 Matteo Spanio
Matteo Spanio Massimiliano Zampini
Massimiliano Zampini Antonio Rodà
Antonio Rodà Franco Pierucci3
Franco Pierucci3- 1Centro di Sonologia Computazionale (CSC), Department of Information Engineering, University of Padova, Padova, Italy
- 2Center for Mind/Brain Sciences (CIMeC), University of Trento, Rovereto, Italy
- 3SoundFood S.r.l., Terni, Italy
In recent decades, neuroscientific and psychological research has identified direct relationships between taste and auditory perception. This article explores multimodal generative models capable of converting taste information into music, building on this foundational research. We provide a brief review of the state of the art in this field, highlighting key findings and methodologies. We present an experiment in which a fine-tuned version of a generative music model (MusicGEN) is used to generate music based on detailed taste descriptions provided for each musical piece. The results are promising: according to the participants' evaluations (n = 111), the fine-tuned model produces music that more coherently reflects the input taste descriptions compared to the non-fine-tuned model. This study represents a significant step toward understanding and developing embodied interactions between AI, sound, and taste, opening new possibilities in the field of generative AI.
1 Introduction
Over recent years, the rapid evolution of generative models have opened new possibilities in manipulating images, audio, and text, both independently and in a multimodal context. These AI advancements have ignited considerable debate about the essence of these human-engineered “intelligences.” Critics have termed large language models (LLMs) as “statistical parrots” (Bender et al., 2021) due to their reliance on data. However, others view them as advanced tools capable of emulating and exploring the intricate structures of the human brain (Zhao et al., 2023; Abbasiantaeb et al., 2024; Fayyaz et al., 2024). Despite this division, it has become increasingly clear that limiting these models to a few specialized areas greatly restricts their potential to fully grasp and portray the complexity of the world. Therefore the integration of sensory modalities through technology, particularly using AI, has emerged as a compelling frontier in computer science and cognitive research (Murari et al., 2020; Turato et al., 2022). As multimodal AI models advance, they increasingly offer innovative solutions for bridging human experiences and machine understanding across diverse sensory domains. These models, which merge information from different modalities enable machines to interpret complex real-world scenarios and provide more nuanced outputs. While recent research has predominantly focused on the intersection of audio and visual modalities, the potential for integrating taste and sound remains relatively unexplored. Nonetheless, advances in neuroscientific and psychological research have established clear links between taste perceptions and other sensory inputs, especially auditory stimuli (Spence, 2011, 2021; Guedes et al., 2023b). These investigations indicate that certain auditory characteristics can impact how tastes are perceived. For example, sounds with a low pitch are often linked with bitterness, whereas high-pitched sounds tend to be associated with sweetness (Crisinel and Spence, 2010a). This rich area of crossmodal associations paves the way for cutting-edge AI applications that craft immersive sensory experiences by integrating taste and sound. Recent progress in generative AI, notably large language models (LLMs), has demonstrated exceptional ability to produce coherent and contextually suitable outputs across various modalities. In music generation, models such as MusicGEN (Copet et al., 2023), MusicLM (Agostinelli et al., 2023), among others, have been designed to craft intricate musical compositions from textual cues. These models are trained extensively on datasets with a wide range of music features, enabling them to generate music that matches particular textual instructions. Nonetheless, incorporating crossmodal information into these models remains largely unexplored, offering both challenges and opportunities for future innovation. To address these challenges, this article proposes a novel approach to incorporating taste information into music generation by refining the data provided to AI models. Building on expert studies and already existing datasets (Guedes et al., 2023a), a dataset has been generated that emphasizes the neuroscientific and experimental psychology knowledge underlying the relationship between taste and music. Subsequently, a generative model for music (MusicGEN) was selected for fine-tuning to assess whether the enriched data contributes effectively to the model's internal representation. Through an online survey to evaluate the model's outputs we discovered that the model trained in this manner produces music that more accurately and coherently represents the input taste descriptions, compared to a non-fine-tuned model. To enhance visual comprehension of the research process, Figure 1 illustrates the experimental pipeline.
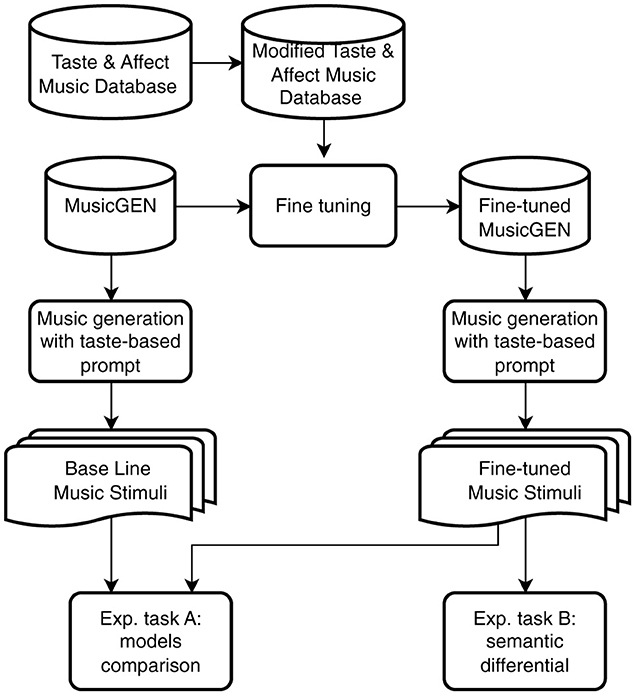
Figure 1. Experimental pipeline for evaluating taste-based music generation. The Taste & Affect Music Database is modified and used to fine-tune MusicGEN, resulting in a Fine-tuned MusicGEN model. Both the base and fine-tuned models generate music using taste-based prompts. The generated stimuli are then evaluated through two experimental tasks: (A) a comparison between baseline and fine-tuned models, and (B) a semantic differential analysis of the fine-tuned stimuli.
The research questions guiding this study are as follows:
1. Does the model fine-tuned with a neuroscientifically validated dataset produce outputs that align more coherently with the crossmodal correspondences between music and taste?
2. Can the fine-tuned model induce gustatory responses?
3. Which underlying connections make the crossmodal effect possible?
4. How much do emotions mediate crossmodal evaluations of the music?
The article is organized as follows: Section 2 provides an overview of the background and related work in both cognitive neuroscience and computer science domains, Section 3 discusses the fine-tuned model and the datasets used in this article, Section 4 introduces the experiment we organized to evaluate the model, Section 5 presents the analysis of the experiment's results, Section 6 discusses the results and compares them with previous literature, and Section 7 concludes with considerations on the implications of our findings and directions for future research.
2 Background and related work
2.1 Cross-modal correspondences between sounds and tastes
The human brain demonstrates a remarkable capacity to establish consistent associations across sensory modalities, a phenomenon broadly termed crossmodal correspondences. These correspondences, systematically defined by Spence (2011), refer to reproducible mappings between perceptual dimensions across different sensory systems. Such associations may occur between both directly perceived and imagined stimulus attributes and can arise from shared redundancies or distinct perceptual features (Spence, 2011). One of the earliest documented examples of this phenomenon dates back to Köhler (1929)'s seminal work, where he observed that individuals tended to associate the pseudoword “baluba” with rounded shapes and “takete” with angular ones. Later research has revealed a diverse range of crossmodal correspondences encompassing nearly all combinations of sensory modalities (Spence, 2011). While much of the foundational research emphasized pairings between visual and other sensory modalities, increasing attention has been directed toward associations involving auditory cues and the chemical senses, such as taste and smell. Auditory inputs, including environmental sounds and those emanating from food (e.g., the crunch of chips), significantly influence flavor perception and eating behavior. For example, modifying food sounds has been shown to enhance perceptions of freshness and crispness (Demattè et al., 2014; Zampini and Spence, 2004), and environmental music or soundscapes can modulate meal duration, eating speed, and consumption patterns (e.g. Mathiesen et al., 2022). Metaphors such as describing a melody as “sweet” or a voice as “bitter” reflect intuitive connections between auditory and gustatory modalities that have long permeated human language. For instance, the Italian musical term dolce denotes both “sweetness” and a gentle, soft playing style (Knöferle and Spence, 2012; Mesz et al., 2012). While taste-related descriptors are infrequent in musical contexts, they do appear as expressive markers on occasion. One notable example is the term âpre (bitter), which features in Debussy's La puerta del vino (1913), a composition distinguished by its low pitch register and moderate dissonance. Despite these intriguing connections, systematic empirical efforts to investigate such crossmodal associations has emerged relatively recently. Holt-Hansen (1968, 1976) pioneered this line of investigation by demonstrating that participants could associate the flavors of various beers with specific pitches of pure tones. For example, higher pitches (640—670 Hz) were linked to Carlsberg's Elephant beer, whereas lower pitches (510—520 Hz) were matched to standard Carlsberg beer. Moreover, participants reported richer sensory experiences when they perceived the pitch and taste as harmonious. While replications of Holt-Hansen's findings (e.g. Rudmin and Cappelli, 1983) yielded mixed results—likely due to methodological limitations such as small sample sizes—they provided the groundwork for future research. Crisinel and Spence (2009, 2010a,b) expanded on these early studies using implicit association tasks to explore pitch-taste correspondences. Their findings revealed robust associations between higher-pitched sounds and sweet or sour tastes, while bitter tastes corresponded to lower-pitched sounds. Follow-up experiments using actual tastants (rather than imagined flavors) confirmed these patterns and additionally identified associations between salty tastes and medium-pitched sounds.
