Abstract
Objective:
Analyze the psychological and clinical factors of clinically significant tinnitus (THI score ≥38) in patients with hearing loss, construct predictive models based on four machine learning (ML) algorithms, and compare the predictive performance of different models.
Methods:
Patients with hearing loss who visited the Department of Otolaryngology at Qinghai University between August 2024 and May 2025 were enrolled in this study. Clinical data were retrieved from the hospital’s electronic medical record system. The study outcome was the occurrence of clinically significant tinnitus. Predictive variables were screened using univariate analysis, the least absolute shrinkage and selection operator (LASSO) regression, and the Boruta algorithm. Four ML algorithms—logistic regression (LR), random forest (RF), extreme gradient boosting (XGBoost), and support vector machine (SVM)—were applied to construct and validate predictive models. The area under the receiver operating characteristic curve (AUC) of each model in the validation set was compared using the DeLong test. Additionally, model performance metrics in the validation set were compared to identify the optimal model. Finally, the Shapley additive explanations (SHAP) algorithm was employed to interpret the best-performing model.
Results:
Nine key variables—age, hypertension, sleep disorder, anxiety, hearing loss severity, depression, noise exposure history, hearing side, and ototoxic drug use—were retained after LASSO and Boruta feature selection. Among the four ML models, the RF algorithm achieved the best predictive performance, with an AUC of 0.973 in the training set and 0.977 in the validation set, followed by XGBoost (AUC = 0.962 and 0.961, respectively). DeLong tests confirmed that RF significantly outperformed LR and SVM models (p < 0.001), while its difference from XGBoost was not significant. In the validation set, the RF model yielded the highest accuracy (0.923), sensitivity (0.929), specificity (0.914), precision (0.945), and F1-score (0.937). SHAP analysis indicated that hearing loss severity, age, and sleep disorder were the most influential predictors, suggesting that both auditory and non-auditory factors contribute substantially to the risk of clinically significant tinnitus.
Conclusion:
The RF model showed the best performance in predicting clinically significant tinnitus, with hearing loss severity, age, and sleep disorder identified as major predictors. Integrating auditory and psychological factors can improve early risk identification in patients with hearing loss.
Introduction
Tinnitus, defined as the perception of sound without an external source, is a common auditory condition with significant global prevalence (1–4). Recent epidemiological estimates indicate that roughly 10–15% of adults experience tinnitus (3, 5). Prevalence increases with age—for example, it affects about 9–14% of middle-aged adults and rises to ~24% or more in those over 65 (5). While many cases are mild, tinnitus can be severe in a subset of patients: around 1–2% of the population suffers disabling tinnitus that substantially impairs quality of life (6). This translates to an estimated >740 million individuals affected worldwide, with over 120 million finding tinnitus to be a “major” problem (7). Such figures underscore the substantial public health burden of tinnitus.
Importantly, tinnitus is strongly associated with hearing loss. It often accompanies sensorineural hearing impairments (e.g., age-related or noise-induced hearing loss), and studies in older adults show an ~80% overlap between chronic tinnitus and measurable hearing deficits (8–10). Indeed, hearing damage (due to presbycusis, noise exposure, ototoxic drugs, etc.) is considered a primary trigger for tinnitus, as peripheral auditory deafferentation can induce aberrant neural activity perceived as “phantom” sound. Correspondingly, large-scale analyses confirm that hearing health is the single strongest predictor of tinnitus onset (11). At the same time, not everyone with hearing loss develops tinnitus, and some tinnitus patients have normal audiograms. This discrepancy suggests that factors beyond the auditory system modulate tinnitus susceptibility and severity (11, 12). In fact, recent genetic evidence indicates that while tinnitus and hearing loss share many risk variants, tinnitus has a distinct pathophysiology—including genetic influences and brain activity patterns—that cannot be explained by hearing loss alone. Tinnitus is now regarded as a cross-disciplinary disorder involving auditory, cognitive, and emotional components (7).
A robust body of research links tinnitus with psychological comorbidities. Many patients with chronic tinnitus experience elevated levels of anxiety, depressed mood, and sleep disturbances (3, 13). For instance, in a large national survey, 25.6% of tinnitus sufferers reported clinically significant depression in the past year, compared to only 9.1% in those without tinnitus (14). A meta-analysis likewise found a median ~33% prevalence of major depression among tinnitus patients (15). Anxiety disorders and symptoms are also frequently reported alongside tinnitus (13). Epidemiological studies and population-based cohorts have shown that even after adjusting for hearing status, individuals with tinnitus (including “non-bothersome” cases) are more likely to exhibit anxiety and depressive symptoms than those without tinnitus (16). Sleep problems are another well-documented companion of tinnitus: about 40–60% of tinnitus patients report poor sleep quality or insomnia, and sleep difficulties correlate with greater tinnitus distress (3). In fact, tinnitus is “not only correlated with hearing loss, but also with a spectrum of psychiatric disorders” including depression, anxiety, and even suicidal ideation in severe cases (7). These comorbid conditions can form a vicious cycle—persistent tinnitus provokes emotional distress and sleep disruption, which in turn can exacerbate the perception of tinnitus and its impact on well-being (11). In this study, we applied and compared multiple machine learning (ML) algorithms to develop predictive models for clinically significant tinnitus in patients with hearing loss, aiming to support early identification and personalized intervention.
Materials and methods
Population selection
Three hundred one patients with hearing loss who visited the Department of Otolaryngology, Qinghai University Affiliated Hospital, between August 2024 and May 2025 were retrospectively enrolled in this study. All participants were identified through the hospital’s electronic medical record system. Inclusion criteria were as follows: (1) age≥18 years; (2) completion of audiological assessments, detailed medical history, and psychological questionnaires; (3) completion of the Tinnitus Handicap Inventory (THI) for the evaluation of tinnitus severity; and (4) availability of all key clinical variables required for the analysis. Exclusion criteria included: (1) the presence of active acute ear diseases (e.g., otitis externa, otitis media, or sudden sensorineural hearing loss); (2) a history of cranial trauma or otologic surgery; (3) diagnosed neurodegenerative or severe psychiatric disorders; and (4) incomplete or missing clinical data.
Data collection
Clinical data of all eligible patients were extracted from the hospital’s electronic medical record system by two independent researchers using a standardized data collection form. Demographic information included age, sex, and BMI. Clinical characteristics comprised hypertension, diabetes, hyperlipidemia, noise exposure history, family history of hearing loss, and the presence of sleep disorders, anxiety, or depression. Audiological data included the hearing loss severity, duration of hearing loss, and ototoxic drug use. Lifestyle factors such as smoking and alcohol consumption were also recorded. All psychological parameters were assessed using validated questionnaires administered at the time of evaluation. Tinnitus severity was quantified using the Tinnitus Handicap Inventory (THI) (17, 18), and patients with clinically significant tinnitus were identified based on THI scores. To ensure data integrity and consistency, all entries were cross-checked, and cases with missing or ambiguous information were excluded from the analysis.
