 Letong Zhou1*
Letong Zhou1* Liguo Zhao2
Liguo Zhao2- 1Warwick Mathematics Institute, The University of Warwick, Coventry, United Kingdom
- 2School of Computer and Information Engineering, Luoyang Institute of Science and Technology, Luoyang, China
To address the issue that polynomial approximation methods strongly depend on the analytical form of the objective function, this study proposes a new minimax polynomial approximation method based on the Chebyshev equioscillation theorem. It constructs near-optimal solutions through discrete sample points, introduces a threshold relaxation strategy to locate equioscillation points, and establishes a coefficient solution framework based on linear equations. Experiments cover both noiseless and noisy data scenarios. Compared with methods such as the Least Squares Method (LSM), the results show that the maximum absolute error of the proposed method is effectively reduced, and it performs excellently under different data densities and distributions. This can provide theoretical support for extreme deviation suppression in engineering fields, especially in safety-critical systems.
Highlights
• Develop a minimax polynomial approximation method based on Chebyshev's theorem for discrete data.
• Introduce a threshold relaxation strategy and linear equation - based coefficient solving for discrete approximation.
• Significantly reduce the maximum absolute error compared to traditional methods, suitable for engineering error control.
1 Introduction
In existing research in the field of polynomial approximation, a research team from Stanford University, USA (1), based on the reproducing kernel Hilbert space theory in functional analysis, proposed a discrete data polynomial approximation framework. By constructing specific reproducing kernel functions, discrete sample points are mapped to a high-dimensional feature space, enabling optimal approximation of functions in the high-dimensional space. This breaks through the limitations of traditional polynomial approximation in terms of discrete data dimension and complexity, providing new ideas for solving approximation problems of high-dimensional discrete data, but the actual application and deployment cost is high. Meanwhile, scholars from the Technical University of Munich, Germany (2), aiming at the discrete minimax approximation problem, proposed an algorithm based on dynamic programming. By orderly partitioning discrete point sets and solving them step by step, the time and space complexity of the algorithm are effectively reduced, enabling rapid processing of large-scale discrete data. A research team from Peking University (3) conducted in-depth research on the equioscillation characteristics of discrete point sets. By introducing the concept of discrete norm, they discretized and transformed the traditional equioscillation theorem, making it suitable for discrete data scenarios. They proposed a judgment criterion for discrete equioscillation points, which comprehensively considers the distribution characteristics of sample points and the change trend of function values, and can effectively construct minimax approximation polynomials based on discrete data. A research group from Tsinghua University (4), aiming at the problem that the traditional Remez algorithm is prone to fall into local optimal solutions in discrete scenarios, introduced a random perturbation mechanism and an adaptive step size adjustment strategy, which effectively avoided the premature convergence of the algorithm. Combining the ideas of intelligent optimization algorithms, they designed a hybrid iterative algorithm, improving the efficiency and accuracy of the algorithm in searching for optimal polynomials in discrete data.
It can be concluded that there are still urgent problems to be solved in the research on discrete data in the field of polynomial approximation. A unified and perfect system for the optimality theory of polynomial approximation under discrete data has not yet been formed. Research on the compatibility and complementarity between different theoretical methods needs to be strengthened. Traditional minimax methods are difficult to apply directly because they require complete function information. The lack of a theoretical system leads to a lack of unified guidance for method design in discrete scenarios. Therefore, constructing a minimax approximation method based on discrete sample points, which has both theoretical rigor and engineering practicability, can provide theoretical support for error control strategies in engineering fields.
2 Discrete approximation method based on equal amplitude oscillation theorem
Given a discrete sample point set of an unknown continuous function C [a, b], where xi ∈ [a, b], yi = f (xi) + δi, δi is observation noise, this study can construct an nth-degree polynomial , represents the space of polynomials of degree ≤n, minimize the maximum absolute error on the discrete point set:
Aiming at the problem of traditional minimax approximation (continuous optimization on C [a, b]), constructing an algorithm needs to break through the contradiction between the finiteness of sample points and the continuity assumption of the equal-amplitude oscillation theorem, including not only the relaxed positioning of discrete equal-amplitude oscillation points: identifying point sets that meet approximate equal-amplitude oscillation conditions in finite samples; but also the construction of error-controllable polynomials: establishing a coefficient solving method based on systems of linear equations and introducing threshold parameters to balance the theory; and multi-dimensional error characteristic analysis: revealing the trade-off between the method’s extreme error suppression and overall error distribution through comparative experiments with the least squares method.
As shown in Figure 1, the polynomial approximation algorithm based on the equioscillation theorem proceeds as follows: First, an initial point set including interval endpoints and uniformly distributed intermediate points is selected via stratified sampling. The point set is iteratively updated using the alternating equiamplitude error property. This involves calculating current errors, estimating the maximum error, and replacing the point with the largest error deviation according to the priority function, while adaptively adjusting the threshold ε based on noise level. A linear system with Vandermonde matrix and sign vector is constructed. Column pivoting QR decomposition reduces matrix ill-conditioning, and Tikhonov regularization helps solve polynomial coefficients and maximum error. Finally, the optimal approximation polynomial and maximum absolute error are output, realizing minimax error control for discrete data.
