 Dominik Alfke
Dominik Alfke Daniel Potts
Daniel Potts Martin Stoll
Martin Stoll Toni Volkmer
Toni Volkmer- 1Chair of Scientific Computing, Faculty of Mathematics, Technische Universität Chemnitz, Chemnitz, Germany
- 2Chair of Applied Functional Analysis, Faculty of Mathematics, Technische Universität Chemnitz, Chemnitz, Germany
The graph Laplacian is a standard tool in data science, machine learning, and image processing. The corresponding matrix inherits the complex structure of the underlying network and is in certain applications densely populated. This makes computations, in particular matrix-vector products, with the graph Laplacian a hard task. A typical application is the computation of a number of its eigenvalues and eigenvectors. Standard methods become infeasible as the number of nodes in the graph is too large. We propose the use of the fast summation based on the nonequispaced fast Fourier transform (NFFT) to perform the dense matrix-vector product with the graph Laplacian fast without ever forming the whole matrix. The enormous flexibility of the NFFT algorithm allows us to embed the accelerated multiplication into Lanczos-based eigenvalues routines or iterative linear system solvers and even consider other than the standard Gaussian kernels. We illustrate the feasibility of our approach on a number of test problems from image segmentation to semi-supervised learning based on graph-based PDEs. In particular, we compare our approach with the Nyström method. Moreover, we present and test an enhanced, hybrid version of the Nyström method, which internally uses the NFFT.
1. Introduction
Graphs are a fundamental tool in the modeling of imaging and data science applications [1–5]. To apply graph-based techniques, individual data points in a data set or pixels of an image represent the vertex set or nodes V of the graph, and the edges indicate the relationship between the vertices. In a number of real-world examples, the graph is sparse in the sense that each vertex is only connected to a small number of other vertices, i.e., the graph affinity matrix is sparsely populated. In other applications, such as the mentioned data points or image pixels, the natural choice for the graph would be a fully connected graph, which is then reflected in dense matrices that represent the graph information. Naturally, if there is no underlying graph the most natural choice is the fully connected graph. As the eigenvectors of the corresponding graph Laplacian are crucial in reducing the complexity of the underlying problem or for the extraction of quantities of interest [2, 6, 7], it is important to compute them accurately and fast. If this matrix is sparse, numerical analysis has provided efficient tools based on the Lanczos process with sparse matrix-vector products that can compute the eigeninformation efficiently. For complex interactions leading to dense matrices, these methods suffer from the high cost of the matrix-vector product.
Our goal is hence to obtain the eigeninformation despite the fact that the graph is fully connected and without any a priori reduction of the graph information. For this we rely on a Lanczos procedure based on Baglama and Reichel [8]. This method needs to perform the matrix-vector product in a fast way and thus, evaluating all information, without ever fully assembling the graph matrices. In a similar fashion the authors in Bertozzi and Flenner [7] utilize the well-known Nyström method to only work with partial information from the graph and only approximately represent the remaining parts. Such methods are well-known within the fast solution of integral equations and have found applicability within the data science community [9, 10]. The technique we present here is known as a fast summation method [11, 12] and is based on the nonequispaced fast Fourier transform (NFFT), see [13] and the references therein. We apply this method in the setting where the weights of the edges between the vertices are modeled by a Gaussian kernel function of medium to large scaling parameter, such that the Gaussian is not well-localized and most vertices interact with each other. For the case of a smaller scaling parameter and consequently a more localized Gaussian, we refer to Morariu et al. [14], which is partially based on a technique presented [15] for Gaussian kernels. Moreover, we remark that the NFFT-based fast summation method considered in this paper does not only support Gaussians but can handle various other rotational invariant functions.
The remaining parts of this paper are structured as follows. In section 2, we first introduce the graph Laplacian and discuss the matrix structure. In section 3, we introduce the NFFT-based fast summation, which allows for computing fast matrix-vector products with the graph Laplacian. In section 4, we then recall Krylov subspace methods and in particular the Lanczos method, which sits at the engine room of the numerical computations to obtain a small number of eigenvectors. We then show that the graph Laplacian provides the ideal environment to be used together with the NFFT-based fast summation, and we obtain the NFFT-based Lanczos method. In section 5 we briefly discuss the Nyström method as a direct competitor to our approach. We improve and accelerate this method, creating a new hybrid Nyström-Gaussian-NFFT version, which incorporates the NFFT-based fast summation. In section 6, we present comparisons between the NFFT-based Lanczos method, the Nyström method and the hybrid Nyström-Gaussian-NFFT method with the direct application of the Lanczos method for a dense, large-scale problem. Additionally, we illustrate on a number of exemplary applications, such as spectral clustering and semi-supervised learning, that our approach provides a convenient infrastructure to be used within many different schemes.
2. The Graph Laplacian and Fully Connected Graphs
We consider an undirected graph G = (V, E) with the vertex set and the edge set E, cf. [16] for more information. An edge e ∈ E is a pair of nodes (vj, vi) with vj ≠ vi and vj, vi ∈ V. For weighted undirected graphs, such as the ones considered in this paper, we also have a weight function w:V×V → ℝ with w(vj, vi) = w(vi, vj)for allj, i. We assume further that the function is positive for existing edges and zero otherwise. The degree of the vertex vj ∈ V is defined as
Let W, D ∈ ℝn×n be the weight matrix and the diagonal degree matrix with entries Wji = w(vj, vi) and Djj = d(vj). Since we do not permit graphs with loops, W is zero on the diagonal. Now the crucial tool for further investigations is the graph Laplacian L defined via
i.e., L = D−W. The matrix L is typically known as the combinatorial graph Laplacian and we refer to von Luxburg [1] for an excellent discussion of its properties. Typically its normalized form is employed for segmentation purposes and we obtain the normalized Laplacian as
obviously a symmetric matrix. Another normalized Laplacian of nonsymmetric form is given by
For the purpose of this paper we focus on the symmetric normalized Laplacian Ls but everything we derive here can equally be applied to the nonsymmetric version, where we would then have to resort to nonsymmetric Krylov methods such as GMRES [17]. It is well-known in the area of data science, data mining, image processing and so on that the smallest eigenvalues and its associated eigenvectors possess crucial information about the structure of the data and/or image [1, 7, 18]. For this we state an amazing property of the graph Laplacian L for a general vector u ∈ ℝn with n the dimension of L
which, as was illustrated in von Luxburg [1], is equivalent to the objective function of the graph RatioCut problem. Intuitively, assuming the vector u to be equal to a constant on one part of the graph A and a different constant on the remaining vertices Ā. In this case uT Lu only contains terms from the edges with vertices in both A and Ā. Thus a minimization of uT Lu results in a minimal cut with respect to the edge weights across A and Ā. Obviously, 0 is an eigenvalue of L and its normalized variants as L1 = D1−W1 = 0 by the definitions of D and W with 1 being the vector of all ones. Additionally, spectral clustering techniques heavily rely on the computation of the smallest k eigenvectors [1] and recently semi-supervised learning based on PDEs on graphs introduced by Bertozzi and Flenner [7] utilizes a small number of such eigenvectors for a complexity reduction. It is therefore imperative to obtain efficient techniques to compute the eigenvalues and eigenvectors fast and accurately. Since we are interested in the k smallest eigenvalues of the matrix it is clear that we can compute the k largest postive eigenvalues of the matrix A: = D−1/2 WD−1/2. In case that the graph G = (V, E) is sparse in the sense that every vertex is only connected to a small number of other vertices and thus the matrix W is sparse, we can utilize the whole arsenal of numerical algorithms for the computations of a small number of eigenvalues, namely the Lanczos process [19], the Krylov-Schur method [20], or the Jacobi-Davidson algorithm [21]. In particular, the ARPACK library [22] in MATLAB via the eigs function is a recommended choice. So frankly speaking, in the case of a sparse and symmetric matrix W the eigenvalue problem is fast and the algorithms are very mature. Hence, we focus on the case of fully connected graphs meaning that the matrix W is considered dense.
The standard scenario for this case is that each node vj ∈ V corresponds to a data vector and the weight matrix is constructed as
with a scaling parameter σ. For example, approaches with this kind of graph Laplacian have become increasingly popular in image processing [23], where the data vectors vj encode color information of image pixels via their color channels. The data point dimension may then be d = 1 for grayscale images and d = 3 for RGB images. Other applications may involve simple Cartesian coordinates for vj. While Equation (2) is derived from a Gaussian kernel function K(y): = exp(−‖y‖2/σ2), other applications might call for different kernel functions like the “Laplacian RBF kernel” K(y): = exp(−‖y‖/σ), the multiquadric kernel K(y): = (‖y‖2 + c2)1/2, or inverse multiquadric kernel K(y): = (‖y‖2 + c2)−1/2 for a parameter c > 0, e.g., cf. section 6.3. This means, the weight matrix may be of the form
Often certain techniques are used to sparsify the Laplacian or otherwise reduce its complexity in order to apply the methods named above. In particular, sparsification has been proposed for the construction of preconditioners [24] for iterative solvers, which still require the efficient implementation of the matrix vector products. In image processing, this can be achieved by considering only patches or other reduced representations of the image [18]. However, this might drop crucial nonlocal information encoded in the full graph Laplacian [23, 25], which is why we want to avoid it here and focus on fully connected graphs with dense Laplacians.
