 Hongjie Tang1
Hongjie Tang1 Hairong Hao
Hairong Hao- 1Department of Critical Care Medicine, Xuzhou Central Hospital, Xuzhou, Jiangsu, China
- 2Department of Endocrinology and Metabolism, Huai’an Hospital Affiliated to Xuzhou Medical University and Huai’an Second People’s Hospital, Huai’an, Jiangsu, China
Purpose: Sepsis is a leading cause of mortality, especially among immunocompromised patients with lung cancer. We aimed to establish machine learning (ML) based model to accurately forecast ICU mortality in patients with sepsis combined lung cancer.
Methods: We incorporated patients with sepsis combined lung cancer from Medical Information Mart for Intensive Care IV (MIMIC IV) database. Univariate and multivariate logistic analysis were employed to select variables. Recursive Feature Elimination (RFE) method based on 6 ML algorithms was used for feature selection. We harnessed 13 ML algorithms to construct prediction model, which were assessed by area under the curve (AUC), accuracy, sensitivity, specificity, precision, cross-entropy and Brier scores. The best ML model was constructed to predict ICU mortality, and the predictive results were interpretated by SHapley Additive exPlanations (SHAP) framework.
Results: A sum of 1096 lung cancer patients combined sepsis from MIMIC IV database and 251 patients from the external validation set were included. We utilized 13 clinical variables to establish prediction model for ICU mortality. CatBoost model was identified as the prime prediction model with the highest AUC in the training (0.931 [0.921, 0.945]), internal validation (0.698 [0.673, 0.724]) and external validation (0.794 [0.725, 0.879]) cohorts. Oxford Acute Severity of Illness Score (OASIS) had the greatest influence on ICU mortality according to SHAP interpretation.
Conclusions: Our ML models demonstrate excellent accuracy and reliability, facilitating more rigorous personalized prognostic forecast to lung cancer patients combined sepsis.
Introduction
Sepsis is triggered by an acute infection that induces an excessive and dysregulated immune response in the body, causing multiple organ dysfunctions (1). Each year, approximately 49 million people worldwide are affected by sepsis (2), and about 30% of intensive care unit (ICU) patients are diagnosed with it (3). The mortality rate for sepsis can be as high as 40% (4). Treatment options and outcomes for sepsis patients vary widely due to the differences in infectious agents, individual characteristics, and medical history. Consequently, it is impractical to assess and manage sepsis cases using a single scoring system, and greater attention should be given to the heterogeneity among sepsis patients (5).
Lung cancer remains one of the most prevalent and deadly tumors in the world, with complex challenges in diagnosis, staging, therapy, and future outlook. Accurate diagnosis and staging are crucial for guiding treatment decisions and assessing prognosis. Diagnostic methods involve imaging techniques such as computed tomography (CT) and positron emission tomography (PET), along with histopathological examination and the use of molecular markers to identify specific mutations (e.g., EGFR, ALK) (6). Molecular typing of lung carcinoma, particularly the distinction between small cell lung cancer (SCLC) and non-small cell lung cancer (NSCLC), has further refined treatment approaches, enabling targeted therapies that improve patient outcomes (7). Treatment strategies for lung cancer have evolved significantly, transitioning from conventional chemotherapy and radiation to more individualized approaches. Targeted therapies and immune checkpoint inhibitors, which harness the body’s immune response against cancer cells, have demonstrated efficacy in NSCLC patients with specific genetic alterations (8). For instance, EGFR inhibitors and ALK inhibitors have shown improved survival in patients with these mutations (9). Meanwhile, immunotherapies such as PD-1 and PD-L1 inhibitors have revolutionized treatment for advanced or metastatic cases by extending survival times, although their efficacy varies widely among patients (10). In clinical practice, diagnosing and treating patients with lung cancer complicated by sepsis presents significant challenges. Patients with lung cancer often have compromised immune function, making them more susceptible to infections that can rapidly progress to sepsis, leading to multi-organ dysfunction and increased mortality (11). The complexity of managing lung cancer with concurrent sepsis stems from factors such as tumor burden, immunosuppression, and the adverse effects of anticancer treatments, which complicate early diagnosis and treatment strategies (12).
Nowadays, nomograms have gained widespread application in predicting tumor mortality (13). However, the sensitivity, specificity and generalizability of the previous models, as well as the existing assessment tools, could be inadequate, highlighting the pressing need for more accurate and specific prognostic prediction methods (14). Machine learning (ML), a branch of artificial intelligence, has garnered increasing popularity owing to its proficiency in managing complex, non-linear relationships, especially when dealing with large datasets and loosely structured data (15). The emergence of big data analytics and ML algorithms has rendered new approaches for identifying risk factors influencing prediction feasible. A number of predictive models utilizing these technologies have demonstrated exceptional performance and are progressively being incorporated into clinical practice (16). Nevertheless, to date, no elaborate model exists for predicting ICU mortality in patients with sepsis complicated by lung cancer, underscoring the necessity for the construction and verification of a new ML model for risk stratification. To the best of our knowledge, our research represents the first endeavor to construct and verify a predictive model employing multiple ML algorithms for ICU mortality prediction in patients with sepsis and lung cancer. Our model harnesses extensive population information and the competence of ML, thereby providing an individual predictive model that can help clinicians in meticulously appraising the ICU mortality risk of septic patients with lung cancer.
Materials and methods
Data collection and study population
The MIMIC-IV database is a publicly available resource containing records of over 76,000 ICU admissions at Beth Israel Deaconess Medical Center in Boston, Massachusetts, USA, from 2008 to 2019. It provides detailed data for every admission, involving laboratory results, vital signs, medications, and discharge status (17). Patients from Xuzhou Central Hospital and Huai’an Hospital Affiliated to Xuzhou Medical University were included to form an external validation set. The research was conducted based on the guidelines of the Declaration of Helsinki and was approved by the Ethics Committee of Xuzhou Central Hospital and Huai’an Hospital Affiliated to Xuzhou Medical University. Informed consent was acquired from patients involved in our research. The flowchart of the patient selection procedure is displayed in Figure 1. Inclusion criteria comprised individuals diagnosed as lung cancer and sepsis based on International Classification of Diseases (Ninth Revision code), as well as aged over eighteen years at the time admitted by ICU. Sepsis diagnosis was conducted according to sepsis definition 3.0 (18). Exclusion criteria comprised patients with repeated ICU admissions except for the first time or clinical variables with more than 50% missing data. Clinical information of septic lung cancer patients in MIMIC IV database included the following (listed in Table 1): (1) demographics (age and sex); (2) tumor stages, with distant metastasis defined by the American Joint Committee on Cancer 8th edition; (3) chronic conditions such as hypertension or diabetes; (4) organ functions assessed by the Sequential Organ Failure Assessment (SOFA) score; (5) laboratory tests. Vital signs and laboratory results from the first 24 hours of ICU admission were included. Missing information was tackled with multiple imputation by chained equations (MICE). The study’s endpoints were ICU death or safe discharge. Raw data extraction via Navicat for SQL Server was processed using R software. We determined the minimum sample size needed for an external validation cohort by formula of Riley et al. (19).
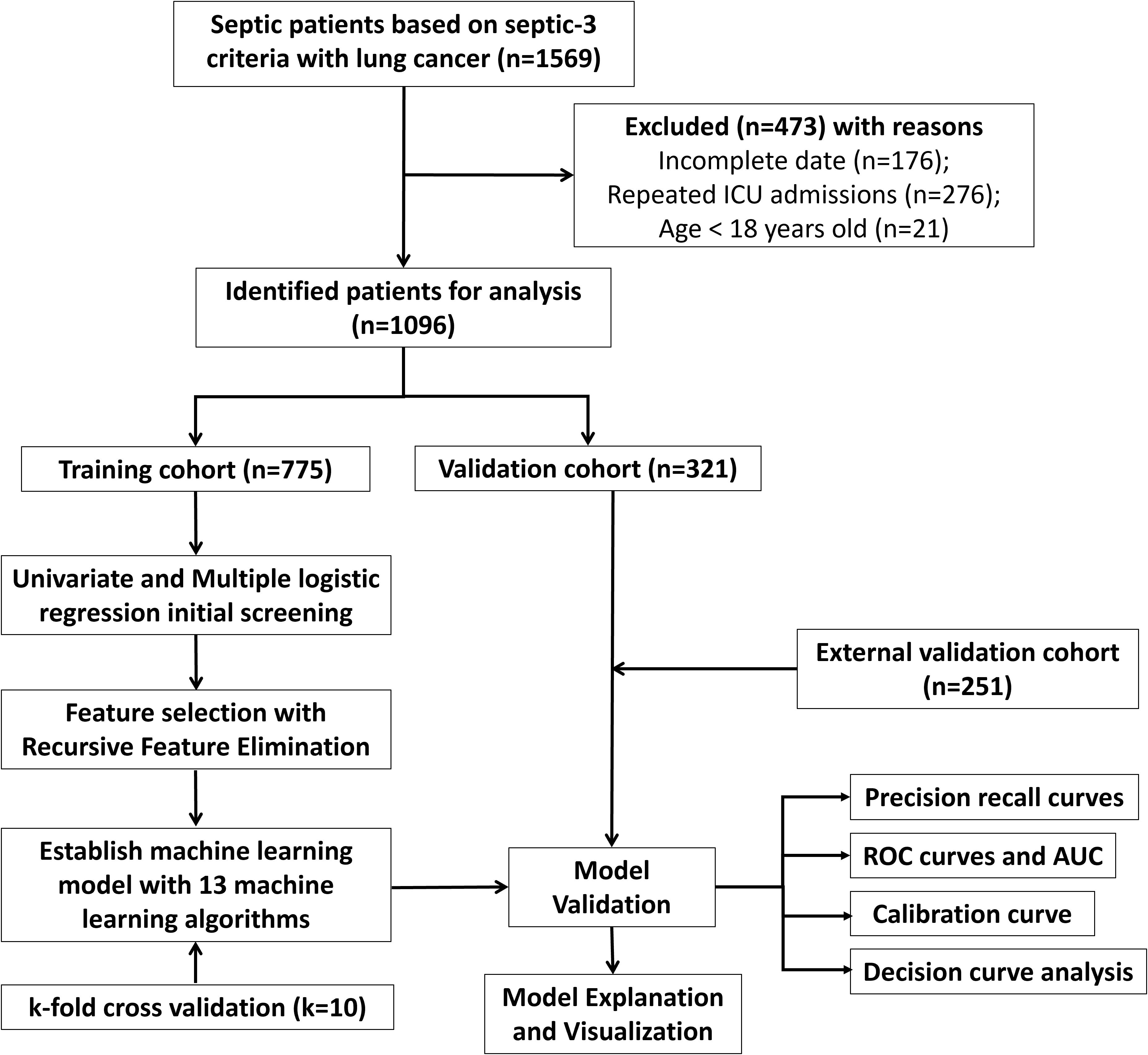
Figure 1. The workflow diagram for study design and patient screening.
