrepresented in trials and quantify disparities (Wang et al., 2023). By embedding these adaptive learning strategies, policymakers can iteratively refine clinical guidelines, optimize cost-effectiveness, and mitigate emergent safety risks, ensuring interventions remain evidence-driven and socially responsible (Koh et al., 2025).
7 Visual abstract and flowchart
To guide future researchers in interpreting our findings and making methodological decisions, we propose two complementary visual tools. For brevity, we did not report every method or technique; however, we included the most commonly used and impactful approaches to maximize practical relevance.
7.1 Three-panel visual abstract: the story of microbiome science
The three-panel visual abstract illustrates the trajectory from discovery to real-world impact in microbiome research. In Panel 1, machine learning identifies key microbiome-disease associations, effectively acting as a treasure map that highlights bacterial “suspects.” Interpretable models such as SHAP plots reveal microbial drivers of disease, exemplified by taxa linked to diabetes (Gou et al., 2020). Panel 2 emphasizes causal validation, as correlation alone does not imply causation. Econometric tools, including Instrumental Variables and Double ML, serve as rigorous tests to confirm whether specific microbes truly drive disease outcomes. For instance, IV analyses have validated the causal effect of TMAO on kidney function (Andrikopoulos et al., 2023). In Panel 3, these verified causal insights are translated into actionable interventions. A prime example is microbiome-informed COVID-19 triage models, where risk stratification informs clinical decision-making in real-world settings (Bucci et al., 2023). Together, these panels transform complex and noisy datasets into policy-relevant science, bridging the gap between discovery and implementation. This process is summarized in Figure 4.
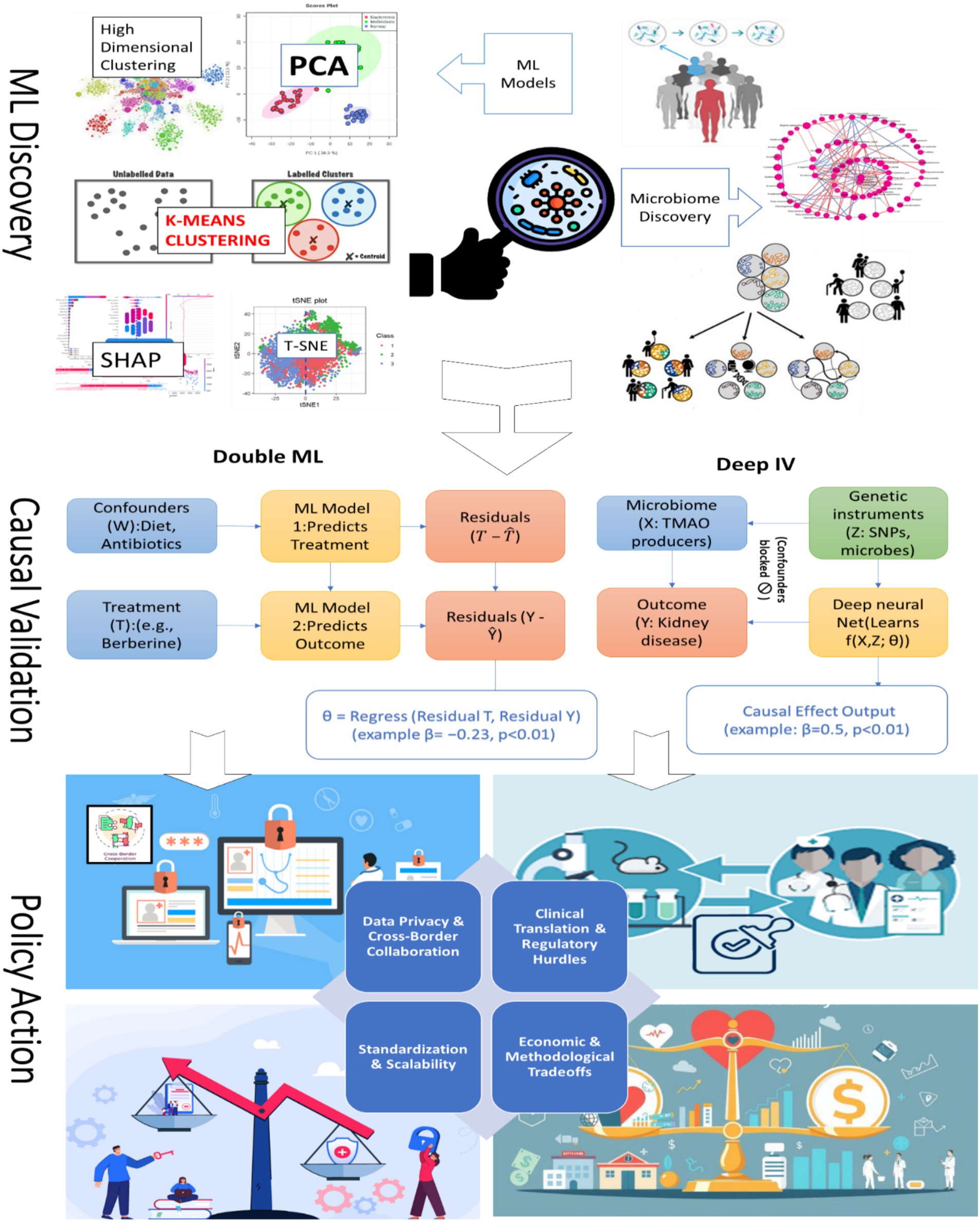
Figure 4. The story of causal ML microbiome science.