3. NFFT-Based Fast Summation
For eigenvalue computation as well as various other applications with the graph Laplacian, one needs to perform matrix-vector multiplications with the matrix W or the matrix A: = D−1/2 WD−1/2. In general, this requires (n2) arithmetic operations. When the matrix W has entries (2), this arithmetic complexity can be reduced to using the NFFT-based fast summation [11, 12]. In general, this method may be applied when the entries of the matrix W can be written in the form Wji = K(vj−vi), where K:ℝd → ℂ is a rotational invariant and smooth kernel function. For applying the NFFT-based fast summation for (3), it would be more convenient to consider the matrix W to have entries equal to K(0) on the diagonal and we refer to this matrix as . Note that it can be written as and thus . In order to efficiently compute the row sums of W, which appear on the diagonal of D, we use
We now illustrate how to efficiently compute the matrix-vector product with the matrix using the NFFT-based fast summation. For instance, for the Gaussian kernel function, we have
with and we rewrite (4) by
with the kernel function K(y): = exp(−‖y‖2/σ2). The key idea of the efficient computation of (5) is approximating K by a trigonometric polynomial KRF in order to separate the computations involving the vertices vj and vi. Assuming we have such a d-variate trigonometric polynomial
with bandwidth N ∈ 2ℕ and Fourier coefficients , we replace K by KRF in (5) and we obtain
Using the NFFT [13], one computes the inner and outer sums for all j = 1, …, n totally in arithmetic operations, where m ∈ ℕ is an internal window cut-off parameter which influences the accuracy of the NFFT. Please note that since KRF and fRF are 1-periodic functions but neither K nor f are, ones needs to shift and scale the nodes vj such that they are contained in a subset of the cube [−1/4, 1/4]d ensuring . Depending on the Fourier coefficients , l ∈ IN, of the trigonometric polynomial KRF, where still have to be determined, we may need to scale the nodes vj to a slightly smaller cube.
We emphasize that we are not restricted to the Gaussian weight function or a rotational invariant weight function. In fact, any kernel function K that can be well approximated by a trigonometric polynomial KRF may be used.
Next, we describe an approach to obtain suitable Fourier coefficients of KRF based on sampling values of K. Especially, we want to obtain a good approximation of K using a small number of Fourier coefficients . Therefore, we regularize K to obtain a 1-periodic smooth kernel function KR, which is p−1 times continuously differentiable (in the periodic setting), such that its Fourier coefficients decay in a fast way. Then, we approximate the Fourier coefficients of KR using the trapezoidal rule and this yields the Fourier coefficients of KRF.
For a rotational invariant kernel function K(y), which is sufficiently smooth except at the “boundaries” of the cube [−1/2, 1/2]d, e.g., K(y) = exp(−‖y‖2/σ2), we only need to regularize near ‖y‖ = 1/2. We use the ansatz
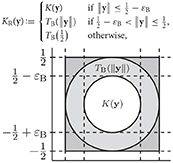
where TB is a suitably chosen univariate polynomial, e.g., computed by a two-point Taylor interpolation. The parameter 0 < εB ≪ 1/2 determines the size of the regularization region, cf. [12, section 2]. For the treatment of a rotational invariant kernel function which has a singularity at the origin, we also refer to [12, section 2]. Now we approximate KR by the d-variate trigonometric polynomial KRF from (6), where we compute the Fourier coefficients
Assuming one evaluation of KR takes arithmetic operations, the computations in (7) require arithmetic operations in total using the fast Fourier transform.
If all vertices vj and their corresponding data vectors , j = 1, …, n, fulfill the property ‖vj‖ ≤ 1/4−εB/2, we have ‖vj−vi‖ ≤ 1/2−εB and we obtain an approximation of (5) by
Otherwise, we compute a correction factor , using transformed vertices , and adjust parameters of the kernel function appropriately. For instance, in case of the Gaussian kernel function, we replace the scaling parameter σ by for the regularized kernel function KR.
The error of the approximation depends on the kernel function as well as on the choice of the regularization smoothness p, the size of the regularization region εB, the bandwidth N, and the window cut-off parameter m. For a fixed accuracy, we fix these parameters p, εB, N, and m. Hence, for small to medium dimensions d, we obtain a fast approximate algorithm for the matrix-vector multiplication of complexity , cf. Algorithm 1. This algorithm is implemented as applications/fastsum and matlab/fastsum in C and MATLAB within the NFFT3 software library1, see also [13], and we use the default Kaiser-Bessel window function. In Figure 1, we list the relevant control parameters of Algorithm 1 and regularization approach (7).

Algorithm 1. Fast approximate matrix-vector multiplication using NFFT-based fast summation, , e.g., .

Figure 1. Control parameters for NFFT-based fast summation.
Note that every part of Algorithm 1 is deterministic and linear in the input vector x, i.e., the algorithm constitutes a linear operator that can be written as with an error matrix E. For theoretical error estimates on , we refer to Potts and Steidl [11], Potts et al. [12], and Kunis et al. [26]. The basic idea is to start with the estimate
caused by the approximation of the kernel K by a trigonometric polynomial KRF, and to additionally take the errors caused by the NFFT into account. In practice, one may guess ‖KERR‖∞ based on sampling values of K and KRF. For theoretical error estimates of the NFFT for various window functions, we refer to Keiner et al. [13] and Nestler [27]. In practice, choosing the window cut-off parameter of the NFFT m = 8 yields approximately IEEE double precision for the default Kaiser-Bessel window, see e.g., [13, section 5.2].
We again emphasize that Algorithm 1 is not restricted to the Gaussian kernel function. Any kernel function K that can be well approximated by a trigonometric polynomial may be used and the corresponding Fourier coefficients , l ∈ IN, are an input parameter of Algorithm 1.
Moreover, for the Gaussian kernel function, one could also use the analytic Fourier coefficients from Kunis et al. [26] for small values of the scaling parameter σ instead of computing by interpolation in (7). In this case, explicit error bounds for ‖KERR‖∞ are available.
3.1. Error Propagation for Normalized Matrices
As seen in section 2, many applications involving the Graph Laplacian require matrix vector products with a matrix A that itself does not follow the form of (3), but results from normalization of such a matrix W. This normalization can be written as A = D−1/2 WD−1/2, where D = diag(W1). Since our approach includes replacing all matrix-vector products Wx by the approximations , this also includes the computation of the degree matrix D. The error occurring from this approximation will then propagate to the evaluation error of Ax.
Algorithm 2 summarizes the usage of Algorithm 1 for this case. Note that if multiple matrix-vector products are required, e.g., in an iterative scheme, steps 1–4 can be performed once in a setup phase. The following lemma gives an estimation of the error of Algorithm 2 depending on the relative error of Algorithm 1.

Algorithm 2. Fast approximate matrix-vector multiplication Ax using NFFT-based fast summation, with A = D−1/2 WD−1/2, W as in (3) and D = diag(W1)
Lemma 1. Let W ∈ ℝn×n be a matrix with non-negative entries and at least one positive entry per row. Given an error matrix E ∈ ℝn×n, we define WE = W + E and
Let dmin > 0 denote the minimum diagonal entry of D and furthermore set
Then, for ε < η, it holds
Proof. Due to
and the fact that x ↦ x−1/2 and its first derivative are monotoneously decreasing, we obtain
Analogously we obtain
Together with and ‖WE‖∞ ≤ (1 + ε)‖W‖∞, this yields
Now detach the left underlined part from its paranthesed expression and combine it with the right underlined part:
Resolve the binomial expression in the first line and simplify the second line:
This concludes the proof for the desired inequality.□
The requirement ε < η means that ‖E‖∞ must be smaller than the smallest diagonal entry in D. This condition cannot be avoided since otherwise, negative entries in DE could not be ruled out, leading to imaginary entries in and thus in AE. On the other hand, if ε is well below η, Lemma 1 yields that the absolute error in A is linear in ε, which is the relative error of Algorithm 1.
Alternatively, by ignoring the error caused by the NFFT, we obtain error estimations of the form
In other words, the perturbation grows linearly in the size of the dataset. If either ‖W‖∞ or dmin grew less fast, then Lemma 1 would not be applicable for large n because ε would eventually supersede η. However, if we assume that increasing n means adding more similarly-distributed data points to the dataset, the average entry in W does not change and thus all row sums of W also grow linearly in n, including dmin and the maximum row sum ‖W‖∞. A mathematical quantification of this observation is beyond the scope of this article, but in practice, the values for η and ε can be approximated and monitored to give a-posteriori error bounds. One way to do this is by using (9) and approximating ‖KERR‖∞ via (8), where the maximum can be discretized in a large number of randomly drawn sample points.
