 Catherine Apio1
Catherine Apio1 Min Kyong Moon
Min Kyong Moon Oran Kwon
Oran Kwon Taesung Park
Taesung Park- 1Interdisciplinary Program in Bioinformatics, Seoul National University, Seoul, Republic of Korea
- 2Department of Statistics and Actuarial Science, Soongsil University, Seoul, Republic of Korea
- 3Department of Internal Medicine, College of Medicine, Seoul National University, Seoul, Republic of Korea
- 4Department of Nutritional Science and Food Management, Ewha Womans University, Seoul, Republic of Korea
- 5Department of Statistics, Seoul National University, Seoul, Republic of Korea
Introduction: The influence of dietary patterns measured using Recommended Food Score (RFS) with foods with high amounts of antioxidant nutrients for Type 2 diabetes (T2D) was analyzed. Our analysis aims to find associations between dietary patterns and T2D and conduct a gene-diet interaction analysis related to T2D.
Methods: Data analyzed in the current study were obtained from the Korean Genome and Epidemiology Study Cohort. The dietary patterns of 46 food items were assessed using a validated food frequency questionnaire. To maximize the predictive power of the RFS, we propose two weighted food scores, namely HisCoM-RFS calculated using the novel Hierarchical Structural Component model (HisCoM) and PLSDA-RFS calculated using Partial Least Squares-Discriminant Analysis (PLS-DA) method.
Results: Both RFS (OR: 1.11; 95% CI: 1.03- 1.20; P = 0.009) and PLSDA-RFS (OR: 1.10; 95% CI: 1.02-1.19, P = 0.011) were positively associated with T2D. Mapping of SNPs (P < 0.05) from the interaction analysis between SNPs and the food scores to genes and pathways yielded some 12 genes (CACNA2D3, RELN, DOCK2, SLIT3, CTNNA2, etc.) and pathways associated with T2D. The strongest association was observed with the adipocytokine signalling pathway, highlighting 32 genes (STAT3, MAPK10, MAPK8, IRS1, AKT1-3, ADIPOR2, etc.) most likely associated with T2D. Finally, the group of the subjects in low, intermediate and high using both the food scores and a polygenic risk score found an association between diet quality groups with issues at high genetic risk of T2D.
Conclusion: A dietary pattern of poor amounts of antioxidant nutrients is associated with the risk of T2D, and diet affects pathway mechanisms involved in developing T2D.
1 Introduction
Diabetes is one of the most significant global public health concerns, imposing a heavy global burden on public health and socioeconomic development. Although incidence has started to decrease in some countries, the prevalence of diabetes has increased in recent decades in other developed and developing countries (1). Type 2 diabetes (T2D) makes up around 90% of cases of diabetes (2), and according to the World Health Organization, the number of people diagnosed with T2D is on the rise annually, even among young people (2).
The development of T2D is caused mainly by an interplay of unhealthy lifestyles and environmental and genetic factors. While some of these factors are under individual control, such as lifestyle, others are not, such as increasing age, sex, and genetics. Diet has also been firmly attributed to the risk of T2D (3, 4). This association has been confirmed in many prospective studies (5–8). In addition, T2D is an increasingly prevalent metabolic disorder causing severe micro- and macrovascular complications, namely, cardiovascular disease (CVD), retinopathy, neuropathy, and nephropathy (3, 9). Moreover, the beneficial effects of weight loss or lifestyle modification have been reported to prevent, delay, and reduce disease incidence (2, 10).
Therefore, valid estimation of overall dietary patterns (habitual food and nutrient intakes) has become a fundamental aspect of studying the relationships between diet and health status (8). General dietary habits can provide insights beyond the role of nutrients and single foods (2, 11). Some of the indices are based on national nutrition recommendations and national dietary guidelines that assess overall nutritional patterns, including the healthy eating index, alternate healthy eating index, healthy diet indicator, Recommended Food Score (RFS), diet quality index, Diet Quality Score, Mediterranean Diet Score (MDS), and Alternate Mediterranean Diet Score (aMDS). The RFS, MDS, and aMDS based on foods and food groups are relatively more straightforward in assessing overall dietary patterns and are based on food groups and nutrients (9, 11).
Recently, the pathophysiological influence of gene–lifestyle or gene–environment (G × E) interactions on the risk of T2D is currently under intensive research. Evidence of G × E interactions on the risk of development of T2D has been reported in many prospective studies reviewed here (3, 4). Here, G × E interaction analyses focusing on gene–diet interaction using RFS and SNPs while controlling for other confounding lifestyle factors like smoking, alcohol and coffee consumption, income and education levels, and so forth, were carried out for the Korean adult population. Odds ratios (ORs) with 95% confidence intervals (CIs) for the association and interaction analyses were calculated. Furthermore, the subjects were grouped into low, intermediate, and high diet quality groups using the food scores and genetic risk groups using an estimated global polygenic risk score (PRS), and interaction analyses between the groups were performed. Data from the Korean Genome and Epidemiology Study (KoGES) consortium, a prospective cohort study conducted in Korea in 2021, was used for our analysis (12–14).
However, a previous study using RFS for the Korean population could not show an acceptable association with the risk of T2D (11, 15, 16). This may be because the contributing power of each food item is different from each other: some food items contribute more than others. Therefore, weighted food scores were developed to maximize the unweighted RFS’s interaction and predictive power. One score, HisCoM-RFS, was proposed using a novel statistical model called the Hierarchical Structural Component model (HisCoM). HisCoM estimates the weights for each food item used in the RFS calculation. HisCoM-RFS was contrasted for comparable results in different association analyses with PLSDA-RFS, another weighted food score calculated using the known partial least squares-discriminant analysis (PLS-DA) method. It finds another set of weights for each food item without considering food group categories. Both approaches assume a linear relationship exists between food items and the outcome T2D.
2 Materials and methods
2.1 Study population
The study participants were recruited through the Korean Genome and Epidemiology Study (KoGES), a consortium established for the identification of gene–environment factors and their interactions in commonly known diseases, such as T2D, hypertension, metabolic syndrome, obesity, and cardiovascular disease in Koreans (12). KoGES is a project comprising six prospective cohort studies categorized into population-based and gene–environment model studies extensively explained elsewhere (13, 14). We focused on the KoGES Ansan–Ansung study cohort whose data collection was initiated in 2001–2002 (baseline), with follow-up examinations conducted every 2 years. The participants were unrelated Korean individuals (N = 10,038) aged 40–69 years, representing urban (Ansan) and countryside (Ansung) populations. Our analyses involved data from the baseline recruit (17). Among the KoGES cohorts, the KoGES Ansan–Ansung cohort was chosen because it possesses the Frequency Food Questionnaire and has a more extended follow-up period than other cohorts.
2.2 Genotype data
The genotype data of the above participants were obtained through the Korea Association Resource (KARE) project, which was established in 2007 to conduct a large-scale genome-wide association study (GWAS) of the participants recruited through the KoGES Ansan–Ansung cohorts (18). The participants’ common standard variant genotype data were generated using the Affymetrix Genome-Wide Human SNP array 5.0. The chip comprised around 50 million autosomal single-nucleotide polymorphisms (SNPs). There were 352,228 SNPs in 8,840 individuals left after quality control (QC) analysis. SNPs having minor allele frequencies<0.05, genotype calling rates<95%, and Hardy–Weinberg equilibrium P-values<10−6 were removed. Only participants with consistent sex and calling rates (>90%) were preserved. Missing values of existing variants were imputed after QC, and PLINK (v1.90) (19) was used during QC. The SNPs were mapped to the UCSC hg19 genomic coordination. Missing genotype data were imputed using the Beagle 5.0 (20) software program.
2.3 Diagnosis of T2D subjects
After participants had fasted for at least 8 h, fasting plasma glucose (FPG; mg/dL), fasting plasma insulin (FPI; IU/mL), and triglycerides (TG; mg/dL) were measured. High-performance liquid chromatography was used to measure glycosylated hemoglobin (HbA1c). The following criteria were used to determine T2D subjects: (1) taking medication any for T2D; (2) fasting plasma glucose (FPG) ≥126 mg/dL, 2-h postprandial blood glucose (Glu120) ≥200 mg/dL, or glycated hemoglobin (HbA1c) ≥6.5%; and (3) age of disease onset ≥40 years. The following criteria selected normal subjects: (1) FPG<100 mg/dL, Glu120<140 mg/dL, and HbA1c<5.7% and (2) no history of diabetes (never been diagnosed with T2D) (21, 22). If a subject does not meet these criteria, then the subject is excluded from being a normal subject.
2.4 Covariates
We selected 10 covariates as adjustment and lifestyle factors for control during the analysis. This included age, sex, area (urban or village), body mass index (BMI), smoking, alcohol consumption, coffee consumption, metabolite equivalents (physical activity), education level, and income level. The covariates were assessed using self-administered questionnaires. The monthly household income is categorized into eight groups (0.5, 0.5~1, 1~1.5, 1.5~2, 2~3, 3~4, 4~6, and >6 million Korean won). Here 1,000 Korean won approximately corresponded to 0.9 US dollars. Smoking was categorized into non-smokers as well as former, occasional, and habitual smokers. Alcohol consumption was categorized into non-drinkers, former drinkers, and current drinkers. Time spent during five physical activity states (inactive, very light, light, moderate, and intense) were classified into nine ranges (0; none, 1;<30 min, 2; 30~60 min, 3; 60~90 min, 4; 90~2 h, 5; 2~3 h, 6; 3~4 h, 7; 4~5 h, 8; >5 h). These were converted to metabolic equivalents (METs) according to (17) (1.0 for inactive, 1.5 for very light, 2.4 for light, 5.0 for moderate, and 7.5 for intensive). The BMI (kg/m2) of the participants was computed by dividing the weight (nearest 0.1 kg) in kilograms by the height (measured to the nearest 0.1 cm) in square meters. A further detailed description of the characteristics of the KoGES cohort can be found here (23). The list of the covariates used in our analyses is shown in Supplementary Table 1.
