 Jidong Lang1
†
Jidong Lang1
†
 Kaimin Guo
1
†Jinna Yang1Pengcheng Yang1Yu Wei1Jingwen Han1Shuang Zhao1Zhihong Liu2Haowei Yi2Xin Yan2Binbin Chen1Cheng Wang1Jian Xu1Jiawei Ge1Wen Zhang1
Kaimin Guo
1
†Jinna Yang1Pengcheng Yang1Yu Wei1Jingwen Han1Shuang Zhao1Zhihong Liu2Haowei Yi2Xin Yan2Binbin Chen1Cheng Wang1Jian Xu1Jiawei Ge1Wen Zhang1
 Xuezhong Zhou
3
Xuezhong Zhou
3
 Jiansong Fang
4Jing Su1Kaijing Yan1
Jiansong Fang
4Jing Su1Kaijing Yan1
 Yunhui Hu
1*Wenjia Wang1*
Yunhui Hu
1*Wenjia Wang1*- 1 Tianjin Tasly Digital Intelligence Chinese Medicine Technology Co., Ltd., Tianjin, China
- 2 Wecomput Technology Co., Ltd., Beijing, China
- 3 Department of Artificial Intelligence, Beijing Key Laboratory of Traffic Data Mining and Embodied Intelligence, School of Computer Science & Technology, Beijing Jiaotong University, Beijing, China
- 4 State Key Laboratory of Traditional Chinese Medicine Syndrome, Science and Technology Innovation Center, Guangzhou University of Chinese Medicine, Guangzhou, China
Introduction: In recent years, the increasing complexity and volume of data in traditional Chinese medicine (TCM) research have rendered the conventional experimental methods inadequate for modern TCM development. The analysis of intricate TCM data demands proficiency in multiple programming languages, artificial intelligence (AI) techniques, and bioinformatics, posing significant challenges for researchers lacking such expertise. Thus, there is an urgent need to develop user-friendly software tools that encompass various aspects of TCM data analysis.
Methods: We developed a comprehensive web-based computing platform, SZBC-AI4TCM, a comprehensive web-based computing platform for traditional Chinese medicine that embodies the “ShuZhiBenCao” (Digital Herbal) concept through artificial intelligence, designed to accelerate TCM research and reduce costs by integrating advanced AI algorithms and bioinformatics tools.
Results: Leveraging machine learning, deep learning, and big data analytics, the platform enables end-to-end analysis, from TCM formulation and mechanism elucidation to drug screening. Featuring an intuitive visual interface and hardware–software acceleration, SZBC-AI4TCM allows researchers without computational backgrounds to conduct comprehensive and accurate analyses efficiently. By using the TCM research in Alzheimer’s disease as an example, we showcase its functionalities, operational methods, and analytical capabilities.
Discussion: SZBC-AI4TCM not only provides robust computational support for TCM research but also significantly enhances efficiency and reduces costs. It offers novel approaches for studying complex TCM systems, thereby advancing the modernization of TCM. As interdisciplinary collaboration and cloud computing continue to evolve, SZBC-AI4TCM is poised to play a strong role in TCM research and foster its growth in addition to contributing to global health. SZBC-AI4TCM is publicly for access at https://ai.tasly.com/ui/\#/frontend/login.
1 Introduction
Traditional Chinese medicine (TCM) is a valued aspect of Chinese heritage, with a long history and widespread use. It encompasses substances and approaches used for the prevention, diagnosis, and treatment of diseases, as well as rehabilitation and health maintenance. The substances are derived primarily from natural sources, such as plants, animals, minerals, and some chemical and biological products, with plant-derived products being predominant. Its pharmacological theories, such as “four natures and five flavors”, “ascending-descending-floating-sinking”, “meridian tropism”, “toxicity”, “compatibility”, and “contraindications”, are applied in clinical practice through the “syndrome differentiation and treatment” approach. Unlike Western medicine, which often targets single component or pathway, TCM operates through a multi-components, multi-target paradigm, which presents unique challenges in research, such as complex compositions, unclear mechanisms, and quality control issues. Although traditional experimental methods have contributed to the development of TCM, their time and resource requirements can be prohibitive.
Recent advances in bioinformatics, computational biology, and artificial intelligence (AI) have opened new avenues for TCM research. These techniques can improve efficiency and success rates across the entire research and drug development pipelines, from initial discovery to clinical trials (Zhang et al., 2024; Wu et al., 2024a; Zhang et al., 2022; Li and Zhang, 2023; Chu et al., 2020; Song et al., 2024). For example, AlphaFold3 can accurately predict the 3D structures of biological molecules (e.g., proteins, DNA, and RNA) and their interactions, offering immense potential for disease research and drug delivery innovation (Abramson et al., 2024). The AutoDock suite enables efficient virtual screening of molecular docking and can facilitate structure-based drug design within approximately 5 hours (Forli et al., 2016; Eberhardt et al., 2021; Trott and Olson, 2010). Song et al.’s compositional message passing neural network predicts the absorption, distribution, metabolism, excretion, and toxicity properties of molecules, which can increase drug development success rates while reduce costs (Song et al., 2020).
Despite these advancements, computational applications in TCM face significant hurdles. First, the complexity and diversity of TCM data pose challenges related to data collection and standardization. Second, the generalizability of AI models and bioinformatics tools in the TCM context is often constrained by the unique characteristics of TCM data, a factor that has spurred the proliferation of specialized tools. These challenges demand significant efforts from researchers to gather and deploy resources, including high-performance GPUs and other costly hardware. Finally, many tools are difficult to deploy and lack user-friendliness due to their reliance on advanced programming and server maintenance skills, which further impedes the efficiency and modernization of TCM research.
To address these challenges, we developed SZBC-AI4TCM, a comprehensive web-based platform that integrates cutting-edge AI algorithms and bioinformatics tools to streamline TCM research. The platform combines a user-friendly and interactive visualization framework with hardware acceleration and leverages server and high-performance computing resources to expedite data analysis. Designed for accessibility, it caters particularly to wet-lab researchers and those without programming expertise. To demonstrate its utility, we present the TCM research related to Alzheimer’s disease (AD) as an example, showcasing its capabilities in data mining, drug screening, and mechanism analysis based on network pharmacology and molecular docking.
2 Materials and methods
2.1 Web-based framework design
The platform utilizes the WeMol computational framework (https://wemol.wecomput.com), developed by Wecomput Technology Co., Ltd., to manage and maintain the analytical modules. WeMol incorporates state-of-the-art streaming architecture, data standardizing capability, modules, workflows, and tasks into its computational processes. This allows users to efficiently manage data, AI tools, workflows, and computational jobs (Figure 1). The framework includes integrated plugins for molecule editing and visualization, such as WeDraw (small molecule editing), WeView (molecular structure visualization), WeSeq (macromolecular sequence editing), and WeVec (gene sequence editing).
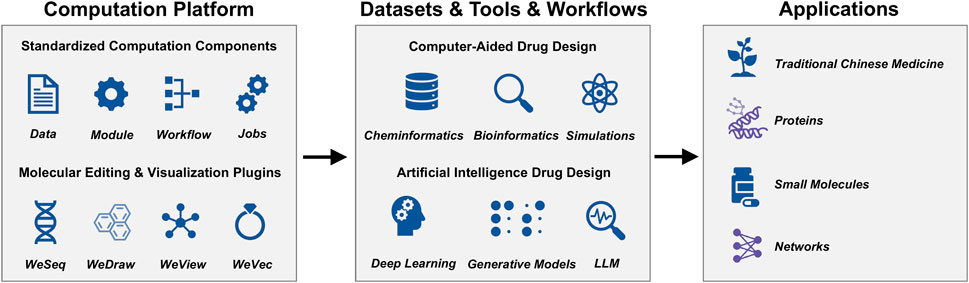
Figure 1. Schematic of the WeMol platform framework.
