 Ran Fu1,2†
Ran Fu1,2† Xin Hao
Xin Hao Ze Yu
Ze Yu- 1Department of Clinical Pharmacy, The First Hospital of Hebei Medical University, Shijiazhuang, China
- 2The Technology Innovation Center for Artificial Intelligence in Clinical Pharmacy of Hebei Province, The First Hospital of Hebei Medical University, Shijiazhuang, China
- 3Dalian Medicinovo Technology Co., Ltd, Dalian, China
- 4Beijing Medicinovo Technology Co., Ltd, Beijing, China
- 5Institute of Interdisciplinary Integrative Medicine Research, Shanghai University of Traditional Chinese Medicine, Shanghai, China
Background: Sertraline is a commonly employed antidepressant in clinical practice. In order to control the plasma concentration of sertraline within the therapeutic window to achieve the best effect and avoid adverse reactions, a personalized model to predict sertraline concentration is necessary.
Aims: This study aimed to establish a personalized medication model for patients with depression receiving sertraline based on machine learning to provide a reference for clinicians to formulate drug regimens.
Methods: A total of 415 patients with 496 samples of sertraline concentration from December 2019 to July 2022 at the First Hospital of Hebei Medical University were collected as the dataset. Nine different algorithms, namely, XGBoost, LightGBM, CatBoost, random forest, GBDT, SVM, lasso regression, ANN, and TabNet, were used for modeling to compare the model abilities to predict sertraline concentration.
Results: XGBoost was chosen to establish the personalized medication model with the best performance (R2 = 0.63). Five important variables, namely, sertraline dose, alanine transaminase, aspartate transaminase, uric acid, and sex, were shown to be correlated with sertraline concentration. The model prediction accuracy of sertraline concentration in the therapeutic window was 62.5%.
Conclusion: In conclusion, the personalized medication model of sertraline for patients with depression based on XGBoost had good predictive ability, which provides guidance for clinicians in proposing an optimal medication regimen.
Introduction
Depression is a common illness that causes dysfunction in various spheres of individual and social life, severely limits psychosocial functioning, and diminishes quality of life (Malhi and Mann, 2018). Currently, depression is considered the fourth leading cause of global disease burden (Farnam et al., 2017). Depression rates in young people have risen sharply in the past decade, and females have a greater incidence of elevated depressive symptoms than males (Shorey et al., 2022; Thapar et al., 2022). Thus, reasonable treatment for depression is a priority.
Sertraline, a kind of selective serotonin reuptake inhibitor (SSRI) antidepressant, exerts antidepressant effects by inhibiting the reuptake of 5-hydroxytryptamine (5-HT) in central neurons and is often used as a first-line treatment for depression (Shorey et al., 2022; Thapar et al., 2022). It has good efficacy in treating various forms of depression, such as psychotic depression and major depressive disorder-related postnatal depression (Milgrom et al., 2015; Kamijima et al., 2018; Flint et al., 2021). Sertraline is metabolized mainly by CYP2B6 and CYP2C19 in the liver, where it generates the metabolite N-desmethylsertraline with lower activity. Sertraline and its metabolites are mainly excreted in feces and urine. During clinical usage, drug-related adverse reactions, such as corrected QT interval prolongation, bleeding, sexual dysfunctions, inflammation, or fracture risk (Kubanek et al., 2021), may occur, which may be related to the dosage and plasma concentration of sertraline. Due to the large individual differences in sertraline concentrations, therapeutic drug monitoring (TDM) is necessary to maintain the plasma concentration within the therapeutic window. Based on empirical evidence, the Arbeitsgemeinschaft für Neuropsychopharmakologie und Pharmakopsychiatrie (AGNP) consensus guidelines define the level of recommendation to use TDM of sertraline as level 2: recommended, with a therapeutic reference range of 10–150 ng/mL (Hiemke et al., 2018-01).
Machine learning (ML), deep learning (DL), and swarm intelligence (SI) are emerging artificial intelligence (AI) techniques that have recently been applied in medical research. By processing high-volume data, they can evaluate data-driven estimations from multiple variables and capture non-linear variable relations to achieve high accuracy in predicting clinical outcomes (Guo et al., 2021; Ma et al., 2022). These techniques have emerged as promising approaches in different fields of medicine. Specifically, convolutional neural networks, which are DL models, are adept at visual recognition and natural language processing and can be used to construct automated image analysis models for recognizing X-ray or MRI data (Bacanin et al., 2022; Zivkovic et al., 2022). Several ML algorithms, including eXtreme Gradient Boosting (XGBoost), Adaptive Boosting (AdaBoost), and gradient-boosted regression tree (GBRT), have been proven to be useful for predicting drug concentration (Ma et al., 2022). For instance, XGBoost was used to establish a model to predict the concentration of tacrolimus in patients with autoimmune diseases and a model to predict the active moiety concentration of risperidone based on initial TDM. CatBoost was used to develop a model to predict the concentration of quetiapine in patients with schizophrenia and depression, and an ensemble model using five algorithms (XGBoost, GBRT, Bagging, ExtraTree, and decision tree) was applied to predict the concentration of vancomycin in children (Huang et al., 2021; Zheng et al., 2021; Hao et al., 2023). Additionally, in response to theoretical and practical global optimization problems, SI techniques are very popular for the model optimization of ML and DL algorithms (Bacanin et al., 2021; Zivkovic et al., 2022). With the larger sample size of input data, these AI models can be continually optimized to achieve better performance and practicality.
In this study, we aimed to explore the factors influencing sertraline concentration and develop a prediction model for sertraline concentration through AI techniques. We pursued to facilitate the rational sertraline regimen at an individualized level and provide a reference for other antidepressant drug doses or for concentration prediction through the combination of medicine and AI techniques.
