 Mark Spiller
Mark Spiller Dirk Söffker
Dirk Söffker- Chair of Dynamics and Control, University of Duisburg-Essen, Duisburg, Germany
This article is addressed to the topic of robust state estimation of uncertain nonlinear systems. In particular, the smooth variable structure filter (SVSF) and its relation to the Kalman filter is studied. An adaptive Kalman filter is obtained from the SVSF approach by replacing the gain of the original filter. Boundedness of the estimation error of the adaptive filter is proven. The SVSF approach and the adaptive Kalman filter achieve improved robustness against model uncertainties if filter parameters are suitably optimized. Therefore, a parameter optimization process is developed and the estimation performance is studied.
1. Introduction
State estimation plays an important role in the field of control. System states are required for the calculation of state feedback controllers, exact input-/output linearizations, equivalent control, backstepping control, etc. Noise reduction of signals is desirable to improve performance of sliding mode approaches under real conditions. Combined input-state estimation is useful for the estimation and rejection of unknown exogenuous inputs. Additionally, robust model-based fault detection and localization approaches can be designed based on filters.
Related to linear systems minimum variance unbiased [1, 2] and augmented state filters [3, 4] can be used for combined input-state estimation. In case of known uncertainty bounds robust Kalman filters [5] can improve state estimation of uncertain linear systems. In the field of
The smooth variable structure filter (SVSF) introduced in Ref. 9 is an approach for state estimation of uncertain nonlinear systems. Several applications of SVSF can be found in the literature. The filter has been applied to estimate the states and parameters of an uncertain linear hydraulic system in Ref. 9. A multiple-model approach has been formulated for fault detection e.g., leakage of the hydraulic system [10]. The state of charge and state of health of batteries is estimated in Refs. 11 and 12. A multiple-model approach has been applied for target tracking in Ref. 13 and a SVSF based probabilistic data association (PDA) approach has been proposed for tracking in cluttered environment [14]. For multiple object tracking a SVSF based joint-PDA approach has been developed [15]. Online multiple vehicle tracking on real road scenarios has been investigated in Ref. 16. Several SVSF based simultaneous localization and mapping algorithms have been proposed e.g., Refs. 17–19. Training of neural networks based on SVSF and classification of engine faults has been studied in Ref. 20. Dual estimation of states and model parameters has been considered in Ref. 21. The estimation strategy works as follows. The bi-section method, the shooting method, and SVSF are combined. The bi-section and shooting method are applied to determine best-fitting model parameter combinations. The obtained model is used by SVSF to estimate the system states. To apply the bi-section method the measurement signals are divided into segments in which the model parameters remain nearly constant. In comparison to the Kalman filter the SVSF approach facilitates detection of these segments based on an evaluation of chattering process.
As described in Ref. 9 the SVSF approach uses a switching gain to drive the estimated state trajectory into a region around the true state trajectory called existence subspace. Due to measurement noise chattering occurs in the existence subspace. By introducing a boundary layer, similar to the saturation function approach of sliding mode control, the high frequency switching in the existence subspace can be attenuated. The claimed advantage of SVSF approach is that if the boundary layer is not used, the filter guarantees to reach the existence subspace for sure although an imprecise system model may be used. It is shown in Ref. 22 that in case of not using the boundary layer the estimations of the filter converge to the measurements, which guarantees the estimation error to be bounded. However, this is a trivial result because if the estimations are equal to the measurements and every state is measured, than the filter is not required. If the boundary layer is used, the estimations diverge from the noisy measurements and estimation performance improves. Unfortunately, it has never been proven that the SVSF with boundary layer has bounded estimation error in case of using an imprecise model.
As already mentioned a serious limitation of the SVSF approach is that all system states have to be measured. Additionally, the measurement model is required to be linear. However, related to tracking a linear measurement model may be achievd by applying a measurement conversion [23] and measurements of the vehicle velocities could also be derived from measured positions.
Another problem of SVSF results from the dependency of the estimation performance on the width of the introduced smoothing boundary layer. In Ref. 24 an estimation error model for the SVSF is proposed and in Ref. 25 the estimation error is minimized according to the smoothing boundary layer width. A maximum a posteriori estimation of the noise statistics of the error model is discused in Ref. 26. However, the derived estimation error model and the related approaches require the system to be linear and precisely known which contradicts the idea of robustness.