The accuracy of this approximation can be validated by explicitly computing the exact absolute row sum ‖E‖∞ via
where |·| is applied elementwise, ei denotes the i-th unit vector, and matrix-vector products with are evaluated using Algorithm 1. The effort of computing (10) is . Equivalently, the true value for ‖A−AE‖∞ can be computed via
4. Krylov Subspace Methods and NFFT
The main contribution of this paper is the usage of NFFT-based fast summation for accelerating Krylov subspace methods, which are the state-of-the-art schemes for the solution of linear equation systems, eigenvalue problems, and more [28]. In the case of large dense matrices, the computational bottleneck is the setup of and multiplication with the system matrix itself. We will here exemplarily illustrate this for the Lanczos algorithm [29], which is the standard method for computation of a few dominating, i.e., largest, eigenvalues of a symmetric matrix A [19, 30]. It is based on looking for an A-invariant subspace in the Krylov space
This is achieved by iteratively constructing an orthonormal basis q1, …, qk of this space in such a way that the matrix yields a tridiagonalization of A, i.e.,
Such a matrix Qk as well as the entries of Tk can be computed by the iteration
where and βk+1 = ‖Aqk−αkqk−βkqk−1‖. The remarkable fact that this iteration produces orthonormal vectors is a consequence of the symmetry of A.
We now summarize the first k steps of the Lanczos process in the relation
where ej denotes the j-th standard basis vector of the appropriate dimension. The eigenvalues and eigenvectors of the small matrix Tk are called the Ritz values and vectors, respectively, and can be computed efficiently. From Tkw = λw we then obtain
where wk is the k-th component of the Ritz vector w. We finally see via
that a small value |βk+1| indicates that (λ, Qkw) is a good approximation to an eigenpair of A and that the Krylov space is close to containing an A-invariant subspace. There are many more practical issues that make the implementation of the Lanczos process more efficient and robust. We do not discuss these points in detail but refer to Parlett [30] and Lehoucq et al. [22] for the details.
Additionally, we want to point out that the above procedure can also be used for the solution of linear systems of equations. Standard methods based on the Lanczos method are the conjugate gradients method [31] and the minimal residual method [32], which are tailored for the solution of linear systems of the form Ax = b. Note that such applications involving the graph Laplacian are commonly found in kernel based methods [33]. In the nonsymmetric case that comes up e.g., when considering Lw, we can employ the Arnoldi method [28], which relies on a similar iteration where Tk is replaced by an upper Hessenberg matrix.
One main contribution of this paper is the fact that by evaluating matrix-vector products via the NFFT-based Algorithms 1 or 2, Krylov subspace methods are still applicable for dense matrices that are too large to store, let alone apply, as long as they stem from the kernel structure of (3) or normalization of such a matrix. In our experiments, this method will be denoted as NFFT-based Lanczos method.
A detailed discussion of the effect of inexact matrix-vector products on Krylov-based approximations can be found in Simoncini and Szyld [34].
5. Alternative Eigenvalue Algorithm: The Nyström Method
5.1. The Traditional Nyström Extension
The Nyström extension is currently used as a method of choice to compute eigenvalue approximations of kernel-based matrices that are too large to allow for direct eigenvalue computation. See e.g., Garcia-Cardona et al. [35] and Merkurjev et al. [36] for its applications in different settings. Originally introduced to the matrix computations context in Williams and Seeger [37], further improvements have been suggested in Fowlkes et al. [38] and Drineas and Mahoney [9] and its usage for classification problems has been proposed in Bertozzi and Flenner [7]. It is based on dividing the data points into a sample set X of L nodes and its complement Y. After permutation, the adjacency matrix W can be split into blocks
where the blocks and are the adjacency matrices of the canonical subgraphs with node sets X and Y, respectively, and the block contains the similarities between all combinations of nodes from X and Y.
The basic idea of the Nyström method is to compute only WXX and WXY explicitly, but not the remaining block WYY. If L ≪ n, the approach significantly decreases the required number of data point comparisons. Assuming that WXX is regular, the method approximates W by
which constitutes a rank-L approximation due to the size and regularity of WXX. This formula is used once in approximating the degree matrix D by DE = diag(WE1) and once in approximating the eigenvalues of A via the rank-L eigenvalue decomposition
This can be computed without having to set up the full matrix, e.g., by the technique described in Fowlke et al. [38] made up mainly of two singular value decompositions of (L×L)-sized matrices, which is technically only applicable if W is positive definite. Alternatively, we have achieved better results by computing the QR factorization and the eigenvalue decomposition , leading to the eigenvector matrix . The arithmetic complexity of this algorithm can be easily confirmed to be (n L2).
The eigenvalue accuracy depends strongly on the quality of the approximation
Since the sample set X is a randomly chosen subset of the indices from 1, …, n, its size L is the decisive method parameter and its choice is a nontrivial task. On the one hand, L needs to be small for the method to be efficient. On the other hand, a too small choice of L may cause extreme errors, especially because the approximation error in DE propagates to the eigenvalue computation. In spite of the positivity of the diagonal of D, negative entries in DE cannot be ruled out and are observed in practice. Hence imaginary entries may occur in and thus AE, making the results extremely unreliable. This behavior follows the same structure as Lemma 1, however, we do not have a meaningful bound on that would guarantee favorable error behavior.
5.2. A NFFT-Based Accelerated Nyström-Gaussian Method
Another important contribution of this paper is the development of an improved Nyström method, which utilizes the NFFT-based fast summation from section 3. It is based on a slightly different algorithm that has been recently introduced as a Nyström method, cf.[39] and the references therein. Their basic idea is rewriting the traditional Nyström approximation as
where Q ∈ ℝn×L is a matrix with orthogonal columns. If Q holds the first L columns of a permutation matrix, one obtains the traditional Nyström method from section 5.1. Inspired by similar randomized linear algebra algorithm such as randomized singular value decomposition, this choice of Q is replaced in Martinsson [39] by Q = orth(AG), where G ∈ ℝn×L is a Gaussian matrix with normally distributed random entries and orth denotes column-wise orthonormalization. Unfortunately, this setup requires 2L matrix-vector products with the full matrix A.
We now propose accelerating these matrix-vector products by computing AQ column-wise via the NFFT-based fast summation Algorithm 1 in order to avoid full matrix setup or slow direct matrix-vector products. In addition, we propose replacing the inverse (QT AQ)−1 by a low-rank approximation based only on the M ∈ ℕ largest eigenvalues of QT AQ. This way, a rank-M approximation of A is produced, where M may be the actual number of required eigenvalues or larger. The resulting method “Nyström-Gaussian-NFFT” is presented in Algorithm 3. Its arithmetic complexity is (n L2). On the first glance, this arithmetic complexity seems to be identical to the one of the traditional Nyström method from section 5.1. However, as we observe in the numerical tests in section 6.1, we may choose the parameter L distinctly smaller for Algorithm 3, i.e., L ~ k, where k is the number of eigenvalues and eigenvectors. Then, the resulting arithmetic complexity is (n k2).

Algorithm 3. NFFT-based accelerated Nyström-Gaussian method (“Nyström-Gaussian-NFFT”) for eigenvalue approximation
6. Numerical Results
All our experiments are performed using MATLAB implementations based on the NFFT3 library and MATLAB's eigs function. A short example code can be found on the homepage of the authors2.
6.1. Accuracy and Runtime of Eigenvalue Computations
We use the function generateSpiralDataWithLabels.m3 to generate varying sets of three-dimensional data. The data points are in the form of a spiral and we can specify the number of classes as well as the number of points per class. We generate data sets with 5 classes and equal numbers of points per class, which have a total number of data points n ∈ {2000, 5000, 10000, 20000, 50000, 100000}. For the generation, we use the default parameters h = 10 and r = 2 in generateSpiralDataWithLabels.m. For each n, we generate 5 random spiral data sets. In Figure 2A, we visualize an example data set with n = 2, 000 total points. For the adjacency matrix W, we set the scaling parameter σ = 3.5. Using the NFFT-based Lanczos method from section 4, we compute the 10 largest eigenvalues and the corresponding eigenvectors of the matrix A: = D−1/2 WD−1/2 for each data set. We consider three different parameter setups for the NFFT in Algorithm 1, achieving different accuracies. We set the bandwidth N = 16 and the window cut-off parameter m = 2 in setup #1, N = 32 and m = 4 in setup #2, as well as N = 64 and m = 7 in setup #3. For all three setups, we use εB = 0. For comparison, we also apply the Nyström method from section 5.1, where we perform 10 repetitions for each data set, since the method uses random sub-sampling in order to obtain a rank-L approximation of the adjacency matrix W. We consider two different Nyström setups with rank L ∈ {n/10, n/4}. Moreover, we use the hybrid Nyström-Gaussian-NFFT method from Algorithm 3 in section 5.2 with L ∈ {20, 50} Gaussian columns, parameter M = 10 as well as fast summation parameters corresponding to setup #2, where we perform 10 repetitions for each data set. Additionally, we compute the eigenvalues and eigenvectors by a direct method, which applies the Lanczos method using full matrix-vector products with the adjacency matrix W. For the Nyström method from section 5.1 and the direct computation method, we only run tests for a total number of data points n ∈ {2000, 5000, 10000, 20000} due to long runtimes.
