 Daniel Fryer
Daniel Fryer Inga Strümke2*
Inga Strümke2* Hien Nguyen
Hien Nguyen- 1School of Mathematics and Physics, The University of Queensland, St Lucia, QLD, Australia
- 2Simula Research Laboratory, Oslo, Norway
- 3Department of Mathematics and Statistics, La Trobe University, Melbourne, VIC, Australia
The coefficient of determination, the
1. Introduction
When conducting statistical estimation and computation, the assumption of randomness of data necessitates that we address not only the problem of point estimation, but also variability quantification. In Ref. 1, variability for the coefficient of determination Shapley values were quantified via the use of bootstrap confidence intervals (CIs). Combined with the usual computational intensiveness of bootstrap resampling (see, e.g., Refs. 2 and 3; Ch. 12)), the combinatory nature of the computation of Eq. 5 (notice that
Our approach uses the joint asymptotic normality result of the elements in a correlation matrix, under an elliptical assumption, via [4], combined with asymptotic normality results concerning the determinants of a correlation matrix, of Refs. 5 and 6. Using these results, we derive the asymptotic joint distribution for the
The remainder of the article proceeds as follows. In Section 3, we present our main results regarding the asymptotic distribution of the coefficient of determination Shapley values, and their CI constructions. In Section 4, we present a comprehensive Monte Carlo study of our CI construction method. In Section 5, we demonstrate how our results can be applied to real estate price data. Conclusions are lastly drawn in Section 6. All data and scripts to reproduce the analyses are available at https://github.com/ex2o/shapley_confidence.
2. Background
2.1. The Coefficient of Determination
The multiple linear regression model (MLR) is among the most commonly applied tools for statistics inference; see Refs. 7 and 8; Part I) for thorough introductions to MLR models. In the usual MLR setting, one observes an independent and identically distributed (IID) sample of data pairs
where
The usual nomenclature is to call the
Let
for each
A common inferential task is to determine the degree to which the response can be explained by the covariate vector, in totality. The usual device for addressing this question is via the coefficient of determination (or squared coefficient of multiple correlation), which is defined as
where
2.2. The Shapley Value
A refinement to the question that is addressed by the
In the past, this question has partially been resolved via the use of partial correlation coefficients (see, e.g., Ref. 8; Sec. 3.4). Unfortunately, such coefficients are only able to measure the contribution of each covariate to the coefficient of determination, conditional to the presence of other covariates that are already in the MLR model.
A satisfactory resolution to the question above, is provided by Refs. 10 and 11, and Ref. 1, who each suggested and argued for the use of the Shapley decomposition of Ref. 12.
The Shapley decomposition is a game-theoretic method for decomposing the contribution to the value of a utility function in the context of cooperative games.
Let
be the elements of
for nonempty subsets
Treating the coefficient of determination as a utility function, we may conduct a Shapley partition of the
where
2.3 Uniqueness of the Shapley Value
Compared to other decompositions of the coefficient of determination, such as those considered in Refs. 13 and 14, the Shapley values, obtained from the partitioning above, have the favorable axiomatic properties that were well exposed in Ref. 1. Specifically, the Shapley values have the efficiency, monotonicity, and, equal treatment properties, and the decomposition is provably the only method that satisfies all three of these properties (cf. Ref. 15; Thm. 2)). Here, in the context of the coefficient of determination, efficiency, monotonicity, and equal treatment are defined as follows:
Efficiency: The sum of the Shapley values across all covariates equates to the coefficient of determination, that is
Monotonicity: For pairs of samples
for every
Equal treatment: If covariates
for each
We note that equal treatment is also often referred to as symmetry in the literature. The uniqueness of the Shapley decomposition in exhibiting the three described properties is often used as the justification for its application. Furthermore, there are numerous sets of axiomatic properties that lead to the Shapley value decomposition as a solution (see, e.g., Ref. 16). In the statistics literature, it is known that the axioms for decomposition of the coefficient of determination that are proposed by Ref. 17 correspond exactly to the Shapley values (cf. Ref. 18).
3. Theoretical Results
3.1. The Correlation Matrix
Let
Let
Lemma 1. If
Remark 1. We note that the elliptical distribution assumption above can be replaced by a broader pseudo-elliptical assumption, as per Refs. 21 and 22. This is a wide class of distributions that includes some that may not be symmetric. Due to the complicated construction of the class, we refer the interested reader to the source material for its definition.
Remark 2. We may state a similar result that replaces the elliptical assumption by a fourth moments existence assumption instead, using Proposition 2 of Ref. 4. In order to make practical use of such an assumption, we require the estimation of
Let
and
The following theorem is adapted from a result of Ref. 5 (also appearing as Theorem 1 in Ref. 23). Our result expands upon the original theorem, to allow for inference regarding elliptically distributed data, and not just normally distributed data. We further fix some typographical matters that appear in both Refs. 5 and 23.
Lemma 2.Assume the same conditions as in Eq. 1. Then, the normalized covariance determinant
where
and
Proof. The result is due to an application of the delta method (see, e.g., Ref. 24; Thm. 3.1)) and the fact that for any matrix
Remark 3. If
where
and
3.2. The Coefficient of Determination
Let plim denote convergence in probability, so that for any sequence
for every
Now, recall definition Eq. 4, and further let
Lemma 3.Assume the same conditions as in Eq. 1. Then, the normalize coefficient of determination
Proof. We apply the delta method again, using the functional form Eq. 4, and using the fact that
Remark 4. When
3.3. A Shapley Value Confidence Interval
For every
where
Remark 5. The form Eq. 9 is a useful computational trick that reduces the computational time of form Eq. 5 and results in more efficient computations for fixed d. It is unclear whether other formulations such as that of Ref. 26 can make the computation time even faster. Unfortunately, however, there is no formulation that reduces the
Theorem 1. Assume the same conditions as in Eq. 1. Then, the normalized Shapley values
and
where
Using the result above, we may apply the delta method again in order to construct asymptotic CIs or hypothesis tests regarding any continuous function of the d Shapley values for the coefficient of determination. Of particular interest is the asymptotic CI for each of the individual Shapley values and the hypothesis test for the difference between two Shapley values.
