 Sanja Trifkovic
Sanja Trifkovic Brad Gilbertson
Brad Gilbertson Emily Fairmaid1
Emily Fairmaid1 Joanna Cobbin
Joanna Cobbin Lorena E. Brown
Lorena E. Brown- 1The Department of Microbiology and Immunology, The University of Melbourne at the Peter Doherty Institute for Infection and Immunity, Melbourne, VIC, Australia
- 2Seqirus, Parkville, VIC, Australia
- 3Global Station for Zoonosis Control, Global Institution for Collaborative Research and Education, Hokkaido University, Sapporo, Japan
A segmented genome enables influenza virus to undergo reassortment when two viruses infect the same cell. Although reassortment is involved in the creation of pandemic influenza strains and is routinely used to produce influenza vaccines, our understanding of the factors that drive the emergence of dominant gene constellations during this process is incomplete. Recently, we defined a spectrum of interactions between the gene segments of the A/Udorn/307/72 (H3N2) (Udorn) strain that occur within virus particles, a major interaction being between the NA and PB1 gene segments. In addition, we showed that the Udorn PB1 is preferentially incorporated into reassortant viruses that express the Udorn NA. Here we use an influenza vaccine seed production model where eggs are coinfected with Udorn and the high yielding A/Puerto Rico/8/34 (H1N1) (PR8) virus and track viral genotypes through the reassortment process under antibody selective pressure to determine the impact of Udorn NA-PB1 co-selection. We discovered that 86% of the reassortants contained the PB1 from the Udorn parent after the initial co-infection and this bias towards Udorn PB1 was maintained after two further passages. Included in these were certain gene constellations containing Udorn HA, NA, and PB1 that confered low replicative fitness yet rapidly became dominant at the expense of more fit progeny, even when co-infection ratios of the two viruses favoured PR8. Fitness was not compromised, however, in the corresponding reassortants that also contained Udorn NP. Of particular note is the observation that relatively unfit reassortants could still fulfil the role of vaccine seed candidates as they provided high haemagglutinin (HA) antigen yields through co-production of non-infectious particles and/or by more HA molecules per virion. Our data illustrate the dynamics and complexity of reassortment and highlight how major gene segment interactions formed during packaging, in addition to antibody pressure, initially restrict the reassortant viruses that are formed.
Introduction
Reassortment, or the swapping of gene segments, is a major mechanism of influenza virus evolution. After co-infection of a single cell by two or more influenza viruses, each viral genome is replicated and various combinations of individual gene segments, in the form of viral ribonucleoprotein complexes (vRNPs), are co-packaged into progeny virions. Since influenza has eight vRNPs, co-infection with two viruses could theoretically yield up to 256 (28) different gene segment constellations. Although reassortment can occur at high frequency (Ghedin et al., 2005; Lu et al., 2014; Steel and Lowen, 2014), studies have shown this to be a non-random process (Lubeck et al., 1979; Rabadan et al., 2008; Varich et al., 2008; Marshall et al., 2013) with progeny populations restricted due to incompatibilities between gene products (Li et al., 2008, 2010; Song et al., 2011), preferential co-packaging of gene segments (Gavazzi et al., 2013b; Cobbin et al., 2014; Gilbertson et al., 2016), and certain genes reassorting at higher frequencies (Downie, 2004; Nelson et al., 2012; Schrauwen et al., 2013; Lu et al., 2014).
Using cross-linking of gene segments in virio together with deep sequencing of digested products, we recently uncovered an extensive network of inter-segment interactions believed to be used by the virus to package its genome (Dadonaite et al., 2019). Contrary to existing dogma, these interactions were not restricted to the previously defined “packaging sequences” at the ends of the segments but occurred throughout their entire length (Cobbin et al., 2014; Dadonaite et al., 2019). The pattern of interactions differed markedly between viruses of different subtypes and to a lesser extent between strains of the one subtype (Dadonaite et al., 2019). Importantly, the observed interactions were numerous, with hundreds being detected in the population of virus particles as a whole. These findings led us to propose that the ability of the influenza virus genome to utilise different sets of interactions to package one of each of the eight gene segments provides sufficient flexibility to allow reassortment to occur between different influenza viruses. Importantly, of this suite of interactions, some were found at very high frequency, indicating these were likely present in the majority of virus particles. One such high-frequency interaction occurred between the NA and PB1 genes in the early H3N2 virus A/Udorn/307/72 (Udorn) (Cobbin et al., 2014; Gilbertson et al., 2016) at nucleotides NA 512-550:PB1 2004-2037 (3′–5′), equivalent to NA 917-955:PB1 305-338 (5′–3′) (Dadonaite et al., 2019). This NA:PB1 interaction was also maintained in a reverse engineered virus containing the NA and PB1 genes from Udorn and the remaining genes from the H1N1 virus A/Puerto Rico/8/34 (PR8) where the pattern of interactions were found to be essentially inherited from both parent viruses (Dadonaite et al., 2019). This supported the notion that the stronger interactions are preferentially maintained and shape the gene constellations of resulting reassortant progeny.
Our initial interest in the NA:PB1 gene segment interaction developed from the retrospective analysis of the gene constellations of H3N2 influenza vaccine seed candidate viruses (Cobbin et al., 2013). These are produced by reassortment with the highly egg-adapted PR8 virus to enable the creation of viruses displaying greater H3N2 surface antigen yields in eggs through incorporation of non-surface antigen genes from the PR8 parent (Kilbourne and Murphy, 1960). This classical reassortment process consists of an initial co-infection step in eggs, followed by antibody selection for reassortant viruses with seasonal haemagglutinin (HA) and neuraminidase (NA) surface antigens, and finally cloning by limit dilution to isolate dominant viruses, some of which will display high haemagglutination titres suitable for vaccine seeds. By genotyping past H3N2 vaccine seed candidates, we showed that, unlike other non-surface antigen genes, the PB1 gene of the seasonal H3N2 virus was present in high frequency in these vaccine seeds. Furthermore, the Udorn virus exemplified this process, with 75% of the progeny virus expressing Udorn PB1 following reassortment with PR8 in eggs (Cobbin et al., 2013). This occurred despite the fact that the resulting reassortant progeny expressing Udorn HA in addition to Udorn NA and PB1 were significantly less fit than viruses that contained the Udorn HA and NA genes together with the PB1 gene from the H1N1 strain (Cobbin et al., 2014).
Here we used the vaccine seed model, where antibody drives selection of viruses with Udorn HA and NA, and gene segment interactions potentially drive co-selection of Udorn NA and PB1 with the aim of better understanding the dynamics of co-selection of the seasonal NA and PB1 genes and the effects of the co-infection ratio of Udorn and PR8 viruses on the outcome. This model also allowed us to examine why the viruses that have gene constellations resulting in inferior replicative fitness, exemplified by those expressing Udorn HA, NA, and PB1 genes, could ever be chosen on the basis of high antigen yield as we had observed in our retrospective analysis of vaccine seed strains. Our study illustrates the dynamics and complexity of classical reassortment and the impact of gene co-selection in this process. We also present data that highlights the effect of genotype on phenotype in relation to antigen expression.
Materials and Methods
Influenza A Viruses
The highly egg-adapted A/Puerto Rico/8/34 (PR8; H1N1) virus, currently used as a reassortment partner for the production of H3N2 vaccine seeds, and A/Udorn/307/72 (Udorn; H3N2) as a model seasonal isolate, were used in this study. An eight-plasmid DNA transfection system (Hoffmann et al., 2000) was used to generate reverse engineered (rg) virus. Specific gene constellations are referred to using the following standard nomenclature e.g., PR8(Ud-HA,NA,PB1,NP) referring to an isolate containing Udorn HA, NA, PB1, and NP genes with the remaining genes from PR8. All viruses were propagated in 10-day old embryonated hen’s eggs at 35°C for 2 days, then allantoic fluid was harvested and stored at −80°C.
Classical Reassortment
This was performed using a modification of the method devised by Kilbourne (1969) (Figure 1A). Ten-day-old embryonated hen’s eggs were co-infected with PR8 and Udorn viruses (Figure 1B) and incubated at 35°C in a moist environment for 24 h. As in seed strain production, different ratios of the two viruses were examined (Figure 1B). Allantoic fluid from the co-infected eggs was harvested and passaged twice in eggs in the presence of antibodies to neutralise the PR8 parent virus. These antibodies were in the form of purified gamma globulin from polyclonal sheep anti-PR8 antiserum that had been trypsin- and periodate-treated to remove non-specific inhibitors. For the first antiserum passage, eggs were inoculated with 0.2 ml virus-infected allantoic fluid from the co-infected eggs (10–3 dilution) followed by 0.2 ml of the anti-PR8 antibody preparation after 1 h. After 48 h the allantoic fluid was harvested and genotyped to detect the presence of the Udorn HA and NA genes. Virus-infected allantoic fluid with both Udorn HA and NA genes present was subjected to a second egg passage, this time being pre-incubated with the antiserum (the same amount as for the first passage) for 1 h prior to inoculation of the mixture into eggs. After 48 h the allantoic fluid was harvested and genotyped to determine the origin of the HA, NA, and M genes. The dominant progeny from classical reassortment were isolated by cloning via limit dilution. Briefly, serial dilutions of the allantoic fluid were inoculated into five eggs each and after 48 h the allantoic fluid was harvested. A haemagglutination assay was performed to detect the highest dilution containing virus for subsequent genotyping. If required, a further round of cloning by limit dilution was performed to obtain a pure population.