Definition of related variables
The primary outcome was tinnitus severity, assessed using the THI. According to standard grading criteria, THI scores were classified as follows: slight (0–16), mild (18–36), moderate (38–56), severe (58–76), and catastrophic (78–100). For analytical purposes, tinnitus severity was dichotomized as clinically significant tinnitus (THI score ≥38), which included moderate, severe, and catastrophic categories, versus no or mild tinnitus (THI score <38), representing the absence or minimal impact of tinnitus. The hearing loss severity was categorized based on pure-tone audiometry as mild (21–40 dB), moderate (41–60 dB), or severe (>60 dB) (19). Laryngopharyngeal reflux (LPR) was defined by a Reflux Symptom Index (RSI) ≥ 13 and a Reflux Finding Score (RFS) ≥ 7 (20, 21). Psychological variables included anxiety and depression, assessed using the Zung Self-Rating Anxiety Scale (SAS) and the Patient Health Questionnaire-9 (PHQ-9), respectively. Anxiety was defined as SAS ≥ 50, and depression as PHQ-9 ≥ 10 (22, 23). Sleep quality was evaluated using the Pittsburgh Sleep Quality Index (PSQI), with a total score >5 indicating poor sleep quality (24). Occupational noise exposure was defined as exposure to noise levels ≥85 dB for at least 8 h per day for a minimum duration of 1 year.
Statistical methods
All statistical analyses were performed using R software (version 4.3.2). A total of 301 patients with hearing loss were included in the analysis. The dataset was randomly divided into a training set (80%) and a validation set (20%) to develop and evaluate predictive models. Continuous variables were expressed as mean ± standard deviation (SD) or median with interquartile range (IQR), depending on data distribution, and categorical variables were summarized as frequencies and percentages. Group comparisons were conducted using the t-test or Mann–Whitney U test for continuous variables and the chi-square or Fisher’s exact test for categorical variables.
The least absolute shrinkage and selection operator (LASSO) regression to penalize overfitting and identify variables with nonzero coefficients. In addition, the Boruta algorithm, a random-forest-based feature selection method, was applied to further validate the robustness of selected predictors. The final feature set was obtained by taking the union of variables identified by these two approaches.
Four supervised ML algorithms—logistic regression (LR), random forest (RF), extreme gradient boosting (XGBoost), and support vector machine (SVM)—were used to construct predictive models for clinically significant tinnitus in patients with hearing loss. Model performance was evaluated in both the training and validation sets. The area under the receiver operating characteristic curve (AUC) was calculated to assess discriminative ability, and DeLong’s test was used to compare AUCs between models. Additionally, accuracy, sensitivity, specificity, precision, recall, and F1-score were computed to comprehensively evaluate predictive performance.
The Shapley additive explanations (SHAP) algorithm was employed to interpret the best-performing model and visualize the relative contribution and direction of each predictor. A p-value <0.05 (two-sided) was considered statistically significant.
Result
General situation
A total of 301 patients with hearing loss were included, including 162 males (53.8%), 139 females (46.2%), 115 patients (38.2%) without tinnitus or mild tinnitus, and 186 patients (61.8%) with clinically significant tinnitus. The data from the training and validation sets were compared, and there was no statistically significant difference in each indicator between the two datasets (p > 0.05) (see Table 1). Baseline characteristics of patients with no or mild tinnitus and those with clinically significant tinnitus in the overall cohort are provided in Supplementary Table S1.
Table 1
| Variables | Overall (301) | Train (210) | Validation (91) | Statistica | p-value |
|---|---|---|---|---|---|
| Age | |||||
| < 60 | 85 (28.2%) | 59 (28.1%) | 26 (28.6%) | 0.01 | 0.933b |
| ≥ 60 | 216 (71.8%) | 151 (71.9%) | 65 (71.4%) | ||
| Sex | |||||
| Male | 162 (53.8%) | 112 (53.3%) | 50 (54.9%) | 0.07 | 0.797b |
| Female | 139 (46.2%) | 98 (46.7%) | 41 (45.1%) | ||
| Diabetes | |||||
| No | 206 (68.4%) | 146 (69.5%) | 60 (65.9%) | 0.38 | 0.538b |
| Yes | 95 (31.6%) | 64 (30.5%) | 31 (34.1%) | ||
| Hypertension | |||||
| No | 185 (61.5%) | 126 (60.0%) | 59 (64.8%) | 0.63 | 0.429b |
| Yes | 116 (38.5%) | 84 (40.0%) | 32 (35.2%) | ||
| Smoke | |||||
| No | 184 (61.1%) | 127 (60.5%) | 57 (62.6%) | 0.12 | 0.724b |
| Yes | 117 (38.9%) | 83 (39.5%) | 34 (37.4%) | ||
| Alcohol consumption | |||||
| No | 114 (37.9%) | 79 (37.6%) | 35 (38.5%) | 0.02 | 0.890b |
| Yes | 187 (62.1%) | 131 (62.4%) | 56 (61.5%) | ||
| Sleep disorder | |||||
| No | 120 (39.9%) | 83 (39.5%) | 37 (40.7%) | 0.03 | 0.853b |
| Yes | 181 (60.1%) | 127 (60.5%) | 54 (59.3%) | ||
| Anxiety | |||||
| No | 147 (48.8%) | 105 (50.0%) | 42 (46.2%) | 0.38 | 0.540b |
| Yes | 154 (51.2%) | 105 (50.0%) | 49 (53.8%) | ||
| Hearing loss severity | |||||
| Mild | 125 (41.5%) | 88 (41.9%) | 37 (40.7%) | 2.09 | 0.352b |
| Moderate | 76 (25.2%) | 57 (27.1%) | 19 (20.9%) | ||
| Severe | 100 (33.2%) | 65 (31.0%) | 35 (38.5%) | ||
| Duration of hearing loss | |||||
| <12 months | 151 (50.2%) | 107 (51.0%) | 44 (48.4%) | 0.17 | 0.679b |
| ≥12 months | 150 (49.8%) | 103 (49.0%) | 47 (51.6%) | ||
| LPR | |||||
| No | 256 (85.0%) | 177 (84.3%) | 79 (86.8%) | 0.32 | 0.572b |
| Yes | 45 (15.0%) | 33 (15.7%) | 12 (13.2%) | ||
| Tinnitus | |||||
| No or mild | 115 (38.2%) | 80 (38.1%) | 35 (38.5%) | 0.00 | 0.952b |
| Moderate-to-severe | 186 (61.8%) | 130 (61.9%) | 56 (61.5%) | ||
| Hearing loss side | |||||
| Bilateral | 161 (53.5%) | 115 (54.8%) | 46 (50.5%) | 0.45 | 0.501b |
| Unilateral | 140 (46.5%) | 95 (45.2%) | 45 (49.5%) | ||
| Depression | |||||
| No | 157 (52.2%) | 107 (51.0%) | 50 (54.9%) | 0.41 | 0.524b |
| Yes | 144 (47.8%) | 103 (49.0%) | 41 (45.1%) | ||
| Ototoxic drug use | |||||
| No | 220 (73.1%) | 154 (73.3%) | 66 (72.5%) | 0.02 | 0.885b |
| Yes | 81 (26.9%) | 56 (26.7%) | 25 (27.5%) | ||
| Noise exposure | |||||
| No | 217 (72.1%) | 154 (73.3%) | 63 (69.2%) | 0.53 | 0.466b |
| Yes | 84 (27.9%) | 56 (26.7%) | 28 (30.8%) | ||
| Family history | |||||
| No | 287 (95.3%) | 200 (95.2%) | 87 (95.6%) | >0.999c | |
| Yes | 14 (4.7%) | 10 (4.8%) | 4 (4.4%) | ||
| Hyperlipidemia | |||||
| No | 212 (70.4%) | 149 (71.0%) | 63 (69.2%) | 0.09 | 0.764b |
| Yes | 89 (29.6%) | 61 (29.0%) | 28 (30.8%) | ||
| BMI | |||||
| Normal | 156 (51.8%) | 111 (52.9%) | 45 (49.5%) | 0.409c | |
| Overweight | 78 (25.9%) | 49 (23.3%) | 29 (31.9%) | ||
| Obese | 51 (16.9%) | 37 (17.6%) | 14 (15.4%) | ||
| Underweight | 16 (5.3%) | 13 (6.2%) | 3 (3.3%) | ||
Comparison of patient data between training set and validation set.
