 Peter Jan van Leeuwen
Peter Jan van Leeuwen- 1Department of Atmospheric Science, Colorado State University, Fort Collins, CO, United States
- 2Department of Meteorology, University of Reading, Reading, United Kingdom
Non-local observations are observations that cannot be allocated one specific spatial location. Examples are observations that are spatial averages of linear or non-linear functions of system variables. In conventional data assimilation, such as (ensemble) Kalman Filters and variational methods information transfer between observations and model variables is governed by covariance matrices that are either preset or determined from the dynamical evolution of the system. In many science fields the covariance structures have limited spatial extent, and this paper discusses what happens when this spatial extent is smaller then the support of the observation operator that maps state space to observations space. It is shown that information is carried beyond the physical information in the prior covariance structures by the non-local observational constraints, building an information bridge (or information channel) that has not been studied before: the posterior covariance can have non-zero covariance structures where the prior has a covariance of zero. It is shown that in standard data-assimilation techniques that enforce a covariance structure and limit information transfer to that structure the order in which local and non-local observations are assimilated can have a large influence on the analysis. Local observations should be assimilated first. This relates directly to localization used in Ensemble Kalman Filters and Smoothers, but also to variational methods with a prescribed covariance structure where observations are assimilated in batches. This suggests that the emphasis on covariance modeling should shift away from the prior covariance and toward the modeling of the covariances between model and observation space. Furthermore, it is shown that local observations with non-locally correlated observation errors behave in the same way as uncorrelated observations that are non-local. Several theoretical results are illustrated with simple numerical examples. The significance of the information bridge provided by non-local observations is highlighted further through discussions of temporally non-local observations, and new ideas on targeted observations.
1. Introduction
The most general form of data assimilation is given by Bayes Theorem that describes how the probability density function (pdf) of the state of the system x is updated when observations y become available:
in which p(x) is the prior pdf of the state, and p(y|x) the likelihood of the observation given that the state is equal to x. This likelihood is determined by the measurement process. For instance, when the measurement error is additive we can write
This equation maps the given state vector x into observation space via the observation operator H(..). Since y is given also this equation determines ϵ, and since the pdf of the observation errors is known we know what the likelihood looks like. It is emphasized that Bayes Theorem is a point-wise equation for every possible state vector x.
A non-local observation is typically defined as an observation that cannot be attributed to one model grid point. The consequence is that model state space and observation space should be treated differently. However, Bayes Theorem is still valid, and general enough to tells us how to assimilate these non-local observations.
This is different in practical data-assimilation methods for high-dimensional systems that are governed by local dynamics. Examples are Ensemble Kalman Filters, in which a small number, typically O(10 − 100), of ensemble members is used to mimic a Kalman Filter. Because of the small ensemble size the sample covariance matrix is noisy, and a technique called localization is used to set long-range correlations to zero, as they physically should be, see [1, 2].
Non-local observations can have a support that is larger than the localization area. With support is meant that part of state space that is needed to specify the model equivalent of an observation. When H is linear it is that part of state space that is not mapped to zero. A larger support is not necessarily a problem as long as non-local observations are allowed to influence those model variables with whom they have strong correlations, see e.g., [3]. Assimilating non-local observations as local ones, e.g., by using the grid points where they have most influence, can lead to degradation of the data-assimilation result, as Liu et al. [4] show and hence it is important to retain their full non-local structure.
There has been an extensive search for efficient covariance localization methods that allow for non-local observations, including using off-line climatological ensembles, groups of ensembles, and augmented ensembles in which the ensemble members are localized by construction, see e.g., [5–9].
All of these methods try to find the best possible localization function based on the prior. The main focus of this paper is not on developing better covariance estimates, but rather on the influence on the data-assimilation results of non-local observations in which the support of the observation operator is larger than the dependency (or, for linear relations, correlation) length scale in the prior. This can be due to a mis-specification of the prior localization area, or due to a real prior covariance influence area that is smaller than the support of the observation operator. Since the prior is expected to contain the physical dependencies in the system, this means that a non-local observation needs information from model variables that are physically independent. As will be shown after assimilation new dependencies between the variables involved in the observation operator are generated, on top of the physical dependencies already present. Hence, the non-local observations generate information bridges that are not present in the prior. These bridges can appear both in space and in time.
As an example of the influence of non-local observations on practical data-assimilation systems, since non-local observations generate information bridges, so build new covariance structures, the order in which observations are assimilated becomes important in serial assimilation when covariance length scales are imposed, as in standard localization techniques and in variational methods. This is also true for local observations, but the effect in the non-local case is much larger.
In this paper we will discuss the implications of these information bridges, and strategies of how to assimilate non-local observations. Furthermore, the connection is made to correlated observation errors where the correlations are non-local in the sense defined above. Finally, we discuss ways how we can exploit the appearance of these information bridges to improve data-assimilation systems.
2. The Assimilation of Non-local Observations
In the following we will first demonstrate the treatment of non-local observations in the most general way, via Bayes Theorem, and how non-local observations generate information bridges in the posterior. Then we show that the order in which local and non-local observations are assimilated does not matter, when we solve the full data-assimilation problem, so building the bridges first or later is not relevant. This conclusions does not hold necessarily when approximations to the full data-assimilation problem are introduced, as we will see in later sections.