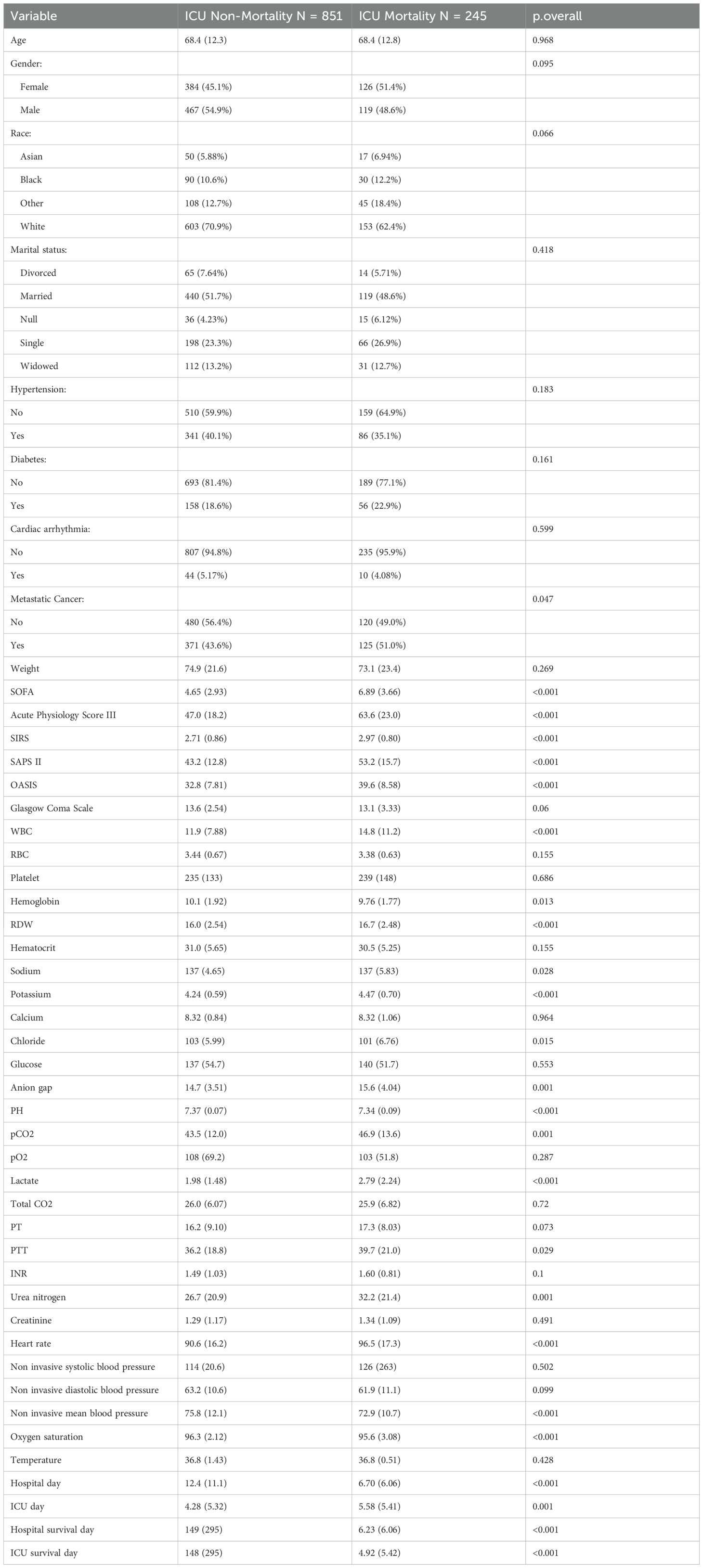
Table 1. Clinicopathological characteristics of septic patients with lung cancer from MIMIC IV database in the ICU Non-Mortality group and ICU Mortality group.
Feature selection
In our initial analysis, clinic variables with a significance level of P < 0.05 in both univariate and multivariate logistic analyses within the training dataset were selected for feature selection. We then applied Recursive Feature Elimination (RFE) according to six ML approaches, namely categorical boosting (CatBoost), random forest (RF), support vector machine (SVM), extreme gradient boosting (XGB), decision tree (DT), and gradient boosting machine (GBM), coupled with 10-fold cross-validation to select the clinic variables. The RFE process involves iteratively building models and ranking features by their importance, systematically removing the least significant ones to generate a comprehensive feature ranking (20). A random seed of “123” was determined for our analysis. Subsequently, the Robust Rank Aggregation (RRA) algorithm was employed to consolidate the feature importance rankings from the six ML algorithms utilized in RFE, yielding a comprehensive ranking of all factors (21). Following the selection of key features, we proceed to the model development stage.
Development and verification of the predictive model for ICU mortality
To develop the ML model, we utilized thirteen ML algorithms, involving CatBoost, RF, SVM, XGB, DT, GBM, k-nearest neighbor (KNN), logistic regression (LR), naive bayes classifier (NBC), linear discriminant analysis (LDA), quadratic discriminant analysis (QDA), neural network (NNET) and generalized linear model (GLM) to forecast ICU mortality with “mlr3” R package (22). This method facilitated the comparison of model performances and the selection of the optimal predictive model. To address class imbalance, which can significantly distort performance metrics, we applied the Synthetic Minority Over-sampling Technique (SMOTE) during model training (23). We then enhanced our methodology by conducting nested resampling, involving a two-tiered k-fold cross-validation process: one for hyperparameter tuning and another for model selection. Additionally, we conducted a 1000-evaluation random searching within a 10-fold cross-validation framework, repeating five times in every model. The best model was selected based on the highest Area Under the Curve (AUC) and the lowest Brier score, while ensuring a well-calibrated curve. Internal and external validation was performed using 10-fold cross-validation. The Precision-Recall Curve (PRC) was used to assess the performances of classification models on imbalanced data. The calibration curve evaluated the model’s discriminative ability, and Decision Curve Analysis (DCA) was conducted to validate the clinical benefits of the ML model using the “runway” R package (https://github.com/ML4LHS/runway). The importance of every factor was quantified by calculating its mean contribution to the AUC as a percentage relative to the full model using the “DALEX” R package (24). SHapley Additive exPlanations (SHAP) values were employed to demonstrate the predictions of the optimal model and to clarify the black-box ML framework using the “shapviz” R package (https://github.com/ModelOriented/shapviz) (25).
Results
Demographic composition and baseline data
A sum of 1096 lung cancer patients combined with sepsis from MIMIC IV database and 251 patients from Xuzhou Central Hospital and Huai’an Hospital Affiliated to Xuzhou Medical University were involved. We separated patients in MIMIC IV cohort randomly into training and internal testing cohorts with a 7:3 ratio, respectively. Meanwhile, patients in Xuzhou Central Hospital and Huai’an Hospital Affiliated to Xuzhou Medical University were involved as the external testing cohort. For patients in MIMIC IV cohort, 854 cases (77.65%) were alive, while 245 cases (22.35%) suffered ICU mortality (Table 1). More clinic data of the training and two testing cohorts can be found in Table 2. In the training, internal validation and external validation sets, the ICU mortality was 161 (20.8%), 84 (26.2%) and 40 (15.9%) (Table 2). The detailed selection process of patients in MIMIC IV cohort is displayed in Figure 1.