The researchers also examined the role of psychoacoustic properties such as timbre—characterized by spectral centroid and attack time—in shaping these associations. For example, sweet tastes were linked to piano sounds (perceived as pleasant), while bitter and sour tastes were associated with trombone timbres (perceived as unpleasant) (Crisinel and Spence, 2010a). Further investigations have consistently observed associations between sweetness (and sometimes sourness) with higher-pitched sounds and bitterness with lower-pitched sounds (Knöferle et al., 2015; Qi et al., 2020; Wang et al., 2016; Watson and Gunther, 2017). For instance, Knöferle et al. (2015) demonstrated that both simple chord progressions and complex soundtracks were encoded with “sweet” (high-pitched) or “bitter” (low-pitched) conceptual associations. Similarly, Wang et al. (2016) used a series of water-based taste solutions and MIDI-generated tones to reveal a gradient, with sour solutions paired with the highest pitches, followed by sweet, and finally bitter solutions paired with the lowest pitches. Initially, Spence (2011) proposed three potential core mechanisms underlying crossmodal correspondences: structural, statistical, and semantic. Structural correspondences derive from shared neural encoding mechanisms across sensory modalities. Statistical correspondences are shaped by regularities in the environment, such as the physical relationship between pitch and size. Semantic correspondences arise from shared descriptive language, such as the metaphorical use of terms like “sweet” across both taste and music (Mesz et al., 2011). More recent literature has proposed an extension to this classification: Motoki et al. (2023) introduced emotional mediation as a fourth mechanism, highlighting how emotional responses to stimuli can influence crossmodal correspondences. This emotional mediation suggests that emotionally evocative stimuli, such as music, often elicit consistent crossmodal mappings (Mesz et al., 2023; Di Stefano et al., 2024). Music-color and music-painting associations are frequently predictable based on the emotional valence of the stimuli (Spence, 2020a). Furthermore, color can modulate music-induced emotional experiences, as shown by Hauck et al. (2022), who demonstrated that emotional responses to musical pieces shifted in alignment with colored lighting. Similarly, Galmarini et al. (2021) found that the emotional tone of background music could shape the sensory experience of drinking coffee. The emotional responses evoked by music and taste could serve as a link for crossmodal associations by aligning the emotional qualities of both stimuli. The emotional valence of both the music and the taste may share similar underlying affective dimensions, such as pleasantness or unpleasantness, which could drive the association. Music and taste can elicit emotional reactions, and when these emotional responses are congruent, it is likely that the brain establishes connections between them, leading to a crossmodal association based on shared emotional experiences. Furthermore, Spence and Di Stefano (2022) have suggested additional categories of crossmodal correspondences, broadening the scope of understanding crossmodal correspondences. In conclusion, crossmodal correspondences offer a compelling framework for investigating the interconnected nature of sensory perception. Moreover, these findings highlight the potential for using auditory stimuli to influence gustatory perception. For example, restaurants might design soundscapes to enhance specific taste qualities or improve the overall dining experience.
2.2 Crossmodal generative models
In recent years, crossmodal generative models have advanced significantly, inspired by an increasing interest in developing systems capable of seamlessly integrating and translating information across diverse sensory modalities. This evolution is driven by the increasing capabilities of artificial intelligence, particularly within the realm of generative models, which have demonstrated potential in producing coherent and contextually relevant outputs across a multitude of domains. The advancement of crossmodal generative models is grounded in foundational research within the disciplines of cognitive neuroscience and experimental psychology, which have long investigated the interactions among different sensory modalities. These models endeavor to emulate the human faculty of perceiving and interpreting multisensory information, a process that is inherently complex and nuanced. By utilizing large-scale datasets and advanced machine learning techniques, researchers have initiated the creation of models capable of generating outputs that reflect the intricate interrelations among modalities such as vision, sound, and taste. Several notable multimodal generative models have emerged, illustrating the substantial capabilities inherent within this domain. Text-to-image generation models, such as DALL · E (Ramesh et al., 2021) and Stable Diffusion (Rombach et al., 2022), are capable of rendering detailed images from textual descriptions. Text-to-audio models, including MusicLM (Agostinelli et al., 2023), translate text prompts into music or soundscapes, presenting intriguing possibilities for the fields of entertainment and virtual environments. Although still at a nascent stage, text-to-video generation (generating both video and audio) is anticipated to offer significant benefits for media content production and simulation environments (Singer et al., 2022). In contrast, image-to-text models (Radford et al., 2021; Li et al., 2022; Alayrac et al., 2022) transform visual data into descriptive narratives, thereby facilitating tasks such as automated captioning and providing assistance to individuals with visual impairments. Audio-to-text models, which have been widely implemented in speech-to-text applications, have historically served the domains of transcription and virtual assistance (Bahar et al., 2019). Recent developments in generative models have enabled more nuanced and context-sensitive analyses of spoken language.
An emerging but relatively underexplored field in multimodal AI is emotional awareness integration. Although significant work has gone into identifying emotions within just one modality (Poria et al., 2017), there is growing interest in synthesizing data from multiple modalities (Poria et al., 2017; Zhao et al., 2019). This multimodal strategy is beneficial because integrating data from various sources enhances emotion recognition capabilities and opens up to new possibilities which are not possible at the moment with just a text-based approach as in Boscher et al. (2024). However, research into how different modalities correlate based on emotions applied to computer science has been rather limited. Recent developments, such as those discussed in Zhao et al. (2020), demonstrate viable ways of linking visual and auditory data through an emotional valence-arousal latent space using supervised contrastive learning methods. This advancement enables a more detailed and flexible representation of emotional states than the traditional concept of distinct emotions, capturing the intricate and nuanced nature of human emotions and offering a broader comprehension of their interactions across diverse sensory stimuli. This approach aligns with the broader goal of creating AI systems that are not only technically proficient but also capable of understanding and responding to human emotions in a meaningful way. Despite these advancements, several challenges remain in the development of crossmodal generative models. One significant hurdle is the need for comprehensive datasets that encompass the full spectrum of sensory experiences. Current datasets often lack diversity, limiting the ability of models to generalize across different contexts and populations. Additionally, the complexity of human emotions and their influence on sensory perception presents a formidable challenge, requiring sophisticated models that can accurately capture and interpret these nuances. The future of crossmodal generative models involves ongoing improvements and enhancements, particularly in terms of developing their emotional intelligence and broadening their range of applications. By tackling present constraints and seizing the possibilities unlocked by multimodal integration, researchers can advance toward AI systems that deliver more engaging and tailored experiences, effectively closing the divide between human perception and machine-generated results.
3 MusicGEN
In this study, MusicGEN—a cutting-edge generative model specifically engineered for music—was fine-tuned and then used to generate music compositions. The fine-tuning process was pivotal in adapting the model to our research context, which centers on exploring the nuanced interplay between musical compositions and sensory-gustatory responses. To facilitate this adaptation, we utilized a patched version of the Taste & Affect Music Database (Guedes et al., 2023a). This database originally encompassed a diverse range of musical pieces, each accompanied by evaluations reflecting gustatory and emotional responses. We enhanced this foundational dataset by incorporating descriptive captions for each audio file, meticulously crafted by the authors to include detailed information on the correspondent tastes and emotional qualities associated with each musical piece as individuated in the original database study. In addition, these captions encompassed relevant audio metadata such as tempo, key, and instrumentation. This enhancement was designed to provide richer contextual information to the model, with the aim of generating music that more accurately mirrors the complexities inherent in taste descriptions and emotional nuances. In our exploration of multimodal generative models for music synthesis, we critically evaluated several candidates, including MusicLM, Riffusion (Forsgren and Martiros, 2022), and MusicGEN. MusicLM, developed by Google, presents a robust architecture for generating music from textual prompts; however, its closed-source nature imposes significant restrictions on customization and adaptability, rendering it less suitable for our specific research objectives. Riffusion, while innovative in its approach to music generation through the utilization of Stable Diffusion, was excluded from consideration due to inherent limitations such as the necessity of converting audio into spectrograms that introduces additional computational overhead and its inability to maintain coherent long-term audio sequences, as discussed in Huang et al. (2023). Unlike Riffusion, MusicGEN's Transformer-based architecture supports the retention of internal states, enabling the model to produce more coherent and contextually relevant. MusicGEN, developed by Meta, is an open-source model that permits extensive modifications and fine-tuning, making it a far more appropriate choice for our study's aims. Thus, MusicGEN was selected for its optimal balance of accessibility, flexibility, and capacity to generate coherent music that is in line with taste descriptors. MusicGEN is characterized as a state-of-the-art autoregressive transformer-based model (Vaswani et al., 2017), specifically designed to generate high-quality music at a sampling rate of 32 kHz. The model operates by conditioning on either textual or melodic representations, which empowers it to produce coherent musical pieces that are in harmony with the provided input context. Its architecture employs a single-stage language model that leverages an efficient codebook interleaving strategy, facilitating the simultaneous processing of multiple discrete audio streams. This innovative approach is made possible through the integration of an EnCodec audio tokenizer (Défossez et al., 2022), which quantizes audio signals into discrete tokens, thus enabling high-fidelity reconstruction from a low frame rate representation. The design of the model incorporates Residual Vector Quantization (RVQ) (Zeghidour et al., 2022), resulting in several parallel streams of discrete tokens derived from distinct learned codebooks.