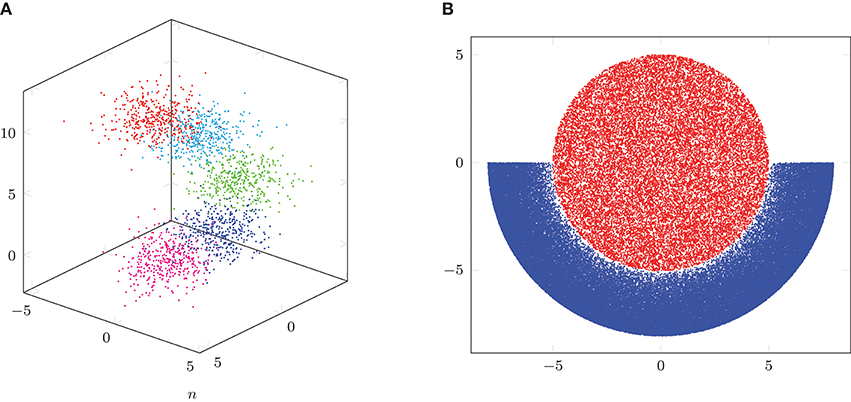
Figure 2. Illustration of spiral and crescent-fullmoon data sets. (A) Spiral example with n = 2,000 points. (B) Crescent-fullmoon example with n = 100,000 points.
In Figure 3, we visualize the results of the test runs. We show the minimum, average and maximum of the maximum eigenvalue errors in Figure 3A. For this, we first determine the maximum eigenvalue errors
for each test run, where λj denotes the j-th eigenvalue computed by the method under consideration and the one computed by a direct method using full matrix-vector products with the matrix A. Then, for fixed total number of data points n and fixed parameter setup, we compute the minimum, average and maximum of (13), where the minimum, average and maximum are computed using 5 instances of (13) for the NFFT-based Lanczos method and 5·10 instances of (13) for the Nyström-based methods. We observe that the averages of the maximum eigenvalue errors (13) are above 10−2 for the two considered parameter choices of the Nyström method from section 5.1, even when the rank L is chosen as a quarter of the matrix size n. Moreover, the minima and maxima of (13) differ distinctly from the averages. In particular, the accuracies may vary strongly across different Nyström runs on an identical data set. For the NFFT-based Lanczos method, each minimum, average and maximum of the maximum eigenvalue errors (13) only differs slightly from one another. The maximum eigenvalue errors (13) are around 10−4 to 10−3 for parameter setup #1, around 10−10 to 10−9 for setup #2, and below 10−14 for setup #3. For the hybrid Nyström-Gaussian-NFFT method, which internally uses 2L many NFFT-based fast summations with parameter setup #2, the maximum eigenvalue errors (13) are around 10−3 to 10−2 for parameter L = 20 and around 10−5 to 10−4 for L = 50. This means that the observed maximum eigenvalue errors (13) are distinctly smaller compared to the ones of the traditional Nyström method, and the errors for parameter L = 50 are slightly smaller than the ones of the NFFT-based Lanczos method with parameter setup #1.
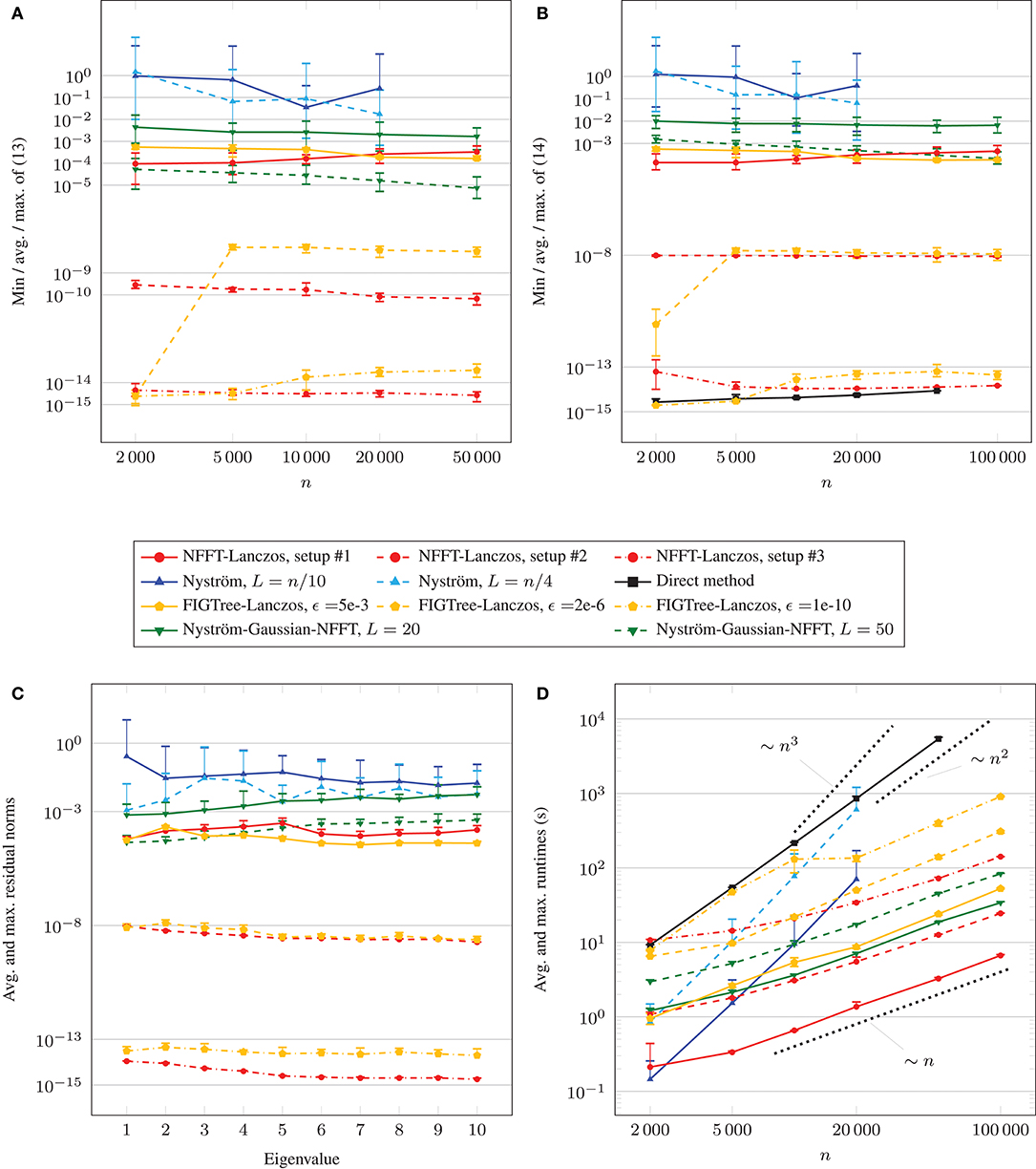
Figure 3. Comparison of accuracies and runtimes for spiral data sets. (A) Comparison of eigenvalue accuracies. (B) Comparison of eigenvector accuracies. (C) Residuals for n = 20,000. (D) Comparison of runtimes.
In Figure 3B, we depict the minimum, average and maximum of the maximum residual norms (14) for each total number of data points n. We compute these numbers by first determining the maximum residual norms
for each test run, where λj denotes the j-th eigenvalue of A and vj the corresponding eigenvector. Then, for fixed n and fixed parameter setup, we compute the minimum, average and maximum of (14). We observe that the averages of the maximum residual norms (14) are above 10−1 for the considered parameter choices of the Nyström method, even when the rank L is chosen as a quarter of the matrix size n. Moreover, the minima and maxima of the maximum residual norms (14) differ distinctly from the averages. Especially, the accuracies may vary strongly across different Nyström runs on an identical data set. For the NFFT-based Lanczos method, each minimum, average and maximum of (14) only differs slightly from one another. The maximum residual norms (14) are around 10−4 to 10−3 for parameter setup #1, around 10−8 for setup #2, and around 10−15 to 10−13 for setup #3. For the hybrid Nyström-Gaussian-NFFT method, maximum residual norms (14) are around 10−2 for parameter L = 20 and around 10−4 to 10−3 for L = 50. In the latter case, the errors are slightly larger than the ones of the NFFT-based Lanczos method with parameter setup #1 for n ∈ {2, 000, 5, 000, 10, 000, 20, 000} data points and slightly smaller for n ∈ {50, 000, 100, 000}.
