 Yehuda I. Dor
Yehuda I. Dor Daniel Algom
Daniel Algom Vered Shakuf3
Vered Shakuf3 Boaz M. Ben-David
Boaz M. Ben-David- 1School of Psychological Sciences, Tel Aviv University, Tel Aviv, Israel
- 2Communication, Aging and Neuropsychology Lab (CANlab), Baruch Ivcher School of Psychology, Reichman University (IDC), Herzliya, Israel
- 3Department of Communications Disorders, Achva Academic College, Arugot, Israel
- 4Toronto Rehabilitation Institute, University Health Networks (UHN), Toronto, ON, Canada
- 5Department of Speech-Language Pathology, University of Toronto, Toronto, ON, Canada
Older adults process emotions in speech differently than do young adults. However, it is unclear whether these age-related changes impact all speech channels to the same extent, and whether they originate from a sensory or a cognitive source. The current study adopted a psychophysical approach to directly compare young and older adults’ sensory thresholds for emotion recognition in two channels of spoken-emotions: prosody (tone) and semantics (words). A total of 29 young adults and 26 older adults listened to 50 spoken sentences presenting different combinations of emotions across prosody and semantics. They were asked to recognize the prosodic or semantic emotion, in separate tasks. Sentences were presented on the background of speech-spectrum noise ranging from SNR of −15 dB (difficult) to +5 dB (easy). Individual recognition thresholds were calculated (by fitting psychometric functions) separately for prosodic and semantic recognition. Results indicated that: (1). recognition thresholds were better for young over older adults, suggesting an age-related general decrease across channels; (2). recognition thresholds were better for prosody over semantics, suggesting a prosodic advantage; (3). importantly, the prosodic advantage in thresholds did not differ between age groups (thus a sensory source for age-related differences in spoken-emotions processing was not supported); and (4). larger failures of selective attention were found for older adults than for young adults, indicating that older adults experienced larger difficulties in inhibiting irrelevant information. Taken together, results do not support a sole sensory source, but rather an interplay of cognitive and sensory sources for age-related differences in spoken-emotions processing.
Introduction
Communication in older age is essential to maintain quality of life, cognitive skills, and emotional wellbeing (Heinrich et al., 2016; Livingston et al., 2017). Abundant evidence suggests that speech processing is impaired in aging, with severe implications (Helfer et al., 2017). Specifically, the literature points to major age-related changes in the perception of emotions in spoken language (Ben-David et al., 2019). However, it is not clear whether these changes are domain-specific or reflect a general age-related decline in emotion perception (Ruffman et al., 2008; Castro and Isaacowitz, 2019). In other words, do these changes stem from a specific deficit in processing of certain types of emotional channels (while processing of others is preserved), or from a general decrease in processing? In addition, there is debate on the mechanisms underlying these age-related changes; various sensory, cognitive, affective, and neural factors have been considered (Mather, 2016; Helfer et al., 2017; Ben-David et al., 2019).
In spoken language, emotions are presented via two main channels: (a) emotional semantics – the emotional meaning of spoken words or a complete sentence (segmental speech information); (b) emotional prosody – the tone of speech (suprasegmental speech information), composed of vocal cues such as stress, rhythm, and pitch. Processing of emotional speech is therefore a complex and dynamic integration of information, which may be congruent or incongruent, from these two channels. Significant age-related changes are indicated when incongruent prosody-semantics emotional combinations are presented. Specifically, when asked to integrate the two channels, young adults rely mainly on emotional prosody, while older adults weigh the two channels more equally (Dupuis and Pichora-Fuller, 2010; Ben-David et al., 2019). In addition, when listeners are asked to focus on only one speech channel, larger failures of selective attention are found for older adults than for young adults (Ben-David et al., 2019). In other words, the same spoken emotional sentences are interpreted differently by older and young listeners.
Mainly, cognitive and sensory sources have been suggested for these age-related differences (Ben-David et al., 2019). Following a cognitive source, age-related differences in executive functions, especially inhibition (Hasher and Zacks, 1988), are at the basis of changes in spoken emotion processing (Wingfield and Tun, 2001; Harel-Arbeli et al., 2021). Namely, both older and young adults may implicitly adopt the same weighting schematics – i.e., more weight to the prosodic than to the semantic channel. However, older adults might find it more difficult to inhibit the semantic information, processing it to a larger extent than intended.
An alternative sensory source lies in the relative imbalance between dimensions. The literature suggests that when one dimension becomes more perceptually salient than the other, the system is biased to rely on the first (Melara and Algom, 2003). Accordingly, young adults may be biased to process the prosody over the semantics, because emotional prosody is more sensory salient than emotional semantics. However, if this dimensional imbalance is reduced for older adults, the prosodic bias might be diminished as well (for a discussion on age-related sensory and dimensional-imbalance changes, see Ben-David and Schneider, 2009, 2010).
Some evidence in the literature may support this sensory source, with a specific age-related deficit in prosodic processing that might not be accompanied by a similar deficit in spoken-word processing. Indeed, age-related decrease in the recognition of prosodic information has been widely reported, both in quiet and in noise (Dmitrieva and Gelman, 2012; Lambrecht et al., 2012; Dupuis and Pichora-Fuller, 2014, 2015; Ben-David et al., 2019), suggesting a specific deficit in decoding emotional prosody in aging (Orbelo et al., 2005; Mitchell, 2007; Mitchell and Kingston, 2011). This prosodic deficit may relate to senescent changes in auditory brain areas and neural activity patterns (Orbelo et al., 2005; Giroud et al., 2019; Myers et al., 2019; Grandjean, 2021). However, there are mixed findings in the literature regarding the extent of age-related changes in semantic processing. While some studies have found a decline in older adults’ ability to extract the emotional meaning from words (Grunwald et al., 1999; Isaacowitz et al., 2007), other studies have maintained that semantic processing is preserved, at least when speech is presented in ideal listening conditions (Phillips et al., 2002; Ben-David et al., 2019). In sum, an age-related decrease in sensory dimensional imbalance may be the source for the age-related decrease in prosodic bias.
In the current study, we adopted a psychophysical approach to test the sensory base of age-related differences in processing of spoken emotions. Following the results obtained by Ben-David et al. (2019), we directly asked older and young listeners to recognize the prosodic emotion and semantic emotion of 50 spoken sentences in separate trials. Sentences were presented in five different signal-to-noise-ratios (SNRs) to calculate emotional recognition thresholds. Take, for example, the semantically happy sentence “I won the lottery” spoken with sad prosody. In previous studies, young adults were found to judge this sentence to convey mostly sadness (prosody), whereas older adults judged the sentence to present a similar extent of happiness (semantics) and sadness (prosody; Ben-David et al., 2019). A sensory source would be supported if a larger prosodic advantage in thresholds were to be found for young over older adults. A cognitive source would be supported if larger failures of selective attention were to be found for older adults, as gauged by accuracy differences between congruent and incongruent sentences. Note, the two sources are not mutually exclusive.
The following hypotheses were made:
1. Age-related advantage: Recognition thresholds and accuracy would be lower (i.e., better) for young than for older adults.
2. Prosodic advantage: Across age groups, recognition thresholds for emotional prosody would be lower (i.e., better) than for emotional semantics.
3. Age-related differences in prosodic advantage: As the literature is not clear, we did not wish to make an a-priori hypothesis as to whether the advantage in prosodic over semantic recognition thresholds would be affected by age group or not.