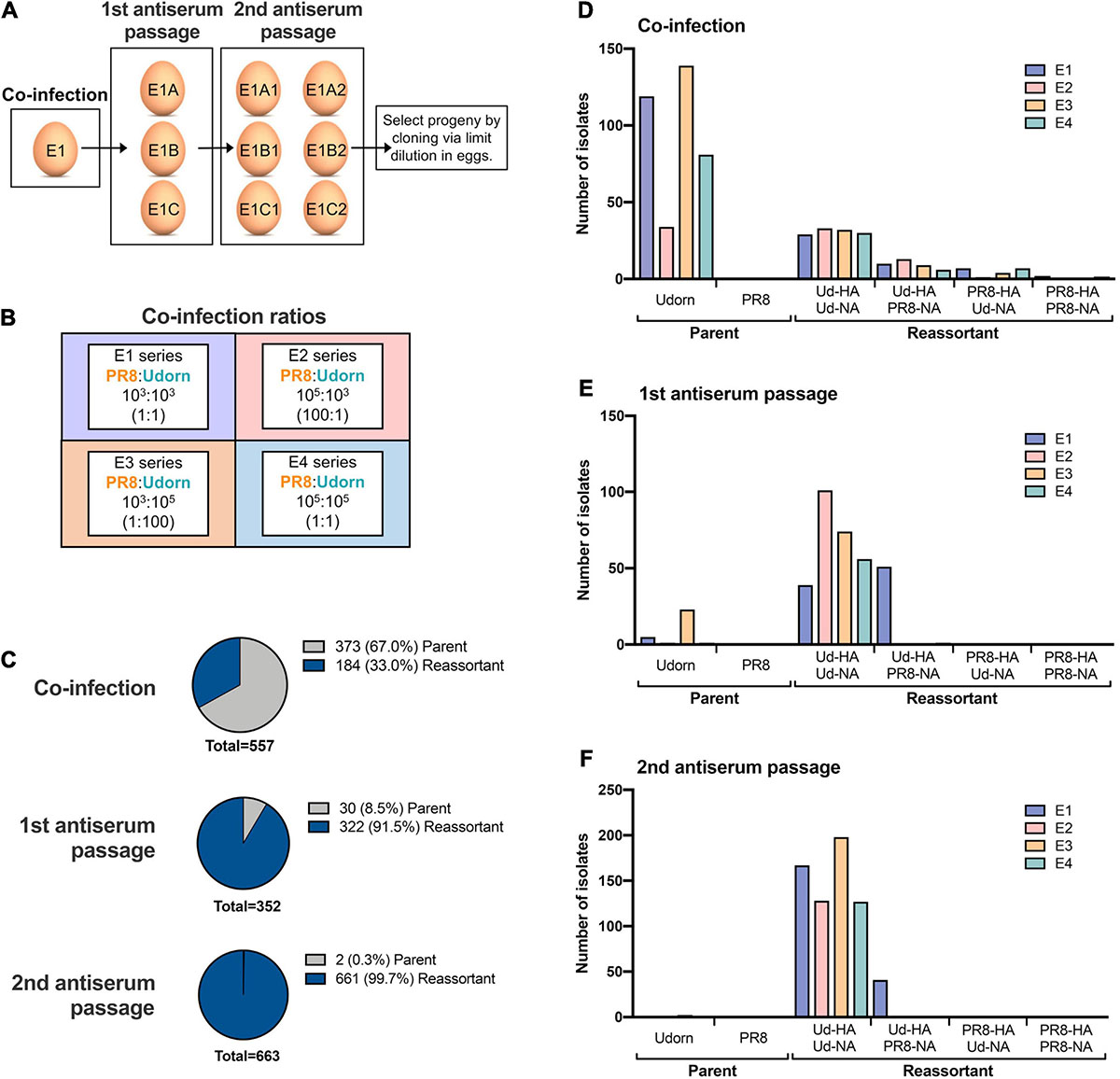
Figure 1. The frequency of parent versus reassortant genotypes isolated throughout the classical reassortment process. (A) Schematic overview of the classical reassortment process used for the generation of seasonal influenza vaccine seeds. Ten-day-old embryonated hen’s eggs were co-infected with PR8 and Udorn viruses. The allantoic fluid from these eggs was then harvested and passaged into three eggs (e.g., E1A, B, and C) in the presence of antiserum against the PR8 surface glycoproteins. The allantoic fluid from each of these eggs was then further passaged into two eggs (e.g., E1A1 and E1A2). Viruses from these were cloned by limit dilution. (B) The experiment was carried out four times at different co-infection ratios (series E1-E4). The co-infection ratios and amounts of infectious PR8 and Udorn virus (PFU) used to inoculate the first eggs of each series are indicated. (C) The ratio of reassortant genotypes to the Udorn parent at each stage of the classical reassortment process. Viruses in the allantoic fluid were isolated by plaque formation in MDCK cells. For the co-infected eggs, plaquing was performed in the presence of anti-PR8 antiserum. Individual plaques were picked into 0.05% Triton X-100 and gene specific RT-PCR performed to determine the origin of each gene. (D–F) The number of PR8 and Udorn parent genotypes recovered as well as the number of viruses containing different combinations of HA and NA genes present on reassortant viruses in (D) the initial coinfection, (E) the first antiserum passage, and (F) the second antiserum passage.
Virus Quantitation
Assays to quantitate haemagglutination (Fazekas De St and Webster, 1966) (as haemagglutinating units, HAU) were performed in microtitre plates with 1% chicken red blood cells and infectious virus yields (plaque-forming units, PFU) were determined by plaque assay on confluent MDCK cells monolayers (Tannock et al., 1984). To establish the relative HA yields of reassortant viruses, a standardised infection was performed by inoculating 10-day embryonated eggs (n = 5) with 100 PFU of virus injected into the allantoic cavity. After 2 days at 35°C the eggs were chilled overnight at 4°C before harvesting the allantoic fluid.
Gene Specific RT-PCR for the Identification of Viral Genes
The origin of viral genes present in samples were determined by gene-specific reverse transcription polymerase chain reaction (RT-PCR) using a SensiFast Probe No-ROX one-step reverse transcription kit (Bioline, Meridian Biosciences, OH, United States). Each 20 μl reaction contained 5 μl of virus sample in 0.05% Triton-X 100, 10 μl of 2x SensiFast Probe No-ROX one-step master mix, 0.2 μl reverse transcriptase, 0.4 μl RiboSafe RNase inhibitor mix, 0.8 μl of each 10 μM forward and reverse primer and 0.08 μl of each 25 μM gene specific probe. The reverse transcription, amplification, and detection were performed in a BioRad CFX96 PCR System. The reaction conditions, primers (Geneworks, Adelaide, SA, Australia) and probe [Integrated DNA Technologies (IDT), Coralville, IA, United States] sequences are available on request.
Viral Replicative Fitness
Viral replication kinetics were determined by infecting MDCK cells using a multiplicity of infection (MOI) of 0.001 PFU/cell. After a 1-h adsorption period the inoculum was removed, cells were washed and incubated in media supplemented with 1 μg/ml TPCK (designated time = 0 h). Cell culture supernatants were harvested at various time points and stored at −80°C until required. Infectious viral titres were determined by plaque assay as above.
Mini Genome Assay
A β-lactamase (BLA) reporter assay (Cavrois et al., 2002) was used to compare the activities of viral polymerase complexes identified in the dominant reassortant viruses as previously described (Cobbin et al., 2013). Briefly, 293T cells were transfected with 2 ng each of plasmids expressing the three influenza virus polymerase genes (PB2, PB1, and PA) and the nucleoprotein (NP) gene, together with 2 ng of a plasmid encoding BLA (provided by CSL Ltd.). These pHW2000 plasmids were those used for genetic engineering of influenza viruses in which viral cDNA is inserted into a bicistronic expression system (CMV and RNA polymerase 1 promotors) (Hoffmann et al., 2000). For the BLA-expressing plasmid the reporter gene was cloned between the 5′ and 3′ non-coding regions of the H1 HA gene to provide specificity for the influenza polymerase complex. Background levels of BLA produced by direct transcription from the CMV promotor was assessed in cells transfected with the reporter gene alone. After incubation at 37°C and 5% CO2 for 24 h, cells were lysed and LyticBLazerTM-FRET B/G substrate (Life Technologies) added. The BLA cleavage of the green substrate to the blue product was measured by optical density every 15 min for a 2-h period using a CLARIOstar (BMG Labtech, Ortenberg, Germany) fluorescence reader with excitation at 405 nm and blue and green emission detected at 445 and 520 nm, respectively. Specific BLA activity and thus relative polymerase activity was calculated as follows: (445 nm/520 nm ratio of the sample)/(445 nm/520 nm ratio of BLA plasmid alone).
Electron Microscopy
Transmission electron microscopy was performed at CSL Ltd. by Ross Hamilton using a method modified from that of Hayat and Miller (1990). Allantoic fluid was transferred onto Formar-coated copper TEM grids (Athene), which were inverted onto 2% agar plates to remove excess liquid. Grids were negatively stained using 2% sodium phosphotungstate (PTA) pH 7.0, excess stain was blotted away using filter paper (Whatman) and allowed to air-dry. Negatively-stained samples were examined using a Philips CM10 transmission electron microscope running iTEM software (EMSIS GmbH).
Quantification of Viral RNA and Viral mRNA/cRNA
To quantitate viral RNA production in MDCK cells, total RNA from infected cells was extracted using an RNeasy Mini Kit (Qiagen). Viral vRNA and mRNA were detected by polarity-specific quantitative RT-PCR using the SensiFast Probe No-ROX one-step kit (Bioline). Each 20 μl reaction contained 5 μl of RNA, 10 μl of 2x SensiFast Probe No-ROX one-step master mix, 0.2 μl Reverse Transcriptase, 0.4 μl RiboSafe RNase inhibitor mix and 0.08 μl of 25 μM gene specific probe. Detection of vRNA or mRNA/cRNA was facilitated by addition of 0.8 μl of 10 μM gene-specific forward or reverse primer, respectively. The RT reaction was incubated at 45°C for 10 min. Following this step, 0.8 μl of 10 μM of the opposite primer was added. In all qRT-PCR assays, serially diluted plasmids of corresponding influenza genes with known copy number were used as standards for quantification.
Viral Protein Quantification by Slot Blot Analysis
The relative protein content of virus in allantoic fluid was determined by staining for viral proteins in native conformation using a slot blot apparatus. Viral samples were adsorbed to nitrocellulose using a vacuum pump. The nitrocellulose strips were blocked in PBS with casein for 30 min at room temperature and then probed for 1 h with monoclonal antibodies (mAb) recognising H3 HA [clone 36/2 (Brown et al., 1990)] or IAV M1matrix protein (clone MCA401, BioRad). Strips were washed and incubated for 1 h with a horse radish peroxidase (HRP)-conjugated secondary immunoglobulin (DAKO). The strips were washed and immersed in citrate-EDTA before addition of the TMB substrate for 1 hour. Strips were then washed, dried overnight and digitised. The signal intensities for the viral HA and M1 protein bands were determined using ImageJ analysis software (NIH, Bethesda, MD, United States).
Viral Protein Quantification by Flow Cytometry
The relative viral protein content within infected MDCK cells was determined by flow cytometry. Infected MDCK monolayers were harvested 6 h after 1-h absorption period. Cells were fixed, permeabilised and incubated with either clone 36/2 recognising the HA or clone MCA401 recognising M1 for 30 min. Cells were washed and incubated with an Alexa Fluor 488-conjugated rabbit anti-mouse immunoglobulin (Life Technologies) for 30 min. Data were acquired using a FACSCanto II and analysed with FlowJo X version 10 (Tree Star, Ashland, OR, United States).
