 Federico Dominguez1†
Federico Dominguez1† Josua Unger2†Matthias Traube1†
Josua Unger2†Matthias Traube1† Barry Mant2†Christian Ertler1†Wolfgang Lechner1,2,3*†
Barry Mant2†Christian Ertler1†Wolfgang Lechner1,2,3*†- 1Parity Quantum Computing Germany GmbH, Munich, Germany
- 2Parity Quantum Computing GmbH, Innsbruck, Austria
- 3Institute for Theoretical Physics, University of Innsbruck, Innsbruck, Austria
We review encoding and hardware-independent formulations of optimization problems for quantum computing. Using this generalized approach, an extensive library of optimization problems from the literature and their various derived spin encodings are discussed. Common building blocks that serve as a construction kit for formulating these spin Hamiltonians are provided. This previously introduced approach paves the way toward a fully automatic construction of Hamiltonians for arbitrary discrete optimization problems and this freedom in the problem formulation is a key step for tailoring optimal spin Hamiltonians for different hardware platforms.
1 Introduction
Discrete optimization problems are ubiquitous in almost any enterprise and many of these are known to be NP-hard (Lenstra and Rinnooy Kan, 1979). The objective of such problems is to find the minimum of a real-valued function f(v0, …, vN−1) (the cost function) over a set of discrete variables vk. The search space is restricted by hard constraints, which are commonly presented as equalities such as g(v0, …, vN−1) = 0 or inequalities as h(v0, …, vN−1) > 0. Besides using classical heuristics (Dorigo and Di Caro, 1999; Melnikov, 2005) and machine learning methods (Mazyavkina et al., 2021) to solve these problems, there is a growing interest in applying quantum computation (Au-Yeung et al., 2023). A common approach for realizing this consists of first encoding the cost function f in a Hamiltonian H such that a subset of eigenvectors of H represents elements in the domain of f and the eigenvalues are the respective values of f:
In such an encoding, the ground state of H is the solution to the optimization problem. Having obtained a Hamiltonian formulation, one can use a variety of quantum algorithms to find the ground state including adiabatic quantum computing (Farhi et al., 2000) and variational approaches, for instance, the quantum/classical hybrid quantum approximate optimization algorithm (QAOA) (Farhi et al., 2014) or generalizations thereof such as the quantum alternating operator ansatz (Hadfield et al., 2019). On the hardware side, these algorithms can run on gate-based quantum computers, quantum annealers, or specialized Ising machines (Mohseni et al., 2022).
In the current literature, almost all Hamiltonians for optimization are formulated as Quadratic Unconstrained Binary Optimization (QUBO) problems (Kochenberger et al., 2014). The success of QUBO reflects the strong hardware limitations of current devices, where multiqubit interactions are not available and must be decomposed into two-qubit interactions using ancilla qubits. Moreover, quantum algorithms with the dynamical implementation of hard constraints (Hen and Sarandy, 2016; Hen and Spedalieri, 2016) require driver terms that can be difficult to design and implement on quantum computers. Hence, hard constraints are usually included as energy penalizations of QUBO Hamiltonians. The prevalence of QUBO has also increased the popularity of one-hot encoding, a particular way of mapping (discrete) variables to eigenvalues of spin operators (Lucas, 2014), since this encoding allows for Hamiltonians with low-order interactions which is especially appropriate for QUBO problems.
However, compelling alternatives to QUBO and one-hot encoding have been proposed in recent years. A growing number of platforms are exploring high-order interactions (Chancellor et al., 2017; Lu et al., 2019; Schöndorf and Wilhelm, 2019; Wilkinson and Hartmann, 2020; Menke et al., 2021; 2022; Dlaska et al., 2022; Pelegrí et al., 2022; Glaser et al., 2023), while the Parity architecture (Lechner, 2020; Fellner et al., 2022; Ender et al., 2023) (a generalization of the LHZ architecture (Lechner et al., 2015)) allows the mapping of arbitrary-order interactions to qubits that require only local connectivity. The dynamical implementation of constraints has also been investigated (Hadfield et al., 2019; 2017; Fuchs et al., 2022; Zhu et al., 2023), including the design of approximate drivers (Wang et al., 2020; Sawaya et al., 2022) and compilation of constrained problems within the Parity architecture (Drieb-Schön et al., 2023). Moreover, simulated and experimental results have shown that alternative encodings outperform the traditional one-hot approach (Chancellor, 2019; Sawaya et al., 2020; Chen et al., 2021; Plewa et al., 2021; Tamura et al., 2021; Glos et al., 2022; Stein et al., 2023). Clearly, alternative formulations for Hamiltonians need to be explored but when the Hamiltonian has been expressed in QUBO using one-hot encoding, it is not trivial to switch to other formulations. Automatic tools to explore different formulations would therefore be highly beneficial.
We present a library of more than 20 problems which is intended to facilitate the Hamiltonian formulation beyond QUBO and one-hot encoding. We build upon the recent work of Sawaya et al. (2022) by making use of the encoding-independent approach to revisit common problems in the literature. With this approach, the problems can be encoded trivially using any spin encoding. We also provide a summary of the most popular encodings. Possible constraints of the problems are identified and presented separately from the cost function so that dynamic implementation of the constraints can also be easily explored. Two additional subgoals that are addressed in this library are:
• Meta parameters/choices: We present and review the most important choices made in the process of mapping optimization problems in a mathematical formulation to spin Hamiltonians. These mainly include the encodings, which can greatly influence the computational cost and performance of the optimization, but also free meta parameters or the use of auxiliary variables. These degrees of freedom are a consequence of the fact that the optimal solution is typically encoded only in the ground state. Other low-energy eigenstates encode good approximations to the optimal solution and it can be convenient to make approximations so that the solution corresponds to these states (Montanez-Barrera et al., 2022).
• (Partial) automation: Usually, each problem needs to be evaluated individually. The resulting cost functions are not necessarily unique and there is no known trivial way of automatically creating H. By providing a collection of building blocks of cost functions and heuristics for selecting parameters, the creation of the cost function and constraints is assisted. This enables a general representation of problems in an encoding-independent way and parts of the parameter selection and performance analysis can be conducted at this intermediate stage. This goal has also been discussed by Sawaya et al. (2022).
In practice, many optimization problems are not purely discrete but involve real-valued parameters and variables. Thus, the encoding of real-valued problems to discrete optimization problems (discretization) as an intermediate step is discussed in Section 7.4.
The focus of this review is on optimization problems which can be formulated as diagonal Hamiltonians written as sums and products of Pauli-z-matrices. This subset of Hamiltonians is usually not applicable to quantum systems or quantum simulations. For an introduction to these more general Hamiltonians, we refer to the reviews of Georgescu et al. (2014) for physics problems and McArdle et al. (2020); Cao et al. (2019) for quantum chemistry simulations.
After introducing the notation used throughout the text in Section 2, we present a list of encodings in Section 3. Section 4 reviews the Parity architecture and Section 5 discusses encoding constraints. Section 6 functions as a manual on how to bring optimization problems into a form that can be solved with a quantum computer. Section 7 contains a library of optimization problems which are classified into several categories and Section 8 lists the building blocks used in the formulation of these (and many other) problems. Section 9 offers conclusions.
2 Definitions and notation
A discrete set of real numbers is a countable subset
If a discrete variable has range
For a variable v with range R we follow Chancellor (2019) and Sawaya et al. (2022) and define the value indicator function to be
where α ∈ R.
We also consider optimization problems for continuous variables. A variable v will be called continuous, if its range is given by
An optimization problem O is a triple (V, f, C), where.
1.
2. f := f(v0, …, vN−1) is a real-valued function, called objective or cost function.
3.
for some
The goal for an optimization problem O = (V, f, C) is to find an extreme value yex of f, such that all of the constraints are satisfied at yex.
Discrete optimization problems can often be stated in terms of graphs or hypergraphs (Berge, 1987). A graph is a pair (V, E), where V is a finite set of vertices or nodes and
A hypergraph is a generalization of a graph in which we allow edges to be adjacent to more than two vertices. That is, a hypergraph is a pair H = (V, E), where V is a finite set of vertices and
is the set of hyperedges.
We reserve the word qubit for physical qubits. To go from an encoding-independent Hamiltonian to a quantum program, binary or spin variables become Pauli-z-matrices which act on the corresponding qubits.
3 Encodings library
For many problems, the cost function and the problem constraints can be represented in terms of two fundamental building blocks: the value of the integer variable v and the value indicator
Representation of the building blocks in terms of Ising operators depends on the chosen encoding. An encoding is a function that associates eigenvectors of the σz operator with specific values of a discrete variable v:
where the spin variables si are the eigenvalues of
A summary of the encodings is presented in Figure 1. Some encodings are dense, in the sense that every quantum state |s0, …, sN−1⟩ encodes some value of the variable v. Other encodings are sparse because only a subset of the possible quantum states are valid states. The valid subset is generated by adding a core term1, i.e., a penalty term for constraints that need to be enforced in order to decode the variable uniquely in the Hamiltonian for every sparsely encoded variable. In general, dense encodings require fewer qubits, but sparse encodings have simpler expressions for the value indicator
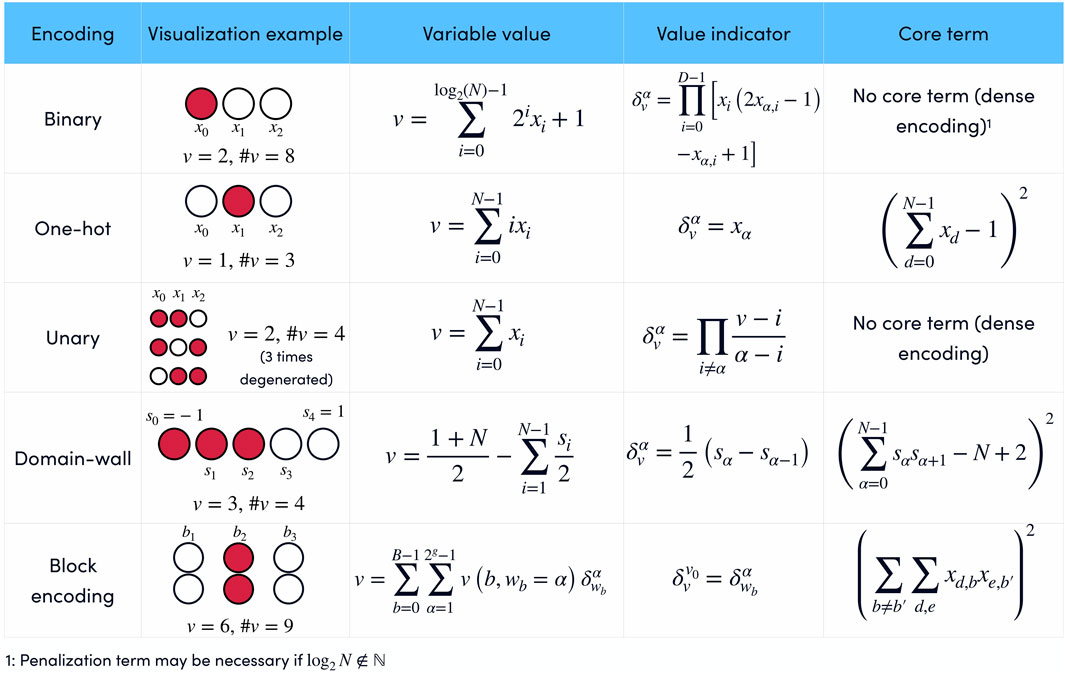
FIGURE 1. Summary of popular encodings of discrete variables in terms of binary xi or Ising si variables. Each encoding has a particular representation of the value of the variable v and the value indicator
3.1 Binary encoding
Binary encoding uses the binary representation for encoding integer variables. Given an integer variable
The value indicator
which is valid for every encoding. The expression for
and so we write
where
are the corresponding Ising variables. Thus, the maximum order of the interaction terms in
If v ∈ {1, …, K} with
for rejecting quantum states in R, we can force v ≤ K, which can be accomplished by adding a core term Hcore in the Hamiltonian
or imposing the sum constraint
The core term penalizes any state that represents an invalid value for variable v. Because core terms impose an additional energy scale, the performance can reduce when
When encoding variables that can also take on negative values, e.g., v ∈ {− K, − K + 1, …, K′ − 1, K′}, in classical computing one often uses an extra bit that encodes the sign of the value. However, this might not be the best option because one spin flip could then change the value substantially and we do not assume full fault tolerance. For binary encoding there is a more suitable treatment of negative values: we can simply shift the values
where 2D−1 < K + K′ ≤ 2D. The expression for the value indicator functions stays the same, only the encoding of the value α has to be adjusted. An additional advantage over using the sign bit is that ranges that are not symmetrical around zero (K ≠ K′) can be encoded more efficiently. The same approach of shifting the variable by −K can also be used for the other encodings.