Pearson’s Chi-squared test; Fisher’s exact test.
Pearson’s Chi-squared test.
Fisher’s exact test.
LPR, laryngopharyngeal reflux; BMI, body mass index.
Univariate analysis was conducted on the training set, comparing patients with no or mild tinnitus and those with clinically significant tinnitus. As shown in Table 2, age, hypertension, sleep disorder, anxiety, hearing loss severity, depression, and noise exposure history were significantly associated with clinically significant tinnitus (p < 0.05).
Table 2
| Variables | No or mild tinnitus (THI<38, n = 80) | Clinically significant tinnitus (THI≥38, n = 130) | Statistica | p-value |
|---|---|---|---|---|
| Age | ||||
| < 60 | 32 (40.0%) | 27 (20.8%) | 9.07 | 0.003b |
| ≥ 60 | 48 (60.0%) | 103 (79.2%) | ||
| Sex | ||||
| Male | 46 (57.5%) | 66 (50.8%) | 0.90 | 0.342b |
| Female | 34 (42.5%) | 64 (49.2%) | ||
| Diabetes | ||||
| No | 54 (67.5%) | 92 (70.8%) | 0.25 | 0.617b |
| Yes | 26 (32.5%) | 38 (29.2%) | ||
| Hypertension | ||||
| No | 56 (70.0%) | 70 (53.8%) | 5.38 | 0.020b |
| Yes | 24 (30.0%) | 60 (46.2%) | ||
| Smoke | ||||
| No | 50 (62.5%) | 77 (59.2%) | 0.22 | 0.638b |
| Yes | 30 (37.5%) | 53 (40.8%) | ||
| Alcohol consumption | ||||
| No | 32 (40.0%) | 47 (36.2%) | 0.31 | 0.576b |
| Yes | 48 (60.0%) | 83 (63.8%) | ||
| Sleep disorder | ||||
| No | 40 (50.0%) | 43 (33.1%) | 5.93 | 0.015b |
| Yes | 40 (50.0%) | 87 (66.9%) | ||
| Anxiety | ||||
| No | 47 (58.8%) | 58 (44.6%) | 3.96 | 0.047b |
| Yes | 33 (41.3%) | 72 (55.4%) | ||
| Hearing loss severity | ||||
| Mild | 44 (55.0%) | 44 (33.8%) | 9.30 | 0.010b |
| Moderate | 18 (22.5%) | 39 (30.0%) | ||
| Severe | 18 (22.5%) | 47 (36.2%) | ||
| Duration of hearing loss | ||||
| <12 months | 39 (48.8%) | 68 (52.3%) | 0.25 | 0.616b |
| ≥12 months | 41 (51.3%) | 62 (47.7%) | ||
| LPR | ||||
| No | 64 (80.0%) | 113 (86.9%) | 1.79 | 0.181b |
| Yes | 16 (20.0%) | 17 (13.1%) | ||
| Hearing loss side | ||||
| Bilateral | 37 (46.3%) | 78 (60.0%) | 3.78 | 0.052b |
| Unilateral | 43 (53.8%) | 52 (40.0%) | ||
| Depression | ||||
| No | 50 (62.5%) | 57 (43.8%) | 6.90 | 0.009b |
| Yes | 30 (37.5%) | 73 (56.2%) | ||
| Ototoxic drug use | ||||
| No | 63 (78.8%) | 91 (70.0%) | 1.94 | 0.164b |
| Yes | 17 (21.3%) | 39 (30.0%) | ||
| Noise exposure | ||||
| No | 65 (81.3%) | 89 (68.5%) | 4.14 | 0.042b |
| Yes | 15 (18.8%) | 41 (31.5%) | ||
| Family history | ||||
| No | 75 (93.8%) | 125 (96.2%) | 0.510c | |
| Yes | 5 (6.3%) | 5 (3.8%) | ||
| Hyperlipidemia | ||||
| No | 59 (73.8%) | 90 (69.2%) | 0.49 | 0.484b |
| Yes | 21 (26.3%) | 40 (30.8%) | ||
| BMI | ||||
| Normal | 44 (55.0%) | 67 (51.5%) | 0.366c | |
| Overweight | 22 (27.5%) | 27 (20.8%) | ||
| Obese | 10 (12.5%) | 27 (20.8%) | ||
| Underweight | 4 (5.0%) | 9 (6.9%) | ||
Baseline feature table of training set.
Pearson’s Chi-squared test; Fisher’s exact test.
Pearson’s Chi-squared test.
Fisher’s exact test.
LPR: laryngopharyngeal reflux, BMI: body mass index.
