 Liang Zhong1,2,3
Liang Zhong1,2,3 Zengyi Zhao1,2Qingshan Hu1,2Yang Li1,2,3Weili Zhao1,2,3Chuang Li1,2Yunqiang Xu1Ruijuan Rong1,2,3Jing Zhang1,2,3Zifeng Zhang1,2,3Nan Li1,2,3Zanchao Liu1,2,3*
Zengyi Zhao1,2Qingshan Hu1,2Yang Li1,2,3Weili Zhao1,2,3Chuang Li1,2Yunqiang Xu1Ruijuan Rong1,2,3Jing Zhang1,2,3Zifeng Zhang1,2,3Nan Li1,2,3Zanchao Liu1,2,3*- 1The Shijiazhuang Second Hospital, Shijiazhuang, China
- 2Hebei Provincial Key Laboratory of Basic Medicine for Diabetes, The Shijiazhuang Second Hospital, Shijiazhuang, China
- 3Shijiazhuang Technology Innovation Center of Precision Medicine for Diabetes, The Shijiazhuang Second Hospital, Shijiazhuang, China
Diabetes mellitus is a highly heterogeneous disorder encompassing different types with particular clinical manifestations, while maturity-onset diabetes of the young (MODY) is an early-onset monogenenic diabetes. Most genetic predisposition of MODY has been identified in European and American populations. A large number of Chinese individuals are misdiagnosed due to defects of unknown genes. In this study, we analyzed the genetic and clinical characteristics of the Northern China. A total of 200 diabetic patients, including 10 suspected MODY subjects, were enrolled, and the mutational analysis of monogenic genes was performed by whole-exome sequencing and confirmed by familial information and Sanger sequencing. We found that clinical features and genetic characteristics have varied widely between MODY and other diabetic subjects in Northern China. FOXM1, a key molecule in the proliferation of pancreatic β-cells, has a rare mutation rs535471991, which leads to instability within the phosphorylated domain that impairs its function. Our findings indicate that FOXM1 may play a critical role in MODY, which could reduce the misdiagnose rate and provide promising therapy for MODY patients.
Introduction
Maturity-onset diabetes of the young (MODY) is a kind of monogenic diabetes mellitus that is characterized by early-onset, autosomal dominant, non-insulin dependent diabetes. Pancreatic β-cell dysfunction reduces glucose-stimulated insulin secretion during early age due to monogenic variation (1, 2). However, MODY not only manifests a distinct clinical phenotype but also emerges metabolically and genetically heterogeneously due to the various MODY-associated genes. To date, 14 genes (HNF4A, GCK, HNF1A, PDX1, TCF2, NEUROD1, KLF11, CEL, PAX4, INS, BLK, ABCC8, KCNJ11, and APPL1) have been identified, and their mutations are responsible for the initiation of MODY (3–5). Despite previous intensive linkage analyses for MODY, there are still diagnosed cases that remain genetically inexplicable (6). In addition, different studies suggest that the prevalence of specific mutations of MODY genes differs considerably among various ethnic groups (7). Without characteristic features and pedigreed awareness, most MODY patients are misdiagnosed with type 1 or type 2 diabetes in Chinese populations, who may potentially receive inappropriate therapy.
The emergence of next-generation sequencing has greatly enhanced the identification of novel mutated genes related to complicated diseases. In particular, whole-exome sequencing (WES) is a more useful and efficient strategy for identifying unknown causative genes in complex disorders, such as GCK-MODY (8) PAX4-MODY (9), and KCNJ11-MODY (10). According to Bonnefond’s finding, WES also provides a clinical tool to assess patients presenting with other monogenic diabetes (6). With regard to MODY, geography and ethnicity specific detection rates have been determined in previous studies (11). Moreover, the low detection rate of given mutations previously reported in Chinese patients suggests that the MODY-X gene may play a major role in these populations (12–14).
The aim of this study was to investigate the prevalence of the diabetic population and novel mutations responsible for MODY, especially in Northern of China. Ten diagnosed and suspected MODY patients underwent WES analysis to elucidate the molecular genotype. Focusing on monogenic diabetes enhances the understanding of pancreatic β-cell dysfunction and insulin resistance, which will promote the criterion of clinical typing and reduce misdiagnosis, finally leading to precise and effective therapy.
Materials and Methods
Experimental Subjects
Diabetes subjects were recruited from the Bio-resource Center of The Shijiazhuang Second Hospital (Shijiazhuang, China). The suspected clinical diagnoses of MODY patients were selected based on (1) the early onset of diabetes (< 25 years of age); (2) negative pancreatic autoantibodies; (3) persistently detectable C-peptide; (4) nonketotic hyperglycaemia; and (5) non-pedigreed information. The study was approved by the ethical committee of the The Shijiazhuang Second Hospital and all the patients provided their written informed consent to participate in this study.
Whole-Exome Sequencing
Five to 10 ml venous blood was collected in plastic EDTA bottles or >5 µg DNA. DNA extraction was performed using the Gentra Puregene Blood Kit (Qiagen) according to the manufacturer’s instructions. DNA was quantified for each sample using the Nanodrop (Thermo Fisher Scientific). Whole-exome libraries were constructed using the TruSeq Exome Library Preparation Kit (Illumina, CA). Sequencing was performed using the XTen system (Illumina, San Diego, CA, USA) to generate 2×150 bp paired-end reads. The depth of each sample was over 100X.
Variant Calling
Sequenced raw reads were mapped against the human reference genome (GRCh38) with Burrows-Wheeler Aligner (BWA, v0.78) (15). Variant identification was performed with Genome Analysis Toolkit (GATK, v4.1.2.0) (16). Duplicate alignments were marked and removed with Picard tool (v2.2). Variant quality filters were applied by a set of criteria (QUAL > 30, 5 < DP) and parameters as recommended by GATK (17). The annotation of variants was performed and ANNOVAR (18).
Genome-Wide Association Analysis
Variation and phenotype data were analyzed by PLINK (v1.9) (19). The variants with a minor allele frequency (MAF) of less than 0.05, missing call frequencies greater than 0.1 and Hardy-Weinberg equilibrium exact test p-value less than 0.00001 were excluded. The three diabetic groups, MODY group used as case and the T1DM and T2DM used as control, C-peptide and FPG, were selected as phenotypes to perform GWAS (Genome Wide Association Analysis) analysis.
