 Elizaveta Okorokova
Elizaveta Okorokova Mikhail Lebedev
Mikhail Lebedev Michael Linderman
Michael Linderman Alex Ossadtchi
Alex Ossadtchi- 1Centre for Cognition and Decision Making, National Research University Higher School of Economics, Moscow, Russia
- 2Department of Neurobiology, Duke University, Durham, NC, USA
- 3Department of Biomedical Engineering, Norconnect Inc., Ogdensburg, NY, USA
- 4Laboratory of Control of Complex Systems, Institute of Problems of Mechanical Engineering, Russian Academy of Sciences, St. Petersburg, Russia
In recent years, several assistive devices have been proposed to reconstruct arm and hand movements from electromyographic (EMG) activity. Although simple to implement and potentially useful to augment many functions, such myoelectric devices still need improvement before they become practical. Here we considered the problem of reconstruction of handwriting from multichannel EMG activity. Previously, linear regression methods (e.g., the Wiener filter) have been utilized for this purpose with some success. To improve reconstruction accuracy, we implemented the Kalman filter, which allows to fuse two information sources: the physical characteristics of handwriting and the activity of the leading hand muscles, registered by the EMG. Applying the Kalman filter, we were able to convert eight channels of EMG activity recorded from the forearm and the hand muscles into smooth reconstructions of handwritten traces. The filter operates in a causal manner and acts as a true predictor utilizing the EMGs from the past only, which makes the approach suitable for real-time operations. Our algorithm is appropriate for clinical neuroprosthetic applications and computer peripherals. Moreover, it is applicable to a broader class of tasks where predictive myoelectric control is needed.
1. Introduction
Handwriting is a unique development of human culture. A skill learned during the early childhood, it remains among the primary means of communication and self-expression throughout the course of life. From the physiological point of view, handwriting is a complex interplay between the nervous system and the numerous muscles of the upper extremity. Despite several attempts to study this intricate activity theoretically (Plamondon and Maarse, 1989; McKeague, 2005) and experimentally (Linderman et al., 2009; Huang et al., 2010; Li et al., 2013), it is still not well understood and can not be reliably replicated in prostheses.
The relationship between the muscle force and the pen trajectory is complicated by the motor redundancy phenomenon (Bernstein, 1967; Guigon et al., 2006). One and the same movement can be accomplished via basically infinite number of muscle activation patterns. Relatively fine spatial scale inherent to the handwriting process and the natural variations of the limb's kinematic variables further complicate the issue.
Additional obstacle in studying the physiology of handwriting is the difficulty of measuring the muscle force directly. Surface and intramuscular Electromyography (EMG) are the common methods to register neuromuscular activity during a motor task. Surface EMG is a non-invasive method which implies placing the electrodes on the skin above the muscles of interest. Being easy and safe to implement, this technique, however, does not yield sufficiently accurate biomechanical measurements, due to the complex relationship between the EMG and muscle force, complicated anatomy of muscles and the inability to record from all the muscles involved, especially from the deep muscles. Intramuscular EMG (iEMG) is invasive and uses needle electrodes inserted into the muscle tissue to yield more spatially specific measurements with less leakage and disturbance. The invasive nature of iEMG limits its utility.
Both EMG registration methods posit several substantial difficulties, primarily related to signal quality and associated issues of noise filtering and source extraction from the observed data. Nonetheless, it was shown that even the surface EMG carries valuable information about the neuromuscular interactions and can therefore be used effectively in modeling and interpreting movements (Reaz et al., 2006; Ahsan et al., 2009).
Despite the evident difficulties of measuring and interpreting neuromuscular activity with the currently available techniques, understanding such complex motor tasks as handwriting is important for both theoretical and practical reasons. Once we learn how to model the relationship between EMG patterns and pen movements during handwriting, we can introduce this knowledge to many rapidly expanding fields and practices, including biomedical engineering, robotics and biofeedback therapy. For instance, we can substantially improve the existing treatment and rehabilitation techniques for patients with a loss or an injury of an upper limb (Xiao and Menon, 2014), create rules for diagnostics of motor diseases based on handwriting (Van Gemmert et al., 1999; Stanford, 2004; Silveri et al., 2007), and even assist young children in learning how to write (Carter and Russell, 1985). Besides, an accurate model and methodolgies for building such models, establishing the correspondence between the handwriting and muscle activation patterns has a potential to become a foundation for creating intelligent neural prosthesis with a substantial number of degrees of freedom and fine spatial scale (Chan et al., 2000; Ohnishi et al., 2007; Shenoy et al., 2008; Bu et al., 2009; Castellini and van der Smagt, 2009).
However, such appealing advances and practices are still in their infancy. To date, the existing research on decoding of handwriting from electromyography is small and restricted to laboratory conditions. Several papers addressed the question of written character classification based on surface EMG, which involved implementation of machine-learning techniques to distinguish between muscle activation patterns for different written characters, such as digits, alphabet letters or simple geometric shapes. Linderman et al. (2009) classified symbols from 0 to 9, using eight bipolar surface electrodes placed on the hand and the forearm muscles. They implemented Fisher Linear Discriminant Analysis to obtain, on average, 90% accuracy of classification across subjects. Huang et al. (2010) used Dynamic Time Warping (DTW) to classify symbols based on 6-channel EMG recordings. Their average classification accuracy was 98.25% for digits, 97.89% for Chinese symbols and 84.29% for Latin capital letters. Li et al. (2013) improved the DTW algorithm by substituting Euclidean Distance with Mahalanobis Distance, to increase classification precision to almost 95%. In their experiment, subjects were instructed to write lower-case letters, while 4-channel EMG signals were recorded from their forearm.
The other studies considered a rather complex task of on-line decoding of the pen traces, based on the incoming EMG signals from the measurement electrodes. Among the most successful methods known to the authors, is the Wiener Filter (Linderman et al., 2009), which allows to attain accuracy of reconstruction of 47 ± 2% for X-coordinate and 63 ± 15% for Y-coordinate, measured by the coefficient of determination. However, the method used the data samples from the future, which would lead to extra delays in cases when used in the on-line mode.
In this paper, we consider the same multisubject data-set as in Linderman et al. (2009) and present our approach to EMG-based pen tracking that by taking into account the dynamic model of the pen coordinate process allows to outperform the previously reported techniques. The main idea behind our method is to fuse two information sources available about the process of handwriting. The first information source comes from the physical and the kinematic characteristics of handwriting. The second information source comes from the multichannel electromyography that indirectly measures the strength of the upper extremity muscles, activated to move the pen. To perform the fusion of the two sources optimally, we employ the Linear Kalman Filter (Kalman, 1960), which is a well-known recursive algorithm for dynamic statistical model-based inference.
