 Feishe Chen1
Feishe Chen1 Lixin Shen
Lixin Shen- 1Department of Mathematics, Syracuse University, Syracuse, NY, USA
- 2Air Force Research Laboratory, Rome, NY, USA
We consider minimization of functions that are compositions of functions having closed-form proximity operators with linear transforms. A wide range of image processing problems including image deblurring can be formulated in this way. We develop proximity algorithms based on the fixed point characterization of the solution to the minimization problems. We further refine the proposed algorithms when the outer functions of the composed objective functions are separable. The convergence analysis of the developed algorithms is established. Numerical experiments in comparison with the well-known Chambolle-Pock algorithm and Zhang-Burger-Osher scheme for image deblurring are given to demonstrate that the proposed algorithms are efficient and robust.
1. Introduction
In this paper, we study minimization problems of the form
where Ai are mi × n matrices and the functions are proper, lower semi-continuous and convex, for i = 1 and 2. We assume that the proximity operators of fi, i = 1, 2 have closed-form or can be efficiently computed numerically. The formulation (1) admits a wide variety of applications including image deblurring, machine learning, and compressive sensing. A large family of instances of Equation (1) arises in the area of regularized minimization, where f1(A1x) serves as a fidelity term while f2(A2x) serves as a regularization term. Concrete examples of Equation (1) in the context of image processing will be given later. Hence, it is practically important to develop efficient numerical algorithms for solving model (1).
The formulation (1), which can be noticed after reformulation, is intrinsically a composite minimization problem. Set m = m1 +m2. Indeed, by defining a mapping A:ℝn → ℝm at x ∈ ℝn by and a function f:ℝm → (−∞, +∞] at by
we are able to rewrite the formulation (1) as the following composite minimization problem
We say a function f : ℝm → (−∞, +∞] is block separable if this function f takes a form of Equation (2).
An efficient scheme proposed in Zhang et al. [1] can be applied to solve Equation (3) by introducing an auxiliary variable and converting it into a linearly constrained minimization problem. Introducing variable w = Ax yields an equivalent problem of Equation (3):
In general, the aforementioned scheme in Zhang et al. [1] solves
via
where Q1 is positive definite, Q2 is semi-positive definite and β, γ > 0. The scheme (6) has explicit form if the Q1, Q2 are chosen appropriately and the proximity operators of f, g have closed form. This feature of scheme (6) makes it efficiently implemented. Recently, some similar algorithms are reported in Chen et al. [2] and Deng and Yin [3].
However, applying Equation (6) directly to solve Equation (4) and therefore solve Equation (1) still have drawbacks. As a matter of fact, the variable w embeds two parts, say w = (u; v), with A1x−u = 0, A2x−v = 0. Under the choice of Q1 such that wk+1 in the first step of Equation (6) has explicit form, it yields two mutually independent, parallel steps in the computation of uk+1 and vk+1. In another word, the new results of uk+1 has not been used in the computation of vk+1 if uk+1 is computed ahead of vk+1. A relatively strict condition is imposed on the parameters brought into in the matrices Q1, Q2. These drawbacks prevents the scheme (6) from converging fast.
The composition of the objective function of Equation (3) is decoupled in its dual formulation. Indeed, the dual formulation of model (3) has a form of
where f* represents the Fenchel conjugate of f whose definition will be given in the next section. A solution of Equation (3) and a solution of Equation (7) can be derived from a stationary point of the Lagrangian function of Equation (7). Augmented Lagrangian methods [4–8] are commonly adopted for searching stationary points of the Lagrangian function of Equation (7). The convergence of an augmented Lagrangian method is guaranteed as long as the subproblem, which is usually involved in the augmented Lagrangian method, is solved to an increasingly highly accuracy at every iteration [8]. Therefore, solving the subproblem may become costly.
Correspondingly, the dual formulation of model (1) has a form of
From the notation point of view, the formulation (8) generalizes the formulation (5) without considering the conjugate, matrix transpose. To find a stationary point of the Lagrangian function of Equation (8) and therefore find solutions of Equations (1) and (8), the well-known ADMM (alternating direction method of multiplier) can be applied. The ADMM allows block-wise Gauss-Seidel acceleration among the variables u, v in solving the subproblems involved in the iterations. This illustrates some advantage of ADMM over the scheme (6) since no Gauss-Seidel acceleration occurs among the variable u, v when scheme (6) is applied to solve Equation (1). But as in Augmented Lagrange Method, solving the subproblems could be costly in ADMM.
Both the advantage and disadvantage of ADMM and scheme (6) motivates us to develop efficient and fast algorithms to solve the problems (1) and (3). Firstly of all, we provides a characterization of solutions of general problem (3) and its dual formulation (7) from the sub-differential point of view and develop proximal type algorithms from the characterization. We shall show the proposed algorithms have explicit form under the assumption that the proximity operators of f has closed form. Further, if the function f exhibits some appealing structures, we are able to derive an accelerated variant algorithm. Indeed, we show that if the function f is separable and problem (3) becomes (1), we are able to relax the parameters introduced in the algorithm and use block-wise Gaussian-Seidel acceleration. We shall show that this variant algorithm is a type of alternating direction method but exhibits some advantage over the classical ADMM (alternating direction method of multiplier).
