 Sara Stefanich
Sara Stefanich Jennifer Cabrelli
Jennifer Cabrelli Dustin Hilderman3
Dustin Hilderman3 John Archibald
John Archibald- 1Department of Spanish and Portuguese, Northwestern University, Evanston, IL, United States
- 2Department of Hispanic and Italian Studies, University of Illinois at Chicago, Chicago, IL, United States
- 3Department of Linguistics, University of Victoria, Victoria, BC, Canada
This paper serves as a critical discussion of the phenomenon of intraword code-switching (ICS), or the combining of elements (e. g., a root and an affix) from different languages within a single word. Extensive research over the last four decades (Poplack, 1988; Myers-Scotton, 2000; MacSwan, 2014) has revealed CS to be a rule-governed speech practice. While interword CS is widely attested, intraword code-switching has been argued to be impossible (Poplack, 1980; Bandi-Rao and den Dikken, 2014; MacSwan and Colina, 2014). However, ICS has recently been documented in language pairs ranging from English/Norwegian (Alexiadou et al., 2015) to Nahuatl/Spanish (MacSwan, 1999) to Greek/German (Alexiadou, 2017), and is a robust phenomenon. We review the foundational research on ICS, followed by an examination of the phenomenon from the perspectives of knowledge and skill. First, we examine intraword CS as part of a bilingual's I-language to determine the morphological and phonological restrictions on the phenomenon. We operationalize these restrictions within a Distributed Morphology (DM) framework (e.g., Halle and Marantz, 1994) in which the traditional lexicon is split into three lists. List 1 contains lexical roots and grammatical features or feature bundles, while Lists 2 and 3 detail instructions for phonological realization (i.e., rules for Vocabulary Insertion) and semantic interpretation, respectively. Here we probe the question of whether words which have morphological mixing also have phonological mixing. Second, building on the DM machinery, we present an account for intraword CS in performance via the modular cognitive performance framework of MOGUL (Sharwood Smith and Truscott, 2014). This modular architecture assumes (a) that lexical items are constituted by chains of representations and (b) that extra-linguistic cognitive mechanisms (e.g., goals, executive control) play a role in ICS (Green and Abutalebi, 2013). ICS is licensed by a bilingual mode of communication (following Grosjean, 2001) where the act of CS itself serves an illocutionary goal; it is the real-world context which triggers the complex CS system. Thus, viewing intraword CS as an I-language and an E-language phenomenon provides an explanatory model of the dynamic knowing that and knowing how which is manifest in the phenomenon of ICS.
Introduction
It is uncontroversial to note that bilinguals sometimes switch languages within a conversation and even within a sentence. In this paper, we seek to explore an even smaller domain of the linguistically-mixed word. When we use the word bilingual, we intend a very broad interpretation which runs the gamut from classroom second language learners to professional simultaneous interpreters. In a predominantly multilingual world, there are many conversations each day which involve people who know more than one language. They may occur within a multilingual family, or friend group, or society. There are two basic facts which underlie this seemingly effortless performance:
(A) bilinguals are normally very good at suppressing the production of a language which is not the language of the current environment, and
(B) the goal of the speaker is to have each utterance in a conversation successfully communicate an intended meaning, and will recruit all available linguistic resources to do so
Given these assumptions, it is interesting for the linguist and the psycholinguist to probe what underlies this phenomenon known as codeswitching, as, on the surface, it would appear that codeswitching might appear to violate both of the above axioms (given that one language is not suppressed, and that perhaps some of the interlocutors do not speak both languages). Research over the past 50 years has revealed that switching languages is not a sign of impoverished linguistic ability, or low proficiency, but rather is a complex performative dance which involves exchanging information, marking solidarity, and revealing identity (Poplack, 1980). However, like many aspects of linguistic performance, the rules and patterns are not open to conscious inspection. Just as when our knee is itchy, we “simply” invoke the motoric commands to scratch (and could not articulate them), when we have a message to convey to a particular listener or group of listeners, we “simply” produce the utterance (and could not explicitly state the grammatical rules which generated that utterance). This is true of both monolingual and bilingual utterances.
Throughout this paper, we will adopt a narrative strategy of referring to two groups of bilingual speakers (one Spanish/English, one Norwegian/English) in a casual, conversational manner to help elucidate some of the technical constructs. There is a rich corpus of data from heritage Norwegian speakers in the United States (Johannessenn, 2015) which we will draw on frequently in this paper. Let us imagine a gathering of members of this group in someone's home to have coffee and cake, and to watch a sporting event. If we were a fly (or tape-recorder) on the wall, we would undoubtedly hear many utterances which had elements of both English and Norwegian. Some of these utterances are produced by a (hypothetical) member of the community whom we will call Gunnar. Perhaps when referring to a particular sandwich type being served, Gunnar will use the Norwegian word Smørbrød as this seems more appropriate than the English sandwich. But perhaps when a hockey game comes on the TV, Gunnar is reminded of the Lillehammer winter Olympics in 1994 and begins to talk about sports completely in Norwegian. Then this sports talk is interrupted by a phone call which proceeds entirely in English. After the phone call, when the discussion switches to the upcoming state elections, the discussion switches to a mixture of Norwegian and English as people talk of both American and Norwegian politicians. This mixture of languages may include language switches within a sentence (intrasentential), switches between sentences (intersentential), or our main focus here, switches within a word (intraword). Such examples of multilingual communication are very common. They occur as effortlessly and automatically as any monolingual conversation.
However, mixing languages within a single word is a seemingly small linguistic phenomenon with surprisingly far-reaching implications, and an interesting history. For one thing, in the literature on codeswitching, there are researchers who have denied that intraword codeswitching (ICS) is even possible. We will argue that it is a robust and widespread characteristic of multilingual speech, and propose mechanisms to account for both the knowledge and performance systems which generate these forms. Surveying examples presented in the literature, it is clear that morphological elements can be combined in a single word in a systematic manner, just like codeswitching at the sentence or discourse level. However, it remains to be seen if phonological elements can be combined in a single word, and how such phonological switching could be accounted for in a theory of bilingual phonology. We will present and discuss how ICS can be examined via experimental methodologies in order to provide the data needed to form the basis of any such account. Consistent with much other research on the mental lexicon, ICS reveals that lexical knowledge is a dynamic cognitive system which involves the interfaces of syntax, morphology, and phonology. We maintain that such knowledge and performance is well-modeled via the machinery of Distributed Morphology (DM). Furthermore, implementing a single word with multilingual components requires an understanding of how the linguistic systems interface with domains of general cognition, such as communication mode, executive control, and goal attainment. Moment-by-moment changes in the real-world environment influence the cognitive context of the speaker and explain the linguistic properties of the ICS speech. In this way, ICS data (perhaps more obviously than monolingual data) reveal how what used to be referred to as the “mental dictionary” is not a passive vocabulary repository to be retrieved but rather a networked, dynamic, distributed system. In our view, this is consistent with late-insertion, non-lexicalist models of morphology. DM offers a competence based, representational account of language which focuses on the well-formedness of grammatical structure (or knowledge). To address the production (or performance) side of things, we will adopt Sharwood Smith and Truscott's (2014) Modular Online Growth and Use of Language (MOGUL) model as it is primarily concerned with real-time performance and language use; the focus is on the production of grammatically acceptable utterances which transmit the desired meaning. By situating a competence-based model of grammatical structure (i.e., DM) inside a performance-based model of cognition (i.e., MOGUL), we hope to be able to account for how, what Chomsky calls I-language informs the E-language phenomenon of ICS.
In section Review of Foundational Research on Intraword Codeswitching, we provide an overview of the literature addressing the phenomenon of intraword codeswitching. In section Discussion: Morphological Restrictions vs. Phonological Restrictions, we look at the reported patterns of ICS, and probe the characteristics of both morphological and phonological switches. In section Distributed Morphology, we introduce the model of Distributed Morphology as the foundation for our accounts of the representational properties of ICS words and the generation of ICS words. Section ICS at the Representational Level summarizes the experimental techniques used to probe the question of whether switching phonology within a word is grammatical. Section Producing ICS introduces the MOGUL framework in order to model what underlies the production of an ICS. Section Conclusion and Future Directions provides our conclusions and future directions.
Review of Foundational Research on Intraword Codeswitching
In order to understand what type of phenomena we are attempting to explain, let us imagine another group of bilinguals. Fulana is a heritage Mexican Spanish speaker living in Chicago. She often gets together with friends and family who are all highly proficient in both Spanish and English. At times, their conversations are completely in English, at times completely in Spanish. Yet, there are also many instances where we can find a single sentence which contains both Spanish and English elements. You might hear Fulana say:
(a) Siéntate Pedro, you're going to spill your juice.
“Sit down, Pedro, you're going to spill your juice.”
or
(b) Last week my sobrina came to visit.
“Last week my niece came to visit.”
Clearly, these sentences reveal elements from both Fulana's Spanish and English. But what of the case of single words? Does Fulana also mix elements of her Spanish and English in a single word? The short answer is yes, Fulana might also say something, such as (c):
(c) Voy a hangear con mis amigos
“I'm going to hang with my friends.”
In this case, she combines the English verb “to hang” with Spanish verbal inflection to create a mixed or codeswitched word. Given Fulana's mixed use of Spanish and English, the question then becomes, how can we account for her use of elements from her two languages in the same way that we account for how a monolingual combines and uses elements from her one language. As this paper is concerned with CS at the word level, we limit our discussion to CS accounts that directly inform the use of two languages within a single word.
Of the foundational work which addresses ICS, most often cited are Poplack's (1980) Free Morpheme Constraint and MacSwan and Colina's (2014) PF Interface Condition (formerly realized as the PF Disjunction Theorem, MacSwan, 2000). Both the Free Morpheme Constraint and the PF Interface Condition claim that ICS is not possible. In her study of Spanish/English bilinguals living in NY, Poplack (1980) did not find many instances of mixed words. To explain their absence, she proposed the Free Morpheme Constraint which states “codes may be switched after any constituent in discourse provided that the constituent is not a bound morpheme” (pp. 585–586). Poplack claims that this strict constraint serves to account for the lack of occurrences of switches, such as (1), comprised of a root from LA (here, English) and affixes from LB (Spanish) in her corpus of Spanish/English CS.
(1)*eat-iendo
In (1), the English verb “eat” is combined with the Spanish bound affixes “-iendo.” Following the Free Morpheme Constraint, a switch into another language cannot occur at this morpheme boundary and therefore the word in (1) is considered unacceptable to Spanish/English bilinguals and is not produced in bilingual discourse.
In a similar vein, the PF Interface Condition (2) also rules out intraword switches of the type shown above in (1).
(2) PF Interface Condition
i. Phonological input is mapped to the output in one step with no intermediate representations.
ii. Each set of internally ranked constraints is a constraint dominance hierarchy, and a language-particular phonology is a set of constraint dominance hierarchies.
iii. Bilinguals have a separately encapsulated phonological system for each language in their repertoire in order to avoid ranking paradoxes, which result from the availability of distinct constraint dominance hierarchies with conflicting priorities.
iv. Every syntactic head must be phonologically parsed at spell-Out. Therefore, the boundary between heads (words) represents the minimal opportunity for codeswitching.
In their formulation of the PF Interface Condition, which adopts a constraint-based (Optimality Theoretic, OT) perspective, MacSwan and Colina (2014) consider morphosyntactic X0s (whether simple or complex) to be the input to PF/phonology. In order to avoid a ranking paradox of the phonological constraints between two languages, only a single phonology can be applied to a word (i.e., an X0). In other words, PF does not allow for a word that has been formed in syntax to undergo a process in which the word is broken down into its individual morphological elements so that each element can undergo the phonological processes of its original phonological system and then be formed back into the original word. Instead, PF demands that a word formed in syntax will serve as the input to a single phonological system. Specifically, this input will yield a set of output candidates that will be evaluated by a (single) language-specific constraint ranking, thereby preventing phonological ICS.
It is essential to note that both Poplack (1980) and MacSwan and Colina (2014) recognize that codeswitched words in which one of the morphemes has been phonologically integrated into the other are attested in CS data. For instance, in (1), if “eat” is phonologically integrated into Spanish (i.e., with Spanish pronunciation [itiendo]), then it is considered acceptable to Spanish/English bilinguals. However, Poplack and MacSwan label instances of phonologically integrated mixed words as borrowings and claim that they arise as a result of a linguistic process distinct from CS. A borrowing (or “loanword”), can be defined as “a word that at some point in the history of a language entered its lexicon as a result of borrowing (or transfer, or copying)” (Haspelmath, 2009, p. 36). In a bilingual context, a borrowing is a word that has been taken from LA and added to the mental lexicon of LB, and, differently than CS, is typically morphologically, syntactically, and phonologically integrated into the recipient language (LB). Because borrowings are accounted for differently than CS, Poplack and MacSwan posit that borrowings, such as [itiendo] do not serve as counter-evidence toward the Free Morpheme Constraint nor the PF Interface Condition. Now, before moving forward, we note that the purpose of this paper is not to comment upon the longstanding discussion of borrowing vs. CS nor to argue that any of the mixed words presented herein should be considered codeswitches instead of borrowings or vice-versa1. Instead, this paper serves as a critical discussion of the bilingual phenomenon of mixed words more generally and provides an overview of mixed words found in bilingual discourse. Furthermore, using phonological integration as the sole deciding factor for borrowings vs. CS (as is the case with [itiendo] and similar examples in the literature) is not optimal given that, at the mixed word level, borrowings can be phonologically indistinguishable from CS (i.e., they both demonstrate integration). For more discussion, see González-Vilbazo and López (2011), Poplack and Dion (2012), Bessett (2017), Grimstad (2017), Alexiadou and Lohndal (2018), among others.
In contrast to the Free Morpheme Constraint and PF Interface Condition, more recent work on ICS claims that intraword CS is possible but strictly constrained. For instance, Bandi-Rao and den Dikken's (2014) analysis of Telugu/English CS notes a difference in acceptability between the mixed word in (3) comprised of a Telugu root and English affixes and that of (4) comprised of a (mirror image) English root and Telugu affixes.
(3) my sister kalp-ified the curry
“my sister stirred the curry”
(4)*vaaDu nanni love-inc-EEDu
He-NOM me-ACC love-do-PST-AGR
Bandi-Rao and Den Dikken claim that the difference between “kalpified” in (3) and “loveinceedu” in (4) is that “loveinceedu” was formed via incorporation in syntax and consists of a single morphosyntactic head, whereas “kalpified” in (4) was formed via a process of phrasal affixation and therefore is composed of two separate morphosyntactic heads. (5)–(6) illustrate this proposed difference in underlying structure2.
(5)
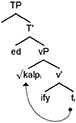
(6)
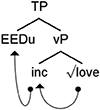
To explain the difference in acceptability, Bandi-Rao and Den Dikken follow MacSwan (2000) and consider single morphosyntactic X0s to be the input to phonology:
(7) Codeswitching within phonological words that are morphosyntactic heads (X0s) is illicit.
