 Iman M. Attia
Iman M. Attia- Department of Mathematical Statistics, Faculty of Graduate Studies for Statistical Research, Cairo University, Giza, Egypt
A global increase in the prevalence of obesity and type 2 diabetes is strongly connected to an increased prevalence of non-alcoholic fatty liver disease (NAFLD) worldwide. In this article, the progression of the NAFLD process is modeled by continuous time Markov chains (CTMCs) with nine states. Maximum likelihood is used to estimate the transition intensities among the states. Once the transition intensities are obtained, the mean sojourn time and its variance are estimated, and the state probability distribution and its asymptotic covariance matrix are also estimated. A hypothetical example based on a longitudinal study assessing patients with NAFLD in various stages is discussed. The mean time to absorption is estimated, and the other abovementioned statistical indices are examined. In this article, the maximum likelihood estimation (MLE) function is utilized in a new approach to compensate for the missing values in the follow-up period of patients evaluated in longitudinal studies. A MATLAB code link is provided, at the end of the article, for the estimation of the transition rate matrix and transition probability matrix.
Introduction
Continuous time Markov chain (CTMC) is commonly used to model data obtained from longitudinal studies in medical research and to investigate the evolution and progression of diseases over time. Estes et al. [1] used multistate Markov chains to model the epidemic of non-alcoholic fatty liver disease (NAFLD). Younossi et al. [2] used multistate Markov chains to demonstrate the economic and clinical burden of NAFLD in the United States and Europe.
According to the American Association for Study of Liver Disease, American College of Gastroenterology, and the American Gastroenterological Association, NAFLD to be defined requires (a) evidence of hepatic steatosis (HS) either by imaging or by histology and (b) no causes of secondary hepatic fat accumulation, such as significant alcohol consumption, use of steatogenic medications, or hereditary disorders [3]. This is the same definition established by the European Association for the Study of the Liver (EASL), the European Association for the Study of Diabetes (EASD), and the European Association for the Study of Obesity (EASO) [4]. NAFLD can be categorized histologically into the non-alcoholic fatty liver (NAFL) or non-alcoholic steatohepatitis (NASH). NAFL is defined as the presence of ≥ 5% HS without evidence of hepatocellular injury in the form of hepatocyte ballooning. NASH is defined as the presence of ≥ 5% HS and inflammation with hepatocyte injury (ballooning), with or without any fibrosis.
In Attia [5], non-alcoholic fatty liver disease (NAFLD) can be modeled by the simplest form of a multistate model for the health-illness-death process as illustrated in Figure 1. The system is composed of 4 states. State 1 represents the individuals with high risk factors such as type 2 diabetes, hypercholesterolemia, obesity, and hypertension. State 2 represents patients suffering from NAFLD with all possible substates that are explained and clarified in a more elaborate manner in this paper. The death state is represented by two states highlightening the competing risk factors for death: state 3 represents the death state as a complication of NAFLD and state 4 represents the death state from other causes than the complications of NAFLD. For this general and abstract system, 5 rates of transitions among states are estimated using the maximum likelihood estimation (MLE) function and quasi-Newton. Once the transition rate matrix is obtained, exponentiation of this rate matrix will yield the transition probability matrix to estimate the eight probability density functions (PDFs). All diseases can be modeled by this abstract form (health-illness-death process), what makes each disease unique from the other is the detailed substages of the illness state: how many substates that encompass the illness state, how the movements among these states can take place, and the definitions specified for each of these substates. In this article; the system is composed of nine unique different states. Each state defines specific biological changes in the whole journey of the disease, and from each state, the patient can be in the death state without specifying the cause of death for simplicity. This more complicated system of the NAFLD process is composed of 22 rates in addition to 49 PDFs to be estimated. The transition rate matrix differs from the simple model as the number and movement among the states are more specified and complicated; consequently, the PDFs are different.