2. Materials and Methods
2.1. The Kalman Filter
2.1.1. Preliminary Remarks
In its classical formulation the Kalman Filter (KF) (Kalman, 1960) is an algorithm that fuses several (usually two) noisy sources of information to produce an estimate of the dynamical system's state vector, which is optimal in the “minimum squared error” sense. The method is over 50 years old, but it is still very popular, due to its intuitive structure, ease of implementation and computational efficiency.
In our application, the first information source is the dynamical model that captures the physical properties of the arm-wrist-pen device and is formalized as a multivariate autoregressive (MVAR) process, whose parameters are estimated from the data. The noisy vector of EMG measurements is the second source of information, whose relation to the pen coordinate is modeled via multivariate linear regression equation with coefficients determined from the training data-set.
For simplicity, the derivations provided in this section are based on the assumption of multivariate normality of the fused sources (Faragher, 2012), which is essential for the Kalman Filter to be the optimal estimator (the best among all other kinds). However, in the general Kalman Filter framework, this does not have to be the case (Arulampalam et al., 2002). When the assumption of normality does not hold, it is still possible to derive the KF equations based on the orthogonality principle (e.g., Jazwinski, 2007), which would guarantee the KF to be the best linear estimator, but not necessarily be optimal. In this case, it might be possible to increase accuracy by employing non-linear techniques that exploit higher order dependencies in the data, such as the Extended Kalman Filter (Julier and Uhlmann, 1997) or its “distribution-free” version, called Unscented Kalman Filter (Wan and Van Der Merwe, 2000). However, since the majority of trials in our multisubject dataset appear to test positively for the normality (see Appendix, Section Testing the Assumptions of the Model) the extent of improvement furnished by the use of the non-linear approaches is hard to predict theoretically. This leaves the question in the empirical realm to be addressed in the future studies.
As demonstrated by the statistical tests described in the Appendix (Section Testing the Assumptions of the Model), we could not reject the hypothesis of independence for the majority of trials. Based on this and, for the simplicity reasons, we base our developments in this paper on the assumption of independence of the two fused sources. In case the independence assumption is violated, the performance gained by taking into account the dynamics of the reconstructed process could have been more sizable should we use a slightly modified form of equations (Shimkin, 2009) to account for the non-trivial cross-covariance structure of the residuals. However, the extent to which modeling the cross-covariance structure of residuals would improve the performance is not entirely clear, due to the inherent non-stationarity and the associated estimation errors.
2.1.2. State Transition Model
As the first information source, we assume that, at each time moment t, the system evolves from the previous state at time t − 1, according to the rule:
where
• , is a 6K × 1 state vector containing pen coordinates and their first and second rates of change for the window of K time moments starting from t;
• A is a [6K × 6K] state transition matrix, which performs the mapping between the state vectors at the two consecutive time moments;
• vt is a [6K × 1] vector containing process noise, which is assumed to be drawn from a multivariate Gaussian distribution with zero mean and covariance matrix Q.
Based on Equation (1), we can derive the following expressions connecting the mean and the covariance matrix of the state vector at the two consecutive time moments.
• μ1t = Aμ1(t−1) is a 6K-dimensional mean state vector at time t;
• is a 6K × 6K positive-definite covariance matrix of the state vector at time t.
Detailed derivations of the model parameters can be found in the Appendix (Section Testing the Assumptions of the Model).
2.1.3. Measurement Model
Usually, in the KF framework, the measurement equation appears in the z = F(s) form, describing the way the process to be estimated (s) is related to the available vector of indirect measurements (z). However, in our application, due to causal and physiological reasons, it is more natural to think that the EMG registered muscle activity gives rise to the pen movement. Therefore, we use the “inverse” form of what is usually called the observation equation in the KF framework and write
where
• zt is a [8L × 1] observation vector containing L groups of eight EMG measurements corresponding to the [t − L + 1, t] window of L most recent samples;
• H is a [6K × 8L] measurement transformation matrix, mapping the measurement domain to the state vector domain;
• wt is a [8L × 1] vector of measurement noise with zero mean and covariance matrix R. Additionally, the measurement noise wt is assumed to be independent from the process noise vt.
The 6K-dimensional state mean vector at time t is given by
Since we do not model zt as a stochastic process, the covariance matrix of st reduces to covariance matrix of the measurement noise, so that . Note that this noise is assumed to be stationary.
2.1.4. Information Fusion
As outlined in the previous two subsections, we have two independent sources of information about the state vector. The first endogenous source bases its predictions on the dynamical characteristics of the pen coordinates during the handwriting and yields f1(st|st−1) as the state vector distribution (red distribution in Figure 1). The second source is exogenous and uses externally registered EMG signals to suggest f2(st|zt) as the state vector distribution (blue distribution in Figure 1). In order to reconstruct the state vector, optimally taking into account the predictions from both sources, we perform the statistical fusion of the estimates based on the dynamical and the measurement models. The schematic procedure of the source fusion is illustrated in Figure 1.
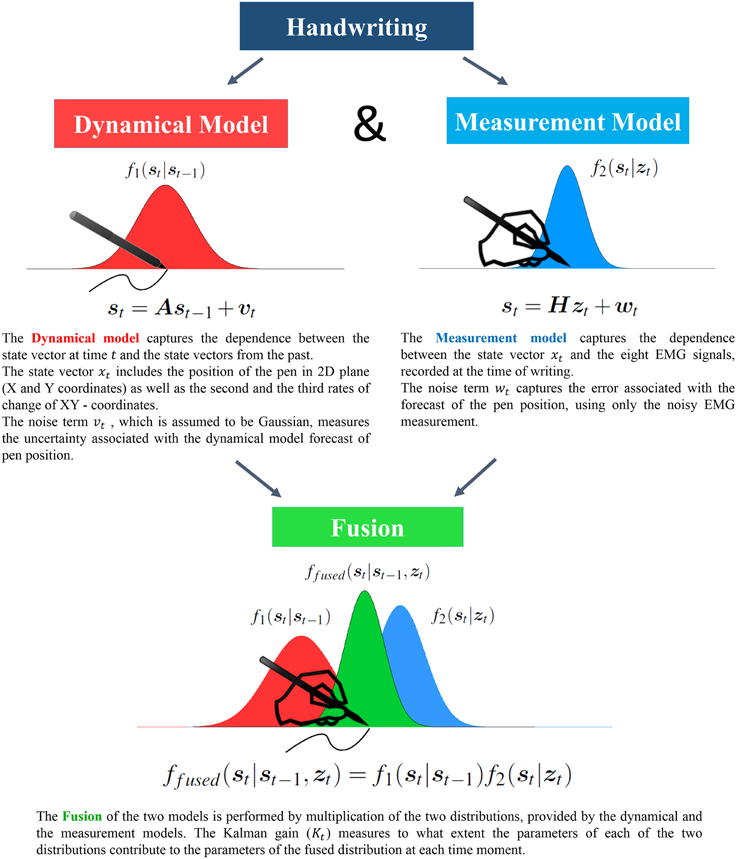
Figure 1. Information Fusion by means of the Kalman Filter allows to improve reconstruction accuracy by adaptively balancing the contribution from the two information sources.
