Abstract
In the censored regression model, the Tobit maximum likelihood estimator is unstable and inefficient in the occurrence of the multicollinearity problem. To reduce this problem's effects, the Tobit ridge and the Tobit Liu estimators are proposed. Therefore, this study proposes a new kind of the Tobit estimation called the Tobit new ridge-type (TNRT) estimator. Also, the TNRT estimator was theoretically compared with the Tobit maximum likelihood, the Tobit ridge, and the Tobit Liu estimators via the mean squared error criterion. Moreover, we performed a Monte Carlo simulation to study the performance of the TNRT estimator compared with the previously defined estimators. Also, we used the Mroz dataset to confirm the theoretical and the simulation study results.
Introduction
The limited dependent variables (LDVs) in the regression models are defined as the censored, the discrete, and the truncated outcomes. Tobin [1] introduced the Tobit model of the censored dependent variable, which is related to the LDVs, and Goldberger [2] gave its current name. The censored data appear when the dependent variable has a loss of information, while the truncated data appear when the dependent and the independent variables have a loss of information. In this study, we used the standard Tobit regression model, which is the Type 1 model of the Tobit models (Type 1–5) categorized by Amemiya [3] to deal with the censored dataset and their estimation. The censored normal regression model, which is called the Tobit model, is used to relieve the deficiency of biasedness and inconsistency of the results of using the least squares estimator (LSE). Therefore, to determine the estimates of the parameter and to find the estimates of statistical inference, the Tobit maximum likelihood estimator (TMLE) is used. When the explanatory (independent) variables are not independent, it becomes a problem called multicollinearity, which this problem often ignored in the censored regression models. Also, the multicollinearity makes the Tobit maximum likelihood estimates of the regression coefficients incorrect, unreliable, and unstable; because the mean squared error (MSE) values of these estimates are inflated. For this case, Khalaf et al. [4] examined the multicollinearity effects on the TMLE, and they introduced the Tobit ridge estimator (TRE). Then, Alhusseini and Odah [5] introduced a Tobit principal component estimator. Also, Toker et al. [6] introduced a Tobit Liu estimator (TLE).
In the linear regression model (LRM), several alternative estimators of the regression coefficients have been produced for the LSE when the multicollinearity problem happens because, in this case, the LSE gives large variances, wrong signs, and becomes unstable. The most popular estimators are the ridge estimator of Hoerl and Kennard [7] and the Liu estimator of Liu [8]. Recently, Kibria and Lukman [9] proposed a new ridge-type estimator (NRTE). The NRTE has been extended in different regression models in different studies, such as Lukman et al. [10], Lukman et al. [11], Akram et al. [12], Dawoud and Abonazel [13], Awwad et al. [14], and Abonazel et al. [15]. The multicollinearity is known to be a terrible problem in the Tobit model like in the LRM. For handling multicollinearity, some studies gave and investigated some biased estimators in the LRM for a long time, but there is little investigation of these estimators in the Tobit model. However, studies of the biased estimators instead of TMLE in deleting multicollinearity effects on regression coefficients in the Tobit model are needed. In this context, the TRE was introduced by Khalaf et al. [4] and the TLE by Toker et al. [6] were the biased estimation beginning points in the Tobit model. Then, we defined the Tobit NRTE (TNRTE) in this study. Also, we focus on the theoretical properties of the TNRTE by the MSE criterion and to compare them to the TMLE, the TRE, and the TLE.
The next content of this study is given as follows: Methodology Section defines the Tobit regression model and provides the TNRTE and the theoretical properties. A Monte Carlo Simulation Section deals with the Monte Carlo simulation study. A Real Life Data Section deals with the Mroz dataset. Conclusion Section includes the concluding remarks.
Methodology
Tobit Regression Model
The model of the Tobit regression is
where is called the dependent latent variable, xi is an i-th row of the known matrix X with the dimension n × (p + 1); where p is the number of the explanatory variables. β is the unknown (p + 1) × 1 coefficient vector (when the model contains the intercept β0), and ui is called an error term that is independent, follows a normal distribution by mean, and equals 0 and variance equals σ2. We considered the left censoring, where yi is defined as follows:
On the basis of n observations on yi and xi, the β and σ2 estimation issues are noted. For the defined model in Equation (1), assuming that na is the observation number for yi = 0 and is the observation number for yi > 0, that is, non-zero for yi occur first, then the log-likelihood function of the censored data is given as
where .
The TMLE of β is identified after solving the derivate of Equation (3), but it is not a linear function of β, so it can be solved iteratively by Fisher's scoring method that comprises using the second derivative. The Fisher's scoring method is given as
where is the matrix of the Fisher information which is given at where is β estimate at iteration(r), is β estimate at iteration (r − 1), , D is called as the diagonal matrix and So, the TMLE is written as:
Then, is given as:
Since the TMLE becomes inefficient and unstable when the multicollinearity problem occurs, Khalaf et al. [4] proposed the TRE and Toker et al. [6] proposed the TLE to eliminate the effects of this problem.
The TRE is given iteratively as
and the first step of the TRE is
such that is the first estimate of β, , is given at β(0), the TMLE first step values are as same as that of the TRE, and is the first step of the TMLE. When k = 0, .
The TLE is given iteratively as
and the first step of the TLE is
where the TMLE first step values are as same as that of the TLE if d = 1, [see Amemiya [16], Fair [17], and Toker et al. [6] for more details].
New Ridge-Type Estimator
The usefulness of the NRTE among the one-parameter estimators (RE and LE) in many different regression models and the extension of the one-parameter estimators to the area of the Tobit regression model encouraged us to derive the NRTE in this model as follows:
By extending Equation (3), which is the censored data log-likelihood function with the term of penalization, as
where is called a Lagrangian multiplier and c is a constant, and by differentiating J due to β, we got
where .
By finding the J second derivative due to β and then taking the expectation, we got the following form for the matrix:
Then, we employed the scoring of Fisher's method in order to introduce the TNRTE as:
By using Equation (4), we have the TNRTE in its final form as:
The TNRTE of Equation (15) was obtained iteratively. The first step of the TNRTE is given as follows:
and the first step of the TNRTE is
where the first step values of the TNRTE are same as that of the Tobit LE and is evaluated at β(0) if k = 0, .
