 David Berthiaume
David Berthiaume Randy Paffenroth
Randy Paffenroth Lei Guo2
Lei Guo2- 1Department of Mathematical Sciences, Worcester Polytechnic Institute, Worcester, MA, United States
- 2Data Science Program, Worcester Polytechnic Institute, Worcester, MA, United States
Neural networks (NN) provide state-of-the-art performance in many problem domains. They can accommodate a vast number of parameters and still perform well when classic machine learning techniques provided with the same number of parameters would tend to overfit. To further the understanding of such incongruities, we develop a metric called the expected spanning dimension (ESD) which allows one to measure the intrinsic flexibility of an NN. We analyze NNs from the small, in which the ESD can be exactly computed, to large real-world networks with millions of parameters, in which we demonstrate how the ESD can be numerically approximated efficiently. The small NNs we study can be understood in detail, their ESD can be computed analytically, and they provide opportunities for understanding their performance from a theoretical perspective. On the other hand, applying the ESD to large-scale NNs sheds light on their relative generalization performances and provides suggestions as to how such NNs may be improved.
1 Introduction
Neural networks (NN) have wide applications in machine learning [1]. For example, in the field of computer vision, convolutional NNs, a specific type of feed-forward NN, greatly outperform any previous traditional computer vision method [2]. However, there are many questions that arise when analyzing large-scale NNs. A deeper theoretical understanding of NNs, besides being a useful goal in itself, can often lead to improved performance on practical real-world problems. In this article, we develop a method to measure the flexibility of an NN, independent of any input data, that is both easily computed and is highly correlated with the testing accuracy of the NNs on standard benchmark datasets. We accomplish this by considering a basis of functions to represent the NN and then analyzing the dimension of the range of the function of the inputs of the NN to the coefficients of the output of the NN with respect to that basis. In particular, our perspective is inspired by classic results in analysis, such as Sard’s theorem [3] and the Reisz representation theorem. Analyzing the rank of appropriately defined Jacobians, which arise naturally from NNs, is one of our key analytical tools. Such Jacobians can be efficiently computed using the automatic differentiation capabilities of deep learning libraries like PyTorch and TensorFlow. We demonstrate how thinking about NNs from such a perspective leads naturally to NNs with improved performance.
NNs are quite popular in many applied problems. The understanding of their performance is often measured in relation to training data and specific learning algorithms [4, 5]. However, NNs often exhibit surprising properties which seem to be at odds with other classic machine learning techniques. For example, in [6], the authors provide strong evidence that understanding the performance of NNs will likely require a rethinking of generalization and the role that the number of parameters of a given machine learning algorithm play in its ability to generalize to new data. Analyzing NNs from the perspective of their generalization performance has led to several important research directions including recent work in “double descent” analysis [7–9], the use of the Takeuchi information criterion [10], the statistical capacity of NNs [11], Kolmogorov Width decay [12], and even analyzing NN capacity from the point of view of algebraic topology [13]. The idea of “double descent” [7–9] begins with the classic bias–variance trade-off curve, where the testing error of a given learning system is small for moderately flexible algorithms but large for under flexible or over flexible algorithms. It then proceeds to observe that as algorithm flexibility increases even further, for certain classes of algorithms, a point is reached at which increasing flexibility begins to again improve testing accuracy (this is the second of the “double descents”). In another direction of research, the Takeuchi information criterion [10], classic extension of the Akaike information criterion (AIC), is used to study NNs. Other similar approaches have developed newer estimators including considering flatness of minima [14] and measures of NN sensitivity to their inputs [15]. The authors of [11] take a wide view of such matters, and make connections among measures of NN performance such as sharpness, robustness, and norm-based control, and PAC-Bayes theory. In [12], the authors study Kolmogorov Width decay in the context of NNs, and they prove several interesting results, including showing that wide NNs can be susceptible to the curse of dimensionality, while shallow NNs are not. While such methods have been widely used in domains such as studying the properties of PDEs, such an approach would seem to have computational hurdles to overcome when applied to large-scale NNs. We also observe that many interesting directions are possible for studying NNs, and even ideas such as algebraic topology have an important role to play [13]. In addition, a recent (2020) survey of NN architectures, including discussion of their representation capacities, can be found in [16]. Our work can be viewed as complementary to ideas such as those in [10, 11], but instead approaching the problem of evaluating NNs from a more analytic point of view.
In particular, our work differs from this body of work in a number of ways. First, the main computational effort required by our analysis is a natural by-product of the classic backpropagation procedure widely used in the optimization of NNs. We can leverage already existing and highly optimized routines for constructing the Jacobians that we require, and our analysis can be accomplished with a cost that is roughly the same as that required by a few hundred backpropagation steps. Second, our analysis applies to NNs ranging from the smallest NNs of which we can conceive to large-scale real-world networks used for practical tasks such as image understanding. Third, and perhaps most importantly, our proposed ESD metric is highly correlated with the generalization performance on both small NNs, in which all details can be theoretically justified, and large real-world networks. As we will demonstrate, considering ESD provides insights into the performance of NNs and provides suggestions on how this performance can be improved.
2 Background
2.1 A Simple Example to Inspire the Approach
Consider the simple multilayer perceptron
This simple NN can be written as
where
for our set of polynomial basis functions
One can then compare 2 to the standard polynomial form with five weights
and consider whether the set of functions that 2 and 3 can represent, given arbitrary weights, are equivalent. It is clear that 3 can represent all 4th-order polynomials, but 2 is rather more complicated. One might ask what set of 4th-order polynomials 2 can represent.
Similar to the line of thought in [18] for linear models, one can approach 2 and 3 as different parameterizations of the space of all 4th degree polynomials. In particular, when comparing 2 and 3, it might seem reasonable, at first glance, to guess that the six parameters of 2 would allow it to have the same representation power as 3, since the latter has only five parameters. However, this is not the case. In fact, the set of all polynomials of degree 4 that
To measure just how restricted the polynomial form of
We can compute this dimension of the range of
Here, we used integers so that we can compute the exact rank without taking into account any floating point uncertainties. Using standard symbolic manipulation software [19], the rank of this matrix can be computed analytically without appealing to any numerical approximations. The rank of this matrix is 4. Again, as 2 is analytic function, we may apply Sard’s theorem [3] to show that the rank is constant everywhere except for a set of measure 0. As a numerical exercise, we computed the rank of the Jacobian at thousands of other random input weights, and, unsurprisingly, we consistently obtained a rank of 4.
The foundational idea is that, while the simple polynomial NN,
2.2 Definition of Polynomial Spanning Dimension
Inspired by the simple NN in 2, we now define the following.
Definition 1. Given a polynomial NN of the form
Theorem 2.1. Let N be an NN with a single input and output, l hidden layers, and height 1 (a single node per hidden layer) with polynomial activation functions in the hidden layers. Let
3 Developing a More General Definition of Spanning Dimension
In Definition 1, we made three assumptions about the NN
1) We assume that
2) We assumed that the activation functions are smooth. Common activation functions like ReLU [20], though differentiable almost everywhere, are not smooth.
3) The NN has only one input and output.
In this section, we will address and relax each of these assumptions in turn and generalize our definition of PSD to apply to a much larger class of NNs including those found in real-world applications.