2.5 Dietary assessment
Dietary assessment was done through a validated semiquantitative food frequency questionnaire (FFQ) (24, 25), which records the consumption frequencies and portion sizes of 106 (Ansan and Ansung study) food items and drinks consumed during the previous year. The FFQ consisted of nine categories: never or seldom, once a month, one to two times a week, two to three times a week, three to four times a week, five to six times a week, once daily, twice daily, or more than three times daily. Furthermore, their daily frequency of meals was recorded as one meal a day, two meals a day, three meals a day, more than four meals a day, or irregular.
2.6 Recommended food score
Intake information from the FFQ was used to calculate the study subjects’ RFS. RFS measures the overall dietary pattern of the individuals, a food tally based on reported consumption of foods bearing high amounts of antioxidant nutrients, consistent with the current American dietary guidelines of Kant et al., modified for the Korean population (11, 15, 16). A total of 45 food items (10 food groups) and one response for “daily frequency of meals” was selected and used to calculate the RFS score. Participants were assigned one point for each recommended food and regular eating pattern (three meals a day) if they ate it at least once a week or more. The food items (and their corresponding points) for the RFS were as follows; daily frequency of meals (1), grains (1), legumes (4), vegetables (16), seaweeds (2), fruits/juices (12), fish (5), dairy products (3), nuts (1), and tea (1). Then, the score ranged from 0 to 46 points, and a higher score implies a better diet quality. The food items and their corresponding points for the RFS are shown in Supplementary Table 2. Subjects with increased consumption of foods rich in high antioxidant nutrients were given a higher score and lower scores to issues with lower consumption. All these antioxidant foods are healthy, and bad/unhealthy foods like sugar or sweets were not considered in the construction of this RFS.
2.7 HisCoM-RFS based on the HisCoM model
The calculated RFS assumes that each food item in a given category contributes equally to the diet quality of an individual. However, it is more reasonable to think that some food items contribute more than others. Therefore, we calculated a weighted food score using the RFS called HisCoM-RFS (Hierarchical Structural Component model (HisCoM) to analyze food scores) to capture this information. HisCoM estimates each food item’s weight and the significance level between the food category and the outcome T2D. The HisCoM used here (Figure 1A) is a modification of the Pathway-based approach using HierArchical components of collapsed RAre variants Of the High-throughput sequencing data (PHARAOH) model (26) that was developed by our laboratory. PHARAOH employs ridge penalization to control for any correlations between variables. It assumes that the biomarkers have a linear relationship with a phenotype of interest while analyzing entire pathways simultaneously.
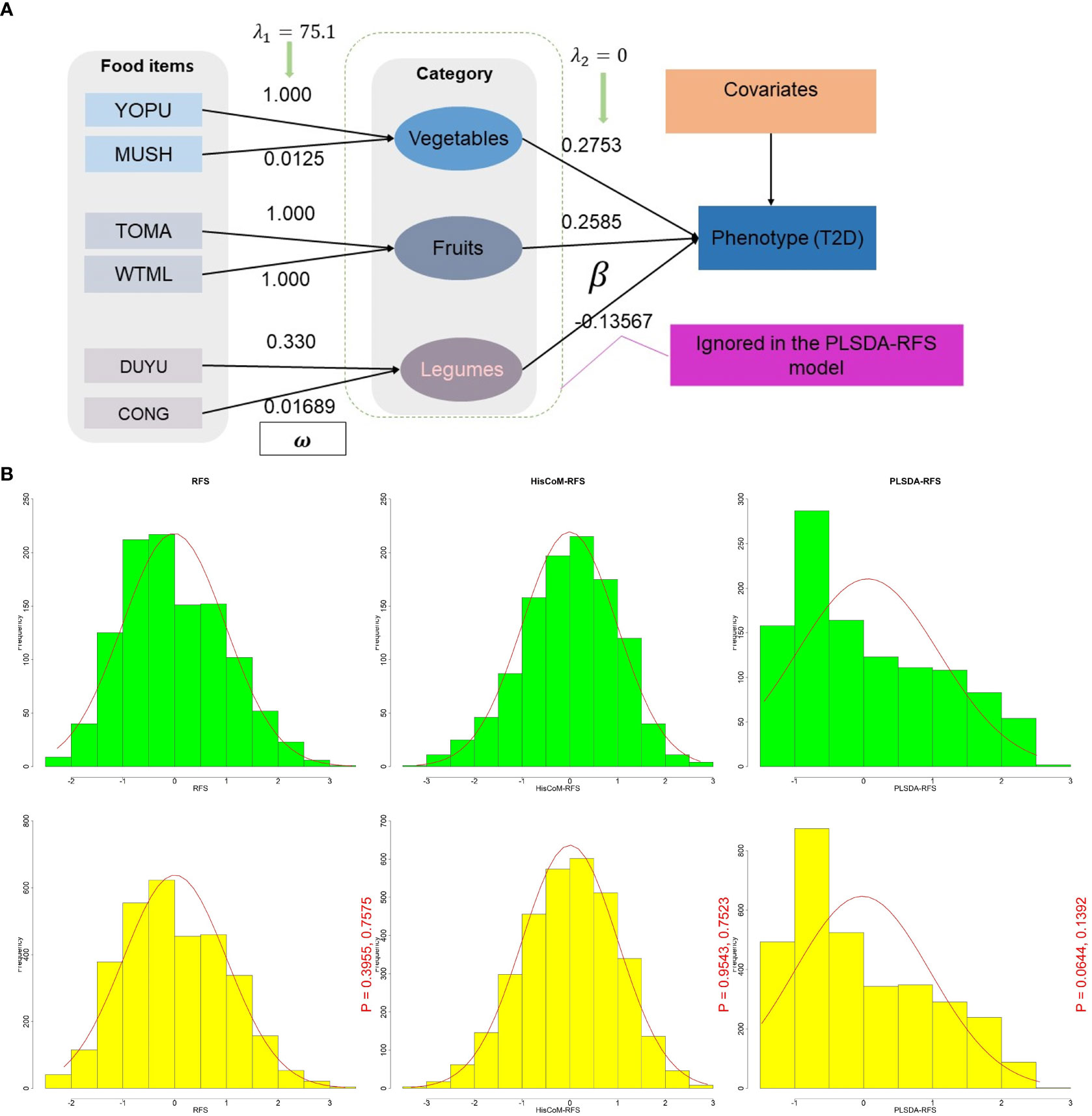
Figure 1 (A) A schematic diagram of the HisCoM model showing HisCoM-RFS calculation using three food categories. The rectangles and ellipses represent food items and food categories, respectively. So that the phenotype is a linear combination of the food items and not the food categories. HisCoM, Hierarchical Structural Component model. (B) Density plot distribution of RFS, HisCoM-RFS, and PLSDA-RFS between T2D (green) and control subjects (yellow). The p-values are from the Wilcoxon rank sum test and the Kolmogorov-Smirnov test, respectively between green and yellow. RFS, Recommended Food Scores; HisCoM, Hierarchical Structural Component model; PLS-DA, Partial Least Squares-D-iscriminant Analysis method; HisCoM-RFS, weighted RFS calculated by HisCoM model; PLSDA-RFS, weighted RFS calculated by PLS-DA method.
For HisCoM, let define a phenotype (T2D) of the ( subject and assume that it independently follows an exponential family distribution. Let be the number of food items in the food category. Let denote the food score of the item in the food category for the subject. Let denote a weight assigned to and indicate the coefficient connecting the food category to the phenotype. Specifically, the relationship between the food scores of each food item and the case–control phenotype is established in such a way that;
Therefore, HisCoM-RFS is calculated as follows:
where . The is the logit function from logistic regression models explaining the log of odds (ratio of T2D subjects to normal subjects).
To estimate parameters HisCoM, the alternating least squares (ALS) algorithm was used, which was initially proposed by de Leeuw et al. (27) and adopted for the generalized structured component analysis (GSCA) (28) and later for the penalized log-likelihood function (26). PHARAOH employed the ALS algorithm in its penalized log-likelihood part (26). This ALS algorithm consists of two steps that iterate until convergence;
Step 1: For fixing the weight coefficient estimates , update the food category coefficient estimates , in the sense of least squares.
Step 2: For fixing food category coefficient estimates , update the weight coefficient estimates , in the sense of least squares.
We use a penalization approach to consider potential correlations between food items and categories. In this study, we adopt a ridge-type penalty to control multicollinearity between food items ( only and not between food categories so that the phenotype is a linear combination of the food items and not the food categories. The significance of the estimated parameters was tested through the permutation by resampling the phenotypes.
2.8 PLSDA-RFS based on the PLS-DA method
In addition to the HisCoM method, another weighted food score called PLSDA-RFS was calculated using the commonly known partial least squares regression (PLS-R) for discriminant analysis (PLS-DA) method (29). PLS-DA is derived from PLS-R, where the response vector assumes discrete values (T2D) and considers the correlation between T2D and the food items while maximizing the covariance between T2D and the weights calculated (30, 31). PLS-DA incorporates T2D and RFS information in defining the scores and loadings (weights) used to calculate PLSDA-RFS. However, PLS-DA does not consider the food groups during the weight and coefficient calculation. PLSDA-RFS was calculated by multiplying the previously calculated unweighted RFS scores with the estimated weight matrix and the coefficient values in the first column of the estimated coefficient matrix.
