 Quynh Nhu Nguyen
Quynh Nhu Nguyen Pamela Reinagel
Pamela Reinagel- Section of Neurobiology, Division of Biological Sciences, University of California, San Diego, San Diego, CA, United States
When observers make rapid, difficult perceptual decisions, their response time is highly variable from trial to trial. In a visual motion discrimination task, it has been reported that human accuracy declines with increasing response time, whereas rat accuracy increases with response time. This is of interest because different mathematical theories of decision-making differ in their predictions regarding the correlation of accuracy with response time. On the premise that perceptual decision-making mechanisms are likely to be conserved among mammals, we seek to unify the rodent and primate results in a common theoretical framework. We show that a bounded drift diffusion model (DDM) can explain both effects with variable parameters: trial-to-trial variability in the starting point of the diffusion process produces the pattern typically observed in rats, whereas variability in the drift rate produces the pattern typically observed in humans. We further show that the same effects can be produced by deterministic biases, even in the absence of parameter stochasticity or parameter change within a trial.
Introduction
One might expect decision-making by humans to be quite different from that of rats. In decisions with wide-reaching long-term consequences, we expect (or at least wish) humans would avail themselves of abstract conceptual thought, logical reasoning, and culturally accumulated knowledge that would be unavailable to a rat. Yet all organisms face a continuous challenge of selecting among alternative available actions in order to pursue goals. In order to select an action, sensory information, internal knowledge, and goals are combined to assess and evaluate the likely outcomes of possible actions relative to survival needs. Often there is not enough time to acquire the evidence necessary to determine with certainty the optimal course of action, so an action must be selected despite unresolved or unresolvable uncertainty. Some mechanism is needed to ensure timely commitment and to optimize outcome on average, and this must adapt flexibly to prevailing sensory context, shifting goal priorities, the urgency of action, and the severity of consequences of errors. When it comes to the continuous sensory guidance of moment-by-moment actions, decisions about sensory evidence are made in a fraction of a second. We speculate that in this case, mechanisms are largely conserved across mammals.
A now-classic series of studies in humans and non-human primates introduced the use of a stochastic visual motion task to study decision making (Britten et al., 1992, 1993, 1996; Shadlen et al., 1996; Shadlen and Newsome, 1996; Gold and Shadlen, 2001, 2007; Shadlen and Newsome, 2001; Roitman and Shadlen, 2002; Mazurek et al., 2003; Huk and Shadlen, 2005; Palmer et al., 2005). In each trial a visual stimulus provides information regarding which of two available actions is associated with reward and which is associated with non-reward or penalty. Stimulus strength is modulated by the motion coherence, which is defined as the fraction of the dots in the display that are “signal” (moving toward the rewarded response side). The remaining dots are “noise” (moving in random directions). As stimulus strength increases, accuracy increases and response time decreases for both monkeys (Roitman and Shadlen, 2002) and humans (Palmer et al., 2005). This is parsimoniously explained by drift diffusion models, which postulate that noisy sensory evidence is integrated over time until the accumulated evidence reaches a decision threshold (Stone, 1960; Ashby, 1983; Busemeyer and Townsend, 1993; Gold and Shadlen, 2001, 2007; Usher and McClelland, 2001; Ratcliff and Tuerlinckx, 2002; Palmer et al., 2005; Brown and Heathcote, 2008; Ratcliff and McKoon, 2008; Ratcliff et al., 2016). Although this class of model is highly successful, more data are needed to test model predictions and differentiate among competing versions of the model and alternative model classes (Wang, 2002; Ratcliff and McKoon, 2008; Pleskac and Busemeyer, 2010; Purcell et al., 2010; Rao, 2010; Heathcote and Love, 2012; Tsetsos et al., 2012; Huang and Rao, 2013; Usher et al., 2013; Scott et al., 2015; Ratcliff et al., 2016; Sun and Landy, 2016; White et al., 2018).
For example, when monkeys or humans perform this task, among trials of the same stimulus strength the interleaved trials with longer response times are more likely to be errors (Roitman and Shadlen, 2002; Palmer et al., 2005). In its simplest form the drift diffusion model does not explain this result; therefore the observation has been an important constraint for recent theoretical efforts. The result can be explained if the decision bound is not constant but instead decays as a function of time (Churchland et al., 2008; Cisek et al., 2009; Bowman et al., 2012; Drugowitsch et al., 2012). A collapsing decision bound can be rationalized as an optimal strategy under some task constraints (Rao, 2010; Hanks et al., 2011; Huang and Rao, 2013; Tajima et al., 2016) though this argument has been challenged by others (Hawkins et al., 2015; Boehm et al., 2016). There are alternative ways to explain the data within the sequential sampling model framework without positing an explicit urgency signal or decaying bound (Ditterich, 2006a,b; Ratcliff and McKoon, 2008; Ratcliff and Starns, 2013).
When rats performed the same random dot motion task, however, the opposite effect was found: their later decisions were more likely to be accurate (Reinagel, 2013b; Shevinsky and Reinagel, 2019). The same has also been reported for image discriminations in rats (Reinagel, 2013a), for visual orientation decisions in mice (Sriram et al., 2020), and in humans in some other tasks (McCormack and Swenson, 1972; Ratcliff and Rouder, 1998; Long et al., 2015; Stirman et al., 2016). This result is not readily explained by some of the models suggested to explain the late errors of primates [reviewed in Heitz (2014), Ratcliff et al. (2016), and Hanks and Summerfield (2017)]. Here, we explore a stochastic variant of the drift-diffusion model (Ratcliff and Tuerlinckx, 2002; Ratcliff and McKoon, 2008) for its ability to explain these problematic findings in both species.
Results
In a basic drift diffusion model (DDM), the relative sensory evidence in favor of a decision (e.g., “motion is rightward” vs. “motion is leftward”) is accumulated by an internal decision variable, resulting in a biased random walk, i.e., diffusion with drift (Figure 1A). The average drift rate is determined by the sensory signal strength (e.g., the coherence of visual motion). When the decision variable reaches either decision threshold, the agent commits to a choice. The time at which the decision variable crosses a threshold (response time), and the identity of the decision threshold that is crossed (correct vs. incorrect), vary from trial to trial. The model parameters are the starting point z, threshold separation a, drift rate v, and non-decision time t (in Figures 1A–E, z=0 a=2, t=0, v = 0.7).