The capability of MusicGEN to generate music is further enhanced by its proficiency in performing both text- and melody-conditioned generation. This dual conditioning mechanism allows the model to maintain fidelity to the textual descriptions while ensuring that the generated audio remains coherent with the specified melodic structure. However, it is important to acknowledge that, despite its numerous strengths, the model does encounter limitations regarding fine-grained control over the adherence of the generated output to the conditioning inputs. To adapt MusicGEN for our specific task of generating music based on taste descriptors, we undertook a comprehensive fine-tuning process. In our fine-tuning endeavors, we opted to utilize the smaller variant of MusicGEN, comprising 300 million parameters, to ensure efficient training while still maintaining sufficient representational capacity. The fine-tuning process was conducted over 30 epochs, employing a batch size of 16 and a learning rate set at 1.0 × 10−4 adjusted according to a cosine schedule. The AdamW optimizer was used, featuring a weight decay of 0.01, and the training process involved 2,000 updates per epoch. This specific configuration was carefully chosen to strike a balance between convergence speed and overall model performance. The fine-tuning was executed on the “Blade” cluster at the Department of Information Engineering (DEI) at the University of Padua, utilizing two NVIDIA RTX3090 GPUs, each equipped with 24 GB of VRAM.
3.1 Dataset
MusicGEN has been originally trained on a non-public dataset of 20k h of music collected by Meta. This kind of dataset is particularly effective to make the model figure out, after a training period, the underlying structures embedded in musical artifacts, on the other side the music generated by the model could lack in specificity or could have some kind of bias. This is where fine-tuning comes into play: it allows us to refine the model by focusing on a specific dataset where particular conditions are met. To fine-tune the model so that it is aware of the correlations between auditory and gustatory experiences, we created a patched version of the Taste & Affect Music Database by Guedes et al. (2023a).
The Taste & Affect Music Database was born as a resource for investigating the intricate relationships between auditory stimuli and gustatory perceptions. This dataset comprises 100 instrumental music tracks, meticulously curated to encapsulate a diverse range of emotional and taste-related attributes. Each musical piece within the database is accompanied by subjective rating norms that reflect participants' evaluations across various dimensions, including basic taste correspondences, emotional responses, familiarity, valence, and arousal. The selection of musical stimuli was guided by the objective of establishing clear associations between auditory and gustatory attributes. The tracks were chosen to represent fundamental taste categories—sweetness, bitterness, saltiness, and sourness—allowing researchers to explore how these tastes can be conveyed through music. Each participant provided ratings on the music tracks using a series of self-report measures that assessed mood, taste preferences and musical sophistication. This multi-dimensional approach to data collection facilitated a nuanced understanding of how individual differences in taste perception and emotional responses can influence the evaluation of musical stimuli. To adapt the dataset for fine-tuning, we generated captions for each music sample. These captions specify musical elements such as tempo, key and instrumentation. Furthermore, we incorporated keywords extracted from the original Taste & Affect Music Database, designating each sample as representative of one or more taste categories only if its score exceeded 25% in the original dataset.
3.2 Generated dataset
We then tested the model prompting it to infer different kind of music, at first few qualitative attempts were made to assess the correspondence between the prompted text and the model's output. In particular we performed a qualitative stress test varying musical genre asking, with many different prompts, for classical, ambient and jazz music. We found that the generated audio matched with varying quality the prompt with the exception of classical music, where the models (both the base and the fine-tuned version) tend to disattend the prompt with non-classical music, one reason could be the fact that the 20k hours training dataset of the MusicGEN model comprehends just a small percentage of classical music, while the corpora better represents other genres such as jazz and ambient. The ambient genre showed to be the most neutral one and adapt to generate music suited to be evaluated by subject without being conditioned by the genre, hence we kept specifing this genre in the successive prompts to avoid other genre biases during the output evaluation. Following a qualitative assessment, we created a dataset using both the original and fine-tuned models. Four prompts were developed, corresponding to each taste under study, with the structured format: 〈TASTE〉 music, ambient for fine restaurant, where 〈TASTE〉 represents sweet, bitter, sour, and salty. Each model produced a total of 100 pieces, each lasting 15 seconds. Of these, 25 were generated using the salty prompt, 25 using the sweet prompt, 25 using the bitter prompt, and 25 using the sour prompt. To compare outputs, we adopted standard metrics to evaluate the fine-tuned model in relation to the base version, specifically measuring the Fréchet Audio Distance (FAD) (Kilgour et al., 2019) between the training dataset and the outputs of both models when given the same prompt. The evaluation has been performed adopting the fadtk implementation (Gui et al., 2024) using VGGish embeddings (Diwakar and Gupta, 2024) as in the original MusicGEN paper, in addition with the EnCodec ones, since the model is based on such encoder we think that this metric should better match the internal representation of the model.
The evaluation results shown in Table 1 display that the music generated by fine-tuned model better matches with the reference dataset; despite could be an expected result that a fine-tuned model generates music more similar to the training dataset than its non fine-tuned version, it is important to denote that the training dataset was just 1 h length and very specific.
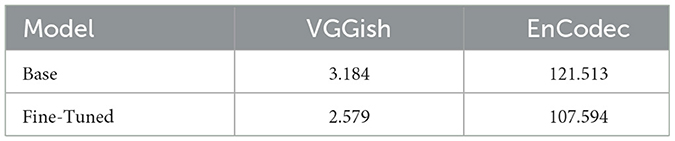
Table 1. FAD evaluation results using VGGish and EnCodec embeddings.
4 Materials and methods
The subjective evaluation of the fine-tuned model was conducted through an online survey administered through PsyToolkit, a widely used platform for psychological research (Stoet, 2017). The survey was structured to gather participants' opinions on the possible crossmodal correspondences between music and taste induced by the fine-tuned model compared to the non-fine-tuned version. Participants were recruited through various online channels to ensure a diverse demographic representation.
The listening tasks consisted of two distinct types. In the first task, participants were asked to express their preference between two audio files generated by the two models. In the second task, they quantified their perceptions and emotional responses to each piece of music. Specifically, participants rated the flavors they perceived using a graduated scale from 1 to 5 for four primary taste categories: salty, sweet, bitter, and sour. Additionally, they rated their emotional responses on various non-gustatory parameters, including happiness, sadness, anger, disgust, fear, surprise, hot, and cold, using the same graduated scale. This survey design enabled the collection of quantitative data specifically related to the qualitative parameters of the stimuli, facilitating a comprehensive analysis of the relationship between music and sensory experiences while acknowledging the mixed nature of the dataset.
To assess the adequacy of the sample size and the reliability of the findings, a power analysis was conducted for both tasks. For Task A, which involved a paired comparison between two audio samples, Cohen's d was computed with respect to a neutral reference point (d = 0.16). The corresponding power for detecting a positive effect with a one-sided paired t-test, given the observed effect size and a sample size of n = 111, was found to be high (1−β = 0.98), indicating a very low probability of Type II error. For Task B, a one-way ANOVA was performed to assess the effect of the prompt variable on participants' responses, controlling for other factors such as adjective, hearing experience, eating experience, and sex. The partial eta squared (η2) for the prompt effect was 0.0064, corresponding to a small Cohen's f of 0.08. Despite the small effect size, the achieved power was exceptionally high (1−β = 0.99), owing to the large sample size and balanced distribution across the four prompt conditions. These results confirm that the study was sufficiently powered to detect even subtle effects in both tasks.
All materials, including the patched database, survey instruments, and detailed instructions for the fine-tuning process, are available for reproducibility and further research.
4.1 Participant selection and demographic data
Participants were recruited through a combination of online platforms and local community outreach, ensuring a diverse sample reflective of the general population. A total of 111 individuals participated in the study, comprising 61 males, 46 females, 2 individuals identified as other, and 2 who did not specify their gender. The mean age of the participants was 32 years (with a minimum age of 19 and a maximum age of 75). Along with gender and age, we collected a self-evaluation of both the auditory (38 professionals, 43 amateurs, 30 not-experienced) and the gustatory experience (1 professional, 44 amaterus, 66 not-experienced), the ethnicity and the type of audio device used to participate in the survey (headphones, speakers or HiFi stereo). Regarding ethnicity, the majority of participants identified as white/European American (n = 90), followed by Latino/a/x or of Spanish origin (n = 4), Middle Eastern or North African (n = 3), Southeast Asian (n = 2), Asian (n = 1), Multi-racial (n = 1), and 10 participants did not disclose their ethnicity.
This study was conducted in accordance with the ethical principles outlined in the Declaration of Helsinki (most recently amended in 2024), ensuring respect for participants' rights, safety, and wellbeing. Prior to participation, all individuals provided an informed consent after receiving a detailed explanation of the study's objectives, procedures, and voluntary nature. Given the non-invasive nature of the survey, the study was classified as zero-risk research according to the ethical self-assessment guidelines of the Committee for Ethical Research (CER) of the University of Trento, and thus did not require additional ethical approval.
4.2 Experiment design
The online survey was structured to explore the relationship between auditory stimuli and taste perception. Initially, participants selected their preferred language to complete the survey, with options available in both English and Italian. Following the language selection, participants engaged in a series of listening tasks.