Variable screening results
LASSO regression retained nine predictive variables: age, hypertension, sleep disorder, anxiety, hearing loss severity, hearing side, depression, ototoxic drug history, and noise exposure history. The Boruta algorithm confirmed three stable predictors—age, sleep disorder, and hearing loss severity—as important features. After integrating the results from all two methods, a total of nine variables (age, hypertension, sleep disorder, anxiety, hearing loss severity, depression, noise exposure history, hearing side, and ototoxic drug history) were selected for subsequent model construction (Figures 1, 2).
Figure 1
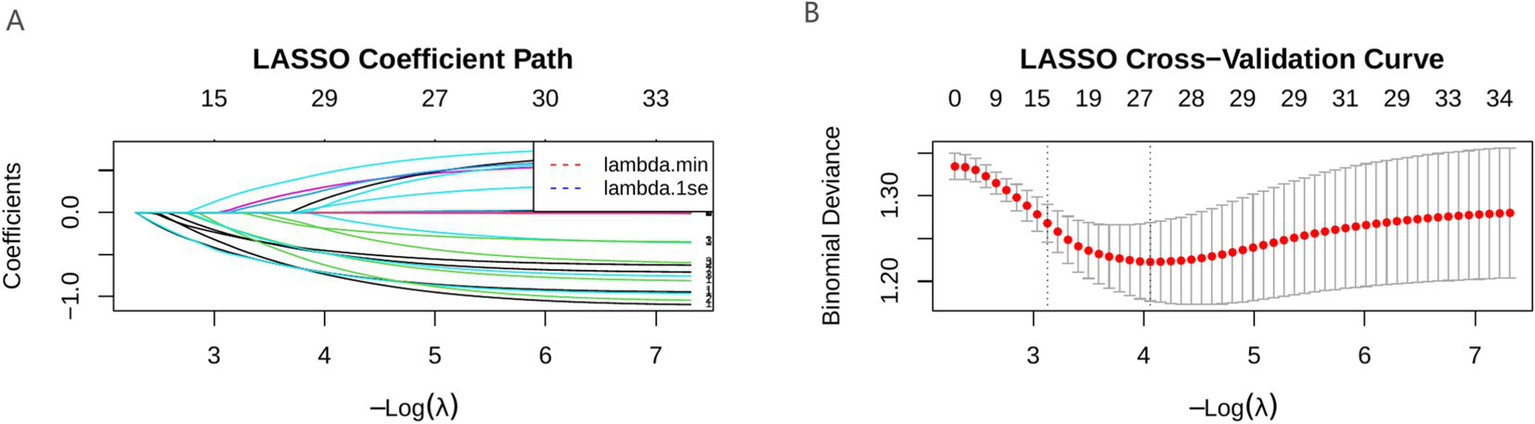
LASSO correlation graph. (A) LASSO coefficient path diagram; (B) LASSO cross-validation curve.
Figure 2
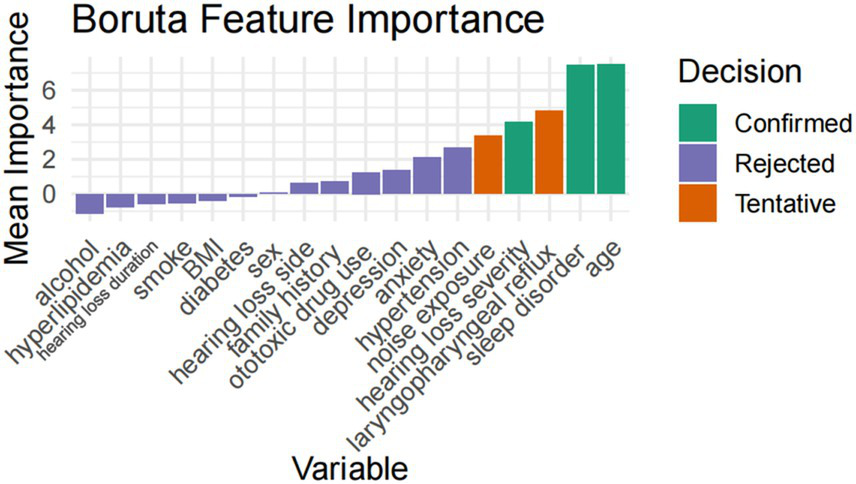
Boruta feature selection results.
Model performance comparison
In the training set, the RF model exhibited the best predictive ability (AUC = 0.973), followed by XGB (AUC = 0.962), LR (AUC = 0.788), and SVM (AUC = 0.817). In the validation set, the RF model again achieved the highest discrimination (AUC = 0.977), followed by XGB (AUC = 0.961), LR (AUC = 0.816), and SVM (AUC = 0.845) (Figure 3). The DeLong test was performed to statistically compare the AUCs among the four models. In both the training and validation sets, the RF model achieved the highest AUC values and demonstrated significantly superior discrimination compared with LR (p < 0.001) and SVM (p < 0.001). However, the differences between RF and XGB were not statistically significant (p = 0.055 in the training set; p = 0.075 in the validation set) (Table 3).
Figure 3
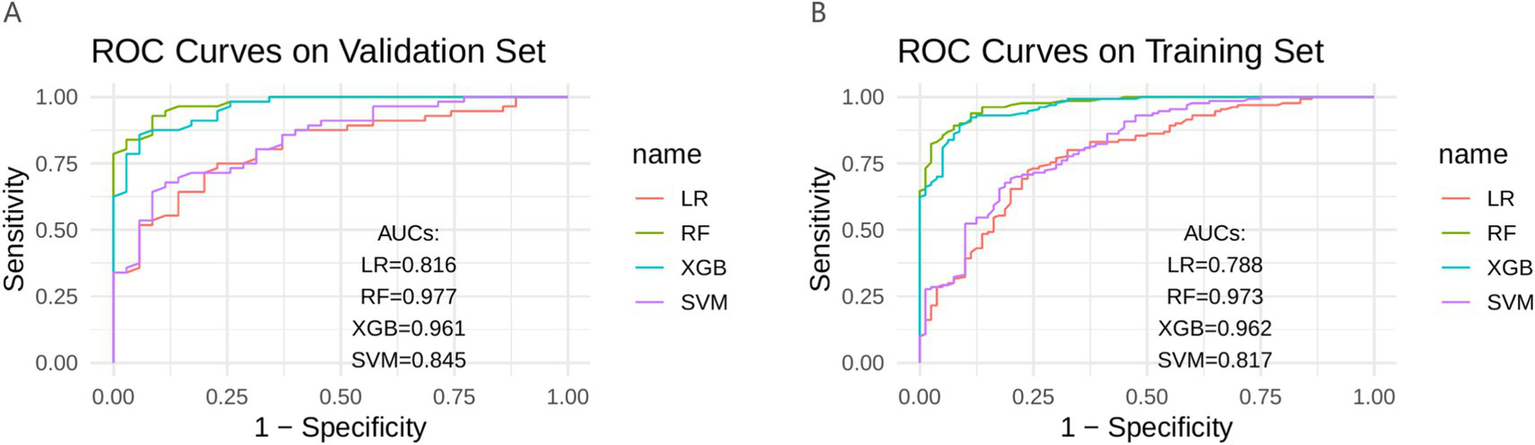
Four models in the training set and validate the ROC curve in the set. (A) Validation set; (B) Train set; ROC, receiver operating characteristic curve; AUC, area under the curve; LR, logistic regression; RF, random forest; XGB, extreme gradient boosting; SVM, support vector machine.