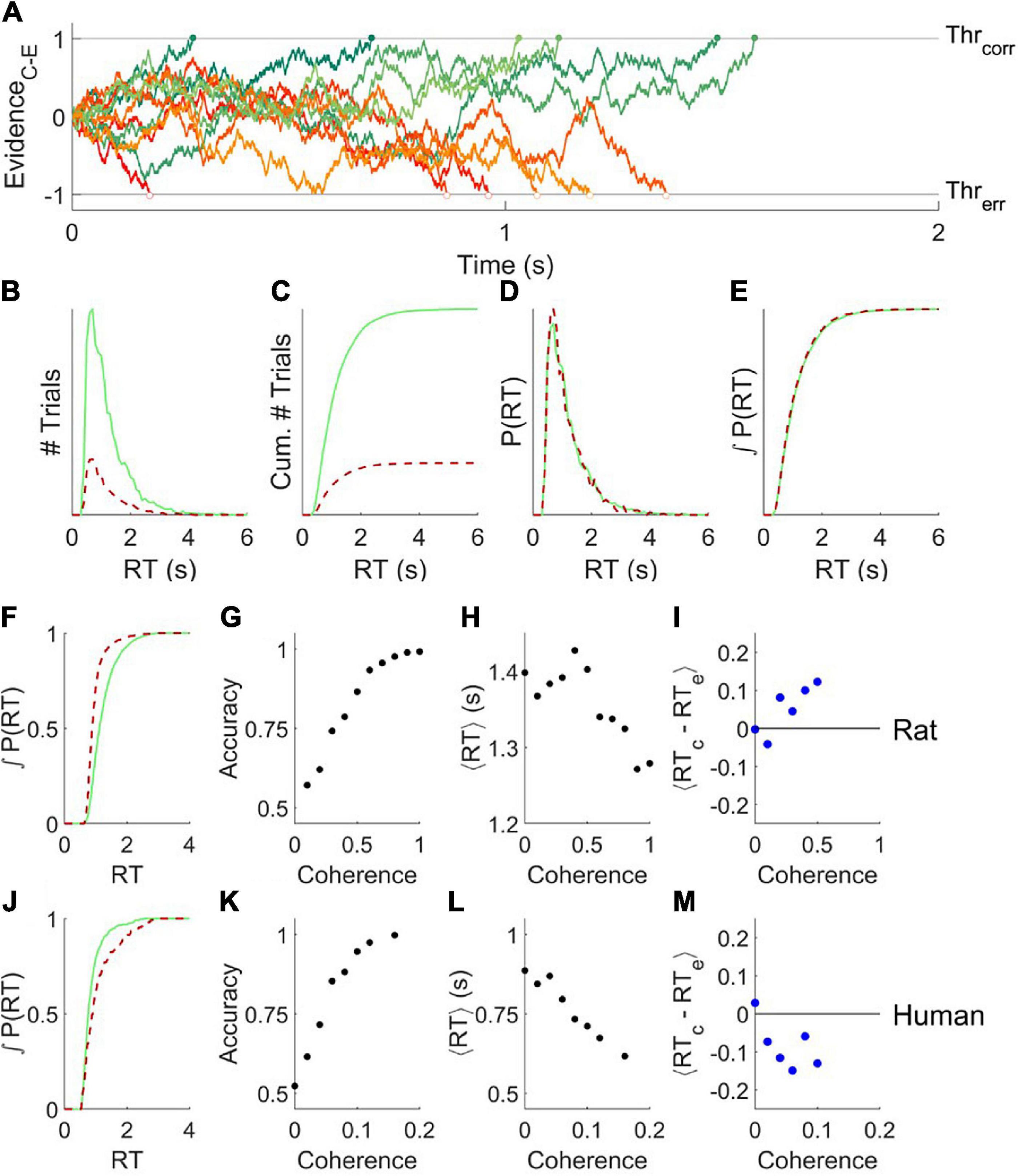
Figure 1. The basic drift diffusion model is incompatible with data from rats or humans. (A) Simulated evidence accumulation in a basic drift diffusion model, for six example trials that terminated in correct decisions (green shades, solid symbols) and six that terminated in error decisions (red shades, open symbols). Although an equal number of traces are shown, in the condition illustrated 80% of the traces terminated by crossing the correct boundary. (B) Response time distributions for errors (red, dashed) vs. correct trials (green, solid) of 104 trials like those simulated as in (A). (C) Cumulatives of the distributions shown in (B). (D,E) Distributions in (B,C) normalized to the number of trials. (F) Cumulative probability distribution of response time for errors and correct trials for an example experiment in a rat, a fixed-coherence experiment with 65% coherence, for which the rat was 82% correct. The null hypothesis that the distributions are the same can be rejected with P = 2.91e-171 (N = 8851,1913) by two-tailed Kolmogorov–Smirnov (KS) test. (G–I). Analysis of an example rat psychometric experiment. (G) Accuracy increased with coherence. (H) Mean response time decreased with coherence. (I) On average, the response time of a correct trial is greater than that of a temporally nearby error trial of the same coherence. (J) Like (F), for an example experiment in a human, a fixed-coherence experiment with 10% coherence for which the subject was 83% correct; P = 4.69e-05 (N = 745,153) by KS test. Errors are later than correct trials, unlike either the DDM model (E) or rats (F). (K–M) Like (G–I), for an example human psychometric experiment. (M) Error trials are longer than correct trials on average, unlike rats, and also incompatible with DDM. Data from Shevinsky and Reinagel (2019) and Reinagel and Shevinsky (2020).
An interesting feature of this model is that for any set of parameters, the errors and correct responses have identical response time distributions (Figures 1B–E, red vs. green). Therefore errors are on average the same speed as correct responses – even if the signal is so strong that errors are very rare.
We note that this does not, but may at first appear to, contradict two other facts. First, responses to stronger stimuli tend to be both more accurate and faster, which in this model is explained by a higher drift rate v. In this sense response time is negatively correlated with accuracy – but only when comparing trials of differing stimulus strengths. Second, conservative subjects tend to take more time to respond and are more accurate, which in this model is explained by a greater threshold separation a. In this sense response time is positively correlated with accuracy – but only when comparing blocks of trials with different overall degrees of caution. Both of these facts are consistent with the fact that within a block of fixed overall caution, comparing among the trials of the same stimulus strength, response time and accuracy are uncorrelated in the basic DDM model.
Both humans and rats deviate systematically from the prediction that correct and error trials have the same mean and probability distribution, however (Shevinsky and Reinagel, 2019). In the random dot motion discrimination task, for example, correct trials of rat subjects tend to have longer response times compared to errors (e.g., Figures 1F, cf. 1E). We quantify this effect by comparing the response times of individual correct trials to nearby (but not adjacent) error trials of the same stimulus strength (Figure 1I). This temporally local measure is robust to data non-stationarities that could otherwise produce a result like that shown in Figure 1F artefactually (Shevinsky and Reinagel, 2019). Humans also violate the basic DDM model prediction, but in the opposite way. For humans, errors tend to have longer response times (e.g., Figures 1J, cf. 1E; summarized in 1M). Our goal is to find a unified framework to account for both these deviations from predictions.
Drift Diffusion Model With Variable Parameters
It was previously shown that adding noise to the parameters of a bounded drift diffusion model can differentially affect the error and correct response time distributions (Ratcliff and Tuerlinckx, 2002; Ratcliff and McKoon, 2008). The version we implemented has three additional parameters: variability in starting point σz, variability in non-decision-time σt, and variability in drift rate σv (Figure 2A). We are able to find parameter sets that produce behavior qualitatively similar to either a rat (Figures 2B–E, cf. 1F–I) or a human (Figures 2F–I, cf. 1J–M). Notably, this model can replicate the shift in the response time distribution of correct trials to either later or earlier than that of error trials (Figures 2B, cf. 1F; and Figure 2F, cf. 1J), unlike the standard DDM (Figure 1E). The model also replicates the fact that the amplitude of this effect increases with stimulus strength (Figure 2E solid blue symbols, cf. Figure 1I; and Figures 2I, cf. 1M). Removing the drift rate variability and starting point variability from these simulations improved accuracy (Figures 2C,G open symbols), increased the response time for ambiguous stimuli (Figures 2D,H), and eliminated the difference between average correct and error response times (Figures 2E,I).
