 Hartmut Stöckl
Hartmut Stöckl- Department of English and American Studies/English and Applied Linguistics, University of Salzburg, Salzburg, Austria
The present contribution exemplifies current models for argument reconstruction on an environmental protection print-ad, identifying deficits in the way the models account for multimodal argumentation. Based on this critical review, three general research perspectives are suggested for making argument reconstruction maximally multimodal: the reach and logic of semiotic modes, multimodal coherence, and genre-specific multimodal discourse structure.
1 Introduction
Recently, the claim has been made that multimodality, rather than being an independent field of study, is “a stage of development through which many disciplines naturally pass” (Bateman, 2022, p. 41). Argumentation studies serve as a case in point, which have recognized and intensively studied multimodally expressed arguments ever since they accepted visual arguments (Birdsell and Groarke, 2007; Kjeldsen, 2015a). Multimodal argumentation has been aptly defined by Tseronis as “a communicative activity, in which more than one mode (besides spoken and written language) play a role in the procedure of testing the acceptability of a standpoint” (Tseronis, 2018, p. 12). Following Bateman's dictum that “more needs to be done (…) than simply assuming that multimodal argumentation exists” (Bateman, 2018, p. 295), I will in this contribution critically review and exemplify selected approaches to argument reconstruction (see van Eemeren et al., 2014) for their suitability to describe the structure and functioning of multimodal argumentation, suggesting ways of enhancing the multimodal analysis. My perspective is that of a discourse linguist, who seeks to determine which place images occupy in a genre-specific multimodal argumentation and how they help constitute an argument.
2 Current models for argument reconstruction
2.1 Formal logic
Formal logic (Smith, 2007) aims to distinguish the elements in a deductive argument, which is made up of two premises and a conclusion, forming what is known as a syllogism. In the Surfrider ad (see Figure 1), the following syllogistic form may be discerned:
Premise 1: If plastic pollution harms humans/the environment, it should be stopped.
Premise 2: Plastic pollution harms the body as much as the ocean.
Claim (Incitive): Say no to plastic.
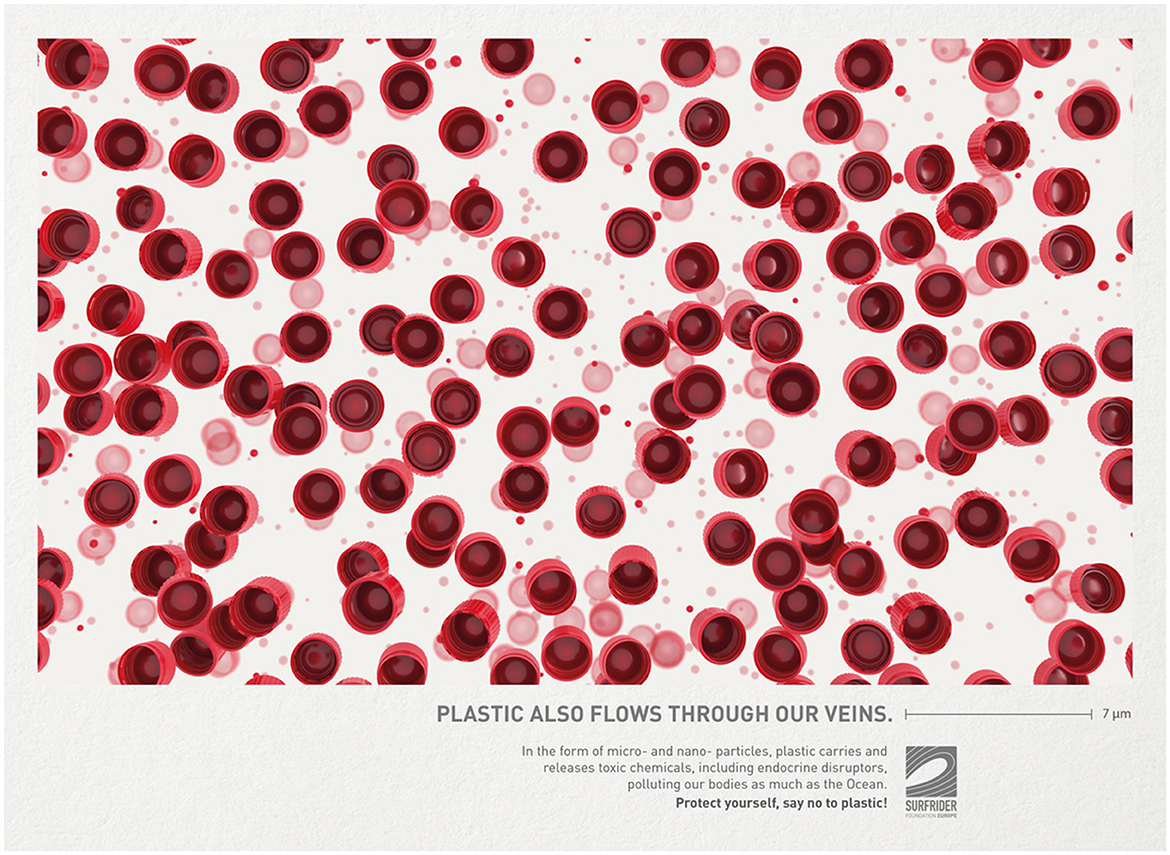
Figure 1. Surfrider Foundation, France, Babel, Paris (Lürzer's Archive, 2/2022, p. 121).
