 Christina E. Andronis1,2*
Christina E. Andronis1,2* James K. Hane1,3
James K. Hane1,3 Scott Bringans2
Scott Bringans2 Giles E. S. J. Hardy4Silke Jacques1Richard Lipscombe2
Giles E. S. J. Hardy4Silke Jacques1Richard Lipscombe2 Kar-Chun Tan1*
Kar-Chun Tan1*- 1Centre for Crop and Disease Management, Curtin University, Bentley, WA, Australia
- 2Proteomics International, Nedlands, WA, Australia
- 3Faculty of Science and Engineering, Curtin Institute for Computation, Curtin University, Perth, WA, Australia
- 4Centre for Phytophthora Science and Management, Murdoch University, Murdoch, WA, Australia
Phytophthora cinnamomi is a pathogenic oomycete that causes plant dieback disease across a range of natural ecosystems and in many agriculturally important crops on a global scale. An annotated draft genome sequence is publicly available (JGI Mycocosm) and suggests 26,131 gene models. In this study, soluble mycelial, extracellular (secretome), and zoospore proteins of P. cinnamomi were exploited to refine the genome by correcting gene annotations and discovering novel genes. By implementing the diverse set of sub-proteomes into a generated proteogenomics pipeline, we were able to improve the P. cinnamomi genome annotation. Liquid chromatography mass spectrometry was used to obtain high confidence peptides with spectral matching to both the annotated genome and a generated 6-frame translation. Two thousand seven hundred sixty-four annotations from the draft genome were confirmed by spectral matching. Using a proteogenomic pipeline, mass spectra were used to edit the P. cinnamomi genome and allowed identification of 23 new gene models and 60 edited gene features using high confidence peptides obtained by mass spectrometry, suggesting a rate of incorrect annotations of 3% of the detectable proteome. The novel features were further validated by total peptide support, alongside functional analysis including the use of Gene Ontology and functional domain identification. We demonstrated the use of spectral data in combination with our proteogenomics pipeline can be used to improve the genome annotation of important plant diseases and identify missed genes. This study presents the first use of spectral data to edit and manually annotate an oomycete pathogen.
Background
The primary role of a genome sequence is to elucidate the entire set of genes expressed by an organism. In silico prediction platforms are the main methods for predicting reliable gene sets. However, they can be problematic as transcriptome data does not always correlate with the protein products and their abundance (Wright et al., 2012). Curating genes correctly and accurately is fundamental in defining the biochemical composition of an organism (Jones et al., 2018). Sequence transcripts and orthologues from related and similar organisms are the primary methods in accurately predicting such genes and identifying interesting and relevant biological components (Mathe, 2002). Evidence-based curation includes transcript data and associated functional annotation such as Gene Ontology (GO) and Protein Families (PFAM) based on sequence homology to other related species (Liang et al., 2009; McDonnell et al., 2018). The challenges in defining comprehensive gene products result in under-represented annotations and incorrectly defined exon boundaries that can miss biologically important features of a genome.
Proteogenomics is a proven but underutilised technology that integrates high confidence peptide data derived from mass spectrometry analysis with genomics as a method to improve gene annotation (Renuse et al., 2011; Nesvizhskii, 2014; Ruggles et al., 2017). Proteogenomic pipelines have been used in phytopathogenic fungi such as Parastagonospora nodorum, where mass spectra were used to validate transcriptomic data, edit the genome annotation and identify new candidate genes, generating a more accurate genome that can be used for downstream work (Bringans et al., 2009; Syme et al., 2016). Proteogenomic analysis has also allowed the identification of potential effector molecules in fungi, which has important implications for characterising virulence and understanding the plant-host interface. The proteome of the causal agent of black spot in pear, Venturia pirina, was analysed by mass spectrometry and 1,085 novel protein groups were identified, 14 of which were fungal candidate effector genes (Cooke et al., 2014). This provides useful insight into the mechanisms of pathogenicity and has the potential to be exploited to control oomycete and fungal plant pathogens.
Phytophthora cinnamomi is a phytopathogenic oomycete that causes dieback and root rot in natural and agricultural systems across the globe. Its hosts include many species of native Australian flora, as well as crops such as avocado and macadamia (Hardham, 2005). Oomycetes proliferate by releasing motile, asexual units of reproduction, called zoospores. When temperatures and humidity reach favourable levels, P. cinnamomi produces fruiting bodies called sporangia which expel free swimming zoospores into the environment, allowing the organism to spread between susceptible hosts. As the zoospores colonise a hosts root system, mature structures including those required for sexual reproduction and nutrient acquisition form, eventually killing the host. The sexual life cycle of P. cinnamomi requires two mating strains to produce sexual oospores, which can persist in soil (Crone et al., 2013). Due to the host range, ability to survive harsh environmental conditions and aggressive pathogenicity, Phytophthora is recognised as one of the most economically important oomycete genera, with insufficient existing control strategies to minimise its impacts (Hardham, 2005; Kamoun et al., 2015). Despite its economic and ecological importance, little is known about the molecular mechanism of P. cinnamomi phytopathogenicity. It is hypothesised that P. cinnamomi secretes effectors based on studies on other oomycetes such as P. infestans and P. ramorum (Birch et al., 2006). Virulence and infection related molecules such as β-cinnamomin have been identified in P. cinnamomi (Horta et al., 2010).
A genome sequence of the West Australian Phytophthora cinnamomi MU94-48 isolate was established (unpublished and publicly available at https://mycocosm.jgi.doe.gov/Phyci1). This is a valuable tool that can be used to identify effectors and elucidate the molecular mechanisms of virulence (Tyler et al., 2006). The version 1 (V1.0 assembly has a coverage of 69.6x and comprises 9,537 contigs, 1,314 scaffolds with 26,131 predicted gene models. The predicted gene models of P. cinnamomi are inflated compared to many Phytophthora species such as P. infestans, P. ramorum, P.capsici, and the more closely related P. sojae, which have reported 17,797, 16,066, 19,805, and 15,743 gene models, respectively (Tyler et al., 2006).
Proteomics data has proven a useful tool to improve the genome annotation of several phytopathogens where high quality mass spectra complemented transcriptomic data and identified potential annotation inaccuracies of exon boundaries and unsuspected gene models. We aimed to use spectral data from several P. cinnamomi sub-proteomes to assist in gene calling. These sub-proteomes represent a wide coverage of the P. cinnamomi proteome and include a diverse repertoire of soluble proteins. Zoospores characterise the infective life stage and the extracellular proteome is likely to contain proteins related to virulence. These were analysed by 2D LC-MS/MS and resulting spectra were matched to the current gene prediction models. To generate a list of peptides which potentially do not match current models, a 6-frame translation was generated and used for spectral matching. A list of peptides indicating potential altered or novel gene models was generated using the genomic coordinates and 6-frame open reading frames. These were subsequently used to carefully manually edit current annotations and curate novel features on a homology basis with proteins of similar species. Using this proteomics dataset, we refined the genome for downstream proteomic work which will aid the identification of virulence factors and metabolic targets for chemical control. By working toward completing the P. cinnamomi genome, downstream proteomic work will be more accurate as the gene set is more representative of what is being expressed. There is also the potential for effector virulence gene discovery and improved biochemical characterisation which can lead to development of resistance (R) gene inclusion in hosts and more targeted methods of chemical control.