Materials and methods
Participants and study design
This retrospective study was conducted from January 2020 to December 2021 at the First Hospital of Hebei Medical University, and data from inpatients with depression receiving routine clinical treatment with sertraline were analyzed. Patients enrolled in the study had two TDM values. One was the initial TDM value, which was measured for at least 5–7 days with a fixed sertraline dose to reach steady-state conditions. The other was the value measured closest to the initial TDM. The inclusion criteria were as follows: (1) patients diagnosed with depression from discharge records; (2) patients treated with sertraline; and (3) patients with at least one TDM value given at a fixed dosage to reach the steady-state conditions. The exclusion criteria were as follows: (1) patients with missing information (such as demographic characteristics and diagnosis records); (2) patients with sertraline concentrations less than the lower limit of quantitation or exceeding the upper limit of quantification; and (3) patients with organic mental disorder. The information assessed in the study included demographic information, the use of sertraline, combined medication, and biochemical indices. The workflow of sample selection is illustrated in Figure 1.
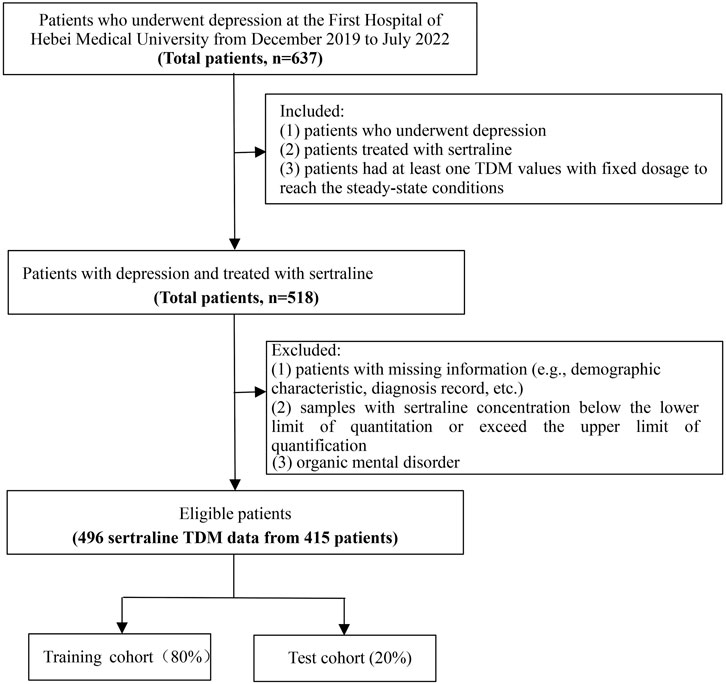
FIGURE 1. Workflow of sample selection.
Sertraline assay
The plasma sertraline concentration was measured via UPLC–MS/MS (Waters ACQUITYI-X, Waters Corp., Milford, United States of America). The sample was separated on a Waters ACQUITY UPLC BEH C18 column (2.1 mm × 50 mm, i.d.; 1.7 μm, Waters, Milford, CT, United States of America) and eluted with a step gradient mobile phase consisting of 0.1% formic water (solvent A) and methanol (solvent B): 0–0.5 min, 20% B; 0.5–0.6 min, 20–45% B; 0.6–1.8 min, 45–80% B; 1.8–1.9 min, 80–95% B; 1.9–2.5 min, 95% B; 2.5–2.6 min, 95–20% B; and 2.6–3.2 min, 20% B. The flow rate was 0.4 mL/min, and the injection volume was 5 μL. Mass spectrometric detection was performed via electrospray ionization in the positive ion multiple reaction monitoring mode. The transitions of the precursor ion and the production of the analyte were m/z 305.97→158.97 for sertraline and m/z 309.00→158.86 for sertraline-d3. The linear range for sertraline was 2.5–320 ng/mL (correlation coefficient R2 = 0.9999). Both the intra- and inter-day precision and accuracy were within 15%.
Variable selection
Multiple variables may influence sertraline concentration, including demographic data (age, sex, weight, and height), sertraline information (dosage and concentration), drug combinations (CYP2B6/CYP2C19 inhibitors, CYP2B6/CYP2C19 competitive inhibitor, and drugs with high plasma protein-binding rates), and data of assay indices (renal function, liver function, prolactin [PRL], and routine blood test results).
The workflow of the data analysis is illustrated in Figure 2. First, univariate analysis was performed on all the data to screen for significant variables, and p < 0.05 was considered to indicate statistical significance. After that, the sequential forward selection (SFS) algorithm was applied for feature engineering to select the minimum size and optimum performance of the feature subset. The algorithm starts the search from an empty set, and a feature is added to this feature subset at a time. Once the evaluation index R2 reaches the optimal value, iteration is stopped. The feature subset of the previous round was considered the optimal feature selection result.
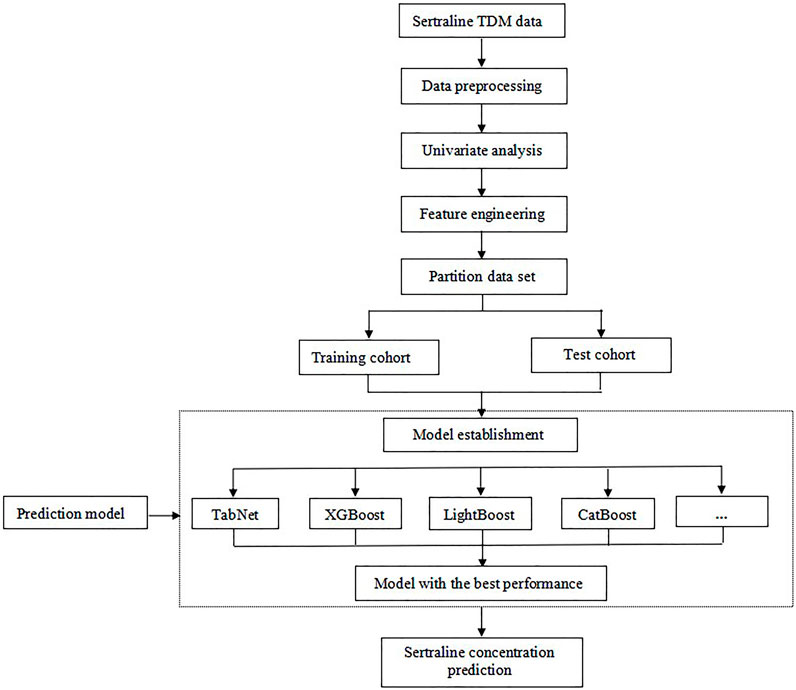
FIGURE 2. Workflow of data processing and modeling.