4.2.1 Task A
The first task involved the presentation of two audio clips, each associated with a specific taste category (sweet, salty, bitter, and sour, see Figure 2). Participants were made aware of the taste category through a text indicating if the music was supposed to be perceived as sweet, salty, bitter or sour, then they had to listen attentively to both clips before indicating which of the stimuli was the most coherent with the given text by moving a cursor along a scale ranging from 0 to 10. This scale allowed for a nuanced expression of preference, where a position of 0 indicated a strong preference for the first audio clip, a position of 10 indicated a strong preference for the second, and a position of 5 signified no preference between the two. To mitigate potential biases, the order of taste categories and audio clips was randomized for each participant. Each audio clip was generated by either the fine-tuned model or the base model as specified in Section 3.2, although the participants were not informed of the specific model used for each clip. This design choice aimed to improve the robustness of the findings by controlling for model-related effects. Participants completed a total of five listening tasks, each featuring different audio clips corresponding to randomly assigned taste categories, assuming the uniform distribution of the random number generator (RNG) provided by PsyToolKit each track has been evaluated in mean 5 times in this task.
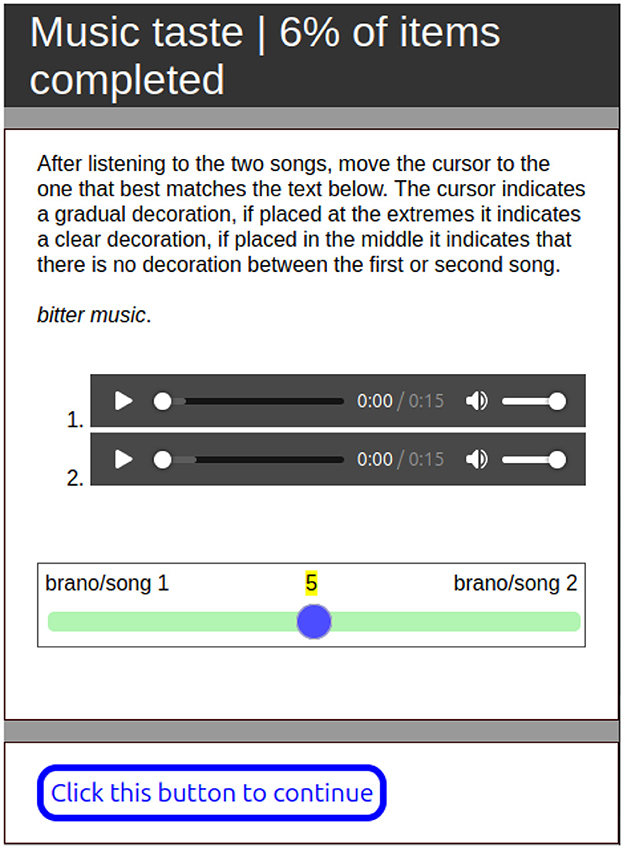
Figure 2. Survey's task A interface, where to express song preference.
4.2.2 Task B
Following the five items of task A, participans were presented with three more items, each one including one single audio stimulus and an evaluation based on the list of 12 adjectives-words (see Figure 3), this list includes the six basic emotions by Ekman (1992), the four basic tastes and temperature feeling (hot, cold), for each of these words participants used a scale from 1 to 5 to quantify their perception (where 1 means not at all and 5 means a lot). We considered these adjective-words to study eventual correlations between tastes and other domains such as emotions and thermal perception. This evaluation allowed participants to articulate the extent to which they recognized each adjective in relation to the music they had just listened to. Basing on the same assumption of task A about the RNG each track has been evaluated in mean 3 times in this task.
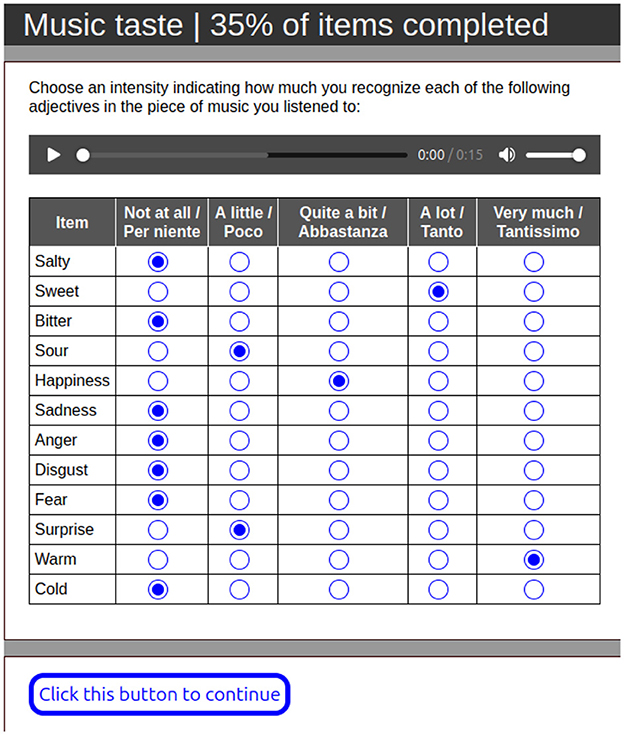
Figure 3. Survey's task B interface.
5 Results
In this section, we present the most meaningful results obtained from a more in-depth analysis. The full analysis along with the scripts used to generate the results can be found at the following website: https://matteospanio.github.io/multimodal-symphony-survey-analysis/.
5.1 Task A analysis
The objective of analyzing these results is to determine whether one model is consistently judged as more accurate than the other in generating music associated with the given prompt. Therefore, we evaluated whether the scores systematically favor one model over the other.
At first, due to the random order of the stimuli presentation, we normalized the scores attributed in task A ordering the preference according to the score function S as defined in Equation 1. This procedure allows us to interpret scores from 0 to 4 as a preference for the base model, scores between 6 and 10 as a preference for the fine-tuned model, and scores of 5 are treated as neutral.
where x ∈ {n ∈ ℕ∣n ≤ 10}, and m can take the values “right” or “left,” according to the position on the survey form of the stimulus generated with the fine-tuned model.
An histogram of the participants' ratings is shown in Figure 4, where a preference for the fine-tuned model is evident, due to the right-skewed statistical distribution. After a Shapiro-Wilk test with p < 0.05 that determined the non normal distrubution of the data, we opted for a Wilcoxon signed-rank test which gave a statistically significant result supporting the hypothesis that the median score is greater than 5 (p < 0.001, W = 73966). Furthermore we continued with a post-hoc analysis performing a Wilcoxon test for each taste group (sweet, sour, bitter, salty) applying a Bonferroni correction to adjust for the multiple comparisons and control the family-wise error rate.
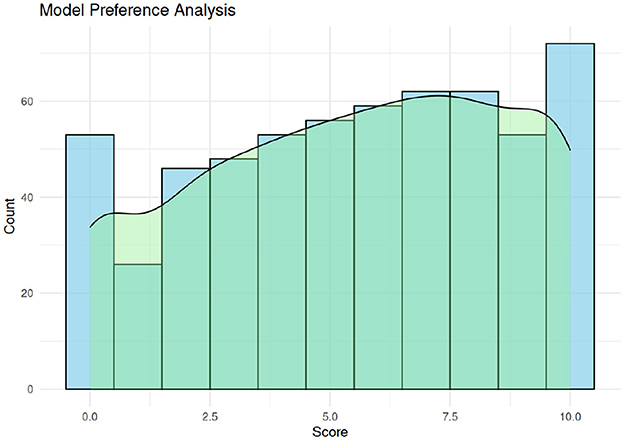
Figure 4. Distribution of the task A results, where a score of zero means a strong preference for the base model, while a score of 10 means a strong preference for the fine-tuned model.
As can be seen from the results of the test reported in Table 2 all audio samples generated by the fine-tuned model but salty, are statistically chosen as better than the base model. We then performed the opposite hypothesis test to test just the mean of the salty group of samples, the result confirm a median score lower than 5, meaning that the base model is overall preferred in the case of salty text suggestions (p≈0.003, W = 2784).
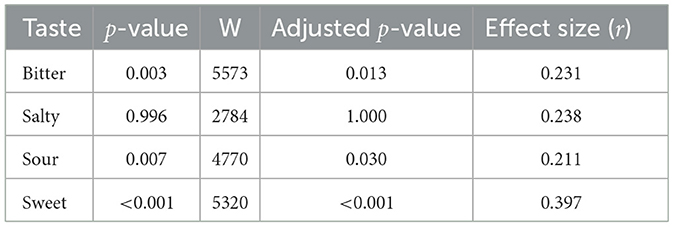
Table 2. p-values and adjusted p-values resulting from the Wilcoxon test for different taste attributes.
5.2 Task B analysis
To investigate whether different prompts and adjectives resulted in significantly different ratings assigned by participants, and to examine the interaction between taste, emotions, and thermal perception, we first conducted an Analysis of Variance (ANOVA), followed by a factor analysis. The ANOVA model is defined as follows:
where × denotes an interaction effect between factors, value represents the score assigned by the participant to a specific adjective, prompt refers to the designated taste category used during stimulus generation, gender corresponds to the participant's self-reported gender, while hearing_experience and eating_experience indicate the participant's self-assessed expertise in auditory and gustatory tasks, respectively.
The dataset was filtered to include only participants identified as Male or Female, excluding other genres and excluding also participants classified as Professional Eaters due to insufficient representation of these categories.