Methods
Growth and Maintenance of P. cinnamomi
P. cinnamomi MU94-48 (Centre for Phytophthora Science and Management, Murdoch University, Western Australia) stocks plugs were stored in sterile water in McCartney bottles and grown on V8 agar at room temperature in the dark. For mycelial, secretome, and zoospore production, four plates were used for each biological replicate. Mycelia grown for 4 days were scraped from the plate and were inoculated into Riberio's minimal media supplemented with 25 mM glucose (Ribeiro, 1978). The cells were incubated for 3 days at 24°C in the dark. Mycelia were isolated by centrifugation and the culture filtrate containing secreted proteins was decanted and philtre sterilised. The mycelial pellet was washed twice with MilliQ water and observed microscopically to confirm that hyphal cells predominated. Formation of sporangia and subsequent release of zoospores were produced as previously described (Byrt and Grant, 1979). For the production of zoospores from sporangia, mycelia were grown on V8 agar plates with a 5 × 5 cm sheet of miracloth on the surface and incubated for 4 days at 24°C in the dark. The mycelial mat was transferred into V8 liquid media and incubated on a shaker at 100 rpm for 24 h at 24°C under fluorescent light. The mycelial mat was subsequently washed three times in a sterile solution of 10 mM calcium nitrate, 5 mM potassium nitrate, 5 mM magnesium sulphate and 1:1,000 v:v chelated iron solution and further incubated in this solution on a shaker at 100 rpm for 24 h at 24°C under fluorescent light. The mycelial mat was transferred to a petri dish and incubated for 1.5 h in water at room temperature followed by 30 min at 4°C for the formation of sporangia and release of zoospores. Release of zoospores was observed under the microscope and the zoospore suspension was slowly (to prevent encystment of zoospores) passed through a glass wool syringe to remove any mycelial fragments. Zoospores were harvested by centrifugation at 3,000 g for 30 min, observed microscopically to ensure purity, and counted with a haemocytometer. This incubation process was repeated until sufficient zoospores were harvested. Approximately 4.8E5 spores were used for each biological replicate.
Protein Extraction
Mycelia and zoospores were ground using mortar and pestle in liquid nitrogen. An extraction buffer of 25 mM Tris-HCl pH 7.5, 0.25% SDS, 50 mM sodium phosphate, 1 mM sodium fluoride, 50 μM sodium orthovandate, and 1 mM phenylmethalsulphonym F all in the presence of a protease inhibitor cocktail (Sigma, St Louis) was used to extract and solubilise proteins as previously described (Resjö et al., 2014). Samples were kept on ice for 30 min with regular gentle mixing and centrifuged at 20,000 g at 4°C for 30 min. The protein solutions were subsequently desalted and protein amount was estimated using Direct Detect cards (Merck Millipore, Darmstadt). Mycelial, secretome, and zoospore extractions yielded ~1.4, 0.6, and 0.7 mg of protein, respectively. All samples were freeze dried before further processing. SDS-PAGE was performed for all samples to ensure proteolysis was minimal.
Sample Preparation
To visualise each sub-proteome, 20 μg of each sample was loaded onto a 1D SDS-PAGE. To determine the amount of intracellular contamination in the extracellular proteome, the activity of an intracellular enzyme marker glyceraldehyde phosphate dehydrogenase (GAPDH) was assayed on each sub-proteome as per the manufacturer's instructions (Sigma, St Louis). Five hundred microgram of each sample was resuspended in 250 uL 0.5 M triethylammonium bicarbonate (pH 8.5) before reduction and alkylation with 25 uL of 50 mM tris (2-carboxyethyl)phosphine (Thermo Scientific, Waltham) and 12.5 uL 200 mM methyl methanethiosulfonate (Sigma, St Louis), respectively. Samples were digested overnight at 37°C with trypsin (Sigma, St Louis) at a ratio of 1:10, subsequently desalted on a Strata-X 33 um polymeric reverse phase column (Phenomenex, Torrance, CA, USA) and dried in a vacuum centrifuge.
High pH Reverse Phase Chromatography
Dried peptides were separated based on hydrophobicity by high pH reverse phased liquid chromatography on an Agilent 1100 HPLC system using a Zorbax Eclipse column (2.1 × 150 mm, 5 μm, C18) (Agilent Technologies, Palo Alto) (Siu et al., 2011; Zhang et al., 2014). Peptides were eluted with a linear gradient of 20 mM ammonium formate pH 10, 90% acetonitrile over 80 min. A total of 98 fractions were collected, concatenated into 12 fractions based on collection order and dried in a vacuum centrifuge. The UV trace was used to visualise the total peptide content and depth of each sub-proteome.
Nano LCMS/MS
Fractions were resuspended in 100 uL of 2% acetonitrile and 0.1% formic acid and loaded onto a Shimadzu Prominence nano HPLC system (Shimadzu, Kyoto, Japan). Peptides were resolved with a gradient of 10–40% acetonitrile (0.1% formic acid) at 300 nL/min over 180 min and eluted through a nanospray interface into a 5600 TripleTOF mass spectrometer (AB Sciex, Framingham, MA). The data was acquired in an information-dependent acquisition mode with Analyst TF 1.6 software (AB Sciex, Framingham, MA). The MS settings were as follows: Ionspray Voltage Floating = 2,300 V, curtain gas = 20, ion source gas 1 = 20, interface heater temperature = 150, and declustering potential = 70 V. The TOF MS scan was performed in the mass range of 400–1,250 Da with a 0.25 s TOF MS accumulation time, whereas the MS/MS product ion scan was performed in the mass range of 100–1,800 Da with a 0.1 s accumulation time. The criteria for product ion fragmentation were set as follows: ions (>400 and <1,250 m/z) with charge states of between 2 and 5 and an abundance threshold of >250 cps. Former target ions were excluded for 10 s after one occurrence. The maximum number of candidate ions per cycle was 20.
Data Analysis
Mass spectral data were analysed using Protein Pilot 4.5 Beta Software (July 2012; Sciex). MS/MS spectra were searched against the genomic proteins and the 6-frame translated data set constructed from the genomic assembly scaffolds using EMBOSS: getorf (v6.6). Search parameters were: Cys Alkylation: MMTS; Digestion: Trypsin; Instrument: TripleTOF 5600; Special factors: None; Quantitation tab checked: Bias correction and Background correction tabs checked; ID focus: Biological modifications; Search effort: Thorough; Detected protein threshold [Unused ProtScore (CONF)]: 0.05 (10%); False discovery rate analysis tab checked. All identified proteins had an Unused Protscore of >1.3 (peptides identified with >95% confidence), as calculated by the software and a global false discovery rate of <0.1% determined at the protein level. To determine the sub-proteome enrichment, the resulting sequences of matched proteins were analysed using the protein localisation tool WolfPSORT (version 0.2, plant parameters) (Horton et al., 2007). Proteins were assigned to a predicted sub-cellular location based on sorting signals, amino acid composition, and functional motifs.
De novo Proteogenomics
Peptide matches to the 6-frame translated assembly from the sub-proteomes were combined and mapped back to their genomic location and a set of criteria described below were applied to determine which genes suggest incorrect boundary annotations and which peptides support discovery of new genes. Firstly, BEDtools (version 2.28.0, 2019) was used to distinguish peptides into the following groups using the intersect and subtract features: (a) peptides more than 200 base pairs from coding regions of genes (CDS), (b) peptides within 200 base pairs from CDS features but do not overlap CDS boundaries, (c) Peptides that overlap CDS boundaries, and (d) peptides that remain within CDS feature boundaries (Bringans et al., 2009; Quinlan and Hall, 2010). Subsequently, the CDS Mapper tool (version 0.6, 2011, https://sourceforge.net/projects/cdsmapper/) was used with default parameters to further classify these based on their frame match to corresponding CDS features of the annotated draft genome (Bringans et al., 2009). All peptides suggesting novel or altered gene models were blasted (BLASTp, version 2.9.0, 2019) with the following search parameters: organism: Phytophthora (tax ID 4783), expect threshold: 2E5, word size: 2, matrix: PAM30, gap costs: existence 9 and extension 1. All peptides with significant returns (e <1E−3) were considered for manual annotation. An additional blast search using tBLASTn (version 2.11, 2020) was also used to indicate if novel (unannotated) sequences might exist that are shared among Phytopththora species. Peptides that did not return significant results were not used for this analysis. All significant BLAST hits were transferred onto the Phytophthora draft genome and manually edited to comply with sequence features such as start/stop codons and non-sequenced regions. The novel annotated genes were further analysed for total number of supporting peptides (as per Protein Pilot methods described above). Genes that had only one high confidence peptide were included for the purposes of gene discovery (Sheng et al., 2012). Protein Family domains (PFAM), Gene Ontology (GO), terms and Kyoto Encyclopaedia of Genes and Genomes (KEGG) were also assigned using Interpro scan (version 5.44-79.0, 2020) using and EGGNOG-mapper (version 2, 2019) using default parameters. To determine whether any pathogenesis related proteins were present within the novel set, annotations were analysed for presence of any potential virulence factors using PHI-BASE (version 4.9, 2020) using default parameters (Urban et al., 2017). The Codon Adaptation Indexes (CAIs) of each novel gene were also calculated using Emboss CAI (version 6.6, default parameters), which indicated gene annotation with anomalous usage of codons (Sharp and Li, 1987).
