 Boon Kin Teh
Boon Kin Teh Darrell JiaJie Tay
Darrell JiaJie Tay Sai Ping Li
Sai Ping Li Siew Ann Cheong
Siew Ann Cheong- 1Division of Physics and Applied Physics, School of Physical and Mathematical Sciences, Nanyang Technological University, Singapore, Singapore
- 2Complexity Institute, Nanyang Technological University, Singapore, Singapore
- 3Institute of Physics, Academia Sinica, Taipei, Taiwan
An increasingly important problem in the era of Big Data is fitting data to distributions. However, many stop at visually inspecting the fits or use the coefficient of determination as a measure of the goodness of fit. In general, goodness-of-fit measures do not allow us to tell which of several distributions fit the data best. Also, the likelihood of drawing the data from a distribution can be low even when the fit is good. To overcome these limitations, Clauset et al. advocated a three-step procedure for fitting any distribution: (i) estimate parameter(s) accurately, (ii) choosing and calculating an appropriate goodness of fit, (iii) test its significance to determine how likely this goodness of fit will appear in samples of the distribution. When we perform this significance testing on exponential distributions, we often obtain low significance values despite the fits being visually good. This led to our realization that most fitting methods do not account for effects due to the finite number of elements and the finite largest element. The former produces sample size dependence in the goodness of fits and the latter introduces a bias in the estimated parameter and the goodness of fit. We propose modifications to account for both and show that these corrections improve the significance of the fits of both real and simulated data. In addition, we used simulations and analytical approximations to verify that convergence rate of the estimated parameters toward its true value depends on how fast the largest element converge to infinity, and provide fast inversion formulas to obtain p-values directly from the adjusted test statistics, in place of doing more Monte Carlo simulations.
1. Introduction
The current era of Big Data has ushered in a new way to look at Science—and that is letting the data speak for itself. Because of this, we are now much more concerned about empirical distributions than we have in the past, and to check what the empirical distributions could be in statistically rigorous ways. In the past, many tests on empirical data were performed against the univariate normal distribution [1]. Some of these tests focus on the goodness-of-fit of higher order moments [2–4], while others compare the test statistics against an Empirical Distribution Function (EDF) [5–8]. In 2011, Nornadiah and Yap performed a systematic comparison of Anderson-Darling (AD), Lilliefors, Kolmogorov-Smirnov (KS), and Shapiro-Wilk (SW), using numerical simulations and concluded that the SW test is the best, followed closely by the AD test for a given significance [9].
Among these tests, the KS and Lilliefors tests can also be applied to non-normal distributions. In fact, many real-world data do not follow normal distributions. For instance, many social systems are known to have power-law distributions [10]. These include the financial returns [11–14], word count [15, 16], city size [17, 18], home price [19–21], wealth and income [22, 23] distributions. One simple but naive way to detect a power law is to plot the data in log-log scale, fit it to a straight line and determine the goodness of fit. However, this simple method has three major flaws: (i) many distributions (e.g., exponential, gamma, log-normal) can also look straight in log-log plot, especially if the range of data is small; (ii) the goodness of fit only quantifies how well the fit is visually but does not tell us how plausible the fit is; and (iii) if our data looks straight in both log-log and semi-log plots, the goodness of fit values obtained from the two cannot be directly compared since they were obtained from plots of different scales. Clauset, Shalizi, and Newman (CSN) address precisely these three points in their 2009 paper [24], and the test they proposed is now considered by many the gold standard in curve fitting. We shall describe the main idea of the CSN technique in greater mathematical detail in section 2.
Since the CSN test can be applied across distributions, we also use it to fit data that appear exponentially distributed. On many occasions, we discovered that the exponential fits look good visually, but have significance values (p-value) much lower than fits of other data to power laws, even though the latter look visibly poorer. In fact, in the CSN paper where empirical data is tested against a power law (PL), log-normal, exponential (EXP), stretched exponential, and a power law with cut-off, the exponential distribution consistently performs poorer than the other distributions. This was also the case when Brzezinski tested the upper-tail wealth data for China, Russia, US, and the World using the CSN method [25]. In these papers, the data might truly be non-exponentially distributed, so it is not surprising the exponential fits fail. However, the low p-values for the visually convincing exponential fits to our data suggest that something fundamental was missed.
We realized there are two issues associated with fitting data to distributions defined over (0, ∞). First, there is the finite largest element effect (FLE), due to the largest element in the data being finite. Second, we also encounter the finite number of elements effect (FNE), due to the sample size dependence of the goodness-of-fit measures. These two finite sample effects are well studied for Generalized Moment Methods (GMMs) [26, 27] but often neglected in tests of statistical significance. After describing the CSN test, we illustrate in section 2 the FLE and FNE effects by applying the test to three real data sets. With the insights gained, we designed both the estimators and test statistic to account for the FLE and FNE effects in section 3.1. Since real data is frequently polluted by noise, we also discuss the impact of noise on the p-value, and propose a test statistic that accounts for noise in section 4. Finally, in section 5, we apply the adjusted test statistics on our real data sets and compare the p-values obtained against those from the CSN test.