In our previous publication [22] a new tuning parameter for the SVSF approach was introduced to achieve online optimization of the estimation performance. In this paper the relation between the SVSF approach and the Kalman filter is studied. An adaptive Kalman filter is obtained from the SVSF approach by replacing the original filter gain. The estimation performance of SVSF and the adaptive filter variant is compared with one another. Therefore, a parameter optimization scheme is proposed. In the simulation results the adaptive Kalman filter shows superior performance compared to the original SVSF approach.
The paper is organized as follows. In Section 2 the preliminaries and the original SVSF approach are discussed. In Section 3 the relation of SVSF and Kalman filter is studied. Parameter optimization of the Kalman filter leading to an adaptive filtering approach is considered in Section 4. The stability of the adaptive filter is studied in Section 5. A performance evaluation of SVSF and adaptive Kalman filter is provided in Section 6.
Notations. An overview of the notations used within the paper is given in Table 1.
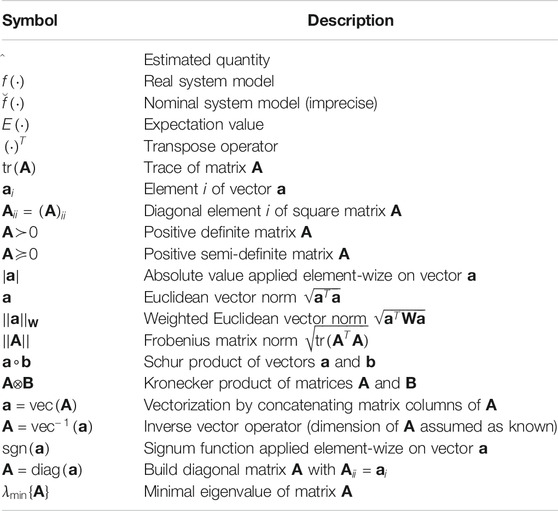
TABLE 1. Nomenclature.
2. Problem Formulation and Previous Work
Consider the dynamics of a nonlinear system to be exactly described by the discrete-time model
with states
where the operator “
where
in case of
Theorem 1 of Ref. 9 proves that the output estimation error
3. Relation Between Smooth Variable Structure and Kalman Filter
In this section the stochastic gain
From Eqs 1, 2, and 9–12 it follows that the state estimation error and the output estimation error can be determined as
and
where
Expanding Eq. 15 and considering the definition of the a priori estimation error covariance
The value of the remaining expectations in Eq. 16 is studied as follows. First of all the a priori estimation error
Next the expression for the a posteriori estimation error covariance is considered. Inserting Eq. 13 into the definition of the a posteriori estimation error covariance
Expanding Eq. 18 and considering the definition of the output error covariance
Based on Eq. 14 the two remaining expectations in Eq. 19 can be written as
where
In the following minimization of MSE is considered. Based on Eq. 21 the error covariance can also be written as
By adding
The trace of
as the trace of the last term is zero for
Theorem 1. The state prediction and correction of algorithm (Eqs 9–12) equals the one of the extended Kalman filter if
Proof. 1The state prediction (Eq. 9) obviously equals the one of the extended Kalman filter. Regarding the correct step (Eq. 11) it follows that
holds true if
step (Eq. 26) and thus (Eq. 11) is identical to the correction step of the Kalman filter. ∎
4. Parameter Optimization of the Kalman Filter
The robustness of SVSF against model uncertainties is achieved by tuning the parameters of the smoothing boundary layer width [25]. However, also the Kalman filter gain can be made adaptive to achieve improved robustness [27]. In this section an adaptation law for the unknown a priori estimation error covariance
As according to Eq. 17 the state error covariance
with
might be considered to gain information about
can be established. If it is assumed that
might be considered to gain information about
In order to find an estimation
subject to
is considered. The solution of this WLS problem is
which is a weighted sum of the solutions of the individual equations. The obtained solution (Eq. 36) is not guaranteed to be positive semidefinite. However, as
where
and matrix
where
with
where
and the diagonal matrix
with
The adaptive filtering approach (Eqs 39–46) depends on the set
of tuning parameters. In order to optimize these parameters a training model is introduced. The filter is applied to the training model instead of the real system. The training model simulates the effects of model uncertainty occurring from the real unknown system by varying the system parameters of the known nominal model
where J denotes the costfunction. The optimization is a mixed integer optimization problem which can be solved by e.g., genetic approaches. In order to make the optimization process more reliable it is recommended to build several training models and optimize the filter parameters for each of them separately. The final optimized filter parameters can be obtained by taking the mean or median of the optimized parameters of the individual training models. The process of filter parameter optimization is illustrated in Figure 1.