Statistical Analysis
All of the data were analysed using GraphPad Prism version 8.4.2 (GraphPad Software Inc., La Jolla, CA, United States). Unless otherwise stated, the data were analysed for statistical significance by either a one-way analysis of variance (ANOVA) with a Tukey post-test or a two-way ANOVA with a Sidak post-test. A probability (p) value of <0.05 was considered to be statistically significant.
Results
Classical Reassortment Generates a Diverse Range of Gene Constellations
To examine the spectrum of reassortants generated through the initial stages of the classical reassortment process (Figure 1A), the model seasonal strain Udorn (H3N2) was reassorted with the highly egg-adapted PR8 strain (H1N1) in four different co-infection conditions representing independent experiments (Figure 1B). Throughout the process, allantoic fluid from individual eggs was screened to detect haemagglutination and the presence of the Udorn HA and NA genes. Viruses were then isolated by plaque assay and the origin of each gene determined by gene-specific RT-PCR.
After the initial co-infection step, the progeny viruses were isolated by plaque formation in the presence of anti-PR8 antisera, which effectively prevented residual PR8 parent virus or viruses with PR8 surface antigens from dominating the plaque assay (Figures 1C,D). Of the remaining viruses present after co-infection, cumulative data across the four co-infection conditions revealed that 33% of the non-neutralised viruses were reassortants and 67% were the Udorn parent (Figure 1C). Consistent with what is observed for a seasonal influenza virus, the Udorn parent was represented least in the E2 series where the co-infection ratio favoured PR8 over Udorn by 100-fold (Figure 1D). The percentage of reassortants continued to increase throughout the process, with 91.5% of the viruses being reassortants after the first antibody passage and 99.7% after the second antibody passage (Figures 1C,E,F), indicating strong selective pressure for reassortment.
Figure 2A illustrates the complexity of the different genotypes present in the resulting reassortant pool (detailed in the Supplementary Table 1). After the initial co-infection, 63 discrete gene constellations were present and after two additional rounds of replication and antibody selection, this reduced to 39 distinct genotypes. Depending on the co-infection ratio and input dose, differences were observed in the gene constellations detected or their frequencies in each reassortment series (Figure 2 and Supplementary Table 1). In most cases, the dominant reassortant detected in the first and second antiserum passages was not identical. In the E4 series, the dominant reassortant of the second antiserum passage represented between 40 and 53% of the total reassortants isolated and yet only represented approximately 10% of the reassortants in the first antiserum passage. When considering reassortants incorporating the PB1 gene from the Udorn parent (Figure 2B), it was clear that these dominated after the initial co-infection and after the second round of antiserum selection for the Udorn HA and NA. Overall, 85.5% (cumulative data from all series) contained the Udorn PB1 after the initial co-infection and 88.5% after two antiserum passages. In the E3 series 100% of the reassortants contained the Udorn PB1 after the first antiserum passage. Even in the E2 series where the co-infection ratio favoured PR8 over Udorn by 100-fold, 90% of isolates contained the Udorn PB1 after the second antiserum passage.
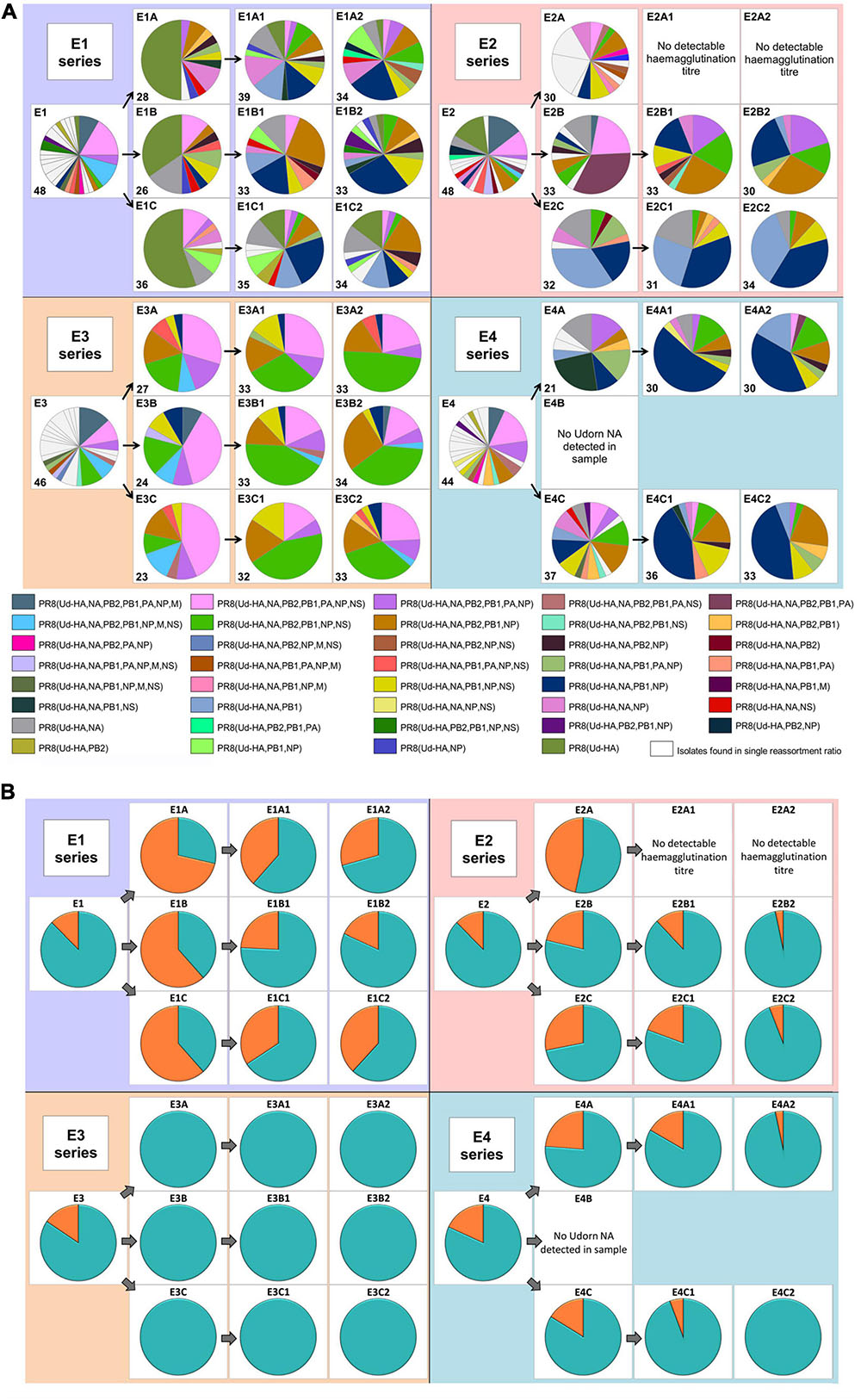
Figure 2. The diversity of reassortant viruses isolated during the reassortment process. Viruses from the allantoic fluid of each egg were isolated by plaque assay. For the co-infected eggs, plaquing was performed in the presence of PR8 antiserum. The genotype of virus in individual plaques was determined using gene specific RT-PCR. Each of the four larger panels represents eggs that originated from the different co-infection ratios (Figure 1B). The pie charts represent the viruses isolated in the individual eggs corresponding to the co-infection and antiserum passages (Figure 1A). The dominant gene constellations present in the individual eggs are represented according to the colours in the key. The nomenclature used indicates the Udorn genes on the PR8 background, e.g., PR8(Ud-HA) is a virus with the HA gene from Udorn and the remaining seven genes from PR8. White segments represent gene constellations that were only present in that particular egg. No data is available for eggs E2A1 and E2A2 as the allantoic fluids did not have detectable haemagglutination titres and were not examined further. Initial screening of egg E4B showed that Udorn NA was not present so complete genotypes were not analysed. The number of individual plaques analysed for each egg is indicated in the bottom left of each pie chart panel. (B) The frequency of the Udorn PB1 gene (teal) and PR8 PB1 gene (orange) in the genotypes of the individual virus plaques shown in panel (A).
The cumulative frequency of other non-HA and NA genes in the reassortants in each series at the different stages is shown for comparison in Figure 3. The pattern observed with Udorn PB1 was closely reflected by that of the Udorn NP, which dominated after both the initial co-infection and second antiserum passage, present in 81 and 81.3% of genotypes, respectively (Figure 3D). In contrast, the PA and M genes of the PR8 virus dominated by the second antiserum passage, present in 84.5 and 99.5%, respectively of the gene constellations isolated (Figures 3C,E). Only the PB2 and NS genes appeared to be greatly influenced by the initial coinfection ratios, with the E3 series having the respective Udorn genes dominating (Figures 3A,F). Three reassortant genotypes, PR8(Ud-HA,NA,PB2,PB1,NP,NS), PR8(Ud-HA,NA,PB2,PB1,NP), and PR8(Ud-HA,NA,PB1,NP), all containing Udorn PB1 and NP in addition to the HA and NA genes, occurred most frequently in the final reassortant populations and were detected in all the reassortment series.
Figure 3. Tracking the frequency of the six internal Udorn (teal) and PR8 (orange) genes throughout the reassortment process. The source of individual genes in the reassortants shown in Figure 2 is summarised for each series. Data are expressed as a percentage of the total viruses isolated in that series at each stage of the reassortment process, with replicate eggs pooled for the first (two eggs) and second (four eggs) antisera passages. The origin of the (A) PB2, (B) PB1, (C) PA, (D) NP, (E) M, and (F) NS genes were determined to be either from the PR8 parent (orange) or the Udorn parent (teal).
Reassortants That Produce High Haemagglutination Titres in Eggs Do Not Always Have a High Yield of Infectious Virus
Use of limit dilution to obtain the most abundant reassortants from each egg after the second antiserum passage yielded 11 different viruses, 9 of which incorporated Udorn NA and PB1 genes. Although PR8(Ud-HA,NA), which is expected to be the high HA yielding vaccine seed virus in our system, was present in some eggs after the second passage, it was not the dominant species in these eggs (Supplementary Table 1) and not isolated by limit dilution. The surrogate virus, rg PR8(Ud-HA,NA), was therefore made by reverse genetics as a comparator. Eight of the 11 reassortants had significantly higher haemagglutination titres than the parent Udorn virus (Figure 4A). Four, namely R9 PR8(Ud-HA,NA,PB1), R4 PR8(Ud-HA,NA,PB2,PB1), R8 PR8(Ud-HA,NA,PB1,NP), and R3 PR8(Ud-HA,NA,PB2,PB1,NP) were not significantly different to PR8 virus, illustrating the power of reassortment to enhance the yield of HA from seasonal isolates. To establish whether a greater replicative capacity was responsible for selection of these reassortants, infectious viral titres were determined by plaque assay in MDCK cells (Figure 4B). Compared to Udorn virus, all but two reassortants had higher infectious virus titres (p < 0.0001; one-way ANOVA), with six reassortants having equivalent titres to PR8 virus (p > 0.05; one-way ANOVA). The rgPR8(Ud-HA,NA) virus also had an infectious virus titre that was comparable to PR8 virus (p > 0.05; one-way ANOVA) and significantly greater than that of Udorn virus and five of the reassortants (p < 0.0001; one-way ANOVA). These data indicate that the absence of PR8(Ud-HA,NA) virus from the final dominant reassortant progeny was not due to a reduced replicative capacity. Of the four reassortants with haemagglutination titres similar to that of PR8 virus, R8 PR8(Ud-HA,NA,PB1,NP) and R3 PR8(Ud-HA,NA,PB2,PB1,NP) viruses also replicated to the same extent as the PR8 virus (p > 0.05; one-way ANOVA) yet the two other reassortants, R9 PR8(Ud-HA,NA,PB1) and R4 PR8(Ud-HA,NA,PB2,PB1), did not (p < 0.0001; one-way ANOVA). These data indicate that the enhanced haemagglutination phenotype for some reassortants must be due to mechanisms other than the acquisition of greater replication capacity.