The joint conditional estimate of the state vector is distributed as ffused(st|st−1, zt) (green distribution in Figure 1). Assuming independence of the sources, the problem of finding f(st|st−1, zt) reduces to a simple multiplication of the two probability density functions, i.e.,
The product of two multivariate normal distributions is also a multivariate normal (Rencher, 2003). Its mean and covariance can be easily expressed in terms of the mean vectors and the covariance matrices of each of the two normal multipliers.
Specifically, Σfused is the covariance matrix of the fused distribution can be computed as
and the 6K-dimensional mean vector of the fused distribution is found to be the following weighted sum of the two mean vectors of the fused information sources:
It is instructive to reformulate the expressions for the mean and the covariance matrix of the new distribution and to separate the influence of the two distributions being fused.
Using the matrix inversion lemma (Henderson and Searle, 1981), and setting
we can rewrite Equations (5) and (6) as
and
For detailed derivation of the parameters see the Appendix.
The term Kt in Equation (7), commonly known as the Kalman Gain, plays a crucial role of the dynamic scaling factor reflecting the distribution of trust in each of the two information sources. It depends on the relative amount of uncertainty present in the estimates by each of the information sources alone, and varies over time.
Since covariance matrices are positive definite, Equation (8) shows that by fusing the two distributions we reduce the variation associated with the state estimate, proportionally to the Kalman gain. At the same time, the fused mean (Equation 9) becomes the weighted average of the endogenously predicted and the measurements-based mean estimates.
2.1.5. The Algorithm
Based on the above equations we are now ready to formulate the algorithm for calculating the Kalman Filter estimate. At each time moment the computation can be split into three consecutive steps.
1. Endogenous state prediction and error covariance update:
2. Kalman Gain Calculation:
3. Measurement Update:
In order to relate our approach to the classical KF paradigm in the equations above, we assigned the variables used in the previous subsection to the standard symbols, commonly employed in the KF literature. In the above algorithm, the first step is to use the State Transition Equation only and to calculate the so-called a priori estimate , with associated variance Pt|t−1 (Equations 10 and 11).
Then, we calculate the Kalman Gain based on the a priori covariance matrix and the covariance matrix of the Measurement Model (Equation 12).
Finally, the a posteriori estimate is computed by adjusting the endogenous a priori estimate with the EMG measurements. The amount of adjustment is governed by the time-varying Kalman Gain (Equation 14) and the innovations process , informing the algorithm on the amount of mismatch between the endogenous and exogenous estimates. The a posteriori uncertainty, associated with the prediction, based on the two models, is given by Pt|t (Equation 15), which shows that, in the final estimate, the a priori uncertainty gets reduced proportionally to the Kalman Gain.
2.2. The Experiment
2.2.1. Data
Six healthy participants were instructed to write symbols from 0 to 9, repeating each symbol approximately 50 times. At the same time, muscle activity was recorded with eight bipolar-surface EMG electrodes, placed on each participants leading hand muscles: opponens pollicis, abductor pollicis brevis, medial and lateral heads of first dorsal interrosseus, and four forearm muscles: flexor carpi radialis, extensor digitorum, extensor carpi ulnaris, and extensor carpi radialis. The reference electrode was placed on each subject's forehead. Position of the pen was recorded using the special digitizing tablet, yielding a pair of coordinates in the two-dimensional space. For a detailed illustration of the experiment set-up, see Linderman et al. (2009).
2.2.2. Preprocessing
Before applying the algorithm, we preprocessed EMG signals to extract the envelope via the standard rectification procedure. For each channel separately, we first calculated the absolute value of the EMG signals and then low-pass filtered the result with a second-order Butterworth Filter with the cut-off frequency of Fc. We optimized the value of the cut-off frequency based on the training subset of the recorded data to obtain the best reconstruction performance. In the final results reported here Fc = 2 Hz. Additionally, we have applied square-root transformation to each signal's envelope, obtained via the described rectification procedure.
2.2.3. Training and Testing
Half of the trials of each symbol was randomly assigned to training the parameters of the model, while the remaining half was used for testing the performance (Figure 2). During training, the parameters of the dynamical model (Equation 1) and the measurement model (Equation 2) were estimated. We applied Ordinary Least Squares Method to estimate matrix A in the state transition equation and matrix H in the measurement equation. Covariance matrices R and Q were estimated based on the residuals of the two fitted models. Note that estimation of the covariance matrices of the error processes is particularly simple here, since, at the model identification step, we have the direct access to both state vector and the actual EMG measurements, thanks to the experimental setup described in Linderman et al. (2009). Figure 2 shows the data flow diagram in the model identification and coordinate reconstruction modes.
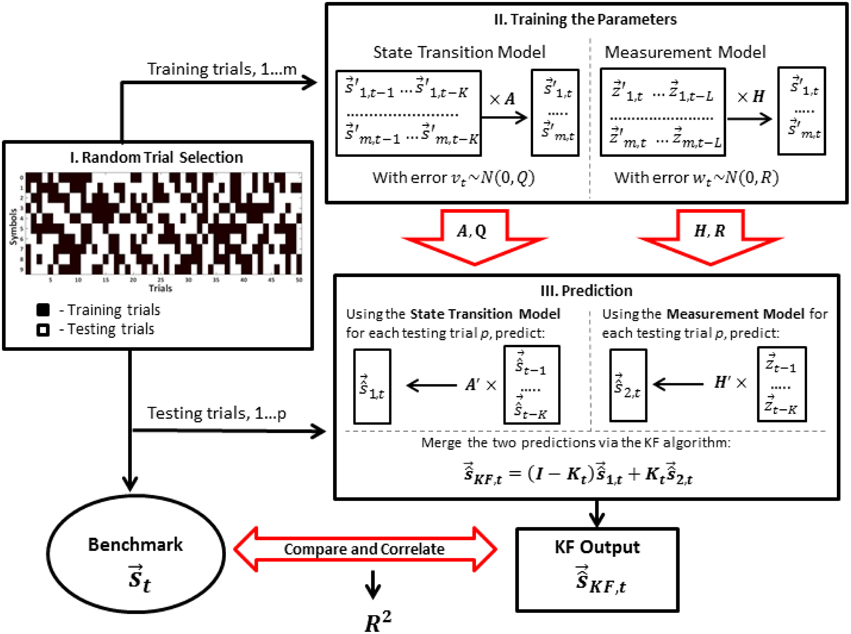
Figure 2. Implementation of the Kalman Filter algorithm. For each participant of the experiment, the trials are randomly divided into training trials (black) and testing trials (white). Then, the training trials are used for learning of the parameters of the state transition model (matrices A and Q) and the measurement model (matrices H and R). The EMG data from the testing trials and the learned matrices are then used for the prediction of the state vector in both models. Finally, the predictions of the two models are merged via the Kalman filter algorithm and the result of the filter is compared to the actual state vector. The squared correlation coefficient (R2) is used as a measure of efficiency of reconstruction.