Gene-Based Rare Variant Association Tests
To test differences burden of the MODY and MODY-X genes, total 56 genes used for burden test were selected by their potential pathogenicity in MODY or the dysfunction of pancreas. RVTESTS was used for the gene-based association by combined multivariate and collapsing (CMC) method (20). Common variants were removed with the following criteria: MAF more than 0.005 in any public database (ExAC, GnomAD, 1000 Genomes) or more than 0.01 in samples of this study; call rate of less than 0.9 in the study samples. The significance threshold here was set to 0.0167 (comparisons between the 3 groups, 0.0167 = 0.05/3), in accordance with Bonferroni correction.
Statistics
Statistical analysis was conducted by R and related packages. Wilcoxon test was used for pairwise comparison of quantitative traits, and Fisher’s exact test was used for qualitative traits. Kruskal-Wallis H test was used for one-way analysis of variance among groups. The p-value was adjusted by Benjamini & Hochberg method, which is also known as false discovery rate (FDR) (21).
Results
Clinical Characteristics of Diabetes Subjects
We sequenced a total of 200 diagnosed diabetes subjects in this study and found significant differences among the 3 groups (Figure 1), such as age (P = 2.60 × 10-8, Kruskal-Wallis test) fasting plasma glucose (FPG) (P = 0.00028, Kruskal-Wallis test), fasting plasma C-peptide (FPGC-peptide) (P = 2.80 × 10-7, Kruskal-Wallis test), insulin (P = 0.0023, Kruskal-Wallis test), HbA1c (P = 0.0015, Kruskal-Wallis test), and body mass index (BMI) (P = 0.0079, Kruskal-Wallis test). There were 130 males (65%) and 70 females (35%), and the average physical age was 53.67 ± 16.83, which ranged from 2 to 87 years. We unexpectedly found significant differences between the suspected MODY group and T1DM or T2DM group within onset age; however, we found that there were significant differences in BMI (P = 0.023, Wilcoxon test), HbA1c (P = 0.00072, Wilcoxon test), FPGC-peptide (P = 0.00044, Wilcoxon test), and FPG (P = 0.017, Wilcoxon test) between the suspected MODY group and T2DM group, whereas those results did not show a remarkable alteration within the MODY group and T2DM group. Comparatively, the T1DM group also differed from T2DM group in FPGC-peptide (P = 3.90 × 10-5, Wilcoxon test), FPG (P = 0.006, Wilcoxon test), and insulin (P = 0.0037, Wilcoxon test) (Table 1). These finding suggested that a number of clinical characteristics have varied widely among various diabetic subjects.
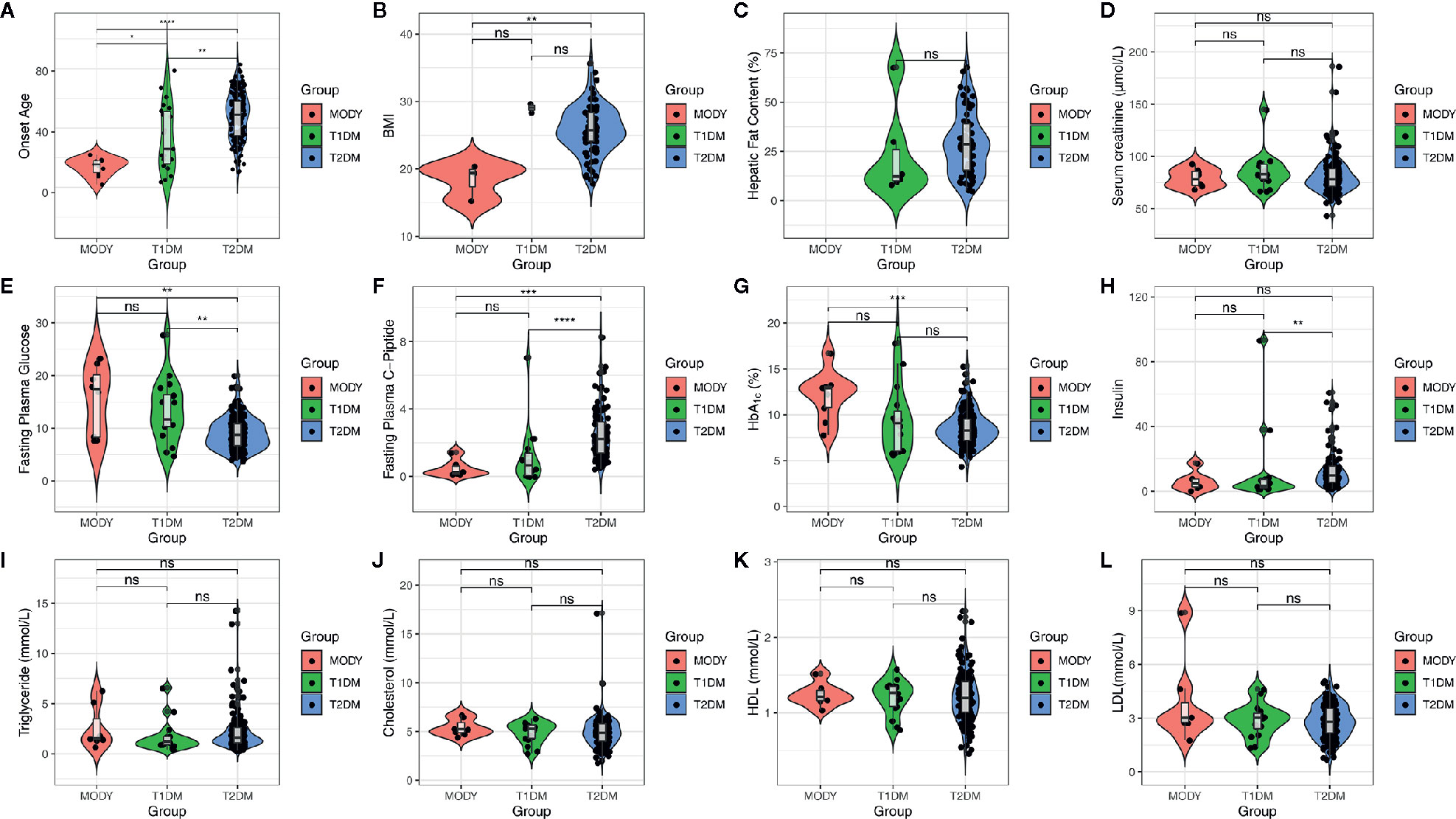
Figure 1 Clinical characteristics of subjects. X axis indicates the clinical characteristics of subjects, which including age, BMI, hepatic fat content, serum creatinine, FPG, FPGC-piptide, HbA1c, insulin, triglyceride, cholesterol, HDL, and LDL. And the colors of figure represent three diabetic group, MODY (red), T1DM (green), and T2DM (blue), respectively. The box plot is inside violin plot and the asterisk represents the significance between pairwised comparison. ns, p > 0.05; *p <= 0.05; **p <= 0.01; ***p <= 0.001; ****p <= 0.0001.