Figure 4. Haemagglutination titres and replicative fitness of dominant reassortant progeny isolated through classical reassortment. (A,B) Eggs were infected with a standard dose (100 PFU) of one of the 11 reassortant viruses (R1–R11) isolated after limit dilution (n = 5), the parental PR8 and Udorn (Ud) viruses (n = 5) or the reverse genetics-derived virus rgPR8(Ud-HA,NA) (n = 4). Virus genotypes are shown in the key by number and colour. Three days post infection, allantoic fluid was harvested and (A) haemagglutination titres and (B) infectious viral titres determined. Each symbol represents the titre of virus from an individual egg and the line represents the geometric mean. Statistical significance was determined by one-way ANOVA with Tukey’s multiple comparisons test (*p < 0.05, **p < 0.01, ***p < 0.001, ****p < 0.0001) for panel (A) (F13,55 = 23.39) and (B) (F13,55 = 61.78). Orange, teal, and grey asterisk indicate comparisons of viruses with PR8, Udorn, and rgPR8(Ud-HA,NA), respectively. (C) MDCK cells were infected with the panel of reassortant viruses and rgPR8(Ud-HA,NA) at an MOI of 0.001. At the specified time points post infection, virus titres in the supernatants were determined by plaque assay on confluent MDCK cell monolayers. The data represents the mean and standard deviation of three individual experiments. (D) Infectious yields in vitro (C) at 24 hr as a function of the infectious viral titres in ovo (B). The dotted line represents a linear regression analysis (p < 0.0001, r2 = 0.81). (E) The data from (C) pertaining only to the reassortants with haemagglutination titres equivalent to PR8 in ovo (A) are shown for clarity. The data represents the mean and standard deviation of three individual experiments. Statistical significance was determined by two-way ANOVA with Sidak’s multiple comparisons test (F3,8 = 97.28, **p < 0.01, ****p < 0.0001). Brown asterisk indicate comparisons between PR8(Ud-HA,NA,PB2,PB1,NP) with PR8(Ud-HA,NA,PB2,PB1) and blue asterisk indicate comparisons between PR8(Ud-HA,NA,PB1,NP) with PR8(Ud-HA,NA,PB1).
To confirm the phenotypes of the viruses observed in eggs, MDCK monolayers were infected with a standardised dose of the different viruses and viral loads within cultures determined over time (Figure 4C). Infectious virus yields at the plateau of the replication curve in MDCK cells mirrored the hierarchy found in embryonated eggs as shown by regression analysis of the titres in MDCK cells at 24 h post infection versus those in eggs (p < 0.0001, r2 = 0.81; Figure 4D). Of the four reassortants with haemagglutination titres not significantly different to PR8 virus, PR8(Ud-HA,NA,PB1) had an approximately 1.5 log lower plateau titre than the corresponding virus with the Udorn NP, PR8(Ud-HA,NA,PB1,NP) (p > 0.0001; two-way ANOVA; Figure 4E). Likewise, PR8(Ud-HA,NA,PB2,PB1) had a 2.5 log lower titre compared to PR8(Ud-HA,NA,PB2,PB1,NP) (p > 0.0001; two-way ANOVA; Figure 4E). Therefore, the addition of the Udorn NP dramatically improved the infectious virus yield obtained when the Udorn HA, NA and PB1 were present in a virion, despite no difference in haemagglutination capacity.
Reduced Replicative Capacities of PR8(Ud-HA,NA,PB2,PB1) and PR8(Ud-HA,NA,PB1) Viruses Are Not Due to Low Polymerase Activity
It has been proposed that differences in polymerase activity can account for differences in viral replication (Li et al., 2008; Octaviani et al., 2011; Nakazono et al., 2012; Hara et al., 2013). To investigate this, a BLA reporter assay was performed in cells co-transfected with the different combinations of viral polymerase and NP genes represented in the viruses under study (Figure 5A). Although infection with PR8(Ud-HA,NA,PB1) and PR8(Ud-HA,NA,PB2,PB1) viruses had resulted in lower infectious virus yields compared to the corresponding viruses with Udorn NP (Figure 4E), their respective RNP complexes (PPB2UPB1PPAPNP and UPB2UPB1PPAPNP), demonstrated no significant difference in activity (p > 0.05; one-way ANOVA; Figure 5A) to complexes with the Udorn NP (PPB2UPB1PPAUNP and UPB2UPB1PPAUNP). Substitution of PR8 PB2 with Udorn PB2 significantly increased the polymerase activity of PPB2UPB1PPAPNP (p < 0.01, one-way ANOVA) and PPB2UPB1PPAUNP (p < 0.001, one-way ANOVA), yet no increase in infectious titres was observed for the corresponding viruses both in vitro and in vivo. These data demonstrate that the viral polymerase activity, as measured by the BLA assay, does not correlate with the efficiency of replication of viruses with these different gene constellations.
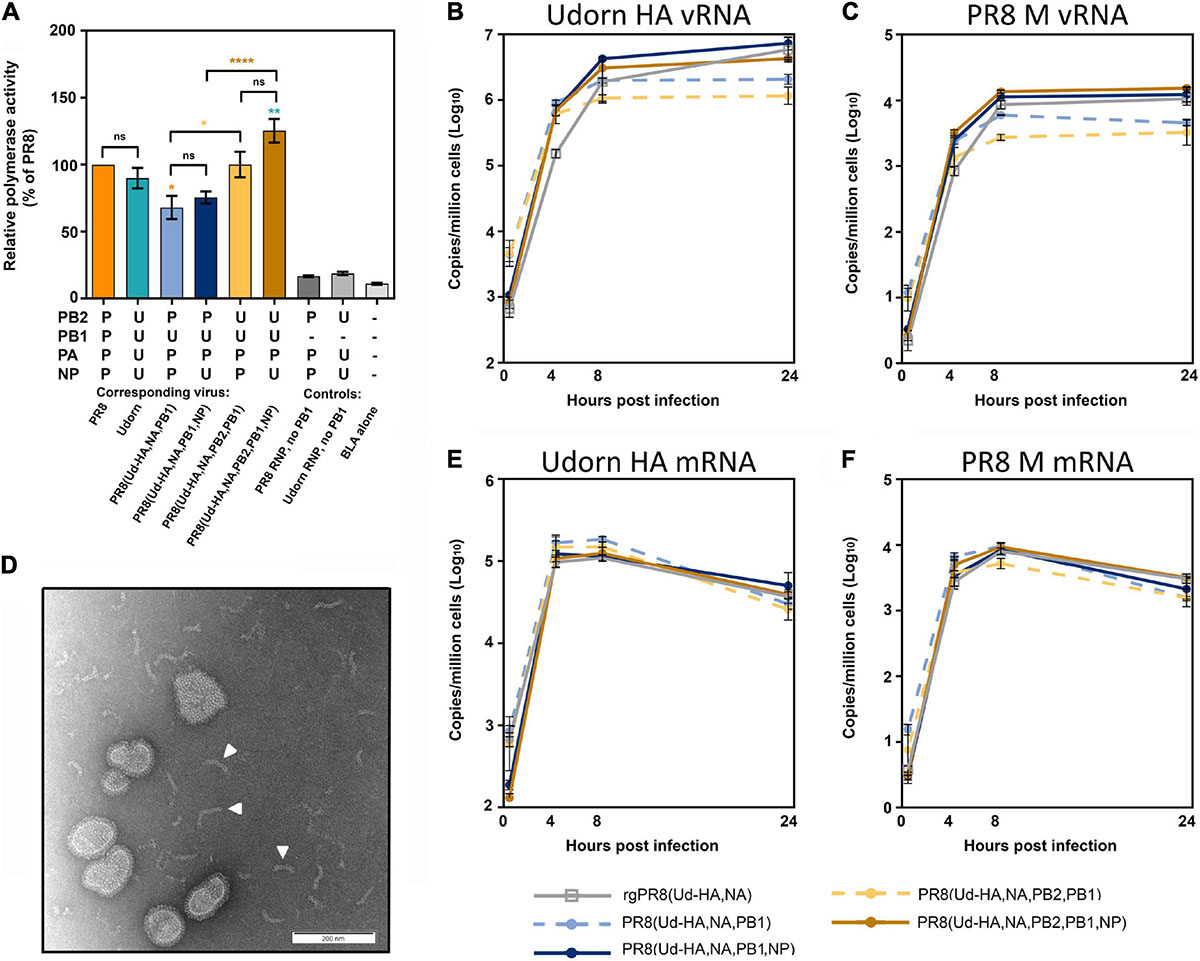
Figure 5. The relative polymerase activity and viral RNA production of the reassortants with high haemagglutination titres. (A) A β-lactamase (BLA) reporter assay was performed in HEK 293T cells that were transfected with the pCAGGS-BLA reporter gene and four pHW2000 plasmids coding for the indicated PB2, PB1, PA, and NP genes, which correspond to the RNPs of the indicated viruses or controls without the PB1-encoding plasmid. The relative polymerase activities were normalised to the PR8 RNP activity and each bar represents the mean and standard error of four experiments at the half max of each curve. Statistical significance was determined by one-way ANOVA with Tukey’s multiple comparison test (F8,27 = 49.28, ns p > 0.05, *p < 0.05, **p < 0.01, ****p < 0.0001). Orange, teal, brown, and yellow asterisk indicate comparisons between the RNP complexes with PPB2PPB1PPAPNP, UPB2UPB1UPAUNP, UPB2UPB1PPAUNP and UPB2UPB1PPAPNP, respectively. (B,C,E,F) MDCK cells were infected with the indicated virus at an MOI of 3 and total RNA extracted from 1 × 106 cells at 0, 4, 8, and 24 h after a 1 h virus absorption period. The copy numbers of (B) Udorn HA vRNA, (C) PR8 M vRNA, (E) Udorn HA mRNA/cRNA, and (F) PR8 M mRNA/cRNA were assessed by quantitative RT-PCR and the data represents the mean and standard deviation (n = 3) and is representative of four experiments. (D) The presence of free RNP complexes in the allantoic fluid of PR8(Ud-HA,NA,PB1,NP) and PR8(Ud-HA,NA,PB2,PB1,NP) were visualised by negative staining transmission electron microscopy. A representative image is shown with some of the free RNP complexes indicated by a white arrowhead.