This truth-conditional approach has been criticized for its artificiality. In van Rees' words: “there is a large gap between ordinary-language discourse and formal-language logic” (Van Rees, 2001, p. 179), a gap that widens considerably when we include visual/multimodal means of argumentation. In the example, the composite doctored image, which likens plastic bottle tops to red blood cells, helps express the second premise. Groarke (2015) has used the elements that establish the logical form of an argument in tables showing its key components, and demonstrates that visuals may be located there. While logical form is a methodological basis in argument reconstruction, it leaves the actual discourse context unaccounted for, most notably all knowledge of the genre.
2.2 Toulmin's model
Toulmin's well-known model for reconstructing argument structure (Toulmin, 2008/1958, see Figure 2) essentially links a claim with data, i.e., reasons, evidence or arguments for justifying the claim. In the Surfrider ad, the toxic chemicals, including endocrine disruptors act as evidential data for the descriptive claim that plastic also flows through our veins. In turn, this claim becomes a ground to protect yourself and say no to plastic. The connection between claim and data lies in an inferential rule or principle, which Toulmin calls warrant. For the incitive claim of the ad, the warrant may be something like “if something is harmful, it must be prevented”. A fourth ingredient in Toulmin's argument structure is called qualifier and allows us to judge how reliable or valid the link between claim and data is. The text of the ad phrases the connection between plastic pollution and bodily harm as a general rule backed by science and the authority of environmental protection campaigns. However, the image with its computer-generated visual analogy between plastic particles and blood cells may give the viewer ground for doubt. Groarke (2009) suggests that visual images or visual structure can in principle (help) express all parts in Toulmin's model for argument reconstruction (see also Kjeldsen, 2012). In the sample ad, the image evidently functions as data, proving the connection between plastic and blood.
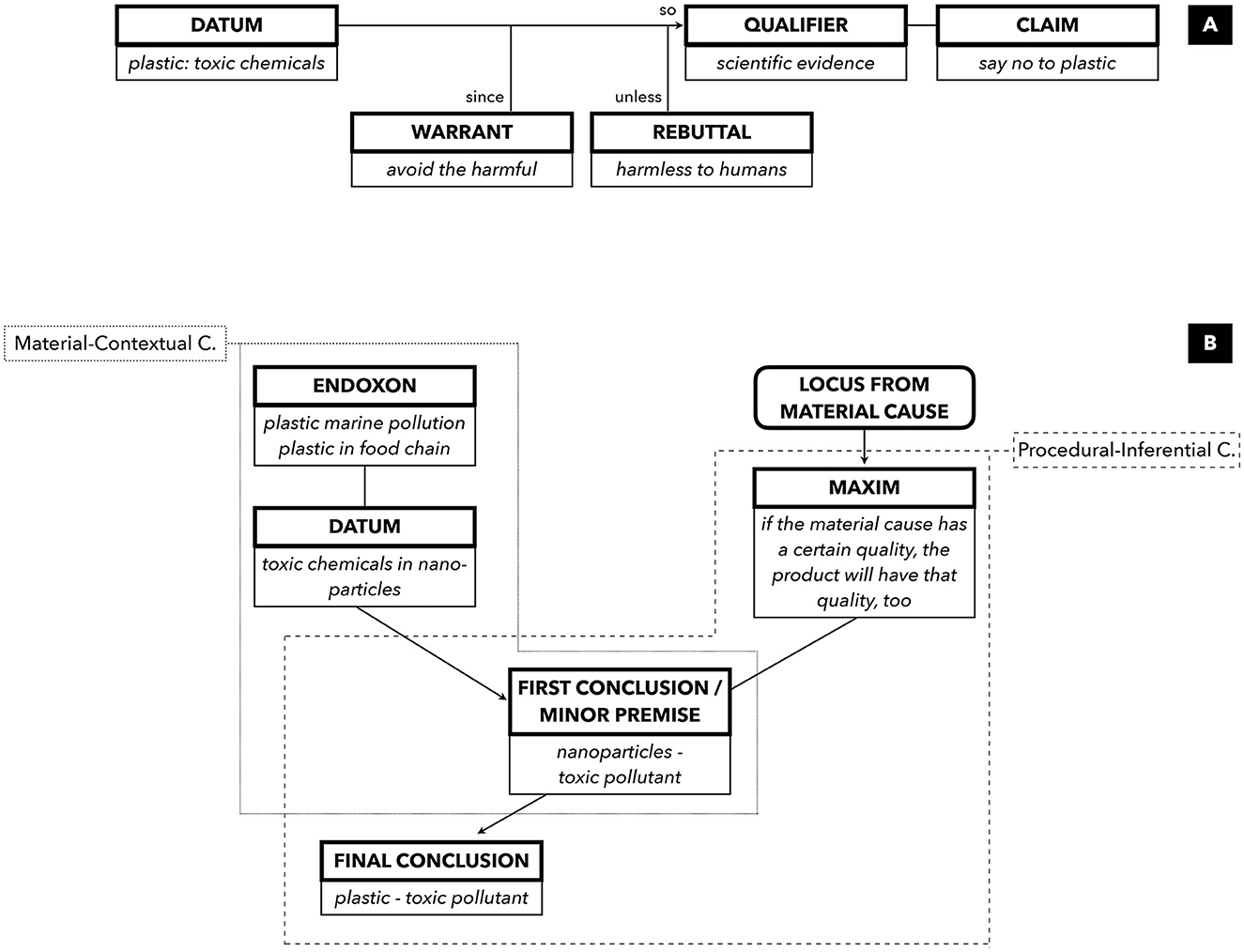
Figure 2. Reconstruction of the argument in the Surfrider ad following Toulmin's model (A) and the AMT (B).
2.3 Pragma-dialectics
