 Maciel C. Vidal
Maciel C. Vidal João R. Sato
João R. Sato Joana B. Balardin
Joana B. Balardin Daniel Y. Takahashi
Daniel Y. Takahashi André Fujita
André Fujita- 1Department of Computer Science, Institute of Mathematics and Statistics, University of São Paulo, São Paulo, Brazil
- 2Center of Mathematics, Computation, and Cognition, Universidade Federal do ABC, Santo André, Brazil
- 3Hospital Israelita Albert Einstein, São Paulo, Brazil
- 4Deparment of Psychology and Princeton Neuroscience Institute, Princeton University, Princeton, NJ, USA
Understanding how brain activities cluster can help in the diagnosis of neuropsychological disorders. Thus, it is important to be able to identify alterations in the clustering structure of functional brain networks. Here, we provide an R implementation of Analysis of Cluster Variability (ANOCVA), which statistically tests (1) whether a set of brain regions of interest (ROI) are equally clustered between two or more populations and (2) whether the contribution of each ROI to the differences in clustering is significant. To illustrate the usefulness of our method and software, we apply the R package in a large functional magnetic resonance imaging (fMRI) dataset composed of 896 individuals (529 controls and 285 diagnosed with ASD—autism spectrum disorder) collected by the ABIDE (The Autism Brain Imaging Data Exchange) Consortium. Our analysis show that the clustering structure of controls and ASD subjects are different (p < 0.001) and that specific brain regions distributed in the frontotemporal, sensorimotor, visual, cerebellar, and brainstem systems significantly contributed (p < 0.05) to this differential clustering. These findings suggest an atypical organization of domain-specific function brain modules in ASD.
Introduction
The brain activity is organized in clusters/modules that have different roles in our behavior (Tononi et al., 1999). Alterations in the clustering pattern can be associated with neurologic disorders (Grossberg, 2000; Sato et al., 2016). Thus, it is important to systematically discriminate the clustering structures among different populations. This leads to the problem of how to statistically test the equality of clustering structures of two or more populations and how to identify the features that contribute to the differential clustering structure. These statistical problems were recently solved for a large class of clustering algorithms by using the Analysis of Cluster Variability—ANOCVA (Fujita et al., 2014a).
Here, we provide an implementation of ANOCVA in R for a better dissemination of this technique in the scientific community. ANOCVA was designed to test whether the clustering structures of several populations are equal. Briefly, ANOCVA uses the silhouette statistic (Rousseeuw, 1987) as a measure of variability of the clustering structure of each population and then compares the variability among populations using an idea similar to the classical analysis of variance (ANOVA). To calculate the statistical significance value, we use a bootstrap procedure that was previously shown to control the type I error.
We illustrate the step-by-step application of ANOCVA by analyzing a large functional magnetic resonance imaging (fMRI) data acquired under a resting-state protocol (ABIDE—The Autism Brain Imaging Data Exchange Consortium) composed of 529 controls and 285 patients diagnosed with autism. Subjects with Autism Spectrum Disorders (ASD) have significant differences in the resting state functional connectivity when compared to healthy subjects (for review, see Kana et al., 2011), suggesting that ASD is as a neural systems disorder with disruptions in several distributed neurocognitive networks of brain regions (Ecker et al., 2015). However, most studies describe integration (Washington et al., 2014; Sporns and Betzel, 2016) and segregation (Assaf et al., 2013) as separate processes. Instead, in this study we consider both processes simultaneously using the idea of clusters, where structures within are integrated and structures between are segregated.
Materials and Methods
To formalize ANOCVA, we will first describe the silhouette statistic to define “clustering variability” and then we introduce the ANOCVA. Finally, we describe its implementation and application to ABIDE dataset.
