 Eugene Pinsky1*
Eugene Pinsky1* Sidney Klawansky2
Sidney Klawansky2- 1Department of Computer Science, Metropolitan College, Boston University, Boston, MA, United States
- 2Department of Health Policy and Management, Harvard School of Public Health, Boston, MA, United States
In classical probability and statistics, one computes many measures of interest from mean and standard deviation. However, mean, and especially standard deviation, are overly sensitive to outliers. One way to address this sensitivity is by considering alternative metrics for deviation, skewness, and kurtosis using mean absolute deviations from the median (MAD). We show that the proposed measures can be computed in terms of the sub-means of the appropriate left and right sub-ranges. They can be interpreted in terms of average distances of values of these sub-ranges from their respective medians. We emphasize that these measures utilize only the first-order moment within each sub-range and, in addition, are invariant to translation or scaling. The obtained formulas are similar to the quantile measures of deviation, skewness, and kurtosis but involve computing sub-means as opposed to quantiles. While the classical skewness can be unbounded, both the MAD-based and quantile skewness always lies in the range [−1, 1]. In addition, while both the classical kurtosis and quantile-based kurtosis can be unbounded, the proposed MAD-based alternative for kurtosis lies in the range [0, 1]. We present a detailed comparison of MAD-based, quantile-based, and classical metrics for the six well-known theoretical distributions considered. We illustrate the practical utility of MAD-based metrics by considering the theoretical properties of the Pareto distribution with high concentrations of density in the upper tail, as might apply to the analysis of wealth and income. In summary, the proposed MAD-based alternatives provide a universal scale to compare deviation, skewness, and kurtosis across different distributions.
1. Introduction
Classical statistics uses the standard deviation σ as the primary measure of dispersion. In computing σ, we use the squares of the distances from the mean μ. As noted in [1], using the L2 norm is convenient in differentiation, estimation, and optimization. The additive property of variance σ2 for independent variables is also cited as one of the prime reasons for using the L2 norm in sampling theory and analysis of variance. A historical survey is given in [2].
At the same time, this norm has a number of disadvantages. For example, large deviations from outliers contribute heavily to mean and standard deviation and could significantly overestimate “typical” deviations. A natural alternative is to use the L1 norm and measure absolute deviations from a central point such as the mean or median.
The idea of using the L1 norm is not new. The L1 norm was considered independently by both Boscovitch and Laplace as early as the eighteenth century. A historical survey using the L1 norm is presented in [3, 4] and a survey of more recent results is given in [1]. However, the L1 norm has not been widely used in statistics and statistical modeling [1].
There is currently a renewed interest in using the L1 norm for robust statistical modeling and inference [e.g., [5–9]]. Using the L2 norm, the influence of outliers is even more magnified when computing skewness and kurtosis as these computations would involve raising means and standard deviation to 3rd and 4th powers. By contrast, using mean absolute deviations from the mean or median (both denoted as MAD in literature) can be more appropriate. Therefore, using the L1 norm, outliers will have less influence on the results. Consequently, results from using the MAD (mean absolute deviation) are more robust to outliers than those obtained using the standard deviation, as is common in classical statistics.
Throughout this paper, we will use MAD to denote the mean absolute deviation from the median. We will use the MAD in deriving alternative expressions for skewness and kurtosis. The proposed MAD-based measures can be computed and interpreted as sub-means of the appropriate left and right sub-ranges. The obtained formulas are analogous to those used in statistics based on quantiles.
The MAD-based alternative measures considered in this paper use only the first-order moment. Consequently, they do not overweight outliers as compared to classical measures. When compared to the quantile metrics, they are more sensitive to concentrations at the extreme ends of distributions. In addition, these alternative measures have many desirable characteristics, such as scale (by absolute value) and/or shift-invariance.
We illustrate our results with several examples. One of the novel contributions of this paper is the MAD-based alternative metric for kurtosis. This metric is shown to be in the [0, 1] range, allowing us to compare the data distribution with different numerical scales. We present a detailed analysis of some well-known distributions. We contrast the proposed MAD-based metrics with both quantile and classical statistics metrics.
2. Organization of the paper
This paper is organized as follows. Section 3 introduces notation and reviews some bounds on mean absolute deviation. In Section 4, we focus on computing MAD, show how it can be computed as a difference of corresponding sub-means, and contrast the expression for MAD deviation with that of quartile deviation. In Section 5, we introduce MAD-based skewness and kurtosis. The MAD expression for skewness has been known before. To our knowledge, the proposed expression for MAD-based kurtosis has not been considered before. Both MAD-based skewness and kurtosis have simple interpretations, and their formulas are similar to quantile-based alternatives skewness and kurtosis. Section 6 discusses the advantages of proposed measures vs. corresponding classical and quantile-based measures. Section 7 focuses on computational considerations and shows how MAD-based measures can be computed from some integrals related to the underlying probability distributions. In Section 8, we provide a detailed comparison for a number of distributions:
1. Continuous uniform (Section 8.1)
2. Normal (Section 8.2)
3. Log-normal (Section 8.3)
4. Exponential (Section 8.4)
5. Laplace (Section 8.5)
6. Pareto (section 8.6).
In Section 9, we present an example of applying our results to analyze wealth distribution. In Section 10, we directly compare MAD-based skewness and kurtosis for the above six distributions. We conclude our paper with Section 11.
For completeness and clarity of presentation, we moved some details of derivations into Appendices. In Appendix 1 (Section A1), we present summary tables for the above distributions. In Appendices 2–4 (Sections A2–A4) we present some computational details for log-normal, Laplace and Pareto distributions, respectively.
3. Preliminaries
We start with preliminary definitions. Consider a real-valued random variable X on a sample space Ω⊆R with density f(x), finite mean E(X), and cumulative distribution function F(x). If X is a discrete random variable, then Ω is some countable sample space, and f(x) is the probability mass function (discrete density function).
We use μ = E(X) and σ to denote mean and standard deviation of X. Let F−1 be the quantile function defined by F−1(t) = inf{x:F(x) ≥ t} with t ∈ [0, 1]. The median M, the quartiles Q1 and Q3 are given by M = F−1(1/2), , and , respectively.
