 Melanie Kircheis
Melanie Kircheis Daniel Potts
Daniel Potts- Faculty of Mathematics, Chemnitz University of Technology, Chemnitz, Germany
The well-known discrete Fourier transform (DFT) can easily be generalized to arbitrary nodes in the spatial domain. The fast procedure for this generalization is referred to as nonequispaced fast Fourier transform (NFFT). Various applications such as MRI and solution of PDEs are interested in the inverse problem, i.e., computing Fourier coefficients from given nonequispaced data. In this article, we survey different kinds of approaches to tackle this problem. In contrast to iterative procedures, where multiple iteration steps are needed for computing a solution, we focus especially on so-called direct inversion methods. We review density compensation techniques and introduce a new scheme that leads to an exact reconstruction for trigonometric polynomials. In addition, we consider a matrix optimization approach using Frobenius norm minimization to obtain an inverse NFFT.
1. Introduction
The NFFT, short hand for nonequispaced fast Fourier transform or nonuniform fast Fourier transform (NUFFT), respectively, is a fast algorithm to evaluate a trigonometric polynomial
with given Fourier coefficients , , at nonequispaced points , j = 1,…, N, N∈ℕ, where with . In case we are given equispaced points xj and , this evaluation can be realized by means of the well-known fast Fourier transform (FFT); an algorithm that is invertible. However, various applications such as magnetic resonance imaging (MRI), cf. [1, 2] and solution of PDEs, cf. [3] need to perform an inverse nonequispaced fast Fourier transform (iNFFT), i.e., compute the Fourier coefficients from given function evaluations f(xj) of the trigonometric polynomial (1.1). Hence, we are interested in an inversion also for nonequispaced data.
In general, the number N of points xj is independent of the number of Fourier coefficients and hence the nonequispaced Fourier matrix
which we would have to invert, is rectangular in most cases. Considering the corresponding linear system with and , this can either be overdetermined, if , or underdetermined, if . Generally, this forces us to look for a pseudoinverse solution. Moreover, we also require that the nonequispaced Fourier matrix A has full rank. Eigenvalue estimates in [4–8] indeed confirm that this condition is satisfied for sufficiently nice sampling sets.
In literature a variety of approaches for an inverse NFFT (iNFFT) can be found. This is why we give a short overview.
1.1. Iterative inversion methods
We start surveying the iterative methods. For the one-dimensional setting d = 1 with an algorithm was published in Ruiz-Antolin and Townsend [9], which is specially designed for jittered equispaced points and is based on the conjugate gradient (CG) method in connection with low-rank approximation. An approach for the overdetermined case can be found in Feichtinger et al. [4], where the Toeplitz structure of the matrix product A*WA with a diagonal matrix of Voronoi weights is used to compute the solution iteratively by means of the CG algorithm.
For higher dimensional problems with d ≥ 1, several approaches compute a least squares approximation to the linear system . In the overdetermined case , the given data can typically only be approximated up to a residual . Therefore, the weighted least squares problem
is considered, which is equivalent in solving the weighted normal equations of the first kind with the diagonal matrix of weights in the time domain. In [10–12], these normal equations are solved iteratively by means of CG using the NFFT to realize fast matrix-vector multiplications involving A, whereas in Pruessmann and Wayer [13] a fast convolution is used.
In the consistent underdetermined case the data can be interpolated exactly and, therefore, one can choose a specific solution, e.g., the one that solves the constrained minimization problem
This interpolation problem is equivalent to the weighted normal equations of the second kind AŴA*y = f, with the diagonal matrix of weights in the frequency domain. In Kunis and Potts [14], the CG method was used in connection with the NFFT to iteratively compute a solution to this problem, see also [15, Section 7.6.2].
1.2. Regularization methods
Moreover, there also exist several regularization techniques for the multidimensional setting d ≥ 1. For example, [16–18] all solve the ℓ1-regularized problem
with regularization parameter λ > 0 and the m-th order polynomial annihilation operator as sparsifying transform, see Archibald et al. [19]. Based on this, weighted ℓp-schemes
were introduced in [20–23], which are designed to reduce the penalty at locations where is nonzero. For instance, Churchill et al. [24] and Scarnati and Gelb [25] each state a two-step method, that first uses edge detection to create a mask, i.e., a weighting that which indicates where nonzero entries are expected in the TV domain, and then targets weighted ℓ2-norm TV regularization appropriately to smooth regions of the function in a second minimization step.
1.3. Direct inversion methods
In contrast to these iterated procedures, there are also so-called direct methods that do not require multiple iteration steps. Already in Dutt and Rokhlin [26] a direct method was explained for the setting d = 1 and that uses Lagrange interpolation in combination with fast multiple methods. Based on this, further methods were deduced for the same setting, which also use Lagrange interpolation, but additionally incorporate an imaginary shift in [27], or utilize fast summation in Kircheis and Potts [28] for the fast evaluation of occurring sums, see also [15, Section 7.6.1].
In the overdetermined setting another approach for computing an inverse NFFT can be obtained by using the fact that A*A is of Toeplitz structure. To this end, the Gohberg-Semencul formula, see Heinig and Rost [29], can be used to solve the normal equations exactly by analogy with Averbuch et al. [72]. Here, the computation of the components of the Gohberg-Semencul formula can be viewed as a precomputational step. In addition, also a frame-theoretical approach is known from Gelb and Song [30], which provides a link between the adjoint NFFT and frame approximation, and could, therefore, be seen as a way to invert the NFFT. Note that the method in Gelb and Song [30] is based only on optimizing a diagonal matrix [the matrix D defined in (2.13)], whereas in Kircheis and Potts [28] similar ideas were used to modify a sparse matrix [the matrix B defined in (2.15)].
For the multidimensional setting d > 1, several methods have been developed that are tailored to the special structure of the linogram or pseudo-polar grid, respectively, see Figure 3B, such that the inversion involves only one-dimensional FFTs and interpolations. On the one hand, in Averbuch et al. [31], a least squares solution is computed iteratively by using a fast multiplication technique with the matrix A, which can be derived in the case of the linogram grid. On the other hand, [32] is based on a fast resampling strategy, where a first step resamples the linogram grid onto a Cartesian grid, and the second phase recovers the image from these Cartesian samples. However, these techniques are exclusively applicable to the special case of the linogram grid, see Figure 3B, or the polar grid by another resampling, cf. Figure 3A. Since we are interested in more generally applicable methods, a brief introduction to direct inversion for general sampling patterns can be found in Kircheis and Potts [33].
1.4. Current approach
In this article, we focus on direct inversion methods that are applicable to general sampling patterns and present new methods for the computation of an iNFFT. Note that the direct method in the context of the linear system means, that for a fixed set of points xj, j = 1,…, N, the reconstruction of from given f can be realized with the same number of arithmetic operations as a single application of an adjoint NFFT (see Algorithm 2.4). To achieve this, a certain precomputational step is compulsory, since the adjoint NFFT does not yield an inversion of the NFFT per se, cf. (3.3). Although these precomputations might be rather costly, they need to be done only once for a given set of points xj, j = 1,…, N. Therefore, direct methods are especially beneficial in the case of fixed points for several measurement vectors f.
For this reason, the current paper is concerned with two different approaches of this kind. First, we consider the very well-known approach of so-called sampling density compensation, which can be written as with a diagonal matrix of weights. The already mentioned precomputations then consist of computing suitable weights wj, while the actual reconstruction step includes only one adjoint NFFT applied to the scaled coefficient vector Wf. In this article, we examine several existing approaches for computing the weights wj and introduce a new method, such that the iNFFT is exact for all trigonometric polynomials (1.1) of degree M.
As a second part, we reconsider and enhance our approach introduced in Kircheis and Potts [33]. Therefore, the idea is using the matrix representation A ≈ BFD of the NFFT to modify one of the matrix factors, such that an inversion is given by . Then the precomputational step consists of optimizing the matrix B, while the actual reconstruction step includes only one modified adjoint NFFT applied to the coefficient vector f.
1.5. Outline of this paper
This article is organized as follows. In Section 2, we introduce the already mentioned algorithm, the NFFT, as well as its adjoint version, the adjoint NFFT. Second, in Section 3, we introduce the inversion problem and deal with direct methods using so-called sampling density compensation. We start our investigations with trigonometric polynomials in Section 3.1. Here, the main formula (3.14) yields exact reconstruction for all trigonometric polynomials of degree M. We also discuss practical computation schemes for the overdetermined and the underdetermined setting. Subsequently, in Section 3.2, we go on to bandlimited functions and show that the same numerical procedures as in Section 3.1 can be used in this setting as well. Section 3.3 then summarizes the previous findings by presenting a general error bound on density compensation factors computed by means of (3.14) in Theorem 3.14. In addition, this also yields an estimate on the condition number of a specific matrix product, as shown in Theorem 3.15. In Section 3.4, we have a look at certain approaches from literature and their connection among each other as well as to the method presented in Section 3.1. Afterward, we examine another direct inversion method in Section 4, where we aimed to modify the adjoint NFFT by means of matrix optimization such that this yields an iNFFT. Finally, in Section 5, we show some numerical examples to investigate the accuracy of our approaches.
2. Nonequispaced fast Fourier transform
Let
denote the d-dimensional torus with d ∈ ℕ. For M := (M,…, M)T, M ∈ 2ℕ, we define the multi-index set
with cardinality . The inner product of two vectors shall be defined as usual as kx := k1x1 + ⋯ + kdxd. and the componentwise product as . In addition, we define the all ones vector and the reciprocal of a vector x with nonzero components shall be given by .
We consider the Hilbert space of all 1-periodic, complex-valued functions, which possess the orthonormal basis {e2πikx : k ∈ ℤd}. It is known that every function is uniquely representable in the form
with the coefficients
where the sum in (2.1) converges to f in the -norm, cf. [15, Thm. 4.5]. A series of the form (2.1) is called Fourier series with the Fourier coefficients (2.2). Numerically, the Fourier coefficients (2.2) are approximated on the uniform grid by the trapezoidal rule for numerical integration as
which is an acceptable approximation for , see e. g., [15, p. 214]. The fast evaluation of (2.3) can then be realized by means of the fast Fourier transform (FFT). Moreover, it is know that this transformation is invertible and that the inverse problem of computing
with , , can be realized by means of an inverse fast Fourier transform (iFFT), which is the same algorithm except for some reordering and scaling, cf. [15, Lem. 3.17].
Now, suppose we are given nonequispaced points , j = 1,…, N, instead. Then, we consider the computation of the sums
for given , , as well as the adjoint problem of computing
for given fj ∈ ℂ, j = 1,…, N. By defining the nonequispaced Fourier matrix
as well as the vectors , and , the computation of sums of the form (2.5) and (2.6) can be written as and h = A*f, where denotes the adjoint matrix of A.
Since the naive computation of (2.5) and (2.6) is of complexity , a fast approximate algorithm, the so-called nonequispaced fast Fourier transform (NFFT), is briefly explained below. For more information see [34–38] or [15, p. 377–381].
2.1. NFFT
We first restrict our attention to the problem (2.5), which is equivalent to the evaluation of a trigonometric polynomial
with given , , at given nonequispaced points , j = 1,…, N. Let be a so-called window function, which is well localized in space and frequency domain. Now, we define the 1-periodic function with absolute convergent Fourier series. As a consequence, the Fourier coefficients of the periodization have the form
For a given oversampling factor σ ≥ 1, we define 2ℕ ∋ Mσ:= 2⌈⌈σM⌉/2⌉ as well as Mσ:= Mσ·1d, and approximate f by a linear combination translates of the periodized window function, i.e.,
where gℓ ∈ ℂ, , are coefficients to be determined such that (2.9) yields a good approximation. By means of the convolution theorem (see [15, Lem. 4.1]), the approximant in (2.9) can be represented as
where the discrete Fourier transform of the coefficients gℓ is defined by
Comparing (2.5) and (2.10) then yields
Consequently, the coefficients gℓ in (2.9) can be obtained by inverting (2.11), i.e., by the application of an iFFT.
Furthermore, we assume that w is well localized such that it is small outside the square with truncation parameter m≪Mσ. In this case, w can be approximated by the compactly supported function
Thereby, we approximate s1 by the short sums
where the index set
contains at most (2m+1)d entries for each fixed xj. Thus, the obtained algorithm can be summarized as follows.

Algorithm 2.1. NFFT.