Asymptotic MSE Comparisons
To observe the estimators' characteristics, the MSE criterion was preferred. When is an estimator of B, then the matrix form of the MSE criterion is given as
where is the matrix form of the variance-covariance and is the bias vector of estimator. Then, the scalar MSE is given by
Since the TMLE for the first step is known as an asymptotically unbiased estimator, it means that the asymptotic matrix form of the MSE equals the asymptotic matrix form of the variance-covariance as follows:
The asymptotic MSE matrix form of is given as
The asymptotic MSE matrix form of is given as
The first step TNRTE asymptotic bias and its asymptotic variance-covariance forms are given as follows:
and
Then, the asymptotic MSE matrix form of is given as
Model (1) is written in the canonical form using the orthogonal transformation and the spectral decomposition such that the Fisher matrix form of the first step is given as , where C = [C0, C1, ..., Cp] is called a (p + 1) × (p + 1) orthogonal matrix form and refers to the eigenvectors columns, is called a (p + 1) × (p + 1) diagonal matrix form with the eigenvalues on the diagonal, such that M = XC. The canonical form formula of the asymptotic matrix form and the scalar MSE for , , and are written as follows:
where α = C′β, , , and .
The lemmas below are useful to be used in the theoretical comparisons among the above estimators.
Lemma 1: Suppose for the matrices n × n, if F > 0 and I > 0 (or I ≥ 0), then F > I iff such that is the matrix IF−1 maximum eigenvalue [18].
Lemma 2: If the matrix F is defined as an n × n positive definite, i.e., F > 0, as well as α is a vector, then, F − αα′ > 0 iff α′F−1 α < 1 [19].
Lemma 3: Suppose αi = Kim, i = 1, 2 are two α linear estimators and suppose , where refers to covariance matrix and , i = 1, 2 [20], then consequently,
iff , where .
Comparisons Among the Estimators
Theorem 1: is superior to iff
Proof : The dispersion difference is:
We observed that is positive definite since for k > 0. By Lemma 3, the proof is completed.
Theorem 2: When , is superior to iff
where
Proof:
where and
It is clear that, for k > 0 and 0 < d < 1, F > 0 and I > 0. It is obvious that F − I > 0 if and only if , where is the maximum eigenvalue of the matrix IF−1. By Lemma 1, the proof is completed.
Theorem 3: is superior to if and only if
where
Proof: The dispersion difference is
We observed that is applicable if and only if . For k > 0, it was observed that . By Lemma 3, the proof is completed.
The Selection of k Parameter of the TNRTE
Using the Kibria and Lukman [9] method, the optimal biasing parameter k of the TNRTE is given as:
and using the unbiased estimates of σ2 and α2, the optimal estimated k of the TNRTE is given as:
A Monte Carlo Simulation
To explain the performance of the proposed TNRTE compared with other mentioned estimators, we conducted the simulation experiments using some different factor levels. The design is constructed by following the techniques of Kibria [21], Yenilmez et al. [22], Khalaf et al. [4], Yenilmez and Kantar [23], Toker et al. [6], and Yenilmez et al. [24]. The correlation degree (τ) among the explanatory variables is one of the essential factors in the simulation. For providing the correlation changing range, the data were also generated using the next model:
where zij is given and follows a standard normal. The dependent variable is given using the next equation:
where ui's are considered as pseudo-random numbers, which are independent and identical and have N(0, σ2), and the parameter vector is considered as β′β = 1 as in the studies of Dawoud and Abonazel [25], Awwad et al. [26], Awwad et al. [14], Abonazel and Dawoud [27], Algamal and Abonazel [28], Abonazel et al. [15], and Abonazel et al. [29]. So, the dependent variable has been censored using Equation (2). Also, all factors used in this simulation are stated in Table 1.
Table 1
| Factor | Symbol | Design |
|---|---|---|
| Censoring level | CL | 5, 25, 50% |
| Sample size | n | 100, 400, 800 |
| Variance | σ | 0.5, 1, 5 |
| Degree of correlation | τ | 0.85, 0.9, 0.95, 0.99 |
| Number of explanatory variables | p | 4, 8 |
| Number of replicates | MCN | 1,000 |
Values of factors that are considered in the simulation.
The TRE, the TLE, and the proposed TNRTE estimated biasing parameters used in this simulation study are given as follows:
The estimated parameter of k for the TRE is considered according to Hoerl and Kennard [7], as
The estimated parameter d for the TLE is considered, according to Liu [8] as follows
when has negative value, Ozkale and Kaciranlar [30] considered the alternative parameter of d as:
Following the study of Kibria and Lukman [9], the estimated biasing parameter minimum value and the harmonic-mean of k for the proposed TNRTE are considered as follows:
To examine the performances of the TMLE, TRE, TLE, and the proposed TNRTE, we computed the estimated MSE (EMSE) as:
where is called an estimator as well as α is called a true parameter. The simulation results (EMSE values) are stated in Tables 2–7, the smallest value of the EMSE is highlighted in bold.