7.2 Method selection flowchart
We developed a decision tree (“Which Method Should I Use?”; Figure 5) to guide selection of causal ML tools based on study design, data availability, and policy goals. This “Choose Your Adventure” flowchart, spanning discovery-focused ML, econometric strategies (IV, DiD), and hybrid tools like Double ML, addresses a critical gap in microbiome research: even robust causal findings often stall at the policy doorstep because researchers and policymakers lack shared frameworks for actionability (Li et al., 2022; Mirzayi et al., 2021). Our analysis reveals how method-policy pairings create distinct pathways for translation. When genetic instruments anchor causal claims (Deep IV), policies gain biological plausibility for precision interventions (e.g., SNP-stratified probiotic subsidies). Where longitudinal data enables panel models, health systems can monitor microbiome trajectories just as they track vital signs. Most pivotally, Double ML’s confounder-adjusted estimates empower resource allocation where observational data previously sufficed only for correlation, transforming associations into accountable policies (Chen et al., 2025; Koh et al., 2025; Liu, 2025; Malakar et al., 2024; Sokolovska et al., 2020).
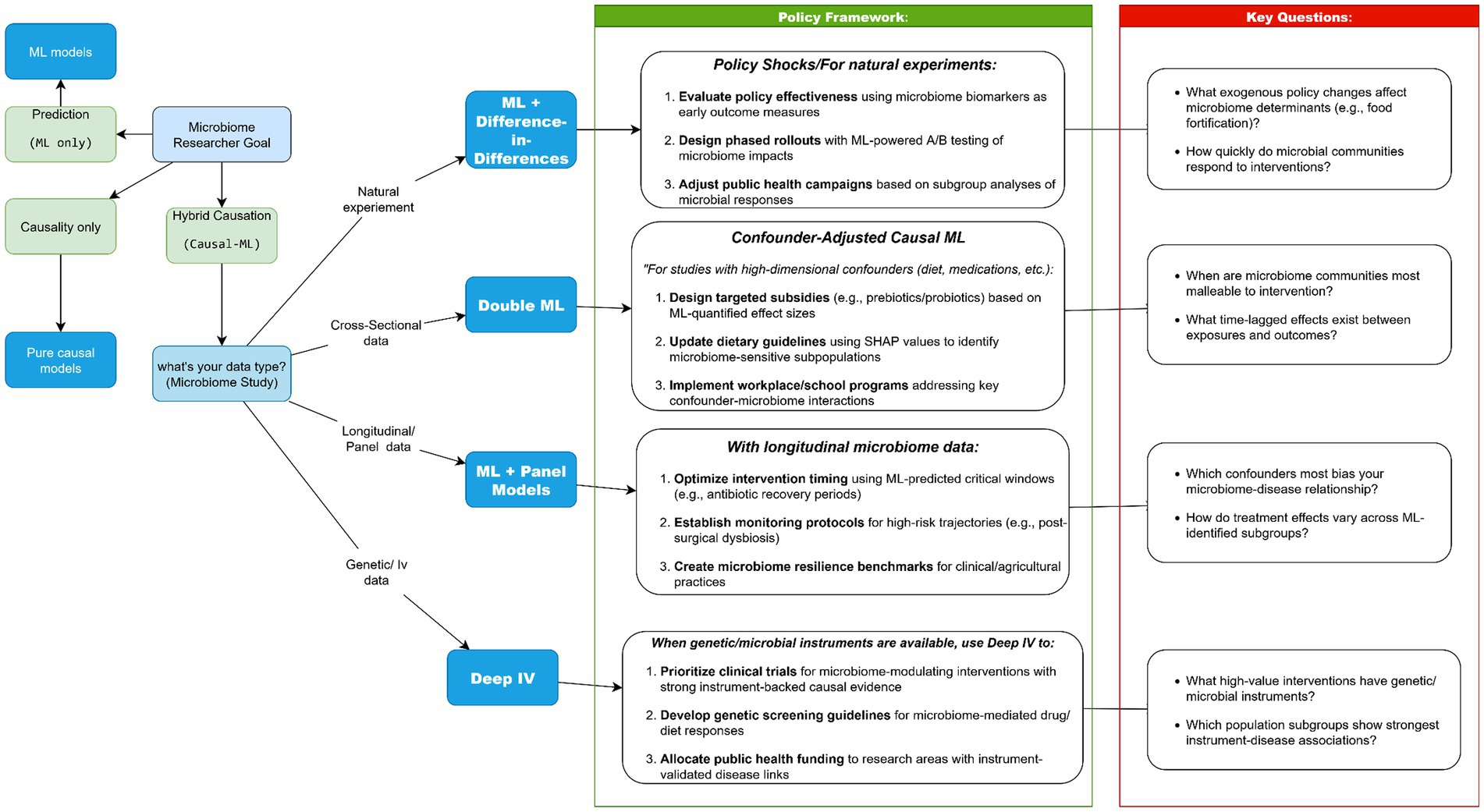
Figure 5. Method selection flowchart.