Remark 2.2. Suitable window functions can be found, e.g., in [34, 35, 37–41].□
Next, we give the matrix-vector representation of the NFFT. To this end, we define
• the diagonal matrix
• the truncated Fourier matrix
• and the sparse matrix
where by definition (2.12) each row of B contains at most (2m+1)d nonzeros. In doing so, the NFFT in Algorithm 2.1 can be formulated in matrix-vector notation such that we receive the approximation A ≈ BFD of (2.7), cf. [15, p. 383]. In other words, the NFFT uses the approximation
Remark 2.3. It has to be pointed out that because of consistency the factor is here not located in the matrix F as usual but in the matrix D.□
2.2. Adjoint NFFT
Now, we proceed with the adjoint problem (2.6). As already seen, this can be written as h = A*f with the adjoint matrix A* of (2.7). Thus, using the matrices (2.13), (2.14), and (2.15) we receive the approximation A* ≈ D*F*B*, such that a fast algorithm for the adjoint problem can be denoted as follows.

Algorithm 2.4. Adjoint NFFT.
The algorithms presented in this section (Algorithms 2.1 and 2.4) are part of the NFFT software [42]. For algorithmic details we refer to Keiner et al. [38].
3. Direct inversion using density compensation
Having introduced the fast methods for nonequispaced data, we remark that various applications such as MRI and solution of PDEs are interested in the inverse problem, i.e., instead of the evaluation of (2.5) the aim was to compute the Fourier coefficients , , from given nonequispaced data f(xj), j = 1,…, N. Therefore, this section shall be dedicated to this task.
To clarify the major dissimilarity between equispaced and nonequispaced data, we start considering the equispaced case. When evaluating at the points , , with n := n·1d and , the nonequispaced Fourier matrix in (2.7) turns into the equispaced Fourier matrix from (2.14) with . Thereby, it results from the geometric sum formula that
as well as
and is divisible by N. Thus, in the equispaced setting a one-sided inverse is given by the (scaled) adjoint matrix. However, when considering arbitrary points , j = 1,…, N, this property is lost, i.e., for the nonequispaced Fourier matrix, we have
Because of this, more effort is needed in the nonequispaced setting.
In general, we face the following two problems.
(1) Solve the linear system
i.e., reconstruct the Fourier coefficients from given function values . This problem is referred to as inverse NDFT (iNDFT) and an efficient solver shall be called inverse NFFT (iNFFT).
(2) Solve the linear system
i.e., reconstruct the coefficients from given data . This problem is referred to as inverse adjoint NDFT (iNDFT*) and an efficient solver shall be called inverse adjoint NFFT (iNFFT*).
Note that in both problems the numbers and N are independent, such that the nonequispaced Fourier matrix in (2.7) is generally rectangular.
At first, we restrict our attention to the problem (3.4). When considering iterative inversion procedures as those mentioned in the introduction, these methods require multiple iteration steps by definition. Therefore, multiple matrix-vector multiplications with the system matrix A, or rather multiple applications of the NFFT (see Algorithm 2.1), are needed to compute a solution. To reduce the computational effort, we now proceed, in contrast to this iterated procedure, with so-called direct methods. In the setting of the problem (3.4) we hereby mean methods, where for a fixed set of points xj, j = 1,…, N, the reconstruction of from given f can be realized with the same number of arithmetic operations as a single application of an adjoint NFFT (see Algorithm 2.4). To achieve this, a certain precomputational step is compulsory, since the adjoint NFFT does not yield an inversion of the NFFT per se, see (3.3). Although these precomputations might be rather costly, they need to be done only once for a given set of points xj, j = 1,…, N. In fact, the actual reconstruction step is very efficient. Therefore, direct methods are especially beneficial in case we are given fixed points for several measurement vectors f.
In this section, we focus on a direct inversion method for solving problem (3.4) that utilizes so-called sampling density compensation. To this end, we consider the integral (2.2) and introduce a corresponding quadrature formula. In contrast to the already known equispaced approximation (2.3) we now assume given arbitrary, nonequispaced points , j = 1,…, N. Thereby, the Fourier coefficients (2.2) are approximated by a general quadrature rule using quadrature weights wj ∈ ℂ, j = 1,…, N, which are needed for sampling density compensation due to the nonequispaced sampling. Thus, for a trigonometric polynomial (2.8), we have
Using the nonequispaced Fourier matrix in (2.7), the diagonal matrix of weights as well as the vector , the nonequispaced quadrature rule (3.6) can be written as . For achieving a fast computation method, we make use of the approximation of the adjoint NFFT, cf. Section 2.2, i.e., the final approximation is given by
with the matrices , , and defined in (2.13), (2.14), and (2.15). In other words, for density compensation methods the already mentioned precomputations consists of computing the quadrature weights wj ∈ ℂ, j = 1,…, N, while the actual reconstruction step includes only one adjoint NFFT (see Algorithm 2.4) applied to the scaled measurement vector Wf.
The aim of all density compensation techniques was then to choose appropriate weights wj ∈ ℂ, j = 1,…, N, such that the underlying quadrature (3.6) is preferably exact. In the following, we have a look at the specific choice of the so-called density compensation factors wj.
An intuitive approach for density compensation is based on geometry, where each sample is considered as representative of a certain surrounding area, as in numerical integration. The weights for each sample can be obtained for instance by constructing a Voronoi diagram and calculating the area of each cell, see e.g., [43]. This approach of Voronoi weights is well-known and widely used in practice. However, it does not necessarily yield a good approximation (3.7), which is why we examine some more sophisticated approaches in the remainder of this section.
To this end, this section is organized as follows. First, in Section 3.1, we introduce density compensation factors wj, j = 1,…, N, that lead to an exact reconstruction formula (3.6) for all trigonometric polynomials (2.8) of degree M. In addition to the theoretical results, we also discuss methods for the numerical computation. Secondly, in Section 3.2, we show that it is reasonable to consider the inversion problem (3.4) and density compensation via (3.7) for bandlimited functions as well. Subsequently, we summarize our previous findings by presenting a general error bound on density compensation factors in Section 3.3. Finally, in Section 3.4, we reconsider certain approaches from literature and illustrate their connection to each other as well as to the method introduced in Section 3.1.
Remark 3.1. Recapitulating, we have a closer look at some possible interpretation perspectives on the reconstruction (3.7).
(i) If we define g := Wf, i.e., each entry of f is scaled with respect to the points xj, j = 1,…, N, the approximation (3.7) can be written as . As mentioned before, this coincides with an ordinary adjoint NFFT applied to a modified coefficient vector g.
(ii) By defining the matrix , i.e., scaling the rows of B with respect to the points xj, j = 1, …, N, the approximation (3.7) can be written as . In this sense, density compensation can also be seen as a modification of the adjoint NFFT and its application to the original coefficient vector.
Note that (i) is the common viewpoint. However, we keep (ii) in mind, since this allows treating density compensation methods as an optimization of the sparse matrix in (2.15), as it shall be done in Section 4. We remark that density compensation methods allow only N degrees of freedom.□
3.1. Exact quadrature weights for trigonometric polynomials
Similar to Gräf et al. [44], we aimed to introduce density compensation factors wj, j = 1,…, N, that lead to an exact reconstruction formula (3.6) for all trigonometric polynomials (2.8) of degree M. To this end, we first examine certain properties that arise from (3.6) being exact.
Theorem 3.2. Let a polynomial degree M ∈ (2ℕ)d, nonequispaced points , j = 1, …, N, and quadrature weights wj ∈ ℂ be given. Then an exact reconstruction formula (3.6) for trigonometric polynomials (2.8) with maximum degree M satisfying
implies the following equivalent statements.
(i) The quadrature rule
is exact for all trigonometric polynomials (2.8) with maximum degree M.
(ii) The linear system of equations
is fulfilled with the matrix in (2.7) and .
Proof: (3.8) ⇒ (i): By inserting the definition (2.8) of a trigonometric polynomial of degree M into the integral considered in (3.9), we have
with the Kronecker delta δ0,k. Now using the property (3.8) as well as definition (3.6) of we proceed with
such that (3.11) combined with (3.12) yields the assertion (3.9).
(i) ⇒ (ii): Inserting the definition (2.8) of a trigonometric polynomial of degree M into the right-hand side of (3.9) implies
This together with the property (i) and (3.11) leads to
and thus to assertion (3.10).
(ii) ⇒ (i): Combining (3.11), (3.10), and (3.13) yields the assertion via
□
Remark 3.3. Comparable results can also be found in literature. A fundamental theorem in numerical integration, see [45], states that for any integral there exists an exact quadrature rule (3.9), i.e., optimal points and weights wj ∈ ℂ, j = 1,…, N, such that (3.9) is fulfilled. In Gröchenig [46, Lemma 2.6], it was shown that for given points , j = 1,…, N, certain quadrature weights wj can be stated by means of frame theoretical considerations that lead to an exact quadrature rule (3.9) by definition. Moreover, it was shown (cf. [46, Lemma 3.6]) that these weights are the ones with minimal (weighted) ℓ2-norm, which are already known under the name “least squares quadrature,” see [47]. According to Huybrechs [47, Sec. 2.1], these quadrature weights wj, j = 1,…, N, can be found by solving a linear system of equations Φw = v, where Φk, j = ϕk(xj) and for a given set of basis functions . In our setting, we have and, therefore,
i.e., the same linear system of equations as in (3.10). We remark that both Gröchenig [46] and Huybrechs [47] state the results in the case d = 1, a generalization to d > 1, however, is straight-forward.□
By means of Theorem 3.2 we can now give a condition that guarantees (3.6) being exact for all trigonometric polynomials (2.8) with maximum degree M.
Corollary 3.4. The two statements (i) and (ii) in Theorem 3.2 are not equivalent to property (3.8), since (3.10) does not imply an exact reconstruction in (3.6).
However, an augmented variant of (3.10), namely,
yields an exact reconstruction in (3.6) for trigonometric polynomials (2.8) with maximum degree M. In addition, (3.14) implies the matrix equation with in (2.7) and the identity matrix of size .
Proof: Utilizing definitions (3.6) and (2.8), we have
Since (3.10) only holds for with , this implies
where for all there exists an with .
As for , the augmented variant (3.14) yields
Moreover, since δ(ℓ−k), 0 = δk,ℓ, the condition (3.14) implies
In matrix-vector notation, this can be written as with in (2.7) and the identity matrix of size . We remark that this matrix equation immediately shows that we have an exact reconstruction of the form (3.8), since if is fulfilled, (3.4) implies that .□
Remark 3.5. Let be an arbitrary 1-periodic function (2.1). Then (3.14) yields
i.e., for a function we only have a good approximation in case the coefficients cℓ(f) are small for , whereas this reconstruction can only be exact for f being a trigonometric polynomial (2.8).□
3.1.1. Practical computation in the underdetermined setting
So far, we have seen in Corollary 3.4 that an exact solution to the linear system (3.14) leads to an exact reconstruction formula (3.6) for all trigonometric polynomials (2.8) with maximum degree M. Therefore, we aimed to use this condition (3.14) to numerically find optimal density compensation factors wj ∈ ℂ, j = 1,…, N.
Having a closer look at the condition (3.14) we recognize that it can be written as the linear system of equations with the matrix , cf. (2.7), and right side . We remark that in contrast to we now deal with the enlarged matrix , such that single matrix operations are more costly. Nevertheless, Corollary 3.4 yields a direct inversion method for (3.4), where the system needs to be solved only once for fixed points , j = 1,…, N. Its solution w can then be used to efficiently approximate for multiple measurement vectors f, whereas iterative methods for (3.4) need to solve each time.
As already mentioned in [47, Sec. 3.1] an exact solution to (3.14) can only be found if , i.e., in case is an underdetermined system of equations. By [47, Lem. 3.1] this system has at least one solution, which is why we may choose the one with a minimal ℓ2-norm. If , then the system is consistent and the unique solution is given by the normal equations of the second kind
More precisely, we may compute the vector v using an iterative procedure such as the CG algorithm, such that only matrix multiplications with and are needed. Since fast multiplication with and can easily be realized by means of an adjoint NFFT (see Algorithm 2.4) and an NFFT (see Algorithm 2.1), respectively, computing the solution w to (3.15) is of complexity , where
Thus, to receive exact quadrature weights wj ∈ ℂ, j = 1,…, N, via (3.15) we need to satisfy the full rank condition . In case of a low-rank matrix for , we may still use (3.15) to obtain a least squares approximation to (3.14).