Table 2
| CL | n | τ | |||||
|---|---|---|---|---|---|---|---|
| 0.05 | 100 | 0.85 | 0.08439 | 0.08177 | 0.08024 | 0.07580 | 0.04701 |
| 0.90 | 0.14477 | 0.14108 | 0.13687 | 0.13340 | 0.09588 | ||
| 0.95 | 0.37866 | 0.30013 | 0.28805 | 0.21957 | 0.14546 | ||
| 0.99 | 2.12123 | 1.69281 | 1.17409 | 1.36538 | 1.07352 | ||
| 400 | 0.85 | 0.06948 | 0.06873 | 0.06862 | 0.06682 | 0.04976 | |
| 0.90 | 0.03736 | 0.03698 | 0.03664 | 0.03595 | 0.02226 | ||
| 0.95 | 0.15997 | 0.15486 | 0.15322 | 0.14427 | 0.10026 | ||
| 0.99 | 0.51461 | 0.44249 | 0.41698 | 0.36556 | 0.26895 | ||
| 800 | 0.85 | 0.01500 | 0.01495 | 0.01492 | 0.01482 | 0.01131 | |
| 0.90 | 0.02420 | 0.02403 | 0.02393 | 0.02356 | 0.01506 | ||
| 0.95 | 0.05889 | 0.05823 | 0.05779 | 0.05653 | 0.03707 | ||
| 0.99 | 0.26189 | 0.24239 | 0.23242 | 0.21132 | 0.13378 | ||
| 0.25 | 100 | 0.85 | 0.15183 | 0.13607 | 0.13891 | 0.11350 | 0.09149 |
| 0.90 | 0.34139 | 0.23299 | 0.27936 | 0.16125 | 0.13711 | ||
| 0.95 | 0.81721 | 0.33112 | 0.47175 | 0.18070 | 0.15651 | ||
| 0.99 | 3.07911 | 1.94488 | 1.30970 | 1.30760 | 0.94765 | ||
| 400 | 0.85 | 0.09315 | 0.09179 | 0.09245 | 0.08912 | 0.09653 | |
| 0.90 | 0.14761 | 0.14084 | 0.14458 | 0.13033 | 0.12393 | ||
| 0.95 | 0.28787 | 0.21218 | 0.25017 | 0.14216 | 0.10127 | ||
| 0.99 | 1.16488 | 0.51121 | 0.64053 | 0.28221 | 0.23849 | ||
| 800 | 0.85 | 0.05474 | 0.05454 | 0.05462 | 0.05407 | 0.06394 | |
| 0.90 | 0.14315 | 0.13700 | 0.14052 | 0.12498 | 0.09854 | ||
| 0.95 | 0.11686 | 0.10747 | 0.11202 | 0.09119 | 0.06602 | ||
| 0.99 | 1.23499 | 0.81775 | 0.89744 | 0.53421 | 0.35129 | ||
| 0.50 | 100 | 0.85 | 0.94398 | 0.49023 | 0.72343 | 0.34857 | 0.32451 |
| 0.90 | 0.89523 | 0.37400 | 0.61122 | 0.29265 | 0.28724 | ||
| 0.95 | 0.45112 | 0.15818 | 0.25473 | 0.12841 | 0.12884 | ||
| 0.99 | 4.57183 | 0.72390 | 0.72960 | 0.39133 | 0.45197 | ||
| 400 | 0.85 | 0.41065 | 0.30470 | 0.38918 | 0.25460 | 0.24267 | |
| 0.90 | 0.36824 | 0.27886 | 0.34462 | 0.22898 | 0.20956 | ||
| 0.95 | 0.78458 | 0.39098 | 0.66041 | 0.29614 | 0.27413 | ||
| 0.99 | 6.15895 | 3.91878 | 2.45550 | 1.67715 | 0.37830 | ||
| 800 | 0.85 | 0.28978 | 0.27517 | 0.28713 | 0.25792 | 0.24808 | |
| 0.90 | 0.38991 | 0.31360 | 0.37730 | 0.26372 | 0.24913 | ||
| 0.95 | 0.32927 | 0.29935 | 0.32278 | 0.28405 | 0.28284 | ||
| 0.99 | 0.64817 | 0.29716 | 0.46906 | 0.25371 | 0.24986 |
Simulation results in case of p = 4 and σ = 0.5.
Table 3
| CL | n | τ | |||||
|---|---|---|---|---|---|---|---|
| 0.05 | 100 | 0.85 | 0.27994 | 0.22248 | 0.23948 | 0.15818 | 0.09746 |
| 0.90 | 0.48548 | 0.36945 | 0.38882 | 0.26648 | 0.18523 | ||
| 0.95 | 1.06487 | 0.53619 | 0.59676 | 0.29376 | 0.21853 | ||
| 0.99 | 6.09446 | 3.40860 | 1.50770 | 1.88323 | 0.79975 | ||
| 400 | 0.85 | 0.12066 | 0.11220 | 0.11558 | 0.09571 | 0.05239 | |
| 0.90 | 0.12223 | 0.11110 | 0.11400 | 0.09042 | 0.04230 | ||
| 0.95 | 0.29436 | 0.24058 | 0.25852 | 0.17596 | 0.10436 | ||
| 0.99 | 1.21836 | 0.66503 | 0.71062 | 0.40058 | 0.30620 | ||
| 800 | 0.85 | 0.03940 | 0.03824 | 0.03857 | 0.03533 | 0.01791 | |
| 0.90 | 0.06245 | 0.05920 | 0.06033 | 0.05186 | 0.02352 | ||
| 0.95 | 0.14561 | 0.13252 | 0.13633 | 0.10842 | 0.05392 | ||
| 0.99 | 0.66375 | 0.42483 | 0.47623 | 0.26713 | 0.19121 | ||
| 0.25 | 100 | 0.85 | 0.33660 | 0.21404 | 0.26973 | 0.14257 | 0.12302 |
| 0.90 | 0.65097 | 0.29570 | 0.45169 | 0.17768 | 0.15457 | ||
| 0.95 | 1.35205 | 0.43767 | 0.61171 | 0.19088 | 0.13035 | ||
| 0.99 | 6.27692 | 2.95777 | 1.26949 | 1.38631 | 0.60606 | ||
| 400 | 0.85 | 0.12446 | 0.11477 | 0.12118 | 0.10195 | 0.10170 | |
| 0.90 | 0.23884 | 0.19092 | 0.22362 | 0.15172 | 0.13461 | ||
| 0.95 | 0.37085 | 0.19966 | 0.30011 | 0.11732 | 0.09775 | ||
| 0.99 | 1.80126 | 0.61418 | 0.76889 | 0.25384 | 0.13237 | ||
| 800 | 0.85 | 0.07414 | 0.07139 | 0.07309 | 0.06594 | 0.06361 | |
| 0.90 | 0.17009 | 0.15060 | 0.16434 | 0.12400 | 0.09976 | ||
| 0.95 | 0.21158 | 0.16012 | 0.19310 | 0.11050 | 0.08175 | ||
| 0.99 | 1.74511 | 0.87871 | 1.07884 | 0.45816 | 0.25214 | ||
| 0.50 | 100 | 0.85 | 1.13850 | 0.51946 | 0.81290 | 0.35420 | 0.33801 |
| 0.90 | 1.13729 | 0.40701 | 0.68195 | 0.30323 | 0.30289 | ||
| 0.95 | 0.85386 | 0.20759 | 0.36866 | 0.13717 | 0.13773 | ||
| 0.99 | 5.99679 | 0.90344 | 0.65449 | 0.41361 | 0.43331 | ||
| 400 | 0.85 | 0.43862 | 0.28981 | 0.40717 | 0.24688 | 0.24386 | |
| 0.90 | 0.42703 | 0.27502 | 0.38620 | 0.22024 | 0.20849 | ||
| 0.95 | 1.02445 | 0.43173 | 0.79452 | 0.29342 | 0.25947 | ||
| 0.99 | 7.23887 | 3.73973 | 2.27123 | 1.30613 | 0.39580 | ||
| 800 | 0.85 | 0.31729 | 0.28246 | 0.31201 | 0.25644 | 0.24980 | |
| 0.90 | 0.43023 | 0.30451 | 0.40978 | 0.25171 | 0.24425 | ||
| 0.95 | 0.38920 | 0.30205 | 0.37000 | 0.27884 | 0.27794 | ||
| 0.99 | 0.88767 | 0.31974 | 0.54905 | 0.25139 | 0.24847 |
Simulation results in case of p = 4 and σ = 1.
