 Hao Chen
Hao Chen Ming Jin
Ming Jin Zhunan Li
Zhunan Li Cunhang Fan
Cunhang Fan Jinpeng Li
Jinpeng Li Huiguang He
Huiguang He- 1HwaMei Hospital, University of Chinese Academy, Ningbo, China
- 2Center for Pattern Recognition and Intelligent Medicine, Ningbo Institute of Life and Health Industry, University of Chinese Academy of Sciences, Ningbo, China
- 3Anhui Province Key Laboratory of Multimodal Cognitive Computation, School of Computer Science and Technology, Anhui University, Hefei, China
- 4Research Center for Brain-inspired Intelligence and National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, Beijing, China
As an essential element for the diagnosis and rehabilitation of psychiatric disorders, the electroencephalogram (EEG) based emotion recognition has achieved significant progress due to its high precision and reliability. However, one obstacle to practicality lies in the variability between subjects and sessions. Although several studies have adopted domain adaptation (DA) approaches to tackle this problem, most of them treat multiple EEG data from different subjects and sessions together as a single source domain for transfer, which either fails to satisfy the assumption of domain adaptation that the source has a certain marginal distribution, or increases the difficulty of adaptation. We therefore propose the multi-source marginal distribution adaptation (MS-MDA) for EEG emotion recognition, which takes both domain-invariant and domain-specific features into consideration. First, we assume that different EEG data share the same low-level features, then we construct independent branches for multiple EEG data source domains to adopt one-to-one domain adaptation and extract domain-specific features. Finally, the inference is made by multiple branches. We evaluate our method on SEED and SEED-IV for recognizing three and four emotions, respectively. Experimental results show that the MS-MDA outperforms the comparison methods and state-of-the-art models in cross-session and cross-subject transfer scenarios in our settings. Codes at https://github.com/VoiceBeer/MS-MDA.
1. Introduction
Emotion as physiological information, unlike widely studied logical intelligence, is central to the quality and range of daily human communications (Dolan, 2002; Tyng et al., 2017). In the human-computer interaction (HCI), emotion is crucial in influencing situation assessment and belief information, from cue identification to situation classification, with decision selection for building a friendly user interface (Jeon, 2017). For example, affective brain-computer interfaces (aBCIs), acting as a bridge between the emotions extracted from the brain and the computer, which has shown potential for rehabilitation and communication (Birbaumer, 2006; Frisoli et al., 2012; Lee et al., 2019). Besides, many studies have shown a strong correlation between emotions and mental illness. Barrett et al. (2001) studies the relation between emotion differentiation and emotion regulation. Joormann and Gotlib (2010) finds that depression is strongly associated with the use of emotion regulation strategies. Bucks and Radford (2004) investigates the identification of non-verbal communicative signals of emotion in people that are suffering from Alzheimer's disease. To quantify emotion, most researchers have focused on using conventional methods such as classifying emotions with facial expression or language (Ekman, 1993). In recent years, with the advantage of reliability, easy accessibility, and high precision, non-invasive BCIs such as electroencephalogram (EEG) are widely used for brain signal acquisition, and analysis of psychological disorders (Sanei and Chambers, 2013; Acharya et al., 2015; Liu et al., 2015; Ay et al., 2019). With EEG signals, many works also investigate the rehabilitation methods for psychological disorders, such as (Jiang et al., 2021) of using spatial information of EEG signals to classify depressions, and Zhang et al. (2020) proposes a brain functional network framework for major depressive disorder by using the EEG signals. Besides, Hosseinifard et al. (2013) investigates the non-linear features from EEG signals for classifying depression patients and normal subjects. The flow of an EEG-based affective BCI (aBCI) for emotion recognition is introduced in section 3.1.
Due to the non-stationary between individual sessions and subjects of EEG signals (Sanei and Chambers, 2013), it is still challenging to get a model that is shareable to different subjects and sessions in EEG-based emotion recognition scenarios, which elicits two scenarios: cross-subject and cross-session (i.e., data collected from the same subject at the same session can be very biased, detailed description is given in section 3.2). Besides, the analysis and classification of the collected signals are time-consuming and labor-intensive, so it is important to make use of the existing labeled data to analyze new signals in the EEG-based BCIs. With this purpose, domain adaptation is widely used in research works. As a sub-field of machine learning, domain adaptation (DA) improves the learning in the unlabeled target domain through the transfer of knowledge from the source domains, which can significantly reduce the number of labeled samples (Pan and Yang, 2009). In practice, we often face the situation that contains multiple source domain data (i.e., data from different subjects or sessions). Due to the shift between domains, adopting DA for EEG data especially when facing multiple sources is difficult. In recent years, the researchers tend to merge all source domains into one single source and then use DA to align the distribution (Source-combine DA in Figure 1) (Zheng and Lu, 2016; Jin et al., 2017; Li et al., 2018, 2019a,b, 2020; Zheng et al., 2018; Zhao et al., 2021). This simple approach may improve the performance because it expands the training data for the model, but it ignores the non-stationary of each EEG source domain itself and disrupts it (i.e., EEG data of different people obey different marginal distributions), besides, directly merging into one new source domain cannot determine whether its new marginal distribution still obeys EEG-data distribution, thus brings a larger bias.
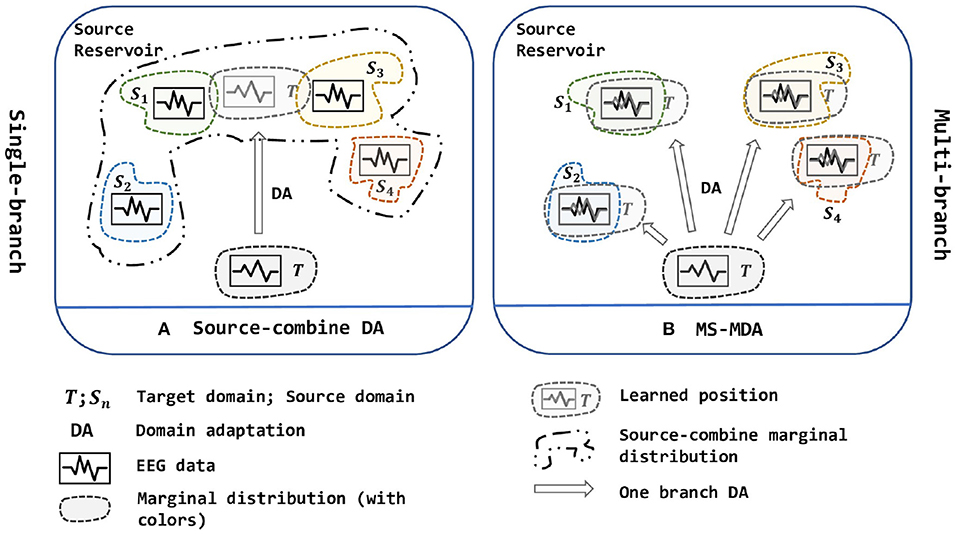
Figure 1. Two strategies of multi-source domain adaptation. (A) is a single-branch strategy while (B) is a multi-branch strategy. In (A), all source domains are combined into one new big source and then been used to align distribution with the target domain, while in (B), multiple sources are being aligned at the same time, and are divided into multiple branches to adopt DA with the target domain. In short, (A) is one source, one branch with one-to-one DA; (B) is multiple sources, multiple branches with one-to-one DA. The figure is best viewed in color.
To solve the multi-source domain adaptation problems in EEG-based emotion recognition, we propose a Multi-Source Marginal Distribution Adaptation for cross-subject and cross-session EEG emotion recognition (MS-MDA, as illustrated in Figure 1). First, we assume all the EEG data share low-level features, especially those taken from the same device, the same subject and the same session. Based on this, we construct a simple common feature extractor to extract domain-invariant features. Then for multiple sources, since each of them has some specific features, we pair every single source domain with the target domain to form a branch for one-to-one DA, and align the distribution and extract domain-specific features. After that, a classifier is trained for each branch, and the final inference is made by these multiple classifiers from multiple branches. The details of MS-MDA are given in section 4.
In this study, we make two following contributions:
1. We proposed and evaluated MS-MDA for EEG-based emotion recognition in a new multi-source adaptation way to avoid disrupting the marginal distributions of EEG data. Extensive experiments demonstrate that our method outperforms the comparison methods on SEED and SEED-IV, and additional experiments also illustrate that our method generalizes well.