4. Failures of selective attention: Selective attention failures would be larger for older adults.
Materials and Methods
Participants
A total of 26 older adults from the community (16 women; 58-75 years old, M = 65.76 years, SD = 4.80) and 29 young adults, undergraduate students from Reichman University (24 women; 22-27 years old, M = 25.40 years, SD = 1.17) were recruited for this study and met the following inclusion criteria: (a) native Hebrew speakers as assessed by self-reports (Ben-David and Icht, 2018), and verified by above-average standard scores for their age range on a vocabulary test (subscale of the WAIS-III, Goodman, 2001), as language proficiency is related to processing of emotional semantics (Phillips et al., 2002); (b) good ocular health; no auditory, cognitive or language problems, and without any medical or mental conditions related to emotional processing as assessed by self-reports (Nitsan et al., 2019); (c) no indication of clinical depression as assessed by self-reports (older: GDS, Zalsman et al., 1998; young: DASS-21, Henry and Crawford, 2005); and (d) pure-tone air-conduction thresholds within clinically normal limits for their age group, for 500, 1,000, and 2,000 Hz (average pure-tone thresholds ≤ 15 dB HL for young, and ≤ 25 dB HL for older adults, difference between ears < 20 dB HL). Note, groups were matched on years of education (M = 14.23 and 14.19 for young and older adults, respectively), taken as a reliable gauge for linguistic skills (Kaufman et al., 1989; Ben-David et al., 2015). Young adults participated in the study for partial course credit, and older adults were compensated by the equivalent of $10. From the final dataset, we excluded data of two young participants who did not follow the instructions, and of four older adults who exhibited very low recognition rates (< 50% correct recognition in the easiest SNR). A detailed description of the demographic and audiological characteristics of participants can be found in Supplementary Appendix A.
Stimuli
The stimulus set was made of 50 spoken sentences taken from the Test for Rating of Emotions in Speech (T-RES; Ben-David et al., 2016, 2019), which presents emotional semantic and prosodic content in different combinations from trial to trial. Five different emotions were used: Anger, Happiness, Sadness, Fear, and Neutrality. Each semantic category was represented in each of the tested prosodies, generating a 5 (semantics) *5 (prosody) matrix (see Figure 1). The experimental set consisted of two sentences in each of the 25 different combinations of emotional semantics and prosody. Ten sentences were congruent (e.g., semantically angry semantics such as “Get out of my room” spoken with congruent angry prosody; black cells in Figure 1) and 40 were incongruent (e.g., semantically happy semantics such as “I won the lottery” spoken with incongruent sad prosody; gray cells in Figure 1). All spoken sentences were recorded by a professional radio drama actress; digital audio files were equated with respect to their duration and root-mean-square amplitude (before they were mixed with noise).
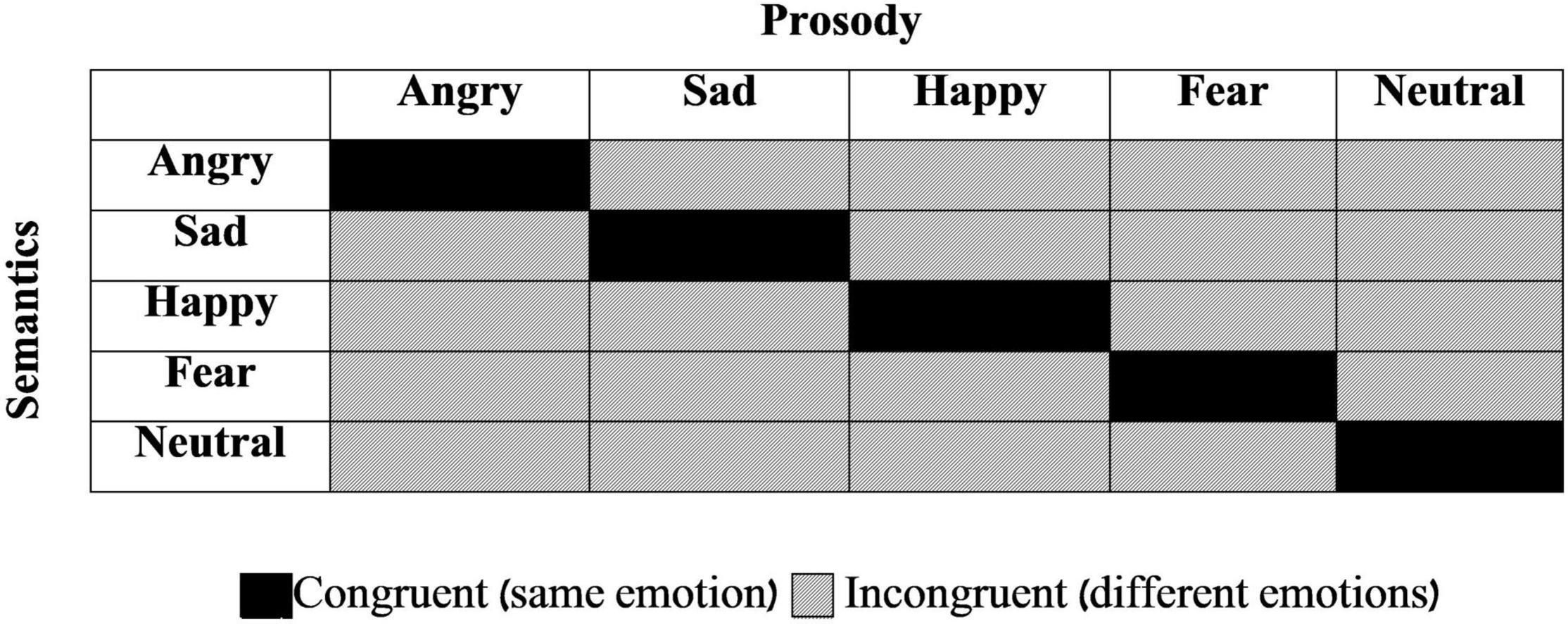
Figure 1. General design of the Stimuli. All combinations of prosodic and semantic emotions are presented. Each cell represents two different sentences used in this study. Black cells: congruent sentences (same emotion in both speech channels). Gray cells: incongruent sentences (different emotions in semantics and prosody).
Reliability, Sensitivity, and Validity
We used the Hebrew version of the T-RES sentences. Content validity (Chan, 2014) was confirmed by verifying that all semantic stimuli were distinctive in their categories and exemplars of their respective semantic categories for both young and older listeners, and equated on main linguistic characteristics. For full details on the procedure for stimuli selection, see Ben-David et al. (2011b,2013, 2019). A recent study from our lab has further shown that the discrete prosodic emotions are clearly distinct in acoustic characteristics (mean F0 and speech rate; Carl et al., 2022) in this set. The T-RES reliability was confirmed as data for young adult undergraduates were found to be equivalent across studies and platforms (Ben-David et al., 2021). The T-RES stimuli were also found to be valid and sensitive in detecting population-related differences in various studies. For example, expected differences in spoken emotional processing were found when comparing cochlear implant users and their peers (Taitelbaum-Swead et al., 2022).
Sentence Division and Combination With Noise
The final set was divided into five subsets of ten sentences each, with each subset consisting of two congruent and eight incongruent sentences. Each of the five emotional prosodies and each of the five emotional semantic categories was represented twice in each subset (see Supplementary Appendix B). Using PRAAT software (Boersma and Weenink, 2019), stimuli in each subset were combined with a different level of background speech-spectrum noise using a standard steady-state noise masker taken from the Revised Speech Perception in Noise test (Bilger et al., 1984; for spectral analysis of this noise, see Figure 6 in Ben-David et al., 2012). Five SNR levels were used: −15 dB, −10 dB, −5 dB, 0 dB, and +5 dB; creating a scale from the most difficult SNR (−15 dB) to the easiest SNR (+5 dB).