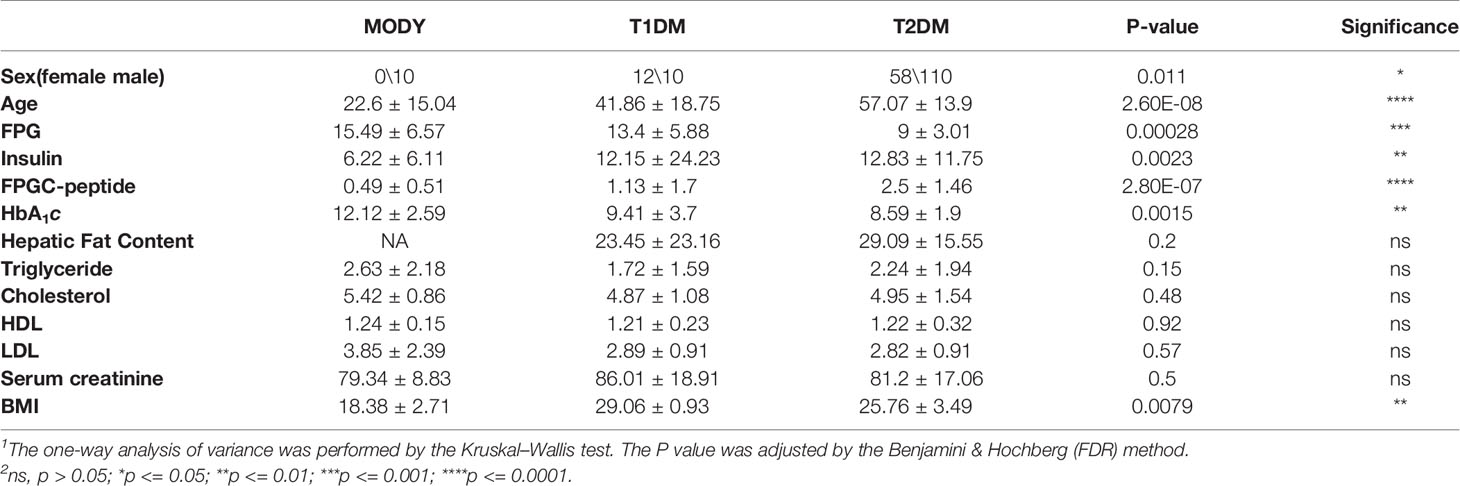
Table 1 Clinical characteristics of diabetes subjects.
Identification and Annotation of Variations
To investigate the relationship between genetic polymorphism and different types of diabetes, we performed whole-exome sequencing of the 200 diabetic cases, including T1DM, T2DM and MODY. The depth of WES achieved >100× coverage for all samples. The joint variants distributed in the genome shown in Figure 2A and the consequence type of variants are displayed in Figure 2B, including total 1,941,129 variants called from WES data, of which 417,468 remained after stringent filtering criteria were applied. We used SIFT (22) and PolyPhen2 (23) to predict whether an amino acid substitution could have an impact on the biological function of proteins, which showed that 23.8 and 26.82% variants might have a deleterious effect on the protein function (Figures 2C, D). However, according to ACMG guidelines, we found only eight likely pathogenic variants and six pathogenic variants that annotated by InterVar (24), unfortunately, none of those 14 variants was associated with diabetes.
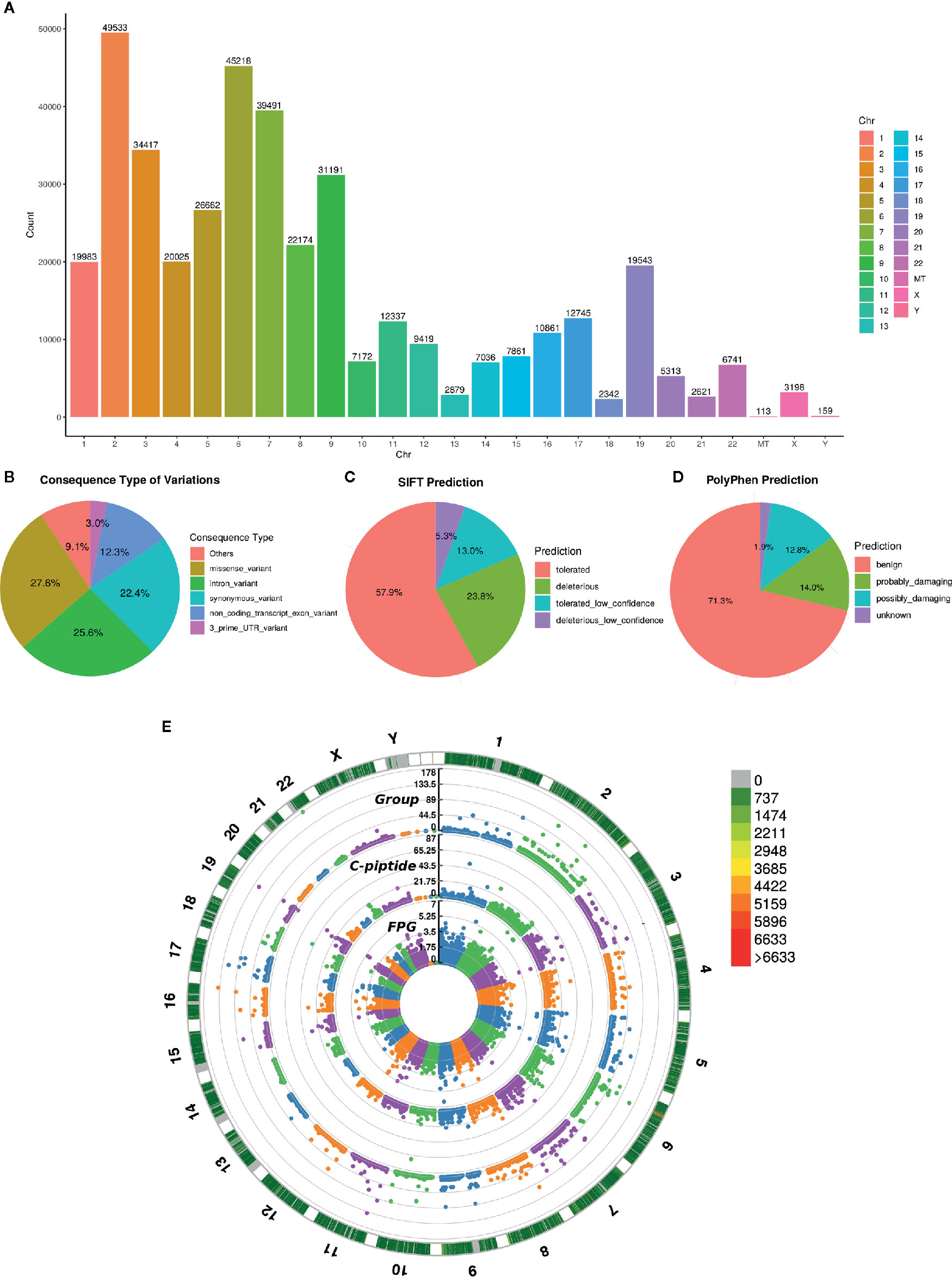
Figure 2 Variant annotation and GWAS analysis. (A) The count of mutation distributed in each chromosome, the X axis indicates the name of chromosome and the Y axis is the count of mutation. (B) Consequence type of identified variations, top five categories of variations are listed. (C, D) The pie chart of pathogenic prediction, variations annotated by Sift and PolyPhen2. (E) Manhattan plot of GWAS results, the most outside track indicates the density of mutation, colors represent the count. The 3 tracks of manhattan plot are the GWAS results calculated by diabetic group, C-piptide and FPG, respectively. The vertical axis of 3 tracks represents the -Log10(P-value).