Although (4) is argued to be illicit in a bilingual grammar because the mixed word consists of a single morphosyntactic head, the example in (3) suggests that ICS is possible as long as the underlying syntactic structure of the word in question is comprised of more than one morphosyntactic head. Each head in a mixed word, such as “kalpified” can receive its own (separate) phonology. However, because Bandi-Rao and den Dikken do not provide any phonetic information, we are unable to determine whether this word indeed demonstrates two phonologies.
González-Vilbazo and López (2011) also argue that ICS is possible but limited with respect to directionality and phonological form. Consider the German/Spanish mixed verbs in (8)–(9).
(8) Utilis-ier-en “we use”
use-v-3.PL.
(9) *benutz-ear “to use”
use-INF
(8) is a mixed word comprised of a Spanish verbal root/base utilis and German affixes -ier-en, whereas (9) is a mixed word comprised of a German verbal root benutz and Spanish affixes -ear. This directional asymmetry parallels that of (3)–(4) in Bandi-Rao and DenDikken in which only one directionality [Spanish to German in (8) and Telugu to English in (3)] gives rise to licit codeswitches while the opposite directionality results in ungrammaticality. Unlike Bandi-Rao and DenDikken, however, González-Vilbazo and López (2011), claim that switches, such as (9) are not possible due to a mismatch in features between the two languages3. They claim that Spanish little v has an unvalued feature for conjugation class4 and that in the case of (9) it is unable to establish a syntactic dependency with the German root benutz because German roots do not have conjugation class features. In the case of (8), however, the conjugation class feature of the Spanish root is already valued and does not need to undergo any feature checking and is free to merge with the German affixes. Thus, the difference in features between Spanish and German verbs gives rise to the directionality asymmetry shown in (8)–(9)5.
In addition to restrictions of directionality, González-Vilbazo and López (2011) also discuss restrictions on the phonological form of mixed words. They claim that “incorporation of a root into a suffix gives rise to an endocentric structure in which all and only the features of the head project to the newly created term” (p. 840). In the case of (8) let us take the German derivational affix -ier- to be the morphological head of the word as it is the highest derivational affix (10).
(10)
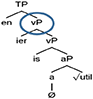
Following González-Vilbazo and López, it should be possible for the Spanish verbal base -utilis to incorporate into the German derivational affix -ier, giving rise to an output that is subject to the phonological rules of -ier (here, German). If this is the case, then the mixed word utilisieren is predicted to evince German phonology ([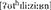 ] and is the attested output according to a Spanish/German bilingual consultant. Thus, based upon the observations made in Bandi-Rao and den Dikken (2014) and González-Vilbazo and López (2011) we see preliminary evidence that certain combinations of roots and affixes from different languages are possible. However, it might be the case that these morphologically mixed words, while having morphemes from two languages, evince a single phonology (that of the morphological head) instead of two phonologies. In order to determine if this is the case we need to take a closer look at the data (we return to this point in sections Discussion: Morphological Restrictions vs. Phonological Restrictions and ICS at the Representational Level).
] and is the attested output according to a Spanish/German bilingual consultant. Thus, based upon the observations made in Bandi-Rao and den Dikken (2014) and González-Vilbazo and López (2011) we see preliminary evidence that certain combinations of roots and affixes from different languages are possible. However, it might be the case that these morphologically mixed words, while having morphemes from two languages, evince a single phonology (that of the morphological head) instead of two phonologies. In order to determine if this is the case we need to take a closer look at the data (we return to this point in sections Discussion: Morphological Restrictions vs. Phonological Restrictions and ICS at the Representational Level).
Contrary to the accounts above, Jake et al. (2002) claim that phonologically mixed words are possible: Roots from LA inflected with morphemes from LB generally retain their LA phonology (p. 75), as in (11)6.
(11) Halafu m-tu-evaluate Swahili/English
then 2PL-1PL-evaluate
“Then you should evaluate us”
Note: evaluate is pronounced in English [ivæljueɪt], not as in Swahili [evaluete].
In (11) the English verb “evaluate” is merged with Swahili affixes. According to Jake et al., English phonology is maintained in the output of the inflected “evaluate,” which suggests that (11) is a phonologically mixed word. With that said, MacSwan (2005) argues that m-tu-evaluate in (11) is formed by a process of phrasal affixation and is therefore composed of two underlying morphosyntactic X0s instead of one [similar to the “kalpified” example provided by (Bandi-Rao and den Dikken, 2014) shown in (5)]. If it is the case that a single X0 is the input to phonology, then m-tu-evaluate does not provide counterevidence toward the bans/constraints on ICS. We return to this issue in section Discussion: Morphological Restrictions vs. Phonological Restrictions.
In this section, we have provided an overview of the foundational work on intraword CS. While most (if not all) work on ICS agrees that there are certain restrictions on the ways in which morphological and phonological elements from different languages can be combined, a clear consensus as to what those restrictions are has not been reached (see also Alexiadou and Lohndal, 2018). In an attempt to clarify these restrictions, we have consolidated examples of word-internal CS from over 22 language pairs, which we present and discuss in the following section.
Discussion: Morphological Restrictions vs. Phonological Restrictions
In this section, we systematically explore patterns and trends found among 57 examples of ICS (Table 1) to better understand the nature of their morphological and phonological restrictions. In other words, we attempt to explain what is meant when researchers say “intraword CS is not possible” or “intraword CS is sharply limited” based on these data. We also refer the reader to Alexiadou and Lohndal (2018) for a similar discussion of morphological restrictions on ICS. In Table 1, the root of each mixed word is italicized, and any affixes are separated by dashes. Ungrammatical or unacceptable mixed words are denoted by an asterisk.
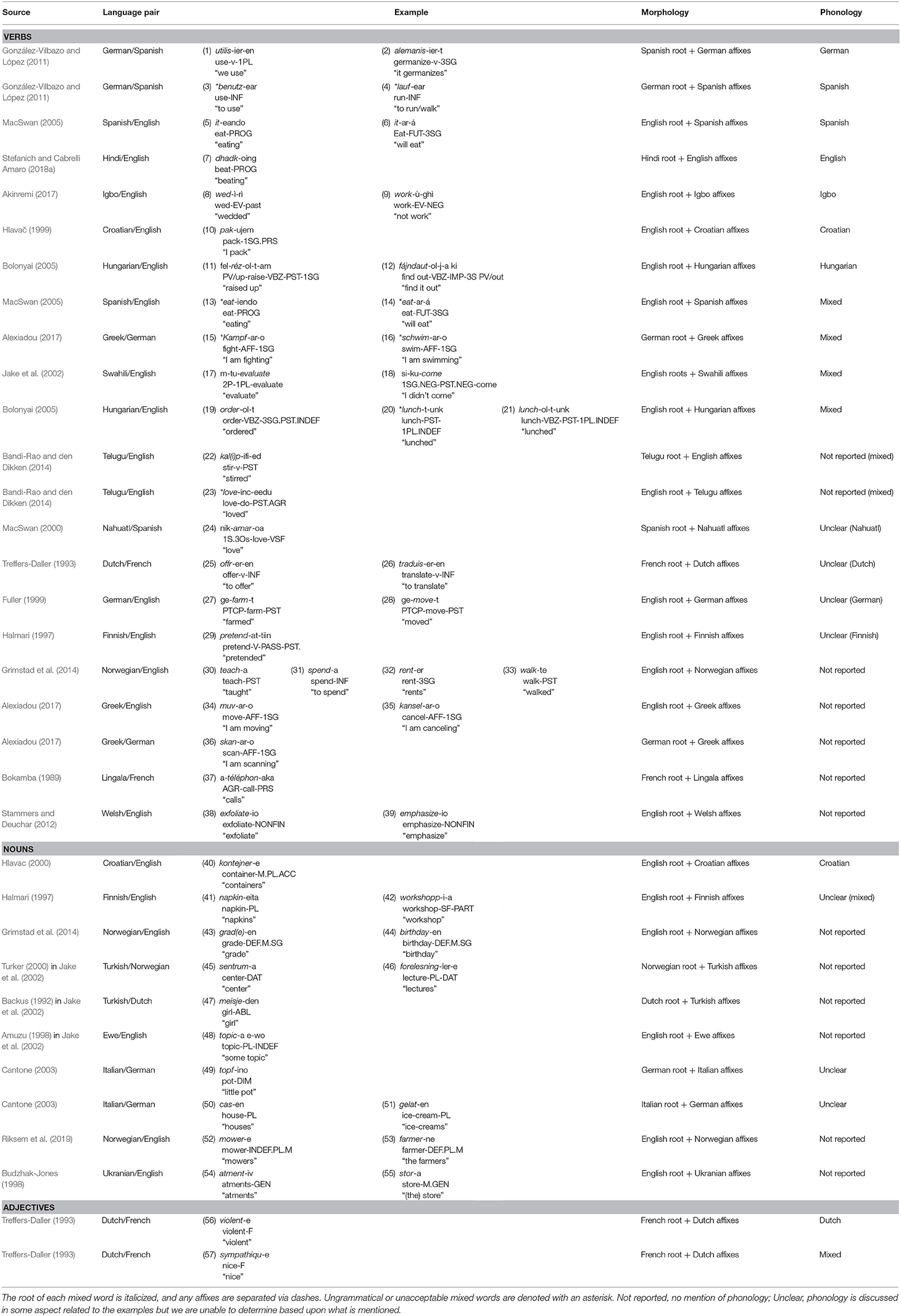
Table 1. A crosslinguistic survey of intraword codeswitching.
Before moving forward, it is important to note that almost all of the data in Table 1 come from corpora. Data from corpora allow us to examine what bilinguals produce but do not allow us to determine what is illicit or impossible in a bilingual grammar. Just because a bilingual does not produce a certain construction, does not mean that it is not possible for that construction to be produced in a different context in a way that would be deemed acceptable by speakers from the relevant community. Studies employing a methodology that targets negative evidence, or what is not possible, are best equipped to answer these questions that arise from analysis of corpus data. As an example, consider an acceptability judgment task or a forced-choice task which exposes bilinguals to mixed words with switches between (a) categorized roots and derivational affixes, (b) different types of derivational affixes, and (c) derivational affixes and inflection. Judgments of these switch types could provide experimental evidence for the morphological restrictions on word-internal CS. These types of studies are often done in conjugation with a syntactic analysis of CS across word boundaries (e.g., Bartlett and González-Vilbazo, 2013; González-Vilbazo and Koronkiewicz, 2016) and should be extended to ICS as well.
As our review of ICS accounts presented in section Review of Foundational Research on Intraword Codeswitching suggest that phonological restrictions on ICS exist separately from morphological restrictions, we treat the morphology and phonology of ICS as two (potentially) unrelated/separate phenomena. In other words, we do not assume that a morphologically mixed word necessarily precludes a phonologically mixed word (see Stefanich, 2019 for further discussion). We begin with morphological aspects, followed by phonological aspects.
Trends in the Morphology of ICS
In Table 1 we see 39 examples of morphologically mixed verbs, 16 examples of morphologically mixed nouns, and two examples of mixed adjectives. Upon first glance, we can see several surface patterns that allow us to explore the following questions: (1) between which morphemes do switches occur? and (2) in which direction do switches occur? Following a theory of DM (see section Distributed Morphology), we can posit that we might see switches occur at the following morpheme boundaries: (a) categorized root + inflection, (b) categorized root + categorizing head/derivational affix, (c) inflection + inflection, and in the following directions: (a) LA to LB and (b) LB to LA. These different options are illustrated in (12).
(12)
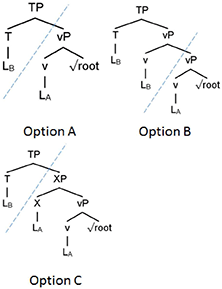
Between Which Morphemes Do Switches Occur?
In general, we see two surface patterns that arise from the data in Table 17:
A) lexical roots tend to come from one language (LA) while affixes, both derivational and inflectional, come from another (LB).
More specifically, in the case of the verbs, we see a switch boundary that occurs between the lexical root and a derivational affix (e.g., little v) or some sort of verbalizing affix [see examples (1)–(2), (11)–(12), (19), (21), (34)–(36) in the table]. The derivational/verbalizing affix tends to be productive in the language of origin (i.e., the affix used to make new verbs in that language). In (1)–(2) this affix is German v -ier, used to verbalize Latinate roots. In (3)–(6) it is Spanish “-ear” and in (25)–(26) it is Dutch -er. In (11)–(12) and (19)–(21) it is Hungarian -ol, and in (34)–(36) Greek -ar.
B) Switches are not attested between the affixes themselves (i.e., between derivational and inflectional affixes or between inflectional affixes).
Instead, the affixes come from a single language, which aligns with the claim by González-Vilbazo (2005) and López et al. (2017) that morphological switches between derivational and inflectional affixes are not possible.
However, surface patterns and generalizations are often misleading. We discuss three examples, (1) and (52)–(53), that challenge the generalizations presented above. First, in (8) [from (1) in the Table 1], the Spanish/German mixed verb utilisieren, let us consider the proposed underlying structure in (13) (cf. Alexiadou and Lohndal, 2018 for an alternative analysis).
(13)
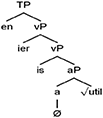
The Spanish part of this mixed word, utilis, which comes from the Spanish verb utilizar, is comprised of an adjectival root util that is merged with a Spanish little v (spelled out here as -is). If this analysis is correct, then the mixed word utilisieren demonstrates a morphological switch between two derivational affixes, here Spanish v and German v. While this example does not directly contradict the generalizations in A-B, it does point out two important things. The first is that for generalization A it would be erroneous to assume that whatever comes from LA is solely the root. The underlying structure of the morphological elements that come from LA could contain an already complex structure. Second, this example illustrates that it is not always the case that all of the affixes come from the same language. If the underlying structure proposed in (13) is correct, then it looks like a derivational affix from one language can be merged with a derivational affix from another.
Now, let us consider (52)–(53) in which we have the Norwegian/English mixed nouns mowere “mowers” and farmerne “the farmers.” On the surface it appears that the English nouns “mower” and “farmer” are merged with Norwegian inflection. However, just like with utilisieren, we can break down the components of the elements from LA, here English. Consider that the English nouns “mower” and “farmer” have the underlying structure shown in (14).
(14a)
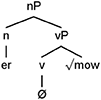
(14b)
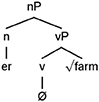
That is, the English nouns “mower” and “farmer” are complex nouns; the verbs “mow” and “farm”8 are merged with the English derivational affix “er” to make them nouns9. If we assume the structure in (14), then the mixed words mowere and farmerne demonstrate morphological switches between a derivational affix (here English n) and Norwegian nominal inflection. Such a switch boundary contradicts generalization B, which precisely states that there should be no switching between derivational and inflectional affixes. The examples in (52)–(53) further demonstrate that we cannot just rely on surface level patterns, but that we must take a look at the underlying structure of the elements from both LA and LB.
For instance, Alexiadou and Lohndal (2018) discuss the Spanish/German mixed word segurat-en “security men,” comprised of a Spanish root and a German plural affix, in their cross-linguistic analysis of ICS in the nominal domain. They point out that, in contrast to mixed words in the verbal domain, “seguraten” does not have overt nominalizing morphology. Alexiadou and Lohndal suggest that there is a covert nominalizing affix (i.e., n) that categorizes the Spanish root and makes it a noun, which is then able to merge with a German plural affix. Following our current line of discussion, the pertinent question here is whether this covert nominalizing affix is a Spanish n or a German n10. This difference in underlying structure is important, because one option (i.e., German n) falls in line with the generalization that there can be no switching between affixes, while the other (i.e., Spanish n) contradicts it.