Model establishment
According to the 8:2 proportional division, the total study population was divided into training and testing cohorts. As depicted in Figure 1, nine different algorithms were used for modeling to compare the ability of various models to predict sertraline concentrations; these included XGBoost, LightGBM, CatBoost, random forest (RF), gradient-boosted decision tree (GBDT), support vector machine (SVM), lasso regression (LR), artificial neural network (ANN), and TabNet algorithms. To measure and compare model performance, R2, mean square error (MSE), root mean square error (RMSE), and mean absolute error (MAE) were used as metrics. The calculating formula is as follows:
where n is the number of samples;
The importance scores of the variables were calculated and ranked using the algorithm with the best predictive performance. Variables with higher importance scores were more closely related to the accurate prediction of sertraline concentration. Then, SHapley Additive exPlanations (SHAP) were conducted to visually interpret the positive or negative impacts of important variables on the model output.
Statistical analysis
Statistical analysis was performed using the Statistical Package for the Social Sciences software version 23.0 and Python 3.9.12. The continuous non-normally distributed variable was expressed as the median and interquartile range (IQR, 25th and 75th percentiles) and was compared by Spearman’s correlation test, as appropriate. For binary variables, the Mann–Whitney U test was used for analysis. The categorical variable was presented as the number and percentage (%) and was analyzed by the chi-squared test.
Results
Baseline information
From December 2019 to July 2022, at the First Hospital of Hebei Medical University, a total of 415 eligible patients were enrolled in this study, with 496 samples from whom the sertraline concentration was measured. The baseline information of the study population is shown in Table 1. It can be seen that the median (IQR) age of the patients was 16 (14.00–27.00) years, the median (IQR) weight of the patients was 56.67 (50.33–68.00) kg, the median (IQR) height was 163.00 (158.00–169.00) cm, and males were 27.42% of the total. The median (IQR) value of sertraline concentration was 59.00 (34.04–85.56) ng/mL, and the median (IQR) dose of sertraline was 100 (100–150) mg. The percentage of patients using combination therapies was 0.81% for the CYP2B6 inhibitor (clopidogrel and voriconazole), 0.81% for the CYP2B6 competitive inhibitor (methadone, fluoxetine, and disulfiram), 3.63% for the CYP2C19 inhibitor (esomeprazole, fluvoxamine, voriconazole, and omeprazole), and 9.27% for the CYP2C19 competitive inhibitor (citalopram, escitalopram, clomipramine, clozapine, venlafaxine, diazepam, doxepin, and fluoxetine). The median (IQR) α-hydroxybutyrate dehydrogenase level was 101.00 (90.30–117.00) U/L, the median (IQR) alanine aminotransferase (ALT) level was 15.60 (10.70–24.60) U/L, the median (IQR) aspartate transaminase (AST) level was 19.30 (15.90–23.50) U/L, and the median (IQR) uric acid (UA) level was 287.75 (235.43–346.52) μmol/L.
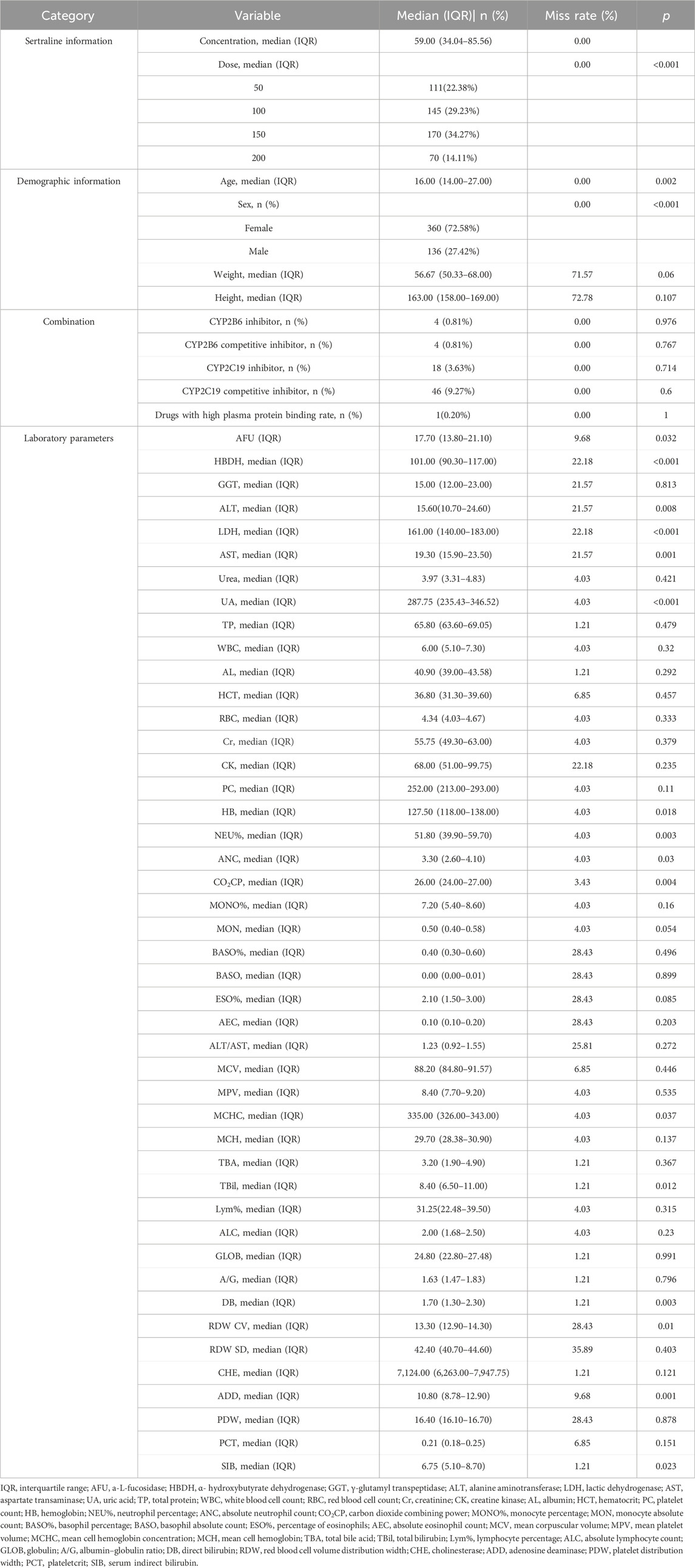
TABLE 1. Description of demographic and clinical characteristics.
