 Ruiquan Chen1
Ruiquan Chen1 Guanghua Xu
Guanghua Xu- 1School of Mechanical Engineering, Xi’an Jiaotong University, Xi’an, China
- 2State Key Laboratory for Manufacturing Systems Engineering, School of Mechanical Engineering, Xi’an Jiaotong University, Xi’an, China
Objective: Compared with the light-flashing paradigm, the ring-shaped motion checkerboard patterns avoid uncomfortable flicker or brightness modulation, improving the practical interactivity of brain-computer interface (BCI) applications. However, due to fewer harmonic responses and more concentrated frequency energy elicited by the ring-shaped checkerboard patterns, the mainstream untrained algorithms such as canonical correlation analysis (CCA) and filter bank canonical correlation analysis (FBCCA) methods have poor recognition performance and low information transmission rate (ITR).
Methods: To address this issue, a novel untrained SSVEP-EEG feature enhancement method using CCA and underdamped second-order stochastic resonance (USSR) is proposed to extract electroencephalogram (EEG) features.
Results: In contrast to typical unsupervised dimensionality reduction methods such as common average reference (CAR), principal component analysis (PCA), multidimensional scaling (MDS), and locally linear embedding (LLE), CCA exhibits higher adaptability for SSVEP rhythm components.
Conclusion: This study recruits 42 subjects to evaluate the proposed method and experimental results show that the untrained method can achieve higher detection accuracy and robustness.
Significance: This untrained method provides the possibility of applying a nonlinear model from one-dimensional signals to multi-dimensional signals.
1. Introduction
Brain-computer interface (BCI) is a normal output pathway system that does not rely on the composition of peripheral nerves and muscles, and can directly convert central nervous activities into artificial output (Vidal, 1973; Li et al., 2017; Jin et al., 2021).
Steady-state visual evoked potentials (SSVEPs) based on BCI systems have the advantages of short training time, high signal-to-noise ratio, and short response time, and are widely used in clinical detection technology (Li et al., 2022). When an external visual stimulus of constant frequencies is applied, the neural network consistent with the stimulation frequency or harmonic components will generate resonance, causing the brain’s potential activity to change significantly at the stimulation frequency or harmonic components, resulting in SSVEP signals. SSVEP signals can exhibit spectral peaks at stimulation frequency or harmonic components in the power spectrum of EEG signals (Kramer et al., 2021). By analyzing and detecting the frequency corresponding to the spectral peak, it is possible to detect the stimulus source of the subject’s visual gaze, thereby identifying the subject’s intention. However, although SSVEP induced by the motion checkerboard paradigm can reduce visual fatigue in subjects, due to its generation mechanism, there are almost no harmonic components and frequency energy is more concentrative, thus leading to low recognition accuracy (Han et al., 2018).
The first application in SSVEP feature classification is the Power Spectral Density Analysis (PSDA) algorithm (Ming Cheng et al., 2002), which uses the Fast Fourier Transform (FFT) to convert SSVEP signals from the time domain to the frequency domain, thereby obtaining the amplitude and phase characteristics of each stimulus frequency. Because this method only analyzes one electrode signal in multi-channel signals, the obtained signal has a low signal-to-noise ratio (SNR). Wavelet Transform (WT) can be regarded as a Fourier Transform with an adjustable window, which provides both relevant frequency components and occurrence time information, but it still cannot identify nonlinear signals well (Hu et al., 2014). Volosyak et al. proposed the Minimum Energy Combination (MEC) algorithm (Friman et al., 2007), which mainly seeks a spatial filter to project multi-channel signals into low dimensional space. MEC can effectively reduce background noise, but useful information in EEG signals may be lost in the linear transformation. The canonical correlation analysis (CCA) algorithm was first applied to SSVEP classification by Lin et al. (2006). CCA mainly projects multi-channel SSVEP signals and corresponding reference signals into a low dimensional space through a spatial filter and then calculates the correlation between the two. The maximum value of the correlation coefficient corresponds to the stimulation frequency, which is superior to the MEC algorithm. Currently, many variants of the CCA method have achieved excellent BCI performance, such as multi-way canonical correlation analysis (MwayCCA; Zhang et al., 2011), multi-set canonical correlation analysis (MestCCA; Zhang et al., 2014a), Filter bank canonical correlation analysis (FBCCA; Chen and Gao, 2015), Task-related component analysis (TRCA; Nakanishi et al., 2017), Task-discriminant component analysis (TDCA; Liu et al., 2021) and so on. Among them, the FBCCA method is the most effective and widely used untrained method in SSVEP-EEG detection technology. Nevertheless, due to the low harmonic components of SSVEP induced by motion checkerboard patterns, the FBCCA method cannot play its role. In addition, some novel methods, such as multivariate synchronization index (Zhang et al., 2014b), likelihood ratio test (Zhang et al., 2014c), and stochastic resonance analysis (Chen et al., 2021a), have also proven to have unique advantages in SSVEP recognition.
Benzi et al. (1981) first proposed the concept of stochastic resonance (SR) when studying the problem of global glacial periods, and successfully applied it to explain the phenomenon of periodic changes in paleoclimate. Shortly after, Fauve and Heslot (1983) observed the phenomenon of SR while studying the synchronization of noise-induced transitions in a bistable system experiment with a trigger circuit. Mcnamara et al. (1988) once again verified the existence of bistable stochastic resonance (BSR) in the ring laser experiment. Collins et al. (1995) first extended SR theory to the field of aperiodic signal processing when studying FitzHugh Nagumo (FHN) neuron models. Recently, Chen et al. (2021a,b) and Chen et al. (2022) demonstrated in experiments that the FHN neuron model can effectively enhance the feature responses of EEG signals, thereby improving recognition accuracy, regardless of the time domain, frequency domain, or time-frequency domain. Lu et al. (2015) proposed underdamped second-order stochastic resonance (USSR) to improve weak signal detection technology. This novel model considers the system inertia and underdamped damping factor based on bistable stochastic resonance (BSR), which is more conducive to high SNR output. Traditional denoising methods improve the SNR by suppressing noise, which may result in the loss of useful features. However, SR utilizes the synergistic effects of input signals, noise, and resonance systems to enhance feature responses of signals, and has excellent nonlinear signal detection capabilities with noise immunity.