Results
Sub-proteome Enrichment
To obtain a representative proteome of P. cinnamomi, vegetative mycelia, and transient short-lived zoospores of P. cinnamomi were used as these are the dominant cell types that grow and initiate infection in hosts. In addition, we extracted soluble secreted proteins (secretome) from the mycelia, which are widely studied due to their implications on pathogen-host interactions. The purity of the mycelia and zoospores was observed under a stereoscope (Figure 1). Figure 1A shows no evidence of intercellular contamination and demonstrated the purity of these cell types. The large mass of mycelia had not produced zoospores or their precursor (the sporangia) in this method of in vitro cell culture. Similarly, vegetative mycelia was not observed in the zoospore preparation (Figure 1B).
Figure 1. Stereo microscope images of (A) a mycelial mass, and (B) free swimming zoospores, indicating minimal to no cross contamination between cell types. Bars represent 1 mm scale. Black arrow indicates mycelia and white arrows indicate zoospores.
1D SDS-PAGE was run to visualise the sub-proteomes of each cell type (Figure 2A). The banding patterns of each sub-proteome show differences in total protein content. The extracellular proteome showed enrichment in lower molecular weight proteins whereas the mycelia and zoospores had proteins that spanned over the whole mass range. To test the purity of the secretome, an enzyme activity assay of the cytoplasmic marker GAPDH was measured, which should only be present in small amounts (Figure 2B) (Tristan et al., 2011). Both the mycelia and zoospores had similar detected amounts of GAPDH detected, ~4.7 and 4.8 mU/mg protein, respectively. GAPDH was also detected in the secretome, however at lower amounts (1.6 mU/mg protein). The RP-HPLC UV total ion count traces indicated differing protein content between the three sub-proteomes, as majority of the peaks do not match in intensity and retention time (Figure 2C). The majority of proteins detected in the mycelial and zoospore were localised intracellularly at 45 and 41%, respectively as predicted by WolfPSORT (Table 1). The secretome was enriched in extracellular localisation proteins with a predicted 18% compared to 5% in both the mycelia and zoospores.
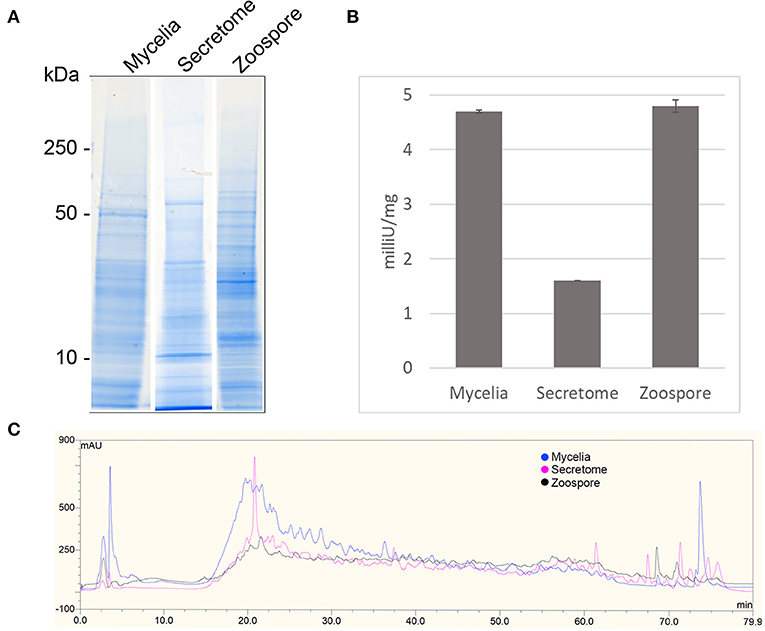
Figure 2. Quality control of sub-proteomes. (A) SDS-PAGE analysis of P. cinnamomi sub-proteomes. (B) Glyceraldehyde phosphate dehydrogenase activity within each sub-proteome indicating relative levels of contamination of intracellular proteins in the extracellular proteome. (C) 214 nm UV High pH reverse phase HPLC separation of 500 μg of each sub-proteome demonstrating sufficient peptide separation and differing protein content.

Table 1. WolfPSORT localisation prediction of the whole genome annotation and sub-proteomes.
Validation of V1.0 Gene Models Using Sub-proteome Spectra
The mass spectra were used to validate the draft annotation of the P. cinnamomi genome. The annotations acquired from JGI Mycocosm (assembly annotation version 1.0) were designated in this study as “V1.0” and the annotation set containing subsequently manually edited loci was designated “V2.0.0.”
Non-redundant peptide matches (at least two 95% confident peptides) resulted in 2,554, 1,362, and 2,304 proteins from the mycelia, secretome and zoospores, respectively. From this data, 2,764 unique proteins from the V1.0 predicted gene set were identified (Figure 3A). 526, 215, and 432 proteins were unique to the mycelia, secretome and zoospores, respectively, which implies a wide range of the whole proteome detected. The mycelia and zoospores had more unique protein identifications than the secretome, which may be a result of an expected lower mass range of an extracellular proteome that were below the acquisition detection limits. Additionally, PFAM assignment of the proteins identified in the sub-proteomes, showed differences in composition of domains (Figure 3B; Supplementary Material 1). Analysis of the top 10 most abundant PFAM of mycelia and zoospores displayed notable differences. The mycelia have unique PFAM domains, including pleckstrin homology (PH) and ATPase associated with diverse cellular activities domain (AAA). The zoospores have unique C2, RCC1, and TIG domains compared to the mycelia and the secretome. When matched to 4,874,027 generated open reading frames (ORF) of the 6-frame translation, 2,752, 1,355, and 2,334 ORFs from the mycelia, secretome and zoospores were identified (Table 2). Although this does allow us to match more peptides to the genome than the V1.0 annotation, some level of redundancy is expected from matching to reading frames that do not form genes. The false discovery rate for all mass spectra analysis was <0.1% using the Protein Pilot decoy database method, which is within the limits of the general consensus for large scale proteomic data (Lam et al., 2010; Bantscheff et al., 2012). Of the V1.0 detected by mass spectrometry, 2,398 had additional support by assigned GO terms and/or PFAM domain.
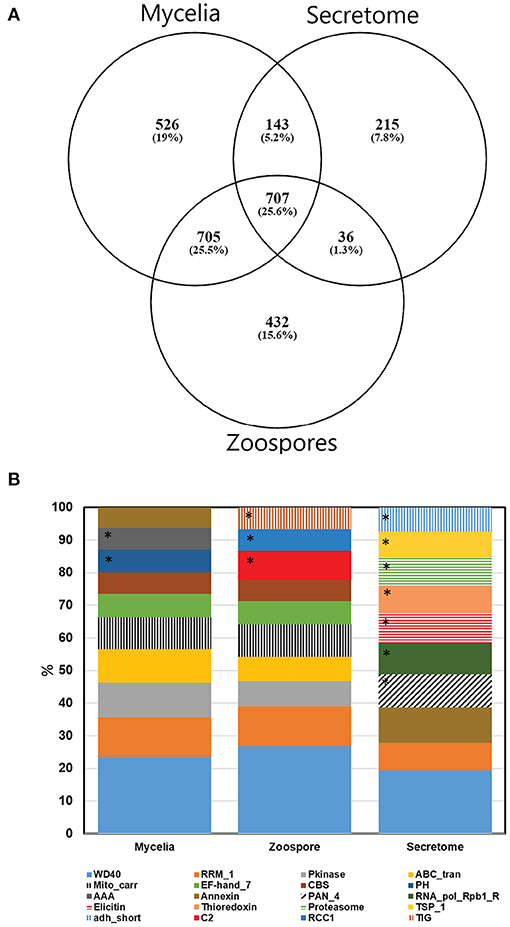
Figure 3. (A) Number of proteins detected by mass spectrometry of each sub-proteome supported by at least two 95% confident peptides. (B) Top 10 PFAM domains based on the number of proteins identified in each sub-proteomes. *Represent unique domains to each sub-proteome. For a complete PFAM assignment, refer to Supplementary Material 1.

Table 2. Summary of mass spectra identification using the annotated protein and 6-frame open reading frame databases.