2.9 Statistical analyses
Unless specified, statistical analyses were conducted using R software (version 4.2.1) to identify the association between T2D and diet. Categorical and continuous variables for participants’ general characteristics according to the case–control study for T2D were compared using the chi-squared test (test) and two-sample t-test, respectively. The generalized linear regression model (GLM) was used to find the association ORs (95% CI) between diet (RFS, HisCoM-RFS, and PLSDA-RFS) and T2D. Secondly, the food scores were grouped into low, intermediate, and high diet quality groups and their ORs (95% CI) were estimated. After ranking the food scores, all food scores with ranks below 33.33% were grouped as low, intermediate for those below 66.6%, and above 66.6% as high. Thirdly, since genetic and lifestyle factors influence the development of T2D, gene–diet interaction analysis focused on the “interaction effect,” unlike the “main effect” between SNPs and food scores, was performed to identify SNPs, genes, and pathways associated with T2D. A significant interaction shows the role of dietary habits affecting pathways during the development of T2D. Logistic regression in PLINK (v1.90, Windows) was used for this analysis (19, 32). The analyses were adjusted for age, sex, area, BMI, smoking, alcohol consumption, coffee consumption, education level, income level, and METs following other studies involving KoGES Ansan–Ansung data (2, 16, 33–37). A statistical significance level of P< 0.05 was used unless specified. To find genes and pathways, significant SNPs from the interaction effect were mapped to genes and then pathways using the Multi-marker Analysis of GenoMic Annotation (MAGMA, windows version) tool, a generalized gene-set analysis tool of GWAS data (38, 39). MAGMA analyzes genes and pathways by multiple linear regression after principal component analysis for each gene. Pathway information was obtained from the Kyoto Encyclopedia of Genes and Genomes (KEGG) (40) database, whereas the gene location file (GRCh37) was downloaded from the National Center for Biotechnology Information (NCBI) website. Lastly, a global polygenic risk score (PRS) for T2D was generated using independent summary statistics (N = 191,764; 36,614 cases and 155,150 controls) from Biobank Japan (Supplementary Figure 1) (41). LDpred (42) was used to reweight each variant according to (1) the effect size, (2) the strength of statistical significance observed for T2D, and (3) linkage disequilibrium (LD) between a variant and others nearby. A tuning parameter that denotes the proportion of causal variants (P) estimated with the validation samples (P = 0.1) was selected. Nine categories capturing the interactions between genetic risk (low (reference), intermediate, and high) based on PRS and diet quality (low, intermediate, and high (reference)) based on the food scores were created. Adjusted ORs of the nine categories were calculated.
3 Results
3.1 Baseline characteristics of the subjects
A total of 350,000 SNPs and 8,840 subjects were left after genotype data QC. Diagnosis of the subjects for T2D left us with 4,975 subjects (1,288 cases and 3,687 control). The control subjects here are normal subjects without T2D. After adjusting for the covariates (for age, sex, area, BMI, smoking, alcohol consumption, coffee consumption, education levels, income levels, and METs), 4,292 (1,090 cases and 3,202 control) subjects were left. The characteristics of the 4,292 subjects are summarized in Table 1, presented as means ± standard deviation for continuous variables and percentage proportions for categorical variables. Smoking and alcohol consumption were left with two groups after data preprocessing. Income was summarized into five levels (<0.5~1, 1.0~2.0, 2.0~3.0, 3.0~4.0, >4.0), education into four classes (combined college, university, and graduate school into one level of higher education) and coffee consumption into four groups (never/seldom, monthly, weekly, and daily) in all analyses, to reduce on the number of levels of these variables. T2D was significantly associated with the area, sex, age, BMI, smoking, education level, income level, coffee consumption, PLSDA-RFS, and PRS.
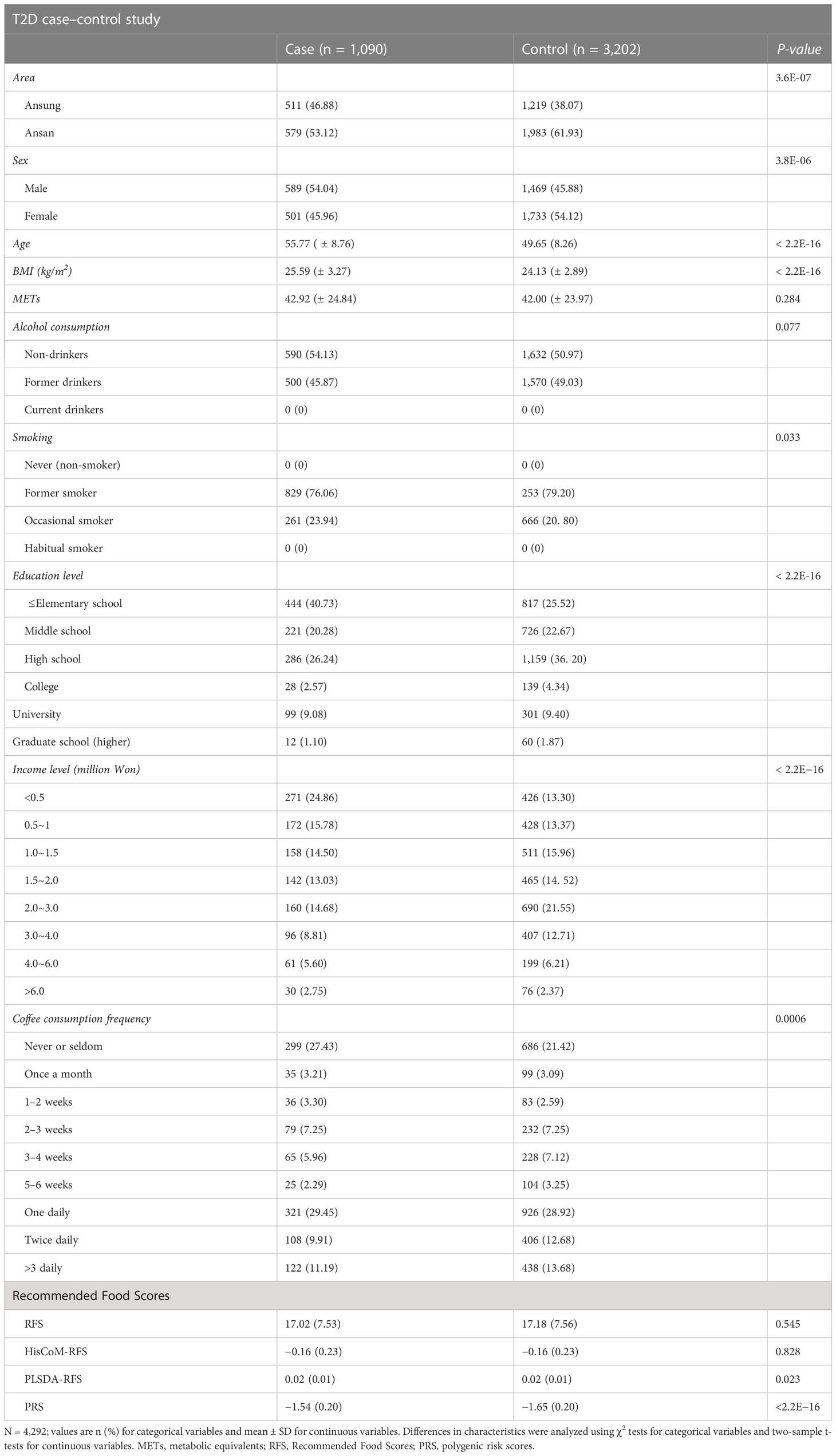
Table 1 Baseline characteristics and food scores of participants according to T2D case–control subjects.
3.2 HisCoM-RFS and PLSDA-RFS
The HisCoM and PLS-DA methods estimated the weights and coefficients (used to calculate the weighted food scores HisCoM-RFS and PLSDA-RFS, as shown in Figure 1A. HisCoM estimated the weights of the 45 food items, the daily frequency of meals, and the coefficients of the 10 food categories and is shown in Supplementary Tables 2, 3. PLS-DA also estimated the coefficients and weights of the 45 food items and the daily frequency of meals and was used to calculate PLSDA-RFS. The density plots of RFS, HisCoM-RFS, and PLSDA-RFS for control subjects (yellow; n = 3,347; bandwidth = 1.351, 0.04067 and 0.002164, respectively) and T2D subjects (green, n = 1,159; bandwidth = 1.653, 0.04929 and 0.002787, respectively) are shown in Figure 1B. There are no noticeable differences between the density plots between T2D and control subjects but between the food scores. We compared the distribution of the food scores between case and control subjects using the Wilcoxon rank-sum test and the Kolmogorov–Smirnov test. The P-values of the tests are shown in Figure 1B. The Wilcoxon rank-sum test showed that the two groups are not different, whereas the Kolmogorov–Smirnov test showed that the two groups come from the same distribution.
