 Ariel Jaffe1*
Ariel Jaffe1* Yuval Kluger1,2,3
Yuval Kluger1,2,3 Ofir Lindenbaum1Jonathan Patsenker1Erez Peterfreund4Stefan Steinerberger5
Ofir Lindenbaum1Jonathan Patsenker1Erez Peterfreund4Stefan Steinerberger5- 1Program in Applied Mathematics, Yale University, New Haven, CT, United States
- 2Department of Pathology, Yale School of Medicine, New Haven, CT, United States
- 3Interdepartmental Program in Computational Biology and Bioinformatics, New Haven, CT, United States
- 4School of Computer Science and Engineering, The Hebrew University, Jerusalem, Israel
- 5Department of Mathematics, University of Washington, Seattle, WA, United States
Word2vec introduced by Mikolov et al. is a word embedding method that is widely used in natural language processing. Despite its success and frequent use, a strong theoretical justification is still lacking. The main contribution of our paper is to propose a rigorous analysis of the highly nonlinear functional of word2vec. Our results suggest that word2vec may be primarily driven by an underlying spectral method. This insight may open the door to obtaining provable guarantees for word2vec. We support these findings by numerical simulations. One fascinating open question is whether the nonlinear properties of word2vec that are not captured by the spectral method are beneficial and, if so, by what mechanism.
1 Introduction
Word2vec was introduced by Mikolov et al. [1] as an unsupervised scheme for embedding words based on text corpora. We will try to introduce the idea in the simplest possible terms and refer to [1–3] for the way it is usually presented. Let
The larger the value of
Assuming a uniform prior over the n elements, the energy function
The exact relation between 1 and the formulation in [4] appears in Supplementary Material. Word2vec is based on maximizing this expression over all
There is no reason to assume that the maximum is unique. It has been observed that if
In Section 5 we show that the symmetric functional yields a meaningful embedding for various datasets. Here, the interpretation of the functional is straight-forward: we wish to pick
Our paper initiates a rigorous study of the energy functional
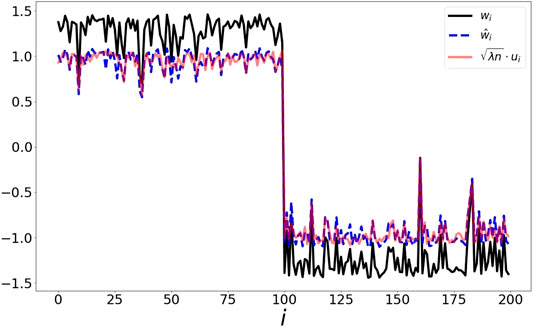
FIGURE 1. Illustration of point set drawn from two distinct Gaussian distributions. The result of maximizing over the word2vec functional (black) is closely tracked (up to scale) by the optimizer of the spectral method (blue) and the eigenvector (red). In Figure 7, we present a scatter plot comparing the values of
2 Motivation and Related Works
Optimizing over energy functions such as 1 to obtain vector embeddings is done for various applications, such as words [4], documents [5] and graphs [6]. Surprisingly, very few works addressed the analytic aspects of optimizing over the word2vec functional. Hashimoto et. al. [7] derived a relation between word2vec and stochastic neighbor embedding [8]. Cotterell et al. [9] showed that when P is sampled according to a multinomial distribution, optimizing over 1 is equivalent to exponential family PCA [10]. If the number of elements is large, optimizing over 1 becomes impractical. As an efficient alternative, Mikolov et al. [4] suggested a variation based on negative sampling. Levy and Goldberg [11] showed that if the embedding dimension is sufficiently high, then optimizing over the negative sampling functional suggested in [4] is equivalent to factorizing the shifted Pointwise Mutual Information matrix. This work was extended in [12], where similar results were derived for additional embedding algorithms such as [3, 13, 14]. Decomposition of the PMI matrix was also justified by Arora et al. [15], based on a generative random walk model. A different approach was introduced by Landgraf [16], that related the negative sampling loss function to logistic PCA.
In this work, we focus on approximating the highly nonlinear word2vec functional by Taylor expansion. We show that in the regime of embedding vectors with small magnitude, the functional can be approximated by the spectral decomposition of the matrix P. This draws a natural connection between word2vec and classical, spectral embedding methods such as [17, 18]. By rephrasing word2vec as a spectral method in the “small vector limit,” one gains access to a large number of tools that allow one to rigorously establish a framework under which word2vec can enjoy provable guarantees, such as in [19, 20].