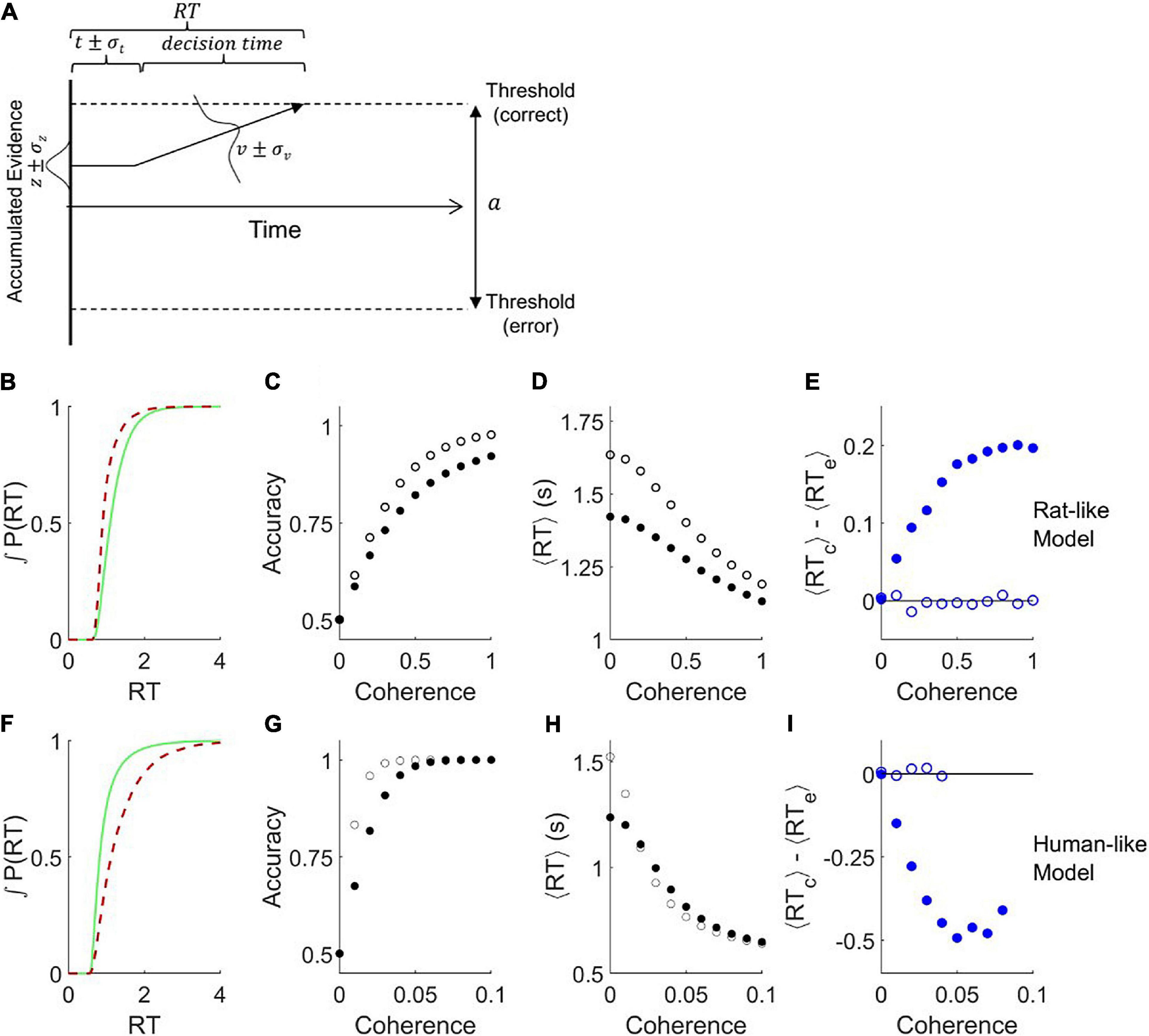
Figure 2. Addition of variability to the parameters of the drift diffusion model. (A) Definition of parameters. The parameter a is the distance between the error and correct thresholds. The starting point of evidence accumulation is given by z. The average drift rate v depends on the stimulus strength. The observable outcomes are response time (RT) and decision (correct or error). The non-decision-time t reflects both sensory latency and motor latency, but is drawn at left for graphical simplicity. Parameters t, z, and v vary from trial to trial according to the variability parameters σt, σz, and σv, respectively. Drift rate variability was simulated by a normal distribution around the mean parameter. Starting point variability and non-decision time variability were simulated by uniform distributions centered on the mean parameter. Diagram after (Ratcliff and McKoon, 2008). (B–E) Analysis of trials simulated with parameters that produce qualitatively rat-like behavior: a = 1.84, t = 0.74, σv = 0.1, σz = 1.5, σt = 0.2, and v = −0.5c2 + 2.5c, where c is coherence (motion stimulus strength). (B) Cumulative probability distributions of correct vs. error trial response times, for c = 0.8. (C) Psychometric curve. (D) Chronometric curve. (E) Difference between mean response times of errors and correct trials. (F–I) Like panels (B–E) but with parameters that produce qualitatively human-like behavior: a = 2.0, t = 0.5, σv = 1.5, σz = 0.3, σt = 0.03, and v = −80c2 + 80c. (F) Cumulative RT probability distributions for c = 0.03. For all these simulations, the mean starting point z=0, timestep τ = 0.001, diffusion noise σn=1, N = 105 trials per coherence. Open symbols show results obtained after setting σz = 0 and σv = 0. Note that in conditions with 100% accuracy the ⟨RTc⟩−⟨RTe⟩ difference is undefined.
We systematically varied the parameters of this model (Figures 3A–C) to determine all the conditions under which the mean RT of correct trials can be greater or less than the mean RT of error trials, using parameter ranges from the literature (Ratcliff and Tuerlinckx, 2002; Wagenmakers et al., 2007; Ratcliff and McKoon, 2008). Like the basic DDM, the simulations with σz = 0, σv = 0 showed no difference between correct and error RT for any drift rate (black curves are on y = 0 line), in spite of the addition of non-decision time variability σt. We never observed a positive RT difference in this model unless the starting point was variable (the dark blue or black curves, σz = 0, lie entirely on or below the abscissa). Whenever σz > 0 and σv = 0, the RT difference was positive (thin lines other than black). We never observed a negative RT difference in the absence of drift rate variability (thin lines, σv = 0, lie entirely on or above the abscissa). Whenever σv > 0 and σz = 0, the RT difference was negative (dark blue curves). Holding other parameters constant, the RT difference always increased (more positive, or less negative) with increasing σz (blue → red) and decreased with increasing σv (thin → thick).
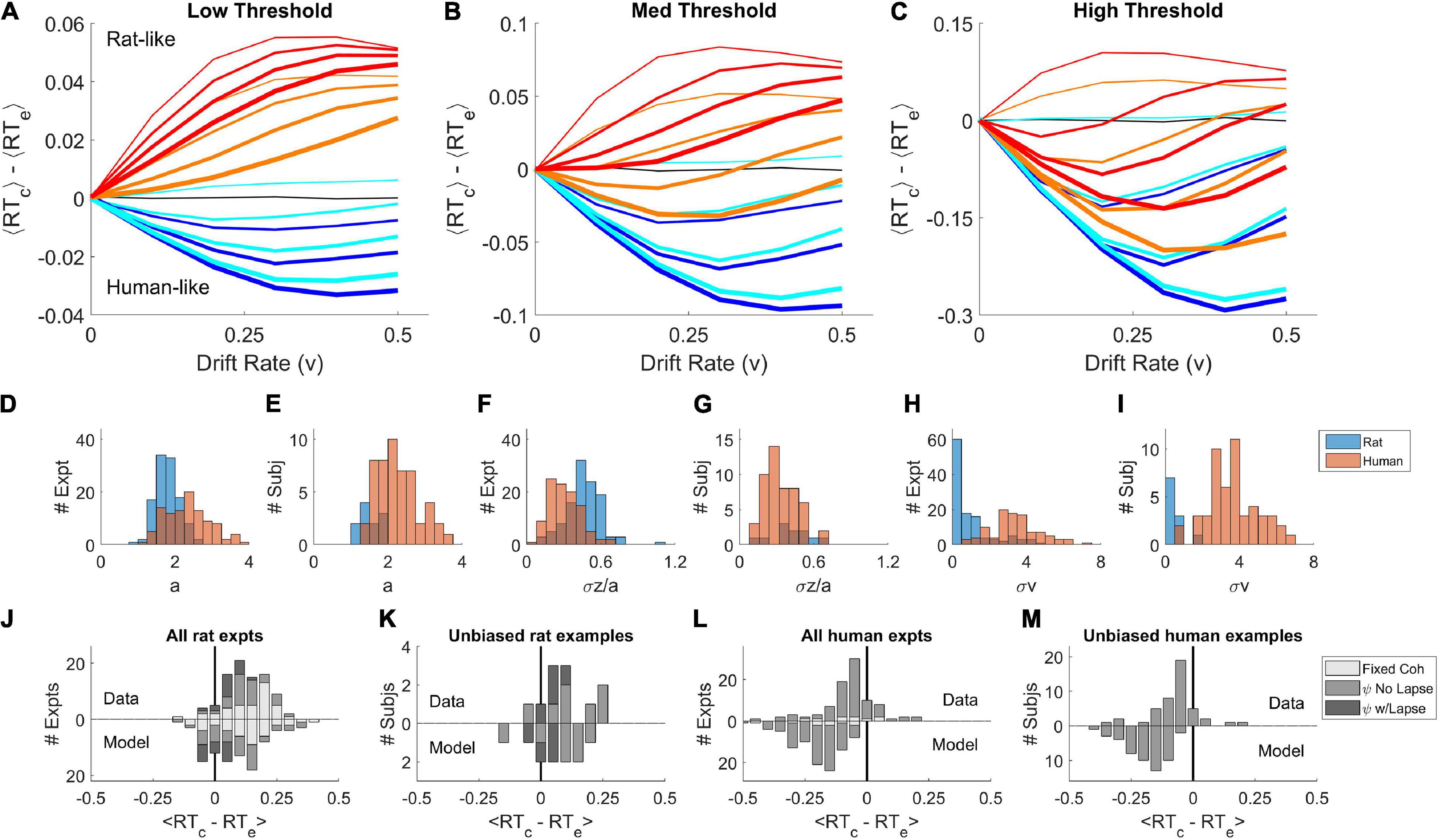
Figure 3. Parameter sweep of the variable-parameter DDM. (A–C) Curves show the difference between correct and error mean response times, ⟨RTcorrect⟩−⟨RTerror⟩, as a function of drift rate parameter v = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5]. Colors indicate starting point variability σz = [0.0, 0.02, 0.07, 0.10], in spectral order from low (dark blue) to high (red). Line thickness indicates drift rate variability σv = [0.0, 0.08, 0.12, 0.16]. Black curve is for σv = 0, σz = 0. (A) Simulations with threshold separation a = 0.08. (B) Simulations with a = 0.11. (C) Simulations with a = 0.16. For all the simulations shown, z=0, t = 0.3, σt = 0.2, τ = 0.001, and σn = 0.1. (D) Distribution of threshold separation a from fits of this model to datasets from Reinagel and Shevinsky (2020). (E) Distribution of a among example psychometric experiments from unique unbiased subjects in those datasets (see section “Materials and Methods”). (F) Distribution of starting point variability, expressed as a fraction of threshold separation: σz/a. (G) Distribution of σz/a in the unbiased example sets. (H) Distribution of drift rate variability σv. (I) Distribution of σv in the unbiased example sets. (J) Average difference between correct and error response times ⟨RTc−RTe⟩ computed locally within coherence, averaged over coherences ≥ 0.4. Fixed coherence (light), psychometric with < 10% lapse (medium) or with ≥ 10% lapse (dark). Upward bars show the results from the rat dataset, as analyzed in Shevinsky and Reinagel (2019); N = 51 psychometric, N = 38 fixed-coherence experiments had sufficient trials for this analysis. Lower bars show results for trial data simulated by the models (N = 58 psychometric and N = 39 fixed). (K) Like (J), but for the rat unbiased example subset; N = 11 data or models. (L) Like (J) but for human dataset (N = 81 psychometric, N = 9 fixed) and models fit to human dataset (N = 93 psychometric, N = 9 fixed), averaged over coherences ≥ 0.04. (M) Like (L) but for the human unbiased example subset, N = 45 (data) or N = 51 (model). For descriptive statistics see Supplementary Materials. Because of the limitations of fitting, we refrain from making statistical claims about comparisons of human-to-rat or data-to-model distributions.