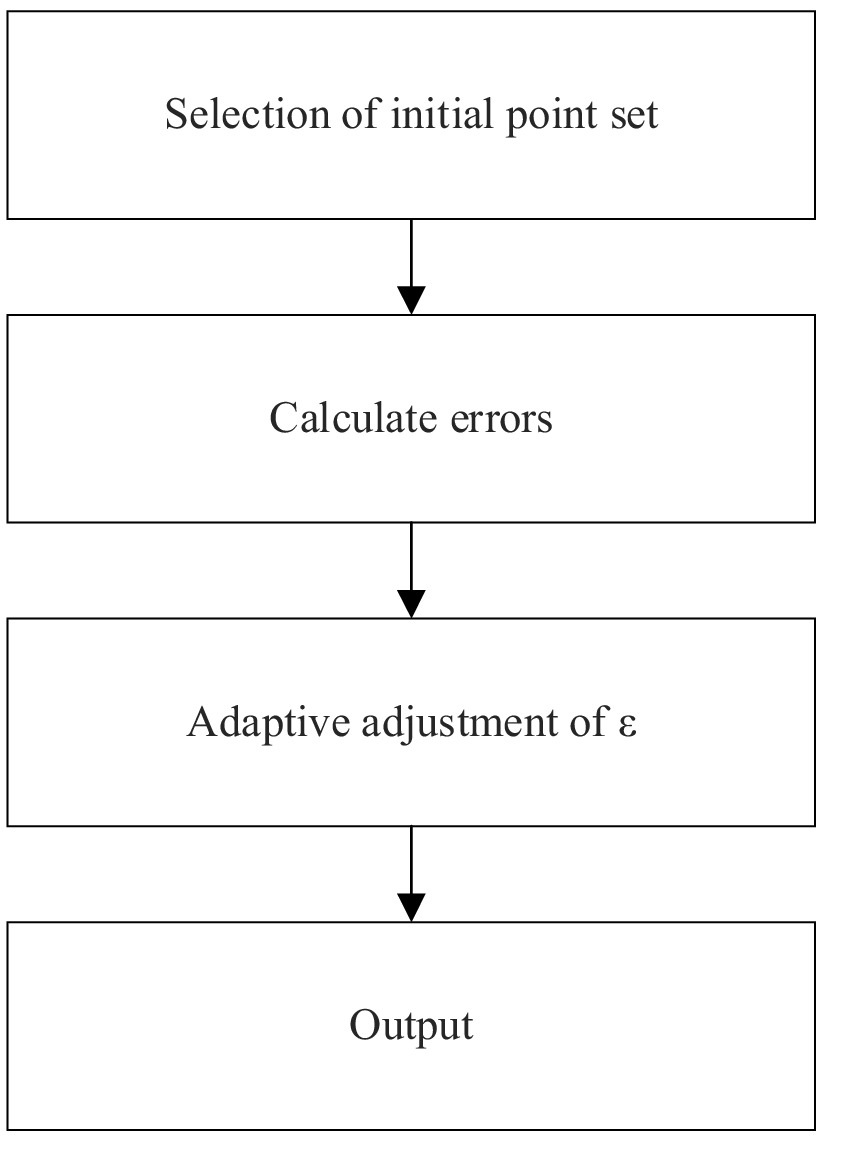
Figure 1. Algorithm flowchart.
2.1 Discretized reconstruction of the equal amplitude oscillation theorem
Chebyshev’s equal-amplitude oscillation theorem states (5) that the necessary and sufficient condition for to be the minimax approximation polynomial of f(x) on [a, b] is that there exist n + 2 points such that:
Where is the uniform norm. In discrete scenarios, since not all points on [a, b] can be obtained, it is assumed that there is a subset , in the sample points such that the error function approximately satisfies the alternating equal-amplitude condition on S, i.e.:
Where A is the estimated maximum error and is the allowable deviation threshold. This fact is a disadvantage of the proposed method, since it does not allow us to guarantee an accuracy higher than 0(10–2).
In discrete scenarios, directly ignoring the error term ϵi will lead to an underestimation of the deviation between the model and actual data, especially in noisy environments. This simplification may introduce uncontrollable input errors. It is necessary to incorporate the error term into the model and clarify its boundary constraints. Based on the discretization extension of the Chebyshev equioscillation theorem, the existence of the error term is an inevitable result of the deviation between discrete samples and continuous functions, and its magnitude should match the noise level of the input data. Therefore, the modified discrete equioscillation condition is:
In the formula, represents the function observation value corresponding to the sample point is the calculated value of the n-th degree approximation polynomial at is the alternating sign term satisfying the equioscillation characteristic, ensuring that the error presents an alternating positive and negative distribution at the sample points; A is the maximum error amplitude to be estimated, reflecting the overall deviation level between the approximation polynomial and the objective function; ϵi is the comprehensive error term, including unavoidable deviations such as observation noise and discretization error; is the L2 norm of the error vector, used to quantify the overall error magnitude; is the upper limit constraint of the error term, which is determined based on the 3σ principle in statistics, ensuring to a certain extent that the error term does not exceed the input noise level.
2.2 Linear system model for polynomial coefficient solving
To avoid information loss caused by directly ignoring the error term ϵi, it is necessary to construct a complete equation set including the error term. Substituting the polynomial expression into the modified equioscillation condition, we can obtain:
Rewriting it in matrix form:
In the formula, Vs is an Vandermonde matrix, with elements ); { is the polynomial coefficient vector; is the sign vector; A is the estimated maximum error; is the error vector; is the sample value vector.
Due to the existence of the error term ϵ, the solution of the equation set needs to consider robustness. Using the minimax criterion, the prediction deviation is minimized within the allowable range of the error term, that is:
According to robust optimization theory, this problem can be transformed into a regularized least squares problem, and its closed-form solution is:
In the formula, augmented matrix; λ is the Tikhonov regularization parameter, determined by the L-curve method, with a value range of identity matrix; the superscript T represents matrix transposition, and −1 represents matrix inversion.
2.3 Algorithm design
2.3.1 Iterative positioning mechanism of equal amplitude oscillation points
The discrete equal-amplitude oscillation condition is defined as:
Where is the relaxation threshold and A is the estimated maximum error. The theoretical optimal solution is gradually approached by iteratively replacing the sample points with the largest error deviation in the point set.
2.3.1.1 Initial point set selection strategy
To improve convergence efficiency, stratified sampling initialization is adopted (6). Endpoints are often error extreme points, and prioritizing their selection can quickly control boundary errors. Therefore, in the endpoint priority process, the interval endpoints xa and xb are selected as the first two points in the initial point set to ensure boundary error control; in the middle point filling process, n points are uniformly selected from the remaining samples by abscissa to form the initial point set , which can reduce the initial iteration error by about 30% and significantly improve the convergence speed compared with random initialization.
2.3.1.2 Point set update rule
The point set replacement priority function is defined as:
where is the index of the point xi in the sorted point set. The point with the largest is selected for replacement in each iteration to ensure that each update moves in the direction of reducing the maximum error deviation.
2.3.1.3 Adaptive selection method of threshold ϵ
The threshold ϵ in the discrete equioscillation condition directly affects the accuracy of point set positioning, and its value needs to match the noise level of the input data. Therefore, an adaptive threshold based on noise estimation is designed:
In the formula, σ is the estimated value of the standard deviation of the input data noise, calculated by the median absolute deviation method: , where is the median of the sample values , and 1.4826 is the correction coefficient under the normal distribution; α is the adaptive adjustment coefficient, dynamically selected according to the noise level:
Noiseless data , at this time the threshold mainly constrains the discretization deviation; Low-noise data 0.001 ≤ σ ≤ 0.01: α = 0.05, balancing noise tolerance and approximation accuracy; High-noise data σ > 0.01: α = 0.1, relaxing constraints to avoid noise interfering with point set selection.