For any a, we define the mean absolute deviation of X from a as
If a = μ, then H(X, μ) is the mean absolute deviation from the mean μ. If we take a = M, then H(X, M) is the mean absolute deviation from the median. Both of these are denoted as MAD (mean absolute deviation) in the statistical literature, leading to some confusion [1]. In this paper, we use MAD to denote mean absolute deviations from the median. It can be interpreted as the average distance of values of X to the median M. We will write H as an abbreviation to H(X, M).
Let us start by establishing a lower and upper bound for H. Since f(x) ≥ 0, is integrable and E(X) < ∞ we have −|x − M|f(x) ≤ (x − M)f(x) ≤ |x − M|f(x) and, therefore, we obtain
To establish an upper bound, we use the well-known fact that H ≤ H(X, a) for any value of a [10–12]. In particular, if a = μ then H ≤ E(|X − μ|). This means that the average absolute deviation from the median H is always less than or equal to the mean absolute deviation from the mean E(|X − μ|). If we apply Jensen's inequality E(g(X)) ≥ g(μ) to the convex function g(t) = t2 (corresponding to σ2) we immediately obtain an upper bound for H:
Of the three metrics to measure deviations, namely H, E(|X − μ|) and σ, the MAD metric H has the lowest value.
Example 1: Consider two uniform random variables X and Y with corresponding sample spaces Ωx and Ωy with n = 12 elements given by
and the discrete density functions fx(·) = fy(·) = 1/n for any value in ΩX and ΩY, respectively. For variable X we have Mx = 6.5, μx = 6.5, σx = 3.45, and Hx = 3 whereas for variable Y we have My = 6.5, μy = 13.83, σy = 26.16, and Hy = 10.33. For the purpose of illustration, let us define an outlier as any numeric value v with |v − μ| > 2σ. Both random variables X and Y have the same median Mx = My = 6.5, but the random variable Y has a much higher outlier value y12 = 100. This much higher outlier value results in a higher mean and a higher standard deviation for Y than for X. The impact of this outlier value on H can be immediately computed: it increases H from Hx = 3 to Hy = 10.33 by (y12 − x12)/n = 7.33. The change in standard deviations due to this outlier would involve a much more complicated expression. The MAD-based deviation HY for Y is about four times higher than the MAD-based deviation Hx for X, whereas the standard deviation σy for Y, is more than seven times greater than σx for X because of the squaring of the deviations. To assess the impact of the outlier y12 = 100, we compare Hx and Hy in terms of σx and σy. For variable X we have Hx ≈ 0.87σx whereas for variable Y we have Hy ≈ 0.39σy. The lower value of Hy as compared with σy for Y indicates that Y has heavier tails compared to X.
The above example with an outlier illustrates one of the advantages of using MAD instead of standard deviation as a measure of variability. When computing the standard deviation or variance of X, the outlier effect is amplified since we square the differences (xi − μ). This effect of outliers is further amplified in computing skewness or kurtosis where we need to raise these differences to the 3rd or 4th power. By contrast, the proposed MAD-based metrics for deviation, skewness, and kurtosis is easy to interpret and express in terms of simple differences and ratios of mean absolute deviations computed over corresponding sub-ranges of X. As a result, these measures are less impacted by outliers than the corresponding measures used in classical statistics.
Another advantage of using mean absolute deviation H instead of standard deviation σ is that H is often simpler to interpret as it is computed directly (without squaring). Consider the example suggested in [1]: if X follows a uniform distribution in [0, 1] then H = 1/4 and (for details see Section 8.1). The MAD value H = 1/4 is easy to interpret: it represents the average distance of X from its median M = 1/2. However, it is more difficult to find an easy interpretation for standard deviation .
4. MAD computation and interpretation
Our approach is to replace standard deviation σ with mean absolute deviation from the median H and to derive MAD-based measures for skewness and kurtosis without resorting to higher powers. The proposed measures are simple to interpret in terms of corresponding sub-ranges.
We will find it convenient to use the indicator function for any subset U ⊂ Ω
Define the left sub-space of Ω by ΩL = {w ∈ Ω|x(w) ≤ M} and right sub-space of Ω by ΩR = {w ∈ Ω|x(w) > M}. Also, define and . Then, from the definition of H in Equation (1) we have
From the above equation, it is easy to show that for any constants b and c we have H(bX + c) = |b|H and, therefore, H is shift invariant. In addition, from Equation (2), we can interpret H as the difference of the sub-means of the right sub-range ΩR and left sub-range ΩL. Since E(X) = E(XL)+E(XR), we have H = E(X)−2E(XL). Therefore, we can also interpret H as the difference between the mean of X and twice the sub-mean of XL.
Let us now compare the mean absolute deviation H in Equation (2) with quartile deviation (or semi-quartile range) HQ = (Q3 − Q1)/2 which is used in descriptive statistics as a measure of statistical dispersion [e.g., [13, 14]]: Both equations for H and HQ have the same form under this correspondence:
Example 2: Consider the same random variable X uniform in Ω = {1, 2, …, 12} as in the previous example. For this sequence n = 12, f(x) = 1/12, E(X) = M = 6.5, and H = 3. Let us re-compute H using the left and right half sub-ranges. To that end, we split Ω into left and right sub-spaces (ΩL and ΩR) around the median:
For the left sub-mean, we have and for the right sub-mean . Then we compute H = E(XR)−E(XL) = 3. Alternatively, we have H = E(X)−2E(XL) = 3. To compute the corresponding quantile-based metric HQ, we note that the first and third quartiles for this sequence are Q1 = 3.75 and Q3 = 9.25. Therefore, the quantile-based deviation HQ = (Q3 − Q1)/2 = 2.75.
5. MAD-based alternatives for skewness and kurtosis
We now consider skewness and kurtosis. In classical statistics, skewness is defined as a measure of the asymmetry of the probability distribution around its mean. For a survey, see [15]. One of the most common measures is the moment coefficient of skewness (or skew) S, defined as the third standardized moment in terms of mean μ and standard deviation σ, namely,
Just like in the computation of variance, this definition is sensitive to outliers. We will define MAD-based alternatives for skewness and kurtosis without resorting to the computation of higher powers. In this way, our proposed expressions for skewness and for kurtosis will be more resilient to outliers.