The asymptotic
where
for
where
Remark 6. In practice, we do not know the necessary elements κ and
and replaces
where
for the hypotheses Eq. 10, retains the property of having an asymptotically standard normal distribution.
The confidence interval calculation is summarized in Algorithm 1.
Algorithm 1: A Shapley value confidence interval
1. Input: dataset
2. Compute the estimate
3. Compute
4. Compute
5. Output: a
4. Monte Carlo Studies and Benchmarks
In each of the following three Monte Carlo studies, we simulate a large number N of random samples
Here, the population Shapley value
where
where
In Study C, we are concerned with covariance matrices with off-diagonal elements deviating from c. We aim to capture a case where the off-diagonal elements of
To accompany our estimates of
To obtain results for each pair
4.1. MC Study A
Here, we choose
The simulation results in Figure 1 (and in Supplementary Figure S12) show very similar coverage and width performance between the two assessed CIs for moderate and high correlations
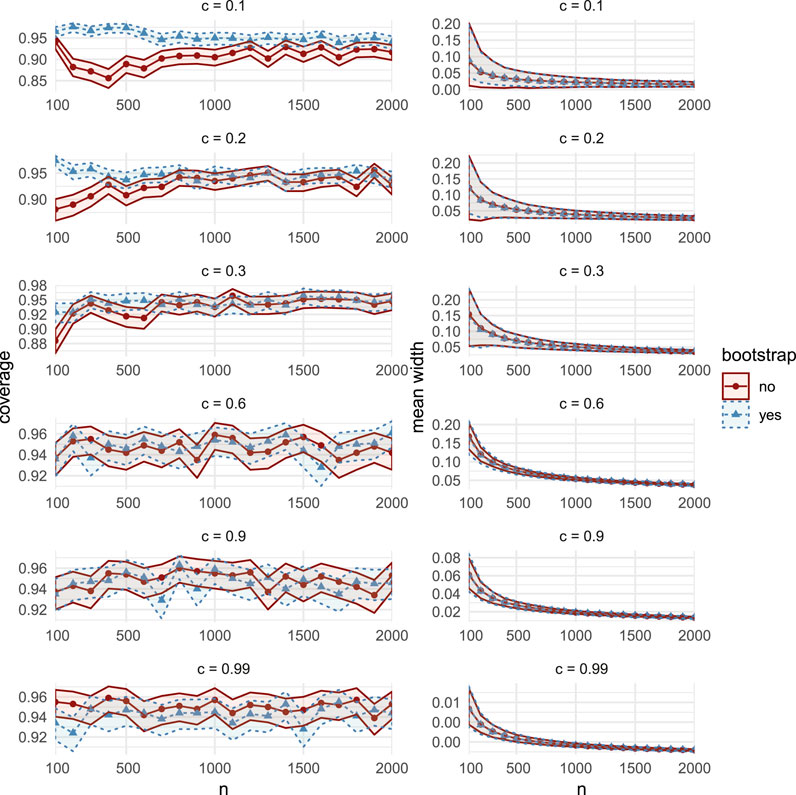
FIGURE 1. Comparisons of coverage (left column) and mean width (right column), between the bootstrap CIs (dashed lines with triangular markers) and the asymptotic CIs (solid lines with circular markers) in MC Study A. Rows represent correlations c, increasing from 0.1 on the top row to 0.99 on the bottom row. The horizontal axes display the sample sizes
4.2. MC Study B
Here, we choose
For all sample sizes n and correlations c, coverage and width performances are similar to MC Study A (see Supplementary Figures S13 and S14). Of particular interest, in both MC Studies A and B (but not in MC Study C), we observe that for
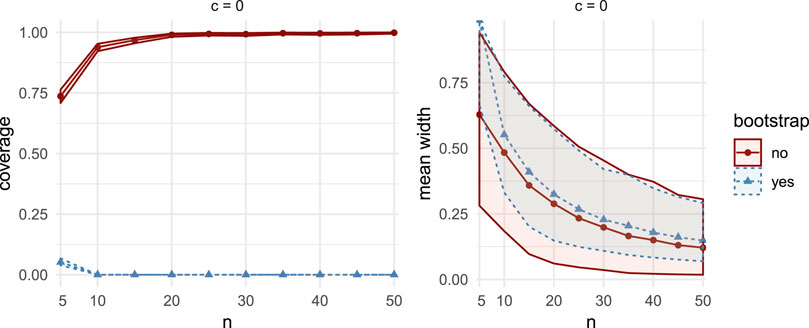