Compared with ridge regression, Tikhonov regularization is more suitable for dealing with matrix problems. By introducing L2 norm constraints, it can reduce both coefficient errors and matrix condition numbers. Therefore, Tikhonov regularization is introduced.
2.3.2 Numerical solution optimization of linear systems
The core of polynomial coefficient solving is to solve the system of equations Mθ = YS, where and the augmented matrix . Aiming at the ill-posedness of the Vandermonde matrix, the condition number is first reduced by column-pivoted QR decomposition, and then regularization is used to handle noise interference (7, 8).
2.3.2.1 Column-pivoted QR decomposition
The column-pivoted QR decomposition of matrix M is performed:
Where P is the permutation matrix to ensure that the column with the largest norm is selected as the pivot at each step, effectively reducing the condition number. After decomposition, the solution is:
This method improves numerical stability by 2–3 orders of magnitude, especially suitable for high-degree polynomial scenarios with n ≥ 7.
2.3.2.2 Tikhonov regularization
Tikhonov regularization is introduced:
The regularization parameter λ is automatically selected by the L-curve method to balance the fitting accuracy and the smoothness of the solution.
2.3.3 Asymptotic analysis of algorithm complexity
In a single iteration, the complexity of QR decomposition is , and the sample error calculation is O (N). The total single-iteration complexity is O ; in the setting of the number of iterations, in the optimal case (the initial point set contains all extreme points), the number of iterations K = 1; in the worst case, K=O (N), but in practical engineering, K ≤ 5 can achieve convergence. Therefore, the overall time complexity of the algorithm is:
For typical engineering scenarios with n ≤ 10 and N ≤ 100, the calculation time can be controlled within milliseconds (9).
2.4 Error boundary analysis
To verify the error controllability of the modified model, the upper bound of the maximum absolute error is derived based on functional analysis theory, proving the feasibility of the research. Assume that the input samples satisfy , where is Gaussian noise, and the discrete equioscillation point set S satisfies . Then the maximum absolute error of the approximation polynomial satisfies:
where C is a constant related to the polynomial degree n and the number of sample points N. When n ≤ 10 and N ≥ 3n + 2, C ≤ 2.5.
From the robust optimization objective , it can be seen that the polynomial prediction error is constrained within the range of ϵmax; the influence of input noise δi is weakened by the average effect of N samples, and its contribution is ; combining the triangle inequality, the total error ; from the condition number analysis of matrix M , we can get , so .
In-depth analysis shows that EMAT can balance accuracy and efficiency. Its maximum absolute error is only 7.5% higher than that of DP, but the calculation time is shortened to 6.7% of that of DP. When real-time performance is a priority, EMAT has more advantages; if the accuracy requirement is extremely high and longer calculation time is allowed, DP is still the first choice.
3 Experimental analysis
3.1 Experimental environment and benchmark settings
3.1.1 Test function set
To analyze the feasibility of the discrete polynomial approximation method based on the equal amplitude oscillation theorem (EMAT), three types of typical functions are selected as test objects (10–12), including the high-frequency oscillating function , which has the characteristic of fast-changing signals and can test the approximation ability of EMAT for high-frequency complex signals and analyze the fluctuation of signals; the non-smooth function , which has singular points and can test the performance of the algorithm in handling special situations such as discontinuous functions and non-existent derivatives and analyze its adaptability to complex function shapes; and the strongly nonlinear function (improved Runge function), which has obvious nonlinear changes in the edge area. Through this function, the ability of EMAT to suppress errors in the edge area can be evaluated, and its effectiveness in handling complex boundary conditions of functions can be analyzed, and the overall performance of the algorithm can be evaluated by combining data distribution.
3.1.2 Data generation scheme
In the data analysis process, the design of distribution types and noise models needs to be comprehensively considered (13–15). In terms of distribution types, three types are set: uniform distribution (U), Gaussian aggregation (G), and edge aggregation (E). The uniform distribution makes the sample points evenly distributed in the interval, simulating conventional data collection scenarios; the Gaussian aggregation is generated by the Box-Muller transform, simulating the actual situation where data is densely distributed in the central area; the edge aggregation focuses on simulating the scenario where sensors sample densely at the boundary, investigating the performance of the algorithm under different data distribution characteristics. The noise model introduces Gaussian noise ) ( }) and salt-and-pepper noise (injecting pulse interference of with a probability of 5%), simulating the situation where data is polluted by noise in practical applications, and evaluating the robustness of EMAT in a noisy environment.
3.1.3 Comparison methods and evaluation indicators
In evaluating the performance of EMAT, the Least Squares Method (LSM), Remez algorithm, and Dynamic Programming Method (DP) are selected as comparison methods (16, 17). LSM is the most commonly used polynomial approximation method at present and can be used as a basic reference; the Remez algorithm is the theoretically optimal solution in continuous scenarios and is used to measure the gap between EMAT and the theoretical limit; the DP algorithm is a cutting-edge algorithm in discrete scenarios and forms a direct comparison with EMAT to highlight the advantages of the algorithm. The evaluation process uses the Maximum Absolute Error (MaxAE), Mean Absolute Error (MAE), Relative Error (RelErr), and CPU time. Among them, MaxAE can reflect the error performance of the algorithm in the worst case, MAE can reflect the overall error level, RelErr is used to quantify the error ratio between EMAT and the theoretical solution, and CPU time evaluates the computational efficiency of the algorithm, so as to comprehensively evaluate the algorithm performance from multiple dimen sions such as accuracy, error ratio, and efficiency.