The main contribution of this study is to propose a novel untrained SSVEP feature enhancement method using CCA dimensionality reduction technology and the USSR model. Compared with mainstream unsupervised dimensionality reduction methods, such as common average reference (CAR; Orekhova et al., 2002), principal component analysis (PCA; Wold et al., 1987), multidimensional scaling (MDS; Saeed et al., 2018), and locally linear embedding (LLE; De Ridder et al., 2003), the CCA method reflects a high degree of matching with SSVEP signals. Experimental results show that the CCA-USSR method has higher recognition accuracy, ITR, and better robustness in all subjects.
The rest of this article is arranged as follows: section 2 introduces in detail typical dimensionality reduction methods and the novel CCA-USSR framework proposed in this study. In section 3, the specific experiments and results obtained by different methods are explained. Compared with the CAR, PCA, MDS, and LLE methods, the CCA-USSR method showed a better BCI performance in all subjects. The processing results of each method are discussed in section 4. Finally, section 5 provides the conclusions.
2. Methodology
2.1. The USSR model and standard FBCCA method
2.1.1. USSR
The Langevin equation for the BSR model is an overdamped first-order differential equation due to neglecting the inertia term and normalizing the damping factor. Nevertheless, it has been proven (Lu et al., 2015) that the system inertia and damping factor can facilitate high-SNR output. Considering these two factors, the BSR model is improved into a second-order differential equation which is called the USSR model. Hence, the USSR model can be expressed as
where and are the system parameters satisfying , is the output signal, is the input signal. is the Gaussian white noise with a mean value of zero and an autocorrelation function satisfying (Wu and Zhu, 2008); represents the overall mean value; is the damping factor. The fourth-order Runge-Kuta algorithm with fixed steps is used to solve the differential equations with higher solution accuracy. To meet the needs of differential equation calculation, the input signal needs to be transformed into a one-dimensional vector.
2.1.2. FBCCA
As a standard untrained SSVEP recognition algorithm, the FBCCA method uses CCA to calculate the canonical correlation coefficient of each sub-band signal which is divided via multiple filter banks. The feature discrimination coefficient at the -th target frequency is obtained by
where is the weight of the -th sub-band signal which can be obtained by
As previously reported (Chen et al., 2015), and constants are set to 1.25 and 0.25.
2.2. Typical unsupervised dimensionality reduction methods
Data dimensionality reduction can be used as a means of feature extraction: to identify the main features from the original features of the dataset, that is, the features that best describe the distribution of data in the dataset. In other words, while preserving the main features of the dataset, high-dimensional data is projected into a low-dimensional feature space. Since the input requirement of the USSR model is a one-dimensional vector, a data dimensionality reduction method that matches the EEG rhythm features is required. The following describes five typical unsupervised dimensionality reduction methods.
2.2.1. CAR
The principle is to calculate the average signal of all recording electrodes, and then subtract this average value from the selected reference electrode. However, the method is influenced strongly by high-amplitude artifacts at the selected reference electrode. Therefore, the selection of reference electrodes is crucial for the CAR method. The single-electrode output potential between the electrode and the reference electrode can be expressed as
Where is the selected reference signal, is the number of electrodes.
2.2.2. PCA
It is one of the most popular unsupervised linear dimensionality reduction methods nowadays. Its main idea is to obtain a new matrix with the largest variance in the projected dimension after data is multiplied by a matrix, thereby using fewer data dimensions while retaining the characteristics of more original data. The measure of information quantity is the variance of data, which is described as follows
where is the -th transformation vector, Σ is the covariance matrix of the original data, is the -th principal component, is the variance of the -th principal component.
The PCA method uses orthogonal transformations to convert the observed data into principal components represented by linear independent variables, the number of which is usually smaller than the number of original variables. Thus, PCA is a common dimensionality reduction method using the linear projection rule.
2.2.3. MDS
It uses the paired similarity of samples to construct a low-dimensional space so that the distance of each pair of samples in the high-dimensional space is as consistent as possible with the sample similarity in the constructed low-dimensional space. A greater similarity between two objects can be reflected by a smaller distance in MDS space. The basic principle is described by
where is the dissimilarity between samples j and k, p is the number of properties used to perform MDS, and y is the elemental concentration or index in this study.
Hence, classic MDS performs dimensionality reduction on high-dimensional data while ensuring a consistent distance between the original space and low-dimensional spatial samples.
2.2.4. LLE
It is one of the commonly used manifold learning methods and a nonlinear dimensionality reduction method suitable for processing nonlinear data. It is based on the manifold assumption that data in high-dimensional space is distributed on low-dimensional manifolds. The LLE dimensionality reduction method can be described as the following three steps:
1. For each data point , find its nearest neighbors.
2. Compute the reconstruction weights of the neighbors that minimize the error of reconstructing .
Subject to , if , and .
1. Compute the low-dimensional embedding Y for that best preserves the local geometry represented by the reconstruction weights.
Subject to , and , where 0 is a column vector of zeros and is an identity matrix. By the Rayleigh-Ritz theorem (Luce and Perry, 1949), minimizing (10) with respect to the ’s can be done via finding the eigenvectors with the smallest (nonzero) eigenvalues.