3.1 Generalizing Spanning Dimension to Nonpolynomial Neural Networks
In Definition 1, we are representing a polynomial as the coefficients of the polynomial basis
When we computed the PSD of polynomial NNs, we considered the coefficients of the polynomial in terms of the polynomial basis
With a polynomial of the form presented in 3, the number of weights is equal to the number of points
Clearly, we cannot ever fit
In the case of polynomials with one input and output, we will now show that an equivalent way to compute the PSD is to determine the rank of the Jacobian of the function from w unique fixed input points to the w output points with respect to the weights of the polynomial, where w is the number of weights in the NN. Note that with this definition, one no longer needs the individual coefficients of the polynomial. One only needs to be able to evaluate the polynomial for a given set of inputs. This is a critical step in generalizing the definition of spanning dimension to nonpolynomial NNs. We will start with a simple example to illustrate the concept.
Consider the NN,
This Jacobian has rank 4. We can see that in this specific instance that
We will now show that these two definitions are equivalent for all polynomial NNs. Given a polynomial NN, we have the following relationship,
where
Why does computing the rank of
Harkening back to 2, we see that V can be interpreted as our basis functions
(1) computing
(2) we have a natural extension for the definition of PSD, which we will simply call the spanning dimension (SD) to nonpolynomial NNs since we do not need to actually pick a basis representation of our NN. Rather, this definition is based on the dimension of the range of the function from the NN evaluated at our selected input points to its outputs and is a necessary, but not sufficient, condition for being able to fit those selected input points to arbitrary output points exactly.
3.1.1 Effective Rank
Our second assumption above was that the NN in consideration had smooth activation functions, but that is not the case for real-world NNs which use activation functions like ReLU [20], which are differentiable almost everywhere but are not smooth. In particular, while the ReLU function is piecewise linear, and therefore has a Taylor expansion with only two non-zero terms away from its singularity (as is not defined at the singularity), in the context of the effective rank, we suggest that it is appropriate to think of the ReLU in two ways, which we will explore numerically in Sections 3.1, 5, and 6.
First, as giving rise to a “faceted manifold” where the Jacobian of interest is also piecewise constant, we observe that if the NN is evaluated exactly at a point at which activation is nonsmooth, then the Jacobian of interest will not uniquely be defined there. However, for all standard activation functions, such as ReLU, the set of nonsmooth points for that activation function is of measure-0, so the Jacobian we require is defined uniquely almost everywhere.
Second, as the ReLU being thought of as the limit of a SoftPlus (i.e., smoothed ReLu) [23] type activation, we conjecture that the difference between the ReLu-type activation functions and sigmoid-type activation functions is the leading order coefficients in their Taylor expansions. In particular, while the first nonconstant term for the sigmoid activation function is linear, the first nonconstant term for the SoftPlus is quadratic.
Furthermore, with polynomial NNs, we selected integer inputs to create a Jacobian that consisted of integer entries. For nonpolynomial NNs with many commonly used activation functions, this is not possible. For example, the sigmoid activation function contains an exponential which is irrational. To estimate the rank of a matrix with floating point entries, and thereby the SD, we can consider the singular values of that matrix. One classic method to compute the rank of a matrix from its singular values is to simply count the number of singular values that are greater than a certain tolerance based on machine epsilon. Of course, there are more sophisticated approaches, and one that we use here is the idea of the effective rank and defined in [24].
Let the n singular values of the Jacobian be
where
The effective rank of the Jacobian is then
This approach has a number of important mathematical properties that make it suitable for our analysis. The following three properties are particularly relevant. For a matrix A, and
(1)
(2)
(3) A unitary transformation on A does not change its effective rank.
Using effective rank, the SD is no longer confined to the set of integers, and the SD can vary based on the values of inputs and weights for smooth activation functions. To account for this, and to handle activation functions which are not smooth like ReLU [20], where the rank of the function will vary depending on the inputs, we introduce the expected SD (ESD) in the next section.
3.1.2 Expected Spanning Dimension
Consider the distribution of SDs for a given NN over all possible inputs within some compact space. We can estimate this distribution by choosing a number λ of sets of random weights and input values and compute the SD for each of these sets. The ESD of the NN is then the average value of these individual SDs, and a formal algorithm for computing the ESD is presented in Algorithm 1.
Figure 1 shows the SD distributions for an MLP with three hidden layers, one input and output, and 8, 8, and 10 nodes for the first, second, and third hidden layers, respectively. Figure 1A shows the SD distribution for this MLP with ReLU activation functions with an ESD of 2.81, and Figure 1B shows the SD for this MLP with sigmoid activation functions with an ESD of 1.07. We see that the SD of the MLP with ReLU activation functions, which are not smooth, varies much more than the MLP with sigmoid activation functions. Furthermore, even though both MLPs have the same number of trainable parameters, the MLP with sigmoid activation functions has a much lower ESD.
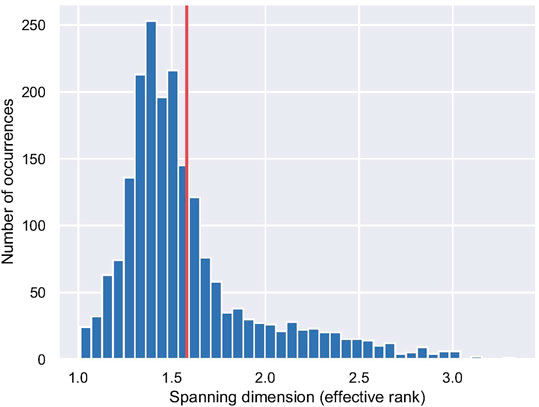
FIGURE 1. Estimated spanning distribution for an MLP with (A) ReLU activation functions, and (B) sigmoid activation functions.
Note, in the case of nonsmooth activation functions, the SD can change if the NN is evaluated at points that bracket a singularity in an activation function such as ReLU. However, as we show in Section 6, the ESD is quite stable even for real-world networks with nonsmooth activation functions.
3.2 Multiple Inputs and Outputs
Here, we address our third assumption above, that
However, this approach does require that there is only one scalar output. To compute the ESD of an NN with multiple outputs, we recommend one of the following approaches.
(1) Compute the ESD of each output and then average the results. This is the most computationally expensive approach for larger networks.
(2) Compute the ESD of the first output. This approach is the least expensive computationally.
(3) Compute the ESD of the sum of squares of the outputs. This approach closely resembles the type of squared loss function used in regression problems.
In Section 6, we will provide numerical results on real-world networks that explore cases 2 and 3.
3.3 Singular Values and Connections to the Riesz Representation Theorem
Previously, when considering exact rank, we did not need to determine the actual magnitude of the singular values. However, when considering effective rank, these singular values are important.
Looking at 7 and Definition 1, some readers might be reminded of ideas such as the Riesz representation theorem [22]. In particular, as we pointed out earlier, when we define the PSD in Definition 1 in terms of the decomposition
Deriving such ideas in the Hilbert space setting would take us too far afield for the current context. However, there is one idea that is inspired by such considerations that we will leverage here. In particular, it is important to note that the expansion 2 is only one such possible expansion of the function
The fact that there are many decompositions of
We are now interested in computing the eigenstructure of
Fortunately, we have a trick that we can leverage. In the decomposition
Since we do not have access to the decomposition
So, in our calculations, we are free to choose to interpret
3.4 Expected Spanning Dimension Algorithm
We are now ready to present the full algorithm for computing the ESD of

3.5 Comparing Effective Rank vs. Actual Rank
Figure 2 shows the estimated spanning dimension distribution for the simple NN from Eq. 1. We see that the ESD (1.59) is significantly smaller than the PSD (4.0). Effective rank does not just consider the number of nonzero singular values; it considers the relative magnitude of these singular values. This distribution of effective rank over the expected range of data inputs and weights provides a rich set of information for the given NN. Effective rank is always less than or equal to the actual rank and can be much smaller if many of the singular values are close to zero. Considering the singular value decomposition of the Jocobian, we can interpret the Jacobian as a rotation or reflection followed by a scaling followed by another rotation or reflection. The singular values represent the amount we move in each dimension during a backpropagation step. Whereas the actual rank considered only how many of these dimension we can move at all, effective rank considers how much we can move in each dimension.