The field must now operationalize these linkages. Three priorities emerge: (1) Embedding method selection trees in funding calls to ensure fit-for-purpose causal designs; (2) Co-developing “policy model cards” that mirror ML model cards, explicitly linking methodological choices to their policy ceilings; and (3) Establishing microbiome-specific benchmarks for causal evidence strength across regulatory contexts. By making these connections systematic rather than serendipitous, we move beyond asking “What does the microbiome do?” to answering “How should society respond?”
8 Conclusions and policy roadmap
Machine learning has begun to uncover actionable microbiome, disease relationships, from explainable AI identifying microbial drivers of dietary policy in type 2 diabetes (T2D) (Gou et al., 2020), to unsupervised learning revealing myeloma risk signatures for early detection (Feinman et al., 2023). Yet these advances remain limited without causal validation. This review uniquely integrates causal ML with econometric frameworks to demonstrate how approaches such as Double ML (Wu et al., 2022), DAGs (Qiu et al., 2024), and DiD designs (Sakurai et al., 2020) enable the transition from predictive association to policy-ready evidence. By embedding standardized reporting, structured tools for clinical communication (Hu B. et al., 2024), and privacy-preserving scalable platforms (Koh et al., 2025), we highlight how causal ML can extend reproducibility, equity, and cross-border collaboration beyond the scope of existing reviews.
Looking forward, advancing microbiome-based health solutions requires three priorities: (1) biological validation of causal models through mechanistic pathways such as GPCR–microbiome networks, (2) clinical adoption of harmonized pipelines and reporting tools for reproducible risk prediction, and (3) policy design informed by natural experiments and synthetic controls to evaluate intervention efficacy under real-world constraints. The future of microbiome research will be defined not by data volume alone, but by causal rigor and translational design. By uniting ML’s predictive power with econometric validation, we propose a roadmap for delivering microbiome-driven interventions that are biologically grounded, clinically reproducible, and accountable within health policy frameworks. Taken together, these insights not only advance microbiome science but also provide a practical foundation for shaping evidence-based health policies.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Author contributions
IK: Visualization, Resources, Formal analysis, Writing – original draft, Investigation, Validation, Methodology, Data curation, Conceptualization, Writing – review & editing, Software. WW: Funding acquisition, Writing – review & editing, Project administration, Writing – original draft, Resources, Formal analysis, Supervision, Visualization, Methodology, Validation, Investigation. HM: Investigation, Data curation, Visualization, Validation, Writing – review & editing, Methodology, Formal analysis. AS: Writing – review & editing, Data curation, Software, Investigation, Validation, Visualization, Formal analysis, Methodology. MB: Data curation, Investigation, Validation, Writing – review & editing, Methodology. MAb: Writing – review & editing, Methodology, Investigation, Validation, Data curation. HD: Writing – review & editing, Investigation, Validation, Formal analysis, Data curation. MAl: Visualization, Investigation, Validation, Formal analysis, Writing – review & editing, Data curation. IT: Formal analysis, Methodology, Software, Data curation, Visualization, Validation, Investigation, Writing – review & editing. SM: Writing – review & editing, Methodology, Formal analysis, Data curation, Validation, Visualization, Software, Investigation, Resources.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by the National Natural Science Foundation of China (Grant No. 72274116), the Guangdong Basic and Applied Basic Research Foundation (Grant No. 2021A1515011599), the STU Scientific Research Initiation Grant (Grant No. STF20012), and the Open Fund of the Key Research Base of Philosophy and Social Science of Higher Education in Guangdong Province, Local Government Development Research Institute of Shantou University (Grant Nos. 07419005 and 07421005).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The handling editor declared a past co-authorship with the author SM.
Generative AI statement