Table 3
| Dataset | Model | AUC (95% CI) | Comparison (RF vs.) | Z value | p-value |
|---|---|---|---|---|---|
| Training | RF | 0.973 (0.961–0.985) | – | – | – |
| LR | 0.788 (0.742–0.834) | RF vs. LR | 6.39 | 1.66 × 10−10 | |
| XGB | 0.962 (0.948–0.975) | RF vs. XGB | 1.92 | 0.055 | |
| SVM | 0.817 (0.773–0.861) | RF vs. SVM | 5.95 | 2.76 × 10−9 | |
| Validation | RF | 0.977 (0.963–0.991) | – | – | – |
| LR | 0.816 (0.764–0.868) | RF vs. LR | 4.14 | 3.49 × 10−5 | |
| XGB | 0.961 (0.945–0.978) | RF vs. XGB | 1.78 | 0.075 | |
| SVM | 0.845 (0.791–0.898) | RF vs. SVM | 3.84 | 1.22 × 10−4 |
AUC comparison and DeLong test results of four models in the training set and validation set.
AUC, area under the curve; LR, logistic regression; RF, random forest; XGB, extreme gradient boosting; SVM, support vector machine.
Evaluate the performance of the model using four indicators: accuracy, precision, recall, and F1 score (25). The predictive performance of the four ML models in both the training and validation datasets is summarized in Table 4.
Table 4
| Dataset | Model | Accuracy | Sensitivity | Specificity | Precision | Recall | F1-score |
|---|---|---|---|---|---|---|---|
| Training | LR | 0.752 | 0.831 | 0.625 | 0.783 | 0.831 | 0.806 |
| RF | 0.914 | 0.962 | 0.838 | 0.906 | 0.962 | 0.933 | |
| XGB | 0.905 | 0.931 | 0.862 | 0.917 | 0.931 | 0.924 | |
| SVM | 0.767 | 0.908 | 0.538 | 0.761 | 0.908 | 0.828 | |
| Validation | LR | 0.769 | 0.857 | 0.629 | 0.787 | 0.857 | 0.821 |
| RF | 0.923 | 0.929 | 0.914 | 0.945 | 0.929 | 0.937 | |
| XGB | 0.890 | 0.875 | 0.914 | 0.942 | 0.875 | 0.907 | |
| SVM | 0.758 | 0.875 | 0.571 | 0.766 | 0.875 | 0.817 |
Comparison of performance evaluation of four models in training and validation sets.
In the training set, RF model achieved the highest overall performance, with an accuracy of 0.914, sensitivity of 0.962, specificity of 0.838, precision of 0.906, recall of 0.962, and F1-score of 0.933. XGB model demonstrated comparable performance (accuracy = 0.905, F1-score = 0.924). LR and SVM models showed relatively lower accuracies of 0.752 and 0.767, respectively.
In the validation set, the RF model again performed best, with an accuracy of 0.923, sensitivity of 0.929, specificity of 0.914, precision of 0.945, recall of 0.929, and F1-score of 0.937. The XGB model also exhibited high predictive ability (accuracy = 0.890, F1-score = 0.907), whereas LR and SVM had moderate predictive performance (accuracies of 0.769 and 0.758, respectively).
Overall, the RF model achieved the most balanced and robust performance across both datasets, showing superior discrimination and generalization ability compared with other algorithms.
Perform interpretability analysis on the model based on SHAP. For each patient, the contribution of each predictor variable to the final outcome is represented by the SHAP value, with a higher SHAP value indicating a higher likelihood of the patient experiencing clinically significant tinnitus. The global SHAP summary plot (Figure 4) demonstrates that hearing loss severity, age, and sleep disorder were the most influential predictors, followed by depression, hearing side, hypertension, and noise exposure history.
Figure 4
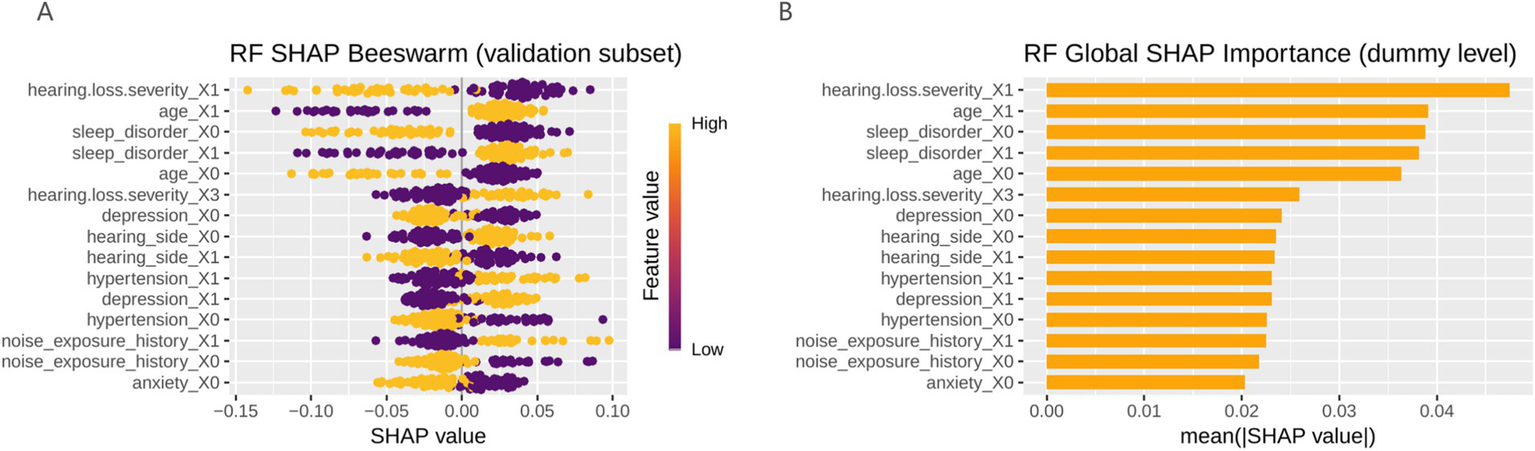
The global SHAP summary plot. (A) Model feature bee colony diagram (the color gradient represents feature magnitude, with yellow indicating higher feature values and purple indicating lower feature values); (B) Bar chart of model features; RF, random forest; SHAP, Shapley additive explanations.