We used two basic experimental designs to calibrate our pen tracking algorithm.
1. Within-Group Design
A single set of parameters (A, H, R, and Q) was estimated using the training trials from all symbols at the same time and then tested on the remaining test trials.
2. Between-Group Design
A separate set of parameters (An, Hn, Rn and Qn, n ∈ 0, ..9) was estimated for each symbol and then tested within the data from the trials of the same symbol.
Note that for Within-Group Design, only one set of matrices was estimated by pooling all the training samples together, while in Between-Group Design the four matrices were estimated separately for each of the ten symbols. Then, the out-of-training sample measurements were used to reconstruct handwriting via the recursive process outlined in Section 2.1.5.
The testing procedure was the same within each experimental design (see Figure 2). For each trial, the starting pen location point was set to zero vector. Then, the estimate of the pen position was computed recursively (Section 2.1.5). Reconstruction accuracy was measured by the squared correlation coefficient R2 between the actual coordinate and its fused estimate (Figure 2). This criterion corresponds to the percentage of energy in the actual pen traces (Total Sum of Squares - SSt) explained by the reconstructed ones (Explained Sum of Squares SSe), i.e.,
The accuracy was computed within each trial, and then averaged across trials for each symbol. Confidence intervals were computed to account for the standard errors associated with the variation across the participants.
2.2.4. Comparison with Other Models
We compared the accuracy of our model to the accuracy of the Wiener Filter (WF) estimate, which was originally tested on the same data-set by Linderman et al. (2009). The Wiener Filter approach is directly equivalent to predicting the pen coordinates, using only the measurement equation of the KF-framework alone (Equation 2). In other words, the Kalman filter is the Wiener filter, accompanied by information about the system's physical properties. Therefore, a comparison between the two models would not only show the possible improvement associated with the Kalman Filter, but also highlight the isolated benefit furnished by employing the dynamical properties of the system.
In the framework of handwriting recognition from electromyography reported in Linderman et al. (2009), the pen trace at time t was represented as a linear combination of EMG signals recorded in the non-causal interval of t: [t − δ1, t + δ2]. The unknown weights, mapping rectified EMG signals into the pen-tip coordinate vector, were estimated using the Ordinary Least Squares Method. It is important to stress that, in contrast to the approach reported in Linderman et al. (2009), our reconstruction procedures (both Kalman Filter and Wiener Filter based) operate causally and use only the samples from the immediate past. For each time moment t, only the samples from the [t − δ1, t] interval were used. It is, therefore, interesting and instructive to test, whether or not the use of the dynamical model compensates for the reduced amount of information in the external measurements. In the situation when both methods use the same amount of exogenously registered data, the Kalman Filter is expected to outperform the Wiener Filter. To test the hypothesis, we performed the coordinate reconstruction with the two filters, fixing all other external parameters related to the data preprocessing step and compared their performance on the testing set of trials.
3. Results
3.1. Finding Optimal Model Order
The dynamical model (Equation 1) and the measurement model (Equation 2) contain model order parameters K and L, corresponding to the number of past samples used. In order to find the optimal values of these parameters, we applied the cross-validation procedure. We used R2 as a metric of the goodness of reconstruction achieved (Figure 3).
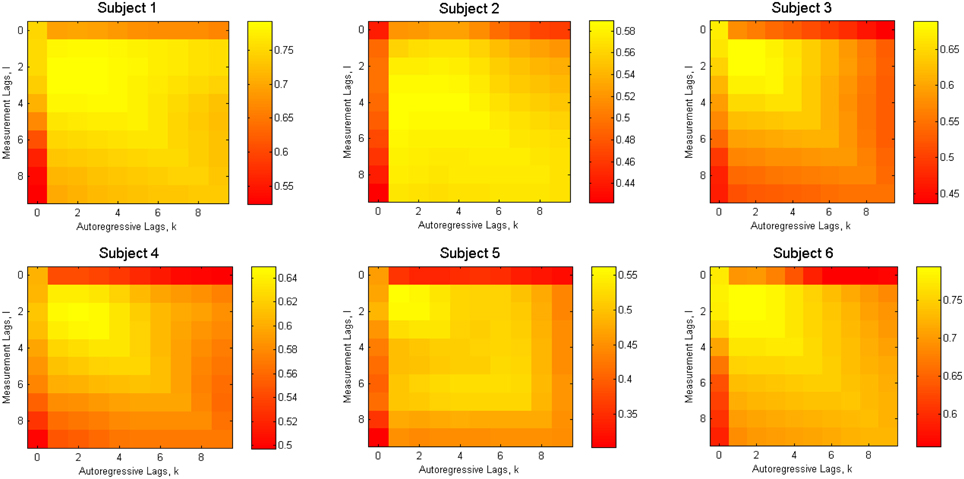
Figure 3. Reconstruction accuracy as a function of model order parameters (K and L) for 6 subjects separately.
To search for the combination of K and L that delivers the highest performance, we looked for the values of these parameters that maximize the g = E(R2)∕std(R2) ratio. The expected value E(R2) and the standard deviation std(R2) were computed over the trials in the data-set used for cross-validation. Therefore, high values of g correspond to the combination of high accuracy and stability of the reconstruction quality. Figure 4 shows the average over all subjects value of g and R2.
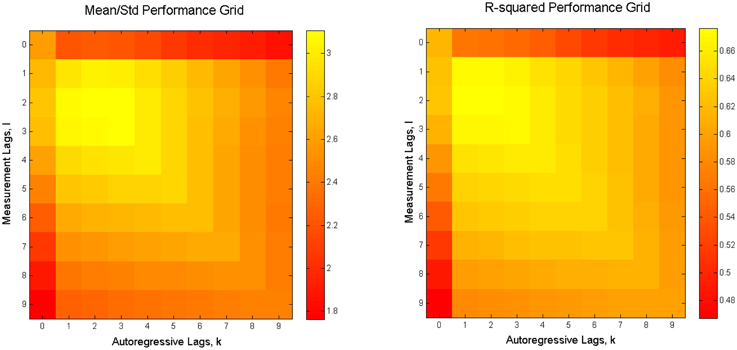
Figure 4. Average reconstruction accuracy as a function of model order parameters (K and L). Left: average over all 6 subjects value of g. Right: Average over all 6 subjects value of R2 for the mean reconstruction accuracy in the two coordinates (X + Y)∕∕2.