The authors declare that no Gen AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Andrikopoulos, P., Aron-Wisnewsky, J., Chakaroun, R., Myridakis, A., Forslund, S. K., Nielsen, T., et al. (2023). Evidence of a causal and modifiable relationship between kidney function and circulating trimethylamine N-oxide. Nat. Commun. 14:5843. doi: 10.1038/s41467-023-39824-4
Athey, S., and Wager, S. (2019). Estimating treatment effects with causal forests: an application. Observ. Stud. 5, 37–51. doi: 10.1353/obs.2019.0001
Bajaj, J. S., Reddy, K. R., O’Leary, J. G., Vargas, H. E., Lai, J. C., Kamath, P. S., et al. (2020). Serum levels of metabolites produced by intestinal microbes and lipid moieties independently associated with acute-on-chronic liver failure and death in patients with cirrhosis. Gastroenterology 159, 1715–1730.e12. doi: 10.1053/j.gastro.2020.07.019
Baranzini, S. E. (2025). The Barancik award lecture: multi-disciplinary research will be the key to stop, restore, and end MS. Mult. Scler. 31, 384–391. doi: 10.1177/13524585251314756
Ben-Yacov, O., Godneva, A., Rein, M., Shilo, S., Lotan-Pompan, M., Weinberger, A., et al. (2023). Gut microbiome modulates the effects of a personalised postprandial-targeting (PPT) diet on cardiometabolic markers: a diet intervention in pre-diabetes. Gut 72, 1486–1496. doi: 10.1136/gutjnl-2022-329201
Bi, G. W., Wu, Z. G., Li, Y., Wang, J. B., Yao, Z. W., Yang, X. Y., et al. (2024). Intestinal flora and inflammatory bowel disease: causal relationships and predictive models. Heliyon 10:e38101. doi: 10.1016/j.heliyon.2024.e38101
Bogart, E., Creswell, R., and Gerber, G. K. (2019). MITRE: inferring features from microbiota time-series data linked to host status. Genome Biol. 20:186. doi: 10.1186/s13059-019-1788-y
Bucci, V., Ward, D. V., Bhattarai, S., Rojas-Correa, M., Purkayastha, A., Holler, D., et al. (2023). The intestinal microbiota predicts COVID-19 severity and fatality regardless of hospital feeding method. mSystems 8:e0031023. doi: 10.1128/msystems.00310-23
Busato, S., Gordon, M., Chaudhari, M., Jensen, I., Akyol, T., Andersen, S., et al. (2023). Compositionality, sparsity, spurious heterogeneity, and other data-driven challenges for machine learning algorithms within plant microbiome studies. Curr. Opin. Plant Biol. 71:102326. doi: 10.1016/j.pbi.2022.102326
Cai, Y., Gu, H., and Kenney, T. (2017). Learning microbial community structures with supervised and unsupervised non-negative matrix factorization. Microbiome 5:110. doi: 10.1186/s40168-017-0323-1
Calvani, R., Giampaoli, O., Marini, F., Del Chierico, F., De Rosa, M., Conta, G., et al. (2024). Beetroot juice intake positively influenced gut microbiota and inflammation but failed to improve functional outcomes in adults with long COVID: a pilot randomized controlled trial. Clin. Nutr. 43, 344–358. doi: 10.1016/j.clnu.2024.11.023
Cammarota, G., Ianiro, G., Ahern, A., Carbone, C., Temko, A., Claesson, M. J., et al. (2020). Gut microbiome, big data and machine learning to promote precision medicine for cancer. Nat. Rev. Gastroenterol. Hepatol. 17, 635–648. doi: 10.1038/s41575-020-0327-3
Chang, H., Liu, Y., Wang, Y., Li, L., Mu, Y., Zheng, M., et al. (2024). Unveiling the links between microbial alteration and host gene disarray in Crohn’s disease via TAHMC. Adv. Biol. 8:e2400064. doi: 10.1002/adbi.202400064
Chen, M., Nguyen, T. T., and Liu, J. (2025). High-dimensional confounding in causal mediation: a comparison study of double machine learning and regularized partial correlation network. J. Data Sci. 1–21, 521–541. doi: 10.6339/25-jds1169
Chen, S., Xue, X., Zhang, Y., Zhang, H., Huang, X., Chen, X., et al. (2022). Vaginal Atopobium is associated with spontaneous abortion in the first trimester: a prospective cohort study in China. Microbiol. Spectr. 10:e0203921. doi: 10.1128/spectrum.02039-21
Chen, W., Zhang, P., Zhang, X., Xiao, T., Zeng, J., Guo, K., et al. (2024). Machine learning-causal inference based on multi-omics data reveals the association of altered gut bacteria and bile acid metabolism with neonatal jaundice. Gut Microbes 16:2388805. doi: 10.1080/19490976.2024.2388805
Chen, Y. H., Xue, F., Yu, S. F., Li, X. S., Liu, L., Jia, Y. Y., et al. (2021). Gut microbiota dysbiosis in depressed women: the association of symptom severity and microbiota function. J. Affect. Disord. 282, 391–400. doi: 10.1016/j.jad.2020.12.143
Comba, I. Y., Mars, R. A. T., Yang, L., Dumais, M., Chen, J., Van Gorp, T. M., et al. (2024). Gut microbiome signatures during acute infection predict long COVID. bioRxiv. Available online at: https://doi.org/10.1101/2024.12.10.626852. [Epub ahead of preprint]
Dang, Y., Zhang, X., Zheng, Y., Yu, B., Pan, D., Jiang, X., et al. (2021). Distinctive gut microbiota alteration is associated with poststroke functional recovery: results from a prospective cohort study. Neural Plast. 2021:1469339. doi: 10.1155/2021/1469339