3.2 Gray encoding
In binary representation, a single spin flip can lead to a sharp change in the value of v, for example, |1000⟩ codifies v = 9 while |0000⟩ codifies v = 1. To avoid this, Gray encoding reorders the binary representation in a way that two consecutive values of v always differ in a single spin flip. If we line up the potential values v ∈ [1, 2D] of an integer variable in a vertical sequence, this encoding in D boolean variables can be described as follows: on the ith boolean variable (which is the ith column from the right) the sequence starts with 2i−1 zeros and continues with an alternating sequence of 2i 1s and 2i 0s. As an example, consider
where D = 4. On the left-hand side of each row of boolean variables, we have the value v. If we, for example, track the right-most boolean variable, we indeed find that it starts with 21–1 = 1 zero for the first value, 21 ones for the second and third values, 21 zeros for the third and fourth values, and so on.
The value indicator function and the core term remain unchanged except that the representation of, for example, α in the analog of Eq. 12 also has to be in Gray encoding.
An advantage of this encoding with regard to quantum algorithms is that single spin flips do not cause large changes in the cost function and thus smaller coefficients may be chosen (see discussion in Section 8). The advantage of using Gray over one-hot encoding was recently demonstrated for quantum simulations of a deuteron (Di Matteo et al., 2021).
3.3 One-hot encoding
One-hot encoding is a sparse encoding that uses N binary variables xα to encode an N-valued variable v. The encoding is defined by its variable indicator:
which means that v = α if xα = 1. The value of v is given by
The physically meaningful quantum states are those with a single qubit in state 1 and so the dynamics must be restricted to the subspace defined by
One option to impose this sum constraint is to encode it as an energy penalization with a core term in the Hamiltonian:
which has minimum energy if only one xα is different from zero.
3.4 Domain-wall encoding
This encoding uses the position of a domain wall in an Ising chain to codify values of a variable v (Chancellor, 2019; Berwald et al., 2023). If the endpoints of an N + 1 spin chain are fixed in opposite states, there must be at least one domain wall in the chain. Since the energy of a ferromagnetic Ising chain depends only on the number of domain walls it has and not on where they are located, an N + 1 spin chain with fixed opposite endpoints has N possible ground states, depending on the position of the single domain wall.
The codification of a variable v = 1, …, N using domain wall encoding requires the core Hamiltonian Chancellor (2019):
Since the fixed endpoints of the chain do not need a spin representation (s0 = −1 and sN = 1), N − 1 Ising variables
The variable indicator corroborates if there is a domain wall in the position α:
where s0 ≡ − 1 and sN ≡ 1, and the variable v can be written as
Quantum annealing experiments using domain wall encoding have shown significant improvements in performance compared to one-hot encoding (Chen et al., 2021). This is partly because the required search space is smaller but also because domain-wall encoding generates a smoother energy landscape: in one-hot encoding, the minimum Hamming distance between two valid states is two, whereas in domain-wall, this distance is one. This implies that every valid quantum state in one-hot is a local minimum, surrounded by energy barriers generated by the core energy of Eq. 21. As a consequence, the dynamics in domain-wall encoded problems freeze later in the annealing process because only one spin-flip is required to pass from one state to the other (Berwald et al., 2023).
3.5 Unary encoding
In unary encodings, a numerical value is represented by the number of repetitions of a symbol. In the context of quantum optimization, we can use the number of qubits in excited states to represent a discrete variable (Rosenberg et al., 2015; Tamura et al., 2021)2. In terms of binary variables xi, we get:
so N − 1 binary variables xi are needed for encoding an N-value variable. Unary encoding does not require a core term because every quantum state is a valid state. However, this encoding is not unique in the sense that each value of v has multiple representations.
A drawback of unary encoding (and every dense encoding) is that it requires information from all binary variables to determine the value of v. The value indicator
which involves 2N interaction terms. This exponential scaling in the number of terms is unfavorable, so unary encoding may be only convenient for variables that do not require value indicators
A performance comparison for the Knapsack problem using digital annealers showed that unary encoding can outperform binary and one-hot encoding and requires smaller energy scales (Tamura et al., 2021). The reasons for the high performance of unary encoding are still under investigation, but redundancy is believed to play an important role because it facilitates the annealer to find the ground state. As for domain-wall encoding (Berwald et al., 2023), the minimum Hamming distance between two valid states (i.e., the number of spin flips needed to pass from one valid state to another) could also explain the better performance of the unary encoding. Redundancy has also been pointed out as a potential problem with unary encodings since not all possible values have the same degeneracy and therefore results may be biased towards the most degenerate values (Rosenberg et al., 2015).
3.6 Block encodings
It is also possible to combine different approaches to obtain a balance between sparse and dense encodings (Sawaya et al., 2020). Block encodings are based on B blocks, each consisting of g binary variables. Similar to one-hot encoding, the valid states for block encodings are those states where only a single block contains non-zero binary variables. The binary variables in block b,
The discrete variable v is defined by the active block b and its corresponding block value wb,
where
The value indicator for the variable v is the corresponding block value indicator. Suppose the discrete value v0 is encoded in the block b with a block variable wb = α:
then the value indicator
A core term is necessary so that only qubits in a single block can be in the excited state. Defining tb = ∑ixi,b, the core terms results in
or, as a sum constraint,
The minimum value of Hcore is zero. If the two blocks, b and b′, have binary variables with values one, then tbtb′ ≠ 0 and the corresponding eigenstate of Hcore is no longer the ground state.
4 Parity architecture
The strong hardware limitations of noisy intermediate-scale quantum (NISQ) (Preskill, 2018) devices have made sparse encodings (especially one-hot) the standard approach to problem formulation. This is mainly because the basic building blocks (value and value indicator) are of linear or quadratic order in the spin variables in these encodings. The low connectivity of qubit platforms requires Hamiltonians in the QUBO formulation and high-order interactions are expensive when translated to QUBO Kochenberger et al. (2014). However, different choices of encodings can significantly improve the performance of quantum algorithms (Chancellor, 2019; Sawaya et al., 2020; Chen et al., 2021; Di Matteo et al., 2021; Tamura et al., 2021), by reducing the search space or generating a smoother energy landscape.
One way this difference between encodings manifests itself is in the number of spin flips of physical qubits needed to change a variable into another valid value (Berwald et al., 2023). If this number is larger than one, there are local minima separated by invalid states penalized with a high cost which can impede the performance of the optimization. On the other hand, such an energy-landscape might offer some protection against errors (Pastawski and Preskill, 2016; Fellner et al., 2022). Furthermore, other fundamental aspects of the algorithms, such as circuit depth and energy scales can be greatly improved outside QUBO (Ender et al., 2022; Drieb-Schön et al., 2023; Fellner et al., 2023; Messinger et al., 2023), prompting us to look for alternative formulations. The Parity Architecture is a paradigm for solving quantum optimization problems (Lechner et al., 2015; Ender et al., 2023) that does not rely on the QUBO formulation, allowing a wide number of options for formulating Hamiltonians. The architecture is based on the Parity transformation, which remaps Hamiltonians onto a 2D grid requiring only local connectivity of the qubits. The absence of long-range interactions enables high parallelizability of quantum algorithms and eliminates the need for costly and time-consuming SWAP gates, which helps to overcome two of the main obstacles of quantum computing: limited coherence time and the poor connectivity of qubits within a quantum register.
The Parity transformation creates a single Parity qubit for each interaction term in the (original) logical Hamiltonian:
where the interaction strength Ji,j,… is now the local field of the Parity qubit
The following toy example, summarized in Figure 2, shows how a Parity-transformed Hamiltonian can be solved using a smaller number of qubits when the original Hamiltonian has high-order interactions. Given the logical Hamiltonian
the corresponding QUBO formulation requires seven qubits, including two ancillas for decomposing the three-body interactions, and the total number of two-body interactions is 14. The embedding of the QUBO problem on quantum hardware may require additional qubits and interactions depending on the chosen architecture. Instead, the Parity-transformed Hamiltonian only consists of six Parity qubits with local fields and two four-body interactions between close neighbors.
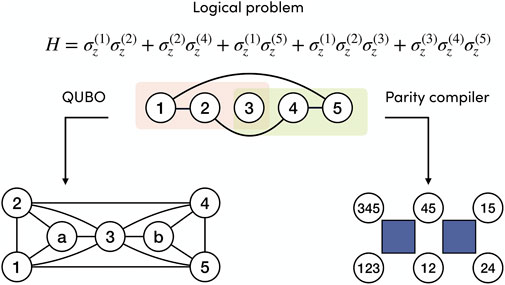
FIGURE 2. Example toy problem H involving high-order interactions that shows how the Parity architecture straightforwardly handles Hamiltonians beyond the QUBO formulation. The problem is represented by the hypergraph at the top of the figure. When decomposed into QUBO form, it requires 7 qubits and 14 two-body interactions, plus additional qubit overhead depending on the embedding. In contrast, the Parity compiler can remap this problem into a 2D grid that requires six qubits with local fields and four-body interactions, represented by the blue squares. No additional embedding is necessary if the hardware is designed for the Parity Architecture.