2.2 SZBC-AI4TCM platform and features
As Figure 2 shows, SZBC-AI4TCM has a web-based user interface, which allows users to use it easily and interactively. The platform currently comprises 67 analytical modules, mainly categorized into five functional groups: TCM analysis (5 modules), protein analysis (7 modules), small-molecule analysis (15 modules), network analysis (10 modules), and databases (9 modules). Other functions are scattered or still in development (total of 21 such modules). These modules relate to TCM formulation analysis, mechanism elucidation, and drug screening (Figure 2; Supplementary Table S1). Three example workflows are provided: Network Pharmacology Analysis Workflow, Network Framework for Drug Re-purposing Workflow, and Knowledge Graph Analysis Workflow. The platform is hosted on a Dell PowerEdge R730XD server featuring an Intel(R) Xeon(R) CPU E5-2673 v4 @ 2.30 GHz (80 threads), 250 GB of memory, and an NVIDIA GeForce RTX 2080 Ti GPU. The operating system is CentOS Linux 8. As an illustration, the Network Pharmacology Analysis Workflow requires approximately 6 min to process a query for “diabetes” with the listed botanical drugs (salvia miltiorrhiza, panax notoginseng and borneol in chinese input), delivering the core network gene set, enrichment analysis, and visualization. Similarly, the Molecular Docking module completes an analysis of a receptor (1STP.pdb) against 100 ligands (demo_100_3D.sdf) under a rigid model in roughly 8 min. This performance markedly enhances analytical throughput and accelerates research development. Users can customize workflows but may need additional modules for integration. For intelligent querying, the platform incorporates Max Knowledge Base (https://github.com/1Panel-dev/MaxKB), an open-source quality assurance system based on large language models (LLMs) and retrieval-augmented generation powered by the Qwen-72B LLM. This feature offers real-time support, helping users resolve queries and understand tools/methods with minimal learning effort. Due to computational and security constraints, this feature is currently limited to intranet access.
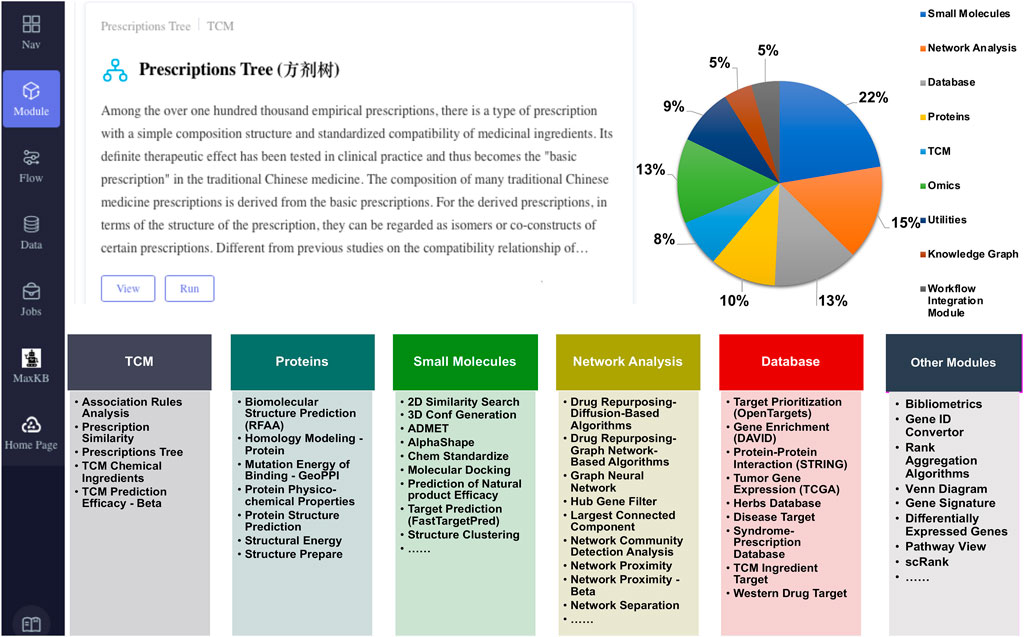
Figure 2. Overview of the SZBC-AI4TCM platform. Upper part: User interface and proportional distribution by functional group; Lower part: List of the modules within each main group.
3 Results
3.1 Statistical depiction and analysis of TCM formulations
The SZBC-AI4TCM platform provides system analysis modules related to TCM, including retrieval of disease-related formulations from the TCM prescription database, analysis of the association rules of formulations, and analysis of formulations similarity. On this platform, we named the prescription database as the “Syndrome-Prescription Database”, which contains a total of 3,716 formulations. To illustrate our research and the application of the platform’s modules, we take Alzheimer’s disease (AD) as an example. First, we conducted a search using “Alzheimer’s disease” as the keyword. This search retrieved 399 AD-related formulations (Supplementary Tables S1,S2), all of which represent potential therapeutic or interventional strategies for AD.
Using the “Association Rules Analysis” module, we performed a frequency analysis of the individual botanical drugs and botanical drug combinations mentioned in the 399 retrieved formulations (Supplementary Tables S1,S2). The results revealed the top 10 most frequently used botanical drugs (Figure 3A), including Yuan Zhi (Polygalae Radix), Ren Shen (Ginseng Radix Et Rhizoma), Fu Ling (Poria), Shi Chang Pu (Acori Tatarinowii Rhizoma), Dang Gui (Angelicae Sinensis Radix), Fu Shen (Poria cum radix pini.), Gan Cao (Glycyrrhizae Radix Et Rhizoma), Mai Dong (Ophiopogonis Radix), Shu Di Huang (Rehmanniae Radix Praeparata), and Suan Zao Ren (Ziziphi Spinosae Semen). Numerous studies have reported the therapeutic potential of the aforementioned botanical drugs for AD. For example, in Liu et al.’s study, Polygalae Radix (Yuan Zhi) was shown to alleviate cognitive decline in AD mouse models by mitigating
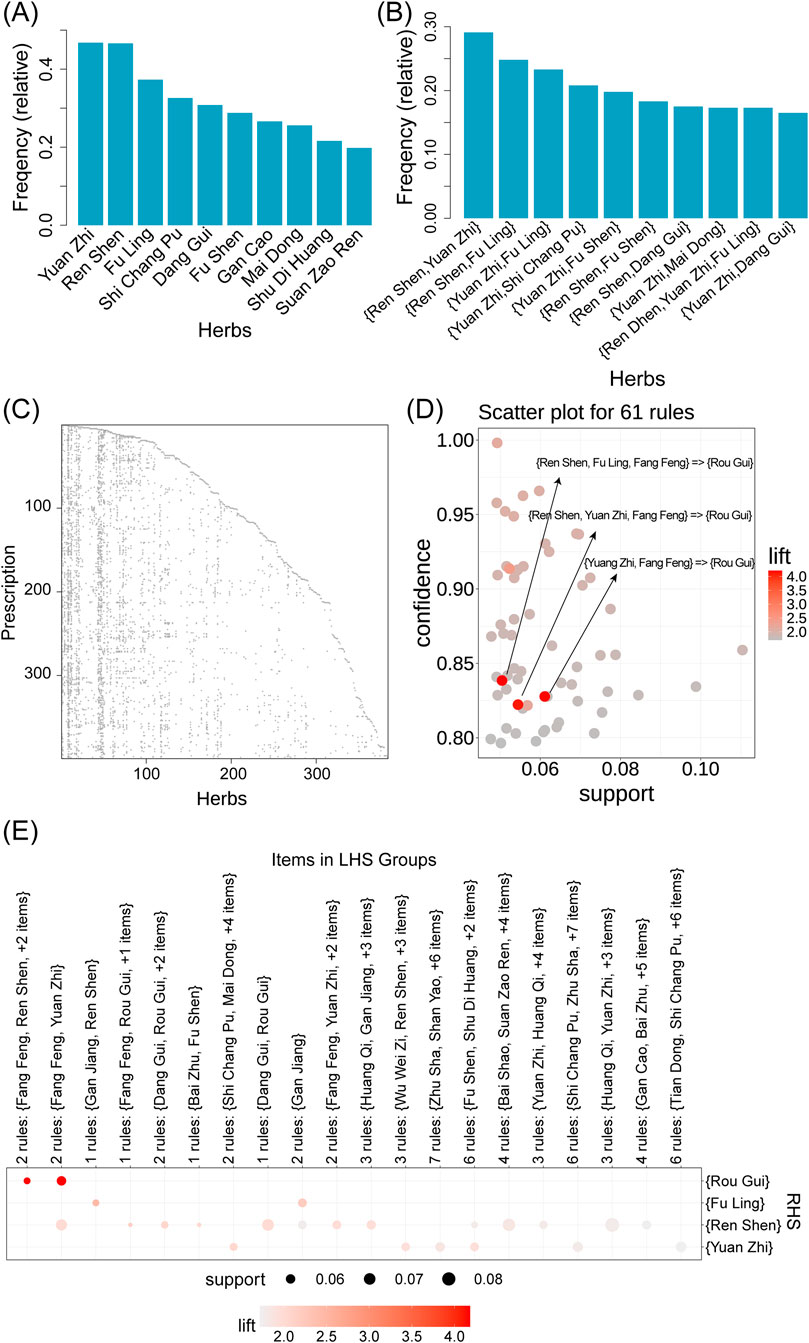
Figure 3. Analysis of 399 formulations related to Alzheimer’s disease using the SZBC-AI4TCM platform. (A) Frequency of simple botanical drug. (B) Frequency of combination of two or more botanical drugs. (C) Scatter plot showing the distribution of botanical drugs in the formulations. (D) Scatter plot for 61 association rules. (E) Visualization of items in the left-hand side groups of the association rules. The size of the dot represents support value, and the color represents the lift valuer.