Table 4
| CL | n | τ | |||||
|---|---|---|---|---|---|---|---|
| 0.05 | 100 | 0.85 | 5.85274 | 0.39991 | 0.80830 | 0.18888 | 0.19297 |
| 0.90 | 9.23801 | 0.43827 | 0.75055 | 0.20275 | 0.17161 | ||
| 0.95 | 20.26041 | 0.63066 | 0.54674 | 0.75467 | 0.93491 | ||
| 0.99 | 107.51962 | 3.14511 | 0.33799 | 1.95772 | 1.76879 | ||
| 400 | 0.85 | 1.70770 | 0.16823 | 0.75322 | 0.04656 | 0.03788 | |
| 0.90 | 2.53743 | 0.16743 | 0.78535 | 0.04929 | 0.04044 | ||
| 0.95 | 4.58955 | 0.17121 | 0.79950 | 0.06594 | 0.04300 | ||
| 0.99 | 21.62036 | 0.42102 | 0.40384 | 0.25861 | 0.13540 | ||
| 800 | 0.85 | 0.73929 | 0.08473 | 0.47144 | 0.02380 | 0.02045 | |
| 0.90 | 1.19120 | 0.09931 | 0.61501 | 0.02961 | 0.02455 | ||
| 0.95 | 2.38632 | 0.08583 | 0.77279 | 0.02664 | 0.01796 | ||
| 0.99 | 11.96986 | 0.24125 | 0.53698 | 0.13878 | 0.06955 | ||
| 0.25 | 100 | 0.85 | 5.77461 | 0.46378 | 0.71224 | 0.29294 | 0.30568 |
| 0.90 | 11.21582 | 0.48987 | 0.74074 | 0.22880 | 0.18155 | ||
| 0.95 | 18.42567 | 0.63905 | 0.54834 | 0.56494 | 0.50903 | ||
| 0.99 | 89.60013 | 2.05524 | 0.26170 | 0.98369 | 0.41537 | ||
| 400 | 0.85 | 1.38431 | 0.42819 | 0.68425 | 0.18593 | 0.17036 | |
| 0.90 | 3.08322 | 0.35974 | 0.97073 | 0.15886 | 0.13434 | ||
| 0.95 | 4.08642 | 0.25720 | 0.67809 | 0.12900 | 0.09643 | ||
| 0.99 | 22.17859 | 0.40916 | 0.36989 | 0.31214 | 0.13774 | ||
| 800 | 0.85 | 0.83619 | 0.17091 | 0.53177 | 0.06465 | 0.05761 | |
| 0.90 | 1.18690 | 0.23904 | 0.63327 | 0.10522 | 0.09467 | ||
| 0.95 | 2.81468 | 0.17317 | 0.85394 | 0.07262 | 0.06217 | ||
| 0.99 | 15.32023 | 0.41075 | 0.72909 | 0.15574 | 0.12420 | ||
| 0.50 | 100 | 0.85 | 9.33358 | 0.75539 | 1.21896 | 0.63396 | 0.61351 |
| 0.90 | 10.71809 | 0.76879 | 0.97905 | 0.71838 | 0.71674 | ||
| 0.95 | 17.16682 | 0.42785 | 0.44256 | 0.42213 | 0.32800 | ||
| 0.99 | 64.19689 | 0.91622 | 0.55578 | 1.46511 | 0.66360 | ||
| 400 | 0.85 | 1.84858 | 0.58827 | 0.86659 | 0.36689 | 0.34593 | |
| 0.90 | 2.42662 | 0.44374 | 0.82334 | 0.25360 | 0.22669 | ||
| 0.95 | 6.36484 | 0.40697 | 0.98929 | 0.29202 | 0.24581 | ||
| 0.99 | 42.22717 | 1.41102 | 0.73127 | 0.44336 | 0.27481 | ||
| 800 | 0.85 | 1.24810 | 0.45470 | 0.82589 | 0.26673 | 0.25520 | |
| 0.90 | 1.79880 | 0.40571 | 0.95688 | 0.25133 | 0.23683 | ||
| 0.95 | 2.05814 | 0.41260 | 0.74084 | 0.26399 | 0.24359 | ||
| 0.99 | 7.95036 | 0.33278 | 0.52525 | 0.32700 | 0.23893 |
Simulation results in case of p = 4 and σ = 5.
Table 5
| CL | n | τ | |||||
|---|---|---|---|---|---|---|---|
| 0.05 | 100 | 0.85 | 0.21299 | 0.21003 | 0.20261 | 0.19563 | 0.12179 |
| 0.90 | 0.56969 | 0.51409 | 0.48277 | 0.36650 | 0.18440 | ||
| 0.95 | 0.83207 | 0.72366 | 0.63084 | 0.50335 | 0.28609 | ||
| 0.99 | 16.52158 | 10.44695 | 2.35048 | 4.92202 | 2.37078 | ||
| 400 | 0.85 | 0.27154 | 0.26411 | 0.26211 | 0.23113 | 0.13296 | |
| 0.90 | 0.13371 | 0.12809 | 0.12646 | 0.10156 | 0.02604 | ||
| 0.95 | 0.31037 | 0.29873 | 0.29093 | 0.25102 | 0.13099 | ||
| 0.99 | 1.18991 | 1.01467 | 0.86321 | 0.71893 | 0.45445 | ||
| 800 | 0.85 | 0.05024 | 0.04994 | 0.04966 | 0.04810 | 0.02107 | |
| 0.90 | 0.05721 | 0.05666 | 0.05614 | 0.05330 | 0.01864 | ||
| 0.95 | 0.18054 | 0.17206 | 0.17089 | 0.13469 | 0.04490 | ||
| 0.99 | 1.35089 | 1.07159 | 1.04126 | 0.69134 | 0.43935 | ||
| 0.25 | 100 | 0.85 | 1.56275 | 0.58823 | 1.03474 | 0.22315 | 0.19675 |
| 0.90 | 1.89425 | 0.74730 | 1.13449 | 0.31928 | 0.26897 | ||
| 0.95 | 3.92006 | 2.28015 | 2.15826 | 1.18369 | 0.83884 | ||
| 0.99 | 15.48598 | 3.40925 | 0.68261 | 0.49189 | 0.45279 | ||
| 400 | 0.85 | 0.21475 | 0.17820 | 0.19909 | 0.09342 | 0.05105 | |
| 0.90 | 0.51782 | 0.36158 | 0.45851 | 0.16621 | 0.10651 | ||