We proceed as follows. From Equation (2), the expression for H can be written as follows:
The first term is the contribution to H from whereas the second term is the contribution to H from X1{ΩR. Our MAD-based alternative AM for skewness can be defined as the (normalized) difference of these contributions as follows:
The above expression immediately implies that the MAD-based skewness is both shift and translation invariant.
From Equation (2), we can re-write the expression for AM in Equation (6) as follows:
Therefore, the MAD-based metric AM for skewness coincides with Groeneveld and Meeden's skewness coefficient [16]. The MAD-based skewness in Equation (7) has a simple interpretation as the ratio of two distances: the numerator E(X)−M is the (signed) distance between the mean and the median, whereas the numerator H is the average distance of values in X to the median. It is more difficult to attach a simple and intuitive interpretation to the classical skewness S in Equation (4).
Let us compare the MAD-based skewness from the above Equation (7) with the non-parametric skewness given by (E(X)−M)/σ. Since H ≤ σ, we have the following relationship between these measures:
Next, we derive the upper and lower bound for AM. Since and from Equations (5) and (6) we easily obtain −1 ≤ AM ≤ 1.
The definition of MAD-based skewness in Equation (6) has been suggested before [e.g., [17]]. However, our results for the representation of H would allow us to derive simple computational expressions for MAD-skewness and compare the obtained results with skewness estimates used in quantile statistics.
To start, let us re-write our definition of AM as follows. From Equation (6), we obtain
We can now compare MAD-based skewness AM from Equation (8) with the quantile skewness AQ often used in descriptive statistics [e.g., [18, 19]]:
where Qi denote the corresponding quartiles. The expressions in Equations (8) and (9) have the same form under the same correspondence as before in Equation (3). The numerator in Equation (9) for AQ is the difference between the average of upper and lower quartiles and the median and the denominator is the quartile deviation HQ. By contrast, in Equation (8) for AM, the numerator is the difference between the concentrations of probability mass for the left and right halves and the half median, whereas the denominator is the mean absolute deviation H.
Finally, note that from Equation (9) we have
Therefore, both MAD-based skewness AM and quantile-based skewness AQ are always in the range [−1, 1]. By contrast, the classical skewness S can be unbounded.
We now turn our attention to kurtosis. Recall that classical Pearson's kurtosis K is defined as [20]:
To define an analogy to kurtosis using absolute deviations from the median, we find it useful to interpret kurtosis as suggested in [21]. We consider a standardized variable Z = (X − μ)/σ and let W = Z2. Then E(W) = 1 and
Note that since Z is normalized and dimensionless, W = Z2 is also automatically dimensionless. Therefore, Var(W) is also dimensionless. The kurtosis K can be viewed then as related to the dispersion of W = Z2 around its mean 1. Equivalently, K is associated with the dispersion of Z around −1 and 1 [21]. This implies that kurtosis is associated with the concentration of X around points μ−σ and μ+σ. High values of kurtosis can occur in a peaked unimodal distribution, in a dual-peaked bi-modal distribution, or with the concentration of probability in the tails of the distribution.
Pursuing this analogy, we want to define MAD-based kurtosis to measure the concentration of X around Q1 (playing the role of μ−σ) and around Q3 (playing the role of μ+σ) as in classical statistics.
Consider ΩL and ΩR defined above. We measure the concentration of probability in ΩL around Q1 by .
Similarly, we measure the concentration of probability in ΩR around Q3 by . We define MAD-based alternative TM for kurtosis by normalizing the total concentration by MAD:
From the above definition, it is easy to show that MAD-based kurtosis TM is scale and translation invariant just as MAD-based skewness AM.
The above expression for TM in Equation (11) can be interpreted as follows. From the definition of the median, F(XL) = F(XR) = 0.5. Therefore, the term E(|X − Q1|1{X ≤ M}) in Equation (11) can be interpreted as one half of the average distance dL of values of XL from Q1. Similarly, the term E(|X − Q3|1{X > M}) in Equation (11) can be interpreted as one half of the average distance dR of values of XR from Q3. The numerator in Equation (11) is then the average of these distances, namely (dL + dR)/2.
Therefore, the proposed MAD-based alternative TM for kurtosis in Equation (11) has a simple and intuitive explanation as the ratio of two distances: the numerator is the average of distances from values in ΩL and ΩR from Q1 and Q3, respectively, whereas the denominator H is the average distance of values of Ω to its median M. It is more difficult to provide an intuitive explanation of the classical kurtosis K in Equation (10).
Let us now establish some simple bounds for TM. Recall that the median minimizes the sum of absolute deviations [11, 12]. Since Q1 is the median for XL and Q3 is the median for XR, we obtain and . Therefore, from (11) we can immediately obtain:
Unlike Pearson's kurtosis K that can be unbounded [22], the proposed MAD-based alternative TM for kurtosis is always in the range 0 ≤ TM ≤ 1. This could allow for more meaningful comparisons of data.
The definition of MAD-based measures to measure tails has been suggested before [17]. In that work, it was suggested to use and as measures of fat tails. By contrast, our suggestion for MAD-based kurtosis in Equation (11) is to use the mean absolute deviations of left and right sub-spaces from their corresponding medians Q1 and Q3, not from the median M. This would allow us to provide additional interpretation for the proposed kurtosis and to compare the proposed formula for TM with quantile kurtosis TQ suggested by Moors [21].
To proceed, let us re-write TM in terms of sub-means of corresponding sub-means. We consider the following sub-spaces:
and define
From the above definitions, we have
and therefore, we can re-write our expression (11) for kurtosis TM as follows
Moors [21] suggested a quantile-based formula for kurtosis in terms of the octiles O1, …, O7 as follows:
The expressions in Equations (12) and (13) have the same form under the following correspondence:
Our justification for (12) is analogous to the justification for a quantile-based alternative to kurtosis in (13) in terms of octiles suggested in [21]. The terms in the numerator of TQ are large if large probability mass is concentrated in O2 and O6 corresponding to large dispersion around μ−σ and μ+σ. The terms in the numerator of TM. are small if small probability mass is concentrated in Q1 and Q3. The difference between our formula in (12) and the quantile-based formula in (13) is that we measure these masses in terms of “partial” means E(XLL), E(XLR), E(XRL) and E(XRR) instead of octiles. This is illustrated in the following example.