The frequency analysis of botanical drugs revealed synergistic relationships between botanical drug pairs. Notably, Ren Shen and Yuan Zhi co-occurred in 116 of 399 (29%) formulations, and Ren Shen with Fu Ling (25%) and Yuan Zhi with Fu Ling (23%) also exhibited high co-occurrence frequencies (Figure 3B; Supplementary Tables S1,S2). Using the “Association Rules Analysis” module that employs the apriori algorithm, we systematically mined botanical drug combinations from the 399 formulations associated with AD (Figure 3C) (Hahsler et al., 2005). With the parameter settings of support threshold = 0.05 and confidence threshold = 0.8, 61 statistically significant botanical drug association rules were identified (Figures 3D,E; Supplementary Tables S2,S3). In the Apriori algorithm, lift quantifies the enhancement effect of the antecedent occurrence on the consequent occurrence. A lift value
For formulation similarity analysis, pairwise comparisons of the 399 AD-related formulations were conducted using the “Formula Similarity” module (Supplementary Tables S2–S4). The results demonstrated that some formulation pairs exhibited high similarity in botanical drug composition, suggesting they may originate from the same theoretical system (e.g., TCM syndrome differentiation principles) or shared clinical empirical knowledge, with potential common therapeutic mechanisms against AD.
Based on the association rules analysis results (Supplementary Tables S2,S3), we ranked the 61 filtered botanical drug combinations by their support value and selected seven key botanical drugs from the top four rules for AD targeted formulation screening. These botanical drugs were Fu Ling, Rou Gui, Ren Shen, Fang Feng, Yuan Zhi, Mai Dong, and Shu Di Huang. All of these had high-frequency occurrence and robust association rules. Therefore, formulations containing all seven botanical drugs were hypothesized to possess good therapeutic efficacy. Among the 399 formulations, only three contain all these seven botanical drugs (Table 1). The taxonomic and medicinal details of botanical drugs in the three formulations are detailed in Supplementary Tables S2–S5. One of them is a formulation named “Shuyu Wan”, which has been previously associated with AD treatment (Zhou, 2022; Cheng et al., 2021; Ma et al., 2022; Qiu, 2020). In the subsequent sections, we use the Shuyu Wan as a representative example of a formulation to demonstrate our platform’s functional modules.

Table 1. Details of three formulations selected based on the botanical drug frequency and association rules.
3.2 Comprehensive analysis at the disease level
For disease-related analysis, the SZBC-AI4TCM platform offers a suite of powerful analytical modules to facilitate in-depth exploration of the disease mechanisms. Using AD as a case study, we demonstrate the integrated application of five core modules: 1) “Disease Target”; 2) “Protein–Protein Interaction (STRING)”; 3) “Hub Genes Identification”; 4) “Largest Connected Component”; and 5) “Gene Enrichment (DAVID)”.
3.2.1 Disease Target module
This module enables rapid screening of disease associated genes across multiple integrated databases. The platform consolidates data from DisGeNET (Piñero et al., 2016), eDGAR (Babbi et al., 2017), GWAS (Hindorff et al., 2009), Pharos (Kelleher et al., 2022), MalaCards (Rappaport et al., 2013), and 23 sub-databases under the Open Targets Platform (Koscielny et al., 2016). We queried it with the keyword “Alzheimer’s disease”. For this study, we selected the DisGeNET database as a representative source. After filtering the entries without valid gene IDs, 3,384 AD-related genes were identified (Supplementary Tables S1–S3), including well-established pathogenic genes such as APP, PSEN1, and PSEN2. This module can substantially increase researchers’ efficiency in aggregating disease–gene associations from heterogeneous databases.
3.2.2 Protein–protein interaction (STRING) module
This module integrates the functional components from the STRING database to enable direct protein–protein interaction (PPI) network analysis of disease related genes (Mering et al., 2003). Inputting the 3,384 AD-related genes into this module with a confidence threshold set to 0.9 (i.e., retaining only the highest confidence interactions) yielded 11,268 PPI pairs involving 2,778 disease-associated genes (Supplementary Tables S2,S3).
3.2.3 Hub Genes Identification module
Hub genes in a disease gene network play pivotal roles in determining the modular characteristics of the network. In a disease gene network, hub genes tend to be involved in regulating biological processes or pathological states. The identification of hub genes aims to pinpoint key regulators within complex gene networks that critically influence biological functions or disease progression, thus providing essential insights into pathogenesis, therapeutic target discovery, and drug development.
The SZBC-AI4TCM platform employs the PageRank algorithm for hub gene prioritization (Page et al., 1999). This algorithm assigns importance scores to genes based on their topological positions within the PPI network, where in higher scores indicate greater functional significance and network centrality. The AD-associated PPI network comprised 2,778 gene nodes and 11,268 interactions (Supplementary Tables S2,S3). This module generated quantified the score for each node. Subsequently, ranking the genes by descending scores enabled systematic identification of disease-relevant hub genes (Supplementary Tables S3–3). The top 20 highest-scoring genes are visualized in Figure 4A.
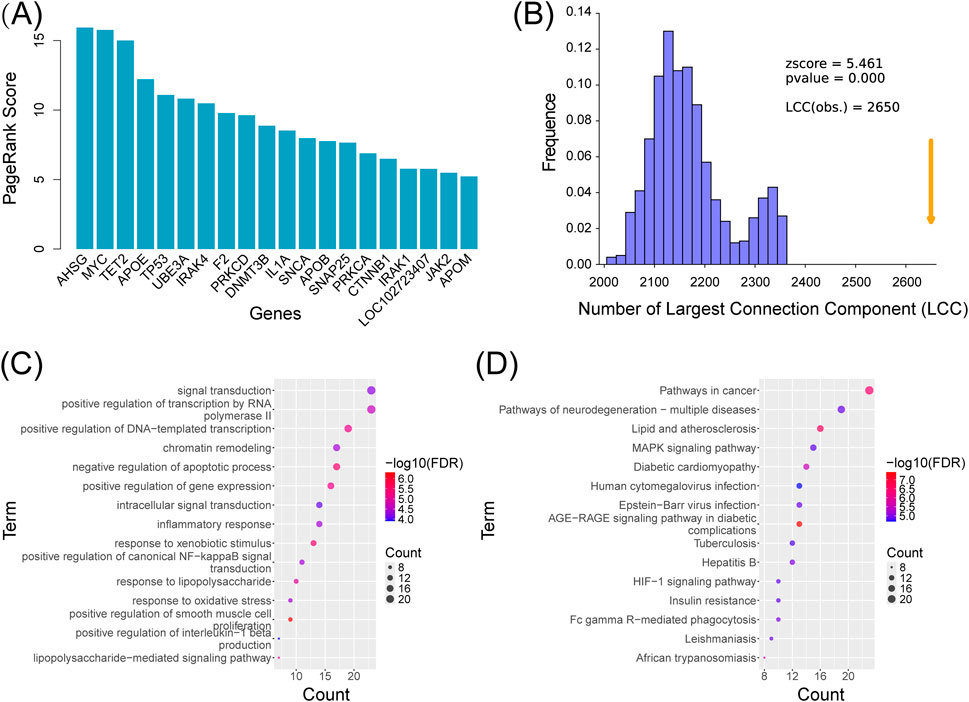
Figure 4. Analysis of Alzheimer’s disease–associated genes using the SZBC-AI4TCM platform. (A) Top 20 prioritized genes associated with Alzheimer’s disease by the PageRank algorithm deployed on the platform. (B) Analysis of the largest connected components for genes associated with Alzheimer’s disease. (C) GO enrichment analysis. (D) KEGG enrichment analysis.