3.1.2. Practical computation in the overdetermined setting
In the setting , we cannot expect to find an exact solution w to (3.14), since we have to deal with an overdetermined system possessing more conditions than variables. However, we still aimed to numerically find optimal density compensation factors wj∈ℂ, j = 1,…, N, by considering a least squares approximation to (3.14) that minimizes . In [60, Thm. 1.1.2] it was shown that every least squares solution satisfies the normal equations of the first kind
By means of definitions of , cf. (2.7), and we simplify the right-hand side via
Since fast multiplication with and can easily be realized by means of an adjoint NFFT (see Algorithm 2.4) and an NFFT (see Algorithm 2.1), respectively, the solution w to (3.16) can be computed iteratively by means of the CG algorithm in arithmetic operations. Note that the solution to (3.16) is only unique if the full rank condition is satisfied, cf. [60, p. 7]. We remark that the computed weight matrix W = diag(w) can further be used in an iterative procedure as in Plonka et al. [[15, Alg. 7.27] to improve the approximation of .
The previous considerations lead to the following algorithms.

Algorithm 3.6. Computation of the optimal density compensation factors.

Algorithm 3.7. iNFFT – density compensation approach.
3.2. Bandlimited functions
In some numerical examples, such as in MRI, we are concerned with bandlimited functions instead of trigonometric polynomials in (2.8), cf. [1]. In the following we show that it is reasonable to consider the inversion problem (3.4) as well as the density compensation via (3.7) for bandlimited functions as well.
To this end, let be a bandlimited function with bandwidth M, i.e., its (continuous) Fourier transform
is supported on . Utilizing this fact, we have and thus by the Fourier inversion theorem [15, Thm. 2.10] the inverse Fourier transform of f can be written as
Analogous to (2.3), the approximation using equispaced quadrature points yields
such that evaluation at the given nonequispaced points , j = 1,…, N, leads to
By means of the definition (2.7) of the matrix this can be written as , where we used the notation in this setting. Thus, also for bandlimited functions f its evaluations at points xj can be approximated in the form (2.5), such that it is reasonable to consider the inversion problem (3.4) for bandlimited functions as well.
Considering (3.17) we are given an exact formula for the evaluation of the Fourier transform . However, in practical applications, such as MRI, this is only a hypothetical case, since f cannot be sampled on whole ℝd, cf. [1]. Due to a limited coverage of space by the acquisition, the function f is typically only known on a bounded domain, w.l.o.g. for . Thus, we have to deal with the approximation
Using the nonequispaced quadrature rule in (3.6), we find that evaluation at uniform grid points can be approximated via
This is to say, equispaced samples of the Fourier transform of a bandlimited function may be approximated in the same form as in (3.6), where we used the notation in this setting. Moreover, we extend this approximation onto the whole interval , i.e., we consider
So all in all, we have seen that it is reasonable to study the inversion problem (3.4) and the associated density compensation via (3.7) for bandlimited functions as well. Analogous to Section 3.1, we now aimed to find a numerical method for computing suitable weights wj ∈ ℂ, j = 1,…, N, such that the reconstruction formula (3.21) is preferably exact. To this end, we have a closer look at (3.21) being exact and start with analogous considerations as in Theorem 3.2.
Theorem 3.8. Let a bandwidth M ∈ ℕd, nonequispaced points as well as quadrature weights wj ∈ ℂ, j = 1,…, N, be given. Then an exact reconstruction formula (3.21) for bandlimited functions with bandwidth M, i.e.,
implies that the quadrature rule
is exact for all bandlimited functions with bandwidth M.
Proof: By (3.17) the assumption (3.22) can be written as
Especially, for v = 0 evaluation of (3.23) yields the assertion
□
However, in contrast to Theorem 3.2, this Theorem 3.8 does not yield an explicit condition for computing suitable weights wj∈ℂ, j = 1,…, N. To derive a numerical procedure anyway, we generalize the notion of an exact reconstruction of f and have a look at the theory of tempered distributions. To this end, let (ℝd) be the Schwartz space of rapidly decaying functions, cf. [15, Sec. 4.2.1]. The tempered Dirac distribution δ shall be defined by for all φ ∈ (ℝd), cf. [15, Ex. 4.36]. For a slowly increasing function f:ℝd → ℂ satisfying almost everywhere with c > 0 and n ∈ ℕ0, the induced distribution Tf shall be defined by for all φ ∈ (ℝd). For a detailed introduction to the topic we refer to [15, Sec. 4.2.1 and Sec. 4.3].
Then the following property can be shown.
Theorem 3.9. Let nonequispaced points , j = 1, …, N, and quadrature weights wj ∈ ℂ be given. Furthermore, let Tf be the distribution induced by some bandlimited function with bandwidth M. Then
with
implies
with the function defined in (3.21).
Proof: Using the definition of the function in (3.21) as well as the fact that the inversion formula (3.18) holds for all x ∈ ℝd, we have
Hence, by (3.24), this implies
□
Considering the property (3.26), we remark that this indeed states an exact reconstruction in the sense of tempered distributions, as distinct from (3.22). Since it is known by Corollary 3.4 that the condition (3.14) yields an exact reconstruction for trigonometric polynomials, we aimed to use this result to compute suitable weights wj ∈ ℂ, j = 1,…, N, for bandlimited functions as well. To this end, suppose we have (3.14), i.e.,
Then this yields
Having a look at Theorem 3.9, an exact reconstruction (3.26) is implied by (3.24), i.e.,
Thus, the property (3.27) that is fulfilled by (3.14) could be interpreted as an equispaced quadrature of (3.24) at integer frequencies .
Remark 3.10. We remark that for deriving the quadrature rule (3.27) from (3.24), we implicitly truncate the integral bounds in (3.24) as
i.e., instead of (3.25) we rather deal with a distribution induced by
However, an analogous implication as in Theorem 3.9 cannot be shown when using the function (3.28) instead of (3.25).□
As seen in Remark 3.10, our numerical method for computing suitable weights wj ∈ ℂ, j = 1,…, N, can also be derived by means of a quadrature formula applied to the property with defined in (3.28). Having a closer look at this property, the following equivalent characterization can be shown.
Theorem 3.11. Let a bandwidth M ∈ ℕd, nonequispaced points , and quadrature weights wj ∈ ℂ, j = 1, …, N, be given. Then the following two statements are equivalent.
(i) For all φ ∈ (ℝd) we have with defined in (3.28).
(ii) We have 〈1, φ〉 = 〈Tψ, φ〉 for all φ ∈ (ℝd), where
with the d-variate sinc function and
Proof: By the definition of the Fourier transform of a tempered distribution T ∈ ′(ℝd) we have , cf. [15, Ex. 4.46]. Moreover, the distribution induced by (3.28) can be rewritten using the Fourier transform (3.17) as
The inner integral can be determined by
such that (3.29) shows the equality . Hence, the assertions (i) and (ii) are equivalent.□
Thus, since the statements (i) and (ii) of Theorem 3.11 are equivalent, one could also consider the property (ii) for deriving a numerical method to compute suitable weights wj ∈ ℂ, j = 1,…, N. To this end, we have a closer look at
for all φ ∈ (ℝd). Due to the integrals on both sides of (3.30), we need to discretize twice and, therefore, use the same quadrature rule on both sides of (3.30). For better comparability to (3.27), we utilize the same number of equispaced quadrature points , , as in (3.27), i.e., we consider
In order that this applies for all φ ∈ (ℝd), we need to satisfy
i.e., one could also compute weights wj∈ℂ, j = 1,…, N, as a least squares solution to the linear system of equations (3.31). Hence, it merely remains the comparison of the two computation schemes.
Remark 3.12. Since we derived discretizations out of both statements of Theorem 3.11, we examine if also the two linear systems (3.14) and (3.31) are related. Considering the statements in Theorem 3.11 we notice that in some sense they are the Fourier transformed versions of each other. To this end, we need to Fourier transform one of the linear systems for better comparability. More precisely, we apply an iFFT of length , cf. (2.4), to both sides of equation (3.31). Since the left side transforms to
we obtain the transformed system
Comparing this linear system of equations to (3.14), we recognize an identical structure. Hence, we have a closer look at the connection between the expressions and .
For this purpose, we consider the function f(t) = e2πitx, t ∈ [−M, M)d, for fixed x ∈ ℂd. By means of we extend it into a (2M)-periodic function. This periodized version then possesses the Fourier coefficients
cf. (2.2), i. e., the Fourier expansion of , t ∈ [−M, M)d, for fixed x is given by
cf. (2.1). Since is continuous and piecewise differentiable, this Fourier series converges absolutely and uniformly, cf. [71, Ex. 1.22]. Thereby, we may consider the point evaluations at x = xj, j = 1,…, N, and , such that we obtain the representation
Thus, we recognize that (3.32) is a truncated version of (3.33). In other words, this implies that the linear system (3.14) is equivalent to a discretization of (3.30) incorporating infinitely many points in (3.31).□
Remark 3. 13. For bandlimited functions several fast evaluation methods including the sinc function are known. The classical sampling theorem of Shannon–Whittaker–Kotelnikov, see [48–50], states that any bandlimited function with maximum bandwidth M can be recovered from its uniform samples f(L−1⊙ℓ), ℓ ∈ ℤd, with L ≥ M, L: = L·1d, and we have
Since the practical use of this sampling theorem is limited due to the infinite number of samples, which is impossible in practice, and the very slow decay of the sinc function, various authors such as [51–55] considered the regularized Shannon sampling formula with localized sampling
instead. Here, is a compactly supported window function with truncation parameter m ∈ ℕ\{1}, such that for φm with small support the direct evaluation of (3.35) is efficient, see [55] for the relation to the NFFT window functions.
On the other hand, in the one-dimensional setting a fast sinc transform was introduced in [56], which is based on the Clenshaw-Curtis quadrature
using Chebyshev points , k = 0,…, n, and corresponding Clenshaw-Curtis weights wk > 0. Thereby, sums of the form
with uniform truncation parameter T ∈ 2ℕ, can efficiently be approximated by means of fast Fourier transforms. More precisely, for the term in brackets one may utilize an NFFT, cf. (2.5). Then the resulting outer sum can be computed using an NNFFT, also referred to as NFFT of type III, see [34, 57, 58] or [15, p. 394–397].□
3.3. General error bound
In this section, we summarize our previous findings by presenting a general error bound on density compensation factors computed by means of (3.14), that applies to trigonometric polynomials, 1-periodic functions , and bandlimited functions as well.
Theorem 3.14. Let p, q ∈ {1, 2, ∞} with . For given d, N ∈ ℕ, M ∈ (2ℕ)d, and nonequispaced points , j = 1,…, N, let be the nonequispaced Fourier matrix in (2.7). Furthermore, assume we can compute density compensation factors by means of Algorithm 3.6, such that
with small εk ∈ ℝ for all .
Then there exists an ε ≥ 0 such that the corresponding density compensation procedure with satisfies the following error bounds.
(i) For any trigonometric polynomial of degree M given in (2.8), we have
where are the coefficients given in (2.8).
(ii) For any 1-periodic function , we have
where are the first coefficients given in (2.1) and pM is the best approximating trigonometric polynomial of degree M of f.
(iii) For any bandlimited function with bandwidth M, we have
where are the integer evaluations of (3.17) and Q in (3.45) is the pointwise quadrature error of the equispaced quadrature rule (3.19).
Proof: We start with some general considerations that are independent of the function f. By (3.36) we can find , such that |εk| ≤ ε, , and thereby
Then for all with this yields
where . Hence, we have
and
□
Considering the approximation error of (3.6), it can be estimated by
Using from (2.7) as well as , we have
and
Hence, from (3.40) to (3.43) and ||·||2 ≤ ||·||F it follows that
for p ∈ {1, 2, ∞} with . Now it merely remains to estimate for the specific choice of f.
(i): Since a trigonometric polynomial (2.8) of degree M satisfies , the second error term in (3.44) vanishes and we obtain the assertion (3.37).
(ii): When considering a general 1-periodic function in (2.1) we have
with the best approximating trigonometric polynomial pM of degree M of f. Thus, this yields and by (3.44) the assertion (3.38).
(iii): For a bandlimited function with bandwidth M we may use the notation as well as the inverse Fourier transform (3.18) to estimate
with the pointwise quadrature error
of the uniform quadrature rule (3.19). For detailed investigations of quadrature errors for bandlimited functions we refer to Kircheis et al. [56] and Gopal and Rokhlin [59]. Hence, we obtain and by (3.44) the assertion (3.39).□
By Corollary 3.4 it is known that in the setting of trigonometric polynomials there is a linkage between an exact reconstruction (3.8) and the matrix product A*WA being equal to identity . The following theorem shows that the error of the reconstruction (3.6) also affects the condition of the matrix A*WA.
Theorem 3.15. Let from (2.7), and ε ≥ 0 be given as in Theorem 3.14. If additionally is fulfilled, then we have
for the condition number .