The pragma-dialectical approach (van Eemeren, 2018) views argumentation primarily as an exchange of speech acts, which become moves in a critical discussion whose participants seek to test the acceptability of a standpoint. Advertisements appear to be atypical representatives of such a critical discussion, as the genre lacks dialogic interaction and an exchange of opinion. However, this does not disqualify the pragma-dialectical approach, since we can conveniently look at an advertisement as realizing a number of argumentative moves. In our example, these are:
1. Protect yourself, say no to plastic
1.1 Plastic in the form of micro-/nano-particles pollutes our bodies as much as the Ocean
(1.1' We do not want to pollute our bodies or the Ocean)
1.1.1a Plastic also flows through human veins
1.1.1b Plastic carries and releases chemicals, including endocrine disruptors
(1.1.1a-1.1.1b' Plastic flowing through human veins and releasing chemicals is a sign that it can pollute our bodies as much as the Ocean)
By comparison with a logical approach, the examination of multimodal arguments from a speech-act perspective evidently allows us to be more explicit and to determine how individual moves are semiotically realized (see Tseronis, 2017). We can now identify moves of an argument that are made through pictures or graphics, such as 1.1 and 1.1.1a, both of which semiotically materialize as combinations of language and image. The pragma-dialectical approach has also sensitized argument analysts to premises that are left implicit and maintains that rhetors must be held responsible for such implied premises. In the advert, one proposition is merely presupposed, namely that plastic particles really find their way into the blood stream. The visual image goes some way toward creating evidence for this proposition, but it cannot count as actual proof. Finally, pragma-dialectics has paid much attention to the inferential link between standpoint and argument(s), distinguishing three major types of argument schemes: causal, comparative and symptomatic. The Surfrider ad develops a dual causal argument: Because plastic flows through our veins, it pollutes the body and because plastic is thus harmful to humans, we must not use it. Interestingly, the visual image also implies a comparative argument scheme, i.e., plastic particles are compared to red blood cells.