FIGURE 2. Comparisons of coverage (left column) and mean width (right column) between bootstrap CIs (dashed lines with triangular markers) and the asymptotic CIs (solid lines with circular markers) in MC Study B, for correlation
4.3. MC Study C
Here, we set
The distribution
Aside for the case
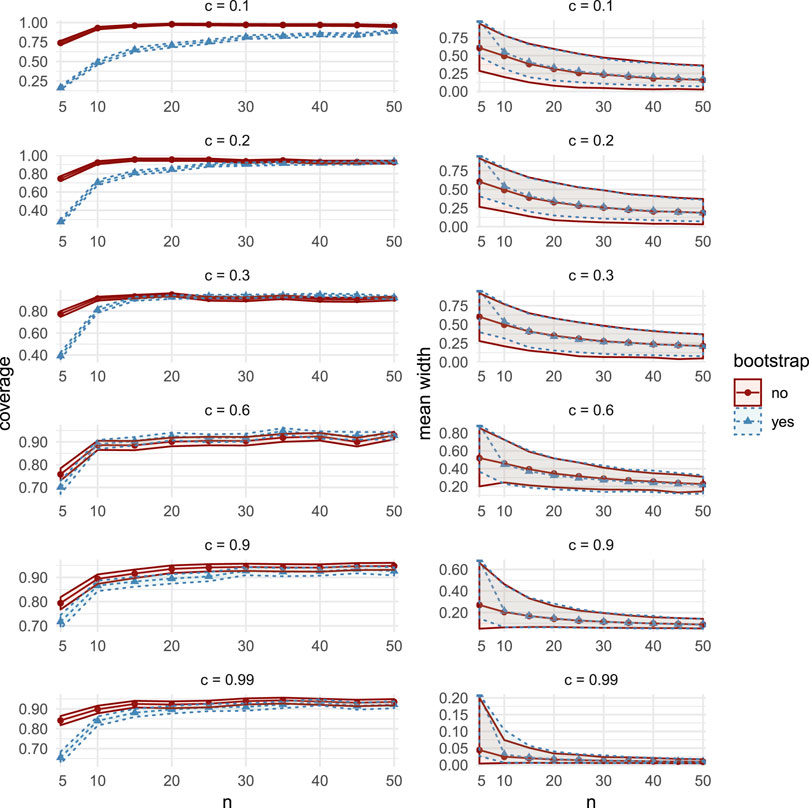
FIGURE 3. Comparisons of coverage (left column) and mean width (right column), between the bootstrap CIs (dashed lines with triangular markers) and the asymptotic CIs (solid lines with circular markers) in MC Study C. Rows represent correlations c, increasing from 0.1 on the top row to 0.99 on the bottom row. The horizontal axes display the sample sizes

FIGURE 4. Comparisons of coverage (left column) and mean width (right column) between bootstrap CIs (dashed lines with triangular markers) and the asymptotic CIs (solid lines with circular markers) in MC Study C, for correlation
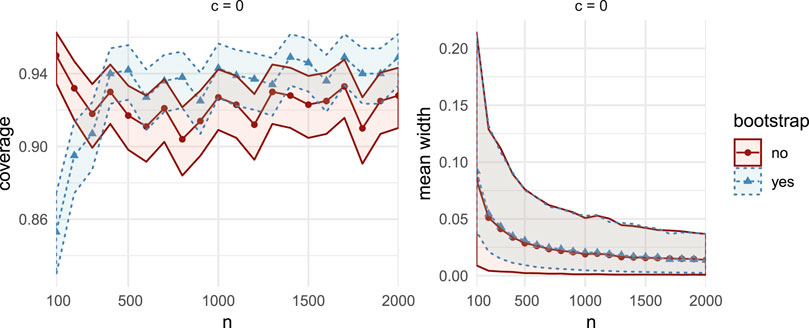
FIGURE 5. Comparisons of coverage (left column) and mean width (right column) between bootstrap CIs (dashed lines with triangular markers) and the asymptotic CIs (solid lines with circular markers) in MC Study C, for correlation
4.4. Computational Benchmarks
From Figure 6, we see that the memory usage (left) and mean execution time (right) for the bootstrap CIs are both higher than that for the asymptotic CIs, and that the ratio increases with sample size given the benchmarking parameters in Table 1. As n increases, asymptotic CIs become increasingly efficient, compared to the bootstrap CIs. On the other hand, as d increases, with n fixed, we expect an increase in the relative efficiency of the bootstrap, since the complexity of calculating
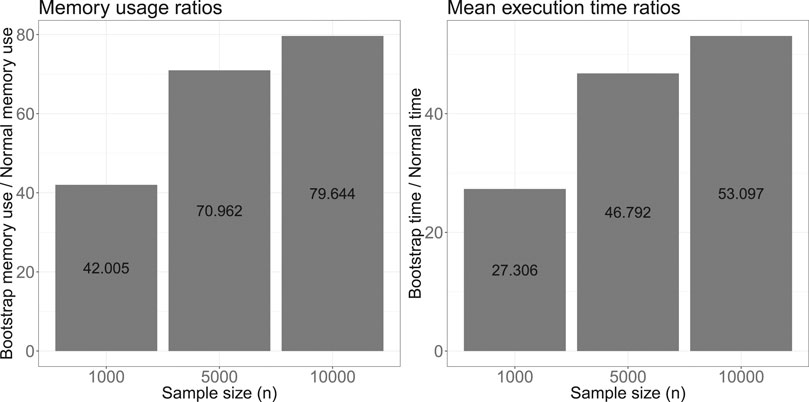
FIGURE 6. Computational benchmark metric ratios of confidence interval estimation using the naïve bootstrap over the asymptotic normality approach.

TABLE 1. Parameters for computational benchmarking.