It is not yet clear what the best Hamiltonian representation is for an optimization problem. The answer will probably depend strongly on the particular use case and will take into account not only the number of qubits needed but also the smoothness of the energy landscape, which has a direct impact on the performance of quantum algorithms (King et al., 2019).
5 Encoding constraints
In this section, we review how to implement the hard constraints associated with the problem, assuming that the encodings of the variables have already been chosen. Hard constraints c(v1, …, vN) = K often appear in optimization problems, limiting the search space and making problems even more difficult to solve. We consider polynomial constraints of the form
which remain polynomial after replacing the discrete variables vi with any encoding. The coefficients gi, gi,j, … depend on the problem and its constraints. Even if the original problem is unconstrained, the use of sparse encodings such as one-hot or domain wall imposes hard constraints on the quantum variables.
In general, constraints can be implemented dynamically (Hen and Sarandy, 2016; Hen and Spedalieri, 2016) (exploring only quantum states that satisfy the constraints) or as extra terms Hc in the Hamiltonian, such that eigenvectors of H are also eigenvectors of Hc and the ground states of Hc correspond to elements in the domain of f that satisfy the constraint. These can be incorporated as a penalty term Hc into the Hamiltonian that penalizes any state outside the desired subspace:
or
in the special case that c(x1, …, xN) ≥ K is satisfied. The constant A must be large enough to ensure that the ground state of the total Hamiltonian satisfies the constraint, but the implementation of large energy scales lowers the efficiency of quantum algorithms (Lanthaler and Lechner, 2021) and additionally imposes a technical challenge. Moreover, extra terms in the Hamiltonian imply additional overhead of computational resources, especially for squared terms such as in Eq. 37. The determination of the optimal energy scale is an important open problem. For some of the problems in the library, we provide an estimation of the energy scales (cf. also Section 8.4.2).
Quantum algorithms for finding the ground state of Hamiltonians, such as QAOA or quantum annealing, require driver terms Udrive = exp(−itHdrive) that spread the initial quantum state to the entire Hilbert space. Dynamical implementation of constraints employs a driver term that only explores the subspace of the Hilbert space that satisfies the constraints. Given an encoded constraint in terms of Ising operators
a driver Hamiltonian Hdrive that commutes with
In general, the construction of constraint-preserving drivers depends on the problem (Hen and Sarandy, 2016; Hen and Spedalieri, 2016; Hadfield et al., 2017; Chancellor, 2019; Bärtschi and Eidenbenz, 2020; Wang et al., 2020; Fuchs et al., 2021; Bakó et al., 2022). Approximate driver terms have been proposed that admit some degree of leakage and may be easier to construct (Sawaya et al., 2022). Within the Parity Architecture, each term of a polynomial constraint is a single Parity qubit (Lechner et al., 2015; Ender et al., 2023). This implies that for the Parity Architecture the polynomial constraints are simply the conservation of magnetization between the qubits involved:
where the Parity qubit
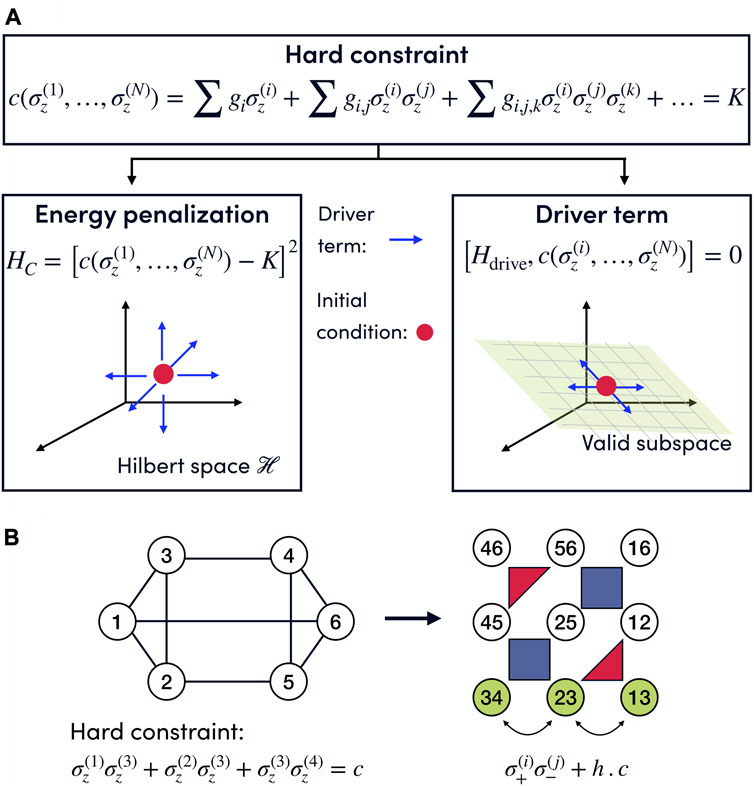
FIGURE 3. (A) Decision tree to encode constraints, which can be implemented as energy penalizations in the problem Hamiltonian or dynamically by selecting a driver Hamiltonian that preserves the desired condition. For energy penalties (left figure), the driver term needs to explore the entire Hilbert space. In contrast, the dynamic implementation of the constraints (right figure) reduces the search space to the subspace satisfying the hard constraint, thus improving the performance of the algorithms. (B) Constrained logical problem (left) and its Parity representation where each term of the polynomial constraint is represented by a single Parity qubit (green qubits), so the polynomial constraints define a subspace in which the total magnetization of the involved qubits is preserved and which can be explored with an exchange driver σ+σ− + h.c. that preserves the total magnetization. Figure originally published in Ref. Drieb-Schön et al. (2023).
6 Use case example
In this section, we present an example of the complete procedure to go from the encoding-independent formulation to the spin Hamiltonian that has to be implemented in the quantum computer, using an instance of the Clustering problem (Section 7.1.1).
Every problem in this library includes a Problem description, indicating the required inputs for defining a problem instance. In the case of the clustering problem, a problem instance is defined from the number of clusters K we want to create, N objects with weights wi, and distances di,j between the objects. Two different types of discrete variables are required, variables vi = 1, …, K (i = 1, …, N) indicate to which of the K possible clusters the node i is assigned, and variables yj = 1, …, Wmax track the weight in cluster j.
The cost function of the problem only depends on
We can choose any encoding for the variables vi. For example, if we decide to use binary or Gray encoding, a variable vi requires D = log2(K) qubits
Alternatively, we can choose a sparse encoding for the variables vi. Using one-hot encoding, we need K qubits per node, so NK qubits are required for the cost function. The product
if this constraint is implemented as an energy penalization
Besides the core constraints associated with the encodings, the clustering problem includes K additional constraints (one per each cluster). The total weight of nodes in any cluster cannot exceed a problem instance specific maximal value Wmax:
For the kth cluster, this constraint can be expressed in terms of auxiliary variables yk:
Variables yk are discrete variables in the range 0, …, Wmax. Because the value indicators of yk are not necessary for the constraints, we can use a dense encoding such as binary without dealing with the high-order interactions associated with value indicators of dense encodings. The variables yk require K log2(Wmax) qubits if we use binary encoding, or KWmax if we use one-hot. These constraints can also be implemented as energy penalizations in the Hamiltonian or can be encoded in the driver term.
The complete procedure for obtaining the spin Hamiltonian is outlined in Figure 4. We emphasize that the optimal encodings and constraint implementations depend on the details of the hardware, such as native gates, connectivity, and the number of qubits. Moreover, the efficiency of quantum algorithms is also related to the smoothness of the energy landscape, and some encodings can provide better results even though they require more qubits (see, for example, Tamura et al., 2021).
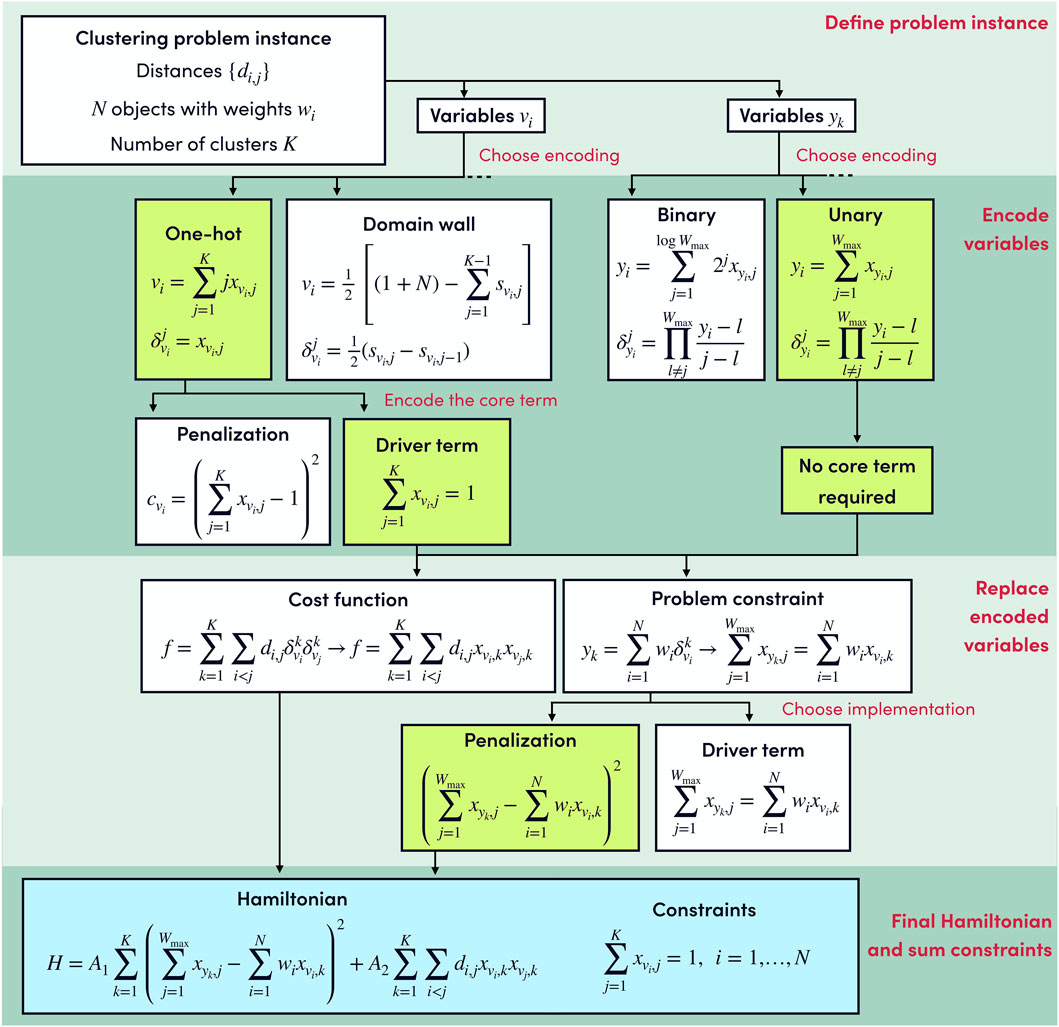
FIGURE 4. Example decision tree for the clustering problem. The entire process is presented in four different blocks and the decisions taken are highlighted in green. The formulation of a problem instance requires the discrete variables vi and yk to be encoded in terms of qubit operators. In this example, the vi variables are encoded using the one-hot encoding while for the yk variables we use the binary encoding. The Hamiltonian is obtained by substituting in the encoding-independent expressions of Eqs 48, 50 the discrete variables vi, yk and the value indicators
7 Problem library
The problems included in the library are classified into four categories: subsets, partitions, permutations, and continuous variables. These categories are defined by the role of the discrete variable and are intended to organize the library and make it easier to find problems but also to serve as a basis for the formulation of similar use cases. An additional category in Section 7.5 contains problems that do not fit into the previous categories but may also be important use cases for quantum algorithms. In Section 8 we include a summary of recurrent encoding-independent building blocks that are used throughout the library and could be useful in formulating new problems.