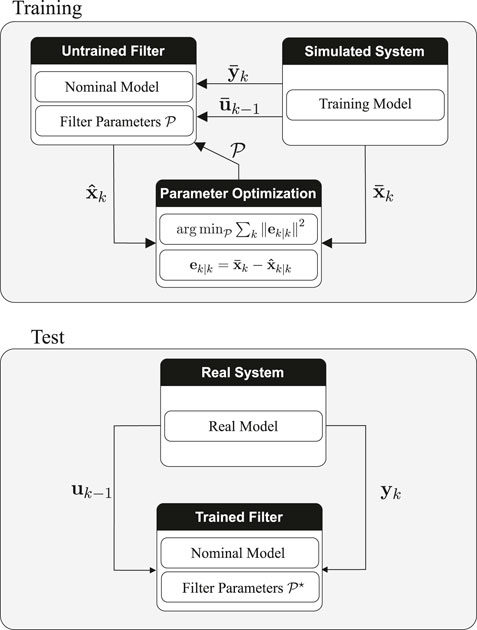
FIGURE 1. Filter parameter optimization. Training: The training is based on a specific system description called training model which is assumed to be the true unknown system model. The training model equals the known nominal system description but with varied system parameters to account for the model uncertainty. The filter runs with the nominal model and its tuning parameters are optimized by comparing the filter estimates with the true states of the training model. Test: The filter is applied to the real system, it runs with the optimized tuning parameters and uses the nominal system description.
5. Stability Analysis of the Adaptive Kalman Filter
As mentioned previously boundedness of the estimation error of SVSF approach (Eqs 3–7) using smoothing boundary layer has never been proven. However, if the adaptive Kalman filter is used instead (
Theorem 2. The estimation error of the a posteriori estimation
of the adaptive Kalman filtering approach (Eqs 39–46) is bounded by
if the measurement noise is bounded by
where
Proof. From Eq. 51 it can be concluded that
with
With the definition
Applying the Sherman-Morrison-Woodbury formular (Fact 2.16.3 [29]) in combination with assumption (Eq. 52) gives
Using the submultiplicative Frobenius norm (Proposition 9.3.5 [29]) and Eq. 58, Eq. 57 can be written as
Based on the minimum eigenvalue of
can be established (Lemma 8.4.1 [29]). Using Eq. 60 and assumption Eq. 53 an upper bound of Eq. 59 is obtained as
Unfortunately,
Based on the derivative of Eq. 62 with respect to
Then (Eq. 50) is proven by applying the triangle inequality on Eq. 56.
6. Numerical Example
In this section state estimation and control of a chemical plant is considered in order to evaluate the performance of original SVSF and the adaptive Kalman filtering variant. According to Ref. 30, Ref. 31 a species A reacts in a continuous stirred tank reactor. The dynamics of the effluent flow concentration
with measurements
The parameters of the system are shown in Table 2. The input of the system is the change of the coolant stream temperature
where the zero-mean, white noise
For the initial state values
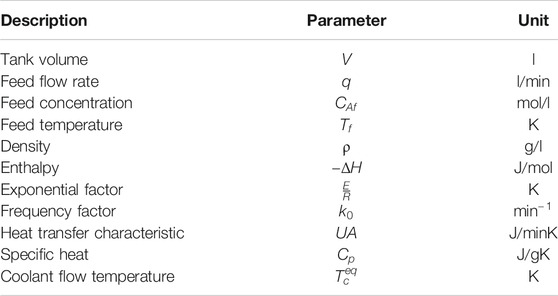
TABLE 2. System parameter description [30].
6.1. Filter Training Process
In the following the optimization of the tuning parameters of A-KF and SVSF approach is considered. As explained in Section 4 variation of the nominal system parameters is required to build the training model. To account for the model uncertainty a variation of 20% of the nominal parameters is considered which is assumed as a priori known. Consequently, the ith parameter of the training model
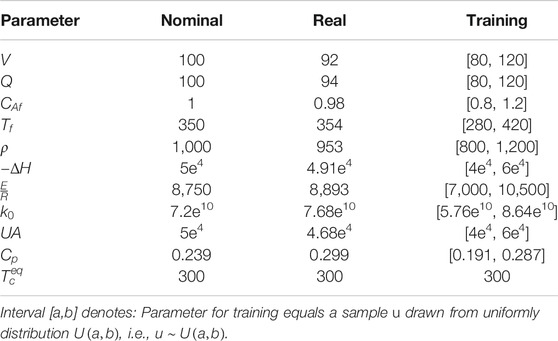
TABLE 3. System parameters of nominal, real, and training model.