3 Results
We now state our main results. In Section 3.1 we establish that the energy functional
3.1 First Order Approximation for Small Data
The main idea is simple: we make an ansatz assuming that the optimal vectors are roughly of size
Theorem 3.1 (Spectral Expansion). If
Naturally, since we are interested in maximizing this quantity, the constant factor
where 1 is the matrix all of whose entries are 1. This suggests that the optimal
Assuming P is similar to a symmetric matrix, the optimal w should be well described by the leading eigenvector of
3.2 Optimal Vectors Are Not Too Large
Another basic question is as follows: how large is the norm of the vector(s) maximizing the energy function? This is of obvious importance in practice, however, as seen in Theorem 3.1, it also has some theoretical relevance: if w has large entries, then clearly one cannot hope to capture the exponential nonlinearity with a polynomial expansion. Assuming
satisfies
This can be seen as follows: if
Theorem 3.2 (Generic Boundedness.). Let
satisfies
While we do not claim that this bound is sharp, however it does nicely illustrate that the solutions of the optimization problem must be bounded. Moreover, if they are bounded, then so are their entries; more precisely,
Writing
is monotonically increasing until
In practice, one often uses word2vec for matrices whose spectral norm is
Theorem 3.3 (Boundedness for row-stochastic matrices). Let
denote the restriction of P to that subspace and suppose that
If w has a mean value sufficiently close to 0,
where
The
3.3 Outlook
Summarizing, our main arguments are as follows:
The energy landscape of the word2vec functional is well approximated by a spectral method (or regularized spectral method) as long as the entries of the vector are uniformly bounded. In any compact interval around 0, the behavior of the exponential function can be appropriately approximated by a Taylor expansion of sufficiently high degree.
There are bounds that suggests that the energy of the embedding vector scale as
Finally, we present examples in Section 4 showing that in many cases the embedding obtained by maximizing the word2vec functional are indeed accurately predicted by the second order approximation.
This suggests various interesting lines of research: it would be nice to have refined versions of Theorems 3.2 and 3.3 (an immediate goal being the removal of the logarithmic dependence and perhaps even pointwise bounds on the entries of w). Numerical experiments indicate that Theorems 3.2 and 3.3 are at most a logarithmic factor away from being optimal. A second natural avenue of research proposed by our paper is to differentiate the behavior of word2vec and that of the associated spectral method: are the results of word2vec (being intrinsically nonlinear) truly different from the behavior of the spectral method (arising as its linearization)? Or, put differently, is the nonlinear aspect of word2vec that is not being captured by the spectral method helpful for embedding?
4 Proofs
Proof of Theorem 3.1. We recall our assumption of
In particular, we note that
We use the series expansion
to obtain
Here, the second sum can be somewhat simplified since
Altogether, we obtain that
Since
and have justified the desired expansion.
Proof of Theorem 3.2. Setting
Now, let w be a global maximizer. We obtain
which is the desired result.
Proof of Theorem 3.3. We expand the vector w into a multiple of the constant vector of norm 1, the vector
and the orthogonal complement via
which we abbreviate as
Since P is row-stochastic, we have
since
Collecting all these estimates, we obtain
We also recall the Pythagorean theorem,
Abbreviating
The function,
is monotonically increasing on
we get, after some elementary computation,
However, we also recall from the proof of Theorem 3.2 that
Altogether, since the energy in the maximum has to exceed the energy in the origin, we have
and therefore,
5 Examples
We validate our theoretical findings by comparing, for various datasets, the representation obtained by the following methods: i) optimizing over the symmetric functional in 1, ii) optimizing over the spectral method suggested by Theorem 3.1 and iii) computing the leading eigenvector of
where α is a scale parameter set as in [21] using a max-min scale. The max-min scale is set to
This global scale guarantees that each point is connected to at least one other point. Alternatively, adaptive scales could be used as suggested in [22]. We then compute P via
The matrix P can be interpreted as a random walk over the data points, (see for example [18]). Theorem 3.1 holds for any matrix P that is similar to a symmetric matrix, here we use the common construction from [18], but our results hold for other variations as well. To support our approximation in Theorem 3.1, Figure 7 shows a scatter plot of the scaled vector u vs.