Procedure and Apparatus
Upon arrival, all participants received a short explanation regarding the experimental task and signed an informed consent form. Participants completed the self-reports and the vocabulary test. Next, they were seated in an IAC sound-attenuated booth and performed the pure-tone hearing thresholds test. All auditory stimuli were presented via MAC-51 audiometer headphones. Spoken sentences (experimental task) were presented 40 dB above individual audiometric thresholds (pure-tone average) in quiet, to partially mitigate age-related differences in auditory thresholds. Instructions were presented on a 17-in. flat color monitor.
Experimental Session
The experimental session consisted of two five-alternative-forced-choice (5-AFC) tasks. In both, participants were instructed to recognize the emotion presented, choosing one of five options (anger, happiness, sadness, fear, and neutrality) by pressing a designated key on the keyboard. Listeners were asked to recognize only the emotion presented by the semantics in the Semantics-recognition task, or only by prosodics in the Prosody-recognition task. Each task consisted of five blocks of ten spoken sentences each, with different levels of SNR in each block. The order of tasks (Semantics-recognition or Prosody-recognition) and the order of blocks in each task were counterbalanced across participants, using a Latin-square design. The order of sentences within each block was fully randomized. The whole session (two tasks with 100 sentences in total) lasted less than 30 min. Participants were given the option to take short breaks before the session, or between the tasks, if needed.
Data Fitting and Psychometric Functions
For each participant, five recognition-accuracy rates were calculated separately for prosody and semantics, based on average accuracy across the ten sentences in each of the five SNRs. Using a customized MATLAB script (McMurray, 2017), data were fitted to the logistic psychometric function of the form,
where f(x) represents recognition-accuracy rates, x is the SNR in dB, L and A are the upper and lower asymptotes of the function, respectively. Most importantly, the parameter x0 represents the function’s crossover point, or the x value that corresponds to middle performance between the boundaries of the function. The crossover point is taken to represent the point at which the rate of increase in recognition as a function of SNR begins to decrease. As such, the value of x0 can serve as an index for individual recognition statistical threshold (Ben-David et al., 2012; Morgan, 2021). Finally, k represents the function’s slope at x0.
The lower asymptote of the function (A) for all conditions was pre-defined as 0.2 (chance level) using two techniques: (1) All performance levels averaging under 0.2 were corrected to 0.2 to avoid function estimations below chance level (1.4% of the data corrected). (2) We added an estimation level of 0.2 recognition rates (chance level) for an SNR of −20 dB, to correspond to the function’s predicted lower bound. However, we chose not to pre-define the upper bound of the function (i.e., maximum recognition rates, see Morgan, 2021), as even without any background noise emotional recognition rates are not expected to reach 100%, especially for older adults (see Ruffman et al., 2008; Ben-David et al., 2019). Hence, the three other parameters (x0, L, and k) were estimated based on our data. Correlations between actual data and the values predicted by the psychometric function were high (Mean correlation, 0.98–0.95), indicating a very good fit (McMurray, 2017) for both young and older adults. For full details regarding recognition rates, fitted psychometric functions’ parameters, and quality of fits, see Supplementary Appendices C and D.
Statistical Analysis
All analyses of the thresholds, maximum asymptotes, and slopes (x0, L, and k, taken from the psychometric function) included mixed linear modeling, MLM (SPSS Statistics 20; IBM Corp, 2011), with each serving as the dependent variable in different models. Group (young adults vs. older adults) was the between participant variable and Speech Channel (Prosody-rating vs. Semantics-rating) was the within participant variable. To test Selective Attention, the same MLM model was used, with recognition-accuracy rates (averaged across all SNRs) as the dependent variable, and the Selective Attention factor (congruent vs. incongruent sentences) added as another within participant factor.
Results
Analysis of Thresholds and Recognition Rates
Table 1A presents the full MLM analyses of recognition thresholds, maximum asymptotes, and slopes. Results indicated a significant main effect for Age Group, F(1,47) = 14.57, p < 0.001, suggesting lower recognition thresholds for young, compared to older adults (average thresholds of −9.57 dB vs. −7.37 dB, respectively). A significant main effect was also found for Speech Channel, F(1,47) = 74.98, p < 0.001, suggesting lower recognition thresholds for emotions in prosody, compared to semantics (average thresholds of −10.09 dB vs. −6.85 dB, respectively). However, the interaction of the two factors was not significant, F(1,47) = 1.24, p = 0.27, indicating that the prosodic threshold advantage was similar for both age groups (left column of Table 1A). When using the same model to test differences in maximum asymptotes (i.e., maximal recognition rates under minimal noise) significant main effects were found for Age Group, F(1,47) = 27.62, p < 0.001, and for Speech Channel, F(1,47) = 5.34, p = 0.025, without a significant interaction between the two, F(1,47) = 0.304, p = 0.584 (middle column of Table 1A). When the same model was used to test differences in slopes, none of the tested effects were significant, indicating similar growth rates across all conditions (right column of Table 1A). When we excluded from analysis all psychometric functions whose fit quality was less than 0.9 (excluding seven functions, 7% of data), the result pattern remained the same (see Supplementary Appendix E).

Table 1. Model Summary and results of MLM analyses.
To sum, our first and second hypotheses were confirmed: Young adults’ recognition thresholds were lower (better) than those of older adults (a difference of about 2.2 dB), and prosodic emotions yielded lower recognition thresholds than did semantics emotions (a difference of about 3.3 dB). Critically, regarding our third hypothesis, the relative extent of the advantage of prosody over semantics was highly similar for older and young adults. Namely, prosodic thresholds were better than semantic thresholds by about a third, 32.16%, and 32.06% (−8.98 vs. −5.96 dB SNR; and, −11.40 vs. −7.74 dB SNR) for older and young adults, respectively. These results and the estimated psychometric functions in different Age Groups and Speech Channels are visually presented in Figure 2.