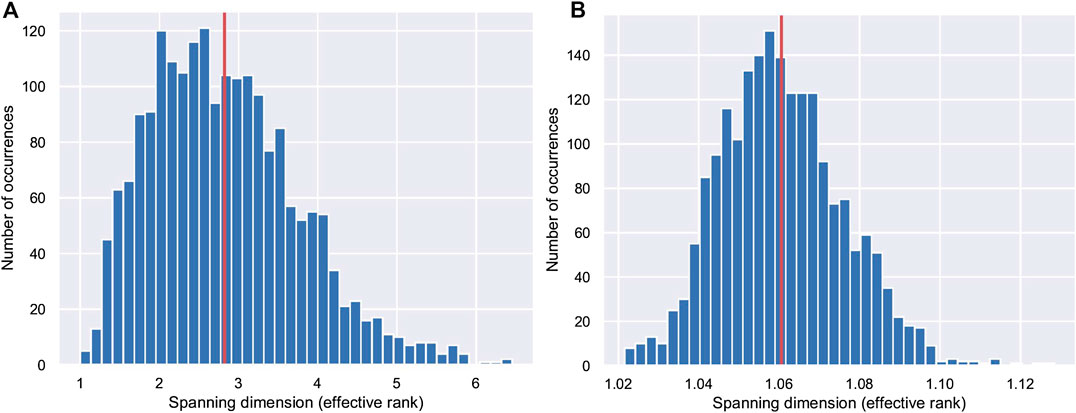
FIGURE 2. Estimated spanning dimension distribution (effective rank) with 2,000 samples of a neural network with
4 Multilayer Perceptrons
In this section, we explore the relationship between ESD and learning capacity in terms of training error for multilayer perceptrons. ESD measures the expressiveness of an NN, its ability to fit input data points. An experimental framework was created to investigate this relationship.
For these experiments, a set of eight random input and output points were generated
Figures 3 and 4 show the results of these experiments. There is a very strong relationship between the training error and the ESD with a correlation of
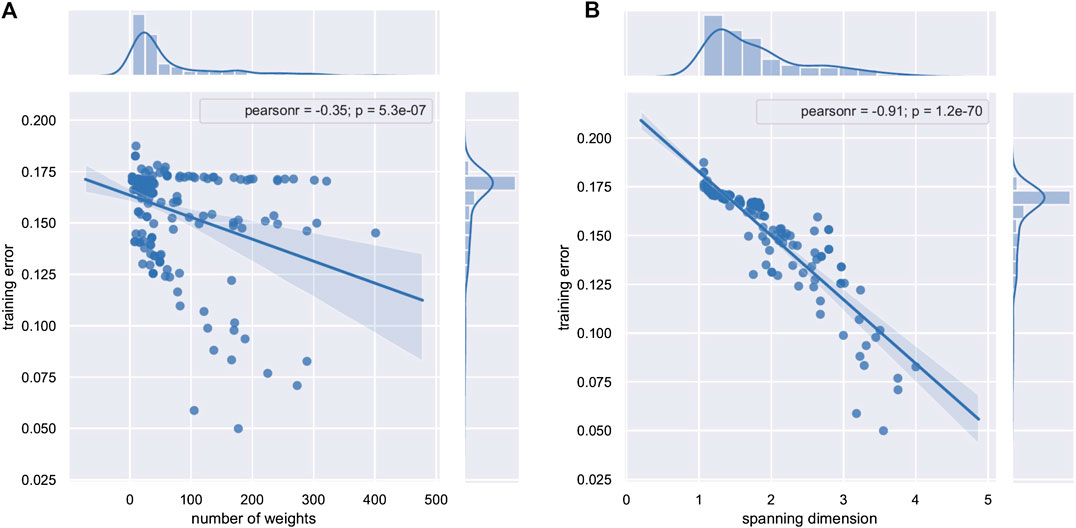
FIGURE 3. Training error vs. (A) number of trainable weights and (B) ESD for 200 randomly generated multilayer perceptrons.
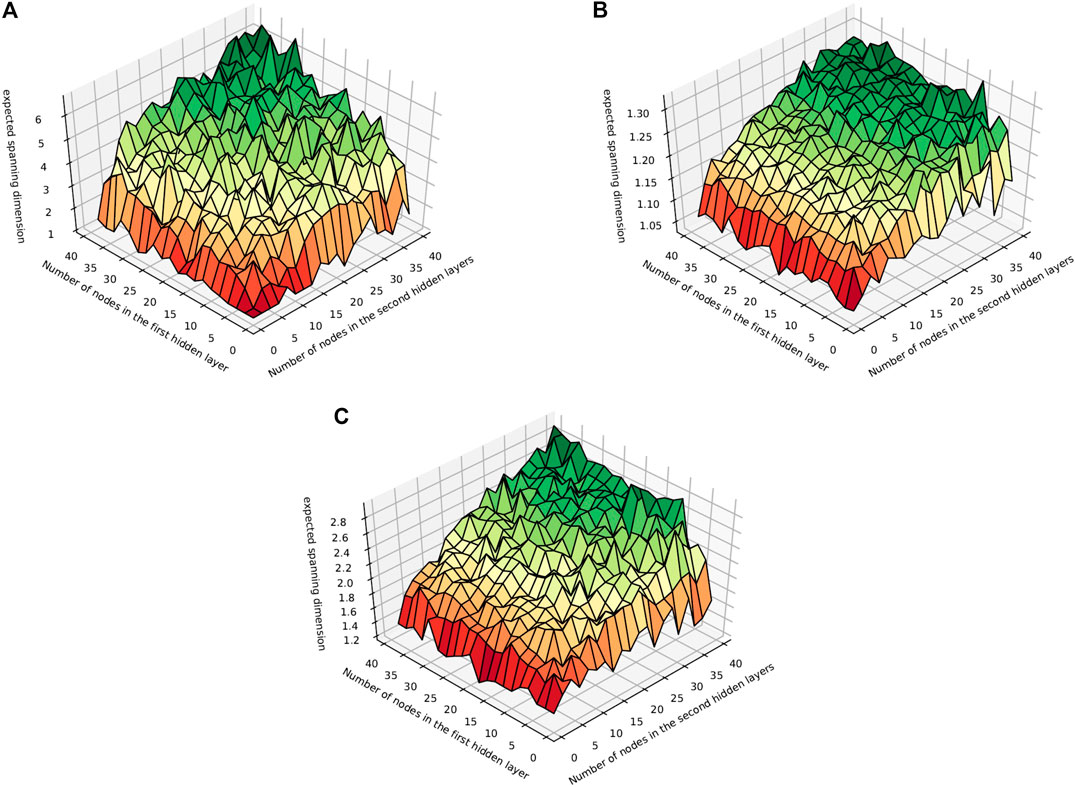
FIGURE 4. The ESD for all MLPs with two hidden layers and nodes per hidden layer less than or equal to 40 with activation function ReLU, sigmoid, or tanh.
4.1 Analyzing Multilayer Perceptrons With Two Hidden Layers
In this section, we describe the results of an exhaustive set of experiments that were run to investigate the ESD of 4800 multilayer perceptrons. For each activation function, sigmoid, ReLU, and tanh, we compute the ESD of all multilayer perceptron with two hidden layers where the first and second hidden layers have i and j nodes, respectively, with
These results show that in general ReLU has a much higher ESD than sigmoid and tanh, and may partly explain why ReLU tends to perform well in deep NNs. Sigmoid in contrast has a very low ESD and appears to plateau earlier. In particular, both sigmoid and tanh, unlike ReLU, do not appear to have a significantly higher ESD when the first hidden layer has more nodes. The number of nodes in the second hidden layer has a greater impact on ESD.