2.2.5. CCA
The projection principle selected by the CCA method is that after dimensionality reduction, the correlation coefficient of the two sets of data is the largest. For input EEG data and the reference signal , the goal of CCA is to find weight vectors and , so that the one-dimensional vectors obtained after and projection are and , respectively. Therefore, one-dimensional vectors are obtained by
The optimization goal of the CCA dimensionality reduction method is to maximize to obtain the corresponding projection vectors and . Then the correlation coefficient between weight vectors and was calculated by
The frequency corresponding to the maximum correlation coefficient is regarded as the gaze target of the subjects.
The template signals of the CCA method are given by
where k is the number of harmonics of SSVEP signals; is the stimulation frequency of the template signals; N is the number of sample points; is the sampling frequency.
2.3. Feature enhancement for SSVEP using canonical correlation analysis and underdamped second-order stochastic resonance
When the human eye receives a fixed frequency of visual stimulation, the potential activity of the cerebral cortex will be modulated to produce a continuous response related to the stimulation frequency. This response has a periodic rhythm similar to the visual stimulation, that is, the steady-state visual evoked potential. The SSVEP signal can exhibit spectral peaks at the stimulus frequency or harmonic components in the power spectrum. By analyzing the frequency corresponding to the spectral peak, the stimulus source of the subject’s visual gaze can be detected, thereby identifying the subject’s intention. The novel untrained framework based on the CCA dimensionality reduction method and USSR model proposed in this study is shown in Figure 1. Detailed procedures are described as follows:

Figure 1. The flowchart of SSVEP detection using the CCA dimensionality reduction method and USSR model.
a. Signal acquisition and preprocessing. Since the raw SSVEP signals are usually weak and mixed with multi-scale noise, it is difficult to extract gaze frequencies in a single trial. Some preprocessing steps such as filtering techniques need to be used to remove noise interference. As previously described (Han et al., 2018), since the motion checkerboard pattern has few harmonic components, in our study, we only consider the fundamental frequency and the primary harmonic to achieve the highest ITR. Hence, a Butterworth filter with a passband range of 3–40 Hz is selected to remove noise and some high-frequency components.
b. Dimensionality reduction. Although the SR model can effectively enhance the feature frequency of SSVEP signals, due to the characteristic of its differential equation, the input signal needs to be transformed into a one-dimensional vector. Common unsupervised dimensionality reduction methods include CAR, PCA, MDS, LLE, and CCA. In our study, these methods are compared to get the optimal dimensionality reduction methods. In the CAR method, we choose the Oz channel as the reference channel. The experimental results indicate that the Oz channel has the highest recognition accuracy compared with other channels. In the LLE method, the number of nearest neighbor points is set to 40.
c. SSVEP feature enhancement. Typical SR models include BSR, FHN, and USSR, among which the USSR model has the best BCI performance despite having the most parameters (Chen et al., 2023). Therefore, in this study, the USSR model was used as a means of feature enhancement.
d. SSVEP feature recognition. Then, PSDA and CCA recognition methods are used to identify the subjects’ gaze targets.
e. Target discrimination. Finally, the recognition accuracy is obtained by matching the recognition frequency with the stimulus frequency.
3. Experiment and results
3.1. Experiments and datasets
The experiment data included 30 males and 12 females (42 subjects, average age ± SD, 27.2 ± 2.6) originating from Chen et al. (2023). Each subject has a normal or corrected vision.
The ring-shaped checkerboards with radial contraction–expansion motion were adopted as the visual stimuli in our experiment. The stimulus paradigm was arranged into a 5 × 7 matrix with a horizontal and vertical separation of 100 pixels and 50 pixels between two adjacent stimuli, respectively. The frequency range of 35 focused targets was 3–20 Hz with a frequency interval of 0.5 Hz. The 35 focused frequencies for each trial were presented simultaneously with the data sampled at 1,000 Hz, as shown in Figure 2. The g.USBamp (g.tec Inc., Austria) was utilized to record SSVEP signals and the channels were set according to the 10/20 electrode system. These eight electrodes POz, PO3, PO4, PO5, PO6, Oz, O1, and O2 were used to record the raw SSVEP signal. SSVEP is a specific EEG signal generated by the occipital region of the brain. These eight electrodes are located closest to the occipital lobe, so the signals collected by them are less noisy and more stable. Each subject is required to conduct 35 trials, each consisting of 0.3 s of cues, 3 s of visual stimuli, and 0.7 s of rest time. The experimental conditions can be found in the study (Chen et al., 2021a). The experimental process is displayed in Figure 3.

Figure 2. The user interface of the 35 focused targets.
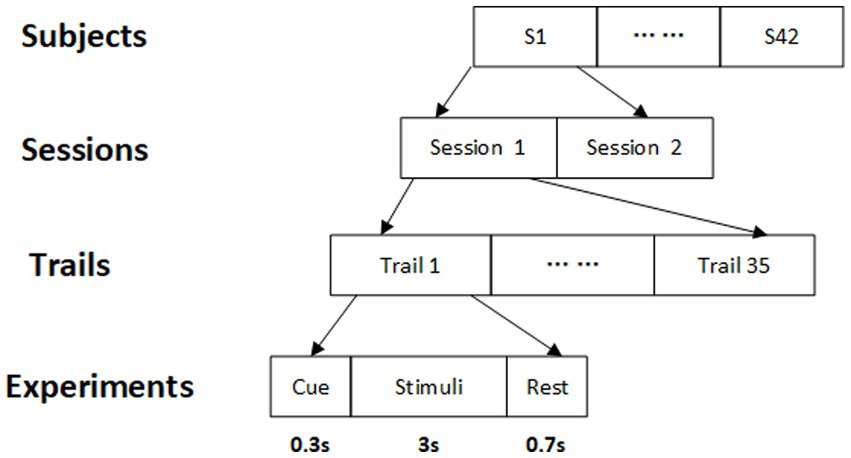
Figure 3. The experimental process.