Variable selection
In the univariate analysis, several variables were excluded because of an extremely uneven distribution or lots of missing values. The statistical results for the remaining 55 variables are shown in Table 1. Among them, 20 significant variables, including dose, sex, age, weight, AFU, HBDH, and ALT, had p < 0.05.
CatBoost models were established using the selected 1 to 20 variables, and the R2 of each model was obtained (Figure 3). With an increasing number of included variables, the R2 value continued to increase, reached its maximum value when five variables were selected (R2 = 0.408), and then, decreased. As we pursued a concise and accurate model with minimal variables but the highest predictive performance, the first five important variables were selected to establish the personalized medication model: daily dose of sertraline, ALT, sex, AST and UA.
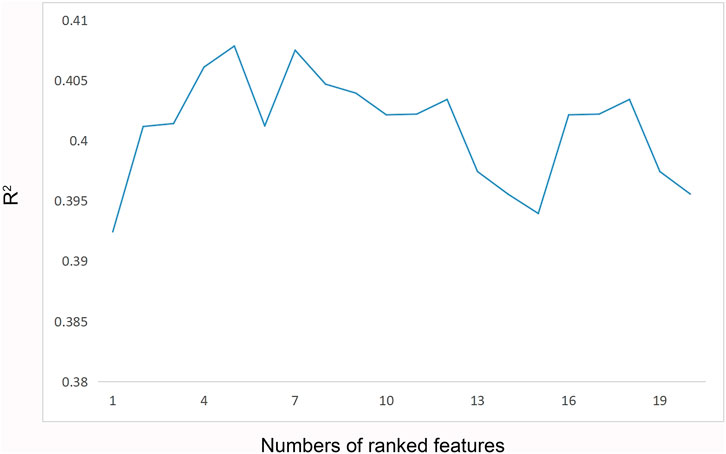
FIGURE 3. R2 of the CatBoost model corresponding to the number of ranked features.
Model performance and interpretation
Based on the selected variables, nine algorithm models (XGBoost, LightGBM, CatBoost, RF, GBDT, SVM, LR, ANN, and TabNet) for predicting sertraline concentration were established. The final model performance in the testing cohort (N = 332) is illustrated in Table 2. In addition, a boxplot of all the models is shown in Figure 4, which illustrates the absolute difference in R2 between two models tested by the Wilcoxon signed-rank test after the R2 was ranked from the highest to lowest. The XGBoost model had the highest R2 (0.63), which was significantly greater than that of the other models (p < 0.05), demonstrating a moderate model fit. In addition to this, in the XGBoost model, the accuracy of the predicted concentration within ±30% of the actual concentration was 60.00%, the highest of the nine models. The MAE and RMSE of the XGBoost model were 15.35 and 20.06, respectively, and these low values represent a good model fit. Thus, XGBoost had the most prominent model performance and was chosen to be applied for the prediction model.
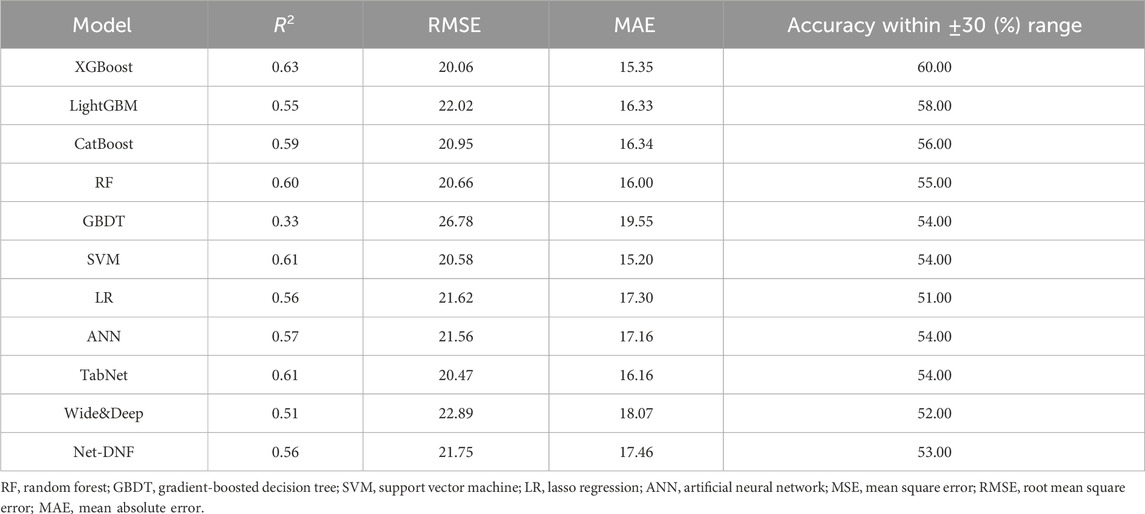
TABLE 2. Prediction results of the nine algorithms models in the testing cohort.