Further, consider an additional question born out of examples (1), (52)–(53): if switching between derivational affixes is possible [as seems to be the case in (1)], are there any restrictions on the type or direction of the derivational affixes? For instance, in (1) the switch boundary occurred between Spanish v and German v (i.e., derivational affixes of the same type). Would it be possible to switch between, say, a Spanish a and German v? Or between Spanish n and German v? In (52)–(53) we see a similar pattern of symmetry between affixes, an English n merged with nominalizing Norwegian inflection. That is, even though we see a switch between a derivational affix and inflection, the inflection used is of the type required by the category of the word (here, noun). In order to answer these questions as to the licit morphological switch boundaries, experimental methodologies that directly examine ICS with different underlying structures are needed.
In Which Direction Do Switches Occur?
Another pattern evident within the data in Table 1 is that of a directional asymmetry in how the morphemes are combined. This asymmetry, which has also recently been reviewed in Alexiadou and Lohndal (2018), supports the examples discussed in section Review of Foundational Research on Intraword Codeswitching; it seems to be the case that mixed words can be composed of roots from LA and affixes from LB but that the reverse is not possible. This asymmetry is attested/claimed for language pairs, such as Spanish/German (González-Vilbazo and López, 2011), Telugu/English (Bandi-Rao and den Dikken, 2014), Greek/English and Greek/German (Alexiadou, 2017), French/Dutch (Treffers-Daller, 1993), Spanish/English (Stefanich and Cabrelli Amaro, 2018a), and Norwegian/English (Grimstad et al., 2014; Riksem et al., 2019).
Of the 57 examples collected in Table 1, there is one instance in which we see possible counter-evidence toward this directionality asymmetry. The Italian/German mixed nouns in (50)–(51) comprise Italian roots and German affixes, while the noun in (49) comprises a German root and Italian affixes. The reported acceptability of these mixed words suggests that a directionality asymmetry in word-internal CS is not universal, but rather that it most likely depends on the feature combinations of the language pair itself. However, these examples come from children between 3 and 4 years of age, in which it could be the case that these bilinguals are still in the process of acquiring the relevant German and Italian features. Moreover, the children were reported to favor switches when in Italian mode over German mode. Thus, the attested bidirectionality of their switches may not be part of an adult bilingual grammar and should be confirmed with adults via methodologies, such as those discussed previously (acceptability judgment task, forced choice, etc.) to tease apart any confounding factors related to language acquisition.
Different analyses have been proposed to account for this directionality asymmetry in ICS (recall discussion of González-Vilbazo and López, 2011 and Bandi-Rao and den Dikken, 2014 in section Review of Foundational Research on Intraword Codeswitching), with some scholars maintaining that asymmetry is a characteristic of CS more generally (e.g., Myers-Scotton, 1992 et seq). In their review of this observed directional asymmetry, Alexiadou and Lohndal (2018) point out that speakers tend to use the default overt realizations of verbalizing affixes (e.g., ar in Greek, ier in German), and they suggest that this tendency might result in this asymmetry. In other words, when codeswitching with a language pair where LA has default overt realizations of v and n but LB does not, the affixes will come from LA. However, this account would not be able to explain what happens in language pairs where either both languages or neither language demonstrates default overt realizations. As we suggest in section Discussion: Morphological Restrictions vs. Phonological Restrictions, making use of experimental methodologies beyond corpora analysis will put us on the path toward answering some of these questions raised by evaluation of these corpora.
Experimental methodology aside, the examples in Table 1 demonstrate that intraword morphological switches are possible but constrained/limited in a systematic way. This is representative of CS as whole, which is considered a systematic and rule-governed phenomenon, the same as any monolingual grammar. We now turn to a discussion of the phonological aspects of ICS.
Trends in Phonology of Word-Internal CS
Phonological switches seem to behave differently than morphological switches at the word level. As previously noted, Bandi-Rao and den Dikken (2014), MacSwan (2000), and MacSwan and Colina (2014) claim that ICS is not possible due to requirements of phonology and thus phonological outputs are predicted to not contain phonological elements from two languages. Looking at our 57 examples in Table 1, is their prediction confirmed, or are there examples of phonologically codeswitched words? Unfortunately, it is not so easy to answer that question. First, phonology is not addressed in most studies on ICS, which makes it either impossible to determine what the phonology of the mixed word is, or at best we must infer from authors' indirect remarks. When phonology is addressed, it is done so in an anecdotal manner or based solely on impressionistic analysis and lacks acoustic information or experimental data.
Second, any phonological analysis provided for the mixed words in Table 1 lacks the bilingual source's monolingual productions as a point of comparison. Just as a growing body of research on syntax and CS uses a bilingual's own monolingual judgments as a control measure for CS data to account for individual variation and language contact (see González-Vilbazo et al., 2013; Ebert and Koronkiewicz, 2018 for a discussion) so must research on phonology and CS.
Third, we must clearly define the parameters used to define the term “word.” Recall from section Review of Foundational Research on Intraword Codeswitching that the accounts that suggest a ban on phonological ICS claim that the restriction only applies to phonological words that are comprised of single morphosyntactic heads (X0s, e.g., verbs whose affixes incorporate into the root). It could be the case that phonological ICS is permitted in phonological words that are comprised of two separate X0s. Thus, when analyzing the phonology of mixed words, it is important to also look at them with respect to their underlying syntactic structure in order to identify and establish a more refined view of the restriction on phonological switches. With that being said, what can we glean from the data in Table 1? Twenty-three examples in Table 1 were provided by authors with a phonological description, 13 of which are said to demonstrate a single phonology. Of the remaining 34 examples, 27 do not contain any mention of phonology. While the other seven do not provide any explicit phonological description, we can make an educated guess based upon the authors' discussion. We discuss each set in turn.
Single Phonology
According to their sources, examples (1)–(12), (40), and (56) all demonstrate a single phonology; in each case, the phonology of the mixed word matches that of the language of the affixes and not the language of the root. For example, in (1), the affixes are German and the phonology is German, as represented by sounds, such as a glottal stop, a high back rounded vowel and a voiced alveolar fricative. In (8)–(9), the affixes are Igbo, and the phonology is Igbo, as represented by vowel harmony, tone and stress. In (56), the affix is Dutch and the phonology is Dutch in that the French nasal vowel has been replaced by a Dutch vowel. This observation that the phonology of a mixed word will come from the language of the affixes is essential because it makes testable predictions for experimental research on ICS (see section ICS at the Representational Level for an overview of one such study). Further, note that this observation falls in line with the work of González-Vilbazo and López (2011) presented in section Review of Foundational Research on Intraword Codeswitching. González-Vilbazo and López claim that the morphological head of the word projects its features to the whole word. It is likely that the morphological head of these mixed words is the highest derivational affix, so it logically follows that the phonology of the mixed words matches that of the affixes (see Stefanich, 2019 for further discussion).
Mixed (Two) Phonologies
Contrary to the examples of mixed words that demonstrate a single phonology, there are ten examples (13)–(21), (57) in Table 1 whose sources state that they are instances of mixed phonological words. We can divide these examples into two groups: (1) considered unacceptable or not licit in a bilingual grammar and (2) considered acceptable or licit in a bilingual grammar. First, (13)–(16) are morphologically mixed words comprised of English/German roots and Spanish/Greek affixes. The roots and affixes each maintain their “donor” language phonology (e.g., the English root has English phonology, but Spanish affixes have Spanish phonology). These phonologically mixed words are considered unacceptable/ungrammatical according to the authors, lending support to the constraints presented in section Review of Foundational Research on Intraword Codeswitching that ban phonologically mixed words.
In contrast to (13)–(16) the other six examples (17)–(21), (57) are considered acceptable/grammatical by the authors and thus could constitute possible counterevidence toward the constraints on phonological ICS discussed in section Review of Foundational Research on Intraword Codeswitching. The mixed word in (17) is comprised of the English verb “evaluate” and Swahili inflection. Jake et al. (2002) claim that the English verb retains its English phonotactics instead of demonstrating Swahili phonotactic (CVCV) and nucleus structure: The final syllable is closed and the front vowels have off-glides. In (57), we see a French adjective sympathique “nice” combined with a Dutch agreement affix-e. Treffers-Daller (1993) claims that while the French adjective is pronounced as it would be in monolingual French, citing the presence of a nasal vowel as evidence, the Dutch affix is pronounced as a schwa, as it would be in Dutch11. The last examples (19)–(21) demonstrate mixed words with English roots and Hungarian affixes. Bolonyai (2005) claims that these mixed words are grammatical and that the English root maintains its English phonology while the Hungarian affixes demonstrate Hungarian phonology. However, she does not provide transcription or acoustic detail.
Pending that acoustic evidence would back up the authors claims that the examples (13)–(21) and (57) are words that demonstrate two phonologies can we say then, that they constitute counterevidence toward the ban on phonological intraword CS addressed in section Review of Foundational Research on Intraword Codeswitching? MacSwan (2005) addresses examples (17) and (57) and claims that mtuevaluate and sympathique are actually two separate morphosyntactic X0s formed by a process akin to phrasal affixation and not a single morphosyntactic X0 [similar to (5) in section Review of Foundational Research on Intraword Codeswitching]. As such, these words are “allowed” to have two phonologies (assuming each X0 can demonstrate its own phonology)12. Thus, following MacSwan's analysis, examples (17) and (57) would not constitute counterevidence toward the ban on phonological intraword CS discussed in section Review of Foundational Research on Intraword Codeswitching.
Following this line of thought, we ask whether examples (19)–(21) are (a) mixed words formed by a process of incorporation [like (1)] where the output is a single but complex X0 that is sent to phonology as one unit (and therefore can only evince one phonology), or (b) formed by a different process in which the output is two separate X0s, each of which can be sent to a different phonology, therefore giving rise to what appears to be a phonologically mixed word. Bolonyai (2005) claims that English verbs are integrated into Hungarian via a “derivational, denominal verbalizer suffix” (p. 317). In (19) and (21) this suffix is realized overtly as ol and (20) demonstrates that without this overt suffix the combination of an English root with Hungarian inflection results in ungrammaticality. This analysis suggests that the mixed verbs in (19) and (21) are formed via a process of incorporation and therefore should be subject to the constraint on intraword phonological switching. A more in-depth analysis of verb formation in Hungarian is needed to confirm.
Additionally, note that (19)–(21) stand in contrast to the English/Hungarian examples (11)–(12). While the mixed words in (11)–(12) demonstrate Hungarian phonology, the words in (19)–(21) reportedly demonstrate mixed phonology (here, English in the root and Hungarian in the affixes). We then ask, why would it be the case that sometimes the mixed words demonstrate Hungarian phonology and sometimes a combination of English and Hungarian phonologies?13 Further, Bolonyai states that (19)–(21) are “morphologically integrated forms that occur with no (or minimal) phonological assimilation to Hungarian (i.e., there appears to be conscious retention or approximation of English pronunciation)” (p. 318). What is meant by “conscious retention” here? If phonologically mixed words are licit in a bilingual grammar, then a bilingual should not be conscious of the fact that s/he is “retaining” a specific phonology; if s/he is, such a production is reflective of metalinguistic knowledge rather than his/her bilingual grammar.
Unclear or Not Reported Phonology
For the remainder of the examples in Table 1, the phonology is either unclear or not explicitly addressed. For instance, in (27)–(28) the phonology is not addressed directly, but the author points out that these words demonstrate final obstruent devoicing, a phonological process that occurs in German (the language of the affixes) and not English (the language of the root). This suggests that it might be the case that (27)–(28) demonstrate German phonology; however, without explicit mention of the phonology of the root we are unable to make that claim. In a few cases, we are able to make an educated guess based upon the discussion of the examples in the original source. For example, we can infer that morphologically mixed words in (22)–(23) are also phonologically mixed words based upon the constraint Bandi-Rao and den Dikken (2014) posit to account for these words (see section Review of Foundational Research on Intraword Codeswitching). Further, if the mixed words are labeled as borrowings and the author(s) assumes a traditional view of borrowing in which borrowings demonstrate phonological integration, then we can assume that the word in question evinces a single phonology [e.g., (24)].
As seen in this section, we are able to see (surface) trends in the morphology of mixed words. We must remember that surface phenomena do not always reveal the nature of the underlying representations in grammar when it comes to such things as morpheme order or word order. This is true of CS as well. However, there remains a (semi) open debate as to whether we have concrete examples of a single word evincing two phonologies. As stated, any attempts to examine the phonology of a mixed word must first set a clear definition for what is considered a “word” and whether any constraints apply strictly to morphological (one X0) vs. phonological words (one or more X0s). Second, an acoustic analysis of the phonology of the mixed word, as well as of the two “monolingual” phonologies involved is essential. Nevertheless, our examination of the examples in Table 1 did reveal (minimally) 2 distinct patterns. On the one hand, mixed words composed of a single X0 seem to demonstrate a single phonology, namely that of the affixes. On the other hand, mixed words that are composed of two separate X0s seem to possibly demonstrate two phonologies. In the next section we present a candidate for a theoretical account of intraword CS.
Distributed Morphology
The central concept of DM (Marantz, 1997; Arad, 2003; Embick and Noyer, 2007; Lohndal, 2013; Grimstad et al., 2014; Harley, 2014) is that a single generative engine governs sound/meaning correspondences, making no distinction between word-level and phrase-level syntax. As McGinnis (2016) notes, “DM departs from the traditional notion of the Saussurean sign, which directly associates a phonological form with a meaning. Instead, the theory postulates that the stored knowledge of a language is distributed across three separate lists” (p. 390). One list is known as the Lexicon. The Lexicon is where elements which are found on the terminal nodes of a syntactic tree are stored. These elements can be either lexical roots or grammatical morphemes. Both inflectional and derivational morphemes are made up of bundles of syntactic/semantic features. However, a content morpheme is represented by a category-neutral lexical root. At this stage of a derivation, there is no phonological content to the morphemes. Phonological content is added later by reference to the second list: the Vocabulary. Vocabulary items are inserted into terminal nodes of the syntactic derivation after Spell-out (hence late insertion). The third list is the Encyclopedia, which associates lexical roots post-syntactically with special, non-compositional aspects of meaning. Of particular relevance here, DM offers a model where under-specified morphological elements compete for late-insertion into a fully generated syntactic tree, complete with syntactic terminal nodes. Let us consider an example which can show how a Determiner might spell out varying morphosyntactic features. A Spanish DP includes features for definiteness, number and gender, as shown in the tree in (15):
(15)
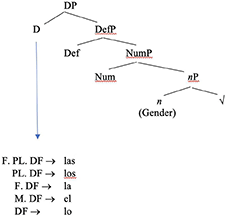
These different Determiners are in competition for insertion into the terminal node. The vocabulary item which matches the most features without being overspecified (i.e., having more features than necessary) will be inserted into the tree.