For each set the tuning parameters of the filters are optimized separately. The parameters of A-KF approach required to be optimized are given by Eq. 47. For the SVSF approach the boundary layer widths
The results of optimization are shown in Table 4. The A-KF approach requires at least 60 times more computational time for the optimization than SVSF. The SVSF algorithm is computationally more efficient and in addition it requires less parameters to be optimized. However, the achieved minimal value of the costfunction is always lower in case of A-KF.
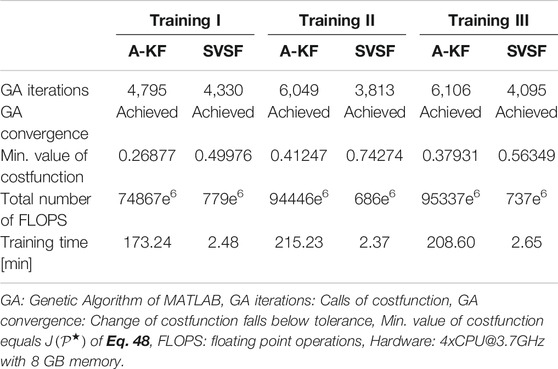
TABLE 4. Computational effort of training process.
6.2. Open Loop Case
In the open loop case the step functions
The performance values of A-KF and SVSF approach are shown in Table 5. The filters are applied based on four sets of optimized parameters. Three sets result from Training I, Training II, and Training III. The fourth set denoted as Training I-III considers the mean values of the optimized parameters of the other three sets. As all states are measured the MSE of the measurements is considered also. In order to account for the effect of different noise realizations the results are obtained by simulating the step response 100 times and taking the mean value and variance of the squared estimation error. The filters are applied to the same measurements with same noise realizations. From the results it can be seen that both A-KF and SVSF estimations are more precise than the measurements. In comparison to SVSF the A-KF approach achieves better estimation performance for all considered sets of optimized parameters and both step responses. For one specific run the step responses and the corresponding state estimations are visualized in Figures 2 and 3. The computational time required to generate Table 5 (to simulate both step responses 100 times and apply 8 filters each time) is 18.90 min on a 4xCPU@3.7Ghz with 8 GB memory. The computational time required to apply only one filter on one specific step response is 0.11 s in case of SVSF and 1.49 s in case of A-KF. Both values are far less than the 6 min of simulated system behavior.