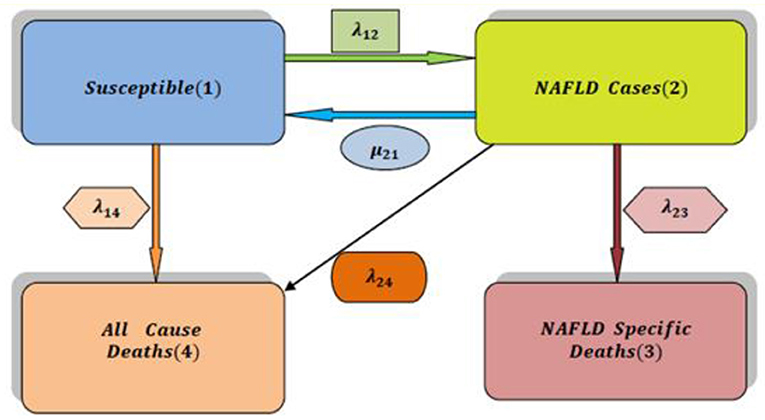
Figure 1. The simplest multistate model for analysis of NAFLD (health-illness-death process) [2].
A MATLAB code illustrating all the calculations is published in the code Ocean site at the URL: https://codeocean.com/capsule/8641183/tree/v2 with doi: 10.24433/CO.6022979.v2.
A full detailed description of a simple form of the model to enhance understanding of the difference between the two forms of the model is illustrated in a thorough explanation in the Supplementary Materials for the simple model (refer to Supplementary Material).
In this article, NAFLD is modeled as a multistage disease process consisting of nine stages, as depicted in Figure 2 [2]. As shown in Figure 2, the patient can move across the stages of the disease process. Whereas, remission rates are allowed from stage 4 (compensated liver cirrhosis) to earlier stages, the patient progresses to HCC and liver transplantation once he arrives at stage 5 (decompensated liver cirrhosis), and remission rates are not allowed. Death state can be reached from any state. The patient can move from the first 5 stages to stage 8 (HCC) with a higher rate of progression from stage 4 (CC) or stage 5 (DCC) to stage 8 (HCC) compared to the first 3 stages. A brief definition of each stage is illustrated below the figure.
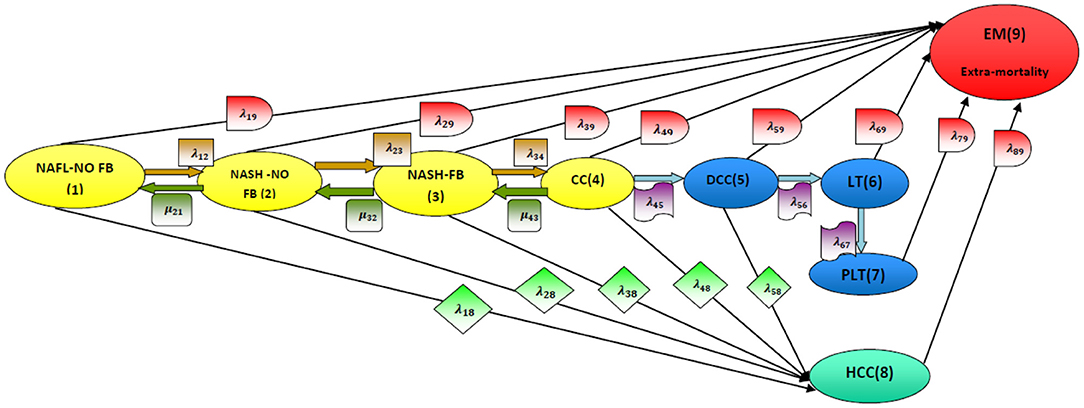
Figure 2. Disease model structure. NAFL-NO FB, non-alcoholic fatty liver with no fibrosis (stage 1); NASH-NO FB, non-alcoholic steatohepatitis with no fibrosis (stage 2); NASH-FB, non-alcoholic steatohepatitis with fibrosis (stage 3); CC, compensated cirrhosis (stage 4); DCC, decompensated cirrhosis (stage 5); LT, liver transplant (stage 6); PLT, post liver transplant (stage 7); HCC, hepatocellular carcinoma (stage 8); EM, extramortality (stage 9). [2].