Now, as we will be looking in depth at the performance of Norwegian/English CS in section Producing ICS, we are going to use Norwegian to demonstrate how DM works. Following Grimstad et al. (2014; page 224), a Norwegian DP would be as shown in (16):
(16)
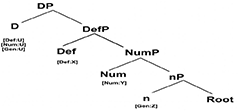
The syntactic terminal list contains two types of primitives: category neutral lexical roots (i.e., √TABLE, √CAT, √RUN, etc.) and grammatical morphemes. While, the exact nature of roots in DM is still a topic of debate (Harley, 2014), this paper will follow Grimstad et al. (2014) in assuming that roots contain no grammatical features themselves and are underspecified both phonologically and semantically.
The tree in (16) has specified syntactic features but no phonological or semantic content. The phonological items of a word which match the abstract features in the template can then be inserted into the derivation. This process is known as vocabulary insertion. For Norwegian, the possible vocabulary items would include those in (17):
(17) M.SG.DF -> -en
F.SG.DF -> -a
N.SG.DF -> -et
PL.DF -> -ene
PL. -> -s
Schematically, we could present the stages in a derivation as given in Figure 1.
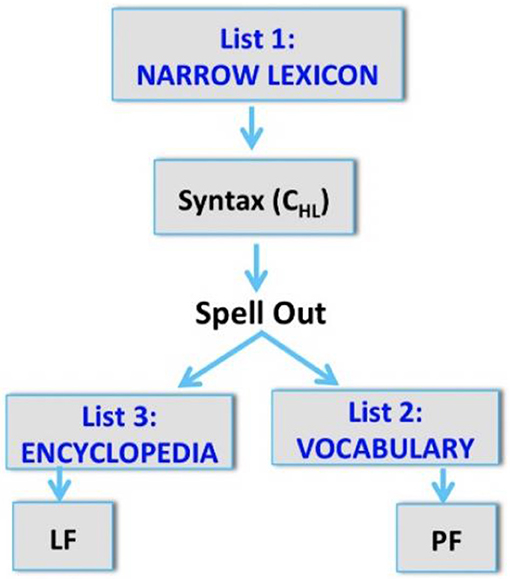
Figure 1. Mapping sound onto meaning (Burkholder et al., 2017).
Much work on DM has been concerned with the spell-out of functional morphemes (though see Archibald, 2016 and (Haugen and Siddiqui, 2013), for a discussion of competition for roots). Here Vocabulary items compete for insertion, subject to the Subset Principle (Halle, 2000).
Subset Principle (Halle): The phonological exponent of a Vocabulary Item is inserted into a position if the item matches all or a subset of the features specified in that position. Insertion does not take place if the Vocabulary Item contains features not present in the morpheme. Where several Vocabulary Items meet the conditions of insertion, the item matching the greatest number of features specified in the terminal morpheme must be chosen.
Two principles are key:
A. Only Vocabulary Items which specify a subset of a head's features can be inserted
B. Only the most specific Vocabulary Item is inserted
In English (De Belder and Van Craenenbroeck, 2015), a DP would consist of the D-Head features and a category-neutral Root, as shown in (18).
(18) DP [[+D,+def]√]
When the syntactic derivation is completed, this structure is handed over to the post-syntactic component responsible for pronouncing it. Now Vocabulary Insertion takes place: the terminal nodes in the syntactic structure in (18) need to be matched up with appropriate lexical exponents. This means that the post-syntactic Vocabulary will contain correspondence rules, such as the ones in (19).
(19) [+D,+def] < -> /ðǝ/ b. √ < -> /b℧k/
Given that the features on the left in the Vocabulary List match the features in the terminal node of the syntactic tree perfectly, then [ðǝ] can be inserted.
Let's consider an example from German to probe more issues of competition. In German it is reasonable to assume that there is one nominal plural suffix in the syntax; hence plural nouns may all have the abstract syntactic representation: [[NOUN]-PL]. However, the German vocabulary provides a variety of vocabulary items that express this node, including: -Ø, -(e)n, -e, -er and-s (ignoring some changes that might occur in the stem). These allomorphs would be in competition for insertion into the tree. The competition would be governed by the subset principle, by stem-conditioned associations, and by familiar morphological blocking conditions which ensure that the insertion of a more-specified vocabulary item blocks the insertion of a less-specified one.
McGinnis (2016) also illustrates matters of allophonic competition. For example, in DM, the alternating forms of the English plural shown in (20a–c) are taken to realize the same syntactic nodes—minimally, a lexical root and a node bearing number features, which has several possible morphological realizations. (20a) shows the unrestricted default plural allomorph, which is also subject to phonologically conditioned variation (as in cat-[s], dog-[z], horse-[ǝz]). (20 b-c) show stem-conditioned (irregular) plural allomorphs, one of which is a zero morpheme, and one of which is an overt suffix, whose distribution is highly restricted. In DM, these irregular plural items are specified for insertion only in the context of a listed set of lexical roots. They are therefore more highly specified than the default item, and thus win the competition for insertion into the syntactic node bearing the plural feature in the context of these roots, ruling out forms, such as *oxes. Inserting one item blocks the insertion of additional items, so forms, such as *oxens are also correctly ruled out.
(20) a. cat ~cat-s
b. ox ~ox-en (cf. box ~box-es)
c. sheep ~sheep-Ø (cf. beep~beep-s)
As pointed out by Grimstad et al. (2014), this Subset Principle plays a vital role in constraining intraword codeswitching. Crucially, during the production of a codeswitch, this allows for phonological exponents from any language to be inserted into the syntactic tree, regardless of the language identity of either the syntactic or phonological elements—assuming the vocabulary item which is inserted meets the demands of the active features in the syntax. In a codeswitching context (i.e., bilingual communicative mode), this allows functional vocabulary items from languages A and B to compete with each other. If the syntactic frame contains features [+X, +Y, +Z], any Vocabulary item matching these features or any subset of these features (i.e., [+X, +Y], [+Y, +Z] or [+X, +Z]) may be inserted into the derivation. However, a Vocabulary Item may not be inserted if it contains additional features not present in the frame (e.g., [+X, +Y, +Z, +A] or [+X, +Y, +B]). This principle will prove crucial to accounting for when intra-language codeswitching may occur.
By separating the syntactic, phonological and semantic components of a word, DM allows for a molecular view of a word which, as we will see in section Producing ICS, is compatible with the MOGUL account14.
Distributed Morphology and ICS
In a DM account of language mixing, the notion of lexical decomposition also plays a central role in allowing ICS to occur. Lexical decomposition is the notion that category-neutral lexical roots (e.g., cat, man, etc.) combine with one or more functional heads in the syntax (e.g., Gen, Def, Num, etc.); proponents of lexical decomposition argue that this accounts for complex syntactic meanings (Halle and Marantz, 1994). Notably, in terms of language mixing, it is the construction of syntactically complex words, where a root is from language X and the syntactic features are from language Y, which ultimately allows ICS to occur in DM. This is in contrast to MacSwan's Lexicalist approach, in which morphologically complex words are viewed as syntactic atoms which cannot be syntactically decomposed, thus preventing ICS. As pointed out by Grimstad et al. (2014), when a model of Distributed Morphology is applied to a bilingual/multilingual's lexicon intraword language mixing appears to be part of the natural fallout of language use; this is a sharp contrast to the lexicalist model proposed by MacSwan. In DM, while syntactic trees can only contain syntactic feature bundles from a single language, these frames are blind to the language identity of Vocabulary items. Phonological exponents from either and/or both languages may be inserted into the tree assuming they match the syntactic features of the terminal nodes. That being said, we will still need to explore the issue of whether the vocabulary items from two languages are implemented with two phonologies. In the next section we discuss how to accomplish this objective via experimental methodologies.
ICS at the Representational Level
As made clear in section Discussion: Morphological Restrictions vs. Phonological Restrictions, we require experimental data from methodologies specifically designed for the questions at hand in order to provide an accurate account of intraword phonological CS15. Our evaluation of the examples in Table 1 shows that existing research on the phonology of morphological switches largely lacks (a) acoustic information, (b) data from multiple speakers, (c) data from methodologies thought to better tap representation (i.e., phonological perception and acceptability judgment tasks), and (d) comparison of the codeswitching data with data provided in monolingual mode in each of the bilingual's languages (i.e., treating each bilingual as her own control). These comparison data are especially important in light of the individual variation found among bilinguals, particularly in contexts in which one of a bilingual's languages is not the dominant community language. With these four criteria in mind, the data points in Table 1 are simply not sufficient to support or refute the claim that intraword phonological switches are not possible.
To address the need for experimental evidence, Stefanich and Cabrelli Amaro (2018a,b), Stefanich (2019) have designed multiple empirical measures to tap phonological representation in cases of intraword morphological switches, taking into account the need for both acoustic and judgment data from large sample sizes collected in bilingual as well as monolingual modes. The first phase of the project tested which phonological system(s) a Spanish/English bilingual utilizes in the production of verbs with English roots and Spanish affixes, with the hypothesis that Spanish phonology would be exclusively applied since Spanish is the language of the affixes (see section Review of Foundational Research on Intraword Codeswitching). Elicited production tasks were completed by 19 English-dominant American English/Mexican Spanish bilinguals who identified as naturalistic code-switchers and had positive attitudes toward CS (see Badiola et al., 2017, for a discussion of effects of attitude on CS behavior). Several design choices were made with the challenges of experimental CS research in mind. Crucially, participants completed three versions of the task on separate days, with the first day always administered in bilingual mode. The bilingual mode session was administered by a member of the participants' bilingual community who was similar in age and was a naturalistic code-switcher. The interlocutor's profile was an important methodological choice, as her presence contributed to a socially motivated codeswitching context (see section MOGUL and Control for discussion of how this type of interaction licenses a bilingual mode). The remaining 2 days of testing were administered in English and Spanish (order was counterbalanced across participants). Testing in these three modes allowed the authors to determine the source of phonology in ICS productions by using the Spanish and English data as a baseline, rather than comparing ICS productions with a monolingual norm (see e.g., Ebert and Koronkiewicz, 2018). Another important consideration was the stimuli design; nonce verbs were used to address the challenges of teasing apart code-switches from borrowings discussed in sections Review of Foundational Research on Intraword Codeswitching and Discussion: Morphological Restrictions vs. Phonological Restrictions and to control for potential frequency effects. To identify any instances of phonological switching, each English verb in the CS task contained one of three phonemes that are not part of Mexican Spanish (/z/, /θ/, /ɪ/). To provide context during the task, participants were presented auditorily with each nonce verb and a definition and example given in CS. They were instructed to teach the experimenter the new words in “Spanglish” (CS), and prompted in Spanish to produce the verb forms with progressive morphology, the Spanish prompt served to prime participants for a switch into Spanish (21).
(21) Slide 1: Repite por favor [please repeat]. To mip.
Slide 2: To mip es cuando bailas [is when you dance] to your favorite song in an empty room. Angela lives in a studio apartment and she mips every night. ¿Qué está haciendo en la foto? [What is she doing in the picture]
Slide 3: Está __________. Expected answer:
Está mipeando.
The monolingual sessions followed a parallel procedure and served to establish a baseline point of comparison for production of /z/, /θ/, and /ɪ/ in English and predicted Spanish-like substitutions /s/, /t/, and /i/. The authors predicted that, if an English verbal root with Spanish progressive morphology were produced using Spanish phonology (the language of the affixes), bilinguals would not produce English segments in the root. Instead, /z/ was expected to surface as [s], /θ/ as [t] or [s], and /ɪ/ as [i] (e.g., Morrison, 2008; Costa, 2009).
The authors found evidence of application of Spanish phonology across the three phonemes. English /z/ was produced as a Spanish-like [s] in the English root of the mixed word by 50% of the bilinguals. Remaining participants produced [z], which could potentially indicate application of English phonology. However, analysis of these participants' monolingual Spanish production of /s/ in a voicing assimilation context revealed production of [z] in this context. The authors posited that, for these participants, [z] is a part of their Spanish phonetic inventory and thus these data could not serve as conclusive evidence of intraword phonological codeswitching. Data from the /ɪ/ and /θ/ phonemes, which do not have a corresponding allophone in Spanish, back the hypothesis that [z] productions in the English root reflect the Spanish phonetic inventory. Specifically, the bilinguals produced /ɪ/ as [i] in the codeswitching task, which the authors took as an indication that the participants applied only Spanish, and not English, phonology in morphologically switched words. In the case of mixed words with /θ/ in the English root, Stefanich and Cabrelli Amaro (2018b) found evidence of substitution of /θ/ via a handful of Spanish-like sounds, namely [ ], [s], [z], [v], and [f]. The production data from this first phase of the project therefore is taken as preliminary support for the posited ban on word-internal phonological switches.
], [s], [z], [v], and [f]. The production data from this first phase of the project therefore is taken as preliminary support for the posited ban on word-internal phonological switches.
The logical question that followed from these data, and which led the authors to the project's second phase, is first mentioned in section Discussion: Morphological Restrictions vs. Phonological Restrictions: Although these bilinguals do not produce morphologically switched words with elements from two phonologies, are such structures illicit in their bilingual grammar? With this question in mind, the authors implemented an aural judgment task as a method to tap the participants' I-language by testing the acceptability of phonologically codeswitched words (see e.g., González-Vilbazo et al., 2013, and Schütze and Sprouse, 2014, for motivation for this type of method). The task consisted of morphologically switched verbs with English roots and Spanish progressive morphology; the stimuli were the same as those used in the production task in the codeswitching session. Each trial belonged to one of three conditions: Items produced with English phonology only, Spanish phonology only, or phonology matching the morphology of the item (i.e., English phonology in the root and Spanish phonology in the affixes). To maximize ecological validity, a member of the bilingual population with phonetic training produced all of the stimuli. The items in the phonological switch condition were constructed via splicing of English roots produced in monolingual English mode and Spanish affixes produced in monolingual Spanish mode; doing so ensured presentation of stimuli which exhibited a true phonological switch without phonetic contact effects16. Twenty seven bilinguals with the same profile as the participants in the production task completed the judgment task. As an inclusion criterion, participants had to be able to distinguish perceptually between the three conditions for each phoneme; this resulted in the inclusion of data from 24 participants for /z/ and 17 for /θ/ and /ɪ/. The results confirmed the findings from the production task, such that the bilinguals assigned the highest ratings [using a scale of 1 (completely unacceptable/not a possible answer in Spanglish) to 7 (completely acceptable/a possible answer in Spanglish, z-score transformed to account for individual variation in scale use)] to items produced with Spanish phonology (the language of the affixes), lower ratings to the phonologically switched items, and the lowest ratings to items produced with English phonology, which is in line with the hypothesis that the phonology of a morphologically switched word must be the language of the affixes. Together, Stefanich and Cabrelli Amaro's production and judgment data designed explicitly for ICS research provide the first comprehensive experimental account of ICS. The data, while evidencing substantial variation, point toward a trend in which Spanish phonology is employed, and one possible explanation here is that phonological ICS are indeed illicit in Spanish/English bilingual grammars. Replication of the results from this and other language pairings using these and novel methodologies will determine whether the proposed ban on phonological ICS holds up to crosslinguistic scrutiny and further inform the theoretical notions reviewed in sections Review of Foundational Research on Intraword Codeswitching and Discussion: Morphological Restrictions vs. Phonological Restrictions more generally.