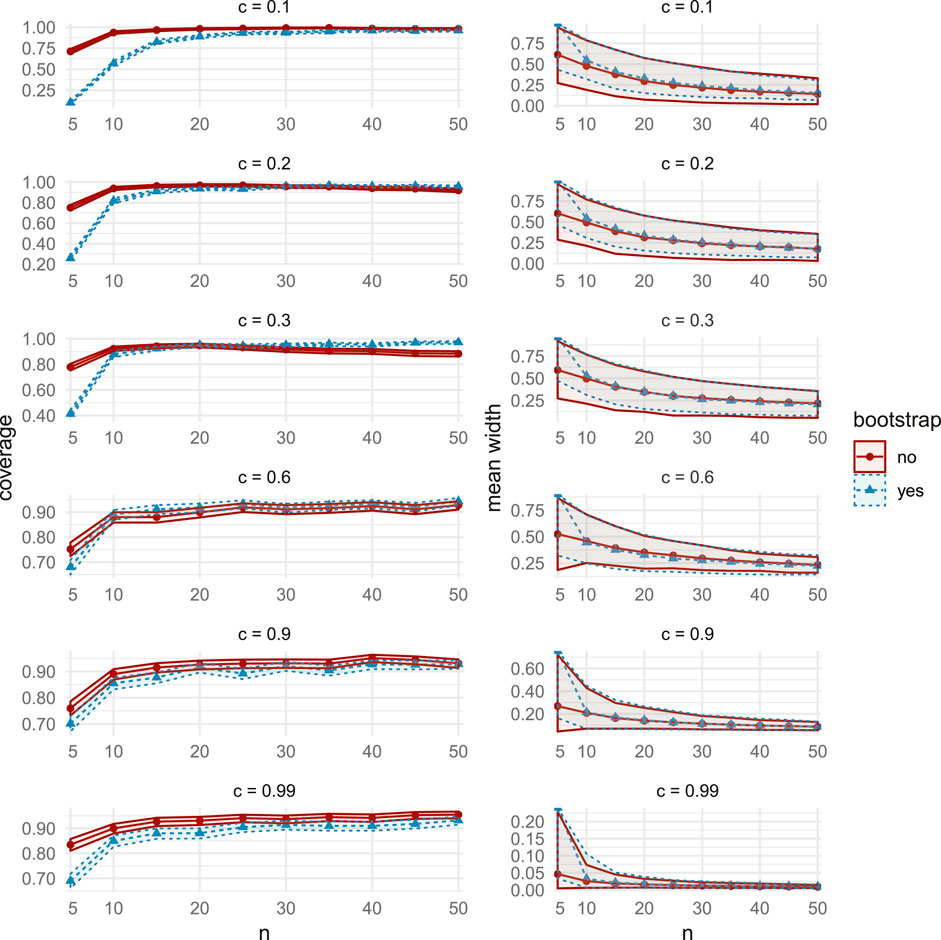
FIGURE 12. Comparisons of coverage (left column) and mean width (right column), between the bootstrap CIs (dashed lines with triangular markers) and the asymptotic CIs (solid lines with circular markers) in MC Study A. Rows represent correlations c, increasing from 0:1 on the top row to 0:99 on the bottom row. The horizontal axes display the sample sizes n = 5;10;50.
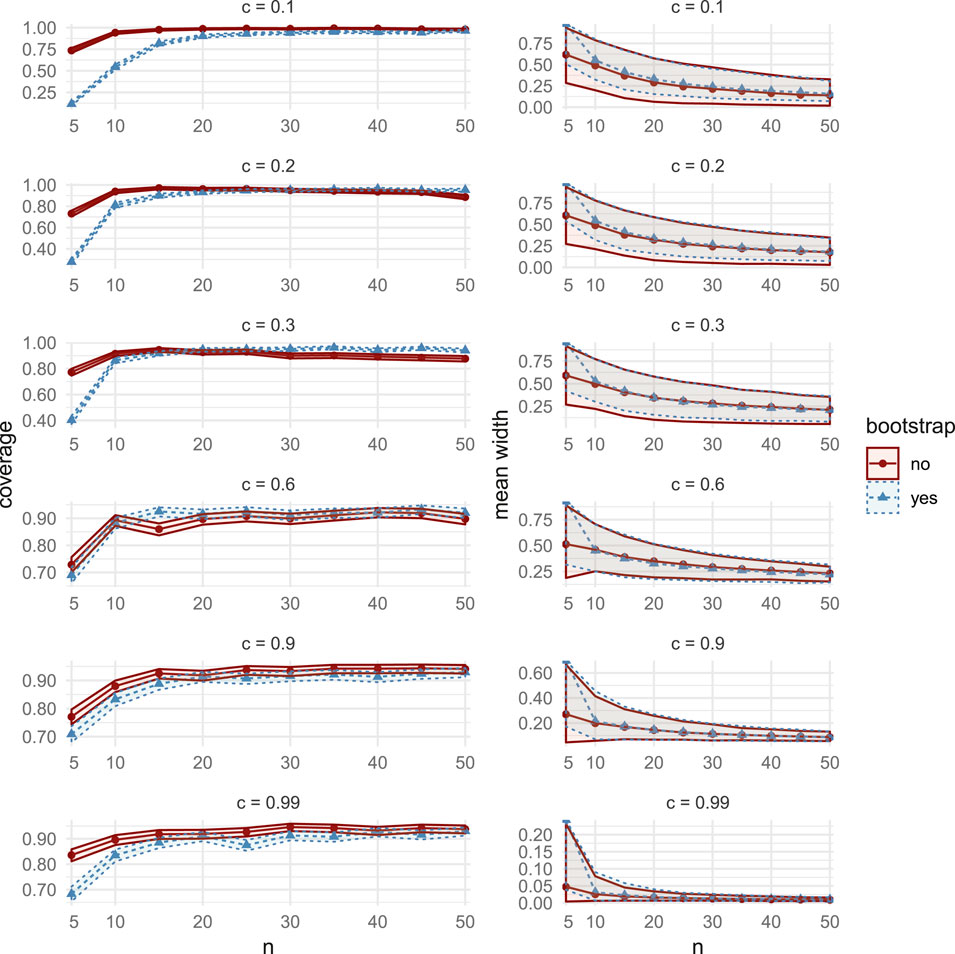
FIGURE 13. Comparisons of coverage (left column) and mean width (right column), between the bootstrap CIs (dashed lines with triangular markers) and the asymptotic CIs (solid lines with circular markers) in MC Study B. Rows represent correlations c, increasing from 0:1 on the top row to 0:99 on the bottom row. The horizontal axes display the sample sizes n = 5; 10;50.