The Silhouette Statistic
The silhouette statistic is a measure of how well an item (regions of interest—ROI in fMRI data) is clustered given a clustering algorithm. In other words, it can also be interpreted as a measure of clustering variability (Rousseeuw, 1987). Formally, let χ = {x1, .., xN} be the N ROIs of one subject that are clustered into C = {C1, …, Cr} clusters by a clustering algorithm. Denote the dissimilarity between ROIs x and y by d(x, y). Let |C| be the number of ROIs of C. Then, define as the average dissimilarity of x to all ROIs of cluster C. Denote Dq ∈ C as the cluster to which xq has been assigned by the clustering algorithm. Define aq = d(xq, Dq) (the within dissimilarity of xq) and bq = minCp≠Dq d(xq, Cp) (the smallest between dissimilarity of xq), for q = 1, …, N. Then, we can measure how well each ROI xq has been clustered by analyzing the silhouette statistic given by
The silhouette statistic sq assumes values from −1 to +1 and its interpretation given by Rousseeuw (1987) is as follows. If sq ≈ 1, it means aq ≪ bq, i.e., the ROI xq has been assigned to an appropriate cluster because the second-best choice cluster is not as close as the actual cluster. If sq ≈ 0, then aq ≈ bq. In this case, it is not clear whether ROI xq should have been assigned to the actual cluster or to the second-best choice cluster because it is equally far away from both. If sq ≈ −1, then aq ≫ bq. In other words, the ROI xq should be assigned to the second-best choice cluster because it lies much closer to it than to the actual cluster. In summary, sq is a measure of how well the clustering algorithm labeled ROI xq.
ANOCVA
In the present section, we briefly describe the ANOCVA. For further details, refer to Fujita et al. (2014a). Let T1, T2, …, Tk be k types of populations (e.g., controls and ASD). For the j th population, nj subjects are collected, for j = 1, …, k. The items (e.g., ROIs) of the i th subject taken from the j th population are represented by the matrix Xi, j = (xi, j, 1, …, xi, j, N), where each ROI xi, j, q (q = 1, .., N) is a vector containing a time series (the blood-oxygen-level dependent signal).
First, define the (N × N) matrix of dissimilarities among ROIs of each matrix Xi,j by , for i = 1, …, nj, j = 1, …, k. Second, let , then define the following average matrices of dissimilarities:
Next, apply a clustering algorithm on the matrix of dissimilarities , to determine the clustering labels Finally, compute the following silhouette statistics: (the silhouette statistic of the qth ROI based on the dissimilarity matrix and the labeling ) and (the silhouette statistic of the qth ROI based on the dissimilarity matrix and the labeling ), for q = 1, …, N. The statistical test consists in verifying whether all k populations are equally clustered (present the same clustering structure) or if at least one is clustered in a different manner. If the ROIs from all populations T1, …, Tk are equally clustered, then the quantities and must be close for all j = 1, …, k and q = 1, …, N.
Given a clustering algorithm and a distance metric, define the following vectors:
Define δSj = S − Sj. We will use the statistic to build the test statistic. Notice that under the null hypothesis, all N ROIs are equally clustered along the k populations, i.e., ≈ for all q = 1, …, N and thus, we expect small ΔS. On the other hand, large ΔS suggests a rejection of the null hypothesis.
To test the contribution of each ROI for the differential clustering, define for q = 1, …, N. This test consists in verifying whether the qth ROI (q = 1, …, N) is equally clustered among populations. We will use the statistic , for q = 1, …, N to build the test statistic. Under the null hypothesis, we expect small Δsq. On the other hand, large Δsq suggests a rejection of the null hypothesis.
To compute distributions of ΔS and Δsq under the null hypothesis, Fujita et al. (2014a) proposed a bootstrap procedure described as follows:
1. Resample with replacement nj subjects from the entire dataset {T1, T2, …, Tk} in order to construct bootstrap samples , for j = 1, …, k.
2. Calculate , using the bootstrap samples .
3. Calculate and .
4. Repeat steps 1 to 3 until the desired number of bootstrap replications is obtained.
5. The p-values from the bootstrap tests based on the observed statistics ΔS and ΔSq are the fraction of replicates of and on the bootstrap dataset , respectively, that are at least as large as the observed statistics on the original dataset.
