 Dan Qin
Dan Qin He Zhang
He Zhang Bin Du
Bin Du Hui Wang
Hui Wang Ligang Liu
Ligang Liu Yun Wang
Yun Wang- 1School of Chinese Materia Medica, Beijing University of Chinese Medicine, Beijing, China
- 2Department of Pharmacy, Medical Supplies Center of Chinese PLA General Hospital, Beijing, China
- 3Beijing International Center for Mathematical Research, Peking University, Beijing, China
- 4School of Mathematical Sciences, Peking University, Beijing, China
- 5Institute of Therapeutic Innovations and Outcomes (ITIO), College of Pharmacy, The Ohio State University, Columbus, OH, United States
Background: Ancient classic and famous prescriptions (ACFPs), derived from traditional Chinese medicine (TCM) classics, are widely utilized due to their precise therapeutic effects and distinctive clinical advantages. Existing research predominantly focuses on individual prescriptions, and there is lack of systematic exploration of medication patterns within the official ACFPs catalog. The property of Chinese materia medica (PCMM), a multidimensional representation of medicinal properties, offers a novel perspective for systematically analyzing TCM formulas.
Objective: In this study, we aim to investigate the implicit medication patterns of ACFPs from the PCMM perspective, establish a feature extraction model based on the property combination of Chinese materia medica (PCCMM), and evaluate its effectiveness in representing and reconstructing ACFPs.
Methods: Based on the Chinese Pharmacopoeia (ChP), we constructed a CMM–PCCMM network as the forward feature extraction process. We formulated the backward process as a constrained combinatorial optimization problem to rebuild ACFPs from their PCCMMs. We evaluated the performance of PCCMM in reconstructing ACFPs using the Jaccard similarity coefficient. Furthermore, we tested the capability of PCCMM to distinguish ACFPs from random pseudo-formulas and classify ACFPs according to deficiency syndromes. Finally, we conducted frequency analysis, association rule analysis, distance analysis, and correlation analysis to explore the implicit medication patterns of ACFPs based on PCCMM.
Results: Numerical experiments showed that PCCMM effectively represented and reconstructed ACFPs, achieving an average Jaccard similarity coefficient above 0.8. PCCMM outperformed the nomenclature of CMM in distinguishing ACFPs from random pseudo-formulas and classifying deficiency syndromes. Frequency analysis revealed that high-frequency CMMs were mainly tonic medicines, whereas high-frequency PCCMMs predominantly mapped to the even–sweet–spleen meridian. The association rule analysis based on PCCMM yielded significantly more implicit compatibility rules than CMM alone. Distance and correlation analyses identified synergistic CMM pairs and PCCMM pairs, such as Jujubae Fructus (Dazao) and Zingiberis Rhizoma Recens (Shengjiang), which is consistent with clinical experience.
Conclusion: The PCCMM-based feature extraction model provides a quasi-equivalent representation of TCM formulas, effectively capturing implicit medication patterns within ACFPs. PCCMM outperforms traditional CMM methods in formula reconstruction, classification, and medication pattern mining. This study offers novel insights and methodologies for systematically understanding TCM formulas, guiding clinical application, and facilitating the design and optimization of new TCM formulas.
1 Introduction
The ancient classic and famous prescriptions (ACFPs), derived from the ancient traditional Chinese medicine (TCM) books, are widely utilized TCM formulas known for their precise curative effects, distinctive features, and notable advantages (Qian et al., 2019). The research, development, and utilization of ACFPs are vital sources for R&D of new drugs in TCM (Xue-Mei et al., 2019). As one of the breakthroughs in the inheritance and development of TCM, the research of ACFPs has been a hotspot in recent years (Su et al., 2024) after the National Administration of Traditional Chinese Medicine and the National Medical Products Administration published the catalog of ACFPs in 2018 (first batch) and 2023 (second batch). Some scholars systematically explored the historical evolution (Bing et al., 2019) of the formulas from the source, composition, dosage, processing, clinical application, function interpretation, and decocting method by comprehensive collation of ancient and modern literature on ACFPs (Li S. et al., 2022). Some scholars researched chemical profiling and quantification of the ACFPs to provide a solid basis for quality control and mechanisms (Zhou et al., 2023). Some studies examined the active components (Wang S. et al., 2021), efficacy (Xiao et al., 2022), and pharmaceutical mechanism (Xia et al., 2023) underlying the effects of ACFPs on some particular diseases using network pharmacology analysis and molecular docking in combination with experimental validation. On this foundation, some studies have found the unexplored therapeutic effects and mechanisms of a particular ACFP (Hao et al., 2022). However, most current studies on ACFPs focus on a specific prescription, and there is still a gap in the systematic regularity study of the catalog of ACFPs issued by the Chinese government.
It is conducive to providing references for evaluating TCM formulas or designing new formulas through the systematic study of the formation and medication patterns of the ACFPs to explore the scientific connotations of the formulas implied by their broad application, safety, and efficacy. To find the medication patterns in the formulas, some studies tried to explore the scientific connotations of the TCM formulas by data mining, such as frequency analysis (Yang et al., 2021), cluster analysis (Guo et al., 2022), and association rule analysis (Liu et al., 2023). Wu and Guo (2025) offered the potential for uncovering commonalities through the analysis of 2,344 prescriptions for pox treatment, and Xue et al. (2024) have employed data mining methods to analyze the medication patterns in the treatment of vascular dementia. However, these studies often focus on the medication patterns of a specific disease. Machine learning and deep learning techniques, such as support vector machines (SVM) (Jin et al., 2020) and graph convolutional networks (GCN) (Zhao et al., 2022), have been widely applied in the design of new TCM formulas, without being restricted to specific diseases. However, these studies often treat medication patterns as black boxes and rely on large-scale datasets (Li D. et al., 2022). Due to the wide variety of names and types of Chinese materia medica (CMMs), we often get a poor reproduction rate of elements in data mining in a limited-scale and nonspecific disease dataset. The sparsity of the signals makes it difficult to dig out the medication patterns of TCM formulas or generate a new TCM formula based on a small sample dataset of known TCM formulas. Feature extraction can transform raw data into meaningful information, facilitating enhanced data reuse through a standardized process (Lamer et al., 2022). For example, Miao et al. (2023) employed an improved ConvNeXt network to extract features for constructing a TCM identification model. Gong et al. (2023) integrated feature extraction with a multi-label deep forest model, which achieves efficient processing of syndrome differentiation in TCM. Therefore, a more efficient representation of TCM formulas than CMMs is needed to enhance the mining of medication patterns, subject to the low repetition rate of CMMs in small TCM formula datasets.
According to the property theory of CMM (PTCMM), the property of CMM (PCMM) is a multi-dimensional systematic representation of the basic properties and characteristics of the CMM’s efficacy (Qiao et al., 2022). Considering the standardization and authority of the Chinese Pharmacopoeia (ChP), the research studies about database construction and data mining related to the PCMM are predominantly based on the data extracted from the ChP, such as ETCM (Zhang et al., 2023a) and FordNet (Zhou et al., 2021). The core components of the PCMM include five herb properties (cold, warm, even, cool, and hot), seven herb flavors (bitter, pungent, sweet, sour, astringent, salty, and bland), and 12 herb meridian tropism (liver meridian, lung meridian, spleen meridian, stomach meridian, kidney meridian, heart meridian, large intestine meridian, small intestine meridian, Sanjiao meridian, bladder meridian, pericardium meridian, and gallbladder meridian) (Zhang et al., 2023b). Some research workers have considered the PCMM as a multidimensional systematic feature of the CMM (Qiao et al., 2022; Zhang et al., 2023b), but the feature extraction process from ACFPs to PCMM remains unclear. Based on these core components of PCMM, our lab has proposed a systematic view of PCMMs called the property combinations of CMM (PCCMM) (Hu et al., 2016) by coupling the elements from these three sets, which provides new ideas for the representation of CMMs in the TCM formulas.
In this study, we have introduced a novel, relatively low-dimensional representation of TCM formulas by feature extraction and employed this approach to analyze the implicit medication patterns of ACFPs. Figure 1 shows the flow diagram of the work. This study commences with the construction of a CMM–PCCMM network and PCCMM matrix as the forward feature extraction process. As for the backward process, utilizing the framework of compressive sensing, we introduce the combinatorial optimization problem and develop a combinatorial formula model based on PCCMM. With the ACFPs serving as a test set, we proceed to rebuild the ACFPs from the PCCMM. The performance of PCCMM in measuring the composition of TCM formulas is then evaluated based on its reconstruction capabilities. To further investigate the quasi-linear measurement capabilities of PCCMM for TCM formulas, we also test its proficiency in separating ACFPs from random pseudo-formulas and its ability to distinguish the deficiency syndromes associated with the ACFPs. Building upon this foundation, we conducted frequency, association rule, distance, and correlation analyses on ACFPs using PCCMM to uncover the underlying medication patterns.