FIGURE 14. Comparisons of coverage (left column) and mean width (right column), between the bootstrap CIs (dashed lines with triangular markers) and the asymptotic CIs (solid lines with circular markers) in MC Study B. Rows represent correlations c, increasing from 0:1 on the top row to 0:99 on the bottom row. The horizontal axes display the sample sizes n = 100; 200;2000.41
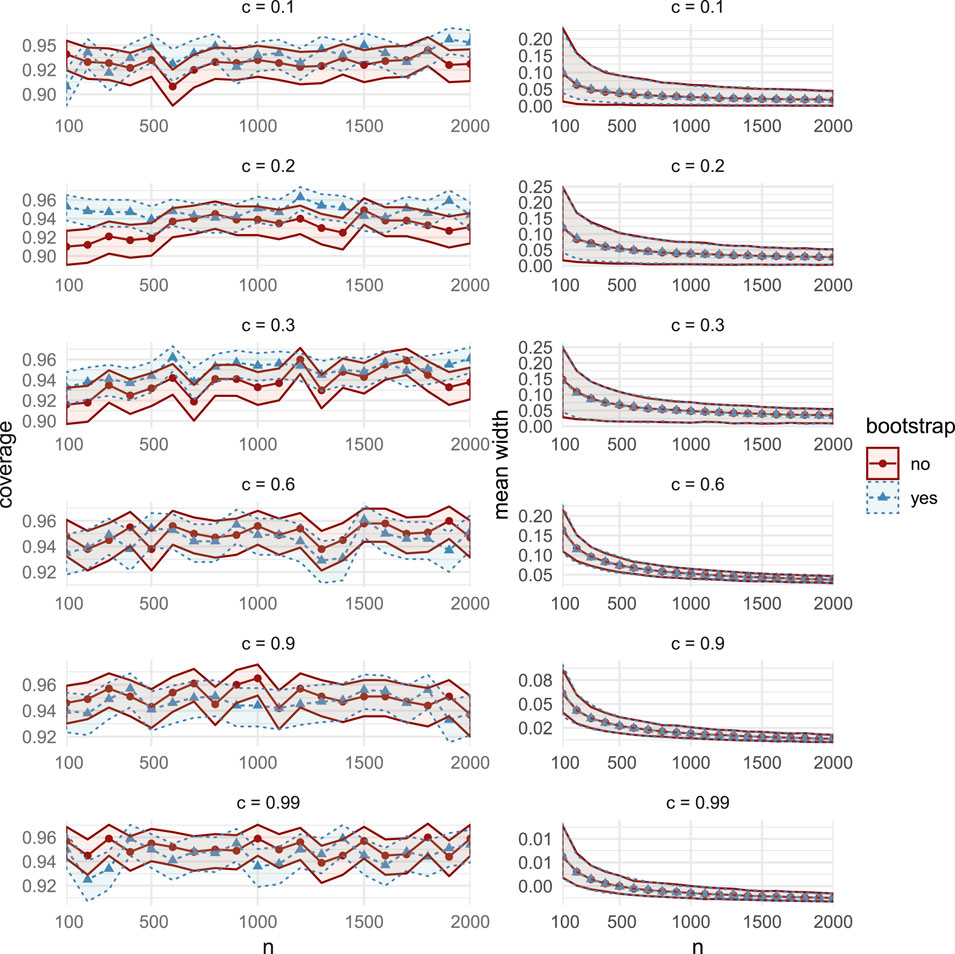
FIGURE 15. Comparisons of coverage (left column) and mean width (right column), between the bootstrap CIs (dashed lines with triangular markers) and the asymptotic CIs (solid lines with circular markers) in MC Study C. Rows represent correlations c, increasing from 0:1 on the top row to 0:99 on the bottom row. The horizontal axes display the sample sizes n = 100; 200; 2000.