Up to this point, our discussion has been limited primarily to language-internal factors and questions of abstract linguistic representation. However, the use of codeswitching is the result of an interaction of language-internal and language-external factors; this interaction is the focus of the following section.
Producing ICS
We situate our account of the real-time production of ICS within MOGUL. MOGUL17 is a modular perspective on language processing presented by Sharwood Smith and Truscott (henceforth SS&T, 2014), with the goal of explaining how language inhabits the mind in real time. The architecture of MOGUL (which stands for Modular Online Growth and Use of Language) draws heavily on Jackendoff's tripartite model of language (Jackendoff, 1997, 2003) where linguistic faculties (i.e., phonology, syntax) are encapsulated modules—in the sense of Fodor (1983)— which interface with motoric and conceptual systems, as well as with general cognitive networks. This architecture is pictured below in Figure 2.
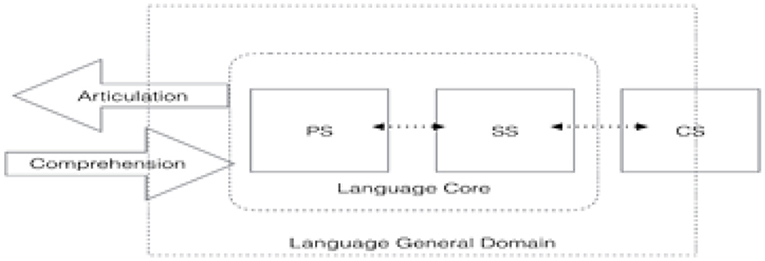
Figure 2. Tripartite model (adapted from SS&T, 2014).
Crucially, each module (where PS, Phonological Structure; SS, Syntactic Structure; CS, Conceptual Structure) contains its own unique set of primitive features which are assembled to form representations triggered by linguistic input. For example, SS&T claim that primitive features in the syntax module's information store may include items like [+noun] and [+tense], while the phonological store might contain distinctive features, such as [+strident], [+continuant], or [+voiced]. Once each module constructs its own representation out of the set of primitives available to it, the representation is then interfaced to neighboring modules. The result of this interfacing is a (PS + SS + CS) representational chain which contains all the necessary phonemic, syntactic and conceptual information equated with a word. Figure 3 is an example of a representational chain which would represent what is commonly thought of as the word lamp (from Truscott and Sharwood Smith, 2004).
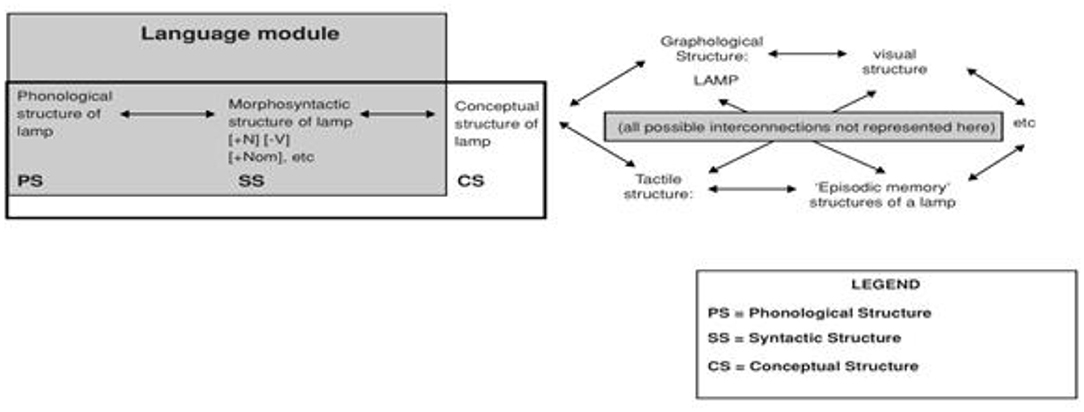
Figure 3. A co-indexed representational chain.
Here we argue that language mixing is the result of constructing representational chains using features from Language-X (Lx) and Language-Y (Ly).
MOGUL, however, is more than just a theory of language or language development; MOGUL is an account of the multilingual mind in which language is plugged into a larger cognitive architecture. The model emphasizes the role of extra-linguistic factors in language production, comprehension and development. The interaction between linguistic and extra-linguistic cognitive systems is particularly relevant to the study of lexical selection (and, more important for our purposes, codeswitching) which may be motivated by any number of non-linguistic factors, such as social circumstances or personal goals. For example, when a speaker is choosing a label to describe members of a militant organization, they will have a number of well-formed options including terms like freedom fighters, rebels, and terrorists (Van Dijk, 1997). In this case, the item that a speaker chooses may be heavily influenced by extra-linguistic such things as their personal experience, emotional reactions, and global politics. Ultimately, the MOGUL platform allows for extra-linguistic aspects of codeswitching (e.g., personal experience) to be accounted for via extra-linguistic processes (e.g., cognitive control).
Basic Architecture
There are two types of modules: linguistic modules and extra-linguistic modules. Linguistic modules include the phonology module (PS) and the syntax module (SS). We assume that PS encodes a phonemic contrastive level of representation (e.g., /kæt/) but the phonetic details of the spell-out would be handled by the production system. Crucially, these two modules are specific to language processing and constitute what we will call the language core (see Figure 2 above). Extra-linguistic modules include the perceptual modules, the motor-control module and the conceptual module. While these modules are involved in language processing (i.e., semantics, speech perception, and production) they are extra-linguistic in the sense that they are part of a general cognitive apparatus that governs action and knowledge beyond language. In addition, the CS contains a “general language representation” (GLR); this GLR (e.g., English, Swedish, Yoruba) is triggered by context and co-indexed with all representations associated with the language it represents. This point will prove crucial when accounting for language selection in the MOGUL framework and will be expanded upon in section Cognitive Context, Conceptual Triggering, and Language Selection.
Information stored in each module includes what SS&T call an activation level. When static, content in the information store will sit at a resting level of activation. All elements will have a resting level of activation based on previous usage as well as the strength of associations to other units. The activation level of an element in the information store is affected by spreading activation between associated elements (Rumelhart et al., 1987). For example, SS&T (2014) note that a listener's interpretation of the term bank will be affected by whether or not they just heard the term river or money. This occurs as the terms river and bank each prime a specific meaning of the term bank—that is, either, the side of a river, or a secure location to deposit one's money. However, as the two senses of the term bank are homographs and homophones, they also prime each other (SS&T, 2014). So, the term bank will in isolation cause the processor to activate both senses of the word, but collocation with another term, such as money, will increase the activation level of a particular sense of bank—in this case, let us say a financial institution—which will cause it to win the competition.
But, as Green (2018) demonstrates, we need more than activation to account for the production of a mixed utterance; we need to include a theory of selection in the production planning process.
Of course, language is more than a grammar. It is a vehicle which allows us to reveal our inner thoughts and feelings to others. It is a tool which allows us to elucidate the pain we are experiencing or the lovely mountains we are seeing while talking on the phone to someone far-removed from the visual stimulus. Let us now expand the model slightly to introduce the sensory and emotional interfaces.
The core language modules interface with the sensory domains of cognition known as Perceptual Output Structures (POpS). Two of these modules (audio and visual structures) are most relevant to language processing (as shown by the connecting lines in Figure 4), but all five sensory-perception modules (including gustatory, olfactory and tactile) can interface with the language core.

Figure 4. An elaborated model.
MOGUL also recognizes the emotional aspects of language use via an affective module—labeled AffS. Similar to POpS, the AffS is a part of general cognitive processing and not specific to language. These AffS structures assign a value feature (e.g., +1 or −1) to interfaced (i.e., co-indexed) representations; higher values in the representations correspond to elevated levels of activation for representations that are part of the same chain. As SS&T explain, “These AffS structures have the effect of assigning either a positive value or a negative value to the representations they are co-indexed with” (2016: p. 3). A lexical example should clarify. Consider the words cheap and thrifty in the context of “Gareth is ____.” Conceptually, these terms are viewed as nearly synonymous, differing only in that thrifty has a positive value representation in the AffS, while cheap has a negative one. Thus, the semantic chain of representations (i.e., CS + POpS + AffS) for these two lexical entries may be nearly identical, differing in that thrifty would be represented as [positive] in the AffS while cheap would have the [negative] AffS representation. As such, the selection of one term over the other may be emotionally motivated; the choice of whether Gareth is cheap or thrifty may depend on whether or not the speaker likes Gareth.
Together, the POpS (perceptual) and AffS (affective) systems play a major role in establishing lexical knowledge. Our conscious understanding of a word's meaning is the synthesis of our perceptual understanding, affective reaction, and CS. More technically, MOGUL accounts for lexical meaning via a (CS + POpS + AffS) chain of representations. A lexical entry is not a single representation but rather an amalgamation of module specific representations that are both external (CS + POpS + AffS) and internal (PS + SS) to the language module. Specifically, a lexical entry is a chain of co-indexed representations [PS + SS + CS (POpS + AffS)] (see Figure 3). The lexicon in MOGUL is merely a subset of highly structured long-term memories which contain patterns of activation (i.e., co-indexations) for feature bundles in multiple modules. In other words, the lexicon consists of chains of representations (i.e., lexical entries) stored in long-term memory. This is one of the reasons why MOGUL is able to implement a Distributed Morphology model in which morphological knowledge is distributed across various representational modules. In sum, conceptual representations and extra-linguistic knowledge are central elements in a MOGUL account of codeswitching; these elements work together to form lexical meanings in the form of complex CS representations.
MOGUL and Cognitive Context
Clearly, in production, certainly at the word and sentence level, bilinguals have conscious control over which language they choose to speak. A central element in accounting for language selection in MOGUL is cognitive context. The notion of cognitive context stems from work on mental models in the field of cognitive science (Johnson-Laird, 1980; Van Dijk, 1997) and may generally be characterized as a mental model which an individual creates to reflect their environment. Such a model is heavily influenced by personal experience (e.g., personal perceptions, pre-conceived opinions, etc.). Factors which may influence cognitive context include (Van Dijk, 1997: p. 193):
- Setting: location, timing of communicative event;
- Social circumstances: previous acts, social situation;
- Institutional environment;
- Overall goals of the (inter)action;
- Participants and their social and speaking roles;
- Current (situational) relations between participants;
- Global (non-situational) relations between participants;
- Group membership or categories of participants (e.g., gender, age).
All of these factors situate an individual in a particular environment. Taken together, this is cognitive context. When discussing codeswitching, cognitive context supplies the set of mental representations that lead an individual to produce one language instead of another in a given setting. SS&T note that an increased activation of “particular languages [(that is PS + SS)] will… be triggered by given patterns of existing conceptual and affective structure: the initial source may be either internal or located in the observable environment” (SS&T, 2014: p. 198). In other words, language selection in production is cued not just by linguistic input being processed but by the social, political and environmental factors emanating from the real-world situation an individual is experiencing (i.e., external factors, such as street signs) as well as an individual's perceptions of said experience (i.e., internal conditions, perceived language prestige).
Influences on Cognitive Context
Three key factors have been identified in playing a critical role in establishing a context which is conducive to language mixing. These factors are:
1. Linguistic Landscape
2. Identity of Language User/ Self-image
3. Identity of Interlocutor
Let us consider them each in turn. An individual's linguistic landscape is a central external factor in establishing cognitive context (SS&T, 2014). A linguistic landscape refers to the real-world linguistic environment individuals find themselves in, taking into account visible aspects of language in a given environment, everything from road signs to gestures. This linguistic landscape is then mentally internalized and becomes part of cognitive context. For example, an individual witnessing a number of English street signs, as pictured in Figure 5, would form an English linguistic landscape which would promote English productions.

Figure 5. Street signs contribute to a language user's linguistic landscape.
The second factor is the language user's self-representation (i.e., a language user's view of self in their cognitive context). While, crucially, the language user must self-identify as a bilingual (or multilingual), self-representation also refers to a language user belonging to or identifying with various social/cultural groups (e.g., university students, musicians, cognitive scientists, etc.; Van Dijk, 1997). The identity (or perceived identity) of the interlocutor is the third factor. The language user must believe that the interlocutor is a bilingual in order to license language mixing. Additionally, if the language user and the interlocutor identify with similar social or cultural groups, the language user may perceive an affinity with the interlocutor which sets the stage for socially motivated codeswitching, spurred by notions of solidarity and group belonging (Poplack, 1980).
Cognitive Context, Conceptual Triggering, and Language Selection
A fundamental property of bilingual performance is a speaker's ability to selectively produce one language or another without mixing elements cross-linguistically. Before we can understand how two linguistic systems can be brought together, we must first examine how they are separated. Thus, any account of language mixing necessitates an account of language selection. This account of language selection is motivated by the observation that bilinguals tend to use specific languages in specific contexts (e.g., language X is used at work but language Y is used at home) (Truscott and Sharwood Smith, 2016). Within the MOGUL framework, a rich cognitive context functions to activate elements in each module's information store that are associated with a specific situational context. This process is known as conceptual triggering (SS&T, 2014). Conceptual triggering relies on a specific CS feature called a general language representation (GLR) which increases the activation level of co-indexed representations associated with a specific language variety. SS&T state, “the contexts that have a triggering effect are particular perceptual and conceptual structures that are associated with elements of one of the person's languages, including general language concepts like FRENCH or YORUBA (2014, p. 199). However, it is also possible that GLRs could activate particular varieties or registers of a language, such as formal French or informal Yoruba. These general language representations are CS representations co-indexed to feature bundles associated with the relevant language variety in the PS and SS; when a GLR from language X becomes active in the CS, all representations which are co-indexed to X-GLR receive an activation boost to their current level of activation. It is worth noting that linguistic representations may be co-indexed to multiple GLRs, as in the case of cognates and interlingual homophones.
This machinery can clearly be employed to account for intentional language mixing at the lexical, phrasal, or sentential level, but we will return later to the question of whether intraword codeswitching is intentional.
MEG studies by Blanco-Elorrieta and Pylkkanen (2015, 2016) have investigated the role of natural occurring language cues (i.e., ethnicity of the interlocutor and orthography) in triggering language selection. These language cues are factors involved in establishing cognitive context. In their study, Arabic-English speakers perform two number-naming tasks: a match task and a mismatch task. For each task there were two conditions, a script condition (i.e., orthographic) and a cultural condition (i.e., a culturally iconic picture). These conditions are displayed in Figure 6.
Figure 6. Stimuli from Blanco-Elorrieta and Pylkkanen (2015: p. 2).
During the match task, participants were shown an image and asked to name the number indicated on the blackboard in the language indicated by either the script or the clothing. The mismatch task required the opposite: participants were to name the number in the language which was not cued by the script or clothing. The results of this study revealed that script—which is part of a linguistic landscape—was a much more effective cue than the cultural condition in terms of triggering language selection.
Neurologically, this distinction between the cultural and orthographic condition is demonstrated by a greater degree of activation in the Anterior Cingulate Cortex (ACC) during the cultural condition (compared to the script condition) which they attribute to greater processing difficulty. Prior research has implicated the ACC as having a major role in establishing attention (Abutalebi et al., 2008, 2013; Costa and Sebastián-Gallés, 2014) which, in turn, is related to executive control (Blanco-Elorrieta and Pylkkanen, 2015: p. 14).