2.1. Non-local Observations in Bayes Theorem
Let us first study how these information bridges are formed via a simple example. Assume two parts of the state space are independent under the prior, so p(x1, x2) = p(x1)p(x2), and we have an observation that combines the two, e.g., y = H(x1, x2, ϵ), where the observation operator H(..) can be a non-linear function of its arguments. Bayes Theorem shows:
Since y depends on both x1 and x2 the likelihood cannot be separated in a function of x1 only times a function of x2 only. This means that we also cannot separate the posterior pdf in this way, and hence x1 and x2 have become dependent under the posterior. Since Bayes Theorem is the basis of all data-assimilation schemes, the same is true for (Ensemble) Kalman Filters/Smoothers, variational methods, or e.g., Particle Filters.
As an example, Figure 1 shows the joint prior pdf of two independent variables. The pdf is constructed from p(x1, x2) = p(x1)p(x2) in which p(x1) is bimodal and p(x2) a unimodal Gaussian. The likelihood is given in Figure 2, related to an observation y = x1 + x2 + ϵ in which ϵ is Gaussian distributed with zero mean. Their product is the posterior given in Figure 3. It is clearly visible that the two variables are highly dependent under the posterior, purely due to the non-local observation.
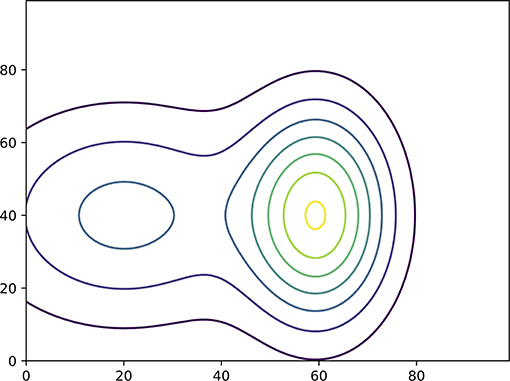
Figure 1. The prior pdf of two independent variables.
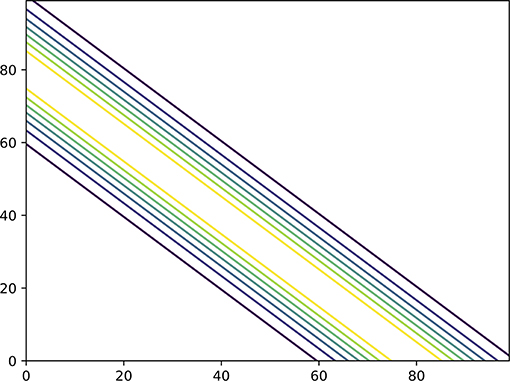
Figure 2. The likelihood as function of the state, corresponding to an observation that is the sum of the two variables. Note that the likelihood is ambiguous on which values of x1 and x2 are most likely as the observation only gives the value of a linear combination of them.
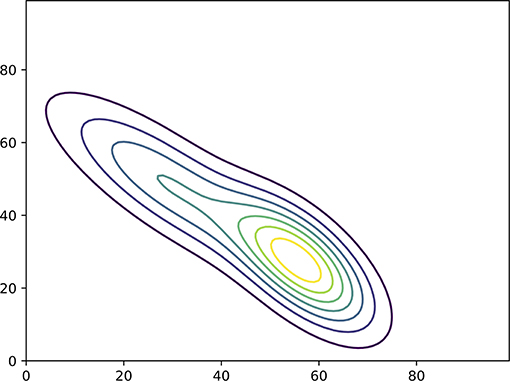
Figure 3. The posterior pdf. Note that the two variables are highly correlated due to the non-local observation.
We now analyse the following simple system in more detail to understand what the influence of non-local spatial observations in linear and linearized data-assimilation methods is. The state is two-dimensional , with diagonal prior covariance matrix B with diagonal elements (b11, b22) and a non-local observation operator H = (1 1). A scalar non-local observation y = Hxtrue + ϵtrue with measurement error variance r is taken. The subscript true reminds us that the observation is from the true system, while x denotes the state of our model of the real world (this can easily be generalized to different parts x1 and x2 of a larger state vector and more, or more complicated, non-local observations y. The two-dimensional system is chosen here for ease of presentation).
The Kalman filter update equation for this system reads:
with posterior covariance matrix:
in which d = b11 + b22 + r.
This simple example illustrates the two points from the general case above. Firstly, even if the prior variables are uncorrelated they are correlated in the posterior because of the non-local observation operator mixes the uncorrelated variables of the prior. A second point is that the update of each variable is dependent on the value of the other, even when the two variables are uncorrelated in the prior. Hence the non-local observation acts as an information bridge between uncorrelated variables, both in terms of mean and covariance.
This conclusion remains valid for variational methods like 3DVar as 3DVar implicitly applies the Kalman Filter equations in an iterative manner.
2.2. Order of Observations
The results from the previous section might suggest that the order in which local and non-local observations are assimilated is important: if a non-local observation is assimilated first the next local observation can influence all variables involved in the non-local observation operator. On the other hand, when the local observation is assimilated first this advantage seems to be lost. However, this is not the case, the order in which we assimilate observations is irrelevant in the full Bayesian setting (this is different when localization is used, as explained in section 4).