When both starting point variability and drift rate variability are present simultaneously, these opposing effects trade off against one another quantitatively, such that there are many parameter combinations consistent with any given sign and amplitude of effect. This explains why parameter fits to data are generally degenerate. Taken together, the simulations show that human-like pattern is associated with dominance of σv and the rat-like pattern with dominance of σz. The non-decision time t and its variability σt were explored in separate simulations and did not impact the effect of interest (not shown).
It is difficult or impossible to recover the true parameters of this model by fitting data (Boehm et al., 2018). Nevertheless, we fit published human and datasets to identify example parameters of the model consistent with the observed data. The parameters obtained from fitting are not guaranteed to be the optimal solutions of the model nor accurate measures of noise in the subjects. Bearing these caveats in mind, the distributions of parameters we obtained (Figures 3D,F,H) were consistent with the parameter sweeps. Parameters fit to humans and rats overlapped substantially, but the human distributions were shifted toward those that favor late errors (higher σv, higher a and lower σz), and rats’ parameters toward those that favor early errors (higher σz, lower a and σv). Trials simulated using the fitted parameters reproduced the sign of the effect (Figures 3J,L). In a subset of examples defined by low bias, the difference between parameter distributions of rats and humans were less pronounced (Figures 3E,G,I). Experiments with low bias still exhibit the species difference, and models fit to those examples still reproduced the species difference (Figures 3K,M).
This analysis does not prove that humans and rats have trial-by-trial variability in drift rate and starting point, much less provide an empirical measure of that variability. What it does show is that if starting point and drift rate vary from trial to trial, that alone could be sufficient to produce the effects previously reported in either species. Only subtle differences in the relative dominance of drift rate vs. starting point variability would be required to explain the reported species difference.
Variability Need Not Be Random
Random trial-to-trial variability in parameters can cause differences between correct and error response times. But “variability” does not have to be noise. Systematic biases in the starting point or drift rate would also vary from trial to trial, and therefore would produce similar effects. We tested whether bias alone could produce results resembling those of Shevinsky and Reinagel (2019).
First, recall that we have defined decision thresholds as “correct” vs. “error” rather than “left” vs. “right” (Figure 2A). Therefore it is impossible for the mean starting point z to be biased, because the agent cannot know a priori which side is correct. If a subject’s starting point were systematically biased to one response side, the starting point would be closer to the correct threshold on half the trials (when the preferred side was the correct response), but further on the other half of the trials (when the non-preferred response was required). Thus the mean starting point would be z=0, but the distribution of z would be binary (or at least bimodal), and thus high in variance. This could mimic a model with high σz, even in the absence of stochastic parameter variability.
We demonstrate by simulation that adding a fixed response-side bias to the starting point of an otherwise standard DDM is sufficient to produce a response bias (Figure 4A). Response accuracy is higher when the correct response (“target”) is on the preferred side, and can fall below chance for weak stimuli to the non-preferred side (Figure 4B). At any given coherence, response times are faster for targets on the preferred side (Figure 4C). For targets on the preferred side, reaction times of correct trials are faster than errors, whereas for targets on the non-preferred side, correct trials are slower than errors (Figure 4D). This is because when the target is on the preferred side, the starting point is closer to the correct threshold, such that correct responses cross threshold faster than error responses, while the opposite is true for targets on the non-preferred side. Thus both the left and right target trials violate the expectation of ⟨RTc⟩ = ⟨RTe⟩, but in opposite directions.
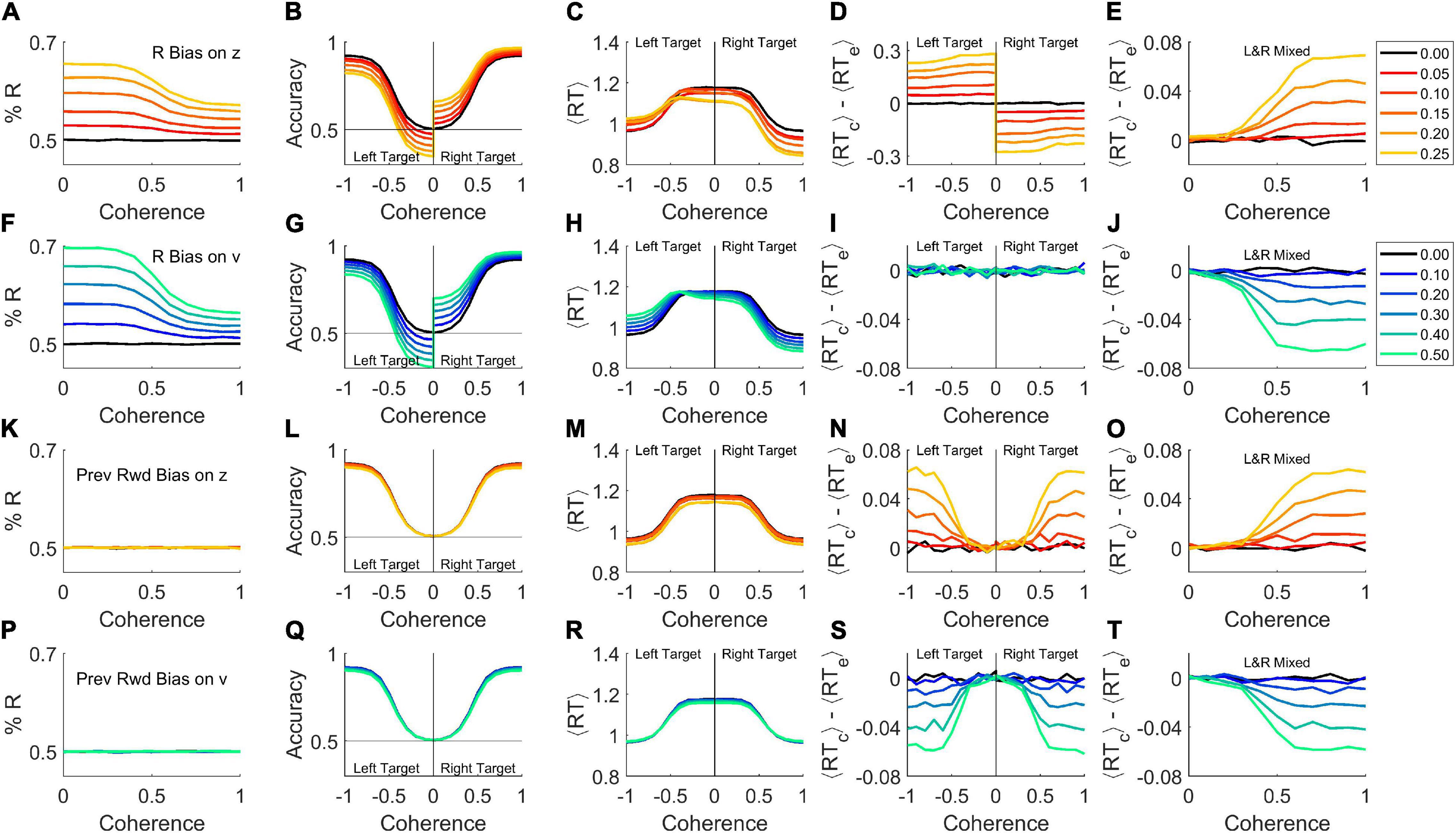
Figure 4. Bias is sufficient to produce either a rat-like or human-like effect within the basic DDM. Simulations were performed with σv = 0, σz = 0, σt = 0 (i.e., the basic model in Figure 1) but with different forms of bias added. Trials were simulated with 50% right response targets (rightward motion), with 5 × 105 trials per coherence. (A–E) A right side bias was simulated by displacing the starting point z toward the correct boundary on right-target trials, or toward the error boundary for left-target trials, by the amount indicated by color key at right. Where coherence is signed, negative indicates leftward motion and positive, rightward motion. If a coherence axis is unsigned, the left and right motion trials are pooled. (A) Percent right responses, as a function of coherence (sensory stimulus strength), which determines the drift rate v. (B) Average accuracy of the response as a function of coherence. (C) Average response time as a function of coherence. (D) Difference between correct and error mean response times, ⟨RTcorrect⟩−⟨RTerror⟩, as a function of coherence. (E) Difference between correct and error mean responses times when left-motion and right-motion trials are pooled. Compare to rat data (Figure 1I) or high σz model (thin red curves in Figures 3A–C). (F–J) Like (A–E), but here bias was simulated by increasing the drift rate v on R-target trials, or decreasing it on L-target trials, by the amount indicated in color key at right. Compare panel (J) to human data (Figure 1M) or high σv model (thick blue curves in Figures 3A–C). (K–O) Like (A–E) but here the starting point z was displaced toward the side that was rewarded in previous trial (if any). Same color key as (A–E). (P–T) Like (F–J) but here the drift rate v was increased if the target was on the side rewarded in previous trial, or decreased if the target was on the opposite side. Same color key as (F–J). For a similar analysis separated by behavioral choice instead, see Supplementary Figure 2 in Supplementary Materials.