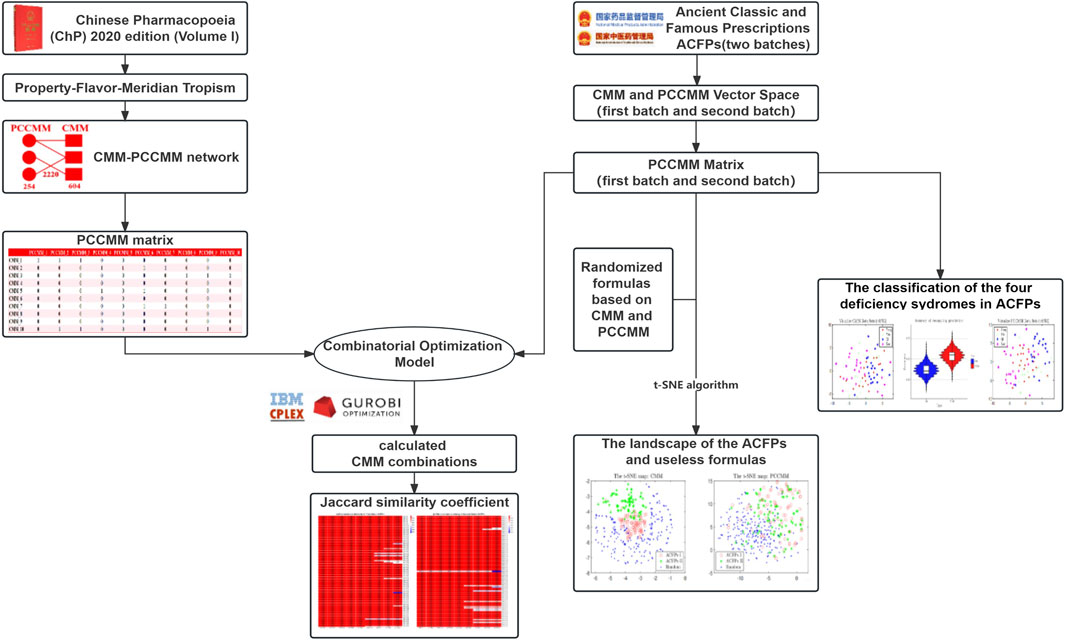
Figure 1. Flow diagram illustrating the process: the left side depicts the preprocessing of CMM and PCCMM data and the construction of the PCCMM matrix, which defines the combinatorial formula model in the center. The right side shows a series of numerical experiments conducted on the ACFP dataset.
2 Materials and methods
2.1 Data sources and preprocessing
2.1.1 The CMM and PCCMM information
The CMM and PCMM information in this study was derived from the current ChP 2020 edition (volume I) (Chinese Pharmacopoeia Commission, 2020). As introduced in Section 1, a PCCMM is a triplet following the “property–flavor–meridian tropism” rule, where the three coupled labels are selected as representatives of PCMMs. For simplicity, throughout the rest of the paper, we will use the term “PCMM” to refer exclusively to these three labels: property, flavor, and meridian tropism. To begin with, we define the PCCMM set of a CMM as the collection of PCCMMs that includes all possible “property–flavor–meridian tropism” triplets subject to the PCMM of the CMM. For example, the property of Ephedra sinica Stapf (Mahuang) (Zheng et al., 2023) is warm, the flavor is bitter and pungent, and the meridian tropism is the lung meridian and bladder meridian based on ChP. Thus, there are four corresponding PCCMMs, namely, warm–bitter–lung meridian, warm–bitter–bladder meridian, warm–pungent–lung meridian, and warm–pungent–bladder meridian, which together form the PCCMM set of the CMM, Ephedra sinica Stapf. In general, if the PCMM of a CMM includes
In practice, based on the dataset involved, one can specify the scope of CMM and the size of
We also conducted observational tests using data from the 2015 edition of the ChP. Compared to the 2020 edition, the 2015 edition includes three additional CMMs with complete “property–flavor–meridian tropism,” that is, PCMM, information: Aristolochiae Fructus (Madouling), Manis Squama (Chuanshanjia), and Aristolochiae Herba (Tianxianteng). As a result, the total number of CMMs with complete PCMM records in the 2015 edition amounts to 607 (see Supplementary Table S10), covering a total of 254 PCCMMs, which is the same as the 2020 edition. Upon a detailed comparison, we observed that the fields “property–flavor–meridian tropism” for the shared 604 CMMs recorded in the 2015 and 2020 editions are identical. This consistency ensures that the core PCMM information remains stable across the two editions, providing a reliable foundation for further computational and experimental studies.
2.1.2 Incompatible CMM pairs
Revealing the connotation of the compatibility of CMM is a requirement for the modernization of TCM (Gao et al., 2023), so we need to avoid contraindications of the CMMs in the candidate formula; for example, the “eighteen incompatible medicaments” theory in TCM (Chen et al., 2019). In particular, according to the “Zhong Yao Pei Wu Jin Ji” (Duan, 2019), we extracted 89 incompatible CMM pairs (Supplementary Table S3), which will not appear simultaneously in the subsequent model calculations.
2.1.3 The ACFP dataset
We extracted 93 and 85 prescriptions from the two batches of ACFP catalogs (Supplementary Tables S4, S5), respectively, published by the National Administration of Traditional Chinese Medicine and the National Medical Products Administration such that the CMMs involved are within the CMM space. Table 1 provides detailed information about the selected prescriptions.

Table 1. Number of prescriptions, CMMs, and PCCMMs of the two ACFP datasets. Repeated occurrences of CMMs or PCCMMs are not counted in the “unique” columns.
Notice that a TCM formula, qualitatively, is a collection of CMMs. Thus, one can extend the concept of PCCMM sets to TCM formulas and even general CMM combinations by combining all the PCCMM sets of the involved CMMs. Thus, we obtain a map from ACFPs to their PCCMM sets.
2.2 Feature extraction of the ACFPs based on PCCMM
2.2.1 The framework of compressive sensing
In this section, we review some fundamental concepts of compressive sensing to mathematically interpret the PCCMM matrix and combinatorial formula model introduced in Section 2.2.2 and Section 2.2.3. Although the compressive sensing framework offers mathematical foundations for the CMM–PCCMM network and the combinatorial formula model to be introduced in Section 2.2.2 and Section 2.2.3, these models are primarily driven by the feature extraction process from ACFPs to PCMM, with all variables holding clear pharmacological significance.
The development of compressive sensing theory started from the initial work by Emmanuel J. Candès, Justin Romberg, and Terence Tao (Candes et al., 2006) along with David Donoho’s study (Donoho, 2006). The success of compressive sensing depends on the sparsity or compressibility of the signal, either in its natural state or over a known basis. As a result, one can recover the essential information within few measurements of the observation by solving an underdetermined linear system of equations. For the mathematical theory and applications of compressive sensing, refer to the studies by Foucart and Rauhut (2013) and Rani et al. (2018), respectively.
In the compressive problem, the observed data
where the matrix
where
As solving Equation
where
2.2.2 Building the CMM–PCCMM network and the PCCMM matrix
In this section, based on the compressive sensing framework reviewed in Section 2.2.1, we will formulate the PCCMM matrix and the measurement process that maps formula vectors to PCCMM set vectors, that is, the forward propagation in the CMM–PCCMM network.
As subsets of
Definition 1. (PCCMM matrix) Let
where
Notably, the order of CMMs and PCCMMs in the set
With the PCCMM matrix
where
Given a formula vector
As
To facilitate understanding, we use Mahuang Decoction (ACFP-1-4, see Supplementary Table S4 for the details) as an example. The formula contains four CMMs: Ephedrae Herba (Mahuang, CMM-307), Cinnamomi Ramulus (Guizhi, CMM-173), Glycyrrhizae Radix et Rhizoma (Gancao, CMM-144), and Armeniacae Semen Amarum (Kuxingren, CMM-269). Thus, the corresponding formula vector
Following Equation 4 and Equation 5, we compute the PCCMM set vectors,
which uniquely determines the 0–1 vector
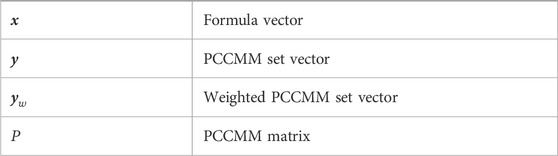
Table 2. List of frequently used mathematical notations introduced in Section 2.2.2.
2.2.3 Constructing the combinatorial formula model based on PCCMM
In this section, we characterize the backward propagation of the CMM–PCCMM network as a sparse recovery problem and propose a constrained combinatorial optimization model to solve it. The sparse recovery problem involves reconstructing a TCM formula from its PCCMM set. Given a target PCCMM vector
Let
To address the issue caused by relaxation, we added an
In the lost function (Equation 6), the
Alternatively, we also consider the case where the available measurement is the weighted PCCMM set vector, denoted by
It is worth mentioning that we can extend the combinatorial optimization model to quantitative cases by considering continuous decision variables. However, at this point, we focus on reconstructing ACFPs utilizing qualitative PCCMM data, and we shall not extend our inquiry to encompass the quantitative dimensions of the subject matter.
2.2.4 Rebuilding the ACFPs from PCCMM
Based on the inverse problem of rebuilding the TCM formula from its PCCMM information and the corresponding constrained combinatorial optimization problems (Equations 6, 7 and Equations 8, 9) in Sections 2.2.3, we will present the numerical experiments and evaluation methods in this section.
The ACFP dataset consists of 178 sample test problems, and each problem is identified by vectors, namely,
To evaluate the level of restoration of ACFPs, we used the Jaccard similarity coefficient (Zeng et al., 2019) to measure the similarity between the estimated formula and the underlying true ACFPs. Recalling that, the Jaccard similarity coefficient of two non-empty sets
As the formulas are encoded as 0–1 vectors, let
where the “
Numerically, we implemented Gurobi Optimizer 10.0.2 (Gurobi Optimization, LLC, 2023) with Python 3.8.4 on an Intel™ Core i5-1135G7 2.40 GHz CPU. In our optimization process, we set
2.3 Differentiation of the ACFPs based on PCCMM
In this section, we will return to the measurement process (5) and aim to explore the potential of PCCMMs in classifying ACFPs.