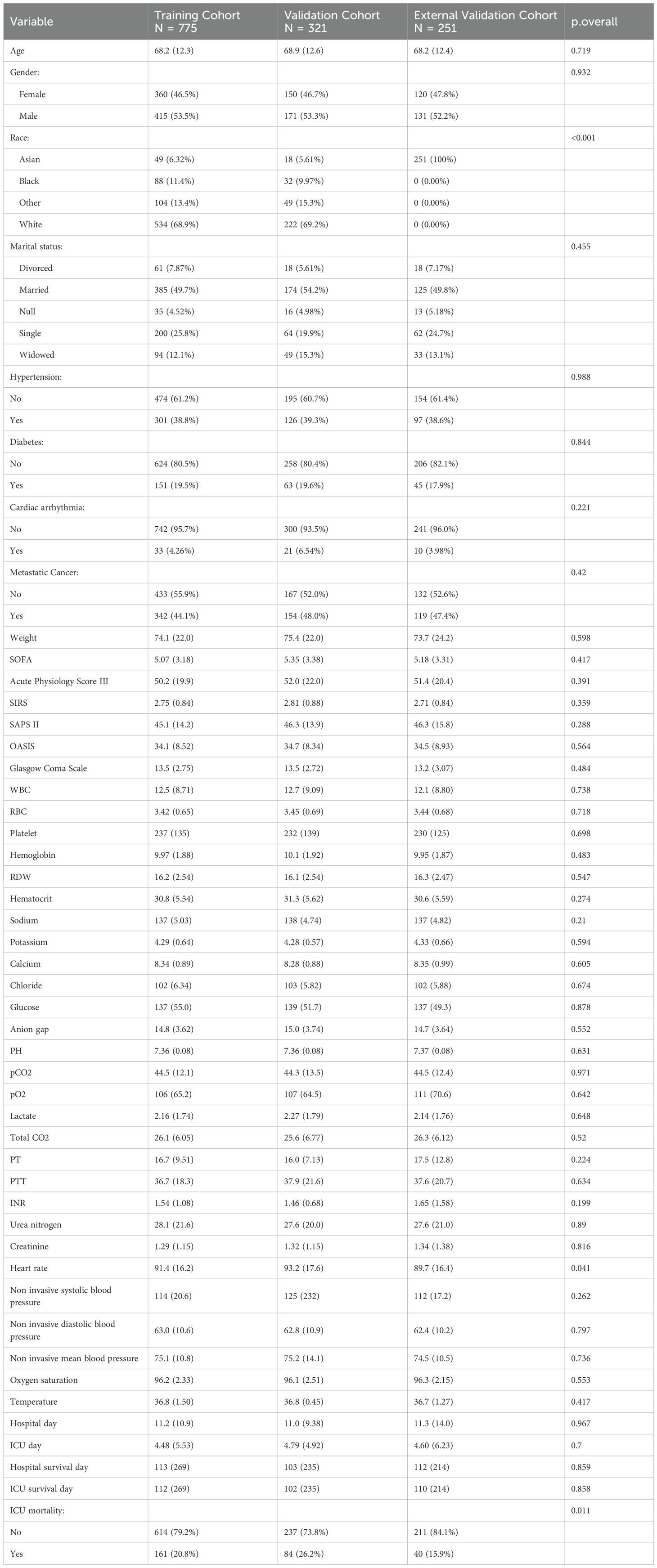
Table 2. Clinicopathological characteristics of septic patients with lung cancer in the training, internal validation and external validation cohorts.
Feature selection of the predictive model
We used the multiple imputation by chained equations (MICE) method to address the missing information in our patient data from MIMIC IV database (Figure 2A). Ultimately, five imputed datasets were created, and Rubin’s rules were utilized to amalgamate the final analytical outcomes (Supplementary Figure 1). Drawing from our clinical expertise, these clinic variables were chosen for subsequent logistic regression analysis (Table 3), with variables with a correlation coefficient exceeding 0.6 excluded (Figure 2B). Thereafter, univariate and multivariate logistic regression analyses were conducted within the training cohort to identify the salient variables predictive of ICU mortality. We then discovered that Urea nitrogen (BUN, OR 1.19 (1.08-1.25), p = 0.003), Chloride (OR 0.94 (0.91-0.96), p < 0.001), Diastolic blood pressure (DBP, OR 0.99 (0.98-1), p = 0.035), Gender (OR 0.69 (0.5-0.97), p = 0.031), Hemoglobin (OR 0.84 (0.77-0.93), p < 0.001), Lactate (OR 1.2 (1.08-1.35), p = 0.001), Mean blood pressure (MBP, OR 1.01 (1-1.04), p = 0.031), Metastatic cancer (OR 2.14 (1.52-3.02), p < 0.001), Oxygen saturation (OR 0.72 (0.66-0.78), p < 0.001), OASIS (OR 1.1 (1.07-1.13), p < 0.001), PH (OR 0.01 (0-0.09), p < 0.001), SOFA (OR 1.13 (1.06-1.2), p < 0.001), WBC (OR 1.04 (1.02-1.06), p < 0.001), Age (OR 1.02 (1-1.03), p = 0.031) and Acute Physiology Score III (OR 1.03 (1.01-1.05), p = 0.009) were exactly important to forecast ICU mortality, with significance (p < 0.05, Table 3). Correlation analysis revealed that OASIS is the most influential variable associated with ICU mortality (Figure 2B). Subsequently, we employed RFE leveraging six ML algorithms (GBM, SVM, RF, DT, XGB and CatBoost), coupled with 1–fold cross-validation to refine the clinical variables (Figures 2C-H). The RFE process identified the optimal feature set using the CatBoost algorithm, which retained thirteen variables and achieved the highest AUC of 0.948 (Figure 2C). The RRA algorithm was then applied to generate a comprehensive ranking of the clinical variables across the six ML algorithms, with OASIS emerging as the most vital (Supplementary Table 1). These thirteen variables, selected by RFE, were subsequently incorporated into the subsequent model establishment procedures. (Supplementary Table 1).
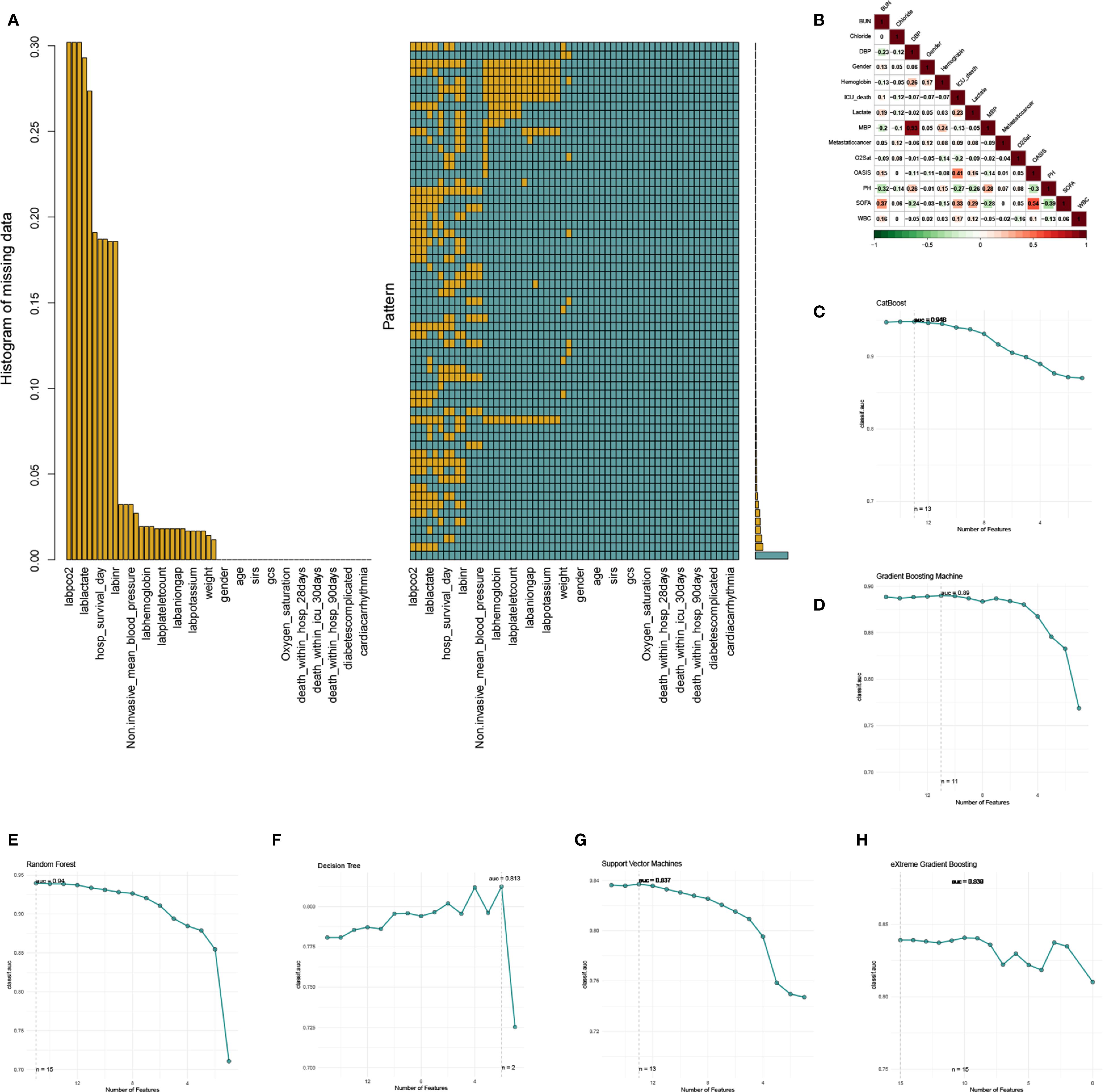
Figure 2. The process of data filtering and feature selection. (A) Visualization of missing data patterns. (B) The heatmap of Spearman’s correlation analysis of the clinic variables with ICU mortality. The correlation index ranges from -1.0 to 1.0, with a brighter color indicating a stronger correlation. (C-H) Feature selection process with Recursive Feature Elimination (RFE) method based on six ML algorithms (CatBoost, GBM, RF, DT, SVM, and XGB).