This paper is organized in the following manner. In Section 2, we provide a characterization of solutions of the primal problem (3) and show that a stationary point of the Lagrangian function of Equation (7) yields a solution of Equation (3). We further develop a proximity operator based algorithm based on the characterization of solutions. In Section 3, we propose an accelerated variant algorithm if the function f is well-structured (i.e., f is separable). A unified convergence analysis of both algorithms is provided in this section. In Section 4, we discuss the connection of the proposed algorithms to CP (Chambolle and Pock's primal-dual) method, Augmented Lagrangian method and Alternating Direction Method of Multipliers. In Section 5, We identify the L2-TV and L1-TV models as special cases of the general problem (3) and demonstrate that the proximity operators of the corresponding functions can be efficiently computed in the proposed algorithms. in section 6, we apply the proposed algorithms to solve L2-TV and L1-TV image deblurring problems. The performance of the proposed algorithms is shown and comparison of proposed algorithms with CP [9] and scheme (6) is fulfilled. The conclusions on the proposed algorithms are given in the last section.
2. Dual Formulation: Algorithm
In this section, we shall see that a saddle point of the Lagrangian function of Equation (7) will yield a solution of Equation (3) and a solution of Equation (7). We identify the saddle point of the Lagrangian function of Equation (7) as a solution of a fixed-point equation in terms of proximity operator and propose an iterative scheme to solve this fixed-point equation. A connection of the resulting iterative scheme with the one given in Zhang et al. [1] is pointed out.
We begin with introducing our notation and recalling some background from convex analysis. For a vector x in the d-dimensional Euclidean space ℝd, we use xi to denote the ith component of a vector x ∈ ℝd for i = 1, 2, …, d. We define , for x, y ∈ ℝd the standard inner product in ℝd. The ℓ2-norm induced by the inner product in ℝd is defined as . For the Hilbert space ℝd, the class of all lower semicontinuous convex functions such that dom ψ: = {x ∈ ℝd : ψ(x) < +∞} ≠ Ø is denoted by . In this paper, we always assume that , , and , where the functions f1 and f2 are in Equation (1) and f in Equation (3).
We shall provide necessary and sufficient conditions for a solution to the model (3). To this end, we first recall the definition of sub-differential and definition of Fenchel conjugate. The subdifferential of is defined as the set-valued operator ∂ψ : x ∈ ℝd ↦ {y ∈ ℝd : ψ(z) ≥ ψ(x) + 〈y, z − x〉 for all z ∈ ℝd}. For a function ψ : ℝd → [−∞, +∞], the Fenchel conjugate of ψ at x ∈ ℝd is ψ*(x): = sup{〈y, x〉 − ψ(y) : y ∈ ℝd}.
The characterization of a solution to the model (3) in terms of sub-differential is given in the following.
Proposition 2.1. is a solution to the model (3) iff there exists a ŵ ∈ ℝm such that the following hold
PROOF. Suppose is a solution to Equation (3). By Fermat's rule, . There exists a such that 0 = A⊤ŵ. Since , implies by Proposition 11.3 in [10]. The Equation (10) follows.
The above reasoning is reversible. That is, if there is a such that Equation (9) holds, then is a solution to model (3). □
In the meantime, Equation (9) also characterizes the KKT conditions for the linear constraint minimization problem
in a way that acts as the Lagrange multipliers of the Lagrangian function f*(w) − 〈x, A⊤w〉.
The Equation (9) in Proposition 2.1 provides a necessary and sufficient condition characterization for a solution to model (3). Based on this Proposition, we shall provide a fixed point equation characterization of a solution to model (3) based on proximity operator. The proximity operator of ψ is defined by . The sub-differential and the proximity operator are closely related. Indeed, if and λ > 0, then
Proposition 2.2. is a solution to the model (3) iff for any positive numbers α > 0, β > 0, γ > 0, there exists an ŵ ∈ ℝm such that the following hold
or equivalently,
PROOF. It follows from proposition 2.1 and Equation (10). □
Intuitively, the fixed-point Equation (11) yield the following simple iteration scheme
which is in nature the classical Arrow-Hurwicz algorithm [11] for a stationary point of Lagrange function L(w, x) = f*(w) − 〈x, A⊤w〉. Although the Arrow-Hurwicz algorithm exhibits appealing simplicity feature, its convergence is only established under the assumption that f* is strictly convex [12]. But the assumption on the strict convexity is usually not satisfied.
A modification of the Arrow-Hurwitz algorithm based on the fixed point Equation (12) yields
We shall show that this modification allow us to achieve convergence for general convex function f*. Further, we are able to develop Gauss-Seidel acceleration if the function f is separable.
The key to the iterative scheme (14) is to compute the proximity operator of the f* in the first step. We point it out that can be easily computed, if necessary, by using the Moreau's decomposition [13, 14] as long as the proximity operator of its Fenchel conjugate of f can be computed easily, and vice-versa.
We adapt the scheme (14) for model (3) to model (1). Specifically, we have
where , , , A1 is an m1 × n matrix, and A2 is an m2 × n matrix. It can be directly verified that for
Hence, an adaptation of the iterative scheme (14) for model (1) is presented in Algorithm 1.

Algorithm 1. Dual Algorithm for Model (1).
3. Parameters Relaxation and Gauss-Seidel Method for Algorithm 1 and Its Convergence Analysis
In this section, Algorithm 1 is modified from two aspects. First, the parameter α will be relaxed such that it is different for updating uk+1 and vk+1. Second, the block Gauss-Seidel technique is applied in the sense that the updated result uk+1 will be immediately used in computing vk+1. As a consequence, we have a new algorithm, as a variant of Algorithm 1, which is depicted in Algorithm 2.

Algorithm 2. Gauss-Seidel Method for Model (1).