Example 3: As before, consider a random variable X with uniform probability in Ω = {1, 2, …, 12}. The corresponding sub-ranges are shown below:
For this sequence, we compute H = 3. This distribution is symmetric and S = AM = AQ = 0. We will therefore focus on MAD-based kurtosis TM. The median for the left sub-range ΩL is Q1 = 3.5 and we compute . The value is one half of the average distance dL from values in ΩL to its median Q1. Similarly, the median for the right sub-range ΩR is Q3 = 9.5 and we compute . The value is one half of the average distance dR from values in ΩR to its median QR. Therefore, the term is the average of the distances from sub-ranges ΩL and ΩR to their respective median. From Equation (11) the MAD-based kurtosis TM = 0.5. It has a simple interpretation as the ratio of the average distances (dL + dR)/2 to H which is the average distance of Ω to its median M = 6.5. Let us re-compute TM using sub-means. We have E(XLL) = 0.5, E(XLR) = 1.25, E(XRL) = 2 and E(XRR) = 2.75. Applying Equation (12) we have TM = 0.5. By contrast, the standard statistical kurtosis is K = 1.78. Let us compare the MAD-based kurtosis TM with quantile-based kurtosis TQ in formula (13). To compute TQ, we compute the octiles O1, …, O7 for our sequence (using midpoint for interpolation): O1 = 2.375 O2 = 3.75, O3 = 5.125, O4 = 6.5, O5 = 7.875, O6 = 9.25 and O7 = 10.625. Then, the quantile formula for kurtosis from Equation (13) gives us TQ = 1.
6. Discussion
One of the reasons to use quantile-based metrics for data is that they are resistant to outliers. One of the measures of this resistance is the sample breakdown point - the proportion of observations that can be altered that can result in statistics being arbitrarily large or small. The median M has a breakpoint of 50%. This means that 50% of the points must be “outliers” before the median can be moved outside the range of outliers [9, 23]. By contrast, the breakpoint of the mean is 0%. This means that a single observation would change it.
The computation of MAD-based measures for deviation, skewness, and kurtosis involves computing the corresponding sub-spaces. A single change in observation value would change these measures. However, these changes will not be as dramatic as changes for the classical measures.
By contrast, the MAD-based measures are determined by the corresponding sub-means. Any change in values would change some of these, and this, in turn, would result in different values for MAD-based measures for each of the sub-spaces. Note that a single observation value change would change the corresponding partial mean without affecting other sub-means. By contrast, a single change in observation would change the mean and result in changes for the corresponding moments, affecting both skewness and kurtosis. However, because the proposed MAD-based measures involve only the first moment whereas classical skewness and kurtosis involve the 3rd and 4th moments, respectively, we would expect that MAD-based measures would change by a smaller percentage than the corresponding classical measures.
For illustration, consider the MAD-based alternative TM for kurtosis. It can capture concentrations in the tails more accurately than can the quantile kurtosis TQ. For example, if the largest 10% of values in X increase in value then this cannot be captured by TQ since octiles will not change. Similarly, if the smallest 10% of values in X decrease, then again octiles will not change resulting in the same value for octile kurtosis. By contrast, the proposed MAD-based formula for kurtosis uses sub-means of appropriate sub-ranges and can, therefore, more accurately reflect the impact of such larger or smaller values.
Schematically, we can indicate this as follows:
If we consider any changes in values in quarter sub-ranges ΩLL, ΩLR, ΩRL or ΩRR that do not change the octiles, then the quantile kurtosis TQ would remain the same. By contrast, these changes in values will change the corresponding sub-means and, therefore the value of MAD-based kurtosis TM. Therefore, MAD-based kurtosis TM can capture changes in probability mass in the tails more accurately than using octiles in TQ.
By the same argument, it is easy to show that quantile skewness AQ and quantile deviations HQ would remain unchanged, whereas the mean absolute deviation from median H and MAD-based skewness AM would change.
The proposed MAD-based alternative measures for deviation, skewness, and kurtosis provide additional tools for data analysis. These measures are less sensitive to outliers in that they change by a smaller percentage as compared to the changes in the classical statistics metrics.
At the same time, they do not ignore outliers as quantile-based measures do. In situations where classical, MAD-based, and quantile-based kurtosis could be computed, MAD-based kurtosis TM has the advantage of 0 ≤ TM ≤ 1, whereas both the classical kurtosis S could be unbounded. For some distributions such as log-normal, the quantile-based kurtosis could be unbounded as well (see Section 8.3). Using the proposed MAD-based alternative measure for kurtosis with a value that is always in [0, 1] provides a potentially useful tool to directly compare distributions in terms of the concentration of data in the tails.
As one potentially important application of these proposed measures considers the national income and wealth distributions [24]. It is widely recognized that there are disproportionate concentrations of income and wealth at the highest quantile. As the above example illustrates, the MAD-based metrics appear to have the ability to characterize concentrations in the upper-most quantiles in a manner that is not possible with the classical and quantile-based methods. This ability likely follows from the property that the MAD-based metrics are sensitive to excessive concentrations in the upper-most quantile, while the quantile-based metrics are not. At the same time, the classical metrics that use the third and fourth moment may overly exaggerate the impact of these concentrations in the upper-most quantile. The foregoing analysis demonstrates that these alternative MAD-based metrics would be able to capture the detailed behavior that is engendered by the concentrations of extreme income and wealth at the highest range of distribution, namely the highest quantile. We illustrate this by a detailed example in Section 9.
7. Computational considerations
In the computation of quantile-based measures, we need to compute the quantiles. These can be obtained from the inverse of the cumulative distribution function F−1(p). The quartiles Q1, M and Q3 are obtained as , M = F−1(1/2) and whereas the remaining octiles are for i = 1, 3, 5, 7. Then the quantile-based measures for deviation, skewness, and kurtosis are
If the distribution is symmetric, the skewness AQ = 0 and for octiles we have O1 = 2M − O7, Q1 = 2M − Q3, and O3 = 2M − O5. In particular, (O7 − O5) = (O3 − O1). In this case, we only need to compute four quantiles, namely M, O5, Q3 and Q7 to obtain
Note that the quantile-based measures are expressed in terms of differences of corresponding quantiles. This implies, in particular, that the above quantile-based measures in Equation (14) are shift-invariant.