Annotating New Gene Models by Homology Criteria
Although there is peptide support for a large number of the V1.0 genes, it is expected that there are some forms of incorrect intron and exon boundary annotations that can be detected using spectral data. In addition, this spectral data can also be used in the detection of new genes. Twenty-three thousand four hundred fifty-seven unique high confidence peptides matched to the 6-frame ORFs were mapped back to their genomic location. Twenty-two thousand four hundred forty-three peptides mapped completely within coding exon boundaries. Two hundred seventy-four peptides mapped partly within exons (i.e., span across boundaries) and 287 within 200 bp of boundaries (Figures 4B,C). Four hundred fifty-three peptides mapped more than 200 bp from exon boundaries (Figure 4A). Furthermore, the frame test applied more stringent criteria for frame matching of these peptides to corresponding V1.0 annotations (Table 3). A total of 1,010 peptides did not match the frame of corresponding CDS features or were further than 200 bp from any gene models. This suggested 438 gene features with potentially incorrect boundaries. These were considered as candidates for new gene models.
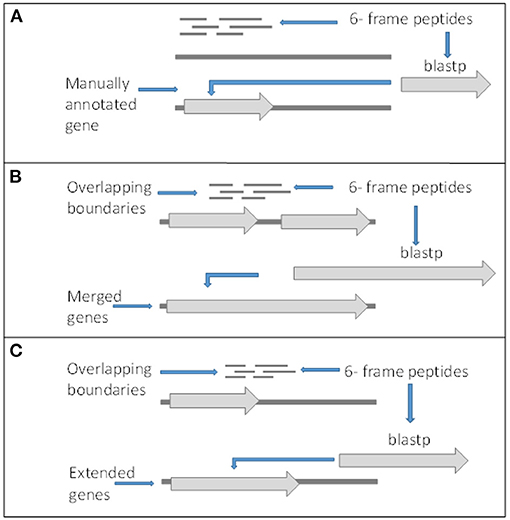
Figure 4. Criteria for gene editing and discovery. (A) Peptides matching to 6-frame open reading frames in loci with no surrounding genes or out of frame from surrounding genes and returned significant BLASTp hits were manually annotated as new genes. (B) Peptides overlapping boundaries of multiple genes within the same frame and returned significant BLASTp hits were used to manually merged genes. (C) Genes with in frame peptides overlapping boundaries and returned significant BLASTp hits were manually edited.

Table 3. Confirmation of genes supported by peptides within or crossing exon boundaries.
To select peptide candidates that would likely result in alteration of V1.0 genes and curation of new genes, Blastp was used. Peptides that returned significant hits to other Phytophthora species were used to manually edit and curate new genes (Table 4). This largely reduced the number of potential edited and new genes due to both the redundancies of 6-frame peptides and rigorous Blastp parameters used for peptide matches. Of those with conflicting boundaries, 72 peptides showed significant homology to other Phytophthora species. Of the peptides that were further than 200 bp from any gene, a total of 160 peptides returned significant BLASTp hits, suggesting the presence of previously unannotated genes on the P. cinnamomi genome. The homologous sequences were transferred onto the P. cinnamomi genome and the annotations were manually integrated, taking into consideration differences in the genome and features such as introns. Of the peptides that returned significant hits using the tBLASTn search, 34 did not have a corresponding BLASTp result, suggesting 33 potential new genes across four Phytophthora species. However, to annotate new genes, we chose those peptides that were confirmed by both BLASTp and tBLASTn hits to increase confidence. To ensure high confidence of newly annotated genes, we chose those genes that have homologues in other Phytophthora species.
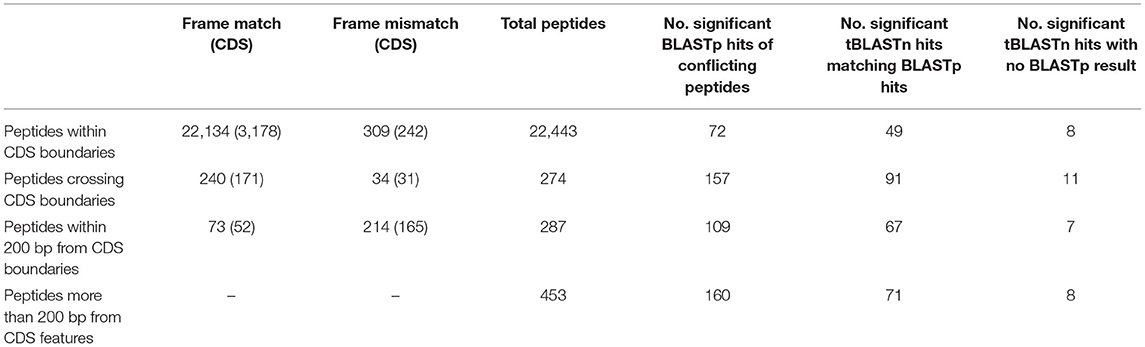
Table 4. Summary of frame matches of peptides with nearby CDS features and number of significant Blastp and tBlastn hits (E value > 1E−3) and number of gene features manually.
Using these criteria, a total of 60 genes were edited, which equates to an error rate of ~2% of the detected proteome. Of these, 44 were modified by extending the exon boundaries and there were 16 instances of merged genes (Supplementary Material 2). Additionally, 23 new previously undefined genes were annotated (Table 5). These annotations were uploaded to the GenBank under accessions MT820663-MT820655. The edited annotations will be referred to by original annotation identification with “V2.0.0” suffixed, as listed in the Supplementary Materials 3, 4, respectively. In summary, we identified errors in 60 V1.0 genes which were manually altered and added a further 23 annotations to the gene set of P. cinnamomi.

Table 5. Summary of original predicted and newly annotated/ edited genes using proteogenomics.
Validating Edited and New Genes
The edited genes were subsequently analysed for total peptide support and differences in functional assignment compared to the original annotation. Peptides within the edited regions were manually counted (Table 6). Of the extended genes, only one had no other supporting information other than the support of one 95% confident peptide in the extended portion of the gene (e_gw1.28.366.1_V2.0). All other extended genes had support from more than two high confidence peptides and/or homologous functional assignment. Similarly, only one merged gene had a single peptide supporting the merged region of the annotation (gw1.160.19.1_V2.0). All others were supported by two or more high confidence peptides, which is the general requirement for protein identification in proteomics (Bringans et al., 2017). Genes were analysed for GO terms, PFAM domains, and KEGG orthologues (KO) to determine whether the altered boundaries change their functional annotation assignment (Table 6). Details of each functional annotation are shown in Supplementary Materials 3, 4.
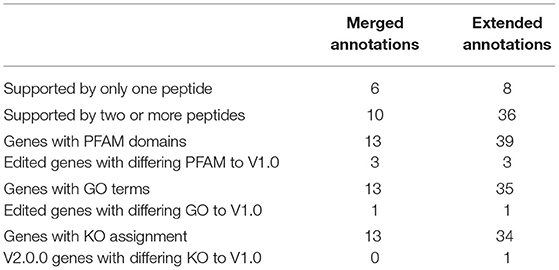
Table 6. Summary of new gene validation using supporting peptides, PFAM, and Gene Ontology terms using Protein Pilot.
The original mass spectra were matched to the set of new genes (using Protein Pilot- see methods) to determine how many peptides supported each gene (i.e., determine if any genes were a product of single peptide matches) (Table 7). Of the 23 new genes identified, one new gene had support from only one high confidence peptide (MT820633). All new genes were detected in the mycelia and most were also identified in the secretome and zoospore (Supplementary Material 5). The remaining 22 genes had at least two or more supporting peptides.

Table 7. Summary of new gene validation using supporting peptides, Protein Families, and Gene Ontology terms.
To further support this new gene set, protein sequences were analysed for protein function by assignment of PFAM Supplementary Material 5. The new annotations were analysed for virulence factors using PHI-BASE. None of these annotations returned a significant hit to any known virulence factors.