Additionally, in Figure 3C, we investigate the average and maximum of the maximum residual norms (14) for each fixed eigenvalue λj for n = 20, 000 data points. For Nyström L = n/10, we observe that the residual norms belonging to the first eigenvalue are distinctly larger than for the remaining eigenvalues. In general, the observed maximal residual norms (14) vary similarly for each eigenvalue. For the NFFT-based Lanczos method with parameter setup #2 and #3, the maximum residual norms (14) of the tail eigenvalues are slightly smaller than of the leading eigenvalues, which is not the case for the parameter setup #1 as well as for the results of the hybrid Nyström-Gaussian-NFFT method.
In Figure 3D, we show the average and maximum runtimes of the different methods and parameter choices in dependence of the total number of data points n. The runtimes were determined on a computer with Intel Core i7 CPU 970 (3.20 GHz) using one thread. We remark that the NFFT supports OpenMP, cf.[40], but we restricted all time measurements to 1 thread for better comparison. We observe that the runtimes of the traditional Nyström method grow approximately like ~n3, and the runtimes of the direct computation method for the eigenvalues grow approximately like ~n2. Moreover, the slopes of the runtime graphs of the NFFT-based Lanczos method are distinctly smaller and the runtimes grow approximately like ~n. Depending on the parameter choices, the NFFT-based Lanczos method is faster than the Nyström method once the total number of data points n is above 2,000–10,000. The hybrid Nyström-Gaussian-NFFT method with parameter L = 20 is slightly slower than the NFFT-based Lanczos method with setup #2. For the parameter L = 50 the method is slower by a factor of approximately 2.5. In both cases, the runtimes grow approximately like ~n. The runtimes of the direct method were the highest ones in most cases. For the tests, we precomputed the diagonal entries of the matrix D−1/2 but we computed the entries of the weight matrix W again for each matrix-vector multiplication with the matrix A. Alternatively, one could store the whole matrix A ∈ ℝn×n for small problem sizes n and this would have reduced the runtimes of the direct method to 1/20. However, then we would have to store at least n(n−1)/2 values, which would already require about 10 GB RAM for n = 50, 000 and double precision.
For comparison, we also applied the FIGTree method from Morariu et al. [14] to our testcases, and we denote the obtained results by “FIGTree-Lanczos” in Figure 3. The FIGTree accuracy parameter ϵ was chosen ∈ {5·10−3, 2·10−6, 10−10} such that the resulting residual norms (14) in Figure 3B approximately match those of the NFFT-based Lanczos method for setup #1,#2,#3. We observe that the obtained eigenvalue accuracies in Figure 3A are similar for ϵ = 5·10−3 and 10−10 to the ones of the NFFT-based Lanczos method for setup #1 and #3, respectively. For n ≥ 5, 000 data points and FIGTree accuracy parameter ϵ = 2·10−6, we observe for our testcase that the obtained eigenvalue accuracies are lower by about two order of magnitudes compared to the NFFT-based Lanczos method with setup #2. When looking at the obtained runtimes, we observe that “FIGTree-Lanczos” requires approximately 4 times to 7 times the runtime of the corresponding NFFT-based Lanczos method with comparable eigenvector accuracy in most cases.
6.2. Applications
In the following, we will showcase the effect of the improved accuracy on popular data science methods that utilize the graph Laplacian matrix. We will compare how the methods perform if the eigenvectors are computed with the NFFT-based Lanczos method or the traditional Nyström extension.
6.2.1. Spectral Clustering
Spectral clustering is an increasingly popular technique [1] and we briefly illustrate the method proposed in Ng et al. [41]. The basis of their algorithm is a truncated eigenapproximation with which is an approximation based on the smallest eigenvalues and eigenvectors of the graph Laplacian. Now the rows of Vk are normalized to obtain a matrix Yk. The normalized rows are then divided into a fixed number of disjoint clusters by a standard k-means algorithm.
Here, we apply spectral clustering to an image segmentation problem. The original image of size 533 × 800 is depicted in Figure 5A. We construct a graph Laplacian where each pixel corresponds to a node in the graph and the distance measure is the distance between the values in all three color channels, such that each vertex . Correspondingly, the graph Laplacian would be a dense matrix of size 426,400 × 426,400. We set the scaling parameter σ = 90. Figure 4 shows the first ten eigenvalues of the matrix A.
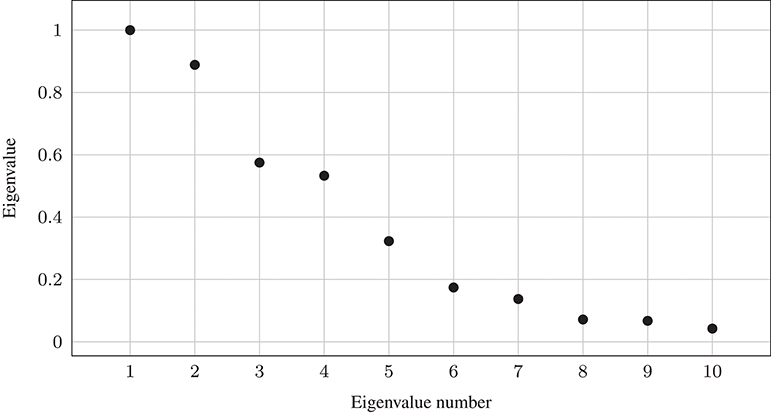
Figure 4. First 10 eigenvalues of A using Gaussian weights and scaling parameter σ = 90 for Figure 5A.

Figure 5. Results of image segmentation (533 × 800 = 426, 400 pixels) via spectral clustering and k-means using the NFFT-based Lanczos method from section 4 and the Nyström method from section 5.1. “Failed run” in (E) means segmentation differences of more than 20% compared to the results obtained when applying eigs on the full matrix A. (A) Original image (Image source: TU Chemnitz/Wolfgang Thieme); (B) k = 2 classes, NFFT-Lanczos; (C) k = 4 classes, NFFT-Lanczos; (D) k = 4 classes, Nyström; (E) k = 4 classes, Nyström (“failed” run); (F) differences between (C) and (E).
For obtaining reference results, we use the Matlab function eigs on the full matrix A computing 4 eigenvectors and this required more than 31 h using up to 32 threads on a computer with Intel Xeon E7-4880 CPUs (2.50 GHz), using more than 500 CPU hours in total. Next, we applied the NFFT-based Lanczos method from section 4 with parameters N = 16, m = 2, p = 2, and εB = 1/8 for the eigenvector computations. We show the results in Figures 5B,C for k = 2 and k = 4 classes, respectively. The segmented images look satisfactory. The main features of the image are preserved and large areas of similar color are correctly assigned to the same cluster, while there are only small “noisy” areas. Compared to the segmented image from the direct computations, we have approximately 0.1 % differences (467 out of 426,400) in the class assignments in the case of k = 4 classes. For the runtimes, we measure approximately 25 s for the NFFT-based Lanczos method and 18 seconds for the k-means algorithm on a computer with Intel Core i7 CPU 970 (3.20 GHz) using one thread.
Additionally, we ran the Nyström method 100 times with parameter L = 250. Here the runtimes were approximately 60 s on average without the runtime for the clustering. We applied the k-means algorithm for k = 4 classes, which required approximately 22 s on average. We observed that in 79 of the 100 test runs of Nyström followed by k-means, the images appear to be very close to the ones obtained when applying eigs on the full matrix A, i.e., the differences are <2%. In Figure 5D, we visualize the results of a corresponding test run. However, in 13 of the 100 test runs, the Nyström method returned eigenvectors which caused segmentation differences of more than 20% with such “noisy” images that we consider these as “failed” runs. See Figure 5E for one example with approximately 25% differences. The differences between Figures 5C,E are shown as a black and white picture in Figure 5F.
Moreover, we tested increasing the parameter L to 500. Then, the run times increased to approximately 152 s on average. When applying the k-means algorithm to the obtained eigenvectors, the results improved. The differences compared to the reference image segmentation are <2% in 85 of the 100 test runs and larger than 20% in 9 test runs.
6.2.2. Semi-Supervised Learning by a Phase Field Method
We here want to state an exemplary method that relies heavily on a number of eigenvectors of the graph Laplacian. It was proposed by Bertozzi and Flenner [7] and corresponds to a semi-supervised learning (SSL) problem. Suppose we have a graph-based dataset as before where each vertex is assigned to one of C classes. A training set of s random sample vertices from each class is set up. For the case of C = 2 classes, a training vector f ∈ ℝn is set up with entries −1 for training nodes from one class, 1 for training nodes from the other class, and 0 for nodes that do not belong to the training data. The task of SSL is to use f to find a classification vector u ∈ ℝn. The sign of its entries is then used to predict each node's assigned class.