The Addition of the Udorn NP to PR8(Ud-HA,NA,PB1) and PR8(Ud-HA,NA,PB2,PB1) Results in Increased vRNA Production
The amount of Udorn HA vRNA (Figure 5B) and PR8 M vRNA (Figure 5C), which are common to all the reassortants, were assessed in infected MDCK cells via quantitative RT-PCR. The presence of the Udorn PB1± the Udorn PB2 in a PR8(Ud-HA,NA) background, resulted in significantly reduced levels of HA and M vRNA at 24 h post-infection compared to the rgPR8(Ud-HA,NA) virus (p < 0.001 and p < 0.0001, respectively; two-way ANOVA). Upon the inclusion of the Udorn NP to the PR8(Ud-HA,NA,PB1) and PR8(Ud-HA,NA,PB2,PB1) backgrounds, the HA and M vRNA levels were restored to the levels seen in rgPR8(Ud-HA,NA) at 24 h post infection. The addition of the Udorn NP to PR8(Ud-HA,NA,PB1) virus increased the amount of HA vRNA at the 8 and 24 h time points (p < 0.05, p < 0.0001 respectively; two-way ANOVA) and also the levels of M vRNA at the 8 and 24 h time points (p < 0.01, p < 0.0001 respectively; two-way ANOVA). Similarly, PR8(Ud-HA,NA,PB2,PB1,NP) displayed significantly higher levels of HA vRNA than PR8(Ud-HA,NA,PB2,PB1) at the 8 and 24 h time points (p < 0.001, p < 0.0001 respectively; two-way ANOVA) and M vRNA at the 4, 8, and 24 h time points (p < 0.001, p < 0.0001, p < 0.0001, respectively; two-way ANOVA). These data suggest that the higher levels of vRNA produced by viruses with Udorn NP, in addition to Udorn HA, NA, PB1 ± PB2, may contribute to the greater infectious particle yields of these viruses compared to the corresponding reassortants with PR8 NP. That said, we observed by electron microscopy of the virus-containing allantoic fluid preparations of PR8(Ud-HA,NA,PB1,NP) and PR8(Ud-HA,NA,PB2,PB1,NP) that free RNPs were present in these (Figure 5D) but not in the corresponding reassortants with PR8 NP, suggesting the possibility that the greater levels of vRNA produced by these Udorn NP-containing viruses may not be all incorporated into virions.
High Haemagglutination Titres Did Not Result From Increased HA Protein in the Virion Due to Increased Transcription or Translation of HA in Infected Cells
It was possible that the lower levels of HA and M vRNA production observed for PR8(Ud-HA,NA,PB2,PB1) and PR8(Ud-HA,NA,PB1) compared to the corresponding viruses with Udorn NP, might be due to the preferential production of viral mRNA over vRNA. To examine this, the level of Udorn HA and PR8 M viral mRNA transcription was quantified in infected MDCK cells by gene-specific qRT-PCR (Figures 5E,F). Comparison between rgPR8(Ud-HA,NA) and the four reassortant viruses showed no difference in viral mRNA production for either the Udorn HA or PR8 M genes at any time point (p > 0.05, two-way ANOVA).
To examine whether selective protein modulation was occurring in our system, the amount of HA present in infected MDCK cells was assessed by flow cytometry 6 h post infection (Figure 6A). Matrix protein was also analysed to determine whether any potential modulation of Udorn HA translation was specific for the HA (Figure 6B). The data showed a trend towards slightly more HA produced in cells infected with rgPR8(Ud-HA,NA) than with PR8(Ud-HA,NA,PB2,PB1) and PR8(Ud-HA,NA,PB2,PB1,NP) (p < 0.05; one-way ANOVA). However, the levels of M1 protein expression between infected cells differed considerably with rgPR8(Ud-HA,NA)-infected cells producing more of this protein than the reassortants (p < 0.0001; one-way ANOVA). When the ratio of HA staining to M1 staining was calculated for each allantoic fluid and the means of the different reassortant groups expressed relative to rgPR8(Ud-HA,NA) (Figure 6 key), the fold difference was less than 1.3 suggesting only minor, if any, effects on protein expression specific for HA in infected cells.
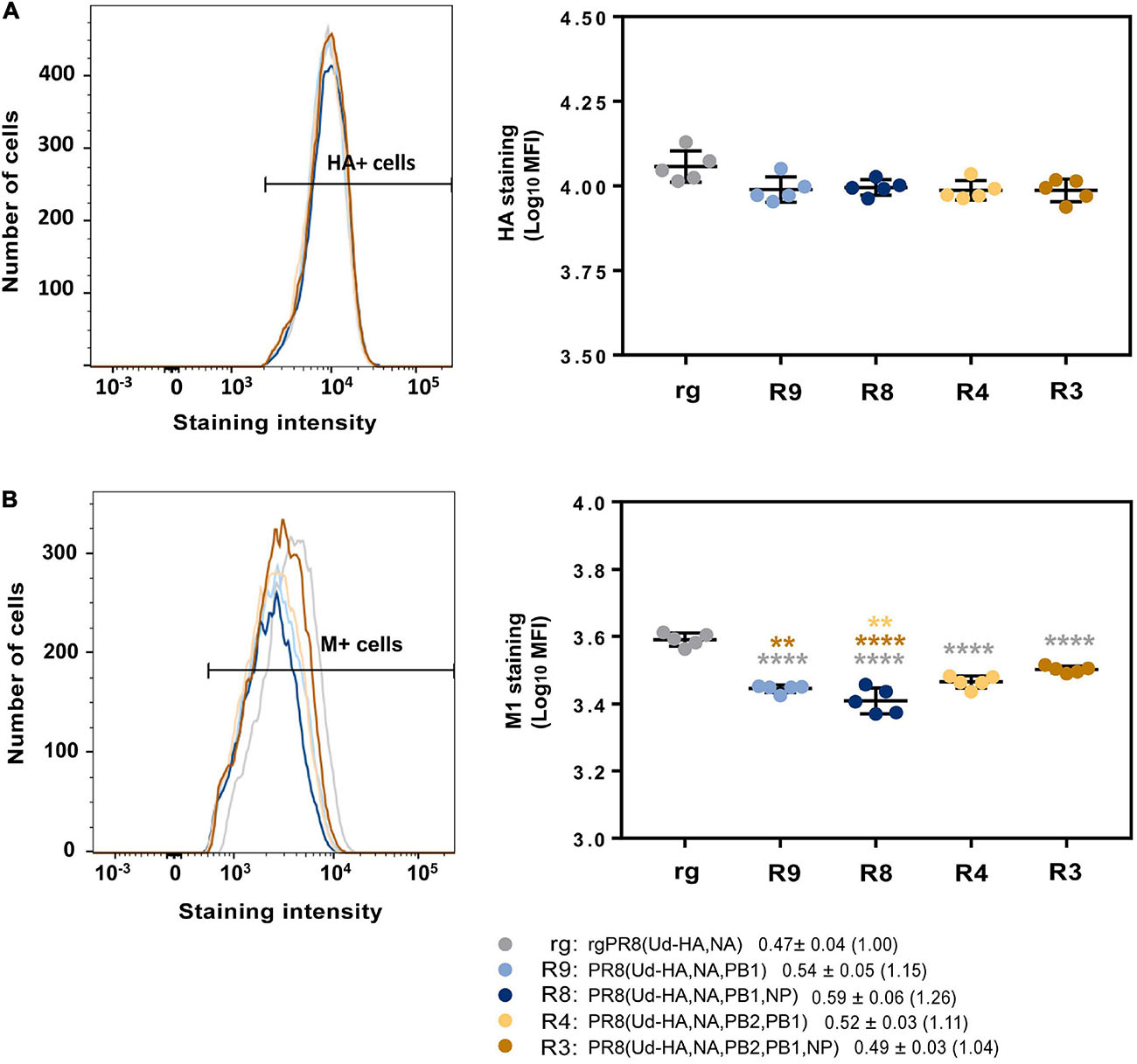
Figure 6. Flow cytometric analysis of Udorn HA and PR8 M1 protein production in infected cells. MDCK cells (1 × 106) were infected with different viruses at an MOI of 3 and protein production assessed 6 h after a 1 h virus absorption period. Cells were stained with either (A) anti-Udorn HA (AF647) or (B) anti-M1 (MCA401) followed by a secondary antibody coupled to a fluorescent dye for the detection of proteins. Left panels show example flow cytometry histograms of stained cells with the fluorescence range for positive cells indicated; right panels show individual data for the mean fluorescent intensity (MFI) from five replicate cultures and is representative of three experiments. Statistical significance was determined by one-way ANOVA with Sidak’s multiple comparison test (**p < 0.01, ****p < 0.0001) for (A) (F4,20 = 3.24) and (B) (F4,20 = 45.59). Grey, brown and yellow asterisks indicate comparison of viruses with rgPR8(Ud-HA,NA), PR8(Ud-HA,NA,PB2,PB1,NP), and PR8(Ud-HA,NA,PB2,PB1) respectively. Values in the key represent the mean and SD of the ratios of HA staining to M1 staining for each individual allantoic fluid within each group with the fold difference compared to rgPR8(Ud-HA,NA) in brackets.
An Increased Number of Non-infectious Particles and a Higher HA Density Contributes to the High HAU
To further examine what contributes to the high haemagglutination titres of the reassortants we required a measure of relative particle number. Usually this is done by some measurement of the RNA, however, we had observed that the Udorn NP-containing reassortants had free RNPs (Figure 5F) that would make such measurement misleading. Instead, an analysis of HA protein relative to M1 protein content of the different viruses was performed. As virion size and morphology were similar between the viruses when observed via electron microscopy (Figure 7A), we made the assumption that the amount of matrix protein (M1) present in the viral particles in the different preparations would be approximately equivalent on average and correlate directly with particle number in the preparation.
