 Alexander Jung
Alexander Jung- Department of Computer Science, Aalto University, Espoo, Finland
Interpreting gradient methods as fixed-point iterations, we provide a detailed analysis of those methods for minimizing convex objective functions. Due to their conceptual and algorithmic simplicity, gradient methods are widely used in machine learning for massive data sets (big data). In particular, stochastic gradient methods are considered the de-facto standard for training deep neural networks. Studying gradient methods within the realm of fixed-point theory provides us with powerful tools to analyze their convergence properties. In particular, gradient methods using inexact or noisy gradients, such as stochastic gradient descent, can be studied conveniently using well-known results on inexact fixed-point iterations. Moreover, as we demonstrate in this paper, the fixed-point approach allows an elegant derivation of accelerations for basic gradient methods. In particular, we will show how gradient descent can be accelerated by a fixed-point preserving transformation of an operator associated with the objective function.
1. Introduction
One of the main recent trends within machine learning and data analytics using massive data sets is to leverage the inferential strength of the vast amounts of data by using relatively simple, but fast, optimization methods as algorithmic primitives [1]. Many of these optimization methods are modifications of the basic gradient descent (GD) method. Indeed, computationally more heavy approaches, such as interior point methods, are often infeasible for a given limited computational budget [2].
Moreover, the rise of deep learning has brought a significant boost for the interest in gradient methods. Indeed, a major insight within the theory of deep learning is that for typical high-dimensional models, e.g., those represented by deep neural networks, most of the local minima of the cost function (e.g., the empirical loss or training error) are reasonably close (in terms of objective value) to the global optimum [3]. These local minima can be found efficiently by gradient methods such as stochastic gradient descent (SGD), which is considered the de-facto standard algorithmic primitive for training deep neural networks [3].
This paper elaborates on the interpretation of some basic gradient methods such as GD and its variants as fixed-point iterations. These fixed-point iterations are obtained for operators associated with the convex objective function. Emphasizing the connection to fixed-point theory unleashes some powerful tools, e.g., on the acceleration of fixed-point iterations [4] or inexact fixed-point iterations [5, 6], for the analysis and construction of convex optimization methods.
In particular, we detail how the convergence of the basic GD iterations can be understood from the contraction properties of a specific operator which is associated naturally with a differentiable objective function. Moreover, we work out in some detail how the basic GD method can be accelerated by modifying the operator underlying GD in a way that preserves its fixed-points but decreases the contraction factor which implies faster convergence by the contraction mapping theorem.
1.1. Outline
We discuss the basic problem of minimizing convex functions in Section (2). We then derive GD, which is a particular first order method, as a fixed-point iteration in Section (3). In Section (4), we introduce one of the most widely used computational models for convex optimization methods, i.e., the model of first order methods. In order to assess the efficiency of GD, which is a particular instance of a first order method, we present in Section (5) a lower bound on the number of iterations required by any first order method to reach a given sub-optimality. Using the insight provided from the fixed-point interpretation we show how to obtain an accelerated variant of GD in Section (6), which turns out to be optimal in terms of convergence rate.
1.2. Notation
The set of natural numbers is denoted ℕ := {1, 2, …}. Given a vector , we denote its lth entry by xl. The (hermitian) transpose and trace of a square matrix A ∈ ℂn×n are denoted (AH) AT and tr{A}, respectively. The Euclidian norm of a vector x is denoted . The spectral norm of a matrix M is denoted . The spectral decomposition of a positive semidefinite (psd) matrix Q ∈ ℂn×n is Q = UΛUH with matrix U = (u(1), …, u(n)) whose columns are the orthonormal eigenvectors u(i) ∈ ℂn of Q and the diagonal matrix Λ containing the eigenvalues λ1(Q) ≥ … ≥ λn(Q) ≥ 0. For a square matrix M, we denote its spectral radius as ρ(M) := max{|λ| : λ is an eigenvalue of M}.