where μ and
5.1 Noisy Circle
Here, the elements
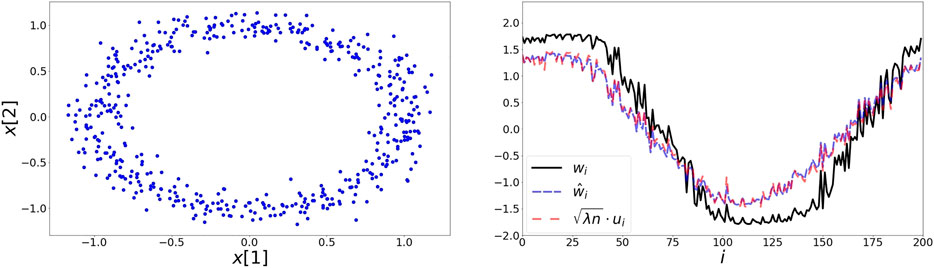
FIGURE 2. Left: 200 elements on the noisy circle data set. Points are generated by adding noise drawn from a two dimensional Gaussian with zero mean and a variance of 0.1. Right: The extracted representations based on the symmetric loss w, second order approximation
5.2 Binary MNIST
Next, we use a set of 300 images of the digits 3 and 4 from the MNIST dataset [23]. Two examples from each category are presented in the left panel of Figure 3. Here, the extracted representations w and
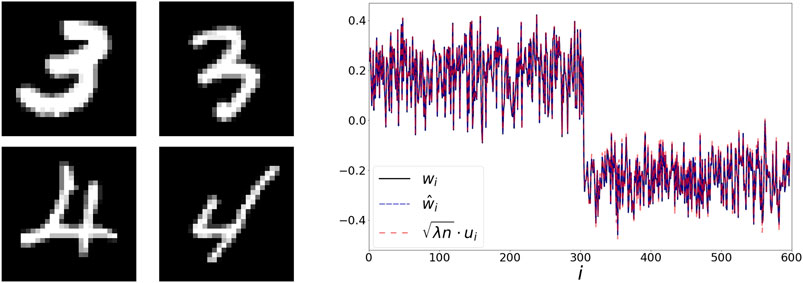
FIGURE 3. Left: handwritten digits from the MNIST dataset. Right: The extracted representations w,
5.3 COIL100
In this example, we use images from Columbia Object Image Library (COIL100) [24]. Our dataset contains 21 images of a cat captured at several pose intervals of 5 degrees (see left panel of Figure 4). We extract the embedding w and
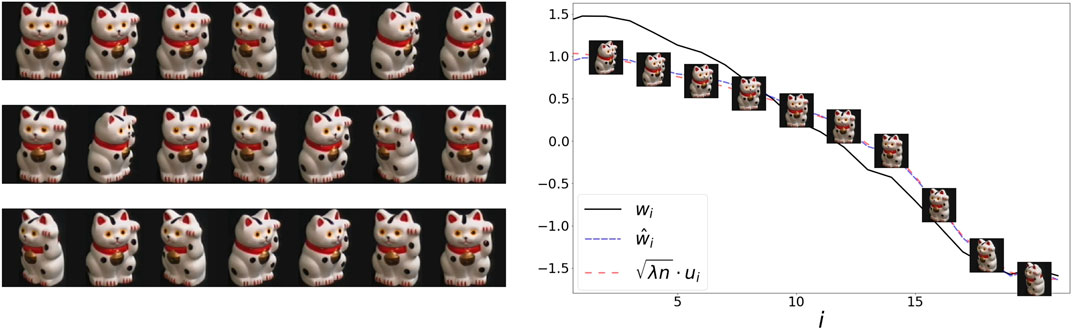
FIGURE 4. Left: 21 samples from COIL100 dataset. The object is captured at several unorganized angles. Right: The sorted values of the representations w,
5.4 Seismic Data
Seismic recordings could be useful for identifying properties of geophysical events. We use a dataset collected in Israel and Jordan, described in [25]. The data consists of 1632 seismic recordings of earthquakes and explosions from quarries. Each recording is described by a sonogram with 13 frequency bins, and 89 time bins [26] (see the left panel of Figure 5). Events could be categorized into 5 groups using manual annotations of their origin. We flatten each sonogram into a vector, and extract embeddings w,
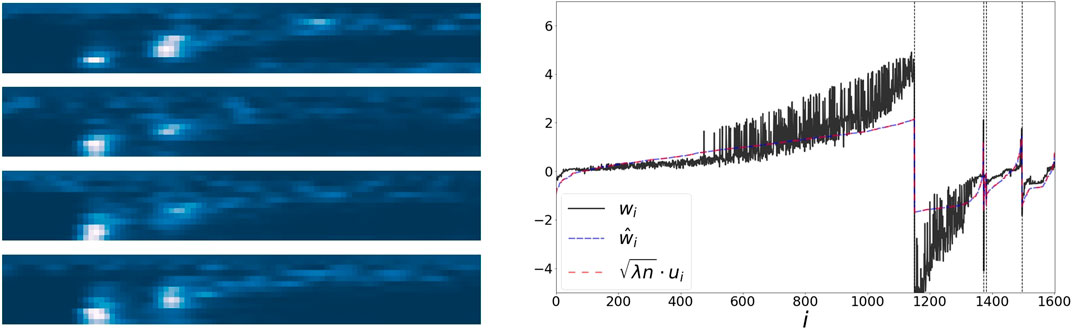
FIGURE 5. Left: 4 samples from the sonogram dataset, of different event types. Right: The values of the representations w,
5.5 Text Data
As a final evaluation we use a corpus of words from the book “Alice in Wonderland” as processed in [27]. To define a co-occurrence matrix, we scan the sentences using a window size covering 5 neighbors before and after each word. We subsample the top 1000 words in terms of occurrences in the book. The matrix P is then defined by normalizing the co-occurrence matrix. In Figure 6 we present centered and normalized versions of the representations w,
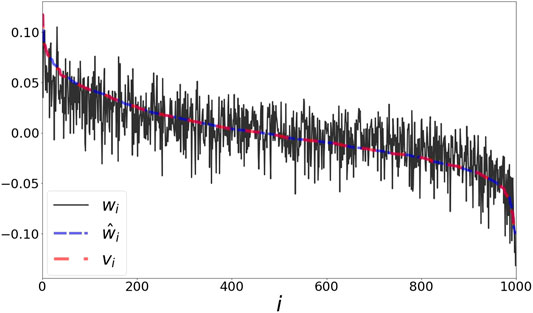