2. Reexamining Significance Testing for Empirical Distributions
Sometimes we have reasons to believe that our large data sets may be described by well known distributions, such as the normal distribution, power law distribution, exponential distribution, and so on, but with best-fit parameter values that we need to determine. Commonly used methods to perform parameter estimation include Maximum Likelihood Estimation (MLE) [28], Maximum Entropy Method (MEM) [29–31], least square regressions [32], and direct or indirect computation of moments [33]. Since it is possible to fit any distribution to any data set, we need to compute its goodness of fit, which can be the KS distance [7], the coefficient of determination (R2) and other forms of distance measure [34, 35].
In a recent statement, the American Statistical Association warned the scientific community that the p-value “was never intended to be a substitute for scientific reasoning” [36, para. 2], and outline six principles that can prevent its misuse [37]. A Nature commentary on this statement also added that “[r]esearchers should describe not only the data analyses that produced statistically significant results, …, but all statistical tests and choices made in calculations” [38, para. 3]. We heed the warning in this paper, but argue that when properly computed and interpreted, the p-value is useful in that it provides a quantitative and objective alternative to visual inspection of the fits. The latter is frequently subjective and biased. This utility becomes important when we are comparing fits of two or more data sets to two or more distributions, and have the ambiguity of being able to choose from two or more definitions of goodness of fit. This is why we need to go beyond the goodness of fits, to establish how plausible different distributions are for different data sets.
In 2009, Clauset, Shalizi, and Newman (CSN) did precisely this by coming up with a p-test model that use the well-known PL distribution as an illustration. They started by writing down the probability density function for the PL distribution
for x ∈ [xmin, ∞), with exponent α. The CSN p-test involves four major steps:
CSN(i) MLE Estimation of α: Given an empirical data with S observations, with the ordered statistic Y = {y1, y2, …, yS}, sorted such that yi ≤ yi+1, the CSN algorithm (CSN(ia)) first constructs the S subsets . (CSN(ib)) For each X(j), we estimate α(j) using the MLE method that maximizes the log-likelihood function,
Applying the maximizing condition yields
where the hat indicates an estimated parameter and indicates the expectation value of the random variable x.
CSN(ii) KS Distance: If X follows probability distribution function fX with cumulative distribution function FX, then its probability integral transform u = FX(x) is a standard uniform distribution function (U(0, 1)). For any PL distributed sample X = {x1 = xmin, x2, …, xN} with estimated , we (CSN(iia)) first transform the sample to . (CSN(iib)) Then we calculate the KS distance
between U(s) and U(0, 1). Here we make use of the fact that the CDF of U(0, 1) is a linear function, FU(u) = u.
CSN(iii) Determining xmin: To determine xmin, (CSN(iiia)) we calculate the KS distance for each X(j) with its corresponding . (CSN(iiib)) The set X(j) that yields the lowest KS distance () gives us and . The superscript “(em)” indicates a parameter obtained from empirical data.
CSN(iv) Significance Testing: After and have been estimated from Y = {y1, y2, …, yS}, we test how plausible it is for to be a sample taken from a PL distribution. This is done by (CSN(iva)) sampling the PL M times using and . (CSN(ivb)) For the mth simulated sample we go through CSN(i) to CSN(iii) to obtain . (CSN(ivc)) The significance measure
is the fraction of simulated samples whose fits are poorer than that of the data.
Extending the CSN method to other distributions, we performed p-testing on the Taiwan home price per square foot (fitted to EXP), Taiwan income (fitted to EXP), and the Straits Times Index normalized return (fitted to PL) (see Supplementary Information section 3 for more descriptions on the data sets). The fits and p-values are shown in Figure 1. All fits are visually good yet only the p-value for the Taiwan housing is appreciable. We realized the reason for this is simple: while the EXP and PL distributions are defined over (0, ∞), when we collect data from the real world we can only obtain a finite number of elements. Moreover, the largest element in the data is finite. However, existing tests for statistical significance generally do not account for the effects produced by having a finite number of elements (FNE) and a finite largest element (FLE). In the next section we will explain how the parameters and test statistics can be adjusted for FNE and FLE.
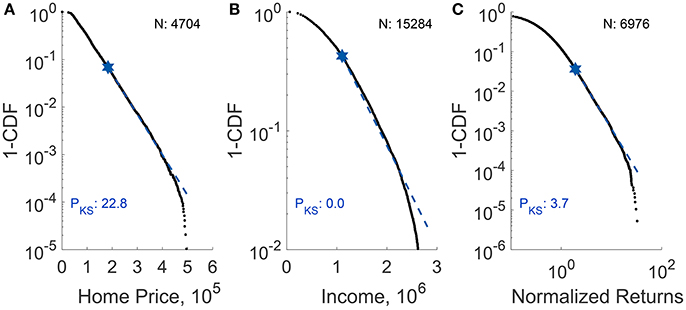
Figure 1. p-testing on (A) 2012–2014 Taiwan home price per square foot, (B) 2012 Taiwan lower-tail income (fitted to EXP), and (C) 2009–2016 Straits Times Index normalized return (fitted to PL). For each plot, N represents the number of data points (larger than xmin) fitted. the black dots represent empirical data while the blue dashed line represents the fit. All fits are visually good, yet only the p-value (PKS in percentage) for Taiwan home price is appreciable.