2.4 The argumentum model of topics
The Argumentum Model of Topics (AMT) (Rigotti and Greco, 2019) ostensibly fuses a logical with a pragmatic reconstruction of argument. For this purpose, it distinguishes between two interlocking components of argument construction, a material-contextual and a procedural-inferential one (see Figure 2). The material-contextual component is comprised of endoxa, i.e., generally accepted knowledge/opinion that is expressed, presupposed or implied in the discourse, and datum/data, i.e., facts, reasons, evidences accumulated in the discourse to support the proposed argument. In the Surfrider ad, some of the endoxical knowledge is explicit, such as knowing about ocean plastic as an environmental problem. Other endoxa are left implicit, such as the argumentatively vital knowledge about plastic in the food chain, which subsequently enters human bodies through seafood. The data brought forward are essentially about the toxic chemicals in the micro- and nano-particles that are released into the blood. The visual image contributes to expressing the datum of the argument as it literally locates micro-plastics in the molecular structure of blood. Taken together, endoxon and datum allow for a first conclusion that acts as a minor premise: “Plastic material is a toxic pollutant”. The procedural-inferential component of the argument structure combines a locus, i.e., “an ontological relation on which a given argument is based” (Rigotti and Greco, 2019, p. 210), with a maxim, i.e., an inferential rule operating on the locus. The causal locus from material cause fits the argument in the Surfrider ad best, which brings plastic (products) and nano-particles/toxic chemicals into an ontological relation. This may then be expressed as an inferential rule: “If the material cause has a certain quality, the product will have that quality, too” (Rigotti and Greco, 2019, p. 258). In an integrational synthesis, endoxon cum datum and locus cum maxim facilitate the final conclusion, i.e., the standpoint expressed in the ad: Plastic pollutes our bodies, and by implication, the advice to boycott plastic. The AMT has been used to reconstruct multimodal arguments in e.g., Serafis (2022).
2.5 Multimodal rhetoric
While the models exemplified so far generally allow for locating semiotic modes in argument structure, they do not specifically attend to the discourse semantics of the modes and to the ways in which they impact on the construction of the argument. Rocci et al. (2018) propose a rhetorically minded multi-layer model which inventories the different modal components of a message and inspects them for how they configure in the overall argument. Most importantly, the model assumes that verbal and visual discourse structures combine to constitute a multimodal rhetorical figure, such as metonymy or metaphor etc. In order to describe the nature of the rhetorical operation, the authors borrow the notions of “visual structure” and “meaning operation” from visual rhetoric (see Phillips and McQuarrie, 2004). In the Surfrider image, the larger plastic particles (i.e., bottle tops) are “juxtaposed” with the smaller blood cells, their identical round shapes and red colors suggesting a “comparison” and an associative “connection”. The phrases plastic also flows through our veins and polluting our bodies as much as the ocean help construe both the formal analogy and the functional association. If, as the image suggests, plastic can get into the bloodstream, this negative consequence of plastic pollution must be avoided at all cost. Such interpretations do not sideline visual images as merely “expressive” or “embellishing” add-ons (Grancea, 2017, p. 18, 21), but regard visual or multimodal rhetorical operations to be inherent facilitators of argumentation. In this view, visual rhetorical qualities, such as presence (evidence), realism and immediacy, or semantic condensation (Kjeldsen, 2012, p. 243–244) are constitutive of multimodal argument.
3 Multimodal perspectives
My brief review shows that approaches to argument reconstruction have difficulties capturing the multimodal qualities of argumentation. The models do not specifically address the semiotic nature and the exact discourse contributions of the modes. Instead, the main emphasis is placed on the logical and inferential structures of the argument. Below I propose some requirements for improving multimodal argument reconstruction.