One successful approach computes u as the end point of the trajectory described by the Allen–Cahn equation
(see [42, 43] for details). Here ψ(u) = (u2 − 1)2 is the double-well potential, which we understand to be applied component-wise, and Ω denotes a diagonal matrix with entries Ωii = ω0 > 0 if vertex i belongs to the training data and Ωii = 0 otherwise. To discretize this ODE we will not introduce an index for the temporal discretization but rather assume that all values u are evaluated at the new time-point whereas indicates the previous time-point. We then obtain
where u is a vector defined on the graph on which we base the final classification decision. Here, c > 0 is a positive parameter for the convexity splitting technique [7]. For a more detailed discussion of how to set these parameters we refer to Bertozzi and Flenner [7] and Bosch et al. [44]. We now use the k computed eigenvalues and eigenvectors (λj, vj) of Ls such that we can write and from this we get
This equation can be solved to obtain the new coefficients uj from the old coefficients ūj. After a sufficient number of time steps, u will converge against a stable solution.
We apply this method to the same spiral data set as seen in section 6.1, again with σ = 3.5 but this time only with n = 100, 000. The data points have been generated by a multivariate normal distribution around five center points, and the true label of each vertex has been set to the center point that is closest to it. We computed the eigenvectors to the k = 5 smallest eigenvalues of the Laplacian; once by the NFFT-based Lanczos method with n = 32, m = 4, and εB = 0, and once with the traditional Nyström method with L = 1, 000 where only 5 columns of VL are used. We then applied the described method with τ = 0.1, ε = 10, ω0 = 10, 000, and . The iteration terminated if the squared relative change in u was less than 1e-10. We repeat this process for 50 instances of the spiral dataset and sample sizes s ∈ {1, 2, 3, 4, 5, 7, 10}.
Figure 6 depicts the average accuracy results. We conclude that in this example, the increased eigenvector quality achieved by the NFFT-based method yields an average accuracy boost of approximately 0.5–1.5% points, as well as the worst result being significantly less bad. On a computer with Intel Core i7 CPU 4770 (3.40 GHz), the runtimes were approximately 8 s for the NFFT-based Lanczos method, 27 s for the Nyström method, and less than a second for the solution of the Allen–Cahn equation, which almost always converged after only three time steps.
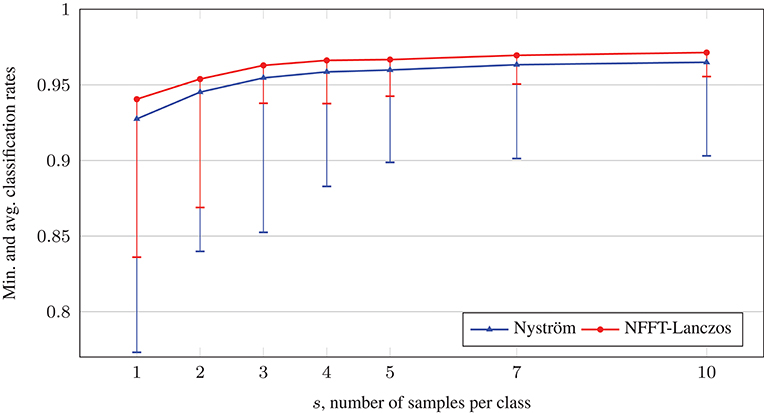
Figure 6. Comparison of average classification rates with the phase field method on relabeled spiral data sets.
6.2.3. Semi-Supervised Learning by a Kernel Method
In addition to the phase field method, we employ a second semi-supervised learning technique used in Zhou et al. [45] and Hein et al. [46] for SSL problems with only two classes. Based on a training vector f holding 1, −1, or 0 just as in the previous section, a similar u is obtained by minimizing the function
where β can be understood as a regularization parameter. For the solution of this minimization problem, we only have to solve the equation
where I is the identity matrix. Similar systems arise naturally in scattered data interpolation [47]. We run numerical tests using the crescentfullmoon.m4 data set with n = 100, 000 data points and parameters r1=5, r2=5, r3=8. As illustrated in Figure 2B, the set is divided into two classes of points in the full moon and the crescent, distributed in a 1-to-3 ratio. We generate 5 random instances of the data set, and for each instance we run 10 repetitions with randomly chosen training data, where we consider s ∈ {1, 2, 5, 10, 25} known samples per class. For the adjacency matrix W, we set the scaling parameter σ = 0.1. The tests are run with regularization parameter β ∈ {103, 3·103, 104, 3·104, 105}. We solve each system (16) using the CG algorithm with tolerance parameter 10−4 and a maximum number of 1,000 iterations. For the fast matrix-vector multiplications with the matrix Ls, we use the NFFT-based fast summation in Algorithm 1 with parameters N = 512, m = 3, εB = 0.
In Figure 7, we visualize the average and maximum misclassification rate of the 5·10 test runs for each fixed s and β. In the left plot, we show the misclassification rate in dependence of the number of samples s per class for the different regularization parameters β. We observe in general that the misclassification rates decrease for increasing s. The lowest rate is achieved for s = 25 samples per class and β = 104, where the average and maximum misclassification rate are 0.0012 and 0.0036, respectively. In the right plot, we depict the misclassification rate in dependence of the regularization parameter β for fixed number of samples s per class. For s ∈ {1, 2, 5}, the average misclassification rates decline for increasing β until β = 3·104 and grow again for β = 105. For s ∈ {10, 25}, the average misclassification rates decline for increasing β until β = 104 and grow again afterwards. We remark that in all test runs, the maximum number of CG iterations was 536 and the maximum runtime for solving (16) was approximately 151 s on a computer with Intel Core i7 CPU 970 (3.20 GHz) using one thread.
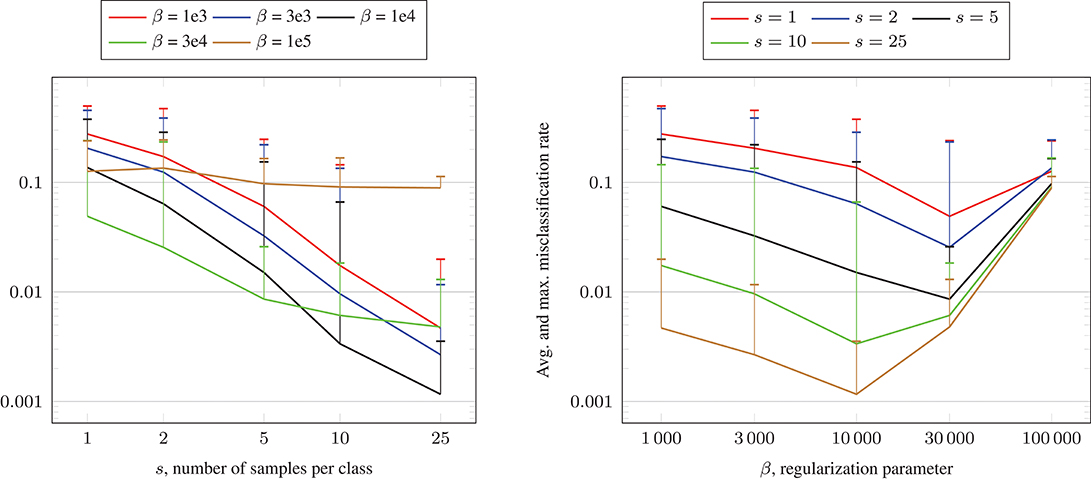
Figure 7. Misclassification rate solving (16) using the CG algorithm and Algorithm 1 for the crescentfullmoon.m data set with n = 100, 000 data points.
Additionally, we used the NFFT-based Lanczos method from section 4 in order to approximate the matrix A: = D−1/2 WD−1/2 by a truncated eigenapproximation with and this allows for computing the matrix-vector products in (16) in a fast way for fixed small k. Using k = 10 eigenvalues and eigenvectors, we achieve similar results as those shown in Figure 7. The computation of the eigenapproximation required up to 6 min on a computer with Intel Core i7 CPU 970 (3.20 GHz) using one thread. The maximum runtime for solving (16) was approximately 0.15 s.
Alternatively, we applied the Nyström method from section 5.1 with parameter L = 5, 000 to obtain a truncated eigenapproximation, where the corresponding computation required more than 3 h for each eigenapproximation. However, the eigenvalues were not computed correctly in our tests. This was due to the matrix block WXX in Equation (12) being ill-conditioned. Consequently the CG method aborted in the first iteration and the output could not be used for classification.