Proof: To estimate the condition number we need to determine the norms and . By (3.36) it is known that , where , and, therefore, we have
Moreover, it is known by the theory of Neumann series, cf. [70, Thm. 4.20], that if holds for a matrix , then T is invertible and its inverse is given by
Using this property for T = A*WA, we have
in case that . Hence, by (3.47) and (3.48) we obtain
In addition, we know that |εk| ≤ ε, , with some ε > 0 and, therefore,
In other words, the correctness of (3.48) is ensured if . Since the spectral norm is a sub-multiplicative norm, (3.50) also implies . Consequently, we have
Thus, combining (3.49), (3.50), and (3.51) yields the assertion (3.46).□
3.4. Connection to certain density compensation approaches from literature
In literature a variety of density compensation approaches can be found that are concerned with the setting of bandlimited functions and make use of a sinc transform
instead of the Fourier transform (3.6). Namely, instead of directly using the quadrature (3.21) for reconstruction, in these methods it is inserted into the inverse Fourier transform (3.18), i.e.,
By using the sinc matrix from (3.52), the weight matrix as well as the vectors and , the evaluation of (3.53) at equispaced points M−1⊙ℓ, , can be denoted as . Using the equispaced quadrature rule in (2.3), we find that evaluations of (3.17) at the uniform grid points can be approximated by (3.20) by means of a simple FFT. In matrix-vector notation, this can be written as where , , cf. (2.14), and . Thus, all in all one obtains an approximation of the form .
Here some of these approaches, cf. [2], shall be reconsidered in the context of the Fourier transform (3.6). We especially focus on the connection of the approaches among each other as well as to our new method introduced in Section 3.1.
3.4.1. Density compensation using the pseudoinverse
Since (3.4) is in general not exactly solvable, we study the corresponding least squares problem, instead, i.e., we look for the approximant that minimizes the residual norm . It is known (e.g., [60, p. 15]) that this problem always has the unique solution
with the Moore-Penrose pseudoinverse A†. Comparing (3.54) to the density compensation approach (3.6), the weights wj should be chosen such that the matrix product A*W approximates the pseudoinverse A† as best as possible, i.e., we study the optimization problem
where ||·||F denotes the Frobenius norm of a matrix. It was shown in Sedarat and Nishimura [61] that the solution to this least squares problem can be computed as
However, since a singular value decomposition is necessary for the calculation in (3.56), we obtain a high complexity of . Therefore, we study some more sophisticated least squares approaches in the following.
3.4.2. Density compensation using weighted normal equations of the first kind
It is known that every least squares solution to (3.4) satisfies the weighted normal equations of the first kind , see e.g., [60, Thm. 1.1.2]. As already mentioned in Corollary 3.4, we have an exact reconstruction formula (3.6) for all trigonometric polynomials (2.8) of degree M, if is fulfilled. Thus, we aimed to compute optional weights wj, j = 1,…, N, by considering the optimization problem
Analogous to Sedarat and Nishimura [61] this could also be derived from (3.55) by introducing a right-hand scaling in the domain of measured data and minimizing the Frobenius norm of the weighted error matrix Er:= E·A, where E:= A*W−A† is the error matrix in (3.55).
In Rosenfeld et al. [62], it was shown that a solution W = diag(w) to (3.57) can be obtained by solving Sw = b with
However, since Sw = b is not separable for single wj, j = 1,…, N, computing these weights is of complexity . This is why the authors in Sedarat and Nishimura [61] restricted themselves to a maximal image size of 64 × 64 pixels, which corresponds to setting M = 64.
3.4.3. Density compensation using weighted normal equations of the second kind
Another approach for density compensation factors is based on the weighted normal equations of the second kind
We recognize that by (3.59) we are given an exact approximation of the Fourier coefficients in (3.6) in case y = f, and thereby .
To this end, we consider the optimization problem
As in Section 3.4.2, we remark that this optimization problem (3.60) could also be derived from (3.55) by introducing an additional left-hand scaling in the Fourier domain and minimizing the Frobenius norm of the weighted error matrix El:= A·E.
Remark 3.16. An analogous approach considering the sinc transform (3.52) instead of the Fourier transform (3.6) was already studied in Pipe and Menon [63]. Another version using a sinc transform evaluated at pointwise differences of the nonequispaced points instead of (3.52) was studied in [64, 65], where it was claimed that this approach coincides with the one in [63]. However, we remark that due to the sampling theorem of Shannon-Whittaker-Kotelnikov, see (3.34), applied to the function f(x) = sinc(Mπ(xj−x)), i.e.,
and its evaluation at x = xh, h = 1,…, N, this claim only holds asymptotically for in the setting of the sinc transform.
In contrast, when using the Fourier transform (3.6) this equality can directly be seen. Then the analog to Greengard et al. [65] utilizes an approximation of the form f ≈ HWf, where the matrix H is defined as the system matrix of (3.4) evaluated at pointwise differences of the nonequispaced points, i.e.,
Since by (2.7) we have H = AA*, minimizing the approximation error
leads to the optimization problem (3.60) as well.□
It was shown in [63] that the minimizer of (3.60) is given by
Since for fixed j the computation of , h = 1,…, N, is of complexity , the weights (3.62) can be computed in arithmetic operations. However, due to the explicit representation (3.61) the computation of , h = 1,…, N, for fixed j can be accelerated by means of the NFFT (see Algorithm 2.1). Then, this step takes arithmetic operations and the overall complexity is given by .
As mentioned in Pipe and Menon [63] one could also consider a simplified version of the optimization problem (3.60) by reducing the number of conditions, e.g., by summing the columns on both sides of as
By means of (2.7) this can be written as . Since fast multiplication with A and A* can be realized using the NFFT (see Algorithm 2.1) and the adjoint NFFT (see Algorithm 2.4), respectively, a solution to the linear system of equations can be computed iteratively with arithmetic complexity .
Finally, we investigate the connection of this approach to our method introduced in Section 3.1. To this end, suppose the linear system (3.10) is fulfilled for given w ∈ ℂN, i.e., by we have . Then multiplication with in (2.7) yields
In other words, an exact solution w to the linear system (3.10) implies that the conjugate complex weights exactly solve the system (3.63). However, the reversal does not hold true and, therefore, (3.63) is not equivalent to (3.10). Moreover, we have seen in Corollary 3.4 that an augmented variant of (3.10), namely (3.14), is necessary to obtain an exact reconstruction in (3.6) for trigonometric polynomials (2.8) with maximum degree M.
4. Direct inversion using matrix optimization
As seen in Remark 3.1, the previously considered density compensation techniques can be regarded as an optimization of the sparse matrix from the NFFT, cf. Section 2.1. Since density compensation allows only N degrees of freedom, this limitation shall now be softened, i.e., instead of searching for optimal scaling factors for the rows of B, we now study the optimization of each nonzero entry of the sparse matrix B, cf. [33]. To this end, we first have another look at the equispaced setting. It is known by (3.1) and (3.2), that for equispaced points and appropriately chosen parameters a one-sided inversion is given by composition of the Fourier matrix and its adjoint. Hence, we aimed to use this result to find a good approximation of the inverse in the general setting.
Considering problem (3.4) we seek to find an appropriate matrix x such that we have , since then we can simply compute an approximation of the Fourier coefficients by means of . To find this left-inverse x, we utilize the fact that in the equispaced case it is known that (3.1) holds in the overdetermined setting . In addition, we also incorporate the approximate factorization A* ≈ D*F*B* of the adjoint NFFT, cf. Section 2.2, with the matrices , , and defined in (2.13), (2.14), and (2.15). Combining both ingredients we aimed for an approximation of the form . To achieve an approximation like this, we aimed to modify the matrix B such that its sparse structure with at most (2m+1)d entries per row and consequently the arithmetic complexity of its evaluation is preserved. A matrix satisfying this property we call (2m+1)d-sparse.
Remark 4.1. We remark that this approach can also be deduced from the density compensation method in Section 3 as follows. By Corollary 3.4 it is known that an exact reconstruction needs to satisfy . Since the reconstruction shall be realized efficiently by means of an adjoint NFFT, one rather studies . Using the definition as in Remark 3.1, we end up with an approximation of the form . Thus, optimizing each nonzero entry of the sparse matrix B using this approximation is the natural generalization of the density compensation method from Section 3.□
Let denote such a modified matrix. By defining , we recognize that the minimization of the approximation error
implies the optimization problem
Note that a similar idea for the forward problem, i.e., the evaluation of (2.5), was already studied in Nieslony and Steidl [66]. By the definition of the Frobenius norm we have , such that (4.2) is equivalent to its adjoint
Since it is known by (2.14) that and is diagonal by (2.13), we have . Thus, due to the fact that the Frobenius norm is a submultiplicative norm, we have
Hence, we consider the optimization problem
Based on the definition of the Frobenius norm of a matrix Z ∈ ℝk×n and the definition of the Euclidean norm of a vector y ∈ ℝn, we obtain for zj being the columns of Z ∈ ℝk×n that
Since we aimed to preserve the property that B is a (2m+1)d-sparse matrix, we rewrite the norm in (4.5) by (4.6) in terms of the columns of considering only the nonzero entries of each column. To this end, analogously to (2.12) we define the index set
of the nonzero entries of the ℓ-th column of . Thus, we have
where denotes the vectors of the nonzeros of each column of ,
are the corresponding submatrices of , cf. (2.7), and are the columns of , cf. (2.14). Hence, we receive the equivalent optimization problems
Thus, if the matrix (4.9) has full column rank, the solution of the least squares problem (4.10) can be computed by means of the pseudoinverse as
Having these vectors we compose the optimized matrix Bopt, observing that only consist of the nonzero entries of Bopt. Then, the approximation of the Fourier coefficients is given by
In other words, this approach yields an inverse NFFT by modifying the adjoint NFFT.
Remark 4.2. To achieve an efficient algorithm we now have a closer look at the computation scheme (4.11). We start with the computation of the matrix . By introducing the d-dimensional Dirichlet kernel
the matrix in (4.11) can explicitly be stated via
i.e., for given index set the matrix can be determined in operations. Considering the right-hand side of (4.11), by definitions (4.9), (2.13), and (2.14), we have
Thus, since , the computation of vℓ involves neither multiplication with nor division by the (possibly) huge number and is, therefore, numerically stable.□
This leads to the following algorithm.

Algorithm 4.3. Optimization of the sparse matrix B.
Note that a general statement about the dimensions of is not possible, since the size of the set heavily depends on the distribution of the points. To visualize this circumstance, we depicted some exemplary patterns of the nonzero entries of the original matrix in Figure 1. It can easily be seen that for all choices of the points each row contains the same number of nonzero entries, i.e., all index sets (2.12) are of the same size of maximum (2m+1)d. However, when considering the columns instead, we recognize an evident mismatch in the number of nonzero entries. We remark that because of the fact that each row of contains at most (2m+1)d entries, each column contains entries on average. A general statement about the maximum size of the index sets (4.7) cannot be made. Roughly speaking, the more irregular the distribution of the points is, the larger the index sets (4.7) can be. Nevertheless, in general is a small constant compared to , such that Algorithm 4.3 ends up with total arithmetic costs of approximately .
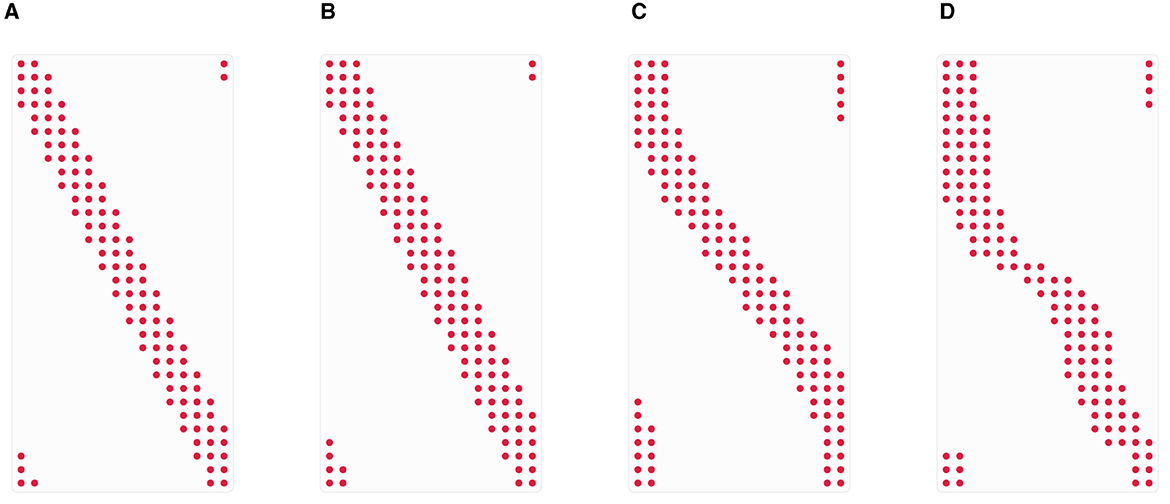
Figure 1. Nonzero entries of the matrix for several choices of the points , j = 1,…, N, with d = 1, Mσ = M = 16, N = 2M, and m = 2. (A) Equispaced points. (B) Jittered points. (C) Chebyshev points. (D) Random points.