3.2.4 Largest connected component module
Numerous studies indicate that disease-associated genes are not randomly distributed in PPI networks but tend to form interconnected sub networks, existing as cohesive “communities” within the global network (Goh et al., 2007). Largest connected component (LCC) analysis identifies the largest and most densely interconnected sub network (“community”) in disease gene networks. This approach enables the extraction of the maximally connected disease sub-network while facilitating, through comparison with randomly sampled networks, an accuracy assessment of the identified disease genes-ones that can represent the disease to a certain extent. Using the SZBC-AI4TCM platform, we performed LCC analysis on the 2,778 AD-related genes. The resultant LCC contained 2,650 genes with 32,686 interactions (Supplementary Tables S3,S4). Comparative analysis with 1,000 randomly sampled networks (matched in gene number) demonstrated that AD-associated genes exhibited significantly higher connectivity (permutation test,
3.2.5 Gene Enrichment (DAVID) module
This module enables Gene Ontology (GO) and Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway analyses of disease-associated genes. Using the top 100 AD related hub genes prioritized by the PageRank scores (Supplementary Tables S2,S3), we performed functional enrichment analysis to identify the significantly overrepresented biological processes and pathways. The GO analysis revealed enrichment in critical AD-related processes, including inflammatory response (GO:0006954,
3.3 Network pharmacology and molecular docking
The SZBC-AI4TCM platform enables systematic network pharmacology analysis relating to TCM through the following workflow: 1) Herbal metabolite extraction (“TCM Ingredient Target” module); 2) Target retrieval (“TCM Ingredient Target” module); 3) Target–gene comparative analysis (“Venn Diagram” module); 4) Network proximity analysis (“Network Proximity” module); 5) Molecular docking (“Molecular Docking” module). Using the formulation, Shuyu Wan, which is an AD targeting formulation identified in the previous analysis as a representative case, we demonstrate the integrated application of this analytical framework.
Using the “TCM Ingredient Target” module of the SZBC-AI4TCM platform, we analyzed data from the HIT2 database. After filtering out the entries lacking valid gene IDs, 143 bioactive metabolites derived from 14 botanical drugs in Shuyu Wan were mapped to 2,083 genes, averaging approximately 14 genes per metabolite (Figure 5A; Supplementary Tables S1–S4). Removing duplication yielded 745 unique genes, indicating that multiple metabolites might target same genes. The CASP3 gene exhibited the highest metabolite association (36 metabolites), followed by 14 genes each linked to
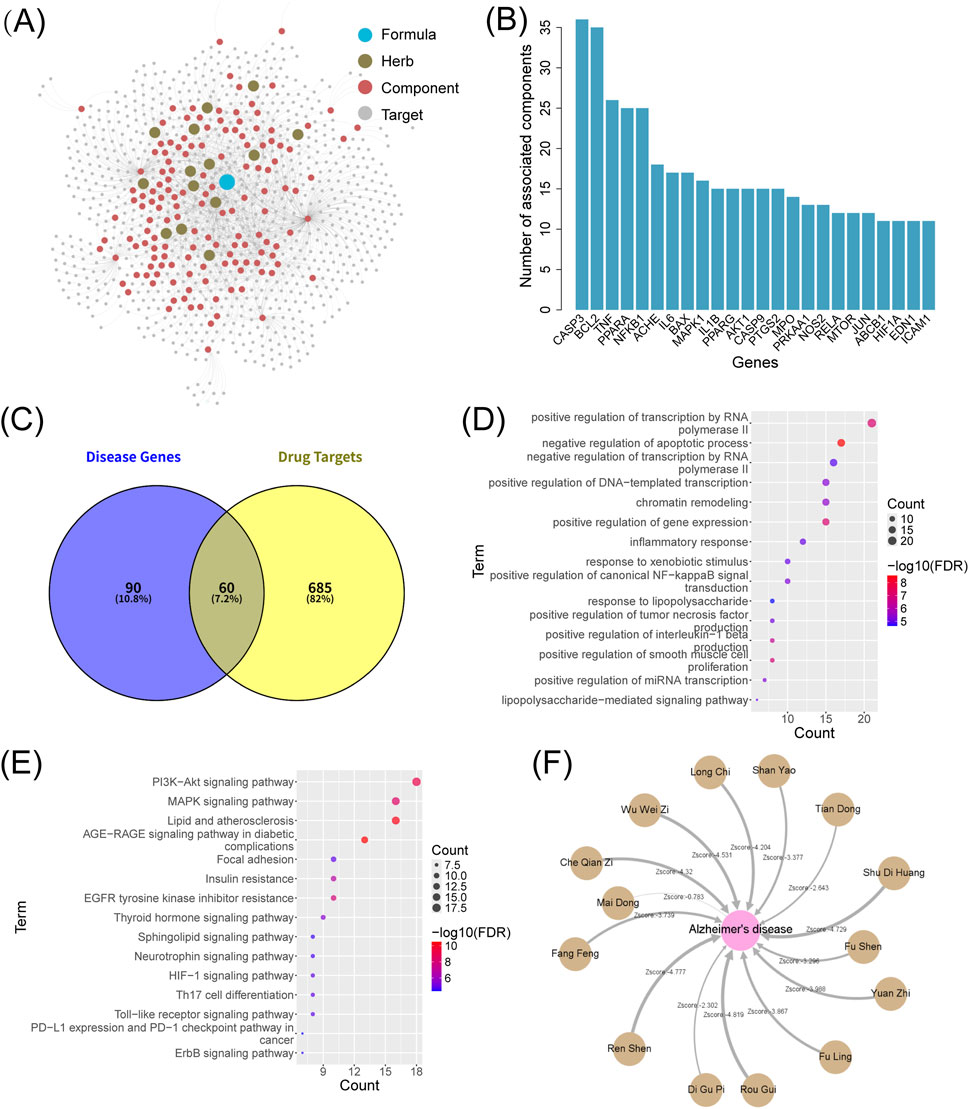
Figure 5. Network pharmacology analysis for the formulation Shuyu Wan using the SZBC-AI4TCM platform. (A) Network of formulation–botanical drugs–metabolites–targets. (B) Number of metabolites associated with targets (only showing targets with number of metabolites more than 10). (C) Venn diagram between the genes associated with AD (the top 150 prioritized genes) and the formulation’s targets. (D) GO enrichment analysis, and (E) KEGG enrichment analysis of the overlapping genes between the AD gene set and drug target gene set. (F) Network proximity analysis between botanical drugs in the formulation and AD. All Zscores are less than 0, and the weight of the edges in network represents the magnitude of the Zscore.
Using the “Network Proximity” module, we systematically assessed the therapeutic potential of Shuyu Wan against AD at both the botanical drug and metabolite levels. In the botanical drug-level analysis, target sets for each botanical drug were constructed by aggregating the non-redundant targets and all their metabolites. Network proximity analysis between the 14 botanical drugs and the AD gene set revealed that all botanical drugs exhibited negative Zscores. Lower values of the Zscore may indicate stronger therapeutic relevance. Notably, 11 out of 14 botanical drugs had Zscore
We also validated bioactive metabolites using the platform’s functionality. We employed the “Molecular Docking” module to predict binding modes and interactions and obtained binding energy and affinity data. Target selection was performed based on the metabolite–target list (Supplementary Tables S1–S4), where 24 targets associated with more than 10 metabolites were prioritized, including ACHE (acetyl-cholinesterase) and PPARG (peroxisome proliferator activated receptor gamma) (Supplementary Tables S4–S5). ACHE was linked to 15 metabolites: chlorogenic acid, ethanol, bisphenol A, caffeic acid, ginsenoside Rg1,
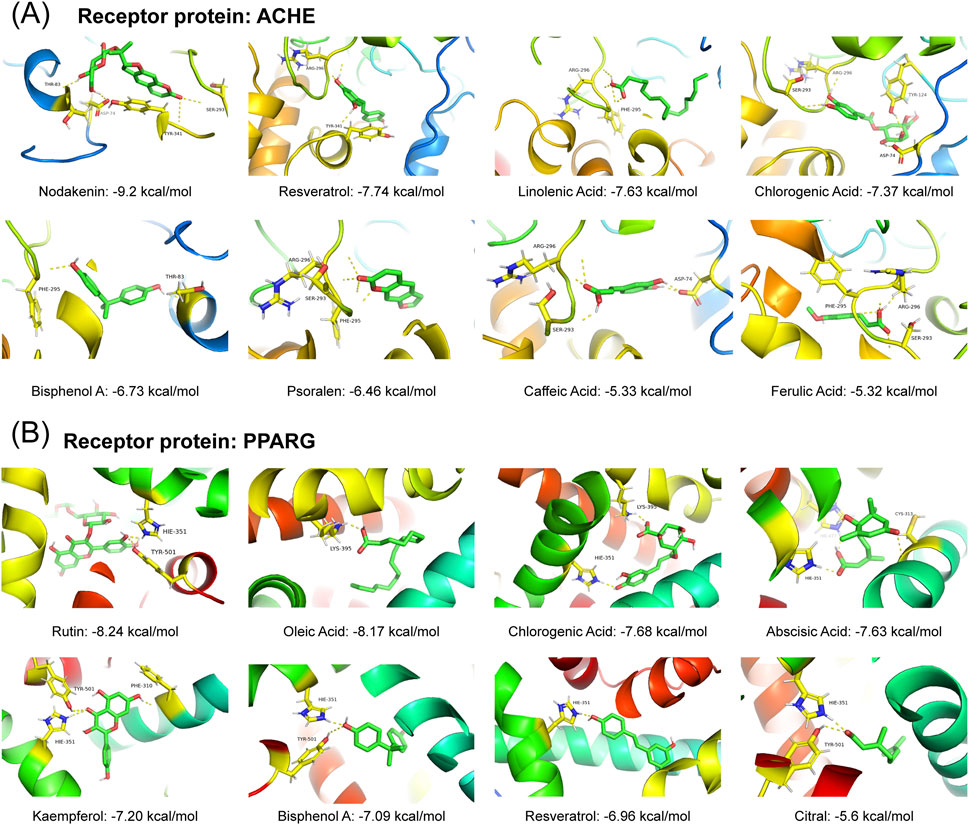
Figure 6. Visualization of the molecular docking of different ligands with the corresponding receptor protein. (A) ACHE as the receptor protein. (B) PPARG as the receptor protein. The corresponding score indicates the binding energy (kcal/mol).