Based on these maps, we set K = 1 and L = 2 to obtain the results reported in this paper. Note that the number of optimal measurement lags was reduced from 20 to 2, comparing to the original paper by Linderman et al. (2009), which significantly reduces computational complexity of the problem and reduces the response time of the system and potentially allows to track brisker movements.
3.2. Within-Group Design
We first trained one set of parameters for all symbols and used it to reconstruct pen traces from the EMG data in the testing set. Figure 5 shows the result of reconstruction of several trials of each character for one of the participants. Despite being noisy and, at times, inaccurate, the symbols are still identifiable and reproducible between trials.
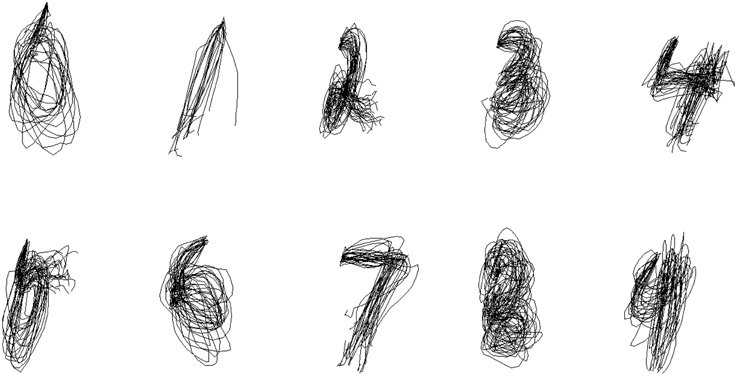
Figure 5. Within-Group Reconstruction: several reconstructed trials of each symbol from cross-validation sample of one of the participants.
Table 1 gives a detailed accuracy distribution for all symbols. Each of the entries in the table were found as follows: we computed accuracy of reconstruction for each test trial available for each symbol, then calculated the statistics within trial of the same symbol to determine the reported mean and standard deviation. Finally, we computed 95% confidence intervals for the average accuracy of every symbol reconstruction, based on the sample of 6 participants. We report reconstruction accuracy by coordinates independently, and as an average between the two coordinates.
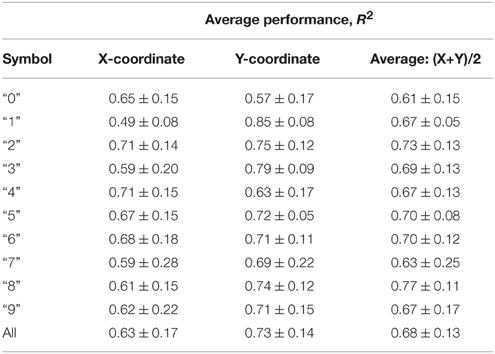
Table 1. Within-Group Reconstruction Performance: 95% confidence intervals for the average reconstruction accuracy of each symbol between the 6 participants.
Statistically speaking, we managed to achieve the average accuracy of 63 ± 17% and 73 ± 14% with 95% confidence, for the two reconstructed coordinates, as estimated for the six participants of the experiment. Note that the average accuracy in both coordinates is higher than that found by Linderman et al. (2009) (47 ± 2% and 63 ± 15% for the two coordinates, respectively), where non-causal Wiener Filter based reconstruction was employed. Additional improvement over that pioneering work lies in the use of the smaller number of measurement lags (L) (2 instead of 20, see Section 3.1) which reduces the response time of the system. These observations demonstrate the benefits brought in by the use of the dynamical properties of the process being identified.
3.3. Between-Group Design
In the Between-group design, we attempted to learn the parameters of the Kalman Filter for each symbol separately, and then reconstruct the traces of the same symbol. Figure 6 shows the results of reconstruction of several trials of each symbol for one of the participants. As predicted, the separate Kalman Filters for each symbol perform a more specific and accurate reconstruction, which is visually evident from the figure.
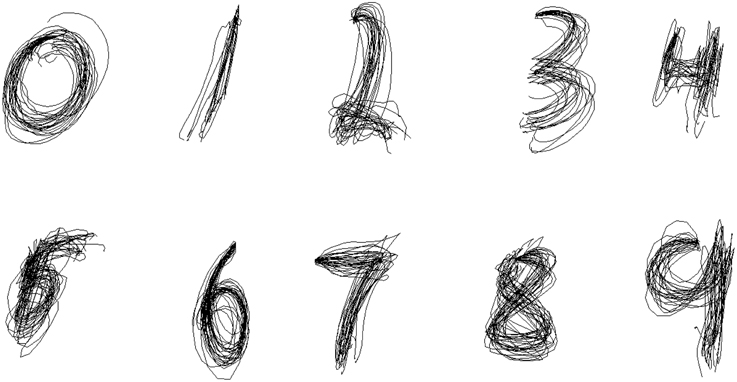
Figure 6. Between-Group Reconstruction: several reconstructed trials of each symbol from cross-validation sample of one of the participants.
The average reconstruction in the two coordinates between subjects was 78 ± 13% and 88 ± 7%, respectively. Table 2 reports 95% confidence intervals for the average reconstruction accuracy of each symbol with separate Kalman Filters.
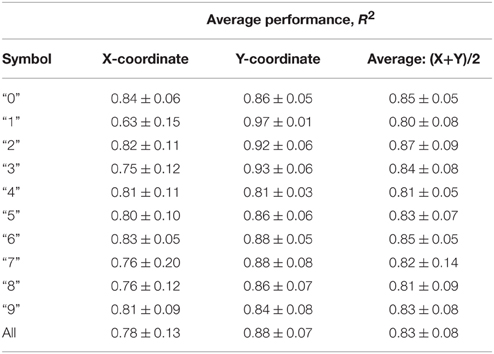
Table 2. Between-Group Reconstruction Performance: 95% confidence intervals for the average reconstruction accuracy of each symbol between the 6 participants.
3.4. Comparison with the Wiener Filter
In the previous subsection we have shown that, as expected, the Kalman Filter improves the reconstruction performance, as compared to the previously proposed method (Linderman et al., 2009). The parameter search (Section 3.1) shows that adding non-zero autoregressive lag(s) to the model, and as a result, capturing the dynamical properties of the system, leads to the increase in accuracy of reconstruction for all subjects (Figures 3, 4).