Next, we describe the general forms of the schemes (14) and (17) based on which the convergence analysis of the two algorithms will be derived. By the definition of proximity operator, the first step of iterative scheme (14) can be equivalently rephrased as
rearranging the objective function in Equation (18) and ignoring some constant, the optimization problem of Equation (18) is equivalent to
Under the condition , where ||A|| is the largest singular value of A, the matrix is symmetric, positive definite. As a result, the iterative scheme (14) can be cast into the following iterative scheme given in Zhang et al. [1]:
where the Q−norm || · ||Q is defined as for a positive definite symmetric matrix Q.
Similarly, the iterative scheme (17) in Algorithm 2 can be cast as a special case of the following scheme
where both Q1 and Q2 are symmetric and positive definite matrices. Indeed, by choosing with and , the matrices Q1, Q2 are symmetric, positive definite and scheme (21) reduces to (17) in Algorithm 2. Recall that the parameters α, β in Algorithm 1 need satisfy , where A is chosen as Equation (15). It can be noticed that , which implies . Hence, more flexibility exhibits for the choice of α1, α2, β in Algorithm 2 than for the choice of α, β in Algorithm 1.
We remark that the iterative scheme (21) generalizes the iterative scheme (22)
whose form is equivalent to Equation (6) by specifying the variables, functions and matrices appropriately. Indeed, when A2 is specified as −I, the iterative scheme (21) reduces to (22). Unlike [1], the iterative scheme (21) is derived from the dual formulation instead of primal problems. In addition, the generality of matrix A2 in iterative scheme (21) generalizes the matrix −I in scheme (6).
The rest of this section is devoted to a unified convergence analysis of the two iterative schemes (20) and (21), from which Algorithm 1 and Algorithm 2 can be derived. The convergence of these two schemes is analyzed in the following manner: we first prove the convergence of schemes (21) and obtain the convergence of scheme (20) as an immediate result.
For convenient exposition, Equation (9) for the special case Equation (15) is rewritten as
We will show that for any initial seed and a positive parameter γ the sequence ({(uk, vk, xk):k ∈ ℕ}) converges to a triple satisfying Equation (23).
First of all, we look at the characterization of uk+1, vk+1 involved in the two subproblems in Equation (21). Using Fermat's rule for the two subproblems, we are able to get
Let
Then . If the sequence ({(uk, vk, xk) : k ∈ ℕ}) converges to a triple satisfying Equation (23), we observe as k → ∞. For convenience, we also introduce the following notations
Next, we shall establish a relationship between a triple and the sequence {(uk, vk, xk):k ∈ ℕ} generated by the iterative scheme (21).
Lemma 3.1. Let Q1 and Q2 be two positive definite symmetric matrices, let the triple satisfy Equation (23), and let {(uk, vk, xk) : k ∈ ℕ} be the sequence generated by scheme (21).
Then the following equation holds:
where
PROOF. It follows from the definitions of r, rk, t, and tk, the iteration scheme (21) and the characterization of saddle points Equation (23) that
By taking the inner product with on the both sides of the first equality of Equation (26) and rearranging the terms and using the identity , we obtain
Likewise, by taking the inner product with and on the both sides of the second and third Equations of (26), we obtain
and
respectively. By adding up the above three equations and using the identity and the fact , we get Equation (25). This completes the proof of the result. □
To show that the convergence of sequence {(uk, vk, xk):k ∈ ℕ} generated by the iterative scheme (21), we need two properties of the subdifferential. The first one is the monotonicity of the subdifferantial. The subdifferential a function as a set-valued function is monotone (see [15]) in the sense that for any u and v in the domain of ψ
Another useful property of the sub-differential is presented in the following lemma.
Lemma 3.2. Let ψ be in and let {(xk, yk) : k ∈ ℕ} be a sequence with yk ∈ ∂ψ(xk). Suppose that xk → x and yk → y as k → ∞. Then y ∈ ∂ψ(x).
PROOF. By the definition of sub-differential, the inequality ψ(z) ≥ ψ(xk) + 〈yk, z − xk〉 holds all z ∈ ℝd and k ∈ ℕ. By taking limit inferior to both sides of the above inequality, it follows that . By virtue of the lower semi-continuity of ψ, i.e., , and the fact of 〈yk, z − xk〉 → 〈y, z − x〉, we obtain that ψ(z) ≥ ψ(x) + 〈y, z − x〉, for all z ∈ ℝd. That is, y ∈ ∂ψ(x). □
With these preparations, we are ready to prove the convergence of the sequence {(uk, vk, xk) : k ∈ ℕ} generated by the iterative scheme (21).
Theorem 3.3. Let Q1 and Q2 be two positive definite symmetric matrices and let {(uk, vk, xk) : k ∈ ℕ} be the sequence generated by scheme (21). If 0 < γ ≤ β, then the sequence {(uk, vk, xk) : k ∈ ℕ} converges to a triple satisfying Equation (23).
PROOF. To show {(uk, vk, xk) : k ∈ ℕ} converges to a triple satisfying Equation (23), we first show {(uk, vk, xk) : k ∈ ℕ} is bounded and therefore has a convergent subsequence, then show that this convergent subsequence converges to a triple satisfying Equation (23) and finally show the entire sequence {(uk, vk, xk) : k ∈ ℕ} converges to this triple .
Let the symbols ρ, ρk, , P, r, rk, , t, tk, , and yk be the same as before. Equations (23) and (24) and the monotonicity of subdifferential yield
Therefore, when 0 < γ ≤ β, the values of yk are non-positive. Thus, from Equation (25) we know that the sequence is decreasing and convergent. This implies the boundedness of the sequence which further yield the boundedness of the sequence {(uk, vk, xk) : k ∈ ℕ}. Therefore, there exists a convergent subsequence such that for some vector
as i goes to infinity.