2. Though many works have achieved considerable results, there is no systematic discussion of the normalization operation of EEG data. Thus we design and conduct extensive experiments to investigate the effects of three normalization types (i.e., electrode-wise, sample-wise, and global-wise, details are given in section 5.4), and the order of whether first concatenating multiple sources or normalizing each session individually. To our knowledge, we are the first to investigate the normalization methods for EEG data, which we believe can be taken as a guide for other future works, and be applied to all data in EEG-based datasets and EEG-related domains.
In the remainder of this paper, we first review related works on domain adaptation in the field of EEG-based emotion recognition in section 2. Section 3 introduces the materials, including the diagram of EEG-based affective BCI with transfer scenarios, datasets and pre-processing methods. The details of MS-MDA are given in section 4, whereas section 5 demonstrates the settings, results, and additional experiments. Section 7 discusses the results of the experiment and our findings, as well as problems and solutions. Finally, section 7 concludes the work and outlines the future extension.
2. Related Work
In recent years, the research of affective computing has become one of the trends of machine learning, neural systems, and rehabilitation study. Among those works, emotions are usually characterized into two types of emotion model: discrete categories (basic emotional states, e.g., happy, sad, neutral; Zheng and Lu, 2015) or continuous values (e.g., in 3D space of arousal, valence, and dominance; Koelstra et al., 2011). With domain adaptation techniques, many works have achieved significant performance in the field of affective computing.
Zheng and Lu (2016) first applies Transfer Component Analysis (Pan et al., 2010) and Kernel Principle Analysis based methods on SEED dataset to personalize EEG-based affective models and demonstrates the feasibility of adopting DA in EEG-based aBCIs. Chai et al. proposes adaptive subspace feature matching (Chai et al., 2017) to decrease the marginal distribution discrepancy between two domains, which requires no labeled samples in the target domain. To solve cross-day binary classification, Lin et al. (2017) extends robust principal component analysis (rPCA) (Candès et al., 2011) to their filtering strategy which can capture EEG oscillations of relatively consistent emotional responses. Li et al., different from the above, considering the multi-source scenario, and proposes a Multi-source Style Transfer Mapping (MS-STM) (Li et al., 2019b) framework for cross-subject transfer. They first take a few labeled training data to learn multiple STMs, which are then being used to map the target domain distribution to the space of the sources. Though they consider adding prior information of source-specific features, they do not take the domain-invariant features into consideration, thus losing the low-level information.
In recent years, with the development of deep learning techniques and its usability, many works of EEG-based decoding with neural networks have been proposed. Jin et al. (2017) and Li et al. (2018) adopts deep adaptation network (DAN) (Long et al., 2015) to EEG-based emotion recognition, which takes maximum mean discrepancy (MMD) (Borgwardt et al., 2006) as a measure of the distance between the source and the target domain, and training to reduce it on multiple layers. Extending the original method, Chai et al. proposes subspace alignment auto-encoder (SAAE) (Chai et al., 2016) which first projects both source and target domains into a domain-invariant subspace using an auto-encoder, and then kernel PCA, graph regularization and MMD are used to align the feature distribution. To adapt the joint distribution, Li et al. (2019a) propose a domain adaptation method for EEG-based emotion recognition by simultaneously adapting marginal distributions and conditional distributions, they also present a fast online instance transfer (FOIT) for improved EEG emotion recognition (Li et al., 2020). Zheng et al. extends SEED dataset to SEED-IV dataset and presents EmotionMeter (Zheng et al., 2018), a multi-modal emotion recognition framework that combines two modalities of eye movements and EEG waves. With the concept of attention-based convolutional neural network (CNN) (Yin et al., 2016), Fahimi et al. (2019) develops an end-to-end deep CNN for cross-subject transfer and fine-tunes it by using some calibration data from the target domain. To tackle the requirement of amassing extensive EEG data, Zhao et al. (2021) proposes a plug-and-play domain adaptation method for shortening the calibration time within a minute while maintaining the accuracy. Wang et al. (2021) present a domain adaptation SPD matrix network (daSPDnet) to help cut the demand of calibration data for BCIs.
These aBCI works have gained significant improvement in their respective directions, transfer scenarios, and on multiple benchmark databases. However, many of them focus on combing multiple sources into one and adopt one-to-one DA, which ignores the differences of the marginal distribution of different EEG domains (source-combine DA in Figure 1). This operation may compromise the effectiveness of downstream tasks, and although it somehow extends the training data, the trained models do not generalize well enough. Therefore, inspired by Zhu et al. (2019), a novel multi-source transfer framework, we propose MS-MDA (multi-source marginal distribution alignment for EEG-based emotion recognition), which transfers multiple source domains to the target domain separately, thus avoiding the destruction of the marginal distribution of the multiple EEG source domains; and also takes the domain-invariant features into consideration. Due to the sensitivity of the EEG data and intuition, we do not adopt complex networks, but just a combination of few multi-layer perceptrons (MLPs) (Gardner and Dorling, 1998), and thus makes our method computationally efficient, and easy to expand.
3. Materials
3.1. Diagram
The flow of one EEG-based aBCI for emotion recognition is shown in Figure 2, which involves five steps:
• Stimulating emotions. The subjects are first stimulated with stimuli that correspond to a target emotion. The most commonly used stimuli are movie clips with sound, which can better stimulate the desired emotion because they mix sound with images and actions. After each clip, self-assessment is also applied for the subject to ensure the consistency of the evoked emotion and the target emotion.
• EEG signal acquisition and recording. The EEG data are collected using the dry electrodes on the BCI, and then be labeled with the target emotion.
• Signal pre-processing. Since the EEG data is a mixture of various kinds of information containing much noise, it is required to pre-process the EEG signal to get cleaner data for subsequent recognition. This step often includes down-sampling, band-pass filtering, temporal filtering, and spatial filtering to improve the signal-to-noise ratio (SNR).
• Feature extraction. In this step, features of the pre-processed signals are extracted in various ways. Most of the current research works are to extract features in the time or frequency domain.
• Pattern recognition. The use of machine learning techniques to classify or regress data according to specific application scenarios.
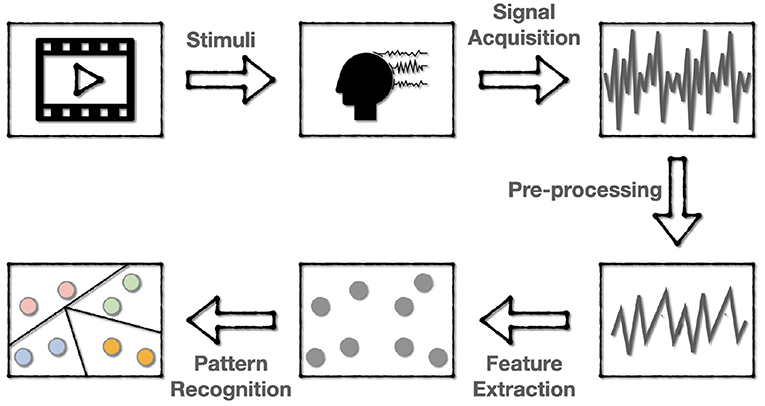
Figure 2. The flowchart of EEG-based BCI for emotion recognition. The emotions are first evoked and encoded into EEG data, then the EEG data are pre-processed and extracted to various forms of features for subsequent pattern recognition.
3.2. Scenarios
Considering the sensitivity of the EEG, domain adaptation in emotion recognition can be divided into several cases: (1) Cross-subject transfer. In one session, new EEG data from a new subject is taken as the target domain, and the rest of existing EEG data from other subjects are taken as the source domains for DA. (2) Cross-session transfer. For one subject, data collected in the previous sessions can be used as the source domain for DA, and data collected in the new session are taken as the target domain.
In our work, since the datasets we evaluate on contains 3 session and 15 subjects (refer to section 3.3 for details), we take the first 2 session data from one subject as the source domains for cross-session transfer, and take the first 14 subjects data from one session as the source domains for cross-subject transfer. The results of cross-session scenarios are averaged over 15 subjects, and the results of cross-subject are averaged over 3 sessions. Standard deviations are also calculated.
3.3. Datasets
The database we evaluate on are: SEED (Duan et al., 2013; Zheng and Lu, 2015) and SEED-IV (Zheng et al., 2018), both are established by the BCMI laboratory led by Prof. Bao-Liang Lu from Shanghai Jiao Tong University.