If the left-target and right-target trials are pooled in a single analysis – even if exactly equal numbers of both kinds are used – these opposite effects do not cancel out (Figure 4E). On average, correct trials would have longer RT than error trials, to an increasing degree as coherence increases (Figure 4E), just as commonly seen in rodents (e.g., Figure 1I; see Shevinsky and Reinagel, 2019). The reason for this, in brief, is that the side with the starting point nearer the error threshold is responsible for the vast majority of the errors, and these errors have short RTs. The imbalance of contributions to correct responses is less pronounced. Although the side with the starting point nearer the correct threshold contributes the majority of correct responses, and those have short RTs, the drift rate ensures that both sides contribute substantial numbers of correct trials. For a more detailed account see Supplementary Figure 1 in Supplementary Materials. Mechanisms aside, the important point is that if a response bias is present (Figure 4A) and an effect like that in Figure 4E is obtained from an analysis that pools left- and right-target trials, starting point bias toward the preferred side should be considered as a possible cause. Either the analysis shown here (Figure 4D) or one that separates left-side from right-side choices (see Supplementary Figure 2D in Supplementary Materials) can be used to reveal the contribution of starting-point bias to early errors.
What if response bias arose, not from a shift in the starting point of evidence accumulation, but rather from an asymmetry in the drift rate for leftward vs. rightward motion: vR 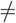 vL? Again, there would be an excess of responses to the preferred side (Figure 4F), and preferred target trials would be more accurate (Figure 4G) and faster (Figure 4H). If left and right targets were analyzed separately, each on its own would have a fixed drift rate, and therefore would behave as predicted by the basic DDM: correct trials and errors would have the same mean reaction time (Figure 4I).
vL? Again, there would be an excess of responses to the preferred side (Figure 4F), and preferred target trials would be more accurate (Figure 4G) and faster (Figure 4H). If left and right targets were analyzed separately, each on its own would have a fixed drift rate, and therefore would behave as predicted by the basic DDM: correct trials and errors would have the same mean reaction time (Figure 4I).
But if left- and right-target trials were pooled, v would be biased toward or away from the correct response in different trials with equal probability, resulting in a binary or bimodal distribution in v. Thus the standard deviation of v (σv) would be large, producing effects equivalent to high drift rate variability σv (Figure 4J), just as commonly seen in primates (e.g., Figure 1M; see Shevinsky and Reinagel, 2019). The reason for this is that pooling left- and right-target trials is equivalent to mixing together trials from high- and low-coherence stimuli: the slower RTs over-represent the low-coherence (slow, inaccurate) trials while faster RTs over-represent the high coherence (fast, accurate) trials, such that errors are on average slower than correct trials (see Supplementary Figure 1 in Supplementary Materials). Therefore, if a response bias is present (Figure 4F) and an effect like that in Figure 4J is observed in a pooled-trial analysis, drift rate bias is a candidate mechanism. Either the analysis shown here (Figure 4I) or one that separates left-side from right-side choices (see Supplementary Figure 2I in Supplementary Materials) can be used to clarify the contribution of drift rate bias to late errors.
Finally, note that rats and humans with the same degree of response-side bias could have opposite effects on ⟨RTcorrect⟩−⟨RTerror⟩ (Figures 4E vs. J), if the starting point were more biased in rats and drift rate more biased in humans.
We belabor the effects of response-side bias in order to draw a broader generalization. The results just shown (Figures 4A–J) require only that a bias to one side (L or R) exists in each trial. It does not matter if that bias is fixed or varying from trial to trial, only that it is uncorrelated with the correct response. If the starting point or drift rate were biased in individual trials based on the recent trial history, for example, this would also bias the decision toward or away from the correct response with equal probability in each trial. Therefore history-dependent bias can also mimic either high σz (Figure 4O) or high σv (Figure 4T). But in this case, there would be no overall left or right side bias (Figures 4K,P), and even after conditioning the analysis on the target side, the “early error” (Figure 4N) or “late error” (Figure 4S) phenotypes would persist. By analogy to the case of response side bias, one could test for this specific kind of bias by conditioning the analysis on the location of the previous trial’s reward.
In principle, therefore, biases due to trial history or other contextual states could also be sufficient to explain the observed difference between error and correct response times in both species, even in the absence of overt side bias, random variability of parameters, or within-trial parameter change. Again, the difference between rats and humans does not require that historical or contextual biases are stronger in either species, only that when present, they have a stronger effect on drift rate in humans and a stronger effect on starting point in rats.
In real data, however, the observed effects could be explained by a combination of response-side bias, history-dependent bias, contextual modulation, and noise, impacting both starting point and drift rate in both species. Therefore, conditioning the analysis on discrete trial types is not a practical way to detect (or rule out) bias effects in most data sets. Other new modeling approaches show promise for dissecting such mixed effects, however (Urai et al., 2019; Ashwood et al., 2020).
Discussion
The impetus for this study was an observed difference between primate and rodent decision-making: for primates correct decisions are on average faster than errors, whereas for rodents correct decisions are on average slower than errors. Both observations violate the predictions of the standard drift diffusion model. In one study this species difference was seen even when the sensory task was matched such that rats were just as accurate and just as fast as humans in the task, and even among subjects with low bias or lapse and comparable accuracy and speed (Shevinsky and Reinagel, 2019).
We do not presume that the difference in response time of correct vs. error trials is functionally significant for either species; the difference is small and accounts for a small fraction of the variance in response time. The reason this effect is interesting is because it places constraints on the underlying decision-making algorithms, and in particular, because it is inconsistent with DDM in its basic form.