3.2. CCA coefficient spectrums analysis for SSVEP
Based on the above analysis, we know that the SR model can utilize the noise energy to enhance the target frequency through synergistic effects and noise immunity. Therefore, the main research direction of this paper is to preserve as many effective features as possible in the original multi-channel signals. As representative dimensionality reduction methods among the eight methods, we compared the coefficient spectrums of CCA, PCA-USSR, LLE-USSR, and CCA-USSR in Figure 4. In this study, the representative subject (S29) with the 2 s data length was utilized to compare the BCI performance. The correlation coefficient between the processed SSVEP signal and the reference signal at a 0.5 frequency interval of 1-40 Hz is described as the CCA coefficient spectrum in our study.

Figure 4. (A) The coefficient spectrums of the CCA method. (B) The coefficient spectrums of the PCA-USSR method. (C) The coefficient spectrums of the LLE-USSR method. (D) The coefficient spectrums of the CCA-USSR method.
The CCA coefficient spectrum between the filtered EEG and the template is presented in Figure 4A. As a classic SSVEP recognition method, the CCA method can effectively identify the target frequency of most subjects. For example, the CCA coefficients corresponding to the seven target frequencies of 3, 7, 3.5, 11.5, 6, 9, and 11 Hz (the CCA spectrums marked by the green box) have the maximum amplitude in the entire spectrum and the recognition succeeds. However, it is worth noting that in these successful cases, the amplitudes of several interference peaks are very close to that of the target frequencies, making the recognition effect not ideal. On the other hand, the CCA coefficients corresponding to the five frequencies of 15, 16, 12, 19, and 14.5 Hz (the CCA spectrums marked by red boxes) have not the maximum amplitude in the CCA spectrum, and their amplitudes are second only to the maximum interference peak. Hence, the feature extraction for SSVEP recognition finally fails and there is a need for new methods to enhance the energy of the target frequency and improve the BCI decoding performance under the motion checkerboard pattern.
According to the previous study (Yao et al., 2019), the optimal parameter combination for the USSR model is [a, b, 𝛽, h] = [0.1, 1, 0.35, 0.1].
Compared with the CCA method, the USSR-based methods reduce the amplitude of interference peaks in the CCA coefficient spectrum and increase the energy of the target frequency, making BCI recognition more accurate. The amplitude of target frequencies depends on the matching between the dimensionality reduction method and the SSVEP rhythm components. As shown in Figure 4B, in the corresponding coefficient spectrums at 17, 16, 12, 19, and 18.5 Hz (the coefficient spectrums marked in green boxes), which cannot be correctly identified by the CCA method, the amplitudes of the focused frequencies are enhanced by the PCA-USSR model and have exceeded the amplitude of the interference peaks. However, for the corresponding coefficient spectrums of 4.5, 7, 3.5, and 8 Hz (the coefficient spectrums marked in red boxes), the PCA-USSR method cannot accurately identify target frequencies. As shown in Figure 4C, the combination of the nonlinear LLE method and the USSR model has similar results compared with the linear dimensionality reduction method. For target frequencies that cannot be identified by the CCA method, some can be corrected by the LLE-USSR method, while others cannot be identified.
As shown in Figure 4D, compared with the typical PCA-USSR and LLE-USSR methods, the CCA-USSR method can significantly increase the amplitude of the target frequency and has an energy concentration effect that matches the checkerboard pattern. Therefore, compared with the CCA method, the recognition accuracy of target frequency has increased by approximately 43%. For example, for the seven frequencies of 17, 9.5, 11.5, 10, 8.5, 19.5, and 4 Hz that cannot be identified by the LLE-USSR method, the USSR model can further enhance the energy of the target frequency and optimize the SSVEP recognition performance. While, in the power spectrums corresponding to 3, 3.5, 5, and 8 Hz, since the CCA dimensionality reduction method does not retain the effective features of the original SSVEP well, the USSR model incorrectly enhances the energy of other frequencies, resulting in recognition failure.
The above analysis has demonstrated that the CCA dimensionality reduction method can preserve the effective features of the original signal to the greatest extent and the nonlinear weak feature enhancement based on USSR dynamics models is highly compatible with the non-stationary SSVEP. The USSR model takes advantage of the unique conversion of noise energy to signal energy, thereby enhancing the amplitude and the energy of focused targets and improving the BCI decoding performance. Table 1 shows the average accuracy and ITR of 42 subjects based on five dimensionality reduction methods and two standard methods for processing SSVEP signals (Data length T = 2 s).