3.3 Association between diet quality measured using food scores and T2D
Of the three food scores, only PLS-DA was positively associated with T2D unadjusted for the other covariates (OR: 1.0839; 95% CI: 0.9293–1.0622; P = 0.0203). The food scores were standardized for comparable results. After adjusting for potential covariates (age, sex, BMI, and area) and lifestyle factors (smoking, alcohol and coffee consumption, education level, income level, and METs), both RFS (OR: 1.11; 95% CI: 1.03–1.20; P = 0.014) and PLSDA-RFS (OR: 1.10; 95% CI: 1.02–1.19, P = 0.011) were positively associated with T2D, as shown in Figure 2. This indicates that a person’s dietary patterns can affect the development of T2D. Grouping the food scores into low, intermediate, and high diet quality groups, with high being the reference group, showed the low diet quality group of RFS (OR: 0.83; 95% CI: 0.68–1.01, P = 0.059) and the intermediate diet quality group of PLSDA-RFS (OR: 0.80, 95% CI: 0.73–1.06; P = 0.017) to be associated with T2D, as shown in Figure 3. From the two analyses, being female, age, BMI, being an occasional smoker, and at least weekly and daily consumption of coffee were constantly associated with T2D (P< 0.05).
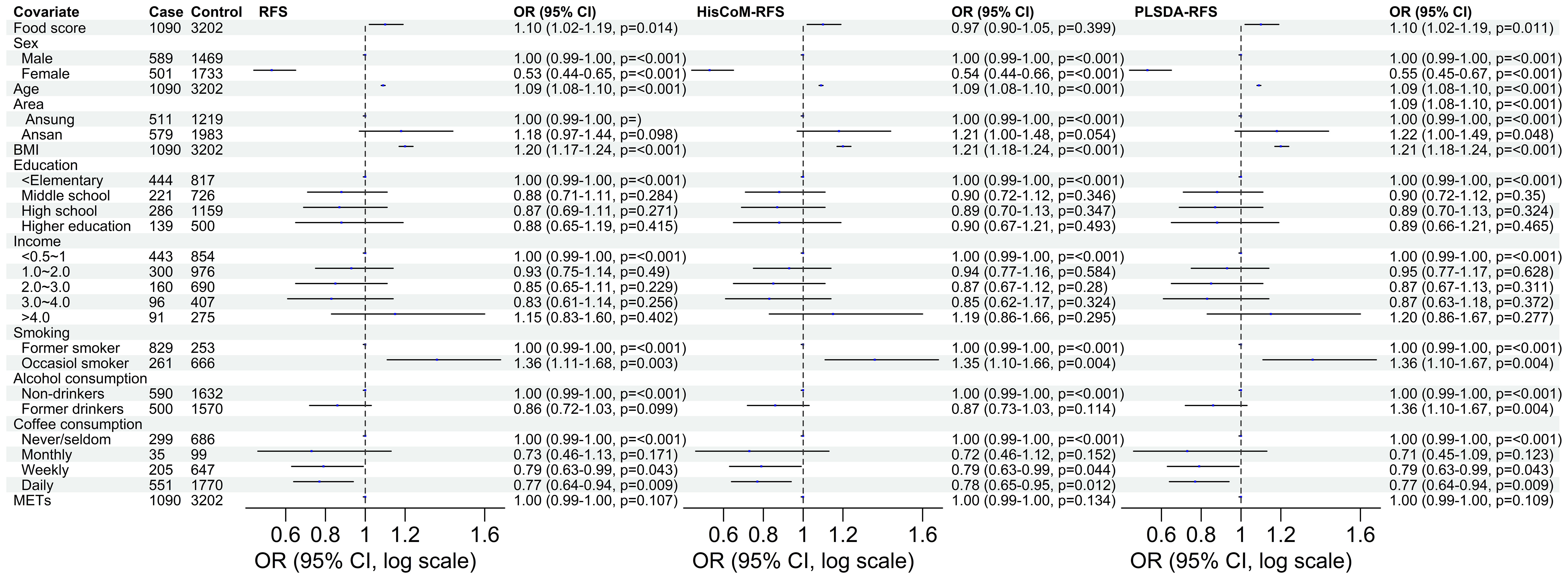
Figure 2 The odd ratios of RFS, HisCoM-RFS and PLSDA-RFS adjusted for age, sex, area, BMI, income level, education level, smoking, alcohol and coffee consumption, and METs, showing the association between dietary habits and T2D. The P-values were calculated using multiple logistic regression. METs, metabolic equivalents; BMI, body mass index; RFS, recommended food scores.
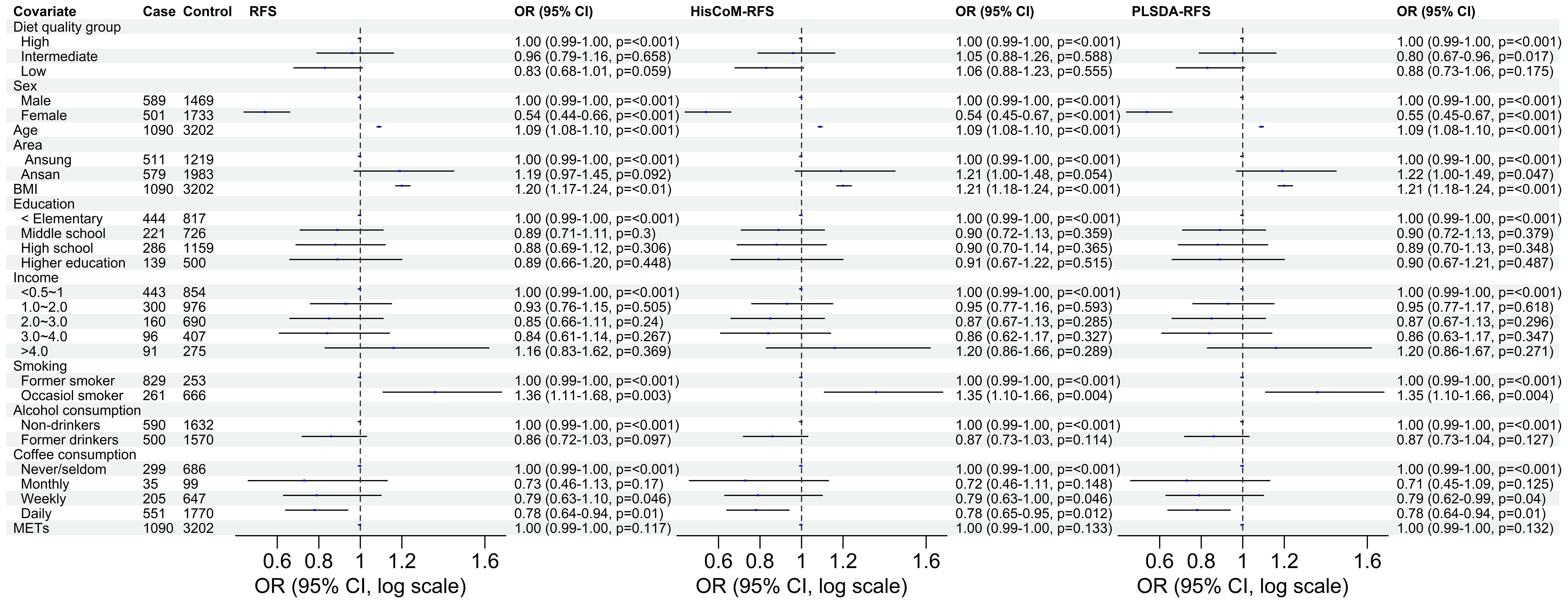
Figure 3 The odd ratios of RFS, HisCoM-RFS and PLSDA-RFS diet quality groups adjusted for age, sex, area, BMI, income level, education level, smoking, alcohol and coffee consumption, and METs, showing the association between dietary quality and T2D. High diet quality group is the reference group. The P-values were calculated using multiple logistic regression. METs, metabolic equivalents; BMI, body mass index; RFS, recommended food scores.
3.4 Gene–diet interaction analysis
The 8,205, 9,331, and 103,408 SNPs for RFS, HisCoM-RFS, and PLSDA-RFS, respectively (3,301, 59, and 4,260 SNPs were significant at P< 0.001), were significant with “interaction effect” P< 0.05. Their Manhattan plots are shown in Supplementary Figure 1. These SNPs were mapped to genes and pathways using the bioinformatics tool MAGMA. Table 2 shows the 19 and 29 genes (12 common genes) found in the gene analysis step of MAGMA using RFS and PLSDA-RFS, respectively, at P< 1.0E-08. HisCoM-RFS did not yield any significant genes at P< 1.0E-08. The 12 genes common to both RFS and PLSDA-RFS include FHIT, CACNA2D3, ITPR1, RELN, CNTNAP2, CTNNA2, DOCK2, ROBO2, SLIT3, MAG12, ASIC2, and CREB5. Supplementary Table 4 shows the pathways from the pathway analysis (or gene-set analysis) step of MAGMA for RFS, HisCoM-RFS, and PLSDA-RFS at P< 0.05. Pathway analysis found some of the pathways to be associated with T2D in literature, for example, pathways such as the insulin signaling pathway, adipocytokine signaling pathway, type II diabetes, prostate cancer, and other metabolic pathways (43–49). Multiple comparison corrections of the discovered pathways using the false discovery rate (FDR) correction method found vascular smooth muscle contraction (q-value = 0.06), small cell lung cancer (q-value = 0.007), long-term potentiation (q-value = 0.065), and adipocytokine signaling (q-value = 0.026) pathways (FDR q-value< 0.1). The strongest association was observed with the adipocytokine signaling pathway yielding a significant gene set of 32 genes listed in Table 3. Some genes include STAT3, AKT1-AKT3, MAPK10, MAPK8, PRKAA1, ACSL1, CAMKK1 RXRG, and NFKB. Finally, genetic risk assessed using global PRS showed a strong positive association with T2D adjusted for the covariates (OR: 17.78; 95% CI: 12.01–26.50; P< 0.01). Grouping of the PRS into low, intermediate, and high genetic risk groups with the low genetic risk as the reference as shown in Supplementary Figure 3 showed both intermediate (OR: 1.46; 95% CI: 1.19–1.79; P< 0.01) and high (OR: 3.36; 95% CI: 2.77–4.08; P< 0.01) genetic risk groups having an association with T2D, as shown in Supplementary Figure 3. The nine groups showing interactions between diet quality groups and genetic risk groups found significant interactions between different genetic risk groups and diet quality groups, as shown in Figure 4, especially the high GRC and the diet quality groups.