At this stage, we might wonder whether the Taiwan income data would have been better fitted to a truncated EXP (TEXP) distribution
since it is obtained by removing the power-law tail. The Taiwan home price per square foot data was also truncated, but for a different reason: the small number of largest elements are clearly outliers that would not fit the EXP distribution. Ideally, we should be using untruncated data, like the Straits Times Index data, to illustrate the method that we will describe in the following sections. In the rest of the paper, we will use all three data sets as if they were untruncated, to illustrate how well our method works on different data types. To do so, we will compare the adjusted parameter and test statistic against the unadjusted parameter and test statistic meant for the untruncated EXP distribution.
3. Finite-Sample Adjustments
3.1. Parameter Adjustment for Finite Largest Element
Here, we will illustrate the effects of FLE using an asymptotic EXP distribution. The same discussion can be generalized to other distributions (see Supplementary Information section 1).
The EXP distribution is defined as
with β as a sole parameter for x ∈ [xmin, ∞). Maximizing the likelihood function , we find the estimated parameter
If we use the mean obtained from data 〈x〉data as 〈x〉 in Equation (8) we will obtain the unadjusted estimator βunadj. However, due to the FLE, we can only average up till xmax. As such 〈x〉data will be biased downwards and Equation (8) over-estimates .
To adjust for the FLE, we add the truncated part back into 〈x〉data, to define the adjusted 〈x〉adj as
Inserting 〈x〉adj into Equation (8), we obtain a nonlinear equation
that we solve using MATLAB's builtin nonlinear solver function nlinfit() to obtain .
To test the performance of this adjustment formula, we simulated 1, 000 sets of EXP distributed data for , by using the inverse cumulative function for EXP distribution
This transforms U(0, 1) distributed elements {ui} to EXP distributed elements {xi}. Using this transformation , 0 and 1 map to xmin and ∞ respectively. It is also useful to note that Equation (11) is the inverse of the CDF of the EXP distribution,
To simulate the effect of a FLE with , we sampled 1,000 sets of EXP distributed data using U(0, 0.9) instead of U(0, 1) with xmin = 0. Thereafter, we estimated and using Equations (8) and (10). Figure 2 shows the relative estimation errors
of and with respect to the true beta βT. As we can see from the Figure 2, is about 38% for small samples N ~ 102 and decreases to 34% for large samples N ~ 104. On the other hand, starts at 20%, but decreases to 2% as the number of data points is increased. Although it can be shown that the bias of vanishes with increasing sample sizes [24, 39], we find it converging very slowly with increasing sample size in the unfortunate situation of a small xmax. In contrast, converges very quickly even for small xmax as we have accounted for the FLE.
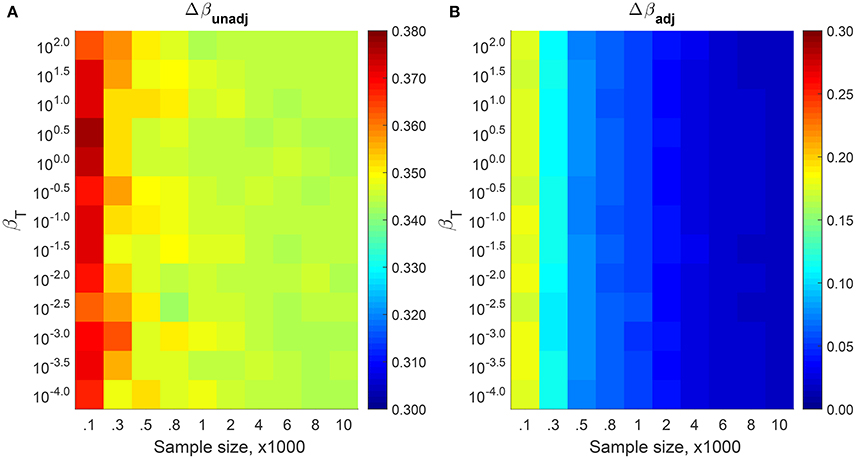
Figure 2. Relative estimation errors of (A) and (B) measured from 1,000 simulated samples using different βT and N with xmin = 0 and . Due to the FLE, Δβunadj remains high (close to the theoretical relative error of ϵ(δ = 0.1, xmin = 0) = 0.1[1 − ln(0.1)] ≈ 33%) even for large N. In contrast, Δβadj decreases rapidly with increasing N.