Codon Adaptation Index
The codon adaptation indices were calculated for the set of new features and compared to the V1.0 gene set to identify significant differences in codon usage and distribution that could indicate possible causes for errors and missed genes (Figure 5). The distribution of the CAIs of the new set were significantly different (t-test, p < 0.05) than those of the predicted gene set suggesting a higher proportion of less common codon usage in the new set. These were also significantly lower to the CAIs of all original annotations that had high confidence supporting peptides. Each new gene was also checked for the presence of start codons other than methionine and stop codons (Table 8). Only one new annotation MT820649 had non-standard codon usage, where an alternate start codon was used in accordance to its homologues in P. infestans and P. sojae.
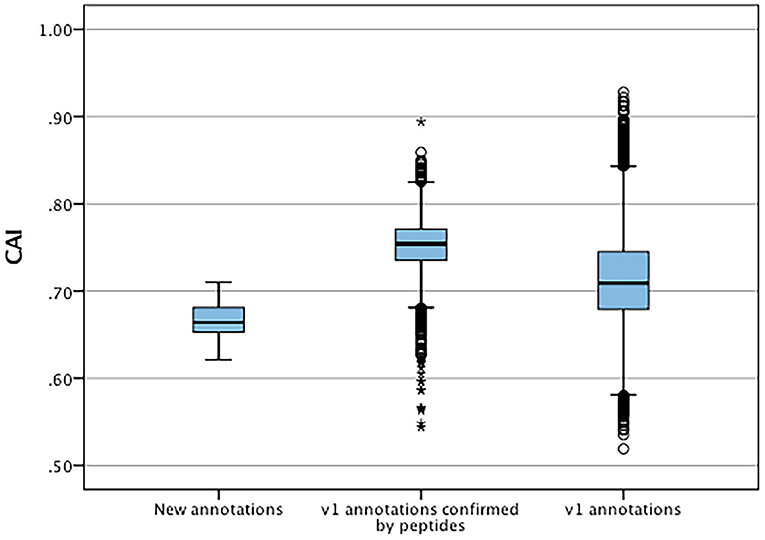
Figure 5. Distribution of codon adaptation indices between new annotation and V1.0 annotations confirmed by mass spectrometry and all V1.0 annotations. *Represent significant differences (p < 0.05) of data sets to V1.0 annotations.

Table 8. Sequence feature summary of the new gene set.
Discussion
The three sub-proteomes (mycelia, secretome, and zoospores) represent a diverse range of proteins and capture the majority of the P. cinnamomi proteome. Although microscopic observation indicated successful purity in the mycelia and zoospores, the GAPDH assay showed some cytoplasmic contamination in the secretome. Cytoplasmic markers such as GAPDH and malate dehydrogenase have been used in other studies as indicators of intracellular contamination in secretome samples of other organisms (Alexandersson et al., 2013; Kim et al., 2013). In these cases, some level of contamination was similarly observed in isolated secretome samples, likely due to some level of cellular leakage. Other known cytoplasmic markers such as malate dehydrogenase have been observed in fungal secretomes, where their extracellular functions are not known (Tan et al., 2009). This set of enrichment data confirms that the sub-proteomes were sufficiently enriched for this study and the total proteome is diverse and represents both growing and infective stages of development.
The aim of using these three sub-proteomes was firstly to validate as much as the P. cinnamomi draft gene set as possible. Through spectral matching, we verified 10.6% of the predicted gene set. The differing sub-proteomes, as shown above, are reflected in the validation of V1.0 genes by spectral matching. Unique protein identifications of ~19, 8, and 16% of the mycelia, secretome and zoospores, respectively, accounted for the differences in observed SDS-PAGE banding patterns and RP-HPLC traces. Proteomic studies of other Phytophthora species indicated variable numbers of unique proteins to these sub-proteomes. A 2- dimensional proteomic study of the oomycete P. palmivora indicated 1% unique proteins for mycelia and zoospores (Shepherd et al., 2003). However, a profile of the P. infestans secretome indicated similar coverage of extracellular proteins to this study (Meijer et al., 2014). PFAM domain assignment of the sub-proteomes also indicated biochemical distinction. The domains unique to the mycelia are involved in a wide range of intracellular signalling of the vegetative state. The domains distinct in zoospores included C2, RCC1, and TIG. Members of the C2 domain target proteins to cell membranes in response to external stimuli (Farah and Sossin, 2012). In zoospores, this is possibly involved in the process of response to chemotactic gradients in the external environment that control their direction of movement. RCC1 domains include proteins involved in chromosome condensation during transition of cell growth, which could be involved in the quick differentiation from zoospores to cysts (Ohtsubo et al., 1989). Plexins are major constituents of the TIG domain that play roles in signalling of axon growth and may be involved in zoospore motility (Negishi et al., 2005). There are several distinct PFAM domains in the secretome compared to the mycelia and zoospores. Elicitins are commonly found in the secretome of Phytophthora species. These molecules induce a hypersensitive response in hosts (Horta et al., 2010). Thioredoxin and proteasome domains were also distinct in this sub-proteome, which are involved in defence to oxidative stress and protein degradation, respectively (Meijer et al., 2014). These are important aspects of the secretome that contribute to the early stages of infection.
Mass spectrometry based proteomics can be used to overcome some of the constraints of traditional gene prediction methods and with continuing advances in proteomics technologies becomes a desirable tool to elucidate the biochemistry of an organism (Cox and Mann, 2007). High throughput proteomic pipelines such as liquid chromatography mass spectrometry (LC-MS/MS) are becoming more sensitive, rapid and less expensive (Law and Lim, 2013). As an added benefit to transcriptome work, quantitative proteomics can inform on differential expression of proteins (Pastorelli et al., 2006).
Using the mass spectra matched to the 6-frame translation of the draft genome, we refined the draft genome of P. cinnamomi. Total peptide support and functional assignment were used to validate and to obtain the most accurate representation of edited and newly curated genes. We compared the functional assignments of V1.0 and V2.0.0 edited genes to identify differences inferred by the changes in annotation features. The PFAM domains associated with the extended genes that differed from V1.0 genes were involved in energy production and one recombination protein (gw1.193.42.1_V2.0 and fgenesh1_kg.277_#_5_V2.0). Similarly, the only differing GO was that of DNA repair (CE70043_1777_V2.0). The KO of V2.0.0 extended genes remained mostly the same with minor changes and one enzyme code, an enzyme involved in carbohydrate metabolism was not present in V1.0 genes. These changes include a PAMP recognition signalling factor in gw1.44.72.1_V2.0.0. The majority of merged gene features were mostly between CDS features of the same gene. Therefore, there were minimal functional assignment differences between V1.0 genes and those altered by merging. However, three instances merged whole genes (fgenesh1_kg.79_#_14_#_15_V2.0, estExt_fgenesh1_pm.C_90019, fgenesh1_pm.9_#_20, e_gw1.9.526.1_V2.0 and gw1.243.65.1, gw1.243.79.1_V2.0). fgenesh1_kg.79_#_14_#_15_V2.0 combined two whole genes from the V1.0 annotation, the V2.0.0 functional assignment included an additional PFAM domain, PF12698, an ABC-2 family transporter protein, which are often highly expressed in plant pathogens such as the oomycetes as they play roles in the biotrophic phase of infection and pathogenicity (Seidl et al., 2011; Ah-Fong et al., 2017). The second, estExt_fgenesh1_pm.C_90019, fgenesh1_pm.9_#_20, e_gw1.9.526.1_V2.0, merged three whole genes, and included three different PFAM domains, two Poly (ADP-ribose polymerase domains and one WGR domain. This edit also resulted in one gene ontology difference, the presence of an NAD+ ADP-ribosyltransferase. There were no other differences in the GO and KEGG ontologies between V1.0 and V2.0.0 merged genes. Although these functional differences do not indicate major functional differences, they can impact the way in which we classify these proteins when trying to understand their role in a system.