| 0.95 | 1.89760 | 1.16085 | 1.37948 | 0.40165 | 0.11108 | ||
| 0.99 | 3.85082 | 1.25270 | 1.42291 | 0.43649 | 0.29770 | ||
| 800 | 0.85 | 0.36483 | 0.31813 | 0.35016 | 0.20515 | 0.13247 | |
| 0.90 | 0.12170 | 0.10803 | 0.11754 | 0.08141 | 0.07711 | ||
| 0.95 | 0.55161 | 0.37153 | 0.48398 | 0.16621 | 0.08142 | ||
| 0.99 | 3.11611 | 0.91577 | 1.55483 | 0.29862 | 0.18130 | ||
| 0.50 | 100 | 0.85 | 4.46921 | 1.76414 | 2.69672 | 0.83017 | 0.64431 |
| 0.90 | 4.40601 | 1.93398 | 2.24012 | 0.70013 | 0.41793 | ||
| 0.95 | 7.70547 | 2.09302 | 1.91177 | 0.47669 | 0.38454 | ||
| 0.99 | 16.11585 | 1.44523 | 0.69649 | 0.80656 | 0.86553 | ||
| 400 | 0.85 | 0.58769 | 0.25876 | 0.50664 | 0.19675 | 0.19763 | |
| 0.90 | 0.86237 | 0.34608 | 0.72974 | 0.22902 | 0.22895 | ||
| 0.95 | 1.80472 | 0.60017 | 1.26100 | 0.35283 | 0.33833 | ||
| 0.99 | 21.83544 | 5.59858 | 3.62775 | 1.13593 | 0.75091 | ||
| 800 | 0.85 | 0.47881 | 0.34735 | 0.46012 | 0.28121 | 0.27713 | |
| 0.90 | 0.83702 | 0.49046 | 0.76243 | 0.29857 | 0.27414 | ||
| 0.95 | 1.49459 | 0.57785 | 1.22709 | 0.31494 | 0.27184 | ||
| 0.99 | 3.12040 | 0.66685 | 1.30715 | 0.27054 | 0.24975 |
Simulation results in case of p = 8 and σ = 0.5.
Table 6
| CL | n | τ | |||||
|---|---|---|---|---|---|---|---|
| 0.05 | 100 | 0.85 | 1.15846 | 0.87888 | 0.91697 | 0.51322 | 0.27689 |
| 0.90 | 1.53553 | 1.15383 | 1.07084 | 0.68093 | 0.38196 | ||
| 0.95 | 4.01636 | 2.37195 | 1.80330 | 1.01617 | 0.57745 | ||
| 0.99 | 12.27522 | 8.05584 | 2.46922 | 4.06623 | 2.06109 | ||
| 400 | 0.85 | 0.19309 | 0.17901 | 0.18189 | 0.12447 | 0.03658 | |
| 0.90 | 0.43058 | 0.37714 | 0.39135 | 0.23424 | 0.09405 | ||
| 0.95 | 0.73881 | 0.55514 | 0.60638 | 0.27658 | 0.12419 | ||
| 0.99 | 4.29109 | 2.14779 | 1.75127 | 0.85536 | 0.46653 | ||
| 800 | 0.85 | 0.11483 | 0.10893 | 0.11095 | 0.08191 | 0.02236 | |
| 0.90 | 0.16419 | 0.15237 | 0.15634 | 0.10503 | 0.02677 | ||
| 0.95 | 0.32358 | 0.28838 | 0.29549 | 0.18040 | 0.05814 | ||
| 0.99 | 1.60044 | 0.77540 | 0.97348 | 0.29564 | 0.18525 | ||
| 0.25 | 100 | 0.85 | 2.32574 | 1.08986 | 1.36734 | 0.27468 | 0.13717 |
| 0.90 | 5.22360 | 2.78669 | 2.68889 | 1.03991 | 0.49823 | ||
| 0.95 | 5.40588 | 3.28294 | 2.54175 | 1.61957 | 0.97862 | ||
| 0.99 | 27.30491 | 8.10032 | 1.35084 | 1.91940 | 1.40683 | ||
| 400 | 0.85 | 0.44521 | 0.26832 | 0.39387 | 0.11254 | 0.08142 | |
| 0.90 | 0.76937 | 0.45170 | 0.65382 | 0.18471 | 0.11600 | ||
| 0.95 | 2.29500 | 1.21621 | 1.50964 | 0.27296 | 0.10602 | ||
| 0.99 | 5.17561 | 1.69015 | 1.39349 | 0.33433 | 0.13233 | ||
| 800 | 0.85 | 0.29510 | 0.24088 | 0.27898 | 0.12772 | 0.06503 | |
| 0.90 | 0.36689 | 0.24308 | 0.33794 | 0.12569 | 0.10288 | ||
| 0.95 | 0.37569 | 0.20298 | 0.31807 | 0.08142 | 0.06467 | ||
| 0.99 | 3.96692 | 1.07023 | 1.72913 | 0.30098 | 0.20096 | ||
| 0.50 | 100 | 0.85 | 3.37604 | 1.06933 | 1.78404 | 0.57155 | 0.55877 |
| 0.90 | 1.37876 | 0.32910 | 0.68637 | 0.19041 | 0.19209 | ||
| 0.95 | 5.84301 | 1.00650 | 1.43225 | 0.41051 | 0.42935 | ||
| 0.99 | 73.10146 | 29.99253 | 1.11649 | 1.68054 | 2.97445 | ||
| 400 | 0.85 | 1.12473 | 0.44371 | 0.94728 | 0.25330 | 0.23185 | |
| 0.90 | 1.83650 | 0.65919 | 1.39858 | 0.25178 | 0.18772 | ||
| 0.95 | 1.39164 | 0.41154 | 0.91057 | 0.30256 | 0.30279 | ||
| 0.99 | 12.10185 | 1.84634 | 1.58779 | 0.38332 | 0.36864 | ||
| 800 | 0.85 | 0.48052 | 0.34534 | 0.46263 | 0.29511 | 0.29213 | |
| 0.90 | 0.53634 | 0.30901 | 0.49602 | 0.26758 | 0.26706 | ||
| 0.95 | 1.81295 | 0.66496 | 1.39854 | 0.30232 | 0.25480 | ||
| 0.99 | 4.02489 | 0.89612 | 1.47110 | 0.29179 | 0.26844 |
Simulation results in case of p = 8 and σ = 1.