Prior to interpreting the results, the homoskedasticity assumption was assessed by examining the residuals. A Shapiro-Wilk test indicated deviation from normality (p < 0.001). Visual inspection of the Q-Q plot suggested that this deviation was primarily limited to the distribution tails. Given the large sample size (N = 3, 996) and balanced group sizes, the analysis proceeded, following established evidence that ANOVA is robust to moderate violations of the normality assumption when sample sizes are sufficiently large and balanced (Glass et al., 1972; Harwell et al., 1992; Lix et al., 1996; Schmider et al., 2010). The ANOVA results (see Table 3) show a significant effect of both prompt and adjective, with an even stronger effect for their interaction. In other words, the prompt influences participants' ratings across the different adjectives-words in the semantic scale. Also hearing experience shows to be relevant in order to evaluate the audio stimuli, whereas neither eating experience nor participant's gender influenced the stimuli evaluations of Task B. A post-hoc analysis was then conducted on the significative factors by means of the Tukey's Honest Significant Difference (HSD) test. Tables 4, 5 list the combinations of, respectively, prompts and adjectives that show statistically significant differences. Notably the sour prompt received higher evaluations compared to other ones. Table 5 instead highlights that anger and disgust received lower values overall, while hot, cold, and sad received the highest evaluations.
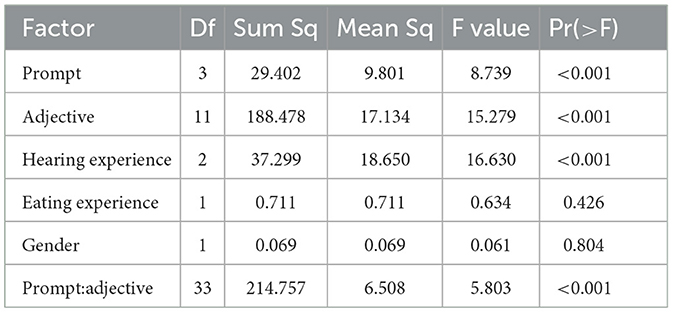
Table 3. Results of the ANOVA test.
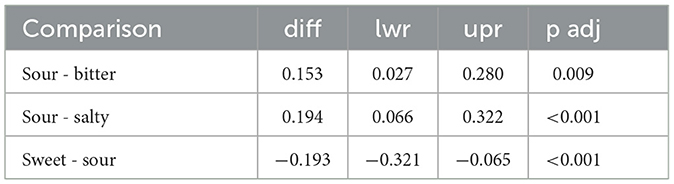
Table 4. Tukey test results for different prompts with a p-value <0.05.
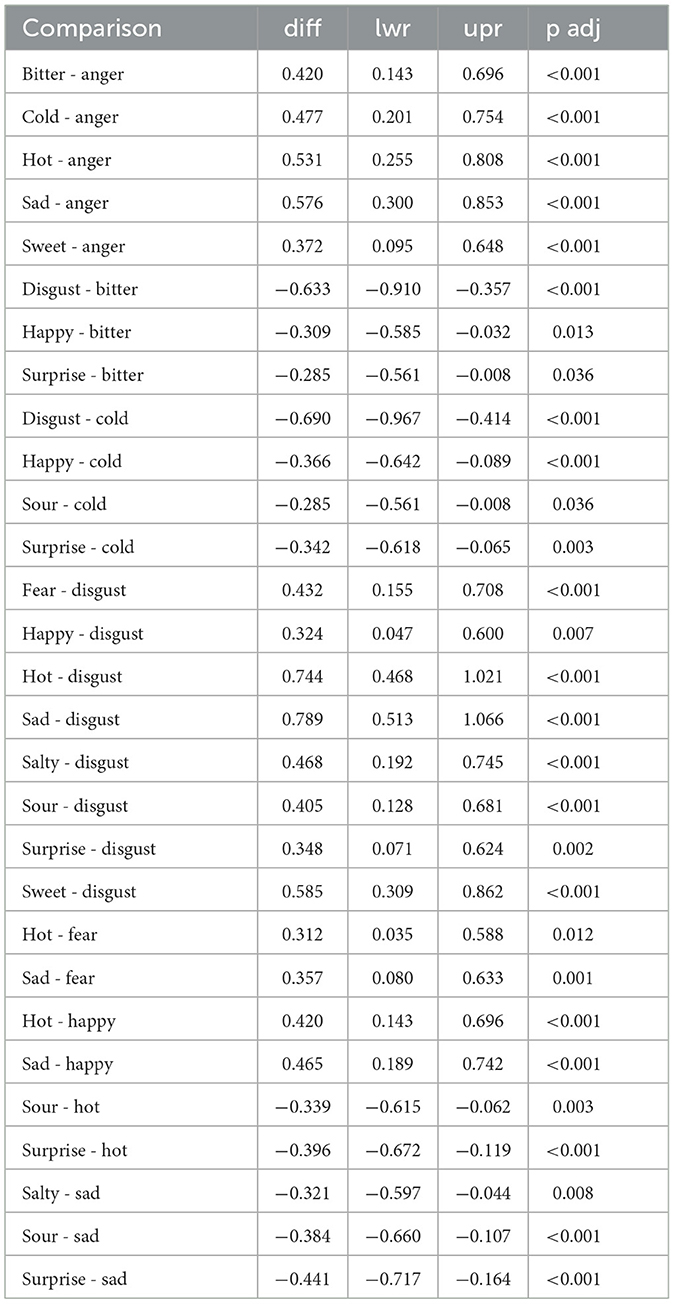
Table 5. Tukey test results for different adjectives with a p-value <0.05.
The prompt-adjective interaction can be seen in Figure 5. In particular Figure 5a shows the mean value assigned to each taste adjective by their prompt, we can clearly see the major diagonal emerge by the matrix, which means that the mean value assigned to the adjective that matches the prompt of each sound is the highest. The rest of the interaction between adjectives and prompts can be seen in Figure 5b, a deeper analysis of emotional aspect assigned to the sounds is presented in Section 6.
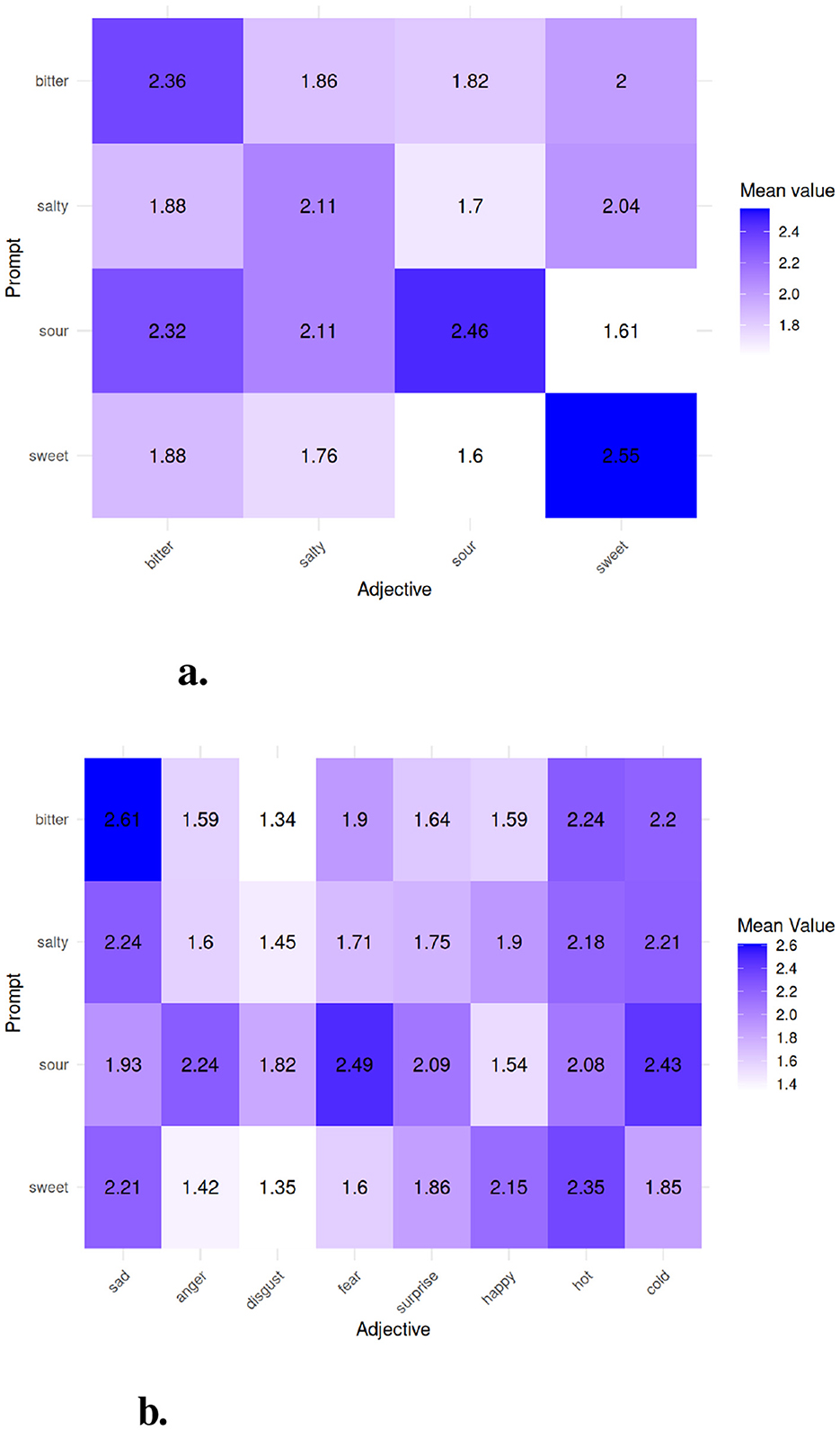
Figure 5. Visualization of the relationship between taste prompts and their perceived characteristics. (a) illustrates the alignment between intended taste prompts and the corresponding perceived taste intensities, while (b) presents the emotional responses elicited by each taste prompt. Color intensity represents the mean reported values. (a) Heatmap of perceived taste in correspondence of the intended one. (b) Heatmap of perceived emotional response in correspondence of the suggested taste.