Then, principal component analysis (PCA) was conducted on the genotypes from our cases and 1000 Genomes Project phase 3 samples (25). The PCA results showed that our 200 cases were mostly close to the East Asian (EAS) samples, as expected confirming the ethnicity of the cases used in this study (Figure S1). Since MODY was a monogenic disease, we assessed the previously reported pathogenic gene of MODY in our cases. Intriguingly, we found that the variants of MODY genes were usually accompanied by rarity and functional impact in suspected MODY cases, while other type diabetes cases were not observed.
Based on the significant difference in the clinical phenotype among the three diabetic groups, we also performed GWAS analysis. FPG, FPGC-peptide, and diabetic groups were selected to investigate the genotypic and phenotypic relationships. As displayed in Figure 2E, several significant sites (P< 10 × 10–7, Fisher’s exact test) were found in all three association results, suggesting that those sites were highly correlated with diabetes (Table S1). Enrichment analysis was performed and confirmed that those genes are relevant to diabetes (Tables S2, S3).
Potential Pathogenic Variants in Suspected Maturity-Onset Diabetes of the Young Cases
Since the allele frequency and population prevalence of MODY were lower than those in T2DM, burden analysis of rare variants across MODY and MODY-X genes was performed. Gene-based burden test was more efficient and justified for identifying associated monogenic traits than GWAS, as a single variant might show negative result due to the low frequency and the heterogeneity of pathogenic genes (26). Based on previous reports, 14 specific MODY type genes and 40 MODY-X genes were collected for the burden test. From Figure 3, we found that the mutations in HNF1A, ABCC8, and BLK were more numerous than the others among 14 MODY genes. Table 2 presents the mutation count of MODY and MODY-X genes in 10 suspected subjects; however, the percentage of non-synonymous mutations in MODY-X genes was higher than that of MODY genes. This implied that the prevalence of MODY in Northern China may be caused by other pathogenic genes, since the 14 types of MODY were first and widely reported among populations in Europe and America.
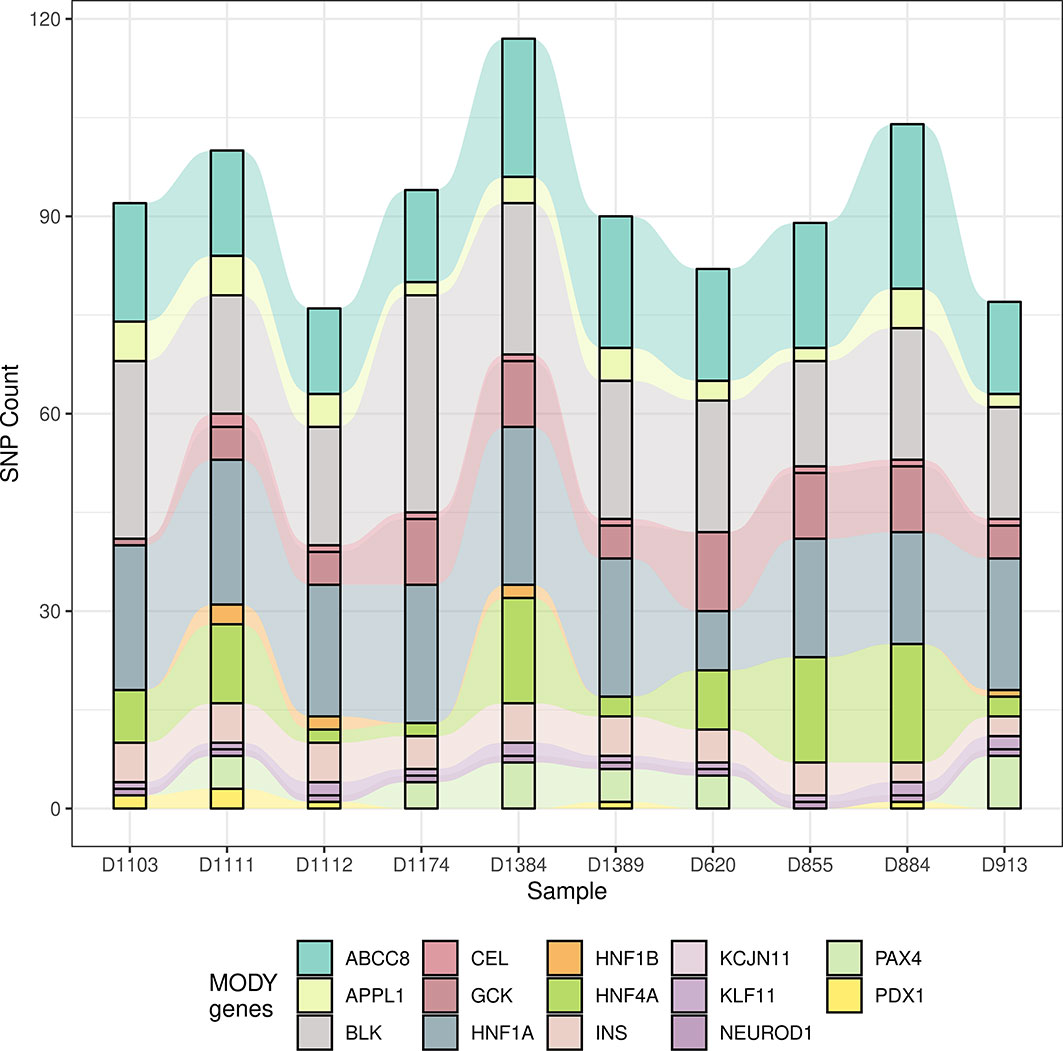
Figure 3 The count of mutation in 14 MODY genes. The alluvial diagram drawed by the count of mutation in 14 MODY genes. X axis indicates the name subjects and Y axis indicates the count of mutation. Different colors represent different genes.