NAFLD stages are modeled as time-homogenous CTMCs, that is, Pij(Δt) depends on Δt and not on t, with constant transition intensities λij over time, exponentially distributed time spent within each state and patient events following a Poisson distribution. The states are finite and can be defined or identified based on various aspects, such as clinical symptoms and invasive or non-invasive investigations. The gold-standard method for the classification of histopathological changes in the liver is invasive liver biopsy. It is presently the most trustworthy procedure for diagnosing the presence of steatohepatitis and fibrosis in patients with NAFLD [6]. The limitations of this procedure are cost, sampling error, and procedure-related morbidity and mortality. MR imaging, by spectroscopy [7] or by proton density fat fraction [8], is an excellent non-invasive technique for quantifying HS and is being widely used in NAFLD clinical trials [9]. The use of transient elastography (TE) to obtain continuous attenuation parameters is a promising tool for quantifying hepatic fat in an ambulatory setting [10]. However, non-invasive quantification of HS in patients with NAFLD is limited in routine clinical care. Additionally, one of the most recent biological markers is the keratin (K18) and its caspase-cleaved fragments (cK18). There are many scoring systems that can identify the stages of the disease process [11]. NAFLD has a higher prevalence rate in individuals with risk factors such as visceral obesity, type 2 diabetes mellitus (T2DM), dyslipidemia, hypertension, older age, male sex, and Hispanic ethnicity [12].
For simplicity, all individuals are assumed to enter the disease process at stage one, and they are all followed up with the same length of the time interval between measurements.
The article is divided into eight sections. In Section 1, the transition probabilities are thoroughly discussed. In Section 2, transition rates are clarified. In Section 3, the mean sojourn time and its variance are reviewed. In Section 4, the state probability distribution and its covariance matrix are discussed. In Section 5, the life expectancy of the patients is considered. In Section 6, the expected numbers of patients in each state are obtained. A hypothetical numerical example is used in Section 7 to illustrate the above concepts. Finally, a brief summary is comprehended in Section 8. A link to the MATLAB code is provided at the end of the article (refer to Supplementary Material, Appendix A & B).
1. Transition Probabilities
NAFLD is modeled by multistate Markov chains that define a stochastic process:
The transitions can occur at any point in time and, hence, are called continuous time Markov chains, in contrast to the discrete time Markov chains in which transitions occur at fixed points in time. The rates at which these transitions occur are constant over time and, thus, are independent of t; that is, the transition of the patient from state i at time = t to state j at t = t +s where s = Δt depends on the difference between two consecutive time points. In addition, it is defined as or the Q matrix; while, the I matrix is the identity matrix, the thetas are the transition rates among states (in this model, they are 22 rates).
For the above multistate Markov model demonstrating the NAFLD process, the forward Kolmogorov differential Equations (1) are as follows:
Solving the Kolmogorov differential equations will give the transition probability matrix Pij(t) (refer to Supplementary Material Section 1).
Pij(t) satisfies the following properties:
1.
2.
3. Pij(t) ≥ 0, ∀ t ≥ 0 and i, j ∈ S.
The Q matrix satisfies the following conditions:
1.
2. qij(t) ≥ 0 i ≠ j.
3.
where qij is the ( i, j) th entry in the Q matrix emphasizing that Pij depends only on the interval between t1 and t2 and not on t1.
2. Maximum Likelihood Estimation of the Q Transition Rate Matrix
Let nijr be the number of individuals in state i at tr−1 and in state j at time tr. Conditioning on the distribution of individuals among states at t0, the likelihood function for θ is (2):
where k is the index of the number of states
According to Kalbfleisch and Lawless [13], applying the quasi-Newton method to estimate the rates mandates calculating the score function S(θ) (3), which is a vector–valued function for the required rates and is the first derivative of the log likelihood function. The second derivative of the probability transition function with respect to theta is assumed to be zero.
where S(θ) is the score function.
Λ is the eigenvalue for each Q matrix in each τ (refer to Supplementary Material Section 2). Taking the second derivative of logL (θ) (4):
Assuming the second derivative is zero and where then:
The quasi-Newton formula is (5).
According to Klotz and Sharples [14], the initial
For this NAFLD process (refer to Supplementary Material Section 2).
3. Mean Sojourn Time
It is the mean time spent by a patient in a given state i of the process. It is calculated in relation to transition rates . These times are independent and exponentially distributed random variables with mean where λi = −λii; i = 1, …, 8.
According to Kalbfleisch and Lawless [13], the asymptotic variance of this time is calculated by applying the multivariate delta method (6):
where si is the mean sojourn time.