In the computation of MAD-based performance measures, we need to compute the corresponding sub-means. To facilitate this computation, consider the following auxiliary integral:
If we can evaluate the above integral for I(Q1), I(M), and I(Q3) then we can compute MAD-based performance measures from these integrals and the mean value E(X). Specifically, E(XL) = I(M) and E(XR) = E(X)−I(M). For the other sub-means, we have , , , and . From this, we obtain the following for MAD-based deviation, skewness and kurtosis:
In some situations, it is easier to evaluate the following integral
Since J(z) = E(X)−I(z), we can compute MAD-based deviation, skewness, and kurtosis as follows:
The computation of MAD-based performance measures requires the computation of I(Q1), I(M) and I(Q3) in addition to computing the expected value E(X). By contrast, in classical statistics, to compute skewness, we need to compute expectation E(X), standard deviation σ, and the third moment E(X3). To compute Pearson's kurtosis would require us also to compute the fourth moment E(X4). Therefore, the computational cost of computing these measures is not higher than that of computing Pearson measures of classical statistics. Moreover, unlike the classical measures, the computation of MAD-based measures requires only the existence of first-order moments. For example, consider Pareto distributions with parameter α (see Section 8.6). For such distributions, the mean is defined for α > 1, variance is defined for α > 2, and kurtosis is defined for α > 3. By contrast, MAD-based measures would require only α > 1. Therefore, for 1 < α < 2 we can only use MAD-based or quantile-based measures to analyze deviation, skewness, and kurtosis.
On the other hand, we should note that there are situations where classical kurtosis K or MAD kurtosis TM does not exists but the quantile-based kurtosis TQ exists and is finite. An example is presented in [21]. If X follows the Cauchy distribution, its expected value, variance, and kurtosis are undefined. However, the quantile-based kurtosis TQ is finite with TQ = 2.
In most situations where classical, MAD-based, and quantile-based kurtosis could be computed, MAD-based kurtosis TM has the advantage of 0 ≤ TM ≤ 1 whereas the classical kurtosis K can be unbounded. For some distributions such as log-normal, the quantile-based kurtosis TQ could also be unbounded (see Section 8.3 below for details). Using a MAD-based measure TM for kurtosis with a value in 0 ≤ TM ≤ 1 allows an additional comparison of all distributions in terms of their tails.
8. Comparisons for distributions
We now turn our attention to some well-known distributions. We will compute MAD-based alternatives for deviation, skewness, and kurtosis and compare them with the corresponding quantile-based and classical metrics for the following well-known probability distributions: continuous uniform, normal, log-normal, exponential, Laplace, and Pareto distributions. A summary table is provided in Section 1.
8.1. Continuous uniform distribution
Suppose X is distributed according to a uniform distribution in [a, b]. Its density f(x) = 1/(b − a) and its cumulative distribution function F(x) = (x − a)/(b − a). For this distribution, E(X) = M = (a + b)/2, and K = 9/5. Since this distribution is symmetric, the skewness measures are 0.
The quantiles are computed from F−1(p) = (1 − p)a + pb. In particular, Q1 = (3a + b)/4, M = (a + b)/2 and Q3 = (a + 3b)/4. Since this distribution is symmetric, we compute the octiles O1 = (7a + b)/8, O3 = (5a + 3b)/6, O5 = (3a + 5b)/8 and O7 = (a + 7b)/8. To compute MAD-based measures, consider the following integral
We have , J(M) = (M2 − a2)/2(b − a) and . From this using Equation (17) and Equation (15) we compute MAD-based and quantile-based measures for deviation and kurtosis. The results are summarized in the Table 1.
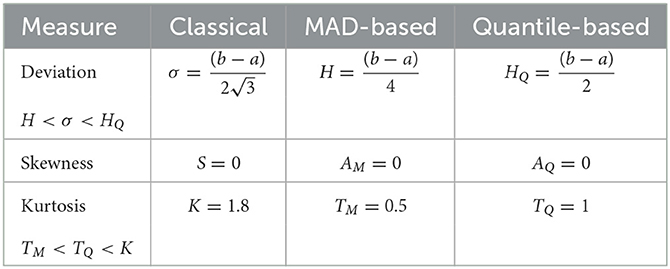
Table 1. A comparison of measures for uniform distribution.
8.2. Gaussian distribution
Suppose X is distributed according to normal distribution N(μ, σ2) with density f(x) and cumulative distribution function F(x):
where Φ(·) denotes the cumulative distribution of the standard normal. Let Q1 and Q3 denote the first and third quartiles of the standard normal distribution. This distribution is symmetric; therefore, all skewness measures are 0.
The MAD-based, quantile-based, and classical measures are invariant under shifts. Skewness and kurtosis are also invariant under scaling whereas for MAD-based deviation, H(X/σ) = (1/σ)H(X). Therefore, we can consider the standard normal distribution for X and multiply the obtained value for H(X) by 1/σ.
The quartiles for this distribution Q3 = −Q1 ≈ 0.67 whereas for the octiles we have O5 = −O3 ≈ 0.32, Q3 = −Q1 ≈ 0.68 and O7 = −O1 ≈ 0.15. To compute MAD-based MAD-based measures, consider the following integral
Since Q3 = −Q1 ≈ 0.67 we have and . Therefore, from the above, using Equation (17) and Equation (15) we compute MAD-based and quantile-based measures for deviation and kurtosis. The results are summarized in Table 2.

Table 2. A comparison of measures for normal distribution.
8.3. Log-normal distribution
Suppose X is distributed according to log-normal distribution with parameters μ ∈ (∞, +∞) and σ2 (σ > 0). Its density f(x) and its cumulative distribution function F(x) are given by
where Φ(·) is the cumulative distribution function of the standard normal.