According to Blanco-Elorrieta and Pylkkanen (2015, p. 14), executive control is “the effort to retrieve…a word amongst competing responses” during language production. As several studies have reported an increase in ACC activity for greater executive control demands (Abutalebi et al., 2008; Garbin et al., 2011; Costa and Sebastián-Gallés, 2014), they suggest that the increase in ACC activity during the cultural condition reflects a greater effort to retrieve the target element; the cultural condition is a weak language cue, and requires additional cognitive effort to satisfy production goals. Alternatively, the lesser demand on the ACC during the script condition seems to indicate that script is a strong cue which appears to dominate cognitive context when selecting a language.
MOGUL and Control
Researchers have often turned to the notion of executive control to explain language control (Green, 1998; Abutalebi et al., 2015). Among its many functions, an executive control mechanism allows language users to suppress representations from language A while permitting representations from language B to surface. Early models of executive control proposed single mechanisms which were capable of performing a number of quasi-related functions which were otherwise unaccounted for. For example, Green (1998) discusses a control mechanism called the Supervisory Attentional System which, “… must command a variety of processes, including the construction or modification of existing schemas and the monitoring of their performance with respect to task goals” (Green, 1998: p. 69). However, more recent work (Abutalebi et al., 2015; Green and Kroll, 2019) recognize the complexity of these extra-linguistic processors. While space does not permit us to explore details of these domain-general control mechanisms, it is uncontroversial to note that there is strong neurolinguistic evidence for the distinction between what Green and Kroll (2019) call the language network and its control.
This is reflected in the work of Green and Wei (2016) on codeswitching and language control. They argue that codeswitching is not the product of activation within the language system, but rather the result of selection in the planning process. When one language is suppressed entirely in production, this is the result of competitive control. However, when forms from more than one language are selected, this is the result of cooperative control. There are two ways in which this can happen. First is what they call coupled control. Under coupled control there is a dominant, target language of the utterance even though items from another language may be inserted. Second is what they call open control. Open control licenses dense codeswitching. Under this scenario, there is no dominant, target language but rather both languages are active and the planning process can select items from either. In this framework, the different types of output are associated with different attentional states. Dense codeswitching would be associated with a broad attentional state18.
From a MOGUL perspective, where modules are believed to be “expert systems” which perform specific tasks, there is no reason to believe that a single mechanism is responsible for performing such seemingly unrelated functions as goal maintenance, schema construction, or conflict monitoring. MOGUL embraces a pluralistic construct of executive control which is consistent with that of Green and Wei (2016). “[There is] no single fixed executive control but [instead] different mental subsystems operate in a way that may be highly constrained” (SS&T, 2014: p. 21). As such, the functions of executive control are broken down and attributed to specific modules. Of the many functions attributed to executive control (e.g., goal maintenance; conflict monitoring; interference suppression; salient cue detection; selective response inhibition; task disengagement; task engagement; opportunistic planning), the notion of goal formation and maintenance is central to our account of ICS in MOGUL.
Goals are realized via goal representations which are constructed in the CS and interfaced to neighboring modules. To illustrate this, let's further explore the notion of goal. Truscott and Sharwood Smith (2016) claim that goal representations are a type of CS structure which help guide thought and action. Goal representations “serve the function of encouraging the satisfaction of basic needs” (Truscott and Sharwood Smith, 2016: p. 5); these basic needs may be non-linguistic and could include the desire for food, water, bathroom, etc. These goals motivate action (Damasio, 2018) such that goals with higher activation levels are prioritized and drive an individual to perform tasks which satisfy the goal. For example, a basic goal like “satisfy hunger” can be satisfied by eating.
In the realm of language production, goal representations (which are most likely below consciousness) related to communicative and social functions are particularly pertinent. SS&T argue that such social goals are formed from a set of primitive CS features representing social motivators which could include affiliation, power or face. Language-oriented goal representations serve to motivate language use. Goal representations play a significant goal in determining the shape and style of language production by increasing the activation level of linguistic representations which can satisfy the goal. These goal representations are co-indexed to value representations in the AffS; the higher the value in the representation, the higher priority the goal, and hence the greater the increase in activation levels to linguistic representations that satisfy the goal.
Let us imagine the following scenario to understand how this machinery can work in a real-world situation. For narrative purposes, we draw on the population which is the source of the Alexiadou et al. (2015) Norwegian/English data: a group of people of Norwegian descent who live in the United States. Let us return to our hypothetical group member Gunnar. When Gunnar is interacting with monolingual English speakers in Minnesota, he usually produces English-only utterances, suppressing the production of Norwegian. In situations, though, where the linguistic landscape includes such things as other Norwegian speakers, or Norwegian food products, or literature, his speech may contain language mixing at the sentence-, phrase-, or word-level. These external factors influence the cognitive context which licenses a bilingual communication mode. When in this mode, Gunnar may have a variety of social goals including let them know I'm Norwegian too, or reminisce about the summers at the lake when I was a child or imitate the funny way that a certain politician spoke. Codeswitching, then, might be a vehicle to satisfy any of these social goals. Linguistically, the tools used to achieve these goals could be a codeswitch within an utterance, or a sentence, or a word. Codeswitching is not the goal.
MOGUL and Communicative Modes
When discussing bilingualism, a number of language mixing researchers have suggested that bilinguals are able to exploit different modes of communication (Poplack, 1980; Poplack et al., 1988; Myers-Scotton, 1992; MacSwan, 1999; Grosjean, 2001; SS&T, 2014). Communication modes are invoked to account for a bilingual's ability to generally suppress one language in production as appropriate to the social setting. In MOGUL, these communicative modes are cognitive states where contexts and goals align to produce the contextually relevant language. When a speaker engages in a bilingual mode, representations from two languages are equally active in the production process. This would be consistent with Green's notion of open, cooperative control. It is this configuration of contextual representations that licenses the mixing of grammatical systems during codeswitching (including ICS). Both external (e.g., linguistic landscape) and internal factors (e.g., goal representations) contribute to the set of conditions which make up a bilingual context; a context conducive to language mixing. The goal representation is, however, crucial for providing the language user with the motivation for engaging in a codeswitch. While these motivations vary—from pride to humor to solidarity—it is goal representations which drive a language user to produce an ICS.
Following Grosjean (2001) we will adopt the term bilingual mode (as opposed to mixed speech mode or codeswitching mode). In such circumstances, it is the act of switching, not the location of switch, that may carry meaning— if the goal of the utterance (or the act of codeswitching) is to promote solidarity, the type of elements switched may not be relevant. A bilingual may switch a consonant (saying Bach as [bax] or [bak]), a word (careful! or ¡cuidado!), or a morpheme (den field-a “that field”) and it signals to the interlocutors that they are members of the same social group.
So, while the production by the speaker may not be a conscious decision to switch at a particular point, the bilingual mode (or open control) licenses the switch. The listeners then recognize the intended goal (e.g., group solidarity).
We saw earlier that representational chains are constructed from the co-indexation of module-specific feature bundles (e.g., PS + SS + CS). What we introduce now is the fact that module-specific features bundles associated with different languages can come together, resulting in an ICS.
When the bilingual communicative mode is engaged, two languages are conceptually triggered and all representations co-indexed to either GLR receive an activation boost. Crucially, goal representations are co-indexed to any representation which helps satisfy that goal which, in turn, increases the activation level of said representation. A representational chain is then formed from the most active content in each module; the resulting chain will contain a SS representation from, say, Lx, a PS representation from Ly and CS representation from both Lx and Ly—this is an intraword codeswitch, as shown in (21).
21) den field-a
that field-DEF.F
“that field”
Notably, there are no special processes or mechanisms evoked to account for codeswitching; language mixing is the natural product of standard MOGUL operations and processes. As Truscott and Sharwood Smith (2016: 903) note, somewhat paradoxically, “a theory of codeswitching should, ideally, not be a theory of codeswitching.” In this model, codeswitching can result from a particular cognitive context and a bilingual communicative mode. The bilingual mode is a reflection of cognitive context, while codeswitching is the act which satisfies a particular communicative goal. When an individual produces an ICS, they do so because bilingual mode is active and codeswitching is the best way to satisfy their goal.
Grammatical Machinery
This account of codeswitching production begins with cognitive context. An internalized mental model is constructed by the speaker to reflect the external environment they are experiencing. We will refer to the language which is conceptually triggered as the prominent language. We do so to avoid confusion with the term dominant which is used in the Matrix Language Frame Model. All representations which are associated (i.e., co-indexed) with the triggered language will receive an additional activation boost. This activation boost means representations co-indexed to the conceptually triggered language will usually come out on top in any competition.
However, in language-mixing situations, cognitive context is oscillating between two prominent language contexts. This notion of oscillation is a crucial one; only one language can be prominent (i.e., conceptually triggered) at a given time; however, context changes in real time. These changes may be external (i.e., changes to the physical environment) or internal (i.e., re-evaluating goals). The metaphor of contextual oscillation represents a rapid alternation of prominent linguistic contexts. This fluctuation between contexts can, in principle, happen a number of times over the course of constructing a single word, or phrase, or sentence. The word level is not a special barrier to language mixing. Such a view is consistent with a dense codeswitching environment which can trigger open cognitive control.
When a speaker experiences a cognitive context which conceptually triggers the prominent language, the result is the construction of a syntactic structure as the speaker plans an utterance. It is the nature of this tree, and the single engine which drives both the morphology and syntax which we focus on here.
In DM, once the syntactic tree has been constructed, Vocabulary items compete for insertion. In order for intraword codeswitching to occur, a speaker must engage the bilingual mode of communication. DM appears to be highly compatible with MOGUL in that DM vocabulary items correspond to PS representations and their co-indices to SS representations. Under most circumstances, the PS representation inserted into the syntactic tree is the PS representation which best matches representations in both the SS and the CS, and which has been conceptually triggered. We are not claiming here that MOGUL requires a DM architecture. Sharwood Smith and Truscott (2014) note that MOGUL is a framework which can implement many different formal models. The goal of this paper is not to assess the broader falsifiability of MOGUL.
When a speaker is in bilingual mode, representations from both languages are able to compete with each other. A DM framework would allow for Vocabulary items from both languages to compete to be inserted into the syntactic tree. Within the MOGUL framework, the activation level of any PS representation will be determined by the activation levels of all co-indexed representations in other modules. If an SS feature bundle increases in activation, representations with co-indexed features will also increase in activation; the PS representation with the most features co-indexed to the active SS representation will be the most active in the PS module and will be inserted into the derivation; this is competition in MOGUL.
During the processing of a derivation in MOGUL, lexical items are formed from the most active co-indexed representations. When considering an instance of codeswitching, each feature bundle in the SS is potentially co-indexed to a pair of PS representations; one from the language that serves as the host in that moment and one from the donor language. In a language mixing situation, a speaker has two general language representations active in their CS thus conceptually triggering two languages. Representations co-indexed to either GLR will receive an additional activation boost. Effectively, this means that PS representations associated with two different languages are competing on an equal playing field; from here competition may proceed in the standard MOGUL fashion.
However, the question remains: when elements from the prominent and attenuated language are in competition, what allows the attenuated language to ever win? In standard bilingual environmental circumstances (i.e., oscillating contexts), when PS representations from both languages are in competition, one would predict that the prominent representation should always win the competition as frequent, salient representational chains will have higher resting levels of activation than newly formed chains; even on a level playing field the prominent language should still win. What are the circumstances under which the attenuated language could ever win? We argue that this phenomenon can be accounted for via the construct of goal representations. Communicative goals contribute to cognitive context but also increase the activation level of representations which satisfy their demands. When a speaker engages a bilingual mode, communicative goals conducive to codeswitching will be active in the CS. In a language mixing situation, this translates to an increase in the activation level of the attenuated language representations in order to satisfy the goal. As such, goal representations play a central role in permitting a speaker to mix languages.
Let us return to the example drawn from a speech corpus of heritage Norwegian speakers in the USA, repeated in (22):
22) den field-a
that field-DEF.F
“that field”
Example (22) is a phrasal constituent which is presumably part of a larger sentence or conversation. The prominent language—conceptually triggered via a specific context—is assumed to be Norwegian, as evidenced by the fact that the syntactic structure was built from Norwegian features. This can be seen by the fact that such mixed sentences show Norwegian V2 syntax. The sentence in (23) is reported in Alexiadou et al. (2015).
(23) Så play-de dom game-r
Then play-PAST they game-INDEF.PL
“Then, they played games.”
This sentence with clear English lexical items is inserted into a syntactic structure which has the verb in second position (V2) as is standard in Norwegian. This cognitive context will reflect a number of internal (e.g., self-image, inter-personal relationships, etc.) and external influences (e.g., location, identity of interlocutor, etc.) which the speaker has co-indexed with the Norwegian GLR in the CS. This means that all modular representations which are interfaced to the Norwegian GLR will receive an activation boost that subsequently causes these representations to dominate any competition. As such, when a speaker chooses to speak, a syntactic tree will be constructed from feature bundles associated with Norwegian.
Let us note here, that while MOGUL includes representational components, it is primarily a model of performance. As a production model, it cannot predict which switches will occur in a given utterance a priori. It can only work after the fact to attempt to account for why the switches occurred the way they did. In this light, we do not feel that our account of performance falls into a trap of circularity of the following sort:
Q: Why did they codeswitch?
A: Because they had a goal of codeswitching.
Q: How do you know they had a goal of codeswitching?
A: Because they codeswitched
The goal of a production model is not to predict which utterance will occur. In our view, this does not diminish the contribution of the model in any way. MOGUL, although it does not allow us to distinguish, say, well-formed ICS strings from ill-formed ICS strings, does add clarity to how real speakers use real languages in real situations.
To illustrate how this model of DM accommodates language mixing let us return to the Norwegian-English example introduced in earlier. We propose that in order for ICS to occur, the speaker has to engage a bilingual communication mode and, as a result, codeswitching may serve the communicative goals. The analysis presented in this paper will closely follow work by Grimstad et al. (2014) and Alexiadou et al. (2015). These data were collected from an American heritage community of Norwegian-English speakers and was drawn from the CANS (Corpus of American Norwegian Speech), which is a spoken corpus. Remember that goals are part of a complex CS representation; any representation which is co-indexed to a goal receives an additional activation boost. High-priority goals are co-indexed to high-value representations in the Affective Module (AffS); the higher the value stored in the representation in the AffS the greater the activation boost spreading through the system. The high-priority goal will result in an activation-level boost to co-indexed vocabulary items. We propose that high-priority goals are further enhanced. This enhancement provides a greater increase to activations levels than regular co-indexed representations; in Figure 7 enhanced representations are marked with (+) to indicate an additional boost (i.e., 4+ > 4). As the English PS representation is co-indexed to a goal it receives an activation boost of (1+) which raises its activation level to (4+) and makes it the most active PS feature bundle representing the root FIELD. The most active features in each module are then chained together and result in the English-Norwegian codeswitch, den field-a as seen below in Figure 7.