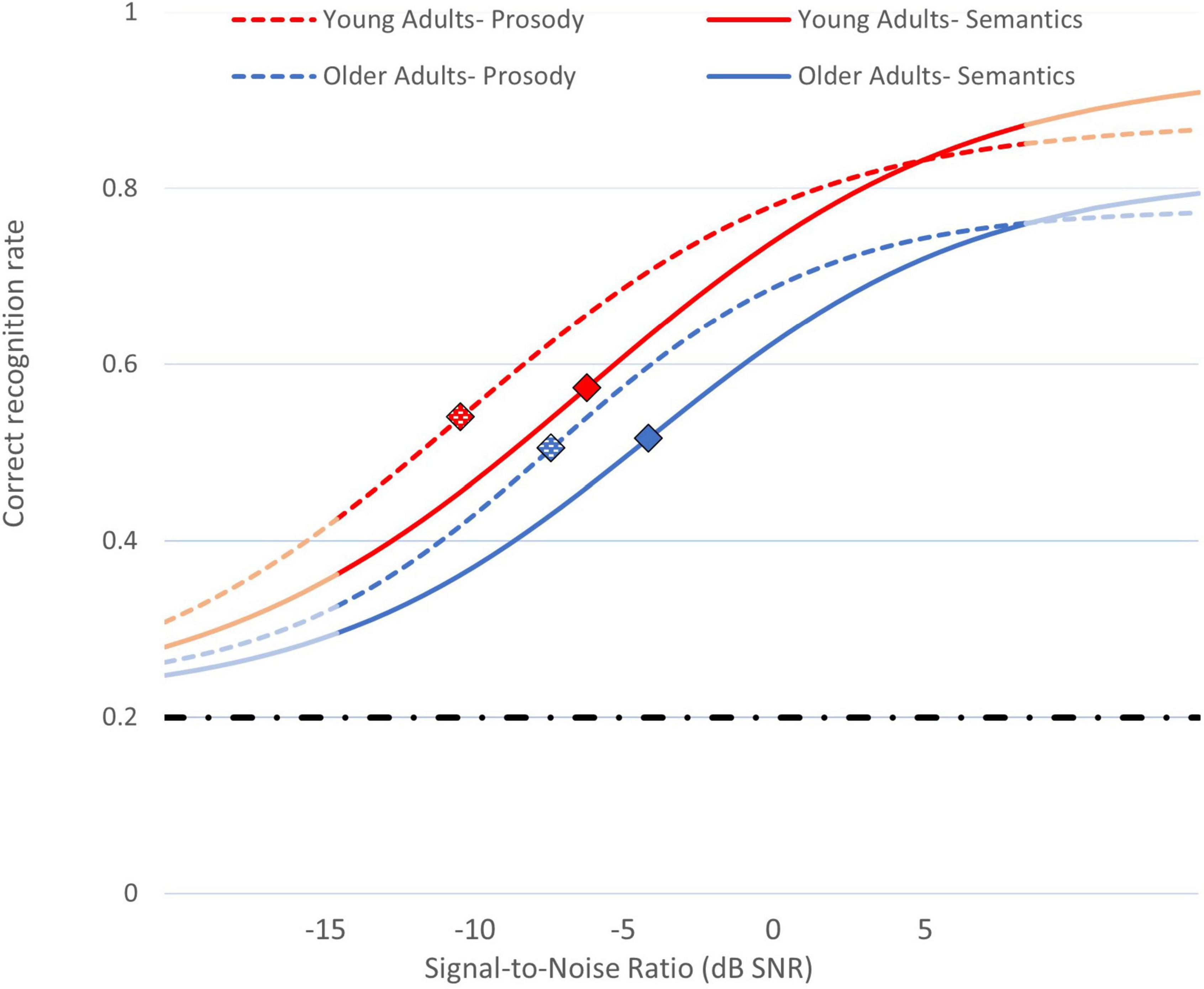
Figure 2. Psychometric functions for recognition of emotions in speech in different SNRs, averaged across participants. Blue lines: older adults; red lines: young adults. Dashed lines: recognition of emotional prosody; full lines: recognition of emotional semantics. Diamond-shaped markers indicate statistical recognition thresholds for each condition. Light-blue and light-red lines represent extrapolations of the functions beyond the SNRs tested in the study. The dashed-and-dot horizontal line indicates the functions’ minimal asymptote (0.2 - chance level).
Analysis of Selective Attention Failures
Table 1B presents the full MLM analyses of the Selective Attention factor. Results show significant main effect for Age Group, F(1,42.82) = 20.45, p < 0.001, and for Speech Channel, F(1,40.64) = 12.88, p = 0.001, with no significant interaction between the two, F(1,40.64) = 0.809, p = 0.374, conceptually replicating the results reported above. Most importantly, we found a significant main effect for Selective Attention, F(1,44.04) = 55.6, p < 0.001, that significantly interacted with Age Group, F(1,44.04) = 10.2, p = 0.003, reflecting larger failures of selective attention for older adults.
To sum, our fourth hypothesis was confirmed: Recognition rates were better for congruent than for incongruent sentences (correct recognition rates of 0.697 vs. 0.606, respectively), indicating overall failures of selective attention. Older adults showed larger failures of selective attention than did young adults (Selective-Attention factors of 0.130 vs. 0.052, respectively). These results are visually presented in Figure 3.
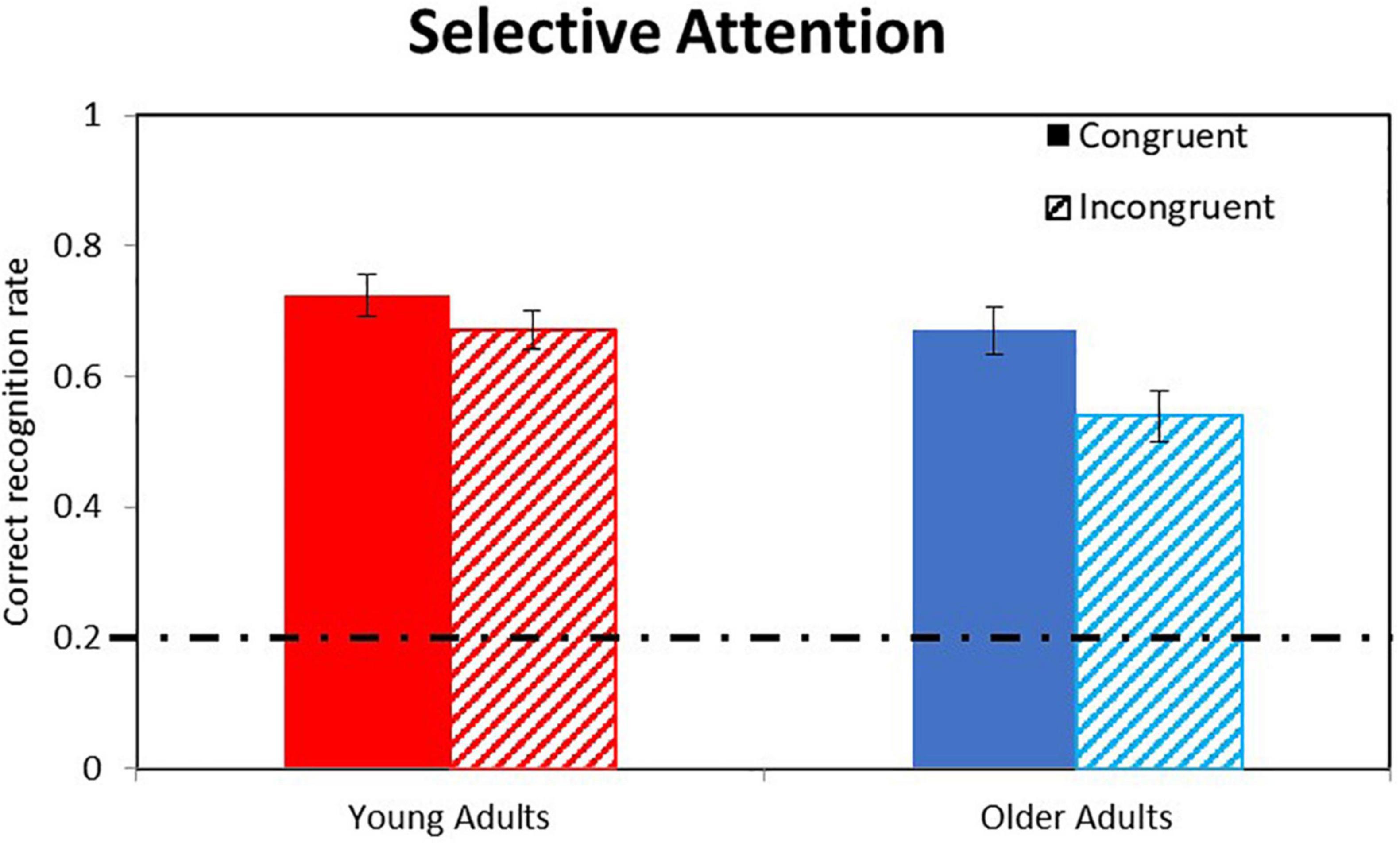
Figure 3. Analysis of Selective Attention effects. Bars indicate correct recognition rates for congruent (full) vs. incongruent (dashed) sentences in young (red) and older (blue) adults averaged across different SNRs. Error bars indicate 95% CI of their respective means (MLM estimates). The dashed-and-dot horizontal line indicates the chance level (0.2).