Dawkins, J. J., Allegretti, J. R., Gibson, T. E., McClure, E., Delaney, M., Bry, L., et al. (2022). Gut metabolites predict Clostridioides difficile recurrence. Microbiome 10:87. doi: 10.1186/s40168-022-01284-1
Dutta, A., Goldman, T., Keating, J., Burke, E., Williamson, N., Dirmeier, R., et al. (2022). Machine learning predicts biogeochemistry from microbial community structure in a complex model system. Microbiol. Spectr. 10:e0190921. doi: 10.1128/spectrum.01909-21
Falagas, M. E., Pitsouni, E. I., Malietzis, G. A., and Pappas, G. (2008). Comparison of PubMed, Scopus, Web of Science, and Google Scholar: strengths and weaknesses. FASEB J. 22, 338–342. doi: 10.1096/fj.07-9492LSF
Feinman, R., Aptekmann, A., Colorado, I., Roy, S., Quino, K., Ahmed, N., et al. (2023). Gut microbiota diversity and composition is associated with high-risk myeloma. Blood 142:3294. doi: 10.1182/blood-2023-190108
Galiwango, R. M., Park, D. E., Huibner, S., Onos, A., Aziz, M., Roach, K., et al. (2022). Immune milieu and microbiome of the distal urethra in Ugandan men: impact of penile circumcision and implications for HIV susceptibility. Microbiome 10:7. doi: 10.1186/s40168-021-01185-9
Gao, J., Zhang, J., and Tang, L. (2025). The association of trimethylamine N-oxide with diabetic retinopathy pathology: insights from network toxicology and molecular docking analysis. Exp. Eye Res. 256:110399. doi: 10.1016/j.exer.2025.110399
Goedert, J. J., Gong, Y., Hua, X., Zhong, H., He, Y., Peng, P., et al. (2015). Fecal microbiota characteristics of patients with colorectal adenoma detected by screening: a population-based study. EBioMedicine 2, 597–603. doi: 10.1016/j.ebiom.2015.04.010
Gou, W., Ling, C., He, Y., Jiang, Z., Fu, Y., Xu, F., et al. (2020). Interpretable machine learning framework reveals robust gut microbiome features associated with type 2 diabetes. Diabetes Care 44, 358–366. doi: 10.2337/dc20-1536
Gupta, V. K., Cunningham, K. Y., Hur, B., Bakshi, U., Huang, H., Warrington, K. J., et al. (2021). Gut microbial determinants of clinically important improvement in patients with rheumatoid arthritis. Genome Med. 13:149. doi: 10.1186/s13073-021-00957-0
Hao, H., Yao, J., Wu, Q., Wei, Y., Dai, M., Iqbal, Z., et al. (2015). Microbiological toxicity of tilmicosin on human colonic microflora in chemostats. Regul. Toxicol. Pharmacol. 73, 201–208. doi: 10.1016/j.yrtph.2015.07.008
Hao, X., Jiang, R., and Chen, T. (2011). Clustering 16S rRNA for OTU prediction: a method of unsupervised Bayesian clustering. Bioinformatics 27, 611–618. doi: 10.1093/bioinformatics/btq725
Hill, T. D., Davis, A. P., Roos, J. M., and French, M. T. (2020). Limitations of fixed-effects models for panel data. Sociol. Perspect. 63, 357–369. doi: 10.1177/0731121419863785
Hu, B., Yang, Y., Yao, J., Lin, G., He, Q., Bo, Z., et al. (2024). Gut microbiota as mediator and moderator between hepatitis B virus and hepatocellular carcinoma: a prospective study. Cancer Med. 13:e70454. doi: 10.1002/cam4.70454
Hu, M., Lin, X., Sun, T., Shao, X., Huang, X., Du, W., et al. (2024). Gut microbiome for predicting immune checkpoint blockade-associated adverse events. Genome Med. 16:16. doi: 10.1186/s13073-024-01285-9
Huws, S. A., Edwards, J. E., Lin, W., Rubino, F., Alston, M., Swarbreck, D., et al. (2021). Microbiomes attached to fresh perennial ryegrass are temporally resilient and adapt to changing ecological niches. Microbiome 9:143. doi: 10.1186/s40168-021-01087-w
Jiang, H., Miao, X., Thairu, M. W., Beebe, M., Grupe, D. W., Davidson, R. J., et al. (2025). Multimedia: multimodal mediation analysis of microbiome data. Microbiol. Spectr. 13:e0113124. doi: 10.1128/spectrum.01131-24
Jung, Y., Lee, T., Oh, H.-S., Hyun, Y., Song, S., Chun, J., et al. (2024). Gut microbial and clinical characteristics of individuals with autism spectrum disorder differ depending on the ecological structure of the gut microbiome. Psychiatry Res. 335:115775. doi: 10.1016/j.psychres.2024.115775
Katsidzira, L., and Misselwitz, B. (2025). Biologic agents for IBD come of age as host–microbe interactions emerge. Nat. Rev. Gastroenterol. Hepatol. 22, 94–95. doi: 10.1038/s41575-024-01029-5
Kieft, K., Zhou, Z., and Anantharaman, K. (2020). VIBRANT: automated recovery, annotation and curation of microbial viruses, and evaluation of viral community function from genomic sequences. Microbiome 8:90. doi: 10.1186/s40168-020-00867-0