TABLE 5. Estimation performance in open loop case (100 realizations).
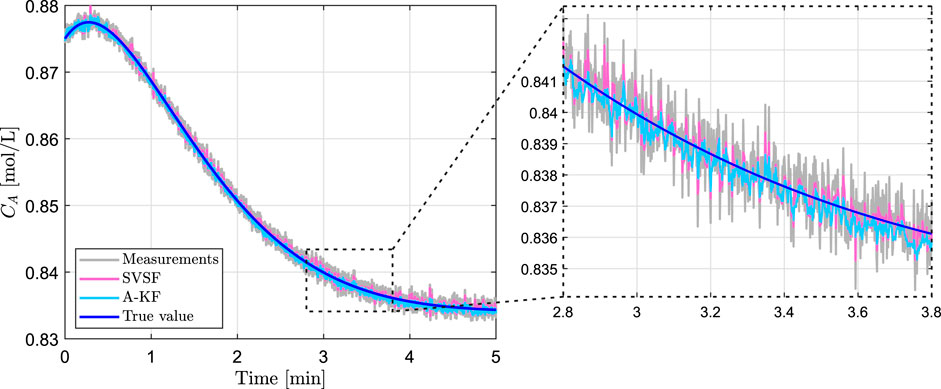
FIGURE 2. Open loop response of step input
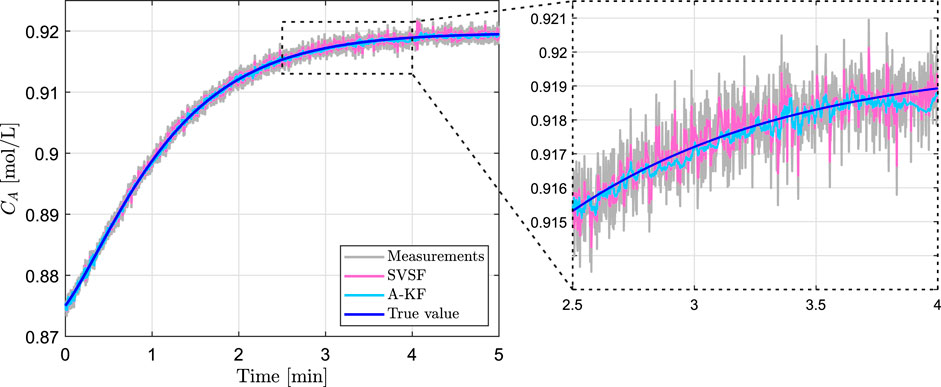
FIGURE 3. Open loop response of step input
6.3. Closed Loop Case
In the closed loop case the effluent flow concentration
In order to achieve reference tracking of the control variable
with reference value
Then reference tracking can be achieved by applying the super-twisting approach [32]
The controller parameters are chosen as
where
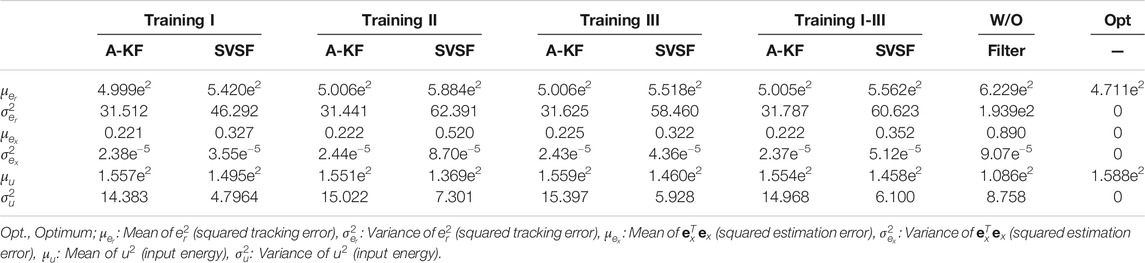
TABLE 6. Control and estimation performance in closed loop case (100 realizations).
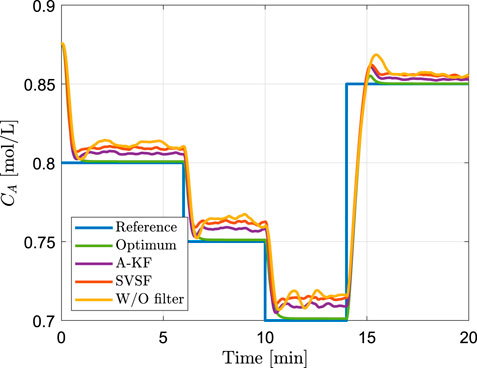
FIGURE 4. Closed loop tracking performance using measured, estimated, or true state values for calculation of the sliding variable (Performance values of shown realization:
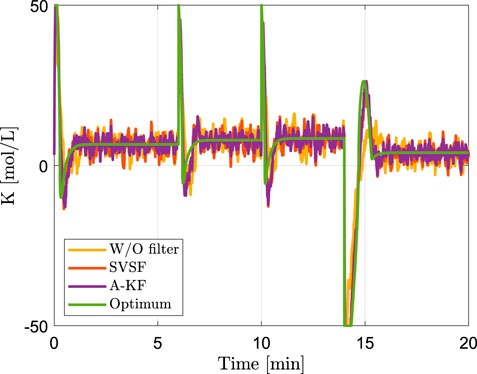
FIGURE 5. Closed loop system inputs generated by controllers (Input energy of shown realization:
7. Conclusion
In this paper the relation of smooth variable structure filter (SVSF) and Kalman filter has been studied. An adaptive Kalman filter (A-KF) was derived from the SVSF approach. Sufficient conditions for the boundedness of the estimation error of A-KF approach have been formulated. The simulation results show that beside the SVSF approach also an adaptive Kalman filter can be used to achieve robust estimation performance.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author Contributions
The development and theoretical description of the adaptive Kalman filter approach was undertaken by MS and DS. The numerical simulation was designed and realized by MS. The manuscript was drafted by MS and reviewed by DS.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors want to thank the reviewers for their valueable comments and suggestions.