3.1 Modal reach and logic
First, the various modes have different “reaches” (Kress, 2010, p. 83), i.e., strengths and weaknesses for meaning making. While language/text is capable of expressing the whole spectrum of logical relations, images confront serious limitations in this regard. The visual image, on the other hand is a powerful means to display the physical properties of objects in rich detail, something referred to as “thick representation” (see Kjeldsen, 2015b). It is, therefore, plausible that multimodal arguments favor unequal mode-status relations (see Stöckl, 2020, p. 190–195), where the image is subordinated to or integrated into the discourse structure of the text. The communicative potential of an image that can be harnessed in a multimodal argument is also determined by its configuration of visual image elements and its representational style. In our example, the multiple repetition of the circular objects in various sizes and shades of red suggest a sense of “floating” in a stream. Following Kress and van Leeuwen (1996, p. 89), this is a conceptual image presenting an “analytical process”. The image is also clearly not a photographic representation of either the blood stream or of floating bottle tops. Its computer-generated qualities are vital when we consider treating the image as direct proof or evidence of the argument. Scrutinizing an image for its material-technological qualities and for its semiotic structure is an important step to a detailed description of its potential semantic contribution to a multimodal argument.
3.2 Multimodal coherence
Second, the hallmark of multimodal discourse is “the linking of semiotic modes and their formal, semantic and functional integration” (Stöckl, 2019, p. 53). If we determine the place of an image in the (logical) structure of an argument, something most models afford, we mainly address the functional integration of modes. An interest in formal integration would require a consideration of the layout of a multimodal text: how much space does the image occupy relative to the text? Does the image precede or follow the text, or do they alternate? Are there visual-graphic components other than the image, for example a brand logo? What about the typography (size, type, color) of the text? These and other questions will provide relevant clues to the special multimodal linking at work in the material. The layout in the Surfrider ad makes the image a dominant entry point for the overall message, whose proximity to the headline suggests a binary unit of a verbal descriptive claim plus an image, which may either render the claim in pictorial form or add visual data. The legend-like line indicating units of size (7 μm) is a separate graphic element that relates to the image, suggesting a heavily magnified depiction, and it links to the verbal expression micro- and nano particles. The spatial proximity of the logo and the bolding of the incitive claim establish another formal unit, this time marking the rhetor and its call for action. Finally, semantic integration is concerned with how the modes construe multimodal coherence, i.e., a sense-continuity across modes and an inter-connectedness of elements from both modes in the form of cohesive ties (see Stöckl and Pflaeging, 2022). Such a cohesive tie is present in the Surfrider ad, where the image evokes the concept of blood and its particles floating in a stream, which relates to the words veins/bodies through meronymy/metonymy. The visual evocation of blood as a carrier of plastic concretizes the claim in the argument and makes the intake of plastic through food a tangible implication. Rather than take the image as a visual restatement of the claim, it is useful to think of the text-image relation as a relational proposition (see Rhetorical Structure Theory, Taboada and Mann, 2006), where the image elaborates the text through specification or illustration, and vice versa.
3.3 Multimodal discourse semantics and structure
Third, “arguments normally rely on an understanding of their contexts (…) in order to be meaningful” (Blair, 2015, p. 218–219). While text-internally, the various modes participating in argumentation-building provide mutual context for each another, text-externally, the single most important contextual factor is genre. It comprises knowledge about the rhetorical situation, the discourse functions, the conventional structure(s) and the appropriate semiotic style in a given discourse type. Environmental protection print-ads, for instance, typically involve such subtopics as causer, affected, problem, solution, consequences and evidence. These may be expressed in text and/or image, producing a multimodal discourse structure. In the Surfrider ad, the image shows the causer (plastic) and the affected (blood/veins/body) of pollution, whereas the text specifies these and calls upon the recipient to act accordingly. Just as genre is likely to constrain multimodal argument structure and argumentation schemes, it also determines the kinds of visuals we are likely to encounter as well as how these will be understood. In environmental protection ads, for example, denotational images may be used as truthful, indexical evidence of the harmful consequences of environmental degradation. But as our example shows, the discourse may equally well utilize CGI-images that involve quite some degree of referential fiction. The latter type of image makes visual sign configurations available that can loosely be integrated into a propositional relation with textual elements. Situating argumentation in a specific genre will also allow the analyst to determine the stereotyped propositional content that forms the substance of the argument structure. In anti-plastic advertising, for example, causal arguments often involve marine plastics causing habitat damage and its concomitant effects on animals and humans (see Figure 1). So, rather than be content with gleaning abstract argumentation schemes, such as argument from cause or analogy, an approach centering on genre will be capable of inventorying the concrete propositions that are used in the argumentation.