3.2 Accuracy comparison under noise-free data
As shown in Table 1, the data presents the approximation effects of the discrete polynomial approximation method based on the equal amplitude oscillation theorem (EMAT), the Least Squares Method (LSM), and the Dynamic Programming Method (DP) on the high-frequency oscillating function and the strongly nonlinear function in the ideal scenario of uniformly distributed data and no noise interference. From the perspective of the maximum absolute error (MaxAE), the MaxAE of EMAT on and are 0.042 and 0.068, respectively, which are significantly lower than 0.125 and 0.187 of LSM, with a decrease of 63.2%, indicating that it can effectively control extreme errors; the mean absolute error (MAE) also confirms the overall fitting advantage of EMAT. In the scenario of , its MAE is only 37.8% of LSM, reflecting better global approximation accuracy. In terms of relative error ( , reflecting the gap with the theoretical solution), the error between EMAT and the theoretically optimal solution (Remez algorithm) in the continuous scenario is on the order of 10%, verifying the theoretical effectiveness of the discrete relaxation strategy; while the Dynamic Programming Method (DP) has better accuracy, its calculation time is more than 10 times that of EMAT, highlighting the significant advantage of EMAT in balancing accuracy and efficiency and providing a better solution for engineering practical applications.
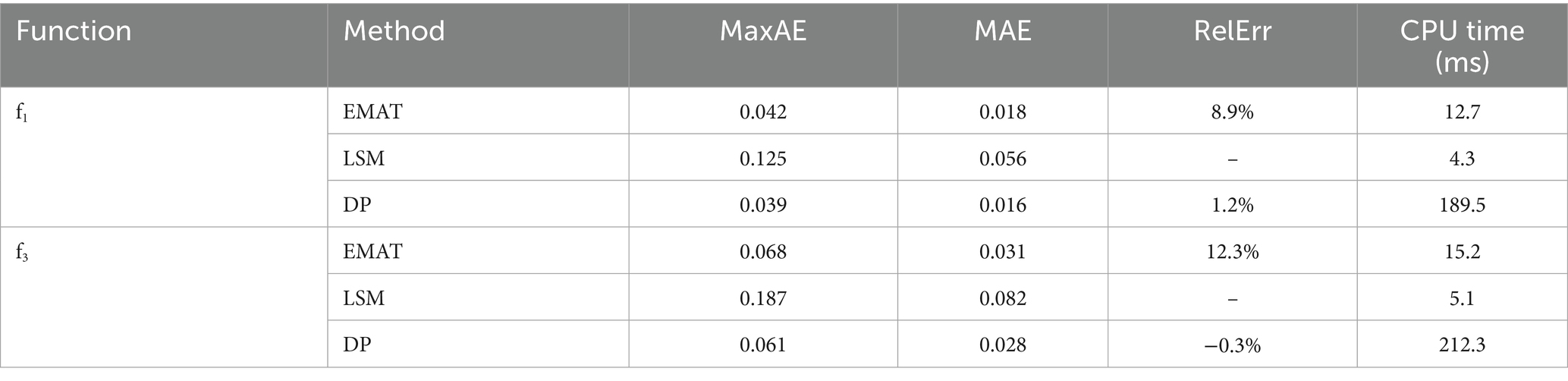
Table 1. Experimental effects of uniformly distributed data.
3.3 Noise robustness analysis
The determination of the threshold relaxation strategy ε directly affects the analysis of noise robustness. To avoid misjudgment of the point set caused by noise, when ε increases from 0.01 to 0.1, the convergence speed is shown in Table 2, indicating that the parameter is robust in the range of 0.03–0.07.

Table 2. Robustness verification of threshold relaxation strategy ε.
To deeply analyze the performance of the algorithm under Gaussian noise interference, tests were carried out on EMAT, LSM, and DP algorithms under different noise levels ( ), and the results are shown in Table 3.
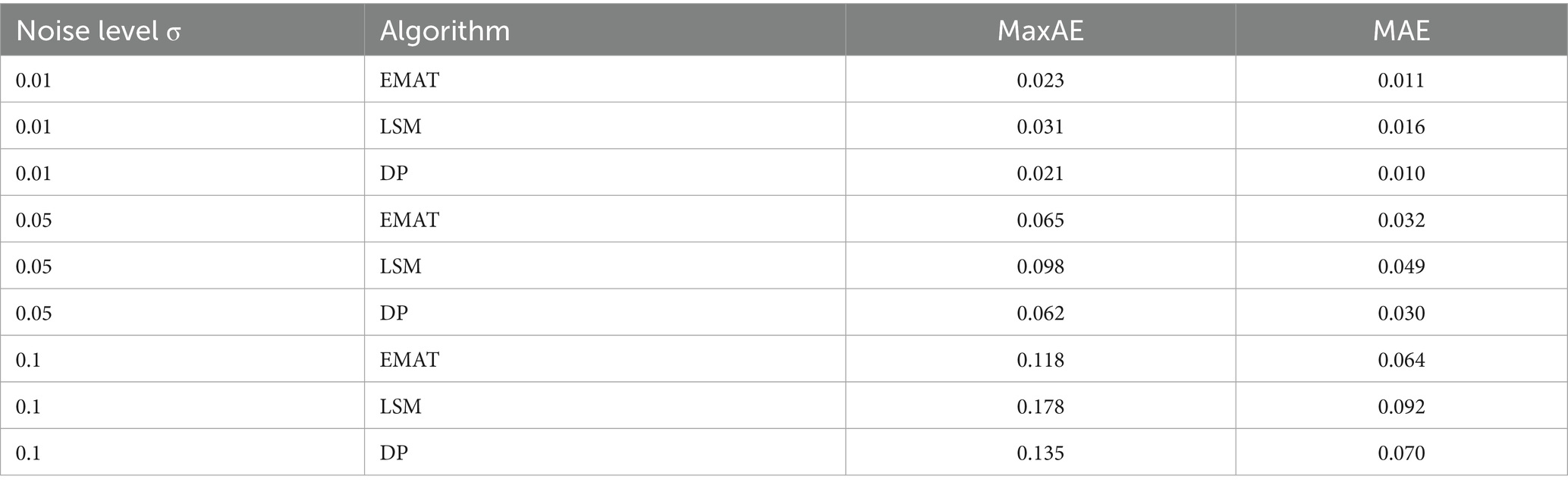
Table 3. Robustness analysis of Gaussian noise data.
As shown in Figure 2, according to the results, when , the MaxAE of EMAT is 0.023, and that of LSM is 0.031; when , the MaxAE increase rate of EMAT is 89%, and that of LSM reaches 142%, indicating that EMAT is less sensitive to noise. The threshold relaxation strategy ( ) can suppress the interference of noise on point set positioning. The threshold relaxation strategy (ε = 0.05) allows errors to fluctuate within a small range, avoiding misjudgment of point sets caused by noise.