Footnote
1The authors thank the anonymous reviewers of European Control Conference 2020 for the insightful comments and suggestions related to the proof of the theorem.
References
1. Kitanidis, PK. Unbiased minimum-variance linear state estimation. Automatica (1987). 23:775–8. doi:10.1016/0005-1098(87)90037-9.
2. Gillijns, S, and De Moor, B. Unbiased minimum-variance input and state estimation for linear discrete-time systems. Automatica (2007). 43:111–6. doi:10.1016/j.automatica.2006.08.002.
3. Anderson, BD, and Moore, JB. Optimal filtering. Englewood Cliffs, NJ: Prentice-Hall (1979). 256 p.
4. Hmida, FB, Khémiri, K, Ragot, J, and Gossa, M. Three-stage Kalman filter for state and fault estimation of linear stochastic systems with unknown inputs. J Franklin Inst (2012). 349:2369–88. doi:10.1016/j.jfranklin.2012.05.004.
5. Dong, Z, and You, Z. Finite-horizon robust Kalman filtering for uncertain discrete time-varying systems with uncertain-covariance white noises. IEEE Signal Process Lett (2006). 13:493–6. doi:10.1109/LSP.2006.873148.
6. Hassibi, B, Sayed, AH, and Kailath, T. Indefinite quadratic estimation and control: a unified approach to H2 and H∞ heories Society for Industrial and Applied Mathematics. Philadelphia, PA (1999). p. 572.
7. Blom, HAP, and Bar-Shalom, Y. The interacting multiple model algorithm for systems with Markovian switching coefficients. IEEE Trans Automat Contr. (1988). 33:780–3. doi:10.1109/9.1299.
8. Martino, L, Read, J, Elvira, V, and Louzada, F. Cooperative parallel particle filters for online model selection and applications to urban mobility. Digit Signal Process (2017). 60:172–85. doi:10.1016/j.dsp.2016.09.011.
9. Habibi, S. The smooth variable structure filter. Proc IEEE (2007). 95:1026–59. doi:10.1109/JPROC.2007.893255.
10. Gadsden, SA, Song, Y, and Habibi, SR. Novel model-based estimators for the purposes of fault detection and diagnosis. IEEE ASME Trans Mechatron (2013). 18:1237–49. doi:10.1109/TMECH.2013.2253616.
11. Kim, T, Wang, Y, Fang, H, Sahinoglu, Z, Wada, T, Hara, S, et al. Model-based condition monitoring for lithium-ion batteries. J Power Sources (2015). 295:16–27. doi:10.1016/j.jpowsour.2015.03.184.
12. Qiao, HH, Attari, M, Ahmed, R, Delbari, A, Habibi, S, and Shoa, T. Reliable state of charge and state of health estimation using the smooth variable structure filter. Contr Eng Pract (2018). 77:1–14. doi:10.1016/j.conengprac.2018.04.015.
13. Gadsden, SA, Habibi, SR, and Kirubarajan, T. A novel interacting multiple model method for nonlinear target tracking. In: FUSION 2010 : 13th international conference on information fusion; 2010 Jul 26 - 29; Edinburgh, Scotland. Piscataway, NJ: IEEE.
14. Attari, M, Gadsden, SA, and Habibi, SR. Target tracking formulation of the SVSF as a probabilistic data association algorithm. In: The 2013 American control conference; 2013 June 17 - 19; Washington, DC; IEEE, Piscataway, NJ. p. 6328–32. doi:10.1109/ACC.2013.6580830.
15. Attari, M, Luo, Z, and Habibi, S. An SVSF-based generalized robust strategy for target tracking in clutter. IEEE Trans Intell Transport Syst (2016). 17:1381–92. doi:10.1109/TITS.2015.2504331.
16. Luo, Z, Attari, M, Habibi, S, and Mohrenschildt, MV. Online multiple maneuvering vehicle tracking system based on multi-model smooth variable structure filter. IEEE Trans Intell Transport Syst (2020). 21:603–16. doi:10.1109/TITS.2019.2899051.
17. Demim, F, Nemra, A, and Louadj, K. Robust SVSF-SLAM for unmanned vehicle in unknown environment. IFAC-PapersOnLine (2016). 49:386–94. doi:10.1016/j.ifacol.2016.10.585.