4.5. Summary of Results and Recommendations for Use
The most relevant observation is that the widths all appear to shrink at a rate that is comparable to the expected
• For all correlations c in all three Studies, the estimated coverage probability of asymptotic intervals is above 0.85 for all sample sizes
• For smaller correlations and sample sizes, in particular
• For all correlations
• For small correlations, in particular
• For
• For sample sizes
• The average asymptotic CI width is lower when c is nearer to the boundaries of
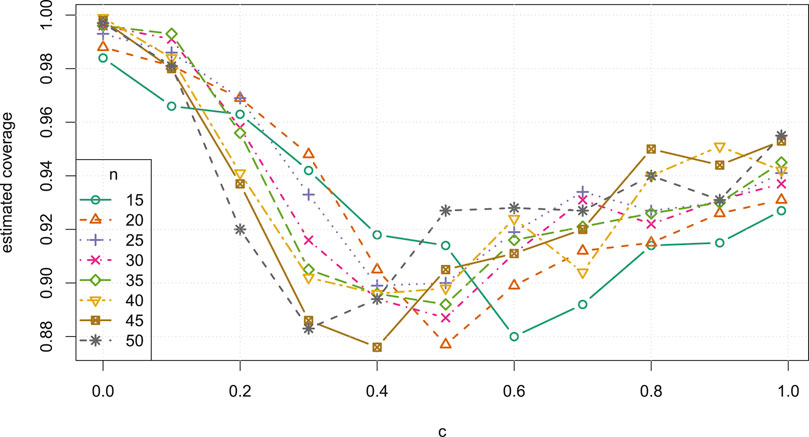
FIGURE 7. Estimated coverage probability versus correlation c, for small samples sizes
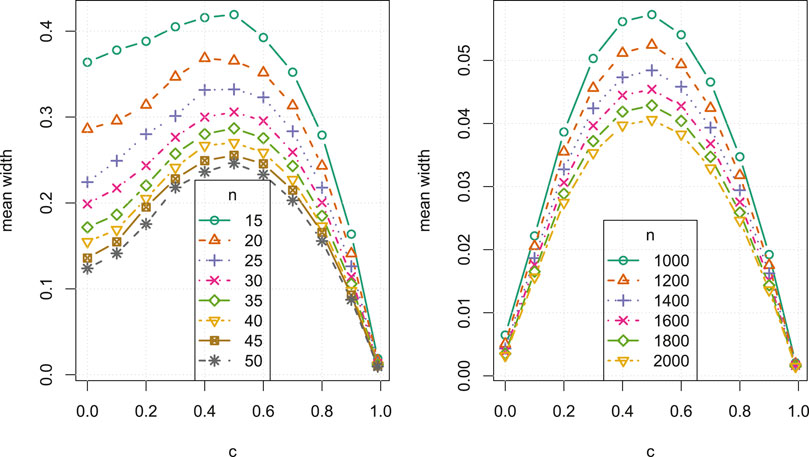
FIGURE 8. Average confidence interval width versus correlation c, for small sample sizes
We now make some general observations which apply to all three Studies. As sample size increases, the estimated coverage initially increases rapidly, as can be seen, for example, in the left column of Figure 3. For small sample sizes between
We further observe that, for all n, there is a general increase in the average CI width as c approaches 0.5 from either direction, as in Figure 8. In all Studies, over all sample sizes and correlations, the bootstrap CI average widths were smaller than the asymptotic CI widths by at most 0.0289, and vice versa by at most 0.0667. In general, the asymptotic intervals display favourable widths, though less so near
4.6. Recommendations for Use
Based on these observations, we recommend using asymptotic CIs over bootstrap CIs under the following conditions:
(i) Computational time is relevant (e.g., estimating a large number of Shapley values).
(ii) The sample size is small (e.g.,
(iii) The correlation between explanatory variables and the response variable is expected to be beyond
We note that our observations are made from an incomplete albeit comprehensive set of simulation scenarios. There are of course an infinite number of combinations of simulation cases and thus we cannot guarantee that our observation applies to all possible DGPs.
5. Application: Real Estate and COVID-19
For an interesting application of our methods, in this section we identify significant changes in the behavior of the local real estate market in Melbourne, Australia, between the period 1 February 2019 to 1 April 2019 and the period 1 February 2020 to 1 April 2020. In 2020, this corresponds to an early period of growing public concern regarding the novel coronavirus COVID-19. We obtain the Shapley decomposition of the coefficient of multiple correlation
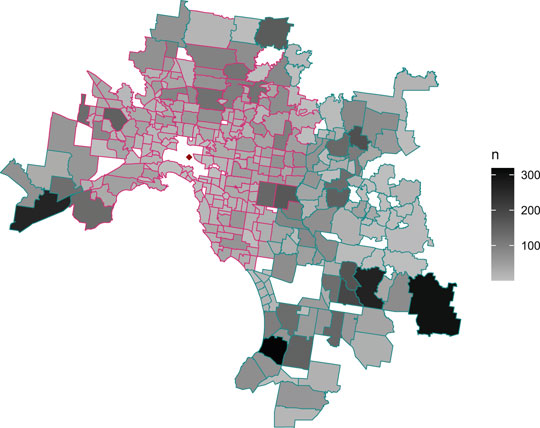
FIGURE 9. Map of Melbourne suburbs included in this study, with greyscale shading to represent sample sizes. Pink dashed polygon borders contain suburbs classified as near to the Central Business District (i.e.,
On 1 February the Australian government announced a temporary ban on foreign arrivals from mainland China, and by 1 April a number of social distancing measures were in place. We scraped real estate data from the AUHousePrices website (https://www.auhouseprices.com/), to obtain a data set of

FIGURE 10. Bar plot of sales per day between 1 January and 18 July in 2019 and 2020. Vertical dashed red lines indicate 1 February and 1 April, between which a spike in sales is observed.

TABLE 2. The four subgroups and their sample sizes after partitioning by distance (where near
We decompose
Fitted to each of the four subgroups, we obtain
(i) In both 2019 and 2020, the attribution for distance to CBD was significantly higher for house sales near to the CBD, compared to house sales farther from the CBD. Correspondingly, the attribution for roominess was significantly lower for house sales near to the CBD.
(ii) Among sales that were near to the CBD, distances to the CBD received significantly greater attribution than both land size and roominess in 2019. Unlike the case for sales that were far from the CBD, these differences remained significant in 2020.
(iii) Distances to stations and schools, as well as images used in advertising, have apparently had little overall impact. In all four subgroups, the attribution for distance to the nearest school is not significantly different from 0. However, distance to a station does receive significantly more attribution among houses that are near to the CBD, compared to those farther away.
(iv) Interestingly, while not a significant result, the number of images used in advertising did appear to receive greater attribution among house sales that were far from the CBD, compared to those near to it.
(v) Among sales that were far from the CBD, land size and roominess both received significantly more attribution than distance to the CBD, in 2019. However, this difference vanished in 2020, with distances to the CBD apparently gaining more attribution, while roominess and land size apparently lost some attribution, in a relative leveling out of these three covariates.