4 Discussion and conclusion
I hope to have shown that, despite recent efforts (see e.g., Serafis and Tseronis, 2023), current models for argument reconstruction insufficiently account for the specific contributions modes other than language make to a multimodal argument. The main reason for this deficit appears to be a heavy focus on the logical structure of arguments and a neglect of the diverse ways in which non-/and para-verbal modes come to interact and cohere with the text. While van Eemeren and Grootendorst (1992, p. 64) suggest a logical minimum and a pragmatic optimum in argument reconstruction, what is required for mode-sensitive reconstructions is a multimodal maximum.
As I suggested, locating an image, for example, in the logical-inferential structure of an argument is a plausible start to modeling multimodal argumentation. Such an approach will of course be complicated by the fact that visual propositions do not simply act as either, standpoint, datum, or endoxa, but often help express these in indirect, implicit and covert ways. The idea that images possess a persuasive rhetorical force by providing a visual structure and a meaning operation that semantically connect to the text is another helpful step toward reconstructing the multimodal nature of argumentation schemes.
Here, I have suggested three main trajectories for future work on multimodal argumentation. First, I advocated due attention to the pragma-semantic reaches and the internal logic of a semiotic mode. This makes the analyst aware of the typical and variable properties that a mode brings to the division of semiotic labor in a process of multimodal argumentation. Second, I proposed to look in detail at how the modes combine, interact, and co-create a coherent argumentative message. This will sensitize the analysis to varying degrees and types of mode-connectedness and information-interplay. Third, I made a plea for studying multimodal argumentation not through logical abstraction but in close relation to a concrete genre with its pre-defined discourse structure. This will give the argument reconstruction the necessary contextual specificity and yield the genre-typical propositional substance of the argument.
In conclusion, “viewing problems (such as argument reconstruction—H.S.) simultaneously from contrasting disciplinary perspectives is (…) a valuable skill to be learnt” (Bateman, 2022, p. 59). The skillset required for multimodal argument reconstruction can only emerge in a productive cooperation between argumentation and multimodality researchers. An issue to be addressed in this field is a beneficial balance between discursive case-study approaches and more empirical, corpus-based approaches to multimodal argumentation (see Bateman, 2022, p. 42–43, 52–53).
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
HS: Writing—original draft, Writing—review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the University of Salzburg Publication Fund.
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bateman, J. A. (2018). Position paper on argument and multimodality. Int. Rev. Pragmat. 10, 294–308. doi: 10.1163/18773109-01002008
Bateman, J. A. (2022). Multimodality, where next? Some meta-methodological considerations. Multim. Soc. 2, 41–63. doi: 10.1177/26349795211073043
Birdsell, D.S., and Groarke, L. (2007). Outlines of a theory of visual argument. Argument. Advoc. 43, 103–113. doi: 10.1080/00028533.2007.11821666
Blair, J. A. (2015). Probative norms for multimodal visual arguments. Argumentation 29, 217–233. doi: 10.1007/s10503-014-9333-3
Groarke, L. (2009). “Five theses on Toulmin and visual argument,” in Pondering on Problems of Argumentation: Twenty Essays on Theoretical Issues, eds. F. H. van Eemeren, and B. Garssen (Dordrecht: Springer), 229–239.
Groarke, L. (2015). Going multimodal: what is a mode of arguing and why does it matter? Argumentation 29, 133–155. doi: 10.1007/s10503-014-9336-0
Kjeldsen, J. E. (2012). “Pictorial argumentation in advertising: Visual tropes and figures as a way of creating visual argumentation,” in Topical Themes in Argumentation Theory, eds. F. H. van Eemeren, and B. Garssen (Dordrecht: Springer), 239–255. doi: 10.1007/978-94-007-4041-9_16
Kjeldsen, J. E. (2015a). The study of visual and multimodal argumentation. Argumentation 29, 115–132. doi: 10.1007/s10503-015-9348-4
Kjeldsen, J. E. (2015b). The rhetoric of thick representation: how pictures render the importance and strength of an argument salient. Argumentation 29, 197–215. doi: 10.1007/s10503-014-9342-2
Kress, G. (2010). Multimodality: A Social Semiotic Approach to Contemporary Communication. London: Routledge.