In order to illustrate the flexibility of the NFFT-based fast summation, we also apply Algorithm 1 to a non-Gaussian weight function w in (2). Here, we consider the “Laplacian RBF kernel” K(y): = exp(−‖y‖/σ), such that the weight matrix is constructed as
In our numerical tests, we set the shape parameter σ = 0.05 and we visualize the test results in Figure 8. We observe that the obtained misclassification rates are similar to the ones in Figure 7, where the Gaussian kernel was used. For some parameter settings, the misclassification rates are slightly better, for other ones slightly worse.
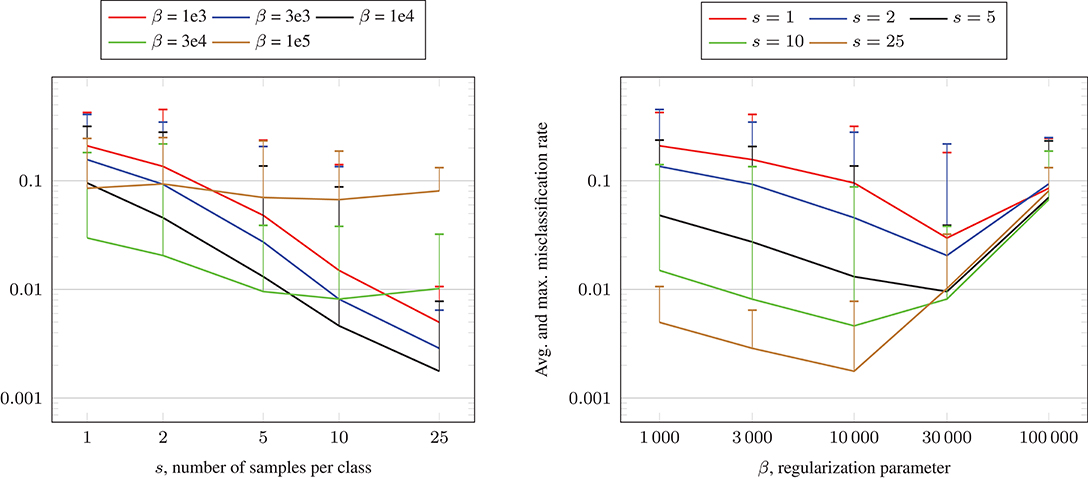
Figure 8. Misclassification rate solving (16) using the CG algorithm and Algorithm 1 for the crescentfullmoon.m data set with n = 100, 000 data points and Laplacian RBF kernel (17).
6.3. Kernel Ridge Regression
In this section we show that our approach can be applied to the problem of kernel ridge regression, which has a similar flavor to the problem from the previous section. We here illustrate that our method is very flexible since other than just Gaussian kernels can be used for the fast evaluation of matrix-vector products. The starting point is a simple linear regression problem via the minimization of
where X ∈ ℝn×d is a design matrix holding training feature vectors in its rows, i.e., , and f ∈ ℝn is a given response vector. The solution u to this problem can then be used in a linear model to predict a response for any new point x ∈ ℝd as F(x) = uT x.
The well-known solution formula can be rearranged using the Sherman–Morrison–Woodbury formula to obtain
Using this formula, we can introduce the dual variable α = (XXT + βI)−1 f and rewrite the predicted response of a new point x as
An idea for increasing the flexibility of this method is replacing expressions with K(xi, xj) where K:ℝd×ℝd → ℝ is an arbitrary kernel function [48]. This leads to replacing XXT with the Gram matrix K with entries
Consequently, the dual variable becomes and we obtain the kernel-based prediction function
For more details we refer to Robert [48]. It is easily seen that the main effort of this algorithm goes into the computation of the coefficient vector Note that this is were we again use the NFFT-based matrix vector products in combination with the preconditioned CG method as the matrix K + βIn is positive definite and amenable to being treated using the NFFT for a variety of different kernel functions. In Figure 9 we illustrate the results when kernel ridge regression is used with two different kernels, namely the Gaussian and the inverse multiquadric kernel.
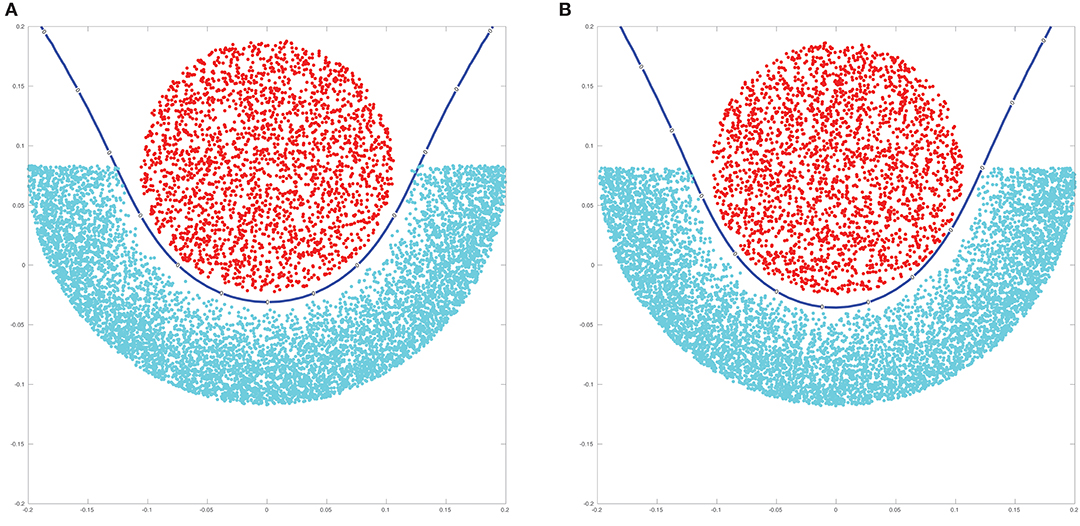
Figure 9. Results of kernel ridge regression applied using an inverse multiquadric kernel (A) and a Gaussian kernel (B). The blue line indicates the decision boundary for the classification of new points.
7. Conclusion
In this work, we have successfully applied the computational power of NFFT-based fast summation to core tools of data science. This was possible due to the nature of the fully connected graph Laplacian and the fact that many algorithms—most notably the Lanczos method for eigenvalue computation—only require matrix-vector products with the Laplacian matrix. By using Fourier coefficients to approximate the Gaussian kernel, we use Algorithm 1 to compute strong approximations of the matrix-vector product in complexity without storing or setting up the full matrix, as opposed to the full matrix's storage, setup, and application complexity.
For eigenvalue and eigenvector computations, we have discussed the current alternative method of choice in the Nyström extension and developed a hybrid method that allows the basic Nyström idea to benefit from NFFT-based fast matrix-vector products. In our numerical experiments, we found that the Nyström-Gaussian-NFFT method achieved much better eigenvalue accuracy than the traditional Nyström extension even for a significantly smaller parameter L, but was in turn outperformed by the NFFT-based Lanczos method.
In strongly eigenvector-dependent applications like in section 6.2.2, the higher accuracy of the NFFT-based Lanczos method directly leads to better classification results. In some other applications, however, it is hard to predict if better eigenvector accuracy distinctly improves the results. For instance in section 6.2.1, the traditional Nyström extension still achieved good image clusterings on average with small parameter L despite its rather inaccurate eigenvectors. Here, the NFFT-based Lanczos method still has very good selling points in its greatly improved runtime as well as its consistency, while the traditional Nyström tends to “fail” in some test runs.
Author Contributions
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1. ^https://www.tu-chemnitz.de/~potts/nfft/
2. ^https://www.tu-chemnitz.de/mathematik/wire/people/files_alfke/NFFT-Lanczos-Example-v1.tar.gz
3. ^https://sites.google.com/site/kittipat/matlabtechniques
4. ^https://www.mathworks.com/matlabcentral/fileexchange/41459-6-functions-for-generating-artificial-datasets
References
1. von Luxburg U. A tutorial on spectral clustering. Stat Comput. (2007) 17:395–416. doi: 10.1007/s11222-007-9033-z
2. Shuman DI, Narang SK, Frossard P, Ortega A, Vandergheynst P. The emerging field of signal processing on graphs: extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process Mag. (2013) 30:83–98. doi: 10.1109/MSP.2012.2235192
3. Belkin M, Niyogi P. Laplacian eigenmaps and spectral techniques for embedding and clustering. In: Advances in Neural Information Processing Systems 14 (Vancouver, BC). (2002). p. 585–91.