7.1 Partitioning problems
The goal of partitioning problems is to look for partitions of a set U, minimizing a cost function f. A partition P of U is a set
7.1.1 Clustering problem
a. Description Let
b. Variables We can define a variable vi = 1, …, K for each element in U. We also require an auxiliary variable yj = 0, 1, …, Wmax per subset Uk, that indicates the total weight of the elements in Uk:
c. Constraints The weight restriction is an inequality constraint:
which can be expressed as:
if the encoding for the auxiliary variables makes it necessary (e.g., a binary encoding and Wmax not a power of 2), this constraint must be shifted as is described in Section 8.2.3.
d. Cost function The sum of the distances of the elements of a subset is:
and the cost function results:
e. References Studied by Feld et al. (2019) as part of the Capacitated Vehicle Routing problem.
7.1.2 Number partitioning
a. Description Given a set U of N real numbers ui, we can look for a partition of size K such that the sum of the numbers in each subset is as homogeneous as possible.
b. Variables The problem requires N variables vi ∈ [1, K], one per element ui. The value of vi indicates to which subset ui belongs.
c. Cost function The partial sums can be represented using the value indicators associated with the variables vj:
there are three common approaches for finding the optimal partition: maximizing the minimum partial sum, minimizing the largest partial sum, or minimizing the difference between the maximum and the minimum partitions. The latter option can be formulated as
In order to minimize the maximum partial sum (maximizing the minimum partial sum is done analogously) we can introduce an auxiliary variable l that can take values 1, …, ∑iui ≡ lmax. Depending on the problem instance the range of l can be restricted further. The first term in the cost function
then enforces that l is as least as large as the maximum pi (Section 8.1.3) and the second term minimizes l. The theta step function can be expressed in terms of the value indicator functions according to the building block Eq. 144 by either introducing auxiliary variables or expressing the value indicators directly according to the discussion in Section 8.4.1.
d. Special cases For K = 2, the cost function that minimizes the difference between the partial sums is
The only two possible outcomes for
e. References The Hamiltonian formulation for K = 2 can be found in Lucas (2014).
7.1.3 Graph coloring
a. Description The nodes of the graph G = (V, E) are divided into K different subsets, each one representing a different color. We can look for a partition in which two adjacent nodes are painted with different colors and which minimizes the number of colors used.
b. Variables We define a variable vi = 1…K for each node i = 1, …, N in the graph.
c. Constraints We must penalize solutions for which two adjacent nodes are painted with the same color. The cost function of the graph partitioning problem presented in Eq. 61 can be used for the constraint of graph coloring. In that case,
d. Cost function The decision problem (“Is there a coloring that uses K colors?”) can be answered by implementing the constraint as a Hamiltonian H = c (note that c ≥ 0). The existence of a solution with zero energy implies that a coloring with K colors exists.
Alternatively we can look for the coloring that uses the minimum number of colors. To check if a color α is used, we can use the following term (see building block Section 8.2.2):
which is one if and only if color α is not used in the coloring, and 0 if at least one node is painted with color α. The number of colors used in the coloring is the cost function of the problem:
This objective function can be very expensive to implement since uα includes products of
e. References The one-hot encoded version of this problem can be found in Lucas (2014).
7.1.4 Graph partitioning
a. Description Graph partitioning divides the nodes of a graph G = (V, E) into K different subsets, so that the number of edges connecting nodes in different subsets (cut edges) is minimized or maximized.
b. Variables We can use one discrete variable vk = 1, …, K per node in the graph, which indicates to which partition the node belongs.
c. Cost function An edge connecting two nodes i and j is cut when vi ≠ vj. It is convenient to use the symbol (see building block Section 8.1.4):
which is equal to 1 when nodes i and j belong to the same partition (vi = vj) and zero when not (vi ≠ vj). In this way, the term:
is equal to 1 if there is a cut edge connecting nodes i and j, being Ai,j the adjacency matrix of the graph. The cost function for minimizing the number of cut edges is obtained by summing over all the nodes:
or alternatively −f to maximize the number of cut edges.
d. Constraints A common constraint imposes that partitions have a specific size. The element counting building block Section 8.1.1 is defined as
If we want the partition α to have L elements, then
must hold. If we want the two partitions, α and β, to have the same size, then the constraint is
and all the partitions will have the same size, imposing
which is only possible if |V|/K is a natural number.
e. References The Hamiltonian for K = 2 can be found in Lucas (2014).
f. Hypergraph partitioning The problem formulation can be extended to hypergraphs. A hyperedge is cut when it contains vertices from at least two different subsets. Given a hyperedge e of G, the function
is only equal to 1 if all the vertices included in e belong to the same partition, and zero in any other case. The product over the vertices i, j of the edge e only needs to involve pairs such that every vertex appears at least once. The optimization objective of minimizing the cut hyperedges is implemented by the sum of penalties
This objective function penalizes all possible cuts in the same way, regardless of the number of vertices cut or the number of partitions to which an edge belongs.
7.1.5 Clique cover
a. Description Given a graph G = (V, E), we seek the minimum number of colors K for coloring all vertices such that the subsets Wα of vertices with the color α together with the edge set Eα restricted to edges between vertices in Wα form complete graphs. A subproblem is to decide if there is a clique cover using K colors.
b. Variables For each vertex i = 1, …, N we define variables vi = 1, …, K indicating the color that vertex is assigned to. If the number of colors is not given, one has to start with an initial guess or a minimal value for K.
c. Constraints In this problem, Gα = (Wα, Eα) has to be a complete graph, so the maximum number of edges in Eα must be present. Using the element counting building block, we can calculate the number of vertices with color α (see bulding block Section 8.1.1):
if Gα is a complete graph, then the number of edges in Eα is tα(tα − 1)/2 and thus the constraint reads
Note that we do not have to square the term as it can never be negative.
d. Cost function The decision problem (“Is there a clique cover using K colors?”) can be answered using the constraint c as the Hamiltonian of the problem. For finding the minimum number of colors Kmin for which a clique cover exists (the clique cover number), we can add a cost function for minimizing K. As in the graph coloring problem, we can minimize the number of colors using
where
indicates if the color α is used or not (see building block Section 8.2.2).
e. References The one-hot encoded Hamiltonian of the decision problem can be found in Lucas (2014).
7.2 Constrained subset problems
Given a set U, we look for a non-empty subset U0 ⊆ U that minimizes a cost function f while satisfying a set of constraints ci. In general, these problems require a binary variable xi per element in U which indicates if the element i is included or not in the subset U0. Although binary variables are trivially encoded in single qubits, non-binary auxiliary variables may be necessary to formulate constraints, so the encoding-independent formulation of these problems is still useful.
7.2.1 Cliques
a. Description A clique on a given graph G = (V, E) is a subset of vertices W ⊆ V such that W and the subset EW of edges between vertices in W is a complete graph, i.e., the maximal possible number of edges in EW is present. The goal is to find a clique with cardinality K. Additionally, one could ask what the largest clique of the graph is.
b. Variables We can define |V| binary variables xi that indicate whether vertex i is in the clique or not.
c. Constraints This problem has two constraints, namely, that the cardinality of the clique is K and that the clique indeed has the maximum number of edges. The former is enforced by
and the latter by
If constraints are implemented as energy penalization, one has to ensure that the first constraint is not violated to decrease the penalty for the second constraint. Using the cost/gain analysis (Section 8.4.2) of a single spin flip this is prevented as long as a1⪆a2Δ, where Δ is the maximal degree of G and a1,2 are the energy scales of the first and second constraints.
d. Cost function The decision problem (“Is there a clique of size K?”) can be solved using the constraints as the Hamiltonian of the problem. If we want to find the largest clique of the graph G, we must encode K as a discrete variable, K = 1, …, Kmax, where Kmax = Δ is the maximum degree of G and the largest possible size of a clique. The cost function for this case is simply the value of K:
e. Resources Implementing constraints as energy penalizations, the total cost function for the decision problem (fixed K),
has interaction terms with maximum order of two and the number of terms scales with |E| + |V|2. If K is encoded as a discrete variable, the resources depend on the chosen encoding.
f. References This Hamiltonian was formulated in Lucas (2014) using one-hot encoding.
7.2.2 Maximal independent set
a. Description Given a hypergraph G = (V, E) we look for a subset of vertices S ⊂ V such that there are no edges in E connecting any two vertices of S. Finding the largest possible S is an NP-hard problem.
b. Variables We use a binary variable xi for each vertex in V.
c. Cost function For maximizing the number of vertices in S, the cost function is
d. Constraints Given two elements in S, there must not be any edge of hyperedge in E connecting them. The constraint
counts the number of adjacent vertices in S, with A as the adjacency matrix. By setting c = 0, the vertices in S form an independent set.
e. References See Lucas (2014) and Choi (2010) for graphs.
7.2.3 Set packing
a. Description Given a set U and a family
b. Variables We define N binary variables xi that indicate whether subset Vi belongs to the packing.
c. Cost function Maximizing the number of subsets in the packing is achieved with the element counting building block
d. Constraints In order to ensure that any two subsets of the packings are disjoint we can impose a cost on overlapping sets with
e. Resources The total cost function H = HA + HB has interaction terms with maximum order of two (so it is a QUBO problem) and the number of terms scales up to N2.
f. References This problem can be found in Lucas (2014).
7.2.4 Vertex cover
a. Description Given a hypergraph G = (V, E) we want to find the smallest subset C ⊆ V such that all edges contain at least one vertex in C.
b. Variables We define |V| binary variables xi that indicate whether vertex i belongs to the cover C.
c. Cost function Minimizing the number of vertices in C is achieved with the element counting building block
d. Constraints With
one can penalize all edges that do not contain vertices belonging to C. Encoding the constraint as an energy penalization, the Hamiltonian results in
by setting B > A we can avoid the constraint being traded off against the minimization of C.
e. Resources The maximum order of the interaction terms is the maximum rank of the hyperedges k and the number of terms scales with |E|2k + |V|.
f. References The special case that only considers graphs can be found in Lucas (2014).