In the Supplementary Information section 1, we show details for our derivation of the theoretical estimation
By defining , and substitute xmax in Equation (14) with δ, the theoretical relative estimation error is expressed as
Equation (15) shows that the estimation error has no explicit dependence on sample size. This tells us that the is always larger than the βT because of the FLE effect. The convergence rate then depends on how rapidly xmax approaches infinity (δ approaches zero) with increasing sample size.
3.2. Test Statistic Adjustment for FLE
For a finite sample, FEXP(x) < 1 for all x < ∞. Mathematically, this means that FEXP(x) ~ U(0, 1 − δ), where . This observation is important, because dKS is obtained by comparing against U(0, 1) (see Equation 4). This tell us that for a fair comparison, we need to rescale all elements in U(s) by a factor of 1/(1−δ). Figure 3 shows the dKS measured for the 1000 sets of EXP distributed data with finite largest element for various βT and sample sizes N. For each sample, we use Equation (10) to estimate the and transformed this data to U(s) using Equation (12). After that, we measure dKS with Equation (4) to obtain unadjusted KS distance, KSunadj and adjusted KS distance, KSadj using the non-rescaled and rescaled U(s), respectively. KSunadj goes from 0.14 for small samples N ~ 102, to 0.10 for large samples N ~ 105. In contrast, KSadj decrease from 0.06 for small samples to 0.006 for large samples.
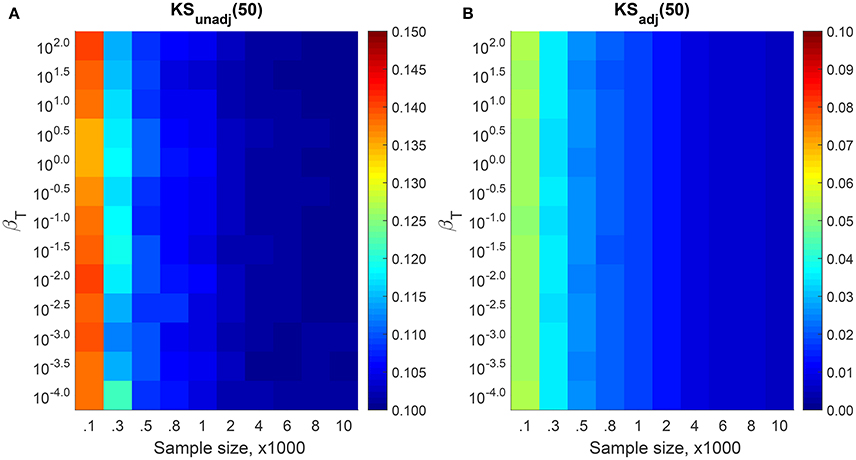
Figure 3. The median KS distances for (A) KSunadj and (B) KSadj measured from 1,000 simulated samples using different βT and N. The xmin is set to 0 and . Because of the FLE, KSunadj remains above δ = 0.10 while KSadj converges to zero for large N.
3.3. Adjustment for Finite Number of Elements
Until now, we have only discussed adjustments to the estimated parameter and the KS distance to eliminate the bias caused by the FLE. Besides the FLE effect, we also need to consider the bias caused by having a finite number of elements in the sample. As we can see from Figure 3, the KS distance decreases as the sample size increases. Therefore, in order to have a fair comparison of the goodness of fit for various sample sizes, we need to determine how dKS changes as a function of N. To do this, we simulated 106 samples of various sizes N from U(0, 1). For each sample we determined dKS using Equation (4), so that for each N we end up with 106 KS distances. In Figure 4 we show the KS distances at different deciles, which exhibits the asymptotic behavior
that we settled for, after experimenting with several functional forms (see Supplementary Information section 2). This result agrees with our expectation that dKS → 0 as N → ∞. It also suggests that if we have two samples with sizes N1 and N2 from the same distribution, we should compare against . Otherwise, if N2 > N1 then naturally and we will be lead to the wrong conclusion that the N2 sample fits the distribution better.
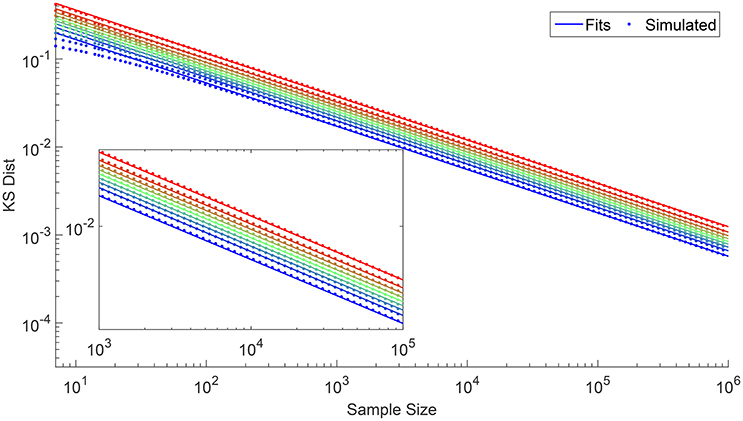
Figure 4. Log-log plot of dKS against N for different deciles going from the 10th percentile (blue) to the 90th (red), obtained from 106 simulations.