4.2 Increasing the Expected Spanning Dimension of Multilayer Perceptrons
Consider the simple multilayer perceptron in Figure 5A. This multilayer perceptron with three inputs, two hidden layers, one output, three nodes per hidden layer, and sigmoid activation function has 27 weights and an ESD of 2.76.
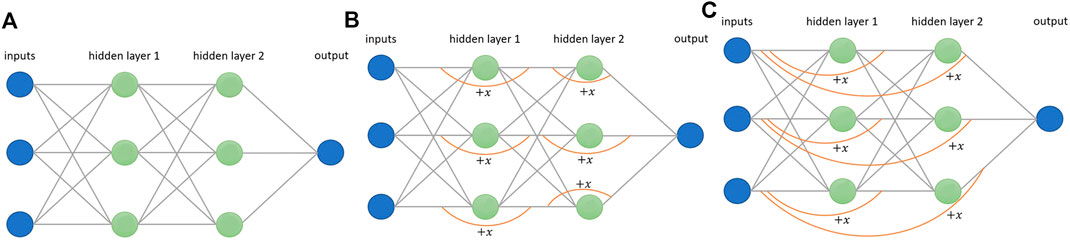
FIGURE 5. (A) A multilayer perceptron with ESD 2.76, (B) adding shortcut paths increases ESD to 4.28, and (C) adding inputs directly to the outputs of the hidden nodes increases ESD to 4.69.
Perhaps, we wish to have a more flexible NN that can represent a larger family of functions. Interestingly, the ESD can be increased without adding weights, merely by adding links similar to those found in ResNets [26]. The full justification of this idea is a subject of future work, but perhaps intuition can be gained by looking back at 2. One may observe that the coefficient in front of the high-order terms with respect to x are high-order polynomials with respect to the coefficients of the NN. It is our experience that such terms lead to low ESD. By adding additional links, additional low-order terms with respect to the higher powers of x are added, increasing the ESD.
Figure 5B shows a multilayer perceptron with shortcut pathways added that skip over the hidden neurons. The input of each hidden neuron is added directly to the output of that same neuron, skipping the multiplication of the weight, the bias term, and the activation function. Adding these extra pathways results in a significant increase of the ESD to 4.28. We call an NN with these extra pathways an add-shortcuts NN.
If adding these shortcuts increases the ESD considerably, a natural extension of this idea is to replace the smaller shortcuts with larger ones that skip over more of the hidden neurons. In fact, inspired by DenseNets [27], we create shortcuts that go directly from the inputs of the NN to the output of each hidden node, as shown in Figure 5C. The inputs of each row in the NN are added directly to the output of each node in the hidden layers. We call this an add-inputs NN. This results in a further increase of the ESD from 4.28 to 4.69.
It is interesting to note that, from the perspective of ESD, the modifications to standard NN architectures used by high-performance networks such as ResNets [26] and DenseNets [27] seem well justified, as opposed to more ad hoc arguments that are sometimes made with regard to these networks.
5 Results on Benchmark Datasets
In this section, we modify larger multilayer perceptrons by adding shortcuts as shown in Figure 5B. Then, we add inputs directly to the outputs of the hidden nodes as shown in Figure 5C. All experiments in this section were performed on an Alienware M15 laptop with an external Alienware amplifier with an NVIDIA GTX 2080 TI GPU.a
5.1 Fitting Random Noise
To measure the fitting power of an NN, we test its ability to fit random noise given a certain number of inputs. One thousand images of size
Indeed, that is the case, and Figure 6 shows that only the add-inputs model is able to fit the noise with gradient descent, indicating that it has greater fitting power or variance than both the add-shortcuts model and the original multilayer perceptron.
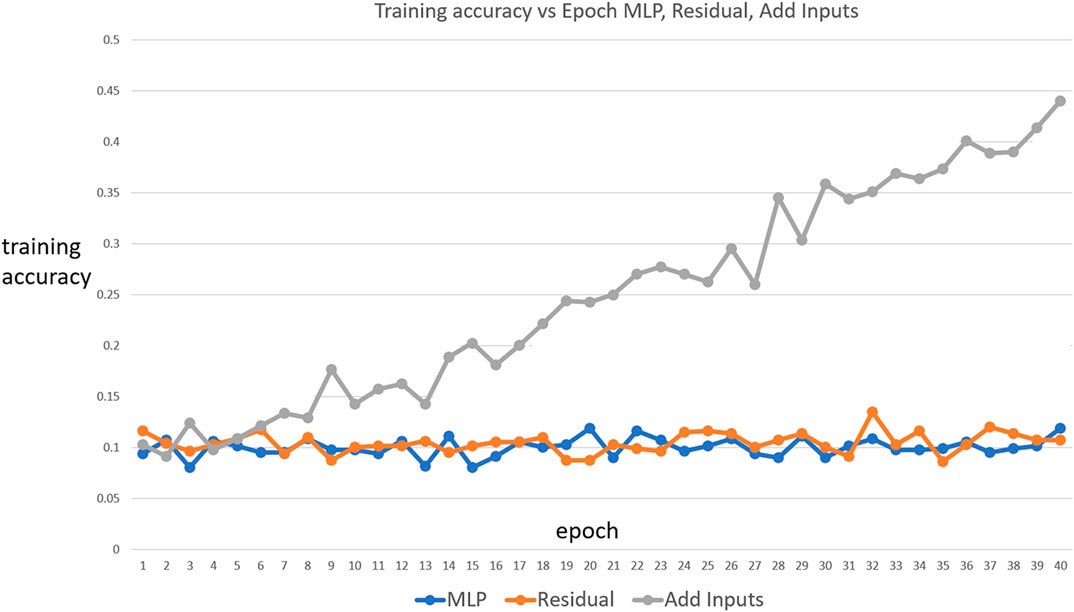
FIGURE 6. Fitting a multilayer perceptron, an add-shortcuts, and an add-inputs network to random noise images with ten arbitrary classes. The add-inputs model is able to fit the noise images while the other two models are not able to. Accordingly, this NN has more flexibility than the other networks, and can overfit.
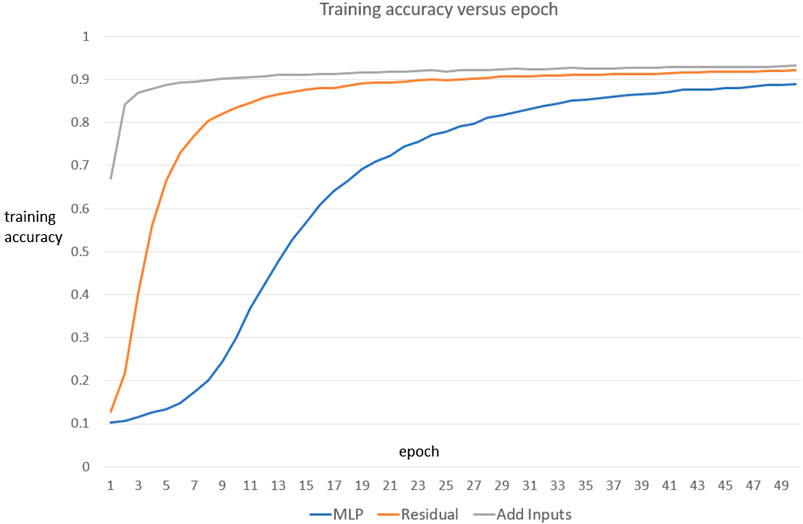
FIGURE 7. Fitting a multilayer perceptron, a residual network, and an add-inputs network to
5.2 Fashion MNIST
These three NN architectures were then trained on fashion MNIST images to determine the effect of increased ESD on performance in a practical setting [28]. Table 1 shows the training and testing accuracy of the multilayer perceptron, the add-inputs model, and the add-shortcuts model for various numbers of epochs. We observe that the testing accuracy is important for judging the performance of NNs, and we note that increasing ESD improves both the training and testing performance of the given NNs. This suggests that the original NN is actually, and perhaps surprisingly, under-fitting the data when only a small number of training epochs are used.