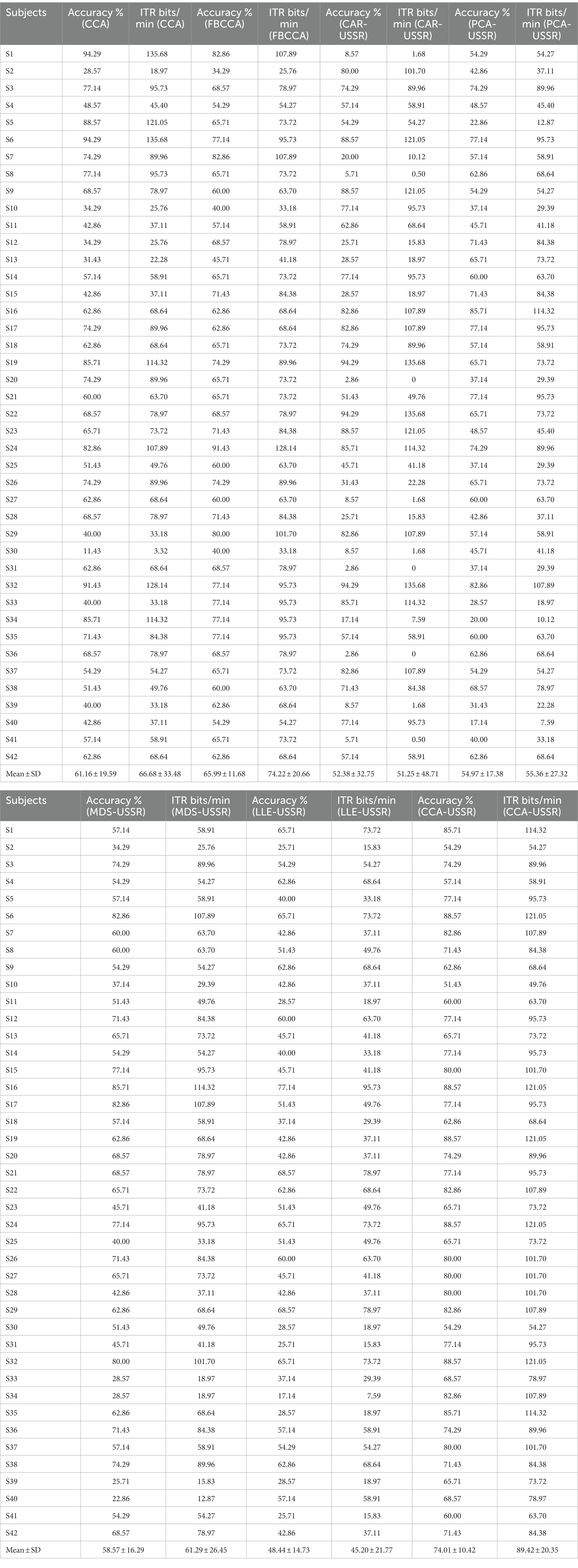
Table 1. Detection performance using the five methods (T = 2 s).
3.3. BCI performance
Here, paired t-tests were performed to determine significant differences (defined as p < 0.05) in accuracy and ITR for different methods. The information transfer rate (ITR) is an important and effective indicator to measure SSVEP-BCI recognition performance among different methods. It is used to express the amount of information transmitted in a unit of time. ITR can be obtained by
where σ refers to the average recognition accuracy, M refers to the number of gaze frequencies and T refers to the data length for analysis.
The higher the average recognition accuracy, the larger the number of gaze targets, the shorter the used data length, and the higher the obtained ITR. Meanwhile, the data length also affects recognition accuracy. For example, too short a data length may result in fewer recognizable SSVEP features and a decrease in recognition accuracy.
Using the classic CCA method to identify the gaze frequencies of 42 subjects can achieve an average accuracy of 61.16 ± 19.59 and an ITR of 66.68 ± 33.48. As the state-of-the-art method for SSVEP recognition, the average accuracy and ITR of FBCCA are increased to 65.99 ± 11.68 and 74.22 ± 20.66 bits/min, respectively.
It is worth noting that the CAR-USSR method is not only affected by the reference channel but also has the worst robustness among the five dimensionality reduction methods with a variance of 48.71 in the ITR. Nevertheless, there is no significant difference between the CAR-USSR, PCA-USSR, MDS-USSR, and LLE-USSR methods (p > 0.05).
As a representative of nonlinear manifold learning methods, the recognition accuracy of the LLE-USSR method greatly depends on the number of nearest neighbors. Meanwhile, from the experimental results, it can be seen that although the number of nearest neighbors is set to 40, the LLE-USSR method has not achieved competitive BCI performance. Compared with other dimensionality reduction methods, CCA can retain the most features of multi-channel SSVEP signals and the CCA-USSR method has the highest recognition accuracy, ITR, and robustness (p < 0.05). Meanwhile, compared with typical CCA and FBCCA methods, the CCA-USSR method is also more suitable for SSVEP signals induced by the motion checkerboard paradigm (p < 0.05). Hence, we can conclude that CCA is currently the best dimensionality reduction method in EEG signals, and the untrained CCA-USSR method can achieve satisfactory results in real-time BCI applications and spectral analysis.
The analysis data length of SSVEP signals is also an important indicator that significantly affects recognition accuracy and ITR. Here, Figure 5 compares the average recognition accuracy and ITR of CCA, FBCCA, and USSR-based methods under different data lengths (3, 2.5, 2, 1.5, and 1 s).

Figure 5. (A) Average accuracy using the CCA recognition method. (B) Average ITR using the CCA recognition method. (C) Average accuracy using the PSDA recognition method. (D) Average ITR using the PSDA recognition method.
From Figure 5, each method exhibits reliable results compared with the previous study (Yan et al., 2021), and among these methods, the CCA-USSR method has the highest recognition accuracy and ITR from 1 to 3 s data length. Note that due to the lack of harmonic components in the SSVEP signal induced by the motion checkerboard paradigm, the FBCCA method did not achieve ideal results in our study. Especially, based on PSDA recognition methods, all USSR-based methods can achieve the best BCI decoding performance only at 2 s date length. The experimental results show that the CCA-USSR method can significantly outperform the classic CCA and FBCCA methods, as well as other USSR-based methods, at any data length (p < 0.05). This also indicates that the CCA method has a high degree of matching with SSVEP, which can retain the most features of the original multi-channel signal after dimensionality reduction. In addition, the CAR-USSR method has excellent BCI performance comparable to the classic CCA method at 1 s data length. One possible explanation is that CAR relies on electrode selection, so when the data length is shorter, the CAR-USSR method can show better BCI decoding ability. On the other hand, it is not difficult to infer that the nonlinear LLE method is not suitable for non-stationary SSVEP signals. One hypothesis is that multi-channel SSVEP signals do not meet the manifold distribution assumption of input signals. The rationale we get from the experimental results is that although multi-scale noise may have negative effects on SSVEP recognition, the CCA dimensionality reduction method can retain the most features of the original multi-channel SSVEP signal, and the USSR model can use noise energy to enhance the amplitude of the target frequency, thereby improving the detection accuracy and ITR of SSVEP decoding.