2.3.1 Separating ACFPs from random pseudo-formulas
In Section 2.2.4, we have introduced two ACFP datasets of 93 and 85 formulas (Table 1), respectively. As representatives of TCM formulas, they should be distinguished from arbitrary CMM combinations. Therefore, in this section, we consider the clustering problem between the ACFP datasets and random pseudo-formulas based on their PCCMM set vectors. We want to explore whether the PCCMMs can separate ACFPs from randomly generated formulas of no pharmacological significance.
We use the Bernoulli’s trails to help generate the random formula dataset of desirable sparsity. Recalling that a Bernoulli random variable with parameter
Let
Thus, given a target sparsity
We mixed the three formula vector datasets and the corresponding weighted PCCMM set vector datasets computed by Equation 5. In other words, we contaminated the ACFP dataset with irrelevant information from the pseudo-formula. As high-dimensional vectors, it is difficult to tell directly whether the point clouds formed by the two types of vectors yield clusters or not under the unsupervised learning setup. As a remedy, we employed t-distributed stochastic neighbor embedding (t-SNE) (Pezzotti et al., 2017) as the dimensional reduction method, which helped us picture the potential clusters. In manifold learning, t-SNE aims to represent high-dimensional points in lower dimensions while preserving their similarities. The t-SNE algorithm finds the similarity measure between pairs of instances in higher and lower dimensional spaces and tries to optimize two similarity measures in the following three steps (Bo et al., 2021):
(i) t-SNE models a point selected as a neighbor of another point in both higher and lower dimensions. It starts by calculating a pairwise similarity between all data points in the high-dimensional space using Gaussian kernels. The points that are far apart have a lower probability of being picked than the points that are close together.
(ii) Then, the algorithm tries to map higher dimensional data points onto lower dimensional space while preserving the pairwise similarities.
(iii) It is achieved by minimizing the divergence between the probability distribution of the original high-dimensional and lower dimensional space. The algorithm uses gradient descent to minimize the divergence. The lower dimensional embedding is optimized to a stable state.
We used MATLAB 2021a simulation software for data preparation and 2D t-SNE implementation. In the “tsne” input arguments, we selected the hamming distance as the distance function in the t-SNE. Recalling that the hamming distance between two vectors corresponds to the number of inconsistent entries, we set
2.3.2 Distinguishing the deficiency syndromes of the ACFPs
Here, we merged the two batches of ACFPs into a single dataset and considered the clustering problem based on the syndromes and efficacy of the prescriptions.
The syndromes and efficacy of the prescriptions were retrieved through the China National Knowledge Infrastructure (CNKI), PubMed, Web of Science, and other databases. In this study, we selected the prescriptions of deficiency syndromes and classified them under the four labels of Yang deficiency pattern (23 cases), Yin deficiency pattern (24 cases), Qi deficiency pattern (27 cases), and blood deficiency pattern (21 cases) (World Health Organization, 2022), and introduced the supervised learning problem by splitting data into the training and testing sets.
Due to the limited data available, we utilized the bootstrap method. In statistics, the bootstrap method is a resampling technique that involves repeatedly sampling with replacement from the original data to estimate the distribution of parameters and calculate confidence intervals (Efron, 1979). For the deficiency pattern clustering problem, instead of fixing the training sets, we repeatedly resampled the prescriptions to build the training data and solved the supervised learning problem. We summarized the learning process as follows:
1) As for data preprocessing, we used the 2D t-SNE, subject to hamming distance,
We set the number of trials in the bootstrap method to 5,000 and applied the above learning process to both formula vectors and weighted PCCMM set vectors. The detailed numerical results are reported in Section 3.2.2.
2.4 Medication pattern analysis of the ACFPs based on PCCMM
Based on CMM and PCCMM, we explored the medication patterns of ACFPs. The “itemFrequency” function of R 4.3.2 was used for frequency analysis. On this basis, association rule analysis, correlation analysis, and cluster analysis on high-frequency CMM and PCCMM were performed, respectively, based on the “a priori” function, “corrplot” function, and “hclust” function, and the above results were visualized.
3 Results
3.1 Evaluating the feature extraction of the ACFPs
3.1.1 The evaluation of the PCCMM matrix
Based on the 604 CMMs and their corresponding PCCMMs introduced in Section 2.1.1, we constructed the CMM–PCCMM network and visualized this binary network in Figure 2A using Gephi version 0.9.2 (Bastian et al., 2009). The CMM–PCCMM network encompasses 604 CMM nodes, 254 PCCMM nodes, and 2,216 edges.
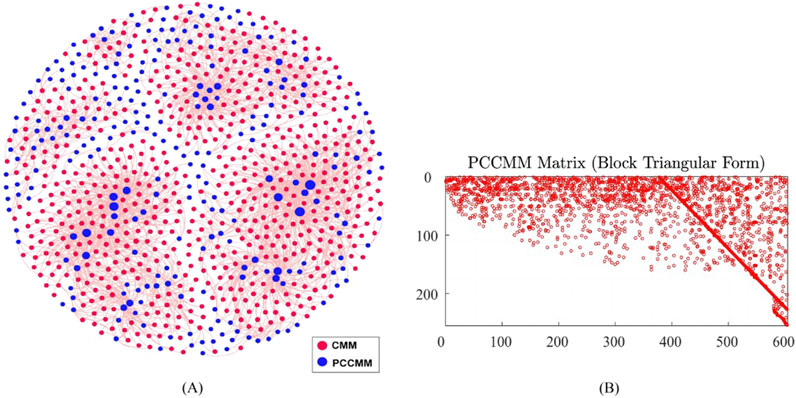
Figure 2. Visualizing the CMM–PCCMM network and the sparsity pattern of the PCCMM matrix
To evaluate the PCCMM matrix
3.1.2 The performance of rebuilding ACFPs from the PCCMM
As reported in Table 1, we considered 178 prescriptions from the first and second batches of the ACFP catalogs (Supplementary Tables S4, S5) to form the sample problem dataset. For each sample problem, we inputted the PCCMM set vector
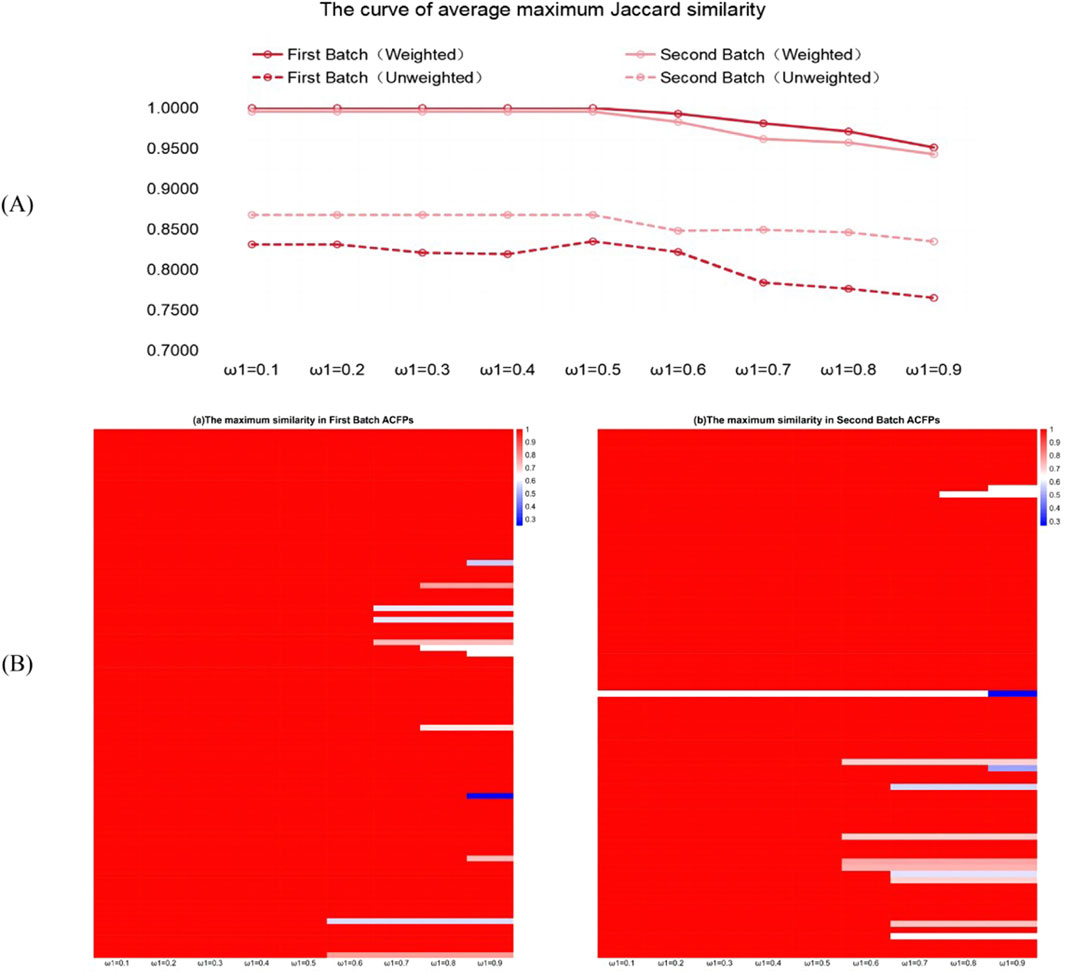
Figure 3. Jaccard similarity of rebuilding ACFPs from the PCCMM. (A) Curve of the average maximum Jaccard similarity as a function of the hyperparameters
From Figure 3A, we can see that the weighted PCCMM set vector
The heatmap in Figure 3B reports the individual recovering performance of each sample problem based on the weighted PCCMM set vector as

Table 3. Original prescription of ACFP-2–46 and the four estimated formulas of the largest Jaccard similarity and fewer CMMs.