We shall show that satisfies Equation (23), that is, , , and . Summing Equation (25) for k from 1 to infinity, we conclude that
The convergence of three series in inequality Equation (29) yields that as k goes to infinity
which particularly indicate
as i goes to infinity. By Equations (28) and (30), we have that
and
Equations (28), (30) and (32) together with the definitions of rk and tk yield
Recall that and Equations (31) and (33). We obtain from Lemma 3.2 that and . Hence, the vector satisfies Equation (28).
Now, let us take . Then from Equation (28) we have that
The monotonicity and convergence of the sequence imply that
Thus, the sequence {(uk, vk, xk) : k ∈ ℕ} converges to satisfying Equation (23). This completes the proof of this theorem. □
Next, we will show that we can specify scheme (20) as a special case of scheme (21) and therefore the convergence of scheme (20) follows automatically. To this end, we consider the two schemes (20), (21) are mutually independent and functions or matrices in the two schemes are not related hereafter.
To cast scheme (20) as scheme (21), we let
in scheme (21). For such the choice of those quantities, we are able to rewrite scheme (21) as
from which one can notice that sequence {vk : k ∈ ℕ} is a constant vector sequence. Ignoring the trivial step involving vk+1, scheme (35) becomes scheme (20).
Lemma 3.4. Let Q be a positive definite symmetric matrix, let the pair satisfy Equation (9), and let {(wk, xk) : k ∈ ℕ} be the sequence generated by scheme (20). Set
Then
PROOF. This is an immediate result of Lemma 3.1 by specifying corresponding quantities as in Equation (34) and noticing that vk+1 = vk for such the choice of those quantities. □
With Lemma 3.4, we can prove our result on the convergence of the sequence {(wk, xk) : k ∈ ℕ} generated by scheme (20).
Theorem 3.5. Let Q be a positive definite symmetric matrix and let {(wk, xk) : k ∈ ℕ} be the sequence generated by scheme (20). If 0 < γ ≤ 2β then the sequence {(wk, xk) : k ∈ ℕ} converges to a pair satisfying Equation (9).
PROOF. It follows the proof of Theorem 3.3 by specifying corresponding quantities in scheme (21) as in (34) and using Lemma 3.4. □
We remark that authors in Zhang et al. [1] only shown convergent subsequence of {(wk, xk) : k ∈ ℕ} converges to a pair satisfying Equation (9). But as shown by Theorem 3.5, the entire sequence {(wk, xk) : k ∈ ℕ} converges to the same point, which strengthens the result in Zhang et al. [1].
4. Connections to Existing Algorithms
In this section, we point out the connections of our proposed algorithms to several well-known methods. Specifically, we would explore the connection of the proposed algorithms to Chambolle and Pock's Primal-Dual method, Augmented Lagrangian Method, Alternating Direction Method of Multipliers, and Generalized ADM.
4.1. Connection to Chambolle and Pock's Algorithm
First of all, let us review Chambolle and Pock's (CP) method [9] for solving the following optimization problem
where , , and A is a matrix of size m × n. We assume that model (37) has a minimizer. The CP method proposed in Chambolle and Pock [9] for model (37) can be written as
For any initial guess , the sequence {(xk, wk) : k ∈ ℕ} converges as long as 0 < στ < ||A||−2.
In particular, when we set g = 0, a direct computation shows that proxτg is the identity operator for any τ > 0. Set α = σ and β = 2τ. Accordingly, the general CP method in Equation (38) becomes
On the other hand, when we set g = 0, model (37) reduces to model (3). Our algorithm for model (3) is presented in scheme (14).
Therefore, by comparing the CP method and the scheme (14) for model (3), we can see that the CP method uses xk−1 while the scheme (14) uses xk in the computation of wk+1. Further, the step size of the CP method for updating xk+1 is fixed as while it can be any number in (0, 2β] for the scheme (14). Although, the relation 0 < αβ < 2||A||−2 is required for the CP method while the relation 0 < αβ < ||A||−2 is needed for the scheme (14), for a fixed α, we can choose the step size for the scheme (14) twice bigger than that for the CP method.
4.2. Connection to Augmented Lagrangian Methods
As we already know that the scheme (14) model (3) is derived from the scheme (20) with a proper chosen Q. The scheme (20) is used to solve the constrained dual optimization problem (7).
In the literature of nonlinear programming [16], augmented Lagrangian methods (ALMs) are often used to convert a constrained optimization problem to an unconstrained one by adding the objective function a penalty term associated with the constraints. For model (7), the augmented Lagrangian method is as follows:
We can see that the scheme (20) reduces to the ALM Equation (40) if we choose Q = 0 and γ = β in Equation (20). Even though we can assume that the proximity operator of f has a closed form, there is lack of an effective way to update wk+1 in Equation (40) when A is not the identity matrix. However, the vector wk+1 in the scheme (20) can be effectively updated once a proper Q is chosen. This essentially illustrates that Algorithm 1 is superior to the ALM from the numerical implementation point of view.
4.3. Connection to Alternating Direction Method of Multipliers
By specializing the dual formulation (7) of model (7) to model (1), we have that
The alternating direction method of multipliers (ADMM) for dual problem (41) reads as
We can see that the scheme (21) reduces to the above ADMM method if we set Q1 = 0, Q2 = 0, and γ = β in Equation (21). Similar to what we have observed for the ALM method, solving the two optimization problems in Equation (42) is still challenging in general when both A1 and A2 are not the identity matrix. However, the vectors uk+1 and vk+1 in the scheme (21) can be effectively updated once Q1 and Q2 are properly chosen. Hence our Algorithm 2 is superior to the ADMM from the numerical implementation point of view.