For this NAFLD process (refer to Supplementary Material Section 3).
4. State Probability Distribution
According to Cassandras and Lafortune [15], it is the probability distribution for each state at a specific time point given the initial probability distribution. Thus, using the rule of total probability, a solution describing the transient behavior of a chain characterized by Q and an initial condition π(0) is obtained by direct substitution to solve (7):
The stationary probability distribution when t goes to infinity or, in other words, when the process does not depend on time is obtained by differentiating both sides of the following Equation (8):
at a specific time point is obtained by solving this system of differential equations. Solving these differential equations for this complex chain is cumbersome.
If the limit of exists, then there is a stationary or steady state distribution, and as , since πz(t) does not depend on time. Therefore, will reduce to π(t)Q = 0. The stationary state probability distribution is obtained by solving π(t)Q = 0 subject to .
For this NAFLD process (refer to Supplementary Material Section 4).
4.1. Asymptotic Covariance of the State Probability Distribution
The multivariate delta method is applied to the following function to obtain the asymptotic covariance matrix of the state probability distribution, as π is not a simple function of theta.
Differentiating F(θh, πi) implicitly with respect to θh is used in the following manner (9):
By multivariate delta method
For this NAFLD process: (refer to Supplementary Material Section 4.1).
5. Life Expectancy of the Patient in the NAFLD Process
The disease process is composed of eight transient states and one absorbing state (death state). So, the Q matrix is partitioned into four sets:
Additionally, the differential equations can be partitioned into the following (10):
B is the transition rate matrix among the transient states and column vector A is the transition rate from each transient state to the absorbing (death) state.
If τk is the time taken from state i to reach the absorbing death state from the initil time
The moment theory for the Laplace transform can be used to obtain the mean of the time that has the above cumulative distribution function. CTMC can be written in a Laplace transform (11) such that:
Rearrange:
Mean time to absorption:
For this NAFLD process: (refer to Supplementary Material Section 5).
6. Expected Number of Patients in Each State
Let u(0) be the size of patients in a specific state at a specific time t = 0. The initial size of patients U(0) = uj(0), as there are eight transient states and one absorbing state, where uj(0) is the initial size or number of patients in state j at time t = 0 given that u9(0) = 0, i.e., the initial size of patients in state 9 (absorbing death state) is zero at initial time point t = 0. As the transition or the movement of the patients among states is independent, at the end of the whole time interval (0, t) and according to Chiang [16], there will be uj(t) patients in the transient states at time t, and there will also be u9(t)patients in state 9 (death state) at time t.
For this NAFLD process: (refer to Supplementary Material Section 6).
7. Hypothetical Numerical Example
To illustrate the above concepts and discussion, a hypothetical numerical example is introduced. It does not represent real data but it is for demonstrative purposes (refer to Supplementary Material Section 7).
A study was conducted over 15 years on 1,050 patients with risk factors for developing NAFLD such as type 2 diabetes mellitus, obesity, and hypertension acting alone or together as a metabolic syndrome. The patients were scheduled to be followed up every year by a liver biopsy to identify the NAFLD cases, but the actual observations were recorded as shown in the (Supplementary Material). Table 1 shows the observed transition counts.
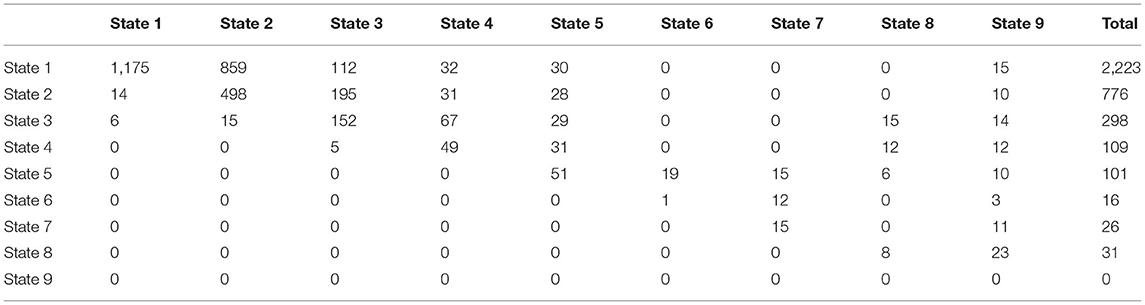
Table 1. The observed transition counts in the whole period of the study (15 years) regardless of the time interval between observations.