R Implementation
ANOCVA is implemented in R and is freely available at the R project website1 (package “anocva”).
This implementation requires as input, the functional brain networks (ROIs dissimilarity matrices), a vector of labels describing which individual belongs to which group, the number of clusters, and the number of bootstrap samples.
ANOCVA uses the spectral clustering algorithm to cluster the ROIs (Ng et al., 2002). Internal to the spectral clustering algorithm, we use the k -medoids procedure instead of the usual k -means because the former is more robust to outliers than the latter (Aggarwal and Reddy, 2013). If the number of clusters is not known a priori, the ANOCVA R package provides the option to estimate it by using the silhouette or the slope statistic (Fujita et al., 2014b). The slope criterion is the difference of the silhouette statistic as a function of the number of clusters. The difference between the slope and silhouette is the fact that by maximizing the silhouette statistic as described by Rousseeuw (1987) the number of clusters is estimated correctly only when the within-cluster variances are equal. The slope criterion is more robust than the silhouette when the within-cluster variances are unequal.
The output consists in one p-value, which represents whether there is at least one group that clusters in a different manner and a vector of p-values representing which ROI is differentially clustered among groups. The entire ANOCVA analysis pipeline can be visualized in Figure 1.
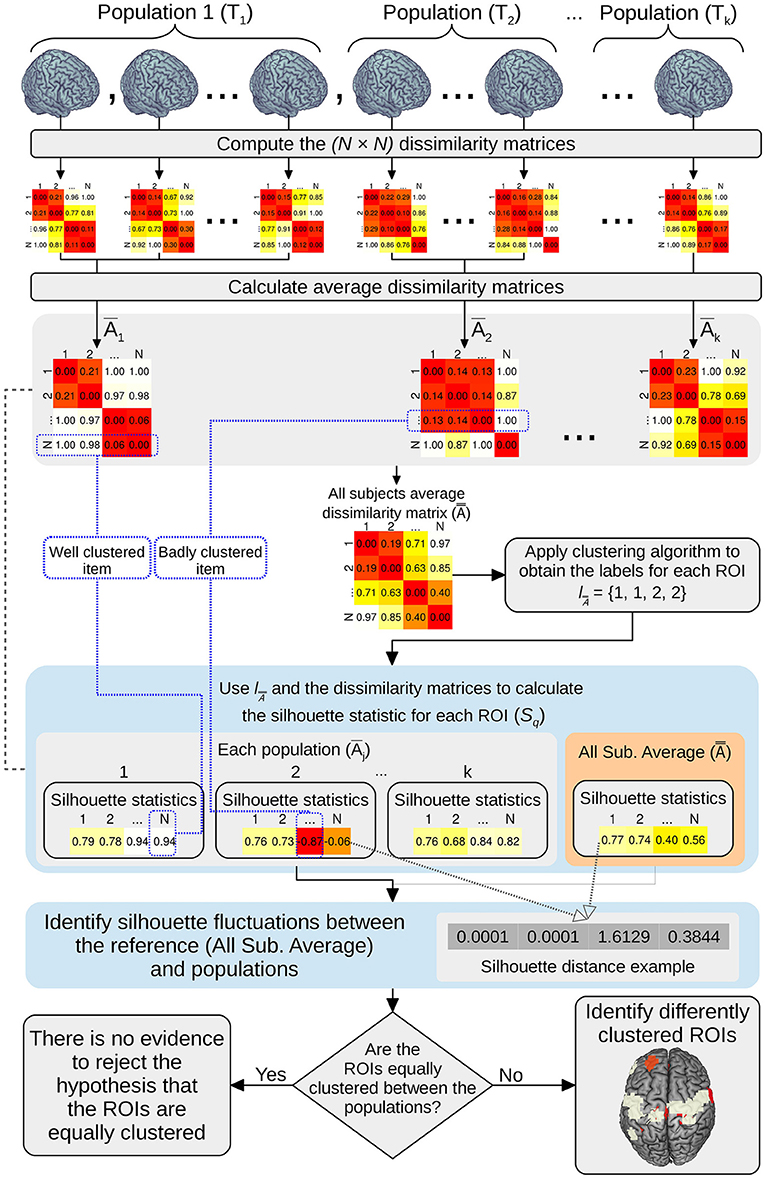
Figure 1. Pipeline schema of the ANOCVA analysis.