Discussion
The current study adopted a psychophysical approach to directly compare young and older adults’ sensory thresholds for emotion recognition across two channels of speech: prosody and semantics. We aimed to better understand age-related differences in the processing of spoken emotions, as indicated in the literature, and specifically an age-related decrease in the dominance of prosody over semantics, as found by Ben-David et al. (2019). A total of 29 young adults and 26 older adults listened to 50 spoken sentences presenting different combinations of emotions across prosody and semantics and, in different tasks, were asked to recognize the emotion presented in one of the channels. Sentences were mixed with speech-spectrum noise ranging from SNR of −15 dB (most difficult) to +5 dB (easiest). Individual recognition thresholds were calculated (by fitting psychometric functions), separately for prosodic and for semantic emotion recognition.
Results indicated the following trends, supporting our hypotheses:
1. Recognition thresholds were better for young over older adults (age-related effects);
2. Recognition thresholds were better for prosodic over semantic information (prosodic advantage);
3. The prosodic advantage in thresholds did not differ between age-groups;
4. However, a significant age-related effect was indicated for selective attention, suggesting that older adults were more affected by the irrelevant channel than were young adults.
To the best of our knowledge, this study is the first to directly examine possible age-related differences in the imbalance between thresholds for emotion recognition in different speech channels. To date, only a few studies have tried to directly compare the recognition of the semantic and prosodic channels, mostly in young adults (but see, Dupuis and Pichora-Fuller, 2014). For example, Morgan (2021) showed that sensory thresholds were better for prosodic-emotion recognition than for word recognition in noise for young adults (see also van Zyl and Hanekom, 2011; Ritter and Vongpaisal, 2018; Morgan et al., 2022). However, these studies did not directly measure semantic-emotion recognition, but rather used word/sentence recognition as a placeholder. Clearly, these two processes differ, as semantic-emotion recognition involves both the identification of the spoken words and their integration as the basis for emotional labeling.
As expected, we found lower (better) recognition thresholds for young over older adults. In other words, older adults needed speech to be presented at ∼2.2 dB SNR louder than young adults to reach their recognition threshold in noise. These results are in line with the abundant literature on speech perception in noise (Heinrich et al., 2016). Semantics: Age-related changes in semantic emotion recognition follow findings on spoken word recognition. Note, our effects are about half the size of the well-observed 4 dB SNR age-related difference in spoken-word recognition accuracy (Pichora-Fuller et al., 1995; Murphy et al., 2000; Ben-David et al., 2011a). This is probably the outcome of the different tasks used, as we tested emotion recognition thresholds rather than word recognition accuracy. Prosody: The current study is the first to directly test age-related changes in recognition thresholds for emotional prosody. Our findings, on an age-related decrease in prosodic recognition thresholds, expand previous findings on age-related diminished prosodic recognition accuracy for speech in noise (Dmitrieva and Gelman, 2012; Dupuis and Pichora-Fuller, 2014). Maximum asymptotes: An age-related difference was found for the maximum asymptote of the psychometric functions, indicating that young adults recognize emotions in speech better than older adults, even under very little noise (see Paulmann et al., 2008; Ben-David et al., 2019). Recognition accuracy for older adults did not reach 100% at the maximum asymptotes (easiest SNR). This is not surprising, as the literature suggests that even in quiet older adults are impaired at emotion recognition (Ruffman et al., 2008), speech recognition (Pichora-Fuller and Souza, 2003) and emotional prosody and semantics recognition (Paulmann et al., 2008).
Our results support a sensory prosodic advantage across both age-groups, where recognition thresholds were lower (better) for emotional prosody than for emotional semantics. This suggests that to reach recognition threshold in noise, emotional semantics call for an addition of ∼3.3 dB SNR as compared to emotional prosody. This prosodic advantage across age groups expands previous evidence that focused mainly on an accuracy advantage for prosodic recognition over spoken word recognition (Dupuis and Pichora-Fuller, 2014; Morgan, 2021; Morgan et al., 2022). A noteworthy study by Morgan (2021) reported a 10 dB SNR advantage between emotional prosodic thresholds and spoken word identification thresholds in young adults. This marks a much larger advantage than the 3.3 dB SNR difference we report. This difference possibly stems from the tasks used (word identification vs. emotion recognition in a sentence) and from other methodological differences (such as the different levels of SNRs used in each condition). Maximum asymptotes: In contrast to the prosodic advantage in SNR thresholds, it is notable that a small but significant semantic advantage was found for the maximum asymptote of the psychometric functions, indicating that emotional semantics are recognized slightly better than are emotional prosodies under very little noise (see also Ben-David et al., 2019).
How to explain this ease of prosodic detection in noise? As aforementioned, spoken emotional semantic recognition is based on both word identification and context generation as the words unfold in time. These tasks are highly sensitive to noise (Pichora-Fuller et al., 1995), as misapprehension of sound-sharing words might change the emotional meaning of the whole sentence. For example, consider the sentences “I’m so /sad/ right now” versus “I’m so /mad/ right now.” Confusing one phoneme for another, a common characteristic of speech-in-noise processing (Ben-David et al., 2011a; Nitsan et al., 2019), shifts the emotional categorization of the sentence from sadness to anger. In contrast, prosodic recognition is based on suprasegmental features that may be less susceptible to noise. Namely, prosodic processing is based on the envelope of speech, speech rate and fundamental frequency fluctuations (Myers et al., 2019). These acoustic features are more immune to interference from energetic masking (Morgan, 2021). Moreover, processing of prosodic features involves several functionally (and anatomically) segregated systems of cortical and sub-cortical networks (Grandjean, 2021). This redundancy might serve to protect from the effects of adverse sensory conditions.
Indeed, prosody has been taken to be a fundamental aspect of speech that scaffolds other aspects of linguistic processing (Myers et al., 2019). Emotional prosody is learned and used already in infancy, before the effective use of semantics in infant-parent interactions (Fernald, 1989). Thus, prosody serves as a basic emotional cue across the life span. Prosody also appears to be a contextualizing marker of verbal interactions that directly leads listeners to the speaker’s emotional message (House, 2007). The critical role prosody plays in interpersonal and social situations (Pell and Kotz, 2021) may be generated by its perceptual salience, or may lead to heightened sensitivity to prosodic cues in noise.
Perhaps our most important finding is the lack of interaction between age group and prosodic advantage in sensory thresholds. In other words, the prosodic advantage was similar in extent for older and young adults (around a 33% advantage in both groups). Our data do not support suggestions in the literature that older adults might have specific impairments in prosodic processing as compared to young adults (Mitchell, 2007; Orbelo et al., 2005). Rather, they are in line with a general age-related auditory decline that spans to both segmental and suprasegmental features (Paulmann et al., 2008). Results could also support a general age-related decrease in emotional perception and processing (Ruffman et al., 2008; but see Castro and Isaacowitz, 2019) across the two speech channels.
In contrast to the preserved prosodic advantage in recognition thresholds, we observed significant age-related differences in selective attention. When asked to focus on one speech channel, older adults were affected to a larger extent by the content of the other, irrelevant channel. This finding could be taken to support the age-related inhibitory deficit hypothesis (Hasher and Zacks, 1988; Ben-David et al., 2014), with older adults experiencing larger difficulties in inhibiting irrelevant information. Alternatively, our results could be based on an information degradation hypothesis (Schneider and Pichora-Fuller, 2000; Ben-David and Schneider, 2009, 2010), whereby age-related sensory changes lead to performance changes. In the current study, information in the prosodic and semantic channels was degraded to a similar extent due to auditory sensory degradation in aging. Clearly, pure-tone thresholds for older adults were significantly worse than for young adults (see Supplementary Appendix A). These and other age-related audiological changes (e.g., frequency selectivity and loudness recruitment; Füllgrabe, 2020) are likely to have had an impact on age-related sensory degradation of speech perception. Consequently, older adults in our study might have adopted a wider processing strategy and integrated information from both speech channels to form a clearer picture of the speaker’s intent (Hess, 2005, 2006, 2014). Whereas this strategy improves processing in congruent prosody-semantic sentences, it leads to failures in selective attention in incongruent sentences.