The observed transition rate matrix Q over the whole period of the study (15 years) is:
The estimated transition rate matrix is:
Using the above approach as illustrated in the main text and Supplementary Materials, the estimated transition rate matrix is nearly approaching equality to the observed transition rate matrix.
where
v2, v3, and v4 are all zero matrices of size (8 by 14), (14 by 8), and (14 by 14), respectively.
Transition probability matrix at 1 year:
Mean time spent by the patient in state 1 is ~2 years and 6 months; in state 2, the mean sojourn time is ~3 years and 6 months; in state 3, it is ~2 years and 9 months; in state 4, it is ~1 year and 10 months; in state 5, it is ~2 years and 10 months; in state 6, it is ~1 year and 1 month; in state 7, it is ~2 years and 5 months and last; in state 8, the mean sojourn time is ~1 year and 4 months.
If a cohort of 5,000 patients with NAFLD has an initial distribution of and the initial counts of patients in each state are then at 1 year, the state probability distribution is and the expected counts of patients are .
To calculate the goodness of fit for the multistate model used in this example, it is similar to the procedure used in the contingency table, and it is calculated in each interval and then summed:
Step 1: H0 = future state does not depend on the current state. H1 = future state depends on the current state.
Step 2: Calculate the Pij(Δt = 1)
Step 3: Calculate the expected counts in this interval by multiplying each row in the probability matrix with the corresponding total marginal counts in the observed transition counts matrix in the same interval to obtain the expected counts.
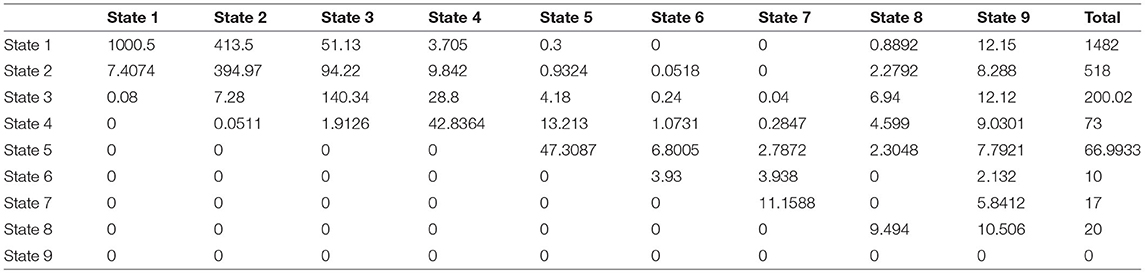
Step 4: Apply .
The same steps are used for the observed transition counts in Δt = 2 and Δt = 3 with the following results:
The expected counts are:
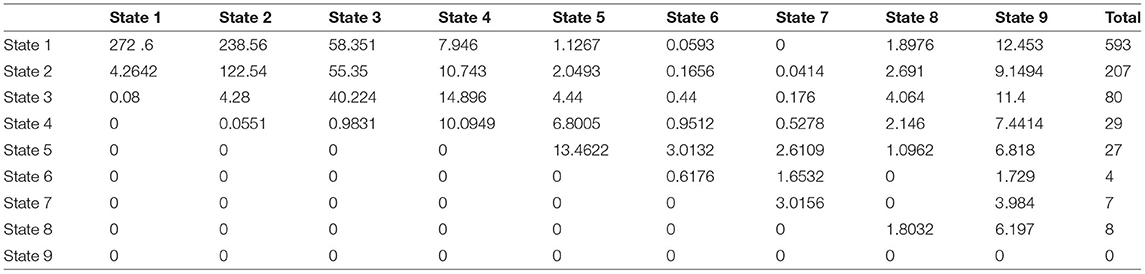
.