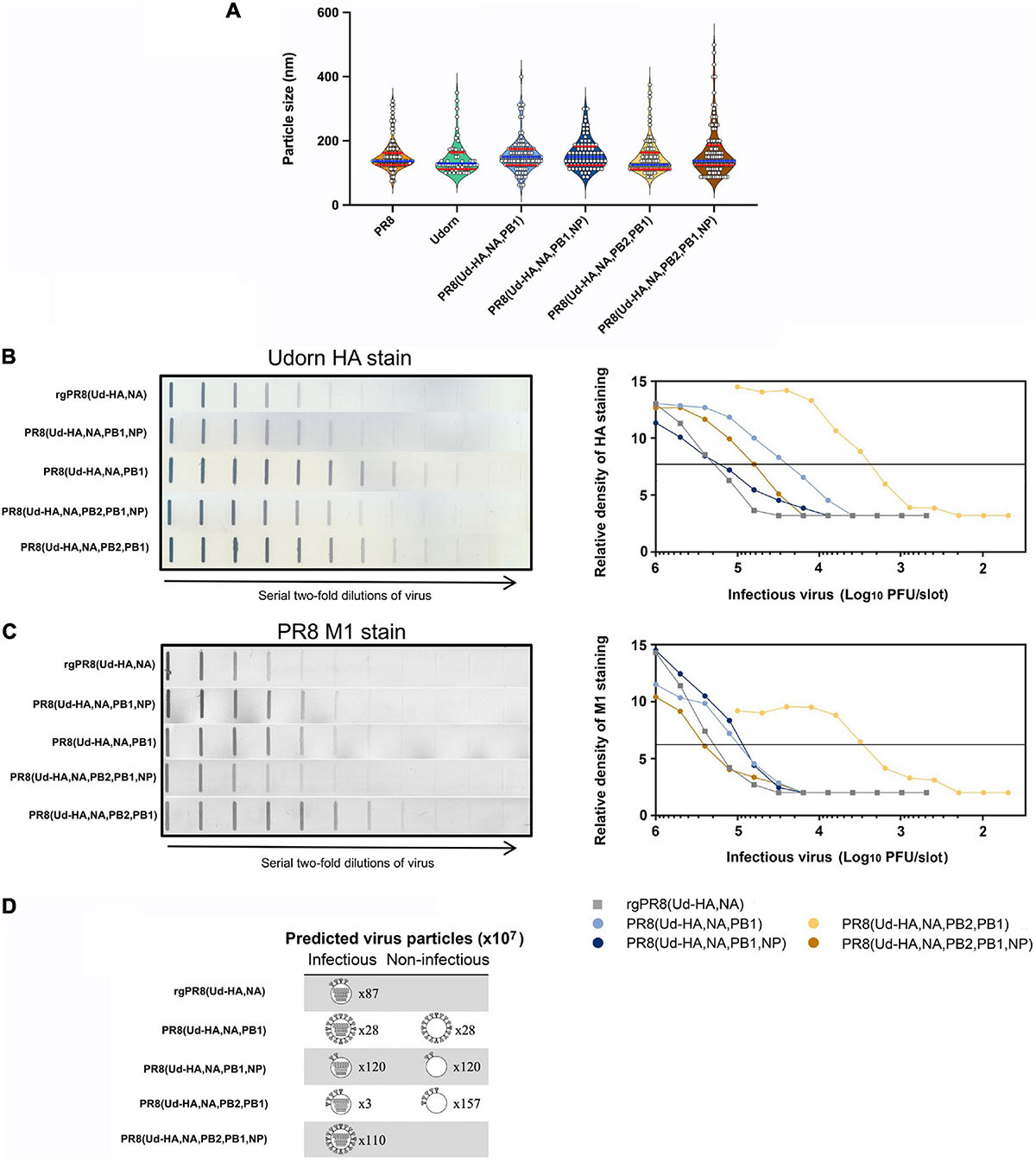
Figure 7. The structure and HA protein content of reassortant viruses. (A) Violin plots of particle sizes visualised by transmission electron microscopy of infected allantoic fluid. White filled circles represent individual measurements along the longest axis of 60–130 distinctive viral particles from one to three printed images per virus preparation converted to nm. The median size is shown as a blue line with quartiles shown as red lines. Analysis by one-way ANOVA shows no difference in the mean particle size (p = 0.27) (B,C) Allantoic fluid containing infectious virus was diluted to 107 PFU/ml, or 106 PFU/ml for PR8(Ud-HA,NA,PB2,PB1), and two-fold serial dilutions were performed. Each dilution (100 μl) was transferred to a nitrocellulose membrane and the (B) Udorn HA protein or (C) PR8 M1 protein was detected with a mouse monoclonal antibody and visualised by secondary staining with rabbit anti-mouse HRP and the addition of substrate (left panels). Densitometry analysis was performed on the bands obtained in each of the strips and the peak heights were plotted against the amount of infectious virus in that sample (right panels). The horizontal line is used to determine the number of PFU required to provide an arbitrary amount of HA or M1 staining. The data is representative of two experiments. (D) Depiction of the relative amount of HA and its distribution between infectious and non-infectious virions. Infectious particles are depicted with gene segments; non-infectious particles are depicted without gene segments. The predicted number of particles (×107) is indicated beside each virion (Table 2). For ease of representation one arbitrary unit of HA protein (Table 1) is depicted as four HA spikes on the virion. The distribution of the HA protein was assumed to be equal between the infectious and non-infectious particles.

Table 1. Amount of infectious virus required to achieve an equivalent level of HA or M1 staining and relative abundance of HA per virion.
Table 2. Predicted HA distribution on infectious and non-infectious particles.
The amounts of HA and M1 in each of the reassortants were determined by the binding of specific monoclonal antibodies using a slot blot assay (Figures 7B,C). Compared to rgPR8(Ud-HA,NA), less infectious virus was required to provide the same amount of HA staining for each of the reassortants (Figure 7B), particularly for PR8(Ud-HA,NA,PB2,PB1) where only about one-hundredth of the infectious virus was required (Table 1). With the exception of PR8(Ud-HA,NA,PB2,PB1,NP), less infectious virus was also required to provide the same amount of PR8 M1 staining compared to rgPR8(Ud-HA,NA) (Figure 7C). By dividing the relative PFU/M1 unit by the relative PFU/HA unit, the resultant HA/M1 ratio indicates the relative amount of HA protein present per arbitrary amount of M1 protein, which, given the assumption of a correlation between M1 and virions, reflects the relative abundance of HA per virion (Table 1). The 3.9-fold greater HA protein density per PR8(Ud-HA,NA,PB1) particle compared to rgPR8(Ud-HA,NA) supports the findings of Cobbin et al. (2013), who also identified a four-fold increase in HA per viral particle for rgPR8(Ud-HA,NA,PB1) by western blotting. The substitution of Udorn NP for PR8 NP in the PR8(Ud-HA,NA,PB1) virus resulted in an 8-fold decrease in HA density from 3.9 to 0.5 HA/M1. The PR8(Ud-HA,NA,PB2,PB1) virus was similar to rgPR8(Ud-HA,NA) with 1.2 HA/M1 and, in this case, the presence of the Udorn NP led to an increase in HA density to 4 HA/M1. Thus, changes in the gene constellation of the virus can dramatically alter the amount of HA on the virion surface.
Data from Table 1, taken in conjunction with the infectious virus titres from the allantoic fluid of eggs infected with a standard amount of each of the viruses (Figure 4B), allows an estimation of how many total virus particles are predicted to be present and the relative total yield of HA from these eggs (Table 2). As an example of these calculations and the underlying assumptions, for a given amount of M1 protein, which we equate to a given amount of virus particles, PR8(Ud-HA,NA,PB1) has only half the number of infectious particles as rgPR8(Ud-HA,NA) (Table 1, relative PFU/M1 unit). To provide a baseline to calculate relative particle numbers of the reassortants we assume that all the virions in the reverse engineered rgPR8(Ud-HA,NA) are infectious. So for a given amount of infectious PR8(Ud-HA,NA,PB1) virions there is an equivalent number of non-infectious virions contributing to the amount of HA in the egg. Dividing the observed titre of infectious virions by the relative PFU/M1 unit ratio for each virus (Table 1) provides the predicted total number of virions in the egg in M1 units/ml (Table 2, predicted total virions). In this way, the PR8(Ud-HA,NA,PB1) virus is predicted to have a total virion count of 5.6 × 108 M1 units/ml. As each particle had 3.9 times the amount of HA than did rgPR8(Ud-HA,NA) (Table 1 relative HA/M1), which we designate as having 1 arbitrary unit of HA per virion, the predicted total yield of HA in the PR8(Ud-HA,NA,PB1)-infected eggs is 2.2 × 109 HA units/ml (M1 units/ml × HA/M1) which is 2.5-fold greater than rgPR8(Ud-HA,NA) (Table 2, relative HA yield). Likewise, PR8(Ud-HA,NA,PB1,NP) had a 1.5-fold greater overall yield of HA, PR8(Ud-HA,NA,PB2,PB1) had 2.3-fold and PR8(Ud-HA,NA,PB2,PB1,NP) had 5.3-fold greater HA yield than did rgPR8(Ud-HA,NA) (Table 2).
The relationship between HA density per particle, the number of virus particles and the capacity to haemagglutinate chicken erythrocytes is yet to be completely understood. Nevertheless, together these data provide a possible explanation of how high HA yields, predicted from HAU titres, could be achieved by PR8(Ud-HA,NA,PB1) and PR8(Ud-HA,NA,PB2,PB1) despite their poor replicative capacity. This work highlights how different mechanisms operate to achieve high HA yields (Figure 7D) in different reassortants. A higher HA density per virion was the main contributing factor for PR8(Ud-HA,NA,PB1) and PR8(Ud-HA,NA,PB2,PB1,NP) whereas a greater number of non-infectious particles allowed for the high HA yields of PR8(Ud-HA,NA,PB2,PB1) and PR8(Ud-HA,NA,PB1,NP).
Discussion
In this study we utilised a model of vaccine seed production with the aim of assessing the influence of selective pressures on viral reassortment over multiple passages. Contrary to current thinking, we show that replicative fitness and antibody resistance are not the only determinants dictating which reassortant progeny will come to dominate in this system. We show data compatible with gene co-selection, resulting from dominant gene segment interactions, as a powerful force for shaping the viruses that are formed and we document the dynamics of the rise and fall of different constellations across the stages of the process. Though counter intuitive, we show that gene co-selection can lead to less fit viruses being positively selected to the point that they are isolated by limit dilution as dominant progeny. We also asked how these dominant but less fit viruses may display high antigen yields such that they can be chosen as vaccine seed candidates and reveal different phenotypes that are likely to account for this.