It is notable that older adults in our sample experienced a larger extent of hearing loss in the higher frequencies (4,000 and 8,000 Hz, see Supplementary Appendix A). This high-frequency hearing loss is common for older adults with clinically normal hearing (in the lower frequency ranges) recruited for speech processing studies (Dupuis and Pichora-Fuller, 2014, 2015; Nagar et al., 2022). It has been suggested that this age-related difference may have a specific effect on semantic processing, as many speech cues are available in a range around 4,000 Hz (Vinay and Moore, 2010); whereas prosodic cues, such as f0 and the envelope of speech, might still be preserved. Our findings do not necessarily support this option, as we found an equivalent SNR prosodic advantage for older and young adults. In other words, age-related sensory degradation appears to have had a similar impact on semantic and prosodic emotional processing in the current study. Thus, our results follow the literature indicating that age-related sensory changes are not the sole source of difficulties older adults experience when speech is presented in adverse listening conditions (Roberts and Allen, 2016). For example, Füllgrabe et al. (2015) found age-related deficits in speech-in-noise identification to persist even when audiograms for older and young adults were matched (see also Grassi and Borella, 2013). Following Cardin (2016), listening in adverse conditions becomes effortful in aging and demands more cognitive resources, thus speech processing is affected by age-related changes in both sensory and cognitive factors.
Caveats, Future Directions, and Implications
Limitations of the current study include relatively small numbers of participants in each age group. However, this number is not different than that found in the pertinent literature (e.g., 20 participants, Morgan, 2021). Even though the range of SNR used was large enough to include individual thresholds, future studies may increase the range to improve the assessment’s accuracy. In addition, the current study used speech-spectrum noise, a standard noise type widely used in age-related comparisons (Ben-David et al., 2011a,2012). Future studies may wish to test further types of auditory distortions (e.g., Ritter and Vongpaisal, 2018; Dor et al., 2020). Future studies may also test the effects of individual audiometric thresholds (see Grassi and Borella, 2013), demographic characteristics (e.g., gender, socio-economic status and education), as well as emotional traits and mental health (e.g., empathy and alexithymia, see Leshem et al., 2019) on emotion recognition thresholds. Indeed, mental health was also found to affect the recognition of negative and positive emotions differently (e.g., detection of emotionally negative words was related to PTSD and forensic schizophrenia; Cisler et al., 2011; Leshem et al., 2020). Finally, this study used a unique set of validated and standardized spoken sentences that present emotional content in both semantics and prosody. Future studies may wish to expand the scope of this study’s findings by using different sets of sentences.
In sum, the current study is the first to directly compare emotion recognition thresholds for spoken semantics and prosody in young and older adults. Mainly, we found a recognition threshold advantage for young over older adults, an advantage for prosody over semantics that was not affected by age group, and larger failures of selective attention for older adults. Previous studies indicate that older adults assign different relative weights to prosodic and semantic spoken emotions than do young adults, possibly resulting in an inter-generational communication breakdown (Dupuis and Pichora-Fuller, 2010; Ben-David et al., 2019). The current study does not support a sensory source for this age-related difference in speech processing, hinting to a possible cognitive source. Future studies should directly test whether processing of prosodic and semantic emotions demands a different extent of cognitive resources for young and older adults.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics Statement
The studies involving human participants were reviewed and approved by Ethics Committee of Reichamn University, Herzliya, Israel. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
YD and BB-D wrote the manuscript, they are responsible for the design of the paradigm, the analysis and interpretation of the data. DA and BB-D supervised the research project, DA and VS made invaluable contributions to the conceptualizing the research question and the final manuscript. BB-D is the corresponding author and the study was conducted in his lab. All authors had a prominent intellectual contribution to the study, are accountable for the data and approved the final version of the manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2022.846117/full#supplementary-material
References
Ben-David, B. M., Eidels, A., and Donkin, C. (2014). Effects of aging and distractors on detection of redundant visual targets and capacity: do older adults integrate visual targets differently than younger adults? PLoS One 9:e113551. doi: 10.1371/journal.pone.0113551
Ben-David, B. M., Erel, H., Goy, H., and Schneider, B. A. (2015). ‘Older is always better:’ age-related differences in vocabulary scores across 16 years. Psychol. Aging 30, 856–862 doi: 10.1037/pag0000051
Ben-David, B. M., Gal-Rosenblum, S., van Lieshout, P. H., and Shakuf, V. (2019). Age-related differences in the perception of emotion in spoken language: the relative roles of prosody and semantics. J. Speech Lang. Hear. Res. 62, 1188–1202. doi: 10.1044/2018_JSLHR-H-ASCC7-18-0166
Ben-David, B. M., and Icht, M. (2018). The effect of practice and visual feedback on oral-diadochokinetic rates for younger and older adults. Lang. Speech 61, 113–134. doi: 10.1177/0023830917708808
Ben-David, B. M., Mentzel, M., Icht, M., Gilad, M., Dor, Y. I., Ben-David, S., et al. (2021). Challenges and opportunities for telehealth assessment during COVID-19: iT-RES, adapting a remote version of the test for rating emotions in speech. Int. J. Audiol. 60, 319–321. doi: 10.1080/14992027.2020.1833255
Ben-David, B. M., Multani, N., Shakuf, V., Rudzicz, F., and van Lieshout, P. H. (2016). Prosody and semantics are separate but not separable channels in the perception of emotional speech: test for rating of emotions in speech. J. Speech Lang. Hear. Res. 59, 72–89. doi: 10.1044/2015_JSLHR-H-14-0323
Ben-David, B. M., and Schneider, B. A. (2009). A sensory origin for color-word Stroop effects in aging: a meta-analysis. Neuropsychol. Dev. Cogn. B Aging Neuropsychol. Cogn. 16, 505–534. doi: 10.1080/13825580902855862
Ben-David, B. M., and Schneider, B. A. (2010). A sensory origin for color-word Stroop effects in aging: simulating age-related changes in color-vision mimics age-related changes in Stroop. Neuropsychol. Dev. Cogn. B Aging Neuropsychol. Cogn. 17, 730–746. doi: 10.1080/13825585.2010.510553
Ben-David, B. M., Thayapararajah, A., and van Lieshout, P. H. (2013). A resource of validated digital audio recordings to assess identification of emotion in spoken language after a brain injury. Brain Inj. 27, 248–250. doi: 10.3109/02699052.2012.740648
Ben-David, B. M., Tse, V. Y., and Schneider, B. A. (2012). Does it take older adults longer than younger adults to perceptually segregate a speech target from a background masker? Hear. Res. 290, 55–63. doi: 10.1016/j.heares.2012.04.022
Ben-David, B. M., Chambers, C. G., Daneman, M., Pichora-Fuller, M. K., Reingold, E. M., and Schneider, B. A. (2011a). Effects of aging and noise on real-time spoken word recognition: evidence from eye movements. J. Speech Lang. Hear. Res. 54, 243–262. doi: 10.1044/1092-4388(2010/09-0233)
Ben-David, B. M., van Lieshout, P. H., and Leszcz, T. (2011b). A resource of validated affective and neutral sentences to assess identification of emotion in spoken language after a brain injury. Brain Inj. 25, 206–220. doi: 10.3109/02699052.2010.536197
Bilger, R. C., Nuetzel, J. M., Rabinowitz, W. M., and Rzeczkowski, C. (1984). Standardization of a test of speech perception in noise. J. Speech Lang. Hear. Res. 27, 32–48. doi: 10.1044/jshr.2701.32
Boersma, P., and Weenink, D. (2019). Praat: Doing Phonetics by Computer [Computer Program]. Version 6.1. Available online at: http://www.praat.org/ (accessed July 2019).