TABLE 3. Shapley values and asymptotic CIs for the covariates of the real estate data.
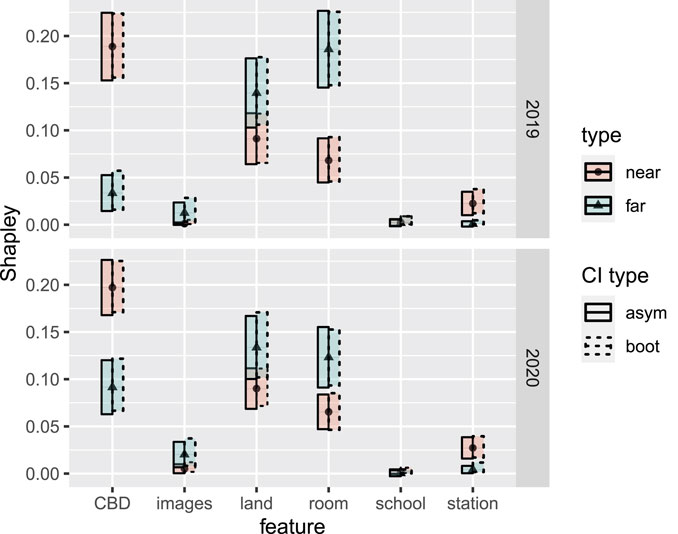
FIGURE 11. Shapley values and associated asymptotic 95% confidence intervals (labelled as CI type “asym”) for each of the six covariates, within the four real estate data subgroups (near/far and 2019/2020). Blue bands and triangle markers represent the near subgroup (i.e.,
Item (i) is perhaps unsurprizing: distances were less relevant far from the city, where price variability was influenced more by roominess and land size. Indeed, we can assume we are less likely to find small and expensive houses far from the CBD. However, the authors find Item (v) interesting: near the city, the behavior did not change significantly during the 2020 period. However, far from the city, the behavior did change significantly, moving toward the near-city behavior. Distance to the city became more important for explaining variability in price, while land size and roominess both became less important, compared with their 2019 estimates. Our initial guess at an explanation was that near-city buyers, with near-city preferences, were temporarily motivated by urgency to buy farther out. However, according to Table 2, the observed ratio of near-city buyers to non-near buyers actually increased in this period, from 1.26 in 2019 to 1.61 in 2020. We will not take this expository analysis further here, but we hope that the interested reader is motivated to take it further, and to this end we have made the data, as well as R and Julia scripts, available at https://github.com/ex2o/shapley_confidence.
6. Discussion
In this work, we focus on regression Shapley values as a means for attributing goodness of fit. There has also been much recent interest in the machine learning literature in using Shapley values to attribute predictions. These approaches, such as SHAP [30], TreeExplainer [31], and Quantitative Input Influence [32] are focused on providing local explanations that depend on the behavior of a fitted model. For more on the differences between prediction, estimation and attribution, see the recent exposition of Ref. 33.
Research into the attribution of goodness of fit using the Shapley value, predates research into attributing predictions. As described in Section 2, regression Shapley values were first introduced in Ref. 10. Then, Ref. 1 advocated for decompositions among exogenously grouped sets of explanatory variables using the both the Shapley and Owen values, where the Owen values are a generalization that permits group attributions.
Our work is the first to determine the asymptotic distribution of the regression Shapley values. In Section 3, we show that under an elliptical (or pseudo-elliptical) joint distribution assumption, the Shapley value decomposition of
In Section 4, we use Monte Carlo simulations to examine the coverage and width statistics of these asymptotic CIs. We compare the coverage and width statistics for different data generating processes, correlations and sample sizes. In Section 4.5 we provide recommendations for when asymptotic CIs should be used rather than bootstrap CIs. We find that the asymptotic CIs have estimated coverage probabilities of at least 0.85 across all studies, are preferable over the bootstrap CIs for small sample sizes (
In Section 5, we derive asymptotic CIs to Melbourne house prices during a period of altered consumer behavior in the initial stages of the arrival of COVID-19 in Australia. Using the CIs, we identify significant changes in model behavior between 2019 and 2020, and attribute these changes among features, highlighting an interesting direction of future research into the period. Implementations of our methods as well as data sets are openly available for use at https://github.com/ex2o/shapley_confidence.
We aim to use our developments to derive the asymptotic distributions of variance inflation factors and their generalizations [34], as well as the closely related Owen values decomposition of the coefficient of determination for exogenously grouped sets of features [1]. We will also investigate calculating Shapley values capable of uncovering non-linear dependencies and their confidence intervals in future work.
Author’s Note
This manuscript has been released as a pre-print on arXiv [35].
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author Contributions
DF Provided Monte Carlo simulations, theoretical contributions, real estate data scraping and analysis, figures, computational benchmarks and general writing. IS Provided real estate data analysis, theoretical contributions, general writing and proofreading. HN Provided theoretical proofs, theoretical contributions, general writing and proofreading.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2020.587199/full#supplementary-material
References
1. Huettner, F, and Sunder, M. Decomposing axiomatic arguments for decomposing goodness of fit according to Shapley and Owen values. Electron J Statist. (2012). 6:1239–50. doi:10.1214/12-ejs710
2. Efron, B. Computer-intensive methods in statistical regression. SIAM Rev. (1988). 30:421–49. doi:10.1137/1030093
3. Baglivo, JA. Mathematica laboratories for mathematical statistics: emphasizing simulation and computer intensive methods. Philadelphia, PA: SIAM (2005).