The easiest way to see this is via Bayes Theorem. Suppose we have two observations, a non-local observation ynl and a local observation yl of only x2. We assume their measurement errors are independent. Bayes Theorem tells us:
If we assimilate yl first we get:
and vice versa:
but the result is the same as the order in a multiplication doesn't matter (this is true in theory, in practice differences may arise due to round-off errors). Since the Kalman Filter/Smoother is a special case of this when all pdf's are Gaussian it is true also for the Kalman Filter/Smoother, and for variational methods. As we will see in a later section, care has to be taken when observations are assimilated sequentially and localization is enforced.
To complete the intuition for the Kalman Filter, if the local observation yl is assimilated first the mean and covariance of variable x2 are updated, but x1 remains unchanged. Hence when the non-local observation is assimilated both the mean and covariance of x2 have changed, and these changed values are used when assimilating the non-local observation, so that x1 does feel the influence of the local observation via the updated x2 and its updated variance. Typically the updated x2 will be such that x1 + x2 is closer to ynl, and its prior covariance before assimilating ynl will be smaller. The result is that x1 will be updated stronger than in the case when x2 has not seen yl first, as proven in the next section.
3. Kalman Filter/Smoother With Temporally Non-local Observations
The above discussed spatially non-local observations. However, we can easily extend this to temporally non-local observations as we show here in a simple example that illustrates the point. We can easily generalize the results below to the vector case.
We study a one-dimensional system with states xn at time n and an observation y = xm + xn + ϵ. This problem can be solved by considering a Kalman Smoother, exploring the cross covariance of the states at time n and m, and is explored in standard textbooks. The interesting case is when this prior cross covariance between time n and m is zero, or negligible (for many systems this would mean that m >> n).
Similarly to the spatially non-local case we define the state vector x = (xm, xn)T. The prior covariance of this vector depends on the model that governs the evolution of the state in absence of observations. As mentioned, we will study the case that the cross covariance between these two times is zero in the prior, so the prior covariance for this state vector x is given by
The Kalman Filter update equation reads for this case:
with posterior covariance matrix:
with d = bmm + bnn + r.
The similarity with the spatial non-local observations is striking, and indeed the cases are completely identical, with time taking the place of space. The same conclusions as for the spatial case hold: even when states at different times are completely uncorrelated in time under the prior they can be correlated under the posterior when the observation is related to a function of the state vectors at both times, providing an information bridge between the two times.
4. Consequences for Sequential Updating Schemes With Fixed Covariance Length Scales
The results above show that when non-local observations are assimilated they significantly change the prior covariance length and/or time-scales during the data-assimilation process. This has direct consequences for methods that assimilate observations sequentially and at the same time enforce covariance structures with certain length scales. An example is a Local Ensemble Kalman Filter, in which spurious correlations are suppressed either by Schur-multiplying the prior ensemble covariance with a local correlation matrix or Schur-multiplying the inverse of the observation error covariance matrix with a distance function. This procedure effectively sets covariances equal to zero above a certain distance between grid points. This localization in combination with sequential observation updating has to be done with care, as shown below. Another example is a 3D or 4DVar in which observations are assimilated in batches.
Assimilation of non-local observations that span length scales larger than the localization correlation length scale can potentially lead to suboptimal updates if the observations are assimilated in the wrong order. This is illustrated below, first theoretically and then with a simple example.
4.1. The Influence of Localization
Let us assume we have two variables x1 and x2 that lie outside each others localization area. A localization area is defined here as the area in which observations are allowed to influence the grid point in consideration. Two observations are made, a non-local observation y1 = x1 + x2 + ϵ1 and a local observation y2 = x2 + ϵ2. We study the result of the data-assimilation process on variable x1 where we change the order of assimilation.
When we assimilate the non-local observation y1 first, we find the update:
As shown in the previous sections, this assimilation generates a cross covariance between x1 and x2 as
When we now assimilate observation y2 the fixed covariance length scale, from localization or otherwise, we will remove the cross covariance before y2 is assimilated, and hence x1 is not updated further, so and and .
The story is different when we first assimilate y2 and then y1. In this case we find that x1 is not updated by y2, but x2 and its variance are. Let's denote these updated variables by and . We then find for the update of x1 by the non-local observation y1:
We can now substitute the ˆ values in these expressions. We start with the posterior variance . We find, after some algebra:
in which . The first and second terms in the expression above appear when we would assimilate y1 first, and the third term proportional to d is an extra reduction of the variance of x1 due to the fact that we first assimilated y2. That reduction is absent when we first assimilate y1 and then assimilate y2 due to the localization procedure as shown above.
This third term can be as large as the second term. We can quantify this with the following example, in which we assume the prior variances of x1 and x2 are the same, hence b22 = b11 = b. In that case d becomes defined by:
This is the extra reduction due to assimilating y1 after y2, relative to the reduction due to assimilating y1 alone. In Figure 4 the size of this term is shown as function of r1/b and r2/b. As expected the size increases when the observation errors are smaller than the prior variances.