In conclusion, our approach for an inverse NFFT can be summarized as follows.

Algorithm 4.4. iNFFT – optimization approach.
Theorem 4.5. Let be the optimized matrix computed by means of Algorithm 4.3 and let be the corresponding approximation of computed by means of Algorithm 4.4. Further assume that each column of as solution to (4.10) possesses a small residual
Then there exists an ε ≥ 0 such that
Moreover, the (asymmetric) Dirichlet kernel
is the optimal window function for the inverse NFFT in Algorithm 4.4.
Proof: As in (4.1) the approximation error can be estimated by
Using the same arguments as for (4.3) and (4.4) we proceed with
To estimate the first Frobenius norm in (4.19), we rewrite it analogously to (4.8) columnwise as
where are the nonzeros of the columns of Bopt, in (4.9) are the corresponding submatrices of , cf. (2.7), and are the columns of , cf. (2.14). Since as solutions to the least squares problems (4.10) satisfy (4.15), we can find , such that εℓ ≤ ε, , and, therefore,
Therefore, we may write (4.19) as
Thus, it remains to estimate the Frobenius norm . By the definitions of the Frobenius norm and the trace tr(Z) of a matrix Z, it is clear that . Since by (2.14) we have that , this yields
Using the definition (2.13) of the diagonal matrix , we obtain
Then combination of (4.20), (4.21), and (4.22) implies
such that (4.18) yields the assertion (4.16).
Since it is known that 0 ≤ ŵ(k) ≤ 1, , for suitable window functions of the NFFT, cf. [67], we have
and, therefore.
Hence, the smallest constant is achieved in (4.16) when ŵ(k) = 1, , i.e., the (asymmetric) Dirichlet kernel (4.17) is the optimal window function for the inverse NFFT in Algorithm 4.4. □
Note that for trigonometric polynomials (2.8) the error bound of Theorem 4.5 with the optimal window function (4.17) is the same as the error bound (3.37) from Theorem 3.14.
Remark 4.6. Up to now, we only focused on the problem (3.4). Finally, considering the inverse adjoint NFFT in (3.5), we remark that this problem can also be solved by means of the optimization procedure in Algorithm 4.3. Assuming again , this is the underdetermined setting for the adjoint problem (3.5). Therefore, the minimum norm solution of (3.5) is given by the normal equations of the second kind
Incorporating the matrix decomposition of the NFFT, cf. Section 2.1, we recognize that a modification of the matrix such that implies y ≈ h and hence f ≈ BFDh. Thus, the optimization problem (4.3) is also the one to consider for (3.5). In other words, our approach provides both, an inverse NFFT as well as an inverse adjoint NFFT.□
5. Numerics
In conclusion, we have a look at some numerical examples. In addition to comparing the density compensation approach from Section 3 to the optimization approach from Section 4, for both trigonometric polynomials (2.8) and bandlimited functions, we also demonstrate the accuracy of these approaches.
Remark 5.1. At first we introduce some exemplary grids. For visualization we restrict ourselves to the two-dimensional setting d = 2.
(i) We start with a sampling scheme, that is, somehow “close” to the Cartesian grid, but also possesses a random part. To this end, we consider the two-dimensional Cartesian grid and add a two-dimensional perturbation, i.e.,
t = 1,…, N1, j = 1,…, N2, and η1, η2 ~ U(−1, 1), where U(−1, 1) denotes the uniform distribution on the interval (−1, 1). A visualization of this jittered grid can be found in Figure 2A. In addition, we also consider the random grid see Figure 2B.
(ii) Moreover, we examine grids of polar kind, as mentioned in Fenn et al. [68]. For R, T ∈ 2ℕ, the points of the polar grid are given by a signed radius and an angle as
Since it is known that the inversion problem is ill-conditioned for this grid we consider a modification, the modified polar grid
i.e., we added more concentric circles and excluded the points outside the unit square, see Figure 3A. Another sampling scheme that is known to lead to more stable results than the polar grid is the linogram or pseudo-polar grid, where the points lie on concentric squares instead of concentric circles, see Figure 3B. There we distinguish two sets of points, i.e.,
(iii) Another modification of these polar grids was introduced in Helou et al. [69], where the angles θt are not chosen equidistantly but are obtained by golden angle increments. For the golden angle polar grid we only exchange the equispaced angles of the polar grid to
The golden angle linogram grid is given by
with θt in (5.5), as illustrated in Figure 3C.□
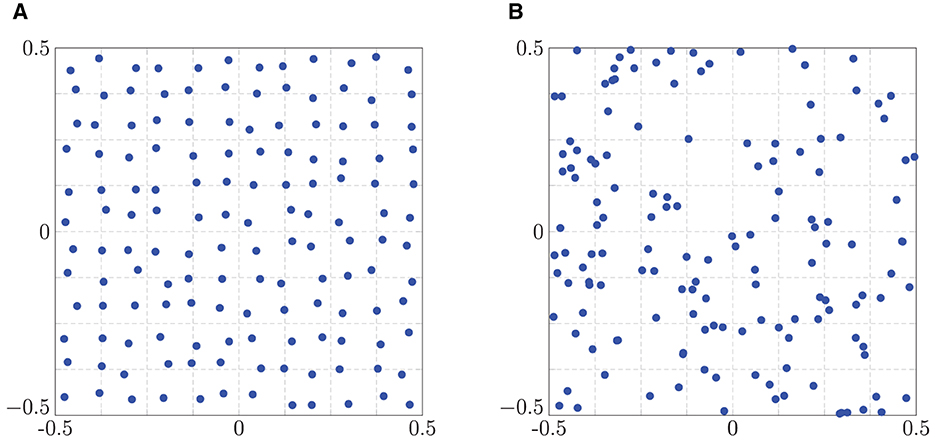
Figure 2. Exemplary randomized grids of size N1 = N2 = 12. (A) Jittered grid. (B) Random grid.
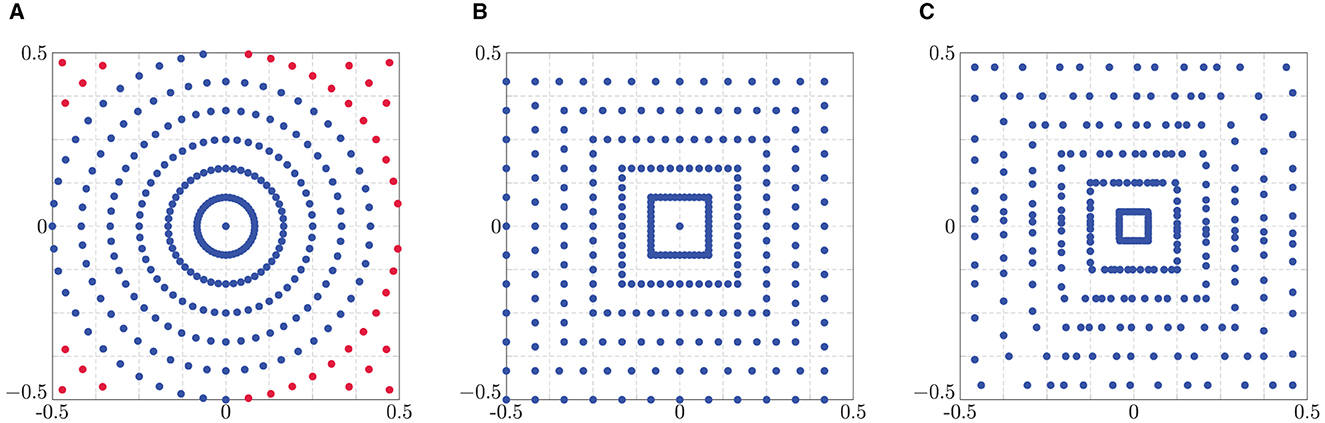
Figure 3. Polar grids of size R = 12 and T = 2R. (A) Polar (blue) and modified polar (red) grid. (B) Linogram/pseudo-polar grid. (C) Golden angle linogram grid.
Before comparing the different approaches from Sections 3 and 4, we study the quality of our methods for the grids mentioned in Remark 5.1. More specifically, in Example 5.2 we investigate the accuracy of the density compensation method from Algorithm 3.7 with the weights introduced in Section 3.1, and in Example 5.3 we check if the norm minimization targeted in Section 4 is successful.
Example 5.2. First, we examine the quality of our density compensation method in Algorithm 3.7 for a trigonometric polynomial f as in (2.8) with given Fourier coefficients , . In this test, we consider several d ∈ {1, 2, 3}. For the corresponding function evaluations of (2.8) at given points , j = 1,…, N, we test how well these Fourier coefficients can be approximated. More precisely, we consider the estimate , cf. (3.7), with the matrix of density compensation factors computed by means of Algorithm 3.6, i.e., by (3.15), in case , or by (3.16), if , and compute the relative errors
By (3.37), it is known that
with the residual , cf. (3.36).
In our experiment, we use random points xj with , t = 1,…, d, cf. Figure 2B, and, for several problem sizes M = M·1d, M = 2c with c = 1,…, 11−d, we choose random Fourier coefficients , . Afterward, we compute the evaluations of the trigonometric polynomial (2.8) by means of an NFFT and use the resulting vector f as input for the reconstruction. Due to the randomness we repeat this 10 times and then consider the maximum error over all runs. The corresponding results are displayed in Figure 4. It can clearly be seen that , i.e., as long as , the weights computed by means of (3.15) lead to an exact reconstruction of the given Fourier coefficients. However, as soon as we are in the setting the least squares approximation via (3.16) does not yield good results anymore.□
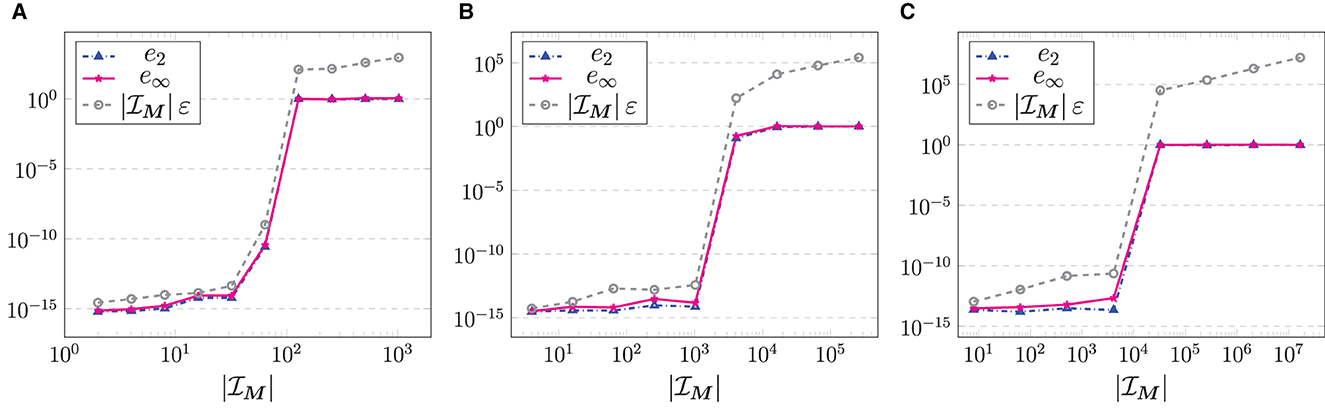
Figure 4. Relative errors (5.6) of the reconstruction of the Fourier coefficients of a trigonometric polynomial (2.8) with given , , computed via the density compensation method from Algorithm 3.7, for random grids with , t = 1,…, d, and M = M·1d, M = 2c with c = 1,…, 11−d. (A) d = 1. (B) d = 2. (C) d = 3.
Example 5.3. To study the quality of our optimization method in Section 4, we consider the Frobenius norms
where B denotes the original matrix from the NFFT in (2.15) and Bopt is the optimized matrix generated by Algorithm 4.3. For the original matrix B we utilize the common B-Spline window function
with the centered B-Spline of order 2m, cf. [15, p. 388]. The optimized matrix Bopt shall be computed by means of the B-Spline (5.8) as well as the Dirichlet window function (4.17), which is the optimal window by Theorem 4.5.