Besides, the processing time of unsupervised dimensionality reduction methods was detected to further compare the online calculation ability of different methods in Table 2.
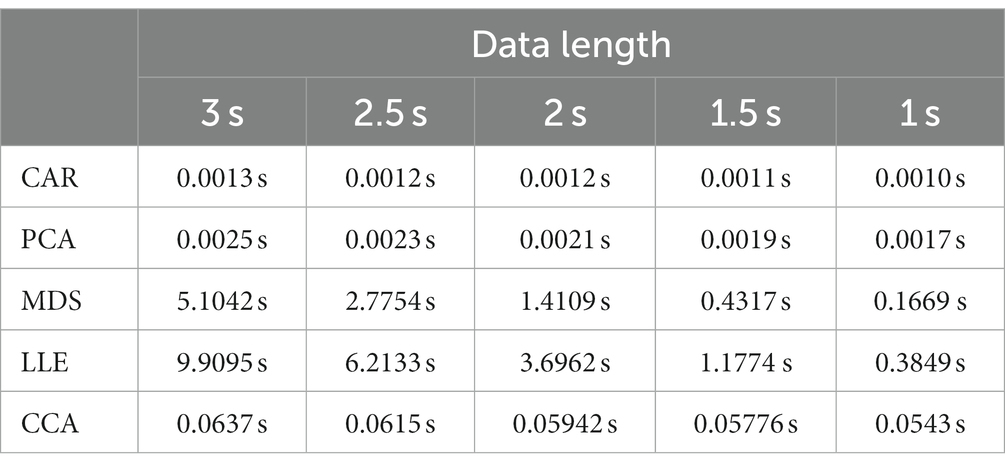
Table 2. Comparison of the processing time of five unsupervised dimensionality reduction methods.
From Table 2, we can see that the CAR and PCA methods have the shortest processing time and the CCA method comes next, while the MDS and LLE methods have the slowest processing speed. In particular, the processing time of the LLE method is determined by the number of nearest neighbor points. The larger the number of nearest neighbor points, the higher the recognition accuracy, but the processing time also increases exponentially. The above results suggest that the CCA-USSR method is suitable for real-time SSVEP detection technology and neuroscience.
4. Discussion
This study discusses the impact of different dimensionality reduction methods on multi-channel SSVEP signals. Five typical unsupervised methods were compared from the perspective of the CCA coefficient spectrum, recognition accuracy, ITR, robustness, and processing speed. In the CAR method, the selection of channels is particularly important. The experimental results found that among these eight electrodes POz, PO3, PO4, PO5, PO6, Oz, O1, and O2, using Oz as the reference channel can achieve the highest recognition accuracy and ITR. This also indicates that the Oz channel which is located over the occipital region retains the most effective features of SSVEP signals. In linear dimensionality reduction methods such as CAR, PCA, MDS, and CCA, although they have different rules for projecting high-dimensional data to low-dimensional space, CCA shows the best adaptability to SSVEP signals and MDS comes next. In nonlinear LLE methods, the number of nearest neighbor points determines the quality of detection results and processing speed. The larger the number of nearest neighbor points, the higher the recognition accuracy and ITR, and the longer the processing time. However, due to the strong limitations of the LLE method, which assumes that the input data satisfies the manifold distribution, it is not suitable for extracting the features of SSVEP data. In terms of processing time, CAR, PCA, and CCA are promising for real-time BCI detection technology, while MDS and LLE need more time for processing BCI.
Only when the dimensionality reduction method retains the most features of the original multi-channel signal, the USSR model can more effectively utilize synergistic effects to enhance the energy and amplitude of target frequencies, thereby increasing ITR. The reason why SR is different from other traditional denoising methods is that the SR model utilizes a dynamic feature enhancement mechanism with the help of the synergetic action of input aperiodic signal, noise, and the nonlinear resonance system. The SR model considers noise as a positive factor, thereby using noise energy to enhance weak signal features. In addition, compared with the first-order bistable stochastic resonance, the underdamped second-order SR considers the inertia term and normalizes the damping factor. To use an analogy, first-order BSR processing means primary filtering and second-order USSR processing means secondary filtering, thereby producing a cleaner filtered response than first-order SR. This is the reason why the USSR can more effectively improve the weak signal detection performance than BSR and other classic linear methods.
Although the motion checkerboard paradigm can effectively reduce the fatigue of subjects and is more suitable for long-time BCI performance detection, its evoked SSVEP signal has fewer harmonic components and more concentrated frequency energy (Han et al., 2018). Therefore, some standard untrained algorithms, such as CCA and FBCCA, are not effective in detecting the subject’s purpose (Yan et al., 2021). In addition, using some traditional linear methods to decode SSVEP signals, the useful features will be attenuated or lost while denoising, which seriously affects the improvement of recognition accuracy. Nevertheless, the nonlinear SR model has a frequency energy concentration effect similar to the motion checkerboard pattern. And among typical SR models, the USSR model has the best performance. Naturally, the study proposes to combine dimensionality reduction methods and nonlinear USSR models to extract non-stationary SSVEP features. The experimental results indicate that among traditional dimensionality reduction methods, the CCA method still has the projecting rule that best matches the SSVEP rhythm, which can retain the most original multi-channel SSVEP features, and the USSR model can effectively highlight the energy and amplitude of the target frequency with noise immunity, thereby increasing the algorithm robustness, recognition accuracy, and ITR. This untrained method also provides the possibility of applying a nonlinear model from one-dimensional signals to multi-dimensional signals.