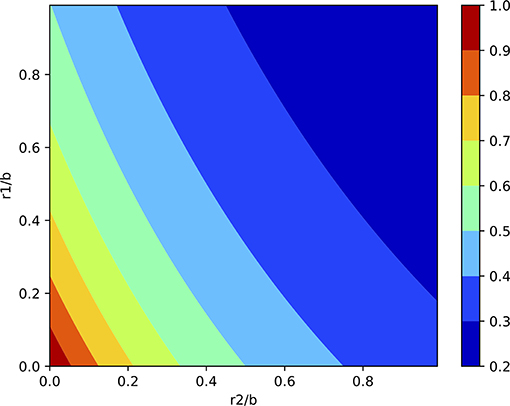
Figure 4. Extra reduction of the posterior variance when the non-local observation is assimilated after the local observations compared to assimilating the observations the other way around (the factor in Equation 19). This is purely due to the fixed covariance length scales used in the prior.
Let us now look at the posterior mean, for which we find:
The first line is the contribution purely from the non-local observation. It appears when we first assimilate the non-local observation and then the local observation, and is equal to Equation (12). However, first assimilating y2 and then the non-local observation y1 leads to the appearance of two extra terms. The term related to y2 − x2 is a direct contribution of the innovation of the local observation at x2 (as can be seen from ), and can be traced back to the fact that x2 has changed due to assimilation of y2 first. The other term is related to the change in the variance of x2 due to the assimilation of y2.
To understand the importance of these two extra terms we again assume b11 = b22 = b, to find:
where d = 1/[(2 + r1/b)(1 + r2/b) − 1]. Of course, the value of depends on the actual values for the observations and the prior means. To obtain an order of magnitude estimate we assume that the innovation y1 − (x1 + x2) is of order . and similarly . Since the signs of the different contributions depend on the actual signs of y1 − (x1 + x2) and y2 − x2 we proceed as follows. We rewrite the expression for as:
Hence the ratio of the first extra term d(y1 − (x1 + x2)) to the contribution only from y1 is proportional to d, and is given in Figure 4. The ratio of the rest to the contribution only from y1 is given in Figure 5. Note that we used the approximations for y2 − x2 and y1 − (x1 + x2) above, which means that this ratio becomes
The sign of this contribution is unclear, as mentioned above, so we have to either add to or subtract this figure from Figure 4.
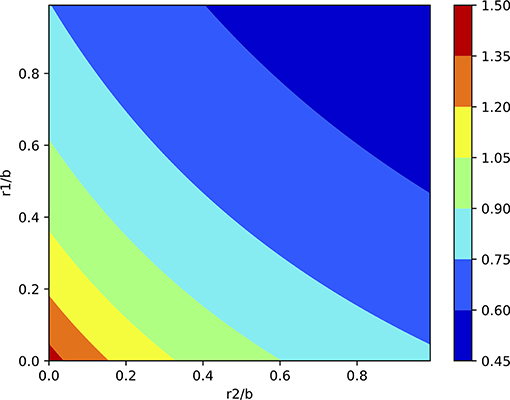
Figure 5. Second contribution of assimilation local observation y2 first, as given as the ratio in Equation (23). This figure should be added to or subtracted from Figure 4.
The importance of Figures 4, 5 is that they show that when the observation errors are small compared to the prior variance the update could be more than 100% too small when localization is used if one first assimilates the non-local observation y1, followed by assimilating y2. Hence non-local observations should be assimilated after local observations.
When the update is not sequential, but instead local and non-local observations are assimilated in one go, we obtain the same result we would obtain by first assimilating the local observation and then the non-local observation. The reason is simple: assimilating the non-local observation means that all grid points in the domain of the non-local observation are allowed to see all other gridpoints in that domain, and hence information from local observations is shared too.
It is emphasized again that the above conclusions are not restricted to Ensemble Kalman Filters and Smoothers. Any scheme that assimilates observations sequentially, or in batches, should ensure that non-local observations in which the support of the observation operator is larger than the correlation length scales used in the covariance models should be assimilated after the local observations.
4.2. An Assimilation Example
To illustrate the effect explained in the previous section the following numerical experiment is conducted. We run a 40-dimensional model, the Lorenz 1996 model, with an evolution equation for each state component given by:
The forcing F = 8 is a standard value ensuring chaotic dynamics. The system is periodic. We use a Runge-Kutta 4 scheme with time step Δt = 0.01. The βi are random variables denoting model errors, white in time and βi ~ N(0, Q) in space, in which Q1/2 is a tridiagonal matrix with 0.1 on the diagonal and 0.025 on the subdiagonals.
The model is spun up from a random state in which each , is independent from the other state components. The spin up time is 10,000 time steps. Then a true model evolution is generated for 10,000 time steps, starting at time zero. Observations are created from this true run every Δtobs time steps, with observation errors drawn from N(0, R) in which R is diagonal. Both Δtobs and R are varied in the experiments below. Local observations are taken from positions [5, 10, 15, 20, 25, 30, 35] and a non-local observation is taken as Hx = x0 + x5.