Decreasing accuracy with response time has been widely reported in both humans and non-human primates (Roitman and Shadlen, 2002; Palmer et al., 2005) and has been explained by a number of competing models (Ditterich, 2006a,b; Ratcliff and McKoon, 2008; Rao, 2010; Hanks et al., 2011; Huang and Rao, 2013; Ratcliff and Starns, 2013; Tajima et al., 2016). It was only recently appreciated that accuracy increases with response time in this type of task in rats (Reinagel, 2013a,b; Shevinsky and Reinagel, 2019; Sriram et al., 2020), and it remains unclear which of those models can accommodate this observation as well. In this study we showed that either parameter noise (Ratcliff and Tuerlinckx, 2002; Ratcliff and McKoon, 2008) or systematic parameter biases could explain the observed interaction between response time and accuracy in either species. Similar effects might be found in other related decision-making models.
On the models explored here, greater variability in the starting point of evidence accumulation would produce the effect seen in rats, whereas greater variability in the drift rate of evidence accumulation would produce the effect seen in humans. We do not know why rodents and primates should differ in this way. It could be, for example, that drift rate is modulated by top-down effects arising in cortex, while starting point is modulated by bottom-up effects arising subcortically, and species differ in the relative strength of these influences. Or perhaps some kinds of bias act on starting point while others act on drift rate, and species differ in which kinds of bias are stronger.
Can Context Account for Variability?
Although stochastic trial-by-trial variability of parameters could explain the effects of interest (Figure 3), systematic variations can also do so. We demonstrate this for simple cases of response side bias or history-dependent bias (Figure 4). Response bias is more prevalent in rats than in humans, but correct trials have longer RT than errors even in rats with no bias (Shevinsky and Reinagel, 2019). In any case, these simulations show that response side bias would only produce the rat-like pattern if that bias impacted starting point to a greater degree than drift rate.
It is known that decisions in this type of task can be biased by the previous trial’s stimulus, response, and outcome in mice (Busse et al., 2011; Hwang et al., 2017; Roy et al., 2021), rats (Lavan et al., 2011; Roy et al., 2021), non-human primates (Sugrue et al., 2004), and humans (Goldfarb et al., 2012; Roy et al., 2021), reviewed in Frund et al. (2014). Such history-dependent biases can be strong without causing an average side preference or an observable lapse rate (errors on strong stimuli). Species differ in the strength of such biases (Roy et al., 2021), but a difference in strength of bias does not determine whether the effect will be to make error trials earlier or later (Figures 4N,O vs. S,T). This requires a difference in the computational site of action of bias.
In support of this idea, recent studies have traced variability to bias and history-dependent effects in both rodents and primates. In a go-nogo task, choice bias (conservative vs. liberal) in both mice and humans could be explained by bias in drift rate (de Gee et al., 2020). In another study, choice history bias (repeat vs. alternate) was specifically linked to drift rate variability in humans (Urai et al., 2019).
Fluctuations in arousal, motivation, satiety or fatigue could conceivably modulate decision thresholds or drift rates from trial to trial independently of either response side or trial history. [Note that in the model of Figures 2 and 3, fluctuations in the threshold separation parameter a are referred to the starting-point variability parameter σz(Ratcliff and Tuerlinckx, 2002; Ratcliff and McKoon, 2008)]. Such sources of variation may or may not be correlated with other measurable states, such as alacrity (e.g., latency to trial initiation, or in rodents the number or frequency of request licks), arousal (e.g., assessed by pupillometry), fatigue (the number of trials recently completed), satiety (amount of reward recently consumed), or frustration/success (fraction of recent trials penalized/rewarded). As models continue to include more of these effects, it will be of interest to determine how much of the observed behavioral variability is reducable to such deterministic components in each species, and whether those effects can be attributed differentially to starting point vs. drift rate effects in either decision-making models or neural recordings.
Is Parameter Variability a Bug or a Feature?
To the extent that parameter variability is attributable to systematic influences rather than noise, a separate question would be whether this variability is adaptive or dysfunctional, in either species. It is possible that non-sensory influences shift the decision-making computation from trial to trial in a systematic and reproducible fashion that would be functionally adaptive in the context of natural behavior, even though we have artificially broken natural spatial and temporal correlations to render it maladaptive in our laboratory task.
For example, in nature some locations may be intrinsically more reward-rich, or very recent reward yields may be informative about the expected rewards at each location. In the real world, recently experienced visual motion might be highly predictive of the direction of subsequent motion stimuli. Therefore biasing either starting point or drift rate according to location or recent stimulus or reward history may be adaptive strategies under ecological constraints, for either or both species.
Consistent with this suggestion, decision biases of mice have been modeled as learned, continuously updated decision policies (Ashwood et al., 2020). Although the policy updates did not optimize expected reward in that study, the observed updates might still reflect hard-wired learning rules that would be optimal on average in natural contexts.
Conclusion
It has been argued that neural computations underlying sensory decisions could integrate comparative information about incoming sensory stimuli (e.g., left vs. right motion signals), internal representations of prior probability (frequency of left vs. right motion trials) and the expected values (rewards or costs) associated with correct vs. incorrect decisions, in a common currency (Gold and Shadlen, 2001, 2007). On the premise that basic mechanisms of perceptual decision-making are likely to be conserved (Cesario et al., 2020), fitting a single model to data from multiple species – especially where they differ in behavior – is a powerful way to develop and distinguish among alternative computational models (Urai et al., 2019), and enables direct comparison of species.
Materials and Methods
The data and code required to replicate all results in this manuscript are archived in a verified replication capsule (Reinagel and Nguyen, 2022).
Experimental Data
No experiments were reported in this manuscript. Example human and rat data were previously published (Shevinsky and Reinagel, 2019; Reinagel and Shevinsky, 2020). Specifically, Figure 1F used rat fixed-coherence epoch 256 of that repository; Figures 1G–I used rat psychometric epoch 146. Figure 1J used human fixed-coherence epoch 63, and Figures 1K–M used human psychometric epoch 81 from that data set. Figures 3D–M used the “AllEpochs” datasets.
To summarize the experiment briefly: the task was random dot coherent motion discrimination. When subjects initiated a trial, white dots appeared at random locations on a black screen and commenced to move. Some fraction of the dots (“signal”) moved at the same speed toward the rewarded response side. The others (“noise”) moved at random velocities. Subjects could respond at any time by a left vs. right keypress (human) or lick (rat). Correct responses were rewarded with money or water; error responses were penalized by a brief time-out. Stimulus strength was varied by the motion coherence (fraction of dots that were signal dots). Other stimulus parameters (e.g., dot size, dot density, motion speed, contrast) were chosen for each species to ensure that accuracy ranged from chance (50%) to perfect (100%) and response times ranged from ∼500 to 2,500 ms for typical subjects of the species.
Computational Methods
The drift diffusion process was simulated according to the equation X(t) = X(t − 1) ± δ with probability p of increasing and (1 − p) of decreasing. Here t is the time point of the process, with time step τ in seconds; denotes the step size, where σ is the standard deviation of the Gaussian white noise of the diffusion; , where v is the drift rate. The values for τ and σ were fixed at 0.1 msec and 1, respectively. For any trial, the process starts at a starting position z, sampled from a uniform distribution of range σz, assumes a constant drift rate v, sampled from a normal distribution of standard deviation σv, and continues until X(t) exceeds either threshold boundary. The non-decision-time t, sampled from a uniform distribution of range σt, is added to the elapsed time to obtain the final RT associated with that trial.
We measured the interaction between accuracy and response time using the temporally local measure ⟨RTcorrect – RTerror⟩ introduced in Shevinsky and Reinagel (2019). This method is preferred for real data because it is robust to non-trending non-stationarities that are commonly present in both human and rat data, not detected by traditional stationarity tests, and that could confound estimation of the effect of interest. The response time of each error trial is compared to a temporally nearby correct trial of the same coherence, requiring a minimum distance of >3 trials to avoid sequential effects, and a maximum distance of 200 trials to avoid confounds due to long-range non-stationarity. For simulated data, where stationarity is guaranteed, the temporally local measure ⟨RTcorrect – RTerror⟩ and global measure ⟨RTcorrect⟩ – ⟨RTerror⟩ are numerically equivalent.
We fit parameters of the model shown in Figure 2A to published human and rat datasets (Reinagel and Shevinsky, 2020) using the Hierarchical Drift Diffusion Model (HDDM) package (Wiecki et al., 2013). We emphasize that fitting the parameters of this model is problematic (Boehm et al., 2018). Our interpretation of the parameters (Figures 3D–M) is limited to asserting that these example parameters can produce human-like or rat-like effects, to the extent demonstrated. For further details of fitting, including scripts, raw output files and summary statistics of parameters, see Supplementary Materials.