TABLE 1. Fashion MNIST training and test accuracy average of three runs comparing multilayer perceptron (MPL) to our proposed architectures.
The testing accuracy for these architectures is higher than both the multilayer perceptron and residual models in every test case. Each experiment was run 3 times, and the average training and test accuracies were computed.
5.3 Deep Residual Networks
Adding shortcuts that skip over individual nodes in a multilayer perceptron was inspired by deep residual networks [26]. As shown above, our findings indicate that replacing these shortcuts with larger shortcuts, which add the inputs directly to the outputs of the hidden neurons, increases ESD. Here, we investigated the effect of replacing some of these shortcuts in the ResNet architecture with these longer shortcuts. Our ResNet implementation is based upon that found in https://keras.io/examples/cifar10_resnet/. After each max pooling layer in the ResNet architecture, the size of the intermediate images decreases by a factor of 2. When this occurs, ResNet adds a subset of a previous layer by sampling every other pixel using a convolutional layer with kernel size 1 and stride 2. We replace these shortcuts with convolutional layers that sample the inputs directly with a stride of
To see how well these NNs perform on a low number of training inputs, these two networks were trained on 3,000 images from the CIFAR-10 dataset for various numbers of epochs using stochastic gradient descent [29]. Figure 8 shows the training accuracy vs. number of epochs for the original ResNet architecture and the add-inputs model. Table 2 shows the final test accuracies for various experiments. For each experiment, the add-inputs model has a higher test accuracy than the original ResNet model. Again, we emphasize that increasing ESD again improves both the training and testing performance of the given NNs, and perhaps indicates that the original NN is also under-fitting the data in this case.
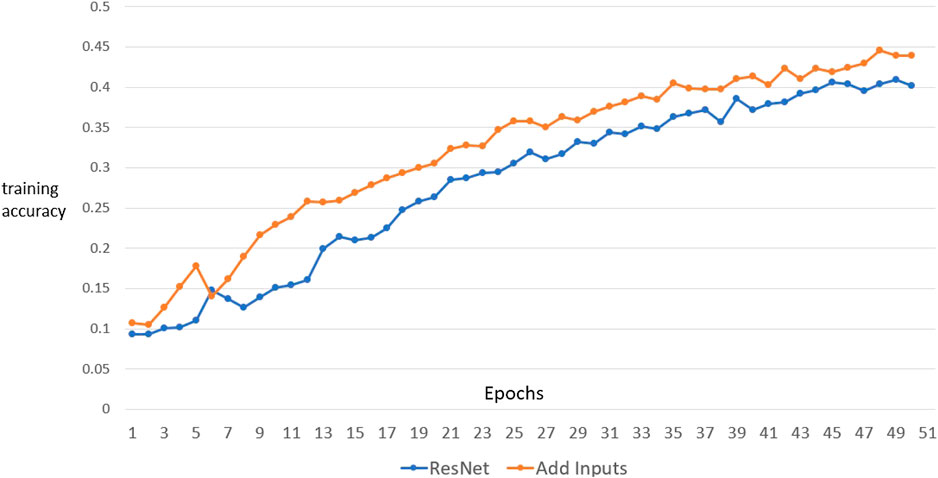
FIGURE 8. Fitting the original ResNet architecture and the add-inputs model to 3,000 images from the CIFAR-30 dataset. The add-inputs model learns faster and has a higher final test accuracy than the ResNet network.
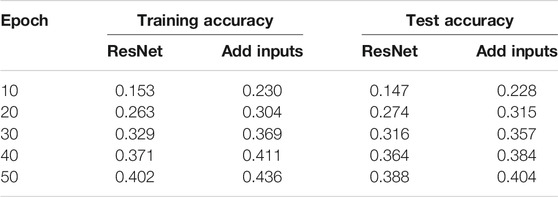
TABLE 2. CIFAR-10 training and test accuracy average of three runs.
6 The Expected Spanning Dimension of Real-World Neural Networks
In previous sections, we have demonstrated the ESD on NNs of our own construction and have focused largely on training error as a measure of the flexibility of an NN. However, these ideas can be applied to arbitrary NNs. In this section, we demonstrate the application of the ESD to eighteen NNs from the literature as implemented by the PyTorch NN library [22] in torchvision.models [30]. Our goal here is to look at the testing error of larger NNs widely used in practice. We might expect that if the ESD is too high, then over-fitting might occur and the testing error will increase. In this section, we show that over-fitting does not appear to be occurring with these real-world NNs. There are a significant number of variables and challenges when measuring the testing error of an NN including difficulty of training, limitations of the learning algorithm, structure and distribution of the input data, size of training data, and outliers in the training data. Despite all of this noise, we see a negative correlation between ESD and testing error. These experiments were conducted on a multi-node high-performance computing system with a variety of Intel-based processors and NVIDIA K20 GPUs.c The network families we examine include
(1) VGG (versions 11, 13, and 19) [31],
(2) ResNet (versions 18, 34, 50, 101, and 152) [32],
(3) SqueezeNet (versions 1.0 and 1.1) [33],
(4) DenseNet (versions 121, 161, 169, 201) [27],
(5) ShuffleNet (version 2-1.0) [34],
(6) MobileNet (version 2) [35], and
(7)ResNext (versions 50 and 101) [36].
Each NN f that we consider has been implemented to ingest RGB images x of size
To demonstrate the effectiveness of our methodology, we choose NNs with a number of parameters that range over several orders of magnitude. We choose networks that range in size from just over one one million parameters to networks with over 100 million parameters. We will denote by θ the set of all parameters of the network, so each network can be written as
To handle the multiple outputs of each NN, we compute the ESD using two of the approaches outlined in Section 3.1. In these calculations, we wish to compute a single Jacobian for each NN, and so we turn each NN into a function g with a scalar output by setting.
(1)
(2)
With the above notation in mind, our experiments proceed as follows.