ABIDE Data Description and Pre-processing
The ABIDE Consortium dataset is a large resting state fMRI dataset that includes controls and ASD subjects. It can be downloaded from the ABIDE website2. This data was collected in 17 sites that compose the ABIDE Consortium. Data collection was conducted with local internal review board approval, and also in accordance with local internal review board protocols. For further details regarding this dataset, refer to the ABIDE Consortium website.
Data pre-processing and network construction (dissimilarity matrices) were carried out as our previous works (Sato et al., 2015, 2016) using the ABIDE dataset. The final dataset used here is composed of 529 controls (430 males, mean age ± standard deviation of 17.47 ± 7.81 years) and 285 autistic patients (255 males, 17.53 ± 7.13 years).
Results
The problem that we want to solve is the following. Given k populations T1, T2, …, Tk where each population Tj (j = 1, …, k) is composed of nj subjects, and each subject has N items that are clustered, we would like to verify whether the clustering structures of the brain networks of the k populations are equal and, if not, which ROIs are differently clustered. In our case, we have k = 2 populations with T1 and T2 as controls and ASD, respectively. The number of subjects in each population is n1 = 529 and n2 = 285, for T1 and T2, respectively. The number of ROIs (items) to be clustered is N = 316. Since head movement during magnetic resonance scanning may affect statistical analysis, ANOCVA was applied to both “scrubbed” and “not scrubbed” data (Power et al., 2012) with the number of bootstrap samples set to 1000.
The first step in ANOCVA analysis is the construction of the average dissimilarity matrix and its clustering. The estimated number of clusters by the silhouette criterion was five as depicted in Figure 2. Notice that the highest silhouette statistic was obtained when the number of clusters is five. The sub-networks obtained by applying the spectral clustering on the dissimilarity matrix can be visualized in Figure 3 where each color represents one sub-network (cluster).
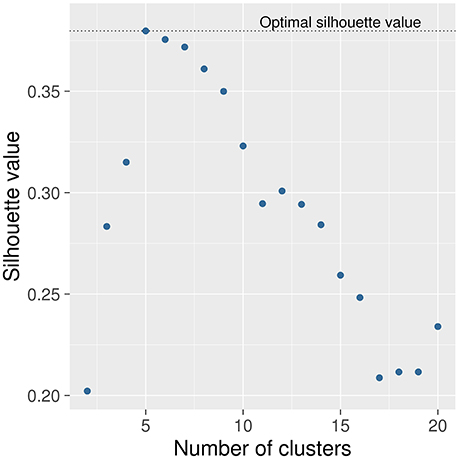
Figure 2. Selection of the number of clusters. The number of clusters was selected by using the silhouette criterion. The number of clusters that presented the highest silhouette statistic is five. In other words, the silhouette criterion suggests that this dataset can be split into five sub-networks.
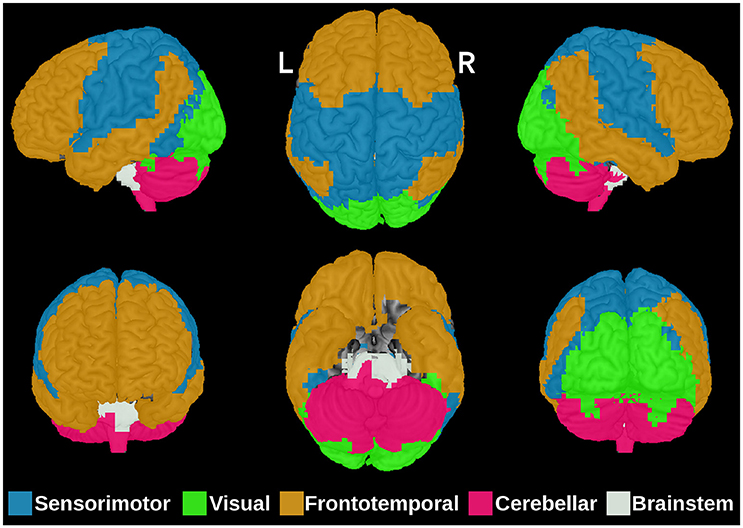
Figure 3. The five brain sub-networks obtained by the spectral clustering algorithm on the dissimilarity matrix . Each color represents one functional sub-network: sensorimotor (blue), visual (green), frontotemporal (orange), cerebellar (pink), and brainstem (white). R, right; L, Left.