FIGURE 6. Word representation based on “Alice in Wonderland.” The values of the representations w,
6 Multi-Dimensional Embedding
In Section 3 we have demonstrated that under certain assumptions, the maximizer of the energy functional in 2 is governed by a regularized spectral method. For simplicity, we have restricted our analysis to a one dimensional symmetric representations, i.e.
Let
where
Note that both the symmetric functional in 5 and its approximation in 6 are invariant to multiplying W with an orthogonal matrix. That is, W and
To understand how the maximizer of 5 is governed by a spectral approach, we perform the following comparison. i) We obtain the optimizer W of 5 via gradient descent, and compute its left singular vectors, denoted
We experiment on two datasets: 1) A collection of 5 Gaussians, and 2) images of hand written digits from MNIST. The transition probability matrix P was constructed as described in Section 5.
6.1 Data from Distinct Gaussians
In this experiment we generate a total of 2,500 samples, consisting of five sets of size 500. The samples in the i-th set are drawn independently according to a Gaussian distribution
Figure 8 shows the absolute correlation value of the pairwise correlation between
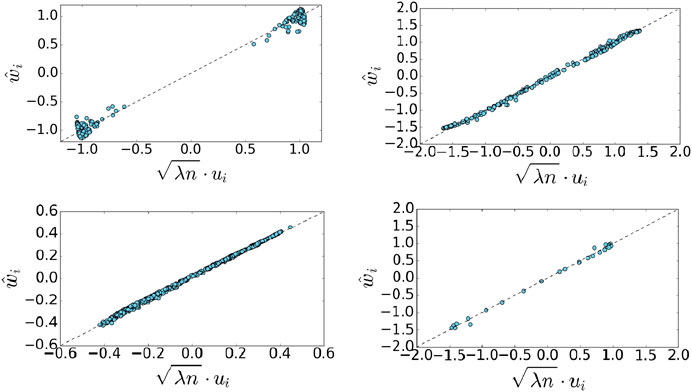
FIGURE 7. Scatter plots of the scaled eigenvector of
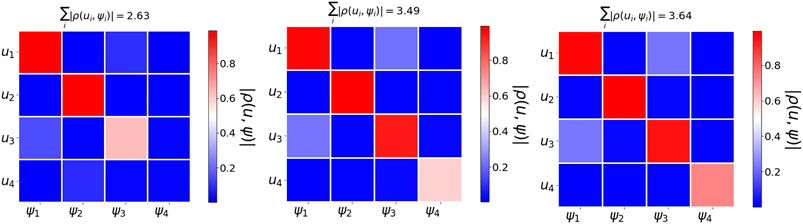
FIGURE 8. Word2vec embedding of a collection of Gaussians. We use 2,500 points generated according to five distinct Gaussians
6.2 Multi-Class MNIST
The data consists of
Figure 9 shows the absolute correlation between the
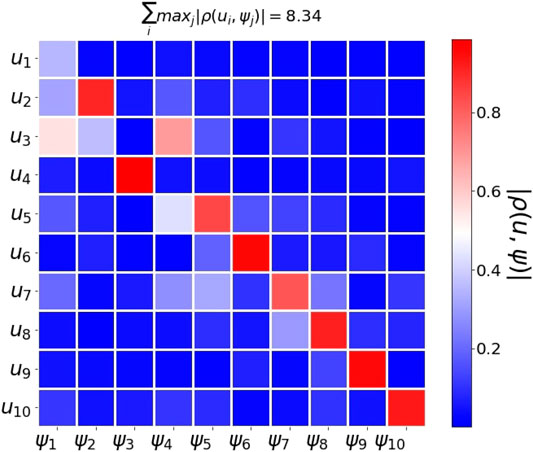
FIGURE 9. Word2vec embedding of samples from multiclass MNIST. We use 10,000 samples drawn from the MNIST handwritten dataset. The figure shows the absolute correlation between the
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
AJ, EP, OL, SS, YK: designed research; EP, OL, AJ, SS, JP: performed research; SS, EP, AJ, OL contributed new reagents or analytic tools; EP, JP, OL: analyzed data; SS, EP, AJ, OL wrote the paper.
Funding
YK is supported in part by NIH grants UM1DA051410, R01GM131642, P50CA121974 and R61DA047037. SS was funded by NSF‐DMS 1763179 and the Alfred P. Sloan Foundation. EP has been partially supported by the Blavatnik Interdisciplinary Research Center (ICRC), the Federmann Research Center (Hebrew University) Israeli Science Foundation research grant no. 1523/16, and by the DARPA PAI program (Agreement No. HR00111890032, Dr. T. Senator).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors thank James Garritano and the anonymous reviewers for their helpful feedback.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2020.593406/full#supplementary-material