3.4 Drug screening
We retrieved RNA-seq raw count data (GSE159699) from the Gene Expression Omnibus (GEO) database, comprising 30 temporal lobe samples (12 AD cases and 18 controls) (Supplementary Tables S1–S5) (Nativio et al., 2020). Using the “Differentially Expressed Genes” module with the thresholds of
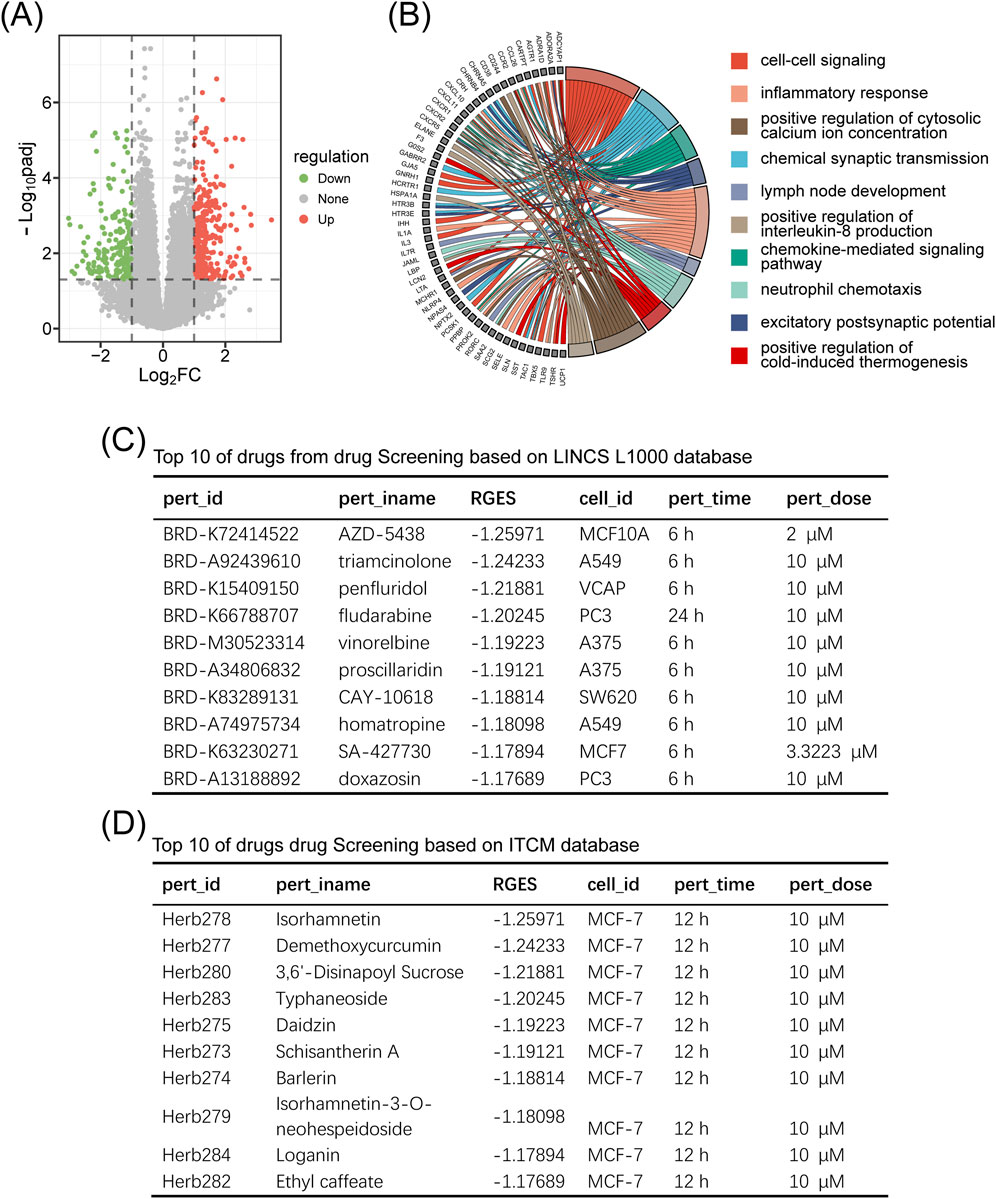
Figure 7. Drug screening using the SZBC-AI4TCM platform. (A) Volcano plot showing gene expression changes between cases and controlsfor Alzheimer’s disease (GSE159699). (B) GO enrichment analysis of the differential expression genes. (C) Top 10 drugs from the drug screening based on the LINCS L1000 database. (D) Top 10 drugs from the drug screening based on the ITCM database.
The “Gene Signature” module was employed to identify potential therapeutics for AD using the LINCS (Library of Integrated Network based Cellular Signatures) L1000 and ITCM (Integrated Traditional Chinese Medicine) databases (Supplementary Tables S4–S5). This module calculates a disease-reversion score by quantifying the ability of compounds to reverse disease-specific gene expression patterns. Negative scores indicate reversal of AD-associated expression (therapeutic potential), and positive score suggest synergy with disease mechanisms (therapeutic risk). The top 10 ranked small molecules (LINCS) and natural products (ITCM) are shown in Figures 7C,D. Notably, six out of the top 10 LINCS small molecules (including penfluridol, fludarabine, vinorelbine, and doxazosin) have been previously reported to exhibit anti-AD effects in peer-reviewed studies (Nativio et al., 2020; Chiba et al., 1997; Lehrer and Rheinstein, 2017; Shamsi et al., 2024; Rahman et al., 2020; Rathi et al., 2025), corroborating the validity of our screening approach.
4 Discussion
Traditional Chinese Medicine (TCM) constitutes a precious cultural heritage of the Chinese nation, embodying millennia of accumulated clinical theories and practical experience in disease prevention and treatment. It has long demonstrated unique advantages in disease prevention and treatment, and it is garnering increasing attention from the global scientific community in recent years. The remarkable advancements in AI and bioinformatics have exerted profound and transformative impacts on TCM research and development. The digitization of biomedical research and intelligent computing have become robust trends in the field (Zhou et al., 2024; Xu, 2024; Buller et al., 2025). However, several challenges persist in TCM research, such as: 1) The inherently complex nature of TCM data, posing difficulties in collection and standardization; 2) Limited generalizability of the existing computational tools/methods for drug development; and 3) Technical barriers in tool deployment and utilization. These factors have significantly constrained the progress of TCM research.