2. Convex Functions
A function f(·):ℝn → ℝ is convex if
holds for any x, y ∈ ℝn and α ∈ [0, 1] [2]. For a differentiable function f(·) with gradient ∇f(x), a necessary and sufficient condition for convexity is [7, p. 70]
which has to hold for any x, y ∈ ℝn.
Our main object of interest in this paper is the optimization problem
Given a convex function f(x), we aim at finding a point x0 with lowest function value f(x0), i.e., .
In order to motivate our interest in optimization problems like Equation (1), consider a machine learning problem based on training data consisting of N data points z(i) = (d(i), y(i)) with feature vector d(i) ∈ ℝn (which might represent the RGB pixel values of a webcam snapshot) and output or label y(i) ∈ ℝ (which might represent the local temperature during the snapshot). We wish to predict the label y(i) by a linear combination of the features, i.e.,
The choice for the weight vector x ∈ ℝn is typically based on balancing the empirical risk incurred by the predictor (2), i.e.,
with some regularization term, e.g., measured by the squared norm ‖x‖2. Thus, the learning problem amounts to solving the optimization problem
The learning problem (3) is precisely of the form (1) with the convex objective function
By choosing a large value for the regularization parameter λ, we de-emphasize the relevance of the training error and thus avoid overfitting. However, choosing λ too large induces a bias if the true underlying weight vector has a large norm [3, 8]. A principled approach to find a suitable value of λ is cross validation [3, 8].
2.1. Differentiable Convex Functions
Any differentiable function f(·) is accompanied by its gradient operator
While the gradient operator ∇f is defined for any (even non-convex) differentiable function, the gradient operator of a convex function satisfies a strong structural property, i.e., it is a monotone operator [9].
2.2. Smooth and Strongly Convex Functions
If all second order partial derivatives of the function f(·) exist and are continuous, then f(·) is convex if and only if [7, p.71]
We will focus on a particular class of twice differentiable convex functions, i.e., those with Hessian ∇2f(x) satisfying
with some known constants U ≥ L > 0.
The set of convex functions f(·):ℝn → ℝ satisfying (6) will be denoted . As it turns out, the difficulty of finding the minimum of some function using gradient methods is essentially governed by the
Thus, regarding the difficulty of optimizing the functions , the absolute values of the bounds L and U in (6) are not crucial, only their ratio κ = U/L is.
One particular sub-class of functions , which is of paramount importance for the analysis of gradient methods, are quadratic functions of the form
with some vector q ∈ ℝn and a psd matrix Q ∈ ℝn×n having eigenvalues λ(Q) ∈ [L, U]. As can be verified easily, the gradient and Hessian of a quadratic function of the form (8) are obtained as ∇f(x) = Qx+q and ∇2f(x) = Q, respectively.
It turns out that most of the results (see below) on gradient methods for minimizing quadratic functions of the form (8), with some matrix Q having eigenvalues λ(Q) ∈ [L, U], apply (with minor modifications) also when expanding their scope from quadratic functions to the larger set . This should not come as a surprise, since any function can be approximated locally around a point x0 by a quadratic function which is obtained by a truncated Taylor series [10]. In particular, we have Rudin [10, Theorem 5.15]
where u = ηx + (1−η)x0 with some η ∈ [0, 1].
The crucial difference between the quadratic function (8) and a general function is that the matrix ∇2f(z) appearing in the quadratic form in (9) typically varies with the point x. In particular, we can rewrite (9) as
with . The last summand in (10) quantifies the approximation error
obtained when approximating a function with the quadratic obtained from (8) with the choices
According to (6), which implies , we can bound the approximation error (11) as
Thus, we can ensure a arbitrarily small approximation error ε by considering f(·) only over a neighborhood with sufficiently small radius r > 0.
Let us now verify that learning a (regularized) linear regression model (cf. 3) amounts to minimizing a convex quadratic function of the form (8). Indeed, using some elementary linear algebraic manipulations, we can rewrite the objective function in (4) as a quadratic of the form (8) using the particular choices Q = QLR and q = qLR with
The eigenvalues of the matrix QLR obey [11]
with the data matrix D := (d(1), …, d(N)) ∈ ℝn×N. Hence, learning a regularized linear regression model via (3) amounts to minimizing a convex quadratic function with L = λ and , where λ denotes the regularization parameter used in (3).