The SEED database contains emotion-related EEG signals that are evoked by 15 film clips (with positive, neutral, and negative emotions) from 15 subjects (7 males and 8 females, with average age of 23.27) with 3 sessions each. The signals are recorded by a 62-channel ESI neuroscan system.
The SEED-IV is an evolution of SEED, which contains 3 sessions, each has 15 subjects and 24 film clips. Comparing to the SEED with EEG signals only, this database also includes eye movement features recorded by SMI eye-tracking glasses.
3.4. Pre-processing
After collecting EEG raw data, pre-processing on signals and feature extractions will be adopted. For both SEED and SEED-IV, to increase the SNR, the raw EEG signals are first down-sampled to a 200 Hz sampling rate, then been processed with a band-pass filter between 1 Hz to 75 Hz. After that, features are then being extracted.
Recent works extract features from EEG data on the time domain, frequency domain, and time-frequency domain. Among them, Differential Entropy (DE) as in (1), has the ability to distinguish patterns from different bands (Soleymani et al., 2015), thus we choose to take DE features as the input data of our model. For SEED and SEED-IV, extracted DE features at five frequency bands of delta (1–4 Hz), theta (4–8 Hz), alpha (8–14 Hz), and gamma (31–50 Hz) are provided.
One data from one subject in one session for both databases is in the form of channel (62) × trial (15 for SEED, 24 for SEED-IV) × band (5), we then merge the channel with the band, and the form becomes trial × 310 (62 × 5). For SEED, 15 trials contain 3394 samples in total for each session. For SEED-IV, 24 trials contain 851/832/822 samples for three sessions, respectively. In the end, all data are formed into 3394 × 310 (SEED), or 851/832/822 × 310 (SEED-IV) with corresponding generated label vectors in the form of 3,394 × 1, or 851/832/822 × 1.
4. Method
For simplicity of demonstration, we list the symbols and their definition in Table 1 that will be used in the following sections.
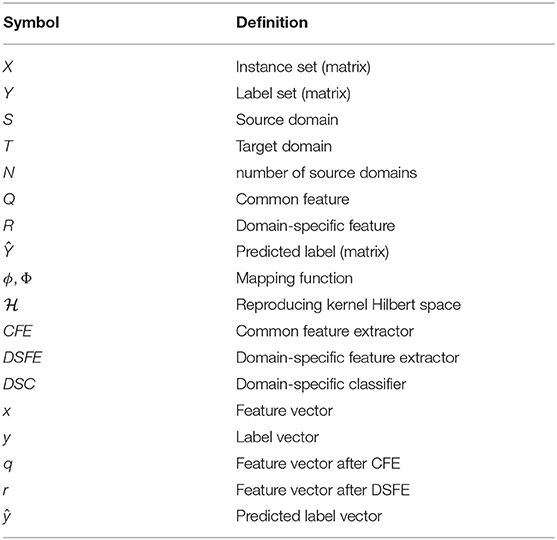
Table 1. Notation table.
Given a set of pre-existing EEG data and a newly collected EEG data, our goal is to learn a model ϕ that is trained on these multiple independent source domain data using DA, and thus has a better prediction on the newly collected data than simply combining the existed data into one source domain. The architecture of the proposed method is illustrated in Figure 3.
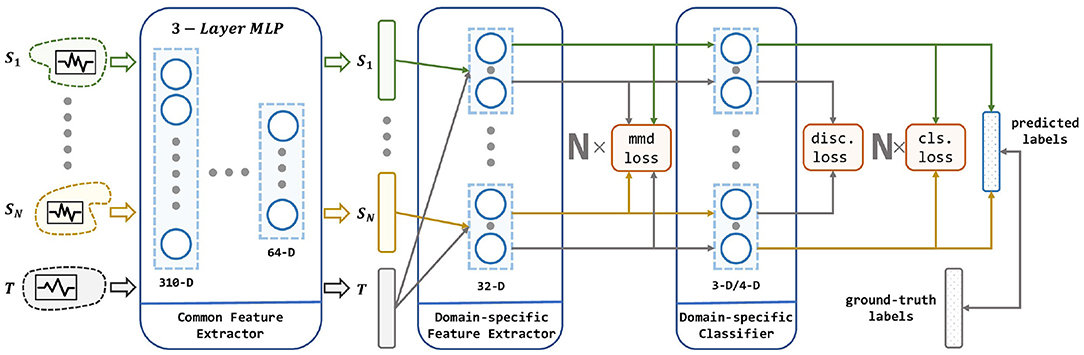
Figure 3. The architecture of our proposed method. Our network consists of a common feature extractor, domain-specific feature extractor, and domain-specific classifier. For each source domain, a branch of DSFE and DSC is conducted for pair-wise domain adaptation. The model receives multiple source domains and leverages their knowledge to transfer to the target domain. Three loss in red squares stands for MMD loss, discrepancy loss, and classification loss which are described in section 4.
As shown in the Figure 3, the input to the MS-MDA are N independent source domain data and a target domain data {XT}, and then these data are fed into a common feature extractor module to get the domain-invariance features and {QT}. Then for each domain-specific feature extractor, extracted common features will be fed into one branch with {QT} and get their domain-specific features: and , and on top of that, the MMD value is calculated, which is a measure of the distance of the current source and the target domain. Next, the target domain features and all the source domain features extracted from the last step will get to the domain-specific classifiers to get the corresponding classification predictions: and , then the results of the source domain are taken to calculate the classification loss. Since the target domain will be fed into all the source domain classifiers, multiple target domain predictions are generated. These predictions are taken to calculate the discrepancy loss. In the end, the average of these target-domain predictions is taken as the output of the model. Details of these modules are given below.
4.1. Common Feature Extractor
Common feature extractor in the MS-MDA is used to map the source and target domain data from the original feature spaces to a common sharing latent space, and then common representations of all domains are extracted. This module can help to extract some low-level domain-invariant features.
4.2. Domain-Specific Feature Extractor
Domain-specific feature extractor follows the Common Feature Extractor (CFE). After obtaining the features of all domains, we set up N single fully connected layers to correspond to N source domains. For each pair of source and target domain, we map the data to a unique latent space via the corresponding Domain-specific Feature Extractor (DSFE), respectively, and then obtain the domain-specific features in each branch. To apply DA and bring the two domains close in the latent space, we choose the MMD to estimate the distance between these two domains. MMD is widely used in the DA and can be formulated in (2). In the process of training, MMD loss is decreased to narrow the source domain and the target domain in the feature space, which helps make better predictions for the target domain. This module aims to learn multiple domain-specific features.
4.3. Domain-Specific Classifier
Domain-specific classifier uses the features extracted from the DSFE to predict the result. In Domain-specific Classifier (DSC), there are N single softmax classifiers that correspond to each source domain. For each classifier training, we choose cross-entropy to estimate the classification loss, as shown in (3). Besides, since there are N classifiers in this module, and these N classifiers are trained on N source domains, if their predictions are simply averaged as the final result, the variance will be high, especially when the target domain samples are at the decision boundary, which will have a significant negative impact on the results. To reduce this variance, a metric called discrepancy loss is introduced to make the predictions of the N classifiers converge, which is shown in (4). The average of the predictions of the N classifiers is taken as the final result.
In summary, MS-MDA accepts N source domain EEG data and one target domain EEG data, and then includes a common feature extractor to get N source domain features and one target domain feature. Next, N domain-specific feature extractors are used to pairwise compute the MMD loss of one individual source with the target domain and extract their domain-specific features. Finally, a domain-specific classifier is used to do the classification task, which also calculates the classification loss of the N classifiers using the features, with the discrepancy loss of the N classifiers for the features of the target domain data after the previous N feature extractors.
The training is based on the (5) and following the algorithm as shown in Algorithm 1. For the three losses, minimizing MMD loss can get domain-invariant features for each pair of the source and target domains; minimizing classification loss will bring more accurate classifiers for predicting the source domain data; minimizing discrepancy loss will get more convergent multiple classifiers. The setting of α is illustrated in section 5.1 and we also investigate different settings of β in section 5.5.1.

Algorithm 1 Overview of MS-MDA.
5. Experiments
In this section, we describe experiments settings and results in classifying of emotions on two datasets SEED and SEED-IV, with the normalization study with three types and two orders to the EEG data for domain adaptation. Besides, we also conduct some exploratory experiments in addition to the evaluation of our proposed methods and comparison methods.