Table 7
| CL | n | τ | |||||
|---|---|---|---|---|---|---|---|
| 0.05 | 100 | 0.85 | 16.48429 | 0.76265 | 1.79934 | 0.47392 | 0.58901 |
| 0.90 | 24.14235 | 1.02268 | 1.45280 | 0.77891 | 1.03974 | ||
| 0.95 | 53.51362 | 2.15790 | 1.02047 | 1.79561 | 2.33215 | ||
| 0.99 | 239.12441 | 9.28487 | 0.34627 | 4.55732 | 5.75055 | ||
| 400 | 0.85 | 3.49016 | 0.13836 | 1.51275 | 0.03610 | 0.03901 | |
| 0.90 | 6.20417 | 0.20077 | 1.81764 | 0.05704 | 0.06378 | ||
| 0.95 | 11.94495 | 0.35280 | 1.73986 | 0.09322 | 0.10407 | ||
| 0.99 | 59.06904 | 1.59133 | 0.78171 | 0.32741 | 0.37704 | ||
| 800 | 0.85 | 1.89563 | 0.08764 | 1.17527 | 0.02067 | 0.02213 | |
| 0.90 | 2.73088 | 0.09386 | 1.39951 | 0.01762 | 0.01943 | ||
| 0.95 | 5.56415 | 0.13841 | 1.71080 | 0.02300 | 0.02574 | ||
| 0.99 | 27.36199 | 0.61708 | 1.10996 | 0.13521 | 0.14900 | ||
| 0.25 | 100 | 0.85 | 18.87774 | 0.82976 | 1.55346 | 0.63487 | 0.74055 |
| 0.90 | 34.43712 | 2.11859 | 1.93708 | 0.82710 | 0.99253 | ||
| 0.95 | 56.67286 | 2.54356 | 1.20241 | 1.20350 | 1.40572 | ||
| 0.99 | 234.54677 | 6.24261 | 0.46401 | 6.35297 | 7.65207 | ||
| 400 | 0.85 | 3.64835 | 0.19408 | 1.46753 | 0.08255 | 0.08183 | |
| 0.90 | 6.64063 | 0.26842 | 1.94108 | 0.10631 | 0.11199 | ||
| 0.95 | 16.55755 | 0.74765 | 2.08509 | 0.21553 | 0.21790 | ||
| 0.99 | 53.92402 | 1.12368 | 0.64415 | 0.37636 | 0.40181 | ||
| 800 | 0.85 | 2.28659 | 0.16307 | 1.35829 | 0.06684 | 0.06702 | |
| 0.90 | 2.58707 | 0.19128 | 1.28871 | 0.10171 | 0.10106 | ||
| 0.95 | 5.41396 | 0.18338 | 1.54659 | 0.06600 | 0.06500 | ||
| 0.99 | 32.35663 | 0.77203 | 1.22296 | 0.19496 | 0.20403 | ||
| 0.50 | 100 | 0.85 | 20.54085 | 1.08011 | 2.06415 | 0.91851 | 0.96065 |
| 0.90 | 21.67315 | 0.57351 | 1.04308 | 0.54817 | 0.55866 | ||
| 0.95 | 65.76152 | 2.32354 | 1.07240 | 2.24306 | 2.64051 | ||
| 0.99 | 299.40422 | 12.27341 | 0.42142 | 11.04547 | 11.98258 | ||
| 400 | 0.85 | 5.14950 | 0.39194 | 1.96635 | 0.25346 | 0.24852 | |
| 0.90 | 7.85514 | 0.34316 | 2.15083 | 0.14905 | 0.14598 | ||
| 0.95 | 14.82821 | 0.65250 | 1.89624 | 0.47094 | 0.45788 | ||
| 0.99 | 69.45204 | 1.45136 | 0.85636 | 0.94116 | 0.88360 | ||
| 800 | 0.85 | 1.88897 | 0.37811 | 1.18269 | 0.25336 | 0.25122 | |
| 0.90 | 3.04633 | 0.40105 | 1.51743 | 0.30356 | 0.30175 | ||
| 0.95 | 8.83255 | 0.40226 | 2.39202 | 0.20527 | 0.20621 | ||
| 0.99 | 26.02972 | 0.54693 | 0.96760 | 0.27806 | 0.25399 |
Simulation results in case of p = 8 and σ = 5.
Based on the simulation results, we conclude the following:
The EMSE increases as n decreases.
The EMSE increases as p increases.
The EMSE increases as τ increases.
The EMSE increases as σ increases.
The EMSE increases as the CL increases.
The TMLE exhibited the least performance at all levels of multicollinearity and censoring.
The TNRTE and the TLE outperform the TRE for all cases.
The proposed TNRTE has few EMSE values near to that of TLE in case of large σ and p values.
The proposed TNRTE with the biasing parameters performs the best of all other mentioned estimators in terms of the EMSE, followed by the proposed TNRTE with the biasing parameters in most cases.
The proposed TNRTE performance and others almost depend on the determination of their biasing parameter estimators.
Finally, the proposed TNRTE performs the best of all other mentioned estimators in terms of the EMSE in most cases.
A Real-Life Data
In this section, we have the Mroz dataset that was originally adopted by Mroz [31] to clarify the performance of the proposed TNRTE and other mentioned estimators. The Mroz data contains 753 cases of married women with 21 variables, and the ages of these women range from 30 to 60 years. Three hundred twenty-five of the 753 cases from these women have an average wage of zero in an hour. Then, Barros et al. [32] considered the average hourly wage of the women as a dependent variable (y), while the independent variables are as follows: age of the women (x1), education of the women (x2), number of children <6 years (x3), number of children between the ages 6 and 18 (x4), and previous labor market experience of the women (x5). With the method of Toker et al. [6], to examine the existence of multicollinearity, or not, the matrix eigenvalues are given as 69,601.81, 1,723.52, 334.22, 54.43, 6.22, and 0.36, and the condition number is calculated as 441.09, and these results connote that there is high multicollinearity. The parameters and MSE are estimated and presented in Table 8.
Table 8
| Estimator | α0 | α1 | α2 | α3 | α4 | α5 | MSE | k/d |
|---|---|---|---|---|---|---|---|---|
| −2.5349 | −0.1648 | 0.6825 | −2.6877 | 0.0781 | 0.2214 | 56.6834 | NA | |
| −0.4558 | −0.1806 | 0.5691 | −2.0635 | −0.0077 | 0.2243 | 7.7517 | 2.270 | |
| −0.8312 | −0.1811 | 0.6051 | −2.4213 | 0.0083 | 0.2230 | 9.9986 | 0.029 | |
| 1.2387 | −0.1987 | 0.5007 | −1.9321 | −0.0770 | 0.2254 | 34.3714 | 1.342 | |
| −0.3934 | −0.1883 | 0.5992 | −2.5793 | −0.0090 | 0.2226 | 8.0258 | 0.296 | |
| −1.4565 | −0.1766 | 0.6405 | −2.6324 | 0.0343 | 0.2220 | 20.1089 | 0.300 | |
| −1.3068 | −0.1766 | 0.6267 | −2.4957 | 0.0278 | 0.2225 | 16.9422 | 0.300 | |
| −0.3780 | −0.1884 | 0.5986 | −2.5771 | −0.0096 | 0.2226 | 8.0235 | 0.300 |
The regression coefficients and the MSE results.