Kim, J. E., Kim, H.-E., Cho, H., Park, J. I., Kwak, M.-J., Kim, B.-Y., et al. (2020). Effect of the similarity of gut microbiota composition between donor and recipient on graft function after living donor kidney transplantation. Sci. Rep. 10:18881. doi: 10.1038/s41598-020-76072-8
Koduru, L., Lakshmanan, M., Hoon, S., Lee, D. Y., Lee, Y. K., and Ow, D. S. (2022). Systems biology of gut microbiota-human receptor interactions: toward anti-inflammatory probiotics. Front. Microbiol. 13:846555. doi: 10.3389/fmicb.2022.846555
Koh, H., Kim, J., and Jang, H. (2025). MiCML: a causal machine learning cloud platform for the analysis of treatment effects using microbiome profiles. BioData Min. 18:10. doi: 10.1186/s13040-025-00422-3
Kurz, C., Arbeeva, L., Azcarate-Peril, M. A., Stewart, D. A., Lascelles, B. D. X., Loeser, R. F., et al. (2025). Exploring associations among pro-inflammatory cytokines, osteoarthritis, and gut microbiome composition in individuals with obesity using machine learning. Osteoarthr. Cartil. Open 7:100603. doi: 10.1016/j.ocarto.2025.100603
Lee, J.-C., Lee, B. J., Park, C., Song, H., Ock, C.-Y., Sung, H., et al. (2023). Efficacy improvement in searching MEDLINE database using a novel PubMed visual analytic system: EEEvis. PLoS One 18:e0281422. doi: 10.1371/journal.pone.0281422
Li, J., Li, J., Liu, Y., Zeng, J., Liu, Y., and Wu, Y. (2024). Large-scale bidirectional Mendelian randomization study identifies new gut microbiome significantly associated with immune thrombocytopenic purpura. Front. Microbiol. 15:1423951. doi: 10.3389/fmicb.2024.1423951
Li, P., Luo, H., Ji, B., and Nielsen, J. (2022). Machine learning for data integration in human gut microbiome. Microbial Cell Factories 21:241. doi: 10.1186/s12934-022-01973-4
Li, R., Guo, Q., Zhao, J., Kang, W., Lu, R., Long, Z., et al. (2023). Assessing causal relationships between gut microbiota and asthma: evidence from two sample Mendelian randomization analysis. Front. Immunol. 14:1148684. doi: 10.3389/fimmu.2023.1148684
Liu, B., Liu, Z., Jiang, T., Gu, X., Yin, X., Cai, Z., et al. (2024). Univariable and multivariable Mendelian randomization study identified the key role of gut microbiota in immunotherapeutic toxicity. Eur. J. Med. Res. 29:161. doi: 10.1186/s40001-024-01741-7
Liu, Y.-Y. (2025). Deep learning for microbiome-informed precision nutrition. Natl. Sci. Rev. 12:nwaf148. doi: 10.1093/nsr/nwaf148
Lu, D.-C., Wang, F.-Q., Amann, R. I., Teeling, H., and Du, Z.-J. (2023). Epiphytic common core bacteria in the microbiomes of co-located green (Ulva), brown (Saccharina) and red (Grateloupia, Gelidium) macroalgae. Microbiome 11:126. doi: 10.1186/s40168-023-01559-1
Mainali, K., Bewick, S., Vecchio-Pagan, B., Karig, D., and Fagan, W. F. (2019). Detecting interaction networks in the human microbiome with conditional Granger causality. PLoS Comput. Biol. 15:e1007037. doi: 10.1371/journal.pcbi.1007037
Malakar, S., Sutaoney, P., Madhyastha, H., Shah, K., Chauhan, N. S., and Banerjee, P. (2024). Understanding gut microbiome-based machine learning platforms: a review on therapeutic approaches using deep learning. Chem. Biol. Drug Des. 103:e14505. doi: 10.1111/cbdd.14505
Mammadova, G., Ozkul, C., Isikhan, S. Y., Acikgoz, A., and Yildiz, B. O. (2020). Characterization of gut microbiota in polycystic ovary syndrome: findings from a lean population. Eur. J. Clin. Investig. 51:e13417. doi: 10.1111/eci.13417
Mao, R., Yu, Q., and Li, J. (2023). The causal relationship between gut microbiota and inflammatory dermatoses: a Mendelian randomization study. Front. Immunol. 14:1231848. doi: 10.3389/fimmu.2023.1231848
Marcos-Zambrano, L. J., Karaduzovic-Hadziabdic, K., Loncar Turukalo, T., Przymus, P., Trajkovik, V., Aasmets, O., et al. (2021). Applications of machine learning in human microbiome studies: a review on feature selection, biomarker identification, disease prediction and treatment. Front. Microbiol. 12:634511. doi: 10.3389/fmicb.2021.634511
Ma, Z., Qiao, Y., and Li, L. (2025). Comparative medical ecology of gut microbiomes in major neurodegenerative, neurodevelopmental, and psychiatric (NNP) disorders. medRxiv. Available online at: https://doi.org/10.1101/2025.03.16.25324039. [Epub ahead of preprint]
Midya, V., Lane, J. M., Gennings, C., Torres-Olascoaga, L. A., Gregory, J. K., Wright, R. O., et al. (2023). Prenatal lead exposure is associated with reduced abundance of beneficial gut microbial cliques in late childhood: an investigation using microbial co-occurrence analysis (MiCA). Environ. Sci. Technol. 57, 16800–16810. doi: 10.1021/acs.est.3c04346
Mirzayi, C., and Renson, AGenomic Standards Consortium, et al. (2021). Reporting guidelines for human microbiome research: the STORMS checklist. Nature Medicine 27:1885–1892. doi: 10.1038/s41591-021-01552-x