5.1. Implementation Details
As mentioned in the section 4, there are many details in the three modules of MS-MDA. First, for the Common Feature Extractor (CFE), since we do not take raw data (i. e. EEG signals) but the extracted DE features as vectors, complex deep models such as deep convolutional neural networks are not suitable for this module, thus we choose 3-layer MLP for simplicity which reduces feature dimensions from 310-dimension (62 × 5, channel × band) to 64-D. In CFE, every linear layer is followed by a LeakyReLU (Xu et al., 2015) layer. We also evaluate the effort of the ReLU (Nair and Hinton, 2010) activation function, but due to the sensitivity of the EEG data, much information would be lost if using ReLU since the value less than zero would be dropped, so we choose LeakyReLU as a compromise. Next, for both domain-specific feature extractor (DSFE) and domain-specific classifier (DSC), there is a single linear which reduces 64-D to 32-D and 32-D to the corresponding number of categories (3 for SEED, 4 for SEED-IV), respectively. In DSFE, same as the settings in CFE, a LeakyReLU layer is followed after the linear layer, while in DSC, there is only one linear layer without any activation function. The network is trained using an Adam (Kingma and Ba, 2014) optimizer with an initial learning rate of 0.01, and train for 200 epoch. The batch size we choose is 256, which means we take 256 samples from each domain in every iteration (we also evaluate different settings of batch size and epoch in section 5.5). The whole model is trained under the (5), for domain adaptation loss, we choose MMD as the metric of the distance between two domains in the feature space (CORAL loss has a similar effect). As for the discrepancy loss, L1 regularization is being used, we also evaluate this loss in section 5.5. Besides, we dynamically adjust the α coefficients to achieve the effect of focusing on the classification results first, and then start aligning MMD and the convergence between the classifiers (). As for the training data, we take the DE features and reform one sample to a 310-D vector as illustrated in the section 3.4. Before feeding into the model, we normalize all the data in electrode-wise, refer to section 5.4 for details.
5.2. Results
Experiment results of comparison methods and our proposed method on SEED and SEED-IV are listed in Table 2, all the hyper-parameters are the same, except for those results taken directly from the original papers. It should be noticed that since many previous works do not make their codes public available, we then customize the comparison methods (in the deep learning domain adaptation field) that are described in their papers with our settings, and also including some typical deep learning domain adaptation models for better comparison (DDC Tzeng et al., 2014, DCORAL Sun and Saenko, 2016). The results indicate that our method largely outperforms the comparison methods in most transfer scenarios. For SEED dataset, our method has a minimum of 7 and 3% improvement in cross-session and cross-subject scenarios, respectively. While in SEED-IV dataset, our method has a minimum of 7 and 18% for two transfer scenarios. The results also show that our method outperforms comparison methods significantly in cross-subject, the reason for that may be that in the cross-subject scenario, the number of sources is 14, much bigger than the number of 2 in cross-session, and thus maximizes the effect of taking multiple sources as multiple individuals in domain adaptation rather than concatenating them.
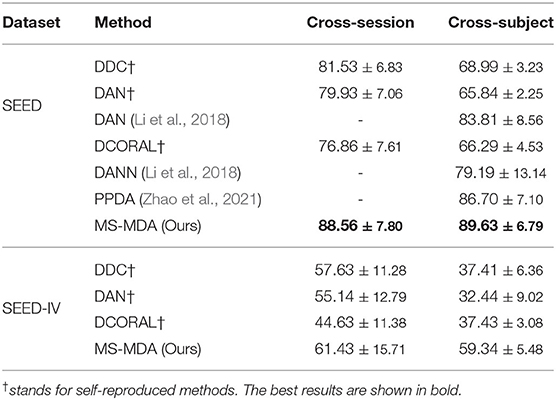
Table 2. Comparison results on SEED and SEED-IV of accuracy.
5.3. Ablation Study
To understand the effect of each module in the MS-MDA, we remove them one at a time and evaluate the performance of the ablated model, the results are shown in Table 3. The first row of SEED and SEED-IV shows the performance of the full model (the same as in Table 2). The second row ablates the MMD loss in the training process, which makes the model focuses only on the classification loss and discrepancy loss. The significant drop compared to the full model indicates the important effect of domain adaptation. Notice that even the results without MMD loss are better than many comparison methods, showing the importance of taking multiple sources as multiple individuals during training. The third row of taking out the discrepancy loss shows that this loss will affect the performance but the impact is minimal, the reason is that we want this discrepancy loss to be the icing on the cake rather than having a dominant effect on the model. The fourth row only considers the classification loss, thus reduces losses (2) and (4).
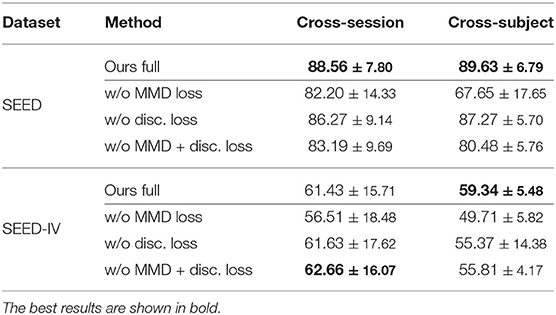
Table 3. Ablation study of MS-MDA on SEED and SEED-IV of accuracy.
Besides, we also conduct experiments to demonstrate how the performance measures change along with the number of source numbers. Since the amount of experiments is massive if following a full cross-validation rule, we simply take the first subject as the source domain to test one branch experiment, the first two subjects on two-branch, the first three subjects on three-branch, etc. The results are plotted in Figure 4. From the figure, it is obvious that with the improvement of source number, our algorithm has a large improvement in the accuracy.
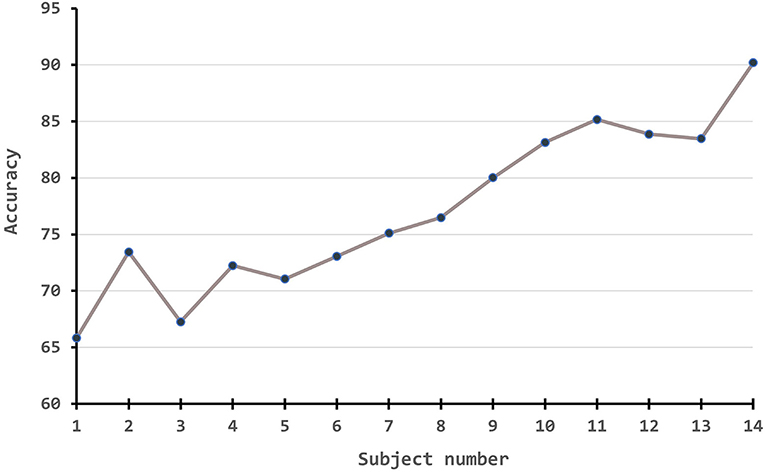
Figure 4. The performance measures change along with the number of source numbers.
5.4. Normalization
During the experiments, we also find that different normalization to data can significantly impact the outcomes, and also the order of whether first concatenating multiple sources or first normalize each session individually. Thus we design diagrams and conduct extensive experiments to investigate the effects of different normalization strategies on the input data, i. e., extracted feature vectors from two datasets. Since we have reformed the origin 4-D matrices (session × channel × trial × band) into 3-D matrices [session × trial × (channel*band)], for each session, there is a 2-D matrix of trial × 310. Following the common machine learning normalization approaches and the prior knowledge and intuition of EEG data (i. e., the data acquired by the same electrode are more consistent with the same distribution), the normalization methods to these 2-D matrices can be categorized into three, as shown in Figure 5. Besides, since we also take the multi-source situation into consideration, the order of normalization may also influence the performance.