These findings suggest that more severe hearing loss, older age, and poor sleep quality were strongly associated with an increased likelihood of developing clinically significant tinnitus.
Discussion
In this study, we developed and validated several ML models—including RF, XGBoost, SVM, and LR—to predict clinically significant tinnitus in patients with hearing loss. Our models achieved robust predictive performance, accurately distinguishing patients at risk of significant tinnitus symptoms. Greater hearing loss severity emerged as a top predictor, consistent with prior large-scale analyses suggesting that hearing impairment is an important risk factor for the development of more severe tinnitus, with population-based models indicating that hearing-related variables contribute substantially to the prediction of tinnitus severity (11, 26). In addition, a range of comorbid conditions—particularly sleep disturbances (e.g., insomnia or poor sleep quality) and psychological symptoms such as depression and anxiety—were strongly associated with higher tinnitus severity (27, 28). These non-auditory factors significantly improved the model’s ability to flag high-risk patients, underlining that tinnitus severity is a multi-factorial outcome. For example, patients reporting frequent fatigue, poor sleep, and “gloomy” mood (indicative of depression) were far more likely to have severe tinnitus. This is consistent with recent research on large-scale populations (14, 29). Among the ML algorithms, ensemble tree-based models (like RF and XGBoost) performed particularly well, suggesting that complex, non-linear interactions among variables were successfully captured. When evaluating model performance using F1 scores from the validation set, the RF model exhibits the most balanced performance through joint optimization of accuracy and recall. This result is in line with other studies where advanced classifiers yielded high accuracy in tinnitus classification; for instance, combining audiometric data with clinical features via an SVM has achieved area-under-curve values around 0.9 in classifying tinnitus distress levels (30). Overall, our findings highlight that an integrative ML approach can effectively identify hearing-impaired patients at risk for clinically significant tinnitus, with hearing loss and comorbid factors jointly driving risk.
Depression, anxiety, and sleep disorders exert a strong influence on tinnitus severity, indicating shared pathophysiological mechanisms between emotional regulation, sleep, and tinnitus perception (31). Tinnitus is now recognized as a disorder involving broader neural networks beyond the auditory system, particularly those related to stress and emotion. Psychological distress is common in chronic tinnitus—up to 60% of patients experience depression, 30–45% report anxiety, and many suffer from insomnia or poor sleep quality (32). These comorbidities not only result from intrusive tinnitus but also amplify its perceived loudness and distress. A vicious cycle may occur: tinnitus triggers stress and negative emotions, which further enhance tinnitus perception through increased limbic and attentional activity (33). Abnormal hypothalamic–pituitary–adrenal (HPA) axis responses and autonomic arousal have also been observed, suggesting dysregulated stress physiology. Poor sleep and fatigue exacerbate this loop, as severe tinnitus patients often show shorter sleep duration and more insomnia (34, 35). Overall, tinnitus severity depends not only on auditory damage but also on emotional and cognitive factors, resembling chronic pain mechanisms. Interventions addressing these non-auditory components—such as improving sleep, treating depression, or correcting hearing loss—can alleviate both tinnitus distress and associated psychological symptoms.
Our study adds to a growing body of research applying ML to tinnitus prediction and management. Historically, clinicians have relied on audiological exams and self-report questionnaires to assess tinnitus, but these methods alone often miss the multidimensional nature of tinnitus severity (36). The use of ML models represents a novel and valuable approach—one that can integrate diverse data (hearing thresholds, psychiatric history, sleep quality, etc.) to improve risk stratification. Recent studies underscore this potential. For instance, Jafari et al. (37) demonstrated that neural network and RF models could successfully differentiate tinnitus sufferers and types of hearing loss, pointing to the feasibility of incorporating ML into routine audiology practice. Recent studies have also explored alternative ML paradigms in hearing research. For example, Yang et al. (38) proposed a soft classification framework based on quadratic discriminant analysis to probabilistically characterize heterogeneous audiometric phenotypes of age-related hearing loss. This approach provides a more nuanced description of hearing phenotypes by allowing individuals to partially belong to multiple classes rather than forcing a single hard classification. In our context, the ability to predict which hearing-impaired patients are likely to develop clinically significant tinnitus has clear clinical importance. Such prognostic insight allows for proactive intervention: patients flagged as high-risk could receive earlier counseling, psychological support, or sound therapies to possibly prevent escalation of tinnitus distress. The present findings particularly highlight the benefit of a multidimensional assessment. By concurrently evaluating audiometric injury (the “input” driving tinnitus) and factors like mood disturbances or poor sleep (which shape the “reaction” to tinnitus), clinicians can obtain a more complete risk profile. This aligns with emerging holistic models of tinnitus care, which emphasize that effective management should address not only the peripheral ear damage but also the patient’s mental health and sleep hygiene (39). The application of ML in this domain is novel in that it provides an objective, data-driven method to combine these elements. It moves tinnitus screening beyond one-size-fits-all metrics toward personalized medicine—for example, an ML-based tool could be used in hearing clinics to automatically flag patients who, based on their hearing loss and questionnaire scores (for insomnia, depression, etc.), are likely to experience severe tinnitus. This approach complements current treatment guidelines that already advocate interdisciplinary management (including cognitive-behavioral therapy for tinnitus-related distress) (40). Together, these advancements illustrate a new paradigm: leveraging ML to integrate audiological and psychosocial dimensions for improved tinnitus risk prediction, thereby enhancing clinical decision-making and patient outcomes.
Limitations
This study has several limitations. First, its retrospective, single-center design limits generalizability. The model was developed in a specific population and lacks external validation, so its performance in other cohorts remains uncertain. Future research should include multi-center data and external validation to improve robustness. Second, the cross-sectional nature of our analysis prevents causal inference and long-term observation. Longitudinal studies are needed to clarify temporal relationships—such as whether depression or poor sleep precede tinnitus worsening—and to identify long-term risk factors. Third, most variables (e.g., sleep disturbance, anxiety, depression) were self-reported, which may introduce bias. Future studies should incorporate objective assessments such as actigraphy, polysomnography, or structured psychiatric evaluations, along with biological markers (e.g., stress hormones or neuroimaging). Moreover, the relatively small sample size may have limited model complexity. Larger datasets could enable the use of advanced or deep learning models to enhance predictive performance. Finally, while our model identified associations, its clinical utility remains to be tested. Prospective implementation studies are required to determine whether applying such models improves early identification and management of patients at high risk for severe tinnitus (36, 37).