5. Conclusion
In this study, we first compare five typical unsupervised dimensionality reduction methods, namely CAR, PCA, MDS, LLE, and CCA. The experimental results show that CCA has the highest adaptability for SSVEP rhythms and can retain the most effective features. Furthermore, compared with the standard CCA and FBCCA methods, the novel untrained CCA-USSR method proposed in this paper can more effectively highlight the target frequency and have higher robustness, thereby increasing recognition accuracy and ITR. In addition, the CCA-USSR method also has advantages in processing speed and has the potential for real-time BCI detection technology.
Data availability statement
The data analyzed in this study is subject to the following licenses/restrictions: the data is available from the corresponding author upon reasonable request. Requests to access these datasets should be directed to GX, Z2h4dUBtYWlsLnhqdHUuZWR1LmNu.
Ethics statement
Ethical approval was not required for the study involving human samples in accordance with the local legislation and institutional requirements because [reason ethics approval was not required]. Written informed consent for participation in this study was provided by the participants’ legal guardians/next of kin.
Author contributions
RC: conceptualization, methodology, software, formal analysis, data curation, writing—original draft, and writing—review and editing. GX: validation, formal analysis, and investigation. HZ: software. XZ and BL: supervision. JW: funding acquisition. SZ: project administration. All authors contributed to the article and approved the submitted version.
Funding
This work was supported in part by the key Research and Development Projects of Shaanxi Province under grant no.2021ZD0204300, in part by the Science and Technology Plan Project of Xi’an under grant 20KYPT0001-10, and in part by the Key Research and Development Program of Shaanxi Province of China under grant 2021GXLH-Z-008.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Benzi, R., Sutera, A., and Vulpiani, A. (1981). The mechanism of stochastic resonance. J. Phys. A Math. Gen. 14, L453–L457. doi: 10.1088/0305-4470/14/11/006
Chen, T. P. J., and Gao, X. (2015). Filter bank canonical correlation analysis for implementing a high-speed SSVEP-based brain-computer interface. J. Neural Eng. 12:046008. doi: 10.1088/1741-2560/12/4/046008
Chen, X., Wang, Y., Nakanishi, M., Gao, X., Jung, T. P., and Gao, S. (2015). High-speed spelling with a noninvasive brain–computer interface. Proc. Natl. Acad. Sci. 112, E6058–E6067. doi: 10.1073/pnas.1508080112
Chen, R., Xu, G., Jia, Y., Zhou, C., Wang, Z., Pei, J., et al. (2022). Enhancement of time-frequency energy for the classification of motor imagery electroencephalogram based on an improved FitzHugh–Nagumo neuron system. IEEE Trans. Neural Syst. Rehabil. Eng. 31, 282–293. doi: 10.1109/TNSRE.2022.3219450
Chen, R., Xu, G., Pei, J., Gao, Y., Zhang, S., and Han, C. (2023). Typical stochastic resonance models and their applications in steady-state visual evoked potential detection technology. Expert Syst. Appl. 225:120141. doi: 10.1016/j.eswa.2023.120141
Chen, R., Xu, G., Zhang, X., Han, C., and Zhang, S. (2021a). Multi-scale noise transfer and feature frequency detection in SSVEP based on FitzHugh–Nagumo neuron system. J. Neural Eng. 18:056054. doi: 10.1088/1741-2552/ac2bb7
Chen, R., Xu, G., Zheng, Y., Yao, P., Zhang, S., Yan, L., et al. (2021b). Waveform feature extraction and signal recovery in single-channel TVEP based on Fitzhugh–Nagumo stochastic resonance. J. Neural Eng. 18:056031. doi: 10.1088/1741-2552/ac2459
Collins, J., Chow, C. C., and Imhoff, T. T. (1995). Aperiodic stochastic resonance in excitable systems. Phys. Rev. E 52, R3321–R3324. doi: 10.1103/PhysRevE.52.R3321
De Ridder, D., Kouropteva, O., Okun, O., and Duin, R. (2003). Supervised locally linear embedding. In: Artificial neural networks and neural information processing—ICANN/ICONIP 2003: Joint international conference ICANN/ICONIP 2003 Istanbul, Turkey, June 26–29, 2003 proceedings. Springer.
Fauve, S., and Heslot, F. (1983). Stochastic resonance in a bistable system. Phys. Lett. A 97, 5–7. doi: 10.1016/0375-9601(83)90086-5
Friman, O., Volosyak, I., and Graser, A. (2007). Multiple channel detection of steady-state visual evoked potentials for brain-computer interfaces. IEEE transactions on biomedical engineering. 54, 742–750. doi: 10.1109/TBME.2006.889160
Han, C., Xu, G., Xie, J., Chen, C., and Zhang, S. (2018). Highly interactive brain–computer Interface based on flicker-free steady-state motion visual evoked potential. Sci. Rep. 8:5835. doi: 10.1038/s41598-018-24008-8
Hu, S., Xu, C., Guan, W., Tang, Y., and Liu, Y. (2014). Texture feature extraction based on wavelet transform and gray-level co-occurrence matrices applied to osteosarcoma diagnosis. Biomed Mater Eng. 24, 129–143. doi: 10.3233/BME-130793
Jin, J., Wang, Z., Xu, R., Liu, C., Wang, X., and Cichocki, A. (2021). Robust similarity measurement based on a novel time filter for SSVEPs detection. IEEE Trans Neural Netw Learn Syst 34, 4096–4105. doi: 10.1109/TNNLS.2021.3118468