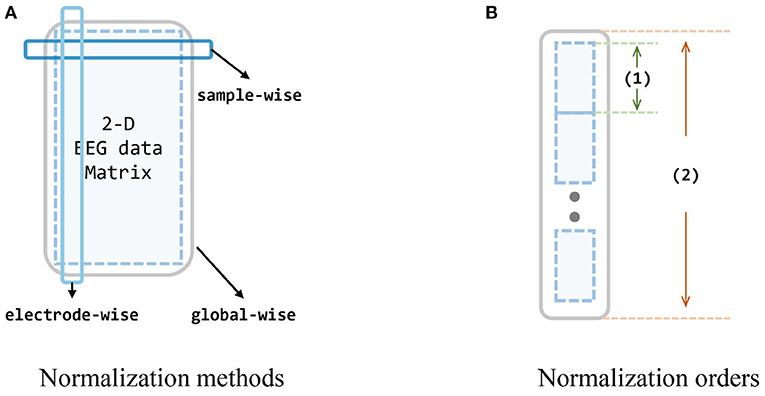
Figure 5. Evaluation of normalization methods and orders. (A) The dark blue box stands for the sample-wise normalization, while the light blue box stands for the electrode-wise normalization. The big gray box stands for the global-wise normalization. (B) There are two normalization orders (involving two operations for single source and all sources): concatenate all sources first, and normalize global-wise, or normalize every single source first, and concatenate them all. Small blue matrices are data from different subjects, (1) is an operation for one single source, and (2) is an operation for all sources. In order A, (1) in the figure stands for the normalization, and (2) stands for the concatenate (i.e., normalize every single source first, and then concatenate them all). In order B: (1) stands for concatenating while (2) is for normalization (i.e., concatenate every single source into one big source domain first, and then normalize this domain).
We evaluate three normalization methods and two normalization orders on SEED and SEED-IV with our proposed method MS-MDA and representative domain adaptation model DAN (Long et al., 2015). The results are listed in Table 4. In all three sets, the normalization of electrode-wise outperforms the other three normalization types significantly. Comparing DAN1 with DAN2, the results indicate that the first normalization order of normalizing the data first and then concatenating them is better. In the third set of MS-MDA, we find that all the results of four normalization types are better than those in the first and second sets, and the improvement is significant. Row w/o normalization in MS-MDA, for example, has a top of 47% improvement, which also indicates the generalization of our proposed method in different normalization types, and the positive effects of taking multiple sources as individual branches for DA.
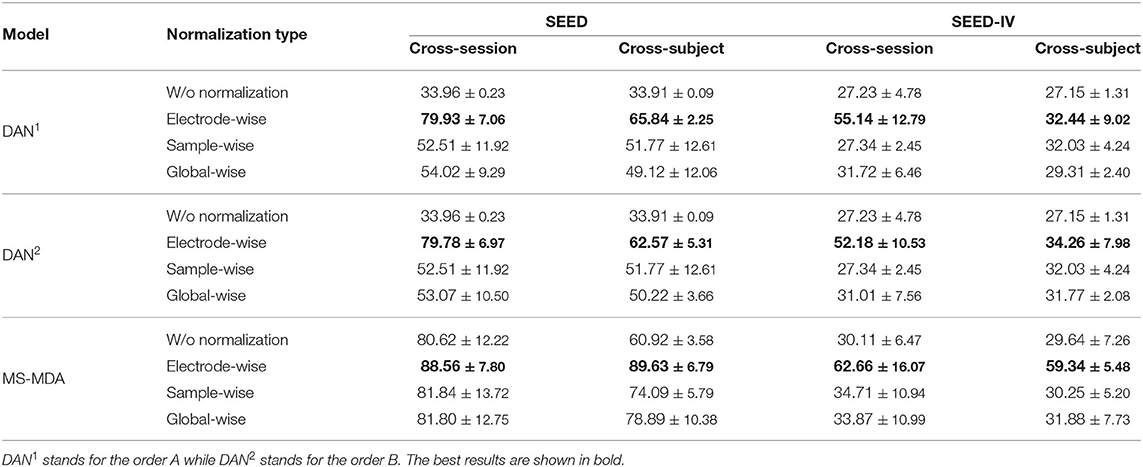
Table 4. Normalization study of MS-MDA and DAN of accuracy.
5.5. Additions
5.5.1. Coefficient Study
After multiple sets of experiments, we find that easy to control the MMD loss and it plays an influential role in the training as shown in Table 3. However, for the disc. loss, it remains many problems. Adding this loss to the model too early will affect the overall effect, and too late will lose the impact of learning convergence. Too large a weight would cause the training to focus on convergence, thus the few correct ones might follow the many incorrect ones; too small may not have enough influence on the model. Also, for better use and simplicity mentioned earlier, we do not make many tests on the β, but simply compared the effects on only a few sets of β, and the results are shown in Table 5. From which we can see that compared to row one (w/o disc. loss), introducing discrepancy loss increases the performance in most cases, especially when training for the whole process in cross-subject for SEED-IV. We then choose the weight of 0.01 and training discrepancy loss for the whole process according to the results.
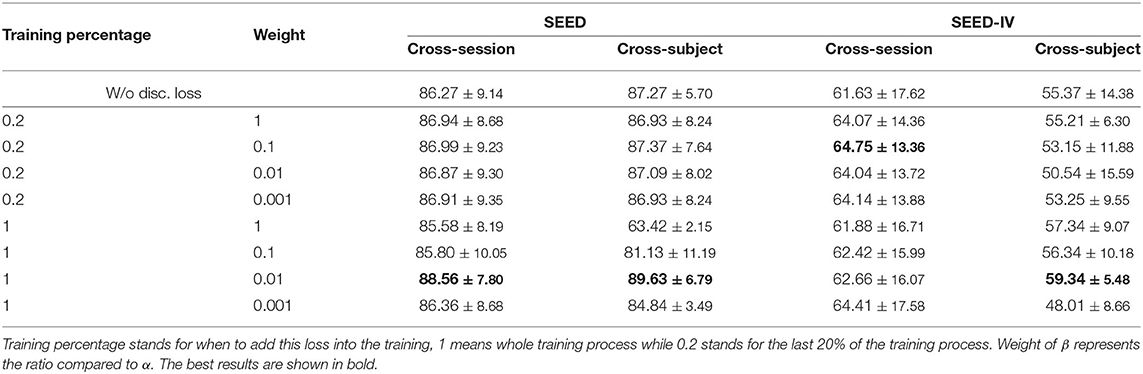
Table 5. Performance of MS-MDA on SEED and SEED-IV of accuracy with different settings of β.
5.5.2. Hyper-Parameters and Visualization
To better investigating our proposed method, we evaluate it with different hyper-parameters, besides, we also take the representative method DAN as the comparison. The results are shown in Figures 6, 7. From them we can see that, with the increase of batch size, both models show a drop in performance, especially when the batch size is 512, which has a significant decrease compared to 256 on SEED-IV. Besides, with the training epoch increases, neither model has a substantial improvement, especially MS-MDA, but our method achieves moderate accuracy and converges faster. Comparing cross-subject experiments on two datasets, it can be significantly seen that MS-MDA has a clear advantage over DAN, which indirectly shows that our approach has a more significant performance improvement for multiple source domain adaptation in EEG-based emotion recognition.
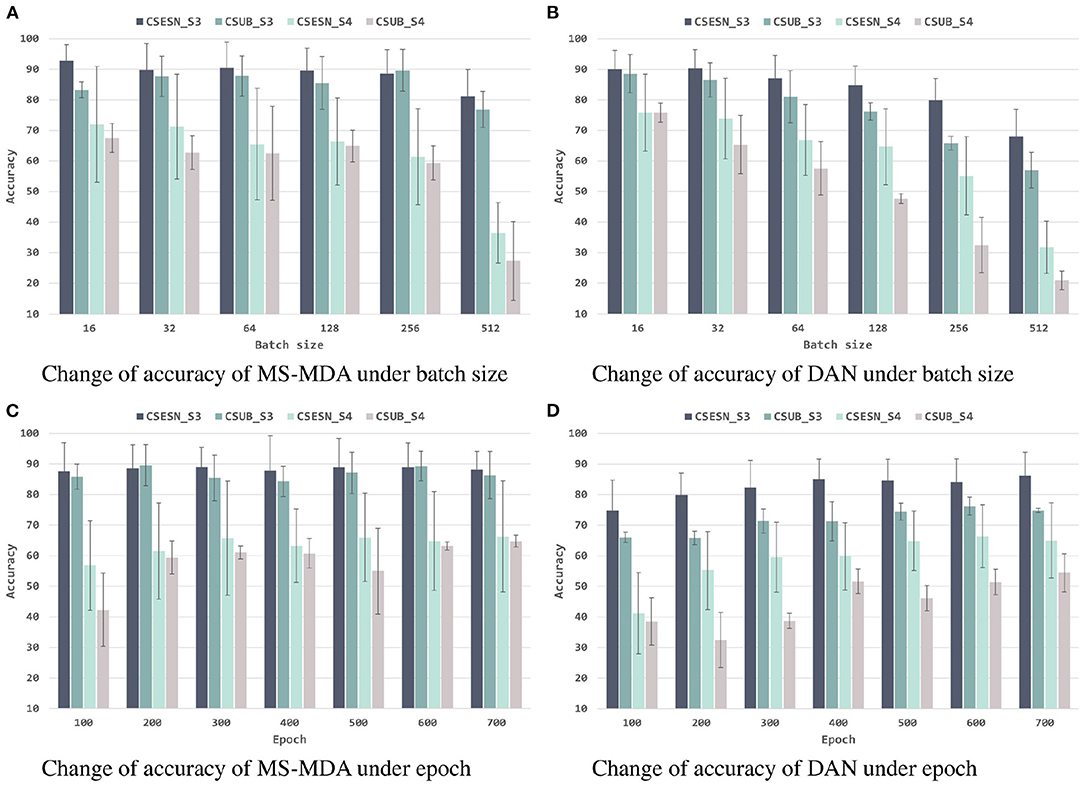
Figure 6. Evaluation of MS-MDA and DAN. The four color bars from left to right correspond to the four transfer scenarios: cross-session for SEED, cross-subject for SEED, cross-session for SEED-IV, cross-subject for SEED-IV. Batch size: {16, 32, 64, 128, 256, 512}, epoch: {100, 200, 300, 400, 500, 600, 700}. (A) Change of accuracy of MS-MDA under batch size. (B) Change of accuracy of DAN under batch size. (C) Change of accuracy of MS-MDA under epoch. (D) Change of accuracy of DAN under epoch.