Then, ANOCVA calculates the silhouette statistic for each ROI by using the labels obtained by clustering the dissimilarity matrix and performs the test. We verified that in fact the entire clustering structure of subjects diagnosed with ASD differs from controls (p < 0.001). Next, we tested each ROI to identify which ones significantly contribute to the differential clustering between controls and subjects diagnosed with ASD. ROIs that presented a difference in p > 5% between “scrubbed” and “not scrubbed” datasets were excluded for subsequent analysis. Remaining p-values were corrected for multiple comparisons by the Bonferroni method. Figure 4 illustrates the statistically significant ROIs at a p-value threshold of 0.05 after Bonferroni correction. The highlighted regions include portions of the cerebellum and middle frontal gyrus, pre- and post-central gyri, inferior temporal gyrus, and lateral occipital cortex.
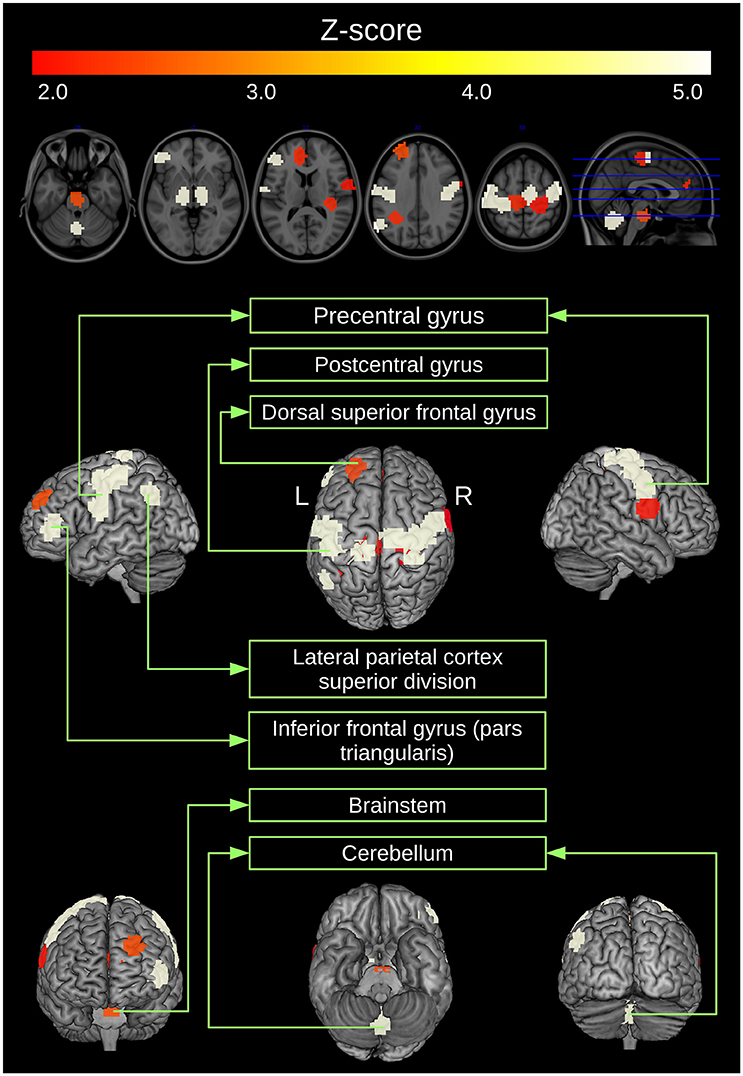
Figure 4. ROIs clustered in a different manner between controls and ASD. ROIs that present a p-value (obtained by ANOCVA) lower than 5% after Bonferroni correction were converted to z-scores and highlighted.