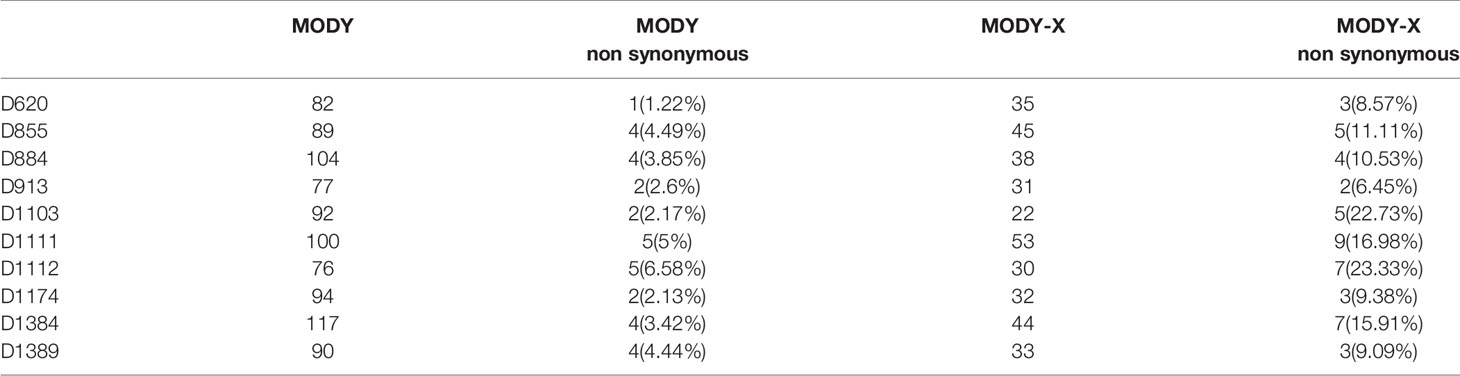
Table 2 Variation count of MODY-related genes.
To deduce the pathogenesis of MODY in Northern China with MODY and MODY-X genes, comprehensive analyses were performed to evaluate the potential sites in those genes. Sites with allele frequencies >0.01 in the 1000 Genome Project, gnomAD-ALL and gnomAD-EAS databases were removed, and burden test was applied with RVTESTS (27) on the remaining mutations between three diabetic groups. Six genes (PAX4, FoxA3, Nr5a2, Hnf4a, Ada, Foxm1) reached the significance level (P < 0.1, adjusted by Bonferroni method) for the burden test of association (Table S4). However, only the sites in ADA and FOXM1 annotated with non-synonymous mutations, which could potentially impact the function of proteins. Thus, several single nucleotide variants of those genes were prioritized in the subjects as potential candidates for MODY.
Maturity-Onset Diabetes of the Young-X Gene: FOXM1 Induced Maturity-Onset Diabetes of the Young
As the single-variant association test of these three potential candidates did not show the association with MODY sufficiently, to address whether those variants in the genes that showed a positive result from the burden test were responsible for the pathogenesis of MODY, the impact of each mutation was thoroughly researched using clinical, population or functional databases. Fortunately, there were two pedigreed subjects among the 10 suspected cases, which was only detected in the father and the son. However, we did not find any pathogenic variant in 14 MODY genes, then extend out our sight to MODY-X genes which were collected from OMIM (Online Mendelian Inheritance in Man) annotation related with diabetes. Finally, rs535471991 was revealed as a heterozygous missense mutation (NM_202002; c.T1895G) in the coding region of FOXM1. This variant was then verified by Sanger sequencing (Figures 4A, B, Figure S2).
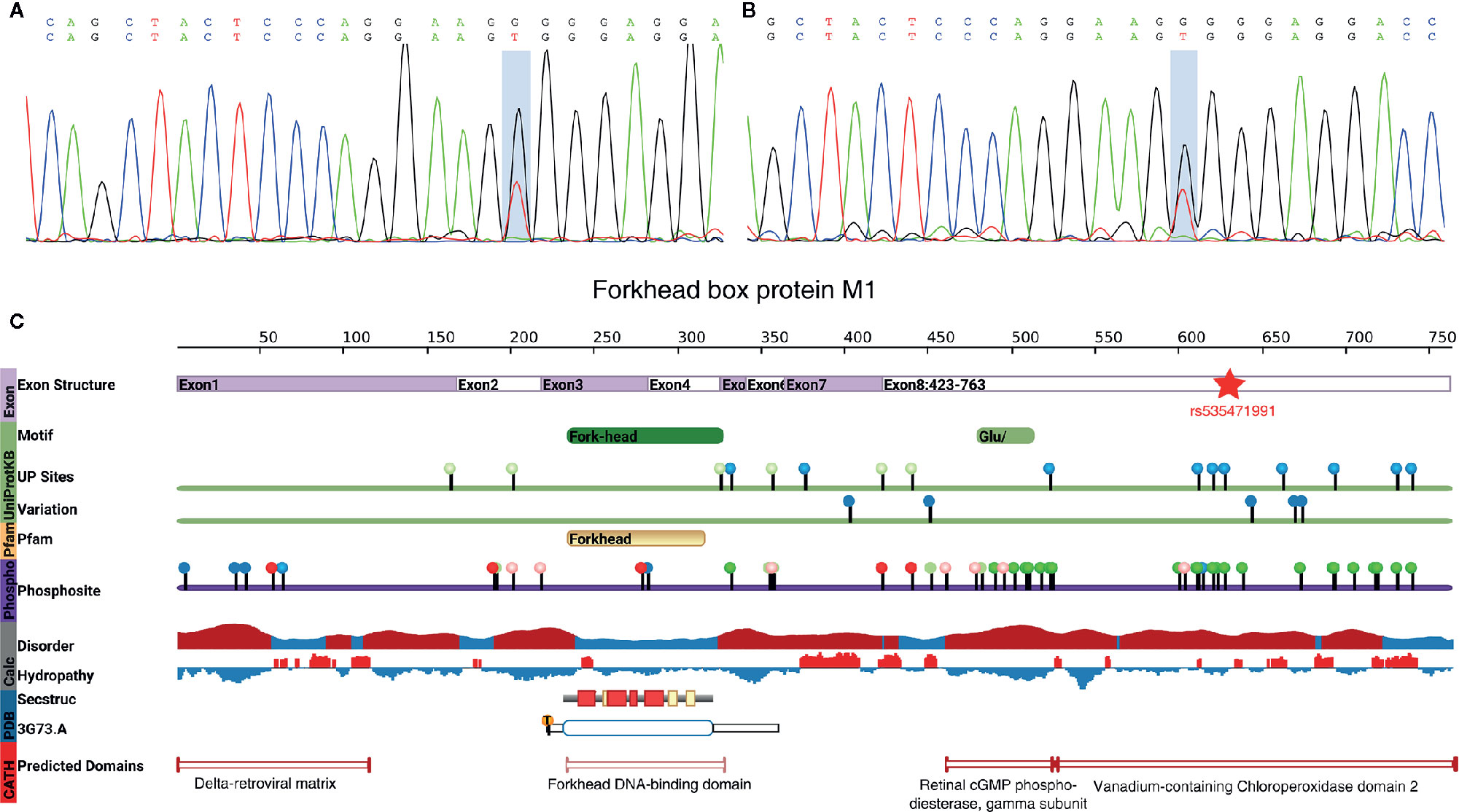
Figure 4 rs535471991 identified in FOXM1. (A, B) Results of Sanger sequencing of rs535471991 in FOXM1 of the subjects. The highlighted position indicates c.T1895G and the results showed the mutation on complementary strand. (C) The vertical color bar on the left side indicates data provenance, the top part in lavender color indicates the genomic exon structure; the green part indicates the motif and variation information from UniProtKB, UP sites shows the Uniprot annotated amino acid modifications and Variation shows non-genetic variation from ExPASy and dbSNP; the oranges part indicates the domain information from Pfam; purple part indicates the phosphorylation annotation from PhosphoSite; the grey part indicates the disorder (red: potentially disordered region, blue: probably ordered region) and hydropathy (red: hydrophobic, blue: hydrophilic) information; the blue part indicates the annotation from PDB, Secstruc shows the secondary structure and 3G73.A shows the structure from PDB; the red part indicates homology models predicted by CATH.
This mutation leads to an alteration in the amino acid sequence (p.Val632Gly). The allele frequency in the 1000 Genomes, Exome Aggregation Consortium (ExAC) (28) and Genome Aggregation Database (gnomAD) (29) was 2.00×10–5, 9.48×10–5 and 1.80×10–5 respectively, but it was not found in the Exome Sequencing Project (ESP) (30). The pathogenic prediction of SIFT, MutationTaster (31), CADD (32), and gerp++ indicated that this mutation was a deleterious mutation. Furthermore, we found that the mutation was located in vanadium-containing chloroperoxidase domain 2, which was annotated by a protein structure classification database (CATH) (33) (Figure 4C). That particular domain played a major role in phosphorylation, and the mutation existed exactly among a series of phosphorylation sites. A single nucleotide polymorphism at codon 1895, leading to the substitution of valine (Val) for glycine (Gly) in FOXM1, implicated the stability of the protein. The alteration caused the loss of isopropyl group and decreased the stability of FOXM1 (34). Furthermore, the hydrophobic state also changed from hydrophobicity to hydrophilicity, which played an important role in cell cycle and insulin signaling pathway, especially in pancreatic cell proliferation (35). These findings extrapolate that rs535471991 may behave as a potentially pathogenic variant in FOXM1.