Cardin, V. (2016). Effects of aging and adult-onset hearing loss on cortical auditory regions. Front. Neurosci. 10:199. doi: 10.3389/fnins.2016.00199
Carl, M., Icht, M., and Ben-David, B. M. (2022). A cross-linguistic validation of the test for rating emotions in speech (T-RES): acoustic analyses of emotional sentences in English, German, and Hebrew. J. Speech Lang. Hear. Res. 65, 991–1000. doi: 10.1044/2021_JSLHR-21-00205
Castro, V. L., and Isaacowitz, D. M. (2019). The same with age: evidence for age-related similarities in interpersonal accuracy. J. Exp. Psychol. Gen. 148, 1517–1537. doi: 10.1037/xge0000540
Chan, E. K. H. (2014). “Standards and guidelines for validation practices: development and evaluation of measurement instruments,” in Validity and Validation in Social, Behavioral, and Health Sciences. Social Indicators Research Series, Vol. 54, B. Zumbo and E. Chan (Cham: Springer), 9–24. doi: 10.1007/978-3-319-07794-9_2
Cisler, J. M., Wolitzky-Taylor, K. B., Adams, T. G. Jr., Babson, K. A., Badour, C. L., and Willems, J. L. (2011). The emotional Stroop task and posttraumatic stress disorder: a meta-analysis. Clin. Psychol. Rev. 31, 817–828. doi: 10.1016/j.cpr.2011.03.007
Dmitrieva, E. S., and Gelman, V. Y. (2012). The relationship between the perception of emotional intonation of speech in conditions of interference and the acoustic parameters of speech signals in adults of different gender and age. Neurosci. Behav. Physiol. 42, 920–928. doi: 10.1007/s11055-012-9658-z
Dor, Y., Rosenblum, M., Kenet, D., Shakuf, V., Algom, D., and Ben-David, B. M. (2020). “Can you hear what I feel? Simulating high-frequency hearing loss mimics effects of aging and tinnitus in emotional speech perception,” in Proceedings of the 36th Annual Meeting of the International Society for Psychophysics Fechner Day 2020, eds J. R. Schoenherr, T. Hubbard, W. Stine, and C. Leth-Steensen (International Society for Psychophysics), 13–16.
Dupuis, K., and Pichora-Fuller, M. K. (2010). Use of affective prosody by young and older adults. Psychol. Aging 25, 16–29. doi: 10.1037/a0018777
Dupuis, K., and Pichora-Fuller, M. K. (2014). Intelligibility of emotional speech in younger and older adults. Ear Hear. 35, 695–707. doi: 10.1097/AUD.0000000000000082
Dupuis, K., and Pichora-Fuller, M. K. (2015). Aging affects identification of vocal emotions in semantically neutral sentences. J. Speech Lang. Hear. Res. 58, 1061–1076. doi: 10.1044/2015_JSLHR-H-14-0256
Fernald, A. (1989). Intonation and communicative intent in mothers’ speech to infants: is the melody the message? Child Dev. 60, 1497–1510. doi: 10.2307/1130938
Füllgrabe, C. (2020). On the possible overestimation of cognitive decline: the impact of age-related hearing loss on cognitive-test performance. Front. Neurosci. 14:454. doi: 10.3389/fnins.2020.00454
Füllgrabe, C., Moore, B. C., and Stone, M. A. (2015). Age-group differences in speech identification despite matched audiometrically normal hearing: contributions from auditory temporal processing and cognition. Front. Aging Neurosci. 6:347. doi: 10.3389/fnagi.2014.00347
Giroud, N., Keller, M., Hirsiger, S., Dellwo, V., and Meyer, M. (2019). Bridging the brain structure—brain function gap in prosodic speech processing in older adults. Neurobiol. Aging 80, 116–126. doi: 10.1016/j.neurobiolaging.2019.04.017
Goodman, L. (2001). Translation of WAIS-III - Wechsler Adult Intelligence Scale. Jerusalem: Psych tech.
Grandjean, D. (2021). Brain networks of emotional prosody processing. Emot. Rev. 13, 34–43. doi: 10.1177/1754073919898522
Grassi, M., and Borella, E. (2013). The role of auditory abilities in basic mechanisms of cognition in older adults. Front. Aging Neurosci. 5:59. doi: 10.3389/fnagi.2013.00059
Grunwald, I. S., Borod, J. C., Obler, L. K., Erhan, H. M., Pick, L. H., Welkowitz, J., et al. (1999). The effects of age and gender on the perception of lexical emotion. Appl. Neuropsychol. 6, 226–238. doi: 10.1207/s15324826an0604_5
Harel-Arbeli, T., Wingfield, A., Palgi, Y., and Ben-David, B. M. (2021). Age-related differences in the online processing of spoken semantic context and the effect of semantic competition: evidence from eye gaze. J. Speech Lang. Hear. Res. 64, 315–327. doi: 10.1044/2020_JSLHR-20-00142
Hasher, L., and Zacks, R. T. (1988). Working memory, comprehension, and aging: a review and a new view. Psychol. Learn. Motiv. 22, 193–225. doi: 10.1016/S0079-7421(08)60041-9
Heinrich, A., Gagne, J. P., Viljanen, A., Levy, D. A., Ben-David, B. M., and Schneider, B. A. (2016). Effective communication as a fundamental aspect of active aging and well-being: paying attention to the challenges older adults face in noisy environments. Soc. Inq. Well Being 2, 51–69. doi: 10.13165/SIIW-16-2-1-05
Helfer, K. S., Merchant, G. R., and Wasiuk, P. A. (2017). Age-related changes in objective and subjective speech perception in complex listening environments. J. Speech Lang. Hear. Res. 60, 3009–3018. doi: 10.1044/2017_JSLHR-H-17-0030
Henry, J. D., and Crawford, J. R. (2005). The short-form version of the Depression Anxiety Stress Scales (DASS-21): construct validity and normative data in a large non-clinical sample. Br. J. Clin. Psychol. 44, 227–239. doi: 10.1348/014466505X29657
Hess, T. M. (2005). Memory and aging in context. Psychol. Bull. 131, 383–406. doi: 10.1037/0033-2909.131.3.383
Hess, T. M. (2006). Adaptive aspects of social cognitive functioning in adulthood: age–related goal and knowledge influences. Soc. Cogn. 24, 279–309. doi: 10.1521/soco.2006.24.3.279
Hess, T. M. (2014). Selective engagement of cognitive resources: motivational influences on older adults’ cognitive functioning. Perspect. Psychol. Sci. 9, 388–407. doi: 10.1177/1745691614527465
House, J. (2007). The role of prosody in constraining context selection: a procedural approach. Nouv. Cah. Linguist. Fr. 28, 369–383.