7.2.5 Minimal maximal matching
a. Description Given a hypergraph G = (V, E) with edges of maximal rank k we want to find a minimal (i.e., fewest edges) matching C ⊆ E which is maximal in the sense that all edges with vertices that are not incident to edges in C have to be included in the matching.
b. Variables We define |E| binary variables xi that indicate whether an edge belongs to the matching C.
c. Cost function Minimizing the number of edges in the matching is simply done by the cost function
d. Constraints We have to enforce that C is indeed a matching, i.e., that no two edges which share a vertex belong to C. Using an energy penalty, this is achieved by:
where ∂v is the set of edges connected to vertex v. Additionally, the matching should be maximal. For each vertex u, we define a variable yu = ∑i∈∂uxi which is only zero if the vertex does not belong to an edge of C. If the first constraint is satisfied, this variable can only be 0 or 1. In this case, the constraint can be enforced by
However, one has to make sure that the constraint implemented by fB is not violated in favor of fC which could happen if for some v, yv > 1 and for m neighboring vertices yu = 0. Then the contributions from v are given by
and since m + yv is bounded by the maximum degree Δ of G times the maximum rank of the hyperedges k, we need to set B > (Δk − 2)C to ensure that the ground state of fB + fC does not violate the first constraint. Finally, one has to prevent fC being violated in favor of fA which entails C > A.
e. Resources The maximum order of the interaction terms is k and the number of terms scales roughly with (|V| + |E|2k)Δ(Δ − 1).
f. References This problem can be found in Lucas (2014).
7.2.6 Set cover
a. Description Given a set
b. Variables We define a binary variable xi = 0, 1 for each subset Vi that indicates if the subset Vi is selected or not. We also define auxiliary variables yα = 1, 2, …, N that indicate how many active subsets (Vi such that xi = 1) contain the element uα.
c. Cost function The cost function is simply
which counts the number of selected subsets Vi.
d. Constraints The constraint
which implies that every element uα ∈ U is included at least once. These inequalities are satisfied if yα are restricted to the valid values (yα = 1, 2, …, N, yα ≠ 0) (Section 8.2.3). The values of yα should be consistent with those of xi, so the constraint is
e. Special case: exact cover If we want each element of U to appear once and only once on the cover, then yα = 1, for all α and the constraint of the problem reduces to
f. References The one-hot encoded Hamiltonian can be found in Lucas (2014).
7.2.7 Knapsack
a. Description A set U contains N objects, each of them with a value di and a weight wi. We look for a subset of U with the maximum value ∑di such that the total weight of the selected objects does not exceed the upper limit W.
b. Variables We define a binary variable xi = 0, 1 for each element in U that indicates if the element i is selected or not. We also define an auxiliary variable y that indicates the total weight of the selected objects:
if the weights are natural numbers
c. Cost function The cost function is given by
which counts the value of the selected elements.
d. Constraints The constraint y < W is implemented by forcing y to take one of the possible values y = 1, …W − 1 (see Section 8.2.3). The value of y must be consistent with the selected items from U:
e. References The one-hot encoded Hamiltonian can be found in Lucas (2014).
7.3 Permutation problems
In permutation problems, we need to find a permutation of N elements that minimizes a cost function while satisfying a given set of constraints. In general, we will use a discrete variable vi ∈ [1, N] that indicates the position of the element i in the permutation.
7.3.1 Hamiltonian cycles
a. Description For a graph G = (V, E), we ask if a Hamiltonian cycle, i.e., a closed path that connects all nodes in the graph through the existing edges without visiting the same node twice, exists.
b. Variables We define a variable vi = 1, …, |V| for each node in the graph, that indicates the position of the node in the permutation.
c. Cost function For this problem, there is no cost function, so every permutation that satisfies the constraints is a solution to the problem.
d. Constraints This problem requires two constraints. The first constraint is inherent to all permutation problems and imposes the |V| variables {vi} to be a permutation of [1, …, |V|]. This is equivalent to requiring vi ≠ vj if i ≠ j, which can be encoded with the following constraint (Section 8.2.1):
The second constraint ensures that the path only goes through the edges of the graph. Let A be the adjacency matrix of the graph, such that Ai,j = 1 if there is an edge connecting nodes i and j and zero otherwise. To penalize invalid solutions, we use the constraint
which counts how many adjacent nodes in the solution are not connected by an edge in the graph. α = |V| + 1 represents α = 1 since we are looking for a closed path.
e. References The one-hot encoded Hamiltonian can be found in Lucas (2014).
7.3.2 Traveling salesperson problem (TSP)
a. Description The TSP is a trivial extension of the Hamiltonian cycles problem. In this case, the nodes represent cities and the edges are the possible roads connecting the cities, although in general it is assumed that all cities are connected (the graph is complete). For each edge connecting cities i and j there is a cost wi,j. The solution of the TSP is the Hamiltonian cycle that minimizes the total cost ∑wi,j.
b. Variables We define a variable vi = 1, …, |V| for each node in the graph, indicating the position of the node in the permutation.
c. Cost function If the traveler goes from city i at position α to city j in the next step, then
otherwise, that expression would be zero. Therefore the total cost of the travel is codified in the function:
as for Hamiltonian cycles, α = |V| + 1 represents α = 1 since we are looking for a closed path.
d. Constraints The constraints are the same as those used in the Hamiltonian cycles problem (see paragraph 7.3.1). If the graph is complete (all the cities are connected) then constraint c2 is not necessary.
e. References The one-hot encoded Hamiltonian can be found in Lucas (2014).
7.3.3 Machine scheduling
a. Description Machine scheduling problems seek the best way to distribute a number of jobs over a finite number of machines. These problems explore permutations of the job list, where the position of a job in the permutation indicates on which machine and at what time the job is executed. Many variants of the problem exist, including formulations in terms of spin Hamiltonians (Venturelli et al., 2015; Kurowski et al., 2020; Amaro et al., 2022). Here we consider the problem of M machines and N jobs, where all jobs take the same amount of time to complete, so the time can be divided into time slots of equal duration t. It is possible to include jobs of duration nt
b. Variables We define variables vm,t = 0, …N, where the subindex m = 1, …M indicates the machine and t = 1, …T the time slot. When vm,t = 0, the machine m is unoccupied in time slot t, and if vm,t = j ≠ 0 then the job j is done in the machine m, in the time slot t.
c. Constraints There are many possible constraints depending on the use case we want to run. As in every permutation problem, we require that no pair of variables have the same value, vm,t ≠ vm′,t′, otherwise, some jobs would be performed twice. We also require each job to be complete so there must be exactly one vm,t = j for each job j. This constraint is explained in Section 8.2.1 and holds for every job j ≠ 0:
Note that if job j is not assigned (i.e., there are no m, t such that vm,t = j) then c1 > 0. Also, if there is more than one variable vm,t = j, then again c1 > 0. The constraint will be satisfied (c1 = 0) if and only if every job is assigned to a single time slot on a single machine.
Suppose job k can only be started if another job, j, has been done previously. This constraint can be implemented as
which precludes any solution in which job j is done after job k. Alternatively, it can be codified as
These constraints can be used to encode problems that consider jobs with different operations O1, …Oq that must be performed in sequential order. Note that constraints
If we want two jobs j1 and j2 to run on the same machine in consecutive time slots, the constraint can be encoded as
or as a reward term in the Hamiltonian,
that reduces the energy of any solution in which job j2 is performed immediately after job j1 on the same machine m. This constraint allows the encoding of problems with different job durations since j1 and j2 can be considered part of the same job of duration 2t.
d. Cost function Different objective functions can be chosen for this problem, such as minimizing machine idle time or early and late deliveries. A common option is to minimize the makespan, i.e., the time slot of the last scheduled job. To do this, we first introduce an auxiliary function
These functions can be generated from vm,t:
Note that the maximum value of τ corresponds to the makespan of the problem, which is to be minimized. To do this, we introduce the extra variable τmax and penalize configurations where τmax < τ(vm,t) for all m, t:
with
For details on how Θ(x) can be expressed see Section 8.1.2. By minimizing
An alternative cost function for this problem is
which forces all jobs to be scheduled as early as possible.
e. References Quantum formulations of this and related problems can be found in Refs. Venturelli et al. (2015); Kurowski et al. (2020); Amaro et al. (2022) and Carugno et al. (2022).
7.3.4 Nurse scheduling problem
a. Description In this problem we have N nurses and D working shifts. Nurses must be scheduled with minimal workload following hard and soft constraints, such as minimum workload nmin,t of nurses i (where nurse i contributes workload pi) in a given shift t, and balancing the number of shifts to be as equal as possible. Furthermore, no nurse should have to work on more than dmax consecutive days.
b. Variables We define ND binary variables vi,t indicating whether nurse i is scheduled for shift t.
c. Cost function The cost function, whose minimum corresponds to the minimal number of overall shifts, is given by
d. Constraints Balancing of the shifts is expressed by the constraint
In order to get a minimal workload per shift we introduce the auxiliary variables yt which we bind to the values
with the penalty terms
Now the constraint takes the form
Note that we can also combine the cost function for minimizing the number of shifts and this constraint by using the cost function
Finally, the constraint that a nurse i should work in maximally dmax consecutive shifts reads
e. References This problem can be found in Ikeda et al. (2019).
7.4 Real variables problems
Some problems are defined by a set of real variables
a. Standard discretization Given a vector
Depending on the problem it might also be useful to have different resolutions for different axes or a non-uniform discretization, e.g., logarithmic scaling of the interval length.
For the discrete variables
b. Random subspace coding A further possibility to encode a vector
for the projection to the ith coordinate. A hyperrectangle
For the fixed set of chosen coordinates Dn, the Dirichlet processes are run m times to get m hyperrectangles
then Random subspace coding is defined as a map
Depending on the set of hyperrectangles
For
holds. From here one can simply use the discrete encodings discussed in Section 3 to map the components zi(x) of z(x) to spin variables. Due to the potential sparse encoding, a core term has to be added to the cost function. Let
Despite this drawback, random subspace coding might be preferable due to its simplicity and high resolution with relatively few hyperrectangles compared to the hypercubes of the standard discretization.
7.4.1 Financial crash problem
a. Description We calculate the financial equilibrium of market values vi, i = 1, …, n of n institutions according to a simple model following Elliott et al. (2014) and Orús et al. (2019). In this model, the prices of m assets are labeled by pk, k = 1, …, m. Furthermore we define the ownership matrix D, where Dij denotes the percentage of asset j owned by i; the cross-holdings C, where Cij denotes the percentage of institution j owned by i (except for self-holdings); and the self-ownership matrix
Crashes are then modeled as abrupt changes in the prices of assets held by an institution, i.e., via
where
b. Variables It is useful to shift the market values and we find a variable
c. Cost function In order to enforce that the system is in financial equilibrium we simply square Eq. 124
where for the theta functions in b(v, p) we use
as suggested in Section 8.1.2.