To explain why there are four estimated formulas of the same Jaccard similarity, we checked the PCCMMs of the CMM that distinguish these estimates. We found that both CMM-32 (Pinelliae Rhizoma, Banxia) and CMM-169 (Pogostemonis Herba, Guanghuoxiang) belong to the following PCCMMs: warm–pungent–lung meridian, warm–pungent–spleen meridian, and warm–pungent–stomach meridian. Furthermore, the two CMMs have the ability to alleviate dampness and prevent vomiting. In addition, CMM-114 (Caryophylli Flos, Dingxiang) and CMM-329 (Caryophylli Fructus, Mudingxiang) also share the same PCCMMs: warm–pungent–lung meridian, warm–pungent–spleen meridian, warm–pungent–kidney meridian, and warm–pungent–stomach meridian, and they have the same efficacy and indications in ChP. Therefore, the PCCMM measurement cannot distinguish between CMM-32 and CMM-169, as well as between CMM-114 and CMM-329, which elucidates the four estimates presented in Table 3.
Furthermore, the numerical experiments indicate that the results based on the ChP 2015 edition are consistent with those derived from the 2020 edition, exhibiting the same maximal Jaccard similarity values and underscoring the robustness of this approach across different reference databases. To further validate the adequacy of Jaccard similarity in our numerical experiment, we reported the comparison between cosine and Jaccard similarities in Supplementary Figure S1, which reveals a high consistency in trends between two similarity curves.
3.2 Distinguishing the ACFPs from different dimensions
3.2.1 The performance of separating ACFPs from random pseudo-formulas
To form the CMM/PCCMM datasets used for the clustering problem, following Section 2.3.1, we generated 150 random pseudo-formula vectors and computed their weighted PCCMM set vectors via Equation 5, . Mixing them with the 178 ACFPs in the two batches in Table 1, we formed the CMM/PCCMM dataset, each consisting of 328 vectors. In this section and also in Section 3.2.2, motivated by the result in Section 3.1.2, we used the weighted PCCMM set vectors to build the PCCMM dataset.
Then, we utilized the t-SNE algorithm to generate 2D projections of the CMM and PCCMM datasets, respectively, providing visual representations of the data distribution and employing Euclidean distances to measure the proximity between data points in the expression space (Bushati et al., 2011) and plotted the scatterplot (Figure 4A). The scatterplots suggest that both the CMM and PCCMM measurements can separate the ACFPs from the random pseudo-formulas, but the weighted PCCMM set vector, after being projected using t-SNE, generated an approximately linear boundary between the clusters of ACFPs and random pseudo-formulas. Thus, in contrast to CMMs, PCCMM measurements offer a more intuitive separation between two clusters, which is convenient for implementation purposes. Another interesting observation is that the distribution patterns of the weighted PCCMM vectors between the first and second batches of ACFPs are similar. Unlike the CMMs, the PCCMM measurements, after being projected using t-SNE, cannot distinguish the ACFPs from the first and second batches. Notice that the involved CMMs of the two batches are quite different (see Table 1 for details), which may explain why the formula vector can separate ACFPs from different batches. On the other hand, the PCCMM measurement is insensitive to the scope of the CMMs, which makes it a more intrinsic indicator in seeking common features among different ACFPs.
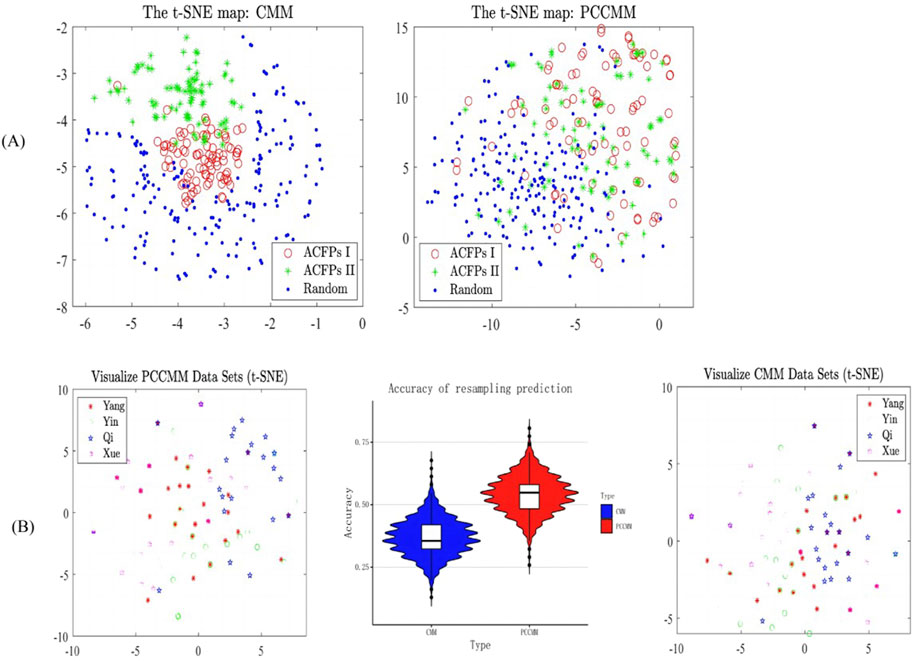
Figure 4. Differentiating the ACFPs based on PCCMM and CMM. (A) Scatterplots of the t-SNE maps of the formula vectors (the left panel) and weighted PCCMM set vectors (the right panel). In the scatterplots, each data point was assigned with the original labels. “ACFPs I” and “ACFPs II” stand for the ACFPs in the first and second batches, respectively. “Random” corresponds to the random pseudo-formulas. The cluster information (“ACFPs I,” “ACFPs II,” and “Random”) of each vector is only used in the scatterplot plotting. In the right panel, there is an approximately linear boundary between the clusters of ACFPs and random pseudo-formulas. Additionally, the distribution patterns of the weighted PCCMM vectors in the two batches of ACFPs are similar, which is different from the patterns of the CMM vectors in the left panel. (B) Classification of the four deficiency syndromes in ACFPs based on CMM and PCCMM. The left and right panels report the t-SNE map of the four deficiency syndromes in ACFPs based on CMM and PCCMM, respectively. The middle panel displays a violin plot of the bootstrap method’s correct rate distribution and quantiles, with the plot’s wiggles reflecting the discrete distribution of the correct rate. The violin plot shows that PCCMM has a higher correct rate than CMM in the classification tasks.
3.2.2 The classification of deficiency syndromes in ACFPs by PCCMM
We retrieved 95 prescriptions relevant to deficiency syndromes from the two batches of ACFPs (Supplementary Table S6). Among them, there are 23 cases of Yang deficiency pattern, 24 cases of Yin deficiency pattern, 27 cases of Qi deficiency pattern, and 21 cases of blood deficiency pattern.
Initially, we utilized the t-SNE algorithm for data preprocessing to obtain 2D projections. However, the distribution differences among the labels of the four deficiency syndromes were not clearly distinguishable in the resulting graph (Figure 4B), making it difficult to differentiate between them visually. To address this issue, we employed the bootstrap method for supervised learning and further analyzed the distribution by resampling with replacement from the original data. Our results showed that the classification accuracy based on the PCCMM was 0.55, which outperformed the classification accuracy of 0.42 obtained using the nomenclature of CMM. The lack of training data might cause the relatively poor performance for both the measurements.
3.3 Analyzing the medication patterns of ACFPs
3.3.1 The frequency and association rules analysis
High-frequency CMMs are those with markedly increased usage rates in clinical practice, classic prescription, or modern research, demonstrating the integration of TCM theory with clinical application, which can be identified by their high frequencies in disease-specific formula databases, clinical guidelines, or bibliometric analyses (Wang J. et al., 2021). A common approach to identifying high-frequency CMMs is frequency analysis, which involves directly counting the occurrences of CMMs. Currently, there is no unified standard for defining high-frequency CMMs. Some studies measure total occurrences, whereas others rely on proportional frequency. For instance, Liu et al. (2024) classified CMMs with a frequency greater than
Among the 196 CMMs mentioned in Table 1, 34 CMMs had a frequency of
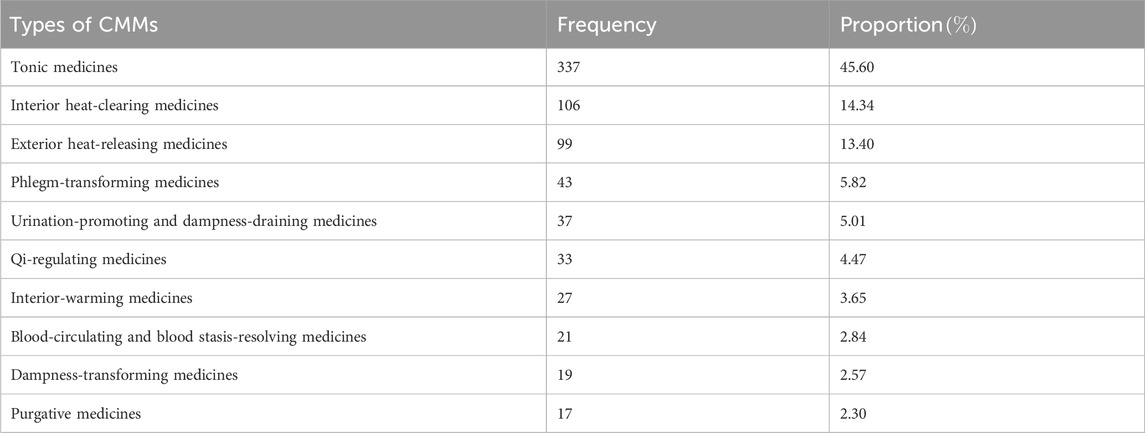
Table 4. Classification of high-frequency CMMs based on their functions.