4.4. Connection to Generalized Alternating Direction Method
Finally, we comment that the generalized ADM proposed in Deng and Yin [3] can be applied for solving the optimization problem (41) and the resulting algorithm is exactly the same as Algorithm 2. However, the motivations behind [3] and our current paper are completely different. The generalized ADM in Deng and Yin [3] was developed based on the augmented Lagrangian function of the objective function of Equation (41) and the work in there focused on linear convergence rate of the corresponding algorithm. In our current work, we formulated the optimization problem (8) as a constrained optimization problem (8) and recognized the solution of Equation (8) as a solution of a fixed-point equation (see Proposition 2.2) from which Algorithm 2 was naturally derived.
5. Applications to Image Deblurring
In this section, we first identity two well-known image deblurring models, namely L2-TV and L1-TV, as special cases of the general model (1). We then give details on how Algorithms 1 and 2 are applied. In particular, we present the explicit expressions of the proximity operators of and . Since the total variation (TV) is involved in the both image deblurring models, we begin with presenting the discrete setting for total variation.
For convenience of exposition, we assume that an image considered in this paper has a size of . The image is treated as a vector in ℝn in such a way that the ij-th pixel of the image corresponds to the -th component of the vector in ℝn. The total variation of the image x can be expressed as the composite function of a convex function ψ : ℝ2n → ℝ and a 2n × n matrix B. To define the matrix B, we need a difference matrix D as follows:
The matrix D will be used to “differentiate” a row or a column of an image matrix. Through the matrix Kronecker product ⊗, we define the 2n × n matrix B by
where I is the identity matrix. The matrix B will be used to “differentiate” the entire image matrix. The norm of B is (see [17]).
We define ψ : ℝ2n → ℝ is at y ∈ ℝ2n as
Based on the definition of the 2n × n matrix B and the convex function ψ, the total variation of an image x can be denoted by ψ(Bx) for (isotropic) total variation, i.e.,
5.1. The L2-TV Image Deblurring Model
The L2-TV image deblurring model is usually used for the recovery of an unknown image x ∈ ℝn from an observable data b ∈ ℝn modeled by
where K is a blurring matrix of size n × n. The L2-TV image deblurring model has the form of
where μ is a regularization parameter.
Now, let us set
where K and b are from Equation (46), ψ is given by Equation (44), and B is defined by Equation (43). Then the L2-TV image deblurring mode (47) can be viewed as a special case of model (1). Therefore, both Algorithms 1 and 2 can be applied for the L2-TV model. Further, we give the explicit forms of the proximity operators and for any positive number α. Actually, using Moreau decomposition and the definition of the proximity operator, we have that for
For , we write . Then for i = 1, 2, …, n, we have that
5.2. The L1-TV Image Deblurring Model
The L1-TV image deblurring model is usually used for the recovery of an unknown image x ∈ ℝn from an impulsive noise corrupted observable data b ∈ ℝn modeled by
where K is a blurring matrix of size n × n, p is the noise level, and the index i runs from 1 to n. The L1-TV image deblurring model has the form of
where μ is again the regularization parameter.
Now, let us set
where K and b are from Equation (49), ψ is given by Equation (44), and B is defined by Equation (43). Then the L1-TV image deblurring mode Equation (50) can be viewed as a special case of model (1). Therefore, both Algorithms 1 and 2 can be applied for the L1-TV model. Further, the proximity operator has been given via Equation (48). We jus need to present the proximity operator . Actually, we have that for
where i = 1, 2, …, n.
In summary, for both the L2-TV and L1-TV image deblurring models, the associated proximity operators and have closed forms. As a consequence, the sequence {(uk, vk, xk) : k ∈ ℕ} generated by Algorithms 1 and 2 can be efficiently computed.
6. Numerical Experiments
In this section, numerical experiments for image deblurring are carried out to demonstrate the performance of our proposed Algorithms 1 and 2 for the 256 × 256 test images “Cameraman,” “Peppers,” “Goldhill,” and 512 × 512 test image “Lena.” The Chambolle-Pock (CP) algorithm and scheme (6) are compared to our algorithms for the L2-TV and L1-TV image deblurring models. In the following, we quote scheme (6) as ZBO algorithm. Each algorithm is carried out until the stopping criterion ||xk+1 − xk||2/||xk||2 ≤ Tol is satisfied, where Tol representing the tolerance, is chosen to be 10−6. The quality of the recovered images from each algorithm is evaluated by the peak-signal- to-noise ratio (PSNR), which is defined as , where x ∈ ℝn is the original image and represents the recovered image. The evolution curve of the function values with respect to iteration will be also adopted to evaluate the performance of algorithms.
In our simulations, blurring matrices K in models (46) and (49) are generated by a rotationally symmetric Gaussian lowpass filter of size “hsize” with standard deviation “sigma” from the MATLAB script fspecial('gaussian', hsize, sigma). Such matrix K is referred to as the (hsize, sigma)-GBM. We remark that the norm of K is always 1, i.e.,
The (15, 10)-GBM and (21, 10)-GBM are used to generate blurred images in our experiments. All experiments are performed in Matlab 7.11 on Dell Desktop Inspiron 620 with Intel Core i3 CPU @3.30G, 4GB RAM on Windows 7 Home Premium operating system.