We choose, at random, a set of
We generate these
In an optimization of Algorithm 1 to save memory for large NNs, we compute the singular values of
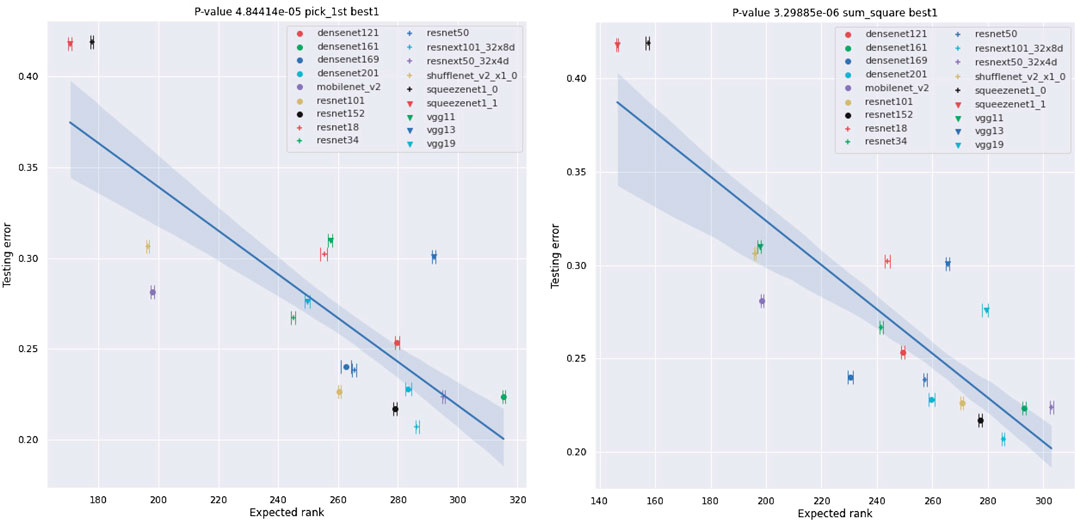
FIGURE 9. Plots of the best-1 testing error of NNs against their ESD. The testing errors are as provided by [30] and are error rates for testing on ImageNet crop images. We also provide the range of the ESD over 10 different experiments using synthetic data of the form
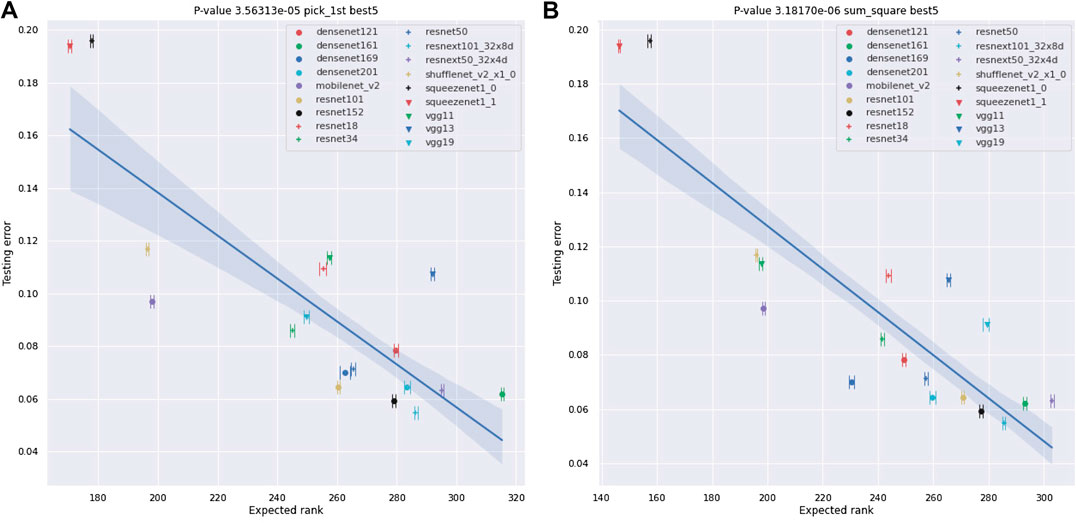
FIGURE 10. Plots of the best-5 testing error of NNs against their ESD. As in Figure 9, the testing errors are as provided by [30] and are error rates for testing on ImageNet crop images. We also provide the range of the ESD over 10 different experiments using synthetic data of the form
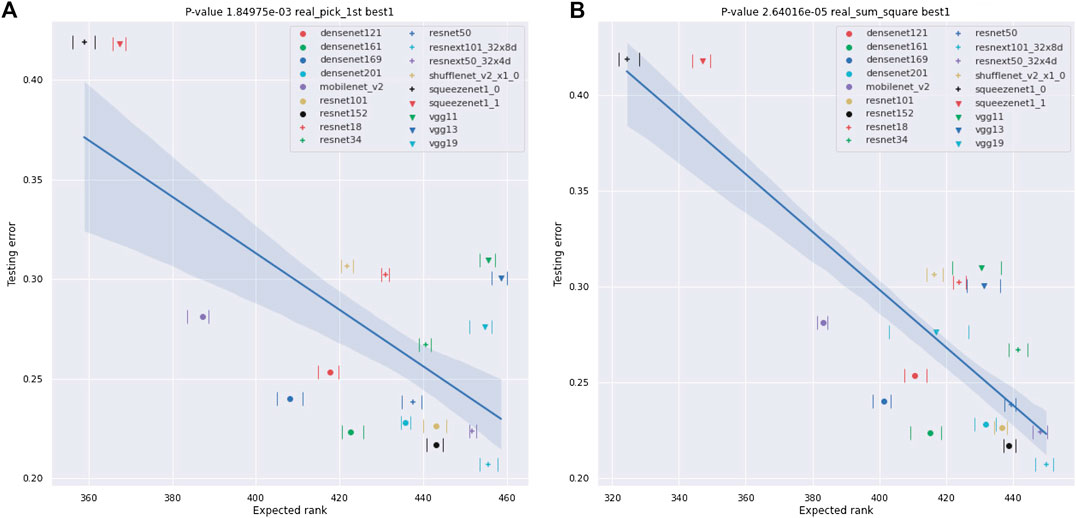
FIGURE 11. Plots of the best-1 testing error of NNs against their ESD. As in Figure 9, the testing errors are as provided by [30] and are error rates for testing on ImageNet crop images. We also provide the range of the ESD over 10 different experiments using an image from the ImageNet dataset for each x, and, again, the ranges are small relative to the differences between the various networks, though somewhat larger than in the
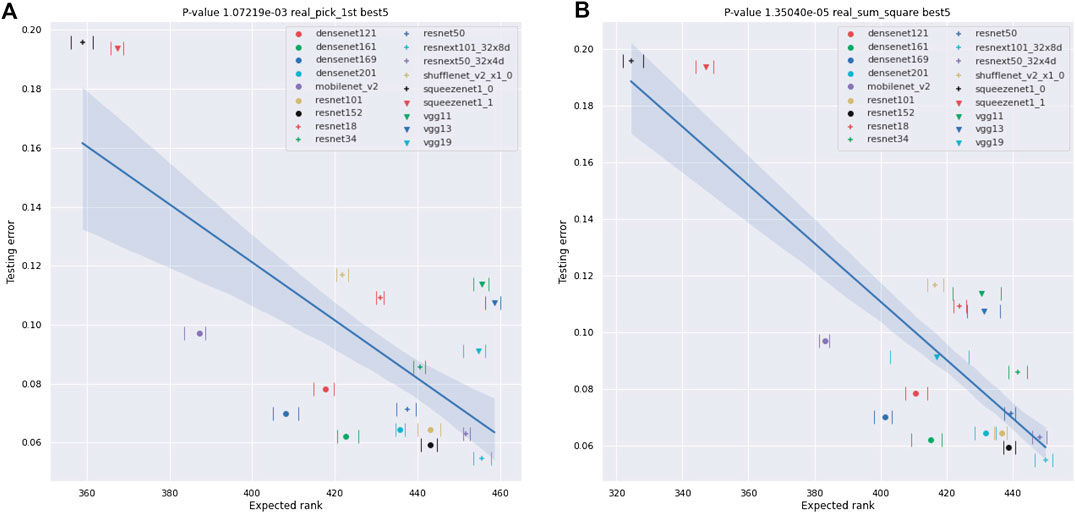
FIGURE 12. Plots of the best-5 testing error of NNs against their ESD. As in Figure 9, the testing errors are as provided by [30] and are error rates for testing on ImageNet crop images. We also provide the range of the ESD over 10 different experiments using an image from the ImageNet dataset for each x, and, again, the ranges are quite small relative to the differences between the various networks, though somewhat larger than in the
This provides one set of singular values. We then iterate this procedure 10 times to get 10 sets of 500 singular values for each NN. Note, the choice of 500 in the above algorithm is not essential to the performance of the algorithm, and many different choices were tried as part of our experiments. 500 was chosen in this case as all singular values for all networks past this point are small.