Due to memory limitations in the computation of the Frobenius norms (5.7), we have to settle for very small problems, which however show the functionality of Algorithm 4.3. For this reason, we consider d = 2 and choose M = (12, 12)T as well as , μ ∈ {2,…, 7}, and T = 2R for the grids mentioned in Remark 5.1. In other words, we test Algorithm 4.3 in the underdetermined setting as well as for the overdetermined setting .
Having a look at the results for the grids in Remark 5.1, it becomes apparent that they separate into two groups. Figure 5A displays the results for the polar grid (5.2), which are the same as for the golden angle polar grid, cf. (5.5). In these cases there is only a slight improvement by the optimization. However, for all other mentioned grids the minimization procedure in Algorithm 4.3 is very effective. The results of these grids are depicted in Figure 5B exemplarily for the modified polar grid (5.3). Moreover, it can be seen that our optimization procedure in Algorithm 4.3 is the most effective in the overdetermined setting .
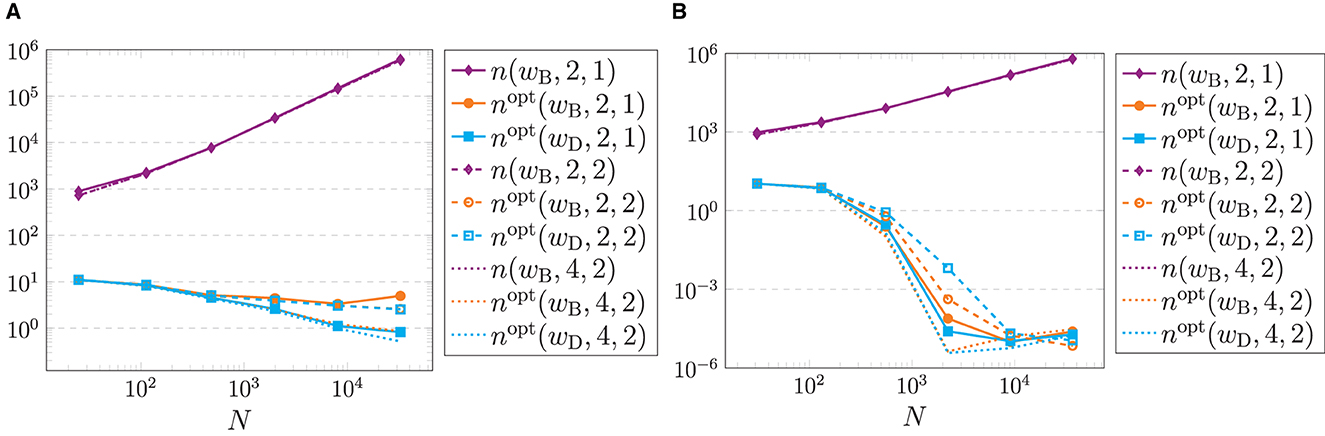
Figure 5. Frobenius norms (5.7) of the original matrix B (violet) and the optimized matrix Bopt generated by Algorithm 4.3 using the B-Spline wB (orange) as well as the Dirichlet window wD (cyan) with R = 2μ, μ ∈ {2,…, 7}, and T = 2R as well as M = (12, 12)T, m ∈ {2, 4}, and σ ∈ {1, 2}. (A) Polar grid (5.2). (B) Modified polar grid (5.3).
One reason for the different behavior of polar and modified polar grid could be the ill-posedness of the inversion problem for the polar grid, which becomes evident in huge condition numbers of , whereas the problem for modified polar grids is well-posed. Another reason can be found in the optimization procedure itself. Having a closer look at the polar grid, see Figure 3A, there are no grid points in the corners of the unit square. Therefore, some of the index sets , cf. (4.7), are empty and no optimization can be done for the corresponding matrix columns. This could also cause the worsened minimization properties of the polar grid.□
Next, we proceed with comparing the density compensation approach from Section 3 using the weights wj introduced in Section 3.1 to the optimization approach for modifying the matrix B from Section 4. To this end, we show an example concerning trigonometric polynomials (2.8) of degree M and a second one that deals with bandlimited functions of bandwidth M. Here, we restrict ourselves to the two-dimensional setting d = 2 for better visualization of the results.
Example 5.4. Similar to Averbuch et al. [32] and Kircheis and Potts [33] we have a look at the reconstruction of the Shepp-Logan phantom, see Figure 6A. Here, we treat the phantom data as given Fourier coefficients of a trigonometric polynomial (2.8). For given points , j = 1,…, N, we then compute the evaluations of the trigonometric polynomial (2.8) by means of an NFFT and use the resulting vector as input for the reconstruction.
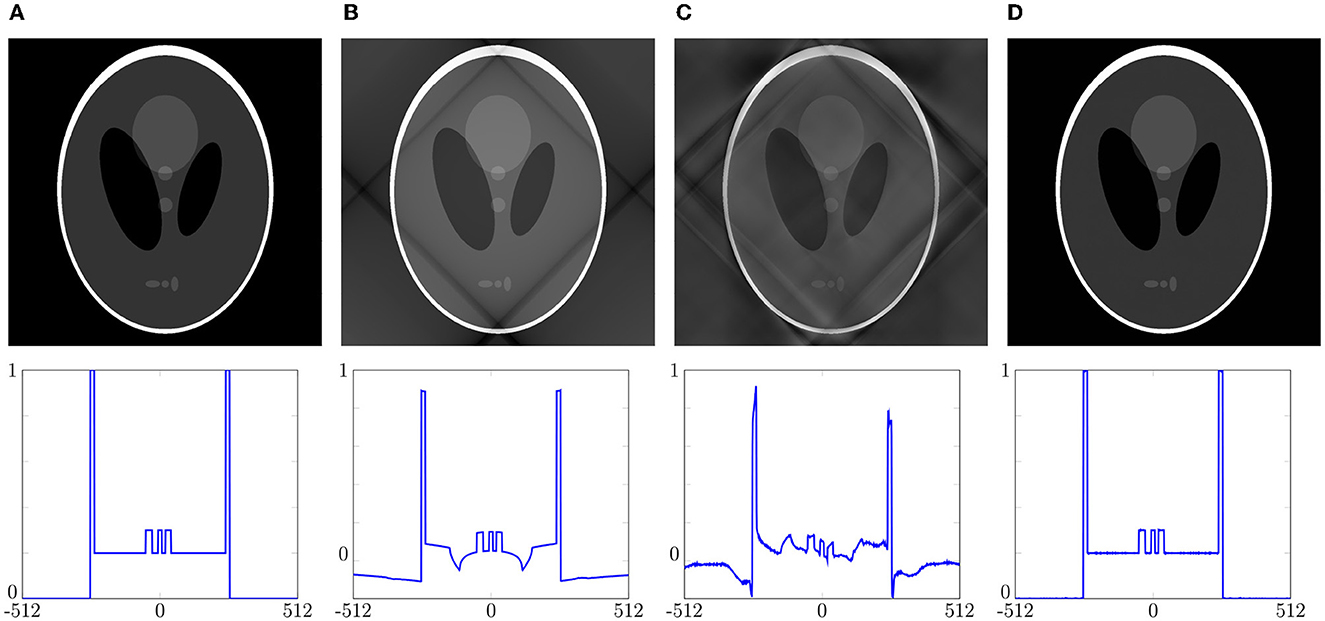
Figure 6. Reconstruction of the Shepp-Logan phantom of size 1024 × 1024 (top) via the density compensation method from Section 3.1 using Voronoi weights and Algorithm 3.7 with weights computed by (3.16) compared to Algorithm 4.4 for the linogram grid (5.4) of size R = M = 1, 024, T = 2R; as well as a detailed view of the 832nd row each (bottom). (A) Original phantom. (B) Voronoi weights with e2=5.3040e-01. (C) Algorithm 3.7 with e2=5.0585e-01. (D) Algorithm 4.4 with e2=2.2737e-03.
In a first experiment, we test the inversion methods from Sections 3 and 4 as in Averbuch et al. [32] for increasing input sizes. To this end, we choose M = (M, M)T, M = 2c with c = 3,…, 10, and linogram grids (5.4) of size R = 2M, T = 2R, i.e., we consider the setting . For using Algorithm 4.4 we choose the oversampling factor σ = 1.0 and the truncation parameter m = 4. For each input size we measure the computation time of the precomputational steps, i.e., the computation of the weight matrix W or the computation of the optimized sparse matrix Bopt, as well as the time needed for the reconstruction, i.e., the corresponding adjoint NFFT, see Algorithms 3.7, 4.4. Moreover, for the reconstruction , cf. (3.7) and (4.12), we consider the relative errors
The corresponding results can be found in Table 1. We remark that since we are in the setting , the density compensation method in Algorithm 3.7 with weights computed by (3.15) indeed produces nearly exact results. Although, our optimization procedure from Algorithm 4.4 achieves small errors as well, this reconstruction is not as good as the one by means of our density compensation method.
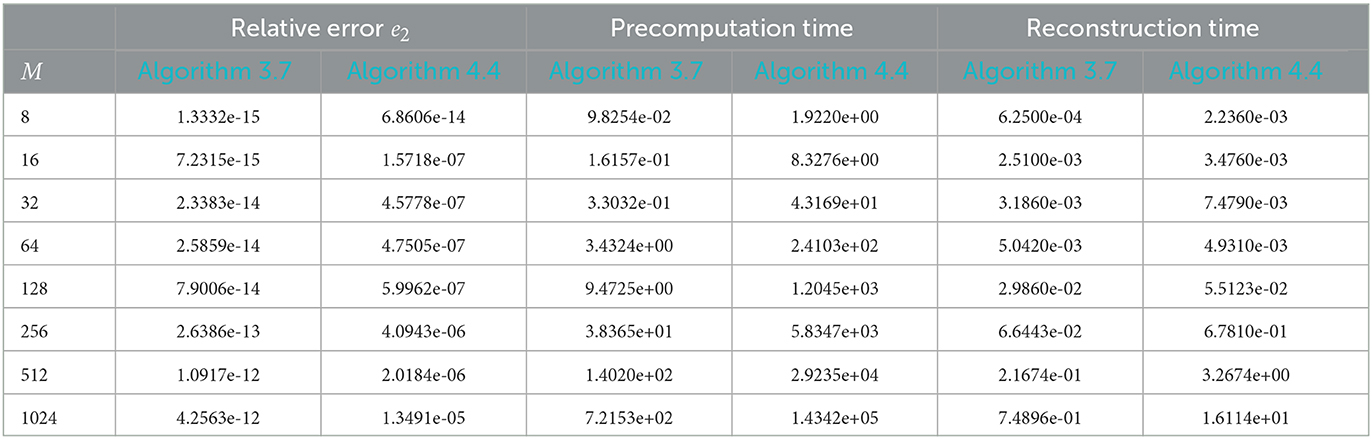
Table 1. Relative errors (5.9) of the reconstruction of the Shepp-Logan phantom of size M as well as the runtime in seconds for the density compensation method from Algorithm 3.7 compared to Algorithm 4.4 with σ = 1.0 and m = 4, using linogram grids (5.4) of size R = 2M, T = 2R.
Note that in comparison to Averbuch et al. [32], our method in Algorithm 3.7 using density compensation produces errors of the same order, but is much more effective for solving several problems using the same points xj for different input values f. Since our precomputations have to be done only once in this setting, we strongly profit from the fact that we only need to perform an adjoint NFFT as reconstruction, which is very fast, whereas in Averbuch et al. [32] they would need to execute their whole routine each time again.
As a second experiment, we aimed to decrease the amount of overdetermination, i.e., we want to keep the size of the phantom, but reduce the number N of the points xj, j = 1,…, N. To this end, we now consider linogram grids (5.4) of the smaller size R = M, T = 2R, i.e., now we have .
The reconstruction of the phantom of size 1, 024 × 1, 024 is presented in Figure 6 (top) including a detailed view of the 832nd row of this reconstruction (bottom). Despite the reconstruction via Algorithm 4.4 as well as the density compensation method using weights computed by means of (3.16), we also considered the result using Voronoi weights. For all approaches we added the corresponding relative errors (5.9) to Figure 6 as well.