Conclusion
The RF model demonstrated superior predictive accuracy for identifying patients with hearing loss at risk of clinically significant tinnitus. Key predictors included hearing loss severity, age, and sleep disorder, indicating that integrating auditory and psychological factors enhances risk assessment and supports early, individualized intervention strategies.
Statements
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by The Ethics Committee of the Affiliated Hospital of Qinghai University. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
CZ: Project administration, Formal analysis, Writing – original draft, Data curation, Methodology, Conceptualization, Investigation, Writing – review & editing. TR: Funding acquisition, Writing – original draft, Resources. YW: Writing – review & editing, Methodology, Software, Data curation, Conceptualization, Writing – original draft. DX: Writing – original draft, Software. YW: Software, Writing – original draft. YZ (6th author): Writing – review & editing, Project administration. YZ (7th author): Funding acquisition, Writing – review & editing, Project administration. BG: Writing – review & editing, Funding acquisition, Validation, Supervision, Project administration, Visualization, Writing – original draft, Conceptualization, Resources.
Funding
The author(s) declared that financial support was received for this work and/or its publication. This study was supported by the Science and Technology Program of Qinghai Province, China (Grant No. 2024-ZJ-731), the 2025 Kunlun Talents High-Level Health Talents Project (2025), and the Key Project of the Young and Middle-Aged Scientific Research Fund of the Affiliated Hospital of Qinghai University (Grant No. ASRF-2022-ZD-01).
Conflict of interest
The author(s) declared that this work was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declared that Generative AI was not used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fneur.2025.1741302/full#supplementary-material
References
1.
Baguley D McFerran D Hall D . Tinnitus. Lancet. (2013) 382:1600–7. doi: 10.1016/S0140-6736(13)60142-7
2.
Langguth B Kreuzer PM Kleinjung T De Ridder D . Tinnitus: causes and clinical management. Lancet Neurol. (2013) 12:920–30. doi: 10.1016/S1474-4422(13)70160-1,
3.
Weber FC Schlee W Langguth B Schecklmann M Schoisswohl S Wetter TC et al . Low sleep satisfaction is related to high disease burden in tinnitus. Int J Environ Res Public Health. (2022) 19:11005. doi: 10.3390/ijerph191711005,
4.
Gallus S Lugo A Garavello W Bosetti C Santoro E Colombo P et al . Prevalence and determinants of tinnitus in the Italian adult population. Neuroepidemiology. (2015) 45:12–9. doi: 10.1159/000431376,
5.
Jarach CM Lugo A Scala M van den Brandt PA Cederroth CR Odone A et al . Global prevalence and incidence of tinnitus: a systematic review and meta-analysis. JAMA Neurol. (2022) 79:888–900. doi: 10.1001/jamaneurol.2022.2189,
6.
McCormack A Edmondson-Jones M Somerset S Hall D . A systematic review of the reporting of tinnitus prevalence and severity. Hear Res. (2016) 337:70–9. doi: 10.1016/j.heares.2016.05.009,
7.
Clifford RE Maihofer AX Chatzinakos C Coleman JRI Daskalakis NP Gasperi M et al . Genetic architecture distinguishes tinnitus from hearing loss. Nat Commun. (2024) 15:614. doi: 10.1038/s41467-024-44842-x,
8.
Chen Z Lu Y Chen C Lin S Xie T Luo X et al . Association between tinnitus and hearing impairment among older adults with age-related hearing loss: a multi-center cross-sectional study. Front Neurol. (2024) 15:1501561. doi: 10.3389/fneur.2024.1501561,
9.
Martinez C Wallenhorst C McFerran D Hall DA . Incidence rates of clinically significant tinnitus: 10-year trend from a cohort study in England. Ear Hear. (2015) 36:e69–75. doi: 10.1097/AUD.0000000000000121,
10.
Shargorodsky J Curhan GC Farwell WR . Prevalence and characteristics of tinnitus among US adults. Am J Med. (2010) 123:711–8. doi: 10.1016/j.amjmed.2010.02.015,
11.
Hobeika L Fillingim M Tanguay-Sabourin C Roy M Londero A Samson S et al . Tinnitus risk factors and its evolution over time. Nat Commun. (2025) 16:4244. doi: 10.1038/s41467-025-59445-3,
12.
Langguth B de Ridr D Schlee W Kleinjung T . Tinnitus: clinical insights in its pathophysiology-a perspective. J Assoc Res Otolaryngol. (2024) 25:249–58. doi: 10.1007/s10162-024-00939-0,
13.
Arsenault V Larouche J Désilets M Hudon MA Hudon A . When the mind meets the ear: a scoping review on tinnitus and clinically measured psychiatric comorbidities. J Clin Med. (2025) 14:3785. doi: 10.3390/jcm14113785,
14.
Chang TG Yao YT Hsu CY Yen TT . Exploring the interplay of depression, sleep quality, and hearing in tinnitus-related handicap: insights from polysomnography and pure-tone audiometry. BMC Psychiatry. (2024) 24:459. doi: 10.1186/s12888-024-05912-y,
15.
Salazar JW Meisel K Smith ER Quiggle A McCoy DB Amans MR . Depression in patients with tinnitus: a systematic review. Otolaryngol Head Neck Surg. (2019) 161:28–35. doi: 10.1177/0194599819835178,
16.
Oosterloo BC de Feijter M Croll PH de Baatenburg Jong RJ Luik AI Goedegebure A . Cross-sectional and longitudinal associations between tinnitus and mental health in a population-based sample of middle-aged and elderly persons. JAMA Otolaryngol Head Neck Surg. (2021) 147:708–16. doi: 10.1001/jamaoto.2021.1049,
17.
Newman CW Jacobson GP Spitzer JB . Development of the tinnitus handicap inventory. Arch Otolaryngol Head Neck Surg. (1996) 122:143–8. doi: 10.1001/archotol.1996.01890140029007,
18.
McCombe A Baguley D Coles R McKenna L McKinney C Windle-Taylor P et al . Guidelines for the grading of tinnitus severity: the results of a working group commissioned by the British Association of Otolaryngologists, head and neck surgeons, 1999. Clin Otolaryngol Allied Sci. (2001) 26:388–93. doi: 10.1046/j.1365-2273.2001.00490.x,
19.
Chadha S Kamenov K Cieza A . The world report on hearing, 2021. Bull World Health Organ. (2021) 99:242–242A. doi: 10.2471/BLT.21.285643,
20.
Mosli M Alkhathlan B Abumohssin A Merdad M Alherabi A Marglani O et al . Prevalence and clinical predictors of LPR among patients diagnosed with GERD according to the reflux symptom index questionnaire. Saudi J Gastroenterol. (2018) 24:236–41. doi: 10.4103/sjg.SJG_518_17,
21.