In this section, we presented explicitly the procedures to obtain the adjusted parameter, as well as the steps to perform significance testing on this estimated parameter. Although we demonstrated this explicitly using the EXP distribution as an example, one should note that this method can also be applied to other distributions. The inclusion of xmax when fitting empirical data have been previously considered by [40–42] for the truncated PL distribution. Like these, the method presented in this paper can be easily extended to fit different distributions, but unlike these, we can easily conduct significance testing across them. This is because by extending xmax to infinity, we can compute the probability integral transform to map arbitrary distributions to the standard uniform distribution, and ensure that during statistical significance testing our goodness-of-fit measure can be distribution independent [see CSN(ii)].
More importantly, fitting data to untruncated distributions defined over [xmin, ∞) is commonly encountered in practice, where no xmax is expected from theoretical considerations, but the largest element in our data is finite. If we fit to the truncated versions of the distributions, we might get better estimates of the distribution parameters, but we will not be able to justify inserting these estimates into the untruncated distributions, in the absence of a limiting procedure involving larger and larger xmax. Moreover, when researchers expect to be dealing with the untruncated distribution, they will not use the truncated distribution for estimation. In contrast, our self-consistent adjustment procedure would be ontologically easier to justify.
4. The Effects of Random Noise
Besides having to work with finite samples and finite largest elements, we will also in practice encounter imperfections while collecting samples for various reasons, such as undetected samples, contamination by background noise, and recording errors. We call such noises that occur at the element level elementary noise. When we convert these samples to a distribution, noise will also be present at the distribution level that we refer to as distribution noise. In principle the information at the distribution level is more robust compared to the elementary level, as we expect random and thus uncorrelated noise to cancel each other. This means that the distribution is less sensitive to elementary noise, but we still worry whether the distribution noise may play an important role in our test of statistical significance. In order to account for the effects of distribution noise, we need to first be able to quantify distribution noise, and thereafter understand how it affects significance testing.
Suppose we now randomly generate a set of EXP data. After adjusting for FLE, we obtained the distribution parameters and use it to transform this set to following the procedure outlined in section 3.1. Then as illustrated in Figures 5A–C, a natural way to measure the distribution noise is to plot the histogram, count the frequency for each bin, and compare it to the expected frequency from U(0, 1). Since this can be more accurately done for smaller bin sizes, we use the intervals between sorted elements as a collection of non-uniform bins, as shown in Figures 5D–F. For a data set consisting of N elements, each bin carry a weight of 1/N, evenly distributed within the interval (ui−1, ui], such that the probability density is
As the theoretical probability density for U(0, 1) is 1, we define the distribution noise dDN mathematically to be
where u0 = 0 and uN = 1. We need to weigh the deviation of each bin by because the bins are non-uniform, and also to keep dDN finite.
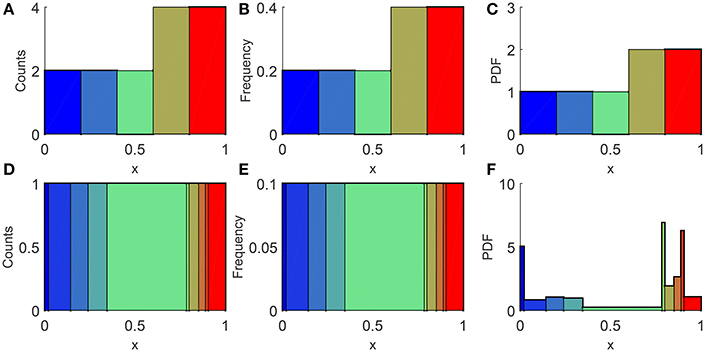
Figure 5. Illustration of the distribution noise we would measure if we sample 10 elements from U(0, 1), rescaled such that the largest element becomes 1. In (A,C) we use 5 uniform bins whereas in (D,F) we use the intervals between sorted elements as the bins. Counts are shown as (A,D), and frequencies are shown as (B,E). Whereas the probability densities calculated using Equation (17) are shown on the as (C,F).
4.1. Relation between Distribution Noise and Sample Size
As with section 3.3, we simulated 106 samples from U(0, 1) with different N. For each sample, we calculate the distribution noise dDN using Equation (18) and plot its deciles against N as shown in Figure 6. After experimenting with several functional forms, we write down the relationship between dDN and N at percentile ℘DN as
where Φ(x) represents the sign of x, and
is the analytically derived distribution noise, that converges to as N → ∞ (refer to Supplementary Information section 2 for more details). This result suggests that if we have two samples with sizes N1 and N2 with N2 > N1 from the same distribution, we should compare against . Otherwise, we risk making the wrong conclusion that the N2 sample fits the distribution better if .