Due to the fact that the exactness condition (cf. Section 3.1.1) is violated, it can be seen in Figure 6C that the density compensation method using weights computed by means of (3.16) does not yield an exact reconstruction is this setting. On the contrary, we recognize that our optimization method, see Figure 6D, achieves a huge improvement in comparison to the density compensation techniques in Figures 6B, C since no artifacts are visible. Presumably, this arises because there are more degrees of freedom in the optimization of the matrix B from Section 4 than with the density compensation techniques from Section 3, cf. Remark 3.1. We remark that although the errors are not as small as in Table 1, by comparing Figures 6A, D and it becomes apparent that the differences are not even visible anymore. Note that for this result the number N of points is ca. four times lower as for the results depicted in Table 1, i.e., we only needed twice as much function values as Fourier coefficients, whereas e.g., in [32] they worked with a factor of more than 4.□
Example 5.5. Finally, we examine the reconstruction properties for bandlimited functions with maximum bandwidth M. To this end, we first specify a compactly supported function and consequently compute its inverse Fourier transform f, such that its samples f(xj) for given , j = 1, …, N, can be used for the reconstruction of the samples , . Here, we consider the tensorized function , where g(v) is the one-dimensional triangular pulse . Then for all b ∈ ℕ with the associated inverse Fourier transform
is bandlimited with bandwidth M. In this case, we consider M = 64 and b = 24 as well as the jittered grid (5.1) of size N1 = N2 = 144, i.e., we study the setting .
Now, the aim was to compare the different density compensation methods considered in Section 3 and the optimization approach from Section 4. More precisely, we consider the reconstruction using Voronoi weights, the weights computed via (3.58), the weights in (3.62), and Algorithm 3.7 with weights computed via (3.15), as well as Algorithm 4.4. For the reconstruction , cf. (3.7) and (4.12), we then compute the pointwise absolute errors . The corresponding results are displayed in Figure 7. It can easily be seen that Voronoi weights, see Figure 7A, and the weights in (3.62), see Figure 7D, do not yield a good reconstruction, as expected. The other three approaches produce nearly the same reconstruction error, which is also obtained by reconstruction on an equispaced grid and, therefore, is the best possible. In other words, in case of bandlimited functions the truncation error in (3.20) is dominating and thus reconstruction errors smaller than the ones shown in Figure 7 cannot be expected.
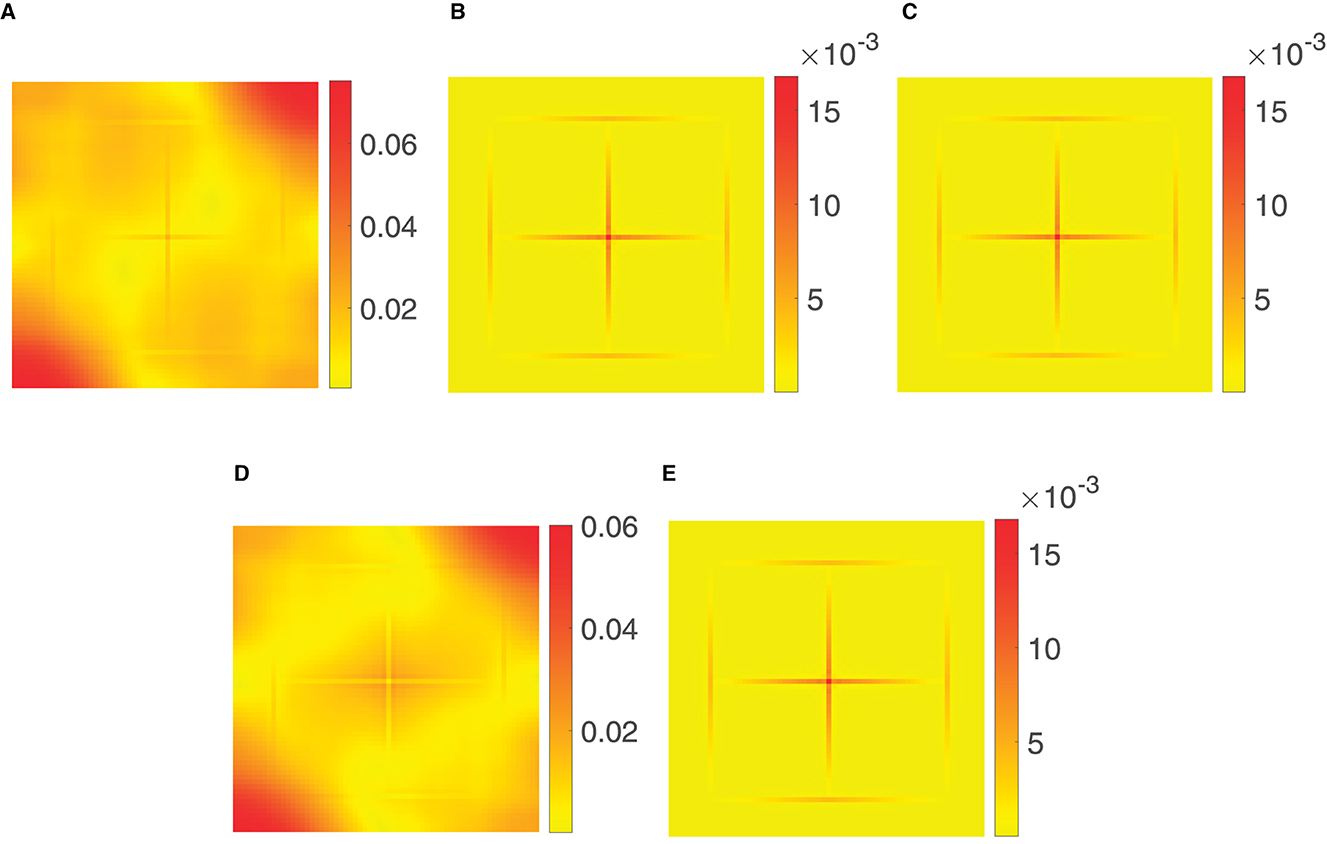
Figure 7. Pointwise absolute error of the reconstruction of samples of the tensorized triangular pulse function with M = 64 and b = 24, using the density compensation methods considered in Section 3 as well as the optimization approach from Algorithm 4.4 for the jittered grid (5.1) of size N1 = N2 = 144. (A) Voronoi weights. (B) Algorithm 3.7. (C) Weights via (3.58). (D) Weights (3.62). (E) Algorithm 4.4.
Note that the comparatively small choice of M = 64 was made in order that the computation of the weights via (3.58), see Figure 7C, as well as the weights in (3.62), see Figure 7D, is affordable, cf. Section 3.4.2. In contrast, our new methods using Algorithm 3.7, see Figure 7B, or Algorithm 4.4, see Figure 7E, are much more effective and, therefore, better suited for the given problem.
6. Conclusion
In the present article, we considered several direct methods for computing an inverse NFFT, i.e., reconstructing the Fourier coefficients , , from given nonequispaced data f(xj), j = 1,…, N. Being a direct method here means, that for a fixed set of points xj, j = 1,…, N, the reconstruction can be realized with the same number of arithmetic operations as a single application of an adjoint NFFT (see Algorithm 2.4). As we have seen in (3.3), a certain precomputational step is compulsory, since the adjoint NFFT does not yield an inversion by itself. Although this precomputations might be rather costly, they need to be done only once for a given set of points xj, j = 1,…, N. Therefore, direct methods are especially beneficial in case of fixed points. For this reason, we studied two different approaches of this kind and especially focused on methods for the multidimensional setting d ≥ 1 that are applicable to general sampling patterns.
First, in Section 3, we examined the well-known approach of sampling density compensation, where suitable weights wj ∈ ℂ, j = 1,…, N, are precomputed, such that the reconstruction can be realized by means of an adjoint NFFT applied to the scaled data wjf(xj). We started our investigations with trigonometric polynomials in Section 3.1. In Corollary 3.4, we introduced the main formula (3.14), which yields exact reconstruction for all trigonometric polynomials of degree M. In addition to this theoretical considerations, we also discussed practical computation schemes for the overdetermined as well as the underdetermined setting, as summarized in Algorithm 3.6. Afterward, in Section 3.2, we studied the case of bandlimited functions, which often occurs in the context of MRI and discussed that the same numerical procedures as in Section 3.1 can be used in this setting as well. In Section 3.3, we then summarized the previous findings by presenting a general error bound on density compensation factors computed by means of Algorithm 3.6 in Theorem 3.14. In addition, this also yields an estimate on the condition number of the matrix product A*WA, as shown in Theorem 3.15. In Section 3.4, we surveyed certain approaches from literature and commented on their connection among each other as well as to the method presented in Section 3.1.
Subsequently, in Section 4, we studied another direct inversion method, where the matrix representation A ≈ BFD of the NFFT is used to modify the sparse matrix B, such that a reconstruction is given by . In other words, the inversion is done by a modified adjoint NFFT, while the optimization of the matrix B can be realized in a precomputational step, see Algorithm 4.4.
Finally, in Section 5, we had a look at some numerical examples to investigate the accuracy of the previously introduced methods. We have seen that our approaches are best-suited for the overdetermined setting and work for many different sampling patterns. More specifically, in the highly overdetermined case we have theoretically proven as well as numerically verified in several examples that the density compensation technique in Algorithm 3.7 leads to an exact reconstruction for trigonometric polynomials. In case not that much data are available and we have to reduce the amount of overdetermination such that , we have shown that the optimization approach from Algorithm 4.4 is preferable, since the higher number of degrees of freedom in the optimization (see Remark 3.1) yields better results. In addition, also for the setting of bandlimited functions we demonstrated that our methods are much more efficient than existing ones.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
MK gratefully acknowledges the support from the BMBF grant 01∣S20053A (project SAℓE). DP acknowledges the funding by Deutsche Forschungsgemeinschaft (German Research Foundation) – Project–ID 416228727 – SFB 1410.
Acknowledgments
The authors thank the referees and the editor for their very useful suggestions for improvements.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Doneva M, Akcakaya M, Prieto C, editors. Magnetic Resonance Image Reconstruction: Theory, Methods and Applications, Volume 6. Cambridge, MA: Academic Press (2022).
2. Eggers H, Kircheis M, Potts D. on-Cartesian MRI reconstruction. In:Doneva M, Akcakaya M, Prieto C, , editors. Magnetic Resonance Image Reconstruction: Theory, Methods and Applications, Volume 6. Cambridge, MA: Academic Press (2022). doi: 10.1016/B978-0-12-822726-8.00013-0
3. Fasshauer GE. Meshfree Approximation Methods with MATLAB. Singapore: World Scientific Publishers (2007). doi: 10.1142/6437
4. Feichtinger HG, Gröchenig K, Strohmer T. Efficient numerical methods in non-uniform sampling theory. Numer Math. (1995) 69:423–40. doi: 10.1007/s002110050101
5. Bass RF, Gröchenig K. Random sampling of multivariate trigonometric polynomials. SIAM J Math Anal. (2004) 36:773–95. doi: 10.1137/S0036141003432316
6. Böttcher A, Potts D. Probability against condition number and sampling of multivariate trigonometric random polynomials. Electron Trans Numer Anal. (2007) 26:178–189.
7. Kunis S, Potts D. Time and memory requirements of the nonequispaced FFT. Sampl Theory Signal Image Process. (2008) 7:77–100. doi: 10.1007/BF03549487
8. Kunis S, Nagel D. On the condition number of Vandermonde matrices with pairs of nearly-colliding nodes. Numer Algor. (2021) 87:473–96. doi: 10.1007/s11075-020-00974-x
9. Ruiz-Antolin D, Townsend A. A nonuniform fast Fourier transform based on low rank approximation. SIAM J Sci Comput. (2018) 40:A529–47. doi: 10.1137/17M1134822
10. Sutton BP, Fessler JA, Noll DC. A min-max approach to the nonuniform N-dimensional FFT for rapid iterative reconstruction of MR images. In: Proceedings of the 9th Annual Meeting of the International Society for Magnetic Resonance in Medicine. Scotland (2001). p. 763.
11. Fessler JA, Sutton BP. Nonuniform fast Fourier transforms using min-max interpolation. IEEE Trans Signal Process. (2003) 51:560–74. doi: 10.1109/TSP.2002.807005
12. Knopp T, Kunis S, Potts D. A note on the iterative MRI reconstruction from nonuniform k-space data. Int J Biomed Imag. (2007) 2007:24727. doi: 10.1155/2007/24727
13. Pruessmann KP, Wayer FTAW. Major speedup of reconstruction for sensitivity encoding with arbitrary trajectories. In: Proc. Intl. Soc. Mag. Reson. Med. 9. Glasgow (2001), p. 767.