7.4.2 Continuous black box optimization
a. Description Given a function
b. Variables The number and range of variables depends on the continuous to discrete encoding. In the case of the standard discretization, we have d variables va taking values in {0, …, ⌈1/q⌉}, where q is the precision.
With the random subspace encoding, we have Δ variables va taking values in {0, …, ds}, where Δ is the maximal overlap of the rectangles and ds is the number of rectangles.
c. Cost function Similar to the classical strategy, we first fit/learn an acquisition function with an ansatz. Such an ansatz could take the form
where k is the highest order of the ansatz and the variables vi depend on the continuous to discrete encoding. In terms of the indicator functions, they are expressed as
alternatively, one could write the ansatz as a function of the indicator functions alone instead of the variables
While the number of terms is roughly the same as before, this has the advantage that the energy scales in the cost function can be much lower. A downside is that one has to consider that usually for an optimization to be better than random sampling one needs the assumption that the function f is well-behaved in some way (e.g., analytic). The formulation of the ansatz in Eq. 129 might not take advantage of this assumption in the same way as the first.
Let
d. Constraints In this problem, the only constraints that can appear are core terms. For the standard discretization, no such term is necessary and for the random subspace coding, we add Eq. 122.
e. References This problem can be found in Izawa et al. (2022).
7.5 Other problems
In this final category, we include problems that do not fit into the previous classifications but constitute important use cases for quantum optimization.
7.5.1 Syndrome decoding problem
a. Description For an [n, k] classical linear code (a code where k logical bits are encoded in n physical bits) the parity check matrix H indicates whether a state y of physical bits is a code word or has a non-vanishing error syndrome η = yH T . Given such a syndrome, we want to decode it, i.e., find the most likely error with that syndrome, which is equivalent to solving
where wt denotes the Hamming weight and all arithmetic is mod 2.
b. Cost function There are two distinct ways to formulate the problem: check-based and generator-based. In the generator-based approach, we note that the generator matrix G of the code satisfies GH T = 0 and thus any logical word u yields a solution to eH T = η via e = uG + v where v is any state such that vH T = 0 can be found efficiently. Minimizing the weight of uG + v leads to the cost function
note that the summation over l is mod 2 but the rest of the equation is over
according to Section 8.3.1.
In the check-based approach, we can directly minimize deviations from eH T = η with the cost function
but we additionally have to penalize higher weight errors with the term
so we have
with positive parameters c 1/c 2.
c. Variables The variables in the check-based formulation are the n bits e i of the error e. In the generator-based formulation, k bits u i of the logical word u are defined. If we use the reformulation Eq. 132, these are replaced by the k spin variables s l . Note that the state v is assumed to be given by an efficient classical calculation.
d. Constraints There are no hard constraints, any logical word u and any physical state e are valid.
e. Resources A number of interesting tradeoffs can be found by analyzing the resources needed by both approaches. The check-based approach features a cost function with up to (n − k) + n terms (for a non-degenerate check matrix with n − k rows, there are (n − k) terms from f 1 and n terms from f 2), whereas in f G , there are at most n terms (the number of rows of G). The highest order of the variables that appear in these terms is for the generator-based formulation bounded by the number of rows of G which is k. In general, this order can be up to n (number of columns of H) for f H but for an important class of linear codes (low-density parity check codes), the order would be bounded by the constant weight of the parity checks. This weight can be quite low but there is again a tradeoff because higher weights of the checks result in better encoding rates (i.e., for good low-density parity check codes, they increase the constant encoding rate n/k ∼ α).
f. References This problem was originally presented in Lai et al. (2022).
7.5.2 k-SAT
a. Description A k-SAT problem instance consists of a boolean formula
in the conjunctive normal form (CNF), that is, σ i are disjunction clauses over k literals l:
where a literal l i,k is a variable x i,k or its negation ¬x i,k . We want to find out if there exists an assignment of the variables that satisfies the formula.
b. Variables There are two strategies to express a k-SAT problem in a Hamiltonian formulation. First, one can use a Hamiltonian cost function based on violated clauses. In this case, the variables are the assignments x ∈ {0,1}
n
. For the second method, a graph is constructed from a k-SAT instance in CNF as follows. Each clause σ
j
will be a fully connected graph of k variables
c. Cost function A clause-violation-based cost function for a problem in CNF can be written as
with (Section 8.3.2)
A cost function for the MIS problem can be constructed from a term encouraging a higher cardinality of the independent set:
d. Constraints In the MIS formulation, one has to enforce that there are no connections between members of the maximally independent set:
If this constraint is implemented as an energy penalty f A = ac, it should have a higher priority. The minimal cost of a spin flip (cf. Section 8.4.2) from f A is a(m − 1) and in f B , a spin flip could result in a maximal gain of b. Thus, a/b ≳ 1/(m − 1).
e. Resources The cost function f
C
consists of up to
f. References This problem can be found in Choi (2010) which specifically focuses on the 3-SAT implementation.
8 Summary of building blocks
Here we summarize the parts of the cost functions and techniques that are used as reoccurring building blocks for the problems in this library. Similar building blocks are also discussed by Sawaya et al. (2022).
8.1 Auxiliary functions
The simplest class of building blocks are auxiliary scalar functions of multiple variables that can be used directly in cost functions or constraints via penalties.
8.1.1 Element counting
One of the most common building blocks is the function t a that simply counts the number of variables v i with a given value a. In terms of the value indicator functions, we have
It might be useful to introduce t a as additional variables. In that case, one has to bind it to its desired value with the constraints
8.1.2 Step function
Step functions Θ(v − w) can be constructed as
with K being the maximum value that the v, w can take on. Step functions can be used to penalize configurations where v ≥ w.
8.1.3 Minimizing the maximum element of a set
Step functions are particularly useful for minimizing the maximum value of a set {v i }. Given an auxiliary variable l, we can guarantee that l ≥ v i , for all i with the penalization
which increases the energy if l is smaller than any v i . The maximum value of {v i } can be minimized by adding to the cost function of the problem the value of l. In that case, we also have to multiply the term from Eq. 145 by the maximum value that l can take in order to avoid trading off the penalty.
8.1.4 Compare variables
Given two variables v, w ∈ [1, K], the following term indicates if v and w are equal:
If we want to check if v > w, then we can use the step function Eq. 144.
8.2 Constraints
Here we present the special case of functions of variables where the groundstate fulfills useful constraints. These naturally serve as building blocks for enforcing constraints via penalties.
8.2.1 All (connected) variables are different
If we have a set of variables
The minimum value of c is zero, and it is only possible if and only if there is no connected pair i, j such that v i = v j . For all-to-all connectivity, one can use this building block to enforce that all variables are different. If K = N, the condition v i ≠ v j for all i ≠ j is then equivalent to asking that each of the K possible values is reached by a variable.
8.2.2 Value α is used
Given a set of N variables v i , we want to know if at least one variable is taking the value α. This is done by the term
8.2.3 Inequalities
a. Inequalities of a single variable If a discrete variable v i , which can take values in 1, …, K, is subject to an inequality v i ≤ a′ one can enforce this with a energy penalization for all values that do not satisfy the inequality
it is also possible to have a weighted penalty, e.g.,
which might be useful if the inequality is not a hard constraint and more severe violations should be penalized more. That option comes with the drawback of introducing in general higher energy scales in the system, especially if K is large, which might decrease the relative energy gap.
b. Inequality constraints If the problem is restricted by an inequality constraint:
it is convenient to define an auxiliary variable y < K and impose the constraint:
so c is bound to be equal to some value of y, and the only possible values for y are those that satisfy the inequality.
If the auxiliary variable y is expressed in binary or Gray encoding, then Eq. 152 must be modified when 2
n
< K < 2
n+1 for some
which ensures c(v 1, …, v N ) < K if y = 0, …, 2 n+1 − 1.
8.2.4 Constraint preserving driver
As explained in Section 5, the driver Hamiltonian must commute with the operator generating the constraints so that it reaches the entire valid search space. Arbitrary polynomial constraints c can for example, be handled by using the Parity mapping. It brings constraints to the form
8.3 Problem specific representations
For selected problems that are widely applicable, we demonstrate useful techniques for mapping them to cost functions.
8.3.1 Modulo 2 linear programming
For the set of linear equations
where
minimizes the Hamming distance between xA and y and thus the ground state represents a solution. If we consider the second factor for fixed i, we notice that it counts the number of 1s in x (mod 2) where A ji does not vanish at the corresponding index. When acting with
on |x⟩ we find the same result and thus the cost function
with spin variables s j has the solution to Eq. 154 as its ground state.
8.3.2 Representation of boolean functions
Given a boolean function f: {0,1} n → {0, 1} we want to express it as a cost function in terms of the n boolean variables. This is hard in general (Hadfield, 2021), but for (combinations of) local boolean functions there are simple expressions. In particular, we have, e.g.,
It is always possible to convert a k-SAT instance to 3-SAT and, more generally, any boolean formula to a 3-SAT in conjunctive normal form with the Tseytin transformation (Tseitin, 1983) with only a linear overhead in the size of the formula.
Note that for the purpose of encoding optimization problems, one might use different expressions that only need to coincide (up to a constant shift) with those shown here for the ground state/solution to the problem at hand. For example, if we are interested in a satisfying assignment for x
1 ∧…∧x
n
we might formulate the cost function in two different ways that both have x
1 = … = x
n
= 1 as their unique ground state; namely,
8.4 Meta optimization
There are several options for choices that arise in the construction of cost functions. These include meta parameters such as coefficients of building blocks but also reoccurring methods and techniques in dealing with optimization problems.
8.4.1 Auxiliary variables
It is often useful to combine information about a set of variables v i into one auxiliary variable y that is then used in other parts of the cost function. Examples include the element counting building block or the maximal value of a set of variables where we showed a way to bind the value of an auxiliary variable to this function of the set of variables. If the function f can be expressed algebraically in terms of the variable values/indicator functions (as a finite polynomial), the natural way to do this is via adding the constraint term
with an appropriate coefficient c. To avoid the downsides of introducing constraints, there is an alternative route that might be preferred in certain cases. This alternative consists of simply using the variable indicator
where the
8.4.2 Prioritization of cost function terms
If a cost function is constructed out of multiple terms,
one often wants to prioritize one term over another, e.g., if the first term encodes a hard constraint. One strategy to ensure that f 1 is not “traded off” against f 2 is to evaluate the minimal cost Δ1 in f 1 and the maximal gain Δ2 in f 2 from flipping one spin. It can be more efficient to do this independently for both terms and assume a state close to an optimum. The coefficients can then be set according to c 1Δ1 ≳ c 2Δ2. In general, this will depend on the encoding for two reasons. First, for some encodings, one has to add core terms to the cost function which have to be taken into account for the prioritization (they usually have the highest priority). Furthermore, in some encodings, a single spin flip can cause the value of a variable to change by more than one 3 . Nonetheless, it can be an efficient heuristic to compare the “costs” and “gains” introduced above for pairs of cost function terms already in the encoding independent formulation by evaluating them for single variable changes by one and thereby fixing their relative coefficients. Then one only has to fix the coefficient for the core term after the encoding is chosen.