Data Availability Statement
Publicly available datasets were analyzed in this study (Reinagel and Shevinsky, 2020). These data can be found at doi: 10.7910/DVN/ATMUIF.
Author Contributions
QN proposed and implemented the model, produced the reported results, and edited earlier drafts of the manuscript. PR provided direction and oversight, generated the figures, and wrote the final manuscript. Both authors contributed to the article and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2022.794681/full#supplementary-material
Supplementary Figure 1 | Intuitions for the pooling effects.
Supplementary Figure 2 | Alternative analysis of simulated bias.
Supplementary Table 1 | Summary of fit parameters.
Supplementary Statistics | Parameters fit to data.
Supplementary Methods | Model fitting.
Scripts Folder | Python scripts to run with HDDM.
Outputs Folder | Output files generated by HDDM.
References
Ashby, F. G. (1983). A biased random-walk model for 2 choice reaction-times. J. Math. Psychol. 27, 277–297. doi: 10.1037/a0021656
Ashwood, Z., Roy, N., Bak, J. H., Laboratory, T. I. B., and Pillow, J. W. (2020). “Inferring learning rules from animal decision-making,” in Advances in Neural Information Processing Systems, eds H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin (Red Hook, NY: Curran Associates, Inc), 3442–3453.
Boehm, U., Annis, J., Frank, M. J., Hawkins, G. E., Heathcote, A., Kellen, D., et al. (2018). Estimating across-trial variability parameters of the diffusion decision model: expert advice and recommendations. J. Math. Psychol. 87, 46–75.
Boehm, U., Hawkins, G. E., Brown, S., van Rijn, H., and Wagenmakers, E.-J. (2016). Of monkeys and men: impatience in perceptual decision-making. Psychon. Bull. Rev. 23, 738–749. doi: 10.3758/s13423-015-0958-5
Bowman, N. E., Kording, K. P., and Gottfried, J. A. (2012). Temporal integration of olfactory perceptual evidence in human orbitofrontal cortex. Neuron 75, 916–927. doi: 10.1016/j.neuron.2012.06.035
Britten, K. H., Newsome, W. T., Shadlen, M. N., Celebrini, S., and Movshon, J. A. (1996). A relationship between behavioral choice and the visual responses of neurons in macaque MT. Vis. Neurosci. 13, 87–100. doi: 10.1017/s095252380000715x
Britten, K. H., Shadlen, M. N., Newsome, W. T., and Movshon, J. A. (1992). The analysis of visual motion: a comparison of neuronal and psychophysical performance. J. Neurosci. 12, 4745–4765. doi: 10.1523/JNEUROSCI.12-12-04745.1992
Britten, K. H., Shadlen, M. N., Newsome, W. T., and Movshon, J. A. (1993). Responses of neurons in macaque MT to stochastic motion signals. Vis. Neurosci. 10, 1157–1169. doi: 10.1017/s0952523800010269
Brown, S. D., and Heathcote, A. (2008). The simplest complete model of choice response time: linear ballistic accumulation. Cogn. Psychol. 57, 153–178. doi: 10.1016/j.cogpsych.2007.12.002
Busemeyer, J. R., and Townsend, J. T. (1993). Decision field theory: a dynamic-cognitive approach to decision making in an uncertain environment. Psychol. Rev. 100, 432–459. doi: 10.1037/0033-295x.100.3.432
Busse, L., Ayaz, A., Dhruv, N. T., Katzner, S., Saleem, A. B., Scholvinck, M. L., et al. (2011). The detection of visual contrast in the behaving mouse. J. Neurosci. 31, 11351–11361. doi: 10.1523/JNEUROSCI.6689-10.2011
Cesario, J., Johnson, D. J., and Eisthen, H. L. (2020). Your brain is not an onion with a tiny reptile inside. Curr. Dir. Psychol. Sci. 29, 255–260.
Churchland, A. K., Kiani, R., and Shadlen, M. N. (2008). Decision-making with multiple alternatives. Nat. Neurosci. 11, 693–702.
Cisek, P., Puskas, G. A., and El-Murr, S. (2009). Decisions in changing conditions: the urgency-gating model. J. Neurosci. 29, 11560–11571. doi: 10.1523/JNEUROSCI.1844-09.2009
de Gee, J. W., Tsetsos, K., Schwabe, L., Urai, A. E., McCormick, D., McGinley, M. J., et al. (2020). Pupil-linked phasic arousal predicts a reduction of choice bias across species and decision domains. Elife 9:e54014. doi: 10.7554/eLife.54014
Ditterich, J. (2006a). Evidence for time-variant decision making. Eur. J. Neurosci. 24, 3628–3641. doi: 10.1111/j.1460-9568.2006.05221.x
Ditterich, J. (2006b). Stochastic models of decisions about motion direction: behavior and physiology. Neural Netw. 19, 981–1012. doi: 10.1016/j.neunet.2006.05.042
Drugowitsch, J., Moreno-Bote, R., Churchland, A. K., Shadlen, M. N., and Pouget, A. (2012). The cost of accumulating evidence in perceptual decision making. J. Neurosci. 32, 3612–3628. doi: 10.1523/JNEUROSCI.4010-11.2012
Frund, I., Wichmann, F. A., and Macke, J. H. (2014). Quantifying the effect of intertrial dependence on perceptual decisions. J. Vis. 14:9. doi: 10.1167/14.7.9
Gold, J. I., and Shadlen, M. N. (2001). Neural computations that underlie decisions about sensory stimuli. Trends Cogn. Sci. 5, 10–16. doi: 10.1016/s1364-6613(00)01567-9
Gold, J. I., and Shadlen, M. N. (2007). The neural basis of decision making. Annu. Rev. Neurosci. 30, 535–574.
Goldfarb, S., Wong-Lin, K., Schwemmer, M., Leonard, N. E., and Holmes, P. (2012). Can post-error dynamics explain sequential reaction time patterns? Front. Psychol. 3:213. doi: 10.3389/fpsyg.2012.00213
Hanks, T. D., Mazurek, M. E., Kiani, R., Hopp, E., and Shadlen, M. N. (2011). Elapsed decision time affects the weighting of prior probability in a perceptual decision task. J. Neurosci. 31, 6339–6352. doi: 10.1523/JNEUROSCI.5613-10.2011
Hanks, T. D., and Summerfield, C. (2017). Perceptual decision making in rodents, monkeys, and humans. Neuron 93, 15–31. doi: 10.1016/j.neuron.2016.12.003
Hawkins, G. E., Forstmann, B. U., Wagenmakers, E. J., Ratcliff, R., and Brown, S. D. (2015). Revisiting the evidence for collapsing boundaries and urgency signals in perceptual decision-making. J. Neurosci. 35, 2476–2484. doi: 10.1523/JNEUROSCI.2410-14.2015
Heathcote, A., and Love, J. (2012). Linear deterministic accumulator models of simple choice. Front. Psychol. 3:292. doi: 10.3389/fpsyg.2012.00292
Heitz, R. P. (2014). The speed-accuracy tradeoff: methodology, and behavior. Front. Neurosci. 8:150. doi: 10.3389/fnins.2014.00150
Huang, Y., and Rao, R. P. (2013). Reward optimization in the primate brain: a probabilistic model of decision making under uncertainty. PLoS One 8:e53344. doi: 10.1371/journal.pone.0053344
Huk, A. C., and Shadlen, M. N. (2005). Neural activity in macaque parietal cortex reflects temporal integration of visual motion signals during perceptual decision making. J. Neurosci. 25, 10420–10436. doi: 10.1523/JNEUROSCI.4684-04.2005
Hwang, E. J., Dahlen, J. E., Mukundan, M., and Komiyama, T. (2017). History-based action selection bias in posterior parietal cortex. Nat. Commun. 8:1242. doi: 10.1038/s41467-017-01356-z
Lavan, D., McDonald, J. S., Westbrook, R. F., and Arabzadeh, E. (2011). Behavioural correlate of choice confidence in a discrete trial paradigm. PLoS One 6:e26863. doi: 10.1371/journal.pone.0026863
Long, M. H., Jiang, W. Q., Liu, D. C., and Yao, H. S. (2015). Contrast-dependent orientation discrimination in the mouse. Sci. Rep. 5:15830. doi: 10.1038/srep15830
Mazurek, M. E., Roitman, J. D., Ditterich, J., and Shadlen, M. N. (2003). A role for neural integrators in perceptual decision making. Cereb. Cortex 13, 1257–1269. doi: 10.1093/cercor/bhg097
McCormack, P. D., and Swenson, A. L. (1972). Recognition memory for common and rare words. J. Exp. Psychol. 95, 72–77. doi: 10.1037/h0033296
Palmer, J., Huk, A. C., and Shadlen, M. N. (2005). The effect of stimulus strength on the speed and accuracy of a perceptual decision. J. Vis. 5, 376–404. doi: 10.1167/5.5.1
Pleskac, T. J., and Busemeyer, J. R. (2010). Two-stage dynamic signal detection: a theory of choice, decision time, and confidence. Psychol. Rev. 117, 864–901. doi: 10.1037/a0019737
Purcell, B. A., Heitz, R. P., Cohen, J. Y., Schall, J. D., Logan, G. D., and Palmeri, T. J. (2010). Neurally constrained modeling of perceptual decision making. Psychol. Rev. 117, 1113–1143. doi: 10.1037/a0020311
Rao, R. P. N. (2010). Decision making under uncertainty: a neural model based on partially observable markov decision processes. Front. Comput. Neurosci. 4:146. doi: 10.3389/fncom.2010.00146
Ratcliff, R., and McKoon, G. (2008). The diffusion decision model: theory and data for two-choice decision tasks. Neural Comput. 20, 873–922. doi: 10.1162/neco.2008.12-06-420
Ratcliff, R., and Rouder, J. N. (1998). Modeling response times for two-choice decisions. Psychol. Sci. 9, 347–356.