To consider the increase in accuracy, specifically associated with the dynamical model, we reconstructed pen traces of several symbols by Within-group design (one set of parameters for all symbols), and then repeated the procedure on the same samples using the Wiener Filter, fixing all other external parameters, including those related to the training-testing split of the data and data preprocessing techniques.
On average, introduction of the KF framework leads to a significant increase in accuracy for both reconstructed coordinates across the six participants (Figure 7). The increase is more or less homogeneous between different symbols. Figure 8 shows the distribution of the difference between the Kalman Filter accuracy and the Wiener Filter accuracy for separate symbols. For all symbols, the difference is significantly greater than zero with at least 95% confidence, guaranteed by the one-sided Wilcoxon test for matched pairs.
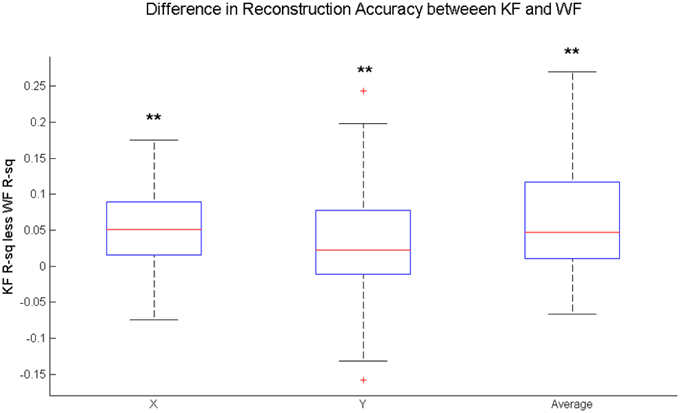
Figure 7. Distribution of the difference in the average performance of the Kalman Filter (KF) and the average performance of the Wiener Filter (WF) for all written characters across subjects. Statistical Difference between the average KF and the average WF performance is measured by one-sided Wilcoxon matched-pair test for X-coordinate, Y-coordinate and the average of the two, i.e., (X+Y)/2: **significantly greater than zero at 1% significance level.
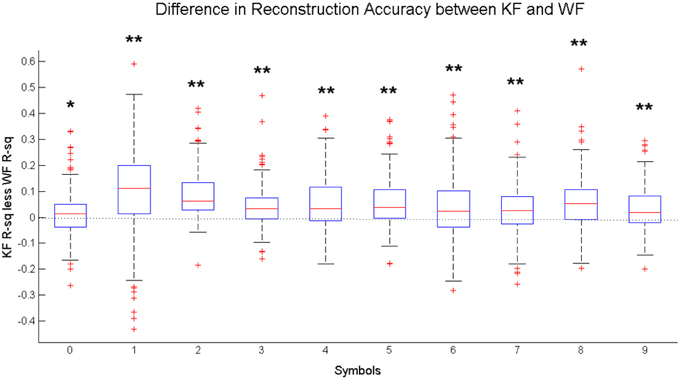
Figure 8. Distribution of the difference between the Kalman Filter Accuracy (KF R2) and the Wiener Filter Accuracy (WF R2) between subjects, measured for each written character independently. Statistical Difference between the KF and the WF performance is measured by one-sided Wilcoxon matched-pair test for each character: *significantly greater than zero at 5% significance level, **significantly greater than zero at 1% significance level.
The ergonomics of the reconstructed handwriting traces plays an important role. The use of the dynamical model to enforce natural smoothness of handwriting yielded improved ergonomics of the recovered traces. Figure 9 allow to visually compare the reconstruction of the pen traces for each symbol obtained with the two methods (left—the Kalman Filter reconstruction, right—the Wiener Filter reconstruction). As we can see from the figures, the use of the Kalman filter furnishes a smoother coordinate reconstruction than that based exclusively on the measurements. While both filters make it possible to visually discriminate between different symbols, the smoothness of the traces, obtained with the Kalman filter, makes them more natural and ergonomically plausible.

Figure 9. Pen trace reconstruction of digits zero to nine with the Kalman Filter (left) and the Wiener Filter (right), Within-Group Method for several cross-validation trials of one of the participants.
4. Discussion
In this work we applied the Kalman Filter approach to reconstruction of handwritten pen traces on the basis of EMG measurements. We have demonstrated that it is possible to obtain accurate and ergonomic reconstruction of pen traces and still remain in the linear framework to utilize all the benefits associated with it. Our results show a significant improvement over the figures, previously reported by Linderman et al. (2009). In contrast to that pioneering work, we used only causal filtering and exploited fewer past samples of the EMG signals.
Although the accuracy of reconstruction does not generally go above 90%, in terms of the coefficient of determination, the method still offers a reliable and ergonomic reconstruction for all symbols. Approximately 25 trials of each symbol were enough to learn the parameters of the filter and yield comparable results in testing samples.
The method works well for both specific (Between-Group design) and general (Within-Group design) models, which reveals its potential for a wide range of applications. The Between-group design, although quite limited at first sight, is not entirely unrealistic, due to the fact that handwritten figures are very well discriminated between each other on the basis of EMG signals (Linderman et al., 2009; Huang et al., 2010). It means that separate Kalman filters can be applied as a second-stage algorithm in the off-line experiments, after another algorithm (such as the Hidden Markov Model of Linear Discriminant Analysis) is used to classify the symbols into groups.
The Within-group design, on the other hand, is more applicable to on-line handwriting reconstruction, when no prior information about the class of the symbol being written is available. In this framework the causality of our approach offers additional benefits and makes the EMG-controlled handwriting feel natural to the user. Also, the natural smoothness of the traces, recovered with the use of the KF, provides for an improved feedback, which is crucial in the real-life on-line scenario.
While our method has shown improvement over the previously proposed technique, it still requires thorough consideration before it can be reliably applied in neuroprosthetic devices and rehabilitation practices. One of the main difficulties in applying the Linear Kalman filter is the high variability of results across subjects. The confidence intervals in Tables 1, 2 clearly show very high margins of error, which indicate that handwriting is very person-specific.
Such heterogeneous performance across individuals apparently stems from a combination of behavioral and physiological factors, which we could not control in this study. Participants vary in the style and neatness of handwriting, including the way they hold and press the pen, and the strategies they apply to write the same symbol. Anatomical differences, such as the individual muscle length, muscle size and attachment to the bones and the differences in the amount of subcutaneous fat might be significant factors influencing the patterns of the recorded neuromuscular activity (EMGs). Additional source of variability may come from the variation in electrode placement sites.