8.4.3 Problem conversion
Many decision problems associated with discrete optimization problems are NP-complete: one can always map them to any other NP-complete problem with only the polynomial overhead of classical runtime in the system size. Therefore, a new problem without a cost function formulation could be classically mapped to another problem where such a formulation is at hand. However, since quantum algorithms are hoped to deliver at most a polynomial advantage in the run time for general NP-hard problems, it is advisable to carefully analyze the overhead. This hope is based mainly on heuristic arguments related to the usefulness of quantum tunneling (Mandra et al., 2016) or empiric scaling studies (Guerreschi and Matsuura, 2019; Boulebnane and Montanaro, 2022). It is possible that there are trade-offs (as for k-SAT in Section 7.5.2), where in the original formulation the order of terms in the cost function is k while in the MIS formulation, we naturally have a QUBO problem where the number of terms scales worse in the number of clauses.
9 Conclusion and outlook
In this review, we have collected and elaborated on a wide variety of optimization problems that are formulated in terms of discrete variables. By selecting an appropriate qubit encoding for these variables, we can obtain a spin Hamiltonian suitable for quantum algorithms such as quantum annealing or QAOA. The choice of the qubits encoding leads to distinct Hamiltonians, influencing important factors such as the required number of qubits, the order of interactions, and the smoothness of the energy landscape. Consequently, the encoding decisions directly impact the performance of quantum algorithms.
The encoding-independent formulation (Sawaya et al., 2022) employed in this review offers a significant advantage by enabling the utilization of automated tools to explore diverse encodings, ultimately optimizing the problem formulation. This approach allows for a comprehensive examination and comparison of various encoding strategies, facilitating the identification of the most efficient configuration for a given optimization problem. In addition, the identification of recurring blocks facilitates the formulation of new optimization problems, also constituting a valuable automation tool. By leveraging these automatic tools, we can enhance the efficiency of quantum algorithms in solving optimization problems.
Finding the optimal spin Hamiltonian for a given quantum computer hardware platform is an important problem in itself. As pointed out by Sawaya et al. (2022), optimal spin Hamiltonians are likely to vary across different hardware platforms, underscoring the need for a procedure capable of tailoring a problem to a specific platform. The hardware-agnostic approach made use of in this review represents a further step in that direction.
Author contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
Work was supported by the Austrian Science Fund (FWF) through a START grant under Project No. Y1067-N27, the SFB BeyondC Project No. F7108-N38, QuantERA II Programme under Grant Agreement No. 101017733, the Federal Ministry for Economic Affairs and Climate Action through project QuaST, and the Federal Ministry of Education and Research on the basis of a decision by the German Bundestag.
Acknowledgments
The authors thank Dr. Kaonan Micadei for fruitful discussions.
Conflict of interest
Authors FD, MT, CE, and WL were employed by Parity Quantum Computing Germany GmbH. Authors JU, BM, and WL were employed by Parity Quantum Computing GmbH.
The author BM declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1 This terminology is adapted from Chancellor (2019).
2 Note that Ramos-Calderer et al. (2021) and Sawaya et al. (2020) use the term “unary” for one-hot encoding.
3 E.g., in the binary encoding a spin flip can cause a variable shift of up to K/2 if the variables take values 1, …, K. This is the main motivation to use modifications like the Gray encoding.
References
Amaro, D., Rosenkranz, M., Fitzpatrick, N., Hirano, K., and Fiorentini, M. (2022). A case study of variational quantum algorithms for a job shop scheduling problem. EPJ Quantum Technol. 9, 5. doi:10.1140/epjqt/s40507-022-00123-4
Au-Yeung, R., Chancellor, N., and Halffmann, P. (2023). NP-Hard but no longer hard to solve? Using quantum computing to tackle optimization problems. Front. Quantum Sci. Technol. 2, 1128576. doi:10.3389/frqst.2023.1128576
Bakó, B., Glos, O., Salehi, A., and Zimborás, Z. (2022). Near-optimal circuit design for variational quantum optimization. arXiv:2209.03386. doi:10.48550/arXiv.2209.03386
Bärtschi, A., and Eidenbenz, S. (2020). “Grover mixers for QAOA: shifting complexity from mixer design to state preparation,” in 2020 IEEE international conference on quantum computing and engineering (QCE), 72–82. doi:10.1109/QCE49297.2020.00020
Berwald, J., Chancellor, N., and Dridi, R. (2023). Understanding domain-wall encoding theoretically and experimentally. Phil. Trans. R. Soc. A 381, 20210410. doi:10.1098/rsta.2021.0410
Boulebnane, S., and Montanaro, A. (2022). Solving boolean satisfiability problems with the quantum approximate optimization algorithm. arXiv preprint arXiv:2208.06909. doi:10.48550/arXiv.2208.06909
Cao, Y., Romero, J., Olson, J. P., Degroote, M., Johnson, P. D., Kieferová, M., et al. (2019). Quantum chemistry in the age of quantum computing. Chem. Rev. 119, 10856–10915. doi:10.1021/acs.chemrev.8b00803
Carugno, C., Ferrari Dacrema, M., and Cremonesi, P. (2022). Evaluating the job shop scheduling problem on a D-wave quantum annealer. Sci. Rep. 12, 6539. doi:10.1038/s41598-022-10169-0
Chancellor, N. (2019). Domain wall encoding of discrete variables for quantum annealing and QAOA. Quantum Sci. Technol. 4, 045004. doi:10.1088/2058-9565/ab33c2
Chancellor, N., Zohren, S., and Warburton, P. A. (2017). Circuit design for multi-body interactions in superconducting quantum annealing systems with applications to a scalable architecture. npj Quantum Inf. 3, 21. doi:10.1038/s41534-017-0022-6
Chen, J., Stollenwerk, T., and Chancellor, N. (2021). Performance of domain-wall encoding for quantum annealing. IEEE Trans. Quantum Eng. 2, 1–14. doi:10.1109/TQE.2021.3094280
Choi, V. (2010). Adiabatic quantum algorithms for the NP-complete maximum-weight independent set, exact cover and 3SAT problems. arXiv:1004.2226. doi:10.48550/ARXIV.1004.2226
Devroye, L., Epstein, P., and Sack, J.-R. (1993). On generating random intervals and hyperrectangles. J. Comput. Graph. Stat. 2, 291–307. doi:10.2307/1390647
Di Matteo, O., McCoy, A., Gysbers, P., Miyagi, T., Woloshyn, R. M., and Navrátil, P. (2021). Improving Hamiltonian encodings with the Gray code. Phys. Rev. A 103, 042405. doi:10.1103/PhysRevA.103.042405
Dlaska, C., Ender, K., Mbeng, G. B., Kruckenhauser, A., Lechner, W., and van Bijnen, R. (2022). Quantum optimization via four-body rydberg gates. Phys. Rev. Lett. 128, 120503. doi:10.1103/PhysRevLett.128.120503
Dorigo, M., and Di Caro, G. (1999). “Ant colony optimization: a new meta-heuristic,” in Proceedings of the 1999 congress on evolutionary computation-CEC99 (Cat. No. 99TH8406) (IEEE), 2, 1470–1477. doi:10.1109/CEC.1999.782657
Drieb-Schön, M., Javanmard, Y., Ender, K., and Lechner, W. (2023). Parity quantum optimization: encoding constraints. Quantum 7, 951. doi:10.22331/q-2023-03-17-951
Elliott, M., Golub, B., and Jackson, M. O. (2014). Financial networks and contagion. Am. Econ. Rev. 104, 3115–3153. doi:10.1257/aer.104.10.3115
Ender, K., Messinger, A., Fellner, M., Dlaska, C., and Lechner, W. (2022). Modular parity quantum approximate optimization. PRX Quantum 3, 030304. doi:10.1103/prxquantum.3.030304
Ender, K., ter Hoeven, R., Niehoff, B. E., Drieb-Schön, M., and Lechner, W. (2023). Parity quantum optimization: compiler. Quantum 7, 950. doi:10.22331/q-2023-03-17-950
Farhi, E., Goldstone, J., and Gutmann, S. (2014). A quantum approximate optimization algorithm, 4028. arXiv:1411. doi:10.48550/ARXIV.1411.4028
Farhi, E., Goldstone, J., Gutmann, S., and Sipser, M. (2000). Quantum computation by adiabatic evolution. arXiv:quant-ph/0001106. doi:10.48550/ARXIV.QUANT-PH/0001106
Feld, S., Roch, C., Gabor, T., Seidel, C., Neukart, F., Galter, I., et al. (2019). A hybrid solution method for the capacitated Vehicle routing problem using a quantum annealer. Front. ICT 6. doi:10.3389/fict.2019.00013
Fellner, M., Ender, K., ter Hoeven, R., and Lechner, W. (2023). Parity quantum optimization: benchmarks. Quantum 7, 952. doi:10.22331/q-2023-03-17-952
Fellner, M., Messinger, A., Ender, K., and Lechner, W. (2022). Universal parity quantum computing. Phys. Rev. Lett. 129, 180503. doi:10.1103/PhysRevLett.129.180503
Fuchs, F. G., Kolden, H. O., Aase, N. H., and Sartor, G. (2021). Efficient encoding of the weighted MAX k-CUT on a quantum computer using QAOA. SN Comput. Sci. 2, 89. doi:10.1007/s42979-020-00437-z
Fuchs, F. G., Lye, K. O., Nilsen, H. M., Stasik, A. J., and Sartor, G. (2022). Constraint preserving mixers for the quantum approximate optimization algorithm. Algorithms 15, 202. doi:10.3390/a15060202
Georgescu, I. M., Ashhab, S., and Nori, F. (2014). Quantum simulation. Rev. Mod. Phys. 86, 153–185. doi:10.1103/RevModPhys.86.153
Glaser, N. J., Roy, F., and Filipp, S. (2023). Controlled-controlled-phase gates for superconducting qubits mediated by a shared tunable coupler. Phys. Rev. Appl. 19, 044001. doi:10.1103/PhysRevApplied.19.044001
Glos, A., Krawiec, A., and Zimborás, Z. (2022). Space-efficient binary optimization for variational quantum computing. npj Quantum Inf. 8, 39. doi:10.1038/s41534-022-00546-y
Guerreschi, G. G., and Matsuura, A. Y. (2019). Qaoa for max-cut requires hundreds of qubits for quantum speed-up. Sci. Rep. 9, 6903. doi:10.1038/s41598-019-43176-9
Hadfield, S. (2021). On the representation of Boolean and real functions as Hamiltonians for quantum computing. ACM Trans. Quant. Comput. 2, 1–21. doi:10.1145/3478519
Hadfield, S., Wang, Z., O’Gorman, B., Rieffel, E. G., Venturelli, D., and Biswas, R. (2019). From the quantum approximate optimization algorithm to a quantum alternating operator ansatz. Algorithms 12, 34. doi:10.3390/a12020034
Hadfield, S., Wang, Z., Rieffel, E. G., O’Gorman, B., Venturelli, D., and Biswas, R. (2017). Quantum approximate optimization with hard and soft constraints. PMES’17. New York, NY, USA: Association for Computing Machinery. doi:10.1145/3149526.3149530
Hen, I., and Sarandy, M. S. (2016). Driver Hamiltonians for constrained optimization in quantum annealing. Phys. Rev. A 93, 062312. doi:10.1103/PhysRevA.93.062312
Hen, I., and Spedalieri, F. M. (2016). Quantum annealing for constrained optimization. Phys. Rev. Appl. 5, 034007. doi:10.1103/PhysRevApplied.5.034007
Ikeda, K., Nakamura, Y., and Humble, T. S. (2019). Application of quantum annealing to nurse scheduling problem. Sci. Rep. 9, 12837. doi:10.1038/s41598-019-49172-3
Izawa, S., Kitai, K., Tanaka, S., Tamura, R., and Tsuda, K. (2022). Continuous black-box optimization with an ising machine and random subspace coding. Phys. Rev. Res. 4, 023062. doi:10.1103/PhysRevResearch.4.023062
King, J., Yarkoni, S., Raymond, J., Ozfidan, I., King, A. D., Nevisi, M. M., et al. (2019). Quantum annealing amid local ruggedness and global frustration. J. Phys. Soc. Jpn. 88, 061007. doi:10.7566/JPSJ.88.061007
Kochenberger, G., Hao, J.-K., Glover, F., Lewis, M., Lü, Z., Wang, H., et al. (2014). The unconstrained binary quadratic programming problem: a survey. J. Comb. Optim. 28, 58–81. doi:10.1007/s10878-014-9734-0
Kurowski, K., Weglarz, J., Subocz, M., Różycki, R., and Waligóra, G. (2020). “Hybrid quantum annealing heuristic method for solving job shop scheduling problem,” in Computational science – ICCS 2020. Editors V. V. Krzhizhanovskaya, G. Závodszky, M. H. Lees, J. J. Dongarra, P. M. A. Sloot, S. Brissoset al. (Springer International Publishing), 502–515.