3. Gradient Descent
Let us now show how one of the most basic methods for solving the problem (1), i.e., the GD method, can be obtained naturally as fixed-point iterations involving the gradient operator ∇f (cf. 5).
Our point of departure is the necessary and sufficient condition [7]
for a vector to be optimal for the problem (1) with a convex differentiable objective function .
Lemma 1. We have ∇f(x) = 0 if and only if the vector x ∈ ℝn is a fixed point of the operator
for an arbitrary but fixed non-zero α ∈ ℝ \ {0}. Thus,
Proof. Consider a vector x such that ∇f(x) = 0. Then,
Conversely, let x be a fixed point of , i.e.,
Then,
□
According to Lemma (1), the solution x0 of the optimization problem (1) is obtained as the fixed point of the operator (cf. 14) with some non-zero α. As we will see shortly, the freedom in choosing different values for α can be exploited in order to compute the fixed points of more efficiently.
A straightforward approach to finding the fixed-points of an operator is via the fixed-point iteration
By tailoring a fundamental result of analysis (cf. [10], Theorem 9.23], we can characterize the convergence of the sequence x(k) obtained from (16).
Lemma 2. Assume that for some q∈[0, 1), we have
for any x, y ∈ ℝn. Then, the operator has a unique fixed point x0 and the iterates x(k) (cf. 16) satisfy
Proof. Let us first verify that the operator cannot have two different fixed points. Indeed, assume there would be two different fixed points x, y such that
This would imply, in turn,
However, since q < 1, this inequality can only be satisfied if ‖x − y‖ = 0, i.e., we must have x = y. Thus, we have shown that no two different fixed points can exist. The existence of one unique fixed point x0 follows from Rudin [10, Theorem 9.23].
The estimate (18) can be obtained by induction and noting
Here, step (a) is valid since x0 is a fixed point of , i.e., .□
In order to apply Lemma (2) to (16), we have to ensure that the operator is a contraction, i.e., it satisfies (17) with some contraction coefficient q ∈ [0, 1). For the operator (cf. 14) associated with the function this can be verified by standard results from vector analysis.
Lemma 3. Consider the operator with some convex function . Then,
with contraction factor
Proof. First,
using z = ηx + (1 − η)y with some η ∈ [0, 1]. Here, we used in step (a) the mean value theorem of vector calculus [10, Theorem 5.10].
Combining (21) with the submultiplicativity of Euclidean and spectral norm [11, p. 55] yields
The matrix M(α): = I−α∇2f(z) is symmetric (M(α) = (M(α))T) with real-valued eigenvalues [11]
Since also
we obtain from (22)
□
It will be handy to write out the straightforward combination of Lemma (2) and Lemma (3).
Lemma 4. Consider a convex function with the unique minimizer x0, i.e., . We then construct the operator with a step size α such that
Then, starting from an arbitrary initial guess x(0), the iterates x(k) (cf. 16) satisfy
According to Lemma (4), and also illustrated in Figure 1, starting from an arbitrary initial guess x(0), the sequence x(k) generated by the fixed-point iteration (16) is guaranteed to converge to the unique solution x0 of (1), i.e., . What is more, this convergence is quite fast, since the error decays at least exponentially according to (25). Loosely speaking, this exponential decrease implies that the number of additional iterations required to have on more correct digit in x(k) is constant.
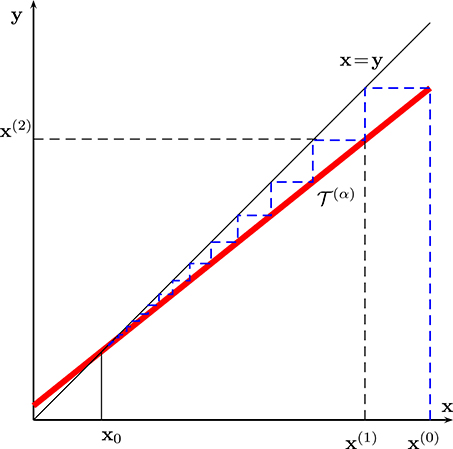
Figure 1. Fixed-point iterations for a contractive mapping with the unique fixed point x0.