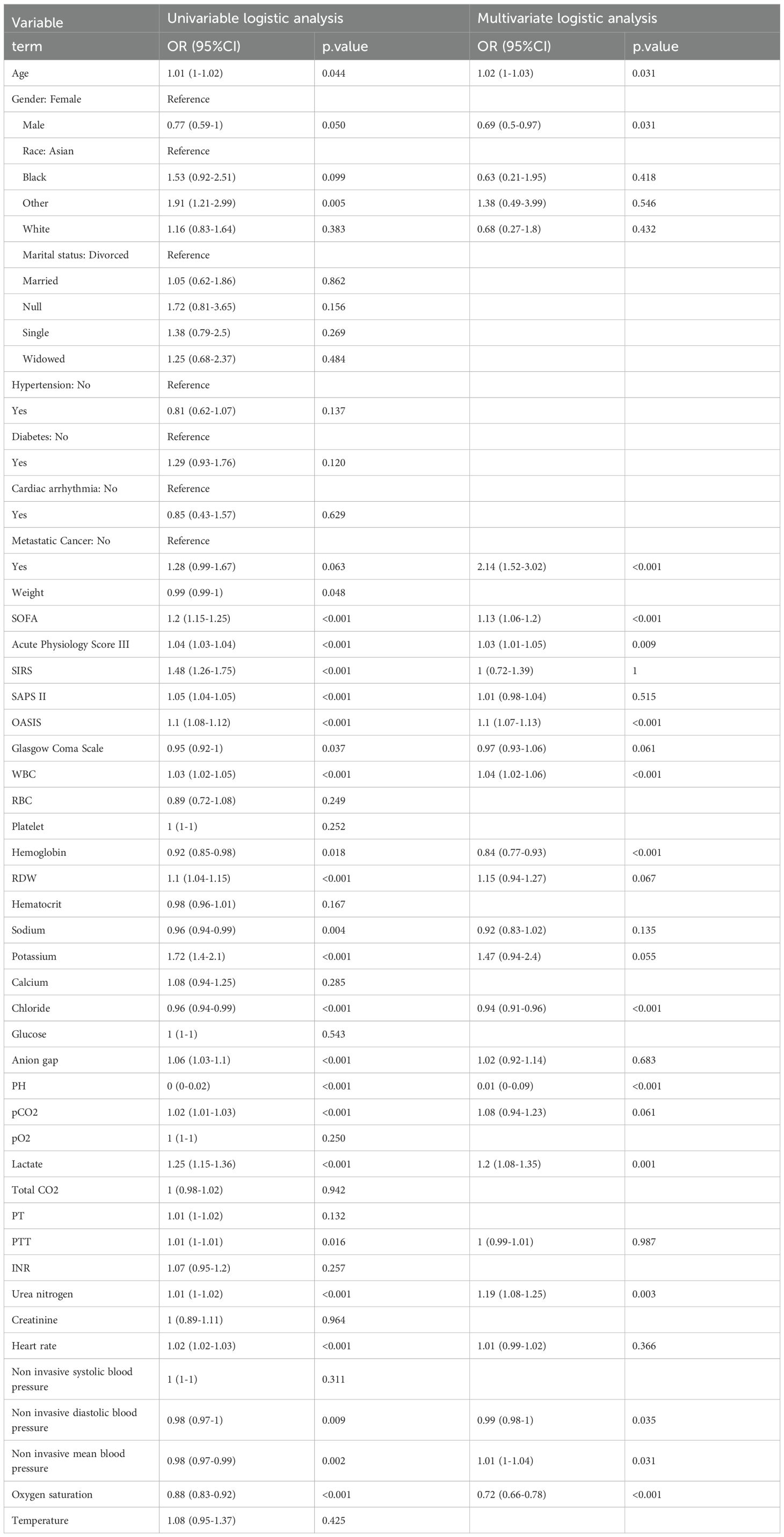
Table 3. Univariate and multivariate logistics analysis of septic patients with lung cancer for predicting ICU mortality in the training cohort.
Construction and verification of ML model for ICU mortality
To construct an accurate model to forecast ICU mortality, we included the thirteen clinic factors (“BUN”, “Chloride”, “DBP”, “Gender”, “Hemoglobin”, “Lactate”, “MBP”, “Metastatic cancer”, “O2Sat”, “OASIS”, “PH”, “SOFA”, “WBC”) selected by RFE based on CatBoost. Totally thirteen ML algorithms, involving CatBoost, RF, SVM, XGB, DT, GBM, KNN, LR, NBC, LDA, QDA, NNET and GLM, were developed using the selected thirteen variables from the training set. Hyperparameter tuning were optimized through 5-fold cross-validation and random searches. The performance of these thirteen models was then assessed in both internal and external validation cohorts. ROC curve analysis indicated that the CatBoost model achieved the highest AUC in the training (0.931 [0.921, 0.945]), internal validation (0.698 [0.673, 0.724]), and external validation (0.794 [0.725, 0.879]) cohorts (Figures 3A, 4A, 5A). Following hyperparameter tuning via grid search, the optimal hyperparameters for CatBoost were identified as depth, 6; learning_rate, 0.02873998; iterations, 662; 12_leaf_reg, 6.735671. PRC analysis demonstrated the CatBoost model’s effectiveness in managing imbalanced data (Figures 3B, 4B, 5B). Calibration curves revealed that CatBoost algorithm had the best fitting ability and could accurately predict ICU mortality (Figures 3C, 4C, 5C). Calibration curves indicated that CatBoost algorithm’s probability predictions are consistent and well-calibrated, and ensured that the risk estimates provided by the model can be trusted to reflect the true likelihood of ICU mortality. DCA curves implied that the CatBoost algorithm had the highest clinical utility and could effectively aid in predicting ICU mortality (Figures 3D, 4D, 5D). DCA curves indicated that using the CatBoost model to guide clinical decision-making would result in net clinical benefit for patients who are likely to benefit from certain interventions, such as more aggressive treatment or intensive monitoring. The curves of sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) of the thirteen ML algorithms were plotted to extensively identified that the CatBoost algorithm was outperforming in predicting ICU mortality (Figures 3E, 4E, 5E). Model performance was further evaluated using accuracy, sensitivity, specificity, precision, cross-entropy, and Brier scores, which collectively indicated the robustness of the CatBoost model in predicting ICU mortality (Figures 3F, 4F, 5F). Tenfold cross-validation in the training cohort also confirmed the superior performance of CatBoost (Figure 3G). Confusion matrices highlighted the outstanding predictive capabilities of CatBoost across all three cohorts (Figures 3H, 4G, 5G). Hence, CatBoost was selected as the optimal model for predicting ICU mortality and model validation was sufficient for proving its capacity.
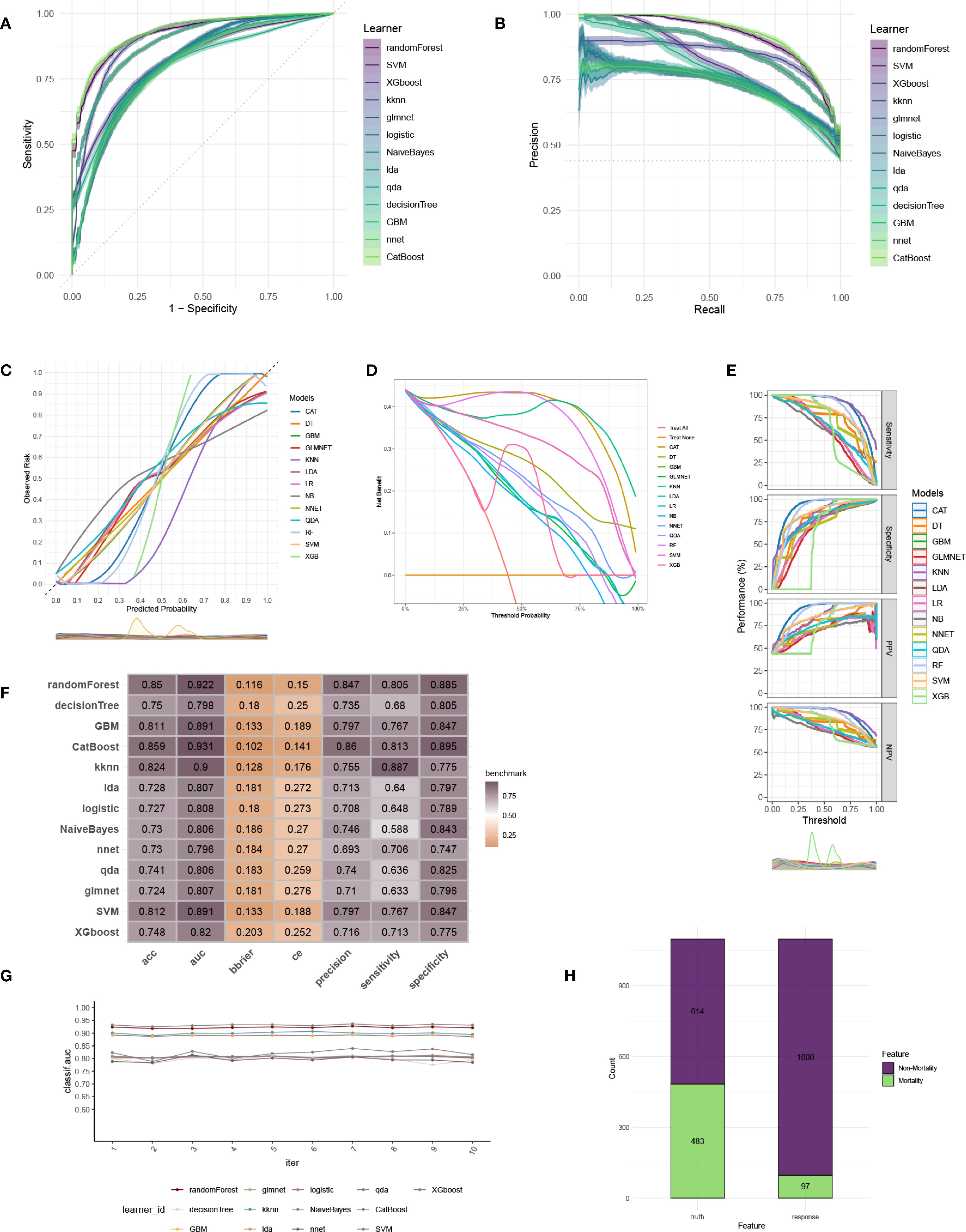
Figure 3. Establishment and evaluation of the ML models in the training set. (A) ROC curves of different ML models in the training set. (B) PR curves of different ML models in the training set. (C) Calibration curves of different ML models in the training set. (D) DCA curves of different ML models in the training set. (E) The curves of sensitivity, specificity, PPV and NPV of the 13 ML models in the training set. (F) The performance of 13 ML models in terms of AUC, accuracy, sensitivity, specificity, precision, cross-entropy and Brier scores in the training set. (G) Ten-fold cross-validation results of different ML models in the training set. (H) Confusion matrix of the best ML model in the training set. ML, machine learning; CAT, categorical boosting; LR, logistic regression; DT, decision tree; RF, random forest; XGB, extreme gradient boosting; GBM, gradient boosting machine; NB, Naive Bayes; LDA, linear discriminant analysis; QDA, quadratic discriminant analysis; NNET, neural network; GLMNET, generalized linear models with elastic net regularization; SVM, support vector machine; KNN, k-nearest neighbor.