Abraham ZS Kahinga AA . Utility of reflux finding score and reflux symptom index in diagnosis of laryngopharyngeal reflux disease. Laryngoscope Investig Otolaryngol. (2022) 7:785–9. doi: 10.1002/lio2.799,
22.
Li H Jin D Qiao F Chen J Gong J . Relationship between the self-rating anxiety scale score and the success rate of 64-slice computed tomography coronary angiography. Int J Psychiatry Med. (2016) 51:47–55. doi: 10.1177/0091217415621265,
23.
Negeri ZF Levis B Sun Y He C Krishnan A Wu Y et al . Accuracy of the patient health questionnaire-9 for screening to detect major depression: updated systematic review and individual participant data meta-analysis. BMJ. (2021) 375:n2183. doi: 10.1136/bmj.n2183,
24.
Zitser J Allen IE Falgàs N Le MM Neylan TC Kramer JH et al . Pittsburgh sleep quality index (PSQI) responses are modulated by total sleep time and wake after sleep onset in healthy older adults. PLoS One. (2022) 17:e0270095. doi: 10.1371/journal.pone.0270095,
25.
Xie Q Ji H Yang Y Gong ML Jia YT . Development of a machine learning-based model to predict drug-induced liver injury risk in children receiving anti-tuberculosis therapy. Chin J Mod Appl Pharm. (2024) 41:3447–55. doi: 10.13748/j.cnki.issn1007-7693.20242822
26.
Goderie T van Wier MF Lissenberg-Witte BI Merkus P Smits C Leemans CR et al . Factors associated with the development of tinnitus and with the degree of annoyance caused by newly developed tinnitus. Ear Hear. (2022) 43:1807–15. doi: 10.1097/AUD.0000000000001250,
27.
Alster J Shemesh Z Ornan M Attias J . Sleep disturbance associated with chronic tinnitus. Biol Psychiatry. (1993) 34:84–90. doi: 10.1016/0006-3223(93)90260-k,
28.
Bhatt JM Bhattacharyya N Lin HW . Relationships between tinnitus and the prevalence of anxiety and depression. Laryngoscope. (2017) 127:466–9. doi: 10.1002/lary.26107,
29.
Brueggemann P Mebus W Boecking B Amarjargal N Niemann U Spiliopoulou M et al . Dimensions of tinnitus-related distress. Brain Sci. (2022) 12:275. doi: 10.3390/brainsci12020275,
30.
Manta O Sarafidis M Schlee W Mazurek B Matsopoulos GK Koutsouris DD . Development of machine-learning models for tinnitus-related distress classification using wavelet-transformed auditory evoked potential signals and clinical data. J Clin Med. (2023) 12:3843. doi: 10.3390/jcm12113843,
31.
Patil JD Alrashid MA Eltabbakh A Fredericks S . The association between stress, emotional states, and tinnitus: a mini-review. Front Aging Neurosci. (2023) 15:1131979. doi: 10.3389/fnagi.2023.1131979,
32.
Hu J Cui J Xu JJ Yin X Wu Y Qi J . The neural mechanisms of tinnitus: a perspective from functional magnetic resonance imaging. Front Neurosci. (2021) 15:621145. doi: 10.3389/fnins.2021.621145,
33.
Betz LT Mühlberger A Langguth B Schecklmann M . Stress reactivity in chronic tinnitus. Sci Rep. (2017) 7:41521. doi: 10.1038/srep41521,
34.
Hébert S Lupien SJ . The sound of stress: blunted cortisol reactivity to psychosocial stress in tinnitus sufferers. Neurosci Lett. (2007) 411:138–42. doi: 10.1016/j.neulet.2006.10.028,
35.
Jiang C Ding Z Zan T Liao W Li H Yang X et al . Pathophysiological insights and multimodal interventions in chronic tinnitus, anxiety, and sleep disorders. Nat Sci Sleep. (2025) 17:2257–73. doi: 10.2147/NSS.S548093,
36.
Sadegh-Zadeh SA Soleimani Mamalo A Kavianpour K Atashbar H Heidari E Hajizadeh R et al . Artificial intelligence approaches for tinnitus diagnosis: leveraging high-frequency audiometry data for enhanced clinical predictions. Front Artif Intell. (2024) 7:1381455. doi: 10.3389/frai.2024.1381455,
37.
Jafari Z Harari RE Hole G Kolb BE Mohajerani MH . Machine learning models can predict tinnitus and noise-induced hearing loss. Ear Hear. (2025) 46:1305–16. doi: 10.1097/AUD.0000000000001670,
38.
Yang C Langworthy B Curhan S Vaden KI Jr Curhan G Dubno JR et al . Soft classification and regression analysis of audiometric phenotypes of age-related hearing loss. Biometrics. (2024) 80:ujae013. doi: 10.1093/biomtc/ujae013,
39.
Wang S Cha X Li F Li T Wang T Wang W et al . Associations between sleep disorders and anxiety in patients with tinnitus: a cross-sectional study. Front Psychol. (2022) 13:963148. doi: 10.3389/fpsyg.2022.963148,
40.
Lukas CF Mazurek B Brueggemann P Junghöfer M Guntinas-Lichius O Dobel C . A retrospective two-center cohort study of the bidirectional relationship between depression and tinnitus-related distress. Commun Med. (2024) 4:242. doi: 10.1038/s43856-024-00678-6,
Summary
Keywords
hearing loss, machine learning, random forest, sleep disorder, tinnitus
Citation
Zhang C, Ran T, Wang Y, Xiao D, Wang Y, Zhang Y, Zhang Y and Guo B (2026) Development and comparison of machine learning models for predicting moderate-to-severe tinnitus in patients with hearing loss. Front. Neurol. 16:1741302. doi: 10.3389/fneur.2025.1741302
Received
22 November 2025
Revised
16 December 2025
Accepted
16 December 2025
Published
12 January 2026
Volume
16 - 2025
Edited by
Kathrine Jauregui-Renaud, Mexican Social Security Institute, Mexico
Reviewed by
Hao Yuan, Air Force Medical University, China
Ce Yang, University of Waterloo, Canada
Updates
Copyright
© 2026 Zhang, Ran, Wang, Xiao, Wang, Zhang, Zhang and Guo.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Bin Guo, guobin.3a@outlook.com
†These authors have contributed equally to this work
ORCID: Chenguang Zhang, orcid.org/0009-0005-0660-3763; Tao Ran, orcid.org/0009-0008-3869-8703; Yicong Wang, orcid.org/0009-0002-3950-775X; Di Xiao, orcid.org/0009-0002-7864-0529; Yuwen Wang, orcid.org/0009-0001-5415-7180; Ying Zhang, orcid.org/0009-0001-5022-9730; Bin Guo, orcid.org/0000-0002-6490-8339; Tao Ran, orcid.org/0009-0008-3869-8703
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.