Let us now work out the iterations (16) more explicitly by inserting the expression (14) for the operator . We then obtain the following equivalent representation of (16):
This iteration is nothing but plain vanilla GD using a fixed step size α [3].
Since the GD iteration (26) is precisely the fixed-point iteration (16), we can use Lemma (4) to characterize the convergence (rate) of GD. In particular, convergence of GD is ensured by choosing the step size of GD (26) such that q(α) = max{|1−Uα|, |1−Lα|} < 1. Moreover, in order to make the convergence as fast as possible we need to chose the step size α = α* which makes the contraction factor q(α) (cf. 20) as small as possible.
In Figure 2, we illustrate how the quantifies |1 − αL| and |1 − αU| evolve as the step size α (cf. 26) is varied. From Figure 2 we can easily read off the optimal choice
yielding the smallest possible contraction factor
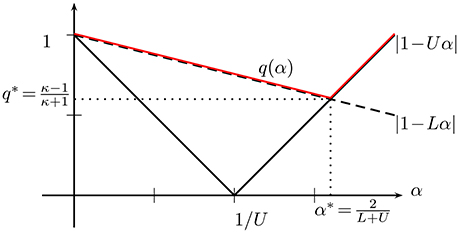
Figure 2. Dependence of contraction factor q(α) = max{|1−αL|, |1−αU|} on step size α.
We have arrived at the following characterization of GD for minimizing convex functions .
Theorem 5. Consider the optimization problem (1) with objective function , where the parameters L and U are fixed and known. Starting from an arbitrarily chosen initial guess x(0), we construct a sequence by GD (26) using the optimal step size (27). Then,
In what follows, we will use the shorthand for the gradient operator (cf. 14) obtained for the optimal step size α = α* (cf. 27).
4. First Order Methods
Without a computational model taking into account a finite amount of resources, the study of the computational complexity inherent to (1) becomes meaningless. Consider having unlimited computational resources at our disposal. Then, we could build an “optimization device” which maps each function to its unique minimum x0. Obviously, this approach is infeasible since we cannot perfectly represent such a mapping, let alone its domain , using a physical hardware which allows us only to handle finite sets instead of continuous spaces like .
Let us further illustrate the usefulness of using a computational model in the context of machine learning from massive data sets (big data). In particular, as we have seen in the previous section, the regularized linear regression model (3) amounts to minimizing a convex quadratic function (8) with the particular choices (12). Even for this most simple machine learning model, it is typically infeasible to have access to a complete description of the objective function (8).
Indeed, in order to fully specify the quadratic function in (8), we need to fully specify the matrix Q ∈ ℝn×n and the vector q ∈ ℝn. For the (regularized) linear regression model (3) this would require to compute QLR (cf. 12) from the training data . Computing the matrix QLR in a naive way, i.e., without exploiting any additional structure, amounts to a number of arithmetic operations on the order of N · n2. This might be prohibitive in a typical big data application with N and n being on the order of billions and using distributed storage of the training data [12].
There has emerged a widely accepted computational model for convex optimization which abstracts away the details of the computational (hard- and software) infrastructure. Within this computational model, an optimization method for solving (1) is not provided with a complete description of the objective function, but rather it can access the objective function only via an “oracle” [2, 13].
We might think of an oracle model as an application programming interface (API), which specifies the format of queries which can be issued by a convex optimization method executed on an application layer (cf. Figure 3). There are different types of oracle models but one of the most popular type (in particular for big data applications) is a first order oracle [13]. Given a query point x ∈ ℝn, a first order oracle returns the gradient ∇f(x) of the objective function at this particular point.