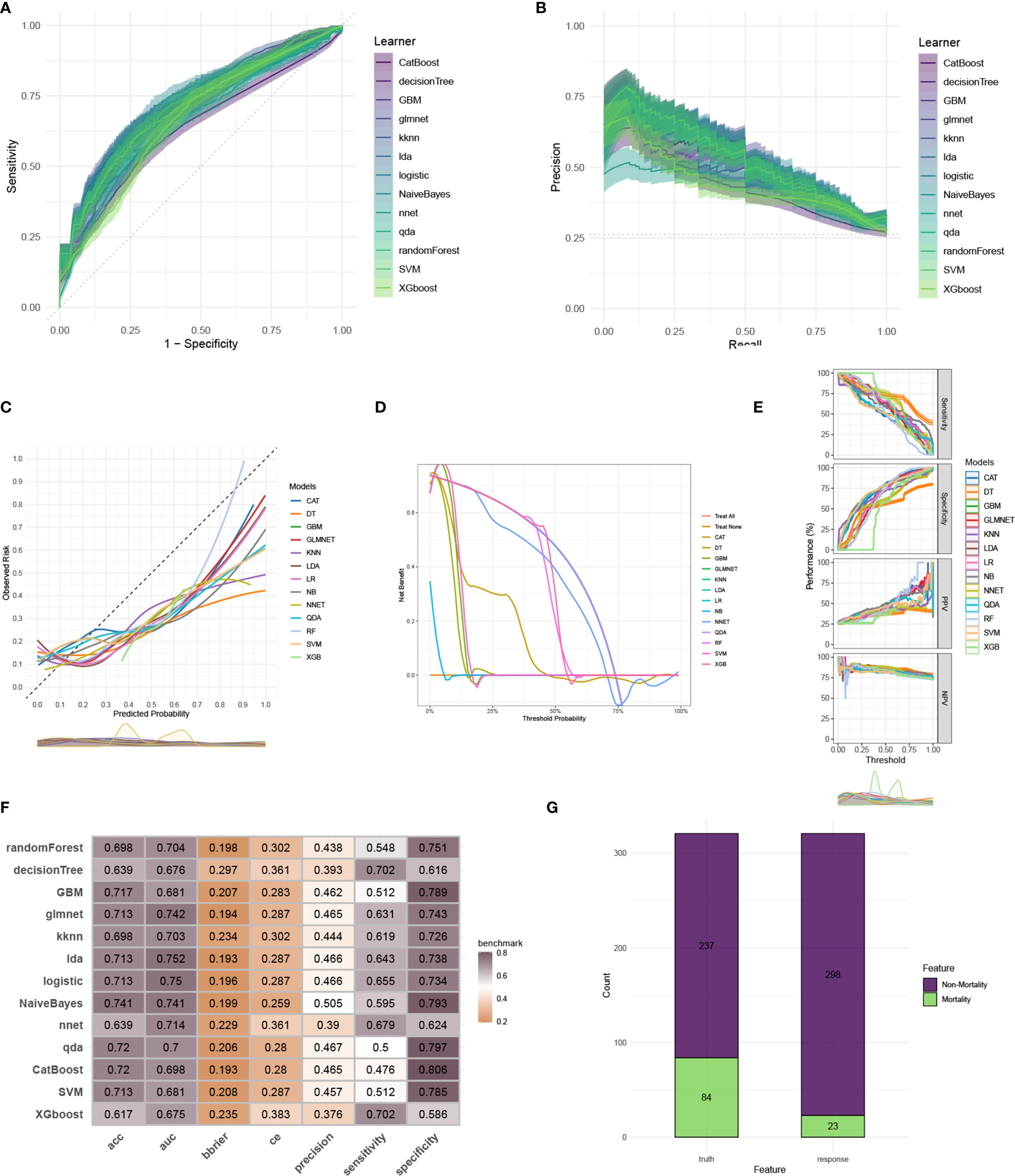
Figure 4. Evaluation of the ML models in the internal validation set. (A) ROC curves of different ML models in the internal validation set. (B) PR curves of different ML models in the internal validation set. (C) Calibration curves of different ML models in the internal validation set. (D) DCA curves of different ML models in the internal validation set. (E) The curves of sensitivity, specificity, PPV and NPV of the 13 ML models in the training set. (F) The performance of 13 ML models in terms of AUC, accuracy, sensitivity, specificity, precision, cross-entropy and Brier scores in the internal validation set. (G) Confusion matrix of the best ML model in the internal validation set. ML, machine learning; CAT, categorical boosting; LR, logistic regression; DT, decision tree; RF, random forest; XGB, extreme gradient boosting; GBM, gradient boosting machine; NB, Naive Bayes; LDA, linear discriminant analysis; QDA, quadratic discriminant analysis; NNET, neural network; GLMNET, generalized linear models with elastic net regularization; SVM, support vector machine; KNN, k-nearest neighbor.
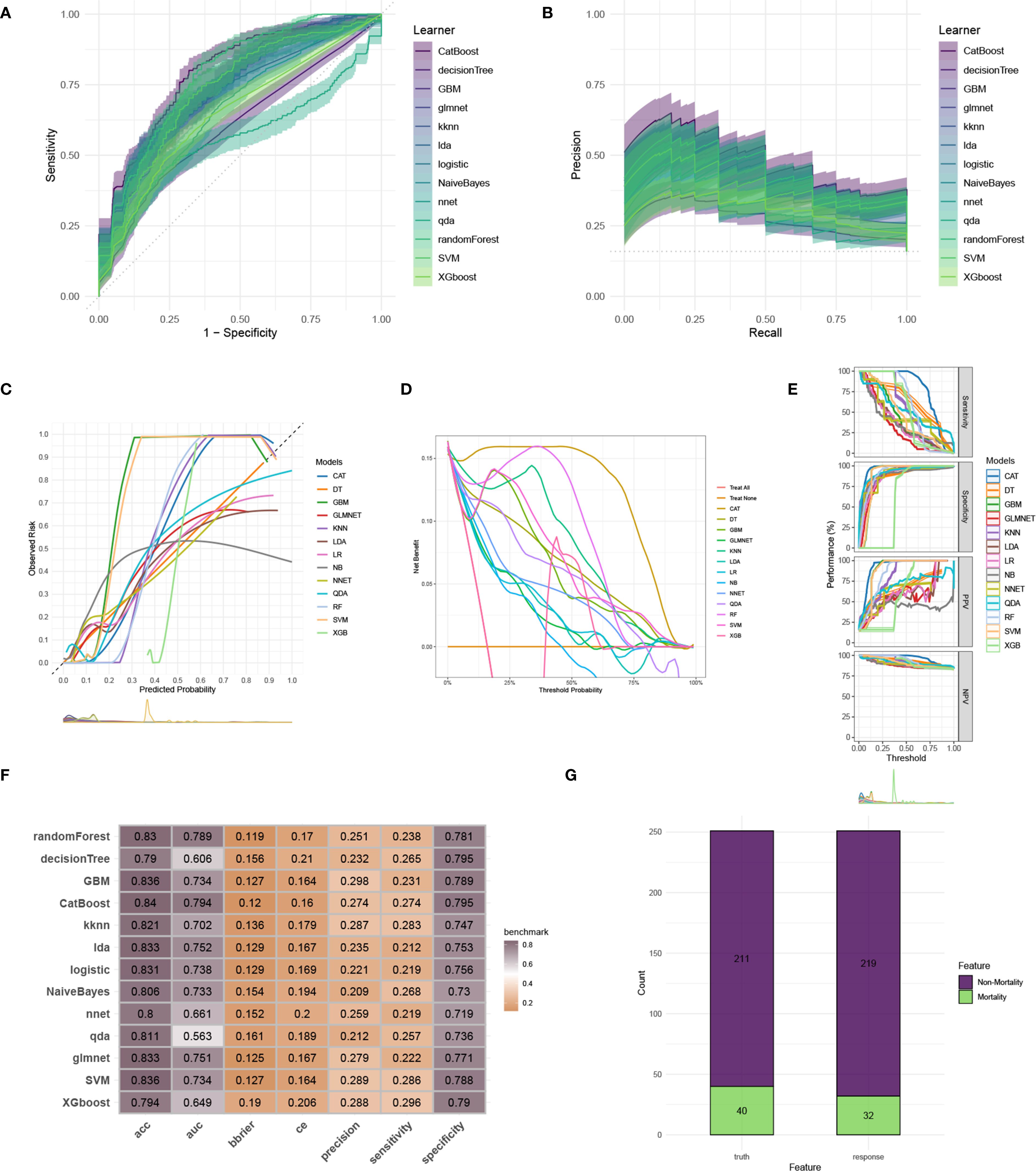
Figure 5. Evaluation of the ML models in the external validation set. (A) ROC curves of different ML models in the external validation set. (B) PR curves of different ML models in the external validation set. (C) Calibration curves of different ML models in the external validation set. (D) DCA curves of different ML models in the external validation set. (E) The curves of sensitivity, specificity, PPV and NPV of the 13 ML models in the training set. (F) The performance of 13 ML models in terms of AUC, accuracy, sensitivity, specificity, precision, cross-entropy and Brier scores in the external validation set. (G) Confusion matrix of the best ML model in the external validation set. ML, machine learning; CAT, categorical boosting; LR, logistic regression; DT, decision tree; RF, random forest; XGB, extreme gradient boosting; GBM, gradient boosting machine; NB, Naive Bayes; LDA, linear discriminant analysis; QDA, quadratic discriminant analysis; NNET, neural network; GLMNET, generalized linear models with elastic net regularization; SVM, support vector machine; KNN, k-nearest neighbor.