The same steps are used for the observed transition counts Δt = 3 in with the following results:
The expected counts are:
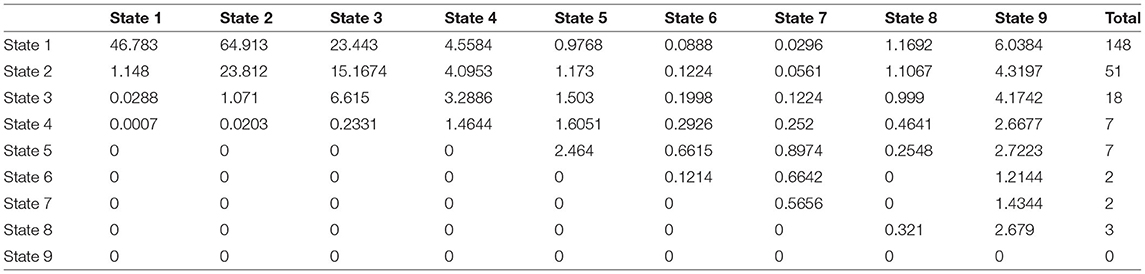
.
Step 5: Sum up the above results to get:
Therefore, from the above results, the null hypothesis is rejected, whereas the alternative hypothesis is accepted, and the model fits the data to mean that the future state depends on the current state with the estimated transition rate and probability matrices as obtained.
8. Conclusion and Summary
Continuous time Markov chains are suitable mathematical and statistical tools to be used for the analysis of disease evolution over time. CTMCs are the type of multistate model utilized to study this evolution in patients with NAFLD, with the main phenotypes being NAFL and NASH, as well as to study the associated presence of fibrosis and its stages. The prevalence of NAFLD is rapidly increasing worldwide and parallels the epidemics of obesity and type 2 diabetes. Metabolic syndrome is a well-known risk factor.
In this study, NAFLD is modeled in a more elaborative expanded form, which includes nine states: the first eight states are the states of disease progression as time elapses, while the ninth state is the death state. The importance of such analysis is that health policy makers can predict the number of affected patients at each stage, the needed investigations and medications for each of them, and the costs and budgets that medical insurance should assign to this disease burden. This analysis is of great value and benefit to physicians, as they can conduct longitudinal studies to explore further investigations that better define each stage specifically and efficiently and to explore further treatment needed for each stage. An example of a non-invasive diagnostic tool is the circulating level of cytokeratin-18 fragments; although promising, it is not available in a clinical care setting, and there is no established cutoff value for identifying NASH [17]. Genetic polymorphism of patatin-like phospholipase domain-containing protein 3 gene variants (PNPLA-3) is associated with NASH and advanced fibrosis; however, testing for these variants in routine clinical care is not supported and needs further study.
A hypothetical example of factitious non-real data is used to emphasize the attributes that need to be estimated:
❖ Transition rate matrix among the various states.
❖ Transition probability matrix among states.
❖ Mean sojourn time in each state.
❖ Life expectancy in each state; in other words, mean time to absorption (death state).
❖ Expected number of patients in each state.
❖ State probability distribution at specific time points in the future.
Such analysis may give better insights to physicians, especially when new drug classes will soon be released on the market. What drug classes are to be used first? How can the disease be monitored throughout the journey of treatment? What investigations are to be used in such monitoring? How to modify the drug treatment? What is the target that needs to be achieved, and how can this target be maintained? Moreover, in the late stage of the disease, when patients suffer from decompensated liver cirrhosis, liver transplantation is the treatment of choice to such patients, which increases the economic burden of NAFLD, as was the disease course during treatment in the early stages. Additionally, a load of what are the best economic non-invasive tests to be used in primary health care units for stratification and identification of high-risk patients, whether to perform genetic tests in health insurance settings, and when to refer for liver biopsy in secondary or special clinics should be considered. All these questions can be answered from longitudinal studies conducted on susceptible individuals. Over and above, some of the recently investigated non-invasive scoring systems of fibrosis need further external validation to be generalized in ethnicities other than the one tested upon. There are some controversies regarding the cutoff points of these scoring systems among countries and ethnicities within the same country. Although liver biopsy is considered the standard method for the diagnosis of NAFLD and staging it, its limitations encourage the development of various non-invasive tests, which necessitate better correlation between the findings obtained from the biopsy and the results of these tests to minimize misclassification errors, which hamper good diagnosis and prognosis of the patient. These tests should be easy, feasible, convenient, and have a high safety profile to be used repeatedly in patients for follow-up in such longitudinal studies.