To address these challenges, we developed SZBC-AI4TCM, a comprehensive web-based computational platform that integrates state-of-the-art AI algorithms, bioinformatics tools, and TCM databases. This one-stop solution provides robust computational support, enabling researchers to obtain analytical results more efficiently and thereby enhancing the productivity and success rate of TCM research. The platform supports multilingual inputs for specific analysis modules. For example, the TCM Targets Search BATMAN module accepts inputs in Pinyin, Chinese, English, and Latin. However, other modules, such as the Herbs Database, currently only support Chinese. This is because many underlying TCM databases are primarily in Chinese, and integrating comprehensive multilingual support requires substantial translation and curation efforts. We acknowledge that this limitation can impair the user experience and potentially affect analytical accuracy, and therefore, its resolution is a key focus for our next development phase. Meanwhile, We have noted that some TCM names (including formulas, medicinal materials and ingredients) often exhibit significant variation across realworld data sources. For example, the same entity might appear as “Shuyu Pill”, “Shuyu Wan”, or “Shu Yu Wan”. Such inconsistencies stem from multiple factors, including differences in Pinyin transliteration, word segmentation conventions, and database design. This lack of standardization can lead to incomplete information retrieval and compromise analytical accuracy. While our current platform does not include dedicated modules to address these variations, we are actively developing a comprehensive TCM synonym dictionary. Furthermore, we plan to leverage large language model (LLM)-based Retrieval-Augmented Generation (RAG) technology for automated name normalization and are designing standardized preprocessing workflows specifically for TCM texts to significantly enhance data consistency and analytical precision in future work.
Using the TCM research in Alzheimer’s disease as an example, we demonstrated the platform’s capabilities in multiple research domains, including TCM formulation data mining, drug screening, mechanism analysis based on network pharmacology analysis and molecular docking. This platform significantly reduces reliance on traditional trial-and-error approaches, while also drastically lowering the time, labor, and financial costs associated with the development of TCM. In addition, based on the modules of this platform, we have also applied them in other studies. For instance, relying on the network proximity module, Yang et al. conducted an analysis of network proximity between vascular calcification associated genes and the targets of Compound Danshen Dripping Pills (CDDP) in their research on the treatment of vascular calcification using this drug (Yang et al., 2024). This analysis was used to evaluate the potential therapeutic effect of the drug on vascular calcification. Meanwhile, Wang et al. applied network proximity to identify the potential pathological mechanisms of Alzheimer’s disease (AD) associated with YangXue QingNao Wan (YXQNW) by integrating the drug-target network (Wang et al., 2024). In the study by Zhao et al., based on the Bibliometrics module on the SZBC-AI4TCM platform, the research focused on exploring the research hotspots and trends in Tourette Syndrome (TS), as well as the roles and potential mechanisms of the botanical drug pairs related to Shaoma Zhijing Granules and their main metabolites in the treatment of TS (Zhao et al., 2024). This work laid a foundation for analyzing the therapeutic mechanism of Shaoma Zhijing Granules in TS and provided evidence support for its clinical application.
SZBCA-I4TCM features a user-friendly web interface with intuitive operation. Integrated with the MaxKB question answering system, the platform facilitates rapid comprehension of each analytical module’s operational procedures and underlying principles, which considerably lowers the learning curve for researchers. Moreover, the analytical modules and workflow in the platform will be regularly optimized and iteratively upgraded. The development and deployment of cutting-edge technical modules, particularly the “Knowledge Graph” module group and the “Large Language Model Application” module group, will substantially enhance the platform’s technical support capabilities. The integration of the existing innovative technical modules not only provides users with a systematic and professional toolkit for TCM research but also offers unique methodological value in critical research scenarios, such as drug interaction analysis and prescription compatibility pattern mining. Of particular note is the platform’s independently developed “Prescriptions Tree” module (Lang et al., 2025), which employs phylogenetic tree construction algorithms to propose innovative solutions for research directions in TCM formulations and TCM formulations’ classification. Through the ongoing development of such analytical tools, a distinctive methodological framework addressing key scientific questions in TCM research will gradually take shape, offering new technical pathways to overcome industry research bottlenecks. However, some limitations of SZBC-AI4TCM warrant acknowledgment: 1) The quality and completeness of the foundational data require continuous updates and supplementation. 2) The currently implemented tools and methodologies may not encompass all computational requirements, necessitating periodic expansion, updates, and optimization of the analytical modules. 3) The intelligent Q&A functionality remains under development and would benefit from integration with additional LLMs, such as ChatGPT (Vaswani et al., 2023) and DeepSeek-AI et al. (2025a); Wu et al., 2024b; DeepSeek-AI et al., 2025b). 4) While designed with user friend lines in mind, the platform’s advanced features still present a non-trivial learning curve that may require targeted training for certain user groups. 5) Exponential growth in computational resource demands is anticipated with increasing module deployment and user adoption, mandating systematic resource scaling.
It is worth noting that although the databases integrated into the platform were initialized with the most recent versions available at the time of development, they are not currently synchronized in real-time with their official sources due to the substantial resource and cost implications involved. The primary objective of the first phase of the SZBC-AI4TCM project is to establish a comprehensive suite of analytical functions for traditional Chinese medicine research. To this end, we have localized several publicly available databases and tools to support users in conducting various analyses. Currently, the platform does not perform in-depth integration or comprehensive evaluation of the results generated by these tools/databases, and each analysis is performed independently. Therefore, the outputs should be regarded as preliminary references, and we strongly reiterate and encourage users to perform further evaluation and experimental validation, such as in vitro assays, animal models, or clinical trials, to remain essential to confirm their biological relevance (Magalhães et al., 2021; Bolz et al., 2021). A key part of our ongoing development strategy includes periodic updates to these underlying databases. Our current plan is to perform updates on a quarterly basis, or more frequently based on significant user demand and newly available data.
In summary, SZBC-AI4TCM represents a significant milestone in the integration of TCM with modern computational technologies. By providing a comprehensive, scalable, and accessible platform for TCM research, we anticipate this tool will substantially enhance the efficiency and effectiveness of TCM-based drug discovery and development. Future efforts will focus on three key directions: 1) Enhancing the platform through functional upgrades; 2) Expanding the analytical tools, algorithms, and databases; and 3) Fostering global collaboration within the TCM research community to advance the modernization and internationalization of TCM.
5 Conclusion
SZBC-AI4TCM is a comprehensive web-based computational platform specifically designed for TCM research and development. The platform integrates an extensive collection of cutting-edge AI algorithms, bioinformatics tools, and specialized TCM databases, collectively offering robust computational solutions that can significantly reduce research costs and dramatically enhance development efficiency from a computational perspective. We envision that SZBC-AI4TCM will serve as a powerful computational backbone for both TCM research and clinical applications. Its continued development and implementation are expected to make substantial contributions to the advancement, modernization, and globalization of TCM.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: (Gene Expression Omnibus (GEO): GSE159699; PubChem database: https://pubchem.ncbi.nlm.nih.gov/; LINCS data portal: https://lincsportal.ccs.miami.edu/dcic-portal/; ITCM database: http://itcm.biotcm.net/). Further inquiries can be directed to the corresponding authors.
Author contributions
JL: Writing – original draft, Methodology, Data curation, Writing – review and editing, Conceptualization, Resources, Investigation. KG: Formal Analysis, Methodology, Data curation, Writing – review and editing, Conceptualization, Writing – original draft, Investigation, Visualization. JY: Writing – review and editing, Resources, Writing – original draft, Methodology, Validation. PY: Project administration, Supervision, Writing – review and editing. YW: Investigation, Conceptualization, Writing – original draft. JH: Data curation, Software, Writing – review and editing. SZ: Resources, Writing – review and editing, Methodology, Software. ZL: Conceptualization, Methodology, Software, Writing – review and editing. HY: Conceptualization, Methodology, Writing – review and editing, Software. XY: Software, Conceptualization, Writing – review and editing, Methodology. BC: Formal Analysis, Investigation, Methodology, Writing – review and editing. CW: Investigation, Resources, Writing – review and editing. JX: Writing – review and editing, Methodology, Visualization. JG: Writing – review and editing, Software, Visualization. WZ: Data curation, Formal Analysis, Writing – review and editing, Software. XZ: Writing – review and editing. JF: Writing – review and editing. JS: Writing – review and editing, Supervision. KY: Writing – review and editing, Supervision. YH: Project administration, Writing – review and editing, Supervision. WW: Project administration, Conceptualization, Writing – review and editing, Supervision.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by the Tianjin Natural Science Foundation (22JCYBJC00180).
Conflict of interest
Author(s) JL, KG, JY, PY, YW, JH, SZ, BC, CW, JX, JG, WZ, JS, KY, YH and WW were employed by Tianjin Tasly Digital Intelligence Chinese Medicine Technology Co., Ltd.