Table 8 shows that the TMLE performs worse as expected. Also, the TRE has a near MSE value with the biasing parameter estimator to that of the proposed TNRTE with biasing parameter estimator . Moreover, the proposed TNRTE has the lowest MSE value among the mentioned estimators (TRE and TLE), followed by TLE and then the TRE, when k = d = 0.3; this means that the proposed TNRTE is the best in this case.
Figure 1 shows that the proposed TNRTE with biasing parameter k from 0.18 to 0.58 performing better than other mentioned estimators, and when k equals 0.36, the proposed TNRTE has the least MSE; which means it is the best of all given estimators, while the TMLE performs the worst as expected.
Figure 1
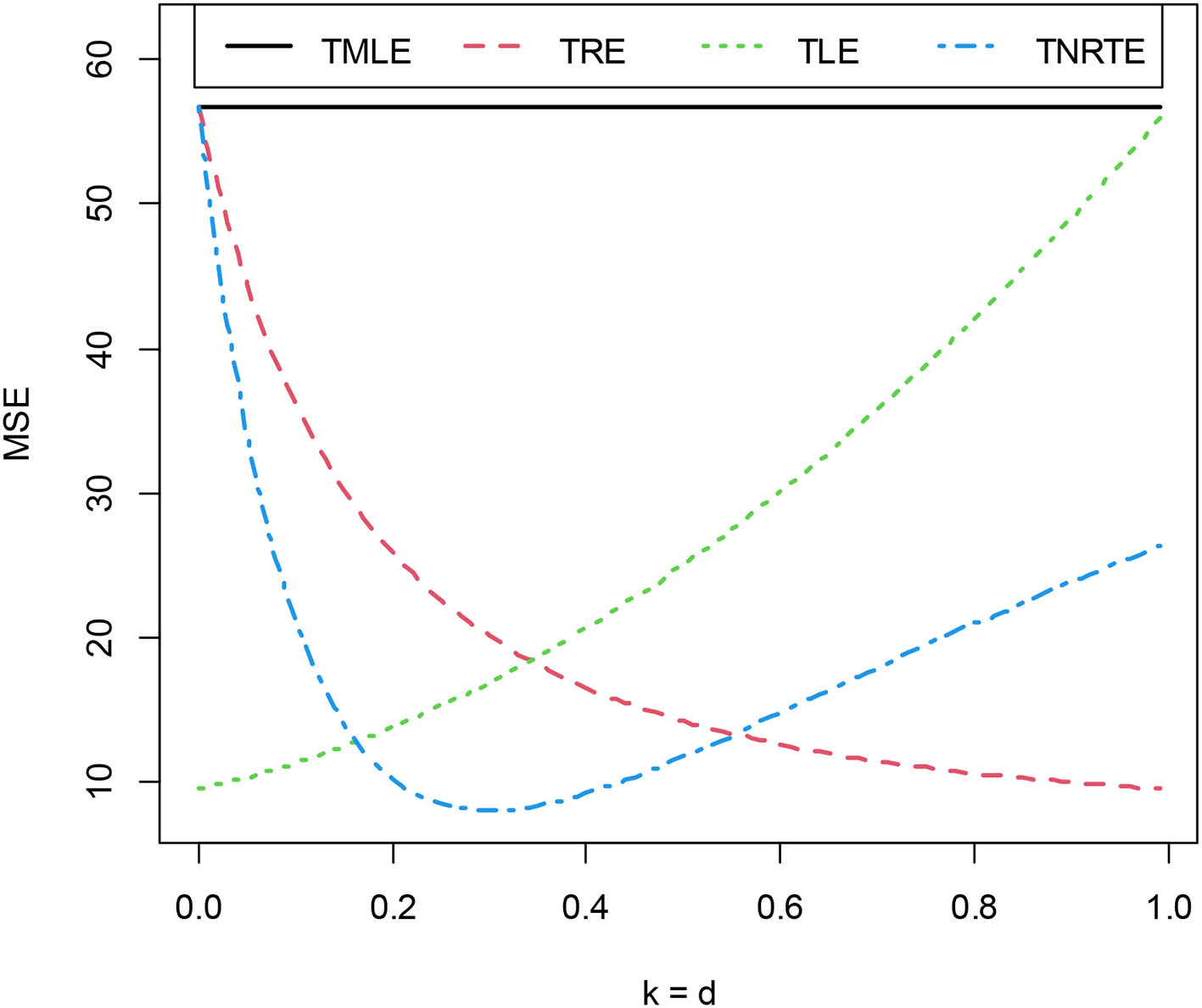
MSE of TMLE, TRE, TLE, and TNRTE for diffrent k, d.
Conclusions
In this study, we proposed the Tobit new ridge-type estimator (TNRTE) for overcoming the multicollinearity problem of the censored model. Theoretically, we compared the proposed TNRTE with some given estimators: the Tobit maximum likelihood estimator (TMLE), the Tobit ridge estimator (TRE), and the Tobit Liu estimator (TLE), and gave biasing parameter estimators of the proposed TNRTE. Then, a simulation study was performed to know the performance of the TMLE, the TRE, and the TLE with the proposed TNRTE. The results of the simulation indicate that the proposed TNRTE is better than other existing estimators in most cases. Moreover, real-life Mroz data were used to clarify the study results.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Statements
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
ID, MA, and FA contributed to conception and structural design of the manuscript. MA performed the simulation and application. All authors contributed to manuscript revision, read, and approved the submitted version.
Acknowledgments
The authors would like to thank the Deanship of Scientific Research at King Saud University represented by the Research Center at CBA for supporting this research financially.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1.
TobinJ. Estimation of relationships for limited dependent variables. Econometrica. (1958) 26:24–36. 10.2307/1907382
2.
GoldbergerAS. Econometric Theory, 1st ed.New York, NY: John Wiley and Sons (1964), p. 1–399.
3.
AmemiyaT. Tobit models: a survey. J Econom. (1984) 24:3–61. 10.1016/0304-4076(84)90074-5
4.