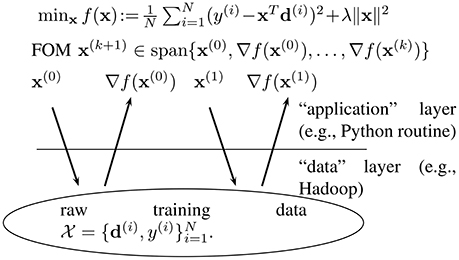
Figure 3. Programming model underlying a FOM.
A first order method (FOM) aims at solving (1) by sequentially querying a first order oracle, at the current iterate x(k), to obtain the gradient ∇f(x(k)) (cf. Figure 3). Using the current and past information obtained from the oracle, a FOM then constructs the new iterate x(k + 1) such that eventually . For the sake of simplicity and without essential loss in generality, we will only consider FOMs whose iterates x(k) satisfy [13]
5. Lower Bounds on Number of Iterations
According to Section (3), solving (1) can be accomplished by the simple GD iterations (26). The particular choice α* (27) for the step size α in (26) ensures the convergence rate with the condition number κ = U/L of the function class . While this convergence is quite fast, i.e., the error decays exponentially with iteration number k, we would, of course, like to know how efficient this method is in general.
As detailed in Section (4), in order to study the computational complexity and efficiency of convex optimization methods, we have to define a computational model such as those underlying FOMs (cf. Figure 3). The next result provides a fundamental lower bound on the convergence rate of any FOM (cf. 29) for solving (1).
Theorem 6. Consider a particular FOM, which for a given convex function generates iterates x(k) satisfying (29). For fixed L, U there is a sequence of functions (indexed by dimension n) such that
with a sequence δ(n) such that .
Proof. see Section (8.1).□
There is a considerable gap between the upper bound (28) on the error achieved by GD after k iterations and the lower bound (30) which applies to any FOM which is run for the same number iterations. In order to illustrate this gap, we have plotted in Figure 4 the upper and lower bound for the (quite moderate) condition number κ = 100.
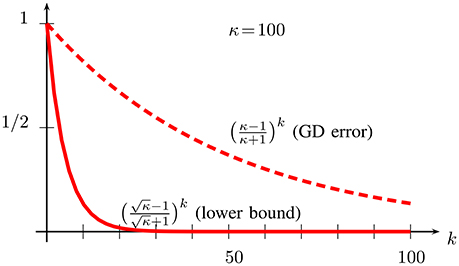
Figure 4. Upper bound (28) on convergence rate of GD and lower bound (30) on convergence rate for any FOM minimizing functions with condition number κ = U/L = 100.
Thus, there might exist a FOM which converges faster than the GD method (28) and comes more close to the lower bound (30). Indeed, in the next section, we will detail how to obtain an accelerated FOM by applying a fixed point preserving transformation to the operator (cf. 16), which is underlying the GD method (26). This accelerated gradient method is known as the heavy balls (HB) method [14] and effectively achieves the lower bound (30), i.e., the HB method is already optimal among all FOM's for solving (1) with an objective function .
6. Accelerating Gradient Descent
Let us now show how to modify the basic GD method (26) in order to obtain an accelerated FOM, whose convergence rate essentially matches the lower bound (30) for the function class with condition number κ = U/L>1 (cf. 7) and is therefore optimal among all FOMs.
Our derivation of this accelerated gradient method, which is inspired by the techniques used in Ghadimi et al. [15], starts from an equivalent formulation of GD as the fixed-point iteration
with the operator
As can be verified easily, the fixed-point iteration (31) starting from an arbitrary initial guess is related to the GD iterate x(k) (cf. 26), using initial guess z(0), as
for all iterations k ≥ 1.
By the equivalence (33), Theorem (5) implies that for any initial guess the iterations (31) converge to the fixed point
with x0 being the unique minimizer of . Moreover, the convergence rate of the fixed-point iterations (31) is precisely the same as those of the GD method, i.e., governed by the decay of , which is obtained for the optimal step size α = α* (cf. 27).