An LETKF is used with a Gaspari-Cohn localization function on R−1 with cut-off radius of 5 gridpoints, which means that observation error variances are multiplied by a factor >10 after 3 grid points, so they have little influence compared to observations close to the updated grid point. This localization is kept constant to illustrate the effects; it might be tuned in real situations. The ensemble consist of 10 members, initialized from the true state at time zero with random perturbations drawn from N(0, I). When assimilating the non-local observation the localization is only applied outside the domain of the non-local observation.
We run two sets of experiments, one set in which all the local observations are assimilated first at an analysis time, followed by assimilating the non-local observation, and one in which the non-local observation is assimilated first, followed by all other observations. We looked at the difference of these two assimilation runs for different values of the observation period Δtobs and different values of the observation error variances in R. All observation error values for local and non-local observations are the same.
Figure 6 shows the posterior RMSE averaged over all assimilation times of the state component x0 as function of the chosen observation error standard deviation. The different lines correspond to the different observation periods, ranging from 10, via 20 to 50 time steps, in colors black, blue, and red, respectively. The solid lines denote the results when the non-local observation is assimilated last, and the dashed lines show results when the non-local observation is assimilated first. All results are averaged over 10 model runs, and the resulting uncertainty is of the order of 0.1. Increasing the average to 100 model runs did not differ the numbers within these error bounds.
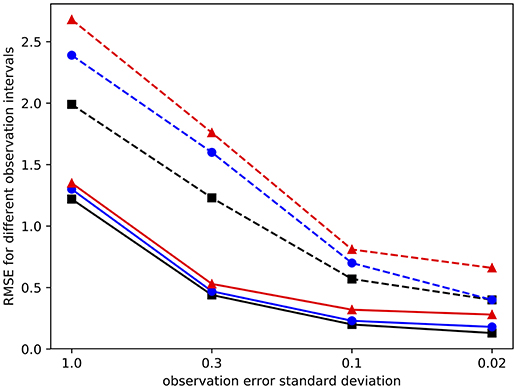
Figure 6. RMSE of state component x0 which is part of a non-local observation, as function of observation error. The black (squares), blue (dots), and red (triangles) lines denote observation periods of 10, 20, and 50 time steps. The solid lines are for cases in which the non-local observation is assimilated last, dashed lines when non-local observation is assimilated first. Note the logarithmic horizontal scale. The figure shows that assimilating the non-local observation after local observations is beneficial.
As can be seen from the figure, assimilating the non-local observation last leads to a systematically lower RMSE for all observation periods and for all observation error sizes. These results confirm the theory in the previous section.
We also performed several experiments in which the observation error in the non-local observation was higher or lower than that in the local observations for the experiment with Δtobs = 20 time steps. As an example of the results, increasing the non-local observation error from 0.1 to 0.3 increased the RMSE in x0 from 0.23 to 0.24 when the non-local observation is assimilated last, but from 0.70 to 0.81 when it is assimilated first. This shows that the impact of a larger non-local observation error is less when the non-local observation is assimilated last because of the benefit of the more accurate state x5. When the non-local observation is assimilated first this update of x5 is not noticed by the data-assimilation system.
In another example we decreased the observation error of the non-local observation from 0.3 to 0.1. In this case the RMSE of x0 remained at 0.47 when the non-local observation is assimilated last, and decreased from 1.60 to 1.50 when it is assimilated first. As expected, the influence is much smaller in the former case as the state at x5 is now less accurate. Hence, also these experiments demonstrate that the theory developed above is useful.
Finally, the results are independent of the dimension of the system; a 1,000-dimensional Lorenz 1996 model yields results that are very similar and with differences smaller than the uncertainty estimate of 0.1. This is because the analysis is local, and the non-local observation spans just part of the state space.
5. Correlated Observation Errors
Although observations errors are typically assumed to be uncorrelated in data-assimilation systems, they in fact are often correlated, and the correlation length scales can even be longer than the correlation length scales in the prior. Correlated observation errors can either arise from the measurement instrument, e.g., via correlated electrical noise in satellite observations, but also from the mismatch between what the observations and the model represent. The latter are called representation errors and typically arise when the observations have smaller length scales than the model can resolve. See e.g., full explanations of representation errors in Hodyss and Nichols [10] and Van Leeuwen [11], and a recent review by Janjić et al. [12].
The latter, representation errors, typically do not lead to non-local correlation structures in the model domain as the origin of these errors is sub grid scale. The discussion here focusses on correlation between observation errors of observations that are farther apart than the localization radius or than the imposed correlation length scales in variational methods. As we will see, there is a strong connection to non-local observations.
5.1. A Simple Example
Let us look at a simple example of two grid points that are farther apart than the imposed localization radius, or than physical correlation length scales. Both are observed, and the observation errors of these two observations are correlated. The observation operator H = I, the identity matrix. The covariance matrices read:
The inverse in the Kalman gain is a full matrix:
in which D is the absolute value of the determinant, given by D = (b11 + r11)(b22 + r22) − r12r21. The factor BHT is diagonal, as H is the identity matrix. Because of the non-zero off-diagonal elements in the resulting Kalman gain the state component x1 is updated as:
To make sense of this equation we rewrite it, after some algebra, as:
in which
This equation shows us several interesting phenomena. The first term in the brackets denotes the update of x1 when we would only use observation y1. The other term has to do with using observation y2 while its errors are correlated with that of y1. Interestingly, the update by y1 gets enhanced by a term with factor ρ1ρ2/(1 − ρ1ρ2), which is positive. This update is also changed by y2, with a sign depending on r12 and y2 − x2. To understand where these terms come from we can rewrite the expression above further as:
We now see that the influence of the correlated observation errors is to change the denominator of the factor that multiplies the innovation y1 − x1. That denominator becomes smaller because of the cross correlations, so the innovation will lead to a larger update.