Isaacowitz, D. M., Löckenhoff, C. E., Lane, R. D., Wright, R., Sechrest, L., Riedel, R., et al. (2007). Age differences in recognition of emotion in lexical stimuli and facial expressions. Psychol. Aging 22, 147–159. doi: 10.1037/0882-7974.22.1.147
Kaufman, A. S., Reynolds, C. R., and McLean, J. E. (1989). Age and WAIS–R intelligence in a national sample of adults in the 20- to 74-year age range: a cross-sectional analysis with educational level controlled. Intelligence 13, 235–253. doi: 10.1016/0160-2896(89)90020-2
Lambrecht, L., Kreifelts, B., and Wildgruber, D. (2012). Age-related decrease in recognition of emotional facial and prosodic expressions. Emotion 12, 529–539. doi: 10.1037/a0026827
Leshem, R., Icht, M., Bentzur, R., and Ben-David, B. M. (2020). Processing of emotions in speech in forensic patients with schizophrenia: impairments in identification, selective attention, and integration of speech channels. Front. Psychiatry 11:601763. doi: 10.3389/fpsyt.2020.601763
Leshem, R., van Lieshout, P. H. H. M., Ben-David, S., and Ben-David, B. M. (2019). Does emotion matter? The role of alexithymia in violent recidivism: a systematic literature review. Crim. Behav. Ment. Health 29, 94–110. doi: 10.1002/cbm.2110
Livingston, G., Sommerlad, A., Orgeta, V., Costafreda, S. G., Huntley, J., Ames, D., et al. (2017). Dementia prevention, intervention, and care. Lancet 390, 2673–2734. doi: 10.1016/S0140-6736(17)31363-6
Mather, M. (2016). The affective neuroscience of aging. Annu. Rev. Psychol. 67, 213–238. doi: 10.1146/annurev-psych-122414-033540
McMurray, B. (2017). Nonlinear Curvefitting for Psycholinguistics (Version 13). Available online at: https://osf.io/4atgv/ (accessed November 21, 2021).
Melara, R. D., and Algom, D. (2003). Driven by information: a tectonic theory of Stroop effects. Psychol. Rev. 110, 422–471. doi: 10.1037/0033-295X.110.3.422
Mitchell, R. L. (2007). Age-related decline in the ability to decode emotional prosody: primary or secondary phenomenon? Cogn. Emot. 21, 1435–1454. doi: 10.1080/02699930601133994
Mitchell, R. L., and Kingston, R. A. (2011). Is age-related decline in vocal emotion identification an artefact of labelling cognitions? Int. J. Psychol. Stud. 3, 156–163. doi: 10.5539/ijps.v3n2p156
Morgan, S. D. (2021). Comparing emotion recognition and word recognition in background noise. J. Speech Lang. Hear. Res. 64, 1758–1772. doi: 10.1044/2021_JSLHR-20-00153
Morgan, S. D., Garrard, S., and Hoskins, T. (2022). Emotion and word recognition for unprocessed and vocoded speech stimuli. Ear Hear. 43, 398–407. doi: 10.1097/AUD.0000000000001100
Murphy, D. R., Craik, F. I., Li, K. Z., and Schneider, B. A. (2000). Comparing the effects of aging and background noise on short-term memory performance. Psychol. Aging 15, 323–334. doi: 10.1037/0882-7974.15.2.323
Myers, B. R., Lense, M. D., and Gordon, R. L. (2019). Pushing the envelope: developments in neural entrainment to speech and the biological underpinnings of prosody perception. Brain Sci. 9:70. doi: 10.3390/brainsci9030070
Nagar, S., Mikulincer, M., Nitsan, G., and Ben-David, B. M. (2022). Safe and sound: the effects of experimentally priming the sense of attachment security on pure-tone audiometric thresholds among young and older adults. Psychol. Sci. 33, 424–432. doi: 10.1177/09567976211042008
Nitsan, G., Wingfield, A., Lavie, L., and Ben-David, B. M. (2019). Differences in working memory capacity affect online spoken word recognition: evidence from eye movements. Trends Hear. 23, 1–12. doi: 10.1177/2331216519839624
Orbelo, D. M., Grim, M. A., Talbott, R. E., and Ross, E. D. (2005). Impaired comprehension of affective prosody in elderly subjects is not predicted by age-related hearing loss or age-related cognitive decline. J. Geriatr. Psychiatry Neurol. 18, 25–32. doi: 10.1177/0891988704272214
Paulmann, S., Pell, M. D., and Kotz, S. A. (2008). How aging affects the recognition of emotional speech. Brain Lang. 104, 262–269. doi: 10.1016/j.bandl.2007.03.002
Pell, M. D., and Kotz, S. A. (2021). Comment: the next frontier: prosody research gets interpersonal. Emot. Rev. 13, 51–56. doi: 10.1177/1754073920954288
Phillips, L. H., MacLean, R. D., and Allen, R. (2002). Age and the understanding of emotions: neuropsychological and sociocognitive perspectives. J. Gerontol. B Psychol. Sci. Soc. Sci. 57, 526–530. doi: 10.1093/geronb/57.6.P526
Pichora-Fuller, M. K., Schneider, B. A., and Daneman, M. (1995). How young and old adults listen to and remember speech in noise. J. Acoust. Soc. Am. 97, 593–608. doi: 10.1121/1.412282
Pichora-Fuller, M. K., and Souza, P. E. (2003). Effects of aging on auditory processing of speech. Int. J. Audiol. 42(Suppl. 2) 11–16. doi: 10.3109/14992020309074638
Ritter, C., and Vongpaisal, T. (2018). Multimodal and spectral degradation effects on speech and emotion recognition in adult listeners. Trends Hear. 22, 1–17. doi: 10.1177/2331216518804966
Roberts, K. L., and Allen, H. A. (2016). Perception and cognition in the aging brain: a brief review of the short-and long-term links between perceptual and cognitive decline. Front. Aging Neurosci. 8:39. doi: 10.3389/fnagi.2016.00039
Ruffman, T., Henry, J. D., Livingstone, V., and Phillips, L. H. (2008). A meta-analytic review of emotion recognition and aging: implications for neuropsychological models of aging. Neurosci. Biobehav. Rev. 32, 863–881. doi: 10.1016/j.neubiorev.2008.01.001
Schneider, B. A., and Pichora-Fuller, M. K. (2000). “Implications of perceptual deterioration for cognitive aging research,” in The Handbook of Aging and Cognition, eds F. I. M. Craik and T. A. Salthouse (London: Lawrence Erlbaum Associates Publishers), 155–219
Taitelbaum-Swead, R., Icht, M., and Ben-David, B. M. (2022). More than words: the relative roles of prosody and semantics in the perception of emotions in spoken language by postlingual cochlear implant recipients. Ear Hear. [Epub ahead of print]. doi: 10.1097/AUD.0000000000001199
van Zyl, M., and Hanekom, J. J. (2011). Speech perception in noise: a comparison between sentence and prosody recognition. J. Hear. Sci. 1, 54–56.
Vinay Moore, B. C. (2010). Psychophysical tuning curves and recognition of highpass and lowpass filtered speech for a person with an inverted V-shaped audiogram. J. Acoust. Soc. Am. 127, 660–663. doi: 10.1121/1.3277218
Wingfield, A., and Tun, P. A. (2001). Spoken language comprehension in older adults: interactions between sensory and cognitive change in normal aging. Semin. Hear. 22, 287–302. doi: 10.1055/s-2001-15632
Keywords: auditory processing, speech perception, aging, semantics, emotions, noise, auditory sensory-cognitive interactions, prosody
Citation: Dor YI, Algom D, Shakuf V and Ben-David BM (2022) Age-Related Changes in the Perception of Emotions in Speech: Assessing Thresholds of Prosody and Semantics Recognition in Noise for Young and Older Adults. Front. Neurosci. 16:846117. doi: 10.3389/fnins.2022.846117
Received: 30 December 2021; Accepted: 14 March 2022;
Published: 25 April 2022.
Edited by:
Leah Fostick, Ariel University, IsraelReviewed by:
Uwe Baumann, University Hospital Frankfurt, GermanyPatrizia Mancini, Sapienza University of Rome, Italy
Copyright © 2022 Dor, Algom, Shakuf and Ben-David. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Boaz M. Ben-David, Ym9hei5iZW4uZGF2aWRAaWRjLmFjLmls