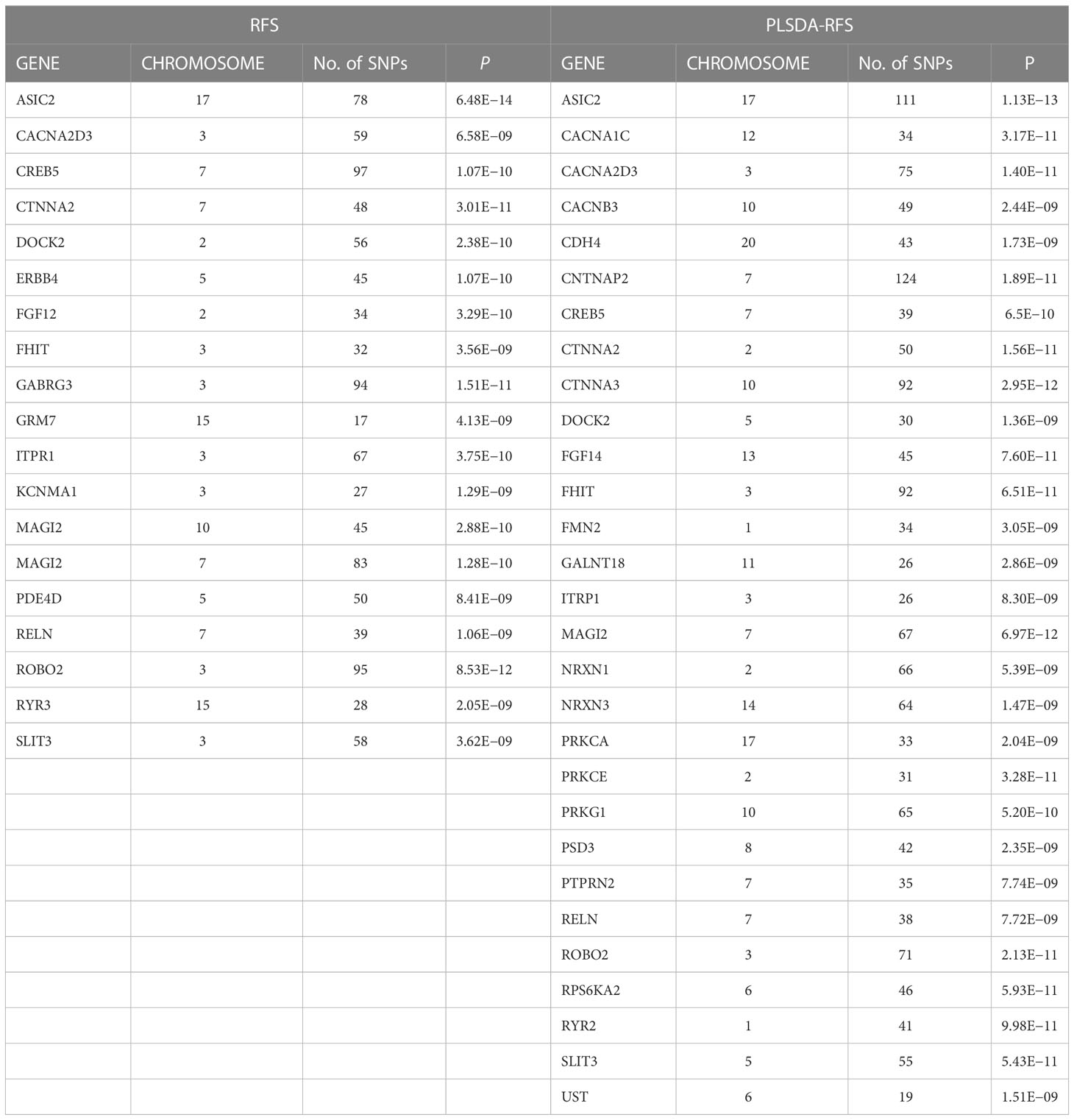
Table 2 List of significant genes from the gene analysis step of MAGMA for RFS and PLSDA-RFS.
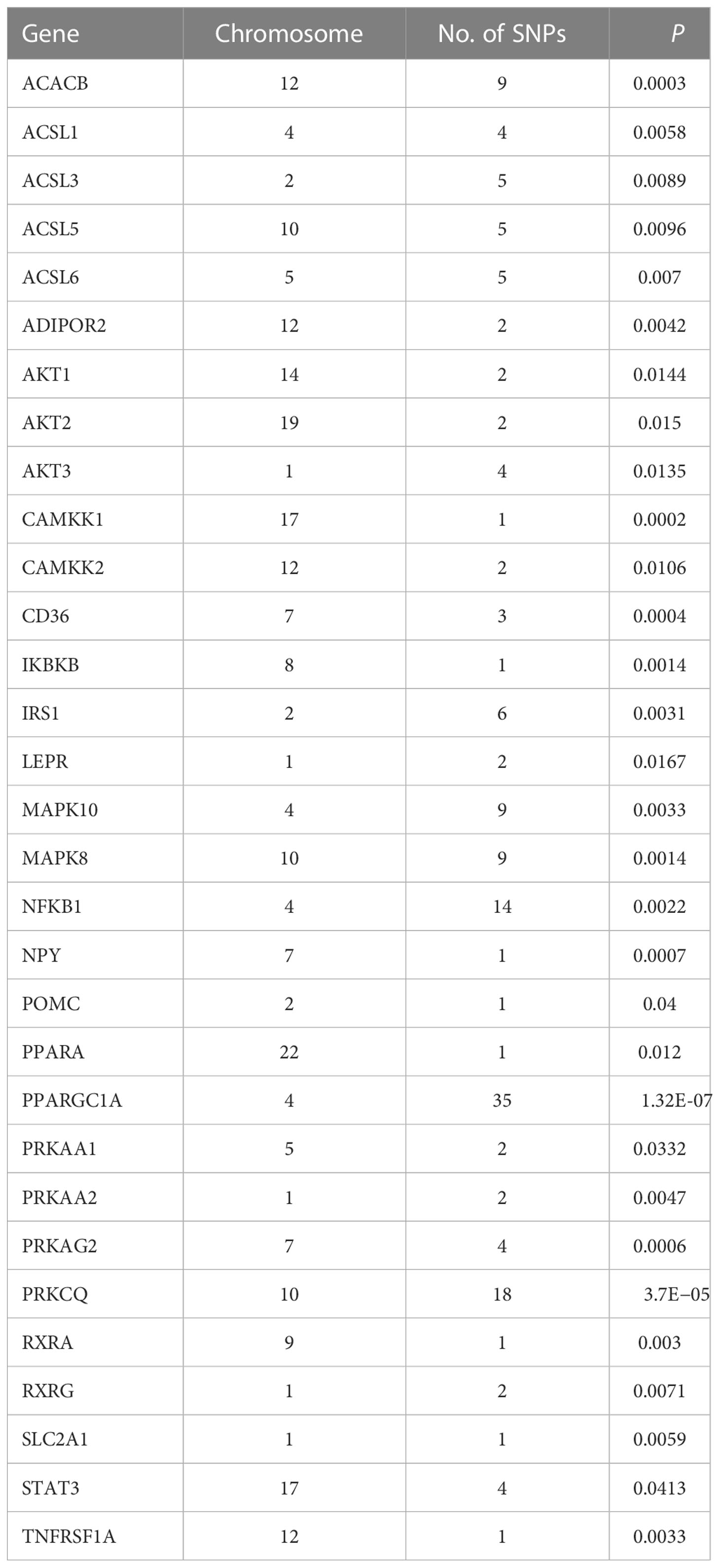
Table 3 List of genes from the gene set of the adipocytokine signaling pathway.