Discussion
Two hundred diagnosed diabatic subjects were analyzed from northern China. However, multiple susceptibility genes involved in diabetes, particularly T1DM or T2DM, presented a distinguishing feature of polygenic inheritance and differed from MODY or neonatal diabetes mellitus (NDM), since WES could provide an accurate molecular diagnosis for monogenic disease.
Clinically, we found that BMI, FPG, C-peptide, and HbA1c had a significant difference between suspected MODY patients and T2DM, while no difference was observed with T1DM. MODY patients usually do not associate with obesity, which is consistent with previous reports. It is interesting to note that FPG and HbA1c were higher than T2DM and C-peptide was lower than T2DM in this study and that phenomenon also occurred in the research of Zhang (12) and Anuradha (36), despite general acceptance that patients with MODY have better glycemic control than patients with T2DM. Based on the phenotypic distinctions, GWAS and gene-based burden test were performed, however, the number of MODY patient was not large enough to obtain a convincing statistical results, which bring a limitation on this study. Besides, we use MODY group as case and T1DM and T2DM as control, some significantly differential traits might also stick out in the association results, such as BMI. Thus, we chose FPG and insulin data as covariates for association analysis to adjust the result. Fortunately, 2 MODY patients was a pair of father and son, which brought us a pedigreed information for investigating the potential pathogenic loci credibly. Since MODY-X might be the main component in China, and the relevant genes could impact the glycemic control even worse than that regulated by other diabetic genes. Therefore, the percentage of non-synonymous 14 MODY genes was sharply less than that of MODY-X genes, indirectly suggesting that the prevalence in China was distinctive, which was also comparable with previous studies (11–13).
Moreover, we also found a missence mutation in ADA except FOXM1. ADA is located in 20q12-q13.1 and has been reported as a MODY-associated region identified by genetic map of chromosomes (37). However, the mutation of emphADA only occurred in one suspected patient, unlike FOXM1 without pedigreed information, and we could not verify as a pathogenic site based on a solitary case. In contrast, the mutation in FOXM1 occurred in two paternity samples. FOXM1 appears to be a transcription factor that regulates the expression of cell cycle proteins and is essential for proper mitotic progression (38, 39). During mitosis, cyclinA-dependent binding of CDK1 (cyclin-dependent kinase 1) affects the phosphorylation of FOXM1 within the vanadium-containing chloroperoxidase domain and then regulates the S/G2 transition (40). Though the vanadium-containing chloroperoxidase domain was annotated as a disordered region that did not have a stable three-dimensional structure but had good plasticity, the disordered region modulated the stability depending on the degree of aromaticity and phosphorylation status (41). In addition, receptor-mediated insulin signaling promotes the expression and binding between FOXM1 and CENPA and PLK1 in pancreatic β-cell to enable proliferation (35). These findings suggest that the mutation in FOXM1 most likely affects the risk of MODY.