6.1. Parameter Settings
Prior to applying Algorithms 1 and 2, and the CP method to the L2-TV model and the L1-TV model for image deblurring problems blurred by (hsize, sigma)-GBMs, the parameters arising from these algorithms need to be determined. Convergence analysis of the algorithms specifies the relation between these parameters. Therefore, once one parameter is fixed, the others can be described by this fixed one. To this end, we fix the value of the parameter β in each above algorithm and then figure out the values of the others.
Let K be a rotationally symmetric Gaussian lowpass filter generated blurring matrix in the L2-TV model and the L1-TV model and let B be the difference matrix defined by Equation (43). We know that ||K|| = 1 by Equation (51) and . To compute the pixel values under the operation of K and B near the boundary of images, we choose to use “symmetric” type for the boundary extension. Correspondingly, we can compute that
For Algorithm 1, we set the parameters α and γ as follows:
For Algorithm 2, we set the parameters α1, α2, and γ as follows:
For the CP method (see Equation 39), we set
With the choices of the parameters given for the algorithms, the convergence of Algorithm 1, Algorithm 2, and the CP method are guaranteed by Theorem 3.5, Theorem 3.3, and a result from Chambolle and Pock [9], respectively. The parameter β in each algorithm is chosen in a way that it would produce better recovered images in terms of PSNR value with the given stopping criterion.
An additional set of parameters for Algorithm 2 will be used as well. They are
By comparing these parameters with those in Equation (53), the parameters α1 and α2 are kept unchanged, but the parameter γ in Equation (55) is twice bigger than that in Equation (53). By Theorem 3.3, although the convergence analysis for Algorithm 2 with the parameters given by Equation (55) is missing currently, our numerical experiments presented in the rest of the paper indicate that Algorithm 2 converges and usually produces better recovered images than that with the parameters given by Equation (53) in terms of the CPU times consumed.
6.2. Numerical Results for the L2-TV Image Deblurring
In problems of image deblurring with the L2-TV model, a noisy image is obtained by blurring an ideal image with a (hsize, sigma)-GBM followed by adding white Gaussian noise. Two blurring matrices, namely (21, 10)-GBM and (15, 10)-GBM, are used in our experiments.
For the blurring matrix (21, 10)-GBM, the white noise with mean zero and the standard deviation 1 is added to blurred images. We set the regularization parameter μ = 0.02 in the L2-TV model (47). We choose β = 50 for Algorithm 2, β = 25 for Algorithm 1, β = 50 for the CP method, and β = 0.005 for ZBO method. With these settings, numerical results for four test images “Cameraman,” “Lena,” “Peppers,” and “Goldhill” are reported in Table 1 in terms of numbers of iterations, the CPU times, and the PSNR values. The evolutions of function values for the images of “Peppers” and “Lena” with the L2-TV model are shown in Figure 1. The corresponding curves for the images of “Peppers,” and “Goldhill” are similar to that of “Peppers,” therefore are omitted here. As shown in the Table, Algorithm 2 performs best in terms of computational cost (total iterations and CPU time) and PSNR. Also, as shown in Figure 1 the sequence of function values generated by Algorithm 2 approaches the minimum value fastest, followed by sequences from Algorithm 1 and then by that from CP and ZBO. For the two versions of Algorithm 2, the one with Equation (55) performs slightly better in terms of computational cost and PSNR. The performance of CP and ZBO methods is quite similar in terms of iterations, CPU time, PSNR and evolution of function values. Indeed, the iterations and PSNR in Table 1 are consistent for CP and ZBO methods and the evolution curves of function values for CP and ZBO methods overlap together. We comment that comparable PSNRs and function value can be achieved in Algorithm 1, CP method and ZBO method as in Algorithm 2 if more iteration or computational time is allowed.

Table 1. Numerical results for the L2-TV model for images blurred by the (21, 10)-GBM.
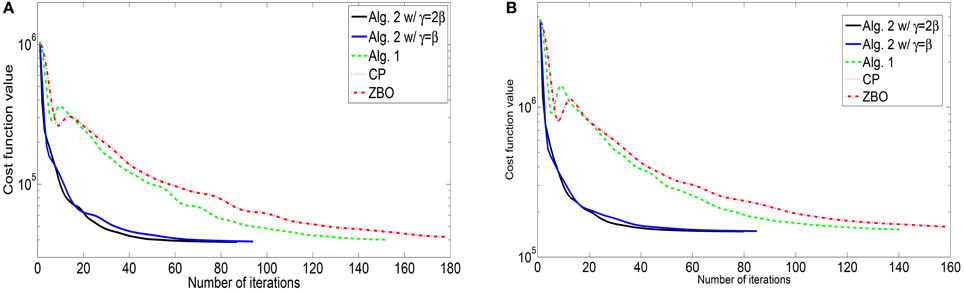
Figure 1. Evolutions of function values of the L2-TV model for images of (A) “Cameraman” and (B) “Lena”.
For the blurring matrix (15, 10)-GBM, the white noise with mean zero and the standard deviation 5 is added to blurred images. We set the regularization parameter μ = 0.2 in the L2-TV model (47). We choose β = 10 for Algorithm 2, β = 5 for Algorithm 1, β = 10 for the CP method, and β = 0.025 for ZBO method. With these settings, numerical results for four test images are reported in Table 2 in terms of numbers of iterations, the CPU times, and the PSNR values. For each image, the PSNR values from each algorithm are comparable. But Algorithm 2 performs better than Algorithm 1, CP and ZBO in terms of computational cost. The evolutions of function values for the images of “Peppers” and “Lena” are shown in Figure 2. The sequence of function values from Algorithm 2 approaches faster to the minimum function value than that from CP and ZBO method. The performance of the two versions of Algorithm 2 is similar. Like in the setting (21, 10)-GBM, the performance of CP and ZBO methods is similar.