3.3.2 The distance and correlation analysis
The “apriori” function was employed to perform association rule analysis. The settings were support
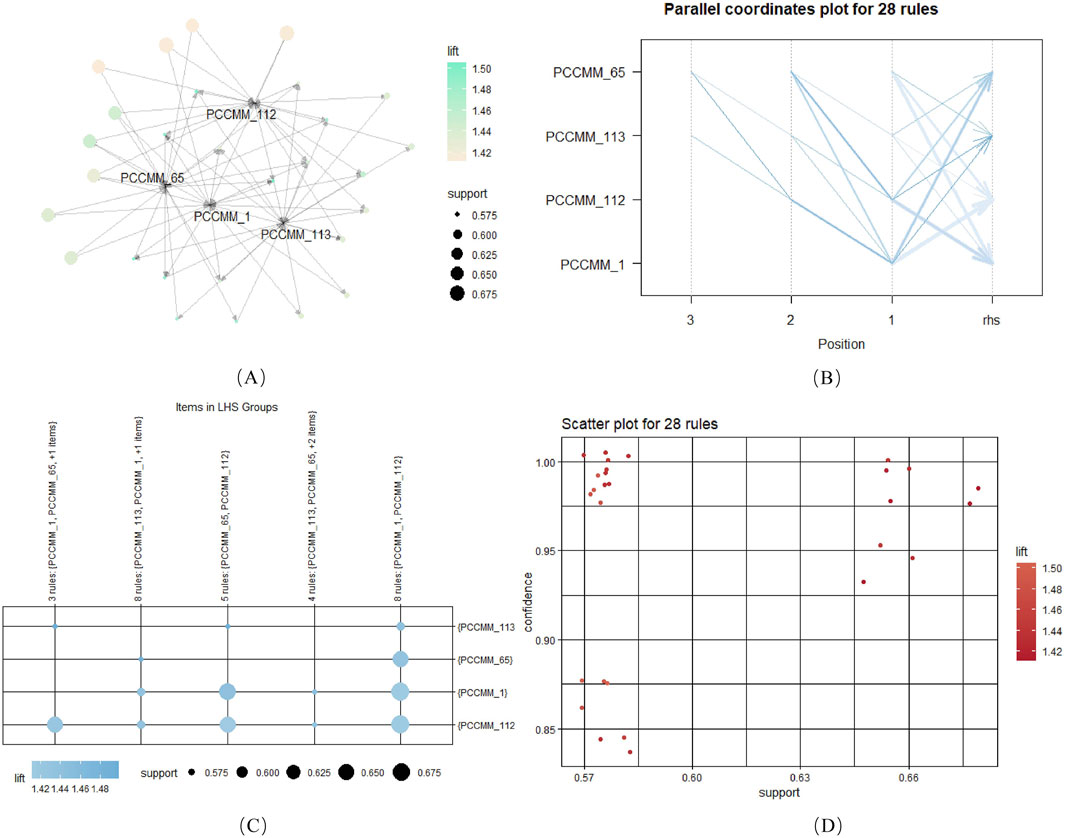
Figure 5. Association rules of ACFPs based on PCCMM, with a minimum support threshold of 0.5. (A) Network graph depicting the association rules for PCCMM-1, PCCMM-65, PCCMM-112, and PCCMM-113. (B) Parallel coordinate plot illustrating the 28 identified association rules. (C) Twenty-eight items categorized under the left-hand side (LHS) groups. (D) Relationship among confidence, support, and lift for the 28 rules.
We calculated the pairwise distances between high-frequency CMM and high-frequency PCCMM, based on the binary distance method, and visualized them in Figure 6. The CMM pairs with the smallest distances are as follows: Jujubae Fructus (Dazao) and Zingiberis Rhizoma Recens (Shengjiang), Saposhnikoviae Radix (Fangfeng) and Chuanxiong Rhizoma (Chuanxiong), and Angelicae Sinensis Radix (Danggui) and Rehmanniae Radix (Dihuang). The PCCMM pairs with the smallest distances are as follows: even–sweet–heart meridian and even–sweet–lung meridian, even–sweet–heart meridian and even–sweet–spleen meridian, and even–sweet–lung meridian and even–sweet–spleen meridian, which indicate that they often co-occur in ACFPs, suggesting a significant synergistic effect.
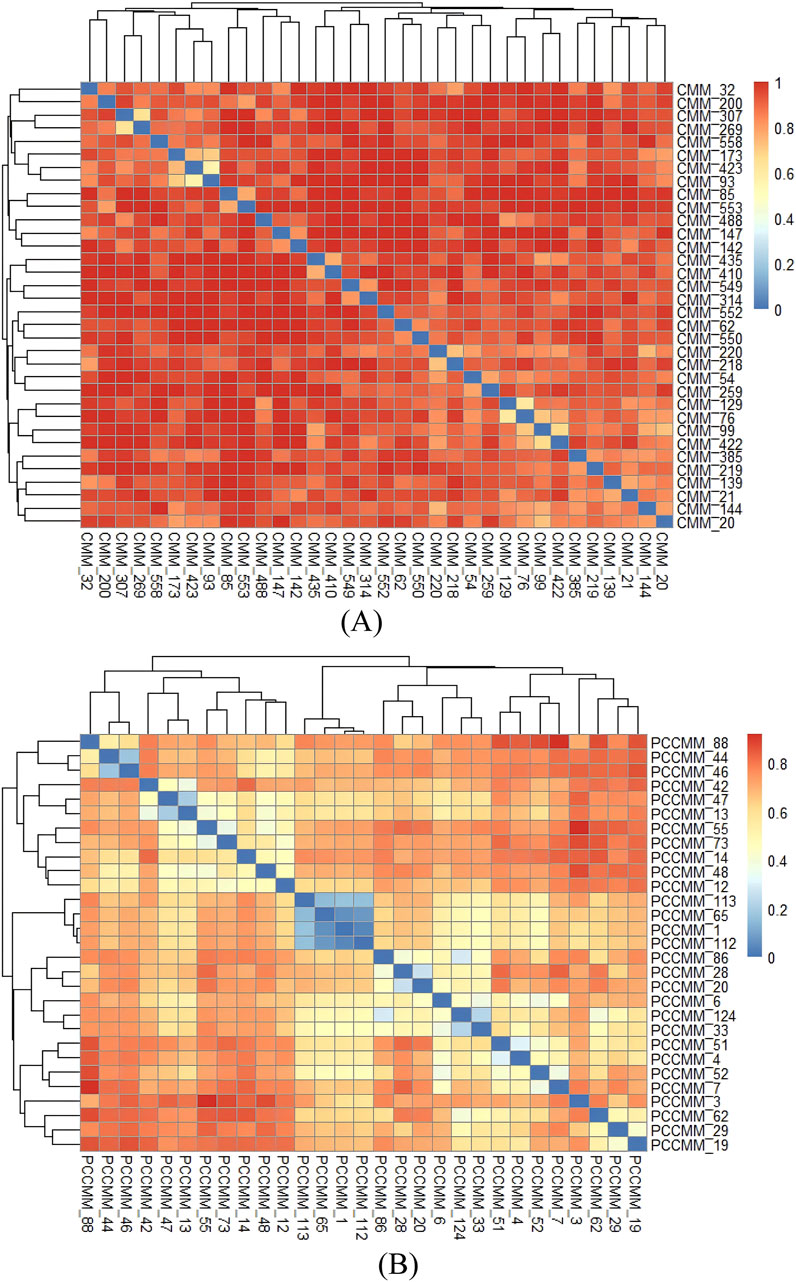
Figure 6. Distance of CMM pairs and PCCMM pairs of ACFPs. (A) Heatmap of the distance between CMM pairs. (B) Heatmap of the distance between PCCMM pairs. The colors of each cell represent the pairwise distance for CMM or PCCMM. Redder cells indicate larger distances, approaching 1, whereas bluer cells indicate smaller distances, approaching 0.
Correlation analysis was performed based on the Pearson correlation coefficient
4 Discussion
In contrast to the previous studies which primarily focused on individual prescriptions, our research systematically investigated the medication patterns of the catalog of ACFPs issued by the Chinese government. We constructed the forward and backward feature extraction processes from ACFPs to PCMM, and analyzed the medication patterns within ACFPs from the PCMM. Motivated by the sparsity feature of the TCM formulas, we employed the compressive sensing framework to establish the CMM–PCCMM network and introduced the combinatorial optimization problem to rebuild the ACFPs from their PCCMMs. The numerical results based on the ACFP datasets demonstrated that the PCCMM set is a quasi-equivalent representation of the TCM formulas and that PCCMMs outperform the nomenclature of CMMs in ACFP classification. Furthermore, PCCMM may facilitate the extraction of implicit compatibility patterns within ACFPs more effectively than CMM alone. The discussion is as follows.