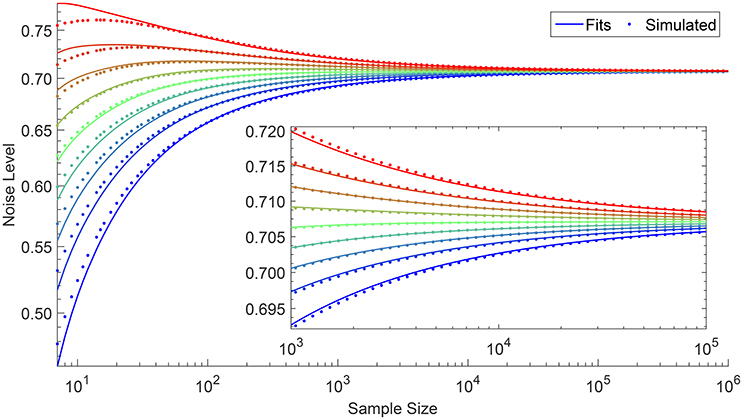
Figure 6. Relationship between distribution noise dDN and sample size N at deciles going from the 10th percentile (blue) to the 90th (red), obtained from 106 simulations. The dDN value converges to as N increases.
4.2. Relationship between Distribution Noise and KS Distance
As measures for statistical deviations, dDN and dKS are different in that dDN measures deviation at the probability density level, whereas the dKS measure it at the cumulative density level. As a result, dKS assigns more weight to the tail of the distribution, while dDN is more sensitive to deviations in the body of the distribution. Therefore, if we wish to combine these two measures to estimate the significance level, we need to first investigate the relationship between dKS and dDN. We do this by simulating 106 samples from U(0, 1) for various sample sizes, and for each sample, we calculate dKS and dDN using Equations (4) and (18) respectively, to obtain 106 pairs of dKS and dDN. We then compute the Pearson correlation between dKS and dDN and learned that (see Supplementary Information section 2 for the comparison of fits)
As expected, dKS is positively correlated with dDN. Since dKS is a measure at the cumulative level, the random distribution noises cancel each other, thus the correlation between dKS and dDN vanishes as N → ∞.
5. Application to Significance Testing
5.1. Significance Level for a Given Distribution
To perform significance testing given dKS and dDN, we need the percentile values ℘KS and ℘DN. ℘KS can be obtained by inverting Equation (16), as
Similarly, we invert Equation (19), and solve
to get ℘DN, where η = dDN − 〈dDN〉.
Substituting the empirical KS distance and empirical distribution noise into Equations (22) and (23), we obtain and . This is an alternative way of obtaining the p-value without the need to perform Monte-Carlo (re)sampling again (CSN method), since we have already done so in sections 3 and 4. The percentage of simulated U(0, 1) samples with is . Since dKS and dDN are not independent (Equation 21), we discount the correlation between dKS and dDN, and define the significance level (p-value) as
to avoid overestimating the significance level.
5.2. Fitting to Empirical Data
We follow the steps outlined in the CSN algorithm (section 2) to fit the empirical data, but with two important modifications: (Ii) the parameters (CSN(ib)) and goodness of fit (CSN(iib)) are adjusted for the finite largest element; and (Iii) the p-value (CSN(ivc)) is adjusted for the finite number of elements effect. Meanwhile, optional modifications are (Oi) to incorporate distribution noise as another dimension for goodness of fit, so that the p-value can be determined via , , or both; (Oii) instead of using bootstrapping to determine the p-value in the CSN method, which is very slow for large samples, one can use the fast inversion formulae Equations (22), (23), or (24).
Figure 7 shows the fits and p-testing results for Taiwan housing price, Taiwan wealth, and Straits Times Index normalized returns. It is reassuring that after modifications the p-values of all distributions increased. In particular, the two distributions (Figures 7B,C) that did not meet the p > 0.1 criterion (as suggested by Clauset et al. [24]) before modification, now have p > 0.5. This is in agreement with our visual assessment of the three fits. We also understand now that a large δ (small xmax) is the main reason for Taiwan wealth to fail p-testing before adjustment (although the fit is visually good). In general, our correction formulas perform the best when δ is large due to small sample sizes or truncations. Readers can refer to Supplementary Information section 4 for more plots and instances where small δ values affects the significance testing.