Generally, reassortment of H3N2 seasonal viruses with PR8 is thought to increase the yields of HA protein by generating reassortants that replicate to high titres (Gerdil, 2003) by virtue of their acquisition of a full complement of genes encoding PR8 non-surface antigens. However, from the four reassortants that expressed high haemagglutination titres equivalent to PR8, only PR8(Ud-HA,NA,PB1,NP) and PR8(Ud-HA,NA,PB2,PB1,NP) displayed high infectious virus yields that likely contributed to the high haemagglutination titres achieved. Comparison between the gene constellations of the four final “vaccine seed candidates” indicated that the presence of the Udorn NP significantly improved infectious virus yields, suggesting some incompatibility of Udorn HA, NA or PB1 with PR8 NP. Viral infectious yields are often associated with the function of the polymerase complex and the relative activity is believed to determine the replicative capacity of a virus (Li et al., 2008; Octaviani et al., 2011; Nakazono et al., 2012; Hara et al., 2013). However, the addition of the Udorn NP had no impact on polymerase activity in the reporter assay, demonstrating that polymerase activity is not necessarily indicative of the replicative ability of a virus. Despite no difference in polymerase activity, in vitro analysis of RNA production demonstrated that viruses with the Udorn NP had significantly increased levels of vRNA, but not viral mRNA, compared to the corresponding viruses with PR8 NP. The NP protein encapsidates vRNA and complementary cRNA but not mRNA and interacts directly with PB1 and PB2 (Biswas et al., 1998). In addition, regions in the NP have been identified as important for vRNA production (Mena et al., 1999; Li et al., 2009; Davis et al., 2017), for selective modulation of NA expression (Brooke et al., 2014) and for efficient packaging (Brooke et al., 2014; Moreira et al., 2016; Bolte et al., 2019). Although virus strain differences in these functions have not yet been investigated, it is possible that a mismatch of NP with PB1 or NA may impair correct packaging of segments resulting in the over-abundance of non-infectious particles in some reassortant genotypes, such as PR8(Ud-HA,NA,PB2,PB1) but not in the corresponding virus with Udorn NP. However it occurs, the restoration of infectious yields by the Udorn NP is possibly contributed to by the increased amounts of vRNA available for packaging into progeny virions to generate a greater number of infectious particles.
In this study, we provide a possible explanation for how dominant gene constellations could provide a high HA yielding phenotype. We show this may be as a result of either a high replicative capacity, the concomitant production of a large number of non-infectious particles, a greater density of HA per virion or a combination of these factors. PR8(Ud-HA,NA,PB1) and PR8(Ud-HA,NA,PB2,PB1,NP) had an overall increase of HA/particle compared to rgPR8(Ud-HA,NA) whereas PR8(Ud-HA,NA,PB1,NP) and PR8(Ud-HA,NA,PB2,PB1) achieved high haemagglutination titres mainly through an increase in the number of total viral particles. Although the calculations used to determine the relative numbers of infectious and non-infectious particles were based on a number of underlying assumptions, the observations on which these assumptions were made, such as infectious yield and the HA and M1 protein content, were all determined experimentally. Therefore, although the actual numbers are notional, relative differences between reassortants stem from empirical data. Previously in our laboratory it was demonstrated that the Udorn PB1 could selectively modulate Udorn HA protein production in cells (Cobbin et al., 2013). This as yet undefined mechanism, thought to operate post-transcriptionally (Cobbin et al., 2013), may be operating here to explain how PR8(Ud-HA,NA,PB1) and PR8(Ud-HA,NA,PB2,PB1) achieved high haemagglutination titres despite their reduced replication kinetics.
Until recently, viral replicative fitness was considered the main factor to drive the emergence of dominant gene constellations (Kimble et al., 2014; Steel and Lowen, 2014). Viruses with lower infectious yields would likely be outcompeted by genotypes with higher replication kinetics, which would then dominate the population. However, in this study, the isolation of six dominant reassortant gene constellations with infectious yields lower than rgPR8(Ud-HA,NA), but not PR8(Ud-HA,NA) itself, demonstrates that viral fitness doesn’t always dictate dominance, at least not in the initial stages of the selection process. Interactions between viral gene segments are known to be important during the assembly and packaging of the eight RNPs into progeny virions (Fournier et al., 2012; Essere et al., 2013; Gavazzi et al., 2013a; Le Sage et al., 2020) and the data shown here enforce our previous observation of the preferential co-packaging of the Udorn PB1 and NA gene segments during progeny virion formation (Cobbin et al., 2014; Gilbertson et al., 2016). We show that the co-selection of the Udorn PB1 gene with the Udorn NA gene is likely responsible for the prevalence of the Udorn PB1 in all stages of the reassortment process and in the final dominant reassortants in our model system and the increased replicative fitness observed upon the inclusion of the Udorn NP in the presence of the Udorn PB1, HA and NA, likely drove the increased prevalence of the Udorn NP. However, we need to entertain the possibility that the Udorn PB1-NA co-selection relationship is reinforced by other co-selection relationships between the PR8 genes that might remove them from the available “packaging pool.” As we are neutralising reassortants expressing PR8 HA and or NA with antisera, genes that co-select strongly with PR8 HA or NA genes will remain unidentified in this study. The fact that the reassortant PR8(Ud-HA,NA) was not isolated as one of the dominant progeny, despite its high replicative capacity and high HA yield, attests to the strength of co-selection in our system and its influence on the availability of genes that would otherwise create highly fit viruses.
The Udorn PB1-NA co-selection relationship is in accord with our retrospective analysis of past H3N2 vaccine seed strains, where the seasonal PB1 was present at a higher frequency compared to the other non-HA and NA genes from the seasonal virus parent (Cobbin et al., 2013). The co-selection of internal genes with the HA or NA genes also has direct implications for the generation of pandemic strains. In the event of reassortment between human and avian IAVs, progeny reassortant viruses expressing the surface glycoproteins of the human strain would be inhibited by pre-existing antibodies within the human population, allowing reassortants with the avian HA and potentially also NA, to dominate. As the HA and NA genes may have co-selection relationships with other internal gene segments, this can dictate which avian internal genes are also carried through into the human-infecting strain, shaping the phenotype of the emergent virus and influencing its impact on the human population. For example, co-selection of an avian PB1 would allow expression of a full-length and inflammatory PB1-F2 (McAuley et al., 2010, 2017) which has been shown to be a driver of severe secondary bacterial infection (McAuley et al., 2007).
Our study provides new information on the drivers of influenza virus reassortment and the factors that may influence the phenotype of dominant progeny. The eventual move from classical reassortment to reverse engineering for vaccine seed generation will require this understanding so that gene constellations that provide greatest HA and NA protein content can be produced. In addition, a greater understanding of the factors that dictate gene constellations and their corresponding phenotypes likely to arise by reassortment between influenza viruses of human and other reservoir species, will help in prediction of the likelihood and impact of future pandemics.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
ST performed all experiments with the exception of the haemagglutination assays, which were performed by EM, and genotyping of certain limit dilution viruses by JC. ST analysed the experiments and wrote the draft manuscript. LB, BG, and SR supervised the work, further analysed the data, and contributed to the writing of the submitted manuscript. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by a National Health and Medical Research Council of Australia Program grant ID1071916 to LB. ST was supported by an Australian Postgraduate Award.
Conflict of Interest
SR is an employee of the influenza vaccine manufacturing company Seqirus.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank Ross Hamilton from CSL Ltd., for providing the electron microscopic images.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmicb.2021.683152/full#supplementary-material
References
Biswas, S. K., Boutz, P. L., and Nayak, D. P. (1998). Influenza virus nucleoprotein interacts with influenza virus polymerase proteins. J. Virol. 72, 5493–5501. doi: 10.1128/JVI.72.7.5493-5501
Bolte, H., Rosu, M. E., Hagelauer, E., García-Sastre, A., and Schwemmle, M. (2019). Packaging of the influenza virus genome is governed by a plastic network of RNA- and nucleoprotein-mediated interactions. J. Virol. 93:e01861-18. doi: 10.1128/JVI.01861-18
Brooke, C. B., Ince, W. L., Wei, J., Bennink, J. R., and Yewdell, J. W. (2014). Influenza A virus nucleoprotein selectively decreases neuraminidase gene-segment packaging while enhancing viral fitness and transmissibility. Proc. Natl. Acad. Sci. U.S.A. 111, 16854–16859. doi: 10.1073/pnas.1415396111
Brown, L. E., Murray, J. M., White, D. O., and Jackson, D. C. (1990). An analysis of the properties of monoclonal antibodies directed to epitopes on influenza virus hemagglutinin. Arch. Virol. 114, 1–26. doi: 10.1007/BF01311008
Cavrois, M., De Noronha, C., and Greene, W. C. (2002). A sensitive and specific enzyme-based assay detecting HIV-1 virion fusion in primary T lymphocytes. Nat. Biotechnol. 20, 1151–1154. doi: 10.1038/nbt745
Cobbin, J. C. A., Ong, C., Verity, E., Gilbertson, B. P., Rockman, S. P., and Brown, L. E. (2014). Influenza virus PB1 and neuraminidase gene segments can cosegregate during vaccine reassortment driven by interactions in the PB1 coding region. J. Virol. 88, 8971–8980. doi: 10.1128/JVI.01022-14
Cobbin, J. C. A., Verity, E. E., Gilbertson, B. P., Rockman, S. P., and Brown, L. E. (2013). The source of the PB1 gene in influenza vaccine reassortants selectively alters HA content of the resulting seed virus. J. Virol. 10, 5577–5585. doi: 10.1128/JVI.02856-12
Dadonaite, B., Gilbertson, B., Knight, M. L., Trifkovic, S., Rockman, S., Laederach, A., et al. (2019). The structure of the influenza A virus genome. Nat. Microbiol. 4, 1781–1789. doi: 10.1038/s41564-019-0513-7
Davis, A. M., Ramirez, J., and Newcomb, L. L. (2017). Identification of influenza A nucleoprotein body domain residues essential for viral RNA expression expose antiviral target. Virol. J. 14, 22–34. doi: 10.1186/s12985-017-0694-8
Downie, J. C. (2004). “Reassortment of influenza A virus genes linked to PB1 polymerase gene,” in Options for the Control of Influenza V, ed. Y. Kawaoka (Elsevier), 714–718.