Discussion
In the current study, we combined spectral clustering analysis with ANOCVA implemented in R to investigate which brain regions are clustered in a different way between controls and ASD groups. Our results suggest that several regions distributed across different neurocognitive systems significantly contributed to the different clustering network structure observed in ASD. First we demonstrated that the spectral clustering method yielded partitions that were well-characterized as functional modules of the brain that have been consistently identified in previous studies using different approaches (Damoiseaux et al., 2006; Power et al., 2011), including the fronto-temporal, sensorimotor, visual, and cerebellar systems. This is consistent with the hypothesis that the spectral clustering algorithm groups anatomically contiguous and also spatially distributed areas with common brain functionalities in the same cluster. Then, using ANOCVA we showed that the superior division of the lateral parietal cortex, precentral, and postcentral gyri, anterior dorsal middle frontal gyrus, and a medial portion of the cerebellum and of the brainstem have a distinct cluster organization between ASD and controls. All these brain regions have been previously identified as presenting ASD-related differences in studies using functional MRI. For example, the recruitment of portions of the precentral and postcentral gyri as well as the cerebellum across sensorimotor tasks are atypical in ASD, and may underlie deficits in fine motor sequencing and visual motor learning observed in autistic individuals (Müller et al., 2001; Mostofsky et al., 2009). Interestingly, these regions have also been implicated in cognitive process crucial for interpersonal interactions such as theory-of-mind (Martineau et al., 2010; Wang et al., 2014). This suggests that these areas are involved in the social communication deficits that are a core clinical feature of ASD. Moreover, the lateral parietal cortex is an important node of the default-mode network, and abnormalities in the connectivity between nodes of this network have been widely investigated in ASD (Kennedy and Courchesne, 2008; Assaf et al., 2010; Weng et al., 2010) giving its associations with social cognition (Buckner et al., 2008). The identification of these regions by our study therefore confirms that they are key brain structures in ASD that may have a role in the development of sub-networks organization in this population.
Head motion is one of the most challenging obstacles in functional connectivity studies involving clinical populations, which usually present high levels of movement. Our attempt to handle this problem was to apply the scrubbing method proposed by Power et al. (2012), which discards scans acquired under excessive head motion. However, although this approach may reduce the influence of movement artifacts, they may still be present in the scrubbed data. Thus, we opted for a more conservative approach, which consisted in excluding the regions where the p-values were more sensitive to scrubbing. We assumed that the analyses of these regions were more vulnerable to artifacts and thus they were removed. This approach is also helpful to reduce the number of multiple comparisons, by excluding the less reliable tests. Another important limitation to be mentioned is that the ABIDE data is multicentric with heterogeneous acquisition parameters across sites. We minimized the site effect by removing it in the pre-processing stage of the data. Finally, all analyses are based on the CC400 atlas (Craddock et al., 2012), obtained by using a functional parcellation. Since other atlases are different on ROIs size, number of ROIs and spatial location, the parcellation choice is expected to influence our findings. However, this variability does not invalidate the results obtained with CC400 because the procedures adopted here are conservative (regarding type I error control). Finally, an important future question for the presented results is whether the contribution of these specific brain regions to a differential network clustering in ASD is static or may exhibit dynamic changes during rest (Hutchison et al., 2013).
Author Contributions
MV, JS, DT, and AF designed the work. MV pre-processed and analyzed the data. JS and JB interpreted the results. All authors drafted the work, read, and approved the final version of the manuscript.