Table 2. Numerical results for the L2-TV model for images blurred by the (15, 10)-GBM.
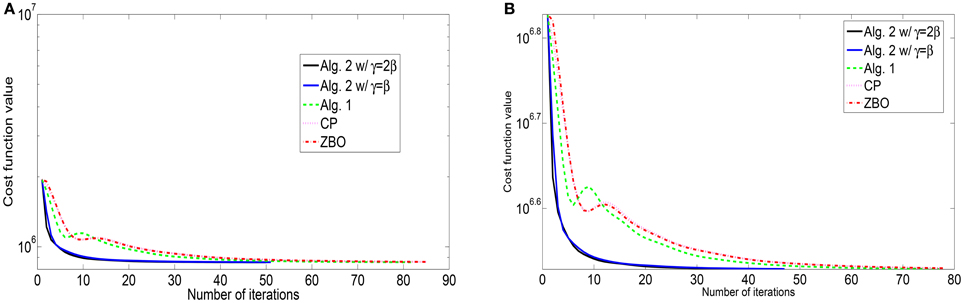
Figure 2. Evolutions of function values of the L2-TV model for images of (A) “Cameraman” and (B) “Lena”.
6.3. Numerical Results for The L1-TV Image Deblurring
In problems of image deblurring with the L1-TV model, a noisy image is obtained by blurring an ideal image with a (hsize, sigma)-GBM followed by adding impulsive noise. Two blurring matrices, namely (21, 10)-GBM and (15, 10)-GBM, are used again in our experiments.
For the blurring matrix (21, 10)-GBM, the impulsive noise with noise level p = 0.3 is added to blurred images. We set the regularization parameter μ = 0.01 in the L1-TV model (50). we set β = 100 for Algorithm 2, β = 50 for Algorithm 1, β = 100 for the CP method, and β = 0.0025 for ZBO method. With these settings, numerical results for four test images “Cameraman,” “Lena,” “Peppers,” and “Goldhill” are reported in Table 3 in terms of numbers of iterations, the CPU times, and the PSNR values. Algorithm 2 yields higher PSNR value but consumes less CPU time than Algorithm 1, CP and ZBO methods. The evolution curves of function values with respect to iteration for the images of “Cameraman” and “Lena” are shown in Figure 3. It can be noticed that sequence of function values generated by Algorithm 2 approaches the minimum value fastest. Regarding the two version of Algorithm 2, the one with setting Equation (55) performs better. We point out that the evolution curves for CP and ZBO overlap with each other. Further, visual quality of the deblurred images of “Cameraman” and “Lena” is shown in Figure 4 for each algorithm. The visual improvement by Algorithm 2 over CP and the ZBO can be seen by the deblurred images.

Table 3. Numerical results for the L1-TV model for images blurred by the (21, 10)-GBM.
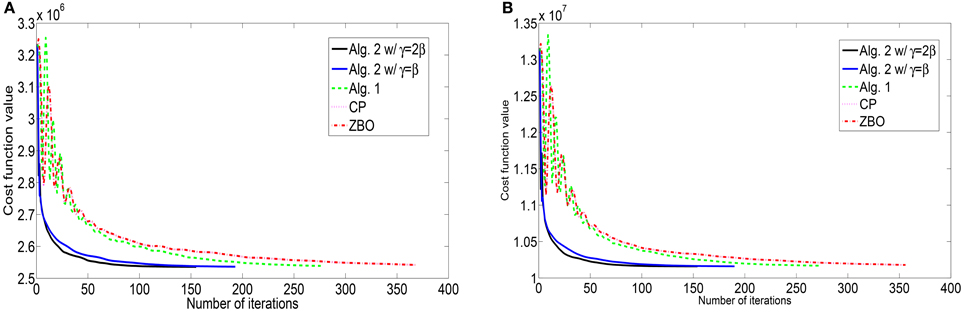
Figure 3. Evolutions of function values of the L1-TV model for images of (A) “Cameraman” and (B) “Lena”.
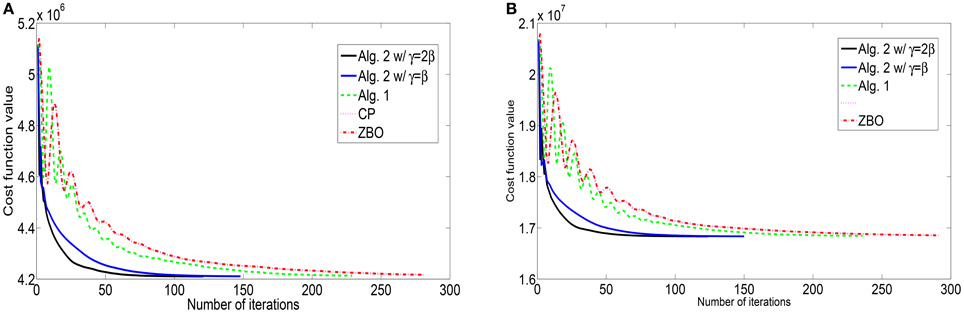
Figure 4. Evolutions of function values of the L1-TV model for images of (A) “Cameraman” and (B) “Lena”.