We will now modify the operator in (32) to obtain a new operator which has the same fixed points (34) but improved contraction behavior, i.e., the fixed point iteration
will converge faster than those obtained from in (31) (cf. Figure 5). In particular, this improved operator is defined as
with
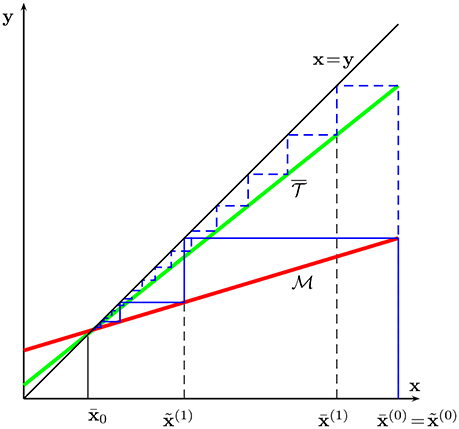
Figure 5. Schematic illustration of the fixed-point iteration using operator (32) (equivalent to GD) and for the modified operator (36) (yielding HB method).
As can be verified easily, the fixed point of is also a fixed point of .
Before we analyze the convergence rate of the fixed-point iteration (35), let us work out explicitly the FOM which is represented by the fixed-point iteration (35). To this end, we partition the kth iterate, for k ≥ 1, as
Inserting (38) into (35), we have for k ≥ 1
with the convention . The iteration (39) defines the HB method [14] for solving the optimization problem (1). As can be verified easily, like the GD method, the HB method is a FOM. However, contrary to the GD iteration (26), the HB iteration (39) also involves the penultimate iterate for determining the new iterate .
We will now characterize the converge rate of the HB method (39) via its fixed-point equivalent (35). To this end, we restrict ourselves to the subclass of given by quadratic functions of the form (8).
Theorem 7. Consider the optimization problem (1) with objective function which is a quadratic (26). Starting from an arbitrarily chosen initial guess and , we construct a sequence via iterating (27). Then,
with
Proof. see Section (8.2).□
The upper bound (40) differs from the lower bound (30) by the factor k. However, the discrepancy is rather decent as this linear factor in (40) grows much slower than the exponential in (40) decays. In Figure 6, we depict the upper bound (40) on the error of the HB iterations (39) along with the upper bound (28) on the error of the GD iterations (26) and the lower bound (30) on the error of any FOM after k iterations.
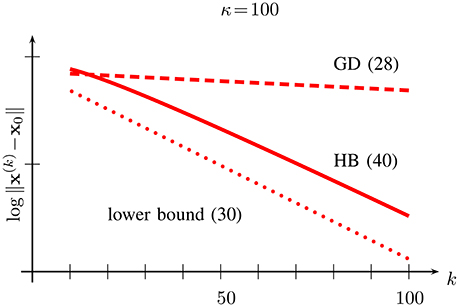
Figure 6. Dependence on iteration number k of the upper bound (40) on error of HB (solid), upper bound (28) for error of GD (dashed) and lower bound (30) (dotted) for FOMs for the function class with condition number κ = U/L = 100.
We highlight that, strictly speaking, the bound (40) only applies to a subclass of smooth strongly convex functions , i.e., it applies only to quadratic functions of the form (8). However, as discussed in Section (2), given a particular point x, we can approximate an arbitrary function with a quadratic function of the form (8). The approximation error ε(x) (cf. (11)) will be small for all points x sufficiently close to x0. Making this reasoning more precise and using well-known results on fixed-point iterations with inexact updates [6], one can verify that the bound (40) essentially applies to any function .
7. Conclusions
We have presented a fixed-point theory of some basic gradient methods for minimizing convex functions. The approach via fixed-point theory allows for a rather elegant analysis of the convergence properties of these gradient methods. In particular, their convergence rate is obtained as the contraction factor for an operator associated with the objective function.
The fixed-point approach is also appealing since it leads rather naturally to the acceleration of gradient methods via fixed-point preserving transformations of the underlying operator. We plan to further develop the fixed-point theory of gradient methods in order to accommodate stochastic variants of GD such as SGD. Furthermore, we can bring the popular class of proximal methods into the picture by replacing the gradient operator underlying GD with the proximal operator.