Author(s) ZL, HY, and XY, were employed by Wecomput Technology Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphar.2025.1698202/full#supplementary-material
References
Abramson, J., Adler, J., Dunger, J., Evans, R., Green, T., Pritzel, A., et al. (2024). Accurate structure prediction of biomolecular interactions with alphafold 3. Nature 630, 493–500. doi:10.1038/s41586-024-07487-w
Babbi, G., Martelli, P. L., Profiti, G., Bovo, S., Savojardo, C., and Casadio, R. (2017). Edgar: a database of disease-gene associations with annotated relationships among genes. BMC Genomics 18, 554. doi:10.1186/s12864-017-3911-3
Bolz, S. N., Adasme, M. F., and Schroeder, M. (2021). Toward an understanding of pan-assay interference compounds and promiscuity: a structural perspective on binding modes. J. Chem. Inf. Model. 61, 2248–2262. PMID: 33899463. doi:10.1021/acs.jcim.0c01227
Buller, R., Damborsky, J., Hilvert, D., and Bornscheuer, U. T. (2025). Structure prediction and computational protein design for efficient biocatalysts and bioactive proteins. Angew. Chem. Int. Ed. 64, e202421686. doi:10.1002/anie.202421686
Chen, X., Li, W., Xiao, X.-F., Zhang, L., and Liu, C. (2013). Phytochemical and pharmacological studies on radix angelica sinensis. Chin. J. Nat. Med. 11, 577–587. doi:10.1016/S1875-5364(13)60067-9
Cheng, Y., Qiu, J., Yan, W., Zhang, Y., Wang, Y., and Tan, Z. (2021). Effects of modified yam pills on ampk/eef2k/eef2 signaling pathway in the hippocampus of app/ps1 mice. West. J. Traditional Chin. Med. 34, 30–34.
Chiba, H., Akita, H., Hui, S.-P., Takahashi, Y., Nagasaka, H., Fuda, H., et al. (1997). Effects of triamcinolone on brain and cerebrospinal fluid apolipoprotein e levels in rats. Life Sci. 60, 1757–1761. doi:10.1016/S0024-3205(97)00135-5
Chu, X., Sun, B., Huang, Q., Peng, S., Zhou, Y., and Zhang, Y. (2020). Quantitative knowledge presentation models of traditional chinese medicine (tcm): a review. Artif. Intell. Med. 103, 101810. doi:10.1016/j.artmed.2020.101810
DeepSeek-AI, , Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., et al. (2025a). Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning. arXiv:2501.12948. Available online at: https://arxiv.org/abs/2501.12948
DeepSeek-AI, , Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., et al. (2025b). Deepseek-v3 technical report. arXiv:2412.19437. doi:10.48550/arXiv.2412.19437
Eberhardt, J., Santos-Martins, D., Tillack, A. F., and Forli, S. (2021). Autodock vina 1.2.0: new docking methods, expanded force field, and python bindings. J. Chem. Inf. Model. 61, 3891–3898. doi:10.1021/acs.jcim.1c00203
Forli, S., Huey, R., Pique, M. E., Sanner, M. F., Goodsell, D. S., and Olson, A. J. (2016). Computational protein–ligand docking and virtual drug screening with the autodock suite. Nat. Protoc. 11, 905–919. doi:10.1038/nprot.2016.051
Goh, K.-I., Cusick, M. E., Valle, D., Childs, B., Vidal, M., and Barabási, A.-L. (2007). The human disease network. Proc. Natl. Acad. Sci. 104, 8685–8690. doi:10.1073/pnas.0701361104
Hahsler, M., Grün, B., and Hornik, K. (2005). arules - a computational environment for mining association rules and frequent item sets. J. Stat. Softw. 14, 1–25. doi:10.18637/jss.v014.i15
Hindorff, L. A., Sethupathy, P., Junkins, H. A., Ramos, E. M., Mehta, J. P., Collins, F. S., et al. (2009). Potential etiologic and functional implications of genome-wide association loci for human diseases and traits. Proc. Natl. Acad. Sci. 106, 9362–9367. doi:10.1073/pnas.0903103106
Kelleher, K. J., Sheils, T. K., Mathias, S. L., Yang, J. J., Metzger, V., Siramshetty, V., et al. (2022). Pharos 2023: an integrated resource for the understudied human proteome. Nucleic Acids Res. 51, D1405–D1416. doi:10.1093/nar/gkac1033
Koscielny, G., An, P., Carvalho-Silva, D., Cham, J. A., Fumis, L., Gasparyan, R., et al. (2016). Open targets: a platform for therapeutic target identification and validation. Nucleic Acids Res. 45, D985–D994. doi:10.1093/nar/gkw1055
Lang, J., Yang, P., Hu, Y., Wei, Y., Zhou, S., Yan, K., et al. (2025). Prestree: an analytical workflow for basic formula and prescription patterns. Res. Square. doi:10.21203/rs.3.rs-6458328/v1
Lehrer, S., and Rheinstein, P. H. (2017). Nasal steroids as a possible treatment for alzheimer’s disease. Discov. Med. 24, 147–152. Available online at: https://www.discoverymedicine.com/Steven-Lehrer/2017/10/nasal-steroids-as-a-possible-treatment-for-alzheimers-disease/
Li, M., and Zhang, J. (2023). A focus on harnessing big data and artificial intelligence: revolutionizing drug discovery from traditional chinese medicine sources. Chem. Sci. 14, 10628–10630. doi:10.1039/d3sc90185h
Li, L., Li, T., Tian, X., and Zhao, L. (2021). Ginsenoside rd attenuates tau phosphorylation in olfactory bulb, spinal cord, and telencephalon by regulating glycogen synthase kinase 3β and cyclin-dependent kinase 5. Evidence-Based Complementary Altern. Med. 2021, 4485957. doi:10.1155/2021/4485957
Li, Y., Wu, H., Liu, M., Zhang, Z., Ji, Y., Xu, L., et al. (2024). Polysaccharide from polygala tenuifolia alleviates cognitive decline in alzheimer’s disease mice by alleviating aβ damage and targeting the erk pathway. J. Ethnopharmacol. 321, 117564. doi:10.1016/j.jep.2023.117564
Ma, Z., Tan, Z., Yin, X., Zhuang, S., and Xu, L. (2022). Study on pharmacological action and molecular mechanism of modified shuyu pills for treating alzheimer’s disease. J. Mod. Med. & Health 38, 906–911.
Magalhães, P. R., Reis, P. B. P. S., Machuqueiro, M., and Victor, B. L. (2021). Identification of pan-assay interference compounds (pains) using an md-based protocol. Methods Mol. Biol. Clift. N.J. 2315, 263–271. doi:10.1007/978-1-0716-1468-6_15
Mering, C. V., Huynen, M., Jaeggi, D., Schmidt, S., Bork, P., and Snel, B. (2003). String: a database of predicted functional associations between proteins. Nucleic Acids Res. 31, 258–261. doi:10.1093/nar/gkg034
Mook-Jung, I., Hong, H.-S., Boo, J. H., Lee, K. H., Yun, S. H., Cheong, M. Y., et al. (2001). Ginsenoside rb1 and rg1 improve spatial learning and increase hippocampal synaptophysin level in mice. J. Neurosci. Res. 63, 509–515. doi:10.1002/jnr.1045
Nativio, R., Lan, Y., Donahue, G., Sidoli, S., Berson, A., Srinivasan, A. R., et al. (2020). An integrated multi-omics approach identifies epigenetic alterations associated with alzheimer’s disease. Nat. Genet. 52, 1024–1035. doi:10.1038/s41588-020-0696-0
O’Boyle, N. M., Banck, M., James, C. A., Morley, C., Vandermeersch, T., and Hutchison, G. R. (2011). Open babel: an open chemical toolbox. J. Cheminformatics 3, 33. doi:10.1186/1758-2946-3-33
Page, L., Brin, S., Motwani, R., and Winograd, T. (1999). “The pagerank citation ranking: bringing order to the web,” in The web conference.