We will use the apostrophe ′ to distinguish the performance measures of X in the log-normal distribution from those of the underlying normal distribution. Therefore, σ′ will denote the standard deviation of X, μ′ will denote the mean of X etc. As before, let Oi denote the octiles of the standard normal and let denote the octiles of the log-normal distribution. Then . In particular, the log-normal median is M′ = eμ and the log-normal mean is μ′ = eμ+σ2/2. Similarly, let Q1 and Q3 denote the first and third quartiles for the standard normal distribution and let and denote the corresponding quartiles for the log-normal distribution. Consider the following integral (derived in Appendix A2)
In particular, , I(M′) = μ′(1 − Φ(σ)) and . Therefore, from the above, using Equation (17) and Equation (15) we compute MAD-based and quantile-based measures for deviation and kurtosis. Note that we can express mean absolute deviation H′ in terms of the error function erf(·). Using we obtain .
In Appendix A2, we show the following relationships between MAD-based and quantile-based measures:
We summarize our results in Table 3. In addition, in Appendix A2, we examined the asymptotic behavior of these measures for σ ↦ 0 and for σ ↦ ∞. For σ ↦ 0 we have , , and . Therefore, for σ ↦ 0, the MAD-based and quantile-based measures for skewness and kurtosis converge to the corresponding values for normal distribution. On the other hand, for σ ↦ ∞

Table 3. A comparison of measures for log-normal distribution.
we have: , , and . Finally, note that for log-normal distribution both quantile kurtosis and classical kurtosis K′ are unbounded whereas the MAD-based kurtosis always satisfies . This allows us to compare distribution in the tails across different distributions. The results are summarized in Table 3.
8.4. Exponential distribution
Suppose X is distributed according to an exponential distribution with rate λ > 0 [22]. Its density f(x) = λe−λx and its cumulative distribution function F(x) = 1 − e−λx with x ∈ [0, ∞). Its mean E(X) = 1/λ and its standard deviation σ = 1/λ. The quantiles of exponential distribution are F−1(p) and are given by −log(1 − p)/λ. In particular, Q1 = log(4/3)/λ, M = log(2)/λ and Q3 = log(4)/λ whereas the octiles are O1 = log(8/7)/λ, O3 = log(8/5)/λ, O5 = log(8/3)/λ and O7 = log(8)/λ.
To compute MAD-based measures, we compute (using integration by parts) the following integral
We compute I(Q1) = (1 − 3log(4/3))/4λ, I(M) = (1 − log2)/2λ and I(Q3) = (3 − log4)/4λ. Then from the above results and from Equations (16 a)nd (15) we compute MAD-based and quantile-based measures for deviation, skewness, and kurtosis. The results are summarized in the Table 4.

Table 4. A comparison of measures for exponential distribution.
8.5. Laplace distribution
Suppose X is distributed according to Laplace distribution with location μ and scale b. Its density f(x) and cumulative distribution function F(x) are given by Feller [22]
This distribution of X is symmetric around μ. its median M and mean E(X) are both the same with E(X) = M = μ. Its standard deviation . Since both MAD-based measures and quantile-based measures are shift-invariant, we let μ = 0.
The quantiles are easily computed as F−1(p). In particular, Q1 = −blog2 and Q3 = blog2. whereas for the octiles we have O1 = −2blog2, O3 = blog3 − 2blog2, O5 = 2blog2−blog3, and O7 = 2blog2.
To compute the MAD-based measures, we compute the integral J(z) (derived in Appendix A3):
We compute J(Q1 = b(1 + log2)/4, J(M) = b/2 and J(Q3) = b(1 + log2)/4. Then from Equations (17) and (15) we can compute MAD-based and quantile-based measures for deviation, skewness, and kurtosis. We summarize our results in Table 5.

Table 5. A comparison of measures for Laplace distribution.
We note that just as for classical kurtosis, the MAD-based kurtosis for Laplace distribution is greater than the MAD-based kurtosis for Normal distribution. This is because the Laplace distribution has fatter tails compared to the Normal distribution.
8.6. Pareto distribution
Suppose X is distributed according to Pareto Type I distribution distribution with shape α > 0 and scale β > 0. Its density f(x) and its cumulative distribution function F(x) are given by
This distribution has infinite mean μ for α ≤ 1, undefined variance σ2 for α ≤ 2, undefined skewness S for α ≤ 3 and undefined (excess) kurtosis K for α ≤ 4. The quantiles are computed from F−1(p) and are given by β/(1 − p)1/α. For Q1, M and Q3 we have , and . For the octiles we have , , and . To compute MAD-based measures, we compute the integral for any z > = β and α > 1
Since 1 − F(Q1) = 3/4, 1 − F(M) = 1/2, and 1 − F(Q3) = 1/4, we immediately compute J(Q1) = 3αβQ1/4(α − 1), J(M) = αβM/2(α − 1), and J(Q3) = αβQ3/3(α − 1). Then from Equations (17) and (15) we can compute MAD-based and quantile-based measures for deviation HQ, skewness AQ, and kurtosis TQ. Moreover, in Appendix (Section A4), we showed the following relationship between measures: HQ < H < σ and AQ < AM < S and TM < TQ < K. These results are summarized in Table 6.

Table 6. A comparison of measures for Pareto distribution.
In Appendix (Section A4), we examined the asymptotic behavior of these measures for α ↦ 1 and for α ↦ ∞. For α ↦ 1, we showed that for MAD-based measures that H ↦ ∞, AM ↦ 1, and TM ↦ 1 whereas for quantile-based measures HQ ↦ 4/3, AQ ↦ 0.5, and TQ ↦ 2.17. By contrast, for α ↦ ∞ we showed in Appendix (Section A4) that both MAD-based and quantile-based measures for skewness and kurtosis converge to the corresponding measures for exponential distribution H ↦ 0, AM ↦ 0.44, TM ↦ 0.62, HQ ↦ 0, AQ ↦ 0.26, TQ ↦ 1.31 (see Table 4). Note that if X is Pareto with shape α and scale β, then Y = log(X/β) is exponentially distributed with rate α [20, 22].
9. Example: wealth distribution
Assume that income is distributed according to a Pareto principle p + q principle [20]: 100p% of all income is received by 100q% of people (p + q = 1) For example, the 60 − 40 rule (p = 0.6, q = 0.4) means that 40% of the people receive 60% of the wealth. We assume that p > 0.5.