Fortunately, PyTorch makes the computation of
Our results for real-world NNs can be found in Figures 9-13 and Tables 3 and 4. In these figures, we plot the ESDs of the 18 NNs we examine against their testing error, as provided by the PyTorch torchvision library [30], along with their least-squares fitting line. The ESDs are quite predictive of the NNs best-1 and best-5 errors, with p-values’ orders of magnitude lower than the classic statistical significance limit of 0.05. The sum_squares method provides a stronger relationship between ESD and testing error vs. the pick_first method. The correlation between the testing error and the number of parameters in the NN is much weaker, with p-values of only 0.553 for the best-1 error and 0.478 for the best-1 error.
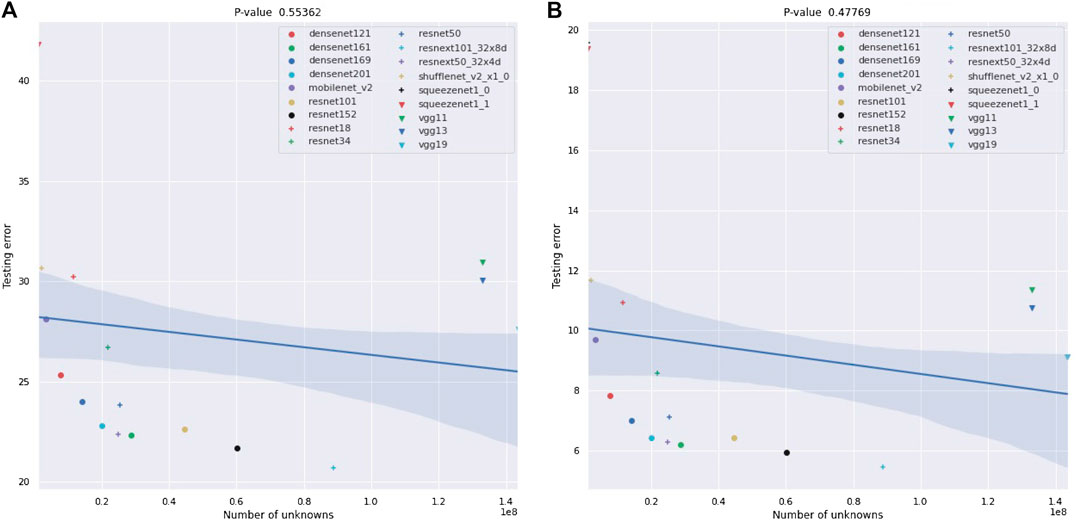
FIGURE 13. Plots of the best-1 and best-5 testing errors of NNs against the number of parameters. Again, the testing errors are as provided by [30] and are error rates for testing on ImageNet crop images. The number of parameters in the network is not a statistically significant predictor of their performance. The confidence bounds on the linear fit are one-σ bounds based on 1,000 bootstrap samples.
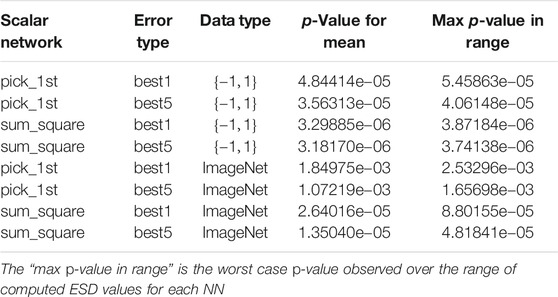
TABLE 3. p-Values for the linear relationship between ESD and accuracy over several different scenarios including examples using both synthetic data and real ImageNet data.
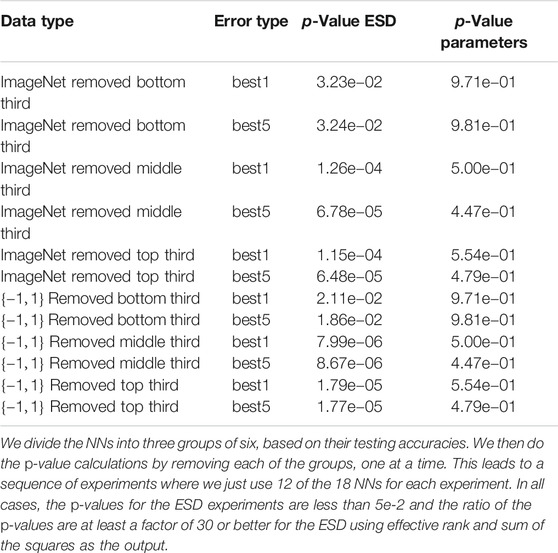
TABLE 4. Comparison between the p-values for the number of parameters and ESD for predicting testing accuracy.
A concise summary of the results for analyzing NNs with ESDs can be found in Tables 3 and 4. In particular, we show results for all possible combinations of best-1 vs best-5 accuracies, our two vector to scalar mappings, pick_first and sum_squares, and real and synthetic data. Our results show high correlations in all of these cases between our ESD-based measures and the accuracies of the 18 NNs, with the lowest p-values for all “sum-squares” examples being less than 5.0e−5, which is 3-orders of magnitude smaller than the classic limit of 5.0e−2. We also show, in Table 4, that ESD results are robust to selecting different subsets of the NNs we analyze.
7 Conclusions
In this article, we have defined the idea of an ESD for NNs and have demonstrated how maximizing this ESD improves the performance of real-world NNs. In many ways, a small ESD can be thought of as a regularization of the NN, and increasing the ESD is an example of the bias–variance trade-off in machine learning. ESD can be controlled by judiciously including additional links in the NN and does not require changing the number of parameters in the NN. Perhaps, most importantly, an ESD analysis provides a mathematical foundation for the superior performance of ResNet type NNs. There are many possible directions for augmenting the results described here. For example, Theorem 2.1 only scratches the surface of the theoretical progress that can be made using ESD-type ideas for the understanding of NNs, and the bounding of the ESD is certainly a worthwhile direction for future work. However, such results appear to be nontrivial, except in the smallest of cases. In particular, the example can be analyzed in terms of algebraic geometry using Gröbner bases [37] and similar ideas. However, generating such results for activation functions with infinite Taylor series has so far proved nontrivial. We expect that such analysis can lead to superior NN architectures in many problem domains.
As a final point, the interpretation of the ESD in context of the recent work in “double descent” is a delicate and quite interesting direction for future work. In particular, several of our results demonstrate that the testing accuracy of NNs improves as the ESD increases. There are two explanations that present themselves. First, large-scale NNs are actually somewhat under-parameterized or, more precisely, have access to far fewer degrees of freedom than their number of unknowns would indicate. Their performance is therefore improved by the additional flexibility that a larger ESD provides. Second, large-scale NNs are already in the “double descent” range and increasing ESD is taking advantage of this fact. Resolving this question would likely take a delicate computational study involving the development of a technique for slowly increasing the ESD in a large-scale NN.
Data Availability Statement
Publicly available datasets were analyzed in this study. These data can be found here: http://www.pymvpa.org/datadb/mnist.html, https://www.cs.toronto.edu/∼kriz/cifar.html, https://pytorch.org/docs/stable/torchvision/index.html.
Author Contributions
The core of writing of this article was performed by DB and RP. The numerical results included in the article were generated by DB and RP, with additional numerical results that inspired some of the approaches presented in the article being generated by LG. The key ideas in the article were generated through discussions between DB and RP, and RP and LG.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This research was performed using computational resources supported by the Academic and Research Computing group at Worcester Polytechnic Institute. The authors would also like to acknowledge the Academic and Research Computing group at Worcester Polytechnic Institute for providing consulting support that contributed to the results reported within this article.