Ratcliff, R., Smith, P. L., Brown, S. D., and McKoon, G. (2016). Diffusion decision model: current issues and history. Trends Cogn. Sci. 20, 260–281. doi: 10.1016/j.tics.2016.01.007
Ratcliff, R., and Starns, J. J. (2013). Modeling confidence judgments, response times, and multiple choices in decision making: recognition memory and motion discrimination. Psychol. Rev. 120, 697–719. doi: 10.1037/a0033152
Ratcliff, R., and Tuerlinckx, F. (2002). Estimating parameters of the diffusion model: approaches to dealing with contaminant reaction times and parameter variability. Psychon. Bull. Rev. 9, 438–481. doi: 10.3758/bf03196302
Reinagel, P. (2013a). Speed and accuracy of visual image discrimination by rats. Front. Neural Circuits 7:200. doi: 10.3389/fncir.2013.00200
Reinagel, P. (2013b). Speed and accuracy of visual motion discrimination by rats. PLoS One 8:e68505. doi: 10.1371/journal.pone.0068505
Reinagel, P., and Nguyen, Q. (2022). Differential effects of variability could explain distinct human and rat deviations from DDM [Source Code]. doi: 10.24433/CO.9600522.v2
Reinagel, P., and Shevinsky, C. A. (2020). Human and rat motion discrimination reaction time task data. Harvard Dataverse. doi: 10.7910/DVN/ATMUIF
Roitman, J. D., and Shadlen, M. N. (2002). Response of neurons in the lateral intraparietal area during a combined visual discrimination reaction time task. J. Neurosci. 22, 9475–9489. doi: 10.1523/jneurosci.22-21-09475.2002
Roy, N. A., Bak, J. H., International Brain, L., Akrami, A., Brody, C. D., and Pillow, J. W. (2021). Extracting the dynamics of behavior in sensory decision-making experiments. Neuron 109, 597–610 e596. doi: 10.1016/j.neuron.2020.12.004
Scott, B. B., Constantinople, C. M., Erlich, J. C., Tank, D. W., and Brody, C. D. (2015). Sources of noise during accumulation of evidence in unrestrained and voluntarily head-restrained rats. Elife 4:e11308. doi: 10.7554/eLife.11308
Shadlen, M. N., Britten, K. H., Newsome, W. T., and Movshon, J. A. (1996). A computational analysis of the relationship between neuronal and behavioral responses to visual motion. J. Neurosci. 16, 1486–1510. doi: 10.1523/JNEUROSCI.16-04-01486.1996
Shadlen, M. N., and Newsome, W. T. (1996). Motion perception: seeing and deciding. Proc. Natl. Acad. Sci. U.S.A. 93, 628–633. doi: 10.1073/pnas.93.2.628
Shadlen, M. N., and Newsome, W. T. (2001). Neural basis of a perceptual decision in the parietal cortex (area LIP) of the rhesus monkey. J. Neurophysiol. 86, 1916–1936. doi: 10.1152/jn.2001.86.4.1916
Shevinsky, C. A., and Reinagel, P. (2019). The interaction between elapsed time and decision accuracy differs between humans and rats. Front. Neurosci. 13:1211. doi: 10.3389/fnins.2019.01211
Sriram, B., Li, L., Cruz-Martin, A., and Ghosh, A. (2020). A sparse probabilistic code underlies the limits of behavioral discrimination. Cereb. Cortex 30, 1040–1055. doi: 10.1093/cercor/bhz147
Stirman, J. N., Townsend, L. B., and Smith, S. L. (2016). A touchscreen based global motion perception task for mice. Vis. Res. 127, 74–83. doi: 10.1016/j.visres.2016.07.006
Stone, M. (1960). Models for choice-reaction time. Psychometrika 25, 251–260. doi: 10.1007/bf02289729
Sugrue, L. P., Corrado, G. S., and Newsome, W. T. (2004). Matching behavior and the representation of value in the parietal cortex. Science 304, 1782–1787. doi: 10.1126/science.1094765
Sun, P., and Landy, M. S. (2016). A two-stage process model of sensory discrimination: an alternative to drift-diffusion. J. Neurosci. 36, 11259–11274. doi: 10.1523/JNEUROSCI.1367-16.2016
Tajima, S., Drugowitsch, J., and Pouget, A. (2016). Optimal policy for value-based decision-making. Nat. Commun. 7:12400. doi: 10.1038/ncomms12400
Tsetsos, K., Gao, J., McClelland, J. L., and Usher, M. (2012). Using time-varying evidence to test models of decision dynamics: bounded diffusion vs. the leaky competing accumulator model. Front. Neurosci. 6:79. doi: 10.3389/fnins.2012.00079
Urai, A. E., de Gee, J. W., Tsetsos, K., and Donner, T. H. (2019). Choice history biases subsequent evidence accumulation. Elife 8:e46331. doi: 10.7554/eLife.46331
Usher, M., and McClelland, J. L. (2001). The time course of perceptual choice: the leaky, competing accumulator model. Psychol. Rev. 108, 550–592. doi: 10.1037/0033-295x.108.3.550
Usher, M., Tsetsos, K., Yu, E. C., and Lagnado, D. A. (2013). Dynamics of decision-making: from evidence accumulation to preference and belief. Front. Psychol. 4:758. doi: 10.3389/fpsyg.2013.00758
Wagenmakers, E. J., van der Maas, H. L., and Grasman, R. P. (2007). An EZ-diffusion model for response time and accuracy. Psychon. Bull. Rev. 14, 3–22. doi: 10.3758/bf03194023
Wang, X.-J. (2002). Probabilistic decision making by slow reverberation in cortical circuits. Neuron 36, 955–968. doi: 10.1016/s0896-6273(02)01092-9
White, C. N., Servant, M., and Logan, G. D. (2018). Testing the validity of conflict drift-diffusion models for use in estimating cognitive processes: a parameter-recovery study. Psychon. Bull. Rev. 25, 286–301. doi: 10.3758/s13423-017-1271-2
Keywords: drift diffusion, comparative decision making, speed accuracy tradeoff, bias, context
Citation: Nguyen QN and Reinagel P (2022) Different Forms of Variability Could Explain a Difference Between Human and Rat Decision Making. Front. Neurosci. 16:794681. doi: 10.3389/fnins.2022.794681
Received: 13 October 2021; Accepted: 17 January 2022;
Published: 22 February 2022.
Edited by:
Jochen Ditterich, University of California, Davis, United StatesReviewed by:
Long Ding, University of Pennsylvania, United StatesAnne Urai, Leiden University, Netherlands
Copyright © 2022 Nguyen and Reinagel. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Pamela Reinagel, cHJlaW5hZ2VsQHVjc2QuZWR1