KhalafGManssonKSjolanderP. A Tobit ridge regression estimator. Commun. Stat. Theory Methods. (2014) 43:131–40. 10.1080/03610926.2012.655881
5.
AlhusseiniFHHOdahMH. Principal component regression for Tobit model and purchases of gold. In: Proceedings of the 10th International Management Conference, Bucharest, Romania. (2016) 10:491–500.
6.
TokerSÖzbayNSirayGÜYenilmezI. Tobit Liu estimation of censored regression model: an application to Mroz data and a Monte Carlo simulation study. J Stat Comput Simul. (2021) 91:1061–91. 10.1080/00949655.2020.1828416
7.
HoerlAEKennardRW. Ridge regression: biased estimation for nonorthogonal problems. Technometrics. (1970) 12:55–67. 10.1080/00401706.1970.10488634
8.
LiuK. A new class of biased estimate in linear regression. Commun Stat Theory Methods. (1993) 22:393–402. 10.1080/03610929308831027
9.
KibriaBMGLukmanAF. A new ridge-type estimator for the linear regression model: simulations and applications. Hindawi. (2020) 2020:1–16. 10.1155/2020/9758378
10.
LukmanAFDawoudIKibriaBMAlgamalZY. A new ridge-type estimator for the gamma regression model. Scientifica. (2021) 2021:5545356. 10.1155/2021/5545356
11.
LukmanAFAlgamalZYKibriaBG. The KL estimator for the inverse Gaussian regression model. Concurr Comput Pract Exp. (2021) 33:e6222. 10.1002/cpe.6222
12.
AkramMNKibriaBGAbonazelMR. On the performance of some biased estimators in the gamma regression model: simulation and applications. J Stat Comput Simul. (2022). 10.1080/00949655.2022.2032059. [Epub ahead of print].
13.
DawoudIAbonazelMR. Generalized Kibria-Lukman estimator: method, simulation, and application. Front Appl Math Stat. (2022) 8:880086. 10.3389/fams.2022.880086
14.
AwwadFAOdeniyiKADawoudIAlgamalZYAbonazelMRBMTag EldinE. New two-parameter estimators for the logistic regression model with multicollinearity. WSEAS Trans Math. (2022) 21:403–14. 10.37394/23206.2022.21.48
15.
AbonazelMRDawoudIAwwadFA. Dawoud–Kibria estimator for beta regression model: simulation and application. Front Appl Math Stat. (2022) 8:775068. 10.3389/fams.2022.775068
16.
AmemiyaT. Regression analysis when the dependent variable is truncated normal. Econometrics. (1973) 41:997–1016. 10.2307/1914031
17.
FairRC. A note on computation of the Tobit estimator. Econometrics. (1977) 45:1723–7. 10.2307/1913962
18.
WangSGWuMXJiaZZ. Matrix Inequalities. 2nd ed. Beijing: Chinese Science Press (2006), p. 1–116.
19.
FarebrotherRW. Further results on the mean square error of ridge regression. J R Stat Soc B. (1976) 38:248–50. 10.1111/j.2517-6161.1976.tb01588.x
20.
TrenklerGToutenburgH. Mean squared error matrix comparisons between biased estimators-an overview of recent results. Stat Pap. (1990) 31:165–79. 10.1007/BF02924687
21.
KibriaBMG. Performance of some new ridge regression estimators. Commun Stat Simul Comput. (2003) 32:419–35. 10.1081/SAC-120017499
22.
YenilmezIMert KantarYAcitaşS. Estimation of censored regression model in the case of non-normal error. Sigma J Eng Nat Sci. (2018) 36:513–521.
23.
YenilmezIMert KantarY. An alternative estimation method based on alpha skew logistic distribution for parameters of censored regression model. Data Sci Appl. (2019) 2:16–20.
24.
YenilmezIIlhanUMert KantarY. Quasi-maximum likelihood estimator based on moyal distribution for censored data. In: 5th International Researchers, Statisticians and Young Statisticians Congress Aydin, Turkey. (2019), p. 419–27.
25.
DawoudIAbonazelMR. Robust Dawoud–Kibria estimator for handling multicollinearity and outliers in the linear regression model. J Stat Comput Simul. (2021) 91:3678–92. 10.1080/00949655.2021.1945063
26.
Awwad FA DawoudIAbonazelMR. Development of robust Özkale–Kaçiranlar and Yang–Chang estimators for regression models in the presence of multicollinearity and outliers. Concurr Comput Pract Exp. (2022) 34:e6779. 10.1002/cpe.6779
27.
AbonazelMRDawoudI. Developing robust ridge estimators for Poisson regression model. Concurr Comput Pract Exp. (2022) 34:e6979. 10.1002/cpe.6979
28.
AlgamalZYAbonazelMR. Developing a Liu-type estimator in beta regression model. Concurr Comput Pract Exp. (2022) 34:e6685. 10.1002/cpe.6685
29.
AbonazelMRAlgamalZYAwwadFATahaIM. A New Two-parameter estimator for beta regression model: method, simulation, and application. Front Appl Math Stat. (2022) 7:780322. 10.3389/fams.2021.780322
30.
OzkaleMRKaçiranlarS. The restricted and unrestricted two-parameter estimators. Commun Stat Theory Methods. (2007) 36:2707–25. 10.1080/03610920701386877
31.
MrozTA. The sensitivity of an empirical model of married women's hours of work to economic and statistical assumptions. Econometrica. (1987) 55:765–99. 10.2307/1911029
32.
BarrosMGaleaMLeivaV. Generalized Tobit models: diagnostics and application in econometrics. J Appl Stat. (2018) 45:145–67. 10.1080/02664763.2016.1268572
Summary
Keywords
censored regression model, multicollinearity, Tobit Liu estimator, Tobit ridge estimator, Tobit new ridge-type estimator
Citation
Dawoud I, Abonazel MR, Awwad FA and Tag Eldin E (2022) A New Tobit Ridge-Type Estimator of the Censored Regression Model With Multicollinearity Problem. Front. Appl. Math. Stat. 8:952142. doi: 10.3389/fams.2022.952142
Received
24 May 2022
Accepted
21 June 2022
Published
15 July 2022
Volume
8 - 2022
Edited by
Han-Ying Liang, Tongji University, China
Reviewed by
Guoliang Fan, Shanghai Maritime University, China; Fuxia Cheng, Illinois State University, United States
Updates
Copyright
© 2022 Dawoud, Abonazel, Awwad and Tag Eldin.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mohamed R. Abonazel mabonazel@cu.edu.eg
This article was submitted to Statistics and Probability, a section of the journal Frontiers in Applied Mathematics and Statistics
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.