Essere, B., Yver, M., Gavazzi, C., Terrier, O., Isel, C., Fournier, E., et al. (2013). Critical role of segment-specific packaging signals in genetic reassortment of influenza A viruses. Proc. Natl. Acad. Sci. U.S.A. 110, E3840–E3848. doi: 10.1073/pnas.1308649110
Fazekas De St, G., and Webster, R. G. (1966). Disquisitions of original antigenic sin. I. Evidence in man. J. Exp. Med. 124, 331–345. doi: 10.1084/jem.124.3.331
Fournier, E., Moules, V., Essere, B., Paillart, J. C., Sirbat, J. D., Cavalier, A., et al. (2012). Interaction network linking the human H3N2 influenza A virus genomic RNA segments. Vaccine 30, 7359–7367. doi: 10.1016/j.vaccine.2012.09.079
Gavazzi, C., Isel, C., Fournier, E., Moules, V., Cavalier, A., Thomas, D., et al. (2013a). An in vitro network of intermolecular interactions between viral RNA segments of an avian H5N2 influenza A virus: comparison with a human H3N2 virus. Nucleic Acids Res. 41, 1241–1254. doi: 10.1093/nar/gks1181
Gavazzi, C., Yver, M., Isel, C., Smyth, R. P., Rosa-Calatrava, M., Lina, B., et al. (2013b). A functional sequence-specific interaction between influenza A virus genomic RNA segments. Proc. Natl. Acad. Sci. U.S.A. 110, 16604–16609. doi: 10.1073/pnas.1314419110
Gerdil, C. (2003). The annual production cycle for influenza vaccine. Vaccine 21, 1776–1779. doi: 10.1016/s0264-410x(03)00071-9
Ghedin, E., Sengamalay, N. A., Shumway, M., Zaborsky, J., Feldblyum, T., Subbu, V., et al. (2005). Large-scale sequencing of human influenza reveals the dynamic nature of viral genome evolution. Nature 437, 1162–1166. doi: 10.1038/nature04239
Gilbertson, B., Zheng, T., Gerber, M., Printz-Schweigert, A., Ong, C., Marquet, R., et al. (2016). Influenza NA and PB1 gene segments interact during the formation of viral progeny: localization of the binding region within the PB1 gene. Viruses 8, 238–255. doi: 10.3390/v8080238
Hara, K., Nakazono, Y., Kashiwagi, T., Hamada, N., and Watanabe, H. (2013). Co-incorporation of the PB2 and PA polymerase subunits from human H3N2 influenza virus is a critical determinant of the replication of reassortant ribonucleoprotein complexes. J. Gen. Virol. 94, 2406–2416. doi: 10.1099/vir.0.053959-0
Hayat, M. A., and Miller, S. E. (1990). Negative Staining. New York, NY: McGraw-Hill Publishing Company.
Hoffmann, E., Neumann, G., Kawaoka, Y., Hobom, G., and Webster, R. G. (2000). A DNA transfection system for generation of influenza A virus from eight plasmids. Proc. Natl. Acad. Sci. U.S.A. 97, 6108–6113. doi: 10.1073/pnas.100133697
Kilbourne, E. D. (1969). Future influenza vaccines and the use of genetic recombinants. Bull. World Health Organ. 41, 643–645.
Kilbourne, E. D., and Murphy, J. S. (1960). Genetic studies of influenza viruses .1. Viral morphology and growth capacity as exchangeable genetic traits – rapid in ovo adaptation of early passage asian strain isolates by combination with PR8. J. Exp. Med. 111, 387–406. doi: 10.1084/jem.111.3.387
Kimble, J. B., Angel, M., Wan, H., Sutton, T. C., Finch, C., and Perez, D. R. (2014). Alternative reassortment events leading to transmissible H9N1 influenza viruses in the ferret model. J. Virol. 88, 66–71. doi: 10.1128/JVI.02677-13
Le Sage, V., Kanarek, J. P., Snyder, D. J., Cooper, V. S., Lakdawala, S. S., and Lee, N. (2020). Mapping of influenza virus RNA-RNA interactions reveals a flexible network. Cell Rep. 31:107823. doi: 10.1016/j.celrep.2020.107823
Li, C., Hatta, M., Nidom, C. A., Muramoto, Y., Watanabe, S., Neumann, G., et al. (2010). Reassortment between avian H5N1 and human H3N2 influenza viruses creates hybrid viruses with substantial virulence. Proc. Natl. Acad. Sci. U.S.A. 107, 4687–4692. doi: 10.1073/pnas.0912807107
Li, C., Hatta, M., Watanabe, S., Neumann, G., and Kawaoka, Y. (2008). Compatibility among polymerase subunit proteins is a restricting factor in reassortment between equine H7N7 and human H3N2 influenza viruses. J. Virol. 82, 11880–11888. doi: 10.1128/JVI.01445-08
Li, Z., Watanabe, T., Hatta, M., Watanabe, S., Nanbo, A., Ozawa, M., et al. (2009). Mutational analysis of conserved amino acids in the influenza A virus nucleoprotein. J. Virol. 83, 4153–4162. doi: 10.1128/JVI.02642-08
Lu, L., Lycett, S. J., and Leigh Brown, A. J. (2014). Reassortment patterns of avian influenza virus internal segments among different subtypes. BMC Evol. Biol. 14:16. doi: 10.1186/1471-2148-14-16
Lubeck, M. D., Palese, P., and Schulman, J. L. (1979). Nonranom association of parental genes in influenza A virus recombinants. Virology 95, 269–274. doi: 10.1016/0042-6822(79)90430-6
Marshall, N., Priyamvada, L., Ende, Z., Steel, J., and Lowen, A. C. (2013). Influenza virus reassortment occurs with high frequency in the absence of segment mismatch. PLoS Pathog. 9:e1003421. doi: 10.1371/journal.ppat.1003421
McAuley, J., Deng, Y.-M., Gilbertson, B., Mackenzie-Kludas, C., Barr, I., and Brown, L. (2017). Rapid evolution of the PB1-F2 virulence protein expressed by human seasonal H3N2 influenza viruses reduces inflammatory responses to infection. Virol. J. 14:162. doi: 10.1186/s12985-017-0827-0
McAuley, J. L., Chipuk, J. E., Boyd, K. L., Van De Velde, N., Green, D. R., and Mccullers, J. A. (2010). PB1-F2 proteins from H5N1 and 20th century pandemic influenza viruses cause immunopathology. PLoS Pathog. 6:e1001014. doi: 10.1371/journal.ppat.1001014
McAuley, J. L., Hornung, F., Boyd, K. L., Smith, A. M., Mckeon, R., Bennink, J., et al. (2007). Expression of the 1918 influenza A virus PB1-F2 enhances the pathogenesis of viral and secondary bacterial pneumonia. Cell Host Microbe 2, 240–249. doi: 10.1016/j.chom.2007.09.001
Mena, I., Jambrina, E., Albo, C., Perales, B., Ortín, J., Arrese, M., et al. (1999). Mutational analysis of influenza A virus nucleoprotein: identification of mutations that affect RNA replication. J. Virol. 73, 1186–1194. doi: 10.1128/JVI.73.2.1186-1194.1999
Moreira, E. A., Weber, A., Bolte, H., Kolesnikova, L., Giese, S., Lakdawala, S., et al. (2016). A conserved influenza A virus nucleoprotein code controls specific viral genome packaging. Nat. Commun. 7:12861. doi: 10.1038/ncomms12861
Nakazono, Y., Hara, K., Kashiwagi, T., Hamada, N., and Watanabe, H. (2012). The RNA polymerase PB2 subunit of influenza A/HongKong/156/1997 (H5N1) restrict the replication of reassortant ribonucleoprotein complexes. PLoS One 7:e32634. doi: 10.1371/journal.pone.0032634
Nelson, M. I., Detmer, S. E., Wentworth, D. E., Tan, Y., Schwartzbard, A., Halpin, R. A., et al. (2012). Genomic reassortment of influenza A virus in North American swine, 1998–2011. J. Gen. Virol. 93, 2584–2589. doi: 10.1099/vir.0.045930-0
Octaviani, C. P., Goto, H., and Kawaoka, Y. (2011). Reassortment between seasonal H1N1 and pandemic (H1N1) 2009 influenza viruses is restricted by limited compatibility among polymerase subunits. J. Virol. 85, 8449–8452. doi: 10.1128/JVI.05054-11
Rabadan, R., Levine, A. J., and Krasnitz, M. (2008). Non-random reassortment in human influenza A viruses. Influenza Other Resp. Viruses 2, 9–22. doi: 10.1111/j.1750-2659.2007.00030.x
Schrauwen, E. J. A., Bestebroer, T. M., Rimmelzwaan, G. F., Osterhaus, A. D. M. E., Fouchier, R. A. M., and Herfst, S. (2013). Reassortment between avian H5N1 and human influenza viruses is mainly restricted to the matrix and neuraminidase gene segments. PLoS One 8:e59889. doi: 10.1371/journal.pone.0059889
Song, M. S., Pascua, P. N., Lee, J. H., Baek, Y. H., Park, K. J., Kwon, H. I., et al. (2011). Virulence and genetic compatibility of polymerase reassortant viruses derived from the pandemic (H1N1) 2009 influenza virus and circulating influenza A viruses. J. Virol. 85, 6275–6286. doi: 10.1128/JVI.02125-10
Steel, J., and Lowen, A. C. (2014). “Influenza A Virus Reassortment,” in Influenza Pathogenesis and Control, Vol. I, eds R. W. Compans and M. B. A. Oldstone (Switzerland: Springer International Publishing), 377–401.
Tannock, G. A., Paul, J. A., and Barry, R. D. (1984). Relative immunogenicity of the cold-adapted influenza virus A/Ann Arbor/6/60 (A/AA/6/60-ca), recombinants of A/AA/6/60-ca, and parental strains with similar surface antigens. Infect. Immun. 43, 457–462. doi: 10.1128/IAI.43.2.457-462.1984
Keywords: influenza virus, reassortment, pandemics, gene segment interactions, vaccine production
Citation: Trifkovic S, Gilbertson B, Fairmaid E, Cobbin J, Rockman S and Brown LE (2021) Gene Segment Interactions Can Drive the Emergence of Dominant Yet Suboptimal Gene Constellations During Influenza Virus Reassortment. Front. Microbiol. 12:683152. doi: 10.3389/fmicb.2021.683152
Received: 20 March 2021; Accepted: 23 June 2021;
Published: 14 July 2021.
Edited by:
Kai Huang, University of Texas Medical Branch at Galveston, United StatesReviewed by:
Hongquan Wan, United States Food and Drug Administration, United StatesGloria Consuelo Ramirez-Nieto, National University of Colombia, Colombia
Copyright © 2021 Trifkovic, Gilbertson, Fairmaid, Cobbin, Rockman and Brown. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Lorena E. Brown, bG9yZW5hQHVuaW1lbGIuZWR1LmF1
†Present address: Sanja Trifkovic, St Jude Children’s Research Hospital, Memphis, TN, United States; Joanna Cobbin, School of Life and Environmental Sciences and School of Medical Sciences, The University of Sydney, Sydney, NSW, Australia