The influence of the second innovation is not that straightforward. Let's take the situation that the errors in the two observations are positively correlated, so ρ2 > 0. Now assume that y1 − x1 is positive. Then, as expected, the K11 element of the gain is positive, so the update to x1 is positive. Indeed, we want to move the state closer to the observation y1. On the other hand, we know that x1 is an unbiased estimate of the truth, so this does suggest that the realization of the observation error of y1 is positive. Let's also assume that y2 − x2 is positive. As also x2 is assumed unbiased this suggests that the observation error in y2 is positive too. The filter knows that these two errors are correlated via the specification of R. Because both innovations indicate that the actual observation error is positive it will incorporate the contribution from y2 − x2 with a negative sign to avoid a too large positive update of x1. If, on the other hand, y2 − x2 would have been negative the filter has no indication that the actual observation error positive or negative, so y2 − x2 would be allowed to add positively to x1. However, note that innovation will act negatively on the update of x2. The Kalman Filter is a clever device, designed to ensure an unbiased posterior for both x1 and x2.
A similar story holds for x2 as the problem is symmetric. This shows that neglecting long-range correlations in observation errors can lead to suboptimal results with analysis errors that are too large. Similar results have been found for locally correlated observations, e.g., [13, 14], and recent discussions on the interplay between HBHT and R in Miyoshi et al. [15] and Evensen and Eikrem [16].
5.2. The Connection to Non-local Observations
An interesting connection can be made with recent ideas to transform observations such that their errors are uncorrelated. The interest for such a transform stems from the fact that many data-assimilation algorithm implementations either assume uncorrelated observation errors or run much more efficiently when these errors are uncorrelated. Let us assume such a transformation is performed on our two observations. There are infinitely many transformations that do this, and let us assume here that the eigenvectors of R are used.
Decomposing R gives R = UΣUT in which the columns of U contain the eigenvectors and Σ is a diagonal matrix with on the diagonal the eigenvalues
If we transform the observation vector as this new vector has covariance matrix Σ, and hence the errors in the components of are uncorrelated. The interesting observation is now that the components of are non-local observations with uncorrelated errors. Hence, our analysis of the influence of non-local observations applies directly to this case.
As a simple example, assume r11 = r22 = r and r12 = r21 = ρr (this could be worked out for the general case, but the expressions become complicated and serve no specific purpose for this paper). In that case λ1,2 = r(1 ± ρ) and the eigenvectors are and . This leads to transformed observations and .
Using the Kalman Filter update equation for variable x1 we find:
in which which turns out to be the same D as found for the correlated observation errors. This is not surprising as with y also H and R have been transformed, and hence HBHT + R has transformed in the same way. This means we can always extract a similar factor from the denominator of the Kalman update. Hence, we have transformed the problem from local observations with non-locally correlated errors to non-local observations with uncorrelated errors.
To show that this is the same as the original problems we now rewrite this analysis for the observations with correlated errors, so in terms of y, and collect terms y1 − x1 and y2 − x2 to find:
With r22 = r and r12 = ρr we recover the analysis equation for the correlated observation error case.
Hence we have shown that assimilating correlated observations with correlation length scales larger than physical length scales is the same as assimilating the corresponding non-local uncorrelated observations (this result has resemblance to but is different from that of Nadeem and Potthast [17], who discuss transforming all observations, local and non-local such that they all become local observations. They then do the localization and data assimilation in this space, and transform back to physical space. This, of course, will lead to correlated errors in the transformed non-local observations).
It will not come as a surprise that if observations are assimilated sequentially and localization, or a fixed covariance length scale, is used the order of assimilation matters, and non-locally correlated observations should be assimilated after local observations. Finally, it is mentioned that the story is similar for non-local observation error correlations in time.
6. Exploiting Non-local Observations
As mentioned above, to avoid cutting off non-local observation information during sequential assimilation it is best to assimilate the non-local observation after the local observations. However, an alternative strategy is to change the localization area if that is possible. Before the non-local observation is assimilated the localization area should remain as is. As soon as the non-local observation is assimilated we have created significant non-zero correlations along the domain of the non-local observation operator. This means that we can include this area in the localization domain.
To illustrate this idea the same experiments from section 4 have been repeated applying the procedure outlined above for Δtobs = 10, and used the real observation error of the observation at x5 in location x0. This means that effectively there is no localization between these two grid points. This is an extreme case, but does illustrate the point we want to make. The results are depicted in Figure 7.