4.1 The simplification of the combinatorial formula model
Using the compressive sensing framework, we showed the ability to recover the TCM formula from its PCCMM information via numerical experiments over the ACFP dataset and numerically demonstrated the legitimacy of the CMM–PCCMM network. We must point out that the quasi-linear measurement process in the combinatorial formula model is a simplified and qualitative model similar to HP-GCN (Liu et al., 2022), treating the CMMs and PCMMs as equal and independent contributors to the formula’s PCCMMs. However, the proportion of each CMM in TCM formulas varies, and previous studies have indicated significant internal correlation among the constituent CMMs in the TCM formulas (Zhang et al., 2024), suggesting important intrinsic links between PCMMs and the physicochemical properties and pharmacological actions of individual metabolites, as shown in the distribution pattern of PCMMs (Ung et al., 2007). Furthermore, among CMMs that share an identical PCMM, the potency of their PCMM is not uniform (Wei et al., 2022). As an essential basis for the composition of TCM formulas, we considered PCCMMs the minimum unit of efficacy characterization. In this study, we focus on the significance of PCCMM as a representation of the TCM formulas’ medication pattern from the perspective of feature extraction. For the sake of computational simplicity and tractability, we have adopted a simplified model that temporarily disregards the complex interactions between multiple efficacies and the variations in their effects, as well as other potential biological factors.
4.2 The generalizability and complexity of the sample problem set
First, the sample problem set covers more than
4.3 The influence across ethnic groups on the research framework
According to PTCMM, the herb properties of TCM include cold, hot, warm, cool, and even. In Tibetan medicine (Dangzhi et al., 2019), the properties are cold, hot, heavy, light, dull, sharp, moist, and rough. In Ayurveda medicine (Rastogi and Singh, 2021), the properties include heavy, greasy, cold, dull, light, rough, hot, and sharp. Similarly, in Mongolian medicine (Siqi et al., 2024), the properties include hot, cold, non-oily, heavy, light, sharp, viscous, and non-viscous. Despite subtle differences, all these medical traditions recognize cold and hot as fundamental properties of botanical drugs. The herb flavors in TCM encompass sour, bitter, sweet, pungent, salty, astringent, and bland. In contrast, Tibetan, Ayurveda, and Mongolian medicine do not include bland among their recognized flavors. Furthermore, multiple medical systems, extending beyond PCMM, consistently assert that the medicinal properties of botanical drugs are inextricably linked to their therapeutic efficacy. We must point out that although the medicinal properties of botanical drugs vary across different ethnic groups, their data structures are highly similar. These properties can be uniformly represented in a multi-tuple format, which is analogous to the PCCMM framework. This consistency allows for the construction of bipartite networks, making it feasible to apply the theoretical framework developed in this study for further analysis.
4.4 The universality of the constructed mathematical framework
The mathematical framework of the CMM–PCCMM network presented in our paper is general, allowing for the substitution of PCCMM with other linear or quasi-linear TCM measurement formulas. It is noteworthy that in another manuscript currently under review, we have applied the feature extraction-based framework developed in this study to identify core CMM pairs for alcoholic liver disease (ALD) and to analyze key active metabolites as well as their biological mechanisms in treating ALD. In that study, we constructed a CMM–target network based on HERB (Fang et al., 2020) and HIT2.0 (Yan et al., 2021). Through bioinformatics analysis, we established a protein–protein interaction network and identified hub genes associated with ALD. Based on clinically validated TCM formulas for ALD, the data mining approach combined with combinatorial optimization modeling identified the core CMM pair of Gardeniae Fructus (Zhizi) and Artemisiae Scopariae Herba (Yinchen). Previous experimental research (Tan et al., 2023) has confirmed the hepatoprotective properties of these botanical drugs. Furthermore, the model predicted that the biological mechanism of the core CMM pair may primarily involve the antioxidant and anti-inflammatory properties of quercetin, mediated by its inhibition of COL1A1 and COL3A1 expression. Molecular docking and molecular dynamics simulations demonstrated stable binding between quercetin and both COL1A1 and COL3A1, with strong binding energy and affinity. In this study, we further validate the versatility of the framework developed in the current research and provide novel insights to advance modern TCM research and development. In addition, one could examine other pharmacopoeias, such as the United States Pharmacopeia and National Formulary, to analyze the corresponding medication patterns using the mathematical framework outlined in the paper.
4.5 Advantages and prospects
Our work has the following significance:
(i) Providing a basis for the exploration of implicit compatibility patterns in TCM formulas based on PCCMM: unlike traditional methods that rely on CMMs, our approach introduces PCCMM as a novel approach for mining medication patterns of ACFPs. Our work enhances the capability of PCCMM for serving as a quasi-equivalent representation of TCM formulas. The classification and identification of ACFPs using PCCMM information yield superior results compared to using CMM information alone, providing a basis for the exploration of implicit compatibility patterns in TCM formulas based on PCCMM. Moreover, compared with CMMs, the PCCMM measurement is more applicable for research related to TCM formula datasets (rather than an individual prescription), for example, clustering TCM formulas and identifying shared features between different TCM formulas.
(ii) Exploring the implicit compatibility patterns of ACFPs using PCCMM: we found that the PCCMMs of ACFPs predominantly map to the even–sweet–spleen meridian. The number of associate rules derived from PCCMM significantly exceeded that derived from CMM, highlighting PCCMM’s advantage in mining hidden compatibility patterns. Data mining revealed positively and negatively correlated PCCMM pairs, potentially guiding the discovery of synergistic and contraindicated CMM combinations in TCM. For instance, The CMM pair with the strongest positive correlation is Jujubae Fructus (Dazao) and Zingiberis Rhizoma Recens (Shengjiang)
(iii) Providing a new perspective for designing new TCM formulas and optimizing existing TCM formulas: in this study, during the rebuilding of the ACFPs based on the combinatorial formula model, a new set of estimated values for CMMs was obtained under constrained conditions. For instance, the estimated values for CMMs derived from our model align more closely with the constraints than the original prescription (ACFP-2-46, LiuHe Decoction) and exhibit a reduced number of CMMs. A prescription with fewer CMMs yet unchanged or improved efficacy is one of the approaches to optimizing TCM formulas. Taking estimate 1 in Table 3 as an example, compared to the original ACFP, it excludes CMM-11, CMM-169, and CMM-405 while incorporating CMM-114 and CMM-145. Through a comprehensive review of Clinical Chinese Pharmacy (Zhang et al., 2020), we identified that the three excluded CMMs are commonly used in modern clinical practice for treating acute and chronic gastroenteritis, as well as gastrointestinal dysfunction. Notably, the two newly added CMMs exhibit similar therapeutic efficacy, particularly in managing chronic gastritis and gastrointestinal disorders. We hypothesize that this might represent an optimized version of LiuHe Decoction with a streamlined list of CMMs, potentially offering a new perspective for TCM formula optimization. Of course, further investigation in subsequent studies is necessary, where such sets of solutions should be further observed in conjunction with experts’ experience or clinical practice.
(iv) Facilitating Western medicine’s acceptance of TCM drug development: in this study, we selected ACPFs as representative samples of TCM formulas and developed a feature extraction model based on PCCMM to reveal their compatibility patterns. We utilized the Jaccard index to quantitatively assess the model’s ability to rebuild ACFPs; however, our CMM–PCCMM network does not depend on Jaccard similarity or any specific similarity measurement. We believe that incorporating quantifiable metrics like Jaccard similarity can enhance Western medical practitioners’ understanding of PTCMM and provide a clearer interpretation of CMM compatibility principles. This approach offers an objective perspective on TCM formulas’ principles based on PCMM.
4.6 Future works
The limited dataset used in the numerical experiments is the main drawback of our study. Both the CMM and PCCMM information are encoded as integer vectors in this study, which did not account for the impact of formula proportions on the properties of ACFPs. The impact of formula proportions on the properties of ACFPs has not been considered. Looking ahead, upon completion of the dosage verification for certain ACFPs, we will attempt to incorporate the dosage of CMMs in TCM formulas and combine it with the PCCMM measurements to refine the weighted PCCMM set vector and introduce the quantitative CMM–PCCMM network. Our long-term goal includes PCCMM-guided methods for TCM formula construction or optimization. Our study emphasizes the role of PCCMM in revealing the medication patterns of ACFPs from the perspective of systematic science. In general, the PCCMM characteristics can be determined by the substances beyond the scope of the CMM–PCCMM network, such as food, nutritional components, and chemical compositions, that is, the PCCMM information does not correspond to an underlying TCM formula. Building meaningful TCM formulas from these types of PCCMM information remains an open problem.
5 Conclusion
In this study, we constructed the forward and backward feature extraction processes from ACFPs to PCCMM, aiming to identify the implicit medication patterns of the ACFPs published by the Chinese government. We constructed the network from CMM to PCCMM based on ChP as the forward feature extraction process. As the backward process, we introduced constrained combinatorial optimization problems to rebuild the ACFPs from their PCCMMs. The two batches of ACFPs could essentially be rebuilt based on the PCCMM; however, the hyperparameter has a significant impact on the results. We also tested the capability of PCCMM in distinguishing ACFPs from random pseudo-formulas and classifying ACFPs of different deficiency syndromes. In both cases, PCCMM outperformed the nomenclature of CMM as the measurement. The numerical results demonstrated the well-posedness of the CMM–PCCMM network. The PCCMMs facilitate the analysis of TCM formulas, especially ACFPs, from the perspectives of systems science and compressive sensing. High-frequency CMMs were mainly tonic medicines, whereas PCCMMs predominantly mapped to the even–sweet–spleen meridian. The number of associate rules derived from PCCMM significantly surpassed that of those derived from CMM, demonstrating PCCMM’s superiority in uncovering hidden compatibility patterns. Notably, data mining revealed synergistic CMM pairs with low distances and correlations, such as Jujubae Fructus (Dazao) and Zingiberis Rhizoma Recens (Shengjiang), which aligns with clinical experience and provides data support for the synergistic use of CMMs. Furthermore, we identified negatively correlated CMM pairs and PCCMM pairs, which may guide the discovery of new potential contraindications in CMM combinations. Our study offers a novel method and insights into the mining of ACPFs’ medication patterns and provides clinicians with guidance on TCM formula use and design based on PCCMM.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author contributions
DQ: Conceptualization, Data curation, Formal analysis, Methodology, Visualization, and Writing – original draft. HZ: Conceptualization, Methodology, and Writing – review and editing. BD: Software, Validation, and Writing – review and editing. HW: Data curation and Writing – review and editing. LL: Data curation and Writing – review and editing. YW: Conceptualization, Funding acquisition, Project administration, Supervision, and Writing – review and editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by the National Natural Science Foundation of China under Grant No. 81973495.