The newly curated genes were validated using total peptide support, functional assignment and also examined for their codon usage to gain a better understanding of why they were missed in the V1.0 annotation. Although MT820633 had only one supporting peptide, it had PFAM, GO and KEGG assignment, all indicating its function to be associated with ankyrin, a protein family that is involved in the formation of the cytoskeleton and has been associated with signal transduction in other oomycete pathogens (Torto-Alalibo et al., 2005). MT820636, MT820637 and MT820651 although had significant blast hits to other oomycetes but did not have any PFAM, GO, or KO assignments. Functional domains were identified for all other new genes, most of which were related to general biochemical processes, including energy production, translation and transporter activity. PFAM domains and GO assignments that were associated with new genes but not present in V1.0 genes were mostly domains of ribosomal proteins and one ferredoxin type domain. Ribosomal proteins are highly conserved between species of oomycetes. This has been shown in Pythium insidiosum using expressed sequence tags, that show homology between several of the Phytophthora species (Win et al., 2006; Krajaejun et al., 2011). Ferredoxin domains have been identified in P. parasitica and were found to be associated with ATP generation (Le Berre et al., 2008). Of the KO assignments, nine from V2.0.0 genes were not present in V1.0 genes. These were mostly associated with general metabolic and cellular functions, translation and genetic information processing functions, with many domains associated with ribosomes (Supplementary Material 5). The remaining peptides matched to the 6-frame translation that were suggestive of 34 new genes but did not return significant BLASTp results to genes of any other Phytophthora species. These 34 hits are still potentially interesting new genes but would need to be validated using other means such as rapid amplification of cDNA ends on the P. cinnamomi and other Phytophthora species genomes.
Effector proteins in Phytophthora species often contain characteristic motifs such as those conserved in RXLR, Crinkler and necrosis inducing Phytophthora protein families (Meijer et al., 2014). These effectors can translocate into host cells and manipulate host immunity in order to successfully colonise hosts (Wang and Jiao, 2019). Characterising effectors is important to understand the mechanisms of pathogen infection and can subsequently be exploited for plant protection. This can be achieved through the development of resistant hosts through stacking of R genes that recognises these effectors, thereby inducing a defence response (Vleeshouwers and Oliver, 2014). Effector prediction is problematic as not all of these molecules have the characteristic motifs (Sperschneider et al., 2015). But the prediction of candidate effectors can be maximised with the use of a combination of tools (Sonah et al., 2016). The present study was unable to detect any candidates that are homologous to characterised effectors using PHI-BASE, showing no significant homology to virulence factors in the new gene set. However, of the total identified proteins in V1.0 genes, putative elicitins with homology to INF1 were identified in the secretome. Elicitins can be recognised as pathogen associated molecular patterns or by corresponding R genes to induce a hypersensitive response in hosts (Horta et al., 2010). Effector discovery in vitro can be difficult as there is minimal stimulation to produce and release virulence factors such as effector molecules. Typically, studies aiming to identify virulence factors such as effectors simulate a host interaction environment as plant pathogens primarily express these molecules at early stages of infection to overcome host defence systems (Baldwin et al., 2006; Bozkurt et al., 2012; Urban et al., 2017). This data also complies with the GO, PFAM, and EC assignments, as the majority of functional annotations indicated core metabolic functions and therefore are unlikely to have virulence or infection related functions.
The significantly lower codon adaptation indices of the new genes compared to detected V1.0 genes can suggest a limited rate of protein translation, which implies that over time optimised transcriptional levels have a selective advantage for gene expression. This can also be influenced by repeat- induced point mutations which can have implication on codon frequencies, and ultimately CAIs (Testa et al., 2016). Additionally, recent lateral gene transfers can result in altered codon frequencies as these involve acquiring genes that have codons optimised for different species (Tuller, 2011). We also observed a bias of CAIs in V1.0 annotations confirmed by mass spectrometry compared to the CAIs of all V1.0 genes. These experimentally confirmed genes had higher CAIs, which indicates that the highly abundant proteins sampled in this study are translated with high efficiency. The only new gene without a typical AUG start codon was MT820649, which is a high confidence prediction with evidence from seven supporting peptides. BlastP analysis of MT820649 revealed high homology with sequence ribosomal protein orthologues found in other well-annotated Phytophthora species such as P. sojae (Supplementary Material 5). These orthologues also lacked the typical AUG start codon. Upon close inspection of the upstream nucleotide sequences of MT820649 and its orthologue in P. sojae, we observed evidence of typical eukaryotic alternate CUG start codon that encode leucine (Supplementary Material 5) (Starck et al., 2012). The usage of alternate start codons were frequently observed in other eukaryotic organisms. In most cases, alternate start codons differ from AUG by a single nucleotide (Kearse and Wilusz, 2017). The CUG leucine codon is a typical alternate start codon observed as an initiator of translation in major histone compatibility complex in mammals (Starck et al., 2012; Sendoel et al., 2017). As such, we are currently using rapid amplification of cDNA ends approach to validate the 5′ terminal transcript sequence of MT820649 and its orthologues in other Phytophthora species (Yeku and Frohman, 2011). The remaining 28 novel predicted genes possessed regular start and stop codons as expected.
Conclusion
The data generated by shotgun LC-MS/MS confirmed 2,764 previously annotated gene models from the P. cinnamomi draft genome using high quality mass spectra from a diverse range of sub-proteome fractions. The spectral data suggested potential errors in gene calling, and using the spectral data, we were able to alter 60 genes by extending and merging exons, and identify 23 previously undescribed annotations in the P. cinnamomi genome. This demonstrates that the correlation between genes called by methods in silico are not always correlated to protein products, with evidence of annotation error rates of 2% of the detected proteome. This work demonstrates there are effective ways to use proteomics to correct boundary discrepancies and discover new genes. To our knowledge, this study presents the first use of spectral data to edit and manually annotate an oomycete pathogen. As more spectral data is accumulated, we expect there will be additional changes to the annotation including the discovery of more new genes.
Data Availability Statement
Spectral data used for this study is available at Dryad (doi: 10.5061/dryad.7h44j0zsc). Newly curated genes have been submitted to Genbank under the accessions MT820633-MT820655.
Author Contributions
CA and K-CT conceived and designed the study. CA performed all the experiments and prepared the draft of the manuscript. CA and JH performed the bioinformatics analysis. GH and SJ provided intellectual input into the study. SB and RL provided input into proteomics sample preparation and mass spectrometry analysis. All authors revised and approved the manuscript.
Funding
Proteomics International provided funded the project. Curtin University provided funding for sample preparation through the postgraduate maintenance fund. K-CT, JH, and SJ are supported by the Centre for Crop and Disease Management, a joint initiative of Curtin University and the Grains Research and Development Corporation (CUR00023).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Funding was provided by Proteomics International. We thank Dr. Paula Moolhuijzen, Johannes Debler, and Darcy Jones for their technical assistance.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmicb.2021.665396/full#supplementary-material
Supplementary Material 1. PFAM domain assignment of proteins identified in each sub-proteome.
Supplementary Material 2. CDS coordinates of edited genes, Description: Gene coordinates of manually edited V1.0 genes. Gene identification names include the original ID from https://mycocosm.jgi.doe.gov/Phyci1 as a reference.
Supplementary Material 3. Master table of genes edited by extending features, Description: Summary of sequence, sequence features, peptide support, codon usage and functional assignment of edited genes generated by extending features.
Supplementary Material 4. Master table of genes edited by merging features, Description: Summary of sequence, sequence features, peptide support, codon usage, and functional assignment of edited genes generated by merging features.
Supplementary Material 5. Master table of new genes, Description: Summary of sequence, sequence features, peptide support, codon usage, and functional assignment of new genes.
Abbreviations
GO, Gene Ontology; PFAM, Protein Families; 1D SDS-PAGE, 1 Dimensional Sodium Dodecyl Suphate Polyachrilamide Gel Electrophoresis; RP-HPLC, Reverse phase High pressure liquid Chromatography; LC-MS, Liquid Chromatography- Mass Spectrometry; MS, Mass Spectrometry; TOF, Time of Flight; CONF, Confidence; FDR, False Discovery Rate; CDS, Coding Sequence; CAI, Codon Adaptation Index; GAPDH, Glyceraldehyde Phosphate Dehydrogenase; JGI, Joint Genome Institute; ORF, Open Reading Frame; KEGG, Kyoto Encyclopaedia of Genes and Genomes; KO, KEGG Orthologues; EC, Enzyme Code.