For the blurring matrix (15, 10)-GBM, the impulsive noise with noise level p = 0.5 is added to blurred images. We set the regularization parameter μ = 0.02 in the L1-TV model (50). we set β = 50 for Algorithm 2, β = 25 for Algorithm 1, β = 50 for the CP method, and β = 0.005 for ZBO method. With these settings, numerical results for four test images “Cameraman,” “Lena,” “Peppers,” and “Goldhill” are reported in Table 4 in terms of numbers of iterations, the CPU times, and the PSNR values. The evolution curves of function values with respect to iteration for the images of “Cameraman” and “Lena” are shown in Figure 5. Visual quality of the deblurred “Cameraman” and “Lena” images is shown in Figure 6 for each algorithm. It is the same as above that Algorithm 2 performs the best.

Table 4. Numerical results for the L1-TV model for images blurred by the (15, 10)-GBM.

Figure 5. Recovered images of “Cameraman” and “Lena” (from top row to bottom row) with the L1-TV model for images blurred by the (21, 10)-GBM and corrupted by impulsive noise of level p = 0.3. Row 1: the CP; Row 2: ZBO; Row 3: Algorithm 1; Row 4: Algorithm 2 with Equation (53); Row 5: Algorithm 2 with Equation (55).

Figure 6. Recovered images of “Cameraman” and “Lena” (from top row to bottom row) with the L1-TV model for images blurred by the (15, 10)-GBM and corrupted by impulsive noise of level p = 0.5. Row 1: the CP; Row 2: the ZBO; Row 3: Algorithm 1; Row 4: Algorithm 2 with Equation (53); Row 5: Algorithm 2 with Equation (55).
7. Conclusion
We propose algorithms to solve a general problem that includes L2-TV and L1-TV image deblurring problems. Algorithm with Block Gauss-Seidel acceleration is also derived for the two term composite minimization Equation (1). The key feature of the proposed algorithms is their ability to yield closed form in each step of iterations. Convergence analysis of the proposed algorithms can be guaranteed under appropriate conditions. Numerical experiments show that the proposed algorithms has computational advantage over CP method and ZBO algorithm.
Author Contributions
All authors listed, have made substantial, direct and intellectual contribution to the work, and approved it for publication.
Funding
The research was supported by the US National Science Foundation under grant DMS-1522332.
Disclaimer
Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of AFRL.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1. Zhang X, Burger M, Osher S. A unified primal-dual algorithm framework based on Bregman iteration. J Sci Comput. (2011) 46:20–46. doi: 10.1007/s10915-010-9408-8
2. Chen P, Huang J, Zhang X. A primal-dual fixed point algorithm for convex separable minimization with applications to image restoration. Inverse Problems (2013) 29:025011. doi: 10.1088/0266-5611/29/2/025011
3. Deng W, Yin W. On the global and linear convergence of the generalized alternating direction method of multipliers. J Sci Comput. (2016) 66:889–916. doi: 10.1007/s10915-015-0048-x
4. Gabay D, Mercier B. A dual algorithm for the solution of nonlinear variational problems via finite-element approximations. Comput Math Appl. (1976) 2:17–40. doi: 10.1016/0898-1221(76)90003-1
5. Glonwinski R, Tallec PL. Augumented Lagrangians and Operator Splitting Methods in Nonlinear Mechanics. Philadephia, PA: SIAM (1989). doi: 10.1137/1.9781611970838
6. Hestenes MR. Multiplier and gradient methods. J Optim Theory Appl. (1969) 4:303–20. doi: 10.1007/BF00927673
7. Powell MJD. A method for nonlinear constraints in minimization problems. In: Fletcher R, editor, Optimization. New York, NY: Academic Press (1969). p. 283–98.
8. Rockafeller RT. The multiplier method of Hestenes and Powell applied to convex programming. J Optim Theory Appl. (1973) 12:555–62. doi: 10.1007/BF00934777
9. Chambolle A, Pock T. A first-order primal-dual algorithm for convex problems with applications to imaging. J Mat Imaging Vision (2011) 40:120–45. doi: 10.1007/s10851-010-0251-1
11. Arrow KJ, Harwicz L, Uzawa H. Studies in Linear and Non-linear Programming. Stanford Mathematical Studies in the Social Science, II. Stanford, CA: Stanford University Press (1958).
12. Esser E, Zhang X, Chan TF. A general framework for a class of first order primal-dual algorithms for convex optimization in imaging science. SIAM J Imaging Sci. (2010) 3:1015–46. doi: 10.1137/09076934X
13. Moreau JJ. Fonctions convexes duales et points proximaux dans un espace hilbertien. CR Acad Sci Paris Sér A Math. (1962) 255:1897–2899.
14. Moreau JJ. Proximité et dualité dans un espace hilbertien. Bull Soc Math France (1965) 93:273–99.
Keywords: proximity operator, deblurring, primal-dual algorithm, ADMM, Gauss-Seidel method
Citation: Chen F, Shen L, Suter BW and Xu Y (2016) Minimizing Compositions of Functions Using Proximity Algorithms with Application in Image Deblurring. Front. Appl. Math. Stat. 2:12. doi: 10.3389/fams.2016.00012
Received: 03 June 2016; Accepted: 22 August 2016;
Published: 22 September 2016.
Edited by:
Yuan Yao, Peking University, ChinaReviewed by:
Alfio Borzìe, University of Würzburg, GermanyXiaoqun Zhang, Shanghai Jiao Tong University, China
Ming Yan, Michigan State University, USA
Xueying Zeng, Ocean University of China, China
Copyright © 2016 Chen, Shen, Suter and Xu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Lixin Shen, bHNoZW4wM0BzeXIuZWR1