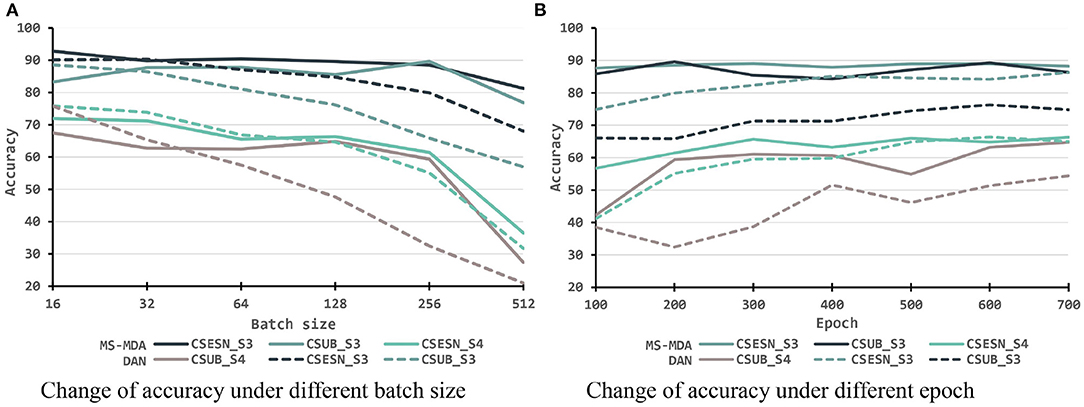
Figure 7. Evaluation of MS-MDA and DAN with different settings of batch size and epochs. The color lines from top to bottom stand for eight transfer scenarios: cross-session for SEED of MS-MDA, cross-subject for SEED of MS-MDA, cross-session for SEED-IV of MS-MDA, cross-subject for SEED-IV of MS-MDA; cross-session for SEED of DAN, cross-subject for SEED of DAN, cross-session for SEED-IV of DAN, cross-subject for SEED-IV of DAN. (A) Change of accuracy under different batch size. (B) Change of accuracy under different epoch.
We also visualize the four loss items (total loss, classification loss, MMD loss, and discrepancy loss) in Figure 8. From the figure, we can see that the total loss, the classification loss, and the discrepancy loss decrease with the training step increases. However, the figure of MMD loss has a relatively significant rise at the 2k step. We assume that the alpha gets to value 1 at the 2k step, which makes the MMD loss the same weight as the classification loss, thus slightly impacting the model.
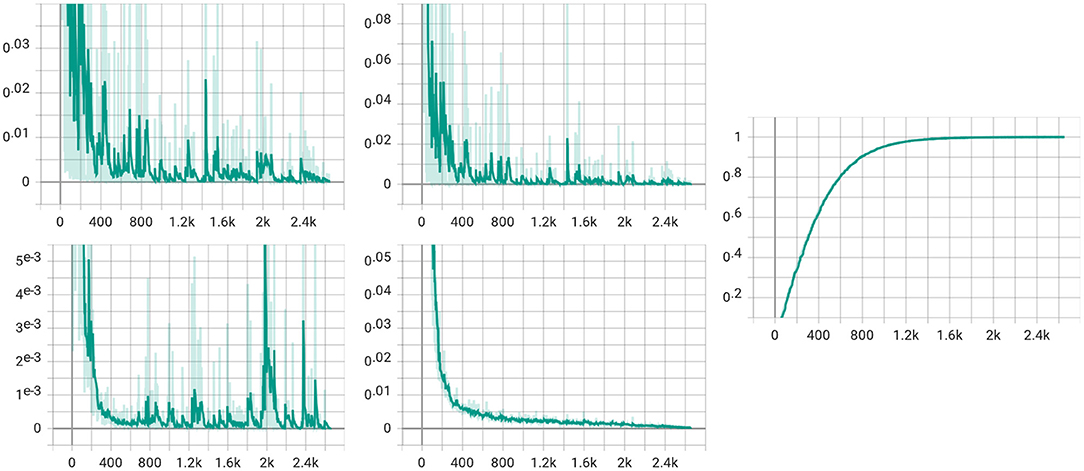
Figure 8. Visualization for four loss items. The upper left is the total loss, while the classification loss is in the upper middle. The lower left is for the MMD loss, and the discrepancy loss is in the lower middle. The figure in the right is the visualization of the α in (5).
For a better understanding of the effect of our proposed method, we randomly pick 100 EEG samples from each subject (domain) in the scenario of cross-subject to visualize with t-SNE (Van der Maaten and Hinton, 2008), as displayed in Figure 9. We only plot the cross-subject since this transfer scenario has more sources that will maximize visualization. In the Figure 9, each color stands for a source domain, and the target domain are in black. To better plotting, we transparent the target sample to avoid overlap. It should be noticed that in the lower left figure, we pick 1400 samples since we concatenate all sources into one.
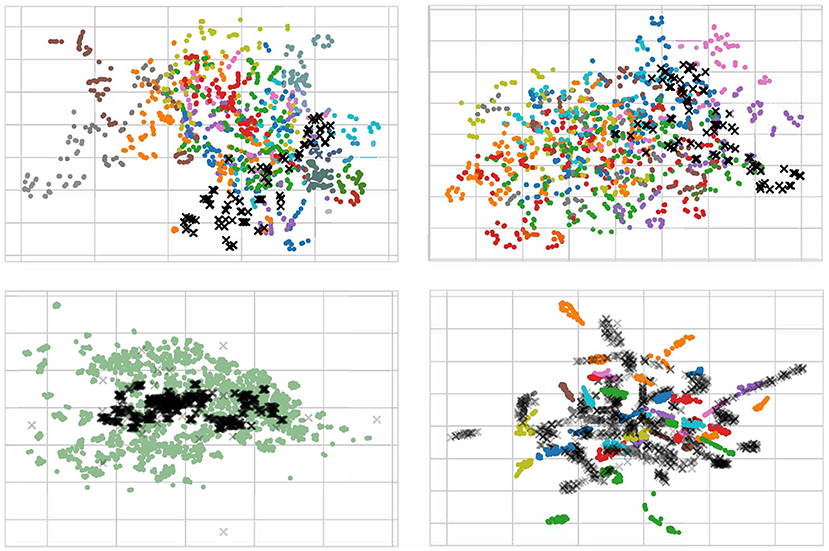
Figure 9. Visualization with t-SNE for raw data (upper left), normalization data (upper right), data using DAN (lower left), and data using MS-MDA (lower right). The input data of the last fully-connected (DSC) layer are used for the computation of the t-SNE. Target data are in the shape of X with black, all other 14 source data are in 14 colors. Notice that since we have concatenated all the source domains, the lower left figure has only one color for the source domain. All four figures are best viewed in color.