References
1. Mikolov, T, Chen, K, Corrado, G, and Dean, J. Efficient estimation of word representations in vector space. In: Bengio, Y, and LeCun, Y, editors. 1st International conference on learning representations, ICLR 2013; 2013 May 2–4; Scottsdale, Arizona, USA. Workshop Track Proceedings (2013).
2. Goldberg, Y, and Levy, O. word2vec explained: deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv preprint arXiv:1402.3722 (2014).
3. Grover, A, and Leskovec, J. node2vec: scalable feature learning for networks. In: Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, San Fransisco, CA, (2016) p. 855–64. doi:10.1145/2939672.2939754.
4. Mikolov, T, Sutskever, I, Chen, K, Corrado, GS, and Dean, J. Distributed representations of words and phrases and their compositionality. Adv Neural Inf Process Syst (2013) 26:3111–9.
5. Le, Q, and Mikolov, T. Distributed representations of sentences and documents. In: International conference on machine learning, Beijing, China, (2014):1188–96.
6. Narayanan, A, Chandramohan, M, Venkatesan, R, Chen, L, Liu, Y, and Jaiswal, S. graph2vec: Learning distributed representations of graphs. arXiv preprint arXiv:1707.05005 (2017).
7. Hashimoto, TB, Alvarez-Melis, D, and Jaakkola, TS. Word embeddings as metric recovery in semantic spaces. TACL (2016) 4:273–86. doi:10.1162/tacl_a_00098.
8. Hinton, GE, and Roweis, ST. Stochastic neighbor embedding. Adv Neural Inf Process Syst (2003) 15:857–64.
9. Cotterell, R, Poliak, A, Van Durme, B, and Eisner, J. Explaining and generalizing skip-gram through exponential family principal component analysis. In: Proceedings of the 15th conference of the European chapter of the association for computational linguistics, (Valencia, Spain: Association for Computational Linguistics), Vol. 2 (2017). p. 175–81. Short Papers.
10. Collins, M, Dasgupta, S, and Schapire, RE. A generalization of principal components analysis to the exponential family. Adv Neural Inf Process Syst (2002):617–24.
11. Levy, O, and Goldberg, Y. Neural word embedding as implicit matrix factorization. Adv Neural Inf Process Syst (2014) 3:2177–85.