References
Ah-Fong, A. M. V., Kim, K. S., and Judelson, H. S. (2017). RNA-seq of life stages of the oomycete Phytophthora infestans reveals dynamic changes in metabolic, signal transduction, and pathogenesis genes and a major role for calcium signaling in development. BMC Genomics 18:198. doi: 10.1186/s12864-017-3585-x
Alexandersson, E., Ali, A., Resj,ö, S., and Andreasson, E. (2013). Plant secretome proteomics. Front. Plant Sci. 4:9. doi: 10.3389/fpls.2013.00009
Baldwin, T. K., Winnenburg, R., Urban, M., Rawlings, C., Koehler, J., and Hammond-Kosack, K. E. (2006). The Pathogen-Host Interactions Database (PHI-base) provides insights into generic and novel themes of pathogenicity. Mol. Plant-Microbe. Interact. 19, 1451–1462. doi: 10.1094/MPMI-19-1451
Bantscheff, M., Lemeer, S., Savitski, M. M., and Kuster, B. (2012). Quantitative mass spectrometry in proteomics: critical review update from 2007 to the present. Anal. Bioanal. Chem. 404, 939–965. doi: 10.1007/s00216-012-6203-4
Birch, P. R. J., Rehmany, A. P., Pritchard, L., Kamoun, S., and Beynon, J. L. (2006). Trafficking arms: oomycete effectors enter host plant cells. Trends Microbiol. 14, 8–11. doi: 10.1016/j.tim.2005.11.007
Bozkurt, T. O., Schornack, S., Banfield, M. J., and Kamoun, S. (2012). Oomycetes, effectors, and all that jazz. Curr. Opin. Plant Biol. 15, 483–492. doi: 10.1016/j.pbi.2012.03.008
Bringans, S., Hane, J. K., Casey, T., Tan, K.-C., Lipscombe, R., Solomon, P. S., et al. (2009). Deep proteogenomics; high throughput gene validation by multidimensional liquid chromatography and mass spectrometry of proteins from the fungal wheat pathogen Stagonospora nodorum. BMC Bioinformatics 10:301. doi: 10.1186/1471-2105-10-301
Bringans, S. D., Ito, J., Stoll, T., Winfield, K., Phillips, M., Peters, K., et al. (2017). Comprehensive mass spectrometry based biomarker discovery and validation platform as applied to diabetic kidney disease. EuPA Open Proteomics 14, 1–10. doi: 10.1016/j.euprot.2016.12.001
Byrt, P., and Grant, B. R. (1979). Some conditions governing zoospore production in axenic cultures of Phytophthora cinnamomi rands. Aust. J. Bot. 27, 103–115. doi: 10.1071/BT9790103
Cooke, I. R., Jones, D., Bowen, J. K., Deng, C., Faou, P., Hall, N. E., et al. (2014). Proteogenomic analysis of the Venturia pirina (PEAR SCAB Fungus) secretome reveals potential effectors. J. Proteome Res. 13, 3635–3644. doi: 10.1021/pr500176c
Cox, J., and Mann, M. (2007). Is proteomics the new genomics? Cell 130, 395–398. doi: 10.1016/j.cell.2007.07.032
Crone, M., McComb, J. A., O'Brien, P. A., and Hardy, G. E. S. J. (2013). Survival of Phytophthora cinnamomi as oospores, stromata, and thick-walled chlamydospores in roots of symptomatic and asymptomatic annual and herbaceous perennial plant species. Fungal Biol. 117, 112–123. doi: 10.1016/j.funbio.2012.12.004
Farah, C. A., and Sossin, W. S. (2012). The role of C2 domains in PKC signaling. Adv. Exp. Med. Biol. 740, 663–683. doi: 10.1007/978-94-007-2888-2_29
Hardham, A. R. (2005). Pathogen profile: Phytophthora cinnamomi. Mol. Plant Pathol. 6, 589–604. doi: 10.1111/j.1364-3703.2005.00308.x
Horta, M., Caetano, P., Medeira, C., Maia, I., and Cravador, A. (2010). Involvement of the β-cinnamomin elicitin in infection and colonisation of cork oak roots by Phytophthora cinnamomi. Eur. J. Plant Pathol. 127, 427–436. doi: 10.1007/s10658-010-9609-x
Horton, P., Park, K. J., Obayashi, T., Fujita, N., Harada, H., Adams-Collier, C. J., et al. (2007). WoLF PSORT: protein localization predictor. Nucleic Acids Res. 35, 585–587. doi: 10.1093/nar/gkm259
Jones, D. A., Bertazzoni, S., Turo, C. J., Syme, R. A., and Hane, J. K. (2018). Bioinformatic prediction of plant–pathogenicity effector proteins of fungi. Curr. Opin. Microbiol. 46, 43–49. doi: 10.1016/j.mib.2018.01.017
Kamoun, S., Furzer, O., Jones, J. D. G., Judelson, H. S., Ali, G. S., Dalio, R. J. D., et al. (2015). The Top 10 oomycete pathogens in molecular plant pathology. Mol. Plant Pathol. 16, 413–434. doi: 10.1111/mpp.12190
Kearse, M. G., and Wilusz, J. E. (2017). Non-AUG translation: a new start for protein synthesis in eukaryotes. Genes Dev. 31, 1717–1731. doi: 10.1101/gad.305250.117
Kim, S. G., Wang, Y., Lee, K. H., Park, Z. Y., Park, J., Wu, J., et al. (2013). In-depth insight into in vivo apoplastic secretome of rice-Magnaporthe oryzae interaction. J. Proteomics 78, 58–71. doi: 10.1016/j.jprot.2012.10.029
Krajaejun, T., Khositnithikul, R., Lerksuthirat, T., Lowhnoo, T., Rujirawat, T., Petchthong, T., et al. (2011). Expressed sequence tags reveal genetic diversity and putative virulence factors of the pathogenic oomycete Pythium insidiosum. Fungal Biol. 115, 683–696. doi: 10.1016/j.funbio.2011.05.001
Lam, H., Deutsch, E. W., and Aebersold, R. (2010). Artificial decoy spectral libraries for false discovery rate estimation in spectral library searching in proteomics. J. Proteome Res. 9, 605–610. doi: 10.1021/pr900947u
Law, K. P., and Lim, Y. P. (2013). Recent advances in mass spectrometry: data independent analysis and hyper reaction monitoring. Expert Rev. Proteomics 10, 551–566. doi: 10.1586/14789450.2013.858022
Le Berre, J. Y., Engler, G., and Panabières, F. (2008). Exploration of the late stages of the tomato-Phytophthora parasitica interactions through histological analysis and generation of expressed sequence tags. New Phytol. 177, 480–492. doi: 10.1111/j.1469-8137.2007.02269.x
Liang, C., Mao, L., Ware, D., and Stein, L. (2009). Evidence-based gene predictions in plant genomes. Genome Res. 19, 1912–1923. doi: 10.1101/gr.088997.108
Mathe, C. (2002). Current methods of gene prediction, their strengths and weaknesses. Nucleic Acids Res. 30, 4103–4117. doi: 10.1093/nar/gkf543
McDonnell, E., Strasser, K., and Tsang, A. (2018). Manual gene curation and functional annotation. Methods Mol. Biol. 1775, 185–208. doi: 10.1007/978-1-4939-7804-5_16
Meijer, H. J. G., Mancuso, F. M., Espadas, G., Seidl, M. F., Chiva, C., Govers, F., et al. (2014). Profiling the secretome and extracellular proteome of the potato late blight pathogen Phytophthora infestans. Mol. Cell. Proteomics 13, 2101–2113. doi: 10.1074/mcp.M113.035873
Negishi, M., Oinuma, I., and Katoh, H. (2005). Review Plexins: axon guidance and signal transduction. C. Cell. Mol. Life Sci. 62, 1363–1371. doi: 10.1007/s00018-005-5018-2
Nesvizhskii, A. I. (2014). Proteogenomics: concepts, applications and computational strategies. Nat. Methods 11, 1114–1125. doi: 10.1038/nmeth.3144
Ohtsubo, M., Okazaki, H., and Nishimoto, T. (1989). The RCC1 protein, a regulator for the onset of chromosome condensation locates in the nucleus and binds to DNA. J. Cell Biol. 109, 1389–1397. doi: 10.1083/jcb.109.4.1389
Pastorelli, R., Carpi, D., Campagna, R., Airoldi, L., Pohjanvirta, R., Viluksela, M., et al. (2006). Differential expression profiling of the hepatic proteome in a rat model of dioxin resistance: correlation with genomic and transcriptomic analyses. Mol. Cell. Proteomics 5, 882–894. doi: 10.1074/mcp.M500415-MCP200