Acknowledgments
The authors thank ZH’s mentor, Prof. Lei Zhang, at PKU for his unwavering support and guidance. ZH also thanks Prof. Chunwei Song at PKU for the helpful discussion on combinatorial matrix theory.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphar.2025.1551531/full#supplementary-material
Abbreviations
ACFP, ancient classic and famous prescription; ChP, Chinese Pharmacopoeia; CMM, Chinese medicinal material; PCMM, property of CMM; PCCMM, property combination of CMM; TCM, traditional Chinese medicine; t-SNE, t-distributed stochastic neighbor embedding.
References
Bastian, M., Heymann, S., and Jacomy, M. (2009). Gephi: an open source software for exploring and manipulating networks. Gephi open source Softw. Explor. Manip. Netw. 3, 361–362. doi:10.1609/icwsm.v3i1.13937
Bing, L. I., You-Juan, H., Si-Hong, L., Sha-Sha, L. I., Yan, D., Wei-Na, Z., et al. (2019). Key points and strategies of textual research in development of famous classical formulas. Chin. J. Exp. Traditional Med. Formulae 25. doi:10.13422/j.cnki.syfjx.20191646
Bo, K., Darío, G. G., Jefrey, L., Raúl, S.-R., and Tijl, D. B. (2021). Conditional t-SNE: more informative t-SNE embeddings. Mach. Learn. 110, 2905–2940. doi:10.1007/s10994-020-05917-0
Bushati, N., Smith, J., Briscoe, J., and Watkins, C. (2011). An intuitive graphical visualization technique for the interrogation of transcriptome data. Nucleic Acids Res. 39, 7380–7389. doi:10.1093/nar/gkr462
Candes, E. J., Romberg, J., and Tao, T. (2006). Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. theory 52, 489–509. doi:10.1109/tit.2005.862083
Chen, Y.-Y., Shen, J., Tang, Y.-P., Yu, J.-G., Wang, J., Yue, S.-J., et al. (2019). Elucidating the interaction of kansui and licorice by comparative plasma/tissue metabolomics and a heatmap with relative fold change. J. Pharm. Analysis 9, 312–323. doi:10.1016/j.jpha.2019.05.005
Chinese Pharmacopoeia Commission (2020). Pharmacopoeia of the people’s Republic of China, Vol. I. Beijing: China Medical Science Press.
Dangzhi, W., Dongzhi, G., Lamu, G., Wangjia, R., Xiangmao, Q., Gaicuo, D., et al. (2019). A New Quantitative Method of Tibetan Medicine Property-Construction of “Ro Nus Zhur Jes” Vector Structural Model. Chinese Journal of Experimental Traditional Medical Formulae, 25 (19), 147–154. doi:10.13422/j.cnki.syfjx.20190952
Donoho, D. (2006). Compressed sensing. IEEE Trans. Inf. theory 52, 1289–1306. doi:10.1109/TIT.2006.871582
Duan, Z., Liu, Y., Zhang, P., Hu, J. Y., Mo, Z. X., Liu, W. Q., et al. (2024). Da-Chai-Hu-Tang Formula inhibits the progression and metastasis in HepG2 cells through modulation of the PI3K/AKT/STAT3-induced cell cycle arrest and apoptosis. J. Ethnopharmacol. 331, 118293. doi:10.1016/j.jep.2024.118293
Efron, B. (1979). Bootstrap methods: another look at the jackknife. Ann. Statistics 7, 1–26. doi:10.1214/aos/1176344552
Fang, S., Dong, L., Liu, L., Guo, J., Zhao, L., Zhang, J., et al. (2020). HERB: a high-throughput experiment- and reference-guided database of traditional Chinese medicine. Nucleic Acids Res. 49, D1197–D1206. doi:10.1093/nar/gkaa1063
Foucart, S., and Rauhut, H. (2013). A mathematical introduction to compressive sensing (New York, NY: Springer Nature), 1;2013 edn.
Gao, Y., Wu, X., Zhao, N., and Bai, D. (2023). Scientific connotation of the compatibility of traditional Chinese medicine from the perspective of the intestinal flora. Front. Pharmacol. 14, 1152858. doi:10.3389/fphar.2023.1152858
Gong, L., Jiang, J., Chen, S., and Qi, M. (2023). A syndrome differentiation model of TCM based on multi-label deep forest using biomedical text mining. Front. Genet. 14, 1272016. doi:10.3389/fgene.2023.1272016
Guo, H.-X., Wang, J.-R., Peng, G.-C., Li, P., and Zhu, M.-J. (2022). A data mining-based study on medication rules of Chinese herbs to treat Heart failure with preserved ejection fraction. Chin. J. Integr. Med. 28, 847–854. doi:10.1007/s11655-022-2892-5
Hao, W., Chen, Z., Wang, L., Yuan, Q., Gao, C., Ma, M., et al. (2022). Classical prescription huanglian decoction relieves ulcerative colitis via maintaining intestinal barrier integrity and modulating gut microbiota. Phytomedicine 107, 154468. doi:10.1016/j.phymed.2022.154468
Hu, M., Li, H., Ni, S., and Wang, S. (2023). The protective effects of Zhi-Gan-Cao-Tang against diabetic myocardial infarction injury and identification of its effective constituents. J. Ethnopharmacol. 309, 116320. doi:10.1016/j.jep.2023.116320
Hu, Y., Sun, J., Wang, Y., and Qiao, Y. (2016). Property combination patterns of traditional Chinese medicines. J. Traditional Chin. Med. Sci. 3, 110–115. doi:10.1016/j.jtcms.2016.05.001
Jin, Y., Zhang, W., He, X., Wang, X., and Wang, X. (2020). “Syndrome-aware herb recommendation with multi-graph convolution network,” in 2020 IEEE 36th international conference on data engineering (ICDE), 145–156. doi:10.1109/ICDE48307.2020.00020
Lamer, A., Fruchart, M., Paris, N., Popoff, B., Payen, A., Balcaen, T., et al. (2022). Standardized description of the feature extraction process to transform raw data into meaningful information for enhancing data reuse: consensus study. JMIR Med. Inf. 10, e38936. doi:10.2196/38936
Li, D., Hu, J., Zhang, L., Li, L., Yin, Q., Shi, J., et al. (2022a). Deep learning and machine intelligence: new computational modeling techniques for discovery of the combination rules and pharmacodynamic characteristics of traditional Chinese medicine. Eur. J. Pharmacol. 933, 175260. doi:10.1016/j.ejphar.2022.175260
Li, J., Miao, B., Wang, S., Dong, W., Xu, H., Si, C., et al. (2022b). Hiplot: a comprehensive and easy-to-use Web service for boosting publication-ready biomedical data visualization. Briefings Bioinforma. 23, bbac261. doi:10.1093/bib/bbac261
Li, S., Hou, Y., Zhang, L., Dong, Y., Liu, S., Li, B., et al. (2022c). Historical evolution of xuanfu daizhe decoction. Zhongguo Zhong Yao Za Zhi 47, 4033–4041. doi:10.19540/j.cnki.cjcmm.20210927.301
Liao, X., Hu, K., Xie, X., Wen, Y., Wang, R., Hu, Z., et al. (2023). Banxia Xiexin decoction alleviates AS co-depression disease by regulating the gut microbiome-lipid metabolic axis. Journal of ethnopharmacology, 313, 116468. doi:10.1016/j.jep.2023.116468
Liu, G.-H., Yang, H.-T., Bai, L., Wang, Y., Wang, E.-L., Sun, X.-Y., et al. (2023). Data mining-based analysis on medication rules of Chinese herbal medicine treating headache with Blood stasis syndrome. Heliyon 9, e14996. doi:10.1016/j.heliyon.2023.e14996
Liu, J., Huang, Q., Yang, X., and Ding, C. (2022). HPE-GCN: predicting efficacy of tonic formulae via graph convolutional networks integrating traditionally defined herbal properties. Methods 204, 101–109. doi:10.1016/j.ymeth.2022.05.003
Liu, Y., Wang, X., Han, W., Li, L., Wu, R., Wang, Y., et al. (2024). Analysis of prescription rules for hyperlipidemia comorbid with hypertension based on latent structure model and association rules. Zhongguo Zhong Yao Za Zhi 49, 5045–5054. doi:10.19540/j.cnki.cjcmm.20240604.501
Miao, J., Huang, Y., Wang, Z., Wu, Z., and Lv, J. (2023). Image recognition of traditional Chinese medicine based on deep learning. Front. Bioeng. Biotechnol. 11, 1199803. doi:10.3389/fbioe.2023.1199803
Pang, K., Wan, Y.-W., Choi, W. T., Donehower, L. A., Sun, J., Pant, D., et al. (2014). Combinatorial therapy discovery using mixed integer linear programming. Bioinformatics 30, 1456–1463. doi:10.1093/bioinformatics/btu046
Pezzotti, N., Lelieveldt, B. P. F., Maaten, L. v. d., Höllt, T., Eisemann, E., and Vilanova, A. (2017). Approximated and user steerable tSNE for progressive visual analytics. IEEE Trans. Vis. Comput. Graph. 23, 1739–1752. doi:10.1109/TVCG.2016.2570755