12. Qiu, J, Dong, Y, Ma, H, Li, J, Wang, K, and Tang, J. “Network embedding as matrix factorization: unifying deepwalk, line, pte, and node2vec,” in Proceedings of the eleventh ACM international conference on web search and data mining, Marina Del Rey, CA (New York, NY: Association for Computing Machinery), (2018):459–67.
13. Perozzi, B, Al-Rfou, R, and Skiena, S. “Deepwalk: online learning of social representations,” in Proceedings of the 20th ACM SIGKDD international conference on knowledge discovery and data mining, (New York, NY: Association for Computing Machinery), (2014):701–10.
14. Tang, J, Qu, M, Wang, M, Zhang, M, Yan, J, and Mei, Q. “Line: Large-scale information network embedding,” in Proceedings of the 24th international conference on world wide web, Florence, Italy (New York, NY:Association for Computing Machinery), (2015):1067–77.
15. Arora, S, Li, Y, Liang, Y, Ma, T, and Risteski, A. Random walks on context spaces: towards an explanation of the mysteries of semantic word embeddings. arXiv abs/1502.03520 (2015).
16. Landgraf, AJ, and Bellay, J. Word2vec skip-gram with negative sampling is a weighted logistic pca. arXiv preprint arXiv:1705.09755 (2017).
17. Belkin, M., and Niyogi, P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput (2003). 15:1373–96. doi:10.1162/089976603321780317.
18. Coifman, R. R., and Lafon, S. Diffusion maps. Appl Comput Harmon Anal (2006) 21:5–30. doi:10.1016/j.acha.2006.04.006.
19. Singer, A, and Wu, HT. Spectral convergence of the connection Laplacian from random samples. Information Inference J IMA (2017) 6:58–123. doi:10.1093/imaiai/iaw016.
20. Belkin, M, and Niyogi, P. Convergence of Laplacian eigenmaps. Adv Neural Inf Process Syst (2007) 19:129–36.
21. Lafon, S, Keller, Y, and Coifman, RR. Data fusion and multicue data matching by diffusion maps. IEEE Trans Pattern Anal Mach Intell (2006) 28:1784–97. doi:10.1109/tpami.2006.223.
22. Lindenbaum, O, Salhov, M, Yeredor, A, and Averbuch, A. Gaussian bandwidth selection for manifold learning and classification. Data Min Knowl Discov (2020) 1–37. doi:10.1007/s10618-020-00692-x.
23. LeCun, Y, Bottou, L, Bengio, Y, and Haffner, P. Gradient-based learning applied to document recognition. Proc IEEE (1998) 86:2278–324. doi:10.1109/5.726791.
24. Nene, SA, Nayar, SK, and Murase, H. Columbia object image library (coil-20). Technical Report CUCS006-96, Columbia University, Available at: https://www1.cs.columbia.edu/CAVE/publications/pdfs/Nene_TR96.pdf (1996).
25. Lindenbaum, O, Bregman, Y, Rabin, N, and Averbuch, A. Multiview kernels for low-dimensional modeling of seismic events. IEEE Trans Geosci Rem Sens (2018) 56:3300–10. doi:10.1109/tgrs.2018.2797537.
26. Joswig, M. Pattern recognition for earthquake detection. Bull Seismol Soc Am. (1990). 80:170–86.
27. Johnsen, P. A text version of “alice’s adventures in wonderland [Dataset]”. Availavle at: https://gist.github.com/phillipj/4944029 (2019). Accessed August 8, 2020.
Keywords: dimensionality reduction, word embedding, spectral method, word2vec, skip-gram model, nonlinear functional
Citation: Jaffe A, Kluger Y, Lindenbaum O, Patsenker J, Peterfreund E and Steinerberger S (2020) The Spectral Underpinning of word2vec. Front. Appl. Math. Stat. 6:593406. doi: 10.3389/fams.2020.593406
Received: 10 August 2020; Accepted: 21 October 2020;
Published: 03 December 2020.
Edited by:
Dabao Zhang, Purdue University, United StatesReviewed by:
Yuguang Wang, Max-Planck-Gesellschaft (MPG), GermanyHalim Zeghdoudi, University of Annaba, Algeria
Copyright © 2020 Jaffe, Kluger, Lindenbaum, Patsenker, Peterfreund and Steinerberger. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ariel Jaffe, YS5qYWZmZUB5YWxlLmVkdQ==