From the Figure 9, it is apparently that the distribution of all EEG data from different subjects (with different colors) is close. Most samples are concentrated in one area, with a few outliers in individual subjects. These distribution confirms our hypothesis that all EEG data share some low-level features, i.e., their distribution on the feature space is slightly overlapping. This is especially noticeable after normalization (upper right in the Figure 9), where the distribution of these EEG data is neater and around the center. In DAN, since all the source data are concatenated as one source domain, there is only one color for the source domain. Lower left figure of Figure 9 illustrates that domain adaptation process brings the source and target domains closer together, and resulting in a high degree of overlap between green and black samples, with a concentration of black samples in the more central region of the source domain. As for MS-MDA, since we adopt the distribution of each source domain separately with the target domain, it is intuitive that the black dots should have some closeness and overlap with each color of the source domain, and the lower right figure of Figure 9 does confirm our suspicion.
6. Discussion
As can be seen from Table 2, comparing the results of selective methods and prior works, our proposed method has a significant improvement, especially for cross-subject DA in which the number of source domains is large. The ablation experiments from Table 3 also show that our proposed method requires both MMD and discrepancy loss in most cases. Eliminating the MMD loss has a significant performance drop on both datasets, confirming the importance of DA, and eliminating disc. loss does not have as large an impact as MMD loss, but also verifies the help of multi-source convergence. Also, during the experiments, we find that the type of normalization of the data has a significant impact on the overall results, so we also design experiments and explore the normalization of EEG data in DA to help improve the performance of our model. As can be seen in Table 4, there is not much difference between the two normalization orders, and it is most appropriate to do data normalization on the electrode-wise, which has a crushing performance improvement compared to the other three methods; for our method, which does not concatenate data, electrode normalization is also the most effective. This conclusion is in line with our intuition that data collected from the same electrode are relatively more regular or conform to a certain distribution, while data collected from different electrodes are very different. In addition, during the experiments, we find that the disc. loss needs to be carefully adjusted, otherwise it is easy to cause harmful effects, which we guess is because this loss introduces a convergence effect on multiple classifiers in the model (in other words, smooth the inferences made from multiple classifiers), and if most of the classifiers are wrong, this convergence effect will cause the correct classifiers to error. Therefore, we also test and evaluate the impact of the disc. loss coefficients on the model at different settings, and from Table 5, we can see that the disc. loss achieves the best results if it is set to 0.01 times the MMD loss coefficient and is being used in the full model training.
After exploring the internal details of the model, we also evaluated the performance of the model under different hyper-parameters. For better comparison, we chose a representative DAN as the comparison method. From Figures 6, 7, we can see that both models have a significant decrease as the batch size is increasing. The reason for this we assume is that small batch size tends to fall into local optimal overfitting. Besides, the hyperparameter epoch has a minimal impact on both models, particularly the MS-MDA. From Figures 6, 7, we can also clearly see that MS-MDA has a significant advantage over DAN in cross-subject DA where the number of multiple source domains is large, which also confirms the importance of constructing multiple branches for multiple source domains to adopt DA separately.
Although it is clear from the results that our proposed method has a significant performance improvement, we also found that the training time consumed increases linearly with the number of source domains, i.e., the larger the number of source domains and the larger the model, the longer the training takes, unlike concatenating all source data into one, where there is only additional time due to the increase in the amount of data. For this problem, our current idea is to discard some less relevant source domains selectively and not build DA branches for them, allowing the disc. loss to play a more prominent role because there is less negative information. In addition, the encoders in the current model are the simplest MLP, and many literature and works have verified the usability of LSTM for EEG data (Ma et al., 2019; Jiao et al., 2020; Tao and Lu, 2020), and we will consider switching to use LSTM as the encoders in future works.
7. Conclusion
In this paper, we propose MS-MDA, an EEG-based emotion recognition domain adaptation method, which is applicable to multiple source domain situations. Through experimental evaluation, we find that this method has a better ability to adapt to multiple source domains, which is validated by comparison with the selective approaches and the SOTA models, especially for cross-subject experiments where our proposed method consists of up to 20% improvement. In addition, we also explore the impact of different normalization methods for EEG data in domain adaptation, which we believe can serve as an inspiration for other EEG-based works while improving the effectiveness of the models. As for our future work, the current model for multiple source domains is to construct a DA branch for each of them without selection, which will increase the model size and training time exponentially, and also introduces information from the source domain that is not relevant to the target into the model. A more efficient approach may be to selectively build DA branches from a reservoir of source domains, allowing the model to be more efficient while only focusing on the source domain information that is relevant to the target domain.
Data Availability Statement
The datasets analyzed for this study can be found in the BCMI laboratory official website at https://bcmi.sjtu.edu.cn/home/seed/index.html.
Author Contributions
HC and JL: conceptualization and writing-original draft. HC, MJ, and ZL: investigations and data analysis and constructed the experiments. CF, JL, and HH: review the draft and editing. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Natural Science Foundation of China (62020106015), the Strategic Priority Research Program of CAS (XDB32040000), the Zhejiang Provincial Natural Science Foundation of China (LQ20F030013), and the Ningbo Public Service Technology Foundation, China (202002N3181).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Acharya, U. R., Sudarshan, V. K., Adeli, H., Santhosh, J., Koh, J. E., and Adeli, A. (2015). Computer-aided diagnosis of depression using eeg signals. Eur. Neurol. 73, 329–336. doi: 10.1159/000381950
Ay, B., Yildirim, O., Talo, M., Baloglu, U. B., Aydin, G., Puthankattil, S. D., et al. (2019). Automated depression detection using deep representation and sequence learning with eeg signals. J. Med. Syst. 43, 1–12. doi: 10.1007/s10916-019-1345-y
Barrett, L. F., Gross, J., Christensen, T. C., and Benvenuto, M. (2001). Knowing what you're feeling and knowing what to do about it: mapping the relation between emotion differentiation and emotion regulation. Cogn. Emot. 15, 713–724. doi: 10.1080/02699930143000239
Birbaumer, N. (2006). Breaking the silence: brain-computer interfaces (bci) for communication and motor control. Psychophysiology 43, 517–532. doi: 10.1111/j.1469-8986.2006.00456.x
Borgwardt, K. M., Gretton, A., Rasch, M. J., Kriegel, H.-P., Schölkopf, B., and Smola, A. J. (2006). Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 22, e49–e57. doi: 10.1093/bioinformatics/btl242
Bucks, R. S., and Radford, S. A. (2004). Emotion processing in alzheimer's disease. Aging Mental Health 8, 222–232. doi: 10.1080/13607860410001669750
Candès, E. J., Li, X., Ma, Y., and Wright, J. (2011). Robust principal component analysis? J. ACM 58, 1–37. doi: 10.1145/1970392.1970395
Chai, X., Wang, Q., Zhao, Y., Li, Y., Liu, D., Liu, X., et al. (2017). A fast, efficient domain adaptation technique for cross-domain electroencephalography (eeg)-based emotion recognition. Sensors 17, 1014. doi: 10.3390/s17051014
Chai, X., Wang, Q., Zhao, Y., Liu, X., Bai, O., and Li, Y. (2016). Unsupervised domain adaptation techniques based on auto-encoder for non-stationary eeg-based emotion recognition. Comput. Biol. Med. 79, 205–214. doi: 10.1016/j.compbiomed.2016.10.019
Dolan, R. J. (2002). Emotion, cognition, and behavior. Science 298, 1191–1194. doi: 10.1126/science.1076358
Duan, R.-N., Zhu, J.-Y., and Lu, B.-L. (2013). “Differential entropy feature for eeg-based emotion classification,” in 2013 6th International IEEE/EMBS Conference on Neural Engineering (NER) (San Diego, CA: IEEE), 81–84.
Ekman, P. (1993). Facial expression and emotion. Am. Psychol. 48, 384. doi: 10.1037/0003-066X.48.4.384
Fahimi, F., Zhang, Z., Goh, W. B., Lee, T.-S., Ang, K. K., and Guan, C. (2019). Inter-subject transfer learning with an end-to-end deep convolutional neural network for eeg-based bci. J. Neural Eng. 16, 026007. doi: 10.1088/1741-2552/aaf3f6
Frisoli, A., Loconsole, C., Leonardis, D., Banno, F., Barsotti, M., Chisari, C., et al. (2012). A new gaze-bci-driven control of an upper limb exoskeleton for rehabilitation in real-world tasks. IEEE Trans. Syst. Man Cybern. C 42, 1169–1179. doi: 10.1109/TSMCC.2012.2226444
Gardner, M. W., and Dorling, S. (1998). Artificial neural networks (the multilayer perceptron)—review of applications in the atmospheric sciences. Atmos. Environ. 32, 2627–2636. doi: 10.1016/S1352-2310(97)00447-0
Hosseinifard, B., Moradi, M. H., and Rostami, R. (2013). Classifying depression patients and normal subjects using machine learning techniques and nonlinear features from eeg signal. Comput. Methods Programs Biomed. 109, 339–345. doi: 10.1016/j.cmpb.2012.10.008
Jeon, M. (2017). “Emotions and affect in human factors and human-computer interaction: taxonomy, theories, approaches, and methods,” in Emotions and Affect in Human Factors and Human-Computer Interaction, ed M. Jeon (Houghton, MI: Elsevier), 3–26.