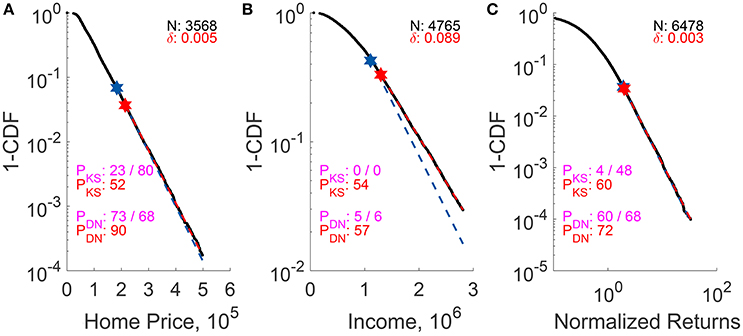
Figure 7. p-testing results for (A) 2012–2014 Taiwan home price per square foot (fitted to EXP), (B) 2012 Taiwan lower-tail income (fitted to EXP), and (C) 2009–2016 Straits Times Index normalized return (fitted to PL) before and after finite-sample adjustments. In this figure, the N represent the number of fitted data, and the empirical CDF that is adjusted for FLE is shown as black dots, while the unadjusted and adjusted fits are shown as blue and red dashed line respectively. PKS/DN-values (in percentage) are for unadjusted (blue) and adjusted (red) fits. We separate the p-values obtained using the CSN method (left) from those using Equations (21) or (23) (right) by a “/”.
There are several limitations one should note while obtaining PKS/DN using Equations (22) or (23). First, it is only applicable to large samples (see Figures 4, 6). Second, these equations are obtained after experimenting with several functional forms and are only approximate. Lastly, pKS measured using the CSN method are consistently smaller than that based on Equation (22). This is due to the CSN algorithm having an extra step to select xmin that minimizes dKS of each simulated sample, and thus the algorithm is stricter than our fast inversion formulae. However, the inversion formulae Equations (22) and (23) are convenient and provide an upper bound for PKS/DN. We make the codes for the procedures used in parameter estimation and significance testing available at https://github.com/BoonKinTeh/StatisticalSignificanceTesting for both these two methods, but leave it to the reader to decide which method to use.
All in all, when we test for statistical significance, we need to be aware of finite sample effects, namely the finite largest element effect and the finite number of elements effect. Beyond the KS distance measured at the cumulative distribution level, we also introduce an alternative measure of the goodness of fit based on the distribution noise at the probability density level.
Author Contributions
BT, DT, and SC: designed research. BT: performed research. BT, DT, and SL: collected data. BT and DT: analyzed data. All authors wrote and reviewed the paper.
Funding
This research is supported by the Singapore Ministry of Education Academic Research Fund Tier 2 under Grant Number MOE2015-T2-2-012.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors would like to thank Chou Chung-I for directing us to the Taiwanese data sets.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2018.00002/full#supplementary-material
References
1. Kac M, Kiefer J, Wolfowitz J. On tests of normality and other tests of goodness of fit based on distance methods. Ann Math Stat. (1955) 26:189–211. doi: 10.1214/aoms/1177728538
2. D'Agostino RB. Transformation to normality of the null distribution of g1. Biometrika (1970) 57:679–81.
3. Jarque CM, Bera AK. A test for normality of observations and regression residuals. Int Stat Rev. (1987) 55:163–72.
5. Anderson TW, Darling DA. Asymptotic theory of certain “goodness of fit” criteria based on stochastic processes. Ann Math Stat. (1952) 23:193–212. doi: 10.1214/aoms/1177729437
7. Massey, FJ Jr. The Kolmogorov-Smirnov test for goodness of fit. J Am Stat Assoc. (1951) 46:68–78.
8. Lilliefors HW. On the Kolmogorov-Smirnov test for normality with mean and variance unknown. J Am Stat Assoc. (1967) 62:399–402.
9. Razali NM, Wah YB. Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests. J Stat Model Anal. (2011) 2:21–33.
10. Newman ME. Power laws, Pareto distributions and Zipf's law. Contemp Phys. (2005) 46:323–51. doi: 10.1016/j.cities.2012.03.001
11. Mantegna RN, Stanley HE. Scaling behaviour in the dynamics of an economic index. Nature (1995) 376:46–9.
12. Plerou V, Gopikrishnan P, Amaral LAN, Meyer M, Stanley HE. Scaling of the distribution of price fluctuations of individual companies. Phys Rev E (1999) 60:6519.
13. Gopikrishnan P, Plerou V, Amaral LAN, Meyer M, Stanley HE. Scaling of the distribution of fluctuations of financial market indices. Phys Rev E (1999) 60:5305.
14. Teh BK, Cheong SA. The Asian correction can be quantitatively forecasted using a statistical model of fusion-fission processes. PloS ONE (2016) 11:e0163842. doi: 10.1371/journal.pone.0163842
16. Cancho RFi, Solé RV. The small world of human language. Proc R Soc Lond B Biol Sci. (2001) 268:2261–5. doi: 10.1098/rspb.2001.1800
18. Gabaix X, Ioannides YM. The evolution of city size distributions. Handb Region Urban Econ. (2004) 4:2341–78. doi: 10.1016/S1574-0080(04)80010-5
20. Ohnishi T, Mizuno T, Shimizu C, Watanabe T. Power laws in real estate prices during bubble periods. Int J Mod Phys Conf Ser. (2012) 16:61–81. doi: 10.1142/S2010194512007787
21. Tay DJ, Chou CI, Li SP, Tee SY, Cheong SA. Bubbles are departures from equilibrium housing markets: evidence from Singapore and Taiwan. PLoS ONE (2016) 11:e0166004. doi: 10.1371/journal.pone.0166004