Miyajima, Y., Karashima, S., Mizoguchi, R., Kawakami, M., Ogura, K., Ogai, K., et al. (2024). Prediction and causal inference of hyperuricemia using gut microbiota. Sci. Rep. 14:9901. doi: 10.1038/s41598-024-60427-6
Murayama, K., and Gfrörer, T. (2024). Thinking clearly about time-invariant confounders in cross-lagged panel models: a guide for choosing a statistical model from a causal inference perspective. Psychol. Methods. doi: 10.1037/met0000647
Neri-Rosario, D., Martínez-López, Y. E., Esquivel-Hernández, D. A., Sánchez-Castañeda, J. P., Padron-Manrique, C., Vázquez-Jiménez, A., et al. (2023). Dysbiosis signatures of gut microbiota and the progression of type 2 diabetes: a machine learning approach in a Mexican cohort. Front. Endocrinol. 14:1170459. doi: 10.3389/fendo.2023.1170459
Noda, K., Hattori, Y., Murata, H., Kokubo, Y., Higashiyama, A., and Ihara, M. (2024). Equol nonproducing status as an independent risk factor for acute cardioembolic stroke and poor functional outcome. Nutrients 16:3377. doi: 10.3390/nu16193377
Onywera, H., Williamson, A. L., Cozzuto, L., Bonnin, S., Mbulawa, Z. Z. A., Coetzee, D., et al. (2020). The penile microbiota of Black South African men: relationship with human papillomavirus and HIV infection. BMC Microbiol. 20:78. doi: 10.1186/s12866-020-01759-x
Oriano, M., Terranova, L., Teri, A., Sottotetti, S., Ruggiero, L., Tafuro, C., et al. (2019). Comparison of different conditions for DNA extraction in sputum—a pilot study. Multidiscip. Respir. Med. 14:6. doi: 10.1186/s40248-018-0166-z
Ossom Williamson, P., and Minter, C. I. J. (2019). Exploring PubMed as a reliable resource for scholarly communications services. J. Med. Libr. Assoc. 107, 16–29. doi: 10.5195/jmla.2019.433
Page, M. J., McKenzie, J. E., Bossuyt, P. M., Boutron, I., Hoffmann, T. C., Mulrow, C. D., et al. (2021). The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ :n71. doi: 10.1136/bmj.n71
Pan, X., Yan, E., Cui, M., and Hua, W. (2018). Examining the usage, citation, and diffusion patterns of bibliometric mapping software: a comparative study of three tools. J. Informetr. 12, 481–493. doi: 10.1016/j.joi.2018.03.005
Pesaran, M. H., and Zhou, Q. (2018). Estimation of time-invariant effects in static panel data models. Econometr. Rev. 37, 1137–1171. doi: 10.1080/07474938.2016.1222225
Portlock, T., Shama, T., Kakon, S. H., Hartjen, B., Pook, C., Wilson, B. C., et al. (2025). Interconnected pathways link faecal microbiota plasma lipids and brain activity to childhood malnutrition related cognition. Nat. Commun. 16:473. doi: 10.1038/s41467-024-55798-3
Qiu, Y., Hou, Y., Gohel, D., Zhou, Y., Xu, J., Bykova, M., et al. (2024). Systematic characterization of multi-omics landscape between gut microbial metabolites and GPCRome in Alzheimer’s disease. Cell Rep. 43:114128. doi: 10.1016/j.celrep.2024.114128
Qu, C., Lu, J., Chen, Y., Li, J., Xu, X., and Li, F. (2024). Unravelling the role of gut microbiota in acute pancreatitis: integrating Mendelian randomization with a nested case-control study. Front. Microbiol. 15:1401056. doi: 10.3389/fmicb.2024.1401056
Ren, J., Ahlgren, N. A., Lu, Y. Y., Fuhrman, J. A., and Sun, F. (2017). VirFinder: a novel k-mer based tool for identifying viral sequences from assembled metagenomic data. Microbiome 5:69. doi: 10.1186/s40168-017-0283-5
Ruggiero, K. M., Wong, J., Sweeney, C. F., Avola, A., Auger, A., Macaluso, M., et al. (2021). Parents’ intentions to vaccinate their children against COVID-19. J. Pediatr. Health Care 35, 509–517. doi: 10.1016/j.pedhc.2021.04.005
Rupf, S., Laczny, C. C., Galata, V., Backes, C., Keller, A., Umanskaya, N., et al. (2018). Comparison of initial oral microbiomes of young adults with and without cavitated dentin caries lesions using an in situ biofilm model. Sci. Rep. 8:14010. doi: 10.1038/s41598-018-32361-x
Sakurai, T., Nishiyama, H., Sakai, K., De Velasco, M. A., Nagai, T., Komeda, Y., et al. (2020). Mucosal microbiota and gene expression are associated with long-term remission after discontinuation of adalimumab in ulcerative colitis. Sci. Rep. 10:19186. doi: 10.1038/s41598-020-76175-2
Schwab, C., Voney, E., Garcia, A. R., Vischer, M., and Lacroix, C. (2019). Characterization of the cultivable microbiota in fresh and stored mature human breast milk. Front. Microbiol. 10:2666. doi: 10.3389/fmicb.2019.02666
Schwenger, K. J. P., Sharma, D., Ghorbani, Y., Xu, W., Lou, W., Comelli, E. M., et al. (2024). Links between gut microbiome, metabolome, clinical variables and non-alcoholic fatty liver disease severity in bariatric patients. Liver Int. 44, 1176–1188. doi: 10.1111/liv.15864