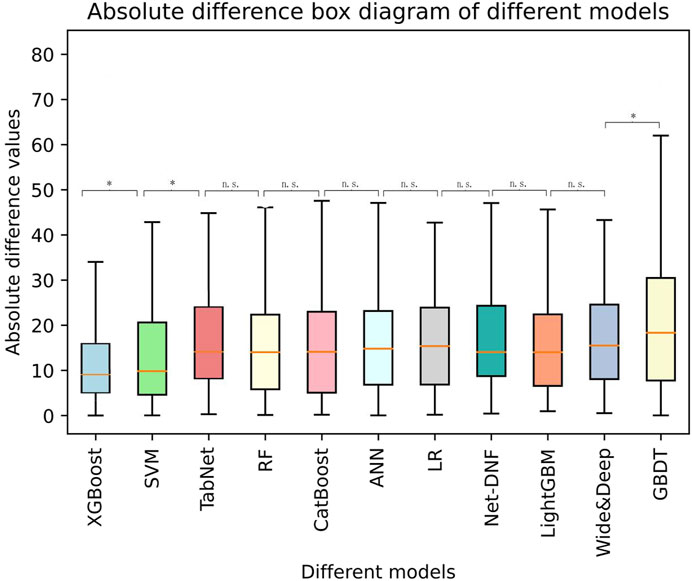
FIGURE 4. A boxplot of the absolute difference in R2 of different models tested by the Wilcoxon signed-rank test. *: significant; ns: not significant.
On this basis, the importance scores of five selected variables were calculated and ranked by XGBoost (Table 3). Specifically, the importance score of the sertraline dose (importance score = 0.629) was markedly greater than that of the other four variables, followed by AST (importance score = 0.109), UA (importance score = 0.1), sex (importance score = 0.082), and ALT (importance score = 0.08). A higher importance score indicates a greater impact of this variable on the prediction of sertraline concentration.
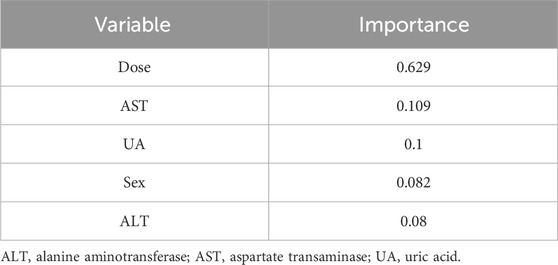
TABLE 3. Importance scores of the variables in the XGBoost model.
For the visualization of the variable importance, we used SHAP to quantify the magnitude and direction (positive or negative) of the variable’s influence on sertraline concentration (Figure 5). The feature value (represented by the dot color) represents the contribution of each variable to the predictive power of the model and was ranked according to the importance. A larger width of the color area indicates a greater impact of the variable. Consistent with the results of XGBoost, the variables in the descending order of effect on sertraline concentration were sertraline dose, AST, UA, sex, and ALT. In terms of the binary variable “sex,” “0” corresponds to females and “1” corresponds to males. For the daily dose of sertraline and for ALT and AST, the dot color is redder (feature value is greater) when the SHAP value becomes larger, while it is bluer (feature value is lower) when the SHAP value becomes smaller, thus revealing the positive impacts of these variables on sertraline concentration. However, UA was negatively correlated with the model prediction outcome. In terms of sex, as a binary variable, male patients had a negative correlation with sertraline concentration, and female patients had a positive correlation with sertraline concentration.
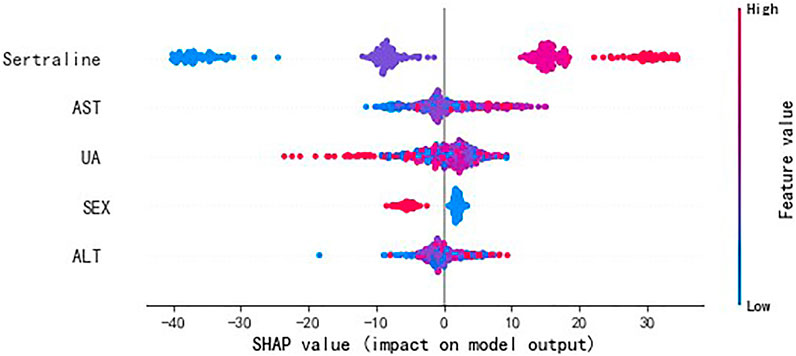
FIGURE 5. SHAP values of important variables. The dot color is redder when the feature value gets higher and bluer when the feature value gets lower. SHAP value means the impact of the variable on the model output.
The testing cohort consisted of 83 patients. The predicted value of sertraline concentration was compared with the true value in the testing cohort. Finally, the proportion of the predicted sertraline blood concentration within ±30% of the true value was calculated. The results are illustrated in Table 4. The prediction accuracy of the drug concentration in the therapeutic window (10–150 ng/mL) was 62.5%.
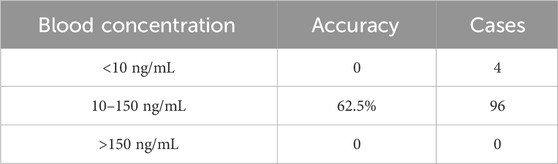
TABLE 4. Prediction accuracy of the XGBoost model.
Discussion
Our study focused on the establishment of a personalized medication model for the prediction of sertraline concentration in patients with depression. In our study, nine ML models were established. By comparison, for XGBoost, the model with the most accurate prediction performance was selected with an R2 of 0.63. XGBoost is an ML algorithm that is a leading-edge method based on the decision tree principle and the effective upgrade of the GBDT algorithm (Yan et al., 2022). It integrates a series of decision trees to achieve the classification or regression goals (Li et al., 2019). ML methods are suitable for processing large volumes of real-world data, addressing missing values and high-dimensional data, and capturing complicated relationships between variables, especially for retrospective studies (Lee et al., 2022; Matsuzaki et al., 2022). Compared with those of other ML models, our study showed better performance (the accuracy of the predicted concentration within ±30% of the actual concentration was 62.5%) in the testing cohort and a larger sample size, which led to a more mature model for the application and reference (Huang et al., 2021). Sertraline is one of the most commonly prescribed antidepressants in China. There are large individual differences in sertraline plasma concentration. Therefore, it is meaningful to establish a model to predict the concentration of sertraline.