14. Kunis S, Potts D. Stability results for scattered data interpolation by trigonometric polynomials. SIAM J Sci Comput. (2007) 29:1403–19. doi: 10.1137/060665075
15. Plonka G, Potts D, Steidl G, Tasche M. Numerical Fourier Analysis. Applied and Numerical Harmonic Analysis. Boston, MA: Birkhäuser (2018). doi: 10.1007/978-3-030-04306-3
16. Stefan W, Renaut RA, Gelb A. Improved total variation-type regularization using higher order edge detectors. SIIMS. (2010) 3:232–51. doi: 10.1137/080730251
17. Wasserman G, Archibald R, Gelb A. Image reconstruction from Fourier data using sparsity of edges. J Sci Comput. (2015) 65:533–52. doi: 10.1007/s10915-014-9973-3
18. Archibald R, Gelb A, Platte RB. Image reconstruction from undersampled Fourier data using the polynomial annihilation transform. J Sci Comput. (2016) 67:432–52. doi: 10.1007/s10915-015-0088-2
19. Archibald R, Gelb A, Yoon J. Polynomial fitting for edge detection in irregularly sampled signals and images. SINUM. (2005) 43:259–79. doi: 10.1137/S0036142903435259
20. Candès EJ, Wakin MB, Boyd SP. Enhancing sparsity by reweighted ℓ1 minimization. J Fourier Anal Appl. (2008) 14:877–905. doi: 10.1007/s00041-008-9045-x
21. Chartrand R, Yin W. Iteratively reweighted algorithms for compressive sensing. In: IEEE International Conference on Acoustics, Speech and Signal Processing. Las Vegas, NV: IEEE (2008), p. 3869–72. doi: 10.1109/ICASSP.2008.4518498
22. Daubechies I, DeVore R, Fornasier M, Güntürk CS. Iteratively reweighted least squares minimization for sparse recovery. Commun Pure Appl Math. (2010) 63:1–38. doi: 10.1002/cpa.20303
23. Liu Y, Ma J, Fan Y, Liang Z. Adaptive-weighted total variation minimization for sparse data toward low-dose X-ray computed tomography image reconstruction. Phys Med Biol. (2012) 57:7923. doi: 10.1088/0031-9155/57/23/7923
24. Churchill V, Archibald R, Gelb A. Edge-adaptive ℓ2 regularization image reconstruction from non-uniform Fourier data. Inverse Probl Imaging. (2019) 13:931–58. doi: 10.3934/ipi.2019042
25. Scarnati T, Gelb A. Accelerated variance based joint sparsity recovery of images from Fourier data. arXiv. (2019). doi: 10.48550/arXiv.1910.08391
26. Dutt A, Rokhlin V. Fast Fourier transforms for nonequispaced data II. Appl Comput Harmon Anal. (1995) 2:85–100. doi: 10.1006/acha.1995.1007
27. Selva J. Efficient type-4 and type-5 non-uniform FFT methods in the one-dimensional case. IET Signal Process. (2018) 12:74–81. doi: 10.1049/iet-spr.2016.0509
28. Kircheis M, Potts D. Direct inversion of the nonequispaced fast Fourier transform. Linear Algebra Appl. (2019) 575:106–40. doi: 10.1016/j.laa.2019.03.028
29. Heinig G, Rost K. Algebraic Methods for Toeplitz-like Matrices and Operators, Volume 19 of Mathematical Research. Berlin: Akademie-Verlag (1984). doi: 10.1515/9783112529003
30. Gelb A, Song G. A frame theoretic approach to the nonuniform fast Fourier transform. SIAM J Numer Anal. (2014) 52:1222–42. doi: 10.1137/13092160X
31. Averbuch A, Coifman R, Donoho DL, Elad M, Israeli M. Fast and accurate polar Fourier transform. Appl Comput Harmon Anal. (2006) 21:145–67. doi: 10.1016/j.acha.2005.11.003
32. Averbuch A, Coifman R, Donoho D, Israeli M, Shkolnisky Y. A framework for discrete integral transformations I—the pseudopolar Fourier transform. SIAM J Sci Comput. (2008) 30:764–84. doi: 10.1137/060650283
33. Kircheis M, Potts D. Efficient multivariate inversion of the nonequispaced fast Fourier transform. PAMM. (2021) 20:e202000120. doi: 10.1002/pamm.202000120
34. Dutt A, Rokhlin V. Fast Fourier transforms for nonequispaced data. SIAM J Sci Stat Comput. (1993) 14:1368–93. doi: 10.1137/0914081
35. Beylkin G. On the fast Fourier transform of functions with singularities. Appl Comput Harmon Anal. (1995) 2:363–81. doi: 10.1006/acha.1995.1026
36. Steidl G. A note on fast Fourier transforms for nonequispaced grids. Adv Comput Math. (1998) 9:337–53.
37. Greengard L, Lee J-Y. Accelerating the nonuniform fast Fourier transform. SIAM Rev. (2004) 46:443–54. doi: 10.1137/S003614450343200X
38. Keiner J, Kunis S, Potts D. Using NFFT 3 – a software library for various nonequispaced fast Fourier transforms. ACM Trans Math Softw. (2009) 36:1–30. Available online at: https://www.researchgate.net/publication/220492570_Using_NFFT_3—A_Software_Library_for_Various_Nonequispaced_Fast_Fourier_Transforms
39. Duijndam AJW, Schonewille MA. Nonuniform fast Fourier transform. Geophysics. (1999) 64:539–51. doi: 10.1190/1.1444560
40. Fourmont K. Non equispaced fast Fourier transforms with applications to tomography. J Fourier Anal Appl. (2003) 9:431–50. doi: 10.1007/s00041-003-0021-1
41. Potts D, Tasche M. Continuous window functions for NFFT. Adv Comput Math. (2021) 47:1–34. doi: 10.1007/s10444-021-09873-8
42. Keiner J, Kunis S, Potts D. NFFT 3.5, C subroutine library. https://www.tu-chemnitz.de/~potts/nfft/. Contributors: Bartel F, Fenn M, Görner T, Kircheis M, Knopp T, Quellmalz M, Schmischke M, Volkmer T, and Vollrath A.
43. Rasche V Proksa R Sinkus R Börnert P and Eggers H. Resampling of data between arbitrary grids using convolution interpolation. IEEE Trans Med Imag. (1999) 18:385–92. doi: 10.1109/42.774166
44. Gräf M, Kunis S, Potts D. On the computation of nonnegative quadrature weights on the sphere. Appl Comput Harmon Anal. (2009) 27:124–32. doi: 10.1016/j.acha.2008.12.003
45. Tchakaloff V. Formules de cubature mécaniques à coefficients non négatifs. Bull Sci Math. (1957) 81:123–34.
46. Gröchenig K. Sampling, Marcinkiewicz-Zygmund inequalities, approximation, and quadrature rules. J Approx Theory. (2020) 257:105455. doi: 10.1016/j.jat.2020.105455
47. Huybrechs D. Stable high-order quadrature rules with equidistant points. J Comput Appl Math. (2009) 231:933–47. doi: 10.1016/j.cam.2009.05.018
48. Whittaker ET. On the functions which are represented by the expansions of the interpolation theory. Proc R Soc Edinb. (1915) 35:181–94. doi: 10.1017/S0370164600017806
49. Shannon CE. Communication in the presence of noise. Proc IRE. (1949) 37:10–21. doi: 10.1109/JRPROC.1949.232969
50. Kotelnikov VA. On the transmission capacity of the “ether” and wire in electrocommunications. In:Benedetto JJ, Ferreira JSG, , editors. Modern Sampling Theory: Mathematics and Application. Boston, MA: Birkhäuser (2001), p. 27–45. Translated from Russian. doi: 10.1007/978-1-4612-0143-4_2
51. Qian L. On the regularized Whittaker-Kotelnikov-Shannon sampling formula. Proc Amer Math Soc. (2003) 131:1169–76. doi: 10.1090/S0002-9939-02-06887-9
52. Strohmer T, Tanner J. Fast reconstruction methods for bandlimited functions from periodic nonuniform sampling. SIAM J Numer Anal. (2006) 44:1071–94. doi: 10.1137/040609586
53. Micchelli C, Xu Y, Zhang H. Optimal learning of bandlimited functions from localized sampling. J Complexity. (2009) 25:85–114. doi: 10.1016/j.jco.2009.02.005
54. Lin R, Zhang H. Convergence analysis of the Gaussian regularized Shannon sampling formula. Numer Funct Anal Optim. (2017) 38:224–47. doi: 10.1080/01630563.2016.1240182
55. Kircheis M, Potts D, Tasche M. On regularized Shannon sampling formulas with localized sampling. Sampl Theory Signal Process Data Anal. (2022) 20:20. doi: 10.1007/s43670-022-00039-1
56. Kircheis M, Potts D, Tasche M. Nonuniform fast Fourier transforms with nonequispaced spatial and frequency data and fast sinc transforms. Numer Algor92. (2022) 2307–39. doi: 10.1007/s11075-022-01389-6
57. Elbel B, Steidl G. Fast Fourier transform for nonequispaced data. In:Chui CK, Schumaker LL, , editors. Approximation Theory IX. Nashville: Vanderbilt University Press (1998), p. 39–46.
58. Lee J-Y, Greengard L. The type 3 nonuniform FFT and its applications. J Comput Phys. (2005) 206:1–5. doi: 10.1016/j.jcp.2004.12.004
59. Gopal A, Rokhlin V. A fast procedure for the construction of quadrature formulas for bandlimited functions. Technical Report, YALEU/DCS/TR-1563. (2022). doi: 10.1016/j.acha.2023.05.001
60. Björck Å. Numerical Methods for Least Squares Problems. Philadelphia, PA: SIAM (1996). doi: 10.1137/1.9781611971484
61. Sedarat H, Nishimura DG. On the optimality of the gridding reconstruction algorithm. IEEE Trans Med Imaging. (2000) 19:306–17. doi: 10.1109/42.848182
62. Rosenfeld D. An optimal and efficient new gridding algorithm using singular value decomposition. Magn Reson Med. (1998) 40:14–23. doi: 10.1002/mrm.1910400103
63. Pipe JG, Menon P. Sampling density compensation in MRI: rationale and an iterative numerical solution. Magn Reson Med. (1999) 41:179–86. doi: 10.1002/(SICI)1522-2594(199901)41:1<179::AID-MRM25>3.0.CO;2-V
64. Choi H, Munson DC. Analysis and design of minimax-optimal interpolators. IEEE Trans Signal Process. (1998) 46:1571–9. doi: 10.1109/78.678470
65. Greengard L, Lee J-Y, Inati S. The fast sinc transform and image reconstruction from nonuniform samples in k-space. Commun Appl Math Comput Sci. (2006) 1:121–31. doi: 10.2140/camcos.2006.1.121
66. Nieslony A, Steidl G. Approximate factorizations of Fourier matrices with nonequispaced knots. Linear Algebra Appl. (2003) 266:337–51. doi: 10.1016/S0024-3795(02)00496-2
67. Potts D, Tasche M. Uniform error estimates for nonequispaced fast Fourier transforms. Sampl Theory Signal Process Data Anal. (2021) 19:1–42. doi: 10.1007/s43670-021-00017-z
68. Fenn M, Kunis S, Potts D. On the computation of the polar FFT. Appl Comput Harmon Anal. (2007) 22:257–63. doi: 10.1016/j.acha.2006.05.009
69. Helou ES, Zibetti MVW, Axel L, Block KT, Regatte RR, Herman GT. The discrete Fourier transform for golden angle linogram sampling. Inverse Probl. (2019) 35:125004. doi: 10.1088/1361-6420/ab44ee
70. Stewart G. Matrix Algorithms: Basic Decompositions. Philadelphia, PA: SIAM (1998). doi: 10.1137/1.9781611971408
71. Lund J, Bowers KL. Sinc Methods for Quadrature and Differential Equations. Philadelphia, PA: Society for Industrial and Applied Mathematics. (1992). doi: 10.1137/1.9781611971637
Keywords: inverse nonequispaced fast Fourier transform, nonuniform fast Fourier transform, direct inversion, iNFFT, NFFT
Citation: Kircheis M and Potts D (2023) Fast and direct inversion methods for the multivariate nonequispaced fast Fourier transform. Front. Appl. Math. Stat. 9:1155484. doi: 10.3389/fams.2023.1155484
Received: 31 January 2023; Accepted: 17 May 2023;
Published: 28 June 2023.
Edited by:
Felix Krahmer, Technical University of Munich, GermanyReviewed by:
Bosu Choi, Dartmouth College, United StatesGuohui Song, Old Dominion University, United States
Copyright © 2023 Kircheis and Potts. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Melanie Kircheis, bWVsYW5pZS5raXJjaGVpc0BtYXRoLnR1LWNoZW1uaXR6LmRl