Kramer, D. R., Lee, M. B., Barbaro, M. F., Gogia, A. S., Peng, T., Liu, C. Y., et al. (2021). Mapping of primary somatosensory cortex of the hand area using a high-density electrocorticography grid for closed-loop brain computer interface. J. Neural Eng. 18:036009. doi: 10.1088/1741-2552/ab7c8e
Li, R., Liu, D., Li, Z., Liu, J., Zhou, J., Liu, W., et al. (2022). A novel EEG decoding method for a facial-expression-based BCI system using the combined convolutional neural network and genetic algorithm. Front. Neurosci. 16:988535. doi: 10.3389/fnins.2022.988535
Li, Y., Wang, F., Chen, Y., Cichocki, A., and Sejnowski, T. (2017). The effects of audiovisual inputs on solving the cocktail party problem in the human brain: an fMRI study. Cereb. Cortex 28, 3623–3637. doi: 10.1093/cercor/bhx235
Lin, Z., Zhang, C., Wu, W., and Gao, X. (2006). Frequency recognition based on canonical correlation analysis for SSVEP-based BCIs. I.E.E.E. Trans. Biomed. Eng. 53, 2610–2614. doi: 10.1109/TBME.2006.886577
Liu, B., Chen, X., Shi, N., Wang, Y., Gao, S., and Gao, X. (2021). Improving the performance of individually calibrated SSVEP-BCI by task-discriminant component analysis. IEEE Trans. Neural Syst. Rehabil. Eng. 29, 1998–2007. doi: 10.1109/TNSRE.2021.3114340
Lu, S., He, Q., and Kong, F. (2015). Effects of underdamped step-varying second-order stochastic resonance for weak signal detection. Digit. Signal Process. 36, 93–103. doi: 10.1016/j.dsp.2014.09.014
Luce, R. D., and Perry, A. D. (1949). A method of matrix analysis of group structure. Psychometrika 14, 95–116. doi: 10.1007/BF02289146
Mcnamara, B., Wiesenfeld, K., and Roy, R. (1988). Observation of stochastic resonance in a ring laser. Phys. Rev. Lett. 60, 2626–2629. doi: 10.1103/PhysRevLett.60.2626
Ming, C., Xiaorong, G., Shangkai, G., and Dingfeng, X. (2002). Design and implementation of a brain-computer interface with high transfer rates. I.E.E.E. Trans. Biomed. Eng. 49, 1181–1186. doi: 10.1109/TBME.2002.803536
Nakanishi, M., Wang, Y., Chen, X., Wang, Y. T., Gao, X., and Jung, T. P. (2017). Enhancing detection of SSVEPs for a high-speed brain speller using task-related component analysis. I.E.E.E. Trans. Biomed. Eng. 65, 104–112. doi: 10.1109/TBME.2017.2694818
Nakanishi, M., Yijun, W., and Tzyy-Ping, J. (2018). Spatial filtering techniques for improving individual template-based SSVEP detection. Signal Process Machine Learn Brain-Machine Interfaces, 219–242. doi: 10.1049/PBCE114E_ch11
Orekhova, E. V., Wallin, B. G., and Hedstr M, A. (2002). Modification of the average reference montage: dynamic average reference. J. Clin. Neurophysiol. 19, 209–218. doi: 10.1097/00004691-200206000-00004
Saeed, N., Nam, H., Haq, M. I. U., and Muhammad Saqib, D. B. (2018). A survey on multidimensional scaling. ACM Computing Surveys (CSUR). 51, 1–25. doi: 10.1145/3178155
Vidal, J. J. (1973). Toward direct brain-computer communication. Annu. Rev. Biophys. Bioeng. 2, 157–180. doi: 10.1146/annurev.bb.02.060173.001105
Wold, S., Esbensen, K., and Geladi, P. (1987). Principal component analysis. Chemom. Intel. Lab. Syst. 2, 37–52. doi: 10.1016/0169-7439(87)80084-9
Wu, D., and Zhu, S. (2008). Stochastic resonance in FitzHugh–Nagumo system with time-delayed feedback. Phys. Lett. A 372, 5299–5304. doi: 10.1016/j.physleta.2008.06.015
Yan, W., du, C., Luo, D., Wu, Y. C., Duan, N., Zheng, X., et al. (2021). Enhancing detection of steady-state visual evoked potentials using channel ensemble method. J. Neural Eng. 18:046008. doi: 10.1088/1741-2552/abe7cf
Yao, P., Xu, G., Jia, L., Duan, J., Han, C., Tao, T., et al. (2019). Multiscale noise suppression and feature frequency extraction in SSVEP based on underdamped second-order stochastic resonance. J. Neural Eng. 16:036032. doi: 10.1088/1741-2552/ab16f9
Zhang, Y., Dong, L., Zhang, R., Yao, D., Zhang, Y., and Xu, P. (2014c). An efficient frequency recognition method based on likelihood ratio test for SSVEP-based BCI. Comput. Math. Methods Med. 2014:908719. doi: 10.1155/2014/908719
Zhang, Y., Xu, P., Cheng, K., and Yao, D. (2014b). Multivariate synchronization index for frequency recognition of SSVEP-based brain–computer interface. J. Neurosci. Methods 221, 32–40. doi: 10.1016/j.jneumeth.2013.07.018
Zhang, Y., Zhou, G., Jin, J., Wang, X., and Cichocki, A. (2014a). Frequency recognition in SSVEP-based BCI using multiset canonical correlation analysis. Int. J. Neural Syst. 24:1450013. doi: 10.1142/S0129065714500130
Keywords: motion checkerboard patterns, brain-computer interface, canonical correlation analysis, underdamped second-order stochastic resonance, information transmission rate
Citation: Chen R, Xu G, Zhang H, Zhang X, Li B, Wang J and Zhang S (2023) A novel untrained SSVEP-EEG feature enhancement method using canonical correlation analysis and underdamped second-order stochastic resonance. Front. Neurosci. 17:1246940. doi: 10.3389/fnins.2023.1246940
Edited by:
Vince D. Calhoun, Georgia State University, United StatesReviewed by:
Rui Li, Xi'an University of Technology, ChinaQingshan She, Hangzhou Dianzi University, China
Copyright © 2023 Chen, Xu, Zhang, Zhang, Li, Wang and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Guanghua Xu, Z2h4dUBtYWlsLnhqdHUuZWR1LmNu