The problem of EMG variability has received significant attention in the recent experimental literature (Linssen et al., 1993; Araújo et al., 2000; Nordander et al., 2003). Fundamentally, one and the same movement can be reproduced by different force patterns in multiple agonist and antagonist muscles. This phenomenon, called motor redundancy (Bernstein, 1967; Guigon et al., 2008) allows a certain kinematic pattern to be reproduced by virtually infinite number of distinct muscular activation patterns (Amis et al., 1979). The EMG recordings which we used captured relatively consistent EMG patterns in individual subjects, which were, however, different from subject to subject. The approach proposed in this paper appears to have sufficient generalization power to capture the within subject variability (both natural and the one that stems from instructed variations of symbol writings to be produced). However, initial training of the algorithm is required for each individual subject independently.
Additionally, the results can be further improved by individually tuning the latent parameters, such as the model orders, filter cut-off frequency and sensor locations. In this work, however, we intentionally used a single set of latent variable values in order to emulate the out-of-box performance of such a system. Methods for non-supervised on-line adaptation and individual tuning of the latent variables need to be developed to address these issues and make the fine-tuning seamless to the user.
The linear framework of the filter offers significant benefits, such as stability and good generalization ability. However, the non-linear nature of the relation between the recorded EMG signals and the actuator trajectory prompts to explore the use of non-linear models in this application. The benefits brought in by the non-linearity, however, have to be leveraged against the additional complexity and potential instability associated with the use of such models.
5. Conclusions
In this paper we investigated the relationship between handwriting and neuromuscular activity measured by electromyography. We built and optimized the Kalman filter in order to reconstruct the pen coordinates based on the dynamical characteristics of handwriting and the corresponding EMG measurements.
We showed that the Kalman filter significantly outperforms previously proposed method (Linderman et al., 2009) and yields a mean accuracy of 68% in Within-Group design and 83% in Between-Group design, measured by the coefficient of determination, averaged for the two reconstructed coordinates. Our method is suitable for real-time applications as it is causal and utilizes only the EMGs from the past. The dynamical nature of the Kalman filter provides for the time-varying optimal fusion of the information and allows to take into account not only the EMG activity, but also the physical properties of handwriting.
The main attraction of the proposed method is its ability to smooth the noise and, as a result, provide a comprehensible and realistic reconstruction. Further progress in this field would potentially create intelligent rehabilitation techniques for patients with hand injuries, as well as become useful in human-computer interfaces, associated with handwriting.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors are grateful for the fruitful comments of Dr. Igor Furtat related to the algorithmic portion of the work. The experimental portion (Section 3) was funded by the government subsidy for improving competitiveness of National Research University Higher School of Economics among the leading world centers for research and education. The data fusion algorithm for reconstruction of pen traces (Section 2) was adapted to the use with the EMG data solely under support of RNF (grant 14-29-00142) in IPME RAS.
References
Ahsan, M. R., Ibrahimy, M. I., and Khalifa, O. O. (2009). Emg signal classification for human computer interaction: a review. Eur. J. Sci. Res. 33, 480–501.
Amis, A., Dowson, D., and Wright, V. (1979). Muscle strengths and musculoskeletal geometry of the upper limb. Eng. Med. 8, 41–48. doi: 10.1243/EMED/JOUR/1979/008/010/02
Araújo, R. C., Duarte, M., and Amadio, A. C. (2000). On the inter-and intra-subject variability of the electromyographic signal in isometric contractions. Electromyogr. Clin. Neurophysiol. 40, 225–230.
Arulampalam, M. S., Maskell, S., Gordon, N., and Clapp, T. (2002). A tutorial on particle filters for online nonlinear/non-gaussian bayesian tracking. Signal Process. IEEE Trans. 50, 174–188. doi: 10.1109/78.978374
Bu, N., Okamoto, M., and Tsuji, T. (2009). A hybrid motion classification approach for EMG-based human–robot interfaces using bayesian and neural networks. Robot. IEEE Trans. 25, 502–511. doi: 10.1109/TRO.2009.2019782
Carter, J. L., and Russell, H. L. (1985). Use of EMG biofeedback procedures with learning disabled children in a clinical and an educational setting. J. Learn. Disabil. 18, 213–216. doi: 10.1177/002221948501800406
Castellini, C., and van der Smagt, P. (2009). Surface EMG in advanced hand prosthetics. Biol. Cybern. 100, 35–47. doi: 10.1007/s00422-008-0278-1
Chan, F. H., Yang, Y.-S., Lam, F. K., Zhang, Y.-T., and Parker, P. A. (2000). Fuzzy emg classification for prosthesis control. Rehabil. Eng. IEEE Trans. 8, 305–311. doi: 10.1109/86.867872
Faragher, R. (2012). Understanding the basis of the kalman filter via a simple and intuitive derivation. IEEE Signal Process. Mag. 29, 128–132. doi: 10.1109/MSP.2012.2203621
Guigon, E., Baraduc, P., and Desmurget, M. (2006). Computational motor control: redundancy and invariance. J. Neurophysiol. 97, 331–347. doi: 10.1152/jn.00290.2006
Guigon, E., Baraduc, P., and Desmurget, M. (2008). Optimality, stochasticity, and variability in motor behavior. J. Comput. Neurosci. 24, 57–68. doi: 10.1007/s10827-007-0041-y
Henderson, H. V., and Searle, S. R. (1981). On deriving the inverse of a sum of matrices. Siam Rev. 23, 53–60. doi: 10.1137/1023004
Huang, G., Zhang, D., Zheng, X., and Zhu, X. (2010). “An EMG-based handwriting recognition through dynamic time warping,” in Engineering in Medicine and Biology Society (EMBC), 2010 Annual International Conference of the IEEE (Shanghai: IEEE), 4902–4905.
Jazwinski, A. H. (2007). Stochastic Processes and Filtering Theory. Mineola, NY: Courier Corporation.
Julier, S. J., and Uhlmann, J. K. (1997). “New extension of the kalman filter to nonlinear systems,” in AeroSense'97, ed I. Kadar (Orlando, FL: International Society for Optics and Photonics), 182–193.
Kalman, R. E. (1960). A new approach to linear filtering and prediction problems. J. Fluids Eng. 82, 35–45. doi: 10.1115/1.3662552
Li, C., Ma, Z., Yao, L., and Zhang, D. (2013). “Improvements on emg-based handwriting recognition with dtw algorithm,” in Engineering in Medicine and Biology Society (EMBC), 2013 35th Annual International Conference of the IEEE (IEEE), 2144–2147.