The Tukey test results for the hearing experience interaction show that amateur listeners tend to give significantly higher ratings compared to professionals (diff = 0.23, p < 0.0001) and the not-experienced people (diff = 0.17, p = 0.0003).
To investigate the connections between sensory qualities and emotional states, we performed a factor analysis. The scree test indicated that 4 factors were optimal. Consequently, we employed a factor analysis with oblique axis rotation and the maximum likelihood method, utilizing the psych R package by William Revelle (2024). The loadings obtained are presented in Table 6, showing the degree to which each variable contributes to the identified factors, thus offering insights into the data's underlying structure. Each of this factors is clearly characterized: the first one is about negative valence adjectives and groups together bitterness and sourness, factor two is strongly aligned with sweetness which also correlates with happiness, hotness and, a little, with sadness, factor three reaches highest scores in hot and cold defining a temperature dimension and factor four binds together saltiness, happiness with surprise.
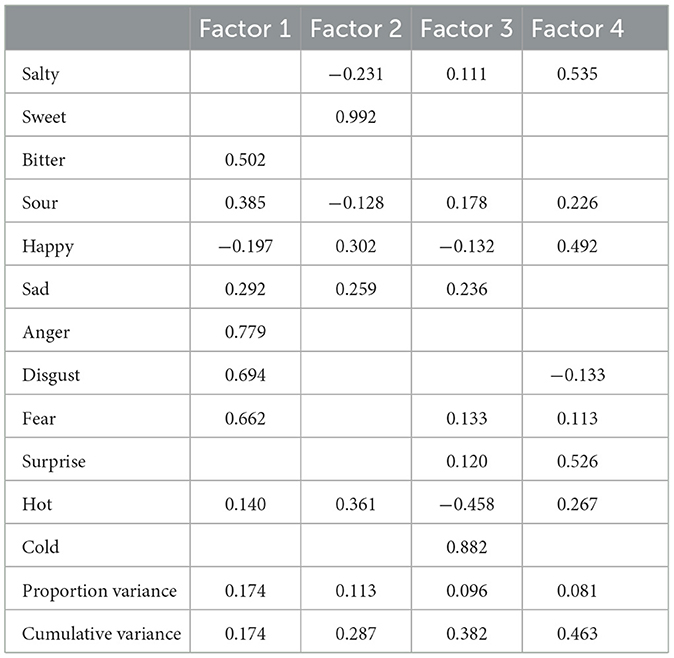
Table 6. Loadings resulting from the factor analysis with 4 factors: Factor 1 includes negative valence emotions and tastes, Factor 2 is primarily associated with sweetness and other positive valence traits, Factor 3 is largely linked to temperature and shows no strong correlation with any specific taste, and Factor 4 combines saltiness and surprise with happiness.
6 Discussion
The findings of this study reveal that the music produced by our model refined with a dataset confirmed by psychological crossmodal research can indeed evoke crossmodal effects. Additionally, the music is not merely perceived generically as tasty; the model can be specifically prompted with particular taste attributes which, according to ANOVA tests, are often identified by listeners.
Regarding the first research question, focused on evaluating the ability of the fine-tuned model to generate audio that accurately describes the investigated flavors, the findings reveal that the fine-tuned model produced music that is more coherently aligned with the taste descriptions for sweet, sour, and bitter categories compared to the non-fine-tuned model. This indicates that the integration of gustatory information into the music generation process was effective, enhancing the model's ability to capture the sensory nuances associated with various tastes. However, music intended to represent salty flavors was less effectively captured by the fine-tuned model than by the base model. Although the overall assessment shows that the fine-tuned model aligns better with the crossmodal effect through both objective and subjective evaluations, the salty music was better represented by the base model. One possible explanation for this phenomenon could be attributed to biases in the specified musical genre within the prompts and the dataset used for fine-tuning, where salty music is underrepresented compared to other categories. Notably, in the dataset provided by Guedes et al. (2023a), the compositions are more frequently perceived as sweet, and many of those scoring well in the salty category also exhibit sweetness. Furthermore, the Fréchet distance based on both used embeddings suggests that the music generated by the fine-tuned model is perceptually more similar to that generated by the other model (Gui et al., 2024). This implies that the sonic characteristics of the tracks in the dataset used for fine-tuning do not adequately reflect saltiness. According to Wang et al. (2021), short and articulated sounds, along with steady rhythm, can evoke this sensation. The average beats per minute (BPM) of our dataset is 111—Moderato, not particularly fast within common Western tempo markings as detailed in Cu et al. (2012)—and recurring keywords include “small emotions” and “ambient.” It should be noted that ambient music is often used as background music, lacking prominent peaks in energy, timbre, and/or aggressive speed (Scarratt et al., 2023). Therefore, we conclude that while the fine-tuning was successful, the reference dataset requires further study and enrichment with music that better represents saltiness, not limited to the ambient genre.
To explore the second, third, and fourth research questions—whether the fine-tuned model can induce gustatory responses, which underlying connections make the crossmodal effect possible, and how much emotions mediate crossmodal evaluations of music—the study examined the extent to which the music generated by the fine-tuned model elicited crossmodal taste perceptions in participants, with a particular focus on emotional correlations. The findings indicate that the music did indeed evoke gustatory sensations, with correlations showing that positive valence emotions are associated with positive valence tastes and vice versa, while temperature also plays a significant role in these correlations. Although emotions explain a substantial portion of the correlations, the factor analysis revealed that the four factors accounted for less than 50% of the total variance. The ANOVA test results confirm that participants perceived taste suggestions guided by an undergoing logic rather than randomly. Specifically, as observed in the interaction matrix in Figure 5a, there is a clear main diagonal, indicating that on average, the intended taste for which the music was generated is recognized. This recognition is more apparent for sweet and bitter music, while sour music is often perceived as bitter, and salty music is frequently associated with sweetness. This aligns with previous discussions about the biases present in the dataset used for fine-tuning. As studied by Wang et al. (2016), our results show a strict correlation between positive emotions and sweetness and negative feelings with bitterness, confirming that anger and disgust were less used in the ratings, a known fact studied by Mohn et al. (2011). These findings are further corroborated by the factor analysis. The factor loadings Table 6 highlights that the first factor is dominated by negative adjectives, bitterness, and sourness, with a notable inverse correlation with happiness. In contrast, the second factor is almost exclusively dominated by sweetness, which resonates with warmth and happiness but also with sadness, demonstrating that sad music might be perceived as pleasant (Kawakami et al., 2013; Sachs et al., 2015). The third factor represents temperature, indicating that negative emotions and sour and salty flavors align with cold sensations, while warmth and happiness align in the opposite direction (Spence, 2020b). The fourth factor combines salty, happiness, surprise, warmth, and sourness. The first, second and fourth factors, when considered in terms of emotional aspects, clearly characterize valence, with positive (factors 2 and 4) and negative (factor 1) dimensions. Temperature appears to be separate from other dimensions, aside from minor, non-significant correlations, suggesting its use as an indicator of perceived arousal from the stimulus. Furthermore, looking at Figure 5b, the prompt “sour” showed a higher average response, possibly due to a greater presence of negative scales or confusion with bitterness. The interaction matrix reveals that bitter music is often rated as sad and independent of temperature, while sour music encompasses more negative sensations and is most associated with disgust, a rarely used adjective in musical contexts, as observed in Argstatter (2016).
7 Conclusions
In this study, we investigated the potential of a fine-tuned generative model to induce crossmodal taste perceptions through music, focusing on the intricate correlations between music, emotions, and taste. The findings revealed that music could indeed evoke gustatory sensations, with positive valence emotions closely aligning with positive valence tastes. Temperature also emerged as a significant factor in these correlations, suggesting a complex interplay between sensory modalities. The results, supported by rigorous ANOVA and factor analysis, underscore the model's capability to bridge sensory modalities, providing valuable insights into the emotional and perceptual connections between sound and taste. Despite the promising results, several limitations of the study must be acknowledged. While the sample size of 111 participants was sufficient from a statistical standpoint—as confirmed by the power analysis—the main limitation lies in the lack of proper sample stratification. Most participants self-identified as belonging to the same ethnic group (White/European American), and the age range was relatively narrow. Although participants were recruited from various regions, the overall demographic homogeneity may have introduced a sampling bias, limiting the generalizability of the findings to more diverse populations. Additionally, while the adjectives used in the study allowed up to a certain degree of freedom in evaluations, they fell short of covering certain aspects necessary to fully encompass Russell's circumplex model of emotions. This gap suggests that the emotional dimensions explored in the study might not capture the full spectrum of human emotional experience. Furthermore, participants were not presented with preparatory stimuli to align their emotional and perceptual states, a factor known to influence perception, as studied by Taylor and Friedman (2014) and Rentfrow et al. (2011). This oversight could have introduced variability in the participants' responses, potentially impacting the study's outcomes.