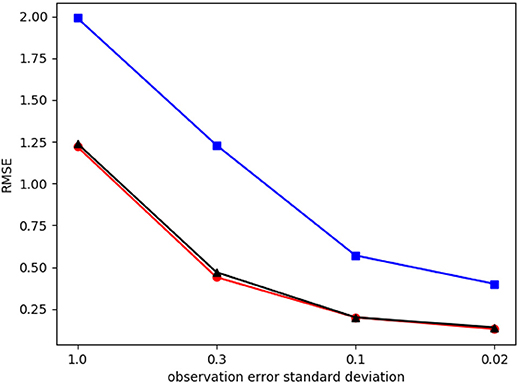
Figure 7. RMSE of state component x0 which is part of a non-local observation, as function of observation error for Δobs = 10. Cases in which the non-local observation is assimilated last (red, dots), when non-local observation is assimilated first (blue, squares), and when the non-local observation is assimilated first and localization area is adapted with localization effectively removed between x5 and x0 (black, triangles).
They show that changing the localization area after assimilating the non-local observation does help. In theory, for two variables, this should give the same result as assimilating the non-local observation after the local observation. That this is not the case here is because grid point 5 is also updated slightly by grid point 10, and that reduces the variance at x1 further when the non-local observation is assimilated last, while that information is not available when the non-local observation is assimilated first. The conclusion is that changing the localization area after assimilating a non-local observation is beneficial for the data-assimilation result.
Another way to explore the features of non-local observations in data assimilation is as follows. Assume we have an area of interest that is poorly observed, and not easily observed locally. We assume that we do not have and cannot obtain accurate local observations in that area, but a non-local observation is possible. Section 4, and specifically Equation (18) shows that is make sense to ensure that the support of this non-local observation contains a well-observed area. In this way the area of interest will benefit from the accurate information from the well-observed area via the information bridge. Another way of phrasing what happens is that by having an accurately observed area in the support of the non-local observation its information is redistributed more toward Another possibility along the same lines is when we already have a non-local observation containing the area of interest in its support. The accuracy in the area of interest can be enhanced by performing extra local observations in an easy to observe area, that is in the support of the non-local observation. Hence again we exploit the information bridge, this time by adding a local observation in a well-chosen position. This idea provides a new way to perform targeted observations that has not been explored as yet, as far as this author knows. This could also be exploited in time, or even in space and time.
Finally, one might think that it is possible to enhance the accuracy of the update in an area of interest by artificially introducing correlated observation errors between observations in that area and observations in another well-observed area. Since correlated observation errors can be transformed to non-local observations a similar information bridge can be build that might be beneficial.
To study this in detail we use the example from section 5.1. Assume that we have two observations with uncorrelated errors, and we add a fully correlated random perturbation with zero mean to them, so y1 = Hx1 + ϵ1 + ϵ and y2 = Hx2 + ϵ2 + ϵ in which ϵ1 and ϵ2 are uncorrelated, and ϵ ~ N(0, r), the same value for each observation. Hence this ϵ term contains the fully correlated part of the observation error that we added to the observations artificially. This leads to a correlated observational error covariance given by:
Using this in the Kalman gain we find for the gain of observation y1:
The first ratio is the Kalman gain without the correlated observation error contribution. This is multiplied by the factor when the correlated observation error is included. We immediately see that this factor is smaller then 1, so reducing the Kalman gain. This shows that adding extra correlated observation errors to observations that are farther apart then the covariance structures in the prior will not lead to better updates: in fact the updates will deteriorate (As an aside, this would be different if we would have access to ϵ1 and ϵ2, in which case ϵ could be a linear combination of these two, and the Kalman gain could be made larger than the gain for just assimilating y1. Unfortunately, we are given y1 and y2, not their error realizations).
7. Conclusions and Discussion
In this paper we studied the information transfer in data-assimilation systems when non-local observations are assimilated. Non-local observations are defined here as observations with a observation operator support that is larger then the covariance length scales. This pertains to both spatial and temporal non-locality. It is found that these observations connect parts of the domain that were not connected in the prior, building an information bridge that is longer than the physics and statistics in the prior predict. Hence the notion that information from observations is spread around via the correlation length scales in B is only part of the story as non-local observations can spread information over larger distances. Indeed, one should look at the full BHT factor of the gain, and realize that the observation operator can change the covariance structures.This suggests that the emphasis on covariance modeling should shift away from the prior covariance and toward the modeling of the covariances between model and observation space.
We showed how non-local observation information is transferred to the posterior in Bayes Theorem and hence in fully non-linear and in linear and linearized data-assimilation schemes, such as (Ensemble) Kalman Filters and variational methods. Then we elaborated on the interaction of localized covariances, as typically used in the geosciences, and the sequential assimilation of observations. It was shown that it is beneficial to assimilate non-local observations after local observations in order to maximize information flow from observations in the data-assimilation system. This was quantified both analytically and numerically.
Furthermore, it was shown that observations with non-locally correlated observation errors can be transformed to non-local observations with uncorrelated observation errors, demonstrating the equivalence of the two.
In an attempt to explore the information flow by non-local observations we showed that non-local observations do not have to be assimilated after local observations if localization areas are extended along the support of the non-local observation operator after the non-local observations are assimilated, both analytically and with a numerical example.
Furthermore, it was shown that targeted non-local observations can be used to bring the information from accurate observations to other parts of the system. It was also shown that it is not beneficial to add correlated observation errors to distant observations to set up an information bridge as that will always be detrimental.