Funding
MV was supported by CAPES and CNPq Fellowships. JS was supported by State of São Paulo Research Foundation—FAPESP (#2013/10498-6). DT was partially supported by Pew Latin American Fellowship and Ciência sem Fronteiras Fellowship (CNPq #246778/2012-1). AF was partially supported by FAPESP (#2014/09576-5, #2013/01715-3, #2015/01587-0, #2016/13422-9, and #2013/03447-6), CNPq (#304020/2013-3 and #473063/2013-1), and NAP eScience—PRP—USP.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors would like to thank the ABIDE Consortium for providing publicly available the fMRI database.
Footnotes
References
Aggarwal, C. C., and Reddy C. K. (eds.). (2013). Data Clustering: Algorithms and Applications. Boca Raton, FL: CRC Press.
Assaf, M., Hyatt, C. J., Wong, C. G., Johnson, M. R., Schultz, R. T., Hendler, T., et al. (2013). Mentalizing and motivation neural function during social interactions in autism spectrum disorders. Neuroimage Clin. 3, 321–31. doi: 10.1016/j.nicl.2013.09.005
Assaf, M., Jagannathan, K., Calhoun, V. D., Miller, L., Stevens, M. C., Sahl, R., et al. (2010). Abnormal functional connectivity of default mode subnetworks in autism spectrum disorder patients. NeuroImage 53, 247–256. doi: 10.1016/j.neuroimage.2010.05.067
Buckner, R. L., Andrews-Hanna, J. R., Schacter, D. L. (2008). The brain's default network: anatomy, function, and relevance to disease. Ann. N. Y. Acad. Sci. 1124, 1–38. doi: 10.1196/annals.1440.011
Craddock, R. C., James, G. A., Holtzheimer, P. E., Hu, X. P., Mayberg, H. S. (2012). A whole brain fMRI Atlas generated via spatial constrained spectral clustering. Hum. Brain Mapp. 33, 1914–1928. doi: 10.1002/hbm.21333
Damoiseaux, J. S., Rombouts, S. A., Barkhof, F., Scheltens, P., Stam, C. J., Smith, S. M., et al. (2006). Consistent resting-state networks across healthy subjects. Proc. Natl. Acad. Sci. U.S.A. 103, 13848–13853. doi: 10.1073/pnas.0601417103
Ecker, C., Bookheimer, S. Y., Murphy, D. G. (2015). Neuroimaging in autism spectrum disorder: brain structure and function across the lifespan. Lancet Neurol. 14, 1121–1134. doi: 10.1016/S1474-4422(15)00050-2
Fujita, A., Takahashi, D. Y., Patriota, A. G. (2014b). A non-parametric method to estimate the number of clusters. Comput. Stat. Data Anal. 73, 27–39. doi: 10.1016/j.csda.2013.11.012
Fujita, A., Takahashi, D. Y., Patriota, A. G., Sato, J. R. (2014a). A non-parametric statistical test to compare clusters with applications in functional magnetic resonance imaging data. Stat. Med. 33, 4949–4962.
Grossberg, S. (2000). The complementary brain: unifying brain dynamics and modularity. Trends Cogn. Sci. 4, 233–246. doi: 10.1016/S1364-6613(00)01464-9
Hutchison, R. M., Womelsdorf, T., Allen, E. A., Bandettini, P. A., Calhoun, V. D., Corbetta, M., et al. (2013). Dynamic functional connectivity: promise, issues, and interpretations. NeuroImage 80, 360–378. doi: 10.1016/j.neuroimage.2013.05.079
Kana, R. K., Libero, L. E., Moore, M. S. (2011). Disrupted cortical connectivity theory as an explanatory model for autism spectrum disorders. Phys. Life Rev. 8, 410–437. doi: 10.1016/j.plrev.2011.10.001
Kennedy, D. P., and Courchesne, E. (2008). Functional abnormalities of the default network during self- and other-reflection in autism. Soc. Cogn. Affect. Neurosci. 3, 177–190. doi: 10.1093/scan/nsn011
Martineau, J., Andersson, F., Barthélémy, C., Cottier, J. P., and Destrieux, C. (2010). Atypical activation of the mirror neuron system during perception of hand motion in autism. Brain Res. 1320, 168–75. doi: 10.1016/j.brainres.2010.01.035
Mostofsky, S. H., Powell, S. K., Simmonds, D. J., Goldberg, M. C., Caffo, B., and Pekar, J. J. (2009). Decreased connectivity and cerebellar activity in autism during motor task performance. Brain 132, 2413–2425. doi: 10.1093/brain/awp088
Müller, R. A., Pierce, K., Ambrose, J. B., Allen, G., and Courchesne, E. (2001). Atypical patterns of cerebral motor activation in autism: a functional magnetic resonance study. Biol. Psychiatry 49, 665–676. doi: 10.1016/S0006-3223(00)01004-0
Ng, A., Jordan, M., and Weiss, Y. (2002). “On spectral clustering: analysis and an algorithm,” in Advances in Neural Information Processing Systems, Vol. 14, eds T. Dietterich, S. Becker, and Z. Ghahramani (London: MIT Press), 849–856.