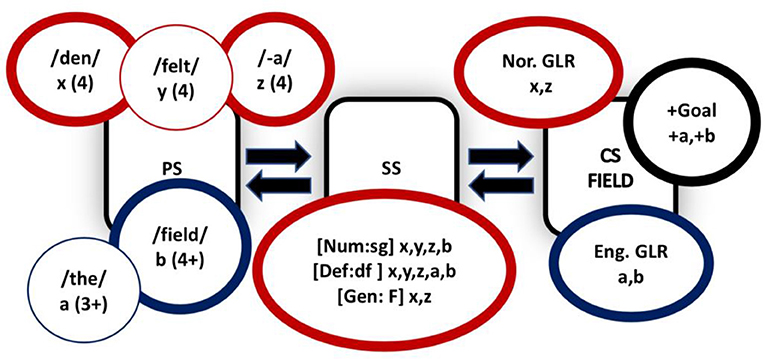
Figure 7. Feature co-indexation with oscillating context and a goal. Bold, most active representation; red, Norwegian; blue, English; round square, module; circle, feature bundle.
To illustrate, we model this process in Figure 8. Starting on the right-most side of Figure 8, contextual factors are associated with language; some factors like the identity of the interlocutor or a self-representation may be co-indexed to multiple languages—this is represented by multi-colored contexts.
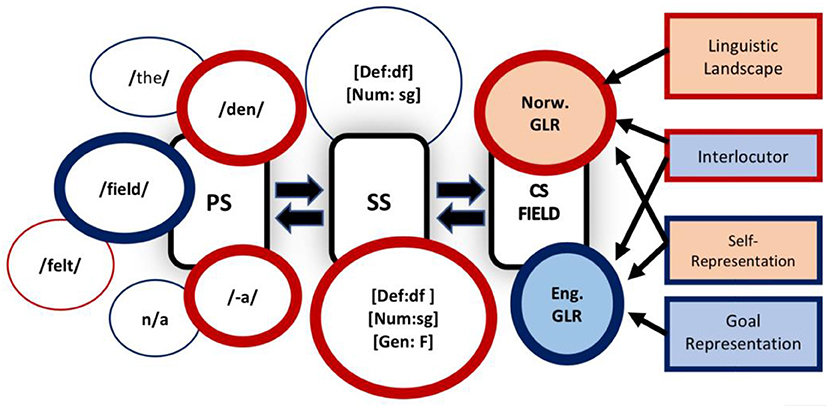
Figure 8. Derivation for den fielda. Bold, most active; red, Host/Norwegian; blue, Donor/English; round square, module; circle, feature bundle; rectangles, contexts.
This mixed language context causes the conceptual triggering of two languages in a near simultaneous (or oscillating) fashion which in turn allows representations from English and Norwegian to compete against each other. In Figure 8, the bolded circles represent feature bundles which are the most active in their respective modules; the most active feature bundle in each module is interfaced to form a (PS + SS + CS) representational chain. The result is ICS; the formation of representational chains which contain feature bundles associated to two different languages.
The picture of the Lexicon being sketched out in MOGUL looks quite different from traditional lexicalist approaches in generative linguistics (e.g., MacSwan, 2005). Recall that in MOGUL, a lexical entry is not a single representation but rather an amalgamation of module- specific representations that are both external (CS + POpS + AffS) and internal (PS + SS) to the language module. Specifically, a lexical entry is a chain of co-indexed representations [PS + SS + CS (POpS + AffS)]. Thus, the MOGUL architecture is consistent with the performance of codeswitching (including ICS) via vocabulary insertion into a syntactic structure to satisfy the goals of the speaker situated in a particular linguistic and cognitive context.
Conclusion and Future Directions
In this paper we hope that we have documented the widespread nature of the phenomenon of ICS. Switching languages within a word is a property of bilingual speech invoking many different languages. And yet, in order to understand this real-world phenomenon, to understand how people like Gunnar and Fulana communicate effortlessly and successfully in a multilingual environment, we need to have sophisticated models of both linguistic knowledge and linguistic performance. In our view, a model of Distributed Morphology couched within the tenets of Minimalist Syntax provides the descriptive and explanatory power to account for the observed facts of ICS. Bilinguals know that ICS is possible but governed by the same type of grammatical machinery that we see in monolinguals. This grammatical machinery is, of course, not open to conscious introspection but nonetheless our analysis demonstrates the principled nature of intraword codeswitches.
Our review of 57 different codeswitched words reveals that the morphological and phonological restrictions on combining elements from two languages in a single word differ from one another. Bilinguals can easily combine roots and affixes from two different languages to form a codeswitched word, and they do so in a systematic manner. While roots can come from LA and affixes from LB, it is generally thought that all affixes in a mixed word must come from a single language. However, our crosslinguistic review of ICS suggests that targeted, experimental research is needed in order to confirm that this is the case. Further, for any given language pair, there seems to be a directional asymmetry with respect to ICS such that the root may come from LA and the affixes from LB, but not the reverse (i.e., root from LB and affixes from LA).
Contrary to mixing roots and affixes from two languages in a single word, it does not seem to be the case that bilinguals can easily mix elements from two phonological systems within a single word. That is, even though a root may come from LA and affixes from LB, the sounds that a bilingual uses to utter this word come from a single language. Our review of ICS indicates a prevailing pattern- the phonology of a codeswitched word matches that of the language of the affixes. We reviewed two experiments (Stefanich, 2019) designed to explicitly test this observation. The results indicate that, while there was considerable variation, in general, Spanish/English bilinguals produced words with English roots and Spanish affixes with Spanish phonology. Future work should examine the phonology of ICS via different language pairs, different types of words (e.g., nouns vs. verbs), and different acoustic cues. Additionally, future research should also examine ICS in its larger context, i.e., beyond the word, to see if any additional patterns can be found with respect to how factors, such as linguistic background of the interlocutors, sociolinguistic context of the discourse and syntactic context of the mixed word inform our understanding of the morphological restrictions and phonological restrictions on ICS.
Bilinguals also have not just knowledge, but ability. Linguistic competence can be used to signal solidarity, channel identity, and achieve any one of the myriad goals that any speaker can seek to satisfy. Linguistic performance integrates seamlessly with other cognitive faculties as we move through our everyday lives, talking, listening, planning, assessing, looking, touching, feeling, thinking. In our view, the MOGUL framework provides the necessary cognitive machinery to account for the real-time instantiation of ICS.
Competence and performance models seek to answer different questions and the questions surrounding ICS have just started to be asked. Future methodologies to further probe the character of ICS should draw on a combination of corpora and experimental research. Corpora can be a good starting point, as they give examples in real world contexts. However, we may be unable to answer certain technical questions from corpora alone (such as whether morphological switch boundaries coincide with phonological switches). We must remember though that just because a particular phenomenon is not found in a corpus, it does not mean the phenomenon is ill-formed in competence – it may have been problematic given some performance domain. Thus, assessing well-formedness via acceptability tasks can also advance our understanding of the phenomenon.
A performance model will never be able to predict with absolute certainty the form an utterance will take. As the philosopher Alfred North Whitehead once said to B.F. Skinner at a dinner, no behaviorist model of speech is able to predict someone saying There is no black scorpion falling on the table. The structural properties of intraword codeswitches are not fully understood. We are not able to predict whether Gunnar will say the field or den fielda, or whether Fulana will say hangear or hang out. But now that we are asking questions about why the switches occur where they do and why not in other places, why certain structures are allowed, and why others are not, we have a program of research that has the possibility of finding answers.
What's in a bilingual word? Only morphology, syntax, concepts, sounds, features, recursion, connotations, and oscillating contexts. A single word can reveal so much.
Data Availability Statement
All datasets generated for this study can be requested directly from the first author: c2FyYS5zdGVmYW5pY2hAbm9ydGh3ZXN0ZXJuLmVkdQ==.
Ethics Statement
This study was carried out in accordance with the recommendations of University of Illinois at Chicago Internal Review Board with written informed consent from all subjects. All subjects gave written informed consent in accordance with the Declaration of Helsinki. The protocol was approved by the University of Illinois at Chicago Internal Review Board.
Author Contributions
SS and JC were the primary contributors of the linguistic competence section. DH and JA were the primary contributors of the linguistic performance section.
Funding
The data presented in Section ICS at the Representational Level was collected as part of a larger research project that was funded by the National Science Foundation Doctoral Dissertation Research Improvement Grant, BCS #1823909.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1. ^As the mixed words presented in section Discussion: Morphological Restrictions vs. Phonological Restrictions are taken from an array of different sources which do not consistently provide the same information, we are, in fact, unable to comment upon this issue. In order to comment upon the borrowing vs. CS debate with respect to mixed words we argue that the very least the following four considerations should be taken into account: (1) morphosyntactic properties. For instance, does the root of the mixed verb behave morphosyntactically like a verb from Language A or B? (2) Phonological properties. What phonology(s) does the mixed word evince? (3) Demographic information on the bilingual who uttered the mixed word and the social and linguistic context in which it was uttered. (4) An analysis of the individual monolingual languages from which the mixed word was formed.
2. ^Note that any and all syntactic trees presented in this paper are simplified representations for ease of explanation.
3. ^González-Vilbazo and López (2011) also claim that mixed words, such as (8) are codeswitches while those, such as (9) are borrowings. In other words, in a bilingual context, Spanish/German bilinguals only utter mixed words comprised of Spanish roots and German affixes. Mixed words with German roots and Spanish affixes are only uttered in a Spanish monolingual context (between a Spanish/German bilingual and a Spanish monolingual with enough knowledge of German to understand the mixed word).
4. ^The three conjugation classes in Spanish are: AR, ER, IR.
5. ^We note that this feature checking analysis is unable to explain the directionality asymmetry in Spanish/English CS. In Spanish/English CS, English roots can combine with Spanish affixes, but Spanish roots cannot combine with English affixes (i.e. the opposite order from Spanish/German). If it is the case that English roots, like German, do not have conjugation class features, then how does the Spanish v become valued in the case of words like dipear “to dip,” mopear “to mop,” parquear “to park”?
6. ^See Jake et al. (2002) for more examples and MacSwan (2005) for critique and discussion of whether the examples serve as counterevidence toward the PF Disjunction Theorem.
7. ^We note that the surface patterns presented here align with those discussed in Alexiadou and Lohndal (2018).
8. ^We note that the word “farm” in English lacking any context could be both a noun and a verb, and that it is potentially ambiguous whether the underlying structure of the verb “to farm” includes the noun or not. For the purposes of our paper whether “farm” maintains the more complex structure or not does not affect the morphological switch point under discussion. See Acquaviva (2009), Alexiadou and Lohndal (2017), Borer (2013), and Embick (2015), among others for a discussion on the categorization of roots.
9. ^The derivational affix “er” is a productive affix in English that is used to convert verbs to nouns with the meaning “one who [verb]s.”
10. ^We use “Spanish” and “German” here as descriptive labels for the underlying features that comprise a nominalizing affix in the Spanish language versus the German language.
11. ^We recognize that there are some varieties of French that may produce word-final schwa. If this word is uttered by a bilingual from one of those varieties, then the production of the Dutch affix as a schwa would not be evidence of a phonological switch.
12. ^We acknowledge that MacSwan (2005) does not provide a detailed syntactic analysis of these examples and that in order to say definitively that they are two separate X0s, such an analysis is required.
13. ^Bolonyai (2005) appeals to a borrowing versus codeswitching account to explain the difference in phonological realization between examples, such as (11)–(12) and (19)–(21). However, she does not provide any details regarding the bilingual speakers who uttered these mixed words nor any information as to the context in which they were uttered. Without this information it is difficult to address whether a borrowing versus codeswitching account holds.
14. ^This compatibility of DM to both competence and performance accounts of ICS is, for us, a virtue; we are not arguing that it is the only possible theory of morphology which could be implemented in MOGUL.
15. ^The only experimental evaluation of potential phonological switches to our knowledge comes from MacSwan and Colina (2014), who examined interword production within English-Spanish mixed DPs, rather than intraword production. They found that phonological processes can apply across word boundaries only if the process is operational in the language of the word that would be affected, an outcome which aligns with the hypothesis that two phonologies do not apply within a word. Akinremi (2017) and Hlavač (1999) explicitly discuss the phonology of mixed words but they do not provide experimental or acoustic data.
16. ^To control for any potential effects in judgments due to splicing, the authors also constructed the items in the Spanish and English phonology conditions by splicing the root and affixes.
17. ^MOGUL has become part of a larger research program known as the Modular Cognition Framework (MCF). In this paper, we will still use the term MOGUL. For more information, see the website: https://www.cognitionframework.com.
18. ^Green (2018) further explores the constructs of coupled and open control. In MOGUL terms, the multilingual cognitive context (and the likely dense codeswitching input) appears to prime open control. Given the results of Stefanich (2019), it would be worth exploring whether the morphological and phonological switches are governed by coupled or open control. The lack of phonological switching could perhaps be the result of the short timespans involved.
References
Abutalebi, J., Annoni, J.-M., Zimine, I., Pegna, A. J., Seghier, M. L., Lee-Jahnke, H., et al. (2008). Language control and lexical competition in bilinguals: an event-related FMRI study. Cereb. Cortex 18, 1496–505. doi: 10.1093/cercor/bhm182
Abutalebi, J., Canini, M., Della Rosa, P. A., Green, D. W., and Weekes, B. S. (2015). The neuroprotective effects of bilingualism upon the inferior parietal lobule: a structural neuroimaging study in aging Chinese bilinguals. J. Neurolinguistics 33, 3–13. doi: 10.1016/j.jneuroling.2014.09.008
Abutalebi, J., Della Rosa, P. A, Ding, G., Weekes, B., Costa, A., and Green, D. W. (2013). Language proficiency modulates the engagement of cognitive control areas in multilinguals. Cortex 49, 905–911. doi: 10.1016/j.cortex.2012.08.018
Acquaviva, P. (2009). “Roots and lexicality in distributed morphology,” in Fifth York-Essex Morphology Meeting (YEMM) (York: Department of Language and Linguistic Science; University of York).
Akinremi, I. (2017). Phonological adaptation and morphosyntactic integration in Igbo-english insertional codeswitching. J. Univ. Lang. 17, 53–79. doi: 10.22425/jul.2016.17.1.53
Alexiadou, A. (2017). Building verbs in language mixing varieties. Z. Sprachwiss. 36, 165–192. doi: 10.1515/zfs-2017-0008
Alexiadou, A., and Lohndal, T. (2017). “The structural configurations of root categorization,” in Labels and Roots, eds L. Bauke and A. Blumel (Germany: de Gruyter Mouton, 203–232.
Alexiadou, A., and Lohndal, T. (2018). Units of language mixing: a cross-linguistic perspective. Front. Psychol. 9:1719. doi: 10.3389/fpsyg.2018.01719
Alexiadou, A., Lohndal, T., Åfarli, T. A., and Grimstad, M. B. (2015). “Language mixing: a distributed morphology approach,” in Proceedings of NELS, Vol. 45, eds T. Bui and D. Özyildiz (Cambridge, MA), 25–38.
Amuzu, E. K. (1998). Aspects of grammatical structure in Ewe-English codeswitching (Unpublished MPhil thesis), University of Oslo, Oslo, Norway.