Qian, Z., Xing-Xing, H., Chun-Qin, M., Hui, X., Li-Hong, C., Jing, M., et al. (2019). Opportunities and challenges in development of compound preparations of traditional Chinese medicine: problems and countermeasures in research of ancient classical prescriptions. Zhongguo Zhong Yao Za Zhi 44, 4300–4308. doi:10.19540/j.cnki.cjcmm.20190630.305
Qiao, Y., Zhang, Y., Peng, S., Huo, M., Li, J., Cao, Y., et al. (2022). Property theory of Chinese Materia Medica: clinical pharmacodynamics of traditional Chinese medicine. J. Traditional Chin. Med. Sci. 9, 7–12. doi:10.1016/j.jtcms.2022.01.006
Rani, M., Dhok, S. B., and Deshmukh, R. B. (2018). A systematic review of compressive sensing: concepts, implementations and applications. IEEE Access 6, 4875–4894. doi:10.1109/ACCESS.2018.2793851
Rastogi, S., and Singh, R. H. (2021). Principle of hot (ushna) and Cold (sheeta) and its clinical application in ayurvedic medicine. Adv. Exp. Med. Biol. 1343, 39–55. doi:10.1007/978-3-030-80983-6_4
Siqi, L., Dongxue, C., and Minhui, L. (2024). New thoughts on the theoretical study of property of Mongolian medicine. J. Med. Pharm. Chin. Minorities 30, 54–57. doi:10.16041/j.cnki.cn15-1175.2024.06.013
Su, J., Chen, X., Xie, Y., Li, M., Shang, Q., Zhang, D., et al. (2024). Clinical efficacy, pharmacodynamic components, and molecular mechanisms of antiviral granules in the treatment of influenza: a systematic review. J. Ethnopharmacol. 318, 117011. doi:10.1016/j.jep.2023.117011
Tan, Y., Zhang, F., Fan, X., Lu, S., Liu, Y., Wu, Z., et al. (2023). Exploring the effect of yinzhihuang granules on alcoholic liver disease based on pharmacodynamics, network pharmacology and molecular docking. Chin. Med. 18, 52. doi:10.1186/s13020-023-00759-z
Ung, C., Li, H., Kong, C., Wang, J., and Chen, Y. (2007). Usefulness of traditionally defined herbal properties for distinguishing prescriptions of traditional Chinese medicine from non-prescription recipes. J. Ethnopharmacol. 109, 21–28. doi:10.1016/j.jep.2006.06.007
Wang, J., Wu, Q., Ding, L., Song, S., Li, Y., Shi, L., et al. (2021a). Therapeutic effects and molecular mechanisms of bioactive compounds against respiratory diseases: traditional Chinese medicine theory and high-frequency use. Front. Pharmacol. 12, 734450. doi:10.3389/fphar.2021.734450
Wang, S., Tang, C., Zhao, H., Shen, P., Lin, C., Zhu, Y., et al. (2021b). Network pharmacological analysis and experimental validation of the mechanisms of action of Si-Ni-san against liver fibrosis. Front. Pharmacol. 12, 656115. doi:10.3389/fphar.2021.656115
Wei, G., Jia, R., Kong, Z., Ji, C., and Wang, Z. (2022). Cold-hot nature identification of Chinese herbal medicines based on the similarity of HPLC fingerprints. Front. Chem. 10, 1002062. doi:10.3389/fchem.2022.1002062
World Health Organization (2022). WHO international standard terminologies on traditional Chinese medicine. Geneva: World Health Organization.
Wu, J., and Guo, D. (2025). Systematic analysis of traditional Chinese medicine prescriptions provides new insights into drug combination therapy for pox. J. Ethnopharmacol. 337, 118842. doi:10.1016/j.jep.2024.118842
Xia, Z., Li, Q., and Tang, Z. (2023). Network pharmacology, molecular docking, and experimental pharmacology explored ermiao wan protected against periodontitis via the PI3K/AKT and NF-κB/MAPK signal pathways. J. Ethnopharmacol. 303, 115900. doi:10.1016/j.jep.2022.115900
Xiao, S., Liu, L., Sun, Z., Liu, X., Xu, J., Guo, Z., et al. (2022). Network pharmacology and experimental validation to explore the mechanism of qing-jin-hua-tan-decoction against acute Lung injury. Front. Pharmacol. 13, 891889. doi:10.3389/fphar.2022.891889
Xue, Q., Huang, S., Liu, L. X., Bai, S., Jiang, S., Ge, R. D., et al. (2024). Efficacy and dispensing patterns of TCM-acupuncture combinations in vascular dementia treatment: a meta-analysis and data mining analysis. Am. J. Transl. Res. 16, 6187–6207. doi:10.62347/ZYCW4830
Xue-Mei, Q., Yao, G., Jun-Sheng, T., Jie, X., Xiao-Xia, G., Yu-Zhi, Z., et al. (2019). Ideas and strategies from quality evaluation of Radix bupleurum for development of new anti-depressant drugs. Acta Pharm. Sin. 54. doi:10.16438/j.0513-4870.2019-0229
Yan, D., Zheng, G., Wang, C., Chen, Z., Mao, T., Gao, J., et al. (2021). HIT 2.0: an enhanced platform for herbal ingredients’ targets. Nucleic Acids Res. 50, D1238–D1243. doi:10.1093/nar/gkab1011
Yang, J., Wang, S., Zhang, Z., Huang, J., Chen, W., and Xu, Z. (2024). Analysis of medication rule of traditional Chinese medicine in treating depression based on data mining. Heliyon 10, e39245. doi:10.1016/j.heliyon.2024.e39245
Yang, M., Luo, J., Yang, Q., and Xu, L. (2021). Research on the medication rules of Chinese herbal formulas on treatment of threatened abortion. Complementary Ther. Clin. Pract. 43, 101371. doi:10.1016/j.ctcp.2021.101371
Zeng, X., Jia, Z., He, Z., Chen, W., Lu, X., Duan, H., et al. (2019). Measure clinical drug–drug similarity using electronic medical records. Int. J. Med. Inf. 124, 97–103. doi:10.1016/j.ijmedinf.2019.02.003
Zhang, B., et al. (2020). Clinical Chinese Materia Medica (Beijing, China: People’s Medical Publishing House). 2nd edn.
Zhang, P., Zhang, D., Zhou, W., Wang, L., Wang, B., Zhang, T., et al. (2024). Network pharmacology: towards the artificial intelligence-based precision traditional Chinese medicine. Briefings Bioinforma. 25, bbad518. doi:10.1093/bib/bbad518
Zhang, Y., Li, X., Shi, Y., Chen, T., Xu, Z., Wang, P., et al. (2023a). ETCM v2.0: an update with comprehensive resource and rich annotations for traditional Chinese medicine. Acta Pharm. Sin. B 13, 2559–2571. doi:10.1016/j.apsb.2023.03.012
Zhang, Y., Li, X., Shi, Y., Chen, T., Xu, Z., Wang, P., et al. (2023b). ETCM v2.0: an update with comprehensive resource and rich annotations for traditional Chinese medicine. Acta Pharm. Sin. B 13, 2559–2571. doi:10.1016/j.apsb.2023.03.012
Zhao, L., Qian, S., Wang, X., Si, T., Xu, J., Wang, Z., et al. (2024). UPLC-Q-Exactive/MS based analysis explore the correlation between components variations and anti-influenza virus effect of four quantified extracts of Chaihu Guizhi decoction. J. Ethnopharmacol. 319, 117318. doi:10.1016/j.jep.2023.117318
Zhao, W., Lu, W., Li, Z., Zhou, C., Fan, H., Yang, Z., et al. (2022). TCM herbal prescription recommendation model based on multi-graph convolutional network. J. Ethnopharmacol. 297, 115109. doi:10.1016/j.jep.2022.115109
Zheng, Q., Mu, X., Pan, S., Luan, R., and Zhao, P. (2023). Ephedrae Herba: a comprehensive review of its traditional uses, phytochemistry, pharmacology, and toxicology. J. Ethnopharmacol. 307, 116153. doi:10.1016/j.jep.2023.116153
Zhou, J., Yu, S., Wang, B., Wei, X., Zhang, L., and Shan, M. (2023). Chemical profiling and quantification of yihuang decoction by high performance liquid chromatography coupled with quadrupole time-of-flight mass spectrometry and a diode array detector. J. Pharm. Biomed. Anal. 224, 115199. doi:10.1016/j.jpba.2022.115199
Keywords: ancient classic and famous prescription, Chinese materia medica, property of Chinese materia medica, medication pattern, feature extraction, combinatorial optimization
Citation: Qin D, Zhang H, Du B, Wang H, Liu L and Wang Y (2025) Understanding the ancient classic and famous prescriptions via the property of Chinese materia medica. Front. Pharmacol. 16:1551531. doi: 10.3389/fphar.2025.1551531
Received: 25 December 2024; Accepted: 14 April 2025;
Published: 12 May 2025.
Edited by:
Suresh Kumar Mohankumar, Swansea University Medical School, United KingdomReviewed by:
Kalpana Raja, Yale University, United StatesBalu Bhasuran, Florida State University, United States
Li-Ching Wu, National Central University, Taiwan
Copyright © 2025 Qin, Zhang, Du, Wang, Liu and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yun Wang, d2FuZ3l1bkBidWNtLmVkdS5jbg==