Model interpretation
We computed and depicted the ranking of every feature importance for every ML model, involving CatBoost, RF, NNET, GBM, SVM, KNN, DT and GLM models (Figure 6A). The importance scores were derived from the intrinsic properties of the respective ML algorithms, highlighting that the factor most strongly associated with ICU mortality were predominantly “OASIS”. Afterwards, we employed the SHAP framework to elucidate the CatBoost model. We visualized the variables by their mean absolute SHAP values, which confirmed that “OASIS” was the most influential variable (Figure 6B). Additionally, a bee swarm plot illustrated the impact of every clinic variable on ICU mortality (Figure 6C). The y-axis represents the magnitude of risk factor, and the x-axis denotes their effect on model output, exactly ICU mortality, as quantified by the SHAP value. The plot revealed that higher OASIS, SOFA, lactate, and WBC levels were related to an elevated risk of ICU mortality, and patients with metastatic cancer were prone to suffer ICU mortality. To demonstrate model interpretability, we examined two representative patients. SHAP values were utilized to assess the influence of each feature on the model’s predictions. In our study, low SHAP values indicated a reduced likelihood of ICU mortality, whereas high SHAP values suggested an elevated probability of ICU mortality. We selected the median score (0.102) as the threshold for predicting low or high ICU mortality risk. For example, the first patient, who experienced ICU mortality, had a higher SHAP value and a prediction score of 0.543, indicating a higher risk of ICU mortality (Figure 6D). Conversely, the second patient, who did not experience ICU mortality, had a lower SHAP value and a prediction score of -0.332, indicating a lower risk of ICU mortality (Figure 6E). Since the higher the prediction score, the higher the probability of ICU mortality, we could use the model to distinguish between different survival probabilities and help clinical decision-making.
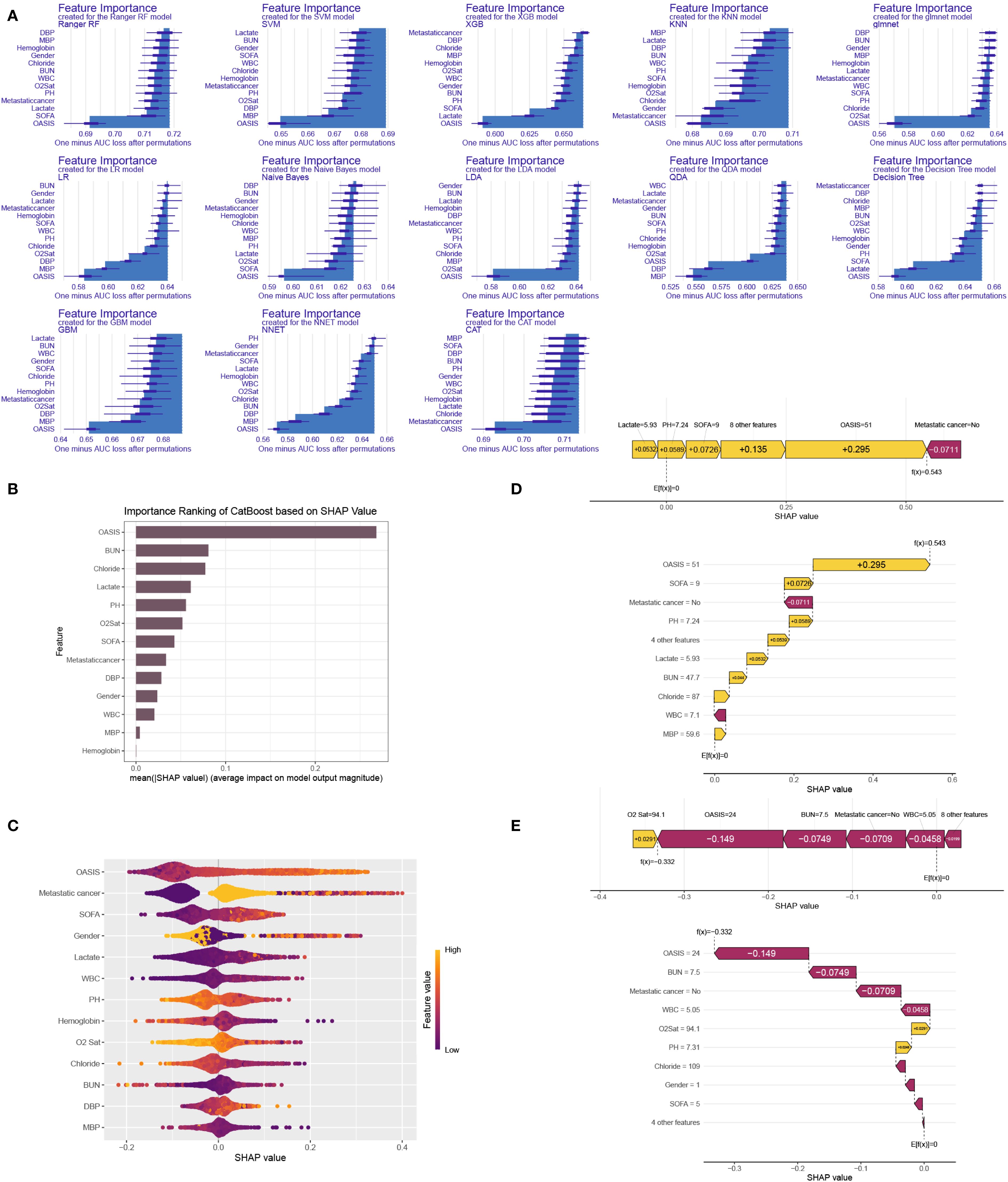
Figure 6. ML model interpretation. (A) Importance ranking of features in 13 ML prediction algorithms (CatBoost, RF, NNET, GBM, SVM, KNN, DT and GLM). (B) The importance ranking of different variables according to the mean (|SHAP value|) using the optimal CatBoost model. (C) The importance ranking of different risk factors with stability and interpretation using the optimal CatBoost model. The higher SHAP value of a feature is given, the higher risk of ICU mortality the patient would have. The yellow part in feature value represents higher value. (D) SHAP value explanation in a classical sample with ICU mortality. (E) SHAP value explanation in a classical sample without ICU mortality.
Discussion
Because of the immunosuppression occurred in cancer patients, sepsis may begin and develop suddenly. The co-occurrence of lung cancer and sepsis presents significant challenges in diagnosis, treatment, and prognosis. Diagnostically, distinguishing between infection-induced systemic inflammatory response syndrome (SIRS) and tumor-related fever is complex, often leading to delays in appropriate therapy. Advanced imaging and biomarker analysis are essential but may be limited by the patient’s critical condition, calling a need for an outstanding biomarker to predict prognosis. In our study, we found that Oxford Acute Severity of Illness Score (OASIS) has the maximum predictability for ICU mortality in patients with sepsis and lung cancer. Several studies have compared OASIS with other severity scores such as Sequential Organ Failure Assessment (SOFA), Simplified Acute Physiology Score II (SAPS II), and Acute Physiology and Chronic Health Evaluation II (APACHE-II). A previous study demonstrated that OASIS, APACHE II, and SAPS II all presented good discrimination and calibration in predicting the 28-day mortality risk of acute kidney injury patients. OASIS, APACHE II, and SAPS II had better predictive accuracy than SOFA, but due to the complexity of APACHE II and SAPS II calculations, OASIS is a good substitute (26). Another study compared APACHE II, SOFA, SAPS II, and OASIS in predicting mortality in patients with sepsis or septic shock. The study found that all scoring systems were positively correlated with mortality, with SAPS II and OASIS showing higher correlations compared to others (27). These studies support our findings that OASIS is a robust predictor in the context of critical illness, which shed light on its predictive capabilities for septic patients with lung cancer.
Therapeutically, managing sepsis in lung cancer patients requires a delicate balance. Immunosuppressive effects of chemotherapy and the cancer itself increase susceptibility to infections, complicating sepsis management. Broad-spectrum antibiotics are standard; however, the potential for drug interactions and organ dysfunction necessitates careful selection and dosing. Recent studies have explored targeted therapies, such as aumolertinib, a third-generation EGFR-TKI, which has shown effectiveness in NSCLC cases with EGFR mutations (28). In the phase 3 AENEAS trial, aumolertinib significantly extended progression-free survival compared to gefitinib in patients diagnosed as advanced EGFR mutation-positive NSCLC (29). Prognostically, the combination of lung cancer and sepsis portends a poor outcome. Sepsis exacerbates the already compromised physiological state due to malignancy, leading to higher mortality rates. Early recognition and prompt, aggressive treatment of sepsis are crucial to improving survival (30).