Lai, C.-Y., Kuo, K.-Y., and Liao, B.-J. (2022). Syndrome decoding by quantum approximate optimization. arXiv:2207.05942. doi:10.48550/ARXIV.2207.05942
Lanthaler, M., and Lechner, W. (2021). Minimal constraints in the parity formulation of optimization problems. New J. Phys. 23, 083039. doi:10.1088/1367-2630/ac1897
Lechner, W., Hauke, P., and Zoller, P. (2015). A quantum annealing architecture with all-to-all connectivity from local interactions. Sci. Adv. 1, e1500838. doi:10.1126/sciadv.1500838
Lechner, W. (2020). Quantum approximate optimization with parallelizable gates. IEEE Trans. Quantum Eng. 1, 1–6. doi:10.1109/TQE.2020.3034798
Lenstra, J. K., and Rinnooy Kan, A. H. G. (1979). Computational complexity of discrete optimization problems. AODM 4, 121–140. doi:10.1016/S0167-5060(08)70821-5
Lu, Y., Zhang, S., Zhang, K., Chen, W., Shen, Y., Zhang, J., et al. (2019). Global entangling gates on arbitrary ion qubits. Nature 572, 363–367. doi:10.1038/s41586-019-1428-4
Lucas, A. (2014). Ising formulations of many NP problems. Front. Phys. 2, 5. doi:10.3389/fphy.2014.00005
Mandra, S., Zhu, Z., Wang, W., Perdomo-Ortiz, A., and Katzgraber, H. G. (2016). Strengths and weaknesses of weak-strong cluster problems: a detailed overview of state-of-the-art classical heuristics versus quantum approaches. Phys. Rev. A 94, 022337. doi:10.1103/physreva.94.022337
Mazyavkina, N., Sviridov, S., Ivanov, S., and Burnaev, E. (2021). Reinforcement learning for combinatorial optimization: a survey. Comput. Oper. Res. 134, 105400. doi:10.1016/j.cor.2021.105400
McArdle, S., Endo, S., Aspuru-Guzik, A., Benjamin, S. C., and Yuan, X. (2020). Quantum computational chemistry. Rev. Mod. Phys. 92, 015003. doi:10.1103/RevModPhys.92.015003
Melnikov, B. (2005). “Discrete optimization problems-some new heuristic approaches,” in Eighth international conference on high-performance computing in asia-pacific region (HPCASIA’05) (IEEE), 73–82. doi:10.1109/HPCASIA.2005.34
Menke, T., Banner, W. P., Bergamaschi, T. R., Di Paolo, A., Vepsäläinen, A., Weber, S. J., et al. (2022). Demonstration of tunable three-body interactions between superconducting qubits. Phys. Rev. Lett. 129, 220501. doi:10.1103/PhysRevLett.129.220501
Menke, T., Häse, F., Gustavsson, S., Kerman, A. J., Oliver, W. D., and Aspuru-Guzik, A. (2021). Automated design of superconducting circuits and its application to 4-local couplers. npj Quantum Inf. 7, 49. doi:10.1038/s41534-021-00382-6
Messinger, A., Fellner, M., and Lechner, W. (2023). Constant depth code deformations in the parity architecture. arXiv:2303.08602. doi:10.48550/arXiv.2303.08602
Mohseni, N., McMahon, P. L., and Byrnes, T. (2022). Ising machines as hardware solvers of combinatorial optimization problems. Nat. Rev. Phys. 4, 363–379. doi:10.1038/s42254-022-00440-8
Montanez-Barrera, A., Maldonado-Romo, A., Willsch, D., and Michielsen, K. (2022). Unbalanced penalization: a new approach to encode inequality constraints of combinatorial problems for quantum optimization algorithms. arXiv:2211.13914. doi:10.48550/arXiv.2211.13914
Orús, R., Mugel, S., and Lizaso, E. (2019). Forecasting financial crashes with quantum computing. Phys. Rev. A 99, 060301. doi:10.1103/PhysRevA.99.060301
Pastawski, F., and Preskill, J. (2016). Error correction for encoded quantum annealing. Phys. Rev. A 93, 052325. doi:10.1103/PhysRevA.93.052325
Pelegrí, G., Daley, A. J., and Pritchard, J. D. (2022). High-fidelity multiqubit Rydberg gates via two-photon adiabatic rapid passage. Quantum Sci. Technol. 7, 045020. doi:10.1088/2058-9565/ac823a
Plewa, J., Sieńko, J., and Rycerz, K. (2021). Variational algorithms for workflow scheduling problem in gate-based quantum devices. Comput. Inf. 40, 897–929. doi:10.31577/cai_2021_4_897
Preskill, J. (2018). Quantum computing in the NISQ era and beyond. Quantum 2, 79. doi:10.22331/q-2018-08-06-79
Rachkovskii, D. A., Slipchenko, S. V., Kussul, E. M., and Baidyk, T. N. (2005). Properties of numeric codes for the scheme of random subspaces rsc. Cybern. Syst. Anal. 41, 509–520. doi:10.1007/s10559-005-0086-8
Ramos-Calderer, S., Pérez-Salinas, A., García-Martín, D., Bravo-Prieto, C., Cortada, J., Planagumà, J., et al. (2021). Quantum unary approach to option pricing. Phys. Rev. A 103, 032414. doi:10.1103/PhysRevA.103.032414
Rosenberg, G., Haghnegahdar, P., Goddard, P., Carr, P., Wu, K., and de Prado, M. L. (2015). “Solving the optimal trading trajectory problem using a quantum annealer,” in Proceedings of the 8th workshop on high performance computational finance (New York, NY, USA: Association for Computing Machinery). doi:10.1145/2830556.2830563
Sawaya, N. P. D., Menke, T., Kyaw, T. H., Johri, S., Aspuru-Guzik, A., and Guerreschi, G. G. (2020). Resource-efficient digital quantum simulation of d-level systems for photonic, vibrational, and spin-s Hamiltonians. npj Quantum Inf. 6, 49. doi:10.1038/s41534-020-0278-0
Sawaya, N. P. D., Schmitz, A. T., and Hadfield, S. (2022). Encoding trade-offs and design toolkits in quantum algorithms for discrete optimization: coloring, routing, scheduling, and other problems, 14432. arXiv:2203. doi:10.48550/arXiv.2203.14432
Schöndorf, M., and Wilhelm, F. K. (2019). Nonpairwise interactions induced by virtual transitions in four coupled artificial atoms. Phys. Rev. Appl. 12, 064026. doi:10.1103/PhysRevApplied.12.064026
Stein, J., Chamanian, F., Zorn, M., Nüßlein, J., Zielinski, S., Kölle, M., et al. (2023). Evidence that PUBO outperforms QUBO when solving continuous optimization problems with the QAOA. arXiv:2305.03390. doi:10.48550/arXiv.2305.03390
Tamura, K., Shirai, T., Katsura, H., Tanaka, S., and Togawa, N. (2021). Performance comparison of typical binary-integer encodings in an ising machine. IEEE Access 9, 81032–81039. doi:10.1109/ACCESS.2021.3081685
Tseitin, G. S. (1983). “On the complexity of derivation in propositional calculus,” in Automation of reasoning (Springer), 466–483. doi:10.1007/978-3-642-81955-1_28
Unger, J., Messinger, A., Niehoff, B. E., Fellner, M., and Lechner, W. (2022). Low-depth circuit implementation of parity constraints for quantum optimization, 11287. arXiv:2211. doi:10.48550/ARXIV.2211.11287
Venturelli, D., Marchand, D. J. J., and Rojo, G. (2015). Quantum annealing implementation of job-shop scheduling. arXiv:1506.08479. doi:10.48550/ARXIV.1506.08479
Wang, Z., Rubin, N. C., Dominy, J. M., and Rieffel, E. G. (2020). XY mixers: analytical and numerical results for the quantum alternating operator ansatz. Phys. Rev. A 101, 012320. doi:10.1103/PhysRevA.101.012320
Wilkinson, S. A., and Hartmann, M. J. (2020). Superconducting quantum many-body circuits for quantum simulation and computing. Appl. Phys. Lett. 116, 230501. doi:10.1063/5.0008202
Keywords: qubit encoding, quantum optimization, quantum annealing, QUBO, PUBO
Citation: Dominguez F, Unger J, Traube M, Mant B, Ertler C and Lechner W (2023) Encoding-independent optimization problem formulation for quantum computing. Front. Quantum Sci. Technol. 2:1229471. doi: 10.3389/frqst.2023.1229471
Received: 26 May 2023; Accepted: 15 August 2023;
Published: 07 September 2023.
Edited by:
Julio De Vicente, Universidad Carlos III de Madrid, SpainReviewed by:
Nicolas Sawaya, Intel, United StatesMingxing Luo, Southwest Jiaotong University, China
Copyright © 2023 Dominguez, Unger, Traube, Mant, Ertler and Lechner. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wolfgang Lechner, d29sZmdhbmdAcGFyaXR5cWMuY29t
† These authors have contributed equally to this work