A multistate model represented by CTMC is a valuable statistical methodology for longitudinal studies in medical research to better comprehend and understand the pathophysiology or the mechanism of the NAFLD process, and the interactions between the different modifiers, either external or internal modifiers. The external modifiers reside in bad dietary habits with excessive fat and carbohydrate ingestion, and sedentary life, whereas the internal modifiers are represented in genetic factors affecting the metabolism of the food stuff (fat and carbohydrates) and other cellular functions, such as risk factors for fibrogenesis (formation of fibrous tissue); fibrosis is a detrimental predictor factor for disease progression to liver cirrhosis and its complications. The importance of such understanding has a great impact on revealing the genes that must be tested if ever needed, for whom to do such a test, and should it be in the utilities or services offered by medical insurance. Moreover, should the degradation byproducts resulting from extracellular matrix destruction be used in routine clinical practice to mirror the fibrosis stages?
In Egypt, there are scarce data or maybe no available data about the prevalence of NAFLD and its phenotypes. Guidelines for risk stratification and identification are also lacking. Thus, more longitudinal studies are needed to address these issues.
Multistate models can also be used for the analysis of competing risks of death in such patients, as the first and second most common causes of death in patients with NAFLD are cardiovascular diseases (CVDs) and kidney diseases, whereas liver-related mortality is the third most common cause of death.
Other statistical methodologies, such as semi-Markov and hidden Markov chains, can be used to model NAFLD, especially hidden Markov CTMC can be used to model misclassification errors encountered in studies analyzed by time-homogenous CTMC.
Hint: A MATLAB code is edited to calculate the statistical indices in the hypothetical example. The code can be found published in the code ocean site with the following URL: https://codeocean.com/capsule/7628018/tree/v3; doi: 10.24433/CO.7719785.v3.
Author Contributions
IA carried the conceptualization by formulating the goals, aims of the research article, formal analysis by applying the statistical, mathematical and computational techniques to synthesize and analyze the hypothetical data, carried the methodology by creating the model, software programming and implementation, supervision, writing, drafting, editing, preparation, and creation of the presenting work.
Conflict of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2021.766085/full#supplementary-material
Supplementary Data-sheet 1. Excel sheet for the timeline of the participants.
Supplementary Data-sheet 2. Supplementary material for the simple data model.
Supplementary Data-sheet 3. Supplementary material for the expanded model.
Supplementary Data-sheet 4. MATLAB code, Appendix A (rate) and Appendix B (probability).
Abbreviations
CC, compensated cirrhosis (stage 4); CTMCs, continuous time Markov chains; CVS, cardiovascular disease; DCC, decompensated cirrhosis (stage 5); EASD, European Association for the Study of Diabetes; EASL, European Association for the Study of Liver; EASO, European Association for the Study of Obesity; EM, extramortality (stage 9); HCC, hepatocellular carcinoma (stage 8); HS, hepatic steatosis; LT, liver transplant (stage 6); NAFLD, non-alcoholic fatty liver disease; NAFL-NO FB, non-alcoholic fatty liver with no fibrosis (stage 1); NASH, non-alcoholic steatohepatitis; NASH-NO FB, non-alcoholic steatohepatitis with no fibrosis (stage 2); NASH-FB, non-alcoholic steatohepatitis with fibrosis (stage 3); PLT, postliver transplant (stage 7); PNPLA-3, patatin-like phospholipase domain containing protein 3 gene variants; TE, transient elastography; T2DM, type 2 diabetes mellitus.
References
1. Estes C, Razavi H, Loomba R, Younossi Z, Sanyal AJ. Modeling the epidemic of nonalcoholic fatty liver disease demonstrates an exponential increase in burden of disease. Hepatology. (2018) 67:123–33. doi: 10.1002/hep.29466
2. Younossi ZM, Blissett D, Blissett R, Henry L, Stepanova M, Younossi Y, et al. The economic and clinical burden of nonalcoholic fatty liver disease in the United States and Europe. Hepatology. (2016) 64:1577–86. doi: 10.1002/hep.28785
3. Chalasani N, Younossi Z, Lavine JE, Charlton M, Cusi K, Rinella M, et al. The diagnosis and management of nonalcoholic fatty liver disease: practice guidance from the American Association for the Study of Liver Diseases. Hepatology. (2018) 67:328–57. doi: 10.1002/hep.29367
4. Association E, Association E, Easd D, Association E, Easo O. Clinical practice guidelines EASL – EASD – EASO clinical practice guidelines for the management of non-alcoholic fatty liver disease q. J Hepatol. (2016) 64:1388–402. doi: 10.1016/j.jhep.2015.11.004
5. Attia IM. Continuous time markov chains for analysis of non-alcoholic fatty liver disease evolution. Int J Res Eng Sci. (2021) 9:1–23.