Power, J. D., Barnes, K. A., Snyder, A. Z., Schlaggar, B. L., Petersen, S. E. (2012). Spurious but systematic correlations in functional connectivity MRI networks arise from subject motion. NeuroImage 59, 2142–2154. doi: 10.1016/j.neuroimage.2011.10.018
Power, J. D., Cohen, A. L., Nelson, S. M., Wig, G. S., Barnes, K. A., Church, J. A., et al. (2011). Functional network organization of the human brain. Neuron 72, 665–78. doi: 10.1016/j.neuron.2011.09.006
Rousseeuw, P. (1987). Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65. doi: 10.1016/0377-0427(87)90125-7
Sato, J. R., Balardin, J. B., Vidal, M. C., and Fujita, A. (2016). Identification of segregated regions in the functional brain connectome of autistic patients by a combination of fuzzy spectral clustering and entropy analysis. J. Psychiatry Neurosci. 41, 124–132. doi: 10.1503/jpn.140364
Sato, J. R., Vidal, M. C., de Siqueira Santos, S., Massirer, K. B., and Fujita, A. (2015). Complex networks measures in autism spectrum disorders. IEEE/ACM Trans. Comput. Biol. Bioinform. doi: 10.1109/TCBB.2015.2476787. [Epub ahead of print].
Sporns, O., and Betzel, R. (2016). Modular brain networks. Annu. Rev. Psychol. 67, 613–640. doi: 10.1146/annurev-psych-122414-033634
Tononi, G., Sporns, O., and Edelman, G. M. (1999). Measures of degeneracy and redundancy in biological networks. Proc. Natl. Acad. Sci. U.S.A. 96, 3257–3262. doi: 10.1073/pnas.96.6.3257
Wang, S. S., Kloth, A. D., and Badura, A. (2014). The cerebellum, sensitive periods, and autism. Neuron 83, 518–532. doi: 10.1016/j.neuron.2014.07.016
Washington, S. D., Gordon, E. M., Brar, J., Warburton, S., Sawyer, A. T., Wolfe, A., et al. (2014). Dysmaturation of the default mode network in autism. Hum. Brain Mapp. 35, 1284–1296. doi: 10.1002/hbm.22252
Keywords: Analysis of Cluster Variability, silhouette statistic, functional brain network, ABIDE, fMRI
Citation: Vidal MC, Sato JR, Balardin JB, Takahashi DY and Fujita A (2017) ANOCVA in R: A Software to Compare Clusters between Groups and Its Application to the Study of Autism Spectrum Disorder. Front. Neurosci. 11:16. doi: 10.3389/fnins.2017.00016
Received: 27 July 2016; Accepted: 09 January 2017;
Published: 24 January 2017.
Edited by:
Alessandro Grecucci, University of Trento, ItalyReviewed by:
Munis Dundar, Erciyes University, TurkeyBaxter P. Rogers, Vanderbilt University, USA
Sydney Moirangthem, National Institute of Mental Health and Neurosciences, India
Copyright © 2017 Vidal, Sato, Balardin, Takahashi and Fujita. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: André Fujita, ZnVqaXRhQGltZS51c3AuYnI=