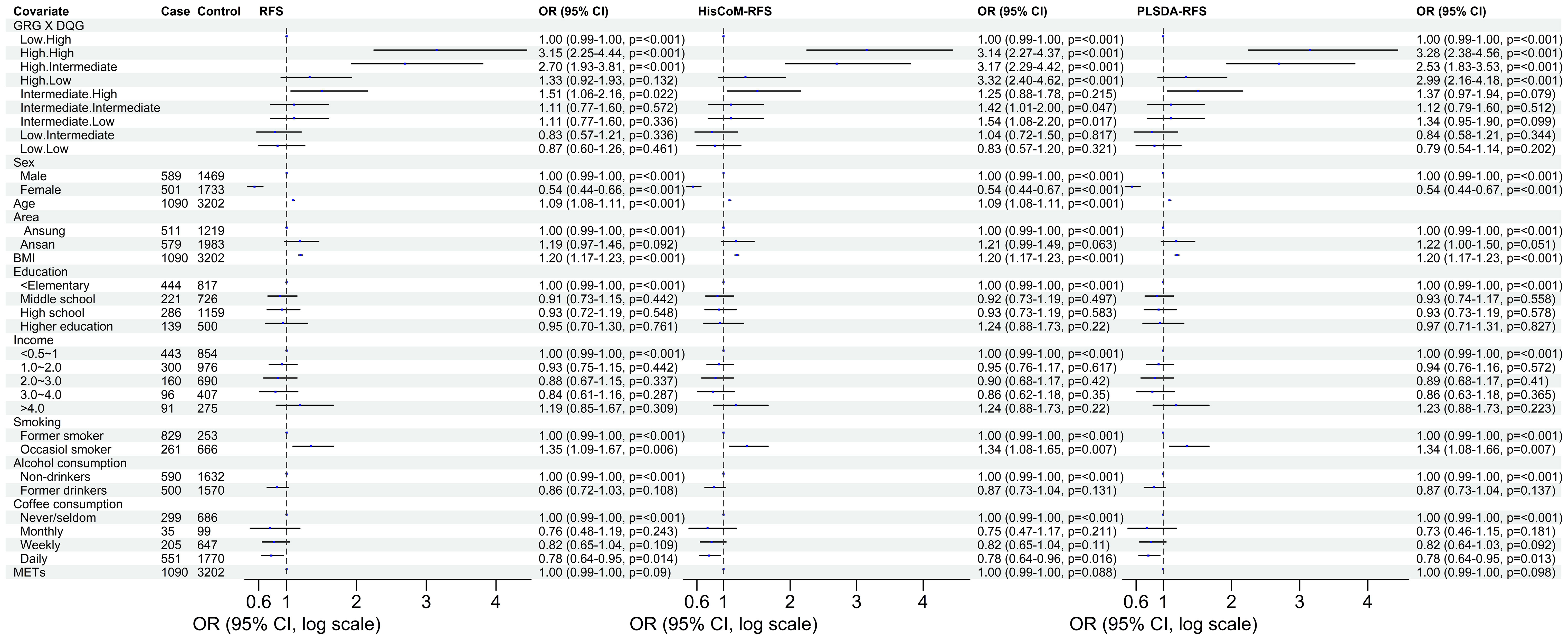
Figure 4 The odd ratios of the interaction between the genetic risk groups and diet quality groups of RFS, HisCoM-RFS and PLSDA-RFS. The analyses were adjusted for the ten covariates. Interaction of low GRC and high DQG is the reference group. METs, metabolic equivalents; BMI, body mass index; RFS, recommended food scores; GRG, genetic risk groups; DQG, diet quality groups.
4 Discussion
Investigating the role of dietary patterns in association with T2D is still a hot research topic worldwide. A previous study showed that a higher RFS score is associated with lower oxidative stress but failed to show an association with T2D in Korean adults (16). To maximize the interaction power of RFS on T2D, we developed weighted RFS scores HisCoM-RFS and PLSDA-RFS using the HisCoM and PLS-DA models, which determine the weights of the food items. The development of weighted food scores is based on the assumption that some food items contribute more than others to the overall food score given the phenotype. After calculating the weighted food scores, we performed analyses contrasting these food scores about the association of dietary patterns with the development of T2D while adjusting for covariates and other lifestyle factors like METs, smoking, alcohol and coffee consumption, and education and income levels. Firstly, a significant association was found between dietary habits, mainly with the weighted food score PLSDA-RFS, unlike the former unweighted RFS score in the previous study (16). After adjusting the 10 covariates, unweighted RFS and PLSDA-RFS food scores were significantly associated with T2D. Grouping the food scores into low, intermediate, and high diet quality groups showed intermediate and low diet quality groups to be associated with T2D. This shows the importance of high diet quality (foods rich in antioxidant properties) playing a preventive role in the occurrence of T2D.
In the literature, a higher Dietary Approaches to Stop Hypertension (DASH) Score was associated with lower T2D risk in men (50). An extended follow-up of urban Chinese adults showed that a higher healthy diet score (HDS) was associated with lower diabetes risk (51). Other studies also associated diet quality with the risk of T2D (9, 52). Secondly, interaction analysis between food scores and SNPs focusing on the “interaction effect” instead of the “main effect” aimed to find genes and pathways associated with T2D. Significant interaction implies that diet is involved with pathway mechanisms related to the development of T2D. The interaction analysis with the respective food scores RFS, HisCoM-RFS, and PLSDA-RFS yielded some significant SNPs (P< 0.05), filtered and used in MAGMA’s gene and pathway analysis steps. We did not get any SNPs below the GWAS significance level of P< 5.0E-08. Gene analysis yielded 19 genes and 29 genes at P< 1.0E-08 with RFS and PLSDA-RFS, respectively, with 12 common genes, namely, FHIT, CACNA2D3, ITPR1, RELN, CNTNAP2, CTNNA2, DOCK2, ROBO2, SLIT3, MAGI2, ASIC2, and CREB5. FHIT is involved in purine metabolism, and CACNA2D3 is engaged with the voltage-dependent calcium channel. Calcium signaling is crucial for insulin secretion in pancreatic cells (53, 54). RELN gene encodes a large secreted extracellular matrix protein thought to control cell–cell interactions critical for cell positioning and neuronal migration during brain development and is involved in multiple disorders. CTNNA2 enables actin filament binding activity, whereas DOCK2 remodels the actin cytoskeleton required for lymphocyte migration in response to chemokine signaling. SLIT3 is associated with cell receptors during cellular migration (55).
The pathway analysis revealed many pathways, some of which have been associated with T2D in literature. The pathways are mainly related to cancer, metabolism, and signaling. However, FDR correction left vascular smooth muscle contraction (q-value = 0.06), small cell lung cancer (q-value = 0.007), long-term potentiation (q-value = 0.065), and adipocytokine signaling (q-value = 0.026) pathways to be strongly associated with T2D at q-value< 0.1. The strongest association was observed with the adipocytokine signaling pathway, which produced a gene set of 32 genes in this pathway strongly associated with T2D. These genes include STAT3, AKT1-AKT3, MAPK10, MAPK8, IRS1, ADIPOR2, ACSL1, CAMKK1, RXRG, and NFKB1. STAT3 is involved in cytokine- and nutrient-induced insulin resistance, and its phosphorylation contributes to skeletal muscle insulin resistance in T2D (56). MAPK10 was identified as a critical gene in diabetes mellitus-induced atrial fibrillation in mice (57). The AKT genes and IRS1 may influence adipocyte insulin resistance (58–61). Variants in the ADIPOR2 gene are associated with increased diabetic risk (62, 63). In a meta-analysis study, RXRG, NFKB1, ACSL1, and CAMKK1 genes were also associated with T2D (64). Briefly, insulin resistance is one of the major hallmarks of the pathogenesis and etiology of T2D (48). It is reflected by impairments in insulin signaling in the diabetic state displaying a reduced insulin sensitivity (43). A generally accepted view is that insulin resistance associated with T2D is caused by defects at one or several levels of the insulin-signaling cascade, for example, in skeletal muscles, adipose tissue, and liver, that quantitatively constitute the bulk of the insulin-responsive tissues (45). Adipocytes and resident macrophages that have migrated to the adipose tissue produce and secrete adipocytokines, including tumor necrosis factor-α, interleukin-6, resistin, and adiponectin, which are thought to contribute to the development of insulin resistance and T2D (46, 47, 64). Dysregulation of vascular smooth muscle excitability using calcium ions occurs during T2D disorder (65–67). Abnormal long-term potentiation behavior is observed in patients with T2D (68, 69).
One limitation of the study is that the genotype data were not imputed with the 1000G population data when the analysis was carried out. Also, larger cohort data are needed to replicate these findings. In the future, we will perform the same analysis using genotype data imputed using 1000G and replicate the findings of our analysis using an independent dataset.
In conclusion, this study revealed the association between dietary patterns and the development of T2D. The risk of T2D increases in individuals with poor dietary habits (foods lacking antioxidant properties). Lifestyle habits like smoking, BMI, age, and alcohol and coffee consumption increase the risk of T2D. The impact of genetics was also observed, especially in people with high genetic risks. The interaction between diet and genetics showed that dietary patterns affect pathway mechanisms in the development of T2D. The study results elucidate the protective role of a healthy diet in lowering the risk of T2D. However, further prospective investigations, more rigorous studies of larger cohorts, intervention research, or different methods of constructing food (indices) quality scores will be needed to investigate if diet can predict the prevalence of T2D (causal–effect relationship). Also, further validation studies of the above pathways are required to find T2D biochemical pathogenesis conclusively.
Data availability statement
The data analyzed in this study is subject to license/restrictions: Data supporting this paper were obtained from the National Biobank of Korea (NBK). The KoGES epidemiology data and the KARE genotype data are available only upon agreement with NBK. Requests to access these data can be directed to National Human Resources Bank (http://biobank.nih.go.kr 1661-9070) or the Human Biobank Information System (HuBIS desk) at https://is.kdca.go.kr/. BBJ summary statistics used in this study were downloaded from the Biobank Japan PheWeb: https://pheweb.jp/.
Author contributions
The authors’ responsibilities were as follows: conceptualization: TP. Methodology: TP and CA. Formal analysis: CA. Resources: TP and OK. Writing—original draft preparation: CA. Writing—review and editing: CA, TP, WC, and MM. Supervision: TP. Project administration: TP. Funding acquisition: TP. All authors contributed to the article and approved the submitted version.