6. Chalasani N, Wilson L, Kleiner DE, Cummings OW, Brunt EM, Ünalp A, et al. Relationship of steatosis grade and zonal location to histological features of steatohepatitis in adult patients with non-alcoholic fatty liver disease. J Hepatol. (2008) 48:829–34. doi: 10.1016/j.jhep.2008.01.016
7. Reeder SB, Cruite I, Hamilton G, Sirlin CB. Quantitative assessment of liver fat with magnetic resonance imaging and spectroscopy. J Magn Reson Imag. (2011) 34:729–49. doi: 10.1002/jmri.22580
8. Idilman IS, Keskin O, Celik A, Savas B, Halil Elhan A, Idilman R, et al. A comparison of liver fat content as determined by magnetic resonance imaging-proton density fat fraction and MRS versus liver histology in non-alcoholic fatty liver disease. Acta radiol. (2016) 57:271–8. doi: 10.1177/0284185115580488
9. Noureddin M, Lam J, Peterson MR, Middleton M, Hamilton G, Le T, et al. Utility of magnetic resonance imaging versus histology for quantifying changes in liver fat in nonalcoholic fatty liver disease trials. Hepatology. (2013) 58:1930–40. doi: 10.1002/hep.26455
10. Lédinghen Vde, Wong GL, Vergniol J, Chan HL, Hiriart J, Chan AW, et al. Controlled attenuation parameter for the diagnosis of steatosis in non-alcoholic fatty liver disease. J Gastroenterol Hepatol. (2016) 31:848–55. doi: 10.1111/jgh.13219
11. Paul J. Recent advances in non-invasive diagnosis and medical management of non-alcoholic fatty liver disease in adult. Egypt Liv J. (2020) 10:43. doi: 10.1186/s43066-020-00043-x
12. Dongiovanni PM, Anstee Q, Valenti L. Genetic predisposition in NAFLD and NASH: impact on severity of liver disease and response to treatment. Curr Pharmaceut Design. (2013) 19:5219–38. doi: 10.2174/13816128113199990381
13. Kalbfleisch JD, Lawless JF. The analysis of panel data under a Markov assumption. J Am Stat Assoc. (1985) 80:863–71. doi: 10.1080/01621459.1985.10478195
14. Klotz JH, Sharples LD. Estimation for a Markov heart transplant model. J Royal Statist Soc Ser D. (1994) 43:431–8. doi: 10.2307/2348579
15. Cassandras CG, Lafortune S. Introduction to Discrete Event Systems. Berlin: Springer Science & Business Media (2009). doi: 10.1007/978-0-387-68612-7
16. Chiang CL. Introduction to Stochastic Processes in Biostatistics. Hoboken, NJ: Wiley, & Sons, Inc. (1968).
Keywords: multistate Markov chains, non-alcoholic fatty liver disease, continuous time Markov chains, maximum likelihood estimation, mean sojourn time, longitudinal study, mean time to absorption
Citation: Attia IM (2022) Novel Approach of Multistate Markov Chains to Evaluate Progression in the Expanded Model of Non-alcoholic Fatty Liver Disease. Front. Appl. Math. Stat. 7:766085. doi: 10.3389/fams.2021.766085
Received: 28 August 2021; Accepted: 28 December 2021;
Published: 14 February 2022.
Edited by:
Hagos Hailu Gidey, Botswana International University of Science and Technology, BotswanaReviewed by:
Saheed Ojo Akindeinde, Botswana International University of Science and Technology, BotswanaAshish Awasthi, NITc, India
Copyright © 2022 Attia. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Iman M. Attia, aW1hbmF0dGlhdGhlc2lzMTk3MkBnbWFpbC5jb20=; aW1hbmF0dGlhMTk3MkBnbWFpbC5jb20=