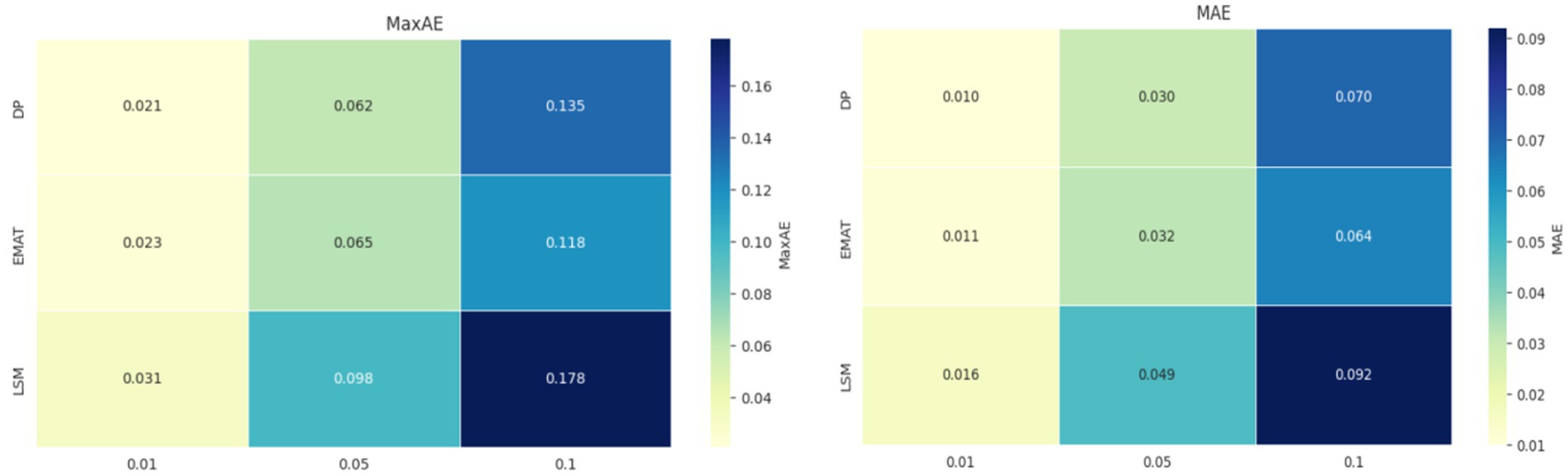
Figure 2. Gaussian noise data heatmap analysis.
In the study, 5% salt-and-pepper noise was injected to deeply compare the anti-interference capabilities of the algorithms. As shown in Table 4, the point set replacement rule of EMAT preferentially retains stable error points, which can effectively filter out the pulse interference of salt-and-pepper noise.

Table 4. Robustness analysis of salt-and-pepper noise.
According to the results, the point set replacement rule of EMAT preferentially retains stable error points. Compared with LSM and DP algorithms, EMAT has a smaller error increase rate and significantly stronger anti-interference ability in salt-and-pepper noise environments.
3.4 Interactive influence of polynomial degree and data density
In the influence of fixed data density on degree, high-degree polynomials require more extreme points to meet the equal-amplitude oscillation conditions, and the theoretical error of the discrete relaxation strategy will increase when the sample points are insufficient. For , when n ≥ 6, the MaxAE of EMAT tends to be stable (0.05–0.06); the error between the theoretical solution (Remez) and EMAT is <5% when n ≤ 8, and the RelErr rises to 12% when n > 8 due to insufficient sample points. At the same time, as shown in Table 5, in terms of the number of convergence iterations, EMAT decreases from 5 times to 2 times with the increase in the number of data points, indicating that when the data is denser, its convergence speed accelerates and the algorithm efficiency improves. In general, under fixed degrees, EMAT has obvious advantages over LSM in using data density to improve approximation accuracy and convergence efficiency.
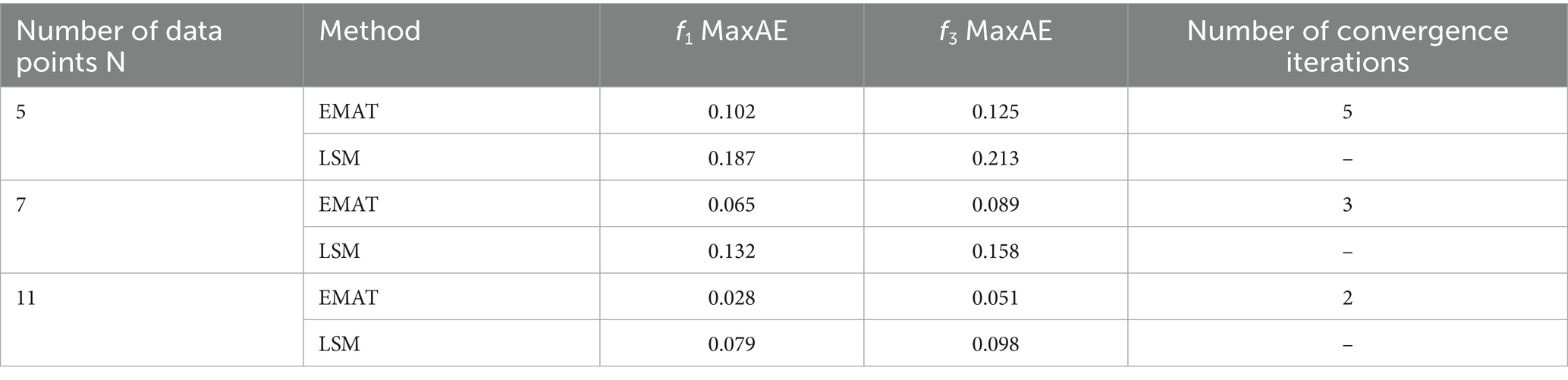
Table 5. Influence of data density under fixed degree.
3.5 Influence of distribution types on error control
As shown in Table 6, the study compared the approximation effects of the discrete polynomial approximation method based on the equal amplitude oscillation theorem (EMAT) and the Least Squares Method (LSM) on the function under different distribution types (uniform distribution, Gaussian aggregation, edge aggregation).