Sheng, C., Huang, W., Liao, M., and Yang, P. (2024). The role of gut microbiota in thromboangiitis obliterans: cohort and Mendelian randomization study. Biomedicine 12:1459. doi: 10.3390/biomedicines12071459
Sohrabi, C., Franchi, T., Mathew, G., Kerwan, A., Nicola, M., Griffin, M., et al. (2021). PRISMA 2020 statement: what’s new and the importance of reporting guidelines. Int. J. Surg. 88:105918. doi: 10.1016/j.ijsu.2021.105918
Sokolovska, N., Permiakova, O., Forslund, S. K., and Zucker, J. D. (2020). Using unlabeled data to discover bivariate causality with deep restricted Boltzmann machines. IEEE/ACM Trans. Comput. Biol. Bioinform. 17, 358–364. doi: 10.1109/TCBB.2018.2879504
Streeter, A. J., Lin, N. X., Crathorne, L., Haasova, M., Hyde, C., Melzer, D., et al. (2017). Adjusting for unmeasured confounding in nonrandomized longitudinal studies: a methodological review. J. Clin. Epidemiol. 87, 23–34. doi: 10.1016/j.jclinepi.2017.04.022
Sze, M. A., Topçuoğlu, B. D., Lesniak, N. A., Ruffin, M. T., and Schloss, P. D. (2019). Fecal short-chain fatty acids are not predictive of colonic tumor status and cannot be predicted based on bacterial community structure. mBio 10:e01454-19. doi: 10.1128/mbio.01454-19
Wang, C., Ahn, J., Tarpey, T., Yi, S. S., Hayes, R. B., and Li, H. (2023). A microbial causal mediation analytic tool for health disparity and applications in body mass index. Microbiome 11:164. doi: 10.1186/s40168-023-01608-9
Warmbrunn, M. V., Boulund, U., Aron-Wisnewsky, J., de Goffau, M. C., Abeka, R. E., Davids, M., et al. (2024). Networks of gut bacteria relate to cardiovascular disease in a multi-ethnic population: the HELIUS study. Cardiovasc. Res. 120, 372–384. doi: 10.1093/cvr/cvae018
Wipperman, M. F., Bhattarai, S. K., Vorkas, C. K., Maringati, V. S., Taur, Y., Mathurin, L., et al. (2021). Gastrointestinal microbiota composition predicts peripheral inflammatory state during treatment of human tuberculosis. Nat. Commun. 12:1141. doi: 10.1038/s41467-021-21475-y
Wu, C., Zhao, Y., Zhang, Y., Yang, Y., Su, W., Yang, Y., et al. (2022). Gut microbiota specifically mediates the anti-hypercholesterolemic effect of berberine (BBR) and facilitates to predict BBR’s cholesterol-decreasing efficacy in patients. J. Adv. Res. 37, 197–208. doi: 10.1016/j.jare.2021.07.011
Yang, C., Qin, L. H., Li, L., Wei, Q. Y., Long, L., and Liao, J. Y. (2025). The causal relationship between the gut microbiota and endometrial cancer: a Mendelian randomization study. BMC Cancer 25:248. doi: 10.1186/s12885-025-13656-5
Yaskolka Meir, A., Keller, M., Hoffmann, A., Rinott, E., Tsaban, G., Kaplan, A., et al. (2023). The effect of polyphenols on DNA methylation-assessed biological age attenuation: the DIRECT PLUS randomized controlled trial. BMC Med. 21:364. doi: 10.1186/s12916-023-03067-3
Yirga, A. A., Melesse, S. F., Mwambi, H. G., and Ayele, D. G. (2020). Negative binomial mixed models for analyzing longitudinal CD4 count data. Sci. Rep. 10:16742. doi: 10.1038/s41598-020-73883-7
Zeng, Q., Li, D., He, Y., Li, Y., Yang, Z., Zhao, X., et al. (2019). Discrepant gut microbiota markers for the classification of obesity-related metabolic abnormalities. Sci. Rep. 9:13424. doi: 10.1038/s41598-019-49462-w
Zeng, S., Wang, Z., Zhang, P., Yin, Z., Huang, X., Tang, X., et al. (2022). Machine learning approach identifies meconium metabolites as potential biomarkers of neonatal hyperbilirubinemia. Comput. Struct. Biotechnol. J. 20, 1778–1784. doi: 10.1016/j.csbj.2022.03.039
Zhang, L., Dong, Q., Wang, Y., Li, X., Li, C., Li, F., et al. (2025). Global trends and risk factors in gastric cancer: a comprehensive analysis of the Global Burden of Disease Study 2021 and multi-omics data. Int. J. Med. Sci. 22, 341–356. doi: 10.7150/ijms.104437
Keywords: human microbiome, causal-ML, econometric methods, explainable artificial intelligence AI, policy translation
Citation: Khelfaoui I, Wang W, Meskher H, Shehata AI, El Basuini MF, Abouelenein MF, Degha HE, Alhoshy M, Teiba II and Mahmoud SS (2025) Beyond just correlation: causal machine learning for the microbiome, from prediction to health policy with econometric tools. Front. Microbiol. 16:1691503. doi: 10.3389/fmicb.2025.1691503
Edited by:
Fahim Sufi, Monash University, AustraliaReviewed by:
Honglei Ren, Heilongjiang Academy of Agricultural Sciences, ChinaMuhammad Kalim, University of Texas Medical Branch at Galveston, United States
Copyright © 2025 Khelfaoui, Wang, Meskher, Shehata, El Basuini, Abouelenein, Degha, Alhoshy, Teiba and Mahmoud. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wenxin Wang, d3h3YW5nQHN0dS5lZHUuY24=