18. Allam, A, Tadjine, M, Nemra, A, and Kobzili, E. Stereo vision as a sensor for SLAM based smooth variable structure filter with an adaptive boundary layer width. In: ICSC 2017, 6th International conference on systems and control. 2017 May 7–9; Batna, Algeria; Piscataway, NJ: IEEE. p. 14–20. doi:10.1109/ICoSC.2017.7958700.
19. Liu, Y, and Wang, C. A FastSLAM based on the smooth variable structure filter for UAVs. In: 15th international conference on ubiquitous robots (UR); June 26-30, 2018; Hawaii Convention Center; Piscataway, NJ IEEE (2018). p. 591–6. doi:10.1109/URAI.2018.8441876.
20. Ahmed, RM, Sayed, MAE, Gadsden, SA, and Habibi, SR. Fault detection of an engine using a neural network trained by the smooth variable structure filter. In: IEEE international conference on control applications (CCA); Denver, CO; 2011 Sep 28-30; Piscataway, NJ IEEE (2011). p. 1190–6. doi:10.1109/CCA.2011.6044515.
21. Al-Shabi, M, and Habibi, S. Iterative smooth variable structure filter for parameter estimation. ISRN Signal Processing (2011). 2011:1. doi:10.5402/2011/725108.
22. Spiller, M, Bakhshande, F, and Söffker, D. The uncertainty learning filter: a revised smooth variable structure filter. Signal Process (2018). 152:217–26. doi:10.1016/j.sigpro.2018.05.025.
23. Longbin, M, Xiaoquan, S, Yiyu, Z, Kang, SZ, and Bar-Shalom, Y. Unbiased converted measurements for tracking. IEEE Trans Aero Electron Syst (1998). 34:1023–7. doi:10.1109/7.705921.
24. Gadsden, SA, and Habibi, SR. A new form of the smooth variable structure filter with a covariance derivation. In: CDC 2010 : 49th IEEE conference on decision and control 2010 Dec 15 - 17; Atlanta, GA; Piscataway, NJ: IEEE (2010). p. 7389–94. doi:10.1109/CDC.2010.5717397.
25. Gadsden, SA, El Sayed, M, and Habibi, SR. Derivation of an optimal boundary layer width for the smooth variable structure filter. In: 2011 American Control Conference - ACC 2011; San Francisco, CA; 2011 Jun 29 - Jul 1; Piscataway, NJ: IEEE (2011). p. 4922–7. doi:10.1109/ACC.2011.5990970.
26. Tian, Y, Suwoyo, H, Wang, W, and Li, L. An ASVSF-SLAM algorithm with time-varying noise statistics based on MAP creation and weighted exponent. Math Probl Eng. (2019). 2019:1. doi:10.1155/2019/2765731.
27. Hide, C, Moore, T, and Smith, M. Adaptive Kalman filtering for low-cost INS/GPS. J Navig. (2003). 56:143–52. doi:10.1017/S0373463302002151.
28. Yang, Y, and Gao, W. An optimal adaptive Kalman filter. J Geodes. (2006). 80:177–83. doi:10.1007/s00190-006-0041-0.
29. Bernstein, DS. Matrix mathematics: theory, facts, and formulas Princeton, NJ: Princeton University Press (2009). 1184 p.
30. Magni, L, Nicolao, GD, Magnani, L, and Scattolini, R. A stabilizing model-based predictive control algorithm for nonlinear systems. Automatica (2001). 37:1351–62. doi:10.1016/S0005-1098(01)00083-8.
31. Seborg, DE, Mellichamp, DA, Edgar, TF, and Doyle, FJ. Process dynamics and control New York, NY: John Wiley & Sons (2010). p. 1085–6.
Keywords: state estimation, nonlinear systems, stochastic systems, Kalman filtering, control
Citation: Spiller M and Söffker D (2020) On the Relation Between Smooth Variable Structure and Adaptive Kalman Filter. Front. Appl. Math. Stat. 6:585439. doi: 10.3389/fams.2020.585439
Received: 20 July 2020; Accepted: 16 October 2020;
Published: 27 November 2020.
Edited by:
Lili Lei, Nanjing University, ChinaReviewed by:
Xanthi Pedeli, Athens University of Economics and Business, GreeceYong Xu, Northwestern Polytechnical University, China
Copyright © 2020 Spiller and Söffker. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mark Spiller, bWFyay5zcGlsbGVyQHVuaS1kdWUuZGU=