This p + q principle with p > q corresponds to a Pareto distribution with a tail index α satisfying
For example, the 60 − 40 rule (p = 0.6, q = 0.4) has α = 2.260 whereas 80 − 20 rule (p = 0.8, q = 0.2) corresponds to α = log(5)/log(4)≈ = 1.161. If we take even larger p as in 95 − 5 rule (p = 0.95, q = 0.05 we get α = log(0.05)/log(0.95)≈1.017. It is easy to prove that ∂α/∂p < 0 and, therefore, α decreases as p increases. In particular, α↘1 as p ↦ 1. Larger values of p correspond to higher concentrations of wealth.
Figure 1 demonstrates that the MAD-based skewness approaches its asymptotic value of +1 more rapidly than the quantile-based skewness approaches its asymptotic value of 0.5. This behavior demonstrates that the MAD-based skewness AM is better able to explore the extreme distribution of wealth and income in the highest brackets than using the quantile-based skewness.
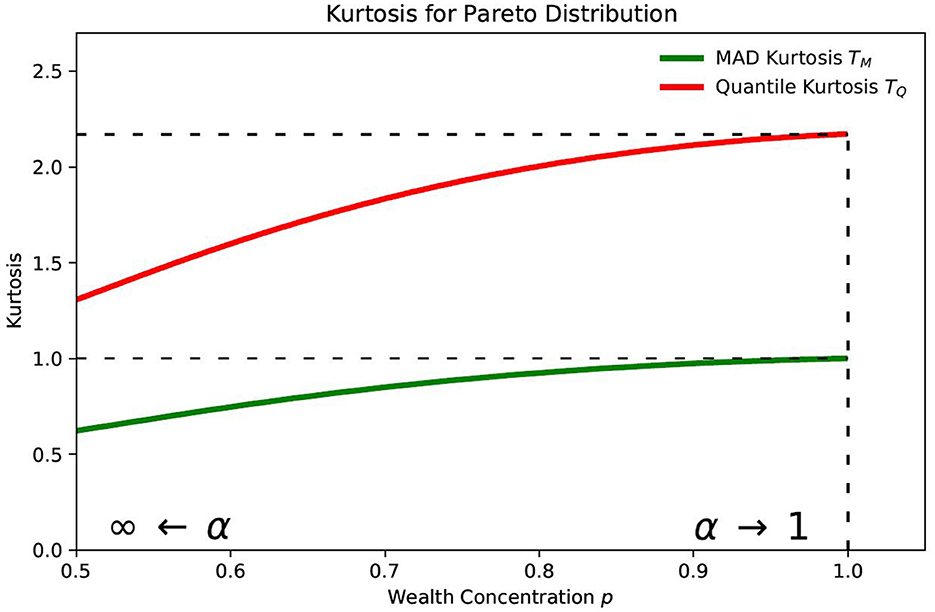
Figure 1. Skew for Pareto distribution.
It is important to note that in the case of α < 2, we cannot use classical measures for standard deviation, skewness, and kurtosis. By contrast, the MAD-based measures could be computed for these lower values of α and compared with the corresponding quantile-based measures.
As shown in Figure 2, the quantile-based kurtosis approaches its asymptotic value of 2.17 (from Equation A15 in Appendix) more rapidly than MAD-based kurtosis approaches its asymptotic value of 1. Despite this behavior in the kurtosis, we believe that skewness is more widely used and more revealing as a measure of the concentration of wealth and income at the highest brackets. The MAD-based kurtosis has the added practical advantage of having a maximum value of 1.
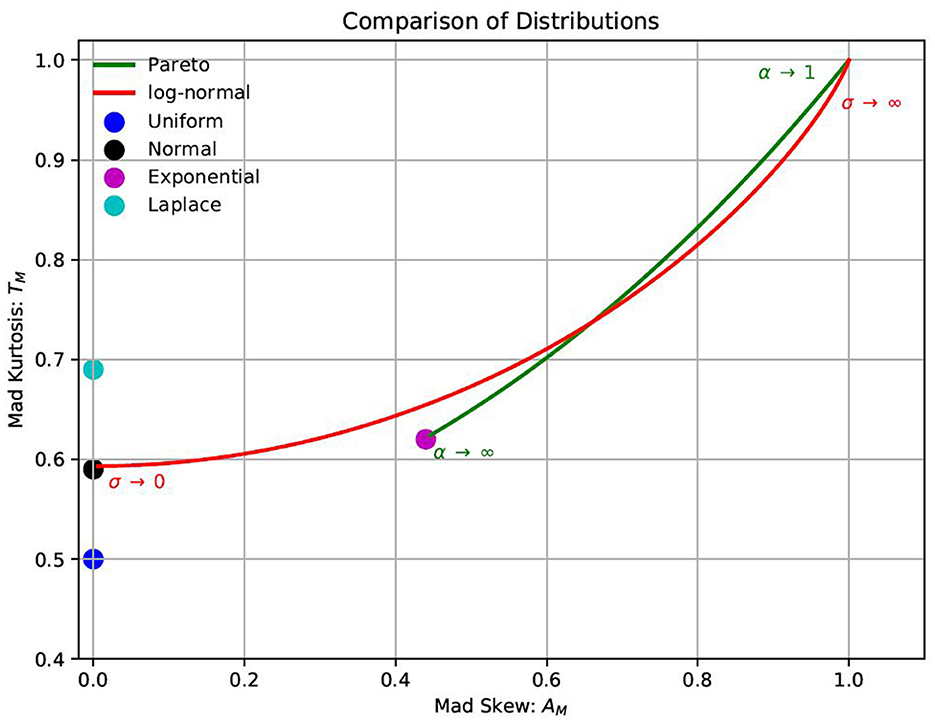
Figure 2. Kurtosis for Pareto distribution.
10. Comparison of distributions
Using MAD-based alternatives for deviation, skewness and kurtosis gives us additional ways to compare distributions. The MAD-based skewness AM and MAD-based kurtosis TM are always in the range −1 ≤ AM ≤ 1 and 0 ≤ TM ≤ 1, respectively. This is in contrast to classical and quantile-based measures that can be unbounded. Therefore, with MAD-based measures, we have a way to directly compare any two distributions in terms of their MAD-based skewness and kurtosis. In Figure 3, we plot both skewness and kurtosis for the distributions considered.