Due to these challenges, accurate prediction of ICU mortality and identification of its risk factors are crucial for lung cancer patients with sepsis. The goal of our study is to establish a novel ML model for early ICU mortality prediction. By collecting essential clinic information and constructing ML models using a benchmark framework, we calculated risk scores for ICU mortality prediction, enabling precise prediction of ICU death probability. Once the risk tiers are established, the next step is to translating these into actionable clinical adjustments, which involves tailoring interventions based on the identified risk level. The clinical significance of this work is in enhancing patient management and therapy plan for patients with both lung cancer and sepsis, aiding clinicians in planning more informed, individual therapies. Moreover, the model’s predictions can assist in selecting adjuvant therapies, determining follow-up frequency, and deciding on additional lab tests. Incorporating this predictive model into clinic practices promotes data-driven decision-making, enhancing therapy outcomes and optimizing resource utilization. Ultimately, this integration helps standardize care across various healthcare providers and institutions, potentially decreasing diversity in treatment methods and therapy outcomes.
Besides, the key contribution of our study is the demonstration of how interpretable ML algorithms, particularly using SHAP values, can effectively identify critical factors influencing ICU mortality. The CatBoost algorithm, a gradient boosting framework based on symmetric decision trees (oblivious trees), excels in accuracy and efficiency, especially in handling categorical features, while requiring fewer parameters (31). Its performance often matches or surpasses that of other advanced ML algorithms, displaying outperforming discrimination, calibration, and clinical utility. However, due to its black-box nature, interpretation is essential for ML model. SHAP summary plots and force maps provide clinicians with clear, visual insights into the factors driving predictions, enhancing the model’s interpretability and highlighting key risk factors. Additionally, advanced ML techniques such as RFECV for feature selection, GridSearchCV for hyperparameter tuning, and SMOTE oversampling to address sample imbalance further improved the accuracy of ICU death prediction. This precise predictive model enables clinicians to develop personalized treatment strategies, ensuring timely interventions and improving the prognosis of lung cancer patients combined sepsis.
For critically sick patients, proactive and proactive treatment to address risk variables is essential (32). Nevertheless, some clinical variables are challenging to obtain in clinical practice, and many clinic variables show varying degrees of limitations in terms of accuracy, sensitivity, or specificity. Studies have indicated that SOFA scores often lack both sensitivity and specificity (33). Additionally, the clinical profiles and therapy outcomes of patients with both sepsis and lung carcinoma differ significantly from these patients with no cancer (34). Notably, the majority of critical illness scoring systems fail to consider cancer-specific factors (35). Specifically, we conducted univariate and multivariate logistic regression analyses to identify significant predictors of ICU mortality, including some cancer-related clinical factors. Leveraging these readily accessible clinic data, we successfully developed a robust CatBoost model for early ICU mortality prediction, thereby assisting clinicians in personalized therapy and decision-making. As observed in Table 2, there are some notable differences in the baseline profiles of patients among the training, internal testing and external testing databases, likely attributable to variations in hospital admissions. Despite these differences, the model demonstrated brilliant performances in both internal and external validation datasets, highlighting its robust applicability.
In our research, we observed that the presence of distant metastasis is linked to poor prognosis, likely due to the immunocompromised state of these patients (36). Immunosuppression has been shown to correlate with adverse outcomes in septic patients (37). Greater focus is needed on managing patients with distant metastasis to improve their outcomes. Older patients are at a higher risk of developing sepsis compared to younger individuals, and they often exhibit reduced resilience when managing the condition (38). Previous research has explored the association between the anion gap and prognosis across various diseases. As a well-established marker for evaluating acid–base balance (39), an abnormal anion gap is linked to acid–base disturbances, which are considered to significantly affect outcomes in critically sick patients (40). Similarly, our findings indicate that serum anion gap is a significantly risk variable for ICU mortality in patients with both sepsis and lung carcinoma. Several scoring systems for critical illness, including SAPS II, OASIS and SOFA scores, have been established to assess disease intensity and forecast short-term outcomes. The SAPS II is a scoring system developed to assess the intensity of illness in patients admitted to ICU (35). It evaluates 17 physiological variables, including vital signs and laboratory results, to generate a score that predicts the probability of hospital mortality, which was robust in our research for septic lung cancer patients’ mortality prediction. The OASIS is a prognostic tool to appraise the severity of intensity in critically sick patients. It incorporates variables such as age, heart rate, mean arterial pressure, temperature, respiratory rate, urine output, Glasgow Coma Scale, and specific laboratory values to generate a score that predicts in-hospital mortality (41), which was the most powerful indicator in our analysis for lung cancer patients’ mortality prediction, calling its application especially in lung cancer patients. The SOFA score is a clinical metric used to evaluate and quantify the degree of organ dysfunction across six physiological systems: respiratory, cardiovascular, hepatic, coagulation, renal, and neurological. It is particularly valuable in ICUs for monitoring disease progression, especially in sepsis cases (42), which was also validated in our analysis with septic lung cancer patients.
This study, while showcasing notable strengths, also has several limitations. First, we determined the required sample size for our external validation cohort. However, due to the limited availability of patients with complete follow-up data, we were unable to assemble a sufficiently large external validation set. While we acknowledge that larger sample sizes enhance the reliability of model evaluation, we have endeavored to utilize the maximum possible sample size given the current research constraints. To maximize the validation reliability despite the smaller external validation set, we employed a 10-fold cross-validation method to assess the model’s generalizability. Moving forward, we intend to expand the sample size of the external validation cohort in future research to further substantiate the model’s universality and reliability. Second, the study relies on retrospective information in the MIMIC IV database, which introduces the potential for selection bias. Variations in data collection across hospitals and the retrospective design also resulted in some missing clinical features. Additionally, the absence of key clinicopathological parameters, such as smoking, socioeconomic factors, and gene mutations, was a limitation, as the MIMIC IV database does not include imaging data. While we included a broad range of baseline and routine clinical features to improve predictive accuracy, this added complexity to the model’s practical use in clinical settings. Lastly, the model remains to be integrated into clinic practices, necessitating additional prospective, multicenter, and large-scale validation studies to confirm its applicability and practical utility in future settings.
Conclusions
In our research, we successfully established a CatBoost-based prediction model using a ML benchmark framework to precisely forecast ICU mortality in lung carcinoma patients combined sepsis. We succeeded in identifying significantly predictive variables for ICU mortality in this patient population. This study establishes a groundwork for subsequent endeavors to refine ICU mortality predictions and prognostic forecasts, which may assist clinicians in making informed decisions and customizing therapeutic strategies.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by the Ethics Committee of Xuzhou Central Hospital and Huai’an Hospital Affiliated to Xuzhou Medical University. The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required from the participants or the participants’ legal guardians/next of kin in accordance with the national legislation and institutional requirements.
Author contributions
HT: Formal Analysis, Writing – original draft, Methodology, Validation, Data curation, Resources, Visualization, Investigation, Conceptualization, Project administration. HH: Writing – review & editing, Conceptualization, Validation, Software, Supervision, Formal Analysis, Resources, Data curation, Visualization. YH: Writing – review & editing, Visualization, Validation, Software, Supervision.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Acknowledgments
We are grateful to the Medical Information Mart for Intensive Care IV (MIMIC IV) database for providing data.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fonc.2025.1661212/full#supplementary-material
Supplementary Figure 1 | Density plot of the variables containing missing values before and after imputation.
Supplementary Table 1 | Comprehensive ranking of the clinic variables to predict ICU mortality in lung cancer patients combined sepsis base on RRA algorithm.