In summary, the study focused on MODY in the Northern China population. Based on WES analysis, we report a mutation in FOXM1 caused MODY potentially. Furthermore, we validated the genetic findings with an alternative sequencing method and performed in silico analysis that suggest that rs535471991 may be relevant to the development of MODY. Therefore, elucidation of the molecular genetics of FOXM1 is likely to result in better an understanding of the pathogenesis of MODY.
Data Availability Statement
Raw reads of whole-exome sequencing data has been submitted to the NCBI Sequence Read Archive (SRA; http://www.ncbi.nlm.nih.gov/sra/) under accession number SRP227138.
Ethics Statement
The study was approved by the ethical committee of The Shijiazhuang Second Hospital, Shijiazhuang, China, and all the patients provided their written informed consent to participate in this study.
Author Contributions
LZ, CL, and ZZ designed the experiment. LZ analyzed the data and wrote the manuscript. YL, QH, CL, and YX collected the samples. WZ tidied up the clinical information. NL, ZZ, and RR constructed the sequencing library. All authors contributed to the article and approved the submitted version.
Funding
We thank the patients and the stuff in The Shijiazhuang Second Hospital in this research. This work was supported by the National Natural Science Foundation of China (81400884), Key Research and Development Program Projects in Hebei Province (20190156), and Key Research and Development Program Self-Financing Projects in Hebei Province (172777120).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fendo.2020.534362/full#supplementary-material
References
2. Tattersall RB, Fajans SS. A difference between the inheritance of classical juvenile onset and maturity-onset type diabetes of young people. Diabetes (1975) 24:44–53. doi: 10.2337/diab.24.1.44
3. Craig ME. Monogenic diabetes: advances in diagnosis and treatment. Medicographia (2016) 38:98–107. doi: 10.1046/j.1464-5491.1999.00188.x
4. Prudente S, Jungtrakoon P, Marucci A, Ludovico O, Buranasupkajorn P, Mazza T, et al. Loss-of-Function Mutations in APPL1 in Familial Diabetes Mellitus. Am J Hum Genet (2015) 97:177–85. doi: 10.1016/j.ajhg.2015.05.011
5. Firdous P, Nissar K, Ali S, Ganai BA, Shabir U, Hassan T, et al. Genetic testing of maturity-onset diabetes of the young current status and future perspectives. Front Endocrinol (2018) 9:253. doi: 10.3389/fendo.2018.00253
6. Bonnefond A, Durand E, Sand O, de Graeve F, Gallina S, Busiah K, et al. Molecular diagnosis of neonatal diabetes mellitus using next-generation sequencing of the whole exome. PLoS One (2010) 5. doi: 10.1371/journal.pone.0013630
7. Hattersley AT. Maturity-onset diabetes of the young: clinical heterogeneity explained by genetic heterogeneity. Diabet Med (1998) 15:15–24. doi: 10.1002/(SICI)1096-9136(199801)15:1<15::AID-DIA562>3.0.CO;2-M
8. Bonnefond A, Philippe J, Durand E, Dechaume A, Huyvaert M, Montagne L, et al. Whole-exome sequencing and high throughput genotyping identified KCNJ11 as the thirteenthMODY gene. PLoS One (2012) 7. doi: 10.1371/journal.pone.0037423
9. Deng M, Xiao X, Zhou L, Wang T. First Case Report of Maturity-Onset Diabetesof the Young Type 4 Pedigree in a Chinese Family. Front Endocrinol (2019) 10:406. doi: 10.3389/fendo.2019.00406
10. Bamshad MJ, Ng SB, Bigham AW, Tabor HK, Emond MJ, Nickerson DA, et al. Exome sequencing as a tool for Mendelian disease gene discovery. Nat Rev Genet (2011) 12:745–55. doi: 10.1038/nrg3031
11. Kleinberger JW, Pollin T II. Undiagnosed MODY: Time for Action. Curr Diabetes Rep (2015) 15:110. doi: 10.1007/s11892-015-0681-7
12. Zhang M, Zhou JJ, Cui W, Li Y, Yang P, Chen X, et al. Molecular and phenotypic characteristics of maturity-onset diabetes of the young compared with early onset type 2 diabetes in China. J Diabetes (2015) 7:858–63. doi: 10.1111/1753-0407.12253
13. Ng MC, Cockburn BN, Lindner TH, Yeung VT, Chow CC, So WY, et al. Molecular genetics of diabetes mellitus in Chinese subjects: identification of mutations in glucokinase and hepatocyte nuclear factor-1alpha genes in patients with early-onset type 2 diabetes mellitus/MODY. Diabet Med (1999) 16:956–63.