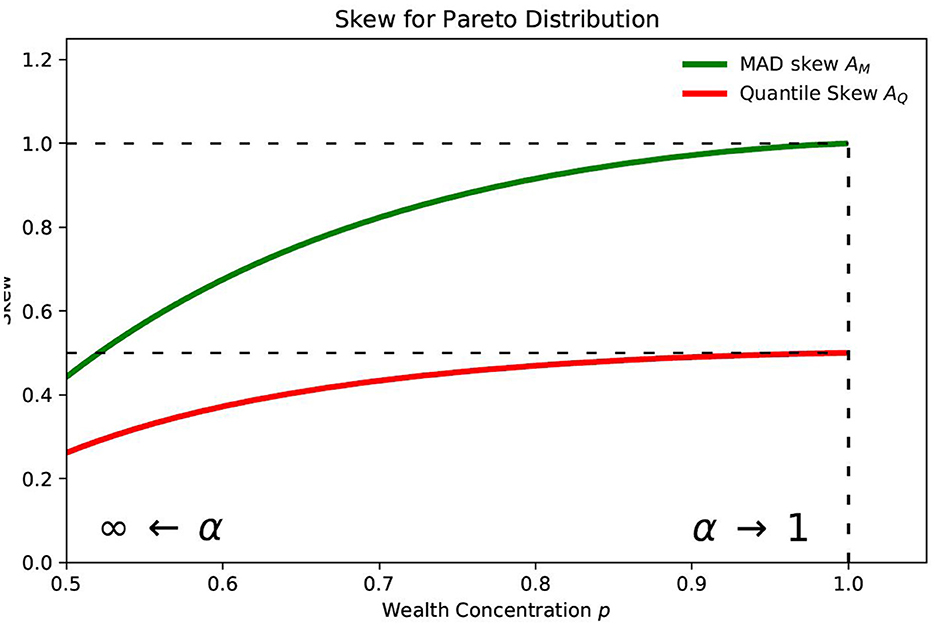
Figure 3. MAD-based skew/kurtosis comparison of distributions.
11. Conclusion
This paper considered MAD (about median)-based alternative metrics for classical standard deviation, skewness, and kurtosis. These MAD-based measures are shift-invariant. The MAD-based measures for skewness and kurtosis are also scale invariant. They can be computed from the corresponding left and right sub-ranges and require the existence of first-order moments only. The mathematical expressions for these measures are similar to those in quantile-based measures but involve computing means as opposed to quantiles. The resulting expressions can be interpreted as average values distance in sub-ranges from their respective medians.
In terms of practical applications, it is widely recognized that the median can be a better measure of centrality when the mean is overly influenced by outlier concentrations at the high end. The median captures the data centrality in many distributions with concentrations at the very high end, such as wealth and income. Building on the recognition that the median is the preferred metric in such applications, we go further in proposing MAD-based (about Median) metrics that give additional information and insight on the concentrations in the highest quantile.
For any distribution, the proposed MAD-based expressions for skewness and kurtosis are shown to be in the range [−1, 1] and [0, 1], respectively. The proposed MAD-based alternative measures provide a universal scale to compare skewness and kurtosis across different data sets.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
SK proposed the initial idea and focused on examples and discussion. EP focused on analytical work. Both authors have read and approved the final manuscript.
Acknowledgments
The authors would like to thank Metropolitan College of Boston University and H. Chen School of Public Health of Harvard University for their support.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2023.1206537/full#supplementary-material
References
1. Pham-Gia T, Hung TL. The mean and median absolute deviations. J Math Comput Modell. (2001) 34:921–36. doi: 10.1016/S0895-7177(01)00109-1
2. Gorard S. Revisiting a 90-year-old debate: the advantages of the mean deviation. Brit J Educ Stud. (2005) 53:417–30. doi: 10.1111/j.1467-8527.2005.00304.x
3. Farebrother RW. The historical development of the L1 and L∞ estimation methods. In: Dodge Y, editor. Statistical data Analysis Based on the L1-norm and Related Topics. Amsterdam: North-Holland (1987). p. 37–63.
4. Portnoy S, Koenker R. The Gaussian hare and the Laplacian tortoise: computability of square-error versus abolute-error estimators. Stat Sci. (1997) 2:279–300.
5. Dodge Y. Statistical Data Analysis Based on the L1 Norm and Related Topics. Amsterdam: North-Holland (1987).
6. Elsayed KMT. Mean absolute deviation: analysis and applications. Int J Bus Stat Anal. (2015) 2:63–74. doi: 10.12785/ijbsa/020201
7. Gorard S. An absolute deviation approach to assessing correlation. Brit J Educ Soc Behav Sci. (2015) 53:73–81. doi: 10.9734/BJESBS/2015/11381
8. Gorard S. Introducing the mean deviation “effect” size. Int J Res Method Educ. (2015) 38:105–14. doi: 10.1080/1743727X.2014.920810
9. Rousseeuw PJ, Croux C. Alternatives to the median absolute deviation. J Am Stat Assoc. (1993) 88:1273–83.
10. Bloomfield P, Steiger WL. Least Absolute Deviations: Theory, Applications and Algorithms. Boston, MA: Birkhauser (1983).
12. Schwertman NC, Gilks AJ, Cameron J. A simple noncalculus proof that the median minimizes the sum of the absolute deviations. Am Stat. (1990) 44:38–41.
14. Zwillinger D, Kokoska S. CRC Standard Probability and Statistics Tables and Formulae. New York, NY: CRC Press (2000).
17. Habib E. Mean absolute deviation about median as a tool of exploratory data analysis. Int J Res Rev Appl Sci. (2012) 11:517–23.
Keywords: computational statistics, mean absolute deviation, kurtosis, quantiles, distributions, data analysis, skewness
Citation: Pinsky E and Klawansky S (2023) MAD (about median) vs. quantile-based alternatives for classical standard deviation, skewness, and kurtosis. Front. Appl. Math. Stat. 9:1206537. doi: 10.3389/fams.2023.1206537
Received: 15 April 2023; Accepted: 15 May 2023;
Published: 02 June 2023.
Edited by:
Han-Ying Liang, Tongji University, ChinaReviewed by:
Alicja Jokiel-Rokita, Wrocław University of Science and Technology, PolandAugustine Wong, York University, Canada
Copyright © 2023 Pinsky and Klawansky. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Eugene Pinsky, ZXBpbnNreUBidS5lZHU=