4. Belkin M, Niyogi P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput. (2003) 15:1373–96. doi: 10.1162/089976603321780317
5. Henaff M, Bruna J, LeCun Y. Deep convolutional networks on graph-structured data. arXiv preprint. (2015).
6. Bertozzi AL, Esedoglu S, Gillette A. Inpainting of binary images using the Cahn–Hilliard equation. IEEE Trans Image Process. (2007) 16:285–91. doi: 10.1109/TIP.2006.887728
7. Bertozzi AL, Flenner A. Diffuse interface models on graphs for classification of high dimensional data. Multiscale Model Simul. (2012) 10:1090–118. doi: 10.1137/11083109X
8. Baglama J, Reichel L. Augmented implicitly restarted Lanczos bidiagonalization methods. SIAM J Sci Comput. (2005) 27:19–42. doi: 10.1137/04060593X
9. Drineas P, Mahoney MW. On the Nyström method for approximating a Gram matrix for improved kernel-based learning. J Mach Learn Res. (2005) 6:2153–75.
10. Liberty E, Woolfe F, Martinsson PG, Rokhlin V, Tygert M. Randomized algorithms for the low-rank approximation of matrices. Proc Natl Acad Sci USA. (2007) 104:20167–72. doi: 10.1073/pnas.0709640104
11. Potts D, Steidl G. Fast Summation at nonequispaced knots by NFFTs. SIAM J Sci Comput. (2003) 24:2013–37. doi: 10.1137/S1064827502400984
12. Potts D, Steidl G, Nieslony A. Fast convolution with radial kernels at nonequispaced knots. Numer Math. (2004) 98:329–51. doi: 10.1007/s00211-004-0538-5
13. Keiner J, Kunis S, Potts D. Using NFFT3 - a software library for various nonequispaced fast fourier transforms. ACM Trans Math Softw. (2009) 36:19.1–19.30. doi: 10.1145/1555386.1555388
14. Morariu VI, Srinivasan BV, Raykar VC, Duraiswami R, Davis LS. Automatic online tuning for fast Gaussian summation. In: Advances in Neural Information Processing Systems 21. Vancouver, BC: Curran Associates, Inc. (2009). p. 1113–20.
15. Yang C, Duraiswami R, Gumerov NA, Davis L. Improved fast gauss transform and efficient kernel density estimation. In: Proceedings of the Ninth IEEE International Conference on Computer Vision (Nice). (2003). p. 464.
16. Chung FRK. “Spectral graph theory,” in Vol. 92 of CBMS Regional Conference Series in Mathematics. Providence, RI: Amer. Math. Soc. (1997).
17. Saad Y, Schultz MH. GMRES: a generalized minimal residual algorithm for solving nonsymmetric linear systems. SIAM J Sci Stat Comput. (1986) 7:856–69.
18. Zelnik-Manor L, Perona P. Self-tuning spectral clustering. In: Advances in Neural Information Processing Systems 17. Vancouver: MIT Press (2004). p. 1601–8.
19. Golub GH, Van Loan CF. Matrix Computations, 3rd Edn. Johns Hopkins Studies in the Mathematical Sciences. Baltimore, MD: Johns Hopkins University Press (1996).
20. Stewart G. A Krylov-Schur Algorithm for large eigenproblems. SIAM J Matrix Anal Appl. (2001) 23:601–14. doi: 10.1137/S0895479800371529
21. Sleijpen GL, Van der Vorst HA. A Jacobi–Davidson iteration method for linear eigenvalue problems. SIAM Rev. (2000) 42:267–93. doi: 10.1137/S0036144599363084
22. Lehoucq RB, Sorensen DC, Yang C. ARPACK Users' Guide: Solution of Large-Scale Eigenvalue Problems With Implicitly Restarted Arnoldi Methods. Philadelphia, PA: SIAM (1998).
23. Romano Y, Elad M, Milanfar P. The little engine that could: Regularization by denoising (RED). SIAM J Imaging Sci. (2017) 10:1804–44. doi: 10.1137/16M1102884
24. Spielman DA, Teng SH. Nearly-linear time algorithms for graph partitioning, graph sparsification, and solving linear systems. In: Proceedings of the Thirty-Sixth Annual ACM Symposium on Theory of Computing (Chicago, IL) (2004). p. 81–90.
25. Gilboa G, Osher S. Nonlocal operators with applications to image processing. Multiscale Model Simul. (2008) 7:1005–28. doi: 10.1137/070698592
26. Kunis S, Potts D, Steidl G. Fast Gauss transform with complex parameters using NFFTs. J Numer Math. (2006) 14:295–303. doi: 10.1163/156939506779874626
27. Nestler F. Automated parameter tuning based on RMS errors for nonequispaced FFTs. Adv Comput Math. (2016) 42:889–919. doi: 10.1007/s10444-015-9446-8
29. Lanczos C. An iteration method for the solution of the eigenvalue problem of linear differential and integral operators. J Res Nat Bur Stand. (1950) 45:255–82.
30. Parlett BN. The Symmetric Eigenvalue Problem. Vol. 20 of Classics in Applied Mathematics. Philadelphia, PA: SIAM (1998).
31. Hestenes MR, Stiefel E. Methods of conjugate gradients for solving linear systems. J Res Nat Bur Stand. (1952) 49:409–36.
32. Paige CC, Saunders MA. Solutions of sparse indefinite systems of linear equations. SIAM J Numer Anal. (1975) 12:617–29.
34. Simoncini V, Szyld DB. Theory of inexact Krylov subspace methods and applications to scientific computing. SIAM J Sci Comput. (2003) 25:454–77. doi: 10.1137/S1064827502406415
35. Garcia-Cardona C, Merkurjev E, Bertozzi AL, Flenner A, Percus AG. Multiclass data segmentation Using diffuse interface methods on graphs. IEEE Trans Pattern Anal Mach Intell. (2014) 36:1600–13. doi: 10.1109/TPAMI.2014.2300478
36. Merkurjev E, Kostic T, Bertozzi AL. An MBO scheme on graphs for classification and image processing. SIAM J Imaging Sci. (2013) 6:1903–30. doi: 10.1137/120886935
37. Williams C, Seeger M. Using the Nyström method to speed up kernel machines. In: Advances in Neural Information Processing Systems 13. Denver, CO: MIT Press (2001). p. 682–8.
38. Fowlkes C, Belongie S, Chung F, Malik J. Spectral grouping using the Nyström method. IEEE Trans Pattern Anal Mach Intell. (2004) 26:214–25. doi: 10.1109/TPAMI.2004.1262185
40. Volkmer T. OpenMP Parallelization in the NFFT Software Library. Preprint 2012-07, Faculty of Mathematics, Technische Universität Chemnitz (2012).
41. Ng AY, Jordan MI, Weiss Y. On spectral clustering: analysis and an algorithm. In: Advances in Neural Information Processing Systems 14 (Vancouver, BC). (2002). p. 849–56.
42. van Gennip Y, Guillen N, Osting B, Bertozzi AL. Mean curvature, threshold dynamics, and phase field theory on finite graphs. Milan J Math. (2014) 82:3–65. doi: 10.1007/s00032-014-0216-8
43. Luo X, Bertozzi AL. Convergence of the graph allen–cahn scheme. J Stat Phys. (2017) 167:934–58. doi: 10.1007/s10955-017-1772-4
44. Bosch J, Klamt S, Stoll M. Generalizing diffuse interface methods on graphs: non-smooth potentials and hypergraphs. SIAM J Appl Math. (2018) 78:1350–77. doi: 10.1137/17M1117835
45. Zhou D, Bousquet O, Lal TN, Weston J, Schölkopf B. Learning with local and global consistency. In: Advances in Neural Information Processing Systems 16 (Vancouver, BC). (2003).
46. Hein M, Setzer S, Jost L, Rangapuram SS. The total variation on hypergraphs – Learning on hypergraphs revisited. In: Advances in Neural Information Processing Systems 26 (Lake Tahoe, NV). (2013). p. 2427–35.
47. Iske A, Borne SL, Wende M. Hierarchical matrix approximation for kernel-based scattered data interpolation. SIAM J Sci Comput. (2017) 39:A2287–316. doi: 10.1137/16M1101167
Keywords: Graph Laplacian, Lanczos method, eigenvalues, nonequispaced fast Fourier transform, machine learning
Citation: Alfke D, Potts D, Stoll M and Volkmer T (2018) NFFT Meets Krylov Methods: Fast Matrix-Vector Products for the Graph Laplacian of Fully Connected Networks. Front. Appl. Math. Stat. 4:61. doi: 10.3389/fams.2018.00061
Received: 07 September 2018; Accepted: 28 November 2018;
Published: 19 December 2018.
Edited by:
Michael Ng, Hong Kong Baptist University, Hong KongReviewed by:
Sergiy Pereverzyev Jr, Innsbruck Medical University, AustriaHyenkyun Woo, Korea University of Technology and Education, South Korea
Chao Chen, Stanford University, United States
Copyright © 2018 Alfke, Potts, Stoll and Volkmer. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Daniel Potts, ZGFuaWVsLnBvdHRzQG1hdGhlbWF0aWsudHUtY2hlbW5pdHouZGU=