These initial explorations of non-local observations might guide the development of real data-assimilation applications where observations are assimilated sequentially and non-local observations and/or non-locally correlated observation errors are used. The main message might be that one should not optimize for the covariance structures in the prior, but optimize the covariance structures between observations and model variables.
Data Availability Statement
The datasets generated for this study are available on request to the corresponding author.
Author Contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Funding
The author thanks the European Research Council (ERC) for funding the CUNDA project 694509 under the European Union Horizon 2020 research and innovation programme.
Conflict of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The handling editor and reviewer AC declared their involvement as co-editors in the Research Topic, and confirm the absence of any other collaboration.
Acknowledgments
I would like to thank the two reviewers for valuable comments that greatly improved the paper.
References
1. Houtekamer PL, Mitchell HL. A sequential ensemble Kalman filter for atmospheric data assimilation. Mon Weather Rev. (2001) 129:123–37. doi: 10.1175/1520-0493(2001)129<0123:ASEKFF>2.0.CO;2
2. Hamill TM, Whitaker JS, Snyder C. Distance-dependent filtering of background-error covariance estimates in an ensemble Kalman filter. Mon Weather Rev. (2001) 129:2776–90. doi: 10.1175/1520-0493(2001)129<2776:DDFOBE>2.0.CO;2
3. Fertig EJ, Hunt BR, Ott E, Szunyogh I. Assimilating non-local observations with a local ensemble Kalman filter. Tellus A. (2007) 59:719–30. doi: 10.1111/j.1600-0870.2007.00260.x
4. Liu H, Anderson JL, Kuo YH, Snyder C, Caya A. Evaluation of a nonlocal quasi-phase observation operator in assimilation of CHAMP radio occultation refractivity with WRF. Mon Weather Rev. (2007) 136:242–56. doi: 10.1175/2007MWR2042.1
5. Anderson JL. Exploring the need for localization in ensemble data assimilation using a hierarchical ensemble filter. Phys D. (2007) 230:99–111. doi: 10.1016/j.physd.2006.02.011
6. Anderson JL, Lei L. Empirical localization of observation impact in ensemble Kalman filters. Mon Weather Rev. (2013) 141:4140–53. doi: 10.1175/MWR-D-12-00330.1
7. Lei L, Anderson JL, Whitaker JS. Localizing the impact of satellite radiance observations using a global group ensemble filter. J Adv Model Earth Syst. (2016) 8:719–34. doi: 10.1002/2016MS000627
8. Campbell WF, Bishop CH, Hodyss D. Vertical covariance localization for satellite radiances in ensemble Kalman filters. Mon Weather Rev. (2010) 138:282–90. doi: 10.1175/2009MWR3017.1
9. Farchi A, Bocquet M. On the efficiency of covariance localisation of the ensemble Kalman filter using augmented ensembles. Front Appl Math Stat. (2019) 5:3. doi: 10.3389/fams.2019.00003
10. Hodyss D, Nichols N. The error of representation: basic understanding. Tellus A. (2015) 67:822. doi: 10.3402/tellusa.v67.24822
11. Van Leeuwen PJ. Representation errors and retrievals in linear and nonlinear data assimilation. Q J R Meteorol Soc. (2015) 141:1612–23. doi: 10.1002/qj.2464
12. Janjić T, Bormann N, Bocquet M, Carton JA, Cohn SE, Dance SL, et al. On the representation error in data assimilation. Q J R Meteorol Soc. (2018) 144:1257–78. doi: 10.1002/qj.3130
13. Garand L, Heilliette S, Buehner M. Interchannel error correlation associated with AIRS radiance observations: inference and impact in data assimilation. J Appl Meteorol Climatol. (2007) 46:714–25. doi: 10.1175/JAM2496.1
14. Stewart L, Dance S N, Nichols. Correlated observation errors indata assimilation. Int J Numeric Methods Fluids. (2008) 56:1521–7. doi: 10.1002/fld.1636
15. Miyoshi T, Kalnay E, Li H. Estimating and including observation-error correlations in data assimilation. Inverse Probl Sci Eng. (2013) 21:387–98. doi: 10.1080/17415977.2012.712527
16. Evensen G, Eikrem KS. Conditioning reservoir models on rate data using ensemble smoothers. Comput Geosci. (2018) 22:1251–70. doi: 10.1007/s10596-018-9750-8
Keywords: data assimilation, non-local observations, localization, Bayesian inference, information transfer
Citation: van Leeuwen PJ (2019) Non-local Observations and Information Transfer in Data Assimilation. Front. Appl. Math. Stat. 5:48. doi: 10.3389/fams.2019.00048
Received: 22 June 2019; Accepted: 10 September 2019;
Published: 26 September 2019.
Edited by:
Axel Hutt, German Weather Service, GermanyReviewed by:
Alban Farchi, Centre d'Enseignement et de Recherche en Environnement Atmosphérique (CEREA), FranceAlberto Carrassi, University of Bergen, Norway
Copyright © 2019 van Leeuwen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Peter Jan van Leeuwen, cGV0ZXIudmFubGVldXdlbkBjb2xvc3RhdGUuZWR1