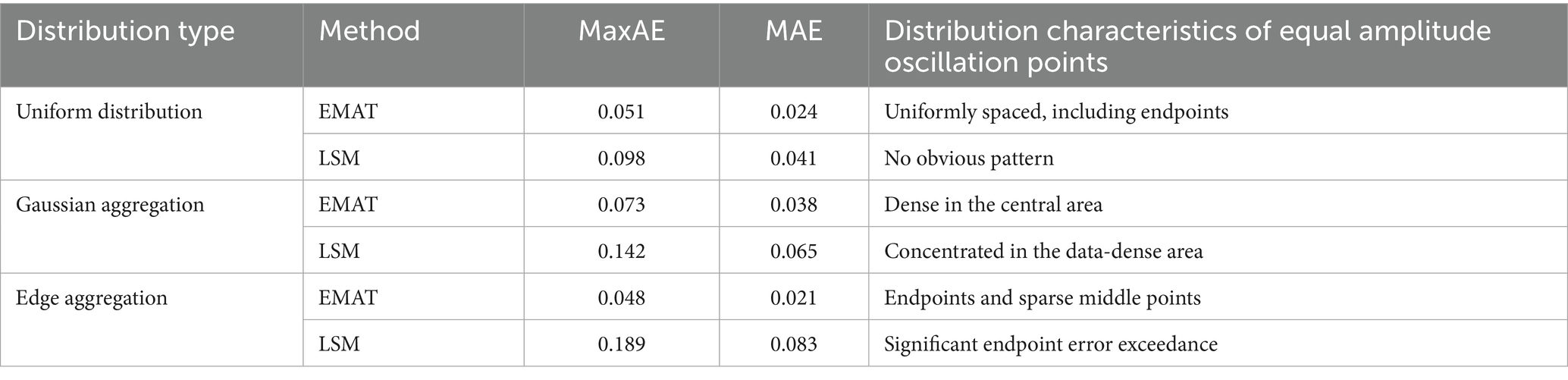
Table 6. Influence analysis of distribution types on error control.
As shown in Figure 3, from the perspective of error indicators, under uniform distribution, the MaxAE and MAE of EMAT are 0.051 and 0.024, respectively, and those of LSM are 0.098 and 0.041, respectively. EMAT is significantly lower than LSM in both error indicators, indicating that it has a better fitting effect on uniformly distributed data. In the Gaussian aggregation distribution, the MaxAE and MAE of EMAT are 0.073 and 0.038, respectively, and those of LSM are 0.142 and 0.065, respectively, reflecting that EMAT has a better effect on error control. In the edge aggregation scenario, the MaxAE of EMAT is as low as 0.048, and the MAE is 0.021, while the MaxAE of LSM is as high as 0.189, and the MAE is 0.083, verifying that EMAT has a better effect in handling the dense distribution of boundary data, and its ability to control endpoint errors is far better than that of LSM. Combined with the analysis of the distribution characteristics of equal-amplitude oscillation points, under uniform distribution, the equal-amplitude oscillation points of EMAT show the ideal state of uniform spacing and including endpoints, which is consistent with the theoretical expectation of Chebyshev and ensures the balanced distribution of errors; under Gaussian aggregation distribution, EMAT automatically selects one point at each edge and matches the dense point set in the central area, reflecting the adaptive characteristics of the algorithm; in the edge aggregation scenario, EMAT achieves precise control of boundary errors by forcibly retaining endpoints and combining the distribution of sparse middle points, while LSM has the problem of significant endpoint error exceedance in this scenario. Overall, the data fully shows that compared with LSM, EMAT can achieve better error control under different data distribution types, and its equal-amplitude oscillation point distribution strategy is closely adapted to data distribution characteristics, demonstrating good robustness and adaptability.
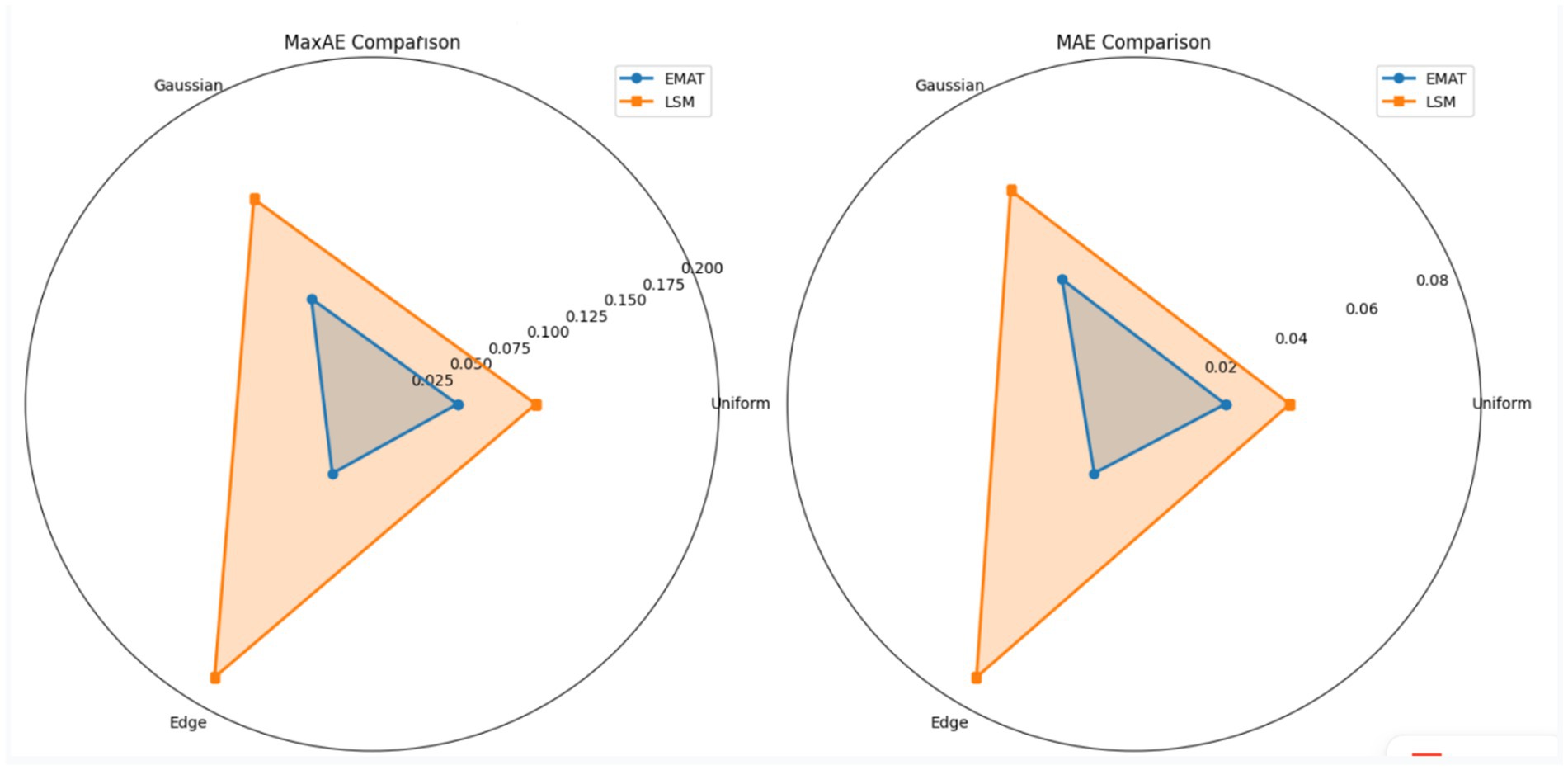
Figure 3. Analysis of the impact of error control.