22. Mandelbrot B. The Pareto-Levy law and the distribution of income. Int Econ Rev. (1960) 1:79–106.
23. Yakovenko VM, Rosser JB Jr. Colloquium: statistical mechanics of money, wealth, and income. Rev Mod Phys. (2009) 81:1703. doi: 10.1103/RevModPhys.81.1703
24. Clauset A, Shalizi CR, Newman ME. Power-law distributions in empirical data. SIAM Rev. (2009) 51:661–703. doi: 10.1137/070710111
25. Brzezinski M. Do wealth distributions follow power laws? Evidence from “rich lists”. Phys A (2014) 406:155–62. doi: 10.1016/j.physa.2014.03.052
26. Hansen LP, Heaton J, Yaron A. Finite-sample properties of some alternative GMM estimators. J Bus Econ Stat. (1996) 14:262–80.
27. Windmeijer F. A finite sample correction for the variance of linear efficient two-step GMM estimators. J Econom. (2005) 126:25–51. doi: 10.1016/j.jeconom.2004.02.005
28. Fisher RA. On an absolute criterion for fitting frequency curves. Messenger Math. (1912) 41:155–60.
29. Kumphon B. Maximum entropy and maximum likelihood estimation for the three-parameter Kappa distribution. Open J Stat. (2012) 2:415–9. doi: 10.4236/ojs.2012.24050
30. Hradil Z, Rehácek J. Likelihood and entropy for statistical inversion. J Phys Conf Ser. (2006) 36:55. doi: 10.1088/1742-6596/36/1/011
31. Akaike H. Information theory and an extension of the maximum likelihood principle. Chapter 4: AIC and Parametrization. In: Parzen E, Tanabe K, Kitagawa G, editors. Information Theory and an Extension of the Maximum Likelihood Principle. New York, NY: Springer New York (1998). p. 199–213.
32. Bates DM, Watts DG. Nonlinear Regression Analysis and Its Applications. New York, NY: Wiley (1988).
33. Wooldridge JM. Applications of generalized method of moments estimation. J Econ Perspect. (2001) 15:87–100. doi: 10.1257/jep.15.4.87
34. Cameron AC, Windmeijer FAG. An R-squared measure of goodness of fit for some common nonlinear regression models. J Econom. (1997) 77:329–42.
35. Janczura J, Weron R. Black swans or dragon-kings? A simple test for deviations from the power law. Eur Phys J Spec Top. (2012) 205:79–93. doi: 10.1140/epjst/e2012-01563-9
36. American Statistical Association. ASA P-Value Statement Viewed > 150, 000 Times. American Statistical Association News (2016). (Accessed March 07, 2017). Available online at: https://www.amstat.org/ASA/News/ASA-P-Value-Statement-Viewed-150000-Times.aspx
37. Wasserstein RL, Lazar NA. The ASA's statement on p-values: context, process, and purpose. Am Stat. (2016) 70:129–33. doi: 10.1080/00031305.2016.1154108
38. Baker M. Statisticians issue warning over misuse of P values. Nature (2016) 531:151. doi: 10.1038/nature.2016.19503
39. Pitman EJ, Pitman EJG. Some Basic Theory for Statistical Inference, Vol. 7. London: Chapman and Hall London (1979).
40. Alstott J, Bullmore E, Plenz D. powerlaw: a Python package for analysis of heavy-tailed distributions. PLoS ONE (2014) 9:e85777. doi: 10.1371/journal.pone.0085777
41. Yu S, Klaus A, Yang H, Plenz D. Scale-invariant neuronal avalanche dynamics and the cut-off in size distributions. PLoS ONE (2014) 9:e99761. doi: 10.1371/journal.pone.0099761
Keywords: significance testing, finite sample effects, curve fitting, maximum likelihood, p-test
Citation: Teh BK, Tay DJ, Li SP and Cheong SA (2018) Finite Sample Corrections for Parameters Estimation and Significance Testing. Front. Appl. Math. Stat. 4:2. doi: 10.3389/fams.2018.00002
Received: 09 September 2017; Accepted: 11 January 2018;
Published: 30 January 2018.
Edited by:
Dabao Zhang, Purdue University, United StatesReviewed by:
Yanzhu Lin, National Institutes of Health (NIH), United StatesJie Yang, University of Illinois at Chicago, United States
Qin Shao, University of Toledo, United States
Copyright © 2018 Teh, Tay, Li and Cheong. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Boon Kin Teh, Ym9vbmtpbnRlaEBnbWFpbC5jb20=
Siew Ann Cheong, Y2hlb25nc2FAbnR1LmVkdS5zZw==