Piñero, J., Bravo, A., Queralt-Rosinach, N., Gutiérrez-Sacristán, A., Deu-Pons, J., Centeno, E., et al. (2016). Disgenet: a comprehensive platform integrating information on human disease-associated genes and variants. Nucleic Acids Res. 45, D833–D839. doi:10.1093/nar/gkw943
Qiu, J. (2020). The role and mechanism of endoplasmic reticulum stress regulation in modified Shuyu Pills to reduce neuronal apoptosis in APP/PS1 double transgenic mice. Hubei University of Chinese Medicine. doi:10.27134/d.cnki.ghbzc.2020.000006
Rahman, M. R., Islam, T., Zaman, T., Shahjaman, M., Karim, M. R., Huq, F., et al. (2020). Identification of molecular signatures and pathways to identify novel therapeutic targets in alzheimer’s disease: insights from a systems biomedicine perspective. Genomics 112, 1290–1299. doi:10.1016/j.ygeno.2019.07.018
Rappaport, N., Nativ, N., Stelzer, G., Twik, M., Guan-Golan, Y., Iny Stein, T., et al. (2013). Malacards: an integrated compendium for diseases and their annotation. Database 2013, bat018. doi:10.1093/database/bat018
Rathi, K. M., Undale, V. R., Wavhale, R. D., Mohammed, F. S., Karwa, P. N., and Patil, H. (2025). From computational screening to zebrafish testing: repurposing of doxazosin, donepezil, and dolutegravir for neuroprotective potential in alzheimer’s disease. Naunyn-Schmiedeberg’s Archives Pharmacol. 398, 10581–10595. doi:10.1007/s00210-025-03933-2
Schrödinger, L., and DeLano, W. (2020). Pymol. Available online at: https://www.pymol.org/pymol
Shamsi, A., Furkan, M., Khan, M. S., Yadav, D. K., and Shahwan, M. (2024). Computational screening of repurposed drugs for hmg-coa synthase 2 in alzheimer’s disease. J. Alzheimer’s Dis. 100, 475–485. doi:10.3233/JAD-240376
Song, Z., Yin, F., Xiang, B., Lan, B., and Cheng, S. (2018). Systems pharmacological approach to investigate the mechanism of acori tatarinowii rhizoma for alzheimer’s disease. Evidence-Based Complementary Altern. Med. 2018, 5194016. doi:10.1155/2018/5194016
Song, Y., Zheng, S., Niu, Z., Fu, Z.-h., Lu, Y., and Yang, Y. (2020). “Communicative representation learning on attributed molecular graphs,” in Proceedings of the twenty-ninth international joint conference on artificial intelligence. Editor C. Bessiere IJCAI-20 (Yokohama, Japan: International Joint Conferences on Artificial Intelligence Organization), 2831–2838. doi:10.24963/ijcai.2020/392
Song, Z., Chen, G., and Chen, C. Y.-C. (2024). Ai empowering traditional Chinese medicine? Chem. Sci. 15, 16844–16886. doi:10.1039/D4SC04107K
Su, Y., Liu, N., Sun, R., Ma, J., Li, Z., Wang, P., et al. (2023). Radix rehmanniae praeparata (shu dihuang) exerts neuroprotective effects on icv-stz-induced alzheimer’s disease mice through modulation of insr/irs-1/akt/gsk-3β signaling pathway and intestinal microbiota. Front. Pharmacol. 14, 1115387. doi:10.3389/fphar.2023.1115387
Trott, O., and Olson, A. J. (2010). Autodock vina: improving the speed and accuracy of docking with a new scoring function, efficient optimization, and multithreading. J. Comput. Chem. 31, 455–461. doi:10.1002/jcc.21334
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2023). Attention is all you need. arXiv:1706.03762. doi:10.48550/arXiv.1706.03762
Wang, Y., Li, Y., Yang, W., Gao, S., Lin, J., Wang, T., et al. (2018). Ginsenoside rb1 inhibit apoptosis in rat model of alzheimer’s disease induced by aβ(1-40). Am. J. Transl. Res. 10, 796–805. Available online at: https://pmc.ncbi.nlm.nih.gov/articles/PMC5883120/
Wang, D., Ho, C.-T., and Bai, N. (2022). Ziziphi spinosae semen: an updated review on pharmacological activity, quality control, and application. J. Food Biochem. 46, e14153. doi:10.1111/jfbc.14153
Wang, X., Yang, J., Zhang, X., Cai, J., Zhang, J., Cai, C., et al. (2024). An endophenotype network strategy uncovers yangxue qingnao wan suppresses aβ deposition, improves mitochondrial dysfunction and glucose metabolism. Phytomedicine 135, 156158. doi:10.1016/j.phymed.2024.156158
Wu, Y., Ma, L., Li, X., Yang, J., Rao, X., Hu, Y., et al. (2024a). The role of artificial intelligence in drug screening, drug design, and clinical trials. Front. Pharmacol. Volume, 1459954–2024. doi:10.3389/fphar.2024.1459954
Wu, Z., Chen, X., Pan, Z., Liu, X., Liu, W., Dai, D., et al. (2024b). Deepseek-vl2: mixture-of-experts vision-language models for advanced multimodal understanding. arXiv:2412.10302. doi:10.48550/arXiv.2412.10302
Xu, W. (2024). Current status of computational approaches for small molecule drug discovery. J. Med. Chem. 67, 18633–18636. doi:10.1021/acs.jmedchem.4c02462
Yang, Y., Li, S., Huang, H., Lv, J., Chen, S., Pires Dias, A. C., et al. (2020). Comparison of the protective effects of ginsenosides rb1 and rg1 on improving cognitive deficits in samp8 mice based on anti-neuroinflammation mechanism. Front. Pharmacol. Volume, 834–2020. doi:10.3389/fphar.2020.00834
Yang, Y., Yuan, L., Xiong, H., Guo, K., Zhang, M., Yan, T., et al. (2024). Inhibition of vascular calcification by compound danshen dripping pill through multiple mechanisms. Phytomedicine 129, 155618. doi:10.1016/j.phymed.2024.155618
Zhang, Y., Ding, S., Chen, Y., Sun, Z., Zhang, J., Han, Y., et al. (2021). Ginsenoside rg1 alleviates lipopolysaccharide-induced neuronal damage by inhibiting nlrp1 inflammasomes in ht22 cells. Exp. And Ther. Med. 22, 782. doi:10.3892/etm.2021.10214
Zhang, Y., Luo, M., Wu, P., Wu, S., Lee, T.-Y., and Bai, C. (2022). Application of computational biology and artificial intelligence in drug design. Int. J. Mol. Sci. 23, 13568. doi:10.3390/ijms232113568
Zhang, P., Zhang, D., Zhou, W., Wang, L., Wang, B., Zhang, T., et al. (2024). Network pharmacology: towards the artificial intelligence-based precision traditional Chinese medicine. Briefings Bioinforma. 25, bbad518. doi:10.1093/bib/bbad518
Zhao, Q., Hu, Y., Yan, Y., Song, X., Yu, J., Wang, W., et al. (2024). The effects of shaoma zhijing granules and its main components on Tourette syndrome. Phytomedicine 129, 155686. doi:10.1016/j.phymed.2024.155686
Zhou, J. (2022). To explore the effect and mechanism of modified Shuyu Pills on reducing oxidative stress injury of neurons in APP/PS1 mice based on mitochondrial mass regulation. Hubei University of Chinese Medicine. doi:10.27134/d.cnki.ghbzc.2022.000002
Keywords: traditional Chinese medicine, artificial intelligence, deep learning, bioinformatics, web-based computing platform, Alzheimer’s disease
Citation: Lang J, Guo K, Yang J, Yang P, Wei Y, Han J, Zhao S, Liu Z, Yi H, Yan X, Chen B, Wang C, Xu J, Ge J, Zhang W, Zhou X, Fang J, Su J, Yan K, Hu Y and Wang W (2025) SZBC-AI4TCM: a comprehensive web-based computing platform for traditional Chinese medicine research and development. Front. Pharmacol. 16:1698202. doi: 10.3389/fphar.2025.1698202
Received: 03 September 2025; Accepted: 21 October 2025;
Published: 17 November 2025.
Edited by:
Lihong Peng, Hunan University of Technology, ChinaReviewed by:
Leyi Wei, Macao Polytechnic University, Macao, SAR ChinaReisa Widjaja, University of Wisconsin - La Crosse, United States
Copyright © 2025 Lang, Guo, Yang, Yang, Wei, Han, Zhao, Liu, Yi, Yan, Chen, Wang, Xu, Ge, Zhang, Zhou, Fang, Su, Yan, Hu and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yunhui Hu, dHNsLWh1eXVuaHVpQHRhc2x5LmNvbQ==; Wenjia Wang, dHNsLXdhbmd3ZW5qaWFAdGFzbHkuY29t
†These authors have contributed equally to this work