Quinlan, A. R., and Hall, I. M. (2010). BEDTools: a flexible suite of utilities for comparing genomic features. Bioinformatics 26, 841–842. doi: 10.1093/bioinformatics/btq033
Renuse, S., Chaerkady, R., and Pandey, A. (2011). Proteogenomics. Proteomics 11, 620–630. doi: 10.1002/pmic.201000615
Resjö, S., Ali, A., Meijer, H. J. G., Seidl, M. F., Snel, B., Sandin, M., et al. (2014). Quantitative label-free phosphoproteomics of six different life stages of the late blight pathogen phytophthora infestans reveals abundant phosphorylation of members of the CRN effector family. J. Proteome Res. 13, 1848–1859. doi: 10.1021/pr4009095
Ribeiro, O. K. (1978). A source book of the genus phytophthora. Mycologia 71, 74–77. doi: 10.2307/3759174
Ruggles, K. V., Krug, K., Wang, X., Clauser, K. R., Wang, J., Payne, S. H., et al. (2017). Methods, tools and current perspectives in proteogenomics. Mol. Cell. Proteomics 16, 959–981. doi: 10.1074/mcp.MR117.000024
Seidl, M. F., van den Ackerveken, G., Govers, F., and Snel, B. (2011). A domain-centric analysis of oomycete plant pathogen genomes reveals unique protein organization. Plant Physiol. 155, 628–644. doi: 10.1104/pp.110.167841
Sendoel, A., Dunn, J. G., Rodriguez, E. H., Naik, S., Gomez, N. C., Hurwitz, B., et al. (2017). Translation from unconventional 5′ start sites drives tumour initiation. Nature 541, 494–499. doi: 10.1038/nature21036
Sharp, P. M., and Li, W. H. (1987). The codon adaptation index-a measure of directional synonymous codon usage bias, and its potential applications. Nucleic Acids Res. 15, 1281–1295. doi: 10.1093/nar/15.3.1281
Sheng, Q., Dai, J., Wu, Y., Tang, H., and Zeng, R. (2012). BuildSummary: using a group-based approach to improve the sensitivity of peptide/protein identification in shotgun proteomics. J. Proteome Res. 11, 1494–1502. doi: 10.1021/pr200194p
Shepherd, S. J., van West, P., and Gow, N. a R. (2003). Proteomic analysis of asexual development of Phytophthora palmivora. Mycol. Res. 107, 395–400. doi: 10.1017/S0953756203007561
Siu, S. O., Lam, M. P. Y., Lau, E., Kong, R. P. W., Lee, S. M. Y., and Chu, I. K. (2011). Fully automatable two-dimensional reversed-phase capillary liquid chromatography with online tandem mass spectrometry for shotgun proteomics. Proteomics 11, 2308–2319. doi: 10.1002/pmic.201100110
Sonah, H., Deshmukh, R. K., and Bélanger, R. R. (2016). Computational prediction of effector proteins in fungi: opportunities and challenges. Front. Plant Sci. 7:126. doi: 10.3389/fpls.2016.00126
Sperschneider, J., Dodds, P. N., Gardiner, D. M., Manners, J. M., Singh, K. B., and Taylor, J. M. (2015). Advances and challenges in computational prediction of effectors from plant pathogenic fungi. PLoS Pathog. 11:e1004806. doi: 10.1371/journal.ppat.1004806
Starck, S. R., Jiang, V., Pavon-Eternod, M., Prasad, S., McCarthy, B., Pan, T., et al. (2012). Leucine-tRNA initiates at CUG start codons for protein synthesis and presentation by MHC class I. Science 336, 1719–1723. doi: 10.1126/science.1220270
Syme, R. A., Tan, K. C., Hane, J. K., Dodhia, K., Stoll, T., Hastie, M., et al. (2016). Comprehensive annotation of the parastagonospora nodorum reference genome using next-generation genomics, transcriptomics and proteogenomics. PLoS ONE 11:e0147221. doi: 10.1371/journal.pone.0147221
Tan, K. C., Heazlewood, J. L., Millar, A. H., Oliver, R. P., and Solomon, P. S. (2009). Proteomic identification of extracellular proteins regulated by the Gna1 Gα subunit in Stagonospora nodorum. Mycol. Res. 113, 523–531. doi: 10.1016/j.mycres.2009.01.004
Testa, A. C., Oliver, R. P., and Hane, J. K. (2016). OcculterCut: a comprehensive survey of at-rich regions in fungal genomes. Genome Biol. Evol. 8, 2044–2064. doi: 10.1093/gbe/evw121
Torto-Alalibo, T., Tian, M., Gajendran, K., Waugh, M. E., Van West, P., and Kamoun, S. (2005). Expressed sequence tags from the oomycete fish pathogen Saprolegnia parasitica reveal putative virulence factors. BMC Microbiol. 5:46. doi: 10.1186/1471-2180-5-46
Tristan, C., Shahani, N., Sedlak, T. W., and Sawa, A. (2011). The diverse functions of GAPDH: views from different subcellular compartments. Cell. Signal. 23, 317–323. doi: 10.1016/j.cellsig.2010.08.003
Tuller, T. (2011). Codon bias, tRNA pools, and horizontal gene transfer. Mob. Genet. Elements 1, 75–77. doi: 10.4161/mge.1.1.15400
Tyler, B. M., Tripathy, S., Zhang, X., Dehal, P., Jiang, R. H. Y., Aerts, A., et al. (2006). Phytophthora genome sequences uncover evolutionary origins and mechanisms of pathogenesis. Science 313, 1261–1266. doi: 10.1126/science.1128796
Urban, M., Cuzick, A., Rutherford, K., Irvine, A., Pedro, H., Pant, R., et al. (2017). PHI-base: a new interface and further additions for the multi-species pathogen-host interactions database. Nucleic Acids Res. 45, 604–610. doi: 10.1093/nar/gkw1089
Vleeshouwers, V. G. A. A., and Oliver, R. P. (2014). Effectors as tools in disease resistance breeding against biotrophic, hemibiotrophic, and necrotrophic plant pathogens. Mol. Plant-Microbe Interact. 27, 196–206. doi: 10.1094/MPMI-10-13-0313-IA
Wang, W., and Jiao, F. (2019). Effectors of Phytophthora pathogens are powerful weapons for manipulating host immunity. Planta 250, 413–425. doi: 10.1007/s00425-019-03219-x
Win, J., Kanneganti, T. D., Torto-Alalibo, T., and Kamoun, S. (2006). Computational and comparative analyses of 150 full-length cDNA sequences from the oomycete plant pathogen Phytophthora infestans. Fungal Genet. Biol. 43, 20–33. doi: 10.1016/j.fgb.2005.10.003
Wright, P. C., Noirel, J., Ow, S. Y., and Fazeli, A. (2012). A review of current proteomics technologies with a survey on their widespread use in reproductive biology investigations. Theriogenology 77, 738–765. doi: 10.1016/j.theriogenology.2011.11.012
Yeku, O., and Frohman, M. A. (2011). Rapid amplification of cDNA ends (RACE). Methods Mol. Biol. 703, 107–122. doi: 10.1007/978-1-59745-248-9_8
Keywords: proteogenomics, oomycete, phytophthora, proteomics, dieback
Citation: Andronis CE, Hane JK, Bringans S, Hardy GESJ, Jacques S, Lipscombe R and Tan K-C (2021) Gene Validation and Remodelling Using Proteogenomics of Phytophthora cinnamomi, the Causal Agent of Dieback. Front. Microbiol. 12:665396. doi: 10.3389/fmicb.2021.665396
Received: 08 February 2021; Accepted: 18 May 2021;
Published: 15 July 2021.
Edited by:
Marco Scortichini, Council for Agricultural and Economics Research (CREA), ItalyReviewed by:
Orlando Borras-Hidalgo, Qilu University of Technology, ChinaHarold Meijer, Wageningen University and Research, Netherlands
Copyright © 2021 Andronis, Hane, Bringans, Hardy, Jacques, Lipscombe and Tan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Christina E. Andronis, Y2hyaXN0aW5hLmFuZHJvbmlzQHBvc3RncmFkLmN1cnRpbi5lZHUuYXU=; Kar-Chun Tan, a2FyLWNodW4udGFuQGN1cnRpbi5lZHUuYXU=