The results of our study revealed that dose is the most important variable affecting the plasma concentration of sertraline and that there is a positive relationship between the daily dose of sertraline and plasma concentration. This finding is consistent with the pharmacokinetics of sertraline and previously described associations (Tini et al., 2022). A study of the population pharmacokinetics of sertraline in healthy subjects also showed that following multiple oral doses, the Cmax and AUC∞ increased proportionally with dose across the entire dose range (5–200 mg), while the bioavailability, Tmax, and t1/2 remained constant with dose (Alhadab and Brundage, 2020).
Sertraline is metabolized mainly in the liver. Hepatic metabolism is thought to play a major role in the overall clearance of sertraline (Zhou et al., 2019). In vivo, the levels of ALT and AST can reflect the liver function of patients. High ALT and AST levels indicate that patients may have impaired liver function, which may inhibit the metabolism of sertraline in the liver, resulting in a high plasma sertraline concentration.
The excretion and secretion of UA are mediated by multiple transporters in the kidney. The level of UA increases once the function of the kidney is impaired (Okui et al., 2020). There have been few studies on the correlation between UA levels and sertraline plasma concentrations, but our study revealed a negative correlation between them. Abnormal renal function may lead to a reduction in the reabsorption of UA in the kidney, resulting in a decrease in UA levels in the body. Sertraline and its metabolites are mainly excreted in feces and urine. Renal dysfunction may inhibit the renal excretion of sertraline, resulting in a high plasma concentration of sertraline. This may explain why UA was negatively correlated with the sertraline concentration.
Sex is another important variable that contributes to the plasma level of sertraline. Several studies have suggested that the apparent clearance of sertraline is significantly increased in male patients and that there is an age/sex interaction, which indicates a low plasma concentration of sertraline in male patients (Davies et al., 2016). Similarly, our study displayed a negative correlation between males and sertraline plasma concentration. The mechanistic processes underlying sex-specific pharmacokinetics can be divided into physiological and molecular factors. First, sertraline and desmethylsertraline showed high affinity for P-gp, which meditates the absorption of sertraline in the small intestine. A study confirmed that, compared with female rats, male rats exhibited higher relative P-gp expression in the intestine, which may result in increased intestinal efflux of sertraline in males (Mai et al., 2018). Second, sex-related pharmacokinetic differences include the generally lower bodyweight and organ size, a greater percentage of body fat, a lower glomerular filtration rate, and different gastric motility in females compared to males, which may explain low sertraline concentration in males (Li et al., 2020).
Previous studies indicated that concomitant treatment with an inhibitor of CYP2B6/2C19 may influence the concentration of sertraline (Preskorn et al., 2007; Gjestad et al., 2015). However, in our study, there was no correlation between the use of combined medication and the plasma concentration of sertraline. This may be due to the small number of patients treated with the combination therapy.
One advantage of this study is that we conducted subgroup analysis based on different concentration ranges to determine the respective prediction performance at diverse concentrations, helping supplement the data for the specified concentration range to refine the model continuously. In addition, we enhanced the model performance by leveraging the capabilities of ML. Through the stratified mining of data, ML methods can recognize and analyze multiple influencing factors in the real world. In particular, XGBoost has the ability to deal with data rapidly and effectively, reduce model overfitting, and process clinical data with a mass of outliers and missing values to construct an accurate prediction model. The combination of ML and personalized medicine has improved the effectiveness of precision medicine in clinical practice. Finally, to the best of our knowledge, our study is the first to use ML techniques to predict sertraline concentration in patients with depression using ML techniques. This study fills the gap in this field and provides a reference for the rational clinical use of sertraline.
However, there are several limitations in our study. First, this was a retrospective study using real-world data rather than a randomized controlled trial, inevitably resulting in some biases. In future studies, we intend to employ a randomized controlled trial utilizing stringent inclusion criteria to effectively manage potential confounding factors that might influence patient outcomes. Following the principle of randomization, subjects are allocated to each group with equal probability. This ensures that potential confounding variables are evenly distributed among the groups. Second, since TDM tests of sertraline were only conducted beginning in November 2019 at the First Hospital of Hebei Medical University, the final sample size was limited, which could lead to inaccurate findings in this study. Expanding the sample size or conducting prospective research in multiple centers is what we should strive for in the future. Third, data for some variables, such as height and weight, were deleted due to a high missing data rate or imbalanced sample size. In future studies, it is necessary to strengthen the training of doctors in recording and collecting data. We will also apply additional methods, such as interpolation, to process missing value to solve this problem. Notably, the theoretical shortcomings of ML models cannot be ignored. ML models suffer from overfitting, especially those with modest datasets (Bacanin et al., 2021). Dropout estimation by SI algorithms can help solve this issue (Bacanin et al., 2021). Previous studies have shown good results by using hybrid methods of SI and ML (Basha et al., 2021; Wainer and Fonseca, 2021; Zivkovic et al., 2021). In the future, we will pursue a more optimized model for predicting the sertraline concentration.
Conclusion
In conclusion, in this study, nine different AI algorithms were used for modeling to compare the ability of the models to predict sertraline concentration, and XGBoost was chosen to establish the personalized medication model with the best performance. Five important variables were found through ML to be correlated with the sertraline concentration. The personalized medication model of sertraline for patients with depression based on XGBoost had an acceptable prediction ability, which can be improved with a larger sample size and provide a reference for clinicians to propose the optimal medication regimen.
Data availability statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by the Ethics Committee of the First Hospital of Hebei Medical University (20220547). The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation in this study was provided by the participants’ legal guardians/next of kin.