However, by contrast to FOMs (such as the GD method), proximal methods use a different oracle model (cf. Figure 3). In particular, proximal methods require an oracle which can evaluate the proximal mapping efficiently which is typically more expensive than gradient evaluations. Nonetheless, the popularity of proximal methods is due to the fact that for objective functions arising in many important machine learning applications, the proximal mapping can be evaluated efficiently.
8. Proofs of Main Results
In this section we present the (somewhat lengthy) proofs for the main results stated in Sections (5) and (6).
8.1. Proof of Theorem (6)
Without loss of generality we consider FOM which use the initial guess x(0) = 0. Let us now construct a function which is particularly difficult to optimize by a FOM (cf. 29) such as the GD method (26). In particular, this function is the quadratic
with vector
and matrix
The matrix is defined row-wise by successive circular shifts of its first row
Note that the matrix P in (43) is a circulant matrix [16] with orthonormal eigenvectors given element-wise as
The eigenvalues λl(P) of the circulant matrix P are obtained as the discrete Fourier transform (DFT) coefficients of its first row [16]
i.e.,
Thus, λl(P) ∈ [L, U] and, in turn, (cf. 6).
Consider the sequence x(k) generated by some FOM, i.e., which satisfies (29), for the particular objective function fn(x) (cf. 41) using initial guess x0 = 0. It can be verified easily that the kth iterate x(k) has only zero entries starting from index k + 1, i.e.,
This implies
The main part of the proof is then to show that the minimizer x0 for the particular function fn(·) cannot decay too fast, i.e., we will derive a lower bound on |x0,k+1|.
Let us denote the DFT coefficients of the finite length discrete time signal represented by the vector as
Using the optimality condition (13), the minimizer for (41) is
Inserting the spectral decomposition [16, Theorem 3.1] of the psd matrix P into (50),
We will also need a lower bound on the norm ‖x0‖ of the minimizer of fn(·). This bound can be obtained from (50) and λl(P) ∈ [L, U], i.e., ,
The last expression in (51) is a Riemann sum for the integral . Indeed, by basic calculus [10, Theorem 6.8]
where the error δ(n) becomes arbitrarily small for sufficiently large n, i.e., .
According to Lemma (9),
which, by inserting into (53), yields
Putting together the pieces,
8.2. Proof of Theorem (7)
By evaluating the operator (cf. 36) for a quadratic function f(·) of the form (8), we can verify
with the matrix
This matrix R ∈ ℝ2n×2n is a 2 × 2 block matrix whose individual blocks can be diagonalized simultaneously via the orthonormal eigenvectors U = (u(1), …, u(n)) of the psd matrix Q. Inserting the spectral decomposition into (56),
with some (orthonormal) permutation matrix P and a block diagonal matrix
Combining (57) with (55) and inserting into (35) yields
In order to control the convergence rate of the iterations (35), i.e., the decay of the error , we will now derive an upper bound on the spectral norm of the block diagonal matrix Bk (cf. 58).
Due to the block diagonal structure (58), we can control the norm of Bk via controlling the norm of the powers of its diagonal blocks (B(i))k since
A pen and paper exercise reveals
Combining (61) with Lemma (8) yields
with and . Using the shorthand , we can estimate the spectral norm of Bk as
Combining (63) with (59),
Using (38), the error bound (64) can be translated into an error bound on the HB iterates , i.e.,
9. Technicalities
We collect some elementary results from linear algebra and analysis, which are required to prove our main results.
Lemma 8. Consider a matrix M = ∈ ℝ2×2 with spectral radius ρ(M). Then, there is an orthonormal matrix U ∈ ℂ2×2 such that
where |λ1|, |λ2| ≤ ρ(M) and |d|(|a| + |b| + 1)ρk−1(M).