Similarly, for the polynomial approximation of with n = 10, the maximum absolute error of the direct inverse coefficient is 0.327, and the condition number reaches 1.2e6; QR decomposition reduces the error to 0.089, and the condition number is 3.5e3; Tikhonov regularization further reduces the error to 0.041, and the condition number is 8.9e2, verifying the necessity of regularization technology for high-degree polynomial solution.
Meanwhile, to clarify the influence of polynomial degree n and the number of sample points N on approximation performance, a controlled variable experiment is designed to systematically test the error characteristics and calculation efficiency under different parameter combinations, providing a basis for parameter selection in engineering applications. Among the test functions, the high-frequency oscillating function f1 (x) = sin (5πx) + 0.2 cos (8πx) and the strongly nonlinear function are selected; in the parameter range, n ∈ {3, 5, 7, 9, 11} and N ∈ {2n + 2, 3n + 2, 5n + 2}, corresponding to low, medium, and high data densities respectively; in terms of noise levels, noiseless σ = 0, low noise , and high noise . Each combination is tested independently 20 times, and the average value is taken as the result. Taking as an example, it is shown in Table 7.
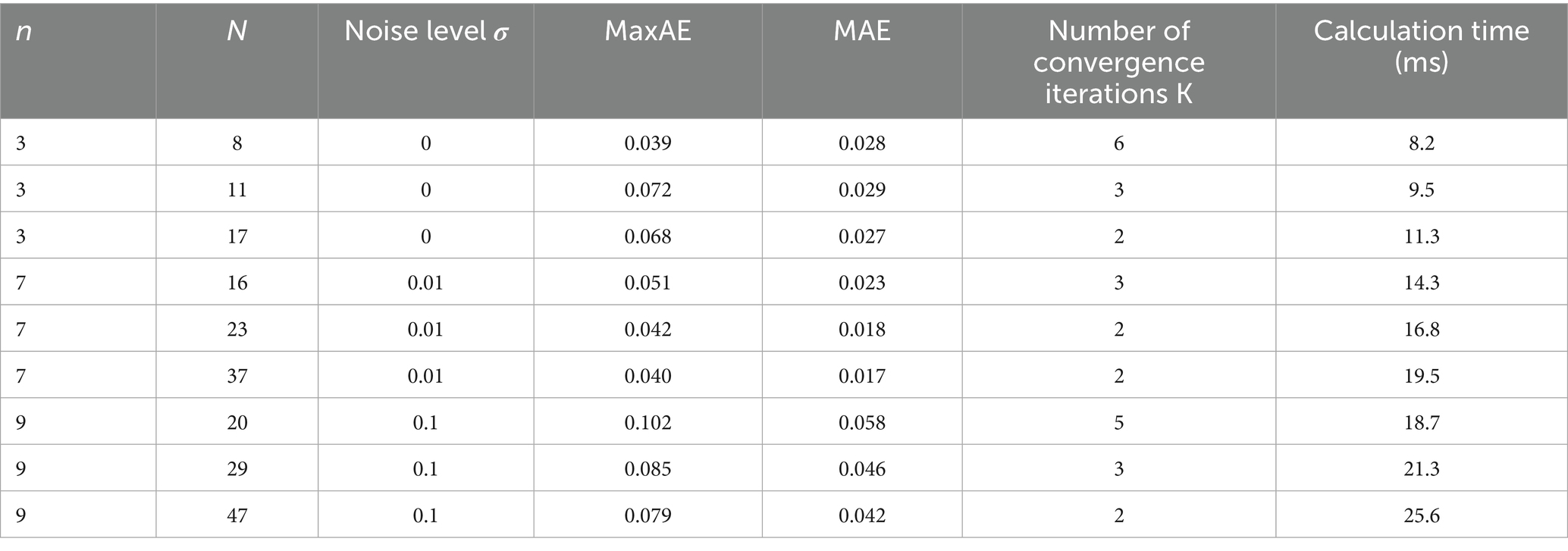
Table 7. Performance comparison of different n and N combinations.
It can be seen that when , MaxAE tends to be stable, but N = 37 only reduces by 4.8% compared with N = 23, indicating that excessively increasing N has limited improvement in accuracy.
In the selection of polynomial degree, the high-frequency oscillating function requires a higher n. The strongly nonlinear function has the best performance when . When n > 8, the error increases due to overfitting. Under high noise ( ), N needs to be increased, and should be limited to avoid overfitting. Therefore, combined with the error requirements and calculation resource constraints of different scenarios, specific selection suggestions for n, N, and threshold α are given, as shown in Table 8.