Jiang, C., Li, Y., Tang, Y., and Guan, C. (2021). Enhancing eeg-based classification of depression patients using spatial information. IEEE Trans. Neural Syst. Rehabil. Eng. 29, 566–575. doi: 10.1109/TNSRE.2021.3059429
Jiao, Y., Deng, Y., Luo, Y., and Lu, B.-L. (2020). Driver sleepiness detection from eeg and eog signals using gan and lstm networks. Neurocomputing 408, 100–111. doi: 10.1016/j.neucom.2019.05.108
Jin, Y.-M., Luo, Y.-D., Zheng, W.-L., and Lu, B.-L. (2017). “Eeg-based emotion recognition using domain adaptation network,” in 2017 International Conference on Orange Technologies (ICOT) (Singapore: IEEE), 222–225.
Joormann, J., and Gotlib, I. H. (2010). Emotion regulation in depression: relation to cognitive inhibition. Cogn. Emot. 24, 281–298. doi: 10.1080/02699930903407948
Kingma, D. P., and Ba, J. (2014). Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Koelstra, S., Muhl, C., Soleymani, M., Lee, J.-S., Yazdani, A., Ebrahimi, T., et al. (2011). Deap: a database for emotion analysis; using physiological signals. IEEE Trans. Affect. Comput. 3, 18–31. doi: 10.1109/T-AFFC.2011.15
Lee, S.-H., Lee, M., Jeong, J.-H., and Lee, S.-W. (2019). “Towards an eeg-based intuitive bci communication system using imagined speech and visual imagery,” in 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC) (Bari: IEEE), 4409–4414.
Li, H., Jin, Y.-M., Zheng, W.-L., and Lu, B.-L. (2018). “Cross-subject emotion recognition using deep adaptation networks,” in International Conference on Neural Information Processing (Siem Reap: Springer), 403–413.
Li, J., Chen, H., and Cai, T. (2020). “Foit: fast online instance transfer for improved eeg emotion recognition,” in 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) (Seoul: IEEE), 2618–2625.
Li, J., Qiu, S., Du, C., Wang, Y., and He, H. (2019a). Domain adaptation for eeg emotion recognition based on latent representation similarity. IEEE Trans. Cogn. Dev. Syst. 12, 344–353. doi: 10.1109/TCDS.2019.2949306
Li, J., Qiu, S., Shen, Y.-Y., Liu, C.-L., and He, H. (2019b). Multisource transfer learning for cross-subject eeg emotion recognition. IEEE Trans. Cybern. 50, 3281–3293. doi: 10.1109/TCYB.2019.2904052
Lin, Y.-P., Jao, P.-K., and Yang, Y.-H. (2017). Improving cross-day eeg-based emotion classification using robust principal component analysis. Front. Comput. Neurosci. 11:64. doi: 10.3389/fncom.2017.00064
Liu, Y., Zhang, H., Chen, M., and Zhang, L. (2015). A boosting-based spatial-spectral model for stroke patients' eeg analysis in rehabilitation training. IEEE Trans. Neural Syst. Rehabil. Eng. 24, 169–179. doi: 10.1109/TNSRE.2015.2466079
Long, M., Cao, Y., Wang, J., and Jordan, M. (2015). “Learning transferable features with deep adaptation networks,” in International Conference on Machine Learning (Lile: PMLR), 97–105.
Ma, J., Tang, H., Zheng, W.-L., and Lu, B.-L. (2019). “Emotion recognition using multimodal residual lstm network,” in Proceedings of the 27th ACM International Conference on Multimedia (Nice), 176–183.
Nair, V., and Hinton, G. E. (2010). “Rectified linear units improve restricted boltzmann machines,” in ICML (Haifa).
Pan, S. J., Tsang, I. W., Kwok, J. T., and Yang, Q. (2010). Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 22, 199–210. doi: 10.1109/TNN.2010.2091281
Pan, S. J., and Yang, Q. (2009). A survey on transfer learning. IEEE Trans Knowl Data Eng. 22, 1345–1359. doi: 10.1109/TKDE.2009.191
Soleymani, M., Asghari-Esfeden, S., Fu, Y., and Pantic, M. (2015). Analysis of eeg signals and facial expressions for continuous emotion detection. IEEE Trans. Affect. Comput. 7, 17–28. doi: 10.1109/TAFFC.2015.2436926
Sun, B., and Saenko, K. (2016). “Deep coral: correlation alignment for deep domain adaptation,” in European Conference on Computer Vision (Amsterdam: Springer), 443–450.
Tao, L.-Y., and Lu, B.-L. (2020). “Emotion recognition under sleep deprivation using a multimodal residual lstm network,” in 2020 International Joint Conference on Neural Networks (IJCNN) (Glasgow: IEEE), 1–8.
Tyng, C. M., Amin, H. U., Saad, M. N., and Malik, A. S. (2017). The influences of emotion on learning and memory. Front. Psychol. 8:1454. doi: 10.3389/fpsyg.2017.01454
Tzeng, E., Hoffman, J., Zhang, N., Saenko, K., and Darrell, T. (2014). Deep domain confusion: maximizing for domain invariance. arXiv preprint arXiv:1412.3474.
Van der Maaten, L., and Hinton, G. (2008). Visualizing data using t-sne. J. Mach. Learn. Res. 9, 2579–2605.
Wang, Y., Qiu, S., Ma, X., and He, H. (2021). A prototype-based spd matrix network for domain adaptation eeg emotion recognition. Pattern Recognit. 110:107626. doi: 10.1016/j.patcog.2020.107626
Xu, B., Wang, N., Chen, T., and Li, M. (2015). Empirical evaluation of rectified activations in convolutional network. arXiv preprint arXiv:1505.00853.
Yin, W., Schütze, H., Xiang, B., and Zhou, B. (2016). Abcnn: attention-based convolutional neural network for modeling sentence pairs. Trans. Assoc. Comput. Linguist. 4, 259–272. doi: 10.1162/tacl_a_00097
Zhang, B., Yan, G., Yang, Z., Su, Y., Wang, J., and Lei, T. (2020). Brain functional networks based on resting-state eeg data for major depressive disorder analysis and classification. IEEE Trans. Neural Syst. Rehabil. Eng. 29, 215–229. doi: 10.1109/TNSRE.2020.3043426
Zhao, L.-M., Yan, X., and Lu, B.-L. (2021). “Plug-and-play domain adaptation for cross-subject eeg-based emotion recognition,” in Proceedings of the 35th AAAI Conference on Artificial Intelligence.
Zheng, W.-L., Liu, W., Lu, Y., Lu, B.-L., and Cichocki, A. (2018). Emotionmeter: a multimodal framework for recognizing human emotions. IEEE Trans. Cybern. 49, 1110–1122. doi: 10.1109/TCYB.2018.2797176
Zheng, W.-L., and Lu, B.-L. (2015). Investigating critical frequency bands and channels for eeg-based emotion recognition with deep neural networks. IEEE Trans. Auton. Ment. Dev. 7, 162–175. doi: 10.1109/TAMD.2015.2431497
Zheng, W.-L., and Lu, B.-L. (2016). “Personalizing eeg-based affective models with transfer learning,” in Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (New York, NY), 2732–2738.
Keywords: brain-computer interface, EEG, emotion recognition, domain adaptation, transfer learning
Citation: Chen H, Jin M, Li Z, Fan C, Li J and He H (2021) MS-MDA: Multisource Marginal Distribution Adaptation for Cross-Subject and Cross-Session EEG Emotion Recognition. Front. Neurosci. 15:778488. doi: 10.3389/fnins.2021.778488
Received: 17 September 2021; Accepted: 27 October 2021;
Published: 07 December 2021.
Edited by:
Yudan Ren, Northwest University, ChinaCopyright © 2021 Chen, Jin, Li, Fan, Li and He. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jinpeng Li, bGlqaW5wZW5nQHVjYXMuYWMuY24=