Proof. Consider an eigenvalue λ1 of the matrix M with normalized eigenvector , i.e., Mu = λ1u with ‖u‖ = 1. According to Golub and Van Loan [11, Lemma 7.1.2], we can find a normalized vector , orthogonal to u, such that
or equivalently
with some eigenvalue λ2 of M. As can be read off (67), d = u1(u2a + v2b) + v1u2 which implies (65) since |u1|, |u2|, |v1|, |v2| ≤ 1. Based on (66), we can verify (65) by induction.□
Lemma 9. For any κ > 1 and k ∈ ℕ,
Proof. Let us introduce the shorthand z := exp(j2πθ) and further develop the LHS of (68) as
The denominator of the integrand in (69) can be factored as
with
Inserting (70) into (69),
Since |z2| < 1, we can develop the second term in (72) by using the identity [17, Section 2.7]
Since |z1|>1, we can develop the first term in (72) by using the identity [17, Section 2.7]
Applying (73) and (74) to (72),
Inserting (75) into (69), we arrive at
The proof is finished by combining (76) with the identity
□
Author Contributions
The author confirms being the sole contributor of this work and approved it for publication.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This paper is a wrap-up of the lecture material created for the course Convex Optimization for Big Data over Networks, taught at Aalto University in spring 2017. The student feedback on the lectures has been a great help to develop the presentation of the contents. In particular, the detailed feedback of students Stefan Mojsilovic and Matthias Grezet on early versions of the paper is appreciated sincerely.
References
1. Bottou L, Bousquet O. The tradeoffs of large scale learning. In: Advances in Neural Information Processing Systems (NIPS). Vancouver, BC (2008). p. 161–8.
2. Cevher V, Becker S, Schmidt M. Convex optimization for big data: scalable, randomized, and parallel algorithms for big data analytics. IEEE Signal Process Mag. (2014) 31:32–43. doi: 10.1109/MSP.2014.2329397
4. Walker HF, Ni P. Anderson acceleration for fixed-point iterations. SIAM J Numer Anal. (2011) 49:1715–35. doi: 10.1137/10078356X
5. Birken P. Termination criteria for inexact fixed-point schemes. Num Lin Alg App. (2015) 22:702–16. doi: 10.1002/nla.1982
6. Alfeld P. Fixed point iteration with inexact function values. Math Comput. (1982) 38:87–98. doi: 10.1090/S0025-5718-1982-0637288-5
7. Boyd S, Vandenberghe L. Convex Optimization. Cambridge: Cambridge University Press (2004). doi: 10.1017/CBO9780511804441
9. Bauschke HH, Combettes PL. Convex Analysis and Monotone Operator Theory in Hilbert Spaces. New York, NY: Springer (2010).
11. Golub GH, Van Loan CF. Matrix Computations, 3rd Edn. Baltimore, MD: Johns Hopkins University Press (1996).
12. Giannakis GB, Slavakis K, Mateos G. Signal processing for big data. In: Tutorial at EUSIPCO. Lisabon (2014).
13. Nesterov Y. Introductory Lectures on Convex Optimization. vol. 87 of Applied Optimization. Boston, MA: Kluwer Academic Publishers (2004).
14. Polyak BT. Some methods of speeding up the convergence of iteration methods. USSR Comput Math Math Phys. (1964) 4:1–17.
15. Ghadimi E, Shames I, Johansson M. Multi-step gradient methods for networked optimization. IEEE Trans Signal Process. (2013) 61:5417–29.
16. Gray RM. Toeplitz and Circulant Matrices: A review. vol. 2 of Foundations and Trends in Communications and Information Theory. Boston, MA (2006).
Keywords: convex optimization, fixed point theory, big data, machine learning, contraction mapping, gradient descent, heavy balls
Citation: Jung A (2017) A Fixed-Point of View on Gradient Methods for Big Data. Front. Appl. Math. Stat. 3:18. doi: 10.3389/fams.2017.00018
Received: 26 July 2017; Accepted: 21 August 2017;
Published: 05 September 2017.
Edited by:
Juergen Prestin, University of Luebeck, GermanyReviewed by:
Yekini Shehu, University of Nigeria, Nsukka, NigeriaMing Tian, Civil Aviation University of China, China
Copyright © 2017 Jung. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alexander Jung, YWxleGFuZGVyLmp1bmdAYWFsdG8uZmk=