14. Xu JY, Dan QH, Chan V, Wat NMS, Tam S, Tiu SC, et al. Genetic and clinical characteristics of maturity-onset diabetes of the young in Chinese patients. Eur J Hum Genet EJHG (2005) 13:422–7. doi: 10.1038/sj.ejhg.5201347
15. Li H, Durbin R. Fast and accurate long-read alignment with Burrows-Wheeler transform. Bioinformatics (2010) 26:589–95. doi: 10.1093/bioinformatics/btp698
16. McKenna A, Hanna M, Banks E, Sivachenko A, Cibulskis K, Kernytsky A, et al. The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res (2010) 20:1297–303. doi: 10.1101/gr.107524.110
17. DePristo MA, Banks E, Poplin R, Garimella KV, Maguire JR, Hartl C, et al. Aframework for variation discovery and genotyping using next-generation DNA sequencing data. Nat Genet (2011) 43:491–8. doi: 10.1038/ng.806
18. Wang K, Li M, Hakonarson H. ANNOVAR: Functional annotation of genetic variants from high-throughput sequencing data. Nucleic Acids Res (2010) 38:1–7. doi: 10.1093/nar/gkq603
19. Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MA, Bender D, et al. PLINK: A Tool Set for Whole-Genome Association and Population-Based Linkage Analyses. Am J Hum Genet (2007) 81:559–75. doi: 10.1086/519795
20. Li B, Leal SM. Methods for Detecting Associations with Rare Variants for Common Diseases: Application to Analysis of Sequence Data. Am J Hum Genet (2008) 83:311–21. doi: 10.1016/j.ajhg.2008.06.024
21. Benjamini Y, Hochberg Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J R Stat Soc Ser B (Methodol) (1995) 57:289–300. doi: 10.1111/j.2517-6161.1995.tb02031.x
22. Ng PC, Henikoff S. Predicting deleterious amino acid substitutions. Genome Res (2001) 11:863–74. doi: 10.1101/gr.176601
23. Adzhubei IA, Schmidt S, Peshkin L, Ramensky VE, Gerasimova A, Bork P, et al. A method and server for predicting damaging missense mutations. Nat Methods (2010) 7:248–9. doi: 10.1038/nmeth0410-248
24. Li Q, Wang K. InterVar: Clinical Interpretation of Genetic Variants by the 2015 ACMG-AMP Guidelines. Am J Hum Genet (2017) 100:267–80. doi: 10.1016/j.ajhg.2017.01.004
25. Auton A, Abecasis GR, Altshuler DM, Durbin RM, Abecasis GR, Bentley DR, et al. A global reference for human genetic variation. Nature (2015) 526:68–74. doi: 10.1038/nature15393
26. Visscher PM, Wray NR, Zhang Q, Sklar P, McCarthy M II, Brown MA, et al. 10 Years of GWAS Discovery: Biology, Function, and Translation. Am J Hum Genet (2017) 101:5–22. doi: 10.1016/j.ajhg.2017.06.005
27. Zhan X, Hu Y, Li B, Abecasis GR, Liu DJ. RVTESTS: An efficient and comprehensive tool for rare variant association analysis using sequence data. Bioinformatics (2016) 32:1423–6. doi: 10.1093/bioinformatics/btw079
28. Walsh R, Thomson KL, Ware JS, Funke BH, Woodley J, McGuire KJ, et al. Reassessment of Mendelian gene pathogenicity using 7,855 cardiomyopathy cases and 60,706 reference samples. Genet Med (2017) 19:192–203. doi: 10.1038/gim.2016.90
29. Lek M, Karczewski KJ, Minikel EV, Samocha KE, Banks E, Fennell T, et al. Analysis of protein-coding genetic variation in 60,706 humans. Nature (2016) 536:285–91. doi: 10.1038/nature19057
30. Fu W, O’Connor TD, Jun G, Kang HM, Abecasis G, Leal SM, et al. Analysis of 6,515 exomes reveals the recent origin of most human protein-coding variants. Nature (2013) 493:216–20. doi: 10.1038/nature11690
31. Schwarz JM, Cooper DN, Schuelke M, Seelow D. MutationTaster2: mutation prediction for the deep-sequencing age. Nat Methods (2014) 11:361–2. doi: 10.1038/nmeth.2890
32. Rentzsch P, Witten D, Cooper GM, Shendure J, Kircher M. CADD: Predicting the deleteriousness of variants throughout the human genome. Nucleic Acids Res (2019) 47:D886–94. doi: 10.1093/nar/gky1016
33. Dawson NL, Lewis TE, Das S, Lees JG, Lee D, Ashford P, et al. CATH: An expanded resource to predict protein function through structure and sequence. Nucleic Acids Res (2017) 45:D289–95. doi: 10.1093/nar/gkw1098
34. Pace CN, Fu H, Fryar KL, Landua J, Trevino SR, Shirley BA, et al. Contribution of Hydrophobic Interactions to Protein Stability. J Mol Biol (2011) 408:514–28. doi: 10.1016/j.jmb.2011.02.053
35. Shirakawa J, Fernandez M, Takatani T, El Ouaamari A, Jungtrakoon P, Okawa ER, et al. Insulin Signaling Regulates the FoxM1/PLK1/CENP-A Pathway to Promote Adaptive Pancreatic _ Cell Proliferation. Cell Metab (2017) 25:868–82.e5. doi: 10.1016/j.cmet.2017.02.004
36. Anuradha S, Radha V, Deepa R, Hansen T, Carstensen B, Pedersen O, et al. A prevalent amino acid polymorphism at codon 98 (Ala98Val) of the hepatocyte nuclear factor-1alpha is associated with maturity-onset diabetes of the young and younger age at onset of type 2 diabetes in Asian Indians. Diabetes Care (2005) 28:2430–5. doi: 10.2337/diacare.28.10.2430
37. Rothschild CB, Akots G, Hayworth R, Pettenati MJ, Rao PN, Wood P, et al. A genetic map of chromosome 20q12-q13.1: Multiple highly polymorphic microsatellite and RFLP markers linked to the maturity-onset diabetes of the young (MODY) locus. Am J Hum Genet (1993) 52:110–23. doi: 10.1016/0378-1119(94)90254-2
38. Wang X, Kiyokawa H, Dennewitz MB, Costa RH. The Forkhead Box m1b transcription factor is essential for hepatocyte DNA replication and mitosis during mouse liver regeneration. Proc Natl Acad Sci USA (2002) 99:16881–6. doi: 10.1073/pnas.252570299
39. Laoukili J, Kooistra MRH, Bras A, Kauw J, Kerkhoven RM, Morrison A, et al. FoxM1 is required for execution of the mitotic programme and chromosome stability. Nat Cell Biol (2005) 7:126–36. doi: 10.1038/ncb1217
40. Saldivar JC, Hamperl S, Bocek MJ, Chung M, Bass TE, Cisneros-Soberanis F, et al. An intrinsic S/G2 checkpoint enforced by ATR. Science (2018) 361:806–10. doi: 10.1126/science.aap9346
Keywords: maturity-onset diabetes of the young (MODY), diabetes, whole-exome sequencing (WES), SNP, FoxM1
Citation: Zhong L, Zhao Z, Hu Q, Li Y, Zhao W, Li C, Xu Y, Rong R, Zhang J, Zhang Z, Li N and Liu Z (2021) Identification of Maturity-Onset Diabetes of the Young Caused by Mutation in FOXM1 via Whole-Exome Sequencing in Northern China. Front. Endocrinol. 11:534362. doi: 10.3389/fendo.2020.534362
Received: 12 May 2020; Accepted: 27 November 2020;
Published: 09 February 2021.
Edited by:
Hanne Scholz, University of Oslo, NorwayReviewed by:
Inês Cebola, Imperial College London, United KingdomSenta Georgia, Children’s Hospital of Los Angeles, United States
Claire C. Morgan, Centre for Genomic Regulation (CRG), Spain
Copyright © 2021 Zhong, Zhao, Hu, Li, Zhao, Li, Xu, Rong, Zhang, Zhang, Li and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zanchao Liu, bGl1emFuY2hhbzIwMDdAMTYzLmNvbQ==