Furthermore, the concept of “sonic seasoning” (see e.g., Spence et al., 2024) could be further developed to enhance culinary experiences by aligning music with taste to influence perception and enjoyment. This innovative approach could revolutionize the way we experience food, adding a new dimension to culinary arts and hospitality. Looking ahead, future research should focus on addressing the limitations identified in this study. Developing a more comprehensive dataset that better represents the diversity of sensory experiences would enhance the accuracy and applicability of the model. Additionally, advancing the sophistication of the model itself could deepen synesthetic and crossmodal inductions, enabling more refined applications. Integrating additional modalities, as suggested in Spanio (2024), may further enhance results through emotional mediation. The improved performance of the fine-tuned model underscores multimodal AI's potential to bridge sensory domains, emphasizing the need for well-curated datasets to support innovative crossmodal applications.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://osf.io/xs5jy/.
Ethics statement
The requirement of ethical approval was waived by the Committee for Ethical Research (CER) of the University of Trento for the studies involving humans because the Committee for Ethical Research (CER) of the University of Trento. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
MS: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Resources, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. MZ: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Supervision, Validation, Writing – original draft, Writing – review & editing. AR: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. FP: Conceptualization, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was funded by the European Union - NextGenerationEU, under the National Recovery and Resilience Plan (PNRR). Open Access funding provided by Università degli Studi di Padova | University of Padua, Open Science Committee.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that Gen AI was used in the creation of this manuscript. We acknowledge the use of AI technology to assist writing of the submitted manuscript using ChatGPT-3.5 and ChatGPT-4 (Open AI).
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abbasiantaeb, Z., Yuan, Y., Kanoulas, E., and Aliannejadi, M. (2024). “Let the LLMs talk: simulating human-to-human conversational QA via zero-shot LLM-to-LLM interactions,” in Proceedings of the 17th ACM International Conference on Web Search and Data Mining, WSDM '24 (New York, NY, USA: Association for Computing Machinery), 8–17. doi: 10.1145/3616855.3635856
Agostinelli, A., Denk, T. I., Borsos, Z., Engel, J., Verzetti, M., Caillon, A., et al. (2023). MusicLM: generating music from text. arXiv:2301.11325.
Alayrac, J.-B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., et al. (2022). “Flamingo: a visual language model for few-shot learning,” in Advances in Neural Information Processing Systems, eds. S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Curran Associates, Inc.), 23716–23736.
Argstatter, H. (2016). Perception of basic emotions in music: culture-specific or multicultural? Psychol. Music 44, 674–690. doi: 10.1177/0305735615589214
Bahar, P., Bieschke, T., and Ney, H. (2019). “A comparative study on end-to-end speech to text translation,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 792–799. doi: 10.1109/ASRU46091.2019.9003774
Bender, E. M., Gebru, T., McMillan-Major, A., and Shmitchell, S. (2021). “On the dangers of stochastic parrots: can language models be too big?” in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT '21 (New York, NY, USA: Association for Computing Machinery), 610–623. doi: 10.1145/3442188.3445922
Boscher, C., Largeron, C., Eglin, V., and Egyed-Zsigmond, E. (2024). “SENSE-LM : a synergy between a language model and sensorimotor representations for auditory and olfactory information extraction,” in Findings of the Association for Computational Linguistics: EACL 2024, eds. Y. Graham, and M. Purver (St. Julian's, Malta: Association for Computational Linguistics), 1695–1711.
Copet, J., Kreuk, F., Gat, I., Remez, T., Kant, D., Synnaeve, G., et al. (2023). “Simple and controllable music generation,” in Thirty-Seventh Conference on Neural Information Processing Systems (Red Hook, NY: Curran Associates, Inc.).
Crisinel, A.-S., and Spence, C. (2009). Implicit association between basic tastes and pitch. Neurosci. Lett. 464, 39–42. doi: 10.1016/j.neulet.2009.08.016
Crisinel, A.-S., and Spence, C. (2010a). As bitter as a trombone: synesthetic correspondences in nonsynesthetes between tastes/flavors and musical notes. Attent. Percept. Psychophys. 72, 1994–2002. doi: 10.3758/APP.72.7.1994
Crisinel, A.-S., and Spence, C. (2010b). A sweet sound? Food names reveal implicit associations between taste and pitch. Perception 39, 417–425. doi: 10.1068/p6574
Cu, J., Cabredo, R., Legaspi, R., and Suarez, M. T. (2012). “On modelling emotional responses to rhythm features,” in PRICAI 2012: Trends in Artificial Intelligence, eds. P. Anthony, M. Ishizuka, and D. Lukose (Berlin, Heidelberg: Springer Berlin Heidelberg), 857–860. doi: 10.1007/978-3-642-32695-0_85
Défossez, A., Copet, J., Synnaeve, G., and Adi, Y. (2022). High fidelity neural audio compression. arXiv:2210.13438.
Demattè, M. L., Pojer, N., Endrizzi, I., Corollaro, M. L., Betta, E., Aprea, E., et al. (2014). Effects of the sound of the bite on apple perceived crispness and hardness. Food Qual. Prefer. 38, 58–64. doi: 10.1016/j.foodqual.2014.05.009
Di Stefano, N., Ansani, A., Schiavio, A., and Spence, C. (2024). Prokofiev was (almost) right: a cross-cultural investigation of auditory-conceptual associations in Peter and the Wolf. Psychon. Bull. Rev. 31, 1735–1744. doi: 10.3758/s13423-023-02435-7
Diwakar, M. P., and Gupta, B. (2024). “Vggish deep learning model: audio feature extraction and analysis,” in Data Management, Analytics and Innovation, eds. N. Sharma, A. C. Goje, A. Chakrabarti, and A. M. Bruckstein (Singapore: Springer Nature Singapore), 59–70. doi: 10.1007/978-981-97-3245-6_5
Ekman, P. (1992). An argument for basic emotions. Cogn. Emot. 6, 169–200. doi: 10.1080/02699939208411068
Fayyaz, M., Yin, F., Sun, J., and Peng, N. (2024). Evaluating human alignment and model faithfulness of LLM rationale. arXiv:2407.00219.
Forsgren, S., and Martiros, H. (2022). Riffusion - Stable diffusion for real-time music generation. Available online at: https://riffusion.com/about
Galmarini, M., Silva Paz, R., Enciso Choquehuanca, D., Zamora, M., and Mesz, B. (2021). Impact of music on the dynamic perception of coffee and evoked emotions evaluated by temporal dominance of sensations (TDS) and emotions (TDE). Food Res. Int. 150:110795. doi: 10.1016/j.foodres.2021.110795
Glass, G. V., Peckham, P. D., and Sanders, J. R. (1972). Consequences of failure to meet assumptions underlying the fixed effects analyses of variance and covariance. Rev. Educ. Res. 42, 237–288. doi: 10.3102/00346543042003237
Guedes, D., Prada, M., Garrido, M. V., and Lamy, E. (2023a). The taste &affect music database: Subjective rating norms for a new set of musical stimuli. Behav. Res. 55, 1121–1140. doi: 10.3758/s13428-022-01862-z
Guedes, D., Vaz Garrido, M., Lamy, E., Pereira Cavalheiro, B., and Prada, M. (2023b). Crossmodal interactions between audition and taste: a systematic review and narrative synthesis. Food Qual. Prefer. 107:104856. doi: 10.1016/j.foodqual.2023.104856
Gui, A., Gamper, H., Braun, S., and Emmanouilidou, D. (2024). “Adapting frechet audio distance for generative music evaluation,” in ICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Piscataway, NJ), 1331–1335. doi: 10.1109/ICASSP48485.2024.10446663
Harwell, M. R., Rubinstein, E. N., Hayes, W. S., and Olds, C. C. (1992). Summarizing monte carlo results in methodological research: the one- and two-factor fixed effects anova cases. J. Educ. Stat. 17, 315–339. doi: 10.3102/10769986017004315
Hauck, P., von Castell, C., and Hecht, H. (2022). Crossmodal correspondence between music and ambient color is mediated by emotion. Multisens. Res. 35, 407–446. doi: 10.1163/22134808-bja10077
Holt-Hansen, K. (1968). Taste and pitch. Percept. Motor Skills 27, 59–68. doi: 10.2466/pms.1968.27.1.59
Holt-Hansen, K. (1976). Extraordinary experiences during cross-modal perception. Percept. Motor Skills 43, 1023–1027. doi: 10.2466/pms.1976.43.3f.1023
Huang, J.-B., Ren, Y., Huang, R., Yang, D., Ye, Z., Zhang, C., et al. (2023). Make-an-audio 2: temporal-enhanced text-to-audio generation. ArXiv, abs/2305.18474.
Kawakami, A., Furukawa, K., Katahira, K., and Okanoya, K. (2013). Sad music induces pleasant emotion. Front. Psychol. 4:311. doi: 10.3389/fpsyg.2013.00311
Kilgour, K., Zuluaga, M., Roblek, D., and Sharifi, M. (2019). “Fréchet audio distance: a reference-free metric for evaluating music enhancement algorithms,” in Interspeech 2019, 2350–2354. doi: 10.21437/Interspeech.2019-2219
Knöferle, K., and Spence, C. (2012). Crossmodal correspondences between sounds and tastes. Psychon. Bull. Rev. 2012, 1–13. doi: 10.3758/s13423-012-0321-z
Knöferle, K. M., Woods, A., Käppler, F., and Spence, C. (2015). That sounds sweet: Using cross-modal correspondences to communicate gustatory attributes. Psychol. Market. 32, 107–120. doi: 10.1002/mar.20766
Li, J., Li, D., Xiong, C., and Hoi, S. (2022). “BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation,” in Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research (Cambridge, MA: PMLR), 12888–12900.