Funding
This work was funded by a Bio-Synergy Research Project funding award (2013M3A9C4078158), as bestowed by the Ministry of Science, ICT, and Future Planning, through the Korean National Research Foundation.
Acknowledgments
This study was conducted with bioresources from the National Biobank of Korea and the Korea Disease Control 621 and Prevention Agency, Republic of Korea (KBN-2020-108).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fendo.2023.1165744/full#supplementary-material
Abbreviations
KoGES, Korean Genome Epidemiology Study; METs, metabolic equivalents; RFS, Recommended Food Score; BMI, body mass index; GRG, genetic risk groups; DQG, diet quality groups; HisCoM, Hierarchical Structural Component model; PLS-DA, partial least squares-discriminant analysis method; HisCoM-RFS, weighted RFS calculated by HisCoM model; PLSDA-RFS, weighted RFS calculated by PLS-DA method; CI, confidence intervals.
References
1. Lin X, Xu Y, Pan X, Xu J, Ding Y, Sun X, et al. Global, regional, and national burden and trend of diabetes in 195 countries and territories: an analysis from 1990 to 2025. Sci Rep (2020) 10(1):14790. doi: 10.1038/s41598-020-71908-9
2. Jung Kim D. The epidemiology of diabetes in Korea. Diabetes Metab J (2011) 35:303–8. doi: 10.4093/dmj.2011.35.4.303
3. Dietrich S, Jacobs S, Zheng J-S, Meidtner K, Schwingshackl L, Schulze MB. Gene-lifestyle interaction on risk of type 2 diabetes: a systematic review. Obes Rev (2019) 20(11):1557–71. doi: 10.1111/obr.12921
4. Franks PW, Pearson E, Florez JC. Gene-environment and gene-treatment interactions in type 2 diabetes: progress, pitfalls, and prospects. Diabetes Care (2013) 36(5):1413–21. doi: 10.2337/dc12-2211
5. van Dam RM, Rimm EB, Willett WC, Stampfer MJ, Hu FB. Dietary patterns and risk for type 2 diabetes mellitus in U.S. men. Ann Intern Med (2002) 136:201–9. doi: 10.7326/0003-4819-136-3-200202050-00008
6. Fung TT, Schulze M, Manson JE, Willett WC, Hu FB. Dietary patterns, meat intake, and the risk of type 2 diabetes in women. Arch Intern Med (2004) 164(20):2235–40. doi: 10.1001/archinte.164.20.2235
7. Chen G-C, Koh W-P, Neelakantan N, Yuan J-M, Qin L-Q, van Dam RM. Diet quality indices and risk of type 2 diabetes mellitus: the Singapore chinese health study. Am J Epidemiol (2018) 187(12):2651–61. doi: 10.1093/aje/kwy183
8. Montonen J, Järvinen R, Heliövaara M, Reunanen A, Aromaa A, Knekt P. Food consumption and the incidence of type II diabetes mellitus. Eur J Clin Nutr (2005) 59(3):441–8. doi: 10.1038/sj.ejcn.1602094
9. Wawro N, Pestoni G, Riedl A, Breuninger TA, Peters A, Rathmann W, et al. Association of dietary patterns and type-2 diabetes mellitus in metabolically homogeneous subgroups in the KORA FF4 study. Nutrients (2020) 12(6):1684. doi: 10.3390/nu12061684
10. Alhazmi A, Stojanovski E, McEvoy M, Brown W, Garg ML. Diet quality score is a predictor of type 2 diabetes risk in women: the Australian Longitudinal Study on Women's Health. Br J Nutr (2014) 112(6):945–51. doi: 10.1017/S0007114514001688
11. Ashima K, Graubard BI. A comparison of three dietary pattern indexes for predicting biomarkers of diet and disease. J Am Coll Nutr (2005) 24(4):294–303. doi: 10.1080/07315724.2005.10719477
12. Introduction of the Korean Genome and Epidemiology Study (KoGES) . Available at: http://www.nih.go.kr/NIH/cms/content/eng/99/65199_view.html (Accessed August, 2021).
13. Shin C, Abbott RD, Lee H, Kim J, Kimm K. Prevalence and correlates of orthostatic hypotension in middle-aged men and women in Korea: the Korean Health and Genome Study. J Hum Hypertens (2004) 18:717–23. doi: 10.1038/sj.jhh.1001732
14. Cho NH, Jang HC, Choi SH, Kim HR, Lee HK, Chan JCN, et al. Abnormal liver function test predicts type 2 diabetes: a community-based prospective study. Diabetes Care (2007) 30(10):2566–8. doi: 10.2337/dc07-0106
15. Kant AK, Schatzkin A, Graubard BI, Schairer C. A prospective study of diet quality and mortality in women. JAMA (2000) 283:2109–15. doi: 10.1001/jama.283.16.2109
16. Kim JY, Yang YJ, Yang YK, Oh SY, Hong YC, Lee EK, et al. Diet quality scores and oxidative stress in Korean adults. Eur J Clin Nutr (2011) 65:1271–8. doi: 10.1038/ejcn.2011.120
17. The official e-Government website of the Republic of Korea. . Available at: http://www.cdc.go.kr/contents.es?mid=a50401010100 (Accessed June 8, 2021).
18. Cho YS, Go MJ, Kim YJ, Heo JY, Oh JH, Ban H-J, et al. A large-scale genome-wide association study of Asian populations uncovers genetic factors influencing eight quantitative traits. Nat Genet (2009) 41(5):527. doi: 10.1038/ng.357
19. Chang CC, Chow CC, Tellier LC, Vattikuti S, Purcell SM, Lee JJ. Second-generation PLINK: rising to the challenge of larger and richer datasets. Gigascience (2015) 4(1):7. doi: 10.1186/s13742-015-0047-8
20. Browning BL, Zhou Y, Browning SR. A one-penny imputed genome from next-generation reference panels. Am J Hum Genet (2018) 103(3):338–48. doi: 10.1016/j.ajhg.2018.07.015
21. Ko KP, Kim C-K, Ahn Y, Park S-J, Kim T-Y, Park JK, et al. Plasma isoflavone concentration is associated with decreased risk of type 2 diabetes in Korean women but not men: results from the Korean Genome and Epidemiology Study. Diabetologia (2015) 58:726–35. doi: 10.1007/s00125-014-3463-x
22. Yang SJ, Kwak SY, Jo G, Song T-J, Shin M-J. Serum metabolite profile associated with incident type 2 diabetes in Koreans: findings from the Korean Genome and Epidemiology Study. Sci Rep (2018) 8(1):8207. doi: 10.1038/s41598-018-26320-9
23. Kim Y, Han BG, KoGES group. Cohort profile: the korean genome and epidemiology study (KoGES) consortium. Int J Epidemiol (2017) 46(2):e20. doi: 10.1093/ije/dyv316
24. Ahn Y, Kwon E, Shim JE, Park MK, Joo Y, Kimm K, et al. Validation and reproducibility of food frequency questionnaire for Korean genome epidemiologic study. Eur J Clin Nutr (2007) 61(12):1435–41. doi: 10.1038/sj.ejcn.1602657
25. Ahn Y, Lee JE, Paik HY, Lee HK, Jo I, Kimm K. Development of a semi-quantitative food frequency questionnaire based on dietary data from the Korea national health and nutrition examination survey. Nutr Sci (2003) 6:172–84.
26. Lee S, Choi S, Kim YJ, Kim BJ, T2d-Genes Consortium, Hwang H, et al. Pathway-based approach using hierarchical components of collapsed rare variants. Bioinformatics (2016) 32(17):i586–94. doi: 10.1093/bioinformatics/btw425
27. De Leeuw J, Young FW, Takane Y. Additive structure in qualitative data: an alternating least squares method with optimal scaling features. Psychometrika (1976) 41(4):471–503. doi: 10.1007/BF02296971
28. Hwang H, Takane Y. Generalized structured component analysis. Psychometrika (2004) 69(1):81–99. doi: 10.1007/BF02295841
29. Wold S, Sjöström M, Eriksson L. PLS-regression: a basic tool of chemometrics. Chemometrics Intelligent Lab Systems (2001) 58(2):109–30. doi: 10.1016/S0169-7439(01)00155-1
30. Wold S. Personal memories of the early PLS development. Chemometrics Intelligent Lab Syst (2001) 58(2):83–4. doi: 10.1016/S0169-7439(01)00152-6
31. Martens H. Reliable and relevant modelling of real world data: a personal account of the development of PLS regression. Chemometrics Intelligent Lab Syst (2001) 58(2):85–95. doi: 10.1016/S0169-7439(01)00153-8
32. PLINK 1.9 home . Available at: https://www.cog-genomics.org/plink/ (Accessed March 03, 2022).
33. Kim D, Kim J. Dairy consumption is associated with a lower incidence of metabolic syndrome in middle-aged and older Korean adults: The Korean Genome and Epidemiology Study (KoGES). Br J Nutr (2017) 117(1):148–60. doi: 10.1017/S000711451600444X
34. Jang JY, Moon S, Cho S, Cho KH, Oh C-M. Visit-to-visit HbA1c and glucose variability and the risks of macrovascular and microvascular events in the general population. Sci Rep (2019) 9(1):1374. doi: 10.1038/s41598-018-37834-7
35. Choi HG, Lee JW, Min CY, et al. Analyses of the association between cervical cancer and osteoporosis/osteoporotic fracture: a cross-sectional study using KoGES HEXA data. Int J Clin Oncol (2021). doi: 10.1007/s10147-021-01951-7
36. Jeong GW, Kim YJ, Park S, Kim H, Kwon O. Associations of recommended food score and physical performance in Korean elderly. BMC Public Health (2019) 19(1):128. doi: 10.1186/s12889-019-6457-2
37. Neck Circumference and Incidence of Cardiovascular Disease over 12 Years in the Korean Genome and Epidemiology Study (KoGES) . Available at: http://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE09232917 (Accessed 27 June; 2021).