Linderman, M., Lebedev, M. A., and Erlichman, J. S. (2009). Recognition of handwriting from electromyography. PLoS ONE 4:e6791. doi: 10.1371/journal.pone.0006791
Linssen, W. H., Stegeman, D. F., Joosten, E. M., Binkhorst, R. A., van't Hof, M. A., and Notermans, S. L. (1993). Variability and interrelationships of surface emg parameters during local muscle fatigue. Muscle Nerve 16, 849–856. doi: 10.1002/mus.880160808
McKeague, I. W. (2005). A statistical model for signature verification. J. Am. Stat. Assoc. 100, 231–241. doi: 10.1198/016214504000000827
Nordander, C., Willner, J., Hansson, G.-Å., Larsson, B., Unge, J., Granquist, L., et al. (2003). Influence of the subcutaneous fat layer, as measured by ultrasound, skinfold calipers and bmi, on the emg amplitude. Eur. J. Appl. Physiol. 89, 514–519. doi: 10.1007/s00421-003-0819-1
Ohnishi, K., Weir, R. F., and Kuiken, T. A. (2007). Neural machine interfaces for controlling multifunctional powered upper-limb prostheses. Expert Rev. Med. Devices 4, 43–53. doi: 10.1586/17434440.4.1.43
Plamondon, R., and Maarse, F. J. (1989). An evaluation of motor models of handwriting. Syst. Man Cybern. IEEE Trans. 19, 1060–1072. doi: 10.1109/21.44021
Reaz, M., Hussain, M., and Mohd-Yasin, F. (2006). Techniques of EMG signal analysis: detection, processing, classification and applications. Biol. Proced. Online 8, 11–35. doi: 10.1251/bpo115
Rencher, A. C. (2003). Methods of Multivariate Analysis, Vol. 492. John Wiley & Sons. Available online at: https://books.google.ru/books?hl=ru&lr=&id=SpvBd7IUCxkC&oi=fnd&pg=PR5&dq=methods+of+multivariate+analysis&ots=ItWFsHM9w3&sig=K7-D_CG8CgdDkrVrYX0wFYmBY-8&redir_esc=y#v=onepage&q=methods%20of%20multivariate%20analysis&f=false
Shenoy, P., Miller, K. J., Crawford, B., and Rao, R. P. N. (2008). Online electromyographic control of a robotic prosthesis. Biomed. Eng. IEEE Trans. 55, 1128–1135. doi: 10.1109/TBME.2007.909536
Silveri, M. C., Corda, F., and Di Nardo, M. (2007). Central and peripheral aspects of writing disorders in alzheimer's disease. J. Clin. Exp. Neuropsychol. 29, 179–186. doi: 10.1080/13803390600611351
Stanford, V. (2004). Biosignals offer potential for direct interfaces and health monitoring. Pervas. Comput. IEEE 3, 99–103. doi: 10.1109/MPRV.2004.1269140
Van Gemmert, A., Teulings, H.-L., Contreras-Vidal, J., and Stelmach, G. (1999). Parkinsons disease and the control of size and speed in handwriting. Neuropsychologia 37, 685–694. doi: 10.1016/S0028-3932(98)00122-5
Wan, E., and Van Der Merwe, R. (2000). “The unscented kalman filter for nonlinear estimation,” in Adaptive Systems for Signal Processing, Communications, and Control Symposium 2000. AS-SPCC. The IEEE 2000 (Beaverton, OR: IEEE), 153–158.
Xiao, Z. G., and Menon, C. (2014). Towards the development of a wearable feedback system for monitoring the activities of the upper-extremities. J. Neuroeng. Rehabil. 11, 1–13. doi: 10.1186/1743-0003-11-2
Appendix
Parameters of the State Transition Model
Equation (A3) shows the distribution of the estimate of the State Transition Model given by Equation (1).
The mean of the distribution is
The covariance matrix is derived the following way:
Since the state estimate noise vt is uncorrelated with the estimate,
and the covariance matrix reduces to:
The Fusion
Under the normality assumption the probability density function (pdf) of the state space vector st can be written as
Since the additive noise term wt in Equation (2) is assumed to be Gaussian, while each of the observed EMG signals are not modeled as stochastic processes, the state vector follows the Gaussian distribution
By multiplying pdf in Equation (A3) by pdf in Equation (A4) we get a scaled fused Distribution of the state estimate:
with parameters
and a normalization constant
Let us reformulate the expressions for the mean and Covariance matrix of the new distribution in such a way that they separate the influence of the two fused distributions.
Using the Matrix Inversion lemma (the Woodbury matrix identity) for two matrices of the same dimension (Σ1t and Σ2t) and setting the parameters of the fused Gaussian can be neatly rewritten in the form of Equations (8) and (9), i.e.,
Testing the Assumptions of the Model
We ran the Royston test for multivariate normality on the residuals of each training sample and concluded that for most samples the assumption of normality is not violated (at 1% significance level). Table A1 summarized the percentages of samples, in which the assumption of normality of the error term holds in the two reconstructed models and in the joint model.
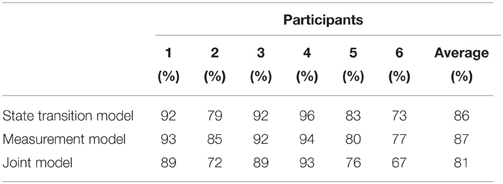
Table A1. Percentages of trials across participants, in which the assumption of multivariate normality of the error term is not violated at 1% significance level.
The fusion of the two information sources described in this paper is heavily based on the assumption that the two merged sources are independent.
Then, we checked to what extent the two information sources can be considered independent. Taking into account the results of the test for multivariate normality, we checked for the absence of correlation between the error terms of the two merged models (Equations 1 and 2). We used the residuals of the two models to calculate the sample cross-correlation matrix and assessed the significance of its elements for each trial.
Given the sample size and the multiplicity of the tested hypothesis (36), we could not reject the null-hypothesis of no-correlation at 5% group level significance for the majority of trials (74%). Detailed distribution of the test performance across the participants is given in Table A2.

Table A2. Percentages of trials across participants, in which the test for uncorrelatedness of residuals of the two fused models was not rejected at 5% significance level.
Keywords: handwriting, electromyography, pattern recognition, dynamical modeling, the Kalman Filter, the Wiener Filter
Citation: Okorokova E, Lebedev M, Linderman M and Ossadtchi A (2015) A dynamical model improves reconstruction of handwriting from multichannel electromyographic recordings. Front. Neurosci. 9:389. doi: 10.3389/fnins.2015.00389
Received: 20 July 2015; Accepted: 05 October 2015;
Published: 29 October 2015.
Edited by:
Giovanni Mirabella, Sapienza University of Rome, ItalyReviewed by:
Giancarlo Ferrigno, Politecnico di Milano, ItalyGiuseppe D'Avenio, Istituto Superiore di Sanità, Italy
Copyright © 2015 Okorokova, Lebedev, Linderman and Ossadtchi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alex Ossadtchi, b3NzYWR0Y2hpQGdtYWlsLmNvbQ==