4. Steiger, JH, and Browne, MW. The comparison of interdependent correlations between optimal linear composites. Psychometrika (1984). 49:11–24. doi:10.1007/bf02294202
5. Hedges, LV, and Olkin, I. Joint distributions of some indices based on correlation coefficients. In: S, Karlin, T, Amemiya, and LA, Goodman, editors Studies in econometrics, time series, and multivariate analysis. Cambridge, UK: Academic Press (1983).
6. Olkin, I, and Finn, JD. Correlations redux. Psychol Bull (1995). 118:155–64. doi:10.1037/0033-2909.118.1.155
9. Cowden, DJ. The multiple-partial correlation coefficient. J Am Stat Assoc. (1952). 47:442–56. doi:10.1080/01621459.1952.10501183
10. Lipovetsky, S, and Conklin, M. Analysis of regression in game theory approach. IED Stoch Models Bus Ind Appl. 17, 319–30. doi:10.1002/asmb.446
11. Israeli, O (2007). A Shapley-based decomposition of the R-square of a linear regression. J Econ Inequal. 5, 199–212.
12. Shapley, LS. A value for n-person games. In: HW, Kuhn, and AW, Tucker, editors Contributions to the theory of games. Princeton, NJ: Princeton University Press (1953).
13. Gromping, U. Relative importance for linear regression R: the package relaimpo. J Stat Softw. (2006). 17, 1–27.
14. Grömping, U. Estimators of relative importance in linear regression based on variance decomposition. Am Stat. (2007). 61, 139–47. doi:10.1198/000313007x188252
15. Young, HP. Monotonic solutions of cooperative games. Int J Game Theory (1985). 14:65–72. doi:10.1007/bf01769885
16. Feltkamp, V. Alternative axiomatic characterizations of the shapley and banzhaf values. Int J Game Theory (1995). 24(2):179–86. doi:10.1007/bf01240041
17. Kruskal, W. Relative importance by averaging over orderings. Am Am Stat. (1987). 41, 6–10. doi:10.2307/2684310
18. Genizi, A. Decomposition of R2 in multiple regression with correlated regressors. Stat Sin. (1993). 13:407–20.
19. Mardia, KV (1970). Measures of multivariate skewness and kurtosis with applications. Biometrika 57:519–30. doi:10.1093/biomet/57.3.519
20. Fang, KT, Kotz, S, and Ng, KW. Symmetric multivariate and related distributions. London, UK: Chapman & Hall (1990).
21. Yuan, K-H, and Bentler, PM. On normal theory and associated test statistics in covariance structure analysis under two classes of nonnormal distributions. Stat Sin. (1999). 9:831–53.
22. Yuan, K-H, and Bentler, PM. Inferences on correlation coefficients in some classes of nonnormal distributions. J Multivar Anal. (2000). 72:230–48. doi:10.1006/jmva.1999.1858
23. Hedges, LV, and Olkin, I. Joint distribution of some indices based on correlation coefficients (1983). Technical Report MCS 81-04262, Stanford University.
26. Hart, S, and Mas-Colell, A. The potential of the shapley value. Shapley Value (1988). 14:127–37.
27. Clopper, CJ, and Pearson, ES. The use of confidence or fiducial limits illustrated in the case of the binomial. Biometrika (1934). 26(4):404–13. doi:10.1093/biomet/26.4.404
28. Fujikoshi, Y, Ulyanov, VV, and Shimizu, R. Multivariate statistics: high-dimensional and large-sample approximations. Vol. 760. Hoboken, NJ: John Wiley & Sons (2011).
29. Yeo, I-K, and Johnson, RA. A new family of power transformations to improve normality or symmetry. Biometrika (2000). 87(4), 954–59. doi:10.1093/biomet/87.4.954
30. Lundberg, SM, and Lee, S-I. A unified approach to interpreting model predictions. In: I, Guyon, UV, Luxburg, S, Bengio, H, Wallach, R, Fergus, and S, Vishwanathan, editors Advances in neural information processing systems. Vol. 30, London, UK: Curran Associates, Inc (2017). p. 4765–74.
31. Lundberg, SM, Erion, G, Chen, H, DeGrave, A, Prutkin, JM, Nair, B, et al. From local explanations to global understanding with explainable ai for trees. Nat Mach Intell. (2020). 2(1):56–67. doi:10.1038/s42256-019-0138-9
32. Datta, A, Sen, S, and Zick, Y. Algorithmic transparency via quantitative input influence: theory and experiments with learning systems. In: 2016 IEEE symposium on security and privacy (SP); 22–26 May 2016; San Jose, CA. IEEE. (2016). p. 598–617.
33. Efron, B. Prediction, estimation, and attribution. J Am Stat Assoc. (2020). 115(530):636–55. doi:10.1080/01621459.2020.1762613
34. Fox, J, and Monette, G. Generalized collinearity diagnostics. J Am Stat Assoc. (1992). 87(417):178–83. doi:10.1080/01621459.1992.10475190
Keywords: variable importance ranking, SHapley Additive exPlanations, R square, variance explained, linear regression, asymptotic distribution, model explanations, explainable machine learning
Citation: Fryer D, Strümke I and Nguyen H (2020) Shapley Value Confidence Intervals for Attributing Variance Explained. Front. Appl. Math. Stat. 6:587199. doi: 10.3389/fams.2020.587199
Received: 25 July 2020; Accepted: 09 October 2020;
Published: 03 December 2020.
Edited by:
Quoc Thong Le Gia, University of New South Wales, AustraliaReviewed by:
Alex Jung, Aalto University, FinlandJiajia Li, Pacific Northwest National Laboratory (DOE), United States
Copyright © 2020 Fryer, Strümke and Nguyen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Daniel Fryer, ZGFuaWVsLmZyeWVyQHVxLmVkdS5hdQ==