38. de Leeuw CA, Mooij JM, Heskes T, Posthuma D. MAGMA: generalized gene-set analysis of GWAS data. PloS Comput Biol (2015) 11(4):e1004219. doi: 10.1371/journal.pcbi.1004219
40. Kanehisa M, Goto S. KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res (2000) 28(1):27–30. doi: 10.1093/nar/28.1.27
41. Suzuki K, Akiyama M, Ishigaki K, Kanai M, Hosoe J, Shojima N, et al. Identification of 28 new susceptibility loci for type 2 diabetes in the Japanese population. Nat Genet (2019) 51(3):379–86. doi: 10.1038/s41588-018-0332-4
42. Vilhjálmsson BJ, Yang J, Finucane HK, Gusev A, Lindström S, Ripke S, et al. Modeling linkage disequilibrium increases acute racy of polygenic risk scores. Am J Hum Genet (2015) 97(4):576–92. doi: 10.1016/j.ajhg.2015.09.001
43. Brännmark C, Nyman E, Fagerholm S, et al. Insulin signaling in type 2 diabetes: experimental and modeling analyses reveal mechanisms of insulin resistance in human adipocytes. J Biol Chem (2013) 288(14):9867–80. doi: 10.1074/jbc.M112.432062
44. Samovski D, Dhule P, Pietka T, Jacome-Sosa M, Penrose E, Son N-H, et al. Regulation of insulin receptor pathway and glucose metabolism by CD36 signaling. Diabetes Jul (2018) 67(7):1272–84. doi: 10.2337/db17-1226
45. Fröjdö S, Vidal H, Pirola L. Alterations of insulin signaling in type 2 diabetes: A review of the current evidence from humans. Biochim Biophys Acta (BBA) - Mol Basis Dis (2009) 1792(2):83–92. doi: 10.1016/j.bbadis.2008.10.019
46. Esteve E, Ricart W, Fernández-Real JoséM. Adipocytokines and insulin resistance. Diabetes Care (2009) 32(suppl 2):S362–7. doi: 10.2337/dc09-S340
47. Fasshauer M, Paschke R. Regulation of adipocytokines and insulin resistance. Diabetologia (2003) 46:1594–603. doi: 10.1007/s00125-003-1228-z
48. Rehman K, Akash MSH. Mechanisms of inflammatory responses and development of insulin resistance: how are they interlinked? J BioMed Sci (2016) 23:87. doi: 10.1186/s12929-016-0303-y
49. cheuermann-Freestone M, Madsen PL, Manners D, Blamire AM, Buckingham RE, Styles P, et al. Abnormal cardiac and skeletal muscle energy metabolism in patients with type 2 diabetes. Circulation (2003) 107(24):3040–6. doi: 10.1161/01.CIR.0000072789.89096.10
50. de Koning L, Chiuve SE, Fung TT, Willett WC, Rimm EB, Hu FB. Diet-quality scores and the risk of type 2 diabetes in men. Diabetes Care (2011) 34(5):1150–6. doi: 10.2337/dc10-2352
51. Yu D, Zheng W, Cai H, Xiang Y-B, Li H, Gao Y-T, et al. Long-term diet quality and risk of type 2 diabetes among urban chinese adults. Diabetes Care (2018) 41(4):723–30. doi: 10.2337/dc17-1626
52. Song SuJ, et al. Dietary patterns based on carbohydrate nutrition are associated with the risk for diabetes and dyslipidemia. Nutr Res Pract (2012) 6:349–56:4. doi: 10.4162/nrp.2012.6.4.349
53. Levy J. Abnormal cell calcium homeostasis in type 2 diabetes mellitus. Endocrine (1999) 10(1):1–6.
54. Hodgkin M, Hills C, Squires P. The calcium-sensing receptor and insulin secretion: a role outside systemic control 15 years on. J Endocrinol (2008) 199(1):1–4. doi: 10.1677/JOE-08-0261
55. National Library of Medicine . Available at: https://www.ncbi.nlm.nih.gov/gene/9586 (Accessed February, 2023).
56. Mashili F, Chibalin AV, Krook A, Zierath JR. Constitutive STAT3 phosphorylation contributes to skeletal muscle insulin resistance in type 2 diabetes. Diabetes (2013) 62(2):457–65. doi: 10.2337/db12-0337
57. Liu F, Deng Y, Zhao Y, Li Z, Gao J, Zhang Y, et al. Time series RNA-seq analysis identifies MAPK10 as a critical gene in diabetes mellitus-induced atrial fibrillation in mice. J Mol Cell Cardiol (2022) 168(2022):70–82. doi: 10.1016/j.yjmcc.2022.04.013
58. Yin X, Xu Z, Zhang Z, Li L, Pan Q, Zheng F, et al, et al. Association of PI3K/AKT/mTOR pathway genetic variants with type 2 diabetes mellitus in Chinese. Diabetes Res Clin Pract (2017) 128:127–35. doi: 10.1016/j.diabres.2017.04.002
59. Choi K, Kim Y-B. Molecular mechanism of insulin resistance in obesity and type 2 diabetes. Korean J Internal Med (2010) 25(2):119. doi: 10.3904/kjim.2010.25.2.119
60. Rung J, Cauchi S, Albrechtsen A, Shen L, Rocheleau G, Cavalcanti-Proença C, et al. Genetic variant near IRS1 is associated with type 2 diabetes, insulin resistance and hyperinsulinemia. Nat Genet (2009) 41(10):1110–5. doi: 10.1038/ng.443
61. Danielsson A, Öst A, Lystedt E, Kjolhede P, Gustavsson J, Nystrom FH, et al. Insulin resistance in human adipocytes occurs downstream of IRS1 after surgical cell isolation but at the level of phosphorylation of IRS1 in type 2 diabetes. FEBS J (2005) 272(1):141–51. doi: 10.1111/j.1432-1033.2004.04396.x
62. Vaxillaire M, Dechaume A, Vasseur-Delannoy V, Lahmidi S, Vatin V, Leprêtre F, et al. Genetic analysis of ADIPOR1 and ADIPOR2 candidate polymorphisms for type 2 diabetes in the Caucasian population. Diabetes (2006) 55(3):856–61:3. doi: 10.2337/diabetes.55.03.06.db05-0665
63. Siitonen N, Pulkkinen L, Lindström J, Kolehmainen M, Scwab U, Johan G, et al. Association of ADIPOR2 gene variants with cardiovascular disease and type 2 diabetes risk in individuals with impaired glucose tolerance: the Finnish Diabetes Prevention Study. Cardiovasc Diabetol (2011) 10(1):1–11. doi: 10.1186/1475-2840-10-83
64. Meta-Analyses of Glucose and Insulin-related traits Consortium (MAGIC) Investigators, et al. Large-scale association analysis provides insights into the genetic architecture and pathophysiology of type 2 diabetes. Nat Genet (2012) 44:981–90:9.
65. Velmurugan GV, White C. Calcium homeostasis in vascular smooth muscle cells is altered in type 2 diabetes by Bcl-2 protein modulation of InsP3R calcium release channels. Am J Physiology-Heart Circulatory Physiol (2012) 302(1):H124–34. doi: 10.1152/ajpheart.00218.2011
66. Nieves-Cintrón M, Syed AU, Buonarati OR, Rigor RR, Nystoriak MA, Ghosh D, et al. Impaired BKCa channel function in native vascular smooth muscle from humans with type 2 diabetes. Sci Rep (2017) 7(1):14058.
67. Riches K, Warburton P, O'Regan DJ, Turner NA, Porter KE. Type 2 diabetes impairs venous, but not arterial smooth muscle cell function: possible role of differential RhoA activity. Cardiovasc Revascularization Med (2014) 15(3):141–8. doi: 10.1016/j.carrev.2014.02.005
68. Martín ED, Sanchez-Perez A, Trejo JL, Martin-Aldana JA, Jaimez MC, Pons S, Umanzor CA, et al. IRS-2 deficiency impairs NMDA receptor-dependent long-term potentiation. Cereb Cortex (2012) 22(8):1717–27. doi: 10.1093/cercor/bhr216
Keywords: type 2 diabetes, recommended food score, polygenic risk scores, case-control study, dietary patterns
Citation: Apio C, Chung W, Moon MK, Kwon O and Park T (2023) Gene–diet interaction analysis using novel weighted food scores discovers the adipocytokine signaling pathway associated with the development of type 2 diabetes. Front. Endocrinol. 14:1165744. doi: 10.3389/fendo.2023.1165744
Received: 14 February 2023; Accepted: 31 July 2023;
Published: 23 August 2023.
Edited by:
Jian-Quan Luo, Central South University, ChinaReviewed by:
Kyung-Won Hong, Theragen Bio, Republic of KoreaAysun Bay Karabulut, Ankara Yıldırım Beyazıt University, Türkiye
Copyright © 2023 Apio, Chung, Moon, Kwon and Park. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Oran Kwon, b3JhbmtAZXdoYS5hYy5rcg==; Taesung Park, dHNwYXJrQHN0YXRzLnNudS5hYy5rcg==