Kress, G., and van Leeuwen, T. (1996). Reading Images: The Grammar of Visual Design. London: Routledge.
Phillips, B., and McQuarrie, E. F. (2004). Beyond visual metaphor: a new typology of visual rhetoric in advertising. Market. Theor. 4, 113–136. doi: 10.1177/1470593104044089
Rigotti, E., and Greco, S. (2019). Inference in Argumentation: A Topics-Based Approach to Argument Schemes. Cham: Springer.
Rocci, A., Mazzali-Lurati, S., and Pollaroli, C. (2018). The argumentative and rhetorical function of multimodal metonymy. Semiotica 220, 123–153. doi: 10.1515/sem-2015-0152
Serafis, D. (2022). Unveiling the rationale of soft hate speech in multimodal artefacts: A critical framework. J. Lang. Discrim. 6, 321–346. doi: 10.1558/jld.22363
Serafis, D., and Tseronis, A. (2023). The front page as a canvas for multimodal argumentation: Brexit in the Greek press. Front. Commun. 8, 1–14. doi: 10.3389/fcomm.2023.1230632
Smith, V. J. (2007). Aristotle's classical enthymeme and the visual argumentation of the twenty-first century. Argument. Advoc. 43, 114–123. doi: 10.1080/00028533.2007.11821667
Stöckl, H. (2019). “Linguistic multimodality – Multimodal linguistics: A state-of-the-art sketch,” in Multimodality: Disciplinary Thoughts and the Challenge of Diversity, eds. J. Wildfeuer, J. Pflaeging, J. Bateman, O. Seizov, and C. Tseng (Berlin/Boston: de Gruyter), 41–68.
Stöckl, H. (2020). “Multimodality and mediality in an image-centric semiosphere: A rationale,” in Visualizing Digital Discourse: Interactional, Institutional and Ideological Perspectives, eds. C. Thurlow, C. Dürscheid, and F. Diémoz (Berlin/Boston: de Gruyter), 189–202.
Stöckl, H., and Pflaeging, J. (2022). Multimodal coherence revisited: Notes on the move from theory to data in annotating print advertisements. Front. Commun. 7, 1–17. doi: 10.3389/fcomm.2022.900994
Taboada, M., and Mann, W.C. (2006). Rhetorical structure theory: looking back and moving ahead. Discourse Stud. 8, 423–459. doi: 10.1177/1461445606061881
Toulmin, S. E. (2008/1958). The Uses of Argument (updated ed.). Cambridge: Cambridge University Press.
Tseronis, A. (2017). “Analysing multimodal argumentation within the pragma-dialectical framework: Strategic maneuvering in the front covers of The Economist,” in Contextualizing Pragma-Dialectics, eds. F. H. van Eemeren, and W. Peng (Amsterdam: John Benjamins), 335–359.
Tseronis, A. (2018). Multimodal argumentation: beyond the verbal/visual divide. Semiotica 220, 41–67. doi: 10.1515/sem-2015-0144
van Eemeren, F. H., Garssen, B., Krabbe, E. C. W., Snoeck Henkemans, A. F., Verheij, B., and Wagemans, J. H. M. (2014). Handbook of Argumentation Theory. Dordrecht: Springer.
van Eemeren, F. H., and Grootendorst, R. (1992). Argumentation, Communication and Fallacies: A Pragma-Dialectal Perspective. Hillsdale, NJ: Lawrence Erlbaum.
Keywords: multimodal argumentation, multimodal coherence, reach of mode, argument reconstruction, discourse semantics
Citation: Stöckl H (2024) Fresh perspectives on multimodal argument reconstruction. Front. Commun. 9:1366182. doi: 10.3389/fcomm.2024.1366182
Received: 05 January 2024; Accepted: 07 February 2024;
Published: 22 February 2024.
Edited by:
Claudia Lehmann, University of Potsdam, GermanyReviewed by:
Dimitris Serafis, University of Groningen, NetherlandsCopyright © 2024 Stöckl. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hartmut Stöckl, aGFydG11dC5zdG9lY2tsQHBsdXMuYWMuYXQ=