Author contributions
RF: conceptualization, data curation, project administration, and writing–original draft. XH: formal analysis and writing–review and editing. JY: data curation and writing–review and editing. DW: formal analysis and writing–review and editing. JZ: data curation, formal analysis and writing–review and editing. ZY: formal analysis and writing–review and editing. FG: conceptualization, supervision, and writing–review and editing. CZ: conceptualization, supervision and writing–review and editing.
Funding
The authors declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Hebei Provincial Department of Science and Technology in China (grant number YZ202304) and the Medical Science Research Project of Hebei Health Commission (grant number 20221440).
Acknowledgments
The authors acknowledge the support of the Department of Clinical Pharmacy, the First Hospital of Hebei Medical University, Shijiazhuang, China, and the Technology Innovation Center for Artificial Intelligence in Clinical Pharmacy of Hebei Province, the First Hospital of Hebei Medical University, Shijiazhuang, China.
Conflict of interest
Authors JZ and FG were employed by Beijing Medicinovo Technology Co., Ltd. Author XH was employed by Dalian Medicinovo Technology Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Alhadab, A. A., and Brundage, R. C. (2020). Population pharmacokinetics of sertraline in healthy subjects: a model-based meta-analysis. AAPS J. 22 (4), 73. doi:10.1208/s12248-020-00455-y
Bacanin, N., Stoean, R., Zivkovic, M., Petrovic, A., Rashid, T. A., and Bezdan, T. (2021). Performance of a novel chaotic firefly algorithm with enhanced exploration for tackling global optimization problems: application for dropout regularization. Mathematics 9 (21), 2705. doi:10.3390/math9212705
Bacanin, N., Zivkovic, M., Al-Turjman, F., Venkatachalam, K., Trojovský, P., Strumberger, I., et al. (2022). Hybridized sine cosine algorithm with convolutional neural networks dropout regularization application. Sci. Rep. 12 (1), 6302. doi:10.1038/s41598-022-09744-2
Basha, J., Bacanin, N., Vukobrat, N., Zivkovic, M., Venkatachalam, K., Hubálovsk`y, S., et al. (2021). Chaotic harris hawks optimization with quasi-reflection-based learning: an application to enhance CNN design. Sensors (Basel) 21 (19), 6654. doi:10.3390/s21196654
Davies, S. J. C., Mulsant, B. H., Flint, A. J., Meyers, B. S., Rothschild, A. J., Whyte, E. M., et al. (2016). SSRI-antipsychotic combination in psychotic depression: sertraline pharmacokinetics in the presence of olanzapine, a brief report from the STOP-PD study. Hum. Psychopharmacol. Clin. Exp. 31 (3), 252–255. doi:10.1002/hup.2532
Farnam, A., MehrAra, A., Dadashzadeh, H., Chalabianlou, G., and Safikhanlou, S. (2017). Studying the effect of sertraline in reducing aggressive behavior in patients with major depression. Adv. Pharm. Bull. 7 (2), 275–279. doi:10.15171/apb.2017.033
Flint, A. J., Rothschild, A. J., Whyte, E. M., Alexopoulos, G. S., Mulsant, B. H., Marino, P., et al. (2021). Effect of older vs younger age on anthropometric and metabolic variables during treatment of psychotic depression with sertraline plus olanzapine: the STOP-PD II study. Am. J. Geriatr. Psychiatry 29 (7), 645–654. doi:10.1016/j.jagp.2020.11.003
Gjestad, C., Westin, A. A., Skogvoll, E., and Spigset, O. (2015). Effect of proton pump inhibitors on the serum concentrations of the selective serotonin reuptake inhibitors citalopram, escitalopram, and sertraline. Ther. Drug Monit. 37 (1), 90–97. doi:10.1097/FTD.0000000000000101
Guo, W., Yu, Z., Gao, Y., Lan, X., Zang, Y., Yu, P., et al. (2021). A machine learning model to predict risperidone active moiety concentration based on initial therapeutic drug monitoring. Front. Psychiatry 12, 711868. doi:10.3389/fpsyt.2021.711868
Hao, Y., Zhang, J., Yang, L., Zhou, C., Yu, Z., Gao, F., et al. (2023). A machine learning model for predicting blood concentration of quetiapine in patients with schizophrenia and depression based on real-world data. Br. J. Clin. Pharmacol. 89 (9), 2714–2725. doi:10.1111/bcp.15734
Hiemke, C., Bergemann, N., Clement, H. W. C., Conca, A., Deckert, J., Domschke, K., et al. (2018). Consensus guidelines for therapeutic drug monitoring in neuropsychopharmacology: update 2017. Pharmacopsychiatry 51 (1-02), e1–e62. doi:10.1055/s-0037-1600991
Huang, X., Yu, Z., Bu, S., Lin, Z., Hao, X., He, W., et al. (2021). An ensemble model for prediction of vancomycin trough concentrations in pediatric patients. Drug Des. Devel Ther. 15, 1549–1559. doi:10.2147/DDDT.S299037
Kamijima, K., Kimura, M., Kuwahara, K., Kitayama, Y., and Tadori, Y. (2018). Randomized, double-blind comparison of aripiprazole/sertraline combination and placebo/sertraline combination in patients with major depressive disorder. Psychiatry Clin. Neurosci. 72 (8), 591–601. doi:10.1111/pcn.12663
Kubanek, A., Paul, P., Przybylak, M., Kanclerz, K., Rojek, J. J., Renke, M., et al. (2021). Use of sertraline in hemodialysis patients. Med. Kaunas. 57 (9), 949. doi:10.3390/medicina57090949
Lee, S., Song, M., Han, J., Lee, D., and Kim, B. H. (2022). Application of machine learning classification to improve the performance of vancomycin therapeutic drug monitoring. Pharmaceutics 14 (5), 1023. doi:10.3390/pharmaceutics14051023