References
1. Singer M, Deutschman CS, Seymour CW, Shankar-Hari M, Annane D, Bauer M, et al. The third international consensus definitions for sepsis and septic shock (Sepsis-3). Jama. (2016) 315:801–10. doi: 10.1001/jama.2016.0287
2. Rudd KE, Johnson SC, Agesa KM, Shackelford KA, Tsoi D, Kievlan DR, et al. Global, regional, and national sepsis incidence and mortality, 1990-2017: analysis for the Global Burden of Disease Study. Lancet. (2020) 395:200–11. doi: 10.1016/S0140-6736(19)32989-7
3. MaChado FR, Cavalcanti AB, Bozza FA, Ferreira EM, Angotti Carrara FS, Sousa JL, et al. The epidemiology of sepsis in Brazilian intensive care units (the Sepsis PREvalence Assessment Database, SPREAD): an observational study. Lancet Infect Dis. (2017) 17:1180–9. doi: 10.1016/S1473-3099(17)30322-5
4. Vincent JL, Sakr Y, Singer M, Martin-Loeches I, MaChado FR, Marshall JC, et al. Prevalence and outcomes of infection among patients in intensive care units in 2017. Jama. (2020) 323:1478–87. doi: 10.1001/jama.2020.2717
5. Cohen J, Vincent JL, Adhikari NK, MaChado FR, Angus DC, Calandra T, et al. Sepsis: a roadmap for future research. Lancet Infect Dis. (2015) 15:581–614. doi: 10.1016/S1473-3099(15)70112-X
6. Ettinger DS, Wood DE, Aisner DL, Akerley W, Bauman JR, Bharat A, et al. Non-small cell lung cancer, version 3.2022, NCCN clinical practice guidelines in oncology. J Natl Compr Canc Netw. (2022) 20:497–530. doi: 10.6004/jnccn.2022.0025
7. Herbst RS, Morgensztern D, and Boshoff C. The biology and management of non-small cell lung cancer. Nature. (2018) 553:446–54. doi: 10.1038/nature25183
8. Hanna N, Johnson D, Temin S, Baker S Jr., Brahmer J, Ellis PM, et al. Systemic therapy for stage IV non-small-cell lung cancer: american society of clinical oncology clinical practice guideline update. J Clin Oncol. (2017) 35:3484–515. doi: 10.1200/JCO.2017.74.6065
9. Mok TS, Wu YL, Ahn MJ, Garassino MC, Kim HR, Ramalingam SS, et al. Osimertinib or platinum-pemetrexed in EGFR T790M-positive lung cancer. N Engl J Med. (2017) 376:629–40. doi: 10.1056/NEJMoa1612674
10. Reck M, Rodríguez-Abreu D, Robinson AG, Hui R, Csőszi T, Fülöp A, et al. Pembrolizumab versus chemotherapy for PD-L1-positive non-small-cell lung cancer. N Engl J Med. (2016) 375:1823–33. doi: 10.1056/NEJMoa1606774
11. Mirouse A, Vigneron C, Llitjos JF, Chiche JD, Mira JP, Mokart D, et al. Sepsis and cancer: an interplay of friends and foes. Am J Respir Crit Care Med. (2020) 202:1625–35. doi: 10.1164/rccm.202004-1116TR
12. Bianchi A, Mokart D, and Leone M. Cancer and sepsis: future challenges for long-term outcome. Curr Opin Crit Care. (2024) 30:495–501. doi: 10.1097/MCC.0000000000001173
13. Li S, Wang J, Zhang Z, Wu Y, Liu Z, Yin Z, et al. Development and validation of competing risk nomograms for predicting cancer−specific mortality in non-metastatic patients with non−muscle invasive urothelial bladder cancer. Sci Rep. (2024) 14:17641. doi: 10.1038/s41598-024-68474-9
14. Li D, Yang M, Zhang J, Zhong J, Ding H, Chen W, et al. Development and validation of nomogram for predicting the risk of community-acquired pneumonia after kidney transplantation of deceased donors. Life Conflux. (2025) 1:e115. doi: 10.71321/kbfm1398
15. Collins GS, Dhiman P, Andaur Navarro CL, Ma J, Hooft L, Reitsma JB, et al. Protocol for development of a reporting guideline (TRIPOD-AI) and risk of bias tool (PROBAST-AI) for diagnostic and prognostic prediction model studies based on artificial intelligence. BMJ Open. (2021) 11:e048008. doi: 10.1136/bmjopen-2020-048008
16. Li S, Wang J, Zhang Z, Ren C, and He D. Individual risk and prognostic value prediction by interpretable machine learning for distant metastasis in neuroblastoma: A population-based study and an external validation. Int J Med Inf. (2025) p:105813. doi: 10.1016/j.ijmedinf.2025.105813
17. Johnson AEW, Bulgarelli L, Shen L, Gayles A, Shammout A, Horng S, et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci Data. (2023) 10:1. doi: 10.1038/s41597-022-01899-x
18. Shankar-Hari M, Phillips GS, Levy ML, Seymour CW, Liu VX, Deutschman CS, et al. Developing a new definition and assessing new clinical criteria for septic shock: for the third international consensus definitions for sepsis and septic shock (Sepsis-3). Jama. (2016) 315:775–87. doi: 10.1001/jama.2016.0289
19. Riley RD, Debray TPA, Collins GS, Archer L, Ensor J, van Smeden M, et al. Minimum sample size for external validation of a clinical prediction model with a binary outcome. Stat Med. (2021) 40:4230–51. doi: 10.1002/sim.9025
20. Wang K, Tian J, Zheng C, Yang H, Ren J, Liu Y, et al. Interpretable prediction of 3-year all-cause mortality in patients with heart failure caused by coronary heart disease based on machine learning and SHAP. Comput Biol Med. (2021) 137:104813. doi: 10.1016/j.compbiomed.2021.104813
21. Kolde R, Laur S, Adler P, and Vilo J. Robust rank aggregation for gene list integration and meta-analysis. Bioinformatics. (2012) 28:573–80. doi: 10.1093/bioinformatics/btr709
22. Lang M, Binder M, Richter J, Schratz P, Pfisterer F, Coors S, et al. mlr3: A modern object-oriented machine learning framework in R. J Open Source Softw. (2019) 4:1903. doi: 10.21105/joss.01903
23. Wang K, Tian J, Zheng C, Yang H, Ren J, Li C, et al. Improving risk identification of adverse outcomes in chronic heart failure using SMOTE+ENN and machine learning. Risk Manag Healthc Policy. (2021) 14:2453–63. doi: 10.2147/RMHP.S310295
24. Biecek P. Dalex: Explainers for complex predictive models in R. J Mach Learn Res. (2018) 19(84):1–5.
25. Lo YT, Liao JC, Chen MH, Chang CM, and Li CT. Predictive modeling for 14-day unplanned hospital readmission risk by using machine learning algorithms. BMC Med Inform Decis Mak. (2021) 21:288. doi: 10.1186/s12911-021-01639-y
26. Wang N, Wang M, Jiang L, Du B, Zhu B, and Xi X. The predictive value of the Oxford Acute Severity of Illness Score for clinical outcomes in patients with acute kidney injury. Ren Fail. (2022) 44:320–8. doi: 10.1080/0886022X.2022.2027247
27. Cirik MO, Doganay GE, Doganci M, Ozdemir T, Yildiz M, Kahraman A, et al. Comparison of intensive care scoring systems in predicting overall mortality of sepsis. Diagn (Basel). (2025) 15(13):1660. doi: 10.3390/diagnostics15131660
28. Shirley M and Keam SJ. Aumolertinib: A review in non-small cell lung cancer. Drugs. (2022) 82:577–84. doi: 10.1007/s40265-022-01695-2
29. Lu S, Dong X, Jian H, Chen J, Chen G, Sun Y, et al. AENEAS: A randomized phase III trial of aumolertinib versus gefitinib as first-line therapy for locally advanced or metastaticNon-small-cell lung cancer with EGFR exon 19 deletion or L858R mutations. J Clin Oncol. (2022) 40:3162–71. doi: 10.1200/JCO.21.02641
30. Awad WB, Nazer L, Elfarr S, Abdullah M, and Hawari F. A 12-year study evaluating the outcomes and predictors of mortality in critically ill cancer patients admitted with septic shock. BMC Cancer. (2021) 21:709. doi: 10.1186/s12885-021-08452-w
31. Zhang C, Chen X, Wang S, Hu J, Wang C, and Liu X. Using CatBoost algorithm to identify middle-aged and elderly depression, national health and nutrition examination survey 2011-2018. Psychiatry Res. (2021) 306:114261. doi: 10.1016/j.psychres.2021.114261
32. Vassallo M, Michelangeli C, Fabre R, Manni S, Genillier PL, Weiss N, et al. Procalcitonin and C-reactive protein/procalcitonin ratio as markers of infection in patients with solid tumors. Front Med (Lausanne). (2021) 8:627967. doi: 10.3389/fmed.2021.627967
33. Costa RT, Nassar AP Jr., and Caruso P. Accuracy of SOFA, qSOFA, and SIRS scores for mortality in cancer patients admitted to an intensive care unit with suspected infection. J Crit Care. (2018) 45:52–7. doi: 10.1016/j.jcrc.2017.12.024
34. Hensley MK, Donnelly JP, Carlton EF, and Prescott HC. Epidemiology and outcomes of cancer-related versus non-cancer-related sepsis hospitalizations. Crit Care Med. (2019) 47:1310–6. doi: 10.1097/CCM.0000000000003896
35. Le Gall JR, Lemeshow S, and Saulnier F. A new Simplified Acute Physiology Score (SAPS II) based on a European/North American multicenter study. Jama. (1993) 270:2957–63. doi: 10.1001/jama.1993.03510240069035
36. Fiorin de Vasconcellos V, Rcc Bonadio R, Avanço G, Negrão MV, and Pimenta Riechelmann R. Inpatient palliative chemotherapy is associated with high mortality and aggressive end-of-life care in patients with advanced solid tumors and poor performance status. BMC Palliat Care. (2019) 18:42. doi: 10.1186/s12904-019-0427-4
37. Moore JX, Akinyemiju T, Bartolucci A, Wang HE, Waterbor J, and Griffin R. A prospective study of cancer survivors and risk of sepsis within the REGARDS cohort. Cancer Epidemiol. (2018) 55:30–8. doi: 10.1016/j.canep.2018.05.001
38. Wardi G, Tainter CR, Ramnath VR, Brennan JJ, Tolia V, Castillo EM, et al. Age-related incidence and outcomes of sepsis in California, 2008-2015. J Crit Care. (2021) 62:212–7. doi: 10.1016/j.jcrc.2020.12.015
39. Kraut JA and Madias NE. Serum anion gap: its uses and limitations in clinical medicine. Clin J Am Soc Nephrol. (2007) 2:162–74. doi: 10.2215/CJN.03020906
40. Mohr NM, Vakkalanka JP, Faine BA, Skow B, Harland KK, Dick-Perez R, et al. Serum anion gap predicts lactate poorly, but may be used to identify sepsis patients at risk for death: A cohort study. J Crit Care. (2018) 44:223–8. doi: 10.1016/j.jcrc.2017.10.043
41. Yuan ZN, Wang HJ, Gao Y, Qu SN, Huang CL, Wang H, et al. Short- and medium-term survival of critically ill patients with solid cancer admitted to the intensive care unit. Ann Palliat Med. (2022) 11:1649–59. doi: 10.21037/apm-21-2352
Keywords: machine learning, sepsis, lung cancer, ICU mortality, MIMIV-IV
Citation: Tang H, Hao H and Han Y (2025) Personalized ICU mortality assessment by interpretable machine learning algorithms in patients with sepsis combined lung cancer: a population-based study and an external validation cohort. Front. Oncol. 15:1661212. doi: 10.3389/fonc.2025.1661212
Received: 07 July 2025; Accepted: 26 August 2025;
Published: 01 October 2025.
Edited by:
Sharon R. Pine, University of Colorado Anschutz Medical Campus, United StatesCopyright © 2025 Tang, Hao and Han. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hairong Hao, aGFpcm9uZ2hhbzIwMjVAMTYzLmNvbQ==; Yue Han, YWhmeWh5QHNpbmEuY24=