Footnotes
aAll codes for experiments are available upon request.
bIn the notation of [26], add-shortcuts would be F(x) + x and add-inputs would be F(x) + x0 where x0 is the input layer.
References
1. Canziani, A, Paszke, A, and Culurciello, E. An analysis of deep neural network models for practical applications. CoRR (2016). abs/1605, 07678.
2. Schelkes, L. Evaluation of neural networks for image recognition applications: designing a 0-1 MILP model of a CNN to create adversarials. CoRR (2018). abs/1809, 00216.
3. Sard, A. The measure of the critical values of differentiable maps. Bull Am Math Soc (1942). 48(12), 883–891. doi:10.1090/s0002-9904-1942-07811-6
4. Ouarti, N, and Carmona, D. Out of the black box: properties of deep neural networks and their applications. CoRR (2018). abs/1808, 04433
5. Neal, B, Mittal, S, Baratin, A, Tantia, V, Scicluna, M, Lacoste-Julien, S, et al. ,. A modern take on the bias-variance tradeoff in neural networks. CoRR (2018). abs/1810, 08591.
6. Zhang, C, Bengio, S, Hardt, M, Recht, B, and Vinyals, O. “Understanding deep learning requires rethinking generalization,” in 5th International conference on learning representations, ICLR, Toulon, France, April 24–26, 2017, (2017).
7. Mei, S, and Montanari, A. The generalization error of random features regression: Precise asymptotics and double descent curve. (2019). arXiv preprint arXiv:1908.05355.
8. Belkin, M, Hsu, D, Ma, S, and Mandal, S. Reconciling modern machine learning and the bias-variance trade-off. (2018). arXiv preprint arXiv:1812.11118.
9. Belkin, M, Hsu, D, and Xu, J. Two models of double descent for weak features. (2019). arXiv preprint arXiv:1903.07571.
10. Thomas, V, Pedregosa, F, van Merriënboer, B, Mangazol, P.-A, Bengio, Y, and Roux, NL. Information matrices and generalization. (2019). arXiv preprint arXiv:1906.07774.
11. Neyshabur, B, Bhojanapalli, S, McAllester, D, and Srebro, N. “Exploring generalization in deep learning,” in Advances in neural information processing systems, pp. 5947–5956 (2017).
12. Wojtowytsch, S, et al. . Kolmogorov width decay and poor approximators in machine learning: shallow neural networks, random feature models and neural tangent kernels. (2020). arXiv preprint arXiv:2005.10807.
13. Guss, WH, and Salakhutdinov, R. On characterizing the capacity of neural networks using algebraic topology. (2018). arXiv preprint arXiv:1802.04443.
14. Hochreiter, S., and Schmidhuber, J. Flat minima. Neural Comput (1997). 9(1), 1–42. doi:10.1162/neco.1997.9.1.1
15. Novak, R, Bahri, Y, Abolafia, DA, Pennington, J, and Sohl-Dickstein, J. Sensitivity and generalization in neural networks: an empirical study. (2018). arXiv preprint arXiv:1802.08760.
16. Khan, A, Sohail, A, Zahoora, U, and Qureshi, AS. A survey of the recent architectures of deep convolutional neural networks. Artif Intell Rev (2020). 17, 1–62.
18. Saxe, AM, McClelland, JL, and Ganguli, S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. (2013). arXiv preprint arXiv:1312.6120.
19. Meurer, A, Smith, CP, Paprocki, G, Čertík, O, Kirpichev, SB, Rocklin, M, et al. . Sympy: symbolic computing in python. PeerJ Comput Sci (2017). 3, e103.
20. Nair, V, and Hinton, GE. “Rectified linear units improve restricted Boltzmann machines,” in Proceedings of the 27th international conference on machine learning (ICML-10), pp. 807–14 (2010).
21. Stoer, J, and Bulirsch, R. Introduction to numerical analysis, Vol. 12. Berlin: Springer Science & Business Media (2013).
22. Paszke, A, Gross, S, Chintala, S, Chanan, G, Yang, E, DeVito, Z, et al. . Automatic differentiation in pytorch (2017).
23. Glorot, X, Bordes, A, and Bengio, Y. “Deep sparse rectifier neural networks,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics, pp. 315–323 (2011).
24. Roy, O, and Vetterli, M. “The effective rank: a measure of effective dimensionality,” in 2007 15th European signal processing conference, New York, NY: IEEE, pp. 606–610 (2007).
25. Halko, N, Martinsson, N. G, and Tropp, J. A. Finding structure with randomness: probabilistic algorithms for constructing approximate matrix decompositions. SIAM Rev. (2011). 53(2), 217–288. doi:10.1137/090771806
26. He, K, Zhang, X, Ren, S, and Sun, J. Deep residual learning for image recognition. CoRR (2015). abs/1512 03385.
27. Huang, G, Liu, Z, Van Der Maaten, L, and Weinberger, KQ. “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4700–4708 (2017).
28.Lecun. The mnist dataset of handwritten digits (images)—pymvpa 2.6.5.dev1 documentation (1999). Available at: http://www.pymvpa.org/datadb/mnist.html. (Accessed April 22 2019).
29.Cifar-10 and cifar-100 datasets. Cifar-10 and cifar-100 datasets (2019). Available at: https://www.cs.toronto.edu/∼kriz/cifar.html. (Accessed April 22, 2019).
30. Marcel, S., and Rodriguez, Y. “Torchvision the machine-vision package of torch,” in Proceedings of the 18th ACM international conference on Multimedia, ACM (2011). pp. 1485–1488.
31. Simonyan, K., and Zisserman, A. Very deep convolutional networks for large-scale image recognition. (2014). arXiv preprint arXiv:1409.1556.
32. He, K, Zhang, X, Ren, S, and Sun, J. “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778 (2016).
33. Iandola, FN, Han, S, Moskewicz, MW, Ashraf, K, Dally, WJ, and Keutzer, K. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size. (2016). arXiv preprint arXiv:1602.07360.
34. Ma, N, Zhang, X, Zheng, H.-T, and Sun, J.“Shufflenet v2: practical guidelines for efficient cnn architecture design,” in Proceedings of the European Conference on computer vision (ECCV), pp. 116–131 (2018).
35. Sandler, M, Howard, A, Zhu, M, Zhmoginov, A, and Chen, L.-C. “Mobilenetv2: Inverted residuals and linear bottlenecks,” inProceedings of the IEEE Conference on computer Vision and pattern recognition, pp. 4510–4520 (2016).
36. Xie, S, Girshick, R, Dollár, P, Tu, Z, and He, K. “Aggregated residual transformations for deep neural networks” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1492–500 (2017).
Keywords: deep learning, neural network, generalization, Sard’s theorem, multilayer perceptron
Citation: Berthiaume D, Paffenroth R and Guo L (2020) Understanding Deep Learning: Expected Spanning Dimension and Controlling the Flexibility of Neural Networks. Front. Appl. Math. Stat. 6:572539. doi:10.3389/fams.2020.572539
Received: 14 June 2020; Accepted: 15 September 2020;
Published: 27 October 2020.
Edited by:
Keaton Hamm, University of Arizona, United StatesReviewed by:
Armenak Petrosyan, Oak Ridge National Laboratory (DOE), United StatesAlex Cloninger, University of California, San Diego, United States
Copyright © 2020 Berthiaume, Paffenroth and Guo. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Randy Paffenroth, cmNwYWZmZW5yb3RoQHdwaS5lZHU=