Li, L., Li, L., Shang, D. W., Wen, Y. G., and Ning, Y. P. (2020). A systematic review and combined meta-analysis of concentration of oral amisulpride. Br. J. Clin. Pharmacol. 86 (4), 668–678. doi:10.1111/bcp.14246
Li, W., Yin, Y., Quan, X., and Zhang, H. (2019). Gene expression value prediction based on XGBoost algorithm. Front. Genet. 10, 1077. doi:10.3389/fgene.2019.01077
Ma, P., Liu, R., Gu, W., Dai, Q., Gan, Y., Cen, J., et al. (2022). Construction and interpretation of prediction model of teicoplanin trough concentration via machine learning. Front. Med. (Lausanne) 9, 808969. doi:10.3389/fmed.2022.808969
Mai, Y., Dou, L., Murdan, S., and Basit, A. W. (2018). An animal's sex influences the effects of the excipient PEG 400 on the intestinal P-gp protein and mRNA levels, which has implications for oral drug absorption. Eur. J. Pharm. Sci. 120, 53–60. doi:10.1016/j.ejps.2018.04.021
Malhi, G. S., and Mann, J. J. (2018). Depression. Lancet 392 (10161), 2299–2312. doi:10.1016/S0140-6736(18)31948-2
Matsuzaki, T., Kato, Y., Mizoguchi, H., and Yamada, K. (2022). A machine learning model that emulates experts’ decision making in vancomycin initial dose planning. J. Pharmacol. Sci. 148 (4), 358–363. doi:10.1016/j.jphs.2022.02.005
Milgrom, J., Gemmill, A. W., Ericksen, J., Burrows, G., Buist, A., and Reece, J. (2015). Treatment of postnatal depression with cognitive behavioural therapy, sertraline and combination therapy: a randomised controlled trial. Aust. N. Z. J. Psychiatry 49 (3), 236–245. doi:10.1177/0004867414565474
Okui, D., Sasaki, T., Fushimi, M., and Ohashi, T. (2020). The effect for hyperuricemia inpatient of uric acid overproduction type or in combination with topiroxostat on the pharmacokinetics, pharmacodynamics and safety of dotinurad, a selective urate reabsorption inhibitor. Clin. Exp. Nephrol. 24 (1), 92–102. doi:10.1007/s10157-019-01817-3
Preskorn, S. H., Shah, R., Neff, M., Golbeck, A. L., and Choi, J. (2007). The potential for clinically significant drug-drug interactions involving the CYP 2D6 system: effects with fluoxetine and paroxetine versus sertraline. J. Psychiatr. Pract. 13 (1), 5–12. doi:10.1097/00131746-200701000-00002
Shorey, S., Ng, E. D., and Wong, C. (2022). Global prevalence of depression and elevated depressive symptoms among adolescents: a systematic review and meta-analysis. Br. J. Clin. Psychol. 61 (2), 287–305. doi:10.1111/bjc.12333
Thapar, A., Eyre, O., Patel, V., and Brent, D. (2022). Depression in young people. Lancet 400 (10352), 617–631. doi:10.1016/S0140-6736(22)01012-1
Tini, E., Smigielski, L., Romanos, M., Wewetzer, C., Karwautz, A., Reitzle, K., et al. (2022). Therapeutic drug monitoring of sertraline in children and adolescents: a naturalistic study with insights into the clinical response and treatment of obsessive-compulsive disorder. Compr. Psychiatry 115, 152301. doi:10.1016/j.comppsych.2022.152301
Wainer, J., and Fonseca, P. (2021). How to tune the RBF SVM hyperparameters? An empirical evaluation of 18 search algorithms. Artif. Intell. Rev. 54, 4771–4797. doi:10.1007/s10462-021-10011-5
Yan, Z., Wang, J., Dong, Q., Zhu, L., Lin, W., and Jiang, X. (2022). XGBoost algorithm and logistic regression to predict the postoperative 5-year outcome in patients with glioma. Ann. Transl. Med. 10 (16), 860. doi:10.21037/atm-22-3384
Zheng, P., Yu, Z., Li, L., Liu, S., Lou, Y., Hao, X., et al. (2021). Predicting blood concentration of tacrolimus in patients with autoimmune diseases using machine learning techniques based on real-world evidence. Front. Pharmacol. 12, 727245. doi:10.3389/fphar.2021.727245
Zhou, X., Lockhart, A. C., Fu, S., Nemunaitis, J., Sarantopoulos, J., Muehler, A., et al. (2019). Pharmacokinetics of the investigational aurora A kinase inhibitor alisertib in adult patients with advanced solid tumors or relapsed/refractory lymphoma with varying degrees of hepatic dysfunction. J. Clin. Pharmacol. 59 (9), 1204–1215. doi:10.1002/jcph.1416
Zivkovic, M., Bacanin, N., Antonijevic, M., Nikolic, B., Kvascev, G., Marjanovic, M., et al. (2022). Hybrid CNN and XGBoost model tuned by modified arithmetic optimization algorithm for COVID-19 early diagnostics from X-ray images. Electronics 11 (22), 3798. doi:10.3390/electronics11223798
Keywords: sertraline, concentrations, therapeutic drug monitoring, machine learning, XGBoost
Citation: Fu R, Hao X, Yu J, Wang D, Zhang J, Yu Z, Gao F and Zhou C (2024) Machine learning-based prediction of sertraline concentration in patients with depression through therapeutic drug monitoring. Front. Pharmacol. 15:1289673. doi: 10.3389/fphar.2024.1289673
Received: 06 September 2023; Accepted: 21 February 2024;
Published: 06 March 2024.
Edited by:
Tong Rongsheng, Sichuan Academy of Medical Sciences and Sichuan Provincial People’s Hospital, ChinaReviewed by:
Christoph Hiemke, Johannes Gutenberg University Mainz, GermanyNebojsa Bacanin, Singidunum University, Serbia
Copyright © 2024 Fu, Hao, Yu, Wang, Zhang, Yu, Gao and Zhou. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chunhua Zhou, emhvdWNodW5odWE4MEAxMjYuY29t; Fei Gao, Z2FvZmVpOTAwMEAxNjMuY29t
†These authors have contributed equally to this work