Lix, L. M., Keselman, J. C., and Keselman, H. J. (1996). Consequences of assumption violations revisited: a quantitative review of alternatives to the one-way analysis of variance "f" test. Rev. Educ. Res. 66, 579–619. doi: 10.3102/00346543066004579
Mathiesen, S. L., Hopia, A., Ojansivu, P., Byrne, D. V., and Wang, Q. J. (2022). The sound of silence: presence and absence of sound affects meal duration and hedonic eating experience. Appetite 174:106011. doi: 10.1016/j.appet.2022.106011
Mesz, B., Sigman, M., and Trevisan, M. (2012). A composition algorithm based on crossmodal taste-music correspondences. Front. Hum. Neurosci. 6:71. doi: 10.3389/fnhum.2012.00071
Mesz, B., Tedesco, S., Reinoso-Carvalho, F., Ter Horst, E., Molina, G., Gunn, L. H., et al. (2023). Marble melancholy: using crossmodal correspondences of shapes, materials, and music to predict music-induced emotions. Front. Psychol. 14:1168258. doi: 10.3389/fpsyg.2023.1168258
Mesz, B., Trevisan, M. A., and Sigman, M. (2011). The taste of music. Perception 40, 209–219. doi: 10.1068/p6801
Mohn, C., Argstatter, H., and Wilker, F.-W. (2011). Perception of six basic emotions in music. Psychol. Music 39, 503–517. doi: 10.1177/0305735610378183
Motoki, K., Marks, L. E., and Velasco, C. (2023). Reflections on cross-modal correspondences: current understanding and issues for future research. Multis. Res. 37, 1–23. doi: 10.1163/22134808-bja10114
Murari, M., Chmiel, A., Tiepolo, E., Zhang, J. D., Canazza, S., Rodá, A., et al. (2020). “Key clarity is blue, relaxed, and maluma: machine learning used to discover cross-modal connections between sensory items and the music they spontaneously evoke,” in Proceedings of the 8th International Conference on Kansei Engineering and Emotion Research (Singapore: Springer Singapore), 214–223. doi: 10.1007/978-981-15-7801-4_22
Poria, S., Cambria, E., Bajpai, R., and Hussain, A. (2017). A review of affective computing: from unimodal analysis to multimodal fusion. Inf. Fusion 37, 98–125. doi: 10.1016/j.inffus.2017.02.003
Qi, Y., Huang, F., Li, Z., and Wan, X. (2020). Crossmodal correspondences in the sounds of Chinese instruments. Perception 49, 81–97. doi: 10.1177/0301006619888992
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., et al. (2021). “Learning transferable visual models from natural language supervision,” in International Conference on Machine Learning.
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., et al. (2021). “Zero-shot text-to-image generation,” in Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research (Cambridge, MA: PMLR), 8821–8831.
Rentfrow, P. J., Goldberg, L. R., and Levitin, D. J. (2011). The structure of musical preferences: a five-factor model. J. Pers. Soc. Psychol. 100, 1139–1157. doi: 10.1037/a0022406
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. arXiv:2112.10752.
Rudmin, F., and Cappelli, M. (1983). Tone-taste synesthesia: a replication. Percept. Mot. Skills 56, 118–118. doi: 10.2466/pms.1983.56.1.118
Sachs, M. E., Damasio, A. R., and Habibi, A. (2015). The pleasures of sad music: a systematic review. Front. Hum. Neurosci. 9:404. doi: 10.3389/fnhum.2015.00404
Scarratt, R. J., Heggli, O. A., Vuust, P., and Sadakata, M. (2023). Music that is used while studying and music that is used for sleep share similar musical features, genres and subgroups. Sci. Rep. 13:4735. doi: 10.1038/s41598-023-31692-8
Schmider, E., Ziegler, M., Danay, E., Beyer, L., and Buhner, M. (2010). Is it really robust? Reinvestigating the robustness of anova against the normal distribution assumption. Meth. Eur. J. Res. Meth. Behav. Soc. Sci. 6, 15–147. doi: 10.1027/1614-2241/a000016
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., et al. (2022). Make-a-video: text-to-video generation without text-video data. arXiv:2209.14792.
Spanio, M. (2024). “Towards emotionally aware AI: challenges and opportunities in the evolution of multimodal generative models,” in CEUR Workshop Proceedings Series, Vol. 3914 (Aachen: RWTH Aachen University).
Spence, C. (2011). Crossmodal correspondences: a tutorial review. Attent. Percept. Psychophys. 73, 971–995. doi: 10.3758/s13414-010-0073-7
Spence, C. (2020a). Assessing the role of emotional mediation in explaining crossmodal correspondences involving musical stimuli. Multisens. Res. 33, 1–29. doi: 10.1163/22134808-20191469
Spence, C. (2020b). Temperature-based crossmodal correspondences: causes and consequences. Multis. Res. 33, 645–682. doi: 10.1163/22134808-20191494
Spence, C. (2021). Sonic seasoning and other multisensory influences on the coffee drinking experience. Front. Comput. Sci. 3:644054. doi: 10.3389/fcomp.2021.644054
Spence, C., and Di Stefano, N. (2022). Coloured hearing, colour music, colour organs, and the search for perceptually meaningful correspondences between colour and sound. i-Perception 13:20416695221092802. doi: 10.1177/20416695221092802
Spence, C., Di Stefano, N., Reinoso-Carvalho, F., and Velasco, C. (2024). Marketing sonified fragrance: designing soundscapes for scent. Iperception. 15:20416695241259714. doi: 10.1177/20416695241259714
Stoet, G. (2017). Psytoolkit: A novel web-based method for running online questionnaires and reaction-time experiments. Teach. Psychol. 44, 24–31. doi: 10.1177/0098628316677643
Taylor, C. L., and Friedman, R. (2014). Differential influence of sadness and disgust on music preference. Psychol. Popular Media Cult. 3, 195–205. doi: 10.1037/ppm0000045
Turato, A., Rodá, A., Canazza, S., Chmiel, A., Murari, M., Schubert, E., et al. (2022). “Knocking on a yellow door: interactions among knocking sounds, colours, and emotions,” in Proceedings of the 10th Convention of the European Acoustics Association Forum Acusticum 2023 (Torino: Politecnico di Torino).
Vaswani, A., Shazeer, N. M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). “Attention is all you need,” in Neural Information Processing Systems (Red Hook, NY: Curran Associates, Inc.).
Wang, Q. J., Keller, S., and Spence, C. (2021). Metacognition and crossmodal correspondences between auditory attributes and saltiness in a large sample study. Multis. Res. 23, 1–21. doi: 10.1163/22134808-bja10055
Wang, Q. J., Wang, S., and Spence, C. (2016). “Turn Up the Taste”: assessing the role of taste intensity and emotion in mediating crossmodal correspondences between basic tastes and pitch. CHEMSE 41, 345–356. doi: 10.1093/chemse/bjw007
Watson, Q. J., and Gunther, K. L. (2017). Trombones elicit bitter more strongly than do clarinets: a partial replication of three studies of crisinel and spence. Multisens. Res. 30, 321–335. doi: 10.1163/22134808-00002573
William, R. (2024). psych: Procedures for Psychological, Psychometric, and Personality Research. Northwestern University, Evanston, Illinois. R package version 2.4.12.
Zampini, M., and Spence, C. (2004). The role of auditory cues in modulating the perceived crispness and staleness of potato chips. J. Sens. Stud. 19, 347–363. doi: 10.1111/j.1745-459x.2004.080403.x
Zeghidour, N., Luebs, A., Omran, A., Skoglund, J., and Tagliasacchi, M. (2022). Soundstream: an end-to-end neural audio codec. IEEE/ACM Trans. Audio, Speech, Lang. Proc. 30, 495–507. doi: 10.1109/TASLP.2021.3129994
Zhao, S., Li, Y., Yao, X., Nie, W., Xu, P., Yang, J., et al. (2020). “Emotion-based end-to-end matching between image and music in valence-arousal space,” in Proceedings of the 28th ACM International Conference on Multimedia, MM '20 (New York, NY, USA: Association for Computing Machinery), 2945–2954. doi: 10.1145/3394171.3413776
Zhao, S., Wang, S., Soleymani, M., Joshi, D., and Ji, Q. (2019). Affective computing for large-scale heterogeneous multimedia data: a survey. ACM Trans. Multimedia Comput. Commun. Appl. 15, 93:1–93:32. doi: 10.1145/3363560
Zhao, Z., Song, S., Duah, B., Macbeth, J., Carter, S., Van, M. P., et al. (2023). “More human than human: LLM-generated narratives outperform human-llm interleaved narratives,” in Proceedings of the 15th Conference on Creativity and Cognition, C&C '23 (New York, NY, USA: Association for Computing Machinery), 368–370. doi: 10.1145/3591196.3596612
Keywords: generative AI, crossmodal correspondences, taste, audition, music
Citation: Spanio M, Zampini M, Rodà A and Pierucci F (2025) A multimodal symphony: integrating taste and sound through generative AI. Front. Comput. Sci. 7:1575741. doi: 10.3389/fcomp.2025.1575741
Received: 12 February 2025; Accepted: 30 May 2025;
Published: 07 July 2025.
Edited by:
Stefania Serafin, Aalborg University Copenhagen, DenmarkReviewed by:
Nicola Di Stefano, National Research Council (CNR), ItalyCarmen Adams, University of Hasselt, Belgium
Copyright © 2025 Spanio, Zampini, Rodà and Pierucci. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Matteo Spanio, c3BhbmlvQGRlaS51bmlwZC5pdA==