Arad, M. (2003). Locality constraints on the interpretation of roots: the case of Hebrew denominal verbs. Nat. Lang. Linguist. Theory 21, 737–778. doi: 10.1023/A:1025533719905
Archibald, J. (2016). Phonology at the Interface: Late Insertion and Spell Out in L2 Morphophonology. New Sounds. Aarhus: University of Aarhus.
Backus, A. (1992). Patterns of Language Mixing: A Study in Turkish-Dutch bilingualism. Vol. 11. Otto Harrassowitz Verlag.
Badiola, L., Delgado, R., Sande, S., and Stefanich, S. (2017). Code-switching attitudes and their effects on acceptability judgement tasks. Linguist. Approach. Biling. 8, 5–24. doi: 10.1075/lab.16006.bad
Bandi-Rao, S., and den Dikken, M. (2014). “Light switches: On V as a pivot in codeswitching, and the nature of ban on word-internal switches,” in Grammatical Theory and Bilingual Codeswitching, ed J. MacSwan (Cambridge, MA: MIT Press, 161–183.
Bartlett, L., and González-Vilbazo, K. E. (2013). The structure of the Taiwanese DP in Taiwanese–Spanish bilinguals: evidence from code-switching. J. East Asian Ling. 22, 65–99. doi: 10.1007/s10831-012-9098-3
Bessett, R. (2017). The Integration of lone English nouns into bilingual Sonoran Spanish (Unpublished doctoral dissertation). The University of Arizona, Tucson, AZ, United States.
Blanco-Elorrieta, E., and Pylkkanen, L. (2015). Brain bases of language selection: MEG evidence from Arabic-English bilingual language production. Front. Hum. Neurosci. 9:27. doi: 10.3389/fnhum.2015.00027
Blanco-Elorrieta, E., and Pylkkanen, L. (2016). Bilingual language control in perception versus action: MEG reveals comprehension control mechanisms in anterior cingulate cortex and domain-general control of production in dorsolateral prefrontal cortex. J. Neurosci. 36, 290–301. doi: 10.1523/JNEUROSCI.2597-15.2016
Bokamba, E. G. (1989). Are there syntactic constraints on code-mixing? World Englishes 8, 277–292. doi: 10.1111/j.1467-971X.1989.tb00669.x
Bolonyai, A. (2005). “English verbs in Hungarian/English code-switching,” in Proceedings of the 4th International Symposium on Bilingualism, eds J. Cohen, K. McAlister, K. Rolstad, and J. MacSwan (Somerville, MA: Cascadilla Press, 317–327.
Borer, H. (2013). “The category of roots,” in The Roots of Syntax, the Syntax of Roots, eds A. Alexiadou, H. Borer and F. Schaffer (Oxford: Oxford University Press), 112–148.
Budzhak-Jones, S. (1998). Against word-internal codeswitching: evidence from Ukrainian-English bilingualism. Int. J. Biling. 2, 161–182. doi: 10.1177/136700699800200203
Burkholder, M., Mathieu, E., and Sabourin, L. (2017). “The role of gender in mixed language nominal phrases: insights from distributed morphology,” in GALSA 14 (Southampton).
Cantone, K. (2003). “Evidence against a third grammar: code-switching in Italian-German bilingual children,” in Proceedings of the 4th International Sympoisum on Bilingualism, eds J. Cohen, K. McAlister, K. Rolstad, K., and J. MacSwan (Somerville, MA: Cascadilla Press, 477–496.
Costa, A., and Sebastián-Gallés, N. (2014). How does the bilingual experience sculpt the brain? Nat. Rev. Neurosci. 15, 336–345. doi: 10.1038/nrn3709
Costa, R. S. (2009). Anglicismos léxicos en dos corpus. Espéculo Rev Estud Liter. 114. Available online at: https://www.biblioteca.org.ar/libros/150590.pdf
Damasio, A. (2018). The Strange Order of Things: Life, Feeling and the Making of Cultures. New York, NY: Pantheon.
De Belder, M., and Van Craenenbroeck, J. (2015). How to merge a root. Linguist. Inq. 46, 625–655. doi: 10.1162/LING_a_00196
Ebert, S., and Koronkiewicz, B. (2018). Monolingual stimuli as a foundation for analyzing code-switching data. Linguist. Approach. Biling. 8, 25–66. doi: 10.1075/lab.16007.ebe
Embick, D., and Noyer, R. (2007). “Distributed morphology and the syntax/morphology interface,” in The Oxford Handbook of Linguistic Interfaces, eds G. Ramchand and C. Reiss (Oxford: Oxford University Press), 289–324. doi: 10.1093/oxfordhb/9780199247455.013.0010
Fuller, J. (1999). The role of English in Pennsylvania German Development: best supporting actress? Am. Speech 74, 36–55.
Garbin, G., Costa, A., Sanjuan, A., Forn, C., Rodriguez-Pujadas, A., Ventura, N., et al. (2011). Neural bases of language switching in high and early proficient bilinguals. Brain Lang. 119, 129–135. doi: 10.1016/j.bandl.2011.03.011
González-Vilbazo, K., Bartlett, L., Downey, S., Ebert, S., Heil, J., Hoot, B., et al. (2013). Methodological considerations in code-switching research. Stud. Hispanic Lusophone Linguist. 6, 119–138. doi: 10.1515/shll-2013-1143
González-Vilbazo, K., and Koronkiewicz, B. (2016). Tú y yo can codeswitch, nosotros cannot. Spanish English Codeswitching Caribbean US 11:237. doi: 10.1075/ihll.11.10gon
González-Vilbazo, K., and López, L. (2011). Some properties of light verbs in code-switching. Lingua 121, 832–850. doi: 10.1016/j.lingua.2010.11.011
González-Vilbazo, K. E. (2005). Die syntax des code-switching. Esplugisch: sprachwechsel an der deutschen schule Barcelona (Unpublished doctoral dissertation), Universität zu Köln, Köln, Germany.
Green, D., and Kroll, J. (2019). “The neurolinguistics of bilingualism: plasticity and control,” in The Oxford Handbook of Neurolinguistics, eds G. de Zubicaray and N. Schiller (Oxford: Oxford University Press), 261–294.
Green, D., and Wei, L. (2016). Code-switching and language control. Biling. Lang. Cogn. 19, 883–884. doi: 10.1017/S1366728916000018
Green, D. W. (1998). Mental control of the bilingual lexico-semantic system. Biling. Lang. Cogn. 1, 67–81. doi: 10.1017/S1366728998000133
Green, D. W., and Abutalebi, J. (2013). Language control in bilinguals: the adaptive control hypothesis. J. Cogn. Psychol. 25, 1–16. doi: 10.1080/20445911.2013.796377
Grimstad, M. B. (2017). The code-switching/borrowing debate: evidence from English-origin verbs in American Norwegian. Ling. Linguaggio XVI, 3–34. doi: 10.1418/86999
Grimstad, M. B., Lohndal, T., and Åfarli, T. A. (2014). Language mixing and exoskeletal theory: a case study of word-internal mixing in American Norwegian. Nordlyd 41, 213–237. doi: 10.7557/12.3413
Grosjean, F. (2001). “The bilingual's language modes,” in One Mind, Two Languages: Bilingual Language Processing, ed J. Nicol (Oxford: Wiley-Blackwell), 122.
Halle, M. (2000). Distributed morphology: impoverishment and fission. Amst. Stud. Theory Hist. Linguist. Sci. Series 4, 125–150. doi: 10.1075/cilt.202.07hal
Halle, M., and Marantz, A. (1994). Some key features of distributed morphology. MIT Working Papers Linguist. 21:88.
Halmari, H. (1997). Government and Codeswitching: Explaining American Finnish. Vol. 12. Amsterdam: John Benjamins Publishing.
Harley, H. (2014). On the identity of roots. Theor. Linguist. 40, 225–276. doi: 10.1515/tl-2014-0010
Haspelmath, M. (2009). “Lexical borrowing: concepts and issues,” in Loanwords in the World's Languages: A Comparative Handbook, eds M. Haspelmath and U. Tadmor (Berlin: De Gruyter Mouton, 35–54.
Haugen, J. D., and Siddiqui, D. (2013). Roots and the derivation. Linguist. Inq. 44, 493–517. doi: 10.1162/LING_a_00136
Hlavač, J. (1999). Phonological integration of English transfers in Croatian: evidence from the Croatian speech of second-generation Croatian-Australians. Filologija 32, 39–74.
Hlavac, J. (2000). Croatian in Melbourne: Lexicon, switching and morphosyntactic features in the speech of second-generation bilinguals (Unpublished doctoral dissertation), Monash University, Clayton, VIC, Australia.
Jackendoff, R. (2003). Précis of foundations of language : brain, meaning, grammar, evolution. Behav. Brain Sci. 26, 651–707. doi: 10.1017/S0140525X03000153
Jake, J. L., Myers-Scotton, C., and Gross, S. (2002). Making a minimalist approach to codeswitching work: adding the matrix language. Biling. Lang. Cogn. 5, 69–91. doi: 10.1017/S1366728902000147
Johannessenn, J. B. (2015). “The Corpus of American Norwegian Speech (CANS),” in Proceedings of the 20th Nordic Conference of Computational Linguistics, NEALT Proceedings Series 23, NODALIDA 2015, ed Béata Megyesi (Vilnius).
Johnson-Laird, P. N. (1980). Mental models in cognitive science. Cogn. Sci. 4, 71–115. doi: 10.1207/s15516709cog0401_4
Lohndal, T. (2013). Generative grammar and language mixing. Theor. Linguist. 39, 215–224. doi: 10.1515/tl-2013-0013
López, L., Alexiadou, A., and Veenstra, T. (2017). Code Switching by Phase. Chicago, IL: The University of Illinois at Chicago.
MacSwan, J. (1999). A Minimalist Approach to Intrasentential Code Switching. New York, NY: Garland Press.
MacSwan, J. (2000). The architecture of the bilingual language faculty: evidence from intrasentential code switching. Biling. Lang. Cogn. 3, 37–54. doi: 10.1017/S1366728900000122
MacSwan, J. (2005). Codeswitching and generative grammar: A critique of the MLF model and some remarks on “modified minimalism”. Biling. Lang. Cogn. 8, 1–22. doi: 10.1017/S1366728904002068
MacSwan, J., and Colina, S. (2014). “Some consequences of language design: codeswitching and the PF interface,” in Grammatical Theory and Bilingual Codeswitching, ed J. MacSwan (Cambridge, MA: MIT Press, 185–210.
Marantz, A. (1997). No escape from syntax: Don't try morphological analysis in the privacy of your own lexicon. Univ. Pennsylvania Working Papers Linguist. 4:14.
McGinnis, M. (2016). “Distributed morphology,” in The Cambridge Handbook of Morphology, eds A. Hippisley and G. Stump (Cambridge: Cambridge University Press, 390–423.
Morrison, G. S. (2008). L1-Spanish Speakers' Acquisition of the English/i/—/I/Contrast: duration-based perception is not the initial developmental stage. Lang. Speech 51, 285–315. doi: 10.1177/0023830908099067
Myers-Scotton, C. (1992). Comparing codeswitching and borrowing. J. Multiling. Multicult. Dev. 13, 19–39. doi: 10.1080/01434632.1992.9994481
Myers-Scotton, C. (2000). Explaining the role of norms and rationality in codeswitching. J. Pragmat. 32, 1259–1271. doi: 10.1016/S0378-2166(99)00099-5
Poplack, S. (1980). Sometimes I'll start a sentence in Spanish y termino en español: toward a typology of codeswitching. Linguistics 18, 581–618. doi: 10.1515/ling.1980.18.7-8.581
Poplack, S. (1988). Contrasting patterns of code-switching in two communities. Codeswitching Anthropol. Sociolinguist. Perspect. 215:44.
Poplack, S., and Dion, N. (2012). Myths and facts about loanword development. Lang. Var. Change 24, 279–315. doi: 10.1017/S095439451200018X
Poplack, S., Sankoff, D., and Miller, C. (1988). The social correlates and linguistic processes of lexical borrowing and assimilation. Linguistics 26, 47–104. doi: 10.1515/ling.1988.26.1.47
Riksem, B., Grimstad, M., Lohndal, T., and Afarli, T. (2019). Language mixing within verbs and nouns in American Norwegian. J. Comp. Germanic Syntax 22, 189–209. doi: 10.1007/s10828-019-09109-6
Rumelhart, D. E., and McClelland, J. L. PDP Research Group. (1987). Parallel Distributed Processing. Vol. 1. Cambridge, MA: MIT Press.
Schütze, C. T., and Sprouse, J. (2014). “Judgment data,” in Research Methods Linguist, 27–50. doi: 10.1017/CBO9781139013734.004
Sharwood Smith, M., and Truscott, J. (2014). The Multilingual Mind: A Modular Processing Perspective. Cambridge: Cambridge University Press.
Stammers, J., and Deuchar, M. (2012). Testing the nonce borrowing hypothesis: counter-evidence from English-origin verbs in Welsh. Biling. Lang. Cogn. 15, 630–643. doi: 10.1017/S1366728911000381
Stefanich, S. (2019). A morphophonological account of Spanish/English word-internal codeswitching (Unpublished doctoral dissertation). University of Illinois at Chicago, Chicago, IL, United States.
Stefanich, S., and Cabrelli Amaro, J. (2018a). “Phonological factors of Spanish/English word-internal code-switching,” in Code-Switching: Theoretical Questions, Experimental Answers, ed L. López (Amsterdam: John Benjamins, 195–222.
Stefanich, S., and Cabrelli Amaro, J. (2018b). “Spanish/English word-internal code-switching: the case of /ɪ/ and /θ/,” in Paper Presented at the Hispanic Linguistics Symposium (Austin, TX).
Treffers-Daller, J. (1993). Mixing Two Languages: French-Dutch Contact in a Comparative Perspective. Berlin: Mouton de Gruyter.
Truscott, J., and Sharwood Smith, M. (2004). Acquisition by processing: a modular perspective on language development. Biling. Lang. Cogn. 7, 1–20. doi: 10.1017/S1366728904001178
Truscott, J., and Sharwood Smith, M. (2016). Representation, Processing and Code-switching. Bilingualism: Language and Cognition, 1–14.
Turker, E. (2000). Turkish-Norwegian codeswitching: evidence from intermediate and second- generation Turkish immigrants in Norway (Un-published PhD dissertation) University of Oslo, Oslo, Norway.
Keywords: codeswitching, intraword codeswitching, Distributed Morphology, MOGUL, morphophonology
Citation: Stefanich S, Cabrelli J, Hilderman D and Archibald J (2019) The Morphophonology of Intraword Codeswitching: Representation and Processing. Front. Commun. 4:54. doi: 10.3389/fcomm.2019.00054
Received: 31 October 2018; Accepted: 30 September 2019;
Published: 01 November 2019.
Edited by:
Gary Libben, Brock University, CanadaReviewed by:
Terje Lohndal, Norwegian University of Science and Technology, NorwayArtemis Alexiadou, Humboldt University of Berlin, Germany
Anna Hatzidaki, National and Kapodistrian University of Athens, Greece
Copyright © 2019 Stefanich, Cabrelli, Hilderman and Archibald. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: John Archibald, am9obmFyY2hAdXZpYy5jYQ==