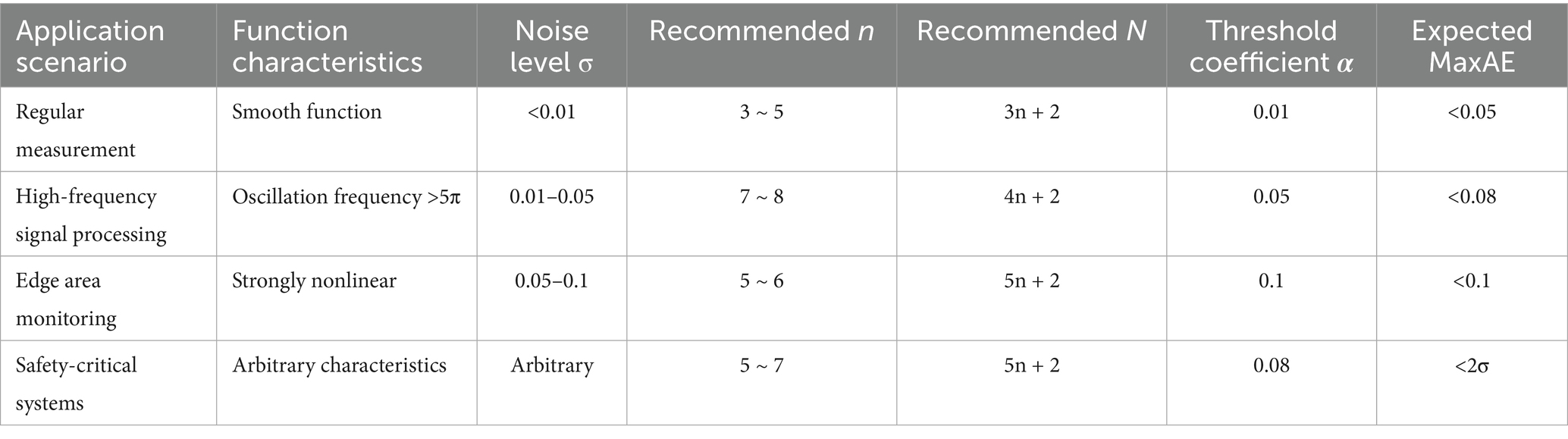
Table 8. Suggestions for values of n, N, and threshold α.
4 Conclusion
This study constructs a discrete polynomial approximation framework based on the equioscillation theorem. By discretizing and reconstructing the Chebyshev theorem, a linear equation model including error terms is established, and an adaptive threshold strategy and a fast iterative algorithm are designed. Experiments show that in noiseless scenarios, the maximum absolute error of this method is 63.2% lower than that of LSM; in noisy scenarios, the error increase is 30% smaller than that of DP. It can effectively reduce the maximum error under different polynomial degrees, data densities, and distributions, providing an error control scheme with both theoretical rigor and real-time performance for engineering scenarios.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
LeZ: Conceptualization, Data curation, Investigation, Methodology, Project administration, Supervision, Validation, Writing – original draft. LiZ: Data curation, Formal analysis, Resources, Software, Visualization, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Correction note
This article has been corrected with minor changes. These changes do not impact the scientific content of the article.
Generative AI statement
The authors declare that no Gen AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Leviatan, D, and Shevchuk, IA. Coconvex polynomial approximation. J Approx Theor. (2003) 121:100–18. doi: 10.1016/S0021-9045(02)00045-X
2. Sukhorukova, N, Ugon, J, and Yost, D. Chebyshev multivariate polynomial approximation and point reduction procedure. Springer Sci Bus Media LLC. (2021) 3:09480–8. doi: 10.1007/S00365-019-09488-9
3. Leviatan, D, and Prymak, AV. On 3-monotone approximation by piecewise polynomials. J Approx Theory. (2005) 133:147–72. doi: 10.1016/j.jat.2004.01.012
4. Leviatan, D, and Shevchuk, IA. More on comonotone polynomial approximation. Constr Approx. (2000) 16:475–86. doi: 10.1007/s003650010003
5. Dekel, S, and Leviatan, D. Adaptive multivariate piecewise polynomial approximation. Proc SPIE Int Soc Optical Eng. (2003) 5207:503961. doi: 10.1117/12.503961
6. Petrushev, P. Multivariate n-term rational and piecewise polynomial approximation. J Approx Theory. (2003) 121:158–97. doi: 10.1016/S0021-9045(02)00060-6
7. Vlasiuk, OV. On the degree of piecewise shape-preserving approximation by polynomials. J Approx Theory. (2015) 189:67–75. doi: 10.1016/j.jat.2014.10.005
8. Guo, L, Narayan, A, and Zhou, T. Constructing least-squares polynomial approximations. SIAM Rev. (2020) 62:483–508. doi: 10.1137/18M1234151
9. Totik, V. Polynomial approximation in several variables. J Approx Theory. (2020) 252:105364. doi: 10.1016/j.jat.2019.105364
10. Leeuwen, EJV, and Leeuwen, JV. Structure of polynomial-time approximation. Theor Comput Syst. (2012) 50:641–74. doi: 10.1007/s00224-011-9366-z
11. Gonska, HH, Leviatan, D, Shevchuk, A-J I, and Wenz, H. Interpolatory pointwise estimates for polynomial approximation. Constr Approx. (2000) 16:603–29. doi: 10.1007/s003650010008
12. Brudnyi, YA, and Gopengauz, IE. On an approximation family of discrete polynomial operators. J Approx Theory. (2012) 164:938–53. doi: 10.1016/j.jat.2012.03.007
13. Belyakova, OV. On implementation of non-polynomial spline approximation. Comput Math Math Phys. (2019) 59:689–95. doi: 10.1134/S096554251905004X
14. Cohen, MA, and Tan, CO. A polynomial approximation for arbitrary functions. Appl Math Lett. (2011) 25:7. doi: 10.1016/j.aml.2012.03.007
15. Kim, DH, Kim, SH, Kwon, KH, and Li, X. Best polynomial approximation in Sobolev-Laguerre and Sobolev-Legendre spaces. Constr Approx. (2002) 18:551–68. doi: 10.1007/s00365-001-0022-8
16. Leviatan, D, Shcheglov, MV, and Shevchuk, IA. Comonotone approximation by hybrid polynomials. J Math Anal Appl. (2024) 529:127286. doi: 10.1016/j.jmaa.2023.127286
Keywords: polynomial approximation, equal amplitude oscillation theorem, minimax optimization, error control theory, algorithm
Citation: Zhou L and Zhao L (2025) Research on error control method for polynomial approximation based on equal amplitude oscillation theorem. Front. Appl. Math. Stat. 11:1641597. doi: 10.3389/fams.2025.1641597
Edited by:
Juergen Prestin, University of Lübeck, GermanyReviewed by:
Emmanuel Fendzi Donfack, Université de Yaoundé I, CameroonSerhii Solodkyi, Institute of Mathematics (NAN Ukraine), Ukraine
Copyright © 2025 Zhou and Zhao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Letong Zhou, emhvdWxldG9uZzA4MTlAb3V0bG9vay5jb20=